
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在算法学习中,贪心算法一直是一个看似简单、实则极具技巧性的专题.它的核心思想并不复杂:在每一步选择中都做出当前看来最优的决策,并希望通过局部最优最终得到全局最优.然而,真正的难点在于------什么时候可以贪?为什么这样贪是正确的?如果贪错了,又该如何调整策略?本篇文章将继续围绕贪心算法的经典实战应用展开,选取几个具有代表性的题目进行分析,包括整数替换、俄罗斯套娃信封问题、可被三整除的最大和、距离相等的条形码以及重构字符串.这些问题虽然题面各不相同,但背后都体现了贪心思想在"选择策略""排序规则""局部调整"和"冲突规避"中的灵活运用.通过这些案例,我们不仅会关注代码实现,更会重点分析每道题中贪心策略的设计过程:如何发现贪心切入点,如何证明当前选择不会影响最终最优解,以及如何将抽象思路转化为高效可执行的算法.希望读完本文后,你能对贪心算法有更深入的理解,并在面对类似问题时,更快地找到解题突破口.废话不多说,下面跟着小编的节奏🎵一起去疯狂学习吧!
目录
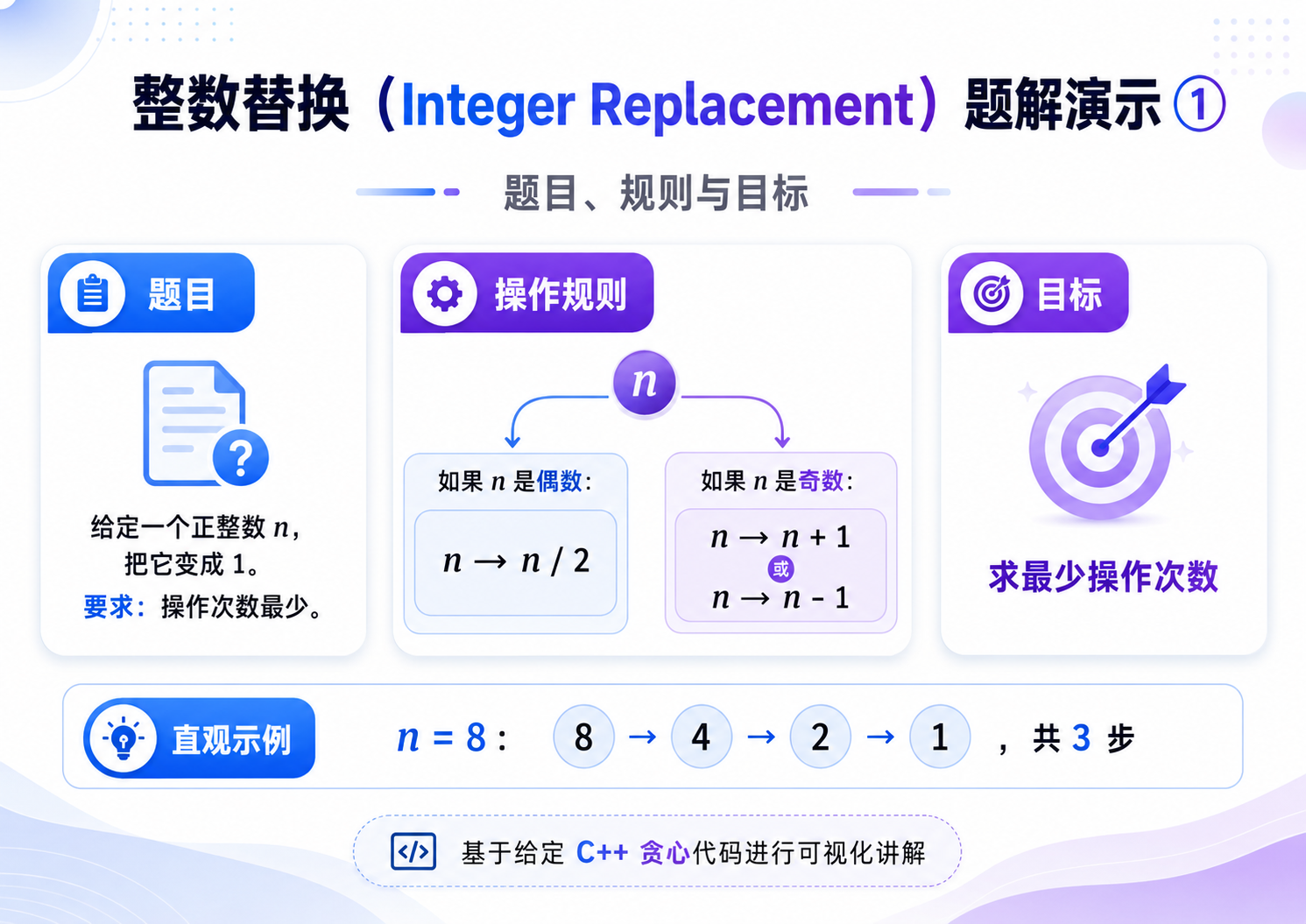
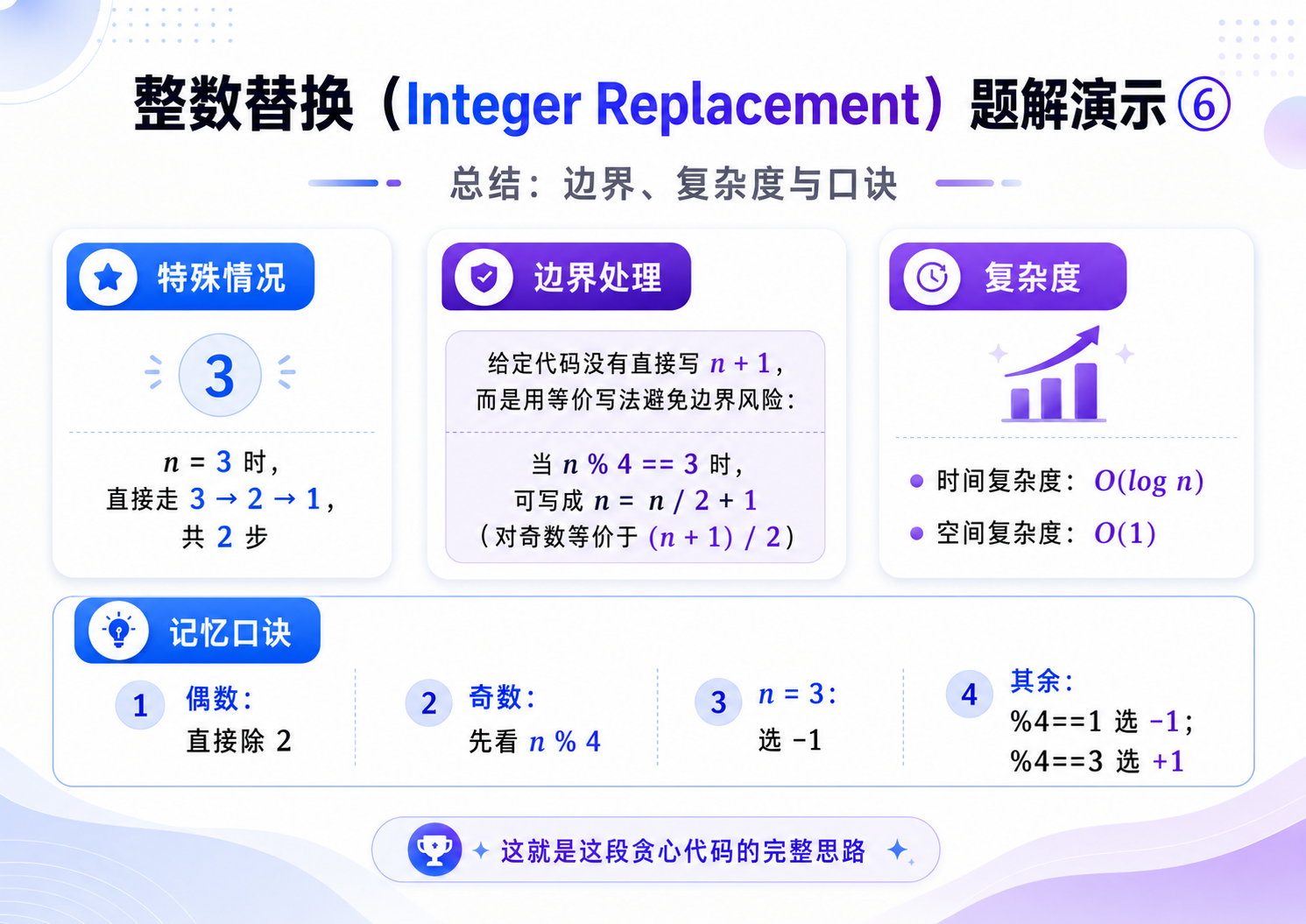
1.整数替换(OJ题)

解法(贪心):
贪心策略:我们的任何选择,应该让这个数尽可能快的变成 1.
对于偶数:只能执行除 2 操作,没有什么分析的;
对于奇数:
i. 当 n == 1 的时候,不用执行任何操作;
ii. 当 n == 3 的时候,变成 1 的最优操作数是 2;
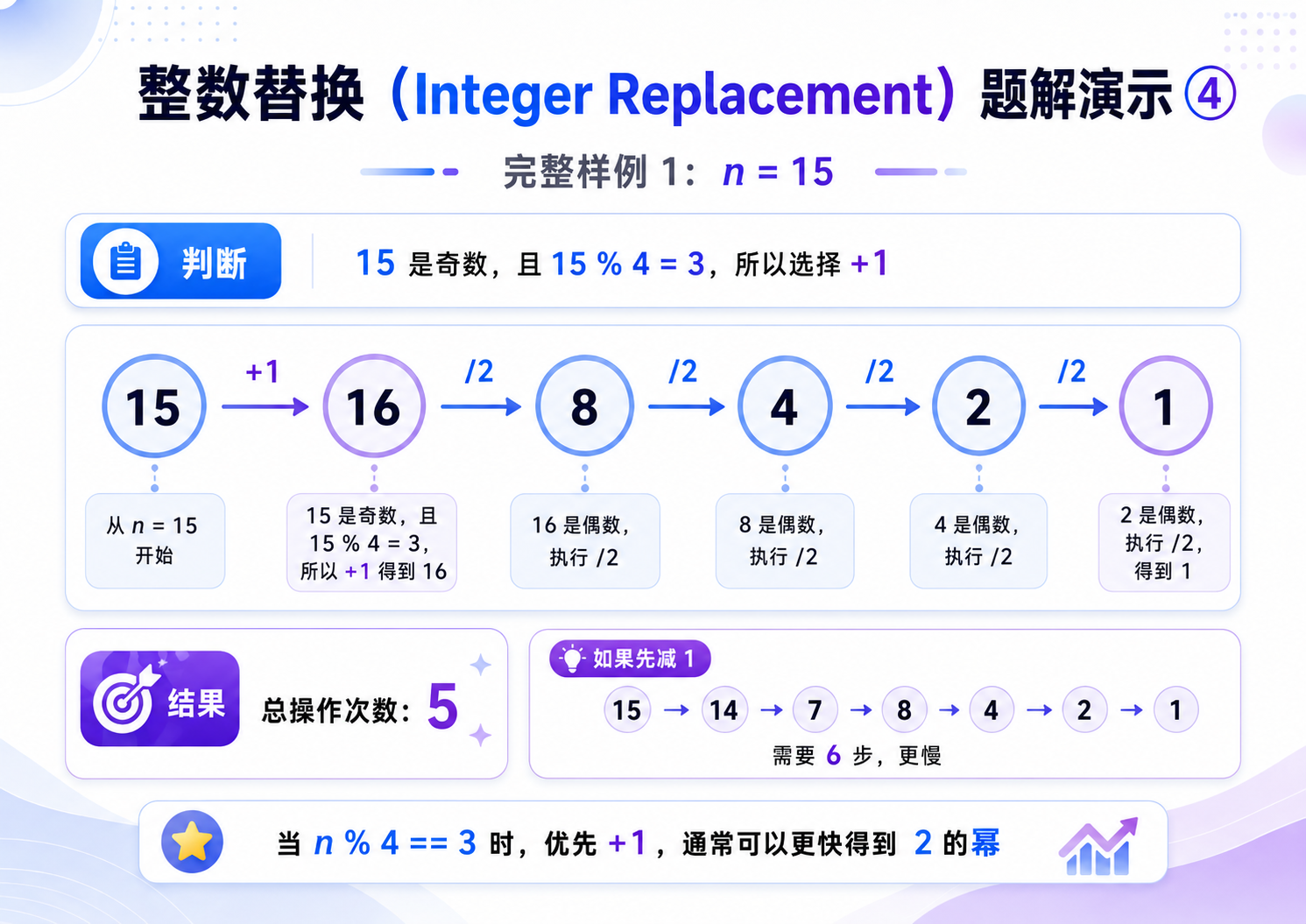
iii. 当 n > 1 && n % 4 == 1 的时候,那么它的二进制表示是 ......01,最优的方式应该选择 -1,这样就可以把末尾的 1 干掉,接下来执行除法操作,能够更快的变成 1;
iv. 当 n > 3 && n % 4 == 3 的时候,那么它的二进制表示是 ......11,此时最优的策略应该是 +1,这样可以把一堆连续的 1 转换成 0,更快的变成 1.


