1、项目介绍
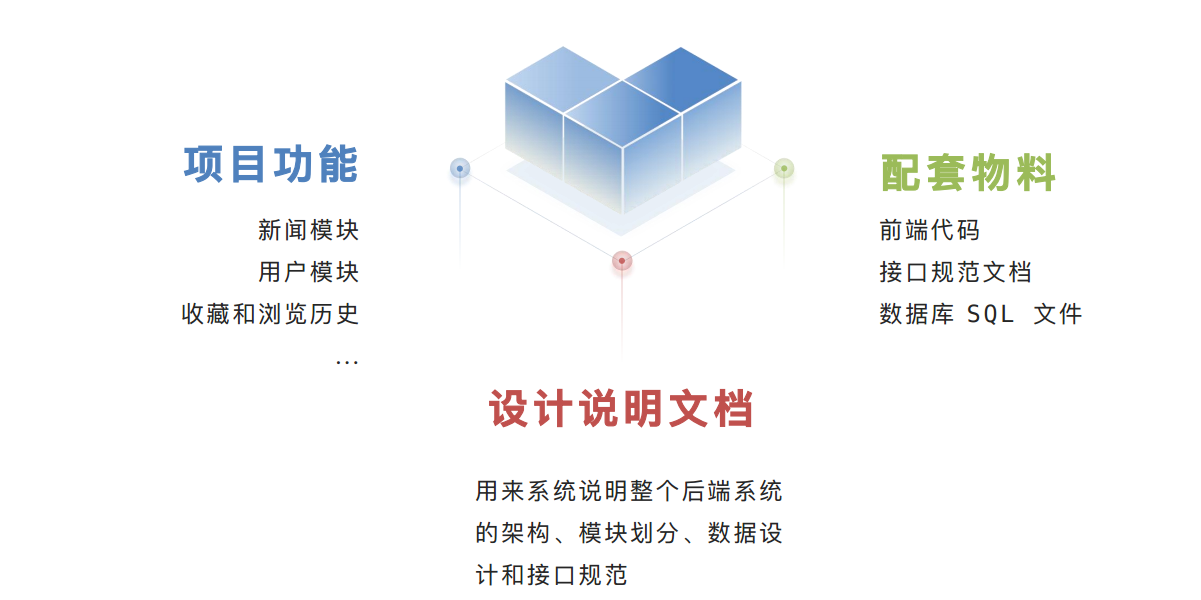
1.1 配套的资料

1.2 运行前端项目

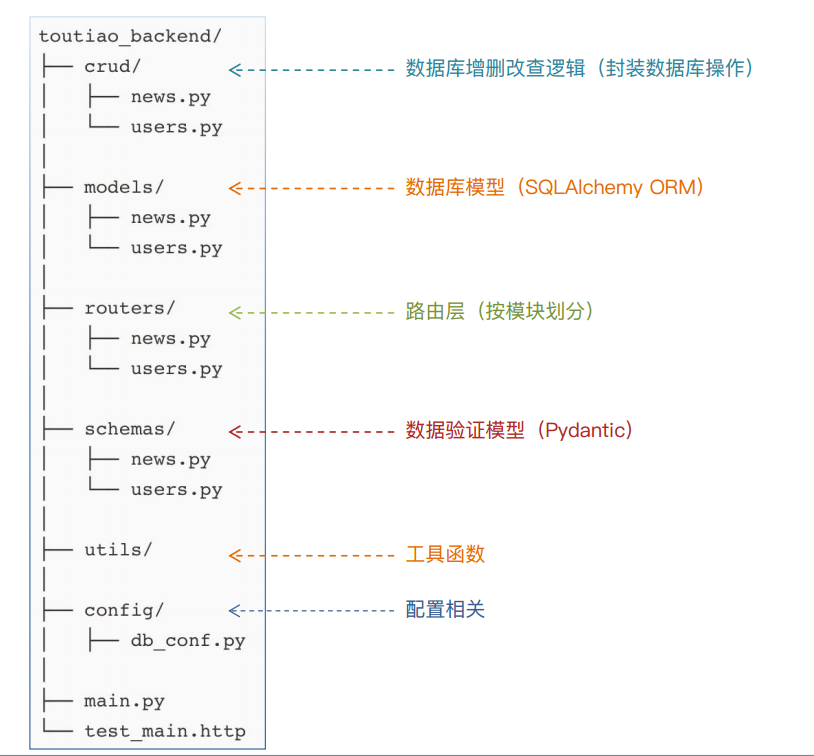
1.3 工程结构
1.4 模块化路由

模块化路由就是把每个业务功能的接口拆分 到独立文件里,再统一挂载到主应用中。
1.4.1 特点
- 项目结构更清晰
- 接口按模块拆分,不会混在一起,让整个项目结构更直观
- 更易维护
- 每个模块都负责自己对应的接口,便于快速查找和定向修改
- 避免 main.py 爆炸
- 把接口拆分出去后,main.py就只负责启动应用,不再堆满业务代码
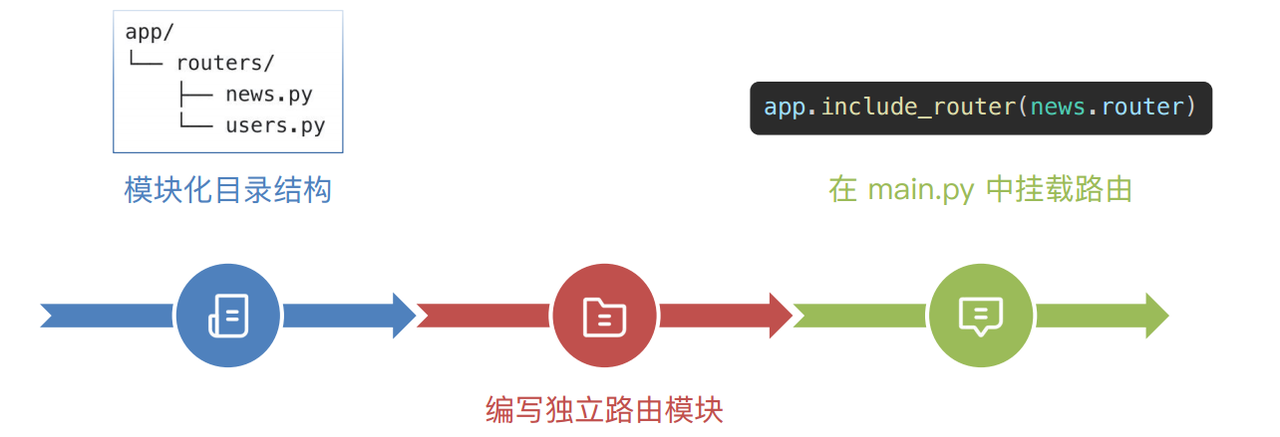
在routers目录下新建一个news.py文件
python
from fastapi import APIRouter
