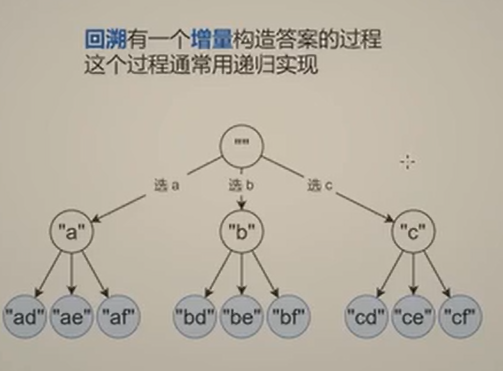
回溯
回溯(Backtracking)是一种通过尝试所有可能的候选解 ,并在发现当前候选解不可行时撤销选择 (回溯),转而尝试其他候选解的算法思想。它通常用于解决组合、排列、子集、分割、棋盘问题等需要穷举所有可能性的问题。
-
需要找出所有满足条件的解(或一个解)。
-
解由多个步骤构成,每一步都有多个选项。
-
某条路径走不通时,需要撤销上一步的选择,回到之前的状态。
常见回溯问题:
-
组合:从 n 个数中选 k 个(力扣 77)
-
排列:全排列(力扣 46)
-
子集:所有子集(力扣 78)
-
分割:分割回文串(力扣 131)
-
棋盘:N 皇后(力扣 51)、解数独(力扣 37)
-
字符串:电话号码的字母组合(力扣 17)
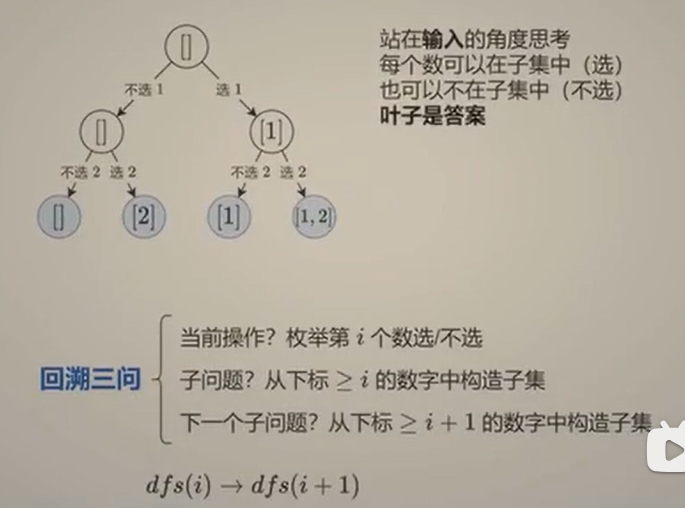
回溯三问

-
当前操作:在递归的这一步,我要做什么选择?
-
子问题:做完这个选择后,剩下的问题是什么?
-
下一个子问题:如何用递归表示剩下的问题?通常就是调用自身,但参数变化了。
其中pathi代表路径上的字母,i代表第i层应该填入那些字母,path最后的结果是囊括了所有的结果。
以力扣17题为例子,pathi是一个和输入一样的长度的列表,它存储的是每一个可能的结果,当前操作是枚举此时pathi需要填入那些参数,而子问题是当构造好第i个字母之后,余下的字母该如何构造,下一个子问题就要交给递归来做,只不过这里的参数就是i+1了。
子集型回溯

17.电话号码的字母组合

解题思路
如上面的回溯做法,按照上面的回溯做法来一步步写就行。
递归:
终止条件:
当前i的值和输入的digits的长度一致的时候,说明path路径到头了,需要返回上一级看有没有别的路,有则继续往前迈进,没有则再回退看是否有别的路径,以此类推。
父问题digits每个数字代表的字母之间如何排列组合,子问题就是第i层的字母如何选择,第i+1层以及之后的字母又要怎么构造呢?
代码
python
.join(list)
python
>>> lst = ['a', 'b', 'c']
>>> ''.join(lst)
'abc'
>>> '-'.join(lst)
'a-b-c'-
join是字符串的一个方法,前面的字符串(这里是'')表示连接符。 -
参数
path是一个列表,里面每个元素都是字符串(通常是一个字符)。 -
结果是将
path中的所有字符串按顺序用连接符拼接起来。
python
MAPPING = "", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"
class Solution(object):
def letterCombinations(self, digits):
"""
:type digits: str
:rtype: List[str]
"""
n = len(digits)
if n == 0:
return []
ans = []
# 构造path数组以存储每次的结果
path = [""] * n
# 用递归来处理
def dfs(i):
#终止条件
if i == n:
ans.append(''.join(path))
return
# 递归逻辑
for c in MAPPING[int(digits[i])]:
path[i] = c
# 处理下一个子问题
dfs(i+1)
# 处理第一个元素
dfs(0)
return ans
C++
string
string的构造
cpp
string path(n, 0);这行代码创建了一个长度为 n 的字符串,并用字符 0(空字符,ASCII 码为 0)填充每个位置。注意:0 是整数,会被隐式转换为 char,得到的是空字符 '\0',而不是字符 '0'。如果你想要字符 '0'(ASCII 48),应该写 string path(n, '0')。
但在这个问题中,我们只是临时占位,后续会直接覆盖每个位置,所以用 0 或任意字符都可以,因为 path[i] = c 会覆盖掉原有值。
对比 vector<char>:
vector<char> path(n, 0); 同样会创建 n 个 char 元素,初始值为 '\0'。行为上非常类似。
string的索引访问
cpp
path[i] = c;string 支持使用 [] 运算符直接访问和修改指定位置的字符,这与 vector<char> 完全一致。索引从 0 开始,且不进行边界检查(建议确保 i < path.size())。
因此,你可以把 string 当作一个"字符数组"来使用,这正是代码中采用 string 而不是 vector<char> 的原因:string 本身就是为存储字符序列设计的,并且可以直接通过 ans.emplace_back(path) 加入结果集,无需额外转换。
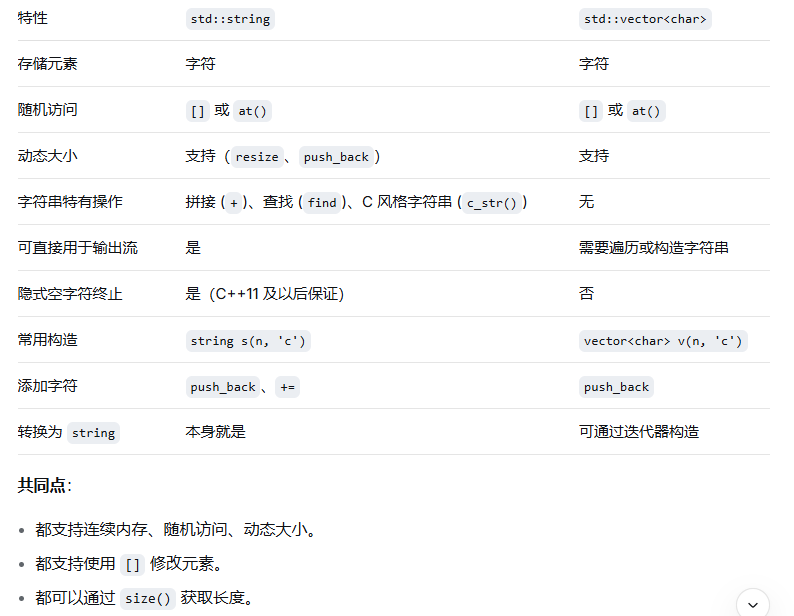
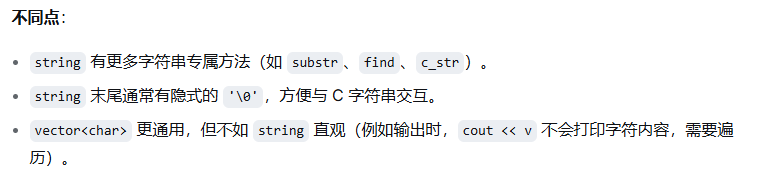
string和vector的异同
cpp
class Solution {
string MAPPING[10] = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
public:
vector<string> letterCombinations(string digits) {
int n = digits.length();
