一、概述
在强化学习中,Q-Learning 是一种基于值函数的无模型(model-free) 强化学习算法之一,用于求解马尔可夫决策过程(MDP)中的最优策略。它不依赖于已知的环境状态转移概率,只需通过智能体与环境的交互经验就能学习最优策略,具体为通过学习一个状态-动作值函数(Q函数)来选择最优策略。
Q-Learning 的目标是通过不断地更新 Q 值,使得智能体能够选择在给定状态下能获得最大累积奖励的动作。Q-Learning 的一个重要特点是,它保证在探索足够多的状态-动作对后,最终会收敛到最优策略。
二、Q函数的定义
Q-Learning 中,Q函数 表示在状态
下采取动作
所能获得的期望回报。Q函数是 Q-Learning 的核心,通过对 Q 值的不断更新,最终得到最优的 Q 函数
。
三、核心思想
Q-Learning 的核心思想是通过贝尔曼方程来更新 Q 值。贝尔曼方程描述了某一状态-动作对的 Q 值与其后续状态-动作对之间的关系。
更新公式为:
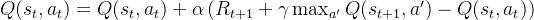
其中:
和
分别是当前状态和当前动作;
是智能体在执行动作
后,从环境中获得的即时奖励;
+1 是观察到的即时奖励;
是折扣因子,表示未来奖励的衰减程度
;
是状态
下所有可能动作的最大 Q 值,代表智能体在下一状态下选择最优动作后的预期回报;
是学习率,决定了新信息覆盖旧信息的程度;
TD误差 = (目标Q值 - 当前Q值)
通过该公式,Q-Learning 在每个时间步 都会根据当前的经验(状态、动作、奖励、下一状态)来更新 Q 值。随着学习的进行,Q 值逐渐收敛到最优 Q 值
,从而得到最优策略。
TD 误差的分解:
TD_Error = (目标Q值)-(当前Q值)
它是一个估计值,由即时奖励 和下一个状态
+1 的估计最优未来折扣奖励
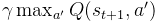 组成。
组成。
通过这个公式,Q-Learning 在每个时间步 都会根据当前的经验(状态、动作、奖励、下一状态)来更新 Q 值。随着学习的进行,Q 值逐渐收敛到最优 Q 值
,从而得到最优策略。
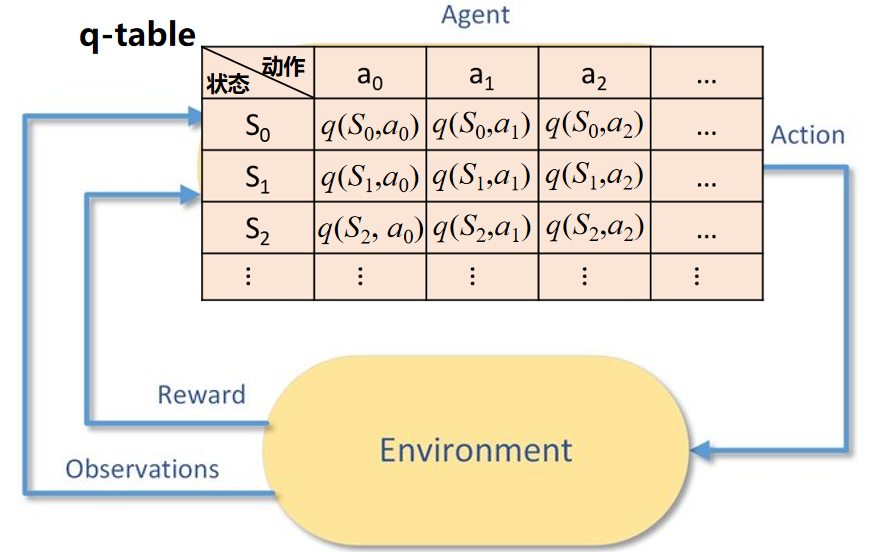
四、Q-Learning 算法流程
Q-Learning 算法的执行步骤如下:
-
初始化 Q 表:首先,初始化 Q 值表格,通常将所有状态-动作对的 Q 值初始化为零或小的随机值。
-
选择动作:在每个时间步 t,智能体基于当前的 Q 值,从状态 s 选择一个动作 a ,常见的选择策略有:
- 贪婪策略(Greedy Policy) :选择当前 Q 值最大的动作,即选择
。
- ε-贪婪策略(ε-greedy Policy) :以
- 贪婪策略(Greedy Policy) :选择当前 Q 值最大的动作,即选择
-
执行动作并更新 Q 值 :智能体执行动作 a ,获得奖励
-
重复步骤2和步骤3:直到达到某个终止条件(例如,达到最大步数或者 Q 值收敛)。
五、Q-Learning 的优点与局限性
5.1 优点
简单易实现:Q-learning 算法简单,易于理解和实现。
无模型学习:不需要环境的完整模型,适用性广泛。
有效性强:在许多实际问题中表现良好,尤其是离散空间的问题。
5.2 缺点
收敛速度慢:在复杂问题中,收敛可能很慢。
维数灾难:状态和动作空间较大时,Q 值表会变得庞大,导致计算和存储困难。
需要大量探索:在初期探索阶段,需要进行大量随机探索,影响学习效率。