# 创建APIrouter实例
router = APIRouter(prefix="/api/news",tags=["news"])
# 创建路由处理函数
@router.get("/categories")
async def get_categories():
return {"message": "获取分类成功"}在main.py中挂载路由
python
from fastapi import FastAPI
from routers import news
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
# 挂载路由/注册路由
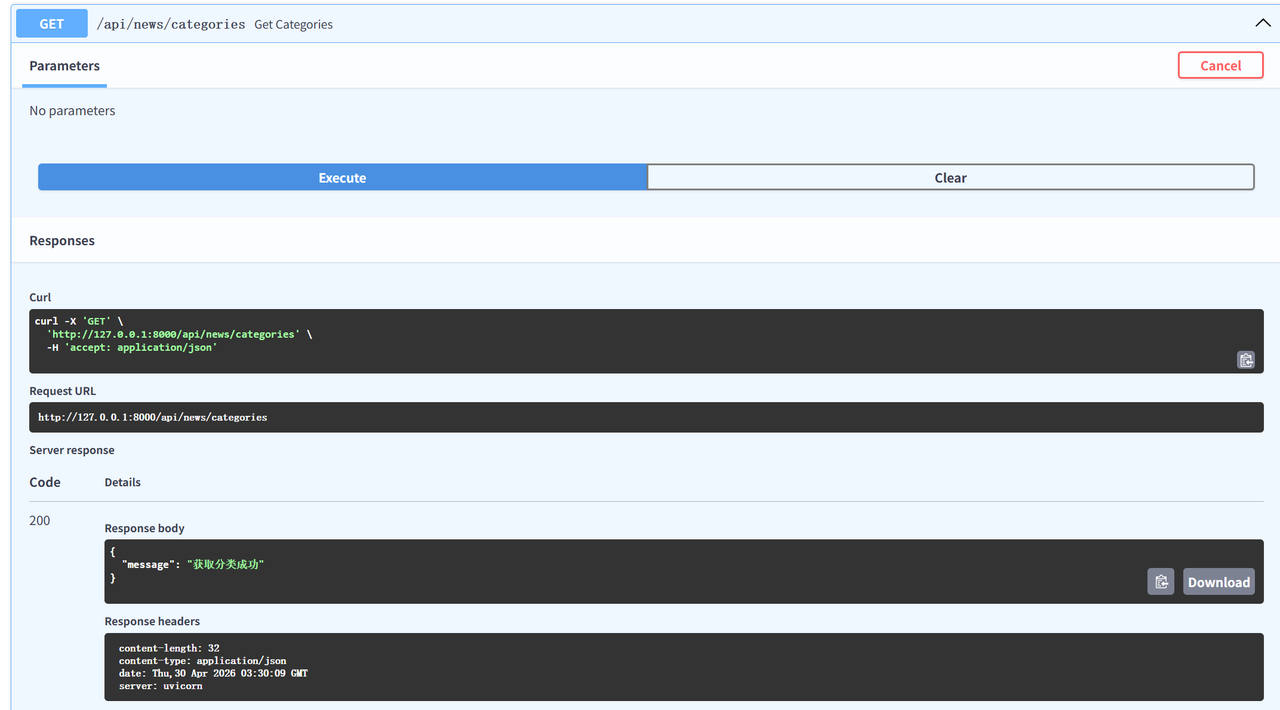
app.include_router(news.router)接着启动项目测试,看接口是否加载成功
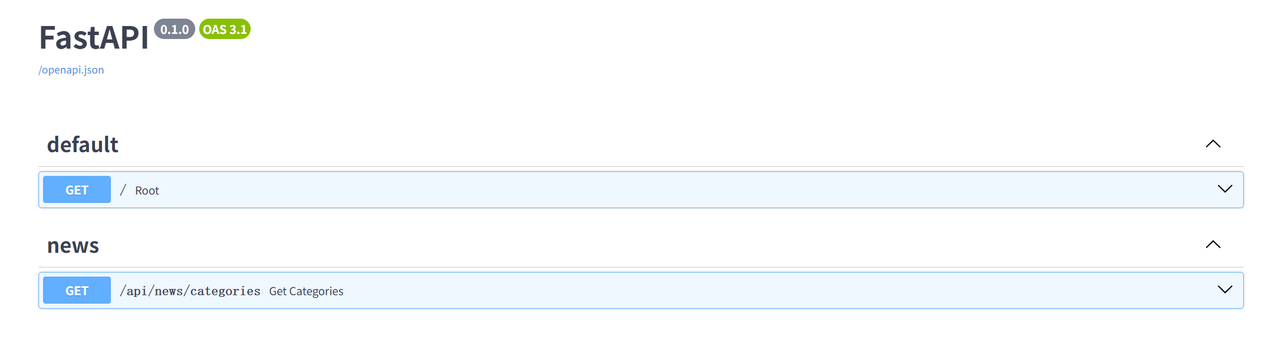
然后执行接口测试一下
1.4.2 小结
1、什么是模块化路由?有什么优势?
