本文目标读者:需要将 AI Agent 接入企业通讯工具(企业微信、钉钉、飞书、Telegram 等)的工程师。读完本文,你将理解 Gateway 的架构设计、IM 适配器的实现模式、多租户会话隔离机制,以及从零接入一个新 IM 平台的完整工程链路------包括那些只有在生产环境踩过坑才会知道的细节。
引导:一个 Demo 级和生产级方案之间,藏着哪些陷阱?
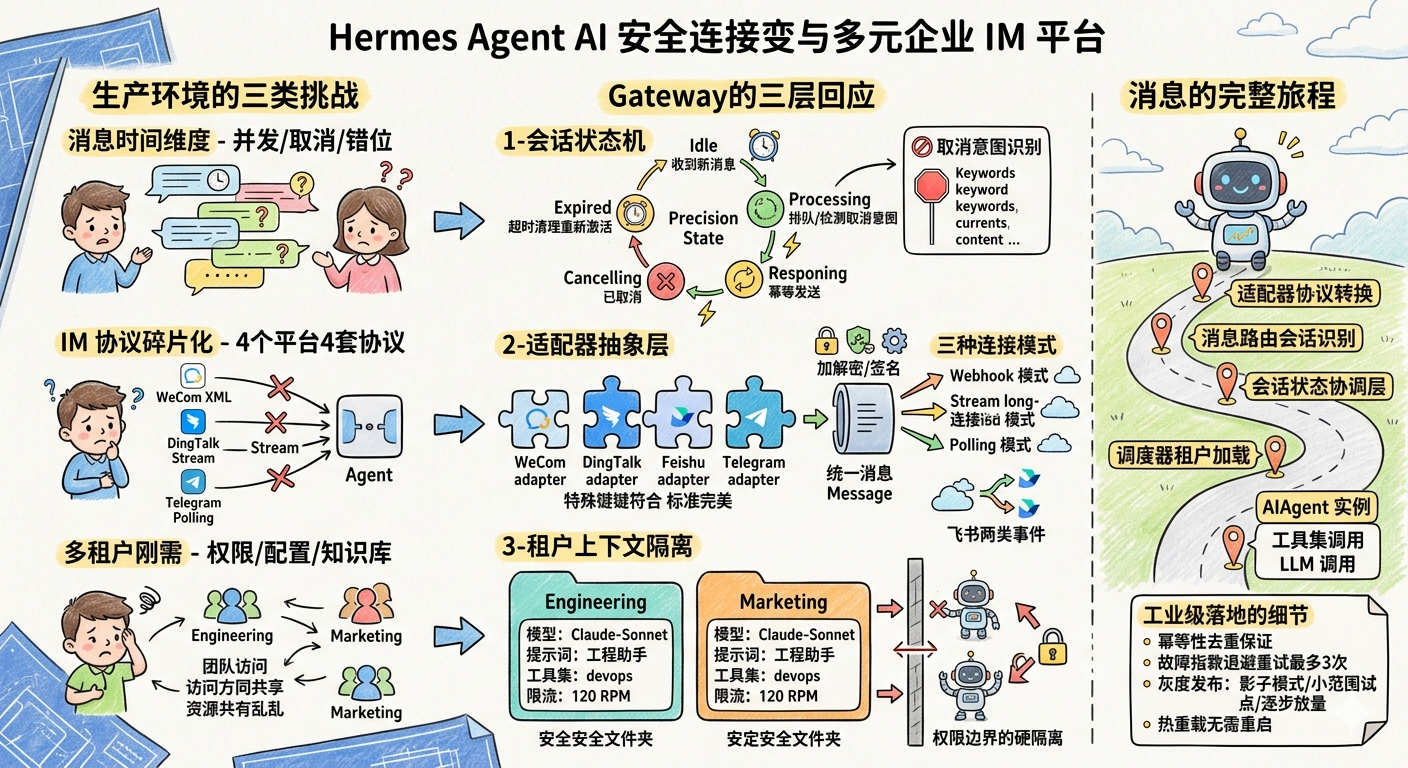
有一类工程问题,表面看起来是 API 调用,实际上是架构设计。接入企业 IM 就是其中之一。
很多工程师的第一直觉是:写个 Flask 接收 Webhook,调 LLM,回复,完事。这个方案在演示时运行得很好。但在真实的企业环境里,它会在三个地方悄悄崩溃------而且每次崩溃的方式都不一样,很难在事前预见。
第一个崩溃点:消息的时间维度。 用户发了一条消息,Agent 需要 8 秒才能回复。第 3 秒时,用户又发了"算了,不用查了"。你的系统此时面临一个没有"正确答案"的状态问题:是继续处理第一条消息然后发出一个用户不再需要的回复,还是中途放弃导致资源浪费?更麻烦的是,如果用户第 5 秒又发了新问题,系统怎么保证回复不错位?
