大家好,我是直奔標杆!专注Java开发者AI转型实战分享,从零基础到项目落地,每一步都力求干货满满、可直接上手,和大家一起突破技术瓶颈,向AI全栈工程师稳步迈进~
欢迎来到《Spring AI 零基础到实战》系列的第二十六课!这节课咱们要解决一个核心痛点------打破本地知识库的"信息围墙",让咱们的AI知识库不仅能回答私有文档里的问题,还能实时联网获取最新资讯,真正实现"全能应答"!
在之前的课程中,咱们搭建的个人知识库就像一位"闭门苦读"的学者:通过ETL流水线喂给它什么私有文档(RAG),它就只能回答什么。这种模式虽然保证了输出的严谨性和数据安全性,但局限性也很致命------面对实时数据、最新资讯,它就彻底"束手无策"。
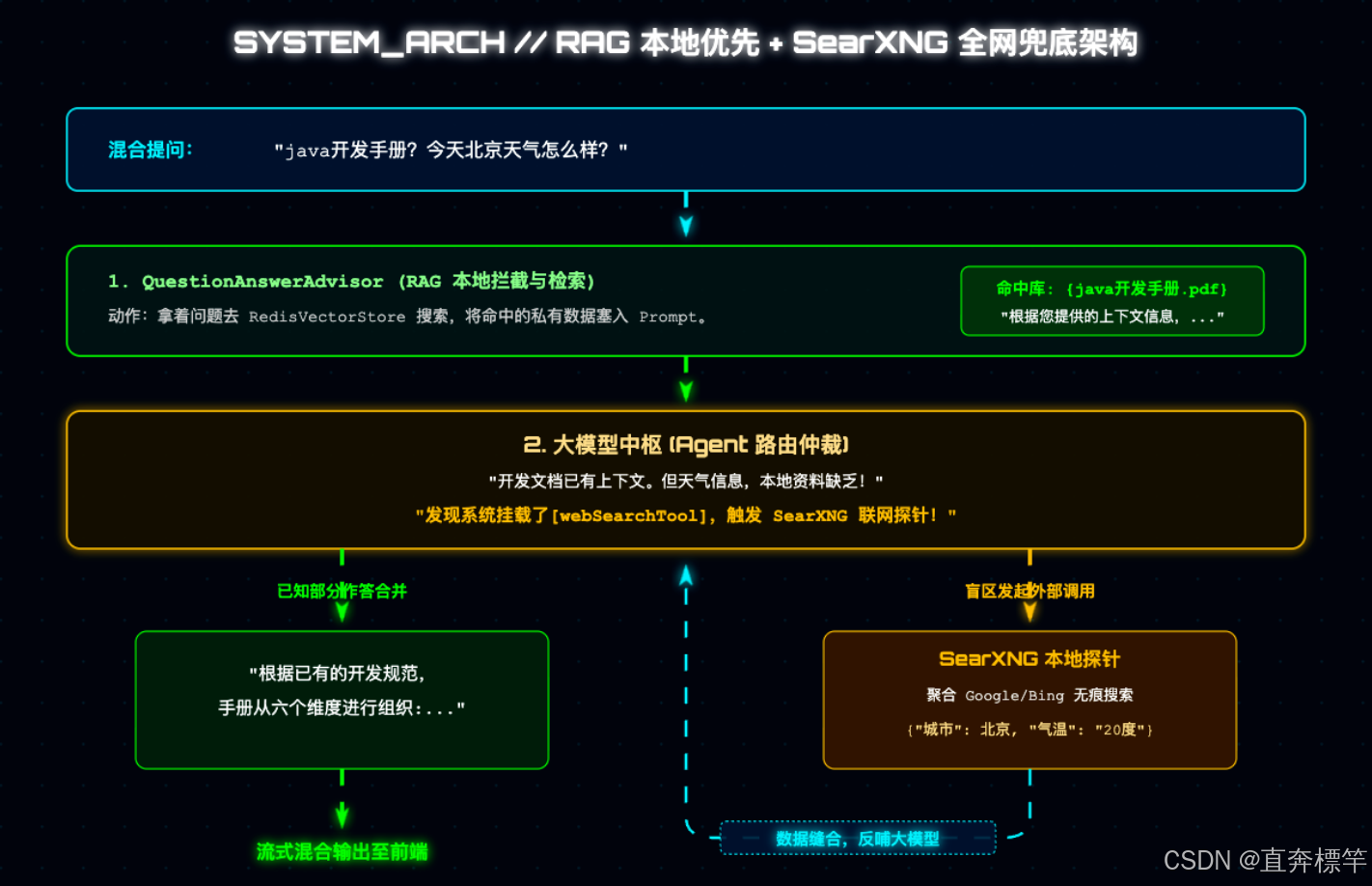
举个很实际的例子:如果用户在对话框提问:"java开发文档是什么?另外,今天北京天气怎么样?" 前半句,咱们本地向量库能轻松给出答案;但后半句的实时天气,本地资料库根本不可能有存储,传统RAG系统只能生硬回复"本地资料库中没有提供该信息",体验感大打折扣。
今天,直奔標杆就带大家把RAG检索与Function Calling工具调用彻底缝合,让大模型化身为具备自主决策能力的Agent(智能体):当本地知识库"答不上来"时,它会自动触发联网搜索,主动获取实时信息------这才是AI知识库该有的样子!