if(n == 0)
return {};
// 构造path
string path(n,0);
vector<string> ans;
// 用lambda来构造递归函数
auto dfs = [&](this auto && dfs, int i) -> void{
// 终止条件
if(i==n)
{
ans.push_back(path);
return;
}
for(int c : MAPPING[digits[i]-'0'])
{
path[i] = c;
dfs(i+1);
}
};
dfs(0);
return ans;
}
};78.子集
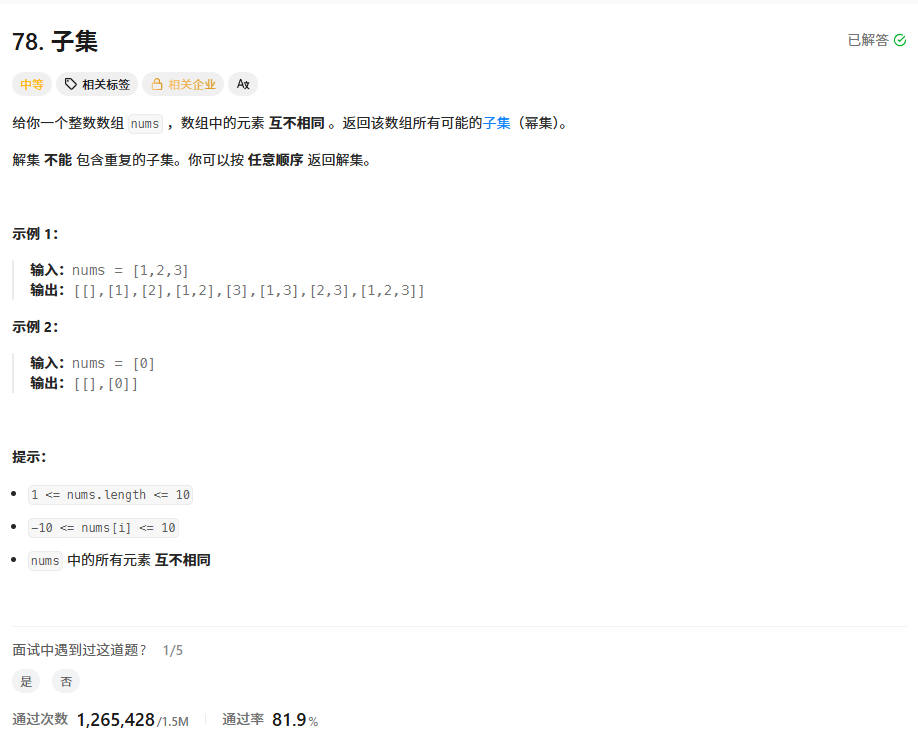
解题思路1------选或不选
解题思路和上述一致,但是这个地方要注意一个问题就是需要恢复现场,每次往path中存入一个元素,但离开该层的时候需要弹出,pop 掉的正是本层递归开始时添加的那个元素。
解题思路是决定当前元素选或者不选。
python
ans = [] # 存放所有解
def backtrack(路径, 选择列表):
if 满足终止条件:
ans.append(路径[:]) # 注意要拷贝路径(因为后续会修改)
return
for 选择 in 选择列表:
做选择(例如:路径.append(选择))
backtrack(新路径, 新选择列表)
撤销选择(例如:路径.pop())C++疑惑
顺序容器(vector、deque、list)
-
添加元素:
push_back(尾部)、push_front(头部,仅deque/list) -
删除元素:
pop_back(尾部)、pop_front(头部) -
原因:它们支持在特定位置(头/尾)操作,方法名明确指出了操作的位置。
容器适配器(stack、queue、priority_queue)
-
添加元素:统一叫
push -
删除元素:统一叫
pop -
原因:它们只提供特定数据结构的语义(如栈的 LIFO、队列的 FIFO),不关心底层具体如何存储,所以接口更简洁,不区分
_back或_front。
例外 :deque 虽属顺序容器,但它也支持 push_back、pop_back、push_front、pop_front,因为它双端操作都高效。而 list 同样支持这些。
总结 :你说"顺序容器用 push_back/pop_back,容器适配器用 push/pop"基本上是对的,但注意顺序容器中 deque 和 list 还有 push_front/pop_front;适配器则只有 push/pop,没有前后之分。
代码
python
python
class Solution(object):
def subsets(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
n = len(nums)
ans = []
path = []
# 选或者不选:nums[i]是否加入到path中
def dfs(i):
if i == n:
ans.append(path[:])
return
# 不选nums[i],直接进入下一层递归
dfs(i+1)
# 选nums[i]
path.append(nums[i])
dfs(i+1)
# 恢复现场
path.pop()
dfs(0)
return ansC++
cpp
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> ans;
vector<int> path;
int n = nums.size();
// 递归
auto dfs = [&](this auto && dfs, int i) -> void
{
// 终止条件
if(i==n)
{
ans.push_back(path);
return;
}
// 不选nums[i]
dfs(i+1);
// 选择nums[i]
path.push_back(nums[i]);
dfs(i+1);
// 恢复现场
path.pop_back();
};
dfs(0);
return ans;
}
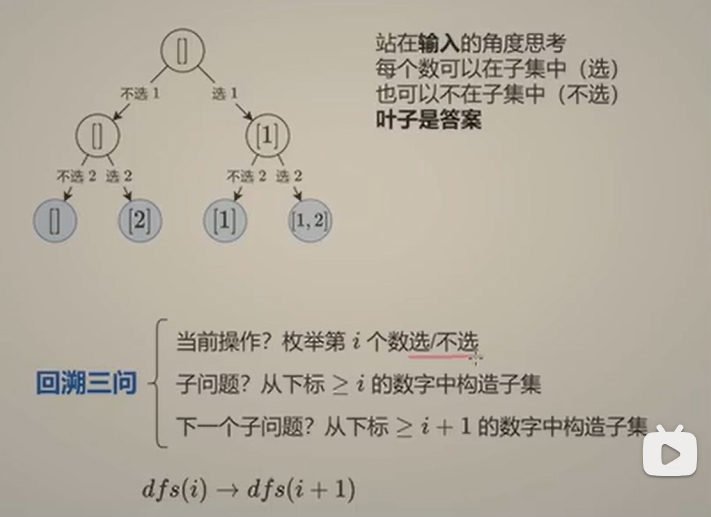
};解题思路2------枚举选哪个
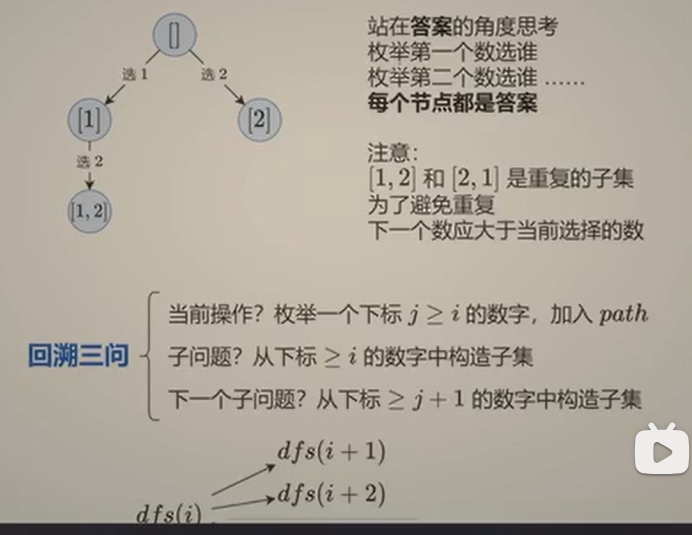
我们不是对每个元素"选或不选",而是直接决定当前子集的下一个元素是谁。
-
所有子集都有一种自然的"字典序"表示(元素按照在原数组中的顺序排列)。
-
我们可以通过依次决定子集中的第一个元素、第二个元素......来构造出所有子集。
例如 nums = [1,2,3],空集:不选任何元素;
长度为1的子集:第一个元素选1,然后终止;第一个元素选2;第一个元素选3;
长度为2的子集:先选1,然后第二个元素从2选起,得到1,2;然后1,3;
然后先选2,第二个元素从3选起,得到2,3;
长度为3的子集:先选1,再选2,再选3。
代码正是模拟这个过程:每次决定"下一个要加进去的元素"(从当前位置 i 开始枚举),然后递归处理后续。
详细解释:
cpp
auto dfs = [&](this auto && dfs, int i) -> void {
// 1. 每次进入函数,都把当前路径(子集)加入答案
ans.push_back(path);
// 2. 如果已经处理完所有元素(i >= n),直接返回(不再尝试添加新元素)
if (i == n) return;
// 3. 枚举下一个要添加的元素
