13. MCP 协议通常采用什么通信方式?
MCP 支持两种主要的传输方式,分别适用于不同场景。
本地场景用 stdio,Client 把 Server 作为子进程启动,通过标准输入输出通信,延迟极低,不用开端口,也没有网络安全问题,我用 Claude Desktop 接本地工具走的就是这种方式。
远程场景现在推荐用 Streamable HTTP,Server 作为独立的 HTTP 服务部署,多个 Client 可以共享同一个 Server,适合团队统一管理工具服务。
MCP 早期版本(2024-11-05 规范)的远程传输是「HTTP + SSE」双端点方案,2025 年 3 月的规范更新里被标记为 deprecated(保留向后兼容但不推荐新项目使用),Streamable HTTP 成为了推荐的远程传输方式。
不管哪种传输方式,底层消息格式都统一用 JSON-RPC 2.0,传输方式只影响「怎么传」,消息协议本身不变。
MCP 的消息格式:JSON-RPC 2.0
在说传输方式之前,先说消息格式,因为不管用哪种传输方式,消息格式都是同一套。
那为什么 MCP 选了 JSON-RPC 2.0 呢?
其实原因很朴素:MCP 需要一种「Client 调用 Server 的方法,Server 返回结果」的通信模式,这本质上就是远程过程调用(RPC)。
而 JSON-RPC 2.0 是现成的、足够轻量的 RPC 规范,用 JSON 格式易读易调试,任何编程语言都能实现,不管 Server 是 Python 写的还是 TypeScript 写的,消息格式都一样,不需要额外的序列化工具。
// 请求消息(Client -> Server)
{
"jsonrpc": "2.0",
"id": 1, // 请求 ID,用于匹配响应
"method": "tools/call", // 调用的方法名
"params": {
"name": "take_screenshot", // 工具名
"arguments": {"url": "https://example.com"}
}
}
// 响应消息(Server -> Client)
{
"jsonrpc": "2.0",
"id": 1, // 对应请求的 ID
"result": {
"content": [{"type": "image", "data": "...base64..."}]
}
}JSON-RPC 本身只定义消息格式,不关心底层怎么传输,MCP 在此基础上定义了两种传输层实现。
传输方式一:stdio(标准输入输出)
stdio 是 MCP 最常用的传输方式,适合本地工具的场景。
工作原理:MCP Client(比如 Claude Desktop)在启动时,把 MCP Server 当作一个子进程启动,然后通过进程的标准输入(stdin)发送请求、从标准输出(stdout)读取响应。两个进程在同一台机器上运行,通过操作系统的管道通信。
这里的「管道」到底是什么?
你可以把它理解成操作系统在内存里给这两个进程分配的一段先进先出的小缓冲区:Client 往里塞一行 JSON,Server 从缓冲区的另一头读出来处理;Server 处理完再往另一条管道里塞一行 JSON,Client 从那头读。
整个过程不经过网卡、不经过 TCP/IP 协议栈,数据在 RAM 里走了一趟就到了,所以延迟天然比网络请求低得多,也不需要序列化成网络可传输的字节流。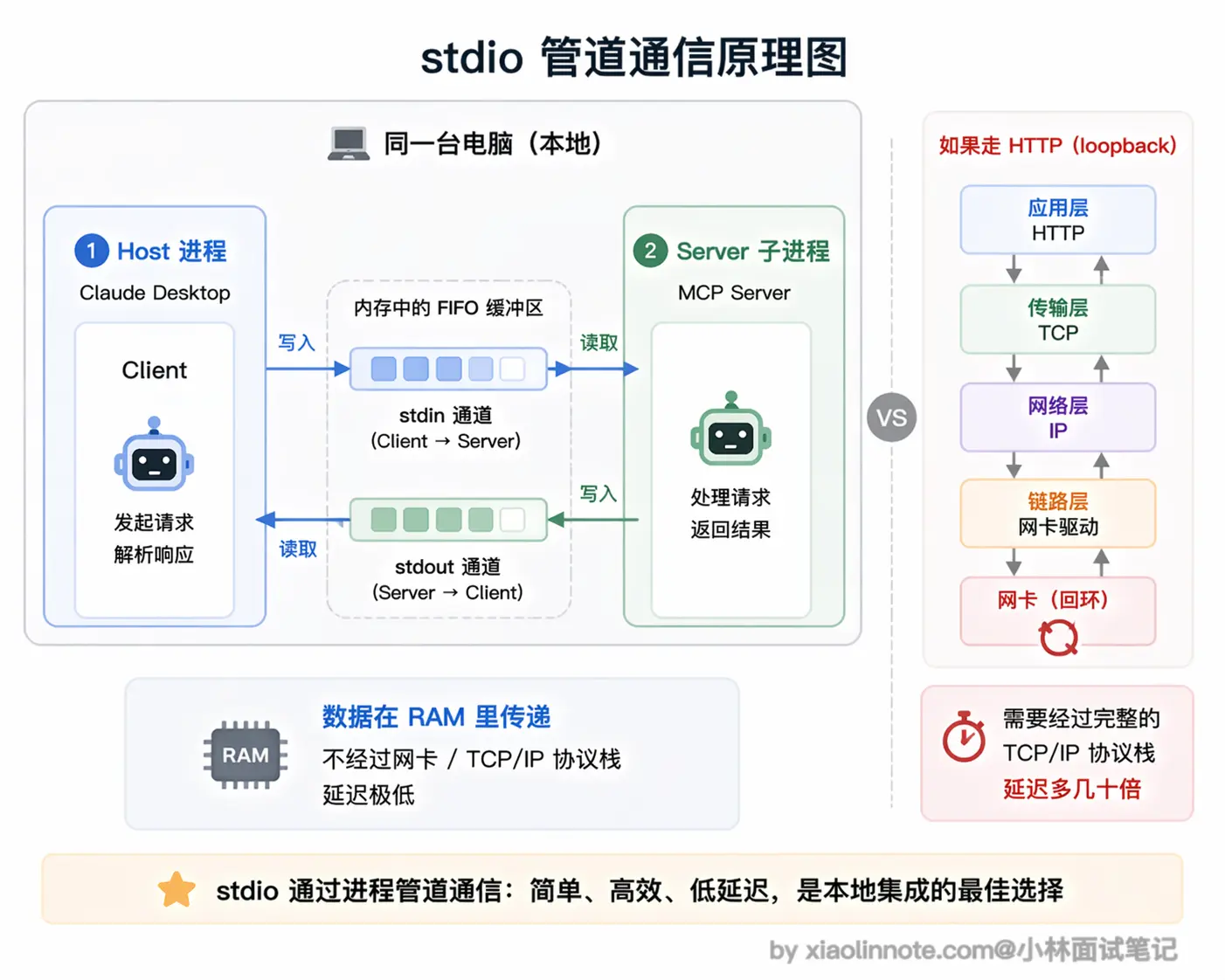
stdio 方式有几个很明显的优点。
-
首先延迟极低,进程间通信比走网络快得多,数据直接在操作系统管道里流转,几乎没有开销。
-
其次不需要开端口,也就没有网络安全问题,不用担心外部访问。另外 Server 的生命周期是自动管理的,随 Client 启动而启动、随 Client 关闭而关闭,不需要你手动去管进程。