第二个崩溃点:平台协议的碎片化。 企业微信要求 AES-256-CBC 加解密 + XML 解析 + 签名验证三层安全机制;钉钉提供 Stream 长连接协议,完全不需要公网 IP;飞书在消息之外还有 Card 交互回调,是另一套事件体系;Telegram 则依赖长轮询。四个平台,四套协议,但你的 Agent 只有一套核心逻辑。任何"为这个平台特化"的代码,都是未来的技术债。
第三个崩溃点:多租户不是加个字段就能解决的。 工程团队需要代码工具集,市场团队需要内容工具集,高管群需要更保守的模型配置。如果所有用户共享同一个 Agent 实例,工具权限无法隔离,一个部门的高频调用会拖慢所有人,更别提一次工具配置错误可能影响整个组织。
这三个问题的交汇,就是 Gateway 设计的核心张力。它们分别对应三个架构层面的解:会话状态机 处理时间维度的并发,适配器抽象层 消灭平台差异,租户上下文隔离实现权限边界。
本文的叙事线索,就是这三个解的设计过程------以及每个设计决策背后,被放弃的那些替代方案。
Gateway的三层回应
生产环境的三类挑战
消息时间维度 - 并发/取消/错位
IM 协议碎片化 - 4个平台4套协议
多租户刚需 - 权限/配置/知识库
会话状态机
适配器抽象层
租户上下文隔离
一、Gateway 架构:一条消息从进入到回复的完整旅程
1.1 全局架构:边界在哪里划定
在写代码之前,先要想清楚 Gateway 的边界。一个常见的误区是把 Gateway 设计成"消息路由器"------消息进来,转发给 Agent,结果出去。这个定义太窄了,它遗漏了最关键的职责:管理消息的生命周期。
Gateway 的实际职责是双重的:作为 IM 平台和 Agent 之间的协议转换层 ,以及作为多个并发会话之间的状态协调层。前者处理"消息是什么格式",后者处理"消息应该在什么时刻被谁处理"。
Agent 执行层
Gateway 核心层
IM 平台层
企业微信 XML+AES
钉钉 Stream
飞书 Event+Card
Telegram Polling
HTTP API REST
1-适配器层 协议转换
2-消息路由器 会话识别
3-会话管理器 状态机
4-Agent调度器 租户加载
AIAgent 实例
工具集
LLM 调用
一条消息的完整生命周期,依次经过四个核心层:
① 适配器层 完成协议转换,将各平台特有的消息格式转换为统一的 Message 对象。这是平台细节的终结点------从这里开始,Gateway 内部不再感知"这条消息来自企业微信还是飞书"。
② 消息路由器 根据 conversation_id 识别会话归属。群聊和私聊的路由逻辑在此分流:群聊共享一个会话上下文,私聊则每个用户独立。
③ 会话管理器是并发控制的核心。它维护每个会话的状态机,保证同一个会话同一时刻只有一个 Agent 实例在工作,并处理消息的排队、取消和超时。
④ Agent 调度器负责为当前会话加载正确的租户上下文,包括工具集、模型配置和系统提示词,然后将消息交给对应的 Agent 实例处理。
1.2 核心数据结构:三个对象,三个边界
Gateway 的内部流转基于三个核心数据结构。它们的设计原则是边界清晰,职责不重叠:
python
@dataclass
class Message:
"""统一消息模型------平台差异在适配器层消化,内部只看这个"""
content: str
conversation_id: str # 会话标识(群聊 ID / 私聊 ID)
sender_id: str
sender_name: str
platform: str # 来源平台(仅用于日志和调试,不影响业务逻辑)
message_type: str # text / image / file / card_action
raw_event: Optional[dict] # 平台原始数据,保留用于 Adapter 回传时的上下文
reply_to: Optional[str]
mentions: Optional[list]
@dataclass
class Conversation:
"""会话上下文------状态机的载体,租户隔离的基本单元"""
conversation_id: str
platform: str
tenant_id: str
agent_config: dict # 从 TenantContext 加载,不可在运行时修改
created_at: float
last_active: float
status: str # idle / processing / queued / cancelling / expired
queued_message: Optional[Message] = None
@dataclass
class TenantContext:
"""租户上下文------权限边界的定义者"""
tenant_id: str
allowed_toolsets: list[str]
model_config: dict
system_prompt_override: str
rate_limit: dict这三个结构的边界划分有一个容易忽视的细节:Conversation 中的 agent_config 在会话创建时从 TenantContext 复制而来,之后不再跟随租户配置变化。这是一个有意的设计选择------正在进行的会话应该有稳定的配置,避免运行时改变租户配置影响到活跃会话。新配置在下次会话重建时才生效。
二、适配器抽象层:消灭平台差异的设计模式
2.1 为什么是"六个接口"而不是更多?