for (int j = i; j < n; ++j) {
// 选择 nums[j] 作为子集的"下一个元素"
path.push_back(nums[j]);
// 递归处理:下一个元素只能从 j+1 开始选(保证元素顺序,避免重复)
dfs(j + 1);
// 回溯:撤销刚才的选择,恢复状态,尝试下一个 j
path.pop_back();
}
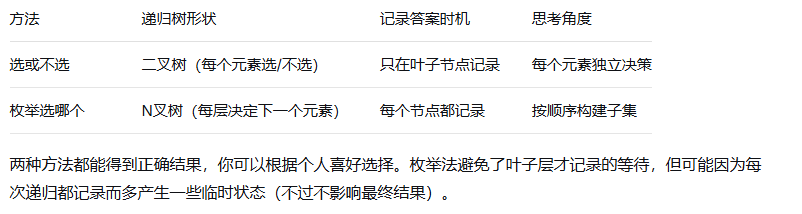
};两种方法对比
代码
python
python
class Solution(object):
def subsets(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
"""
n = len(nums)
ans = []
path = []
# 选或者不选:nums[i]是否加入到path中
def dfs(i):
if i == n:
ans.append(path[:])
return
# 不选nums[i],直接进入下一层递归
dfs(i+1)
# 选nums[i]
path.append(nums[i])
dfs(i+1)
# 恢复现场
path.pop()
dfs(0)
return ans
"""
n = len(nums)
ans = []
path = []
def dfs(i):
ans.append(path[:])
if i == n:
return
for j in range(i, n):
path.append(nums[j])
dfs(j+1)
# 恢复现场
path.pop()
dfs(0)
return ansC++
cpp
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
/*
vector<vector<int>> ans;
vector<int> path;
int n = nums.size();
// 递归
auto dfs = [&](this auto && dfs, int i) -> void
{
// 终止条件
if(i==n)
{
ans.push_back(path);
return;
}
// 不选nums[i]
dfs(i+1);
// 选择nums[i]
path.push_back(nums[i]);
dfs(i+1);
// 恢复现场
path.pop_back();
};
dfs(0);
return ans;
*/
vector<vector<int>> ans;
vector<int> path;
int n = nums.size();
// 递归
auto dfs = [&](this auto && dfs, int i) -> void
{
// 每次都将当前的path存入结果列表当中
ans.push_back(path);
// 终止条件
if(i==n)
return;
for(int j = i;j<n; j++)
{
// 选择nums[i]
path.push_back(nums[j]);
dfs(j+1);
// 恢复现场
path.pop_back();
}
};
dfs(0);
return ans;
}
};组合型回溯+剪枝
22.括号生成
解题思路
具体解题思路就是:
题目中要我们生成n*2的括号对,并且要求是有效的括号对,从结果上来看,就是说我们需要得到的数组长度是n*2,而我们在这个长度的每个位置填左括号或者右括号。
因为题目中说明了需要是有效的括号对,所以就是每个组有效的答案中,前缀中的左括号的数目一定是大于右括号的,否则就不是有效的括号对。
代码
python------选或者不选
python
class Solution(object):
def generateParenthesis(self, n):
"""
:type n: int
:rtype: List[str]
"""
m = n * 2
ans = []
path = ['']*m
# open是左括号的数目
def dfs(i, open):
# 此时已经选完了所有m个括号
if i == m:
ans.append(''.join(path))
return
if open < n:
path[i] = "("
dfs(i+1, open +1)
# 右括号的个数小于左括号的
# 右括号的数目i-open 其中在前缀中左括号的数目一定是要大于右括号的
if i - open < open:
path[i] = ")"
dfs(i+1, open)
dfs(0,0)
return ansC++------选或不选
cpp
class Solution {
public:
vector<string> generateParenthesis(int n) {
int m = n * 2;
vector<string> ans;
string path(m, 0);
auto dfs= [&](this auto && dfs, int i, int open)->void
{
// 取到了m个有效括号
if(i==m)
{
ans.push_back(path);
return;
}
// 左括号的数目小于n
if(open<n)
{
path[i]='(';
dfs(i+1, open+1);
}
// 右括号的数目小于左括号
if(i-open<open)
{
path[i] = ')';
dfs(i+1, open);
}
};
dfs(0,0);
