摘要 :MoCo(Momentum Contrast for Unsupervised Visual Representation Learning, He et al., 2020)是一篇把对比学习讲得非常"工程化"的经典论文:作者把对比学习看成 字典查找(dictionary look-up) ------给你一个查询向量 q q q,你要在一个很大的"字典"里找到与它匹配的正样本键 k + k^+ k+,并把其他键都当作负样本。MoCo 的关键创新是用 队列(queue) 动态维护一个很大的负样本字典,同时用 动量更新(EMA) 维护一个"慢变化"的 key encoder,让队列里的键向量长期保持一致性。这样就实现了:batch 不用很大,但负样本可以很多,训练稳定、可扩展,且迁移效果强。本文将把 MoCo 的动机、InfoNCE 损失、队列机制、动量编码器更新、Shuffling BN 等关键细节用更直观的方式讲清楚。
一句话理解 MoCo:让"学生编码器"负责学习、让"老师编码器"慢慢跟随;学生每次都去一个很大的"历史记忆库(队列)"里做对比学习,而不是只跟当前 batch 里的少量负样本比。
关键词:MoCo;Momentum Contrast;对比学习;InfoNCE;动量编码器(EMA);队列字典(queue);Shuffling BN;自监督视觉表征;负样本
系列文章(多模态路线相关):
- Transformer 31. ALBEF:Align before Fuse (https://zhuanlan.zhihu.com/p/2032736897567569131)
- Transformer 29. ViLT:Vision-and-Language Transformer 所有细节
- Transformer 28. CLIP(Contrastive Language--Image Pre-training)
- Transformer 27. Vision Transformer(ViT):把图像当作「词序列」的编码器
- (完整系列文章列表参见文章末尾)
0. MoCo 速览:输入什么?输出什么?
MoCo 的目标不是"直接做分类",而是 学一个视觉 encoder,让它输出"好用的特征",之后再迁移到分类/检测/分割等任务。
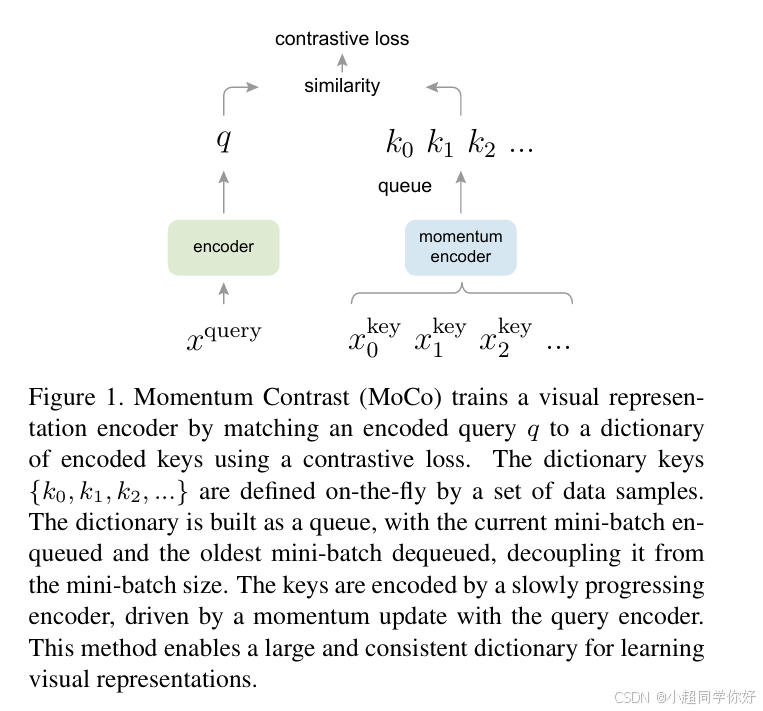
0.1 输入(Input)
对同一张图像 x x x 做两次独立随机增强(裁剪、颜色扰动等),得到两张不同视图(views / 增强版本):
- query view : x q x^q xq
- key view : x k x^k xk
💡 理解要点 :这里的两张视图只用于构造正样本对 : ( x q , x k ) (x^q, x^k) (xq,xk) 来自同一张原图 x x x。
图里看到的很多个 k 0 , k 1 , k 2 , ... k_0,k_1,k_2,\dots k0,k1,k2,...(队列 queue)对应的是负样本集合 ,来自历史 batch 的其它图像的 key 表征,并不是同一张 x x x 生成出来的很多个 key。
0.2 输出(Output)
- query 表征 : q = f q ( x q ) q = f_q(x^q) q=fq(xq)
- key 表征 : k = f k ( x k ) k = f_k(x^k) k=fk(xk)
- 队列字典 : { k 0 , k 1 , ... , k K − 1 } \{k_0, k_1, \dots, k_{K-1}\} {k0,k1,...,kK−1}(来自历史 batch 的 key 表征)
训练的目标是:让 q q q 与它对应的 正样本 k + k^+ k+ 更相似,让它与队列里的 负样本 更不相似。
💡 理解要点 :MoCo 的"自监督"来自数据增强:同一张图的两种视图算正样本,不同图算负样本。它没有人工标签,但会逼 encoder 学到"跨增强不变"的语义特征。
1. 先把对比学习讲清楚:InfoNCE 在做什么?