在实际使用中,你只需要在配置文件里告诉 Client「用什么命令启动 Server」就行了,比如在 Claude Desktop 的 claude_desktop_config.json 里这样配置:
{
"mcpServers": {
"filesystem": {
"command": "npx", // 启动命令
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/tmp"],
"env": {} // 环境变量(可选)
}
}
}传输方式二:Streamable HTTP(当前标准的远程传输)
远程场景下,Server 作为独立的 HTTP 服务运行,Client 通过网络连接访问。MCP 当前推荐的远程传输方式是 Streamable HTTP。
Streamable HTTP 的核心设计是用单个 HTTP 端点(通常是 /mcp)同时处理请求和响应。Client 通过 POST 请求发送 JSON-RPC 消息,Server 可以选择两种方式返回:如果是简单的同步操作,直接返回一个普通的 JSON 响应就行;如果是需要流式输出的操作,Server 返回一个 SSE 流,持续推送数据。这种「按需选择」的设计非常灵活,不需要强制建立长连接。
Streamable HTTP 的优点很明确。Server 可以部署在云端,多个 Client 共享同一个 Server,这对团队来说特别实用,比如团队共用一个部署在服务器上的数据库 MCP Server,所有人连同一个服务就行,不需要各自在本地跑一份。而且支持跨机器访问,不局限于本地环境,适合需要统一管理工具服务的团队或平台。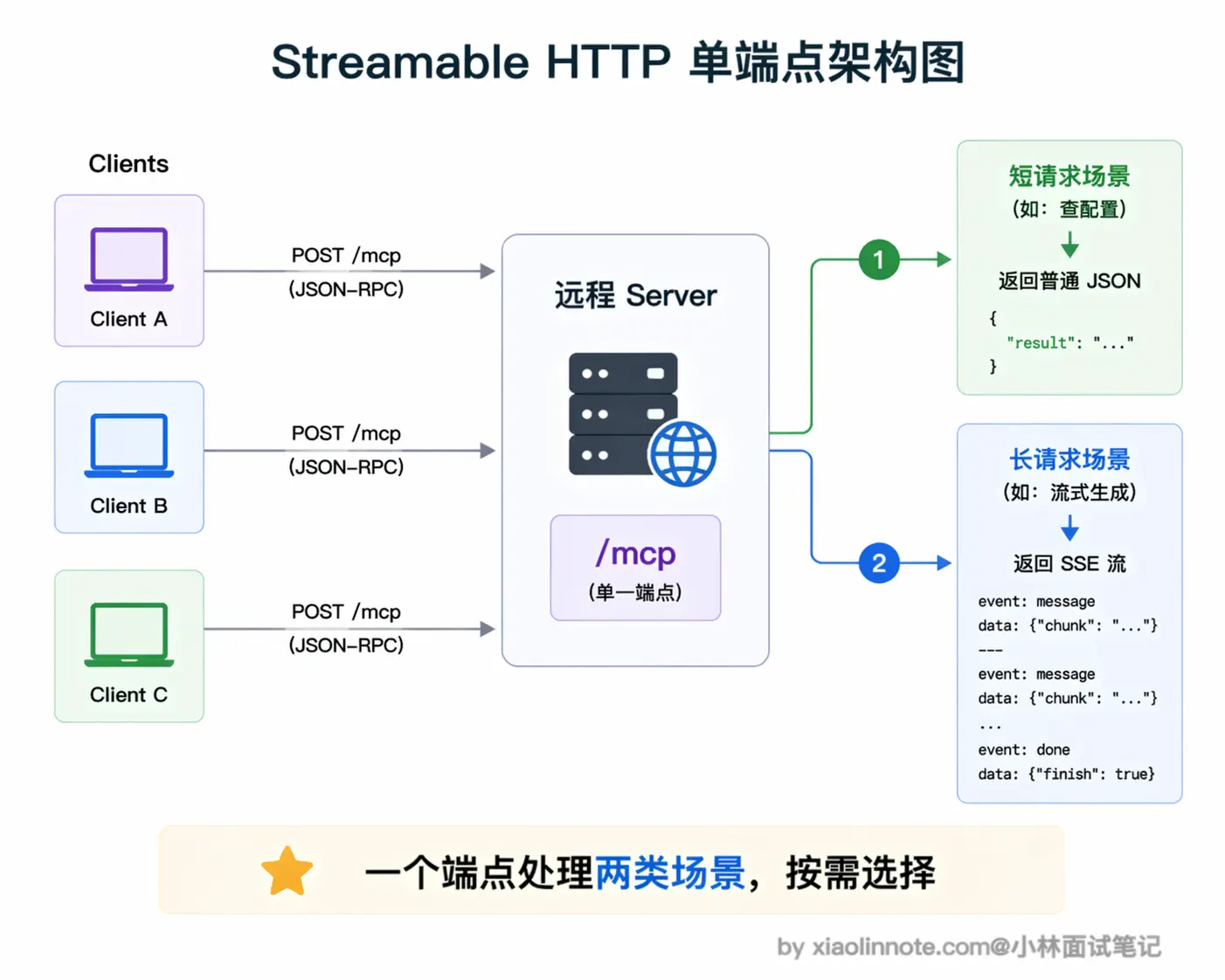
当然,相比 stdio 多了网络开销,延迟会略高一些,而且你还需要处理认证、网络中断重连等在本地场景下完全不用操心的问题。
为什么 SSE 被弃用了
你可能看到一些早期的 MCP 教程还在讲 SSE(Server-Sent Events)传输方式,这里要说明一下:HTTP + SSE 双端点方案是 MCP 早期版本(2024-11-05 规范)采用的远程传输方案,在 2025 年 3 月的规范更新里被标记为 deprecated,仍然保留向后兼容,但新项目应该直接用 Streamable HTTP。
为什么要替换?原因是架构上有一个小尴尬:Client 向 Server 发请求要走 POST 端点,Server 向 Client 推数据要走另一条 SSE 长连接端点,同一个对话被拆成了两条通道。这带来的具体问题是状态管理复杂,比如 Client POST 了一条消息之后网络突然断了,那条消息到底被处理了没、SSE 流会不会推回结果,Client 没有一个简单的办法判断,出问题时排查链路很长。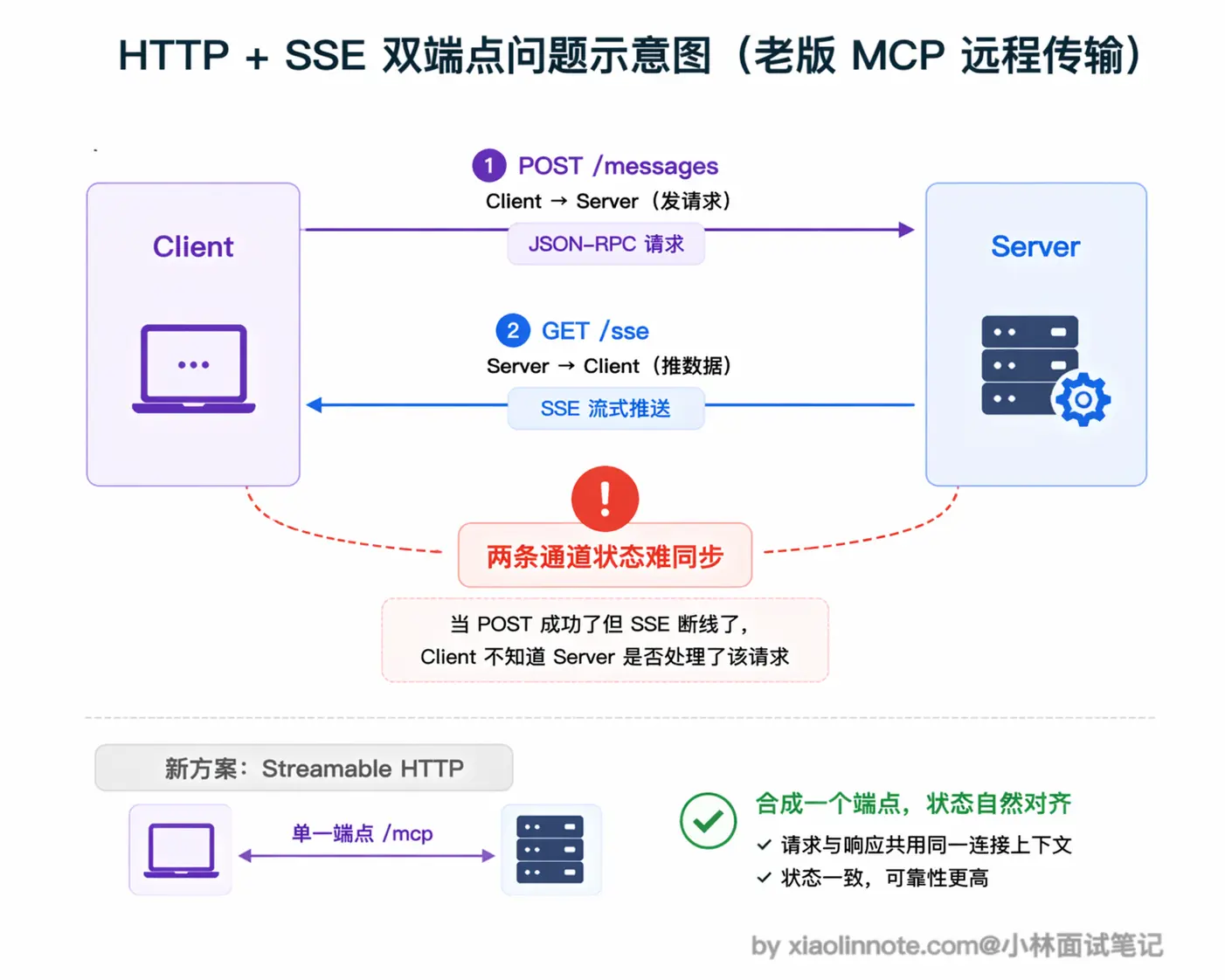
Streamable HTTP 的做法是把这两条通道合并成一个端点:Client 照样 POST 发请求,Server 根据情况决定返回「一个普通 JSON」还是「一条 SSE 流」,不需要 Client 提前开另一条连接。
注意这里的关键:Streamable HTTP 并没有抛弃 SSE,流式推送的部分底层还是 SSE(Content-Type: text/event-stream),只是把端点从两个合成一个。架构更简洁、对负载均衡和 serverless 环境都更友好。目前主流的 MCP 客户端和 SDK 都已经迁移到了 Streamable HTTP。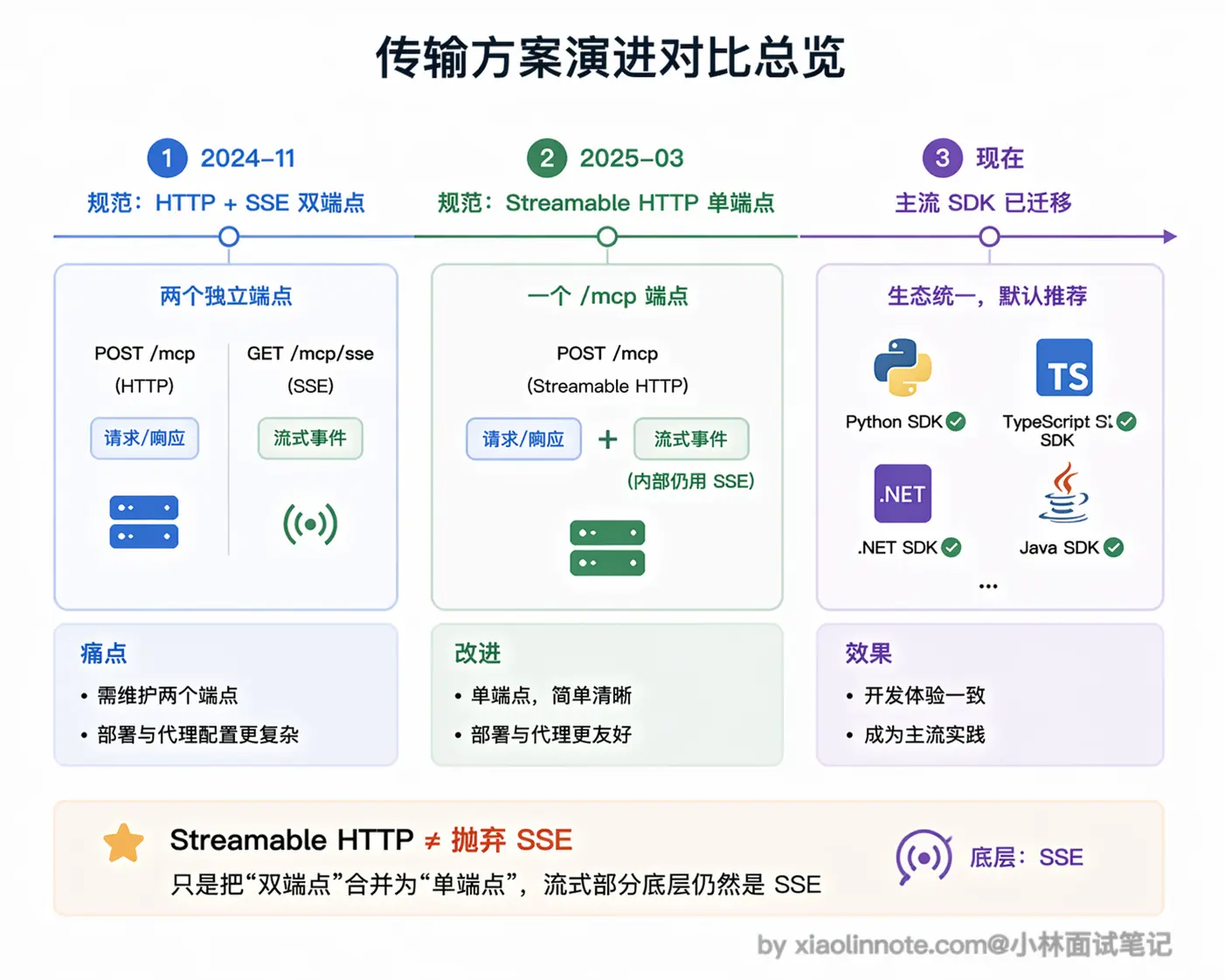
14. 说说 WebSocket 和 SSE 通信的区别及局限性?