return ans;
}
};枚举下一个左括号的位置
思路:
①总共有n个左括号,并且左括号在数组中的下标是逐渐增加的;
②左括号的位置确定了,右括号的位置其实也就确定了,因为数组的长度就是2n,其中n个左括号的位置我们已经定下来了,那么其余的位置就是放上右括号就行;
③那么问题就在于如何合法的放置这n个左括号呢?
在结果数组中的任意位置的前缀中,左括号的数目是一定要大于右括号的,否则就违法,假设任意位置i的前缀中左括号的数目为m,那么右括号的数目就是i-m,其中i-m<m ==> 2m > i;
但是在代码中的处理是下面这个样子的:
代码通过递归处理第t个左括号的位置,t从0开始,等于len(path)
递归主体:
python
for right in range(balance + 1):
path.append(i + right) # 下一个左括号的位置
dfs(i + right + 1, balance - right + 1)
path.pop()i:已经处理了的字符串中前i个位置,(0......i-1)
balance:前i个位置中的净左括号数目,就是左括号数目比右括号数目多的数目,决定了在填入了下一个左括号之前,可以加入多少右括号。
path:列表中存储的是放置左括号的下标;
i+right:right是在下一个左括号放置之前可以放的右括号的数目,范围在0,balance之间,那么i+right就是下一个左括号放置的位置;
那么下一个位置就是i+right+1,而在这个位置之前可以放置的右括号的数目是:balance-right+1:balance是前i个位置的净左括号数目,而我们在第i个位置,放了right个右括号,在第i+right个位置放了1个左括号,那么在i+right+1这个位置之前的净左括号数目就是balance-right+1。
python------枚举下一个左括号的位置
python
class Solution(object):
def generateParenthesis(self, n):
"""
:type n: int
:rtype: List[str]
"""
"""
m = n * 2
ans = []
path = ['']*m
# open是左括号的数目
def dfs(i, open):
# 此时已经选完了所有m个括号
if i == m:
ans.append(''.join(path))
return
if open < n:
path[i] = "("
dfs(i+1, open +1)
# 右括号的个数小于左括号的
# 右括号的数目i-open 其中在前缀中左括号的数目一定是要大于右括号的
if i - open < open:
path[i] = ")"
dfs(i+1, open)
dfs(0,0)
return ans
"""
# path中存放的是放置左括号的下标
path = []
ans = []
m = n * 2
def dfs(i, balance):
# 终止条件
if len(path)==n:
s = [')'] * m
for j in path:
s[j] = '('
ans.append(''.join(s))
return
# 内部逻辑
for right in range(balance+1):
# 从第i个位置开始放置right个右括号
# 那么下一个左括号的位置从i+right开始
path.append(i+right)
dfs(i+right+1, balance - right+ 1)
# 恢复现场
path.pop()
dfs(0,0)
return ansC++------枚举下一个左括号的位置
cpp
class Solution {
public:
vector<string> generateParenthesis(int n) {
int m = n * 2;
vector<string> ans;
vector<int> path;
auto dfs= [&](this auto && dfs, int i, int balance)->void
{
// 终止条件
if(path.size()==n)
{
string s(n*2, ')');
for(int j:path)
s[j] = '(';
ans.push_back(s);
return;
}
// 递归逻辑
// 右括号在第i个位置之前可以放多少个
for(int right=0;right<=balance;right++)
{
path.push_back(i+right);// i+right位置放左括号
// 下一个位置就是i+right+1
// 这个位置的前缀中净左括号含量是balance-right+1
dfs(i+right+1, balance - right + 1);
path.pop_back();
}
};
dfs(0,0);
return ans;
}
};排列型回溯+N皇后
46.全排列
解题思路
python
python代码中我们实现的是枚举下一个数的位置的思路,每一个答案都是nums的一个排列,那我们就看这n个位置中每个位置出现那些数字。
当i==n的时候,此时path中已经装好了满足题目要求的排列,添加到ans中即可;
对于i位置,i之前的数都已经加入到了path当中,对于第i个位置,我们从还没有被选过的数字当中选取一个数,放到pathi中,递归处理第i+1个位置。
对于这个从还没有被选过的数字当中选取一个数字,我们用的是set,为什么用set呢?
