大家好,我是直奔標杆!专注Java开发者AI转型干货分享,和大家一起从零基础吃透Spring AI,稳步向AI开发标杆迈进~ 今天带来《Spring AI 零基础到实战》系列的第二十课,也是MCP协议实战的核心内容,全程干货无废话,手把手带大家实现Spring AI MCP客户端与服务端的双向交互,新手也能跟着敲出可运行代码!
在上一节《Java开发者AI转型第十九课!MCP协议揭秘与无边界插件生态实战》中,我们已经领略了MCP协议打破"N×M接口灾难"的强大魅力------仅仅几行YAML配置,就能跨网络对接魔搭社区的菜谱服务,让大模型秒变"超级厨师"。但很多小伙伴不知道,这只是MCP的冰山一角,它的真正实力远不止被动提供工具调用!
做企业级AI开发的小伙伴,大概率会遇到这样的痛点,咱们一起来探讨下:
-
企业级标准化难题:业务专家精心打磨的Prompt模板,怎么统一分发给全公司的AI助手?总不能让大家手动复制粘贴,既低效又容易出错吧?
-
异步与反向交互难题:后台执行一个耗时5分钟的任务,前端大模型只能傻等吗?如果服务端执行到一半,需要反向调用客户端的大模型帮忙处理文本,能实现吗?
答案是肯定的!本节课,直奔標杆就带大家亲手用Spring AI搭建一套MCP客户端与服务端,演示如何将Spring Boot打造成具备资源投喂、提示词分发、智能补全、底层状态反向穿透的超级中枢,彻底解决以上痛点,掌握企业级MCP实战核心能力!
本节学习目标(建议收藏,对照练习)
咱们学习不盲目,明确目标再动手,效率翻倍:
-
认知升级:跳出Function Calling的局限,读懂MCP协议中Resources、Prompts、Completions的核心架构设计,理解双向交互的底层逻辑;
-
服务端实战:手写4个常用Provider组件,让Spring Boot不仅能"干活",还能为大模型提供"静态记忆"(资源)和"代码提示"(补全);
-
回调实战:掌握服务端反向控制客户端的"黑魔法"------跨网络打印日志、推送进度、调用客户端大模型;
-
双模通信:打通Streamable-HTTP(网络模式)与Stdio(进程模式),适配不同部署场景,应对企业级实战需求。
先搞懂:MCP双向交互流转逻辑
动手写代码前,咱们先理清MCP客户端与服务端的核心交互逻辑(建议结合自己的理解画个流程图,加深记忆):
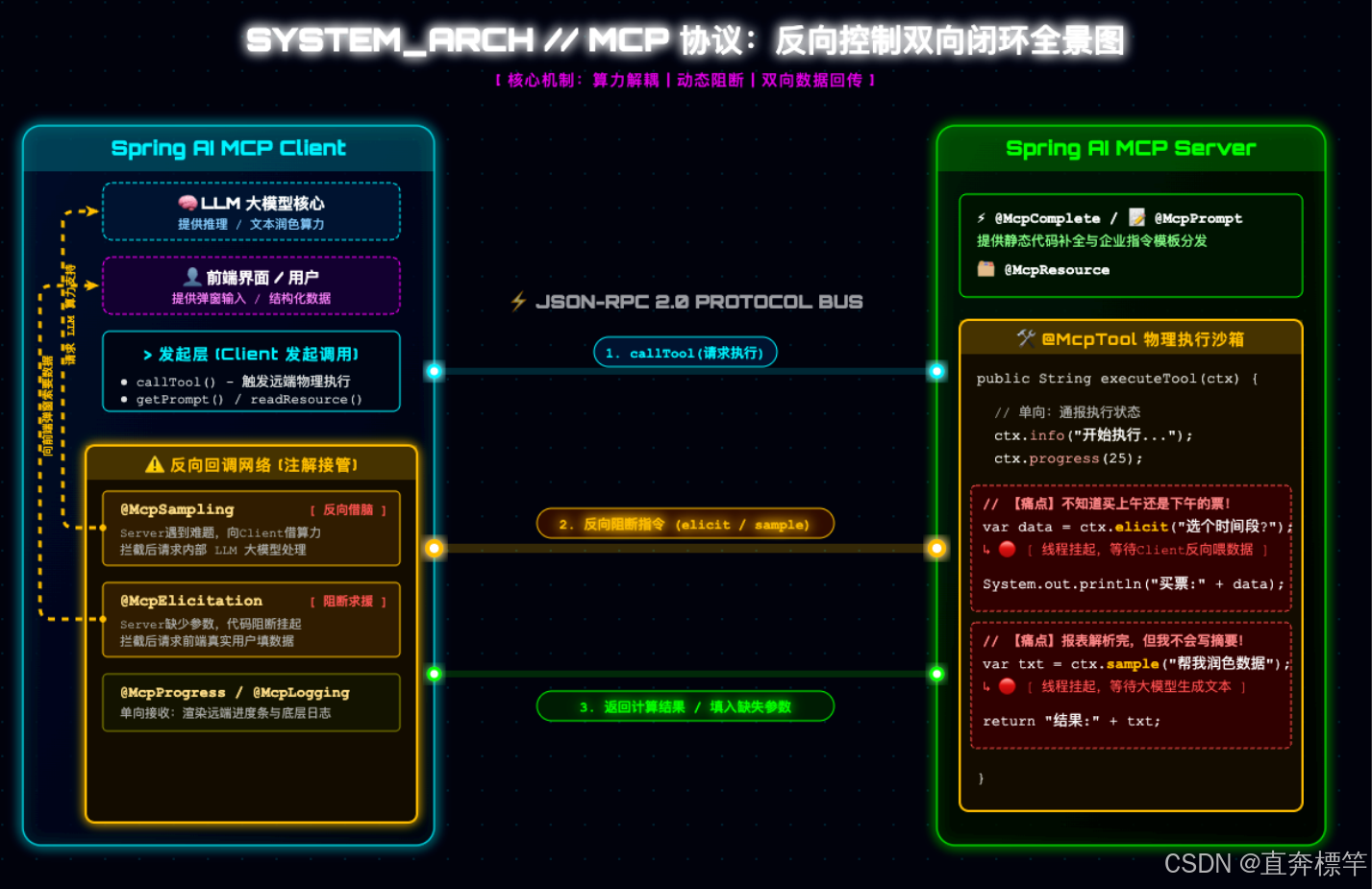
当MCP客户端(大模型)成功连接Spring Boot MCP服务端后,会获得5大核心能力,这也是咱们本节课要实战落地的重点,直奔標杆帮大家拆解清楚,通俗易懂:
-
Resources(资源):大模型的"只读文件柜"------服务端将系统日志、用户详情等静态数据以URI形式暴露,大模型直接通过URI读取,不用再手动拼接海量Prompt,效率拉满;
-
Prompts(提示词):企业级"指令库"------服务端固化专家级Prompt模板,大模型只需请求模板名称并传入参数,就能获取组装好的标准提示词,保证全公司AI操作标准化;
-
Completions(数据补全):大模型的"IDE自动补全"------输入前缀(比如"张"),服务端直接返回候选词(张三、张三丰),大幅降低大模型幻觉,提升交互准确性;
-
Tools(终极工具):双向通信的核心------不只是简单的方法调用,更是服务端与客户端双向交互的终极形态,支持反向控制;
-