MoCo 使用的核心损失是 InfoNCE(对比损失的一种常用形式)。如果你之前看 CLIP 已经熟悉"相似度矩阵 + softmax + 交叉熵",那么 MoCo 其实就是"同一套损失",只是把 负样本来源 从 "in-batch" 改成了 "queue"。(下面我们会详细解释和对比两者差别)
设 q q q 的正样本为 k + k^+ k+,负样本集合为 { k i } \{k_i\} {ki}(来自队列),温度为 τ \tau τ,相似度用点积(通常都做 L2 normalize 让点积=余弦相似度)。单个样本的 InfoNCE:
L = − log exp ( q ⋅ k + / τ ) exp ( q ⋅ k + / τ ) + ∑ i = 1 K exp ( q ⋅ k i / τ ) . \mathcal{L} = -\log \frac{\exp(q\cdot k^+/\tau)}{\exp(q\cdot k^+/\tau) + \sum_{i=1}^{K}\exp(q\cdot k_i/\tau)}. L=−logexp(q⋅k+/τ)+∑i=1Kexp(q⋅ki/τ)exp(q⋅k+/τ).
🔍 实际例子 :想象你把"同一只猫"的两张增强图当作一对朋友(正样本),队列里塞了几万张"别的动物/别的猫/别的场景"(负样本)。InfoNCE 就是在问:在这么多候选里,模型能不能把真正的朋友排到第一名?
2. 对比 MoCo 和 CLIP
这一节非常重要,因为 ALBEF 的 ITC / MoD 就是在 "CLIP 的对齐目标" 与 "MoCo 的队列+动量机制" 之间做组合与改造。
一个结论先:
- 相同点(核心) :二者都在做 "softmax + 交叉熵" 的 检索式多分类:对每个 query,在很多候选里把唯一正确的正样本选出来。
- 不同点(关键):负样本候选集的来源、logits 的形状、是否对称、以及是否需要 momentum encoder 来保证候选集的一致性。
2.1 同一件事:都是"让正确匹配在 softmax 里概率最大"
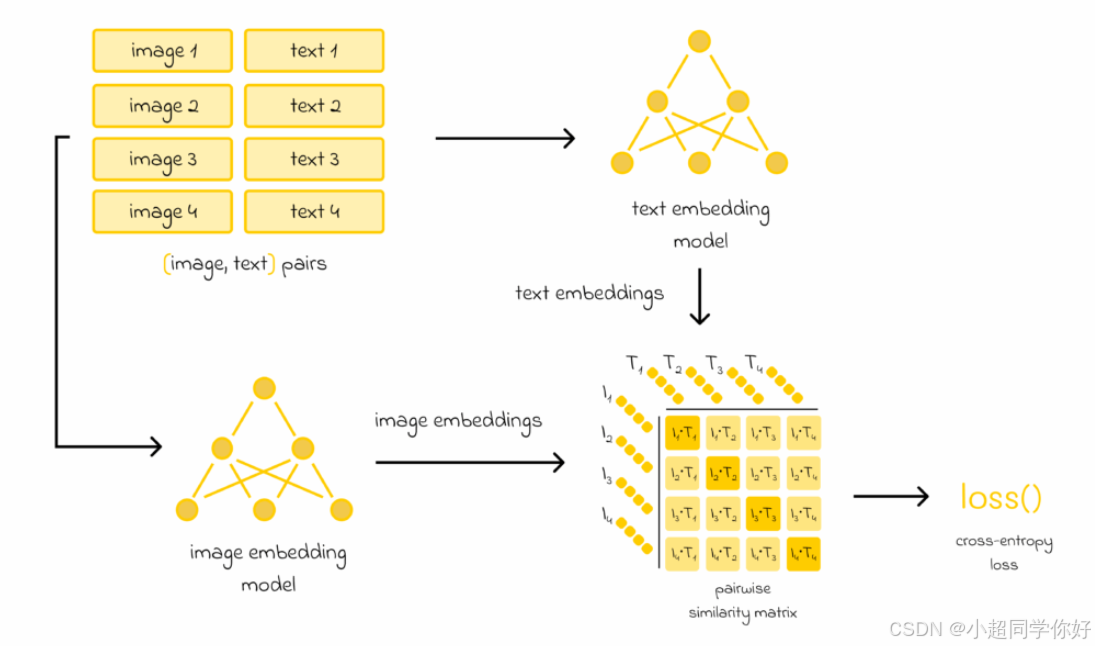