我觉得最核心的区别是通信方向:SSE 是服务端单向推,客户端只能接收,想发消息只能另起一个 HTTP 请求;WebSocket 是全双工,双方都可以随时主动发消息。
对于 LLM 流式输出这种「模型一直在推 token、用户只是看」的场景,SSE 完全够用,而且轻量、HTTP 原生支持、运维简单,OpenAI 和 Anthropic 的 API 用的都是 SSE。
WebSocket 的复杂性只有在真正需要双向实时交互的时候才值得引入,比如用户要在模型说话过程中随时打断。
两者各有局限:SSE 在 HTTP/1.1 下有连接数上限,只支持文本传输;WebSocket 有状态、横向扩展麻烦,还容易被企业代理或防火墙拦掉。大多数 LLM 文字对话产品用 SSE 就够了。
先从 HTTP 的本质说起
要真正理解 SSE 和 WebSocket 的区别,不能只看它们各自的功能列表,得先回到更底层的问题:它们到底在解决什么问题?答案是普通 HTTP 做不到的事情。
标准的 HTTP 请求是「一问一答」模型:客户端发请求,服务端返回响应,连接关闭(或者进连接池等待下次复用)。
服务端在任何时候都不能主动「推」数据给客户端,它只能被动等客户端来问。你可以把它想象成打电话:你说一句「你好」,对方回一句「你好」,然后挂电话,这条线就断了。这套机制在传统 Web 里够用,但 AI 对话场景不行。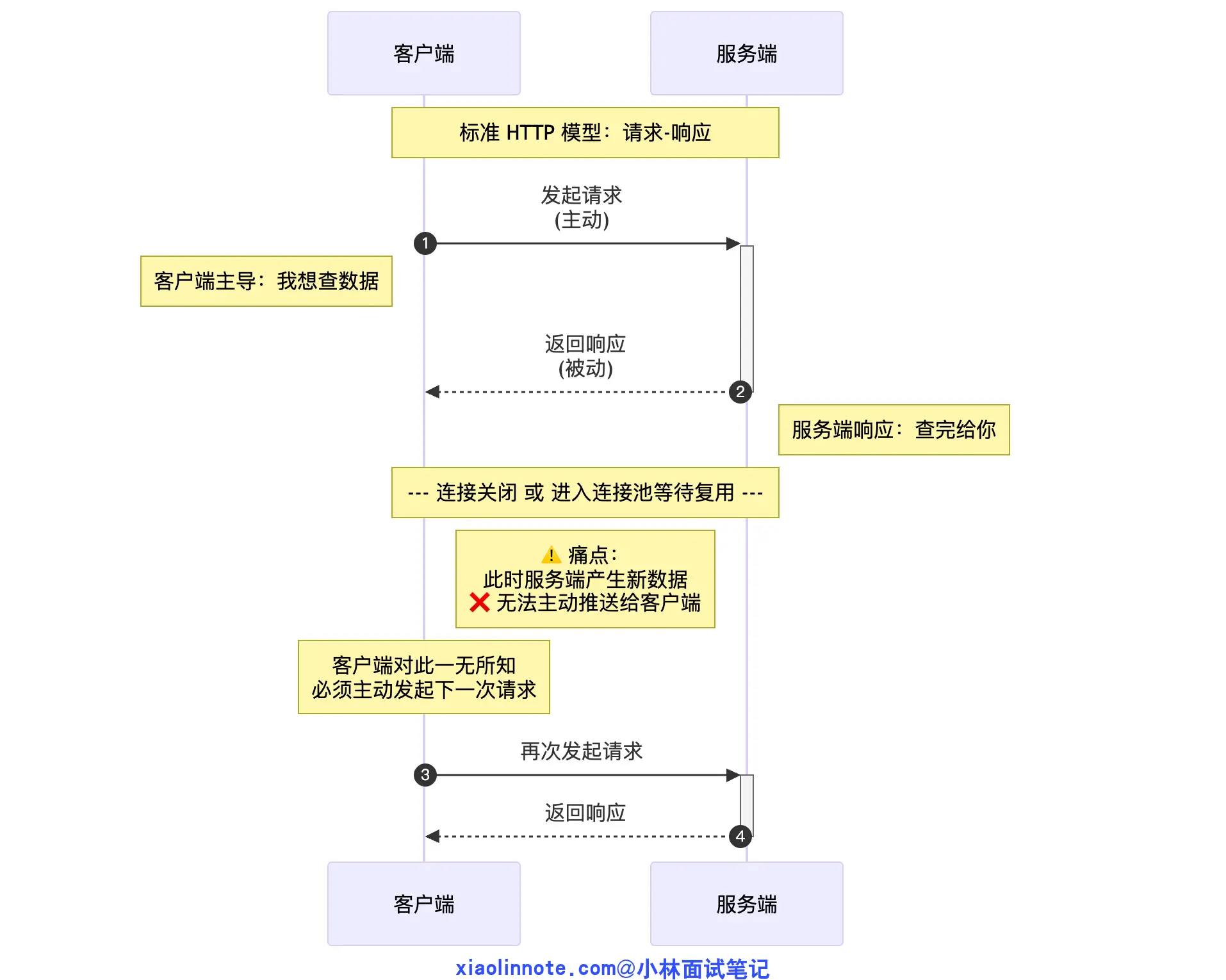 模型生成一个完整回答需要几秒甚至十几秒,如果等全部生成完再一次性返回,用户只能干瞪着空白屏幕等待,体验极差。我们需要的效果是:模型生成一个词就推一个词,用户实时看到文字逐渐出现,就像 ChatGPT 那样一个字一个字「打」出来。这就需要连接保持打开、服务端能主动持续往外推数据,HTTP 的「问一答一然后断」做不到这件事。
模型生成一个完整回答需要几秒甚至十几秒,如果等全部生成完再一次性返回,用户只能干瞪着空白屏幕等待,体验极差。我们需要的效果是:模型生成一个词就推一个词,用户实时看到文字逐渐出现,就像 ChatGPT 那样一个字一个字「打」出来。这就需要连接保持打开、服务端能主动持续往外推数据,HTTP 的「问一答一然后断」做不到这件事。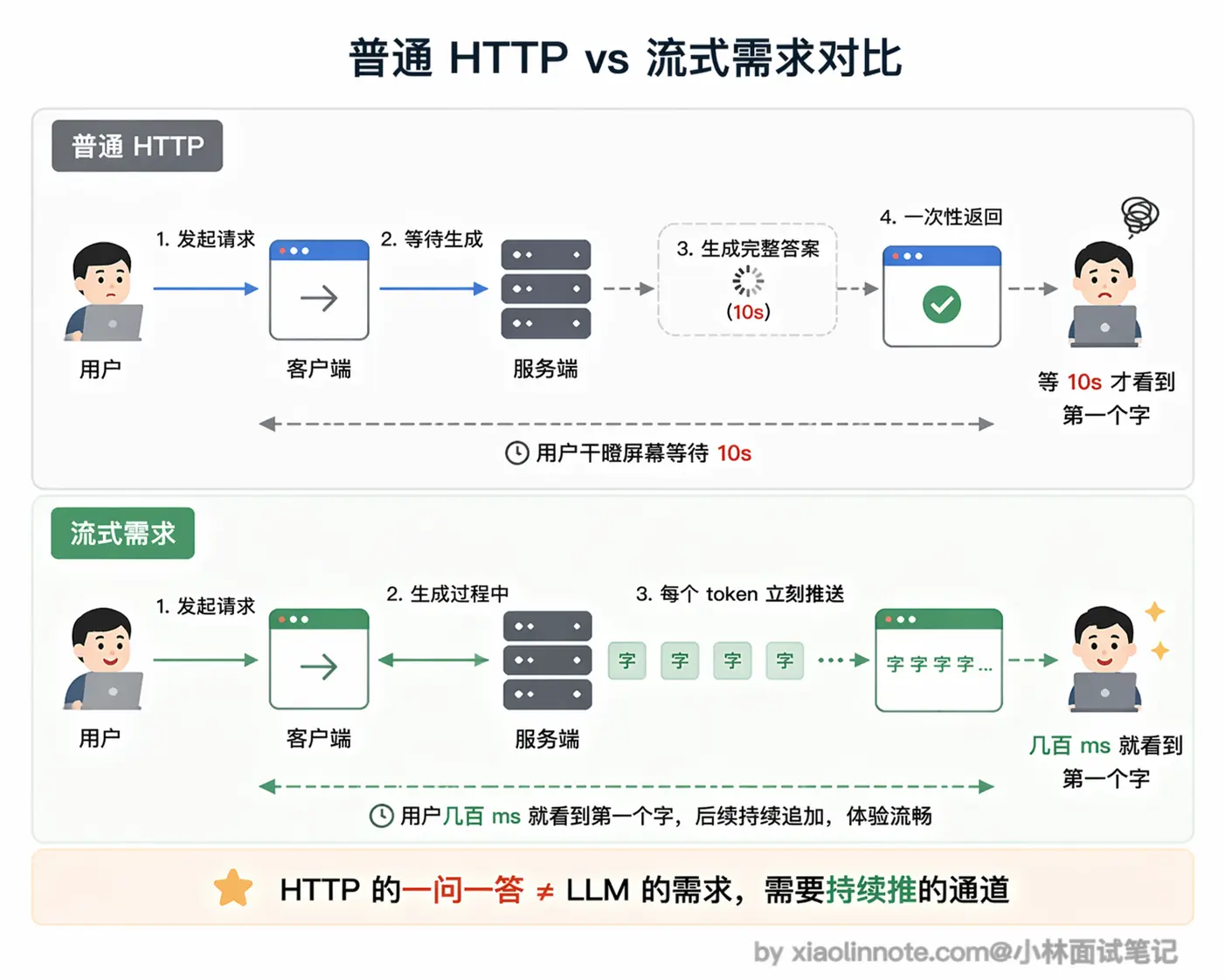
SSE:用普通 HTTP「撑开」一条单向水管
SSE(Server-Sent Events,服务器推送事件)本质上是对 HTTP 的一种「巧用」,不是新协议,而是 HTTP/1.1 里本来就有的特性,只不过以前很少用。