本节课咱们全程实战,手把手带大家在本地部署开源免Key的聚合搜索引擎SearXNG,再将其挂载到Spring AI中,完成从"封闭知识库"到"智能Agent"的升级,话不多说,直接上干货!
本节学习目标(建议收藏,对照实操)
-
认知升级:搞懂Fallback(兜底/回退)机制在AI Agent架构中的路由决策逻辑,明白"本地检索+联网兜底"的核心价值;
-
实操落地:用Docker快速私有化部署SearXNG隐私聚合搜索引擎,全程免Key,新手也能一次成功;
-
工具封装:基于Spring RestClient,零成本将SearXNG封装为大模型可调用的Function工具,无需第三方SDK;
-
架构缝合:在ChatClient中同时挂载RAG与联网搜索工具,亲眼见证大模型的混合编排能力,完成实战测试。
Agent 混合路由图(核心逻辑必看)
引入联网搜索工具后,咱们的系统不再是单向的线性流水线,大模型相当于拥有了一个"多功能工具箱",会在底层自动进行路由仲裁。简单来说,数据流的切换逻辑如下(建议结合实操理解):
用户提问 → 大模型先检索本地RAG向量库 → 能找到答案→ 直接返回(标注本地来源);找不到答案→ 触发Fallback机制→ 调用SearXNG联网搜索→ 获取实时结果→ 大模型归纳后返回(标注联网来源)。
这个逻辑的核心的是"优先本地、兜底联网",既保证了私有数据的安全严谨,又解决了实时信息获取的痛点。
核心实操一:认识并部署SearXNG(免Key开源神器)
很多小伙伴担心联网搜索需要申请API Key、配置复杂,今天咱们用的SearXNG完美解决这个问题------它是一款开源、免费、保护隐私的"元搜索引擎(Metasearch Engine)",自身不爬取网页,而是将搜索关键词分发给百度、Bing、DuckDuckGo等多家搜索引擎,再聚合返回纯净结果。
最关键的是,它原生支持JSON格式返回结果,简直是为咱们的AI Agent量身定制的!接下来,用Docker快速部署,全程复制命令即可,新手也能搞定。
Docker部署SearXNG(Mac/Linux版,Windows可参考适配)
温馨提示:部署前确保Docker已启动,若未启动,先启动Docker(Windows启动Docker Desktop,Linux执行sudo systemctl start docker),避免部署失败。另外,若8888端口被占用,可替换为其他空闲端口(如8889),具体方法后面会补充。
bash
# 1. 创建配置和数据持久化目录(避免容器删除后配置丢失)
mkdir -p /Users/docker-data/searxng/config/ /Users/docker-data/searxng/data/
cd /Users/docker-data/searxng
# 2. 启动SearXNG容器(映射到8888端口,可根据需求修改)
docker run --name searxng -d \
-p 8888:8080 \
-v "./config/:/etc/searxng/" \
-v "./data/:/var/cache/searxng/" \
docker.io/searxng/searxng:latest部署避坑提示:若执行命令后容器未启动,可执行docker logs searxng查看日志排查问题。常见问题:端口冲突(用lsof -i:8888查看占用进程,kill -9 进程ID即可)、Docker未启动(启动Docker后重新执行命令)。
启动成功后,打开浏览器访问 http://localhost:8888 ,就能体验这款隐私搜索引擎了,界面简洁,无广告、不追踪,非常适合作为咱们AI Agent的联网工具。
核心实操二:开发SearXNG搜索工具(Spring AI封装)
部署好SearXNG后,下一步就是将它封装成大模型可调用的Function工具。这里不需要引入任何第三方SDK,直接用Spring Boot内置的RestClient,配合Spring AI的@Bean和@Description注解,就能轻松实现,直奔標杆已经把完整代码整理好,大家直接复制到项目中,稍作修改即可使用。
java
public class AiToolsConfig {
/**
* 注册 SearXNG 联网搜索工具
* 备注:@Description注解很关键,大模型会根据这个描述判断何时调用该工具
*/
@Bean(WEB_SEARCH_TOOL)
@Description("联网实时搜索引擎。当本地知识库无法回答最新资讯、实时数据(如股价、天气、新闻)等问题时,调用此工具获取互联网实时信息进行补充。")
public Function<WebSearchRequest, String> webSearchTool(RestClient.Builder restClientBuilder) {