模块化路由就是把每个业务功能的接口拆分到独立文件里,再统一挂载到主应用中。
优势:项目结构更清晰、项目更易维护
2、说出下方代码的含义
python
# 1. 从 fastapi 库中导入 APIRouter 工具
from fastapi import APIRouter
# 2. 创建一个路由对象(专门管理新闻相关的接口)
router = APIRouter(
prefix="/api/news", # 接口前缀:所有这个路由下的接口,URL 都会以这个开头
tags=["news"] # 接口文档标签:方便在文档里分类查看
)
# 3. 定义一个 GET 接口
@router.get("/categories")
async def get_categories():
# 4. 接口返回的数据
return {"msg": "获取分类成功"}
- APIRouter = 接口分类管理工具
- prefix = 给接口统一加 URL 前缀
- @router.get = 定义 GET 接口
- 完整接口地址:/api/news/categories
- 返回固定的 JSON 成功消息
3、如何注册路由?
在 main.py 中添加 app.include_router()
2、数据库和配置ORM
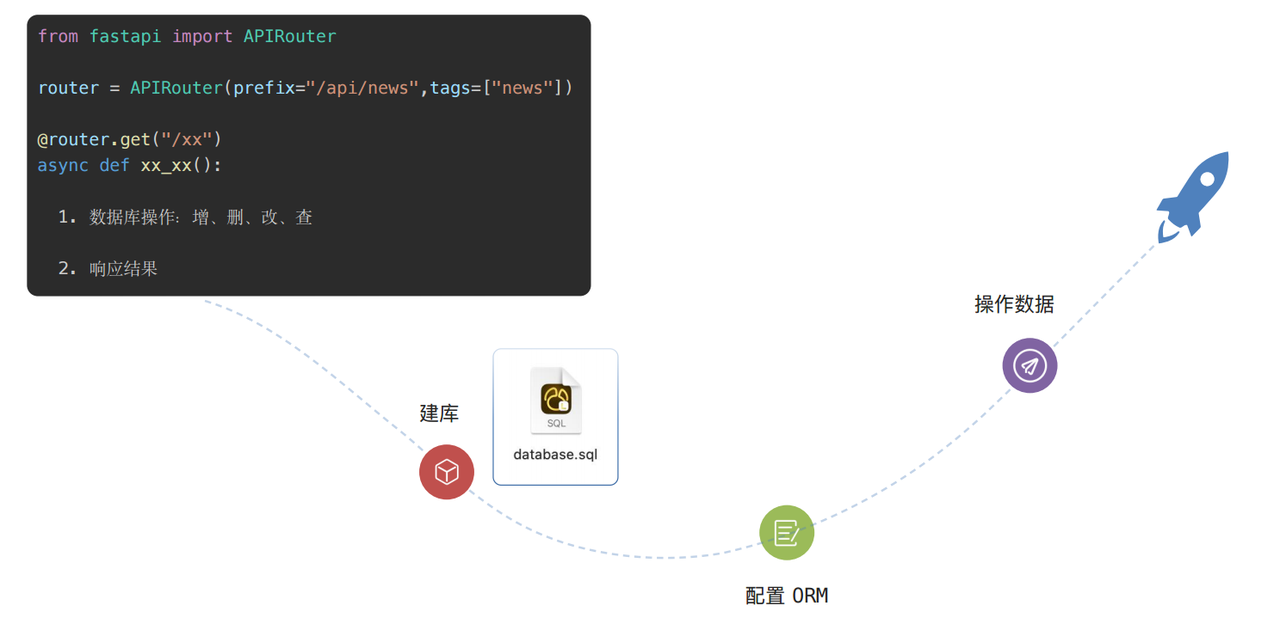
2.1 创建流程

2.2 配置 ORM
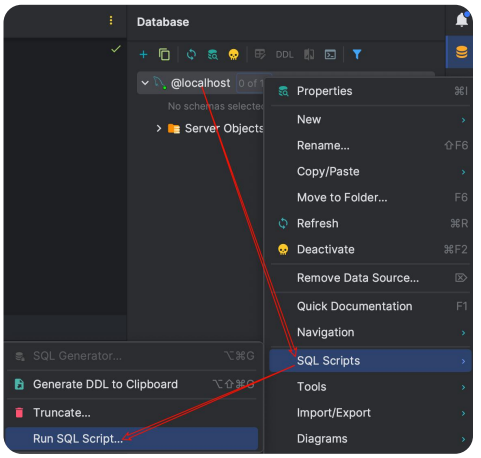
MySQL 导入 SQL 文件:
PyCharm中 Database 插件 → 数据库连接 → 右键 → SQL Script → Run SQL Script → 浏览 SQL 文件 → 确认
1、安装SQLAlchemy
python
pip install "sqlalchemy[asyncio]" aiomysql2、ORM 配置
python
from sqlalchemy.ext.asyncio import async_sessionmaker, AsyncSession, create_async_engine
# 数据库URL
ASYNC_DATABASE_URL = "mysql+aiomysql://root:123456@localhost:3306/news_app?charset=utf8mb4"
# 创建异步引擎
async_engine = create_async_engine(
ASYNC_DATABASE_URL,
echo=True, # 可选:输出SQL日志
pool_size=10, # 设置连接池中保持的持久连接数
max_overflow=20 # 设置连接池允许创建的额外连接数
)
# 创建异步会话工厂
AsyncSessionLocal = async_sessionmaker(
bind=async_engine,
class_=AsyncSession,
expire_on_commit=False
)
# 依赖项,用于获取数据库会话
async def get_db():
async with AsyncSessionLocal() as session:
try:
yield session
await session.commit()
except Exception:
await session.rollback()
raise
finally:
await session.close()3、项目功能开发
3.1 新闻模块

1、获取新闻分类

2、接口实现流程:

1️⃣ 模块化路由(API 入口层)
作用:定义接口的 URL 结构,实现接口的模块化管理。
- 定义
APIRouter实例,给不同模块(如新闻、用户)创建独立路由。 - 给路由设置
prefix(统一前缀)和tags(文档分类)。 - 在主程序中用
include_router()注册路由,挂载到 FastAPI 应用。 - 遵循接口规范文档,统一接口风格和路径设计。
2️⃣ 定义模型类(数据库映射层)
作用:用 Python 类映射数据库表结构,让 ORM 能操作数据库。
- 继承 SQLAlchemy 的
DeclarativeBase创建基类Base。 - 为每个数据库表定义对应的模型类(如
Category、News)。 - 用
tablename指定表名,用mapped_column定义字段、类型、约束(主键、外键、索引等)。 - 字段设计完全参照数据库表结构,确保一一对应。
3️⃣ 数据库 CRUD(数据操作层)
作用:实现对数据库的增删改查操作,封装业务逻辑的数据交互。
- 查询 :用
select(模型类)语句,配合await session.execute()获取数据。 - 新增 :用
session.add()把模型对象加入会话,再await session.commit()保存。 - 更新 :通过
