目录
- 索引创建与B+树原理:MySQL性能优化的核心一课
-
- 一、为什么需要索引?
- 二、索引的核心概念
-
- [2.1 索引是什么?](#2.1 索引是什么?)
- [2.2 索引的类型对比](#2.2 索引的类型对比)
- 三、创建索引的五种方式
-
- [3.1 建表时创建](#3.1 建表时创建)
- [3.2 使用create index语句](#3.2 使用create index语句)
- [3.3 使用alter table语句](#3.3 使用alter table语句)
- 四、创建索引的最佳实践
-
- [4.1 命名规范](#4.1 命名规范)
- [4.2 创建索引的黄金法则](#4.2 创建索引的黄金法则)
- [4.3 组合索引的顺序原则](#4.3 组合索引的顺序原则)
- 五、索引的查看、修改和删除
-
- [5.1 查看索引](#5.1 查看索引)
- [5.2 修改索引](#5.2 修改索引)
- [5.3 删除索引](#5.3 删除索引)
- 六、索引失效的常见场景
- 七、索引的结构
-
- [7.1 MySQL与磁盘交互](#7.1 MySQL与磁盘交互)
- [7.2 理解单个Page](#7.2 理解单个Page)
- [7.3 理解目录](#7.3 理解目录)
- [7.4 B+ 树的结构](#7.4 B+ 树的结构)
- [7.5 为什么不使用别的数据结构](#7.5 为什么不使用别的数据结构)
- [八、聚簇索引VS 非聚簇索引](#八、聚簇索引VS 非聚簇索引)
索引创建与B+树原理:MySQL性能优化的核心一课
本文将带你从零开始,全面掌握数据库索引的创建方法,包含大量实战代码和避坑指南
一、为什么需要索引?
想象一下,你在一本没有目录的书中找一句话,只能一页页翻。数据库也是一样,没有索引就会进行全表扫描,数据量一大就慢得离谱。
sql
-- 没有索引:扫描100万行数据
select * from users where name = '张三'; -- 耗时3秒
-- 有索引:通过目录快速定位
create index idx_name on users(name); -- 创建索引
select * from users where name = '张三'; -- 耗时0.01秒二、索引的核心概念
2.1 索引是什么?
索引是一种以空间换时间的数据结构,就像书的目录或字典的拼音检索表。
2.2 索引的类型对比
| 索引类型 | 关键词 | 允许重复 | 生活例子 | 使用场景 |
|---|---|---|---|---|
| 普通索引 | index |
✅ 允许 | 学生姓名(可重名) | 日常查询字段 |
| 唯一索引 | unique |
❌ 不允许 | 身份证号 | 需要唯一性的字段 |
| 主键索引 | primary key |
❌ 不允许 | 学号 | 每张表的唯一标识 |
| 组合索引 | index(a,b) |
✅ 允许 | 拼音+笔画查字典 | 多条件查询 |
| 全文索引 | fulltext |
✅ 允许 | 百度搜索 | 文章关键词搜索 |
三、创建索引的五种方式
3.1 建表时创建
sql
create table users (
-- 主键索引(自动创建)
id int primary key auto_increment,
-- 唯一索引
email varchar(100) unique,
-- 普通索引
name varchar(50),
age int,
create_time datetime,
-- 在字段定义后创建索引
index idx_name (name), -- 普通索引
index idx_age_time (age, create_time), -- 组合索引
unique index idx_email2 (email) -- 唯一索引
);3.2 使用create index语句
sql
-- 普通索引
create index idx_name on users(name);
-- 唯一索引
create unique index idx_email on users(email);
-- 全文索引
create fulltext index idx_content on articles(content);
-- 组合索引
create index idx_name_age on users(name, age); # 以name, age组合作为索引
-- 前缀索引(只取前10个字符)
create index idx_name_prefix on users(name(10)); # users表名,idx_name_prefix 索引名3.3 使用alter table语句
sql
-- 添加普通索引
alter table users add index idx_age (age);
-- 添加唯一索引
alter table users add unique index idx_phone (phone);
-- 添加主键
alter table users add primary key (id);
-- 添加全文索引
alter table articles add fulltext index idx_content (content);实战案例:电商系统索引设计
用户表
sql
create table users (
id bigint primary key auto_increment,
username varchar(50) not null,
email varchar(100) not null,
phone char(11),
real_name varchar(20),
age tinyint,
city varchar(50),
status tinyint default 1,
last_login datetime,
create_time datetime
);
-- 索引设计
-- 1. 登录相关(唯一索引)
create unique index idx_username on users(username);
create unique index idx_email on users(email);
create unique index idx_phone on users(phone);
-- 2. 统计查询(组合索引)
create index idx_status_city on users(status, city);
-- 3. 时间查询
create index idx_last_login on users(last_login);
-- 4. 前缀索引(节省空间)
create index idx_real_name on users(real_name(5));
-- 验证索引效果
explain select * from users where username = 'zhangsan';为什么需要加 EXPLAIN?