它的做法是:客户端发一个普通 HTTP GET 请求,但在请求头里声明 Accept: text/event-stream,告诉服务端「我想收流式数据」。服务端收到后,不关闭连接,而是保持连接持续打开,不停往里写数据。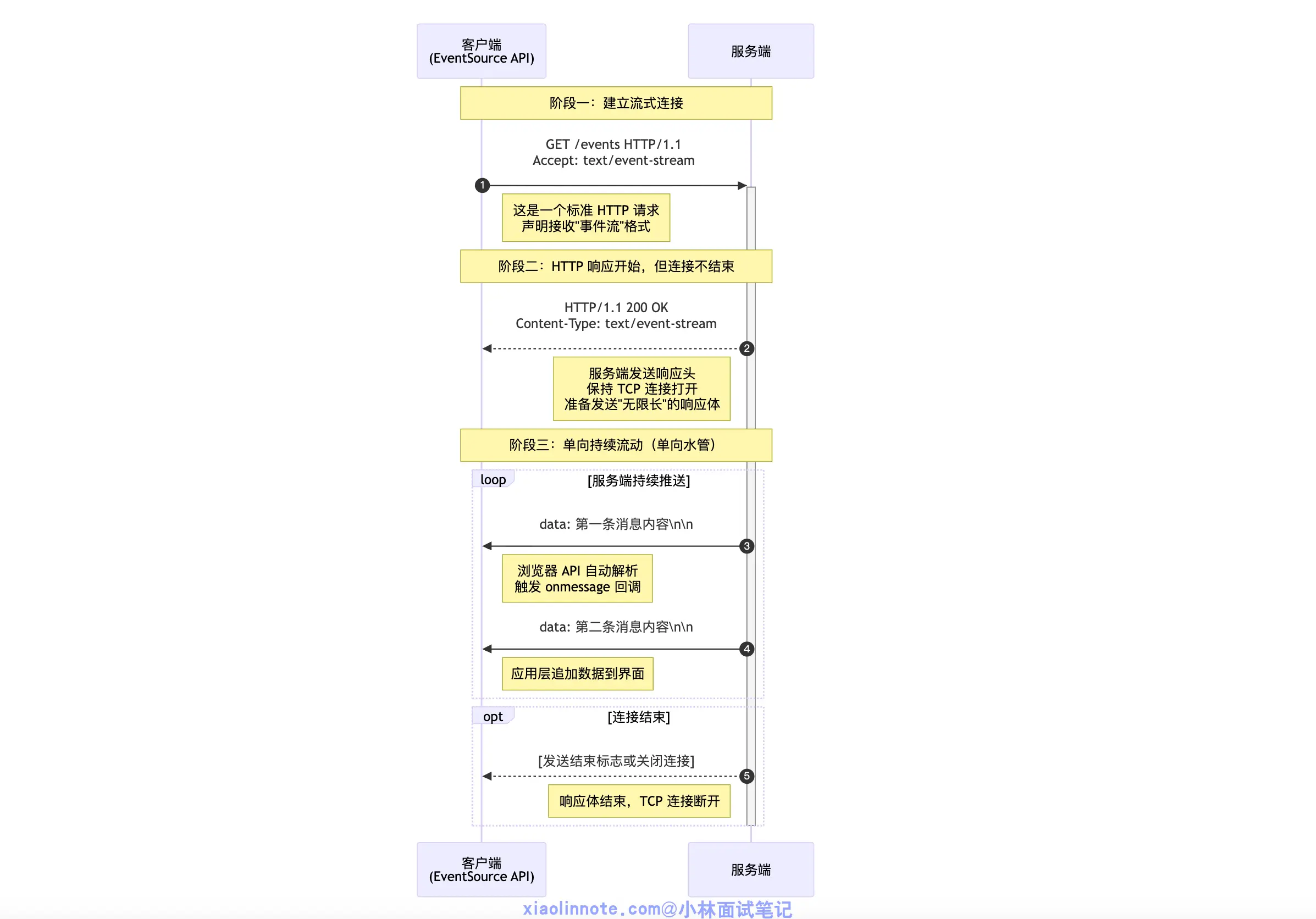 这条连接在技术上仍然是一个 HTTP 响应,只不过响应体是「无限长」的,服务端在不断往里追加内容,直到模型生成完毕才发送结束标志。可以把它理解为「一根从服务端流向客户端的单向水管」,水(数据)只能从服务端流向客户端,客户端没法往管子里倒水。
这条连接在技术上仍然是一个 HTTP 响应,只不过响应体是「无限长」的,服务端在不断往里追加内容,直到模型生成完毕才发送结束标志。可以把它理解为「一根从服务端流向客户端的单向水管」,水(数据)只能从服务端流向客户端,客户端没法往管子里倒水。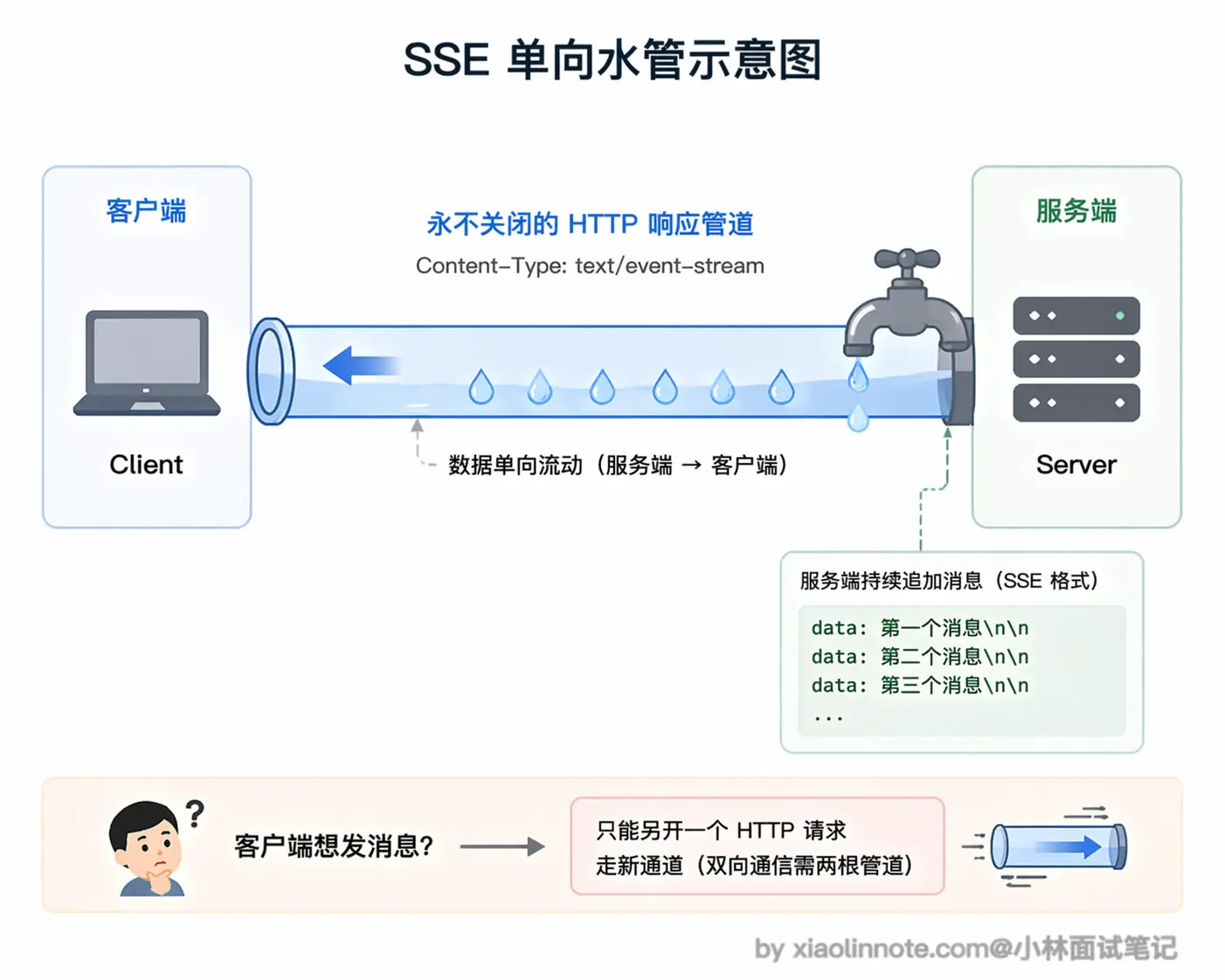
有必要讲一下 SSE 的消息格式是什么样的,因为这直接决定了它为什么这么好用。
SSE 的数据不是 JSON,而是一种非常简单的纯文本格式,每条消息以 data: 开头,后面跟数据内容,结尾是两个换行符。
如果你现在打开 ChatGPT,按 F12 打开开发者工具,切到 Network 面板,找到流式响应请求,就能看到一行一行类似 data: {"token": "你"} 这样的文本在不断追加进来,每出现一行浏览器就触发一次事件。
浏览器专门有一个叫 EventSource 的内置 API 来处理这种格式,你只需要打开这个连接,注册一个 onmessage 回调函数,每收到一条消息就自动触发,完全不用自己解析底层数据流,用起来非常方便。
SSE 之所以成为 LLM 流式输出的行业标准,还有一个很关键但容易被忽视的原因:文字传输天然适合 TCP 的可靠有序传输。模型输出是一个个 token 组成的连续文本,如果中间某个 token 丢了,整段话的意思可能完全变了,顺序乱了更是无法阅读。
所以你希望每个 token 都准确到达、不乱序,这恰恰是 TCP 的强项。你愿意等网络重传,因为等来的是正确的内容。这和语音场景(WebRTC)完全相反,那里 TCP 的重传机制会造成不可接受的延迟,所以语音要换 UDP;但文字场景里 TCP 反而是你的朋友,你需要它。
WebSocket:从 HTTP 升级成真正的双向信道
理解了 SSE 是怎么回事,WebSocket 就很好对比了。WebSocket 是一个独立的协议,建立在 TCP 之上,但不是 HTTP 的特性。它的建立过程有一个特殊的「握手仪式」:客户端先发一个看起来像普通 HTTP 请求的东西,但请求头里带了一句话「我想升级成 WebSocket」。