CLIP(以图像→文本方向为例):
- batch 有 N N N 对图文,得到相似度矩阵 L ∈ R N × N \mathbf{L}\in\mathbb{R}^{N\times N} L∈RN×N,其中
L i , j = τ ⋅ i i ⊤ t j . L_{i,j} = \tau \cdot \mathbf{i}_i^\top \mathbf{t}_j. Li,j=τ⋅ii⊤tj.
- 对每一行做 softmax,标签是对角线 y i = i y_i=i yi=i:
L i → t CLIP = C E ( L , y ) . \mathcal{L}^{\text{CLIP}}_{i\to t} = \mathrm{CE}(\mathbf{L}, \mathbf{y}). Li→tCLIP=CE(L,y).
MoCo(单个 query):
- 只有 1 个正样本 k + k^+ k+,以及 K K K 个负样本(来自队列),得到 logits 向量 ℓ ∈ R K + 1 \ell\in\mathbb{R}^{K+1} ℓ∈RK+1:
ℓ 0 = q ⊤ k + / τ , ℓ j = q ⊤ k j / τ ( j = 1 ... K ) . \ell_0 = q^\top k^+/\tau,\quad \ell_j = q^\top k_j/\tau\ (j=1\dots K). ℓ0=q⊤k+/τ,ℓj=q⊤kj/τ (j=1...K).
- 对 logits 做 softmax,标签恒为 0(正样本在第 0 位):
L MoCo = C E ( ℓ , 0 ) . \mathcal{L}^{\text{MoCo}} = \mathrm{CE}(\ell, 0). LMoCo=CE(ℓ,0).
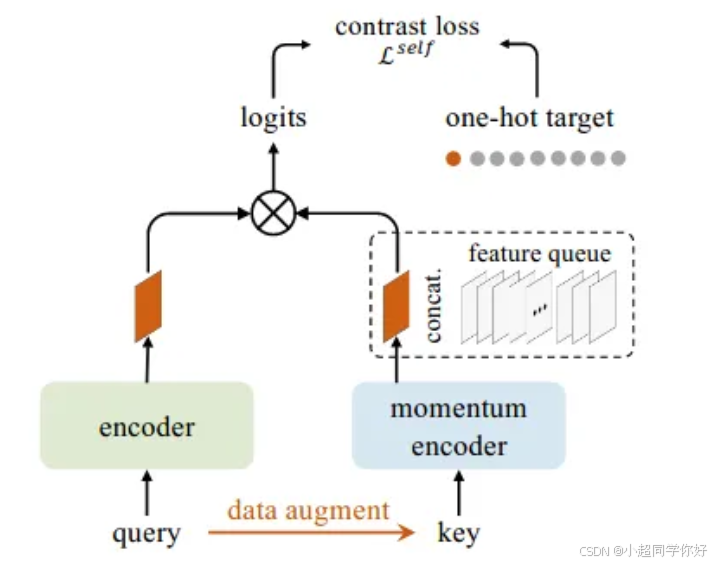
💡 理解要点 :你可以把 CLIP 的 " N × N N\times N N×N" 想成 同时做了 N 次 MoCo:每行都是一个 query 的 "在 N 个候选文本里选对的那个"。
2.2 最关键差别 1:负样本来自哪里?