- 不加
EXPLAIN:只是正常执行查询,返回查询结果(数据行),你看不到索引的使用情况。 - 加
EXPLAIN:不返回实际数据,而是返回查询执行计划,告诉你 MySQL 是如何执行这条 SQL 的(用了哪个索引、扫描了多少行等)。
四、创建索引的最佳实践
4.1 命名规范
sql
-- 推荐命名格式:idx_表名_字段名
create index idx_users_name on users(name);
create index idx_users_age_status on users(age, status);
-- 唯一索引:uidx_表名_字段名
create unique index uidx_users_email on users(email);
-- 主键:pk_表名
alter table users add primary key pk_users (id);4.2 创建索引的黄金法则
sql
-- ✅ 适合创建索引的场景
-- 1. where条件中的列
create index idx_age on users(age);
-- 2. order by和group by的列
create index idx_create_time on orders(create_time);
-- 3. join连接的列
create index idx_user_id on orders(user_id);
-- 4. 区分度高的列(唯一性强)
create index idx_id_card on users(id_card); -- 几乎唯一
-- ❌ 不适合创建索引的场景
-- 1. 数据量小的表(<1万行)
-- 2. 频繁更新的列
-- 3. 区分度低的列(如性别)
-- 4. 很少使用的条件列4.3 组合索引的顺序原则
sql
-- 原则:等值查询在前,范围查询在后,高区分度在前
-- ✅ 正确顺序
create index idx_name_age on users(name, age);
-- 查询:where name = '张三' and age > 18 -- 都能用到索引
-- ❌ 错误顺序
create index idx_age_name on users(age, name);
-- 查询:where name = '张三' and age > 18 -- name用不到索引五、索引的查看、修改和删除
5.1 查看索引
sql
-- mysql
show index from users;
show keys from users;
-- 结果示例:
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Index_type | Cardinality |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+
| users | 0 | PRIMARY | 1 | id | BTREE | 1000 |