服务端如果同意,回一个 101 Switching Protocols 的响应,从这一刻起,这条 TCP 连接就「变性」了,不再遵循 HTTP 的一问一答规则,变成了一条双方都可以随时说话的全双工信道。你可以把这个转变想象成:原来是对讲机(你说完按按钮让对方说),升级成了电话(双方都可以随时开口,谁都不用等谁)。
和 SSE 最本质的区别是通信方向。SSE 只有服务端能主动推,客户端想发消息必须另起一个 HTTP 请求,两个方向用了两套机制;WebSocket 是真正的双向,客户端和服务端都可以随时主动发消息,对方立刻就能收到,没有任何「谁先说话」的限制,一条连接搞定两个方向。
用「用户要在模型说话中途打断」这个场景来感受两者的差别:用 SSE 时,用户想打断,只能先关掉当前 SSE 流(第一个请求结束),再发一个新的 POST 请求(第二个请求开始),这两个动作之间有一个明显的断-重连过程,操作上有割裂感;用 WebSocket 时,用户直接在同一条连接里发送「停止」指令,服务端立刻收到,立刻停止生成,整个过程流畅、无缝,真正的实时双向交互。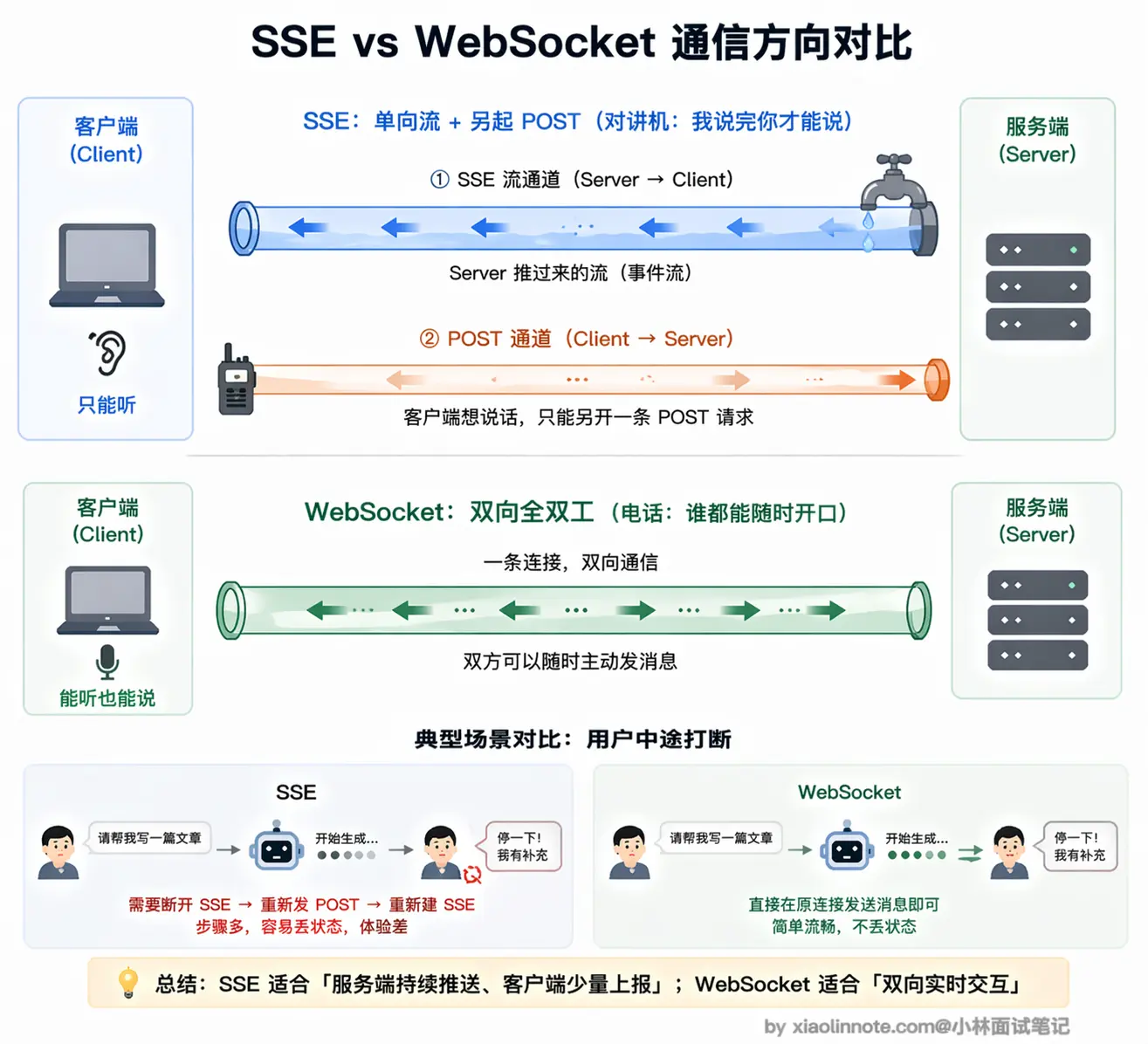
SSE 的局限:不只是「单向」那么简单
说完了两者的核心区别,接下来要聊它们各自的局限性了,这往往是面试官追问的重点。先看 SSE。
SSE 的单向性带来的第一个麻烦,是架构上的「双通道尴尬」。
SSE 只能从服务端推向客户端,用户发消息必须走一个独立的 POST 请求,这意味着同一个对话用了两条通道,用户发消息走 POST,模型回复走 SSE,两者之间要靠一个 conversation ID 关联起来。
服务端收到 POST 请求后,找到对应的 SSE 长连接,把模型输出推过去。对于简单场景这套机制够用,但状态管理比 WebSocket 的单一通道复杂,出问题时排查链路也更长。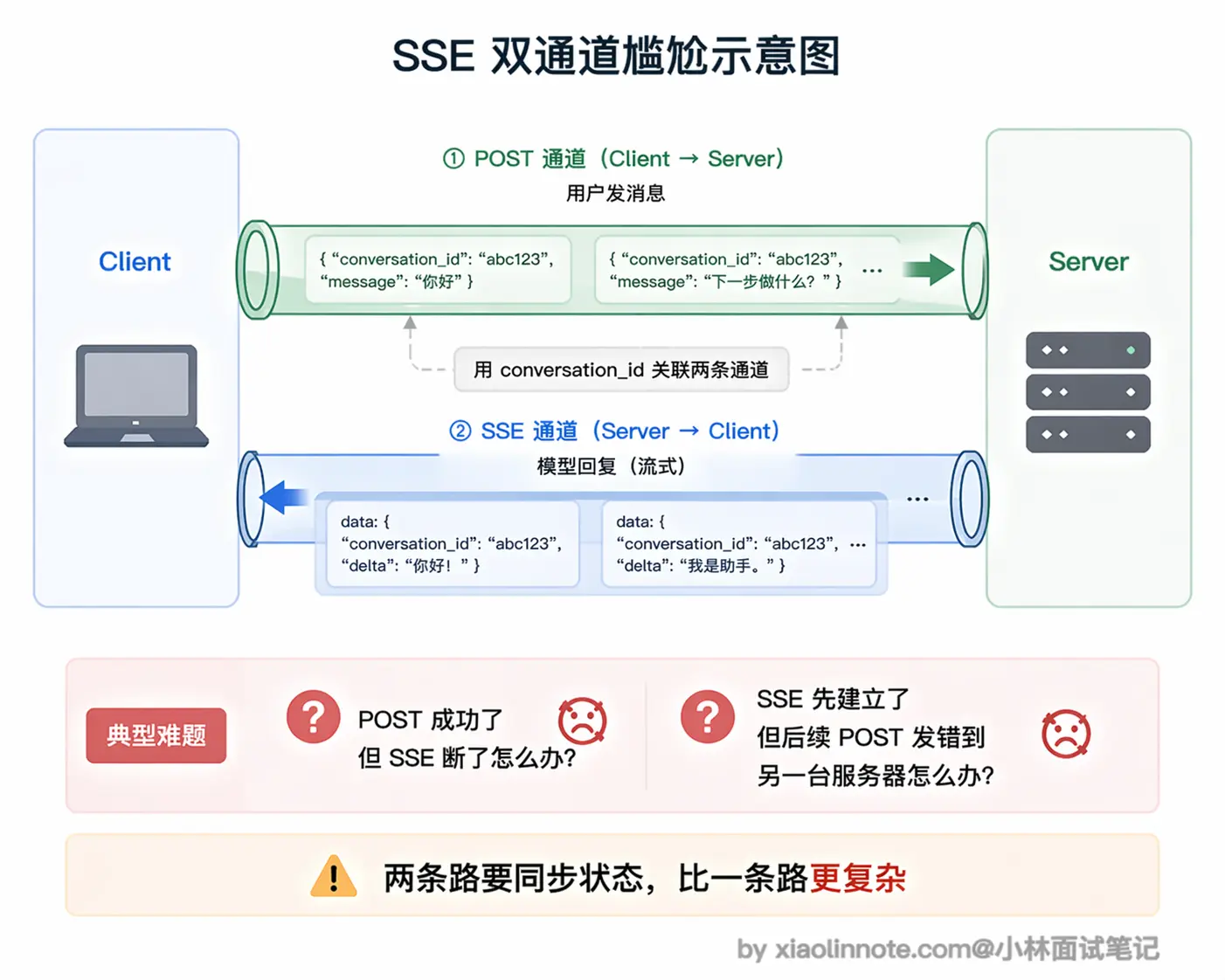
第二个容易被忽视的坑是 HTTP/1.1 的连接数限制。
浏览器对同一个域名的 HTTP/1.1 连接有 6 条的上限,SSE 占一条长连接,如果用户同时开了多个标签页,第 7 个标签页的 SSE 请求会被浏览器排队等待,导致某些标签页没有响应,看上去就是「页面卡死了」。HTTP/2 通过多路复用解决了这个问题,一条 TCP 连接上可以跑无数条逻辑流,所以现代部署一般要求 HTTP/2,这个问题也就消失了。但如果你的用户环境里有老浏览器或者不支持 HTTP/2 的代理,这就是一个真实的坑。
第三个是 SSE 只能传文本这条限制。
传语音或者图片时,必须先做 Base64 编码才能用 SSE 传输,数据量会膨胀约 33%,接收端还要额外解码,延迟和 CPU 开销都不小。实时语音场景下这个代价完全不可接受,所以实时语音要用 WebRTC 而不是 SSE。