Observability(监控与反向代理):优雅的双向监控------支持日志、进度条实时双向推送,方便排查问题、监控任务执行状态。
实战一:开发MCP服务端(核心步骤,全程可复制)
直奔標杆始终坚持"实战为王",所有代码都经过亲自验证,大家可以直接复制到项目中,跟着步骤一步步操作,遇到问题可以在评论区留言,咱们一起交流解决~
第一步:引入服务端依赖
新建Spring Boot项目,在pom.xml中引入MCP服务端核心依赖(WebFlux版本,支持流式通信):
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>第二步:手写4大Provider业务组件
这是服务端的核心,每个组件对应一个核心能力,注释已经写得非常详细,大家重点关注注解的使用和业务逻辑,不用死记硬背,理解原理更重要。
组件1:CompletionProvider(智能补全,避免大模型瞎猜)
通过@McpComplete注解,实现前缀补全功能,比如输入姓氏前缀,返回对应的姓名候选词,适用于用户输入提示、参数补全等场景。
java
// 直奔標杆:MCP智能补全组件,提供姓名前缀补全能力
@Service
public class CompletionProvider {
// 模拟姓名数据库,实际开发中可对接MySQL、Redis等
private final Map<String, List<String>> usernameDatabase = new HashMap<>();
// 初始化模拟数据
public CompletionProvider() {
usernameDatabase.put("张", List.of("张三", "张三丰", "张小小"));
usernameDatabase.put("李", List.of("李四", "李小明"));
}
// 匹配URI的补全(比如通过user-status://张 触发补全)
@McpComplete(uri = "user-status://{username}")
public List<String> completeUsername(String usernamePrefix) {
return matchPrefix(usernamePrefix);
}
// 匹配Prompt模板参数的补全(比如personalized-message模板的name参数补全)
@McpComplete(prompt = "personalized-message")
public List<String> completeName(String name) {
return matchPrefix(name);
}
// 核心补全逻辑:根据前缀匹配候选词(实际开发可扩展更复杂的匹配规则)
private List<String> matchPrefix(String prefix) {
return usernameDatabase.getOrDefault(prefix, List.of());
}
}组件2:PromptProvider(提示词分发,企业级标准化)
将专家级Prompt模板固化在服务端,客户端只需请求模板名称并传入参数,服务端直接返回组装好的提示词,避免重复编写、复制粘贴,保证标准化。
java
// 直奔標杆:MCP提示词分发组件,提供标准化Prompt模板
@Service
public class PromptProvider {
// 定义Prompt模板,name唯一标识,description说明模板用途
