快速了解部分
基础信息(英文):
- 题目: HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
- 时间: 2026.04
- 机构: Tencent Robotics X × HY Vision Team
- 3个英文关键词: Embodied Intelligence, Vision-Language Models, Mixture-of-Transformers
1句话通俗总结本文干了什么事情
腾讯团队研发了一套专为机器人设计的视觉语言模型(VLM),通过独特的架构和训练方法,让机器人能更精准地看懂世界、进行空间推理并规划行动。
研究痛点:现有研究不足 / 要解决的具体问题
通用的大模型(LLM/VLM)虽然知识渊博,但在物理世界面前"眼高手低":缺乏对物体细节、空间位置的精细感知能力,也缺少在物理环境中进行预测、交互和规划的"具身智能"思维。
核心方法:关键技术、模型或研究设计(简要)
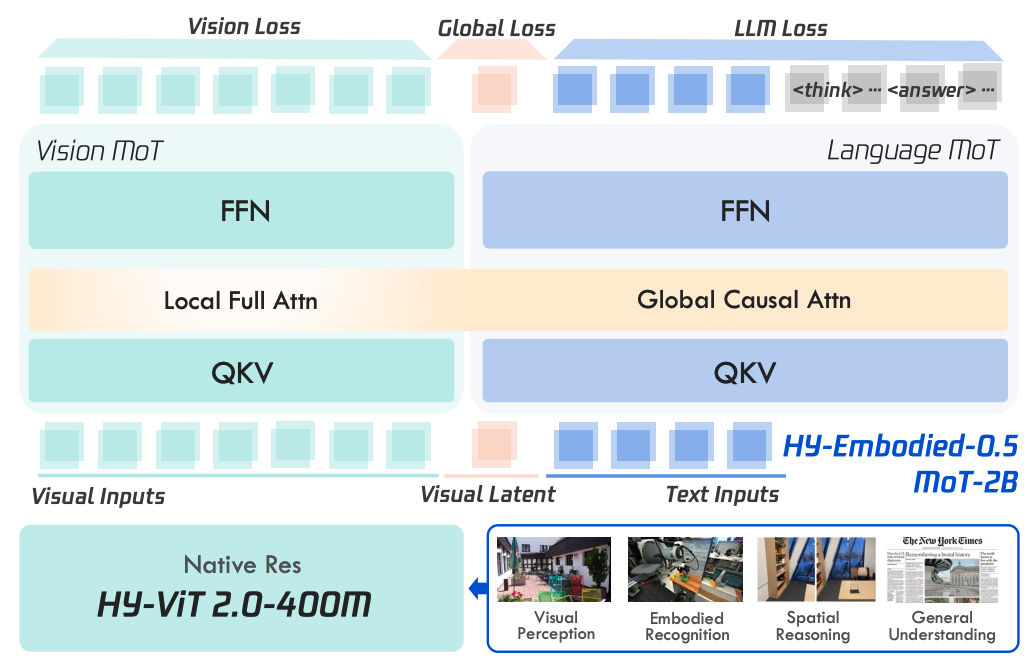
搞了两个模型:一个2B参数的小模型专供边缘设备(机器人本体)使用,一个32B参数的大模型负责"传帮带"。核心技术是用MoT架构让模型对图像和文字分别处理,加上"视觉潜token"来连接视觉与语言,并用迭代强化学习提升推理能力。
深入了解部分
作者想要表达什么
作者认为,要让数字智能走进物理世界,不能直接套用通用模型,必须专门设计一种既能像人一样通过视觉感知环境,又能像AI一样进行深度逻辑思考的"机器人大脑"。
相比前人创新在哪里
- 架构创新 :采用了Mixture-of-Transformers (MoT),把处理图像和文字的参数分开,互不干扰,既提升了视觉感知能力,又不牺牲语言能力。
- 连接机制 :引入了Visual Latent Tokens,作为视觉和语言之间的桥梁,专门用来捕捉图像的整体语义信息。
- 训练策略:设计了一套**"大带小"**(Large-to-Small Distillation)的策略,让强大的大模型把自己的"思考过程"教给小模型,让小模型也能拥有接近大模型的智商。
解决方法/算法的通俗解释
想象一下,这是在训练一个"机器人驾驶员"。
- MoT架构就像是给驾驶员配了两个专门的助手:一个专门负责"看路"(处理图像),一个专门负责"听导航"(处理文字),而不是让一个助手同时干两件事导致手忙脚乱。
- 视觉潜token就像是驾驶员脑海里对当前路况生成的一个"核心印象",这个印象直接决定了他怎么理解导航语音。
- 大带小就像是让一个经验丰富的老司机(32B大模型)坐在新手(2B小模型)旁边,不仅告诉新手该怎么做,还把自己的思考逻辑直接传授给他。
解决方法的具体做法
- 数据大杂烩:喂给模型海量数据,包括普通图文、机器人操作视频、3D空间坐标、物体深度信息等(总计超600B tokens)。
- 分阶段训练 :
- 预训练:用大数据打基础,学会看懂图像和理解语言。
- 中期训练:引入专门的具身和空间数据,让模型学会"深度思考"(Chain-of-Thought)。
- 强化学习:通过打分机制(Reward),让模型自己试错,不断优化自己的回答,直到满分。
- 蒸馏:最后,让32B的大模型去指导2B的小模型做题,把大模型的"解题思路"压缩进小模型里。
基于前人的哪些方法
- 基于 Vision Transformer (ViT) 进行图像编码。
- 借鉴了 Mixture-of-Experts (MoE) 的思想,发展出了针对模态的 Mixture-of-Transformers (MoT)。
- 使用了 Chain-of-Thought (CoT) 和 Rejection Sampling 等强化学习方法来提升推理能力。
实验设置、数据、评估方式、结论
- 模型规模:MoT-2B(20亿参数,边缘端) vs MoE-A32B(320亿参数,云端)。
- 数据集:自建了包含1亿+样本的高质量数据集,涵盖视觉感知、空间、具身任务。
- 评估基准:在22个公开基准测试中横扫千军,包括视觉感知(CV-Bench)、空间理解(3DSRBench)、机器人任务(RoboBench)等。
- 结论 :
- 2B小模型:在同类小模型中拿了16个第一,甚至能打败参数量比它大的竞品,且在通用任务上不输Qwen3-VL。
- 32B大模型:性能对标甚至超越了Gemini 3.0 Pro等顶尖模型。
- 真机测试:在真实的机械臂(插头打包、叠餐具、挂杯子)任务中,成功率显著高于基线模型(π0/π0.5)。
提到的同类工作
- 通用VLM:Qwen3-VL, Gemini 3.0, GPT-5
- 具身/机器人模型:RoboBrain 2.5, RoboMind, RT-X, OS-Copilot
和本文相关性最高的3个文献
- Liang et al., 2024 (Mixture-of-Transformers):本文核心架构MoT的直接理论基础,提供了模态自适应计算的思路。
- Zelikman et al., 2024 (Latent Thinking):启发了本文使用Visual Latent Tokens来连接视觉与语言,增强模型的感知表示。
- Shao et al., 2024 (DeepSeekMath / Iterative RL):本文在后训练阶段采用的迭代强化学习范式的参考来源,用于提升模型的深度思考能力。
我的
- 训练了一个32B的VLM,只能做VQA和Spatial reasoning任务。然后蒸馏到一个2B的VLM上,然后加了一个action expert头(和pi系列一样)。