一、筑基篇-pytorch基础
1、入门
1.1pytorch介绍
PyTorch是一个开源的Python机器学习库,基于Torch库开发。它之所以成为研究和生产中最受欢迎的深度学习框架之一,主要因为以下几个特点:
1.1.1动态计算图(Imperative Execution)
定义:PyTorch使用"Define-by-Run"的方式,计算图在代码运行时动态构建
优势:
- 调试更直观:可以使用标准Python调试工具(如pdb)
- 灵活性更高:可以轻松实现条件分支、循环等复杂控制流
- 更Pythonic:代码写法更接近原生Python
1.1.2 强大的GPU加速
原生支持CUDA,可以无缝在CPU和GPU之间切换计算。自动利用GPU的并行计算能力加速模型训练
1.1.3 活跃的生态系统
TorchVision(图像处理)、TorchText(文本处理)、TorchAudio(音频处理),丰富的预训练模型和数据集\庞大的社区支持和持续更新
1.2环境安装与配置
1.2.1安装工具包
Anaconda是Python的科学计算发行版,内置了大量常用的数据科学包,并提供了conda包管理工具。官网网址:
https://www.anaconda.com/download![]() https://www.anaconda.com/download注意:
https://www.anaconda.com/download注意:
-
安装路径不要包含中文或空格
-
勾选"Add Anaconda3 to my PATH environment variable"
-
勾选"Register Anaconda3 as my default Python"
验证安装情况:conda --version python --version
1.2.2创建pytorch虚拟环境
创建名为pytorch_env的虚拟环境,指定Python版本为3.9
conda create -n pytorch_env python=3.9
-n pytorch_env表示名字为pytorch_env
激活虚拟环境
conda activate pytorch_env
查看当前环境中的包
conda list
1.2.3安装pytorch
按照要求按照:(一般都安装gpu的cudu显卡版本)
https://pytorch.org/get-started/locally/![]() https://pytorch.org/get-started/locally/
https://pytorch.org/get-started/locally/
两种安装gpu的方法:
- 对于有NVIDIA GPU的机器(CUDA 11.7):
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
- 使用pip安装(CUDA 11.7):
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
以下是整理后的对比表格,清晰展示 Conda 与 Pip 在 PyTorch 安装中的核心差异:
| 对比维度 | Conda 安装 | Pip 安装 |
|---|---|---|
| 包管理范围 | 支持多语言(Python/C++等)依赖 | 仅限 Python 包 |
| 环境隔离 | 内置 conda create 管理虚拟环境 |
需额外安装 virtualenv 等工具 |
| 依赖处理 | 自动处理 CUDA/cuDNN 等系统级依赖 | 仅解决 Python 包依赖,CUDA 需手动 |
| 安装来源 | 从 Conda 仓库(含 PyTorch/NVIDIA 频道)预编译包 | 从 PyPI 拉取 PyTorch 官方 whl 包 |
关键差异说明
- 非Python依赖:Conda 在安装 PyTorch 时会自动匹配 CUDA 工具包版本,适合不熟悉手动配置 CUDA 的用户。
- 环境隔离效率 :Conda 直接通过
conda install pytorch在新建环境中完成安装,Pip 需结合venv或virtualenv分步操作。 - 适用场景:若需纯净 Python 环境或自定义 CUDA 版本,Pip 更灵活;若追求依赖自动化,Conda 更高效。
2、张量(Tensor)
张量(Tensor)是深度学习的"数据容器"。张量不仅是PyTorch中最核心的数据结构,也是所有前向传播计算和后向梯度求导的物理载体。要真正理解张量,我们需要从数学定义 和底层计算结构两个维度来剖析。
2.1 物理与数学原理:什么是张量?
在数学和物理学中,张量是一个定义在向量空间和对偶空间上的多线性映射。在深度学习的语境下,我们可以将其通俗地理解为多维数组的泛化。
维度(Dimension)在张量中被称为阶(Rank)或轴(Axis):
-
0阶张量(标量 Scalar): 只有大小,没有方向。数学表示为
。例如:Loss的具体数值。
-
1阶张量(向量 Vector): 有大小和方向,是一维数组。数学表示为
-
2阶张量(矩阵 Matrix): 二维数组。数学表示为
-
3阶及以上张量: 多维数组。数学表示为
[Channels, Height, Width]的3阶张量;而一批(Batch)RGB图片则是[Batch_Size, Channels, Height, Width]的4阶张量。
图示讲解:
2.2 底层内存逻辑(C++/硬件视角)
PyTorch在前端使用的是极具表现力的Python,但其核心计算是由后端的C++库(ATen)以及CUDA驱动的。
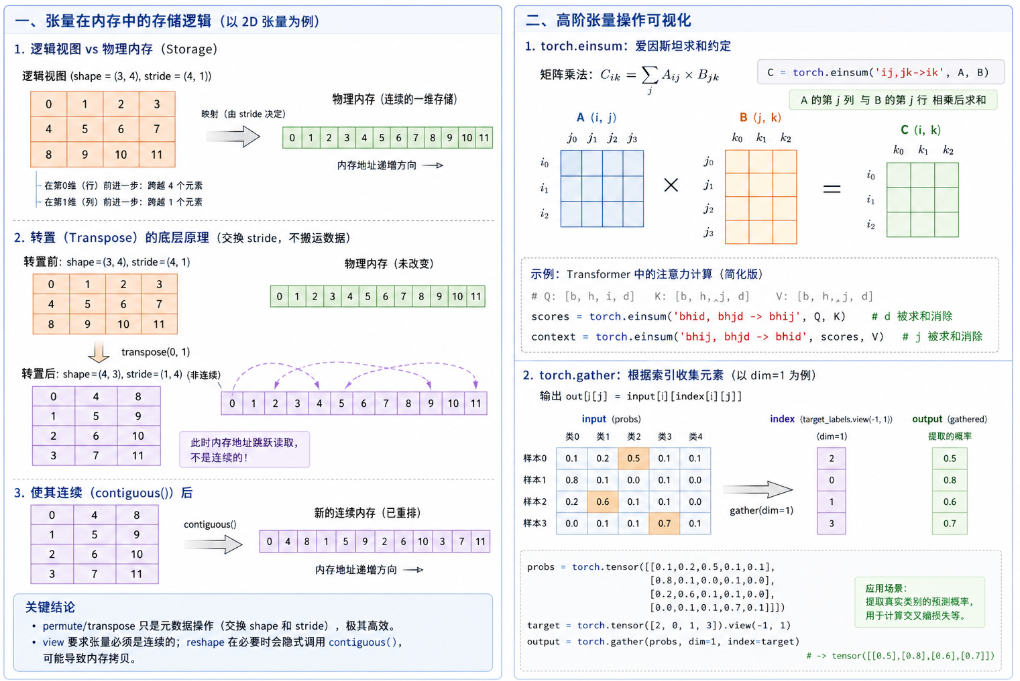
在内存中,无论张量是多少阶,物理存储通常都是一维的、连续的内存块(Storage)。PyTorch通过步长(Stride)机制来实现从一维内存到多维逻辑结构的映射。
例如,一个形状为 (3, 4) 的二维张量,在内存中是12个连续的数据。它的 stride 可能是 (4, 1),这意味着:
-
在第0维度(行)前进1个位置,物理内存需要跨越4个元素。
-
在第1维度(列)前进1个位置,物理内存只需跨越1个元素。
这种设计使得类似转置(Transpose)这样的操作具有极高的效率------转置时,PyTorch不需要在内存中搬运实际数据,只需交换维度的 stride 和 shape 信息即可,这也是为什么在执行某些变形操作后,张量会变成"非连续"(non-contiguous)状态,需要调用 .contiguous() 在内存中重新开辟连续空间。
2.3 张量的三大核心属性
在工程实践中,每个张量都绑定了三个至关重要的属性:
-
dtype(数据类型): 决定了内存占用和精度。常见的有torch.float32(默认,单精度)、torch.float16(半精度,常用于大模型显存优化)、torch.int64(常用于类别标签)。 -
shape(形状): 定义了各个维度的长度。 -
device(设备): 决定了张量存储在主存(CPU RAM)还是显存(GPU VRAM)上。在边缘计算设备或本地服务器上进行部署和训练时,频繁的CPU与GPU之间的数据拷贝(Host to Device)会成为性能瓶颈,因此控制张量所在的 device 极其重要。
python
import torch
# 创建一个2x3的随机张量
tensor_a = torch.randn(2, 3)
print(tensor_a.shape) # 输出: torch.Size([2, 3])
print(tensor_a.dtype) # 输出: torch.float32
print(tensor_a.device) # 输出: cpu
# 将张量转移到GPU计算(如果CUDA可用)
if torch.cuda.is_available():
tensor_a = tensor_a.to('cuda')
print(tensor_a.device) # 输出: cuda:0效果预览:

2.4 核心操作与数学运算
1. 形状变换(Reshape / View)
改变张量的逻辑视图而不改变底层数据。
python
x = torch.arange(12) # [0, 1, ..., 11],形状为 (12,)
y = x.view(3, 4) # 变形为 3行4列 的矩阵
print(x)
print(y)效果预览:

2. 矩阵乘法(Matrix Multiplication)
这是神经网络前向传播中最耗时的操作。给定矩阵 和
,它们的乘积
,其元素定义为:
在PyTorch中,通常使用 @ 运算符或 torch.matmul():
python
A = torch.randn(3, 4)
B = torch.randn(4, 5)
C = A @ B # 或者 torch.matmul(A, B),结果形状为 (3, 5)
print(C.shape)效果预览:

3. 广播机制(Broadcasting)
在进行逐元素(element-wise)运算时,如果两个张量形状不严格一致,PyTorch会尝试自动扩展(广播)它们的维度以完成计算,而无需实际复制内存数据。 规则是从后向前对比维度,如果当前维度大小相等,或者其中一个为1,则可以广播。
python
matrix = torch.ones(3, 4)
vector = torch.arange(4) # 形状 (4,),相当于 (1, 4)
# vector 会在第0维被逻辑上复制3次,与 matrix 对齐后相加
result = matrix + vector
print(result)效果预览:

张量操作是构建各种复杂神经网络结构(尤其是处理不同维度的传感器数据或图像数据)的基本功。
2.5 进阶张量讲解
1. 维度重排与内存连续性(CV中的 HWC 转 CHW)
在视觉任务中,OpenCV 读取的图像格式通常是 [Height, Width, Channels] (HWC),而 PyTorch 神经网络要求的输入是 [Channels, Height, Width] (CHW)。这就需要用到维度重排。
这里最容易踩坑的就是 .view() 和 .reshape() 的区别,它的核心在于我们上节提到的步长(Stride)和内存连续性(Contiguous)。
python
import torch
# 模拟一张 1080x1920 的 RGB 图像,Batch Size 为 4
# 初始形状: [B, H, W, C] -> [4, 1080, 1920, 3]
images_hwc = torch.randn(4, 1080, 1920, 3)
# 查看底层内存步长 (stride)
# 输出通常是 (1080*1920*3, 1920*3, 3, 1) -> 内存是连续的
print("初始 Stride:", images_hwc.stride())
print("是否连续:", images_hwc.is_contiguous()) # True
# 场景:我们需要将其转换为 PyTorch 支持的 [B, C, H, W]
# 操作:将第3维(C)提到第1维,H和W顺延
images_chw = images_hwc.permute(0, 3, 1, 2)
print("\nPermute后的形状:", images_chw.shape) # [4, 3, 1080, 1920]
# 核心原理:permute 并没有在内存中移动实际的像素数据,它只是交换了 stride 的读取顺序!
print("Permute后的 Stride:", images_chw.stride()) # 变成了 (6220800, 1, 5760, 3)
print("是否连续:", images_chw.is_contiguous()) # False!(因为stride的最后一维不再是1)
# 踩坑警告:此时如果你尝试直接用 .view() 展平张量,会报错!
# flattened = images_chw.view(4, -1) # RuntimeError: view size is not compatible with input tensor's size and stride
# 正确做法1:先在内存中重新开辟连续空间,再 view
flattened_1 = images_chw.contiguous().view(4, -1)
# 正确做法2:直接使用 reshape (它在内部会自动判断,如果不连续会隐式调用 contiguous 拷贝内存)
flattened_2 = images_chw.reshape(4, -1)效果预览:

总结:在做硬件部署或底层算子优化时,频繁的非连续操作和隐式的内存拷贝会极大拖慢前向传播速度。
2. 张量操作的"瑞士军刀":爱因斯坦求和约定 (torch.einsum)
在编写大语言模型(如 Transformer 架构)时,经常遇到多维张量的批量矩阵乘法(BMM)、转置、求迹等复杂操作。用传统的 matmul 和 permute 会让代码变得极长且难以阅读。
torch.einsum 通过显式定义维度的字母映射,可以用一行代码解决几乎所有线性代数操作。
数学表达:
假设我们要计算矩阵乘法 ,数学上是
。在
einsum 中,表达式写为 'ij, jk -> ik'。箭头左边是输入维度,右边是输出维度,未出现在输出中的维度(这里是 j)会被自动求和消除。
python
# 场景:Transformer 中的注意力机制 (Self-Attention) 核心计算
# Attention(Q, K, V) = softmax(Q * K^T / sqrt(d)) * V
batch_size = 32
num_heads = 8
seq_len = 128
head_dim = 64
# Q, K, V 张量形状: [Batch, Heads, Seq_Len, Head_Dim] -> [b, h, s, d]
Q = torch.randn(batch_size, num_heads, seq_len, head_dim)
K = torch.randn(batch_size, num_heads, seq_len, head_dim)
V = torch.randn(batch_size, num_heads, seq_len, head_dim)