@McpPrompt(name = "personalized-message", description = "根据用户信息生成个性化消息")
public GetPromptResult personalizedMessage(
// 定义模板参数,required=true表示必填,description方便客户端理解参数含义
@McpArg(name = "name", description = "用户名称", required = true) String name) {
// 模板内容,实际开发中可结合业务场景编写更复杂的Prompt
String msg = "\n你好, " + name + "!\n我在此可以解答您关于"模型上下文协议"方面的任何疑问。";
return new GetPromptResult("个性化消息",
List.of(new PromptMessage(Role.ASSISTANT, new TextContent(msg))));
}
}组件3:ResourceProvider(只读资源柜,静态数据快速访问)
将系统静态数据(如用户详情)封装为URI,大模型像读取本地文件一样直接访问,不用通过对话询问,提升效率,减少Prompt冗余。
java
// 直奔標杆:MCP资源提供组件,暴露静态资源供客户端访问
@Service
public class ResourceProvider {
// 模拟用户详情数据库,实际开发中可对接业务数据库
private final Map<String, Map<String, String>> userProfiles = new HashMap<>();
// 初始化模拟用户数据
public ResourceProvider() {
userProfiles.put("zs", Map.of("name", "张三", "age", "32", "location", "北京"));
}
// 定义资源URI,客户端通过该URI访问用户详情
@McpResource(uri = "user-profile://{username}", name = "用户详情", description = "使用 URI 提供用户详细信息")
public ReadResourceResult getUserDetails(String username) {
// 获取用户详情,无匹配用户返回提示信息
Map<String, String> profile = userProfiles.getOrDefault(username.toLowerCase(), new HashMap<>());
String info = profile.isEmpty() ? "用户信息没找到" : profile.toString();
// 返回资源结果,指定URI、数据类型和内容
return new ReadResourceResult(
List.of(new TextResourceContents("user-profile://" + username, "text/plain", info)));
}
}组件4:ToolProvider(工具与反向控制,双向交互核心)
这是本节课的重点和难点------通过McpSyncRequestContext,服务端可以跨网络反向控制客户端:打印日志、推送进度条、请求客户端填充数据、调用客户端大模型,实现真正的双向交互!