核心代码
cpp
class Solution
{
public:
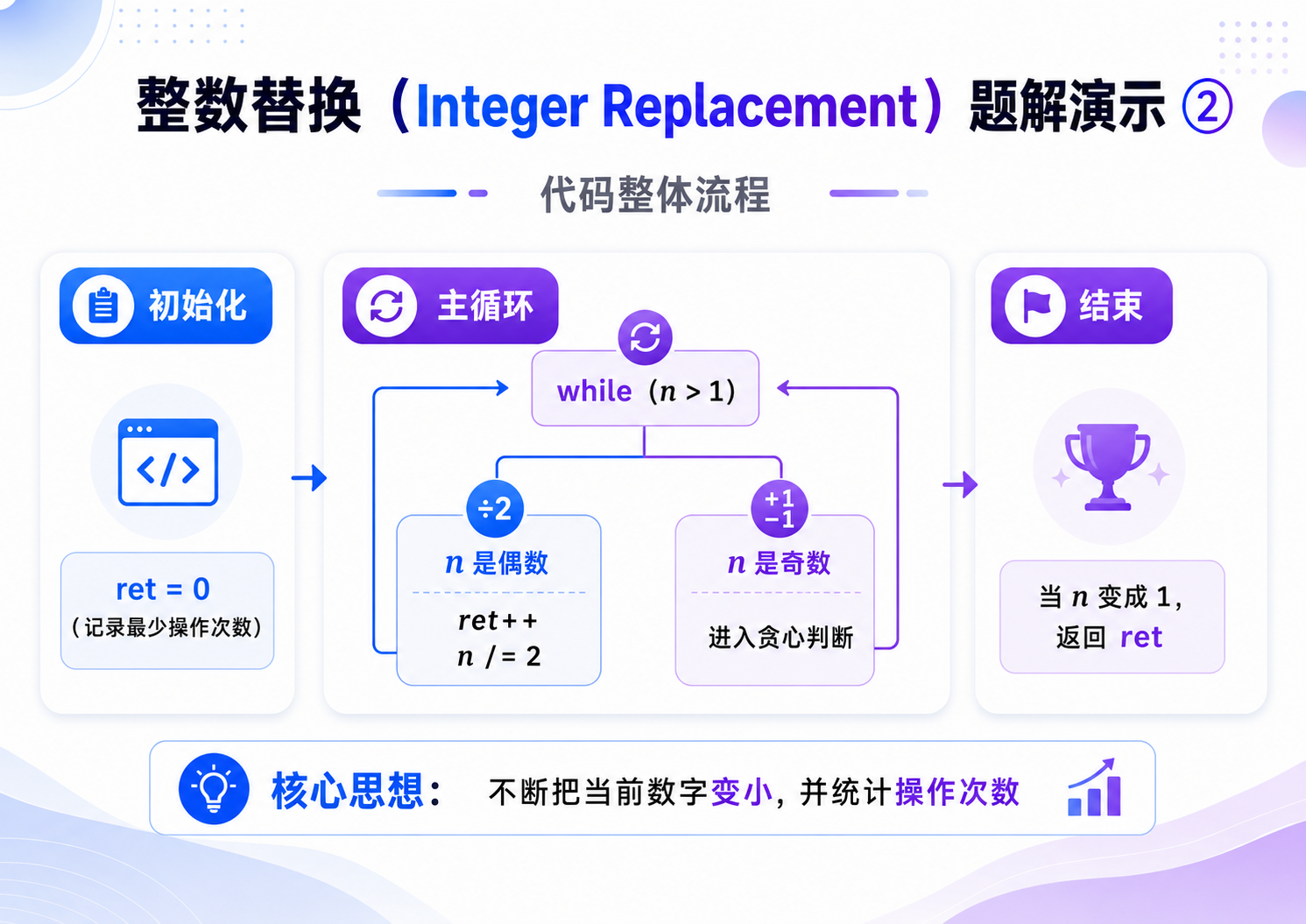
int integerReplacement(int n)
{
int ret = 0; //记录最少操作次数
//循环:直到数字变为1为止
while(n > 1)
{
//分类讨论:偶数 / 奇数
if(n % 2 == 0)
{
//偶数:唯一操作 → 除以2
ret++; //操作次数+1
n /= 2; //执行除以2
}
else
{
//奇数:贪心选择 +1 或 -1
if(n == 3)
{
//特殊情况:3 → 2 → 1,仅需2步(比3→4更快)
ret += 2;
n = 1;
}
else if(n % 4 == 1)
{
//奇数模4余1:选择减1(n-1),再除以2
//两步操作:减1 + 除以2 → 次数+2
ret += 2;
n /= 2;
}
else
{
//奇数模4余3:选择加1(n+1),再除以2
//两步操作:加1 + 除以2 → 次数+2
ret += 2;
n = n / 2 + 1;
}
}
}
//返回最少操作次数
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
class Solution
{
public:
int integerReplacement(int n)
{
int ret = 0; // 记录最少操作次数
// 循环:直到数字变为 1 为止
while (n > 1)
{
// 分类讨论:偶数 / 奇数
if (n % 2 == 0)
{
// 偶数:唯一操作,除以 2
ret++;
n /= 2;
}
else
{
// 奇数:贪心选择 +1 或 -1
if (n == 3)
{
// 特殊情况:3 -> 2 -> 1,仅需 2 步
ret += 2;
n = 1;
}
else if (n % 4 == 1)
{
// 奇数模 4 余 1:选择减 1
// 等价于执行:n = (n - 1) / 2
// 两步操作:减 1 + 除以 2
ret += 2;
n /= 2;
}
else
{
// 奇数模 4 余 3:选择加 1
// 等价于执行:n = (n + 1) / 2
// 两步操作:加 1 + 除以 2
ret += 2;
n = n / 2 + 1;
}
}
}
return ret;
}
};
int main()
{
Solution sol;
vector<int> testCases = {
1, // 已经是 1,结果 0
2, // 2 -> 1,结果 1
3, // 3 -> 2 -> 1,结果 2
4, // 4 -> 2 -> 1,结果 2
5, // 5 -> 4 -> 2 -> 1,结果 3
7, // 7 -> 8 -> 4 -> 2 -> 1,结果 4
8, // 8 -> 4 -> 2 -> 1,结果 3
15, // 15 -> 16 -> 8 -> 4 -> 2 -> 1,结果 5
16, // 16 -> 8 -> 4 -> 2 -> 1,结果 4
17, // 17 -> 16 -> 8 -> 4 -> 2 -> 1,结果 5
31, // 31 -> 32 -> 16 -> 8 -> 4 -> 2 -> 1,结果 6
1024, // 2 的幂,连续除以 2
100000, // 普通较大数字
INT_MAX // int 最大值,测试边界情况
};
for (int i = 0; i < testCases.size(); i++)
{
int n = testCases[i];
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "输入 n:" << n << endl;
cout << "最少操作次数:";
cout << sol.integerReplacement(n) << endl;
cout << "------------------------" << endl;
}
return 0;
}
2.俄罗斯套娃信封问题(OJ题)

解法(重写排序 + 贪心 + 二分):
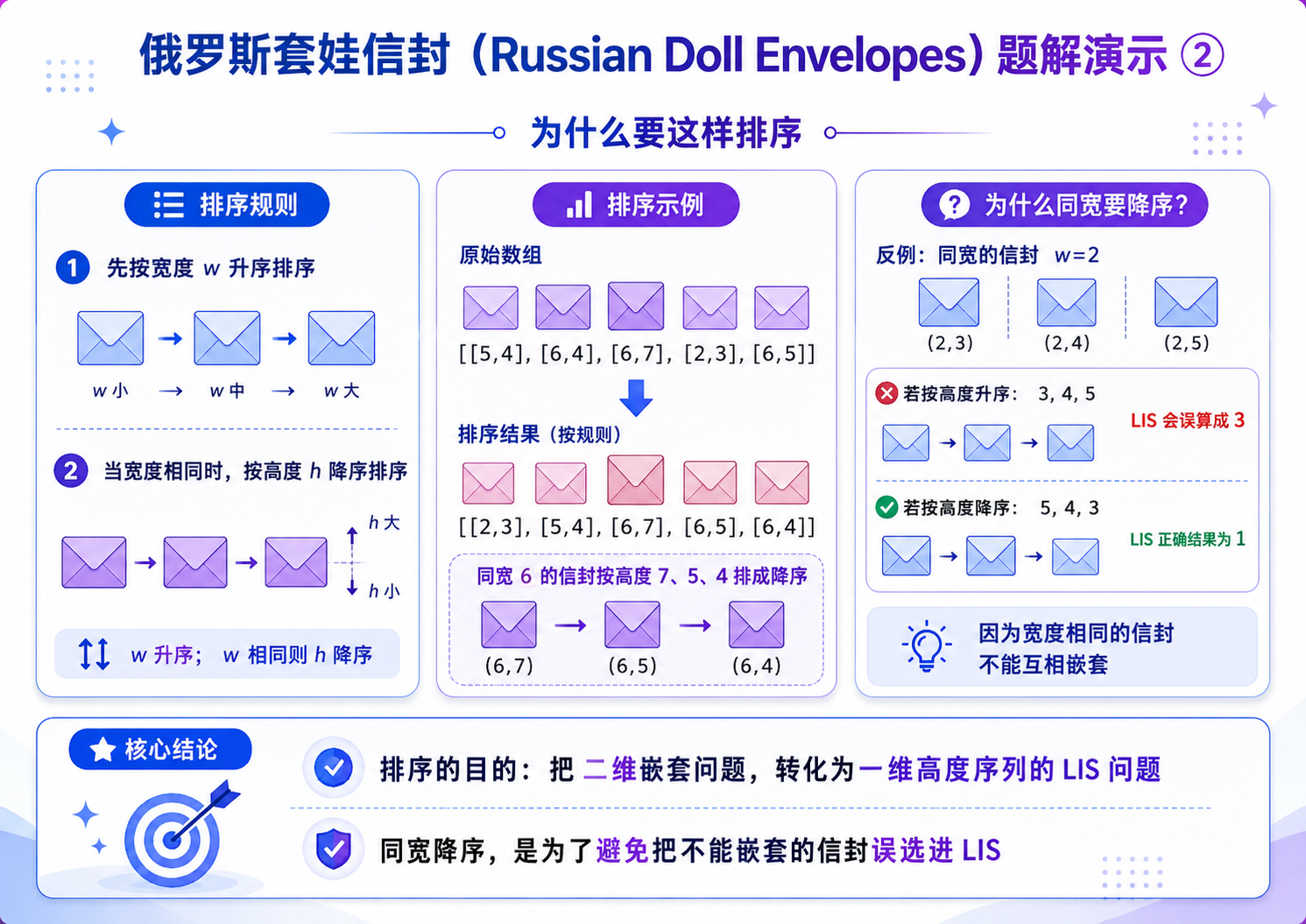
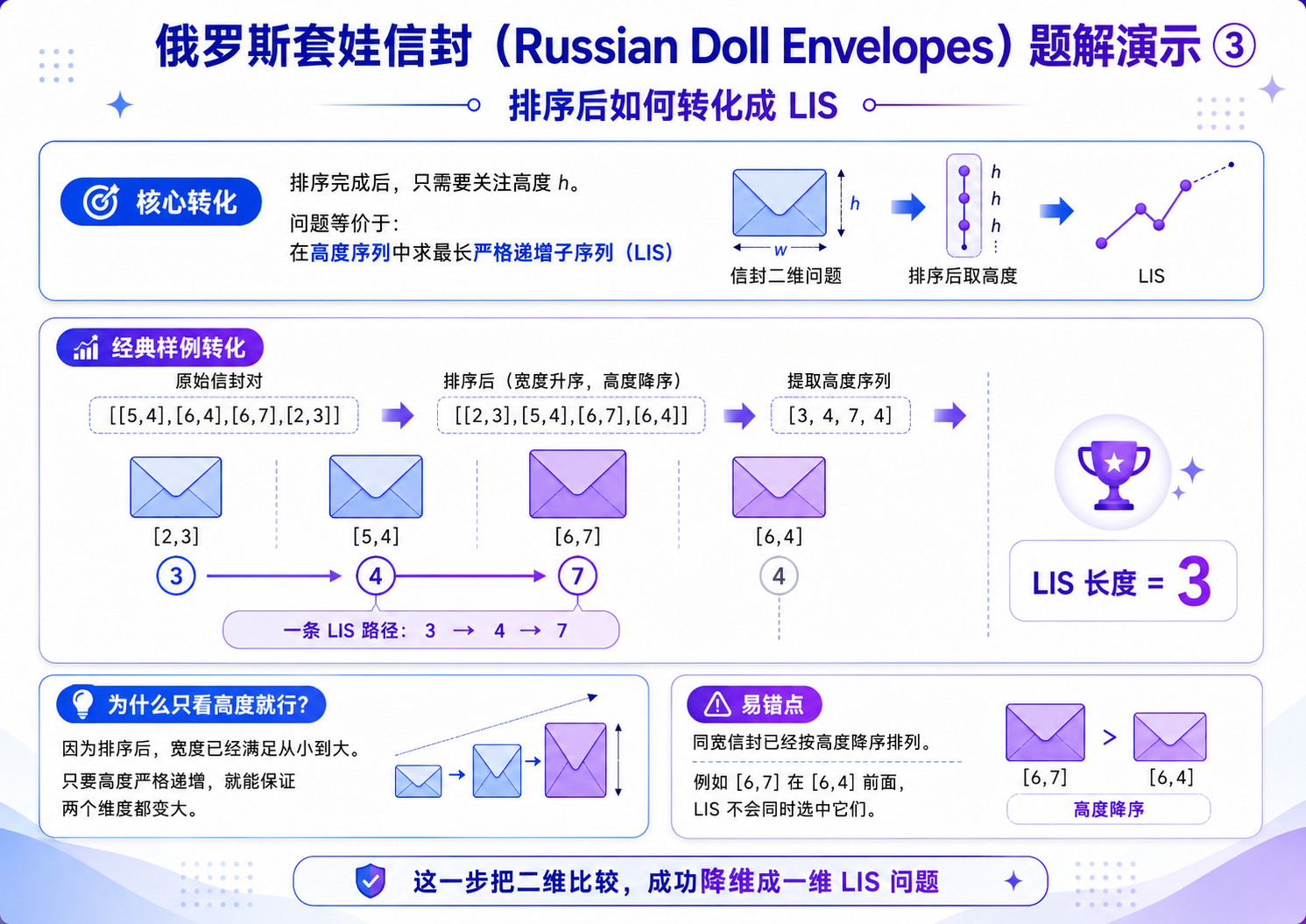
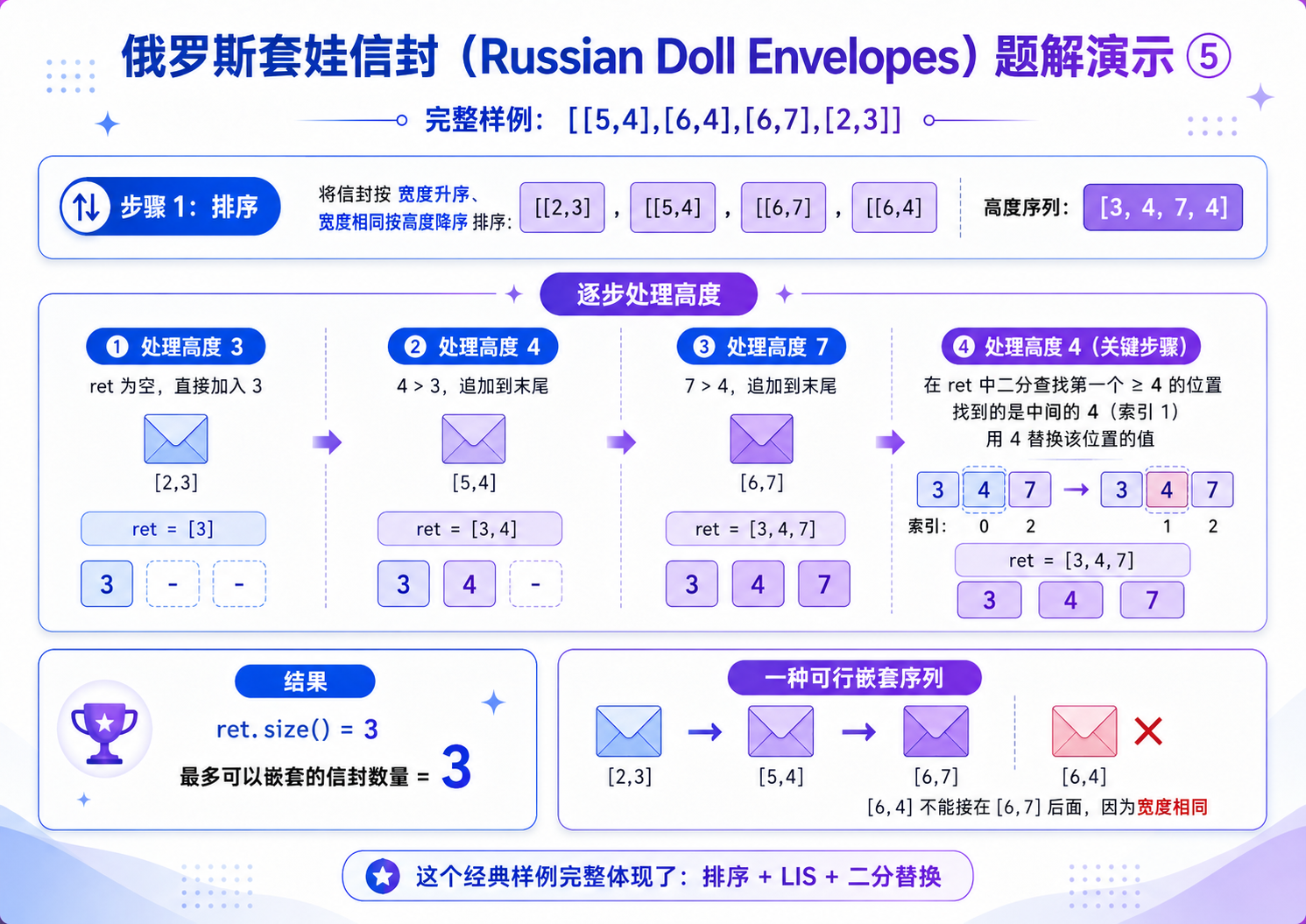
当我们把整个信封按照下面的规则排序之后:
i. 左端点不同的时候:按照左端点从小到大排序;
ii. 左端点相同的时候:按照右端点从大到小排序
我们发现,问题就变成了仅考虑信封的右端点,完完全全的变成的最长上升子序列的模型.那么我们就可以用贪心 + 二分优化我们的算法.