适配器抽象层的核心是 BaseAdapter 基类,它定义了六个必须实现的接口。这个数量不是随意选择的------六个接口覆盖了 IM 接入的三个关键能力域:连接管理 (start / stop)、消息发送 (send_message / send_image)、安全验证与解析 (validate_request / parse_event)。
任何超出这六个接口的平台特有能力,都应该作为平台适配器的私有方法实现,而不是暴露给 Gateway 核心层。这个原则保证了新增平台不会"污染"Gateway 的内部接口。
<<abstract>>
BaseAdapter
+start() : asyncio.Task
+stop() : None
+send_message(conversation_id, content) : str
+send_image(conversation_id, image_url) : str
+parse_event(raw_event) : Message
+validate_request(request) : bool
WeComAdapter
+validate_request()
+parse_event()
DingTalkAdapter
+start()
+parse_event()
FeishuAdapter
+parse_event()
TelegramAdapter
+start()
六个接口的职责与关键设计决策:
| 接口 | 职责 | 关键决策 |
|---|---|---|
start() |
启动消息监听 | 返回 asyncio.Task,统一异步模型 |
stop() |
优雅关闭 | 必须等待队列消费完毕,不能强杀 |
send_message() |
发送文本消息 | 返回消息 ID,用于幂等性追踪 |
send_image() |
发送图片 | 与文本分开,避免接口过载 |
parse_event() |
原始事件 → Message |
最关键的接口,平台差异在此终结 |
validate_request() |
验证请求合法性 | 安全防线,假消息在这里被过滤 |
2.2 三种连接模式:同一个 start() 背后的不同世界
不同 IM 平台的消息接收方式截然不同,但 BaseAdapter 的 start() 接口将它们统一呈现为同一个 asyncio.Task。Gateway 核心层只从 asyncio.Queue 消费消息,完全不知道消息是通过 Webhook 推送来的、还是通过长连接收到的、还是轮询拉取的。
Polling轮询模式
Stream长连接模式
Webhook模式
平台主动推送
需要公网IP+HTTPS+签名验证
Agent主动连接
无需公网IP
内置心跳保活+自动重连
定期调用getUpdates
长轮询timeout30s
asyncio.Queue 统一消息队列
Gateway核心层
这三种模式中,钉钉的 Stream 模式值得特别关注。它解决了一个在企业内网部署中极为常见的困境:大量企业有严格的防火墙策略,允许出站 HTTPS,但不允许外网访问内网服务器。Webhook 模式在这种环境下完全无法工作,而 Stream 模式因为是 Agent 主动发起连接,天然穿透了这个限制,无需 Nginx 反向代理和 SSL 证书配置。
这不只是技术选择,也是部署门槛的选择。
2.3 企业微信适配器:安全机制是主要复杂度来源
企业微信的接入复杂度在四个平台中最高,原因不是业务逻辑复杂,而是安全机制层次多:URL 验证握手 → 请求签名验证 → 消息体 AES 解密 → XML 解析,四步缺一不可。这些复杂度是企业微信安全设计的代价,理解它的结构,比死记 API 文档更重要。
消息的完整解密流程如下:
WeComAdapter Gateway 企业微信 WeComAdapter Gateway 企业微信 Agent处理在后台异步进行 POST /gateway/wecom 加密XML validate_request 验证签名 token+timestamp+nonce AES-256-CBC解密消息体 PKCS7去填充 XML解析为dict parse_event返回Message对象 HTTP 200 必须在5秒内响应
这里有一个容易忽视的生产陷阱:企业微信要求 Webhook 端点在 5 秒内返回 200,否则会重试并最终报警。但 Agent 的处理时间往往远超 5 秒。正确的做法是把消息放入队列后立即返回 200,Agent 的处理完全异步进行。返回 200 只是"我收到了",不是"我处理完了"。
python
def _decrypt_message(self, encrypted: str) -> dict:
"""企业微信消息解密:AES-256-CBC + PKCS7 去填充 + XML 解析"""
aes_key = base64.b64decode(self.encoding_aes_key + "=")
cipher = Cipher(algorithms.AES(aes_key), modes.CBC(aes_key[:16]))
decryptor = cipher.decryptor()
plain_text = decryptor.update(base64.b64decode(encrypted)) + decryptor.finalize()
# PKCS7 去填充
pad_len = plain_text[-1]
plain_text = plain_text[:-pad_len]
# 格式:16字节随机串 + 4字节消息长度 + 消息内容 + AppID
content = plain_text[16:]
msg_len = int.from_bytes(content[:4], "big")
msg_content = content[4:4 + msg_len].decode("utf-8")
return xml_to_dict(msg_content)加解密逻辑写完后,务必用企业微信官方提供的测试工具验证,而不是靠自测------字节序、填充方式的细微差异在自测中很难发现,但在真实消息下会直接报错。
2.4 飞书适配器:两类事件,一个解析器
飞书的接入有一个区别于其他平台的设计细节:消息事件 和 Card 交互事件 是两套完全不同的数据结构,但都通过同一个 Webhook 端点推送。parse_event() 必须根据 header.event_type 字段区分两种路径,否则会在 Card 按钮点击时抛出解析异常。
python
def parse_event(self, raw_event: dict) -> Message:
event_type = raw_event.get("header", {}).get("event_type", "")
if event_type == "im.message.receive_v1":
# 普通消息路径
event_data = raw_event["event"]["message"]
content = json.loads(event_data.get("content", "{}"))
return Message(
content=content.get("text", ""),