- 之所以用
set,是因为它天然能表达"剩余可选数字",并用s - {x}简洁地生成下一层的集合,省去了手动维护used和恢复现场的麻烦。
C++
C++中使用了布尔数组的形式,同样也是枚举每一个位置,从余下的数中选的思路,不过这里省去了set的开销,用一个on_path布尔数组作处理,可以进一步减小开销。
初始化的on_path数组都是false,代表每个数都没有被使用。
对于第i个位置,遍历整个on_path数组,找到还没有被使用的位置j,说明这个数没有在路径上,用pathi来记录这个值,之后将该位置上的on_path记为true,递归处理i+1位置。
这里需要注意的是恢复现场:
如果使用的是定长vector<int> path(n)。那么之后恢复现场只需要恢复on_path数组即可,因为在下一次递归中是可以直接对path中的数值直接覆盖,直接被改写的,不需要恢复现场的;
如果使用的是不定长的vector<int> path,那么之后存入还没有被使用的数字的时候,应该用push_back()以及pop_back(),因为不这样的话,找到一个数字之后,进入下一个分支,原始结果还在,没有被弹出,这样得到结果就不符合题目要求。
代码
python------时间复杂度较高(O(n! * n))
python
class Solution(object):
def permute(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
n = len(nums)
path = [0] * n
ans = []
def dfs(i, s):
# 终止条件
if i == n:
ans.append(path[:])
return
# 递归逻辑
# 在集合中的数,加入到path中,继续下一层递归,把当前已经选择的数给去掉
for x in s:
path[i] = x
dfs(i+1, s - {x})
dfs(0, set(nums))
return ansC++------布尔数组(path不给定长度,用push_back/pop_back,需要恢复现场)
cpp
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
int n = nums.size();
// 存储是下标
vector<int> path;
vector<vector<int>> ans;
// 记录当前下标是否选择
vector<bool> on_path(n, false);
auto dfs = [&](this auto && dfs, int i)
{
if(i == n)
{
ans.push_back(path);
return;
}
for(int j = 0; j < n;j++)
{
if(!on_path[j])
{
path.push_back(nums[j]); // 从没有选的数字中选一个
on_path[j] = true;
dfs(i+1);
// 恢复现场
on_path[j] = false;
path.pop_back();
}
}
};
dfs(0);
return ans;
}
};C++------布尔数组(path给定长度,只需要对on_path恢复现场,不需要对path恢复现场)
cpp
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
int n = nums.size();
// 存储是下标
vector<int> path(n);
vector<vector<int>> ans;
// 记录当前下标是否选择
vector<bool> on_path(n, false);
auto dfs = [&](this auto && dfs, int i)
{
if(i == n)
{
ans.push_back(path);
return;
}
for(int j = 0; j < n;j++)
{
if(on_path[j]==false)
{
path[i] = nums[j]; // 从没有选的数字中选一个
on_path[j] = true;
dfs(i+1);
// 恢复现场
on_path[j] = false;
}
}
};
dfs(0);
return ans;
}
};N皇后

解题思路
本题依旧是排列型回溯的解法:
对于布尔数组我们一般使用vector<bool>,但是vector<uint8_t> 效率比 vector<bool> 高
我们用queenr = c来表示,第 r 行的皇后放在第 c 列(列号从 0 开始),其中colc是一个布尔数组,表示哪一列存放皇后;至于正副斜线,我们同样用2个对角布尔数组来表示,来确定斜线上是否有皇后,有则标记。
假设此时我们处在棋盘的第i行,我们需要遍历第i行的各个col列,查看是否有满足条件的可行解,同时也要注意到冲突条件,皇后不能同行不能同列不能在同一对角线上,满足条件则加入结果中,同时给标记位,进入第i+1行,恢复现场。
这里要注意的是对于主对角线r-c,它的取值范围是-(n-1) ~ (n-1),副对角线r+c,取值范围是0 ~ 2n-2,都是2n-1个数。
对于下标而言是不能有负数的,因此对于主对角线,我们需要将下标进行偏移,在原有的基础上加上n-1,这样下标就避免出现负值的情况。
至于这里为什么要对主副斜线进行恢复现场,是因为回溯需要遍历所有可能的结果,可以有多种结果,那么皇后在每一行上放置结果也就不止有一种情况,所以在每一行的情况下,在递归返回后,需要撤销当前列及对角线的标记,以便在同一行的下一列尝试时,棋盘状态是干净的,这样不影响下一列的判断。
代码
python
python
class Solution(object):
def solveNQueens(self, n):
"""
:type n: int
:rtype: List[List[str]]
"""
ans = []
queens = [0] * n
# 记录那一列被queen占用
col = [False] * n
# 正对角线,以及斜对角线上不能有其他queen
diag1 = [False] * (n * 2 -1)
diag2 = [False] * (n * 2 -1)
# 枚举每一行,从第0行开始,遍历每一列,看那一列符合情况
def dfs(r):
if r == n:
# 我们用 queens[r] = c 记录:第 r 行的皇后放在第 c 列(列号从 0 开始)
ans.append(['.'*c + 'Q' + '.'*(n-1-c) for c in queens])
return
# 递归逻辑
for c, ok in enumerate(col):
# col[c]为false说明该列没有被占用
# 还有判断对角线上是否有queen
if not ok and not diag1[r+c] and not diag2[r-c+n-1]:
# 直接覆盖,后续不需要恢复现场
queens[r] = c
col[c] = diag1[r+c] = diag2[r-c+n-1] = True
dfs(r+1)
# 恢复现场
col[c] = diag1[r+c] = diag2[r-c+n-1] = False
dfs(0)
return ansC++
cpp
class Solution {
public:
vector<vector<string>> solveNQueens(int n) {
vector<vector<string>> ans;
// n皇后
vector<int> queen(n);