update()语句修改字段值,提交事务。 - 删除 :通过
delete()语句删除数据,提交事务。 - 所有操作都通过异步
AsyncSession完成,保证事务安全。
4️⃣ 路由调用逻辑(接口业务层)
作用:连接路由、依赖和 CRUD,处理请求并返回响应。
- 用
Depends(get_db)注入数据库会话,在接口函数中拿到session。 - 调用第 3 步封装的 CRUD 函数,完成业务逻辑(如获取新闻列表、新增分类)。
- 处理请求参数、异常情况,返回统一格式的响应结果(如 JSON)。
3、获取新闻分类列表
1️⃣ 接口文档
- 接口地址 :
GET /api/news/categories - 请求参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| skip | integer | 否 | 跳过的记录数,默认为0 |
| limit | integer | 否 | 返回的记录数限制,默认为100 |
- 请求示例:
plain
GET /api/news/categories
GET /api/news/categories?skip=0&limit=10- 响应示例:
json
{
"code": 200,
"message": "success",
"data": [
{
"id": 1,
"created_at": "2023-01-01T00:00:00",
"updated_at": "2023-01-01T00:00:00",
"name": "科技",
"sort_order": 0
}
]
}代码实现:
python
router = APIRouter(prefix="/api/news", tags=["news"])
@router.get("/categories")
async def get_categories(skip: int=0, limit: int=100):
return {
"code": 200,
"message": "success",
"data": "新闻分类列表"
}
接口实现流程
-
模块化路由->API接口规范文档
-
定义模型类->数据库表(数据库设计文档)
-
在crud文件夹里面创建文件,封装操作数据库的方法
-
在路由处理函数里面调用 crud封装好的方法,响应结果
2️⃣ 定义模型类
模型类规范:
- 基类 ,继承 DeclarativeBase
- 数据库表模型类 ,继承基类
- 属性及类型参照数据库表定义
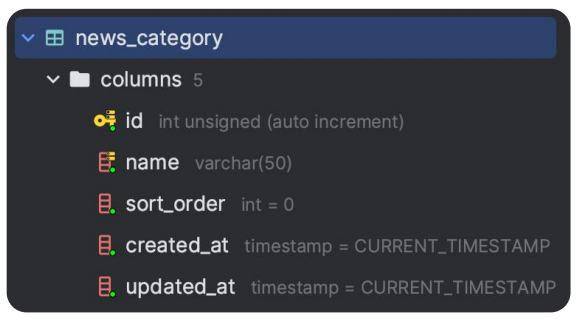
- 属性及类型参照数据库表定义
模型类,就是对应表数据库表的字段
python
from datetime import datetime
from sqlalchemy import DateTime
from sqlalchemy.orm import DeclarativeBase,Mapped, mapped_column
from sqlalchemy import Integer,String
class Base(DeclarativeBase):
created_at: Mapped[datetime] = mapped_column(
DateTime,
default=datetime.now,
comment="创建时间"
)
updated_at: Mapped[datetime] = mapped_column(
DateTime,
default=datetime.now,
onupdate=datetime.now,
comment="更新时间"
)
class Category(Base):
__tablename__ = "news_category"
id: Mapped[int] = mapped_column(
Integer,
primary_key=True,
autoincrement=True,
comment="分类id"
)
name: Mapped[str] = mapped_column(
String(50),
unique=True,
nullable=False,
comment="分类名称"
)
sort_order: Mapped[int] = mapped_column(
Integer,
default=0,
nullable=False,
comment="排序"
)
def __repr__(self):
return f"<Category(id={self.id}, name={self.name}, sort_order={self.sort_order})>"3️⃣ 数据库 CRUD
实现增删改查的数据库方法
python
from sqlalchemy import select