conversation_id=event_data.get("chat_id", ""),
sender_id=raw_event["event"]["sender"]["sender_id"]["user_id"],
platform="feishu",
message_type=event_data.get("message_type", "text"),
raw_event=raw_event,
)
elif event_type == "card.action.trigger":
# Card 交互路径------content 是 JSON 序列化的 action.value
action = raw_event.get("action", {})
return Message(
content=json.dumps(action.get("value", {})),
conversation_id=raw_event.get("open_chat_id", ""),
sender_id=raw_event.get("operator", {}).get("user_id", ""),
platform="feishu",
message_type="card_action",
raw_event=raw_event,
)
else:
raise ValueError(f"不支持的飞书事件类型: {event_type}")飞书适配器还有一个容易被忽视的运维细节:tenant_access_token 的有效期只有 2 小时,需要在适配器内部实现自动续期逻辑,在过期前 5 分钟主动刷新。这个逻辑如果遗漏,会导致每天凌晨前后出现一批"发送失败"的错误,难以排查。
三、会话管理:状态机为什么是正确答案
3.1 没有状态机时会发生什么
在引入状态机之前,先把"没有状态机"的系统行为想清楚。假设消息进来就直接调 Agent,不维护任何状态:
用户 A 在群里问了一个复杂问题(预计 10 秒处理完),3 秒后又说"我换个方式问",再发了一条新消息。此时系统有两个 Agent 实例同时在运行,它们共享同一个会话历史,会出现两种糟糕结果:要么两个实例都生成了回复,用户看到两条冲突的答案;要么第二个实例覆盖了第一个实例的会话状态,最终回复语义混乱。
更严重的问题是资源:如果一个用户快速发了 10 条消息,系统会同时启动 10 个 Agent 实例,每个都在调用 LLM,费用翻倍,响应质量下降。
状态机的引入从根本上解决了这个问题。它不是"锁",而是对系统在每个时刻"能做什么"的明确定义。
3.2 会话状态模型:每个状态的语义
会话创建
收到新消息
Agent生成完毕
回复发送成功
用户发出取消意图
任务已取消
收到新消息排队等待
当前任务完成
超时未活跃
会话资源回收
收到新消息重新激活
Idle
Processing
Responding
Cancelling
Queued
Expired
每个状态的语义必须精确,歧义会导致边界情况下的 bug:
| 状态 | 精确语义 | 收到新消息时的行为 |
|---|---|---|
Idle |
空闲,等待新消息 | 立即进入 Processing |
Processing |
Agent 正在执行(包括 LLM 调用和工具调用) | 检测取消意图;否则排队 |
Responding |
回复正在通过 IM API 发送 | 排队,不中断发送 |
Cancelling |
正在取消当前 asyncio.Task | 忽略,等待取消完成 |
Queued |
有一条消息在等待,当前任务未完成 | 覆盖队列(只保留最新一条) |
Expired |
超时清理候选 | 重新激活并处理 |
Queued 状态有一个值得讨论的设计决策:只保留最新一条排队消息,而不是维护一个完整队列。原因是:在 IM 场景下,用户连续快速发送的消息通常是对前一条的补充或修正,如果都排队处理,用户会等待很久,体验极差。只保留最新一条,配合适当的提示("上一条问题已收到,正在处理中......"),是更符合人类对话习惯的设计。
3.3 并发控制:锁的粒度选择
并发控制的核心约束是:同一个 conversation_id 同一时刻只能有一个 Agent 实例在执行。实现这个约束有两种思路:
- 全局锁:所有会话共享一把锁,保证绝对顺序。代价是所有会话串行,完全牺牲了并发能力。
- 会话级锁 :每个
conversation_id独立一把锁。不同会话之间完全并行,同一会话内串行。
Hermes 选择会话级锁,这是正确的粒度------约束的边界在会话内部,不应该扩散到会话之间。
python
class SessionManager:
def __init__(self):
self._sessions: dict[str, Conversation] = {}
self._locks: dict[str, asyncio.Lock] = {}
self._agent_tasks: dict[str, asyncio.Task] = {}
async def handle_message(self, message: Message) -> None:
conv_id = message.conversation_id
if conv_id not in self._locks:
self._locks[conv_id] = asyncio.Lock()
async with self._locks[conv_id]:
conv = self._sessions.get(conv_id)
if conv is None:
conv = self._create_conversation(message)
self._sessions[conv_id] = conv
await self._dispatch_to_agent(conv, message)
elif conv.status == "idle":
conv.status = "processing"
await self._dispatch_to_agent(conv, message)
elif conv.status == "processing":
if self._is_cancel_intent(message):
conv.status = "cancelling"
await self._cancel_current_task(conv_id)
else:
conv.queued_message = message # 覆盖,只保留最新
conv.status = "queued"3.4 取消意图识别:一个被低估的细节
"用户想取消当前任务"这件事,听起来简单,实际上需要一套明确的识别规则。Hermes 使用关键词 + 语义两层判断:
关键词层:["停止", "取消", "算了", "stop", "cancel", "nevermind"]
语义层:当关键词匹配失败时,用轻量模型做一次快速意图分类(避免误判)。
取消成功后,系统会向 IM 发送一条确认:"已取消当前任务,有什么新问题可以继续问。" 这条消息至关重要------如果没有它,用户不知道取消是否生效,很可能会反复发送取消指令。
四、多租户隔离:同一套代码,不同的世界
4.1 隔离需要回答的核心问题
在设计多租户隔离之前,有一个基础问题必须先想清楚:隔离的边界是什么?