// vector<uint8_t> 效率比 vector<bool> 高
// 记录哪一列是被皇后占用
/*
vector<bool> col(n,false);
// 记录斜线,避免会和皇后同一斜线
vector<bool> diag1(2*n-1,false);
vector<bool> diag2(2*n-1,false);
*/
vector<uint8_t> col(n,false);
// 记录斜线,避免会和皇后同一斜线
vector<uint8_t> diag1(2*n-1,false);
vector<uint8_t> diag2(2*n-1,false);
auto dfs = [&](this auto && dfs, int r) -> void
{
// 边界条件
// 法一
/*
if(r==n)
{
vector<string> qq(n);
for(int i=0;i<n;i++)
{
qq[i] = string(queen[i], '.') + 'Q' + string(n-1-queen[i], '.');
}
ans.push_back(qq);
return;
}
*/
// 法二
if(r==n)
{
vector<string> qq;
for(int i=0;i<n;i++)
{
qq.push_back(string(queen[i], '.') + 'Q' + string(n-1-queen[i], '.'));
}
ans.push_back(qq);
return;
}
// 内部逻辑
for(int c=0; c<n; c++)
{
if(!col[c] && !diag1[r+c] && !diag2[r-c + n -1])
{
// 我们用 queens[r] = c 记录:第 r 行的皇后放在第 c 列(列号从 0 开始)
queen[r] = c;
// 标记位也需要改变
col[c] = diag1[r+c] = diag2[r-c + n -1] = true;
// 下一行递归
dfs(r+1);
// 标记为需要恢复现场
col[c] = diag1[r+c] = diag2[r-c + n -1] = false;
}
}
};
dfs(0);
return ans;
}
};路径型回溯
在网格上找一条连贯的路径,使得路径上的字母按顺序和给定的字符串一致。
解题思路:
遍历网格上的每一个位置,将每一个位置作为起点,进入递归,而递归中:
终止条件:当要遍历的网格中元素的下标越界或者说当前网格所对应的字符和给定的字符不一致的时候,直接返回false;而当遍历到给定字符串的最后一个都匹配的时候,直接返回True,说明在当前网格中找到了与之相对应的连贯序列。
递归逻辑:
对于第(i, j)个网格,我们要将其作特殊标记(python中用空字符,C++中用'\0'来表示,可以自己选择),代表该网格我们已经搜索遍历过,而对于当前网格,下一次搜索的方向是上下左右四个方向都要查询,也即递归(i-1,j) 、(i+1,j) 、(i, j-1)、(i, j+1)这四个位置,只要找到一个方向的数是与给定字符串下一个对应,就停止递归,返回当前结果,而后我们需要恢复现场。
79.单词搜索

解题思路
代码
python
python
class Solution(object):
def exist(self, board, word):
"""
:type board: List[List[str]]
:type word: str
:rtype: bool
"""
# i, j代表在board中的索引,即行、列
# k代表在word中的索引
def dfs(i, j, k):
# 终止条件
if not 0 <= i <len(board) or not 0 <= j < len(board[0]) or board[i][j]!=word[k]:
return False
# 递归到word最后一个元素,返回结果
if k == len(word) - 1:
return True
# 递归逻辑
# 当前访问过的元素用''表示标记过,防止重复访问
board[i][j] = ''
# 下、上、右、左四个方向开启递归,只要有一个满足条件直接返回,不做后续的dfs
res = dfs(i+1, j, k+1) or dfs(i-1, j, k+1) or dfs(i, j+1, k+1) or dfs(i, j-1, k+1)
board[i][j] = word[k]
return res
# 遍历所有格子作为起点
for i in range(len(board)):
for j in range(len(board[0])):
if dfs(i, j, 0):
return True
return FalseC++
cpp
class Solution {
public:
bool exist(vector<vector<char>>& board, string word) {
int rows = board.size();
int cols = board[0].size();
auto dfs = [&](this auto && dfs, int i, int j, int k) -> bool
{
if(i < 0 || i >= rows || j < 0 || j>= cols || word[k]!=board[i][j])
return false;
if(k==word.size()-1)
return true;
// 将当前元素作特殊标记,以证明遍历过当前元素
board[i][j] = '\0';
// 递归处理上,右,下,左,有一个满足条件即剪枝返回
bool res = dfs(i-1, j, k+1) || dfs(i, j+1, k+1) || dfs(i+1, j, k+1) || dfs(i, j-1, k+1);
// 恢复现场
board[i][j] = word[k];
return res;
};
// 遍历所有起点
for(int i=0;i<rows;i++)
{
for(int j=0;j<cols;j++)
{
if(dfs(i,j,0))
return true;
}
}
return false;
}
};301.删除无效的括号
解题思路
这道题需要我们删除多余的左右括号,使得余下的字符串是合理的,其实这道题的解法十分像括号生成,只不过比括号生成要复杂些。
具体思路如下:
首先,对于一个有效的字符串而言,它的左右括号的数目是相等的,二者的差值为0;
其次就是在当前位置的任意前缀当中,左括号的数目其实要大于右括号的数目的。
所以我们要做的:
①遍历原始的字符串,统计原始字符串当中多余的左右括号数目,分别记作l_remove, r_remove;
②设计一个检验字符串是否有效的布尔函数isValid(),初始化一个检验裁剪字符后的字符串是否是有效的,通过上面讲到的左右括号的数目要相等这一点,进行判断,取cnt代表二者括号的差值,一旦cnt<0,直接返回false;反之则比较cnt与0的大小,与0相等则有效返回True,反之一样是false。
③递归逻辑,首先我们原始字符串s的首字符出发,根据第①步统计得到的l_remove以及r_remove去s中删除对应的左右括号:
终止条件:
当l_remove以及r_remove都为0的时候,说明字符串当中已经没有多余的左右括号了,将当前字符结果压入res中;
回溯逻辑:
python