-
CLIP / SimCLR(in-batch negatives) :负样本主要来自 当前 batch 的其它样本。
- 优点:实现简单、完全端到端更新。
- 缺点:想要很多负样本往往需要 大 batch(更吃显存/算力)。
-
MoCo(queue negatives) :负样本主要来自 队列 queue(历史多个 batch 的 key 表征)。
- 优点:batch 不用很大也能有很多负样本( K K K 可很大)。
- 代价:因为 key 来自历史,需要解决"历史 key 一致性"问题 → 引出动量编码器。
2.3 最关键差别 2:为什么 MoCo 需要 momentum encoder?
如果把队列里的 key 看成"候选字典",那么这个字典必须满足一个基本条件:候选向量处在同一个坐标系里,才能比较大小。
- CLIP 的负样本都来自同一个 batch 的同一次前向,坐标系天然一致。
- MoCo 的负样本来自很多过去的 step,如果 encoder 每步变化很快,队列里的旧 key 会"用旧坐标系编码",新旧 key 不可比 → 训练抖动甚至崩。
因此 MoCo 用 EMA:
θ k ← m θ k + ( 1 − m ) θ q \theta_k \leftarrow m\theta_k + (1-m)\theta_q θk←mθk+(1−m)θq
让 key encoder "慢更新",保证队列里一段时间内的 key 比较一致。
2.4 重要差别 3:CLIP 通常是"双向对称",MoCo 通常是"单向"
- CLIP:一般做两次 CE:图像→文本 与 文本→图像,取平均(对称)。
- MoCo:通常只做 query→keys 的一个方向(但本质仍是同一个 InfoNCE/softmax-CE 框架)。
2.5 一张"形状对照表"(建议你记住)
| 项目 | CLIP | MoCo |
|---|---|---|
| 正样本数量(每个 query) | 1 | 1 |
| 负样本来源 | 当前 batch 其它样本(in-batch) | 历史队列(queue) |
| logits 形状 | N × N N\times N N×N(每行一个 query) | ( K + 1 ) (K+1) (K+1)(每个 query 一条向量) |
| 是否对称方向 | 通常是(i→t + t→i) | 通常否(q→k) |
| 是否需要 momentum encoder | 不需要(同 step 一致) | 需要(跨 step 一致) |
🔍 实际例子 :如果你的 batch 是 N = 256 N=256 N=256,CLIP 每个 query 只有 255 个负样本;但 MoCo 可以轻松设队列 K = 65536 K=65536 K=65536,每个 query 一步就能对比 6 万多个负样本。MoCo 的贡献就在于"把负样本数量从 batch 大小里解耦出来"。
3. MoCo 的核心动机:为什么要把对比学习看成"字典查找"?
- 字典里的每个 key 都是一个向量(特征)
- query 也是一个向量
- 正样本就是"应该匹配的那个 key"
于是训练就变成了:让 query 在一个很大的字典里匹配到正样本。
这里有两个矛盾目标:
- 字典要大:负样本多,学习信号强(更不容易"侥幸"学到坏特征)。
- 字典要一致(consistent):字典里的 key 不应该因为 encoder 变化太快而"前后不是同一种坐标系"。
MoCo 的两个设计正好分别解决这两点:队列让字典大;动量编码器让字典一致。
4. 关键设计 1:队列(Queue)------让负样本很多,但不需要超大 batch
4.1 为什么 CLIP/SimCLR 会"依赖大 batch"?
如果负样本只来自当前 batch,那么 batch 越小,负样本越少;而 InfoNCE 的分母里要对负样本求和,负样本太少时训练容易不稳定或效果差(很多讲解都会强调这一点,例如 Youngdo Lee, 2023)。
4.2 常见疑问:负样本越多,正负比例越不均衡,会不会不稳定?