# 任务1:计算 Q 和 K^T 的点积,得到 Attention Score 矩阵
# 传统写法:K需要先转置最后两维,然后用 batch matrix multiply (matmul)
# scores_trad = torch.matmul(Q, K.transpose(-2, -1))
# einsum 高阶写法:
# Q: b(Batch) h(Heads) i(Seq_Len_Q) d(Head_Dim)
# K: b(Batch) h(Heads) j(Seq_Len_K) d(Head_Dim)
# 输出: b(Batch) h(Heads) i(Seq_Len_Q) j(Seq_Len_K) -> d 被求和消除了!
scores = torch.einsum('bhid, bhjd -> bhij', Q, K)
print("Attention Scores 形状:", scores.shape) # [32, 8, 128, 128]
# 假设经过了 softmax (省略)
attn_probs = torch.softmax(scores, dim=-1)
# 任务2:将权重乘回 V
# attn_probs: [b, h, i, j]
# V: [b, h, j, d]
# 输出: [b, h, i, d] -> j 被求和消除
context_layer = torch.einsum('bhij, bhjd -> bhid', attn_probs, V)
print("Context Layer 形状:", context_layer.shape) # [32, 8, 128, 64]效果预览:
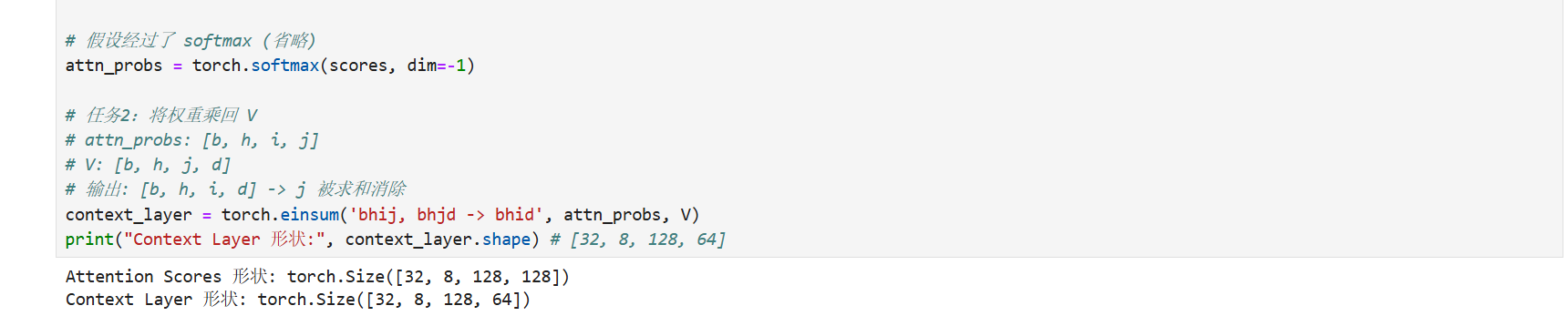
einsum 不仅优雅,而且在后端C++实现中经常会被优化合并操作,是高阶玩家的必备技能。
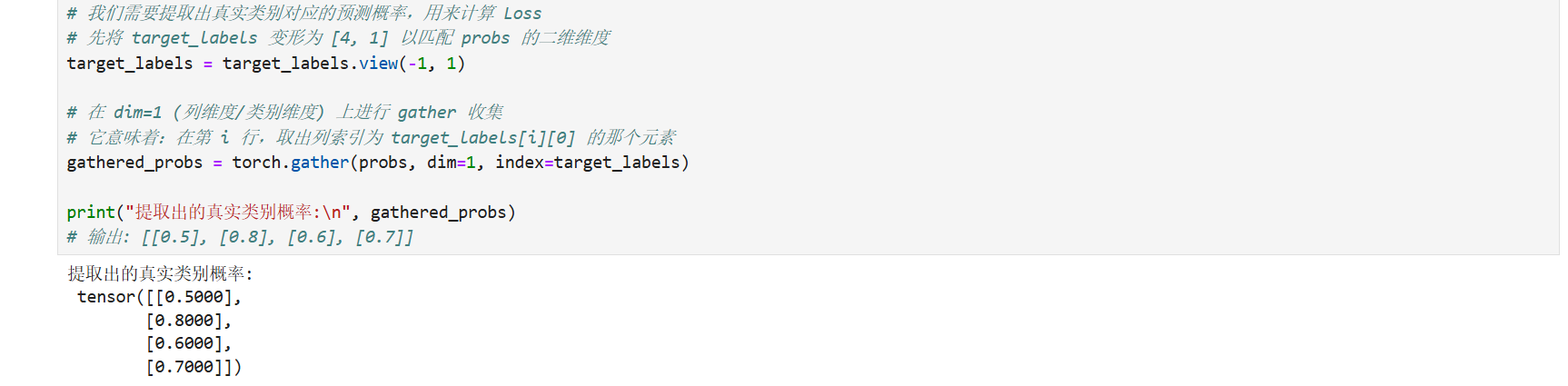
3. 高阶索引操作:torch.gather 机制
在写复杂的损失函数(如强化学习中的 Q-learning 或带有 Masking 的交叉熵)时,我们需要根据一个索引张量,从原张量中"抠"出特定的值。这在非循环算法编程中极其常见。
gather(dim, index) 的数学定义比较绕,对于二维情况(dim=1),其运算逻辑是:
python
# 场景:分类模型输出计算 (提取正确类别的预测概率)
# 假设有 4 个样本,类别数为 5
batch_size = 4
num_classes = 5
# 神经网络输出的 Logits (或者 Softmax 后的概率),形状 [4, 5]
# 行是样本,列是类别概率
probs = torch.tensor([
[0.1, 0.2, 0.5, 0.1, 0.1], # 样本0的概率分布
[0.8, 0.1, 0.0, 0.1, 0.0], # 样本1的概率分布
[0.2, 0.6, 0.1, 0.1, 0.0], # 样本2的概率分布
[0.0, 0.1, 0.1, 0.7, 0.1] # 样本3的概率分布
])
# 假设真实的标签 (Ground Truth Labels),形状 [4]
# 样本0真实类别是2,样本1是0,样本2是1,样本3是3
target_labels = torch.tensor([2, 0, 1, 3])
# 我们需要提取出真实类别对应的预测概率,用来计算 Loss
# 先将 target_labels 变形为 [4, 1] 以匹配 probs 的二维维度
target_labels = target_labels.view(-1, 1)
# 在 dim=1 (列维度/类别维度) 上进行 gather 收集
# 它意味着:在第 i 行,取出列索引为 target_labels[i][0] 的那个元素
gathered_probs = torch.gather(probs, dim=1, index=target_labels)
print("提取出的真实类别概率:\n", gathered_probs)
# 输出: [[0.5], [0.8], [0.6], [0.7]]效果预览:
从底层内存步长、到降维打击的 einsum、再到免循环的高阶索引 gather,这三个操作如果能融会贯通,在复现和优化任何前沿 AI 算法时基本就不会有张量操作上的瓶颈了。
3、自动微分(Autograd)
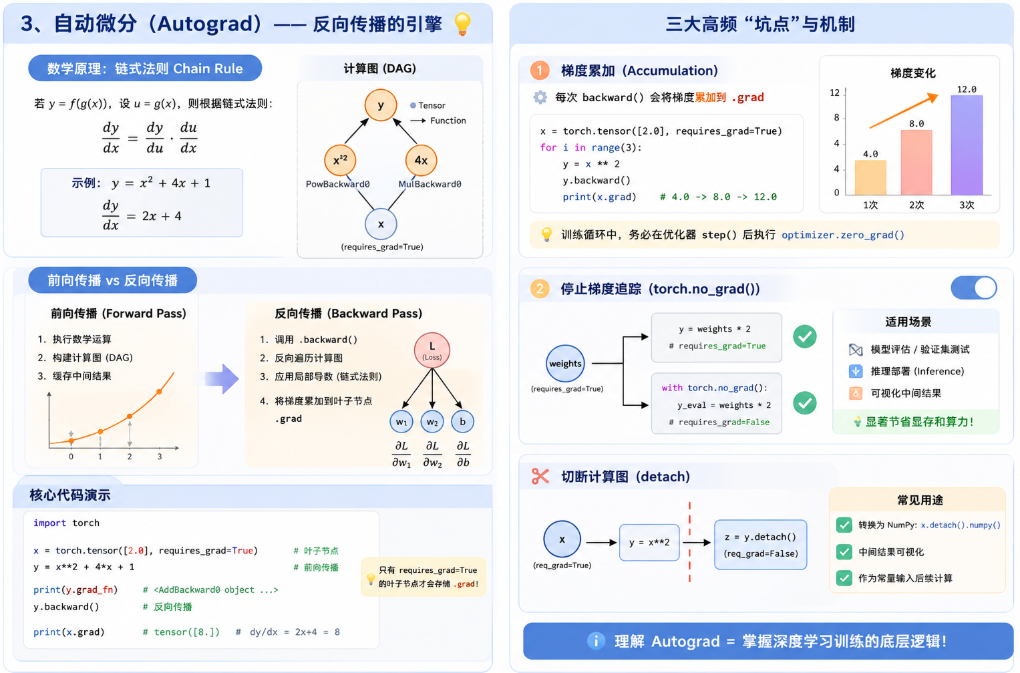
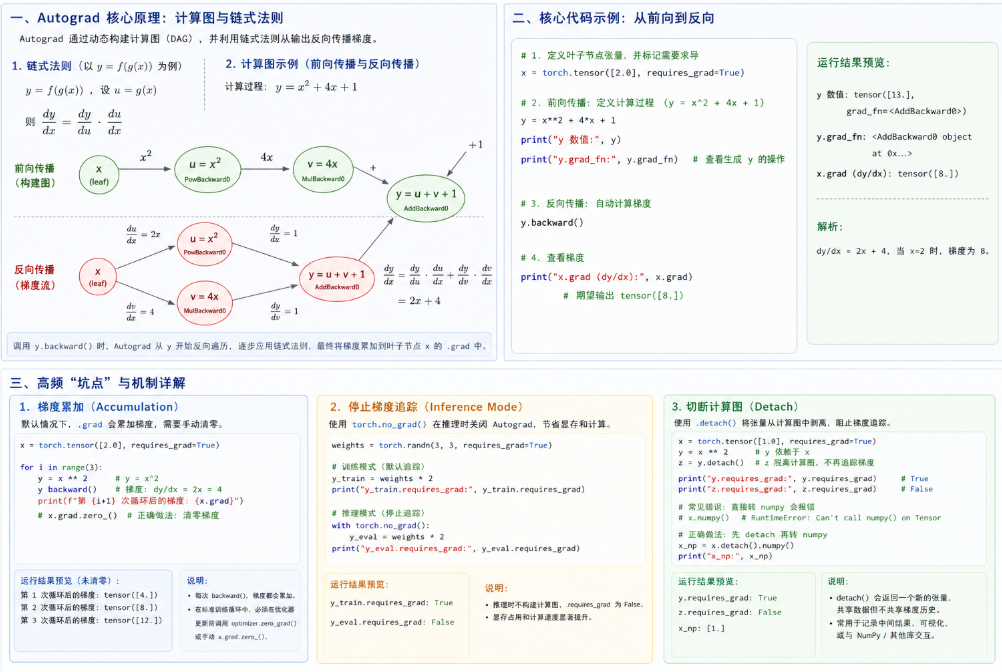
自动微分(Autograd)是反向传播的引擎。在 PyTorch 中,torch.autograd 是自动微分引擎。神经网络训练的核心是反向传播(Backpropagation),即通过计算损失函数对网络权重的偏导数(梯度)来更新权重。Autograd 自动且动态地完成了这一求导过程。
3.1 数学原理:链式法则(Chain Rule)与计算图
Autograd 的本质是反向模式自动微分(Reverse-mode Automatic Differentiation)。
在数学上,如果有一个复合函数 y = f(g(x)),设 u = g(x),则根据链式法则,偏导数为:
在 PyTorch 中,这通过有向无环图(DAG)实现:
-
前向传播(Forward Pass): PyTorch 计算输出张量的值,并同时在后台构建一个计算图。图的节点是张量(Tensor),边是操作符(Function,如加法、乘法)。
-
反向传播(Backward Pass): 当调用
.backward()时,PyTorch 从根节点(通常是标量 Loss)开始,沿着计算图反向遍历。每个操作符节点会自动调用其对应的反向求导公式,并将计算出的梯度累加到叶子节点(Leaf Tensor,即网络权重)的.grad属性中。
图示讲解:
3.2 核心操作与代码展示
要让 PyTorch 追踪张量的梯度,必须在创建时设置 requires_grad=True,或者调用 .requires_grad_() 方法。
python
import torch
# 1. 定义叶子节点张量,并标记需要求导
x = torch.tensor([2.0], requires_grad=True)
# 2. 前向传播:定义计算过程
# 公式: y = x^2 + 4x + 1
y = x**2 + 4*x + 1
# 查看中间节点的反向传播函数
print(y.grad_fn) # 输出: <AddBackward0 object ...> 说明这是一个加法操作产生的节点
# 3. 反向传播:自动计算梯度
y.backward()
# 4. 查看梯度
# dy/dx = 2x + 4. 当 x=2 时, 梯度应为 2*2 + 4 = 8
print(x.grad) # 输出: tensor([8.])效果预览:

图示讲解:
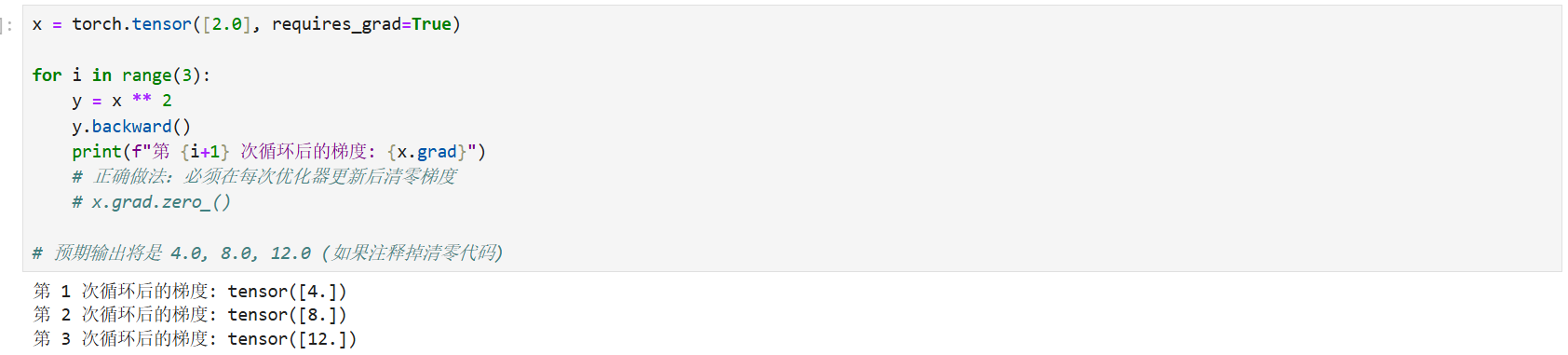
3.3 自动微分的三个高频"坑点"与机制
在实际工程中,以下三个机制是引发计算错误和显存泄漏的重灾区:
1. 梯度的累加(Accumulation)
PyTorch 的默认机制是:每次调用 .backward(),计算出的梯度会累加 到 .grad 属性中,而不是覆盖。这在内存有限时实现大 Batch Size(梯度累加策略)非常有用,但在标准的单次迭代更新中,必须手动清零。
python
x = torch.tensor([2.0], requires_grad=True)
for i in range(3):
y = x ** 2
y.backward()
print(f"第 {i+1} 次循环后的梯度: {x.grad}")
# 正确做法:必须在每次优化器更新后清零梯度
# x.grad.zero_()
# 预期输出将是 4.0, 8.0, 12.0 (如果注释掉清零代码)效果预览:
2. 停止梯度追踪(Inference Mode)
在模型评估(验证集/测试集推理)阶段,我们不需要计算梯度。继续追踪计算图会极大地浪费显存和算力。使用上下文管理器 torch.no_grad() 可以挂起 Autograd 引擎。
python
# 假设 weights 是需要求导的模型权重
weights = torch.randn(3, 3, requires_grad=True)
# 训练模式(默认追踪)
y = weights * 2
print(y.requires_grad) # True
# 推理模式(停止追踪)
with torch.no_grad():
y_eval = weights * 2
print(y_eval.requires_grad) # False效果预览:

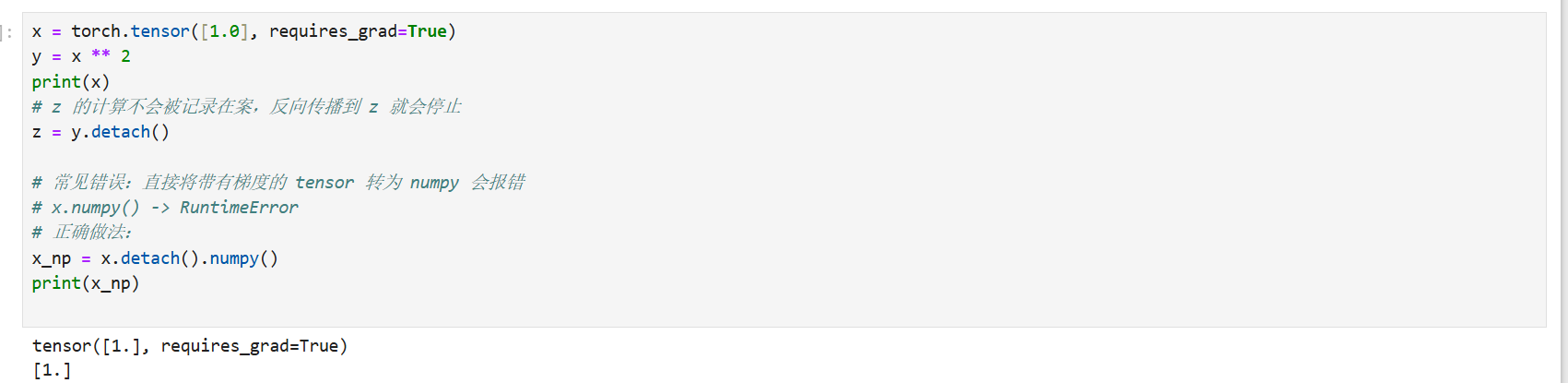
3. 切断计算图(Detach)
如果你需要将一个张量从计算图中剥离出来,作为普通的张量参与其他数学运算(不计算梯度),或者将其转换为 NumPy 数组,必须使用 .detach()。
python
x = torch.tensor([1.0], requires_grad=True)
y = x ** 2
print(x)
# z 的计算不会被记录在案,反向传播到 z 就会停止
z = y.detach()
# 常见错误:直接将带有梯度的 tensor 转为 numpy 会报错
# x.numpy() -> RuntimeError
# 正确做法:
x_np = x.detach().numpy()
print(x_np)效果预览:
二、网络篇-构建神经网络
1、神经网络核心模块