for i in range(start, len(str))这里遍历要从start开始,到字符串结束,start第一次是开始遍历的字符起始位置,start 后续表示上次删除的位置,下次应该从该位置继续扫描,避免重复考虑前面的字符。
①去重**:**这里有几个需要注意的点,如果当前几个连续的左/右括号是多余的,我们先删除最左边的括号。因为连续相等的字符都是一样的,删哪个都一样,因为我们从左遍历到右,所以我们规定先删除最左边的,也就是第一个。
②剪枝:当前遍历到第i个字符,如果该字符之后的字符数目小于l_remove + r_remove,也就是剩下的字符不够我们删除的,那之后的字符其实也就没有必要去遍历了,说明这条路走不通,直接返回,避免不必要的递归。
当前l_remove>0并且当前字符是'(',那么说明左括号多余,删掉当前左括号,我们直接对str原地操作,将第i个字符删除,把第i个字符之后的所有字符都往前移动一位即可,此时l_remove-1;
当前r_remove>0并且当前字符是')',那么说明右括号多余,删掉当前右括号,我们直接对str原地操作,将第i个字符删除,把第i个字符之后的所有字符都往前移动一位即可,此时r_remove-1;
代码
python
python
class Solution(object):
def removeInvalidParentheses(self, s):
"""
:type s: str
:rtype: List[str]
"""
res = []
# 判断字符有效与否的函数
def isValid(str):
cnt = 0
for c in str:
if c == '(':
cnt += 1
elif c == ')':
cnt -= 1
if cnt < 0:
return False
return cnt == 0
# 记录字符串当中多余的左右括号数目
l_remove = 0
r_remove = 0
for c in s:
if c == '(':
l_remove += 1
elif c == ')':
if l_remove == 0: # 说明该右括号没有左括号与之对应,是多余的
r_remove += 1
else:
l_remove -= 1
# 递归函数
# start第一次是开始遍历的字符起始位置
# start 后续表示上次删除的位置,下次应该从该位置继续扫描,避免重复考虑前面的字符。
def dfs(str, start, l_remove, r_remove):
# 终止条件
if l_remove == 0 and r_remove == 0: # 外加判断是否有效
if isValid(str):
res.append(str)
return
for i in range(start, len(str)):
# 去重
if i != start and str[i] == str[i-1]:
continue
# 剪枝
if l_remove + r_remove > len(str) - i:
return
# 真正逻辑,下一次递归还是从当前位置开始
if l_remove > 0 and str[i] == '(':
dfs(str[:i]+str[i+1:], i, l_remove - 1, r_remove)
if r_remove > 0 and str[i] == ')':
dfs(str[:i]+str[i+1:], i, l_remove, r_remove - 1)
dfs(s, 0, l_remove, r_remove)
return resC++
cpp
class Solution {
public:
vector<string> res;
// 合理的字符串是,左右括号是对齐的,没有多余的左右括号的,也就是二者数目相减==0
// 并且当前字符的前缀中左括号的数目是一定要大于等于右括号数目的
bool isValid(const string& str)
{
int cnt = 0;
for(char c : str)
{
if(c=='(')
cnt++;
else if(c == ')')
{
cnt--;
// 左括号数目小于右括号,明显不合理,直接返回false即可
if(cnt<0)
return false;
}
}
return cnt == 0;
}
vector<string> removeInvalidParentheses(string s) {
// 扫描确定多余的括号数目
int l_remove = 0;
int r_remove = 0;
for(char c : s)
{
// 统计左括号的个数
if(c == '(')
l_remove++;
else if(c==')')
{
// 当l_remove为0的时候,说明此时前面的括号都是正确成对的,那么此时的右括号就是多余的;
// 如果l_remove不为0,那么此时的右括号和前面对于的左括号可以配对,因此l_remove需要--
if(l_remove==0)
r_remove++;
else
l_remove--;
}
}
// l_remove + r_remove是我们最终需要从原始字符串当中删掉的
// 回溯逻辑
auto dfs = [&](this auto && dfs, string str, int start, int l_remove, int r_remove)
{
// 终止条件
if(l_remove == 0 && r_remove == 0)
if(isValid(str))
{
res.push_back(str);
return;
}
// 回溯逻辑
for(int i=start; i<str.size();i++)
{
// 去重:对于连续重复的括号,我们只删除第一个
if(i!=start && str[i] == str[i-1])
continue;
// 剪枝:当遍历到第i个字符
// 剩下的字符数目不够l_remove + r_remove的时候,直接返回
if(l_remove + r_remove > str.size() - i)
return;
// 选择
if(l_remove > 0 && str[i] == '(')
{
// 删除当前位置的左括号,这个左括号多余
// 拼接余下的字符,之后还是从第i个位置开始,因为把后面的字符往前移了
dfs(str.substr(0,i) + str.substr(i+1), i, l_remove - 1, r_remove);
}
if(r_remove > 0 && str[i]==')')
{
// 删除当前位置的右括号,这个右括号多余
// 拼接余下的字符,之后还是从第i个位置开始,因为把后面的字符往前移了
dfs(str.substr(0,i) + str.substr(i+1), i, l_remove, r_remove - 1);
}
}
};
dfs(s, 0, l_remove, r_remove);
return res;
}
};200.岛屿数量

解题思路
岛屿数量这道题的解题思路其实和单词搜索这道题的解题思路十分相像,但唯一不同的点在于,本题不需要恢复现场。
因为本题是要统计岛屿数量,找出所有的陆地数量,并确保每块陆地只被统计一次,一旦我们顺着一块陆地搜索过一片区域(组成一个岛屿),那么这些格子其实已经被消耗掉了,不能再被后续的搜索使用,因此我们需要的是标记了这块已经搜索过的陆地区域,并不需要恢复它们,以免被重复计数。
代码
python
python
class Solution(object):
def numIslands(self, grid):
"""
:type grid: List[List[str]]