隔离不是"每个租户一个数据库表"这么简单的事。它至少涵盖三个维度:
资源隔离
API调用频率限制
并发Agent数量上限
工具调用次数配额
数据隔离
会话历史不跨租户可见
文件和知识库独立
日志按租户分区
配置隔离
使用哪个模型
系统提示词是什么
允许调用哪些工具
租户体验
三个维度缺一不可。只做配置隔离,租户 A 的高频调用仍然会耗尽资源,影响租户 B 的体验。只做资源隔离,租户的工具权限没有边界,存在误操作风险。只做数据隔离,不同团队看到相同的 Agent 能力,失去了定制化的价值。
4.2 为什么不用数据库行级隔离?
一个常见的替代方案是:所有租户的配置存入数据库,每次请求查询对应行。这个方案的问题在于,它把运行时性能和持久化存储耦合在一起。
Agent 处理消息的链路已经包含 LLM 调用(高延迟),如果每次消息处理都要额外查询数据库获取租户配置,会引入不必要的 I/O 延迟,也增加了数据库故障对消息处理的影响面。
Hermes 的选择是:租户配置在启动时加载到内存,运行时直接访问 TenantContext 对象。配置更新触发热重载(通过信号量或管理接口),不需要重启 Gateway。这在配置变更频率低(通常以天或周为单位)的企业场景下,是合理的权衡。
4.3 配置隔离的实现
python
class TenantManager:
def __init__(self, config_path: str):
self._tenants: dict[str, TenantContext] = {}
self._load_config(config_path)
def get_context(self, tenant_id: str) -> TenantContext:
return self._tenants.get(tenant_id, self._tenants["default"])配置文件示例:
yaml
tenants:
- id: engineering
toolsets: [core, code, devops]
model: {name: claude-sonnet, temperature: 0.3}
system_prompt: "你是工程团队的 AI 助手,专注于代码审查和 DevOps 问题"
rate_limit: {rpm: 120}
- id: marketing
toolsets: [core, writing, web]
model: {name: claude-sonnet, temperature: 0.7}
system_prompt: "你是营销团队的 AI 助手,专注于内容创作和数据分析"
rate_limit: {rpm: 60}
- id: default
toolsets: [core]
model: {name: default}
rate_limit: {rpm: 30}4.4 工具权限隔离:为什么 LLM 绕不过这一层
工具权限隔离的关键在于:权限检查不能依赖 LLM 的"自律"。
如果只是在系统提示词里写"不要调用 devops 工具",理论上 LLM 会遵守,但实际上无法保证。一旦 LLM 被诱导或幻觉,它可能仍然会尝试调用不该调用的工具。
正确的实现是:在 Agent 初始化时,只向 LLM 注册该租户被允许的工具集。LLM 根本看不到其他工具的 Schema,自然无法调用它们,无论 prompt 如何构造。
正确做法-硬隔离
Agent初始化时只加载allowed_toolsets
LLM只看到被允许的工具Schema
物理上不存在其他工具无法调用
错误做法-软约束
系统提示词不要调用devops工具
LLM可能违反无法保证
五、消息路由:群聊与私聊的差异处理
5.1 路由策略的三种模式
Gateway 的路由策略根据部署规模有三个演进阶段:
单租户模式适合个人使用或小团队:所有消息路由到同一个 Agent 实例,配置最简单,维护成本最低。
多租户模式 是企业部署的标准:根据 conversation_id 查找对应租户,每个租户独立的 Agent 配置和工具集。
多 Agent 路由模式适合复杂企业场景:一个会话中有多个专业 Agent,根据消息意图动态路由。用户问代码问题路由到代码 Agent,问数据问题路由到分析 Agent。这个模式的实现复杂度显著高于前两者,适合有明确需求的场景,不建议作为默认起点。
5.2 群聊路由:只响应 @,是一个业务决策
在群聊场景下,一个核心设计决策是:是否要响应群里所有消息,还是只响应 @Agent 的消息?