还有一个实现细节是断线重连。SSE 有内置的重连机制,断线后会自动尝试重连,这是优点。但要做到「断了接着上次继续」而不丢消息,服务端必须支持 Last-Event-ID,客户端重连时带上上次收到的最后一条消息 ID,服务端从那条之后重放。很多实现省略了这块,结果断线后用户会丢失中间的内容,重连看到的是截断的回答。
WebSocket 的局限:有状态带来的扩展麻烦
WebSocket 最麻烦的问题是「有状态」。
每条 WebSocket 连接在建立时被负载均衡器路由到某一台后端服务器,之后这个用户的所有消息都必须发到同一台服务器,因为连接状态就保存在那里。
当你想横向扩容、加新的机器时,新机器接不到老连接,老连接的用户无法迁移到新机器,扩容的效果大打折扣。
常见的解决办法是把连接状态外移到 Redis 等共享存储,通过发布订阅机制把消息中转到正确的服务器,但这让架构明显变复杂,多了一跳,延迟也增加了。
相比之下,SSE 的每次请求都是普通 HTTP,负载均衡器可以把任意请求路由到任意后端,横向扩展非常简单,这是 SSE 在大规模部署场景的一个明显优势。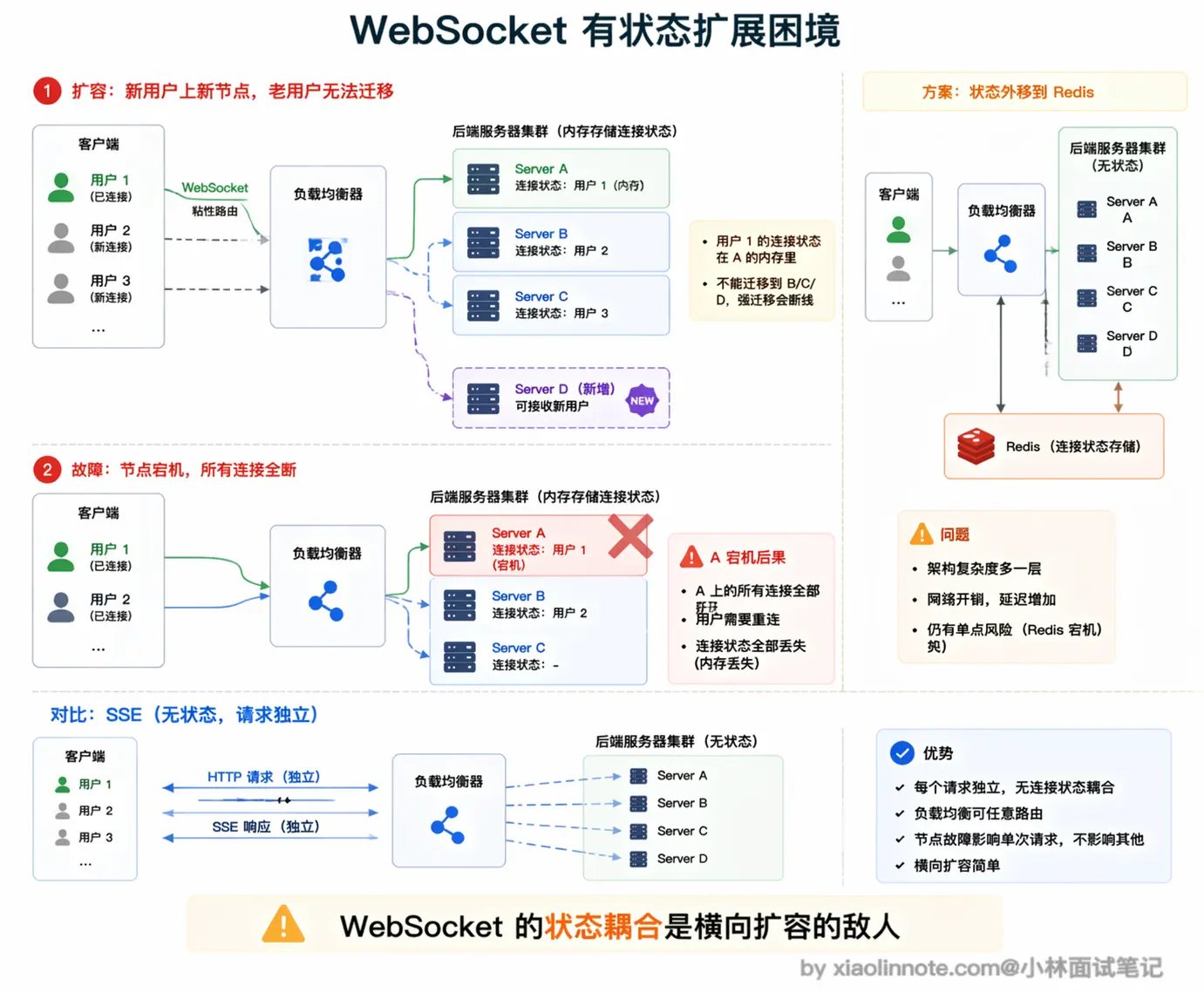
第二个实际部署中频繁踩的坑是代理和防火墙穿透。
很多企业的 HTTP 代理(比如 Squid)、老版本 CDN、某些安全网关不支持 WebSocket 的 Upgrade 握手,直接把这个请求当成异常 HTTP 请求拒掉,导致 WebSocket 连接建立失败。
SSE 就不会有这个问题,它始终是普通 HTTP 请求,任何代理都能透传,不需要任何特殊配置。
这也是为什么早期 MCP 协议的远程传输选择了 SSE 而不是 WebSocket,MCP Server 需要在各种复杂的网络环境下都能工作,SSE 对这些环境的兼容性好得多(MCP 在 2025 年 3 月的规范更新里进一步升级到了 Streamable HTTP,本质上还是走 HTTP + SSE 流,详见 13 题)。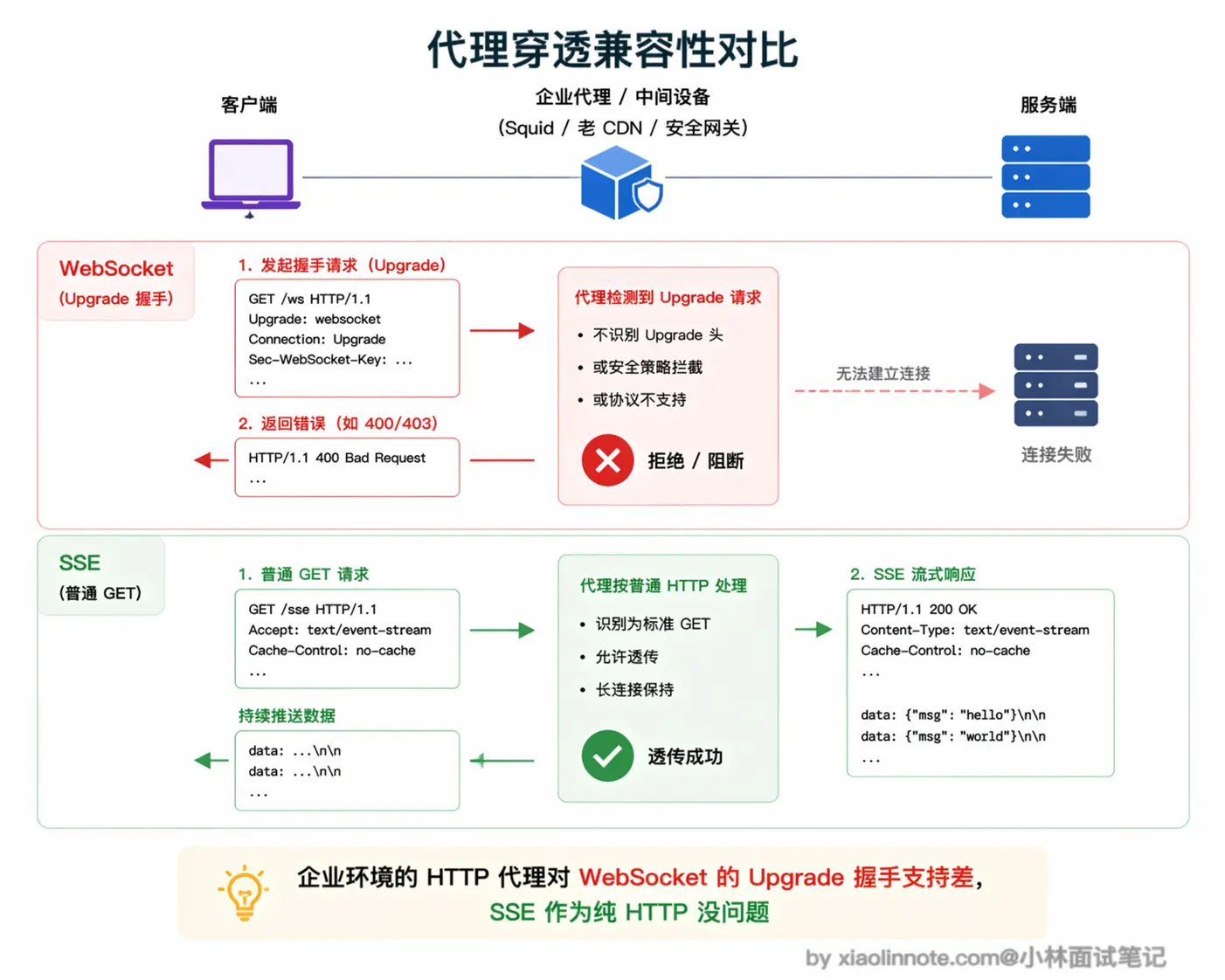
第三个是 WebSocket 没有内置的请求-响应配对机制。HTTP 里每个请求有自己的响应,天然一一对应。WebSocket 里消息就是消息,服务端发来一条消息,你不知道它对应哪个请求,需要自己在消息里加请求 ID,在客户端维护请求 ID 到等待回调的映射表,才能实现「发出一条消息,等待特定响应」的语义。
说起来不难,但实现起来是不少的工作量,而且一旦断线重连,那些还在等待响应的请求该怎么处理,也需要专门设计重试逻辑。
在 AI 场景下怎么选?