RestClient restClient = restClientBuilder.baseUrl(SEARXNG_BASE_URL).build();
// 这里的SEARXNG_BASE_URL就是咱们部署的本地地址:http://localhost:8888
return request -> {
log.info("[Agent 路由] RAG 本地知识不足,触发 SearXNG 联网搜索,关键词: [{}]", request.keyword());
try {
// 向本地 SearXNG 发起 GET 请求,获取搜索结果(JSON格式)
String responseJson = restClient.get()
.uri(uriBuilder -> uriBuilder
// 补充完整请求参数,这里省略的部分可参考SearXNG官方API文档
.queryParam("q", request.keyword())
.queryParam("format", "json") // 指定返回JSON格式
.build())
.retrieve()
.body(String.class);
// 解析 JSON 提取content摘要,只保留核心信息,避免冗余
JsonNode rootNode = objectMapper.readTree(responseJson);
JsonNode resultsNode = rootNode.path("results");
if (resultsNode.isMissingNode() || resultsNode.isEmpty()) {
return "联网搜索未找到相关信息,请基于已有知识尽力回答。";
}
// 提取Top N条摘要返回(建议取3条以内,避免信息过多影响大模型归纳)
List<String> summaries = new ArrayList<>();
for (int i = 0; i < Math.min(MAX_RESULTS, resultsNode.size()); i++) {
String content = resultsNode.get(i).path("content").asText("");
summaries.add(content);
}
log.info("[Agent 路由] SearXNG 搜索完成,返回 {} 条摘要", summaries.size());
return "【联网实时搜索摘要】:\n" + String.join("\n---\n", summaries);
} catch (Exception e) {
log.error("[Agent 路由] SearXNG 搜索异常: {}", e.getMessage());
return "联网搜索暂时不可用,请基于本地知识库内容尽力回答。";
}
};
}
}底层细节剖析(必懂,避免踩坑)
很多小伙伴封装工具后,发现大模型不调用,核心问题就是没搞懂这个底层逻辑,直奔標杆给大家拆解清楚:
-
入参WebSearchRequest:Spring AI底层会自动将其反射解析为parameters结构,咱们只需要定义好keyword参数即可;
-
工具调用触发:当大模型判断本地知识库无法回答问题时,会输出一个特殊的Tool Call指令(包含{"keyword": "查询关键词"});
-
自动执行与结果返回:Spring框架拦截到Tool Call指令后,会自动触发上面的Lambda表达式,调用SearXNG获取结果,再将结果回传给大模型,大模型最终归纳生成回答。
这里重点提醒:@Description注解的描述一定要精准,要明确告诉大模型"什么时候该调用这个工具",否则大模型可能会乱调用或不调用。
核心实操三:挂载工具+Prompt调优(关键一步)
工具封装好后,需要把它挂载到大模型的"工具箱"里,同时调整System Prompt,让大模型知道如何混合使用本地RAG和联网搜索工具,两步就能搞定。
第一步:挂载工具到ChatClient
进入咱们之前写的聊天模型策略类(如DeepSeekChatStrategy),在ChatClient.builder中追加.defaultTools(),将封装好的搜索工具挂载进去,代码如下:
java
@Component
public class DeepSeekChatStrategy implements ChatModelStrategy {
private final ChatClient chatClient;
public DeepSeekChatStrategy(DeepSeekChatModel deepSeekChatModel) {