全消息响应的问题在于"噪音"和成本------群聊中大量消息与 Agent 无关,全部处理会产生无意义的 LLM 调用,也让其他群成员感到困扰。
Hermes 的默认策略是只响应三类触发:① @Agent 的消息,② 直接回复 Agent 之前发送的消息,③ 私聊消息。
python
def should_process(message: Message, bot_id: str, agent_message_ids: set) -> bool:
# 私聊:总是处理
if message.conversation_id == message.sender_id:
return True
# 群聊:@Agent
if message.mentions and bot_id in message.mentions:
return True
# 群聊:回复 Agent 的历史消息
if message.reply_to and message.reply_to in agent_message_ids:
return True
return False这个策略不是技术约束,而是业务决策。如果业务需要 Agent 监听全量群消息(如情报收集、自动摘要等场景),可以修改 should_process 逻辑,其他部分无需改动。
六、从零接入新 IM 平台:踩坑记录与工程链路
6.1 接入前的四个关键问题
在写任何代码之前,必须先回答四个问题。这四个问题的答案决定了接入工作 80% 的设计:
消息如何到达我
决定start实现
如何证明我是合法接收者
决定validate_request实现
消息是什么格式
决定parse_event实现
如何发送回复
决定send_message实现
这四个问题的答案,在平台的官方文档里都能找到,但文档通常分散在不同章节。建议在开始编码前,专门花 2-3 小时通读文档,把这四个答案写下来,再开始实现。
6.2 实战:接入 Slack 的完整过程与踩坑记录
以接入 Slack 为例,展示真实的接入过程。Slack 相对友好,因为 Bolt 框架处理了大量底层细节,但仍有几个坑值得提前知道。
坑一:Bot 自身消息的过滤。 Slack 的事件会包含 Bot 自身发出的消息(当 Agent 回复时,Slack 会把这条回复作为事件再次推送回来)。如果不过滤 bot_id,会触发无限循环:Agent 回复 → Slack 推送事件 → Agent 再次回复 → 循环。过滤逻辑必须是第一道检查。
坑二:<@UXXXXX> 格式的 @ 提及。 Slack 的消息文本中,@ 用户的格式是 <@U1234567>,如果不处理,这个字符串会被原样送给 LLM,影响语义理解。需要在 parse_event() 中用正则去除或替换。
坑三:消息 ID 是 timestamp。 Slack 用消息发送时间戳(如 1704067200.123456)作为消息 ID,精度到毫秒级,可以认为是唯一的,但格式与其他平台的整数 ID 不同,在幂等性去重时需要按字符串处理。
python
class SlackAdapter(BaseAdapter):
def parse_event(self, raw_event: dict) -> Optional[Message]:
# 坑一:过滤 Bot 自身消息,防止无限循环
if raw_event.get("bot_id"):
return None
text = raw_event.get("text", "")
# 坑二:去除 <@UXXXXX> 格式的 @ 提及
text = re.sub(r"<@U\w+>", "", text).strip()
return Message(
content=text,
conversation_id=raw_event.get("channel", ""),
sender_id=raw_event.get("user", ""),
platform="slack",
message_type=raw_event.get("subtype", "text"),
raw_event=raw_event,
)
async def send_message(self, conversation_id: str, content: str) -> str:
response = await self._client.chat_postMessage(
channel=conversation_id,
text=content,
)
return response["message"]["ts"] # 坑三:timestamp 作为消息 ID6.3 新平台接入的五步流程
1-研究平台API
2-实现BaseAdapter
3-注册到Gateway
4-配置与测试
5-生产部署
生产部署前检查清单(不是装饰,是血泪经验):
- Webhook URL 可从平台服务器访问(用平台官方的"测试回调"功能验证,不要依赖自己的 curl)
- SSL 证书有效且未过期(自签证书几乎所有平台都不接受)
- 消息加解密逻辑通过平台官方 SDK 的测试用例
- Webhook 端点已实现幂等性保证(见第七章)
- Bot 自身消息已过滤(避免无限循环)
- 并发压力测试:模拟 50 并发用户同时发消息,确认无状态竞争
- 网络故障恢复测试:断网 30 秒后恢复,验证 Stream 模式自动重连
- Token 过期测试:手动使 Token 失效,验证自动续期逻辑
七、生产级部署:幂等性、容错与灰度
7.1 幂等性:被忽视的生产陷阱
Webhook 模式下,IM 平台的消息重试机制是幂等性问题的根源。企业微信在未收到 200 响应时会重试 3 次,间隔 5 秒。如果第一次请求因为网络抖动未能及时返回 200,第二次重试会带来同一条消息,Gateway 如果不做去重,用户会收到两条相同的 Agent 回复。
幂等性保证的核心是:以消息 ID 为去重键,在一定 TTL 内(通常 5 分钟)拒绝处理重复消息。
python
class IdempotentHandler:
def __init__(self, ttl: int = 300):
self._processed: dict[str, float] = {}