大原则是「单向推就用 SSE,真正需要双向才上 WebSocket」。文字对话天然是单向推:模型在说话,你在看,你想回复直接发一个新的 POST 就行,SSE 完全够。只有当你需要客户端在任意时刻主动说话,比如实时打断、多人协同编辑、游戏类实时同步,才值得引入 WebSocket 的复杂度。绝大多数 LLM 文字对话产品用 SSE 就够了,这也是为什么 OpenAI、Anthropic 的 API 都选 SSE 而不是 WebSocket。WebSocket 的复杂性只有在真正需要双向实时通信时才值得引入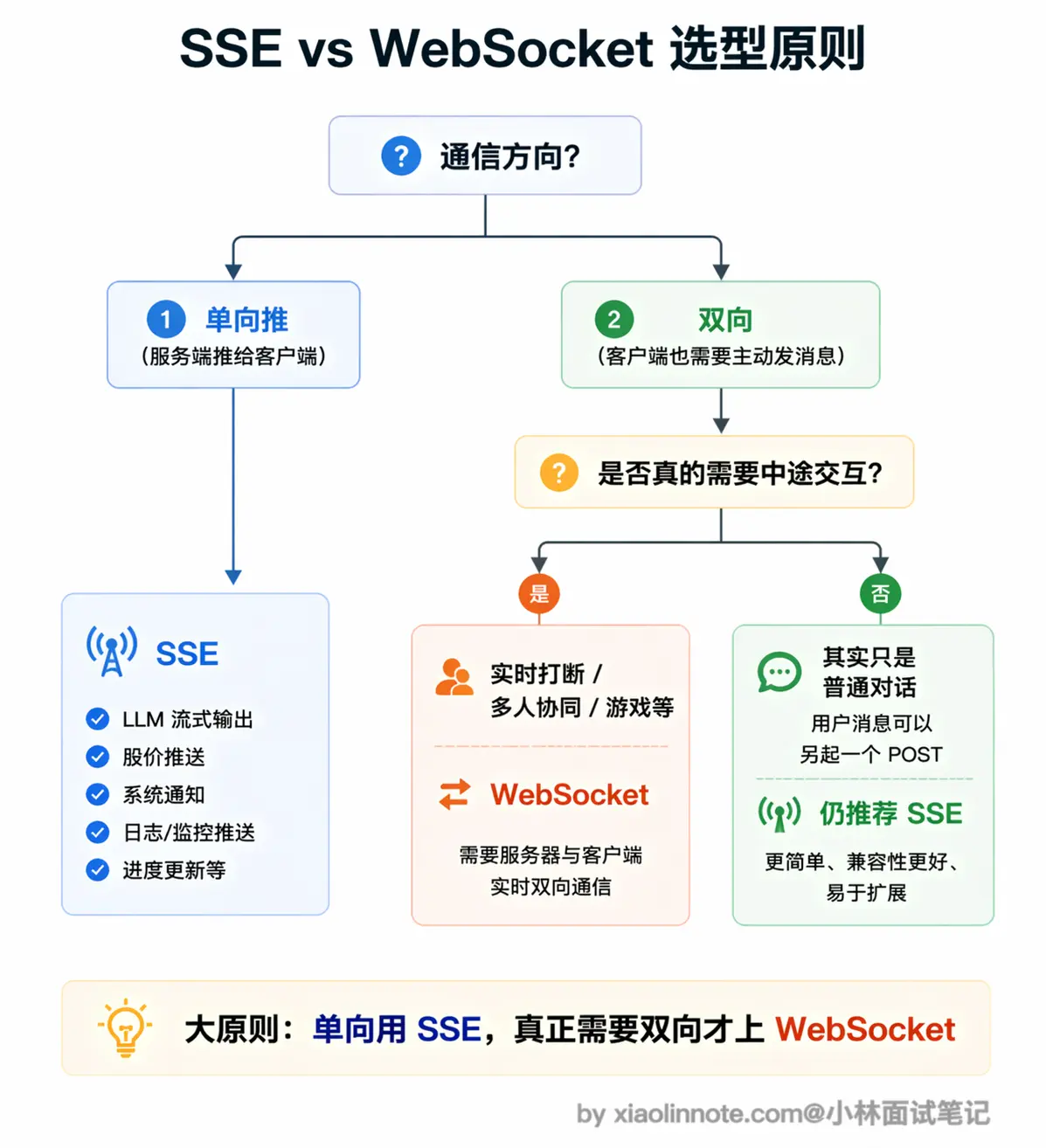
面试回答这道题,第一个核心要点是通信方向的区别:SSE 是服务端单向推送,客户端想发消息要另起 HTTP 请求;WebSocket 是全双工,双方都可以随时主动发消息。这是两者最本质的差异,不是「简单 vs 复杂」的关系。
第二个要点是各自的局限性,这往往是面试官追问的重点。
SSE 的三个坑要记住:HTTP/1.1 下同域名连接数上限(6 条)、只支持文本格式(传二进制要 Base64 编码膨胀 33%)、单向性导致的双通道架构复杂度。
WebSocket 的三个坑也要说到:有状态导致横向扩展麻烦(需要 Redis 等共享存储做连接状态外移)、容易被企业代理和防火墙拦截(Upgrade 握手被当异常请求拒掉)、没有内置的请求-响应配对机制(需要自己维护请求 ID 映射)。
第三个要点是选型原则:单向推用 SSE,真正需要双向才上 WebSocket。LLM 文字对话场景绝大多数用 SSE 就够了,这也是 OpenAI 和 Anthropic 的选择。能说出这个判断依据,比单纯罗列功能差异更有说服力。
15. 为什么要用 WebRTC 协议?它和 WebSocket(WS)在 AI 对话流中的核心差异是什么?
我理解核心原因是 WebSocket 基于 TCP,而 TCP 的可靠性设计在实时语音场景里反而是负担。
语音可以容忍丢包,但绝对不容忍延迟;一旦网络抖动丢了包,TCP 强制等重传,后续所有音频都得跟着等,延迟一堆积通话就卡。
WebRTC 走的是 UDP,丢包了不等重传,直接用插值算法填补,用一点点音质损失换来稳定的低延迟,延迟能控制在 50 到 150 毫秒。
另外 WebRTC 还内置了回声消除、噪声抑制、自适应码率这些语音处理能力,这些用 WebSocket 都得自己实现。
所以 OpenAI Realtime API 这类实时语音产品选 WebRTC,就是因为 TCP 根本撑不住语音场景的延迟要求。
要理解为什么语音场景需要 WebRTC,得先想清楚一个问题:传输文字和传输语音,对网络的要求本质上是不同的。
传输文字时,你希望每个字符都能准确到达,顺序不能乱,丢一个字母整段话可能就不对了。所以 TCP 的可靠有序传输对文字来说是刚需,你愿意等网络重传,因为等来的是完整正确的内容。
传输语音时,情况完全反过来。人类大脑对语音时序极其敏感,当两个人对话时,超过 200ms 的延迟就会让人明显感觉到「卡顿」,超过 400ms 就会开始出现「说话串线」的尴尬:你以为对方说完了开口说话,结果对方话还没说完。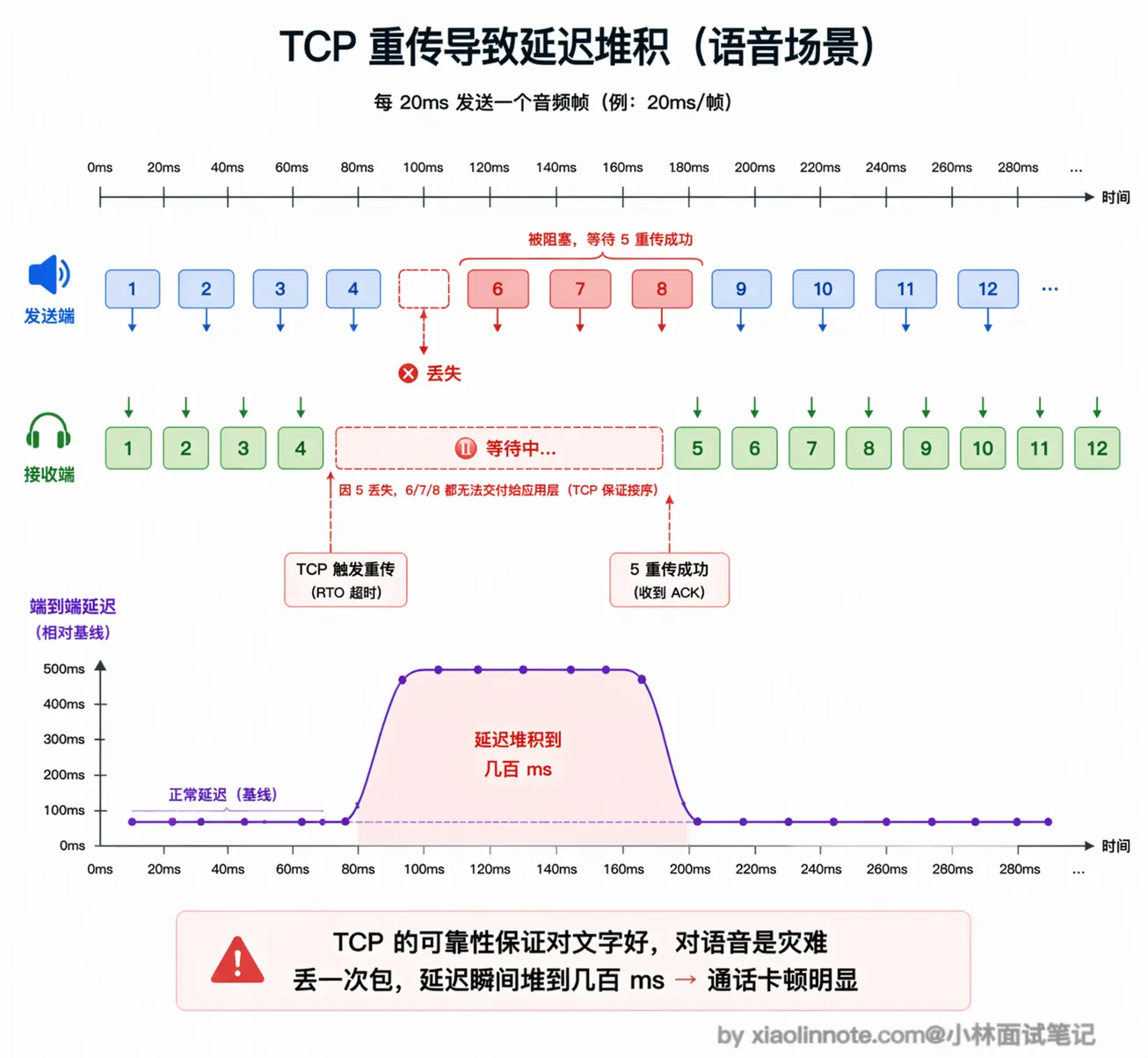
在这个场景里,丢掉一个 20ms 的音频小片段不是什么大事,人耳感知不到一小段静音;但为了等这 20ms 的片段重传,把后续所有音频都堵住,延迟积累到几百毫秒,体验就彻底崩了。语音容忍丢包,绝不容忍延迟,TCP 的设计哲学正好和这个需求相反。