核心代码
cpp
class Solution
{
public:
int maxEnvelopes(vector<vector<int>>& e)
{
//第一步:自定义排序(核心预处理)
//排序规则:
//1.宽度 升序排列 → 保证后续只需要考虑高度
//2.宽度相同时,高度 降序排列 → 避免同宽度信封被选中嵌套
sort(e.begin(), e.end(), [&](const vector<int>& v1, const vector<int>& v2)
{
return v1[0] != v2[0] ? v1[0] < v2[0] : v1[1] > v2[1];
});
//第二步:贪心 + 二分查找 求解 高度的最长递增子序列(LIS)
//ret数组:存储长度为i+1的递增子序列的**最小末尾元素**
vector<int> ret;
//初始化:放入第一个信封的高度
ret.push_back(e[0][1]);
//遍历剩余所有信封的高度
for(int i = 1; i < e.size(); i++)
{
int b = e[i][1]; //当前信封的高度
//情况1:当前高度 > 序列最后一个元素 → 直接加入,延长递增序列
if(b > ret.back())
{
ret.push_back(b);
}
//情况2:当前高度 ≤ 最后一个元素 → 二分查找替换,维护最优序列
else
{
//二分查找:找到ret中第一个 ≥ b 的元素位置
int left = 0, right = ret.size() - 1;
while(left < right)
{
int mid = (left + right) / 2;
if(ret[mid] >= b)
right = mid; //目标在左半区间
else
left = mid + 1; //目标在右半区间
}
//替换:用更小的b更新该位置,让后续能接更多元素(贪心核心)
ret[left] = b;
}
}
//ret数组的长度 = 最长递增子序列长度 = 最多嵌套信封数
return ret.size();
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution
{
public:
int maxEnvelopes(vector<vector<int>>& e)
{
// 边界情况:没有信封,无法嵌套
if (e.empty())
return 0;
// 第一步:自定义排序
// 1. 宽度升序
// 2. 宽度相同时,高度降序
sort(e.begin(), e.end(), [&](const vector<int>& v1, const vector<int>& v2)
{
return v1[0] != v2[0] ? v1[0] < v2[0] : v1[1] > v2[1];
});
// 第二步:对高度求最长递增子序列
vector<int> ret;
// 初始化:放入第一个信封的高度
ret.push_back(e[0][1]);
for (int i = 1; i < e.size(); i++)
{
int b = e[i][1];
// 当前高度大于 ret 最后一个元素,可以直接延长递增序列
if (b > ret.back())
{
ret.push_back(b);
}
else
{
// 二分查找:找到 ret 中第一个 >= b 的位置
int left = 0, right = ret.size() - 1;
while (left < right)
{
int mid = (left + right) / 2;
if (ret[mid] >= b)
right = mid;
else
left = mid + 1;
}
// 替换该位置,让递增子序列的末尾尽可能小
ret[left] = b;
}
}
return ret.size();
}
};
void printEnvelopes(const vector<vector<int>>& envelopes)
{
cout << "[";
for (size_t i = 0; i < envelopes.size(); i++)
{