from sqlalchemy.ext.asyncio import AsyncSession
# 导入模型类
from models.news import Category
async def get_categories(db: AsyncSession,skip: int=0, limit: int=100):
stmt = select(Category).offset(skip).limit(limit)
result = await db.execute(stmt)
return result.scalars().all()4️⃣ 路由调用逻辑
在模块化路由中调用实现增删改查的数据库方法
python
from fastapi import APIRouter,Depends
from sqlalchemy.ext.asyncio import AsyncSession
from config.db_config import get_db
from crud import news
# 创建APIrouter实例
# prefix 路由前缀(API 接口规范文档)
# tags 分组 标签
router = APIRouter(prefix="/api/news",tags=["news"])
# 接口实现流程
# 1. 模块化路由->API接口规范文档
# 2. 定义模型类->数据库表(数据库设计文档)
# 3. 在crud文件夹里面创建文件,封装操作数据库的方法
# 4. 在路由处理函数里面调用 crud封装好的方法,响应结果
# 创建路由处理函数
@router.get("/categories")
async def get_categories(skip: int=0, limit: int=100, db: AsyncSession = Depends(get_db)):
# 先获取数据库里面的新闻分类数据->先定义模型类->封装查询数据的方法
categories = await news.get_categories(db,skip,limit)
return {
"code": 200,
"message": "success",
"data": categories
}接口测试
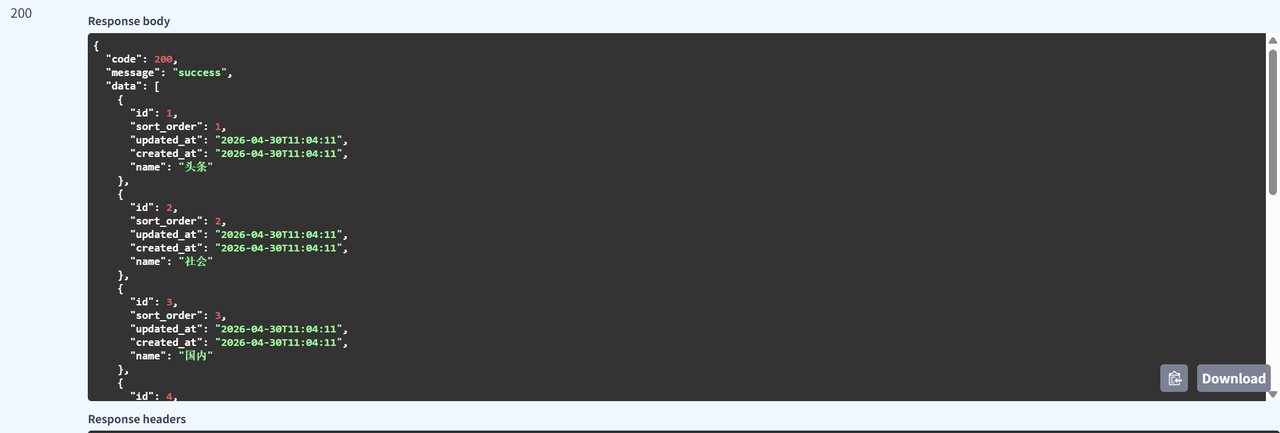
4、跨域资源共享 CORS
跨域资源共享(CORS)是一种浏览器安全机制 ,用于允许运行在一个源(Origin)的 Web 应用,通过浏览器向另一个源的服务器发起跨域 HTTP 请求,并在服务器授权的前提下获取资源。
同源的三个条件:
- 协议
- 域名
- 端口

1️⃣ CORS 中间件
CORS:让后端主动告诉浏览器:这个前端"允许访问"。
python
from fastapi.middleware.cors import CORSMiddleware
# 允许的来源(可以是域名列表)
origins = [
"http://localhost",
"http://localhost:3000",
"https://your-frontend-domain.com"
]
# 添加 CORS 中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许访问的源,开发时候可以使用*,项目上线就不能使用了,需要写一个能访问的列表
allow_credentials=True, # 允许携带 Cookie
allow_methods=["*"], # 允许所有请求方法
allow_headers=["*"], # 允许所有请求头
)2️⃣ 跨域代码实现
python
from fastapi import FastAPI
from routers import news
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许的源,开发的时候允许所有源,生产环境需要指定源
allow_credentials=True, # 允许的凭证cookie
allow_methods=["*"], # 允许的请求方法
allow_headers=["*"], # 允许的请求头
)
@app.get("/")
async def root():
return {"message": "Hello World"}
# 挂载路由/注册路由
app.include_router(news.router)现在启动前后端代码进行前后端联调测试
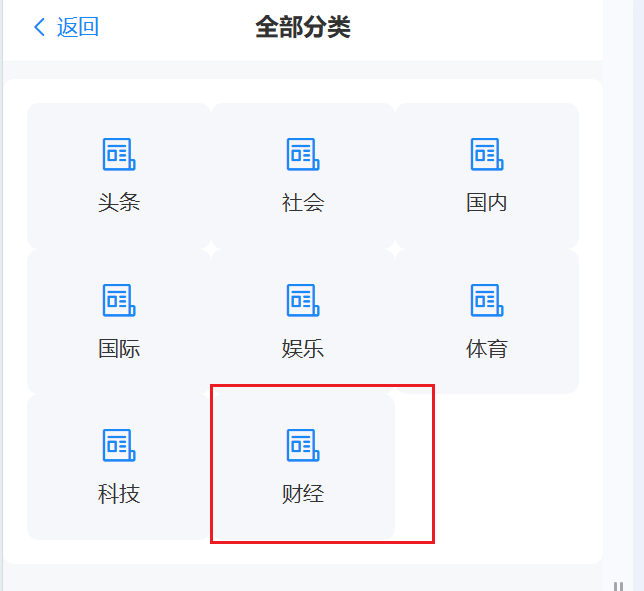
现在我们可以发现,财经这个分类出现了
3️⃣ 小结
1、分析下图浏览器报错的原因?

浏览器向另一个源 的服务器发起了跨域 HTTP 请求(浏览器的安全机制,只允许同源请求)
2、同源的三个条件是什么?
- 协议
- 域名
- 端口
3、如何解决跨域问题?