:rtype: int
"""
def dfs(grid, i ,j):
# 终止条件
if not 0<=i<len(grid) or not 0<=j<len(grid[0]) or grid[i][j] == '0':
return
grid[i][j] = '0'
dfs(grid, i+1, j)
dfs(grid, i, j+1)
dfs(grid, i-1, j)
dfs(grid, i, j-1)
# 递归逻辑
count = 0
for i in range(len(grid)):
for j in range(len(grid[0])):
if grid[i][j] == '1':
dfs(grid, i, j)
count += 1
return countC++
cpp
class Solution {
public:
int numIslands(vector<vector<char>>& grid) {
int count = 0;
auto dfs = [&](this auto && dfs, vector<vector<char>>& grid, int i, int j)->void
{
// 终止条件
if(i<0 || i>=grid.size() || j<0 || j>=grid[0].size() || grid[i][j]=='0')
return;
// 递归逻辑
// 进入陆地格子,把陆地格子给标记,以免后续重复计算
grid[i][j] = '0';
dfs(grid, i-1, j);
dfs(grid, i, j+1);
dfs(grid, i+1, j);
dfs(grid, i, j-1);
};
// 遍历网格的每一个起点
for(int i=0;i<grid.size();i++)
{
for(int j=0;j<grid[0].size();j++)
{
if(grid[i][j]=='1')
{
dfs(grid, i, j);
count += 1;
}
}
}
return count;
}
};分享
207.课程表

解题思路
要解决这道题,首先需要知道以下前置条件:
这道题的核心就是检测图(Graph)中是否有环 。你可以把课程和依赖关系想象成一个"选课地图",用图论(Graph Theory)的术语来解读:
-
节点(Node/Vertex):图中的每一个圆圈,代表一门课程(0 到 numCourses-1)。
-
有向边(Directed Edge) :图中带箭头的线,代表依赖关系。例如,
[a, b]意味着要先学b才能学a,我们就从b画一个箭头指向a,记作b -> a。 -
入度(Indegree):对于一个节点,有多少条边直接指向它,也就是这门课有多少门"前置课程"刚需。如果一门课的入度为 0,就表示它没有前置课程要求,可以随时学习。
本题问题转化
输入总共 2 门课(节点 0 和 1),依赖关系是 \[1,0](边:0 -> 1)。
这是一个有向无环图 (DAG) ,所以可以完成,答案是 true。
我们用三色标记法来解决这个问题:
-
0(白色 / 未访问) :colors[x] == 0表示节点x从未被探索过。这是所有节点的初始状态。 -
1(灰色 / 访问中) :colors[x] == 1表示节点x正在被探索,它位于当前 DFS 的递归调用栈中。这是我们判断环的关键信号。 -
2(黑色 / 已安全) :colors[x] == 2表示节点x以及它能到达的所有下游节点都已被完整探索过,并且确认没有环,它是一个"安全"节点。
而灰色和黑色之间的区别如下:
-
正在被探索 = 当前递归路径上的节点,表示依赖链还没有走完,如果回头遇到它,就是环。
-
已经探索完 = 这个节点以及它后面的所有节点都已经确认无环,可以永久跳过,避免重复劳动。
-
循环依赖的实质:在依赖图中存在一个有向环,导致没有任何课程可以最先学习。
DFS 中,当我们沿着一条路径探索时,如果发现某个节点已经在当前的递归路径中(即状态为灰色),就意味着我们绕了一圈回到了之前正在处理的节点,这就相当于发现了环。反过来,如果节点是黑色,表示它后面已经是安全的,我们不必重复探索。
遍历所有白色的节点,并递归处理,如果返回True说明有环,返回false,反之则返回True
具体过程:
1.建图
2.初始化状态数组,所有的元素都初始化为白色;
3.递归:
探索节点,将当前节点标为灰色,说明正在被探索,然后遍历当前节点的所有邻居,观察对应的颜色和0/1/2相比,等于哪个,等于0,则继续递归处理;等于1说明我们遇到了环,返回True;等于2,说明当前邻居是安全的,直接剪枝,跳过,无需重复遍历。
而当前节点的所有邻居都被探测过后,当前节点的颜色标记为黑色,并返回false,继续下一个递归。
代码
python
python
class Solution(object):
def canFinish(self, numCourses, prerequisites):
"""
:type numCourses: int
:type prerequisites: List[List[int]]
:rtype: bool
"""
# 建图
g = [[] for _ in range(numCourses)]
for a, b in prerequisites:
g[b].append(a)
colors = [0]* numCourses
# 返回True说明找到了环
# 返回False说明没有找到环
def dfs(x):
# 等于1说明正在查询
colors[x] = 1
for y in g[x]:
# colors为1说明存在环
# colors为0,说明该节点没有被访问过,那么就递查询y,返回值为True说明有环
if colors[y] == 1 or colors[y] == 0 and dfs(y):
return True
# 遍历完x的所有前置课程,没有环的存在,标记为黑色
colors[x] = 2
return False
for i ,c in enumerate(colors):
if c==0 and dfs(i):
# 说明有环的存在
return False
return TrueC++
cpp
class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
// 建图
vector<vector<int>> graph(numCourses);
// 举例:a的前置课程是b,那么b -> a
// 所里这里同理在构建这种关系
for(auto& p: prerequisites)
graph[p[1]].push_back(p[0]);
// 颜色数组
vector<int> colors(numCourses, 0);
// 递归
auto dfs = [&](this auto && dfs, int x) -> bool
{
// 先标记当前节点
colors[x] = 1;
// 处理当前节点的所有邻居,也就是所有前置课程
for(auto& y : graph[x])
{
if(colors[y]==1 || colors[y]==0 && dfs(y))
return true;
}
// 反之,遍历完x的所有邻居,都没有找到环
// 对x进行变色
colors[x] = 2;
return false;
};
for(int i=0;i<numCourses;i++)
{
// 成立则说明有环
if(colors[i]==0 && dfs(i))
return false;
}
return true;
}
};