这是一个非常"监督学习直觉"的问题:我们常说类别不均衡会导致模型偏向多数类。但 MoCo/SimCLR/CLIP 的对比学习 其实不是传统意义的"正 vs 负二分类采样",而更像是一个 softmax 的检索/多分类问题。
把 InfoNCE 写出来(单个 query):
L = − log exp ( q ⋅ k + / τ ) exp ( q ⋅ k + / τ ) + ∑ i = 1 K exp ( q ⋅ k i / τ ) . \mathcal{L} = -\log \frac{\exp(q\cdot k^+/\tau)}{\exp(q\cdot k^+/\tau) + \sum_{i=1}^{K}\exp(q\cdot k_i/\tau)}. L=−logexp(q⋅k+/τ)+∑i=1Kexp(q⋅ki/τ)exp(q⋅k+/τ).
你可以把它理解为:对每个 q q q,在 ( K + 1 ) (K+1) (K+1) 个候选 key 里做 softmax,要求模型把 唯一正确的那个正样本 k + k^+ k+ 排到第一名。
在这种设定里,"负样本多"并不是类别不均衡问题,而是 候选集合变大了,任务变难了。
💡 理解要点:对比学习里最典型的监督信号就是 "1 个正样本 + 很多负样本"。它不是 bug,反而是让表示更区分、更泛化的关键来源。
为什么大量负样本通常不会导致训练不稳定?
- softmax 会自动归一化 :并不是每个负样本都会同等影响梯度。相似度很低的"容易负样本" ⇒ exp ( ⋅ ) \Rightarrow \exp(\cdot) ⇒exp(⋅) 很小,几乎不贡献梯度;真正主导梯度的是少数"难负样本"。
- 温度 τ \tau τ 控制梯度的"软硬" : τ \tau τ 小 → 分布更尖、更关注最难的负样本; τ \tau τ 大 → 更平滑、更稳。
- 负样本多降低"侥幸与走捷径"的概率:负样本太少时模型可能靠肤浅线索也能分开;负样本多时更逼迫模型学更稳定的语义特征。
对比学习更常见的风险是什么?(这比"比例不均衡"更值得担心)
- False negative:队列里可能有语义相近样本,被当作负样本推开,会伤害上限。
- 字典不一致:key encoder 变化太快导致队列里的 key 前后不可比,MoCo 用 EMA 专门解决这个问题。
4.3 MoCo 怎么做?
MoCo 维护一个 FIFO 队列,存储最近若干个 batch 的 key 表征:
- 当前 batch 的 key 表征 入队(enqueue)
- 队列最旧的一批 key 表征 出队(dequeue)
这样负样本数 K K K 就可以很大(比如几万),同时当前 batch 可以保持中等大小。
💡 理解要点:队列就像一个"滚动的负样本记忆库"。你不需要一次性把所有负样本塞进 GPU(超大 batch),但你依然可以在训练时"看到"很多负样本。
5. 关键设计 2:动量编码器(Momentum Encoder)------让队列里的 key 不至于"过期得太快"
如果 key encoder f k f_k fk 每一步都像 query encoder f q f_q fq 一样用反向传播快速更新,那么队列里旧 key 的坐标系会变得非常"老旧",新旧 key 不可比,字典就不一致。
MoCo 的做法是:不对 key encoder 反向传播 ,而是用 query encoder 的参数做指数滑动平均(EMA)更新:Youngdo Lee, 2023:
θ k ← m θ k + ( 1 − m ) θ q , \theta_k \leftarrow m\,\theta_k + (1-m)\,\theta_q, θk←mθk+(1−m)θq,
其中 m ∈ [ 0 , 1 ) m\in[0,1) m∈[0,1) 通常取很大(如 0.999)。
💡 理解要点:
- θ q \theta_q θq:学生,更新很快(梯度下降)。
- θ k \theta_k θk :老师,更新很慢(EMA)。
老师慢慢跟着学生走,于是"老师产出的 key"在一段时间内处于同一坐标系,队列就更一致。
为什么队列里的 key 不能"过期得太快":
你可以把 encoder 想成一把"测量相似度的尺子"(也就是特征空间的坐标系)。队列里存的 key 是过去很多步用当时的 key encoder 算出来的:
- 第 t t t 步入队: k ( t ) = f k ( t ) ( x ) k^{(t)} = f_k^{(t)}(x) k(t)=fk(t)(x)
- 第 t + Δ t+\Delta t+Δ 步训练:我们还会拿当前的 q ( t + Δ ) q^{(t+\Delta)} q(t+Δ) 去和这些旧 key 做点积比较