| users | 1 | idx_name | 1 | name | BTREE | 950 |
| users | 1 | idx_age_time | 1 | age | BTREE | 50 |
| users | 1 | idx_age_time | 2 | create_time | BTREE | 500 |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+
-- 查看索引详细信息
select * from information_schema.statistics
where table_name = 'users';
-- 查看索引大小
select
table_name,
index_name,
round(stat_value * @@innodb_page_size / 1024 / 1024, 2) as size_mb
from mysql.innodb_index_stats
where stat_name = 'size';5.2 修改索引
sql
-- mysql不支持直接修改,需要删除后重建
-- 1. 删除旧索引
drop index idx_name on users;
-- 2. 创建新索引
create index idx_name_new on users(name);
-- 或者使用alter table
alter table users drop index idx_name;
alter table users add index idx_name_new (name);5.3 删除索引
sql
-- 方法1:drop index
drop index idx_name on users;
-- 方法2:alter table
alter table users drop index idx_name;
alter table users drop primary key; -- 删除主键六、索引失效的常见场景
sql
-- 1. 使用函数
where date(create_time) = '2024-01-01' -- ❌ 失效
-- 改为
where create_time >= '2024-01-01' and create_time < '2024-01-02' -- ✅
-- 2. 隐式类型转换
where phone = 13800138000 -- ❌ phone是varchar
-- 改为
where phone = '13800138000' -- ✅
-- 3. 前导通配符
where name like '%张三' -- ❌ 失效
-- 改为
where name like '张三%' -- ✅
-- 4. or条件(两边都要有索引)
where age = 25 or name = '张三' -- 如果name没索引,❌
-- 5. 不等号
where age != 25 -- ❌ 大部分情况失效