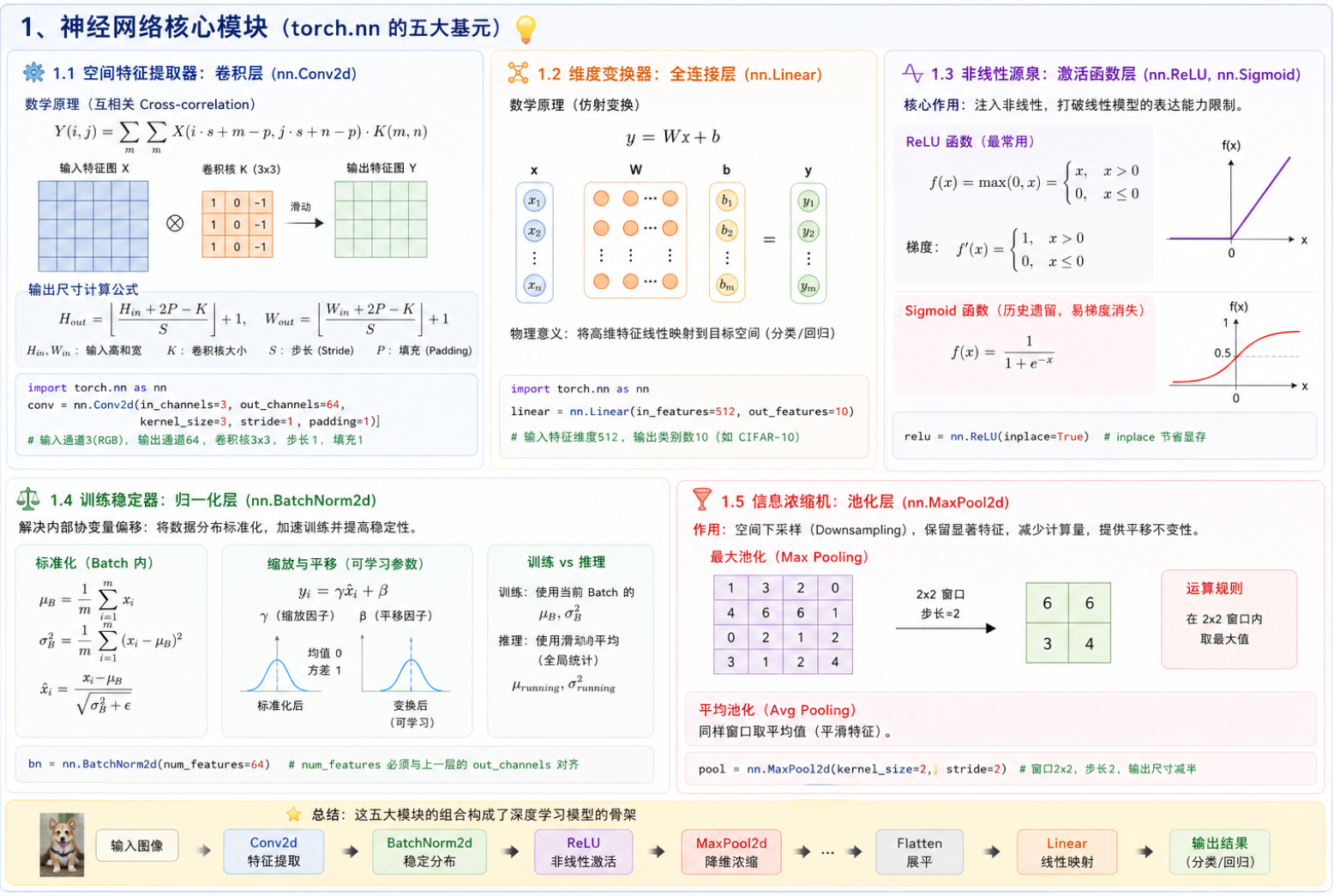
在 PyTorch 的 torch.nn 库中,有成百上千个模块,但真正撑起深度学习大厦的核心骨架其实只有五类。我们逐一剖析它们的数学原理和物理意义。
1.1 空间特征提取器:卷积层 (nn.Conv2d)
这是计算机视觉(CV)的绝对核心。与全连接层(每个输入神经元连接每个输出)不同,卷积层利用局部连接 和权重共享来提取图像的边缘、纹理等空间特征。
数学原理:
严格来说,深度学习中的卷积实际上是数学中的互相关(Cross-correlation) 。给定二维图像 和二维卷积核(Kernel)
,其运算过程是将卷积核在图像上滑动,按元素相乘后求和:
核心参数与尺寸计算公式(重中之重):
在搭建网络时,最容易报错的就是张量尺寸不匹配。假设输入尺寸为 ,输出尺寸
的计算公式为:
-
kernel_size):卷积核大小(如 3x3)。 -
padding):在边缘填充的圈数(常用于保持图像尺寸不缩水)。 -
stride):卷积核滑动的步长(常用于下采样缩减尺寸)。
python
import torch.nn as nn
# 输入通道3(RGB),输出通道64(提取64种特征),卷积核3x3,步长1,填充1
conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)1.2 维度变换器:全连接层 (nn.Linear)
也叫线性层。通常放在网络的末端,负责将前面卷积层提取出的高维局部特征进行"汇总",映射到最终的分类概率或回归数值上。
数学原理: 本质是一个带有偏置项的仿射变换(Affine Transformation):
-
-
-
python
# 输入特征维度 512,输出类别数 10 (例如 CIFAR-10 分类)
linear = nn.Linear(in_features=512, out_features=10)1.3 非线性源泉:激活函数层 (nn.ReLU, nn.Sigmoid)
如果神经网络只有卷积和全连接,那么无论堆叠多少层,数学上都可以被等效合并为一层线性变换(因为线性操作的组合依然是线性的)。激活函数的引入,为网络注入了非线性,使其能够拟合任意复杂的函数。
核心函数:ReLU (Rectified Linear Unit)
目前最常用的激活函数,完美解决了以往 Sigmoid 函数在深层网络中容易导致的"梯度消失"问题。
数学原理:
当输入 时,梯度恒为 1,误差可以无损耗地反向传播;当
时,神经元被"静默"(输出为 0)。
python
# inplace=True 表示直接在底层内存中修改原张量,节省显存
relu = nn.ReLU(inplace=True)1.4 训练稳定器:归一化层 (nn.BatchNorm2d)
在深层网络训练中,随着参数的不断更新,每一层输入的分布也会不断剧烈改变(称为内部协变量偏移 Internal Covariate Shift)。这会导致训练极其困难。Batch Normalization 的出现,使得极其深的网络(如 ResNet-152)成为可能。
数学原理:
它会在一个 Batch 的数据中,针对每个特征通道独立计算均值 \\mu 和方差 \\sigma\^2,然后将数据强行拉回到均值为 0、方差为 1 的标准正态分布:
为了不破坏网络已经学到的特征,它还会加上两个可学习的参数(缩放因子 和平移因子
):
python
# 假设前一个卷积层的 out_channels 为 64,这里的参数必须对齐
bn = nn.BatchNorm2d(num_features=64)1.5 信息浓缩机:池化层 (nn.MaxPool2d)
池化层没有需要学习的权重参数。它的作用是空间下采样(Downsampling),即保留最显著的特征,同时舍弃冗余信息。这不仅能成倍减少计算量,还能带来一定的平移不变性(即目标在图像中轻微移动,依然能被识别)。
数学原理:
以最大池化(Max Pooling)为例,就是在指定的窗口内(例如 2x2)取最大值:
python
# 窗口大小 2x2,步长 2。这会让图像的长宽各自缩小一半。
pool = nn.MaxPool2d(kernel_size=2, stride=2)这五大模块(卷积、全连接、激活、归一化、池化),就是搭建任何主流深度学习网络的最底层"基元"。
图片讲解:
2、搭建网络的"乐高积木
有了基础的"五大基元"(卷积、全连接、激活、归一化、池化),我们现在来看看如何将这些散落的零件,高效且优雅地拼装成一个强大的深度学习模型。
在 PyTorch 中,搭建网络就像搭乐高,你可以选择按说明书一步步线性拼接,也可以发挥想象力做复杂的机械传动(比如分支和跳跃连接)。
2.1 极简流水线:nn.Sequential
当我们搭建的网络是一个纯粹的"直筒子"(即数据流向是严格的 ),不需要在中间分叉或跳跃时,
nn.Sequential 是最优雅的工具。
核心优势:
它会自动将内部的所有模块串联起来,你甚至不需要手写 forward 函数中的中间过程。
python
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 使用 Sequential 封装一个完整的特征提取模块 (特征金字塔)
self.features = nn.Sequential(
# Block 1
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
nn.MaxPool2d(2), # 图像尺寸减半
# Block 2
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(2) # 图像尺寸再次减半
)
# 分类头
self.classifier = nn.Sequential(
nn.Linear(32 * 8 * 8, 128), # 假设输入图像是 32x32
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # 在送入全连接层前,将 [B, C, H, W] 展平为 [B, C*H*W]
x = self.classifier(x)
return x底层逻辑: nn.Sequential 本质上也是一个 nn.Module。当你调用 self.features(x) 时,它内部会遍历列表中的每个模块,执行 x = module(x)。
2.2 动态拼装的陷阱与解法:nn.ModuleList
在复现一些前沿模型(比如包含多个重复层的 Transformer 或复杂的视觉主干网络)时,我们经常需要通过一个 for 循环动态生成很多层。
一个无数新手都会踩的致命坑:直接使用 Python 原生的 list。
python
# ❌ 错误示范:参数丢失!
class WrongModel(nn.Module):
def __init__(self):
super().__init__()
self.layers = [] # Python 原生列表
for _ in range(5):
self.layers.append(nn.Linear(10, 10))
# 为什么错?
# 记得我们上一节提到的底层魔法吗? nn.Module 是通过重写 __setattr__ 来拦截参数注册的。
# 把 Linear 层塞进普通的 Python list,__setattr__ 根本拦截不到!
# 结果就是:这 5 个 Linear 层的参数完全没有被注册到模型中,优化器根本找不到它们,梯度永远无法更新。正确解法:使用 nn.ModuleList 或 nn.ModuleDict
它们表现得就像普通的列表或字典,但会将内部包含的所有 nn.Module 的参数正确注册到网络中。
python
# ✅ 正确示范
class CorrectModel(nn.Module):
def __init__(self):
super().__init__()
# 使用 nn.ModuleList 包装
self.layers = nn.ModuleList([nn.Linear(10, 10) for _ in range(5)])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x2.3 复杂拓扑结构(高阶乐高):残差连接 (Residual Connection)
在实际的工程开发中(尤其是处理机器视觉或机器人感知任务时),网络往往需要极深的层数来提取高级语义特征。但网络越深,梯度在反向传播时就越容易消失。
何恺明提出的 ResNet(残差网络)通过一个极其简单的"跳跃连接"解决了这个问题,这也是搭建复杂网络"拓扑结构"的最佳范例。
数学原理:
传统的网络层拟合的是一个直接的映射函数 。
残差模块则让网络层拟合残差 ,最终的输出是:
即便 的梯度消失(权重趋于0),那个直接跳过来的
也能保证梯度畅通无阻地传回浅层。
代码实现:如何在 forward 中操控数据分流
python
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
# 主干路径 (F(x))
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 捷径路径 (x)
# 如果通道数改变或步长不为1(尺寸改变),需要用一个 1x1 卷积来对齐张量形状
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
# 1. 记录初始的 x (走捷径)
identity = self.shortcut(x)