java
// 直奔標杆:MCP工具组件,实现服务端对客户端的反向控制
@Service
public class ToolProvider {
// 定义结构化数据模型,用于客户端填充数据
public record Person(String name, Number age) {}
// 定义MCP工具,generateOutputSchema=true自动生成输出Schema
@McpTool(description = "测试工具,演示服务端反向控制客户端", name = "tool", generateOutputSchema = true)
public String ultimateTool(McpSyncRequestContext ctx, @McpToolParam String input) {
// 1. 反向推送日志到客户端(客户端可接收并打印)
ctx.info("调用工具: " + input);
// 2. 反向推送进度条(25%)到客户端UI,方便用户查看任务进度
ctx.progress(p -> p.percentage(25).message("工具开始执行"));
ctx.ping(); // 探测客户端是否存活,避免无效执行
// 3. 反向要求客户端填充结构化数据(比如弹窗让用户输入)
StructuredElicitResult<Person> elicitResult = ctx.elicit(
e -> e.message("客户端填充用户数据"), Person.class);
ctx.progress(p -> p.progress(50).message("客户端填充用户数据完成"));
// 4. 反向调用客户端的大模型,生成指定文本(指定模型偏好)
CreateMessageResult samplingResponse = ctx.sample(s -> s
.message("sampling 测试消息")
.maxTokens(500)
.modelPreferences(mp -> mp.modelHints("OpenAi", "Ollama"))); // 指定客户端优先使用的大模型
// 推送100%进度,告知客户端任务完成
ctx.progress(p -> p.progress(100).message("sampling 测试消息响应完成"));
ctx.info("工具执行完成");
// 返回执行结果,包含客户端填充的数据和大模型生成的内容
return "响应: " + samplingResponse.toString() + ", " + elicitResult.toString();
}
}第三步:服务端YAML配置(开启Streamable网络流)
配置服务端通信协议、端口,关闭启动横幅和控制台日志,为后续切换Stdio模式做准备,配置简洁,直接复制即可:
bash
spring:
ai:
mcp:
server:
# 通信协议:STREAMABLE(支持流式通信),还支持SSE、STATELESS模式
protocol: streamable
request-timeout: 60s # 请求超时时间,根据业务调整
main:
banner-mode: off # 禁用启动横幅,避免日志干扰
server:
port: 9090 # 服务端端口,客户端需对应配置实战二:开发MCP客户端(接收服务端指令,实现双向交互)
服务端搭建完成后,咱们来开发客户端------客户端的核心作用是连接服务端,接收服务端的日志、进度推送,响应服务端的反向请求(填充数据、调用大模型),Spring AI提供了声明式注解,不用写复杂的通信逻辑,非常优雅。
第一步:引入客户端依赖
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client-webflux</artifactId>
</dependency>第二步:客户端配置(连接服务端)
配置服务端地址,对应服务端的Streamable协议,直接指定服务端URL即可:
bash
spring:
ai:
mcp:
client:
streamable-http: # 对应服务端的STREAMABLE协议
connections:
server1: # 服务端名称,可自定义
url: http://localhost:9090 # 服务端地址,与服务端port一致第三步:注解式回调处理(接收服务端指令)
通过@McpProgress、@McpLogging等注解,自动接管服务端传来的事件流,不用手动处理通信细节,重点关注每个回调方法的逻辑,对应服务端的反向操作。
java
// 直奔標杆:MCP客户端回调处理器,接收服务端指令并响应
@Service
public class McpClientHandlerProviders {
private static final Logger logger = LoggerFactory.getLogger(McpClientHandlerProviders.class);
// 接收服务端推送的进度条信息
@McpProgress(clients = "server1") // 指定对接的服务端名称(与配置一致)
public void progressHandler(ProgressNotification progress) {
logger.info("MCP 进度: [{}] progress: {} total: {} message: {}",
progress.progressToken(), progress.progress(), progress.total(), progress.message());
}
// 接收服务端推送的日志信息
@McpLogging(clients = "server1")
public void loggingHandler(LoggingMessageNotification logMsg) {
logger.info("MCP 日志: [{}] {}", logMsg.level(), logMsg.data());
}
// 响应服务端的反向大模型调用请求(服务端让客户端调用大模型生成文本)
@McpSampling(clients = "server1")
public CreateMessageResult samplingHandler(CreateMessageRequest llmRequest) {
logger.info("MCP SAMPLING 触发: {}", llmRequest);
// 模拟客户端大模型响应,实际开发中可对接真实大模型(OpenAI、Ollama等)
return CreateMessageResult.builder()
.content(new McpSchema.TextContent("响应 Server 的反向生成请求!"))