-- 6. 组合索引不满足最左前缀
-- 索引(a,b,c)
where b = 2 -- ❌ 失效
where a = 1 and c = 3 -- ❌ 跳过b
-- 7. 使用is not null
where email is not null -- ❌ 通常失效七、索引的结构
7.1 MySQL与磁盘交互
- 磁盘(机械硬盘)的物理结构:"整体 → 盘面 → 磁道 → 扇区"
- 每个扇区都有独立编号,是磁盘最小寻址单位。每个扇区容量为 512 字节。
- 系统读取磁盘,是以块为单位的,基本单位是4KB。叫做一个
Page MySQL和磁盘进行数据交互的基本单位是16KB。也叫做Page。
让我们理清这两个 Page 的关系:
- 操作系统的 Page (4KB):这是文件系统与磁盘交互的最小单位。磁盘硬件按 512 字节或 4KB 寻址,操作系统按 4KB 组织数据。你可以把它想象成"乐高积木的最小颗粒"。
- MySQL (InnoDB) 的 Page (16KB):这是 MySQL 自己定义的和操作系统(进而和磁盘)交互的基本单位。它是数据库自己"组装"的一个大积木块。
- 接下来,我们讲的Page 都是这指的是MySQL (InnoDB) 的 Page (16KB)
7.2 理解单个Page
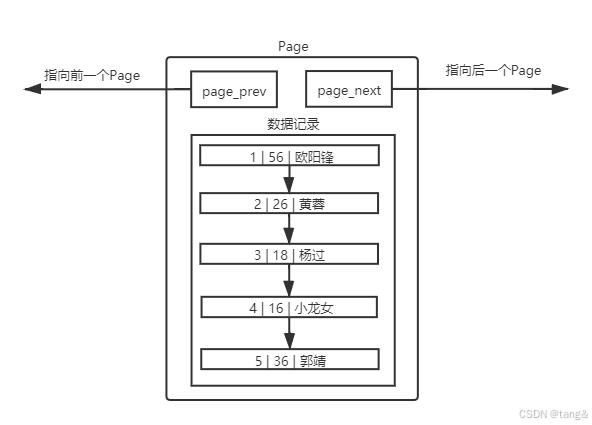
不同的Page,在MySQL 中,都是16KB,使用prev和next构成双向链表。因为有主键的问题,MySQL会默认按照主键给我们的数据进行排序
7.3 理解目录
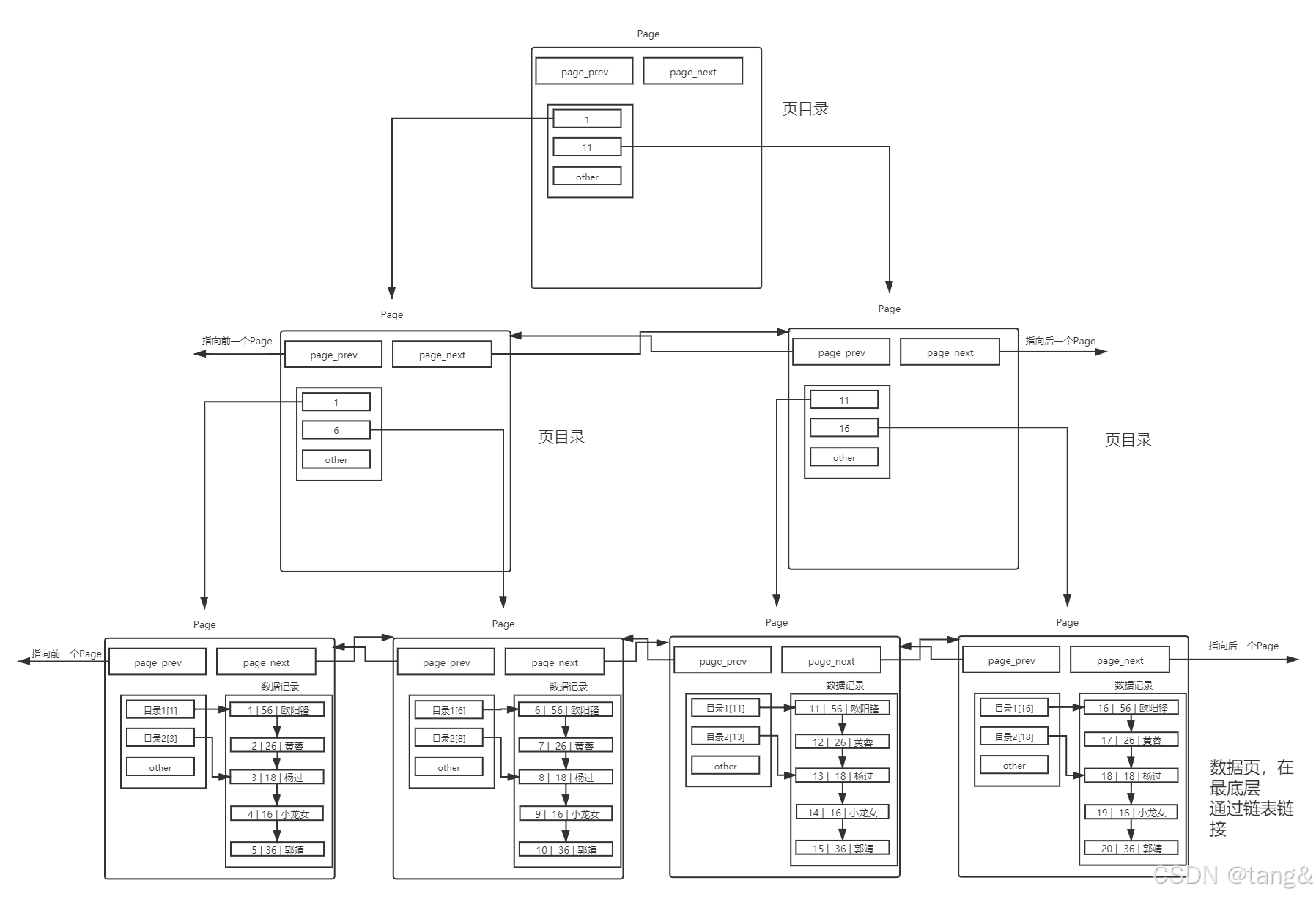
- 索引使用B+树
- 非叶子节点是目录(只导航),叶子节点是数据页(存数据)。
- 每个目录项的构成是:键值+指针(prev,next)。
7.4 B+ 树的结构
B+树 是一种专门为磁盘存储(如数据库、文件系统)设计的数据结构。它解决了传统数据结构(如二叉搜索树、B树)在磁盘I/O上的性能瓶颈。
B+树 = 多路搜索树 + 所有数据都在叶子节点 + 叶子节点形成有序链表
核心结构(用你熟悉的Page来理解)
[根节点 Page]
/ | \
[内节点 Page] [内节点 Page] [内节点 Page]
/ | \ / | \ / | \
[叶子][叶子][叶子]→[叶子][叶子][叶子]→[叶子][叶子][叶子]
↑所有数据都在这里,并且用指针连成链表↑B+树的4大核心特性
| 特性 | 说明 |
|---|---|
| 1. 多路分支 | 每个节点可以有多个孩子(如1000个),而不是二叉树的2个 → 树极矮 |
| 2. 数据只在叶子 | 非叶子节点只存键值+指针(目录),不存数据 → 一个Page能放更多键 |
| 3. 叶子有序链表 | 所有叶子节点通过指针连成双向链表 → 范围查询极快 |
| 4. 节点=Page | 每个节点存储在一个Page中 → 一次I/O读一个节点 |
为什么B+树比B树更适合数据库?