# 2. 计算主干网络 F(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 3. 核心机制:在最后的 ReLU 之前,将 F(x) 和 x 相加!
out += identity
# 4. 激活输出
out = self.relu(out)
return out图片讲解:
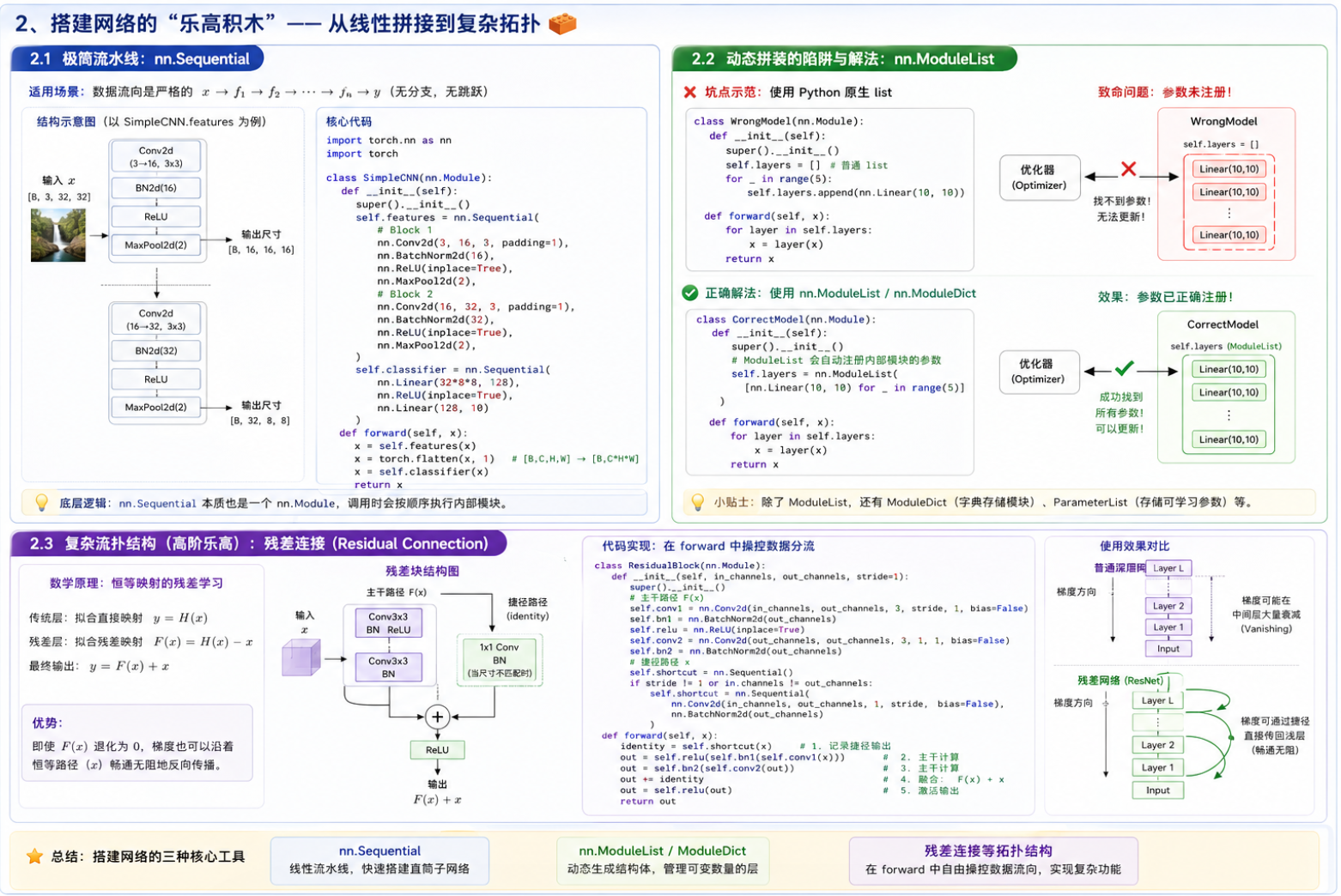
这种通过 identity 保存张量状态,再与经过计算后的 out 进行加法融合的方式,就是搭建复杂网络(如 U-Net 的特征拼接、Transformer 的残差与注意力融合)的底层范式。现在,我们不仅有了基础的神经元零件,还掌握了组装流水线 (Sequential)、动态列表 (ModuleList) 以及复杂分流 (残差结构) 的方法,网络结构本身已经构建完毕。
3、训练模型的"发动机" (torch.optim)
真实世界中的深度学习参数动辄上亿,它们的损失曲面极其复杂,就像连绵不断的山脉 。优化器的任务,就是蒙着眼睛,只通过脚底感受到的坡度(梯度),一步步走到谷底。如果说构建 nn.Module 是造好了汽车的车架和传动轴,那么现在,我们要为这辆车装上指南针(损失函数 Loss Function)和发动机(优化器 Optimizer),让它真正在数据大地上跑起来。
3.1 指南针:损失函数 (Loss Function)
优化器只负责"走",而损失函数负责告诉它"往哪走"。损失函数计算的是模型预测值与真实标签之间的差距。
PyTorch 的损失函数都封装在 torch.nn 模块中:
-
回归任务(预测连续数值,如房价):
通常使用均方误差
nn.MSELoss()。 -
分类任务(预测离散类别,如猫狗识别):
绝对主力是交叉熵损失
nn.CrossEntropyLoss()。⚠️ 史诗级避坑指南: PyTorch 的
nn.CrossEntropyLoss内部已经自动集成了Softmax激活函数和负对数似然损失(NLLLoss)。因此,你的网络最后一层绝对不要加 Softmax,直接输出原始的 Logits 即可,否则会导致数学上的重复计算和梯度发散。
3.2 发动机:优化器 (torch.optim)
所有的优化算法本质上都在做一件事:利用 Autograd 算出来的梯度(偏导数),去更新网络的权重。
公式原型:
常用优化器对比:
-
SGD (随机梯度下降): 最基础的算法。
-
缺点: 容易卡在鞍点或局部最优,如果各个维度的曲率不同,会发生严重的震荡。
-
进阶: 通常配合
momentum(动量)参数使用。这相当于给小球增加了物理惯性,遇到小坑可以直接冲过去。
-
-
Adam (Adaptive Moment Estimation): 现代深度学习的"万金油"标配。
-
原理: 它不仅记录了梯度的动量,还计算了梯度的平方移动平均。这就好比它能自动感知每个参数的坡度陡缓,为每个参数自适应地调整学习率。
-
使用建议: 在 90% 的CV和NLP任务中,闭着眼睛选 Adam 或它的变体 AdamW。
-
3.3 融会贯通:神圣的"五步训练法"
这是整个 PyTorch 最核心的模板。无论是训练几千参数的玩具模型,还是几千亿参数的大语言模型,其核心的单步训练循环永远是这五步(背也要背下来):
python
import torch
import torch.nn as nn
import torch.optim as optim
# ================= 1. 完整拼装我们的网络 =================
class SimpleMLP(nn.Module):
def __init__(self, input_dim, hidden_dim, num_classes):
super().__init__()
self.network = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, num_classes) # 注意:末尾没有 Softmax!
)
def forward(self, x):
return self.network(x)
# 实例化模型 (输入20维,隐藏层64维,输出10个类别)
model = SimpleMLP(input_dim=20, hidden_dim=64, num_classes=10)
# ================= 2. 装上指南针和发动机 =================
# 指南针 (分类损失)
criterion = nn.CrossEntropyLoss()
# 发动机 (将模型的所有参数交给 Adam 管理,设置学习率为 0.001)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# ================= 3. 真正的双重训练循环 =================
# 模拟 100 个样本的数据集
dataset_size = 100
inputs_data = torch.randn(dataset_size, 20)
labels_data = torch.randint(0, 10, (dataset_size,))
epochs = 5 # 外层循环:把所有数据看 5 遍
batch_size = 32 # 内层循环:每次抓取 32 个样本进行更新
for epoch in range(epochs):
# 【工程规范】每个 Epoch 开始前,确保模型处于训练模式
model.train()
# 简单的 Batch 切分逻辑 (实际工程中由 DataLoader 完成)
for i in range(0, dataset_size, batch_size):
# 抓取当前 Batch 的数据
inputs = inputs_data[i:i+batch_size]
labels = labels_data[i:i+batch_size]
# ---------------- 核心五步训练法 ----------------
# 第 1 步:清空残余梯度 (发动机归零)
# 必须做!否则 PyTorch 会把上次迭代的梯度累加到这次上
optimizer.zero_grad()
# 第 2 步:前向传播 (数据流经网络,得到预测输出)
outputs = model(inputs)
# 第 3 步:计算损失 (看预测值偏离了真实标签多少)
loss = criterion(outputs, labels)
# 第 4 步:反向传播 (计算梯度 ------ "看清下山的方向")
# Autograd 引擎会算出 loss 对所有权重的偏导,存入各个参数的 .grad 属性中
loss.backward()
# 第 5 步:更新权重 (执行优化 ------ "发动机发力,往前迈一步")
# 优化器根据刚才算出的 .grad,更新所有模型参数
optimizer.step()
# ------------------------------------------------
print(f"Epoch [{epoch+1}/{epochs}], 最后的 Loss: {loss.item():.4f}")3.4 必须知道的评估模式 (model.eval())
当你的模型训练好,要拿去测试集上跑(或者进行实际部署推理)时,绝大多数新手都会死在这里:忘记切换模式。
测试时,必须写上这两句:
python
# 1. 切换为评估模式
# 这会关闭 Dropout 的随机丢弃,并固化 BatchNorm 的统计量
model.eval()
# 2. 停止计算图的追踪
# 因为测试时不需要反向传播,停止追踪可以省下极大的显存,并大幅加速推理!
with torch.no_grad():
test_inputs = torch.randn(10, 20)
predictions = model(test_inputs)
# 使用 argmax 找出概率最大的那个类别的索引
predicted_classes = torch.argmax(predictions, dim=1)
print("预测的类别:", predicted_classes)示例预览:
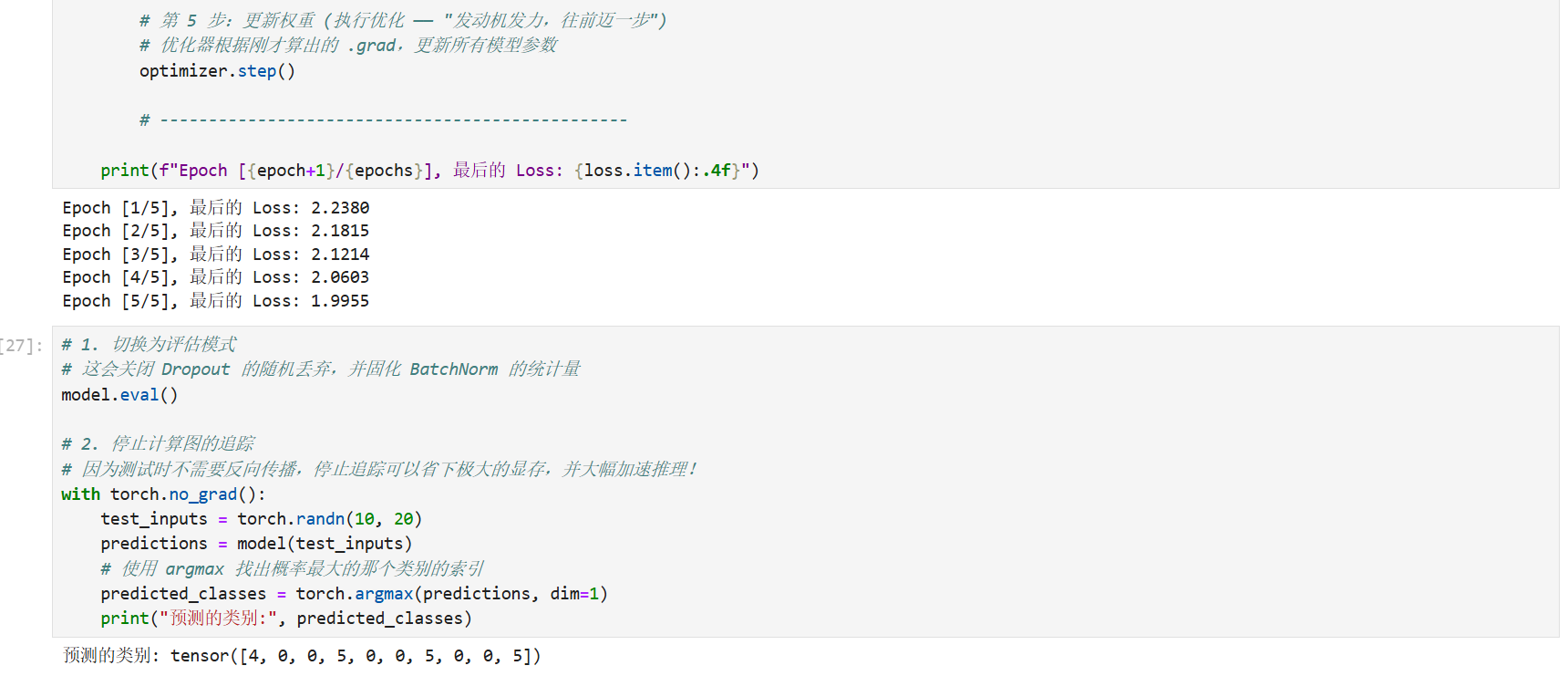
图片讲解:

4、数据加载与处理 (torch.utils.data)
在真实场景中,数据(比如几十万张图片)不可能一次性塞进内存(RAM),否则直接 OOM(Out of Memory)。PyTorch 解决这个问题的标准范式是:用 Dataset 定义"如何拿一个样本",用 DataLoader 实现"如何开多进程并行拿一批样本"。
1. 核心接口一:Dataset (单样本定义)
torch.utils.data.Dataset 是一个抽象类。你要读取自己的数据,必须继承它,并且重写三个魔术方法(Magic Methods)。
-
__init__(self, ...):初始化。通常在这里传入文件路径列表、标签列表。绝对不要在这里把所有图片读进内存,这里只存"索引"。 -
__len__(self):告诉 PyTorch 数据集一共有多少个样本。 -
__getitem__(self, index):灵魂所在 。当外部传入一个索引index时,这里负责去硬盘读取那一张图片,进行预处理(如 Resize、转 Tensor),然后返回(图片, 标签)。
实战代码模板:
python
import torch
from torch.utils.data import Dataset
class MyCustomDataset(Dataset):
def __init__(self, image_paths, labels, transform=None):
"""
初始化:传入数据的路径和标签,以及可能的预处理函数
"""
self.image_paths = image_paths
self.labels = labels
self.transform = transform
def __len__(self):
"""返回数据集的总大小"""
return len(self.image_paths)
def __getitem__(self, index):
"""
核心逻辑:根据 index 按需加载硬盘上的数据,绝不提前占用内存
"""
# 1. 根据索引拿到硬盘路径 (模拟)
img_path = self.image_paths[index]
# 2. 从硬盘读取数据 (这里用伪代码代替真实的 cv2.imread 或 Image.open)
# img_data = read_image_from_disk(img_path)
img_tensor = torch.randn(3, 224, 224) # 模拟读出了一张 224x224 的 RGB Tensor
# 3. 拿到对应的标签
label = self.labels[index]
# 4. 执行数据增强/预处理 (如果有)
if self.transform:
img_tensor = self.transform(img_tensor)
return img_tensor, label2. 核心接口二:DataLoader (多进程流水线)
Dataset 一次只能吐出一个样本。但在 GPU 训练时,我们需要打包成 Batch,且 GPU 计算极快,如果用单线程慢吞吞地从硬盘读数据,GPU 就会一直处于闲置等待状态(典型的 I/O 瓶颈)。
DataLoader 就是用来解决这个问题的包装器:
-
Batching :自动把多个
__getitem__返回的数据堆叠成一个张量。 -
Multiprocessing:开启多个后台进程(Workers)提前读取数据,塞进队列,填饱 GPU。
python
from torch.utils.data import DataLoader
# 1. 模拟一些数据路径和标签
dummy_paths = [f"/data/img_{i}.jpg" for i in range(1000)]
dummy_labels = [i % 10 for i in range(1000)]
# 2. 实例化我们刚才写的 Dataset
my_dataset = MyCustomDataset(dummy_paths, dummy_labels)
# 3. 封装进 DataLoader (重点看参数)
train_loader = DataLoader(
dataset=my_dataset,
batch_size=32, # 每次扔给 GPU 32 张图
shuffle=True, # 每个 Epoch 打乱顺序,防止模型死记硬背
num_workers=0, # 开启 4 个子进程并行读取硬盘(注意:Windows下有时设大于0会报错,Linux随便开)
pin_memory=True, # 开启锁页内存,加快 CPU 内存到 GPU 显存的拷贝速度!(必开)
drop_last=False # 如果最后剩下的样本不够 32 个,是否丢弃
)
# 4. 在训练循环中使用
# train_loader 本质上是一个迭代器
for epoch in range(2):
for batch_idx, (images, labels) in enumerate(train_loader):