cout << "[" << envelopes[i][0] << ", " << envelopes[i][1] << "]";
if (i != envelopes.size() - 1)
cout << ", ";
}
cout << "]";
}
int main()
{
Solution sol;
vector<vector<vector<int>>> testCases = {
{{5, 4}, {6, 4}, {6, 7}, {2, 3}}, // 经典示例,结果 3
{{1, 1}, {1, 1}, {1, 1}}, // 宽高完全相同,结果 1
{{1, 1}}, // 单个信封,结果 1
{}, // 空数组,结果 0
{{1, 1}, {2, 2}, {3, 3}, {4, 4}}, // 完全递增,结果 4
{{4, 4}, {3, 3}, {2, 2}, {1, 1}}, // 原始逆序,排序后结果 4
{{1, 4}, {2, 3}, {3, 2}, {4, 1}}, // 宽递增,高递减,结果 1
{{2, 3}, {2, 4}, {2, 5}}, // 宽度相同,不能嵌套,结果 1
{{2, 5}, {3, 4}, {4, 3}, {5, 2}}, // 高度递减,结果 1
{{2, 2}, {3, 3}, {3, 4}, {4, 5}}, // 同宽度处理,结果 3
{{5, 4}, {6, 4}, {6, 7}, {2, 3}, {7, 8}}, // 可嵌套更多,结果 4
{{4, 5}, {4, 6}, {6, 7}, {2, 3}, {1, 1}}, // 混合情况,结果 4
{{10, 8}, {1, 12}, {6, 15}, {2, 18}}, // 宽递增但高度不适合全部嵌套,结果 2
{{1, 10}, {2, 9}, {3, 8}, {4, 7}, {5, 6}} // 高度严格递减,结果 1
};
for (int i = 0; i < testCases.size(); i++)
{
vector<vector<int>> envelopes = testCases[i];
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "信封数组:";
printEnvelopes(envelopes);
cout << endl;
cout << "最多可以嵌套的信封数量:";
cout << sol.maxEnvelopes(envelopes) << endl;
cout << "------------------------" << endl;
}
return 0;
}
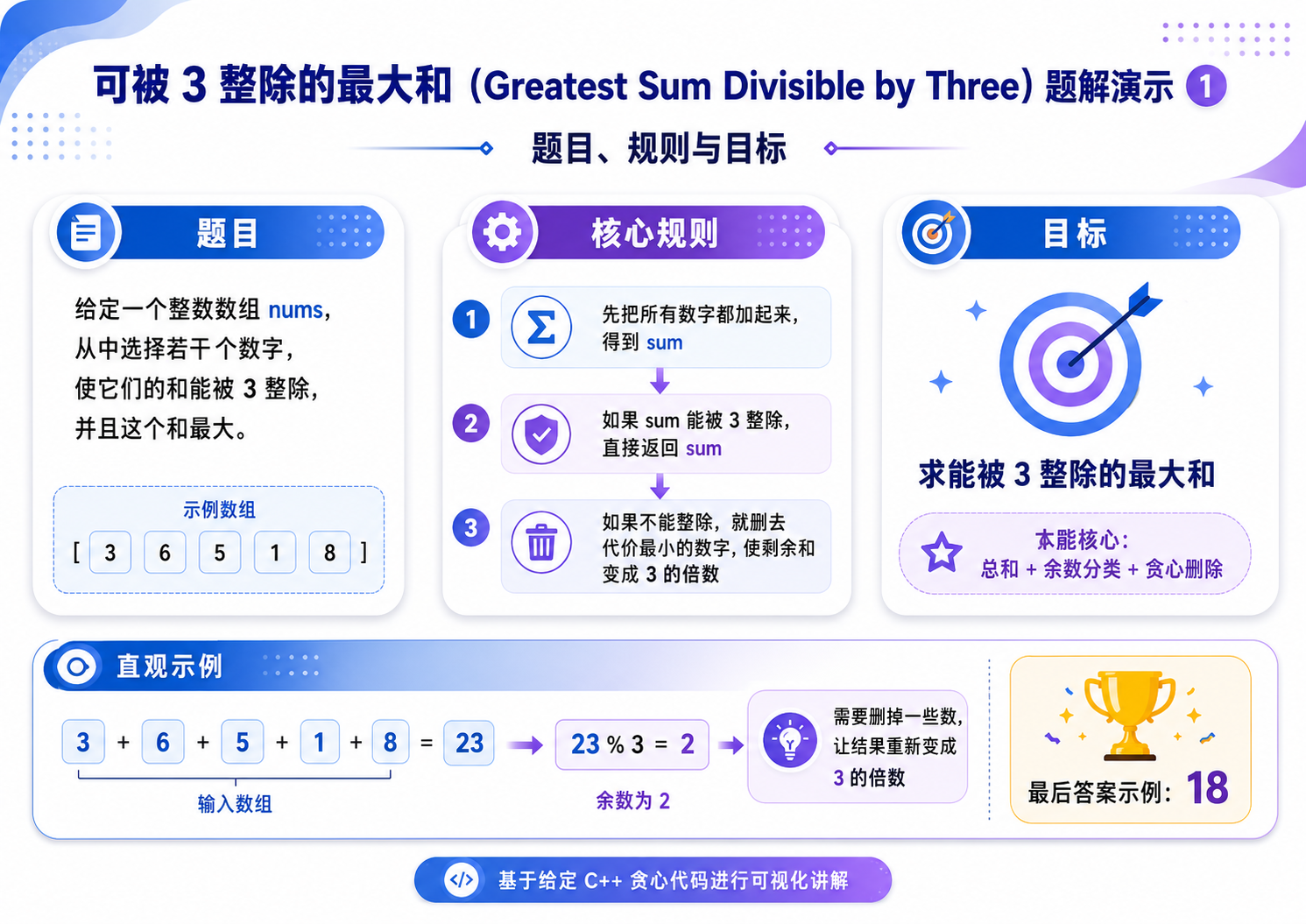
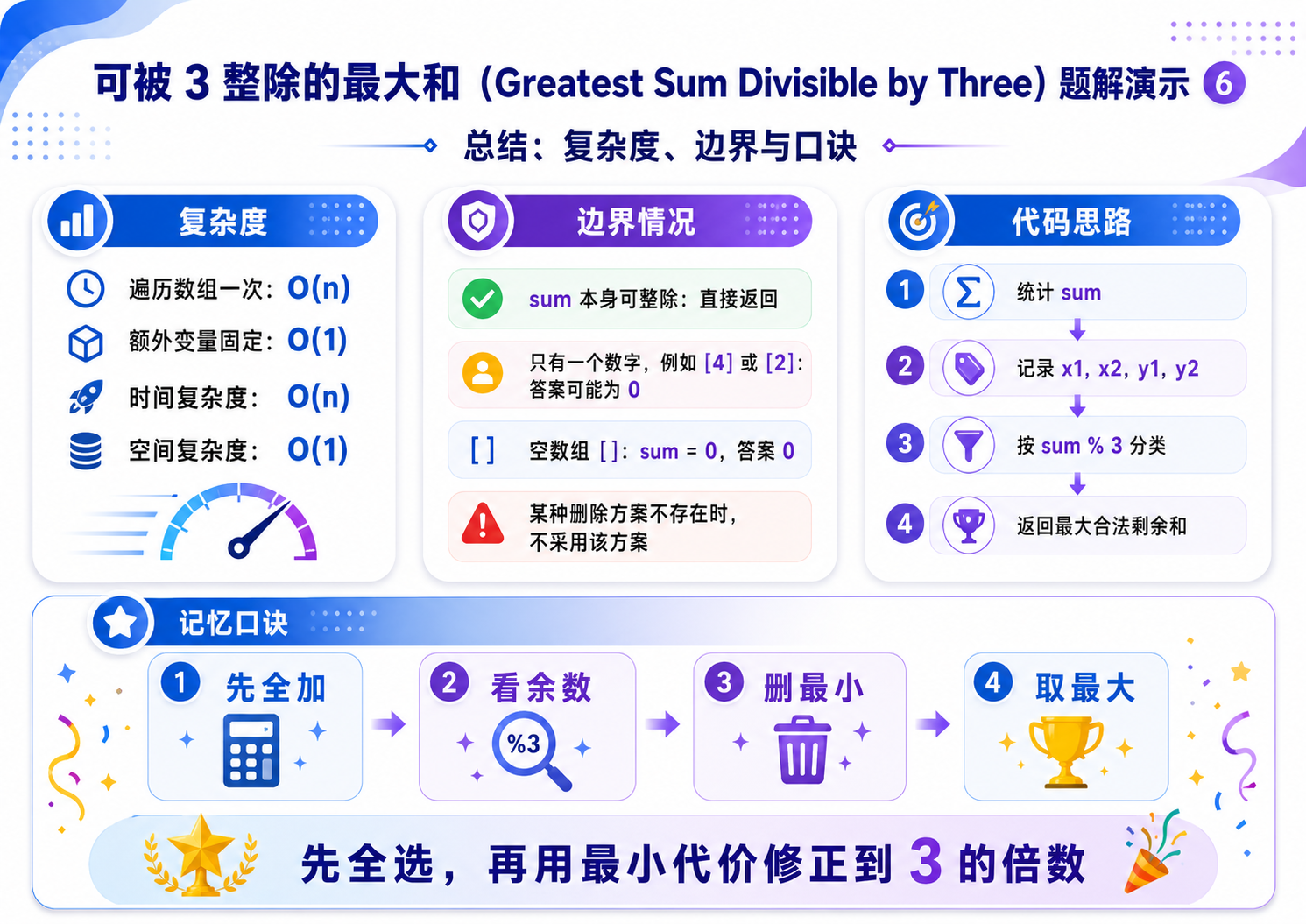
3.可被三整除的最⼤和(OJ题)

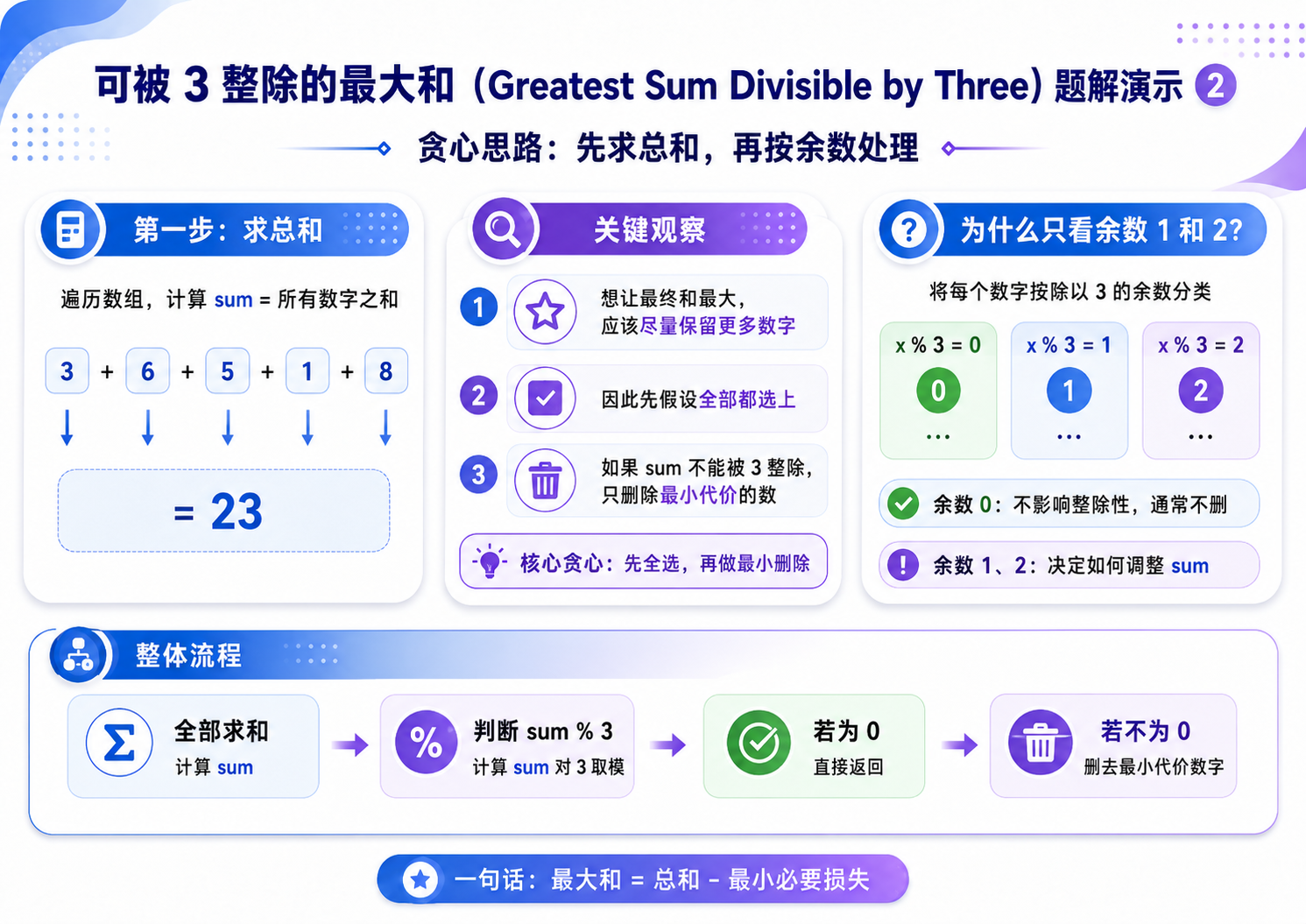
解法(正难则反 + 贪心 + 分类讨论):
正难则反:
我们可以先把所有的数累加在一起,然后根据累加和的结果,贪心的删除一些数.
分类讨论:
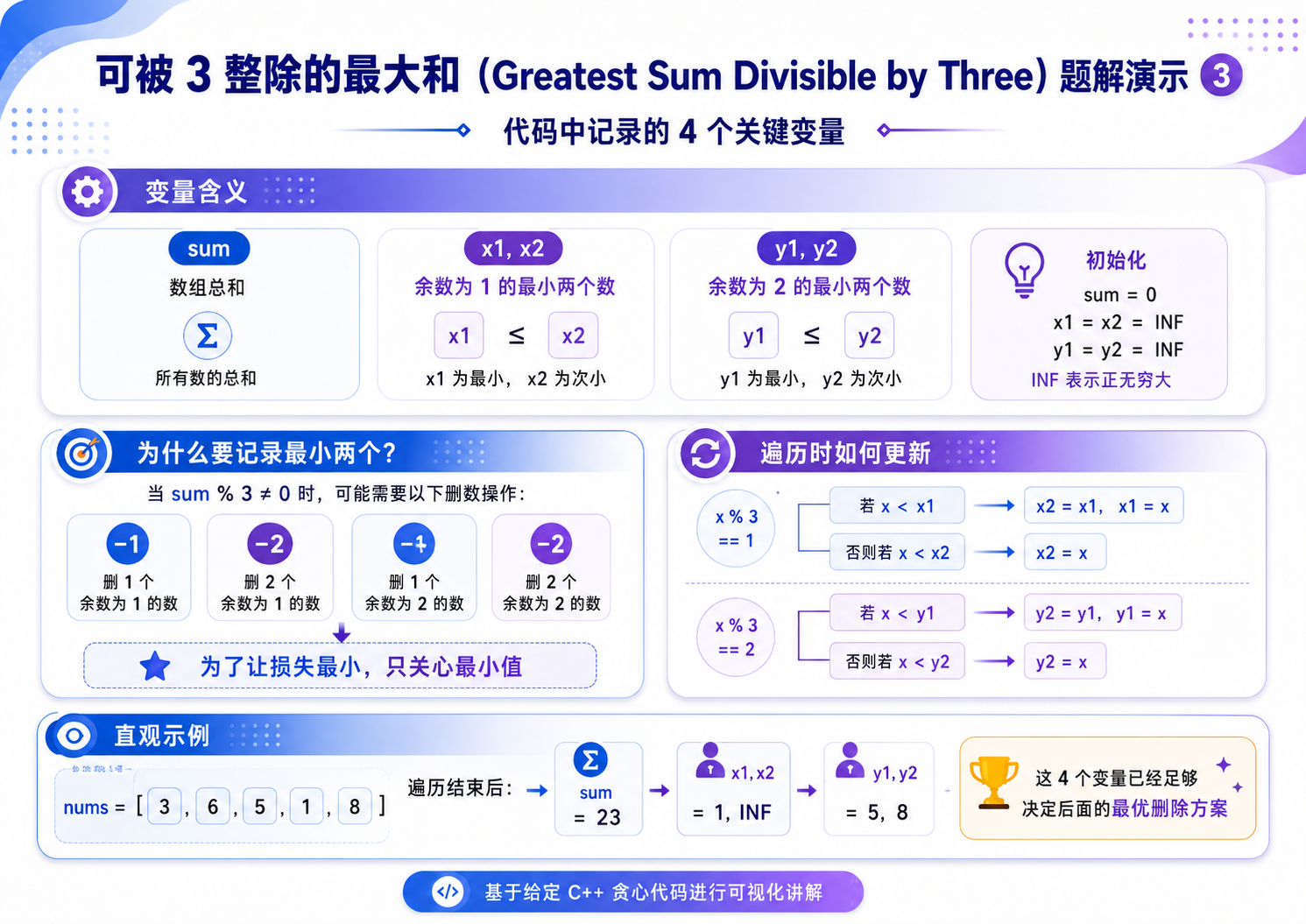
设累加和为 sum,用 x 标记 %3 == 1 的数,用 y 标记 %3 == 2 的数.
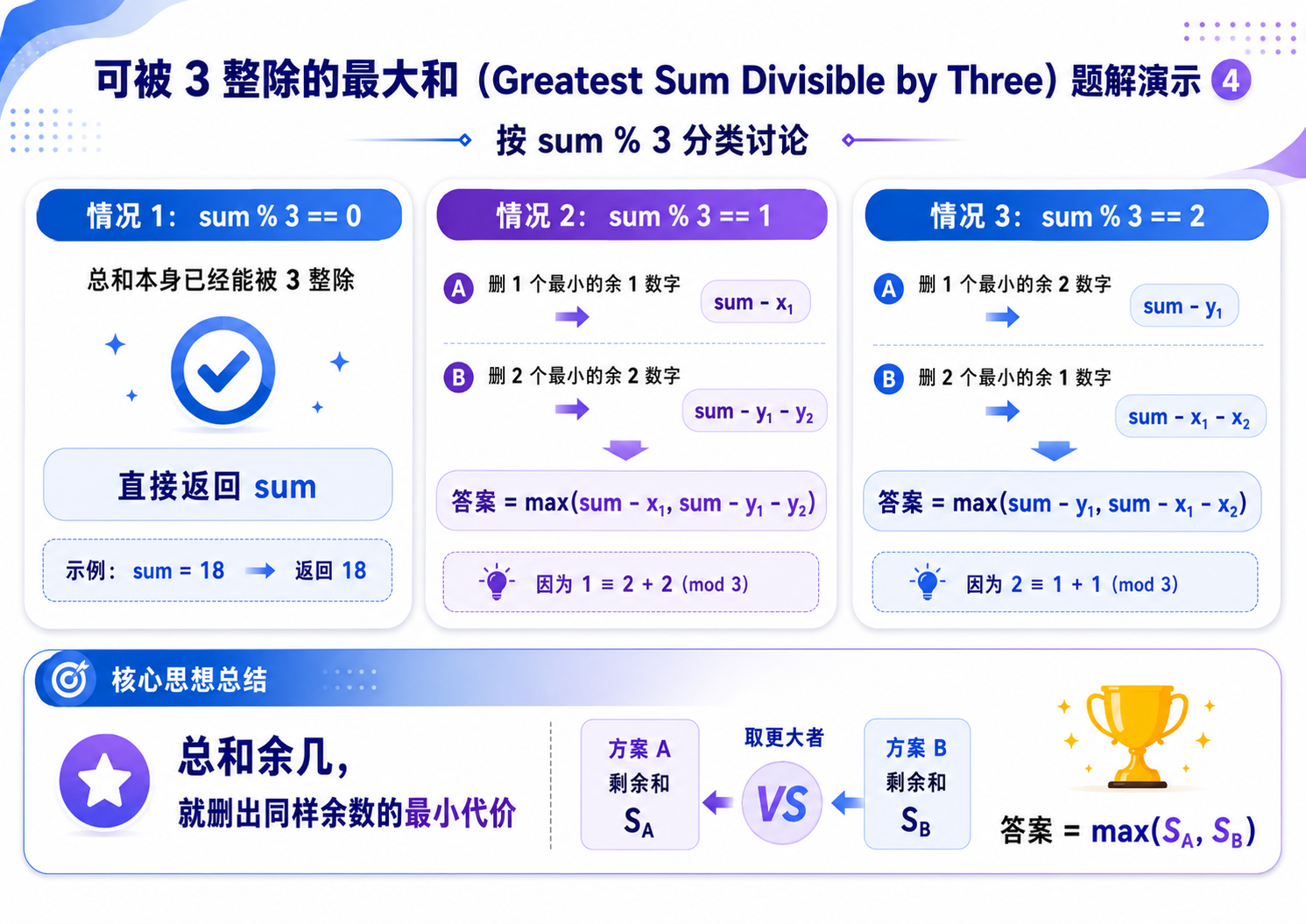
那么根据 sum 的余数,可以分为下面三种情况:
a. sum % 3 == 0,此时所有元素的和就是满足要求的,那么我们一个也不用删除;
b. sum % 3 == 1,此时数组中要么存在一个 x,要么存在两个 y.因为我们要的是最大值,所以应该选择 x 中最小的那个数,记为 x1,或者是 y 中最小以及次小的两个数,记为 y1, y2.
那么,我们应该选择两种情况下的最大值:max(sum - x1, sum - y1 - y2);
c. sum % 3 == 2,此时数组中要么存在一个 y,要么存在两个 x。因为我们要的是最大值,所以应该选择 y 中最小的那个数,记为 y1,或者是 x 中最小以及次小的两个数,记为 x1, x2.