B树:非叶子节点也存数据
[50|数据] ← 非叶子节点就存数据了
/ \
[20|数据] [80|数据]问题:一个Page能放的键变少了 → 树变高 → 更多I/O
B+树:非叶子节点只存键
[50] ← 只存键,不存数据
/ \
[20] [80]
↓ ↓
[20|数据]→[50|数据]→[80|数据] ← 叶子节点存数据+链表优势:非叶子节点Page能放更多键 → 树更矮 → 更少I/O
这也解释了为什么MySQL用16KB的Page:每个Page能存放1000个键 → 树只有3-4层 → 亿级数据只需3-4次磁盘I/O。
7.5 为什么不使用别的数据结构
B+树并非在所有场景下都是最优的,只是在"磁盘数据库"这个特定场景下,它是最佳选择。
我们可以通过分析"为什么不选其他结构"来反向理解 B+ 树的优势。
- 为什么不选哈希表?
哈希表在等值查询(WHERE id = 5)上极快(O(1)),但致命缺陷如下:
| 问题 | 说明 | 实际后果 |
|---|---|---|
| 不支持范围查询 | 数据无序,无法执行 WHERE id BETWEEN 5 AND 10 |
需要全表扫描,彻底失效 |
| 不支持排序 | 无法 ORDER BY,无法做 >、<、MAX、MIN |
几乎每个查询都要额外排序 |
| 哈希冲突 | 大量数据映射到同一哈希桶 | 退化成链表,性能崩溃 |
| 不适合磁盘 | 哈希表是"内存友好"结构,随机跳转多 | 磁盘I/O剧增 |
结论 :哈希表只能做等值查询的内存缓存,不能做磁盘数据库的主索引。
- 为什么不选二叉搜索树(BST)或 AVL 树?
| 问题 | 说明 | 实际后果 |
|---|---|---|
| 树太高 | 2叉 → 百万级数据需要约20层 | 查询需要20次磁盘I/O(约200ms) |
| 磁盘预读失效 | 每一层能覆盖的数据量太少了 | 每次I/O只能读一个Page,预读的其他Page都用不到 |
| B+树一页1000叉 | 百万级数据只需3层 | 3次磁盘I/O(约30ms) |
对比 :B+树比二叉树快 6-7 倍。
- 为什么 B 树也不行?
B 树和 B+树很像,但有一个关键区别:B 树在非叶子节点也存数据。
| 问题 | 说明 | 后果 |
|---|---|---|
| 非叶子节点存数据 | 一个 Page 能放的键数量变少 | 树变高,I/O 变多 |
| 范围查询慢 | 叶子节点之间没有链表 | 需要反复回溯父节点,遍历成本高 |
B树范围查询:找到起点 → 回溯到父节点 → 再找下一个叶子 → 多次回溯
B+树范围查询:找到起点 → 沿叶子链表直接走 → 一次回溯都不需要
结论:B+ 树在磁盘 I/O 和范围查询上全面优于 B 树。
- 为什么不选跳表(Skip List)?