# images 的形状会自动变成 [32, 3, 224, 224]
# labels 的形状会变成 [32]
# ... 这里接上节讲的 优化器清零、前向、算Loss、反向、更新 核心五步 ...
if batch_idx == 0:
print(f"Epoch {epoch}, Batch 0 拿到的数据形状: {images.shape}")核心避坑总结
-
内存爆炸 :千万别在
Dataset的__init__里读取大文件(如视频、高分图片)。 -
多进程死锁 :如果在 Windows 系统下运行
num_workers > 0报错,必须把你的主训练逻辑放在if __name__ == '__main__':保护块里面,这是 Pythonmultiprocessing库在 Windows 下的底层限制。
图片讲解:
三、实战篇-应用与调试
1、计算机视觉CV实战 (ResNet, YOLO, U-Net)
第一步:环境配置 (The Foundation)
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
from torchvision.datasets import OxfordIIITPet
import matplotlib.pyplot as plt
import numpy as np
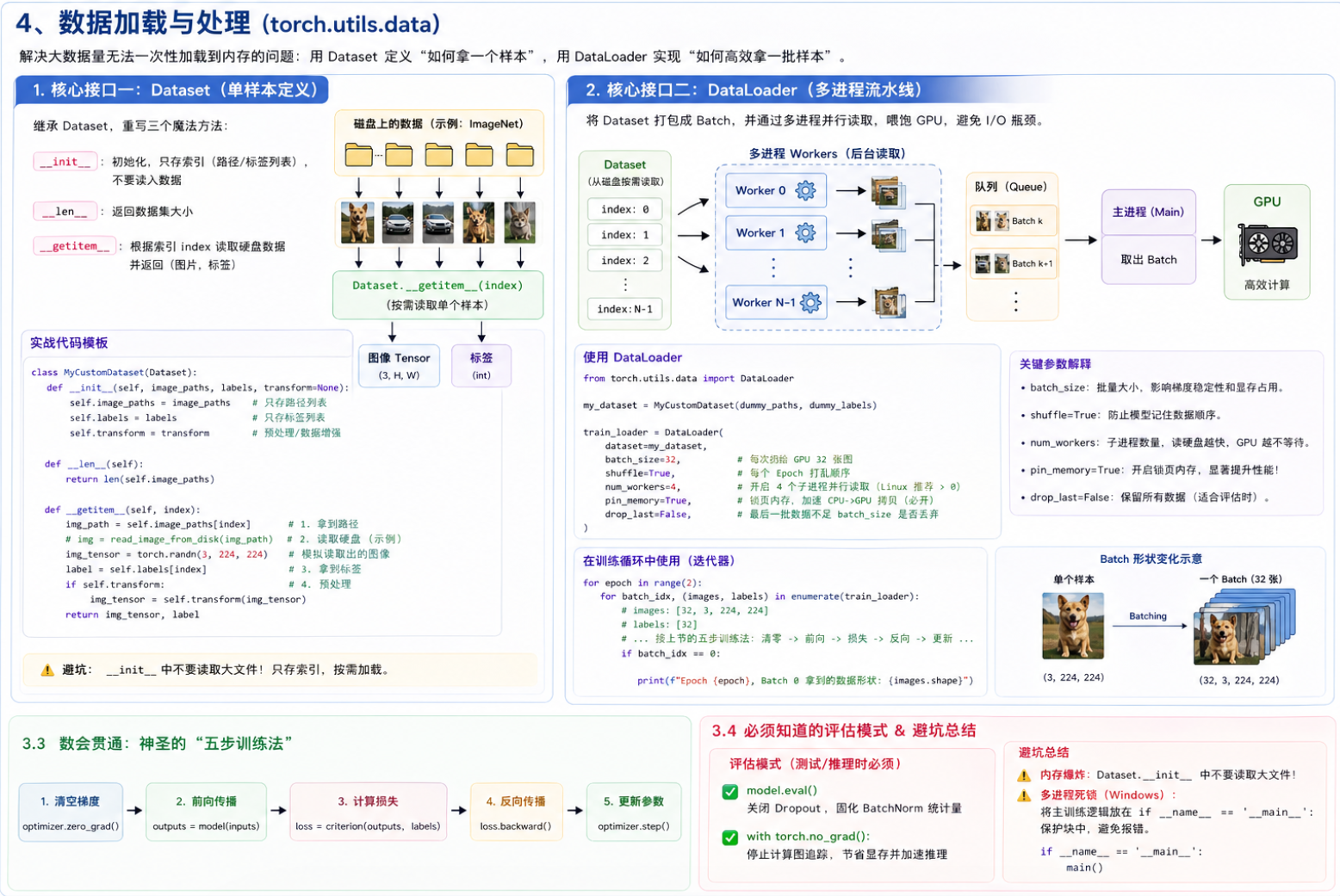
# 检查 GPU 是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前使用的设备: {device}")第二步:数据集获取与预处理 (Data Pipeline)
我们选用 Oxford-IIIT Pet Dataset。它包含 37 种宠物,每种约 200 张图。
1. 定义"数据预处理" (Transforms)
原始图片大小不一,模型无法直接读取。我们需要将它们统一缩放,并转化为张量(Tensor)。
-
Resize : 统一成
-
ToTensor: 将像素值从 0-255 缩放到 0-1 之间。
-
Normalize: 标准化处理,加快模型收敛。
python
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])2. 下载并加载数据集
python
# 下载训练集和测试集
train_data = OxfordIIITPet(root='./data', split='trainval', target_types='category', download=True, transform=transform)
test_data = OxfordIIITPet(root='./data', split='test', target_types='category', download=True, transform=transform)
# 使用 DataLoader 分批次读取数据
# batch_size 设为 32,如果显存不够可以调成 16
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = DataLoader(test_data, batch_size=32, shuffle=False)第三步:数据可视化 (Sanity Check)
在写模型之前,一定要先看一眼数据长什么样。这是 CV 工程师的职业习惯。
python
def imshow(img):
img = img / 2 + 0.5 # 反标准化 (简单处理)
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 获取一组图片
dataiter = iter(train_loader)
images, labels = next(dataiter)
# 展示图片
imshow(torchvision.utils.make_grid(images[:4]))
print('标签 (类别编号):', labels[:4].tolist())效果预览:
第四步:ResNet 详解与构建 (Classification)
我们先从最简单的分类任务开始。ResNet(残差网络)是视觉任务的"入场券"。
为什么选 ResNet?
传统的网络堆叠深了之后会出现梯度消失。ResNet 通过"快捷连接 (Shortcut Connection)"让网络学习"残差",即 。
实战:使用预训练模型进行"迁移学习"
你不需要从头训练一个 ResNet(那需要数周时间)。我们加载在 ImageNet 上练好的权重,只修改最后一层。
python
from torchvision import models
# 1. 加载预训练的 ResNet18
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
# 2. 冻结部分参数 (可选,为了加快初次训练速度)
for param in model.parameters():
param.requires_grad = False
# 3. 修改最后一层全连接层 (Fully Connected Layer)
# Oxford Pets 有 37 个类别
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 37)
model = model.to(device)第五步:定义损失函数与优化器
在开始训练前,我们要给模型制定"奖惩制度"和"优化策略"。
python
# 1. 损失函数:分类任务的标准配置 CrossEntropyLoss
# 它内置了 Softmax,会将模型输出转化为概率,并计算与真实标签的差距
criterion = nn.CrossEntropyLoss()
# 2. 优化器:Adam 是目前最通用、收敛较快的选择
# 注意:由于我们之前冻结了预训练层,所以这里只需优化 model.fc 的参数
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
# 3. 学习率调度器(可选):训练几轮后让学习率降一点,有助于模型更稳地收敛
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)第六步:编写训练与验证函数
为了让代码更清晰,我们把"训练一轮"和"验证一轮"封装起来。
1. 训练函数
python
def train_one_epoch(model, loader, criterion, optimizer, device):
model.train() # 切换为训练模式
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
# 梯度清零(PyTorch 会累加梯度,所以每批次开始前要清空)
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播与优化
loss.backward()
optimizer.step()
# 统计数据
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return running_loss / len(loader), 100. * correct / total2. 验证函数
python
def validate(model, loader, criterion, device):
model.eval() # 切换为评估模式(不更新权重,关闭 Dropout 等)
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 验证阶段不需要计算梯度,节省显存
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return val_loss / len(loader), 100. * correct / total第七步:正式开始训练 (The Main Loop)
现在我们运行 10 个 Epoch(轮次)。你可以观察 Loss 是否在下降,Accuracy 是否在上升。
python
num_epochs = 10
train_losses, val_accs = [], []
print("开始训练...")
for epoch in range(num_epochs):
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, device)
val_loss, val_acc = validate(model, test_loader, criterion, device)
# 更新学习率
scheduler.step()
train_losses.append(train_loss)
val_accs.append(val_acc)
print(f'Epoch [{epoch+1}/{num_epochs}] '
f'Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}% | '
f'Val Acc: {val_acc:.2f}%')
print("训练完成!")效果预览:
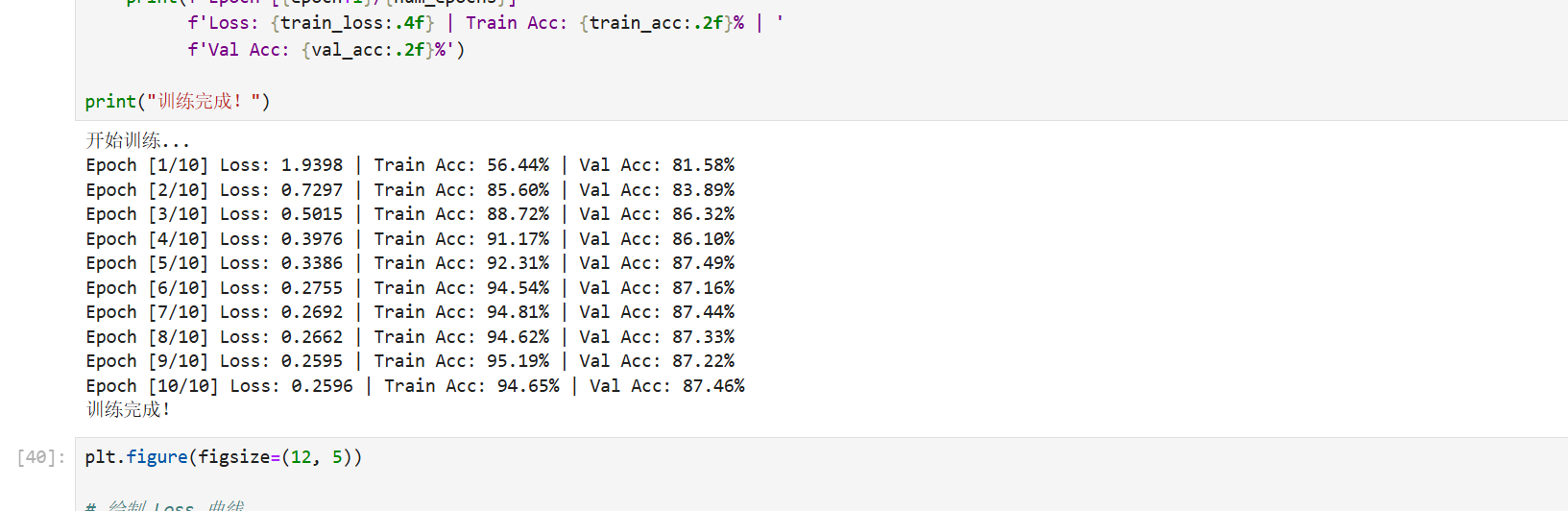
第八步:绘制 Accuracy 和 Loss 曲线
在你的 Jupyter 中新建一个单元格,运行以下代码,它会将训练过程可视化:
python
plt.figure(figsize=(12, 5))
# 绘制 Loss 曲线
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 绘制 Accuracy 曲线
plt.subplot(1, 2, 2)
plt.plot(val_accs, label='Val Accuracy', color='orange')
plt.title('Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()效果预览:
第九步:进阶 U-Net ------ 语义分割 (Segmentation)
既然分类已经跑通了,我们现在进入 CV 的更高阶领域:语义分割。我们要做的不再是猜品种,而是把宠物的轮廓从背景中剥离出来。
1. 重新准备数据 (Target: Segmentation)
我们需要重新加载数据集,告诉 PyTorch 我们想要的是 Mask(掩码图) 而不是类别标签。
python
# 定义分割任务的预处理
# 注意:Mask 通常不需要 Normalization,只需要 Resize 和变为 Tensor
mask_transform = transforms.Compose([