如果 key encoder 每一步都像 f q f_q fq 那样被反向传播"快速改变",那么 f k ( t ) f_k^{(t)} fk(t) 和 f k ( t + Δ ) f_k^{(t+\Delta)} fk(t+Δ) 之间差异会很大,相当于"尺子的刻度每天都在改"。这会带来两个直接后果:
- 新旧 key 不可比:旧 key 来自旧坐标系,新 key 来自新坐标系,把它们混在一起做相似度排序会失真。
- 训练信号抖动:今天 loss 逼你把某些旧 key 推远;明天坐标系变了,同样的旧 key 可能又"不那么像负样本"了,梯度方向来回摇摆,整体更不稳定。
🔍 实际例子 :假设队列长度 K = 65536 K=65536 K=65536,batch size B = 256 B=256 B=256,那么一个 key 平均要在队列里停留约 K / B ≈ 256 K/B\approx256 K/B≈256 个 step 才会被挤出。如果 key encoder 在这 256 步内变化很大,那么队列里大部分 key 都会"用过期尺子测出来",字典一致性就会变差。
这就是 MoCo 需要用 EMA( m ≈ 0.999 m\approx0.999 m≈0.999) 让 f k f_k fk "慢慢变",保证队列在一段时间内仍处于近似同一坐标系。
6. 一段最关键的伪代码:把 MoCo 的训练循环串起来
下面这段是"论文思路版"的伪代码(更接近你读 CLIP 时的思维方式),把队列和动量更新放在同一个循环里:

🔍 实际例子:你可以把它想象成"做题":
- 学生 f q f_q fq 每次做完题就立刻改进(梯度更新)。
- 老师 f k f_k fk 每天晚上把学生今天学到的东西"慢慢记下来"(EMA)。
- 题库(queue)不断更新:今天新题进来,最老的题出库。
7. Shuffling BN:为什么还要"打乱 BatchNorm"?
如果 encoder 里用了 BatchNorm,那么同一个 batch 内的样本会在 BN 统计量里"互相通信"。论文指出这会带来信息泄露(model 可能走捷径),影响对比学习质量,于是提出 Shuffling BN (多卡训练时对 key 分支打乱样本顺序,算完再还原)。这一点在 Youngdo Lee, 2023 里解释得很清楚。
💡 理解要点:对比学习希望每个样本"独立抽特征",不要在 batch 内互通消息,否则模型可能利用 batch 统计信息做作弊式匹配。
8. 关于 MoCo v2
MoCo v2(后续工作)主要参考 SimCLR 的一些经验:更强的数据增强、MLP projection head 等,让线性评估更高。参考:Youngdo Lee 文章对 v2 的总结;也可看 5 分钟速读:Casual GAN Papers。这篇博客我们不继续研究 v2 版本。
💡 理解要点:MoCo 的"骨架创新"是 queue+momentum;v2 更像是在这个骨架上借鉴 SimCLR 的训练 recipe。
9. MoCo 在 ALBEF 中的作用
我们在读 ALBEF 时会反复看到 "momentum model / queue / 对比学习" 这些关键词,它们背后的工程直觉很大一部分来自 MoCo。
可以把 MoCo 在 ALBEF 里的作用理解为:把对比学习做得更"可扩展"和更"稳定"。
- ALBEF 的 ITC(对比学习) :借鉴 MoCo 的 "队列字典" 思想,用更大的负样本集合做对比学习,让图文对齐更有区分度。
- ALBEF 的 Momentum Distillation(MoD) :借鉴 MoCo 的 "动量编码器/EMA teacher" 思想,让 teacher 输出变化更平滑,用软目标缓冲网页噪声带来的训练抖动。
- 整体效果 :相比只用 in-batch negatives 的做法,ALBEF 更容易在 噪声更大、规模更大 的图文数据上稳定训练。
🔍 实际例子:当网页 caption 很多噪声时,动量模型输出的 soft target 往往比 one-hot 更"温和",不至于把模型往错误方向硬拉------这正是你在 ALBEF 里看到的 Momentum Distillation 的直觉来源。
10. 小结
- MoCo 的贡献 :把对比学习抽象成"字典查找",提出 队列字典(大负样本) + 动量编码器(字典一致性) 的组合。
- 训练节奏:只反传更新 query encoder;key encoder 用 EMA 跟随;key 表征进入队列滚动维护。
- 为什么重要:它是后续大量多模态/自监督方法里"动量教师 + 负样本库"范式的源头之一,读懂它能显著降低你读 ALBEF 的门槛。
参考与引用:
- 论文(PDF):Momentum Contrast for Unsupervised Visual Representation Learning
- 论文(摘要页):arXiv:1911.05722
- 入门讲解(结构直观):Easily Explained: MoCo | Nour Eldin Alaa, Medium, 2022
- 更系统的公式/细节(含 Shuffling BN):Representation Learning The MoCo Family | Youngdo Lee, 2023
- 5 分钟速读(队列/动量直觉不错):MoCo v1 & v2 Explained | Casual GAN Papers
系列文章:
- Transformer 29. ViLT:Vision-and-Language Transformer 所有细节
- Transformer 28. CLIP(Contrastive Language--Image Pre-training)
- Transformer 27. Vision Transformer(ViT):把图像当作「词序列」的编码器
- Transformer 26. Gated DeltaNet 架构详解与 Qwen 3.5 的联系:把「精准改写」的 Delta Rule 和「一键清空」的 Gating 组合起来
- Transformer 25. Gemma 2 架构详解:交替局部/全局注意力、GQA、双层 RMSNorm 与 Logit Soft-Capping
- Transformer 24. Linear Transformer(Linear Attention)详解:用核技巧把 O(L^2) 注意力变成 O(L)
- Transformer 23. Qwen 3.5 架构介绍:混合线性/全注意力、MoE 与相对 Qwen 1 / 2 / 3 的演进
- Transformer 22. Gemma 1 架构详解:Decoder-only、GeGLU、RoPE 与每一步计算
- Transformer 21. 从 LLaMA 到 Qwen:Rotary Position Embedding(RoPE)与 YaRN 一文读懂
- Transformer 20. Qwen 3 架构介绍:模块详解与相对 Qwen 1 / Qwen 2 的演进
- Transformer 19. Qwen 2 架构介绍:相对 Qwen 1 / Qwen 1.5 的演进与 MoE 扩展
- Transformer 18. DeepSeek-R1 解析:用强化学习激励推理能力------架构、训练与「为什么看起来更聪明」
- Transformer 17. Qwen 1 / Qwen 1.5 架构介绍以及与 Transformer、LLaMA 的对比
- Transformer 16. DeepSeek-V3 架构解析:在 MLA + DeepSeekMoE 上的规模化与训练/系统创新
- Transformer 15: DeepSeek-V2 架构解析:MLA + DeepSeekMoE 与主流架构对比
- Transformer 14. DeepSeekMoE 架构解析:与 LLaMA 以及 Transformer 架构对比
- Transformer 13. DeepSeek LLM 架构解析:与 LLaMA 以及 Transformer 架构对比
- Transformer 12. LLaMA 架构介绍以及与 Transformer 架构对比
- Transformer 11. Encoder-Decoder Transformer 经典架构以及每一步骤的详细计算
- Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算
- Transformer 9. Decoder-Encoder 层多头自注意力机制
- Transformer 8. Decoder: 掩码注意力机制以及数学推导
- Transformer 7. Decoder:架构选择、Teacher Forcing 与并行计算
- Transformer 6. Encoder 模块总结 以及 Autoencoder 介绍
- Transformer 5. Transformer中的残差连接、归一化与前馈神经网络
- Transformer 4. Embedding层与位置编码技术
- Transformer 3. Transformer的整体架构
- Transformer 2. Attention 注意力机制
- Transformer 1. 讲在 Transformer 之前:序列模型的基本思路与根本诉求