那么,我们应该选择两种情况下的最大值:max(sum - y1, sum - x1 - x2);

核心代码
cpp
class Solution
{
public:
int maxSumDivThree(vector<int>& nums)
{
//定义无穷大,用于初始化最小值变量(表示初始无有效值)
const int INF = 0x3f3f3f3f;
//sum:数组所有元素的总和
//x1, x2:余数为 1 的数字中,最小的两个数(从小到大)
//y1, y2:余数为 2 的数字中,最小的两个数(从小到大)
int sum = 0, x1 = INF, x2 = INF, y1 = INF, y2 = INF;
//遍历数组,统计总和,并记录余数1、2的最小两个数
for(auto x : nums)
{
sum += x; //累加总和
if(x % 3 == 1) //当前数字余数为1
{
//更新最小的两个余数1的数:比x1小,x1退位给x2,x1更新为x
if(x < x1) { x2 = x1; x1 = x; }
//比x1大但比x2小,直接更新x2
else if(x < x2) { x2 = x; }
}
else if(x % 3 == 2) //当前数字余数为2
{
//更新最小的两个余数2的数:比y1小,y1退位给y2,y1更新为x
if(x < y1) { y2 = y1; y1 = x; }
//比y1大但比y2小,直接更新y2
else if(x < y2) { y2 = x; }
}
}
//核心分类讨论:根据总和对3取余的结果,计算最大合法和
if(sum % 3 == 0)
{
//情况1:总和本身能被3整除,直接返回总和
return sum;
}
else if(sum % 3 == 1)
{
//情况2:总和余1,有两种优化方案,取最大值
//方案1:删除1个最小的余1数字;方案2:删除2个最小的余2数字
return max(sum - x1, sum - y1 - y2);
}
else
{
//情况3:总和余2,有两种优化方案,取最大值
//方案1:删除1个最小的余2数字;方案2:删除2个最小的余1数字
return max(sum - y1, sum - x1 - x2);
}
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution
{
public:
int maxSumDivThree(vector<int>& nums)
{
// 定义无穷大,用于初始化最小值变量
const int INF = 0x3f3f3f3f;
// sum:数组所有元素的总和
// x1, x2:余数为 1 的数字中,最小的两个数
// y1, y2:余数为 2 的数字中,最小的两个数
int sum = 0, x1 = INF, x2 = INF, y1 = INF, y2 = INF;
// 遍历数组,统计总和,并记录余数 1、2 的最小两个数
for (auto x : nums)
{
sum += x;
if (x % 3 == 1)
{
if (x < x1)
{
x2 = x1;
x1 = x;
}
else if (x < x2)
{
x2 = x;
}
}
else if (x % 3 == 2)
{
if (x < y1)
{
y2 = y1;
y1 = x;
}
else if (x < y2)
{
y2 = x;
}
}
}
// 根据总和对 3 取余的结果,计算最大合法和