transforms.Resize((128, 128), interpolation=transforms.InterpolationMode.NEAREST),
transforms.ToTensor()
])
img_transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载分割数据集
# 注意 target_types='segmentation'
train_seg_data = OxfordIIITPet(root='./data', split='trainval',
target_types='segmentation', download=True,
transform=img_transform, target_transform=mask_transform)
seg_loader = DataLoader(train_seg_data, batch_size=16, shuffle=True)2. 构建 U-Net 网络结构
U-Net 的精髓在于 Encoder(下采样提取特征) 和 Decoder(上采样恢复尺寸) ,以及中间的 Skip Connection(跳跃连接)。
为了让你快速理解,我们手动实现一个微型 U-Net:
python
class TinyUNet(nn.Module):
def __init__(self):
super(TinyUNet, self).__init__()
# 简单的编码器
self.enc1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.enc2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
# 简单的解码器
self.dec1 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.final = nn.Conv2d(64, 1, kernel_size=1) # 输出 1 个通道表示 Mask
self.pool = nn.MaxPool2d(2, 2)
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x):
# Encoder
x1 = torch.relu(self.enc1(x))
x2 = self.pool(x1)
x2 = torch.relu(self.enc2(x2))
# Decoder
x = self.upsample(x2)
x = torch.relu(self.dec1(x))
x = torch.sigmoid(self.final(x)) # 将输出限制在 0-1 之间
return x
seg_model = TinyUNet().to(device)任务:查看分割数据
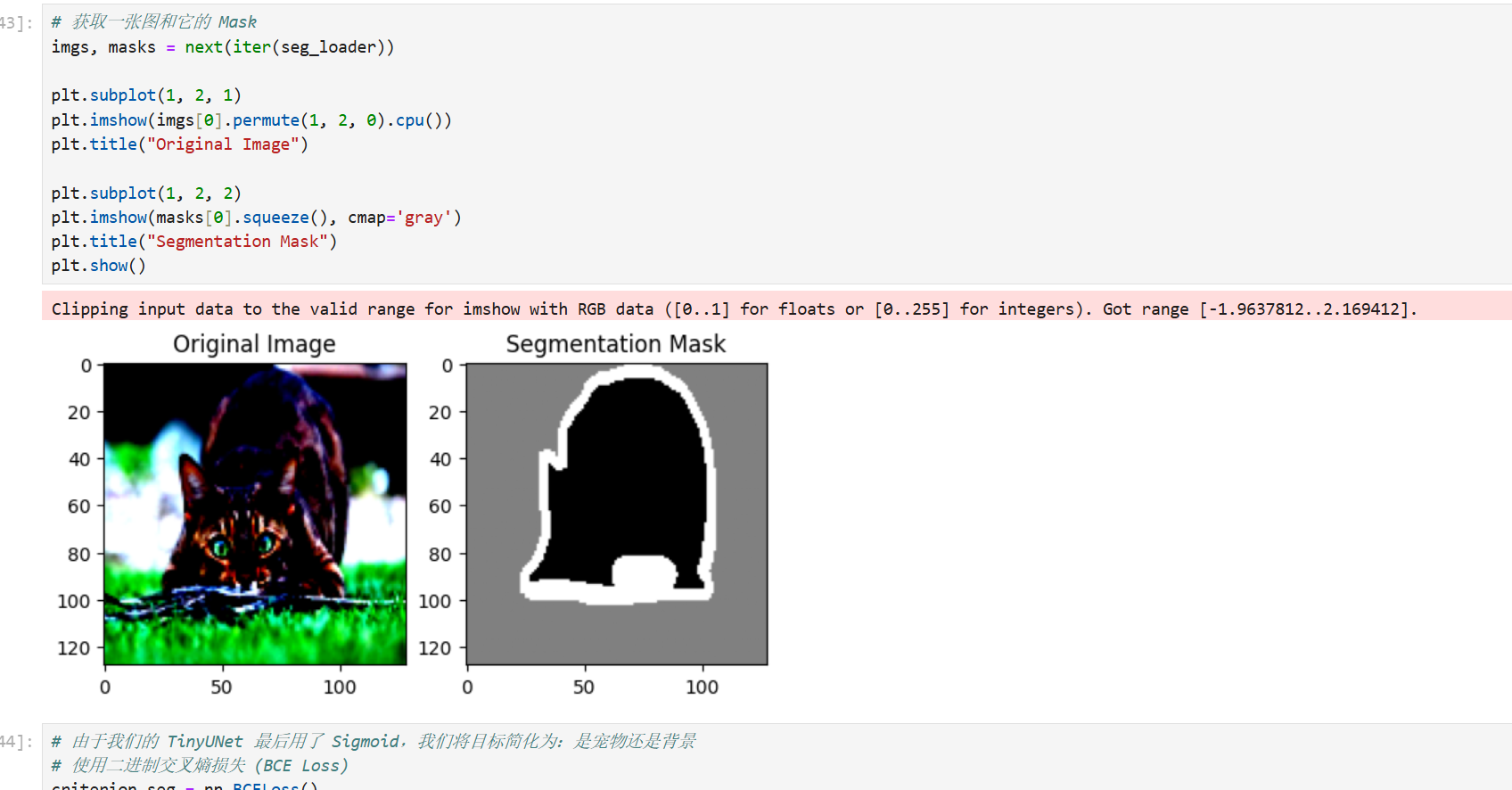
在训练分割模型前,你得先看看 Mask 到底长啥样。请在 Jupyter 里运行这段代码并告诉我你看到了什么:
python
# 获取一张图和它的 Mask
imgs, masks = next(iter(seg_loader))
plt.subplot(1, 2, 1)
plt.imshow(imgs[0].permute(1, 2, 0).cpu())
plt.title("Original Image")
plt.subplot(1, 2, 2)
plt.imshow(masks[0].squeeze(), cmap='gray')
plt.title("Segmentation Mask")
plt.show()看到你的结果图了!这张 Mask 图非常经典:
-
白色部分:宠物的身体(前景)。
-
黑色边缘:宠物的轮廓边界。
-
灰色部分:背景。
在 Oxford-IIIT Pet 数据集中,Mask 的像素值通常是 1, 2, 3。为了简化,我们现在的目标是训练模型实现二值化分割(宠物 vs 背景)。
效果预览:
第十步:定义分割任务的损失函数与优化器
分割任务本质上是"像素级"的分类。对于 U-Net 输出的每一张 128 \\times 128 的图,我们都要和真实的 Mask 进行对比。
python
# 由于我们的 TinyUNet 最后用了 Sigmoid,我们将目标简化为:是宠物还是背景
# 使用二进制交叉熵损失 (BCE Loss)
criterion_seg = nn.BCELoss()
# 优化器
optimizer_seg = optim.Adam(seg_model.parameters(), lr=0.001)第十一步:编写 U-Net 训练循环
这个循环和 ResNet 的很像,但有一点关键区别:标签(Mask)不再是一个标量,而是一张图。
python
def train_seg_epoch(model, loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for inputs, masks in loader:
# 将 Mask 转化为二值(1为宠物及边缘,0为背景)
# 原始数据中 1:前景, 2:背景, 3:轮廓。这里我们将 1和3 统一视为目标
masks = (masks != 2/255.0).float() # 简单处理逻辑,根据你读取的像素值调整
inputs, masks = inputs.to(device), masks.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
running_loss += loss.item()
return running_loss / len(loader)
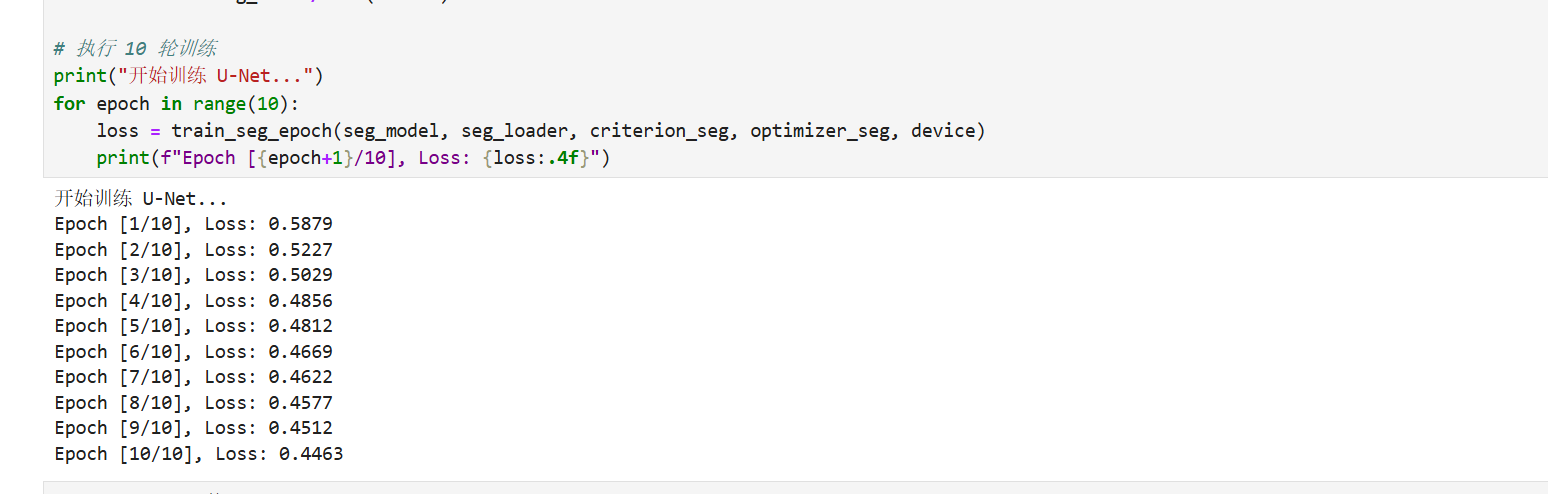
# 执行 10 轮训练
print("开始训练 U-Net...")
for epoch in range(10):
loss = train_seg_epoch(seg_model, seg_loader, criterion_seg, optimizer_seg, device)
print(f"Epoch [{epoch+1}/10], Loss: {loss:.4f}")效果预览:
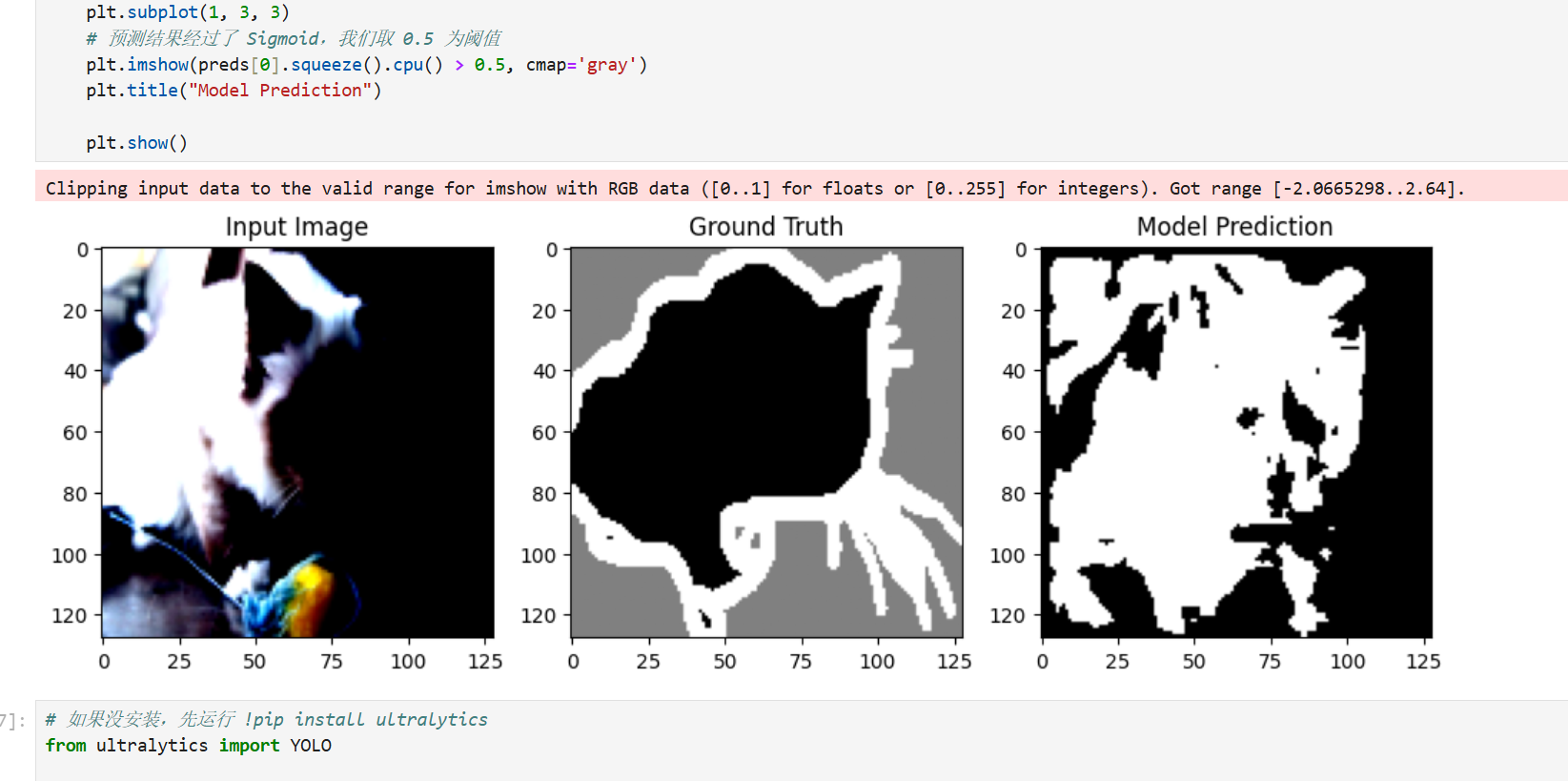
第十二步:验证 U-Net 的"抠图"效果
训练完后,最激动人心的就是看看模型生成的预测图(Prediction)和原图对比。
python
seg_model.eval()
with torch.no_grad():
# 拿一组数据测试
test_imgs, test_masks = next(iter(seg_loader))
test_imgs = test_imgs.to(device)
# 模型预测
preds = seg_model(test_imgs)
# 绘图展示
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.imshow(test_imgs[0].permute(1, 2, 0).cpu())
plt.title("Input Image")
plt.subplot(1, 3, 2)
plt.imshow(test_masks[0].squeeze().cpu(), cmap='gray')
plt.title("Ground Truth")
plt.subplot(1, 3, 3)
# 预测结果经过了 Sigmoid,我们取 0.5 为阈值
plt.imshow(preds[0].squeeze().cpu() > 0.5, cmap='gray')
plt.title("Model Prediction")
plt.show()效果预览:
第十三步:YOLO 目标检测 (Object Detection) 简述
在 Jupyter 环境中直接手写 YOLO 的整个 Backprop 非常复杂,通常我们会直接调用成熟框架。作为实战项目的最后一部分,你可以尝试用一行命令跑通检测。
-
原理 :YOLO 会在图中预测出
-
捷径 :利用你已经熟悉的
ultralytics库。
python
# 如果没安装,先运行 !pip install ultralytics
from ultralytics import YOLO
# 直接加载一个官方预训练模型 (YOLOv8 nano 极其轻量)
yolo_model = YOLO('yolov8n.pt')
# 对你刚才数据集里的图片直接预测(YOLO 自带宠物类别)
# 假设你有一张图片路径 img_path
# results = yolo_model.predict(source='path_to_your_image.jpg', save=True)YOLO详细过程
1. 安装 Ultralytics 库
如果你还没有安装这个库,先运行下面这个单元格。它是目前使用 YOLO 最简单、最标准的工具。
!pip install ultralytics
2. 执行检测代码
我们将加载一个预训练好的 YOLOv8 模型。这个模型在 COCO 数据集上训练过,原生就支持猫、狗等宠物的检测。
python
from ultralytics import YOLO
import cv2
from matplotlib import pyplot as plt
# 1. 加载预训练模型 (n 代表 nano,速度最快)
yolo_model = YOLO('yolov8n.pt')
# 2. 定义图片路径 (使用你提供的路径)
img_path = r"C:\Users\34970\Desktop\partjava_ai\pj_pytorch\data\oxford-iiit-pet\images\Abyssinian_177.jpg"
# 3. 进行推理
# conf=0.5 表示只显示置信度大于 50% 的结果
results = yolo_model.predict(source=img_path, conf=0.5)
# 4. 可视化结果
# results[0].plot() 会返回一个带有检测框、标签和置信度的 BGR 图像 (numpy 数组)
res_plotted = results[0].plot()
# 5. 在 Jupyter 中显示
plt.figure(figsize=(10, 10))
# 因为 OpenCV 是 BGR 格式,Matplotlib 需要 RGB,所以要做个转换
plt.imshow(cv2.cvtColor(res_plotted, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()详细解析:这最后一步做了什么?