全局配置 CORS 中间件
5、获取新闻列表
1️⃣ 接口文档
- 接口地址 :
GET /api/news/list - 请求参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| categoryId | integer | 是 | 分类ID |
| page | integer | 否 | 页码,默认为1 |
| pageSize | integer | 否 | 每页显示的新闻数量,最大值为100,默认为10 |
- 请求示例:
plain
GET /api/news/list?categoryId=1
GET /api/news/list?categoryId=1&page=2&pageSize=20- 响应示例:
json
{
"code": 200,
"message": "success",
"data": {
"list": [
{
"id": 1,
"publish_time": "2023-01-01T00:00:00",
"created_at": "2023-01-01T00:00:00",
"updated_at": "2023-01-01T00:00:00",
"category": null,
"title": "新闻标题",
"description": "新闻简介",
"content": "新闻内容",
"image": null,
"author": null,
"category_id": 1,
"views": 0
}
],
"total": 100,
"hasMore": true
}
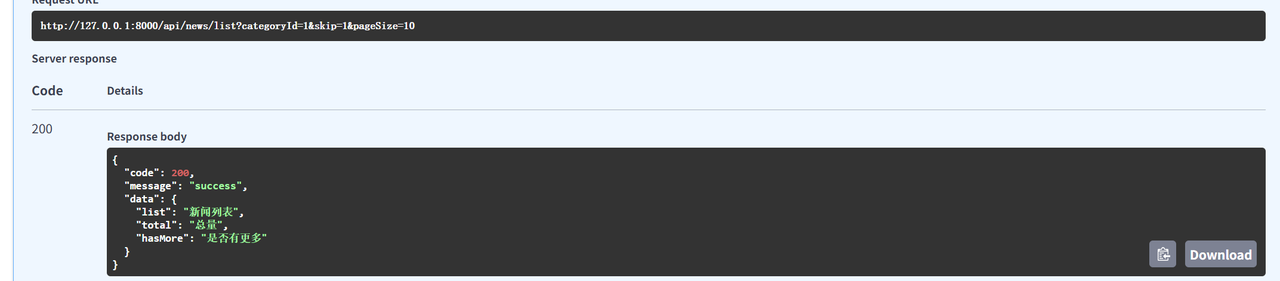
}2️⃣ 代码实现
python
@router.get("/list")
async def get_news_list(
category_id: int = Query(..., alias="categoryId"),
page: int = 1,
page_size: int = Query(..., alias="pageSize", le=100),
db: AsyncSession = Depends(get_db)
):
return {
"code": 200,
"message": "success",
"data": {
"list": "新闻列表",
"total": "总量",
"hasMore": "是否有更多"
}
}
3️⃣ News模型类
python
class News(Base):
__tablename__ = "news"
# 创建索引: 提升查询速度->添加目录
__table_args__ = (
Index('fk_news_category_idx', 'category_id'), # 高频查询场景
Index('idx_publish_time', 'publish_time') # 按发布时间排序
)
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True, comment="新闻ID")
title: Mapped[str] = mapped_column(String(255), nullable=False, comment="新闻标题")
description: Mapped[Optional[str]] = mapped_column(String(500), comment="新闻简介")
content: Mapped[str] = mapped_column(Text, nullable=False, comment="新闻内容")
image: Mapped[Optional[str]] = mapped_column(String(255), comment="封面图片URL")
author: Mapped[Optional[str]] = mapped_column(String(50), comment="作者")
category_id: Mapped[int] = mapped_column(Integer, ForeignKey('news_category.id'), nullable=False, comment="分类ID")
views: Mapped[int] = mapped_column(Integer, default=0, nullable=False, comment="浏览量")
publish_time: Mapped[datetime] = mapped_column(DateTime, default=datetime.now, comment="发布时间")
def __repr__(self):
return f"<News(id={self.id}, title='{self.title}', views={self.views})>"4️⃣ 查询功能
查询功能响应结果:当前分类新闻列表、新闻总量、是否还有更多新闻
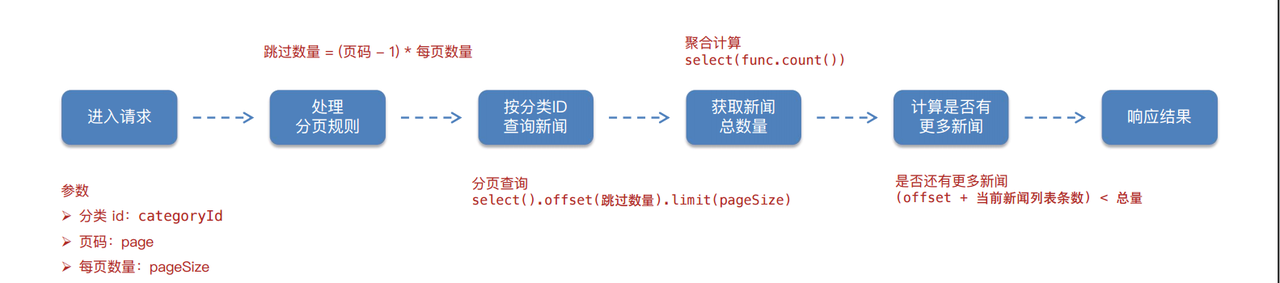
实现数据库的crud方法
python
async def get_news_list(db: AsyncSession,category_id: int,skip: int=0, limit: int=10):
# 查询指定分类下的所有新闻,limit指定每页展示的数量
stmt = select(News).where(News.category_id==category_id).offset(skip).limit(limit)
result = await db.execute(stmt)
return result.scalars().all()路由实现
python
@router.get("/list")
async def get_news_list(
category_id: int = Query(..., alias="categoryId"),
page: int = 1,
page_size: int = Query(..., alias="pageSize", le=100),
db: AsyncSession = Depends(get_db)
):
# 思路:处理分页规则->查询新闻列表->计算总量->计算是否还有更多
offset = (page - 1) * page_size
news_list = await news.get_news_list(db, category_id, offset, page_size)
return {
"code": 200,
"message": "success",