if (sum % 3 == 0)
{
return sum;
}
else if (sum % 3 == 1)
{
// 删除 1 个最小的余 1 数字,或删除 2 个最小的余 2 数字
return max(sum - x1, sum - y1 - y2);
}
else
{
// 删除 1 个最小的余 2 数字,或删除 2 个最小的余 1 数字
return max(sum - y1, sum - x1 - x2);
}
}
};
void printVector(const vector<int>& nums)
{
cout << "[";
for (size_t i = 0; i < nums.size(); i++)
{
cout << nums[i];
if (i != nums.size() - 1)
cout << ", ";
}
cout << "]";
}
int main()
{
Solution sol;
vector<vector<int>> testCases = {
{3, 6, 5, 1, 8}, // 总和 23,删除 5,结果 18
{4}, // 总和 4,删除 4,结果 0
{1, 2, 3, 4, 4}, // 总和 14,删除 2,结果 12
{3, 6, 9}, // 总和 18,直接返回 18
{1, 1, 1}, // 总和 3,结果 3
{2, 2, 2}, // 总和 6,结果 6
{1, 1, 2}, // 总和 4,删除 1,结果 3
{2, 2, 1}, // 总和 5,删除 2,结果 3
{1, 4, 7, 2, 5, 8}, // 多个余 1 和余 2
{100, 200, 300}, // 大数测试
{1}, // 单个余 1 数字,结果 0
{2}, // 单个余 2 数字,结果 0
{}, // 空数组,结果 0
{5, 2, 2, 2}, // 总和 11,删除 5 或两个 2,结果 6
{8, 8, 2, 1}, // 总和 19,删除 1,结果 18
{7, 2, 6, 6, 1} // 总和 22,删除 1,结果 21
};
for (int i = 0; i < testCases.size(); i++)
{
vector<int> nums = testCases[i];
cout << "测试用例 " << i + 1 << ":";
printVector(nums);
cout << endl;
cout << "能被 3 整除的最大和:";
cout << sol.maxSumDivThree(nums) << endl;
cout << "------------------------" << endl;
}
return 0;
}
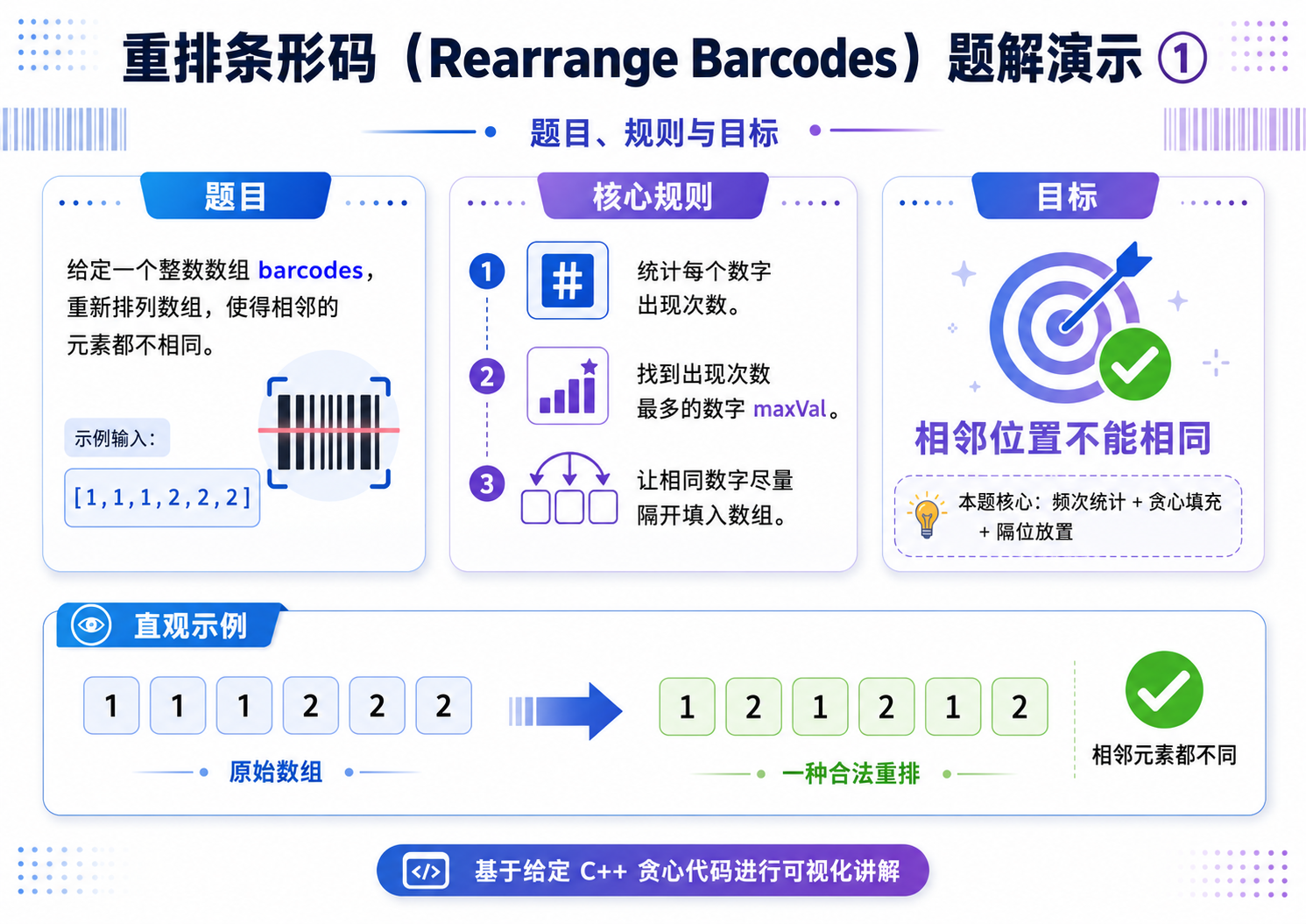
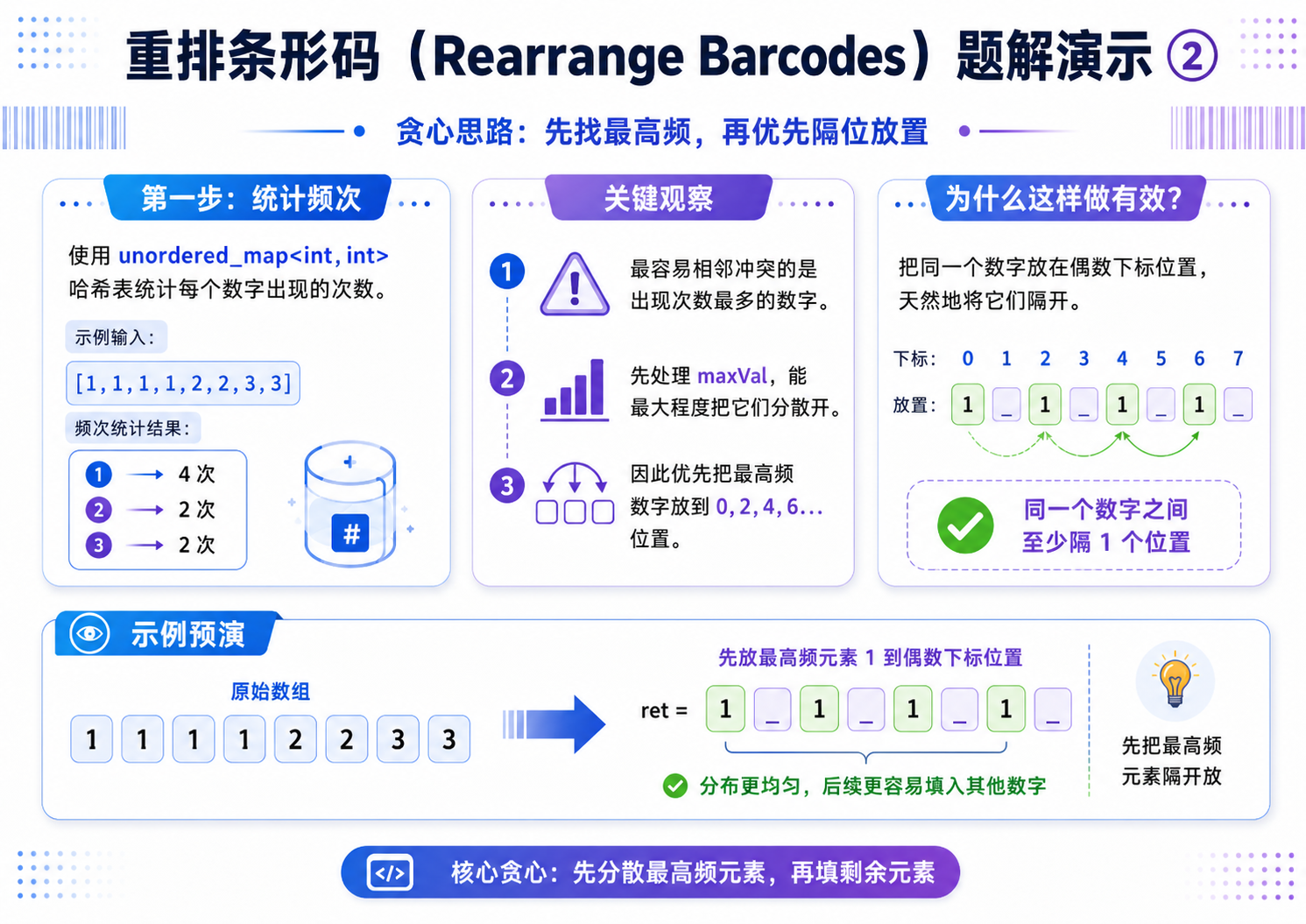
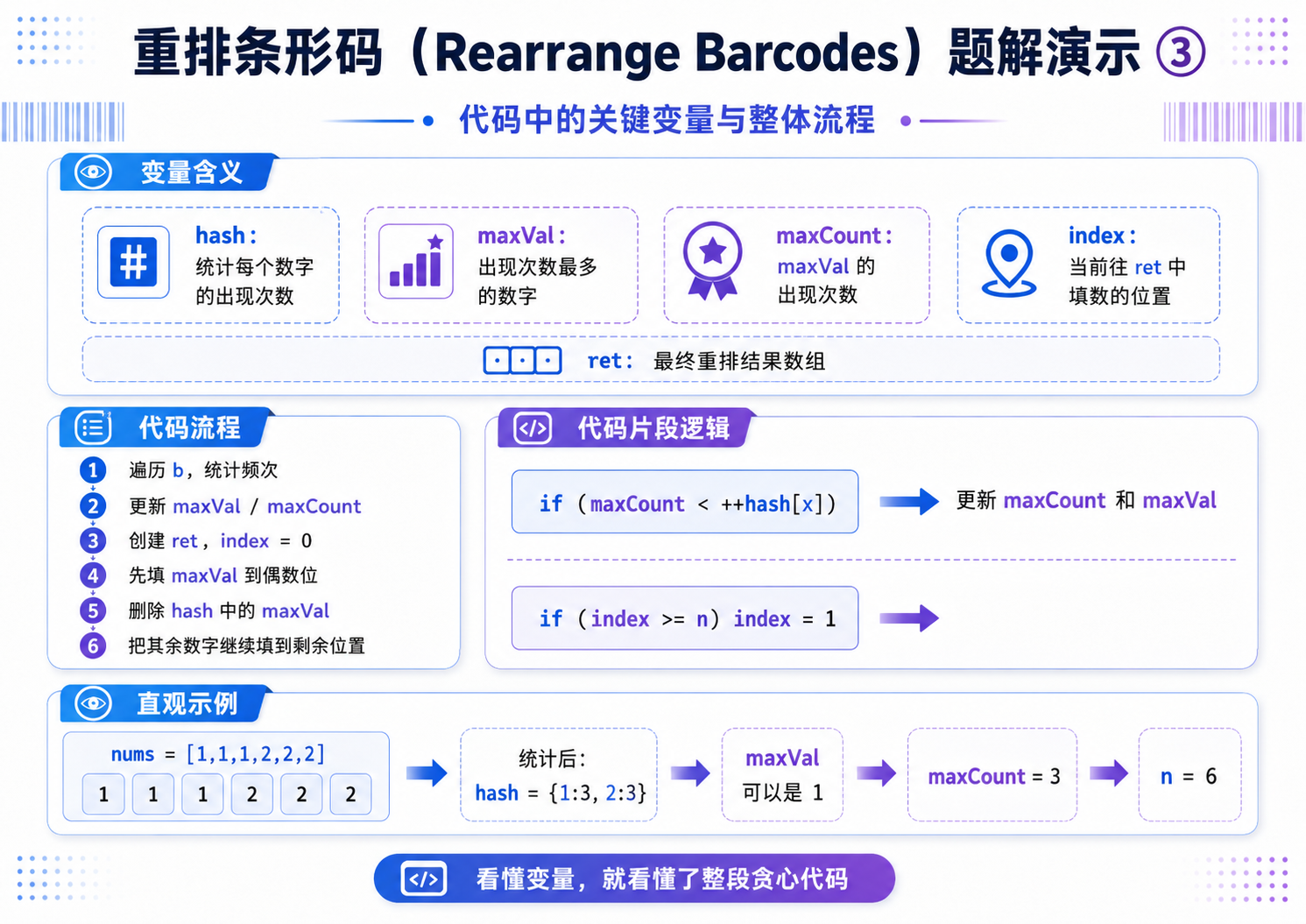
4.距离相等的条形码(OJ题)

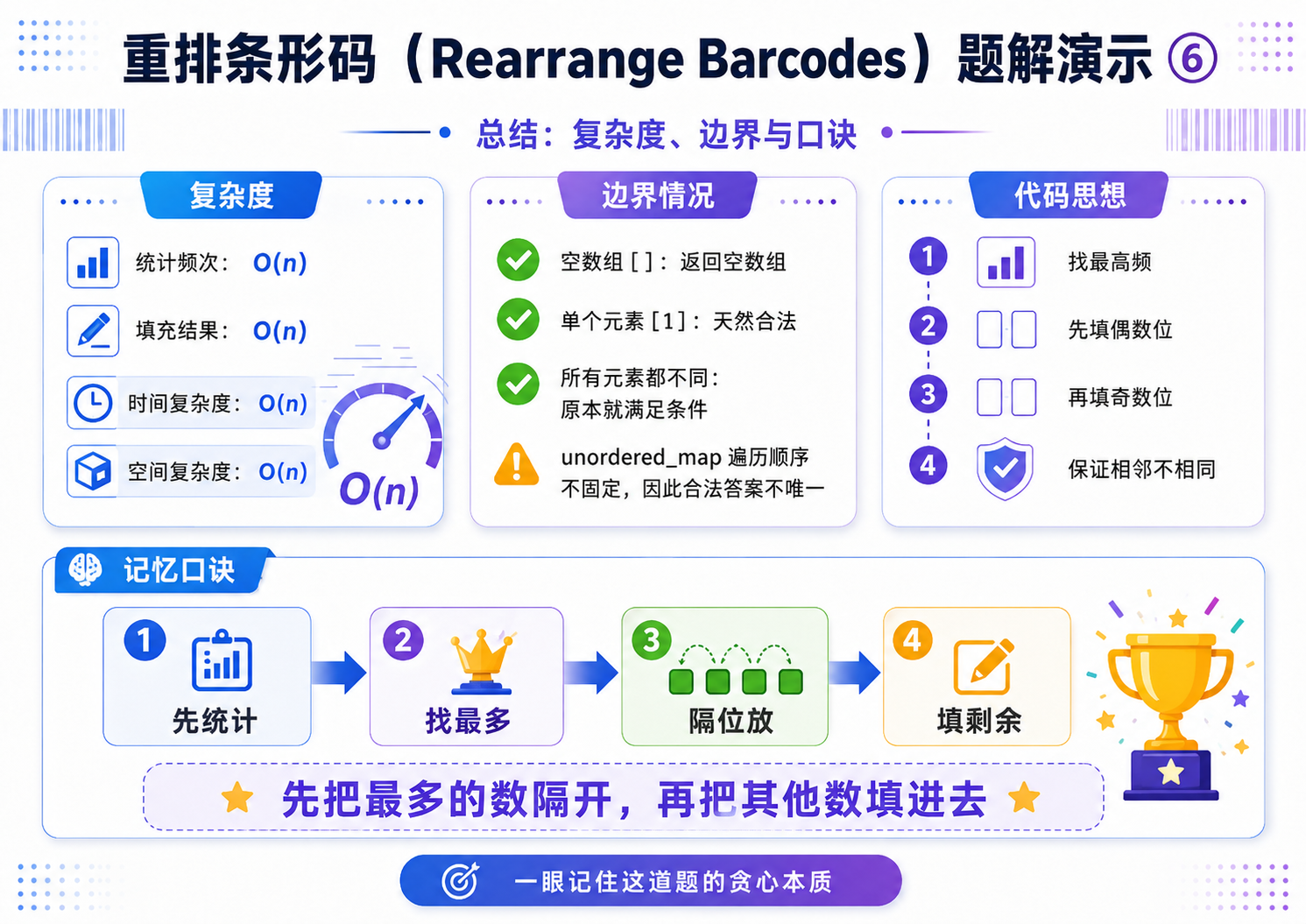
解法(贪心):
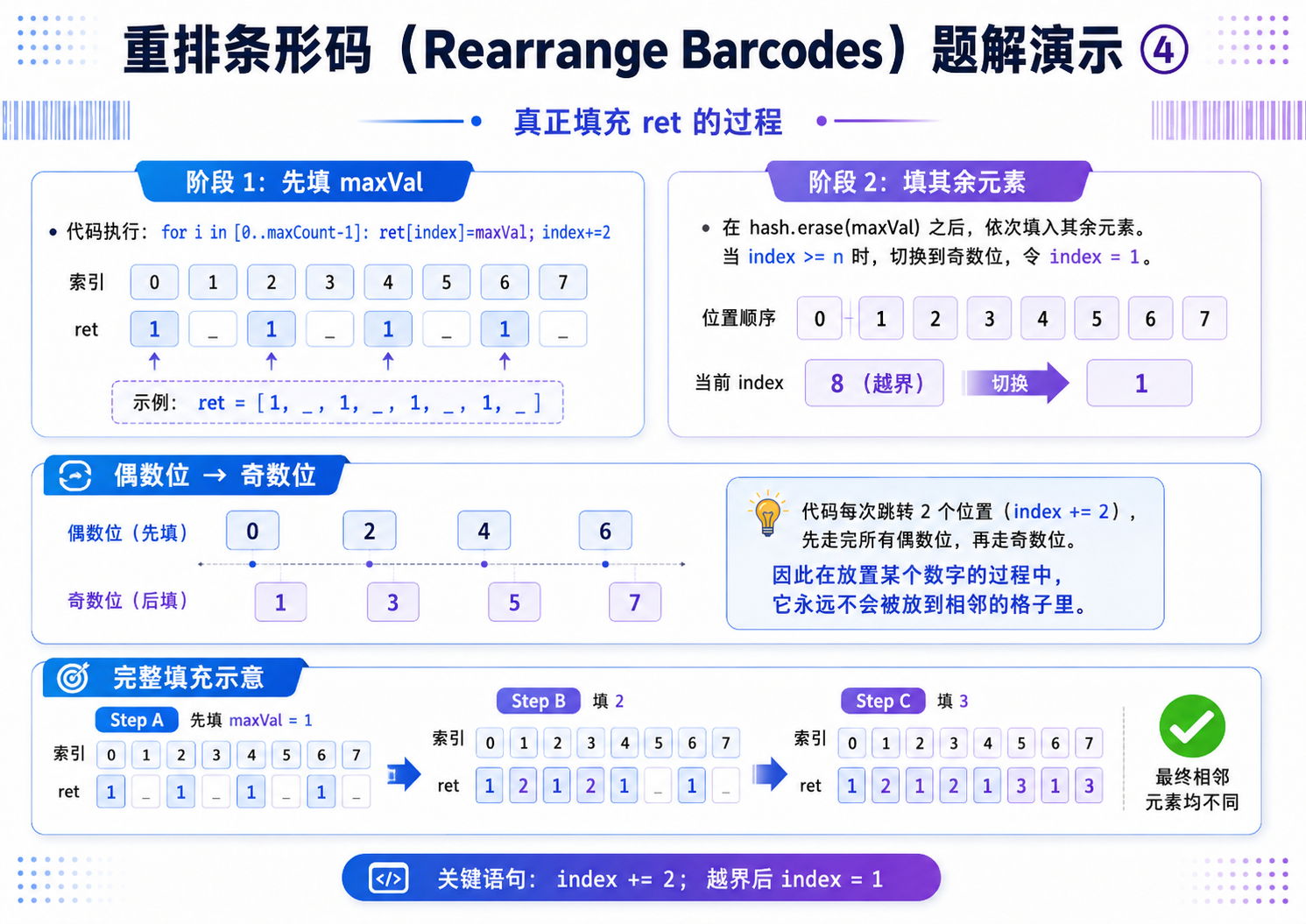
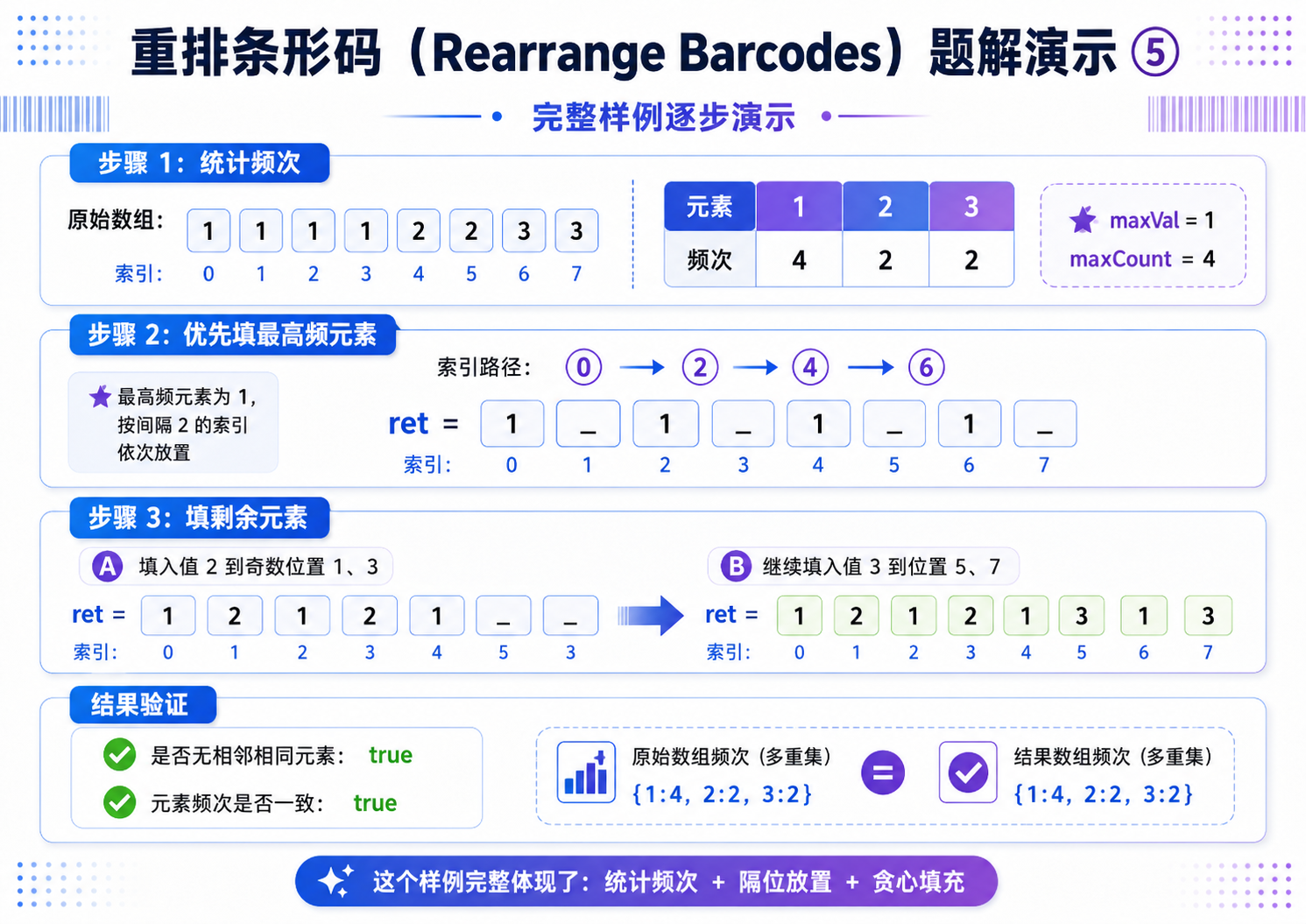
贪心策略:每次处理一批相同的数字,往 n 个空里面摆放;每次摆放的时候,隔一个格子摆放一个数;优先处理出现次数最多的那个数.