跳表是 Redis 有序集合的底层结构,在内存中很快。
| 问题 | 说明 |
|---|---|
| 内存随机访问 | 跳表依赖指针跳跃,内存中快(纳秒级) |
| 磁盘随机访问 | 磁盘跳一个指针需要 10ms,无法接受 |
| 空间局部性差 | 节点在磁盘上分散存储,预读失效 |
结论 :跳表是内存数据结构,不适合磁盘。
八、聚簇索引VS 非聚簇索引
聚簇索引 和非聚簇索引 是InnoDB中最核心的两个概念,它们的本质区别是:数据究竟存放在哪里。
一句话总结
- 聚簇索引(Clustered Index) :数据和索引放在一起。找到了索引,就找到了数据本身。
- 非聚簇索引(Secondary Index,辅助索引) :索引和数据分开存放。索引只存一个"门牌号"(主键值),找到门牌号后,再用这个门牌号去聚簇索引里找数据。
- 聚簇索引(主键索引)
-
必须有一个。如果你不主动定义主键,InnoDB会偷偷给你加一个隐藏的行ID来充当。
-
叶子节点Page里存放的是整行的完整数据(所有列:id、name、age...)。
-
整个表就是一棵B+树。表数据本身就是聚簇索引的叶子节点。
聚簇索引的叶子节点Page(16KB):
┌────────────────────────────────────────┐
│ page_prev │ page_next │ 页头 │ 其他元信息 │
├────────────────────────────────────────┤
│ id=1 │ 欧阳锋 │ 教主 │ ...(整行数据) │
│ id=2 │ 黄蓉 │ 帮主 │ ...(整行数据) │
│ id=3 │ 杨过 │ 大侠 │ ...(整行数据) │
└────────────────────────────────────────┘
- 非聚簇索引(辅助索引)
-
可以有多个(你可以在name、age等列上分别建立索引)。
-
叶子节点Page里不存完整数据,只存两样东西 :
- 索引列的值(比如
name='欧阳锋') - 对应的主键值 (比如
id=1)
非聚簇索引的叶子节点Page(name列上建的索引):
┌────────────────────────────────────────┐
│ page_prev │ page_next │ 页头 │ │
├────────────────────────────────────────┤
│ name='欧阳锋' │ 主键 id=1 │
│ name='黄蓉' │ 主键 id=2 │
│ name='杨过' │ 主键 id=3 │
└────────────────────────────────────────┘ - 索引列的值(比如
整个 B+树按照 name 的字典序(字母顺序/拼音顺序/Unicode顺序)组织。
查询过程对比:
聚簇索引查询(主键查找)
sql
SELECT * FROM user WHERE id = 5;步骤:直接走聚簇索引(主键B+树)
- 从根节点Page开始,二分查找
- 走到叶子节点Page
- 直接在叶子节点拿到整行数据(id=5, name='欧阳锋', age=56...)
磁盘I/O:3-4次(B+树的高度)
非聚簇索引查询(非主键查找)
sql
SELECT * FROM user WHERE name = '欧阳锋';步骤:
- 走name列上的非聚簇索引(另一棵B+树)
- 在非聚簇索引的叶子节点上找到:
name='欧阳锋'→ 主键id=5 - 拿着主键 id=5,再走聚簇索引(主键B+树)
- 在聚簇索引的叶子节点上拿到完整数据
磁盘I/O:4-8次(两次B+树查找)
这个"先找辅助索引,再回主键索引"的过程,就叫"回表"
什么时候不需要"回表"?(覆盖索引)
如果你查询的所有列都在非聚簇索引里,就不需要回表了。
sql
-- 只需要 name 和 id(id是主键)
SELECT id, name FROM user WHERE name = '欧阳锋';因为非聚簇索引的叶子节点里已经包含了 name 和 id,不需要再去聚簇索引里拿其他列。
这就叫"覆盖索引"------索引覆盖了查询需要的所有列。
聚簇索引的优缺点
| 优点 | 缺点 |
|---|---|
| 主键查询极快 | 插入依赖主键顺序(乱序插入可能导致页分裂) |
| 范围查询快(叶子节点链表) | 更新主键代价高(会导致数据物理移动) |
| 回表快(只需一次) | 非聚簇索引需要两次查找 |
| 节省空间(数据只存一份) |
一个常见面试题
问:为什么InnoDB表强烈建议设置一个自增整数作为主键?
答:
- 自增:新插入的主键值总是比之前的大,B+树在叶子节点最右边插入 → 页分裂次数最少 → 性能好
- 整数:聚簇索引的键值比较快(整数比较比字符串快得多)
- 不推荐用UUID做主键:UUID是随机的、很大的字符串 → 插入位置随机 → 频繁页分裂 → 性能差、空间浪费
总结一句话
聚簇索引 = 整个表本身就是B+树,数据挂在叶子节点上;非聚簇索引 = 另一棵B+树,叶子节点只挂主键值,需要"回表"才能拿到完整数据。