-
加载模型 (
yolov8n.pt):这行代码会自动从服务器下载一个约 6MB 的小模型。它比你刚才训练的 ResNet 复杂,因为它不仅要分类(猫),还要回归出边界框(Bounding Box)的坐标。 -
推理 (
predict) :模型会扫描整张Abyssinian_177.jpg。-
Backbone:提取图像特征。
-
Neck:融合多尺度特征(为了能检测大猫和小猫)。
-
Head:输出结果。
-
-
结果解读:
-
你会看到图片上出现了一个框,标着 "cat" 以及一个 0.9 左右的数字。
-
这就是 YOLO 的威力:它不仅知道这张图里有猫,还精准地定位了猫的位置。
-
2、自然语言处理NLP实战 (LSTM, Transformer, BERT)
在 CV 项目中,图片缩放一下就是像素矩阵;但在 NLP 中,我们需要建立一个词表 (Vocabulary)。
第一阶段:文本预处理与数值化 (Tokenization & Numericalization)
我们要处理的是电影评论数据集(或其他短文本)。为了让你在本地 Jupyter 快速跑通,我们先手动模拟这个过程。
原始文本到词索引
你需要经历这四个步骤:
-
分词 (Tokenization):把句子拆成词。
-
构建词表 (Build Vocab):统计所有出现的词,给每个词一个唯一的 ID。
-
对齐长度 (Padding):句子长短不一,需要统一填充到固定长度。
-
嵌入 (Embedding):将 ID 变成稠密向量。
python
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# 模拟简单的数据集
sentences = ["I love this AI project", "This model is bad", "Amazing neural network", "Poor performance"]
labels = [1, 0, 1, 0] # 1: 正面, 0: 负面
# 1. 简单的分词和词表构建
words = set(" ".join(sentences).split())
vocab = {word: i + 2 for i, word in enumerate(words)} # 从2开始,留出0和1给特殊符号
vocab["<PAD>"] = 0 # 填充符号
vocab["<UNK>"] = 1 # 未知单词符号
# 2. 将句子转换为数字序列
def encode_sentence(text, vocab, max_len=5):
tokenized = text.split()
# 转换为ID,如果词表没有就用 <UNK>
encoded = [vocab.get(word, 1) for word in tokenized]
# Padding: 长度不足补0,超过则截断
if len(encoded) < max_len:
encoded += [0] * (max_len - len(encoded))
else:
encoded = encoded[:max_len]
return torch.tensor(encoded)
# 测试一下
print(f"词表大小: {len(vocab)}")
print(f"编码后的句子: {encode_sentence('I love AI', vocab)}")第二阶段:LSTM 实战 (Long Short-Term Memory)
为什么不用普通 RNN?因为 RNN 记不住前面的信息。LSTM 引入了"细胞状态",就像是一个传送带,信息可以在上面流传而不被轻易改变。
构建 LSTM 模型
在 Jupyter 中定义一个简单的分类器:
python
class SimpleLSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):
super(SimpleLSTM, self).__init__()
# Embedding层:把数字ID变成向量
self.embedding = nn.Embedding(vocab_size, embed_dim)
# LSTM层
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
# 全连接层:从隐藏层到最后的分类输出
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x shape: [batch_size, seq_len]
embedded = self.embedding(x) # [batch_size, seq_len, embed_dim]
# lstm_out: 每一个时间步的输出
# hidden: 最后一个时间步的状态 (也就是句子的"总结")
output, (hidden, cell) = self.lstm(embedded)
# 我们取最后一个时刻的 hidden state 进行分类
return self.fc(hidden[-1])
# 初始化模型
# 假设词表大小是len(vocab),每个词变成8维向量,隐藏层16维
model_lstm = SimpleLSTM(len(vocab), 8, 16, 2).to("cuda" if torch.cuda.is_available() else "cpu")第三阶段:Transformer 核心核心------自注意力 (Self-Attention)
Transformer 之所以强,是因为它不再"按顺序阅读",而是"一眼全局"。
核心逻辑:
每个单词会生成三个向量:Query (Q) , Key (K) , Value (V)。
-
Q 去问其他人的
-
计算出的权重分配给
python
# 这是一个精简版的 Self-Attention 逻辑演示
import torch.nn.functional as F
def basic_attention(q, k, v):
# 计算相关度得分
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k).float())
# 归一化为概率
attn_weights = F.softmax(scores, dim=-1)
# 加权求和
return torch.matmul(attn_weights, v)第一步:安装核心库
在 Jupyter 中运行以下命令。除了 transformers,我们还需要 datasets(方便加载公开数据集)和 evaluate(方便计算准确率)。
!pip install transformers datasets evaluate accelerate -U
第二步:加载 BERT 预训练模型与分词器
NLP 的处理流程和 CV 不同。在 CV 中,我们只需 Resize 图片;但在 NLP 中,分词器(Tokenizer)必须与模型完全匹配。如果 BERT 是用词 A 训练的,你给它词 B 的 ID,结果会全乱。
python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 我们选择一个更轻量、速度更快的模型:DistilBERT(BERT的蒸馏版)
model_name = "distilbert-base-uncased"
# 1. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 2. 加载模型(指定分类类别数为2:正面/负面)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)验证:
python
# 测试一个未训练的模型输出(此时结果是随机的)
inputs = tokenizer("I love this project!", return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits)效果预览:
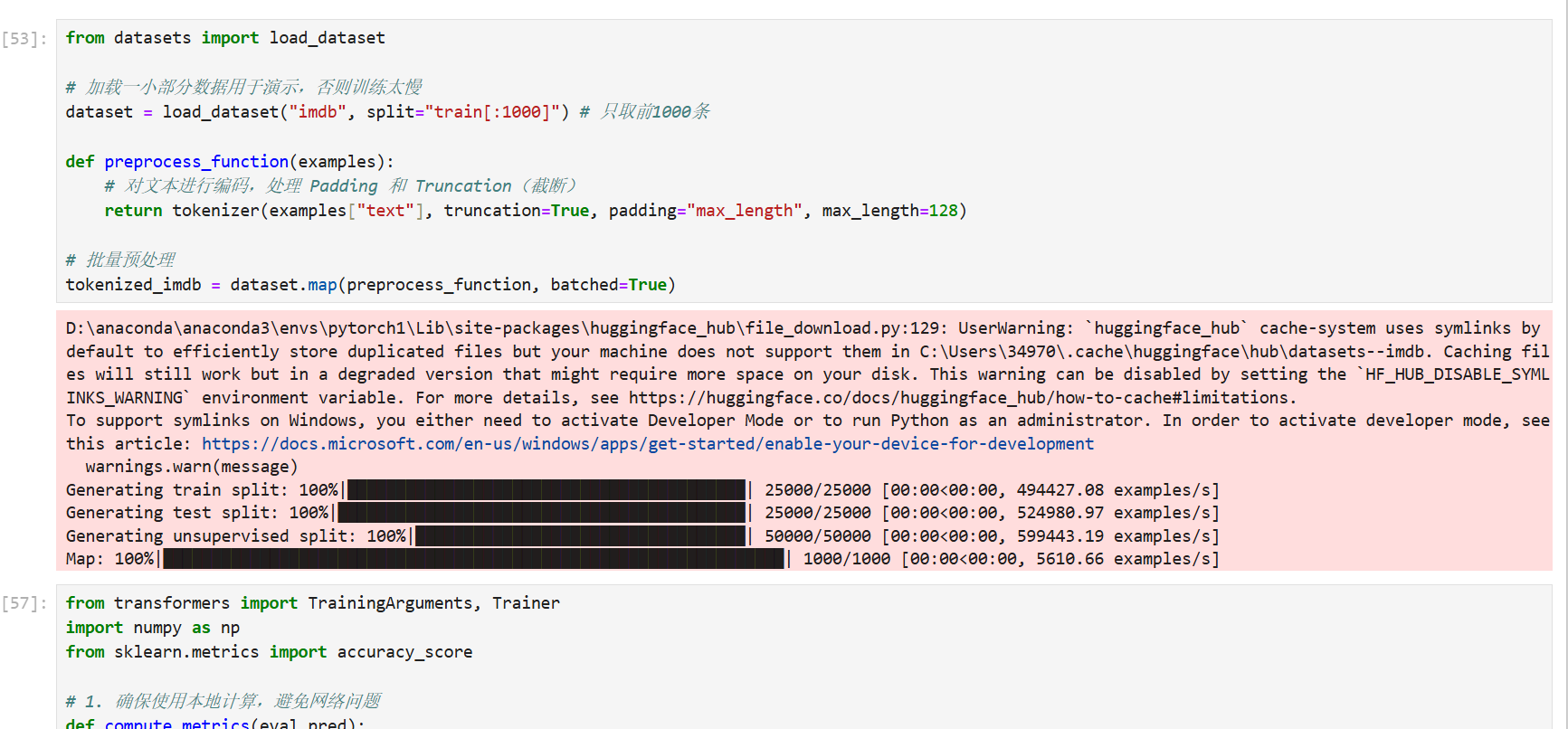
第三步:准备数据集 (IMDb 电影评论)
为了看到"实战"效果,我们直接从 Hugging Face Hub 加载 IMDb 数据集。
python
from datasets import load_dataset
# 加载一小部分数据用于演示,否则训练太慢
dataset = load_dataset("imdb", split="train[:1000]") # 只取前1000条
def preprocess_function(examples):
# 对文本进行编码,处理 Padding 和 Truncation(截断)
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
# 批量预处理
tokenized_imdb = dataset.map(preprocess_function, batched=True)效果预览:
第四步:理解 Transformer 的核心------自注意力机制
既然你希望详细了解,我们必须谈谈为什么 BERT 比 LSTM 强。
-
LSTM 的局限:必须按顺序读。读到句尾时,开头的细节可能已经模糊了。
-
Transformer 的优势 :通过 Self-Attention,句子中的每个 Token 都会计算与其他所有 Token 的"关联权重"。
核心公式(LaTeX 版):
在这个公式中,你可以理解为:
-
-
-
第五步:开始微调 (Fine-tuning)
我们使用 Trainer API,这是目前最标准、最不容易出错的训练方式。
python
from transformers import TrainingArguments, Trainer
import numpy as np
from sklearn.metrics import accuracy_score
# 1. 确保使用本地计算,避免网络问题
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
acc = accuracy_score(labels, predictions)
return {"accuracy": acc}
# 2. 修改参数名:evaluation_strategy -> eval_strategy
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
per_device_train_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
eval_strategy="epoch", # 这里改成了 eval_strategy
logging_steps=10,
report_to="none" # 建议加上这个,防止它尝试连接 wandb 等在线日志平台
)
# 3. 实例化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_imdb,
eval_dataset=tokenized_imdb, # 验证集,这里暂时复用训练集看效果
compute_metrics=compute_metrics,
)
# 4. 开始训练
trainer.train()第六步:拆解 Transformer 核心------自注意力机制的数学逻辑
在你的 Jupyter 环境里,我们已经感受到了 BERT 的威力,但它的核心(Transformer 块)其实就是通过 Scaled Dot-Product Attention 实现了对文本权重的"动态分配"。
1. 为什么叫"自"注意力?
在 LSTM 中,每个词只能看前面的词;而在 Transformer 中,每个词都会看句子里的每一个词(包括它自己)。
2. 的三位一体计算过程
为了让你透彻理解,我们直接看这三层含义在代码和数学上的对应关系:
-
Query (
-
Key (
-
Value (
核心计算公式:
效果预览:
第七步:在 Jupyter 中手动模拟一次 Attention
我们可以写一个极简的 Numpy 代码来模拟这个过程,这能帮你理解为什么 1.0 的 Accuracy 那么容易达到(因为权重分配非常精准)。
python
import torch
import torch.nn.functional as F
# 假设一句话有3个词,每个词的向量维度是4
# x 的形状: [batch_size, seq_len, embed_dim]
x = torch.randn(1, 3, 4)
# 定义三个线性变换矩阵 (也就是模型训练要学的参数)
Wq = torch.randn(4, 4)
Wk = torch.randn(4, 4)
Wv = torch.randn(4, 4)
# 第一步:生成 Q, K, V
Q = torch.matmul(x, Wq)
K = torch.matmul(x, Wk)
V = torch.matmul(x, Wv)
# 第二步:计算注意力得分 (Q 乘以 K 的转置)
# 这一步决定了词与词之间的关联程度
scores = torch.matmul(Q, K.transpose(-2, -1)) / (4 ** 0.5)
# 第三步:Softmax 归一化,变成概率分布
attn_weights = F.softmax(scores, dim=-1)
# 第四步:加权求和 V
output = torch.matmul(attn_weights, V)
print("注意力权重矩阵:\n", attn_weights)
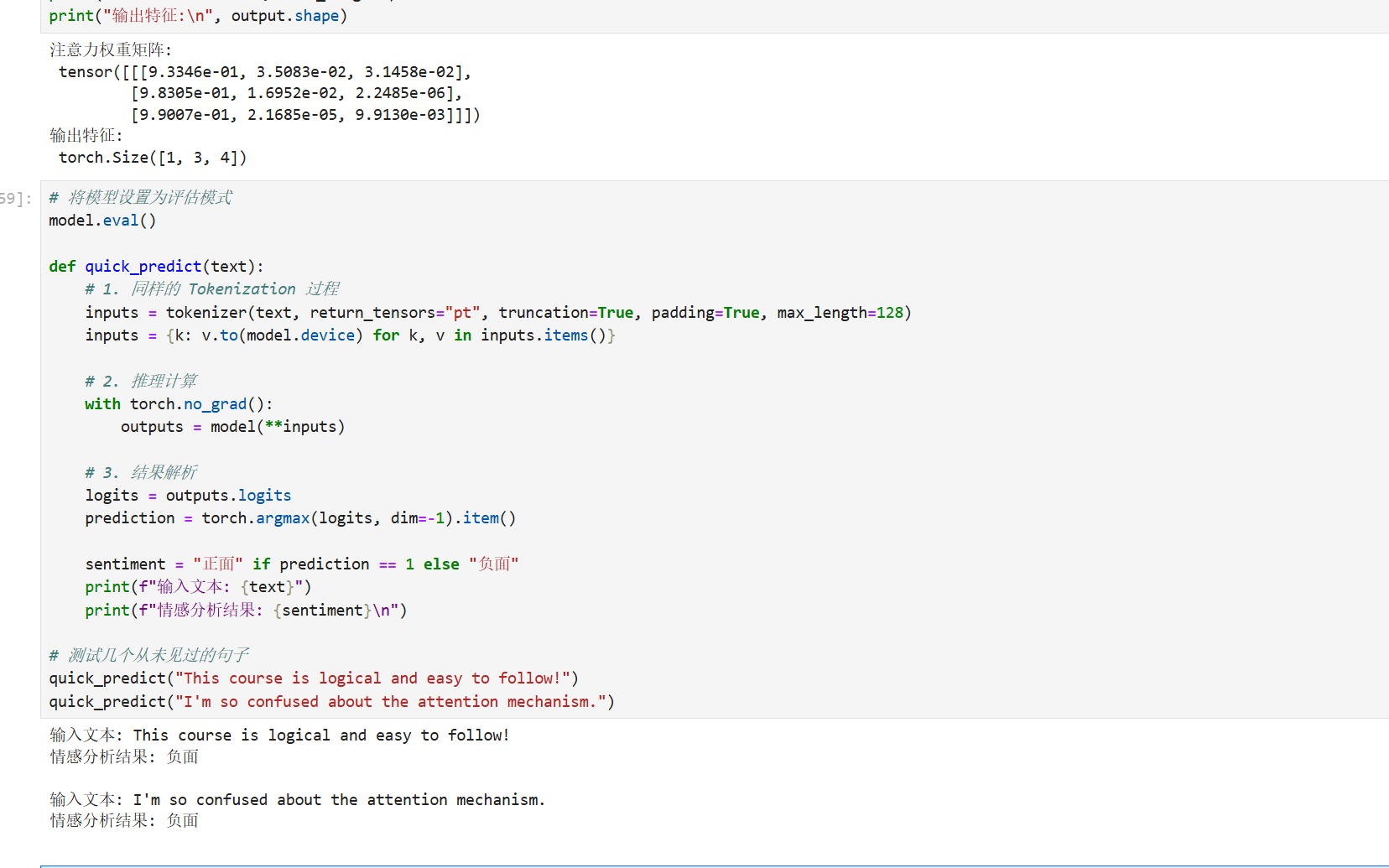
print("输出特征:\n", output.shape)第八步:模型推理 (Inference) 与效果验证
模型在训练集上 Accuracy 是 1.0,但我们要测试它对全新文本的理解能力。
python
# 将模型设置为评估模式
model.eval()
def quick_predict(text):
# 1. 同样的 Tokenization 过程
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True, max_length=128)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
# 2. 推理计算
with torch.no_grad():
outputs = model(**inputs)
# 3. 结果解析
logits = outputs.logits
prediction = torch.argmax(logits, dim=-1).item()
sentiment = "正面" if prediction == 1 else "负面"
print(f"输入文本: {text}")
print(f"情感分析结果: {sentiment}\n")
# 测试几个从未见过的句子
quick_predict("This course is logical and easy to follow!")