"data": {
"list": news_list,
"total": "总量",
"hasMore": "是否有更多"
}
}这里运行的时候,接口测试如果出现了报错,报错中含有这个cryptography
python
aise RuntimeError( RuntimeError: 'cryptography' package is required for sha256_password or caching_sha2_password auth methods这个错误是因为你的 MySQL 数据库使用了 caching_sha2_password 认证方式(MySQL 8.0 默认的认证方式),但是缺少了必需的 cryptography 包。
python
pip install cryptography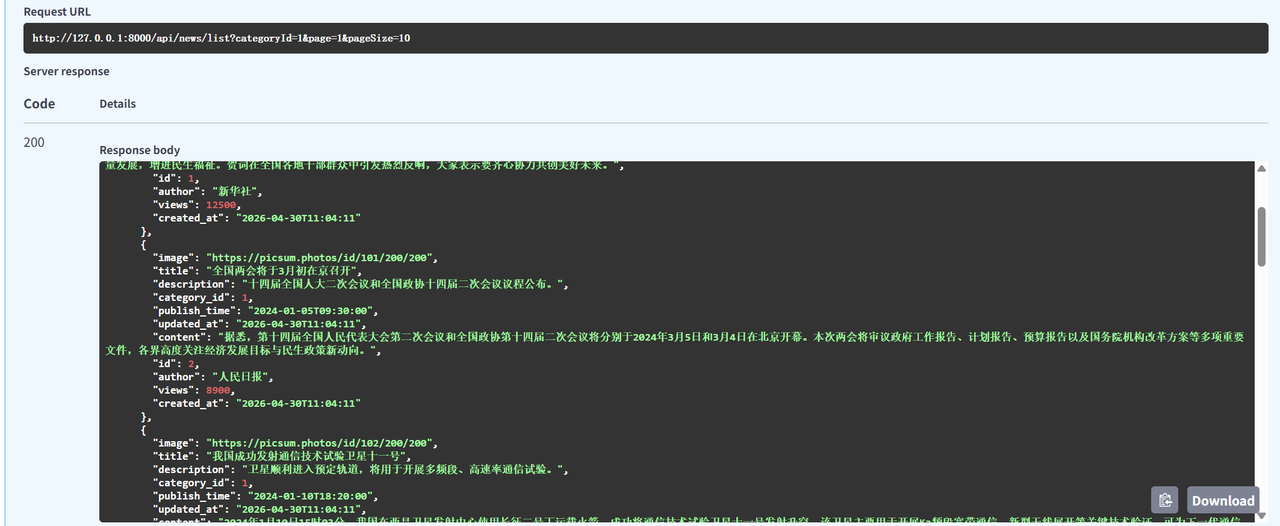
在crud当中实现查询指定分类下的所有新闻列表的总量
python
async def get_news_count(db: AsyncSession,category_id: int):
# 查询指定分类下的所有新闻的总量
stmt = select(func.count(News.id)).where(News.category_id==category_id)
result = await db.execute(stmt)
return result.scalar_one() # 只能有一个结果,否则报错完整的路由方法
python
@router.get("/list")
async def get_news_list(
category_id: int = Query(..., alias="categoryId"),
page: int = 1,
page_size: int = Query(..., alias="pageSize", le=100),
db: AsyncSession = Depends(get_db)
):
# 思路:处理分页规则->查询新闻列表->计算总量->计算是否还有更多
offset = (page - 1) * page_size
news_list = await news.get_news_list(db, category_id, offset, page_size)
total = await news.get_news_count(db, category_id)
# (跳过的 + 当前列表里面的数量) < 总数量
has_more = len(news_list) + offset < total
return {
"code": 200,
"message": "success",
"data": {
"list": news_list,
"total": total,
"hasMore": has_more
}
}如果发现total可以显示总量,而且hasmore是否还有更多为true,就说明接口测试成功
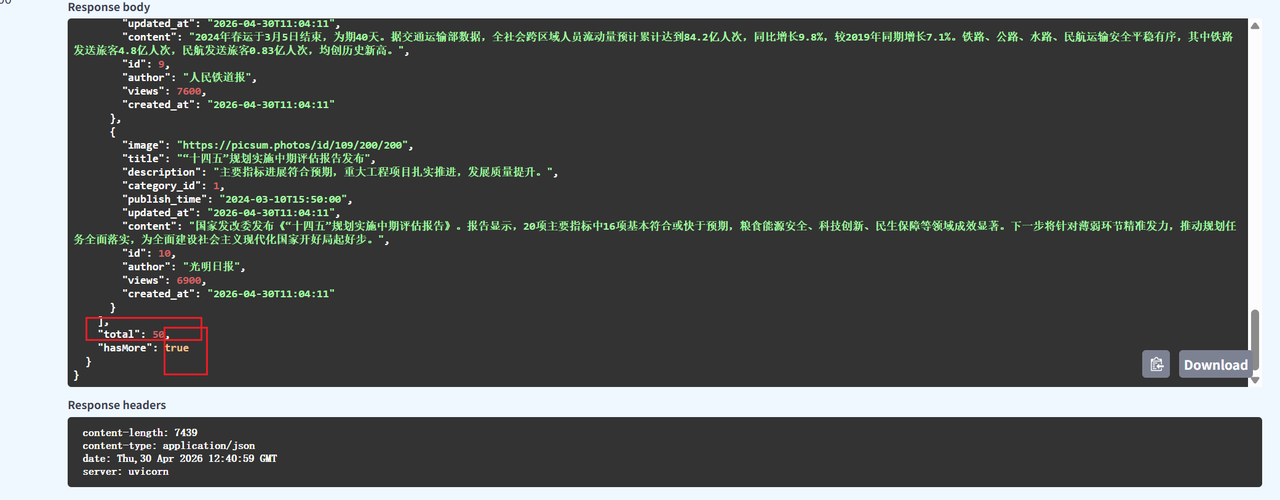
前端测试,现在发现,现在已经出现了列表
6、获取新闻详情
1️⃣ 接口文档
- 接口地址 :
GET /api/news/detail - 请求参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | integer | 是 | 新闻ID |
- 请求示例:
plain
GET /api/news/detail?id=1- 响应示例:
json
{
"code": 200,
"message": "success",
"data": {
"id": 1,
"title": "新闻标题",
"content": "新闻内容",
"image": null,
"author": null,
"publishTime": "2023-01-01T00:00:00",
"categoryId": 1,
"views": 1,
"relatedNews": []
}
}2️⃣ 代码实现
响应结果:当前新闻详情 + 增加1次浏览量 + 相关新闻(同分类 id 的新闻)
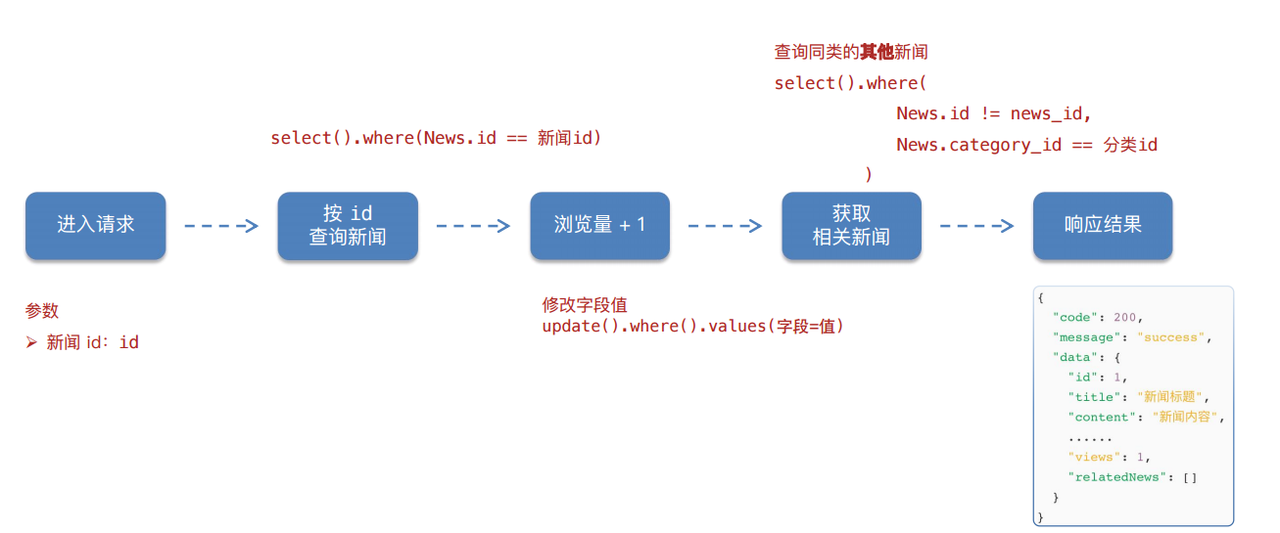
实现数据库的crud方法
python
async def get_news_detail(db: AsyncSession,news_id: int):
# 根据新闻ID查询新闻
stmt = select(News).where(News.id==news_id)
result = await db.execute(stmt)
return result.scalar_one_or_none()路由请求实现
python
@router.get("/detail")
async def get_news_detail(news_id: int=Query(..., alias="id"), db: AsyncSession = Depends(get_db)):
# 获取新闻详情 + 浏览量+1 + 相关新闻
news_detail = await news.get_news_detail(db, news_id)
if not news_detail:
raise HTTPException(status_code=404, detail="新闻不存在")
return {
"code": 200,
"message": "success",
"data": {
"id": news_detail.id,
"title": news_detail.title,
"content": news_detail.content,
"image": news_detail.image,
"author": news_detail.author,
"publishTime": news_detail.publish_time,
"categoryId": news_detail.category_id,
"views": news_detail.views,
"relatedNews": []
}
}3️⃣ 实现浏览量+1
数据库的crud实现
python
async def increase_news_views(db: AsyncSession, news_id: int):
# 增加新闻的浏览量
stmt = update(News).where(News.id == news_id).values(views=News.views + 1)
result = await db.execute(stmt)