.build();
}
// 定义与服务端一致的结构化数据模型
public record Person(String name, Number age) {}
// 响应服务端的反向数据填充请求(服务端让客户端填充结构化数据)
@McpElicitation(clients = "server1")
public StructuredElicitResult<Person> elicitationHandler(McpSchema.ElicitRequest request) {
logger.info("MCP ELICITATION 触发: {}", request);
// 模拟客户端填充数据,实际开发中可对接前端表单、数据库等
return new StructuredElicitResult<>(ElicitResult.Action.ACCEPT, new Person("王五", 42), null);
}
}实战三:测试双向交互(验证成果,重中之重)
代码写完成后,一定要测试验证,直奔標杆为大家准备了测试代码,在客户端中添加CommandLineRunner,启动客户端即可自动触发服务端的所有能力,查看运行结果是否符合预期。
测试代码(客户端添加)
java
// 直奔標杆:MCP客户端测试代码,启动后自动触发服务端四大能力
@Bean
public CommandLineRunner predefinedQuestions(List<McpSyncClient> mcpClients) {
return args -> {
for (McpSyncClient mcpClient : mcpClients) {
System.out.println(">>> MCP Client: " + mcpClient.getClientInfo());
// 1. 测试Tool调用(触发服务端反向控制)
var toolReq = McpSchema.CallToolRequest.builder()
.name("tool").arguments(Map.of("input", "test input")).progressToken("工具标记").build();
System.out.println("【tool响应】: " + mcpClient.callTool(toolReq));
// 2. 测试数据补全(触发CompletionProvider)
var nameCompletion = mcpClient.completeCompletion(
new McpSchema.CompleteRequest(new McpSchema.PromptReference("personalized-message"),
new McpSchema.CompleteRequest.CompleteArgument("name", "张")));
System.out.println("【姓名补全】: " + nameCompletion.completion().values());
// 预期输出: [张三, 张三丰, 张小小]
// 3. 测试获取官方提示词(触发PromptProvider)
var promptResp = mcpClient.getPrompt(
new McpSchema.GetPromptRequest("personalized-message", Map.of("name", "张三")));
System.out.println("【提示词响应】: " + promptResp);
// 4. 测试读取静态资源(触发ResourceProvider)
var resourceResp = mcpClient.readResource(new McpSchema.ReadResourceRequest("user-profile://zs"));
System.out.println("【资源响应】: " + resourceResp);
}
};
}预期运行结果(对照排查问题)
启动服务端,再启动客户端,控制台会输出以下内容,说明双向交互成功(重点关注日志、进度和各模块响应):
bash
>>> MCP Client: Implementation[name=spring-ai-mcp-client - server1, title=server1, version=1.0.0]
MCP 日志: [INFO] 调用工具: test input
MCP 进度: [工具标记] progress: 25.0 total: 100.0 message: 工具开始执行
MCP ELICITATION: ElicitRequest[message=客户端填充用户数据, ....
MCP 进度: [工具标记] progress: 50.0 total: 1.0 message: 客户端填充用户数据完成
MCP SAMPLING: CreateMessageRequest[...text=sampling 测试消息, meta=.....
MCP 进度: [工具标记] progress: 100.0 total: 1.0 message: sampling 测试消息响应完成
MCP 日志: [INFO] 工具执行完成
【tool工具响应】: ....structuredContent=Person[name=王五, age=42]...