quick_predict("I'm so confused about the attention mechanism.")效果预览:
3、调试与可视化 (TensorBoard, 梯度检查,Hook机制)
基于卷积神经网络(CNN)的信号/频谱分类 。 它的好处是:数据结构比自然语言规整,但比猫狗图片更抽象,非常适合用来演示 Hook 机制 和梯度检查,因为你无法直观地用肉眼判断模型看信号看对没对。
第一步:基础配置与环境检查
首先定义计算设备。
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
# 自动选择设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前运行设备: {device}")
# 初始化 TensorBoard 写入器
writer = SummaryWriter('logs/signal_analysis_v1')第二步:构建模型 (带有 Hook 兼容接口)
我们采用 nn.Sequential 结构,并确保你理解如何通过索引访问它。
python
class SignalCNN(nn.Module):
def __init__(self):
super(SignalCNN, self).__init__()
# 使用 Sequential 容器
self.features = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, padding=1), # [0]
nn.ReLU(), # [1]
nn.MaxPool2d(2, 2), # [2]
nn.Conv2d(16, 32, kernel_size=3, padding=1),# [3]
nn.ReLU(), # [4]
nn.MaxPool2d(2, 2) # [5]
)
self.classifier = nn.Linear(32 * 8 * 8, 10)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
return self.classifier(x)
model = SignalCNN().to(device)
# 记录模型结构到 TensorBoard
dummy_input = torch.randn(1, 1, 32, 32).to(device)
writer.add_graph(model, dummy_input)第三步:部署 Hook 探针 (特征图捕捉)
在训练开始前,我们要确定 Hook 能正确拿到第一层卷积后的结果。
python
visual_data = {}
def hook_fn(module, input, output):
# 记录特征图输出
visual_data['conv1_features'] = output.detach()
# 注册到 features 的第 0 层 (即第一个 Conv2d)
handle = model.features[0].register_forward_hook(hook_fn)第四步:核心训练循环 (集成梯度监控)
这里我们模拟 100 步训练,并实时向 TensorBoard 发送 Loss、梯度直方图和特征图图像。
python
# 模拟数据:假设 32x32 的频谱图
inputs = torch.randn(16, 1, 32, 32).to(device)
targets = torch.randint(0, 10, (16,)).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
print("开始训练与监控...")
for step in range(101):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
# 1. 记录 Loss
writer.add_scalar('Train/Loss', loss.item(), step)
# 2. 梯度检查与权重直方图
total_grad_norm = 0
for name, param in model.named_parameters():
if param.grad is not None:
# 记录权值和梯度的分布情况
writer.add_histogram(f'Weights/{name}', param, step)
writer.add_histogram(f'Gradients/{name}', param.grad, step)
total_grad_norm += param.grad.data.norm(2).item() ** 2
writer.add_scalar('Train/Total_Grad_Norm', total_grad_norm ** 0.5, step)
# 3. 每 20 步捕捉一次特征图并写入 TensorBoard
if step % 20 == 0:
# 提取当前 Batch 第一张图的前 8 个特征通道
features = visual_data['conv1_features'][0:1, 0:8, :, :].transpose(0, 1)
img_grid = torchvision.utils.make_grid(features, normalize=True)
writer.add_image('Visual/Conv1_Features', img_grid, step)
print(f"Step {step}: 损失 {loss.item():.4f} | 梯度范数已记录")
optimizer.step()
# 移除 Hook 并关闭 Writer
handle.remove()
writer.close()
print("训练完成!日志已保存至 logs/ 文件夹。")第五步:查看结果 (Checklist 验证)
现在,请在终端或 Jupyter 中启动界面:
python
# 1. 加载 TensorBoard 扩展插件
%load_ext tensorboard
# 2. 再次尝试启动
%tensorboard --logdir logs效果预览:
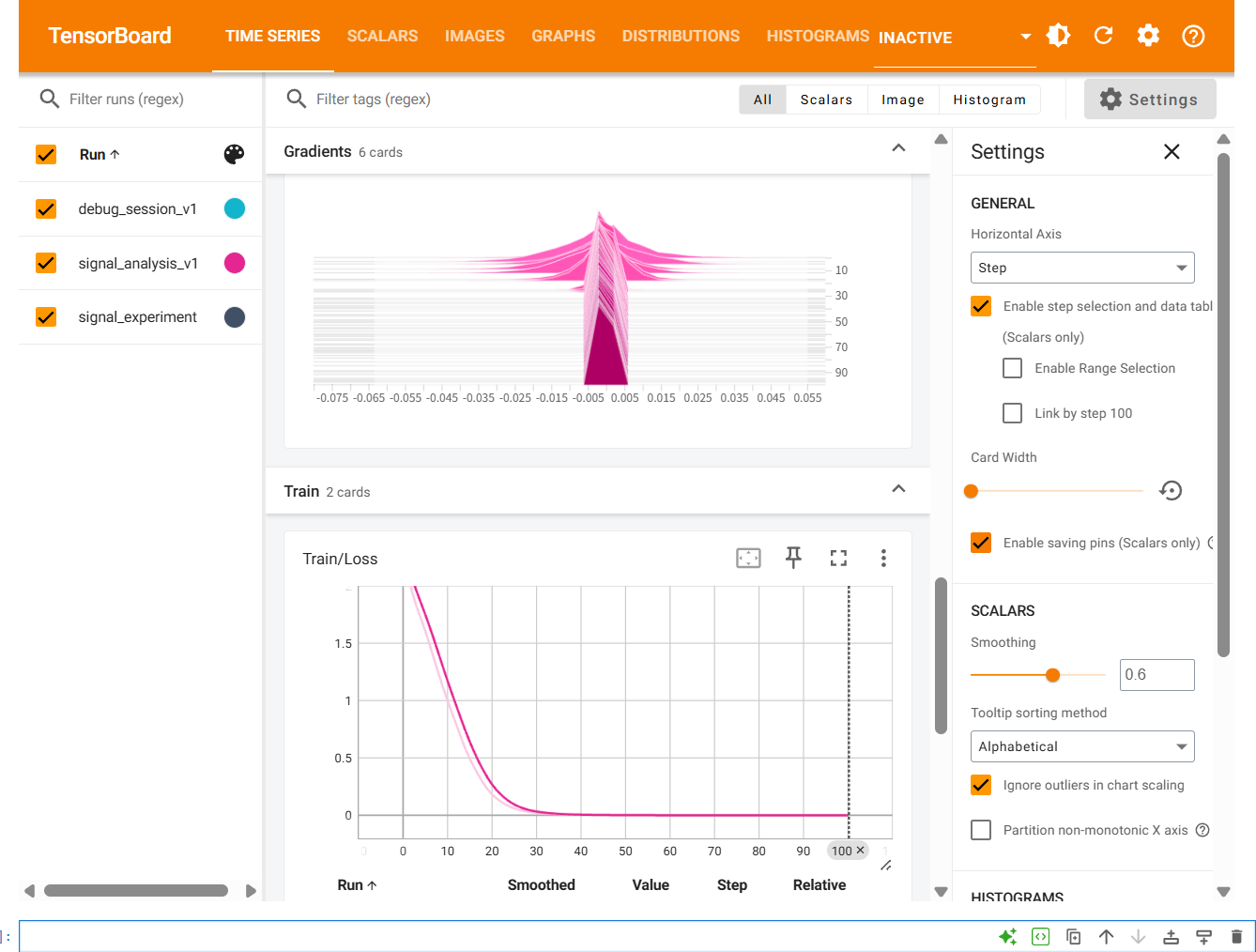
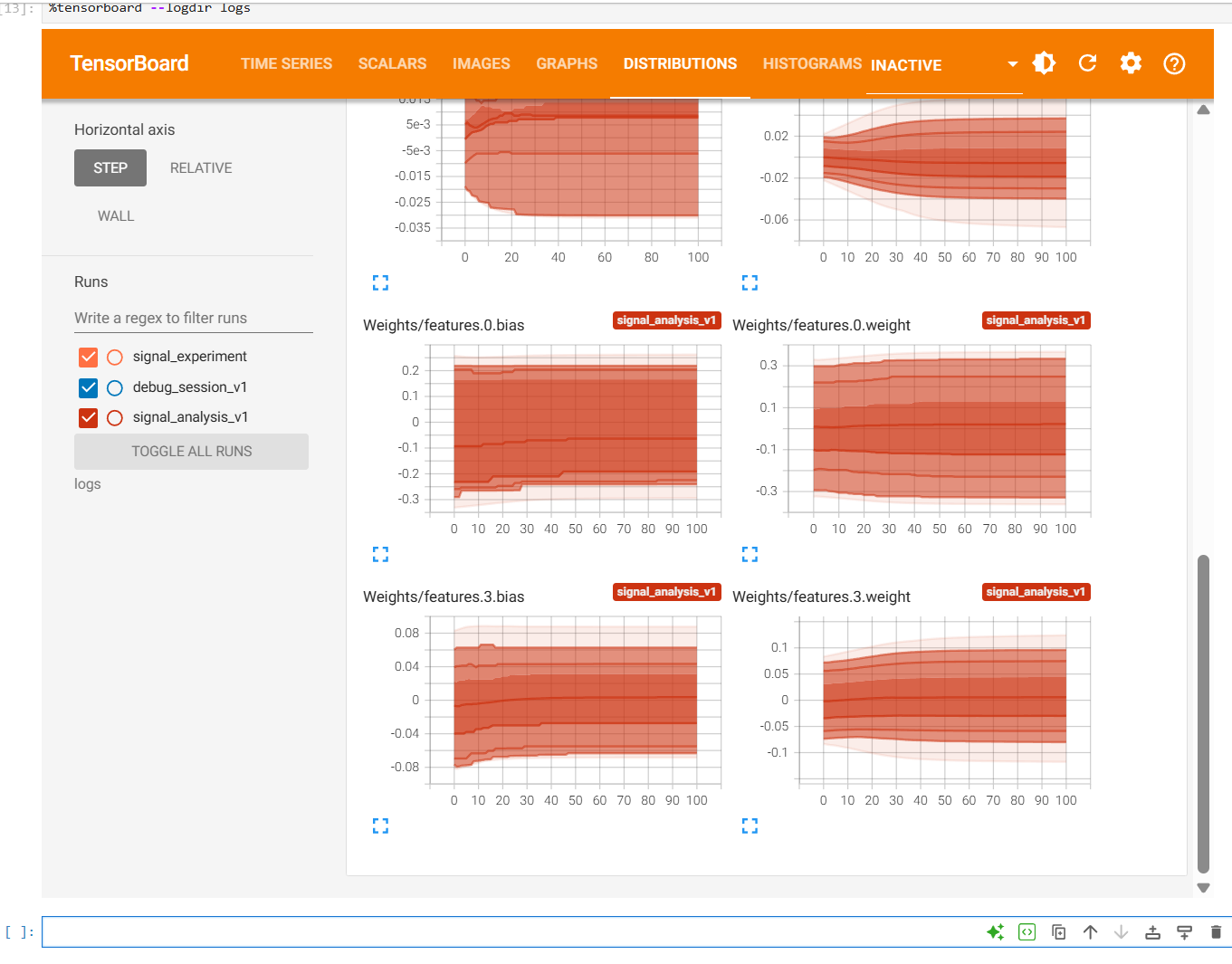
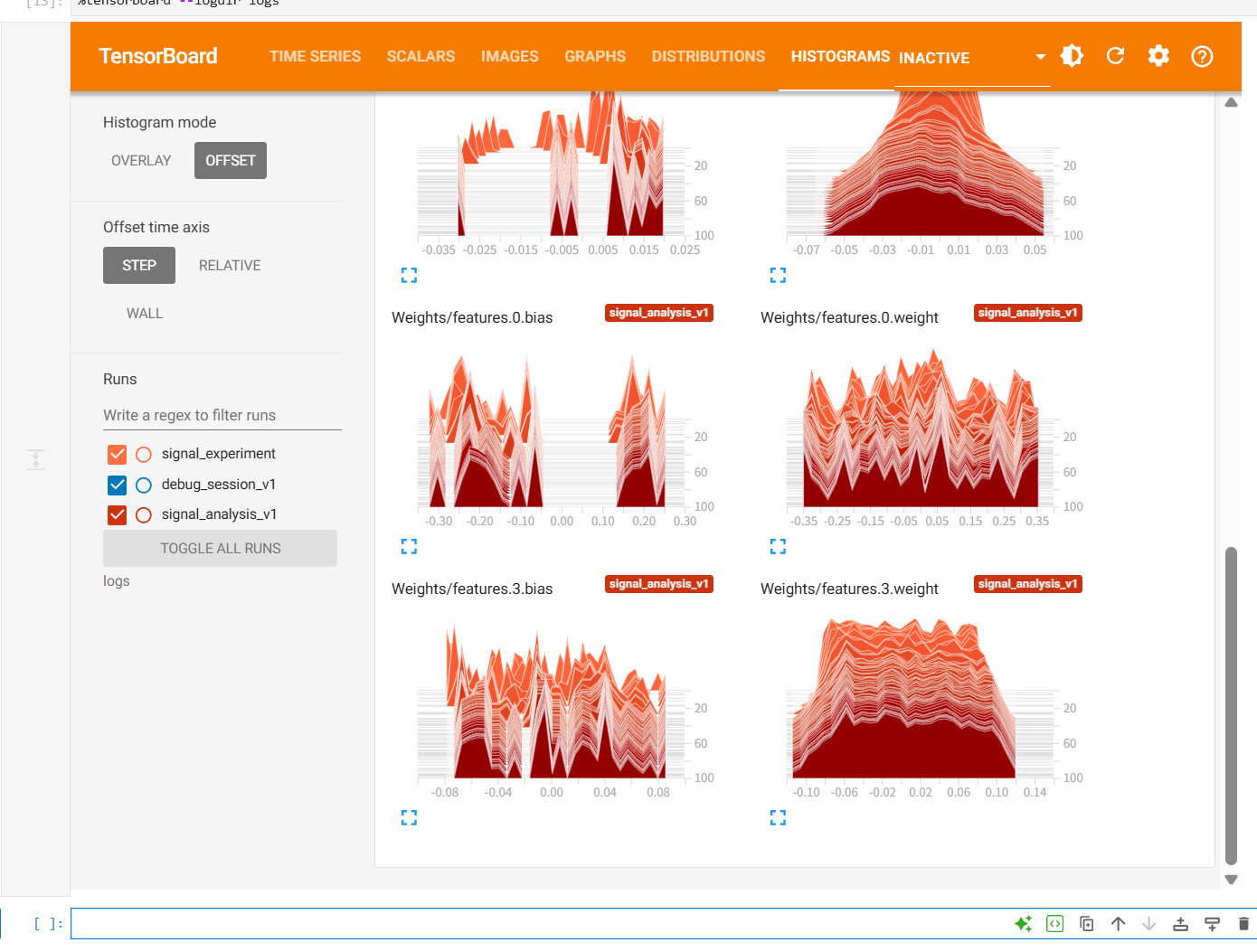
深度学习调试指南:你在图中该看什么?
当你成功打开界面后,结合我们刚才的项目,这就是你要做的"体检"工作:
1. 梯度范数 (Total_Grad_Norm)
-
健康状态:曲线应该在训练初期有波动,随后逐渐趋于稳定,不应归零也不应飙升。
-
异常 :如果曲线直接掉到
2. 特征图 (Visual/Conv1_Features)
-
健康状态 :在 IMAGES 选项卡里,你应该能看到 8 张不同的灰度图,它们代表第一层卷积核提取的原始频谱特征。
-
异常:如果全是黑块,说明权重初始化有问题,或者学习率太大导致神经元全部"坏死"。
3. 权重分布 (Histograms)
- 通过观察
Weights的分布,你可以看到模型参数是否在正常更新。一个健康的分布应该是随着训练步数不断变化的。
四、进阶篇:性能与部署