self._ttl = ttl
def is_duplicate(self, message_id: str) -> bool:
now = time.time()
# 定期清理过期记录,避免内存泄漏
self._processed = {k: v for k, v in self._processed.items() if now - v <= self._ttl}
if message_id in self._processed:
return True
self._processed[message_id] = now
return False这个实现用内存存储去重记录,适合单机部署。如果 Gateway 是多实例水平扩展,需要改用 Redis 作为共享存储,否则同一条消息在不同实例上都会被处理。
7.2 三类故障与对应容错策略
容错策略
故障类型
IM平台故障 API限流服务不可用
Agent执行故障 LLM超时工具异常
网络故障 连接断开DNS失败
指数退避重试最多3次
全局超时熔断120秒
Stream模式内置自动重连
有一个设计细节值得强调:Agent 执行超时后,必须 将会话状态重置为 idle,而不是让它停留在 processing。如果状态卡在 processing,这个会话的所有后续消息都会被排队或拒绝,直到 Gateway 重启------这是一个静默的、难以发现的故障模式。
7.3 监控的核心指标
Gateway 的监控不需要大而全,但以下六个指标是必须的:
| 指标 | 含义 | 告警阈值参考 |
|---|---|---|
gateway.messages.received |
入站消息数(每分钟) | 下降 > 50% 可能是 Webhook 配置失效 |
gateway.messages.processed |
成功处理数(每分钟) | 与 received 差值持续增大说明有积压 |
gateway.agent.latency_p95 |
Agent 处理延迟 P95 | > 30 秒说明 LLM 或工具链有瓶颈 |
gateway.adapter.errors |
适配器错误数(每分钟) | 持续上升说明平台 API 或网络有问题 |
gateway.sessions.active |
当前活跃会话数 | 异常快速增长可能是消息风暴 |
gateway.rate_limit.hits |
限流触发次数(按租户) | 频繁触发需要重新评估限流配置 |
这六个指标的关联分析通常比单独看更有价值:received 正常但 processed 下降,说明 Agent 端有问题;两者同时下降,说明 Webhook 端有问题。
7.4 灰度发布:新平台或新适配器的上线策略
新 IM 平台或适配器逻辑修改上线时,建议三阶段推进:
影子模式 (第 1-2 天):新适配器接收消息、完成解析,但不真正调用 Agent,只把处理结果写入日志,与生产逻辑对比。这个阶段主要验证 parse_event() 的正确性。
小范围试点(第 3-7 天):在一个内部测试群启用真实处理,核心团队成员作为第一批用户,快速发现边界情况。
逐步放量(第 2-4 周):按 10% → 30% → 50% → 100% 推进,每个阶段观察错误率和延迟指标,无异常再继续。
八、HTTP API 适配器:机机交互的接入口
除了人机交互场景,Gateway 还提供了通用的 HTTP API 适配器,让任何 HTTP 客户端都能与 Agent 交互------前端页面、移动 App、自动化脚本、其他微服务。
IM 适配器解决的是"人机交互"问题,API 适配器解决的是"机机交互"问题。两者共享同一套 Gateway 核心层(会话管理、租户隔离、状态机),只是接入层不同。
API 适配器的关键设计挑战是同步 vs 异步的权衡:HTTP 调用方通常期望同步响应(调用即得到结果),但 Agent 的处理时间不确定(可能 5 秒,可能 60 秒)。
Hermes 的解法是提供两种模式:同步模式 (等待回复,带超时)适合简单问答场景;异步模式(立即返回 task_id,通过轮询或回调获取结果)适合长任务场景。
python
@app.post("/v1/chat")
async def chat(request: ChatRequest):
message = Message(
content=request.message,
conversation_id=request.conversation_id or str(uuid4()),
platform="api",
message_type="text",
)
await self._message_queue.put(message)
if request.mode == "async":
# 异步模式:立即返回 task_id
return {"status": "accepted", "task_id": message.conversation_id}
else:
# 同步模式:等待回复(默认超时 120 秒)
try:
reply = await asyncio.wait_for(
self._wait_for_reply(message.conversation_id),
timeout=request.timeout or 120,
)
return {"status": "success", "reply": reply}
except asyncio.TimeoutError:
return {"status": "timeout", "message": "处理超时,请使用异步模式"}九、与 MCP 协议的协同:工具热插拔的 Gateway 视角
Gateway 与 MCP 协议的协同体现在一个在生产环境中极为重要的场景:工具热插拔。
在没有热插拔能力时,添加一个新的 MCP 工具需要重启整个 Gateway 进程,这会中断所有正在进行的会话。对于全天候使用的企业场景,这个代价是不可接受的。
Hermes 通过 /reload-mcp 指令实现不停机的工具热更新:Gateway 通知所有 Agent 实例重新扫描 MCP 工具服务器,更新工具注册表,已有会话继续正常处理。