【姓名补全】: CompleteCompletion[values=[张三, 张三丰, 张小小], total=3, hasMore=false]
【提示词响应】: GetPromptResult[description=个性化消息, messages=[PromptMessage[role=ASSISTANT, content=TextContent[annotations=null, text=
你好, 张三!
我在此可以解答您关于"模型上下文协议"方面的任何疑问。, meta=null]]], meta=null]
【资源响应】: ReadResourceResult[contents=[TextResourceContents[uri=user-profile://zs, mimeType=text/plain, text=name: 张三, age: 32, location: 北京, meta=null]], meta=null]如果运行结果与预期一致,说明你已经成功实现了MCP双向交互!如果出现异常,优先检查端口是否冲突、依赖是否正确、配置是否匹配,有问题可以在评论区交流~
进阶实战:一行配置切换Stdio进程模式(企业级部署必备)
实际企业部署中,为了安全和性能,我们可能需要将服务端打成jar包,让客户端在操作系统底层拉起服务端,通过标准输入输出流(Stdio)进行超高速通信(内网级速度),Spring AI支持一行配置切换,非常便捷。
第一步:修改客户端YAML配置
移除streamable-http配置,改为Stdio模式,指定服务端配置文件路径:
bash
spring:
ai:
mcp:
client:
stdio:
servers-configuration: classpath:mcp-servers.json # 服务端配置文件路径第二步:创建mcp-servers.json配置文件
在客户端resources目录下创建该文件,配置服务端启动命令,重点注意:必须关闭控制台日志,否则会破坏协议通信!
bash
{
"mcpServers": {
"springai-mcp-server": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dlogging.pattern.console=", // 必须关闭控制台日志,避免破坏协议
"-jar",
"ai-thinking/springai-mcp-server/target/springai-mcp-server-1.1.0.jar" // 服务端jar包路径
],
"env": {}
}
}
}提示:实际部署时,替换jar包路径为你本地或服务器上的服务端jar包路径,启动客户端后,会自动拉起服务端进程,实现Stdio模式通信。
本节课总结(重点回顾,加深记忆)
直奔標杆和大家一起,亲手完成了Spring AI MCP客户端与服务端的双向实战,相信大家已经掌握了核心要点,这里再提炼3个重点,帮助大家巩固:
-
MCP的核心价值:打破接口壁垒,实现客户端与服务端双向交互,解决企业级AI开发的标准化、异步交互、反向控制等痛点;
-
服务端核心:4大Provider组件(Completion、Prompt、Resource、Tool),对应补全、提示词、资源、反向控制四大能力,注解式开发,简洁高效;
-
双模通信:Streamable-HTTP(网络模式)适合跨网络部署,Stdio(进程模式)适合本地/内网部署,一行配置即可切换,适配不同场景。
其实Spring AI的设计理念非常简单------"复杂留给底层,优雅还给业务",我们不用关心底层通信细节,只需专注业务逻辑,这也是Spring框架的魅力所在,更是Java开发者AI转型的捷径。
下节预告(持续跟进,稳步进阶)
本节课我们完成了MCP双向实战,下一节课,直奔標杆将带大家"刨根问底"------《Java开发者AI转型第二十一课!Spring AI MCP 源码解析》,一起阅读Spring AI MCP源码,搞懂客户端与服务端如何通信、服务端工具如何加载、反向控制的底层原理,彻底吃透MCP协议!
精彩继续,咱们下节见~
往期干货(连贯学习,不迷路)
为了方便大家连贯学习,这里整理了往期核心课程,点击即可跳转:
-
Java开发者AI转型第十七课!SpringAI Tool Calling底层三剑客拆解与编程式注册源码实战
-
Java开发者AI转型第十八课!吃透Agent智能体:多工具协同与ReAct动态决策实战
-
Java开发者AI转型第十九课!MCP协议揭秘与无边界插件生态实战
最后,直奔標杆想说:AI转型没有捷径,唯有实战才能成长!大家一定要亲手敲一遍本节课的代码,遇到问题多思考、多交流,评论区欢迎大家留言讨论,一起进步,一起成为AI开发标杆~