核心代码
cpp
class Solution
{
public:
vector<int> rearrangeBarcodes(vector<int>& b)
{
//哈希表:统计每个数字出现的频次
unordered_map<int, int> hash;
//maxVal:出现次数最多的数字;maxCount:该数字的最大出现次数
int maxVal = 0, maxCount = 0;
//遍历数组,统计频次并找到出现次数最多的数字
for(auto x : b)
{
//先将当前数字频次+1,再判断是否为新的最大频次
if(maxCount < ++hash[x])
{
maxCount = hash[x]; //更新最大频次
maxVal = x; //更新频次最高的数字
}
}
int n = b.size(); //数组总长度
vector<int> ret(n); //结果数组,存储最终重排后的条形码
int index = 0; //填充位置的下标,初始从偶数位 0 开始
//第一步:优先填充出现次数最多的数字,间隔放置(0,2,4...偶数位)
//避免该数字相邻重复,这是贪心核心
for(int i = 0; i < maxCount; i++)
{
ret[index] = maxVal;
index += 2; //每次跳一个位置,保证不相邻
}
//第二步:填充剩余的数字
hash.erase(maxVal); //从哈希表中删除已填充的最大频次数字
//遍历哈希表中剩余的数字和频次
for(auto& [x, y] : hash)
{
//按频次填充当前数字
for(int i = 0; i < y; i++)
{
//如果偶数位已经填满,切换到奇数位(1,3,5...)
if(index >= n) index = 1;
ret[index] = x;
index += 2; //依旧间隔填充,保证不相邻
}
}
//返回重排完成的条形码数组
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <unordered_map>
using namespace std;
class Solution
{
public:
vector<int> rearrangeBarcodes(vector<int>& b)
{
// 哈希表:统计每个数字出现的频次
unordered_map<int, int> hash;
// maxVal:出现次数最多的数字;maxCount:该数字的最大出现次数
int maxVal = 0, maxCount = 0;
// 遍历数组,统计频次并找到出现次数最多的数字
for (auto x : b)
{
if (maxCount < ++hash[x])
{
maxCount = hash[x];
maxVal = x;
}
}
int n = b.size();
vector<int> ret(n);
int index = 0;
// 第一步:优先填充出现次数最多的数字
for (int i = 0; i < maxCount; i++)
{
ret[index] = maxVal;
index += 2;
}
// 第二步:填充剩余的数字
hash.erase(maxVal);
for (auto& [x, y] : hash)
{
for (int i = 0; i < y; i++)
{
if (index >= n)
index = 1;
ret[index] = x;
index += 2;
}
}
return ret;
}
};
void printVector(const vector<int>& nums)
{
cout << "[";
for (size_t i = 0; i < nums.size(); i++)
{
cout << nums[i];
if (i != nums.size() - 1)
cout << ", ";
}
cout << "]";
}
bool checkValid(const vector<int>& nums)
{
for (int i = 1; i < nums.size(); i++)
{
if (nums[i] == nums[i - 1])
return false;
}
return true;
}
bool checkSameElements(vector<int> a, vector<int> b)
{
unordered_map<int, int> hashA;
unordered_map<int, int> hashB;
for (int x : a)
hashA[x]++;
for (int x : b)
hashB[x]++;
return hashA == hashB;
}
int main()
{
Solution sol;
vector<vector<int>> testCases = {
{1, 1, 1, 2, 2, 2}, // 两种数字频次相同
{1, 1, 1, 1, 2, 2, 3, 3}, // 一个数字出现次数最多
{1, 1, 2}, // 简单情况
{1, 2, 3, 4}, // 全部不同
{1}, // 单个元素
{7, 7, 7, 8, 8, 9, 9}, // 奇数长度
{2, 2, 2, 3, 3, 3, 4, 4}, // 多个高频元素
{5, 5, 5, 5, 6, 6, 6, 7, 7}, // 高频数字占比较大
{10, 10, 20, 20, 30, 30}, // 多种数字重复
{100, 100, 100, 200, 200, 300}, // 大数值元素
{} // 空数组
};
for (int i = 0; i < testCases.size(); i++)
{
vector<int> barcodes = testCases[i];
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "原始数组:";
printVector(barcodes);
cout << endl;
vector<int> result = sol.rearrangeBarcodes(barcodes);
cout << "重排结果:";
printVector(result);
cout << endl;
cout << "是否无相邻相同元素:";
cout << (checkValid(result) ? "true" : "false") << endl;
cout << "元素频次是否一致:";
cout << (checkSameElements(barcodes, result) ? "true" : "false") << endl;
cout << "------------------------" << endl;
}
return 0;
}
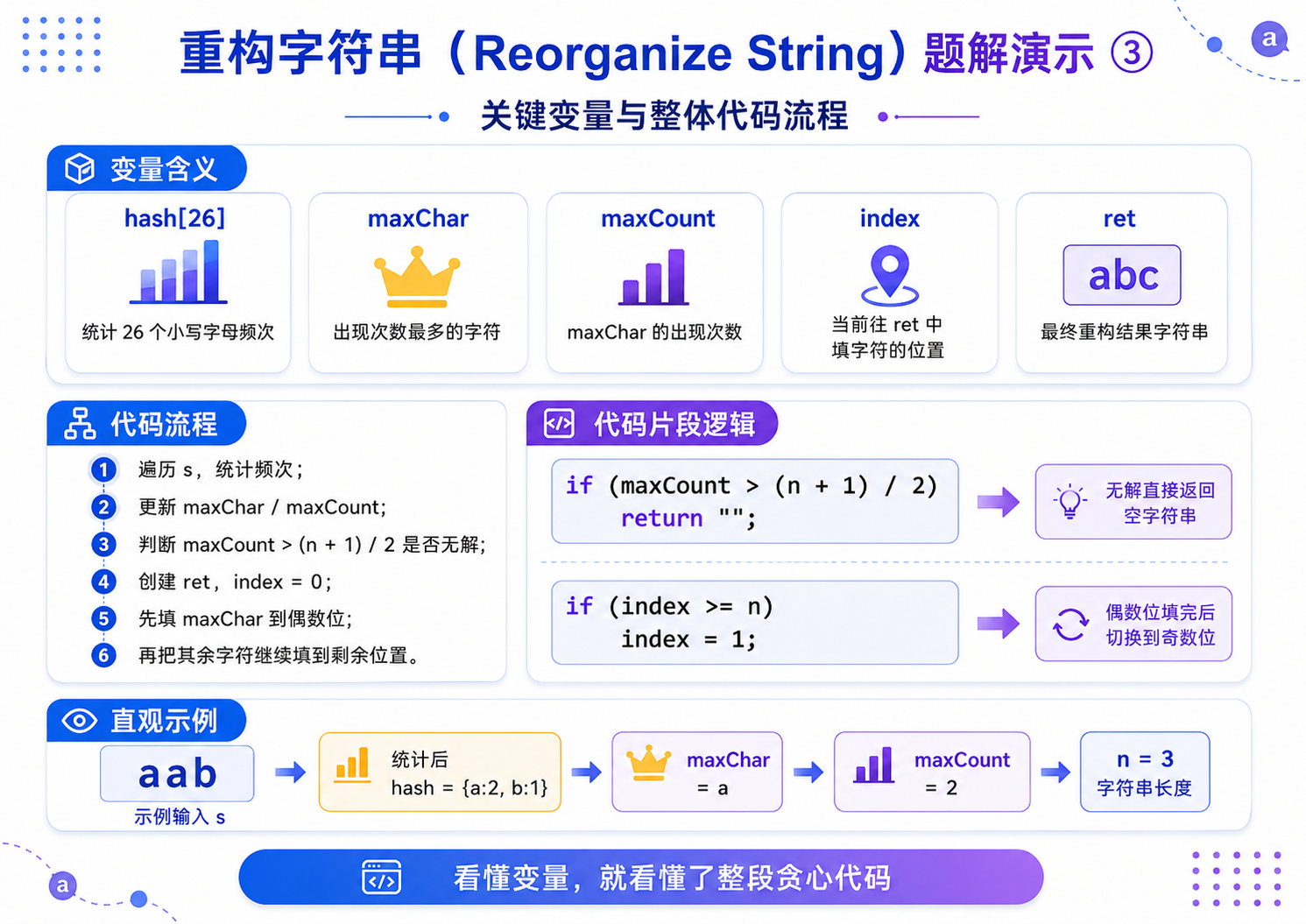
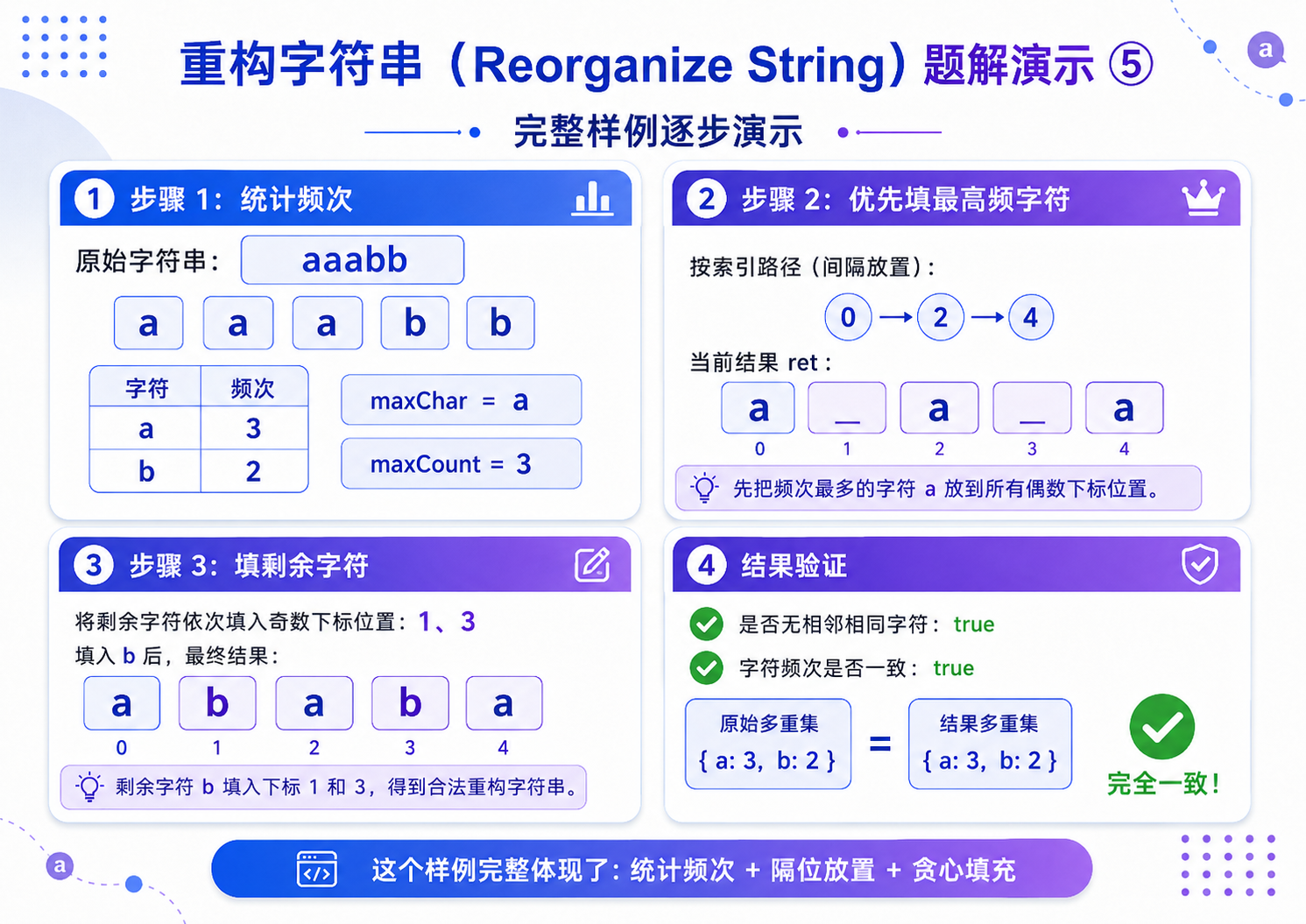
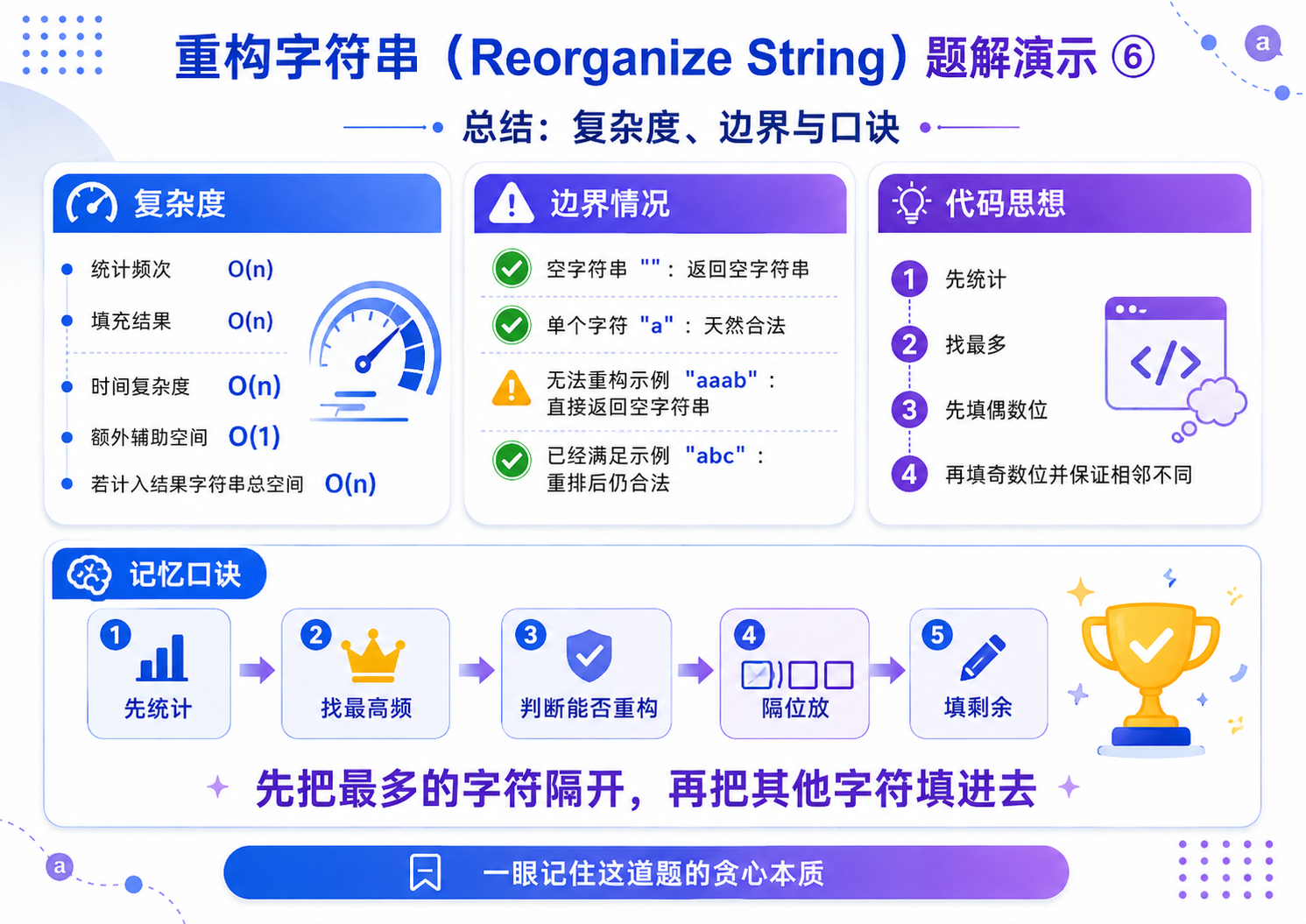
5.重构字符串(OJ题)

解法(贪心策略):
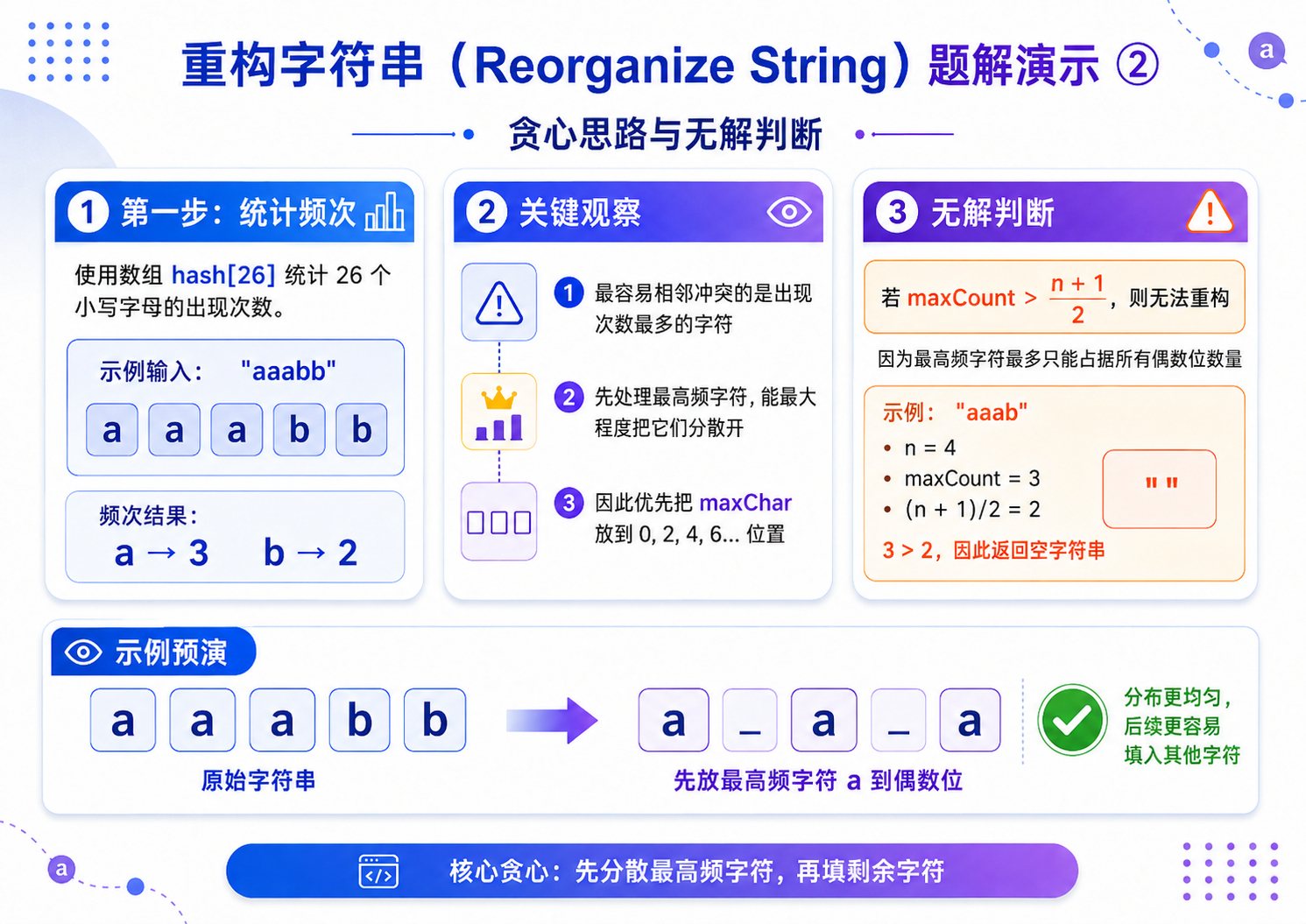
1.统计所有元素的出现频次,找到出现次数最多的元素;
2.本题题目保证存在合法解,无需判断无解情况;
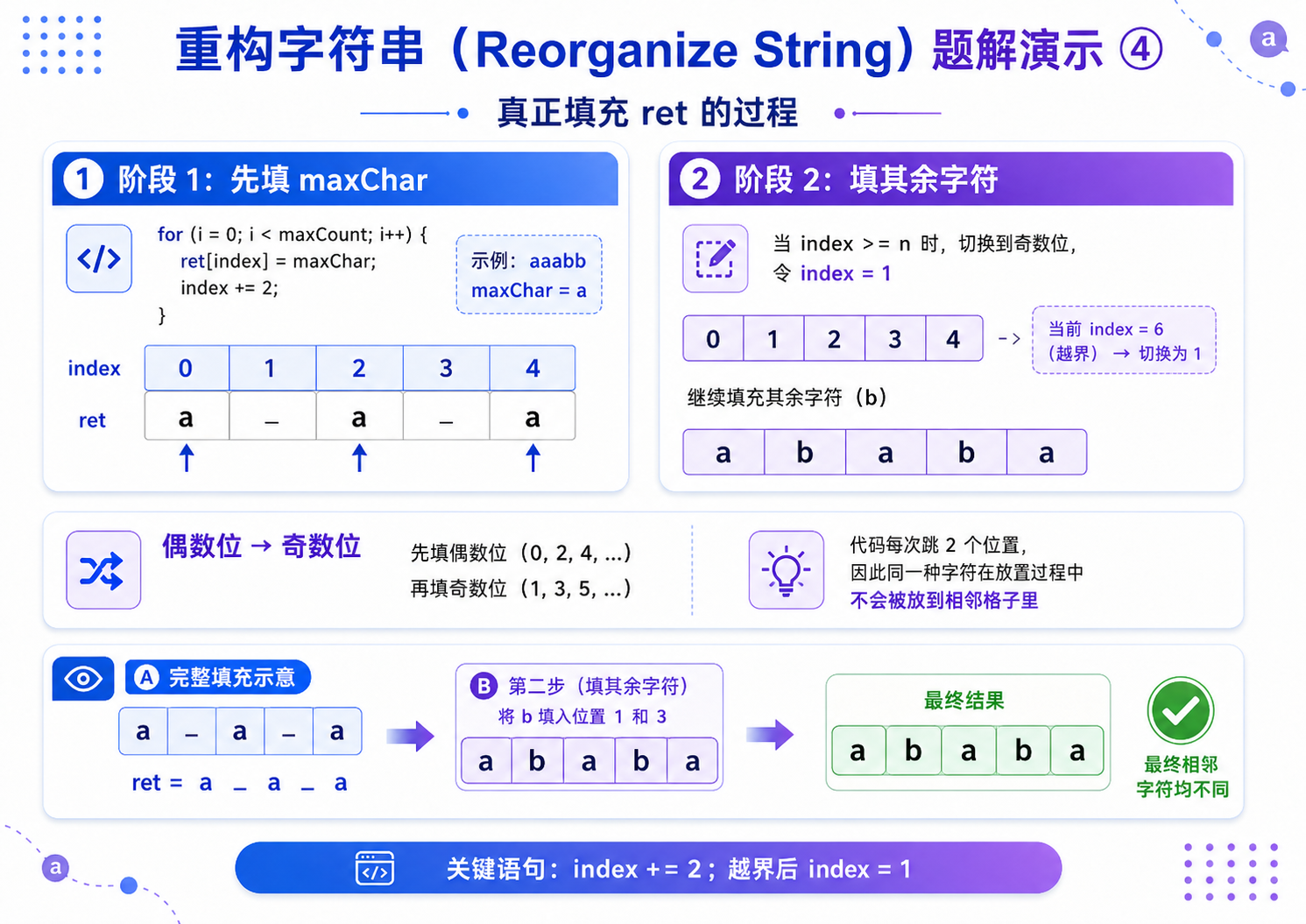
3.间隔填充:先将出现次数最多的元素,间隔放置在偶数下标位置(0、2、4......),彻底避免相邻重复;
- 填充剩余元素:偶数位填满后,切换到奇数下标位置(1、3、5......),继续间隔填充所有剩余元素,最终完成合法重排.