this.chatClient = ChatClient.builder(deepSeekChatModel)
// 挂载 SearXNG 搜索工具,与本地RAG工具协同工作
.defaultTools(AiToolsConfig.WEB_SEARCH_TOOL)
.build();
}
// ... 省略其他代码(保持不变即可)
}第二步:调优System Prompt(核心配置)
如果不调整Prompt,大模型可能不知道优先使用本地知识库,或者不会区分信息来源,咱们微微放宽ChatServiceImpl里的System Prompt约束,明确规则:
java
private static final String SYSTEM_PROMPT = """
你是一个由 Spring AI 驱动的全能知识库助手,由直奔標杆开发维护,专注于为Java开发者提供精准、全面的回答。
请优先根据提供的本地文档参考资料回答用户问题,确保回答的严谨性和准确性。
如果本地资料不足以回答(例如涉及实时数据、最新资讯、本地未收录的知识点等),
你可以调用可用的联网搜索工具webSearchTool获取互联网信息进行补充。
回答时请清晰区分信息来源:明确标注"本地知识库"和"联网搜索",提升用户体验。
""";
核心实操四:流转测试(验证成果)
所有配置完成后,咱们发起一次混合边界测试,验证本地RAG和联网搜索是否能正常协同工作,步骤如下:
-
启动咱们的Spring Boot项目,确保SearXNG容器处于运行状态;
-
打开浏览器,发起请求(替换为自己的项目端口和chatId):
bash
http://localhost:8099/api/chat/stream?chatId=春风不晚&model=deepseek&message=java开发文档是什么?另外,今天北京天气怎么样?【结果验证】大家可以查看服务端控制台日志,会看到如下关键信息,说明路由和搜索正常:
bash
[Agent 路由] RAG 本地知识不足,触发 SearXNG 联网搜索,关键词: [今天北京天气]
[Agent 路由] SearXNG 搜索完成,返回 3 条摘要同时,浏览器会以SSE流式响应的方式返回结果,类似这样:
data:由于提供的参考资料中没有包含天气信息,我需要使用联网搜索工具来获取最新的北京天气情况。根据您的问题,我来分别回答:
data:【本地知识库】java开发文档是......(此处为本地RAG返回的内容)
data:【联网搜索】今天北京天气为......(此处为SearXNG联网返回的实时天气)
如果能看到这样的结果,说明咱们的实战已经成功了!如果出现异常,优先查看SearXNG容器是否正常运行、端口是否冲突、工具挂载是否正确。
本节课总结(重点回顾)
今天这节课,咱们完成了一个关键升级------打破本地知识库的围墙,将RAG检索与SearXNG联网搜索完美缝合,核心收获有3点,大家可以对照自查:
-
掌握了Fallback兜底机制的路由逻辑,理解了"本地优先、联网兜底"的AI Agent核心思想;
-
实操部署了SearXNG搜索引擎,学会了Docker部署的关键步骤和常见问题排查方法;
-
完成了搜索工具的封装与挂载,实现了本地RAG与联网搜索的协同工作,解决了实时信息获取的痛点。
这里再和大家多说一句:AI时代,Java开发者的核心竞争力不再是单纯的CRUD,而是"智能中枢编排"------将不同的工具、组件缝合起来,实现更强大的功能。咱们今天做的,就是从"CRUD搬运工"向"智能架构师"转型的关键一步。
至此,咱们个人知识库的后端开发就全部完成了!从ETL流水线、记忆交互、来源追溯,到今天的联网增强,每一步都是实战落地,大家跟着实操下来,相信已经掌握了Spring AI的核心用法。
下期预告(干货预警)
【第二十七课:Spring AI 个人知识库实战(六)- 前端联调实战】
下节课,直奔標杆将带大家搞定前端联调,用HTML + Vue 3 (CDN) 写一个简单的单页面应用,对接咱们的PDF上传接口,解析SSE混合数据流,实现顺滑的打字机特效和引用卡片,让咱们的知识库既有强大的后端能力,又有美观的前端界面!
精彩继续,咱们下节课不见不散~
往期内容回顾(连贯学习不迷路)
-
Java开发者AI转型第二十三课!Spring AI个人知识库实战(二):异步ETL流水线搭建与避坑指南
-
Java开发者AI转型第二十四课!Spring AI 个人知识库实战(三)------记忆交互+SSE流式响应落地
-
Java开发者AI转型第二十五课!Spring AI 个人知识库实战(四)------RAG来源追溯落地,拒绝AI幻觉
我是直奔標杆,专注Java开发者AI转型实战分享,每节课都力求干货、可落地。如果大家在实操中遇到问题,欢迎在评论区留言交流,咱们一起学习、一起进步,早日实现AI转型!