# 更新之后,立刻提交事务
await db.commit()
# 更新->检查数据库是否真的命中了数据->命中了返回True
return result.rowcount > 0路由实现
python
@router.get("/detail")
async def get_news_detail(news_id: int=Query(..., alias="id"), db: AsyncSession = Depends(get_db)):
# 获取新闻详情 + 浏览量+1 + 相关新闻
news_detail = await news.get_news_detail(db, news_id)
if not news_detail:
raise HTTPException(status_code=404, detail="新闻不存在")
views_res = await news.increase_news_views(db, news_detail.id)
if not views_res:
raise HTTPException(status_code=404, detail="新闻不存在")
return {
"code": 200,
"message": "success",
"data": {
"id": news_detail.id,
"title": news_detail.title,
"content": news_detail.content,
"image": news_detail.image,
"author": news_detail.author,
"publishTime": news_detail.publish_time,
"categoryId": news_detail.category_id,
"views": news_detail.views,
"relatedNews": []
}
}4️⃣ 实现同类相关新闻查询
封装一个crud方法
python
async def get_related_news(db: AsyncSession, news_id: int, category_id: int, limit: int = 5):
# 获取新闻的关联新闻,order_by 排序->浏览量和发布时间排序
stmt = select(News).where(
News.id != news_id,
News.category_id == category_id
).order_by(
News.views.desc(), # 默认是升序,desc是降序
News.publish_time.desc()
).limit(limit)
result = await db.execute(stmt)
return result.scalars().all()路由代码实现
python
@router.get("/detail")
async def get_news_detail(news_id: int=Query(..., alias="id"), db: AsyncSession = Depends(get_db)):
# 获取新闻详情 + 浏览量+1 + 相关新闻
news_detail = await news.get_news_detail(db, news_id)
if not news_detail:
raise HTTPException(status_code=404, detail="新闻不存在")
views_res = await news.increase_news_views(db, news_detail.id)
if not views_res:
raise HTTPException(status_code=404, detail="新闻不存在")
related_news = await news.get_related_news(db, news_detail.id, news_detail.category_id)
return {
"code": 200,
"message": "success",
"data": {
"id": news_detail.id,
"title": news_detail.title,
"content": news_detail.content,
"image": news_detail.image,
"author": news_detail.author,
"publishTime": news_detail.publish_time,
"categoryId": news_detail.category_id,
"views": news_detail.views,
"relatedNews": related_news
}
}
这时我们会发现,推荐的相关新闻返回的数据太多,我们只需要返回关键的信息即可,比如更新时间呀什么的,是不需要返回的
应该直接像这样,只返回关键的

更新代码
python
async def get_related_news(db: AsyncSession, news_id: int, category_id: int, limit: int = 5):
# 获取新闻的关联新闻,order_by 排序->浏览量和发布时间排序
stmt = select(News).where(
News.id != news_id,
News.category_id == category_id
).order_by(
News.views.desc(), # 默认是升序,desc是降序
News.publish_time.desc()
).limit(limit)
result = await db.execute(stmt)
# return result.scalars().all() # 这个方法会返回所有的字段
related_news = result.scalars().all()
# 这里使用一个列表推导式,推导出新闻的核心数据(字段),然后再return
return [{
"id": news_detail.id,
"title": news_detail.title,
"content": news_detail.content,
"image": news_detail.image,
"author": news_detail.author,
"publishTime": news_detail.publish_time,
"categoryId": news_detail.category_id,
"views": news_detail.views,
} for news_detail in related_news]