核心代码
cpp
class Solution
{
public:
string reorganizeString(string s)
{
//用数组统计26个小写字母的出现频次(哈希思想,效率更高)
int hash[26] = { 0 };
char maxChar = ' '; //记录出现次数最多的字符
int maxCount = 0; //记录字符的最大出现次数
//遍历字符串,统计字符频次,并找到频次最高的字符
for(auto ch : s)
{
//当前字符频次+1,若超过最大频次,更新最大值和对应字符
if(maxCount < ++hash[ch - 'a'])
{
maxChar = ch;
maxCount = hash[ch - 'a'];
}
}
int n = s.size();
//核心边界判断:
//如果某字符出现次数 > (n+1)/2,**无法**重构(必然相邻重复),直接返回空串
if(maxCount > (n + 1) / 2)
return "";
//初始化结果字符串,长度为n,初始填充空格
string ret(n, ' ');
int index = 0; //填充下标,从偶数位置 0 开始放置
//第一步:优先填充出现次数最多的字符,间隔放置(0,2,4...)
//避免该字符相邻重复,是贪心的核心
for(int i = 0; i < maxCount; i++)
{
ret[index] = maxChar;
index += 2; //每次跳一个位置,保证不相邻
}
hash[maxChar - 'a'] = 0; //标记该字符已填充完毕,后续不再处理
//第二步:填充剩余所有字符
for(int i = 0; i < 26; i++)
{
//遍历当前字符的所有剩余频次
for(int j = 0; j < hash[i]; j++)
{
//如果偶数位已填满,切换到奇数位(1,3,5...)继续间隔填充
if(index >= n)
index = 1;
ret[index] = 'a' + i; //放入当前字符
index += 2; //间隔放置
}
}
//返回重构完成的字符串
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
using namespace std;
class Solution
{
public:
string reorganizeString(string s)
{
// 用数组统计 26 个小写字母的出现频次
int hash[26] = { 0 };
char maxChar = ' ';
int maxCount = 0;
// 遍历字符串,统计字符频次,并找到频次最高的字符
for (auto ch : s)
{
if (maxCount < ++hash[ch - 'a'])
{
maxChar = ch;
maxCount = hash[ch - 'a'];
}
}
int n = s.size();
// 如果某字符出现次数 > (n + 1) / 2,无法重构
if (maxCount > (n + 1) / 2)
return "";
// 初始化结果字符串
string ret(n, ' ');
int index = 0;
// 第一步:优先填充出现次数最多的字符
for (int i = 0; i < maxCount; i++)
{
ret[index] = maxChar;
index += 2;
}
hash[maxChar - 'a'] = 0;
// 第二步:填充剩余所有字符
for (int i = 0; i < 26; i++)
{
for (int j = 0; j < hash[i]; j++)
{
if (index >= n)
index = 1;
ret[index] = 'a' + i;
index += 2;
}
}
return ret;
}
};
// 判断字符串是否不存在相邻相同字符
bool checkNoAdjacentSame(const string& s)
{
for (int i = 1; i < s.size(); i++)
{
if (s[i] == s[i - 1])
return false;
}
return true;
}
// 判断重构前后字符频次是否一致
bool checkSameChars(const string& original, const string& result)
{
unordered_map<char, int> hash1;
unordered_map<char, int> hash2;
for (char ch : original)
hash1[ch]++;
for (char ch : result)
hash2[ch]++;
return hash1 == hash2;
}
int main()
{
Solution sol;
vector<string> testCases = {
"aab", // 可以重构,例如 aba
"aaab", // 无法重构,返回空串
"vvvlo", // 可以重构
"a", // 单个字符
"aa", // 无法重构
"ab", // 已经满足
"abc", // 全部不同
"aaabb", // 可以重构
"aaabc", // 可以重构
"aaaabc", // 无法重构
"aabbcc", // 多字符频次相同
"aaaaabbbbb", // 两个高频字符
"abbabbaaab", // 混合情况
"" // 空字符串
};
for (int i = 0; i < testCases.size(); i++)
{
string s = testCases[i];
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "原始字符串:\"" << s << "\"" << endl;
string result = sol.reorganizeString(s);
cout << "重构结果:\"" << result << "\"" << endl;
if (result.empty())
{
cout << "说明:无法重构或原字符串为空" << endl;
}
else
{
cout << "是否无相邻相同字符:";
cout << (checkNoAdjacentSame(result) ? "true" : "false") << endl;
cout << "字符频次是否一致:";
cout << (checkSameChars(s, result) ? "true" : "false") << endl;
}
cout << "------------------------" << endl;
}
return 0;
}

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容:贪心算法的内容到这里就圆满结束啦!小编的算法学习暂时就告一段落啦!后面小编还是会每天不断的学习算法,精进自己的算法能力!这样才能提高自己的算法能力!为了更远大的目标努力前进!我们大家一起共同努力💪!
每日心灵鸡汤: 认知不同,不必争辩!
这个世界上最愚蠢的行为,就是不停的跟别人讲道理,古语有云,三年学说话,一生学闭嘴.永远不要和不同层次的人争辩,因为每个人都只能在自己的认知基础上思考问题.真正格局大的人,不是站在某一角度争论说服别人,而是坚持自己的同时也能尊重别人.记住:位置不同,少言为贵;认知不同,不争不辩;三观不合,浪费口舌.人生最舒适的状态,就是和志趣相投的朋友彻夜长谈,对话不投机的人一笑了之.