MCP工具服务器 Agent实例 Gateway 管理员 MCP工具服务器 Agent实例 Gateway 管理员 loop 遍历所有活跃Agent实例 /reload-mcp 验证管理员权限 触发工具重载 重新发现工具列表 返回新工具Schema 更新工具注册表 重载完成新增X个工具移除Y个工具
MCP 工具的租户隔离同样在 Gateway 层处理:不同租户的 TenantContext 中配置了不同的 MCP 服务器列表,工具发现和注册按租户独立进行。工程团队看到代码分析工具,营销团队看到内容工具,两者之间没有交叉。
十、延伸思考:Gateway 的架构边界与演进方向
10.1 Gateway 不是消息队列------边界在哪里
一个需要辨清的架构误区:Gateway 的内部有 asyncio.Queue,看起来像消息队列,但它不是。消息队列(如 Redis Streams、Kafka)关注的核心问题是持久性和吞吐量 ------消息不能丢,堆积时不能崩溃。Gateway 关注的核心问题是会话状态和租户隔离------哪个消息归属哪个会话,每个会话的状态机处于什么位置。
如果 Gateway 进程重启,内存中的 asyncio.Queue 会丢失正在排队的消息。这在大多数 IM 场景下是可接受的(用户重发就好),但如果业务上不可接受,应该在 Gateway 上游引入持久化消息队列,而不是在 Gateway 内部重新发明持久化。职责边界不能模糊。
10.2 适配器粒度:平台内部的差异如何处理
当前设计是"一个平台一个适配器"。但在实际接入中,同一个平台内部可能有多种接入方式------比如企业微信的"应用消息"和"群机器人"使用不同的 API 和不同的消息格式,但共享相同的加解密逻辑。
Hermes 的处理方式是:在同一个适配器内通过 message_type 区分不同子类型,而不是拆分成两个适配器。这避免了加解密逻辑的重复实现,同时保持了"一个平台一个适配器"的概念一致性。当子类型之间的差异足够大(超过 50% 的代码不同),才考虑拆分。
10.3 多 Agent 编排:下一阶段的演进
当前 Gateway 是"一个会话一个 Agent"的模型。随着业务复杂度增长,下一个自然的演进方向是"一个会话,多个专业 Agent 协同"。
用户发了一个问题,主 Agent(Orchestrator)做意图识别,判断需要代码审查,将子任务分发给代码 Agent,代码 Agent 完成后将结果返回给 Orchestrator,由 Orchestrator 汇总并回复用户。
这种模式要求 Gateway 支持消息的二次内部路由 和子任务结果的聚合,是比当前架构复杂度高一个量级的演进。Hermes 目前通过"工具链"在单 Agent 内模拟了部分这种能力(Agent 调用工具,工具内部调用另一个专业模型),是一个实用的过渡方案。真正的多 Agent 编排,建议在业务需求明确后再引入,不要提前设计。
附录:Gateway 完整配置示例
yaml
# config/gateway.yaml
gateway:
host: "0.0.0.0"
port: 8080
session_timeout: 3600 # 会话超时(秒),超时后进入 Expired 状态
max_concurrent_agents: 10 # 全局并发 Agent 上限
agent_timeout: 120 # 单次处理超时(秒)
idempotency_ttl: 300 # 幂等性去重 TTL(秒)
platforms:
wecom:
enabled: true
adapter: wecom
config:
corp_id: "${WECOM_CORP_ID}"
agent_id: "${WECOM_AGENT_ID}"
secret: "${WECOM_SECRET}"
token: "${WECOM_TOKEN}"
encoding_aes_key: "${WECOM_ENCODING_AES_KEY}"
webhook_url: "https://your-server.com/gateway/wecom"
dingtalk:
enabled: true
adapter: dingtalk
config:
client_id: "${DINGTALK_CLIENT_ID}"
client_secret: "${DINGTALK_CLIENT_SECRET}"
# Stream 模式,无需 webhook_url,无需公网 IP
feishu:
enabled: true
adapter: feishu
config:
app_id: "${FEISHU_APP_ID}"
app_secret: "${FEISHU_APP_SECRET}"
verification_token: "${FEISHU_VERIFICATION_TOKEN}"
encrypt_key: "${FEISHU_ENCRYPT_KEY}"
webhook_url: "https://your-server.com/gateway/feishu"
telegram:
enabled: false
adapter: telegram
config:
bot_token: "${TELEGRAM_BOT_TOKEN}"
api:
enabled: true
adapter: api
config:
port: 8081
api_key: "${GATEWAY_API_KEY}"
tenants:
- id: engineering
toolsets: [core, code, devops]
model: {name: claude-sonnet, temperature: 0.3}
system_prompt: "你是工程团队的 AI 助手"
rate_limit: {rpm: 120}
- id: marketing
toolsets: [core, writing, web]
model: {name: claude-sonnet, temperature: 0.7}
system_prompt: "你是营销团队的 AI 助手"
rate_limit: {rpm: 60}
- id: default
toolsets: [core]
model: {name: default}
rate_limit: {rpm: 30}