WebSocket 底层是 TCP,所以它天然带着 TCP 的这个问题。用 WebSocket 传语音,每次网络轻微抖动导致丢包,TCP 就会触发重传等待,整条流的延迟都会随之堆积,不可避免。
WebRTC 的根本:选择 UDP,主动放弃可靠性
WebRTC 是 Google 主导开发、W3C 和 IETF 联合标准化的协议族,2011 年开始推进,最初目的就是让浏览器之间能直接做实时音视频通话,不需要安装任何插件。它最核心的设计决策是把底层从 TCP 换成 UDP。
UDP 完全不管可靠性,发出去的包丢了就丢了,没有重传,也没有等待。
这听起来很不可靠,但对语音来说恰恰是正确的选择。WebRTC 在 UDP 之上自己实现了一套对语音友好的丢包处理策略:当一个音频帧丢失时,不是等待重传,而是用「丢包隐藏(Packet Loss Concealment)」技术自动填补,用前后帧插值生成一段听起来合理的音频来替代,整体播放不中断,只是极短暂的音质轻微下降,人耳感知不到。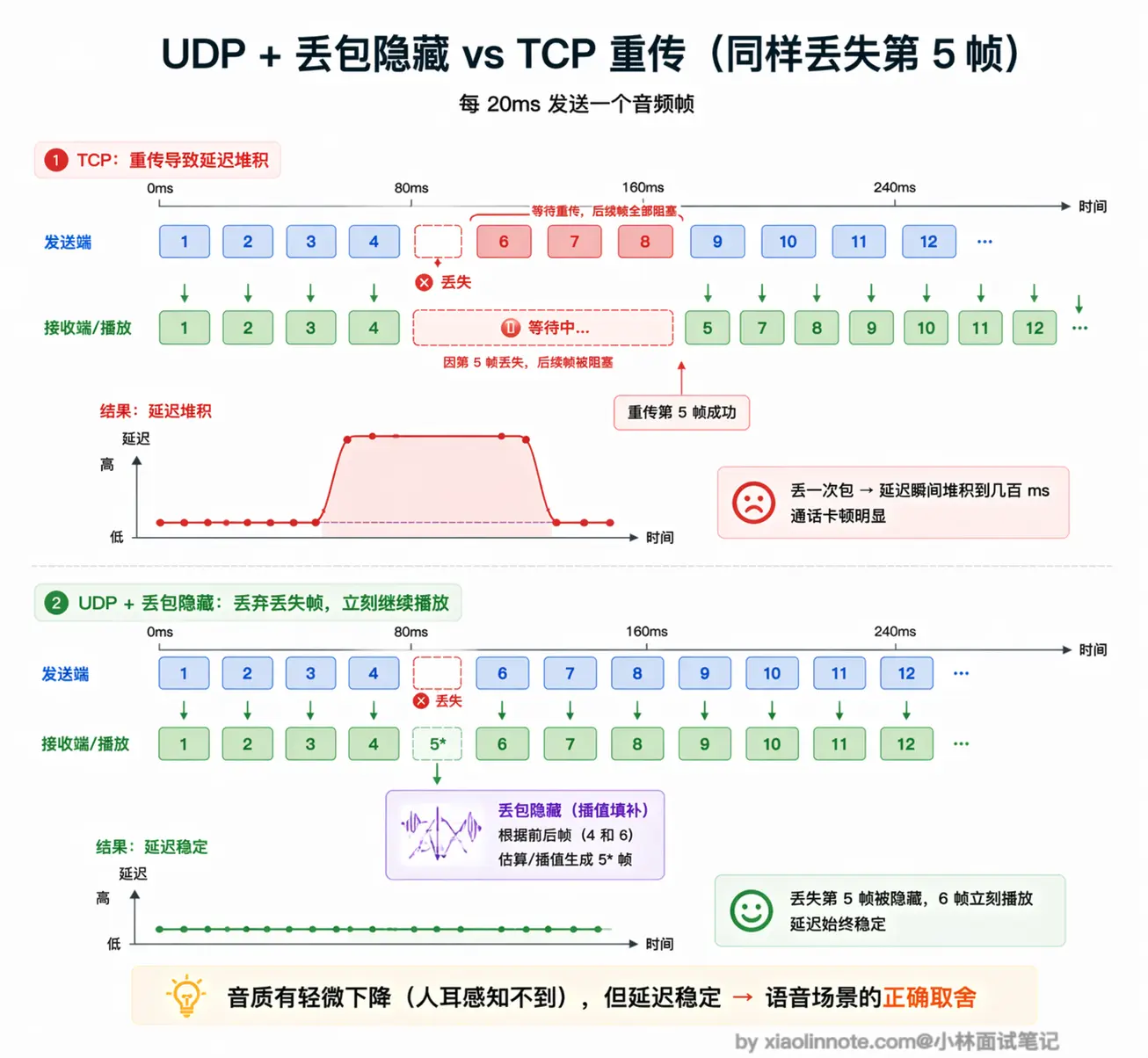
这是一个典型的工程权衡:用偶尔轻微的音质损失,换取稳定的低延迟。对语音通话而言,这是正确的取舍。
WebRTC 不是单一协议,而是一套协议组合
你可能以为 WebRTC 就是一个协议,跟 WebSocket 一样,换个名字而已。其实不是,WebRTC 更像是一套「协议全家桶」,在 UDP 之上叠加了好几层协议,每层各管一件事,组合在一起才能完成实时音视频通信。

最底层是 UDP,负责低延迟传输,这是整个 WebRTC 的地基。
UDP 上面跑的是 DTLS,负责密钥协商和加密。为什么需要单独搞一层加密呢?因为 UDP 不像 TCP 有现成的 TLS 握手机制,所以 WebRTC 用 DTLS(可以理解为「UDP 版的 TLS」)来完成加密通道的建立,保证音视频数据在传输过程中不会被窃听。
加密通道建好之后,媒体数据用 SRTP(Secure RTP)传输。
RTP 是专门为实时媒体设计的协议,每个包都带时间戳和序列号,接收方可以知道包的时序和是否有丢失,配合 RTCP 做传输质量的监控和反馈。你可以把 RTP 理解成「给每个音频包贴了标签」,接收方根据标签知道这个包应该排在哪里、前面有没有包丢了。
在连接建立阶段,WebRTC 使用 ICE(Interactive Connectivity Establishment)框架来处理 NAT 穿透,这是实际部署中最复杂的部分,后面单独解释。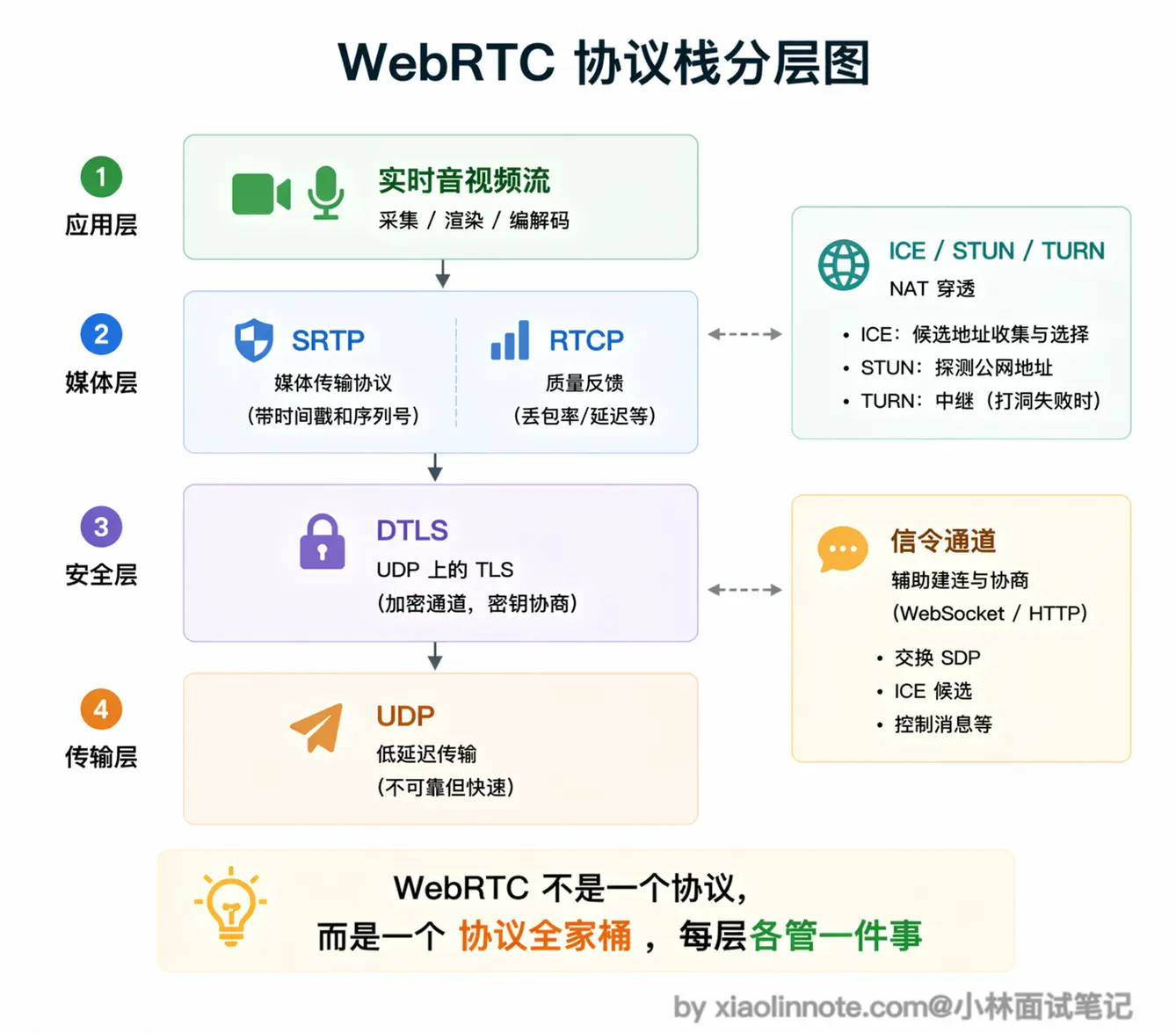
SDP 信令:WebRTC 握手的「协商书」
WebRTC 建立连接前,双方需要互相告知对方自己的能力:支持哪些音视频编解码格式、网络地址是什么、加密参数是什么。这个协商过程通过 SDP(Session Description Protocol)来完成。
SDP 本身只是一种格式,不规定如何传输。双方需要通过一个「信令通道」来交换 SDP,这个信令通道可以是 WebSocket、HTTP 或者任何能双向传输的方式,WebRTC 不关心。这就是为什么用 WebRTC 做 AI 语音时,还是需要一个 WebSocket 连接:WebSocket 负责信令交换(告诉对方「我的网络地址是 xxx,我支持 Opus 编解码」),真正的音频流走 WebRTC 的 UDP 通道。两者各司其职,不是替代关系。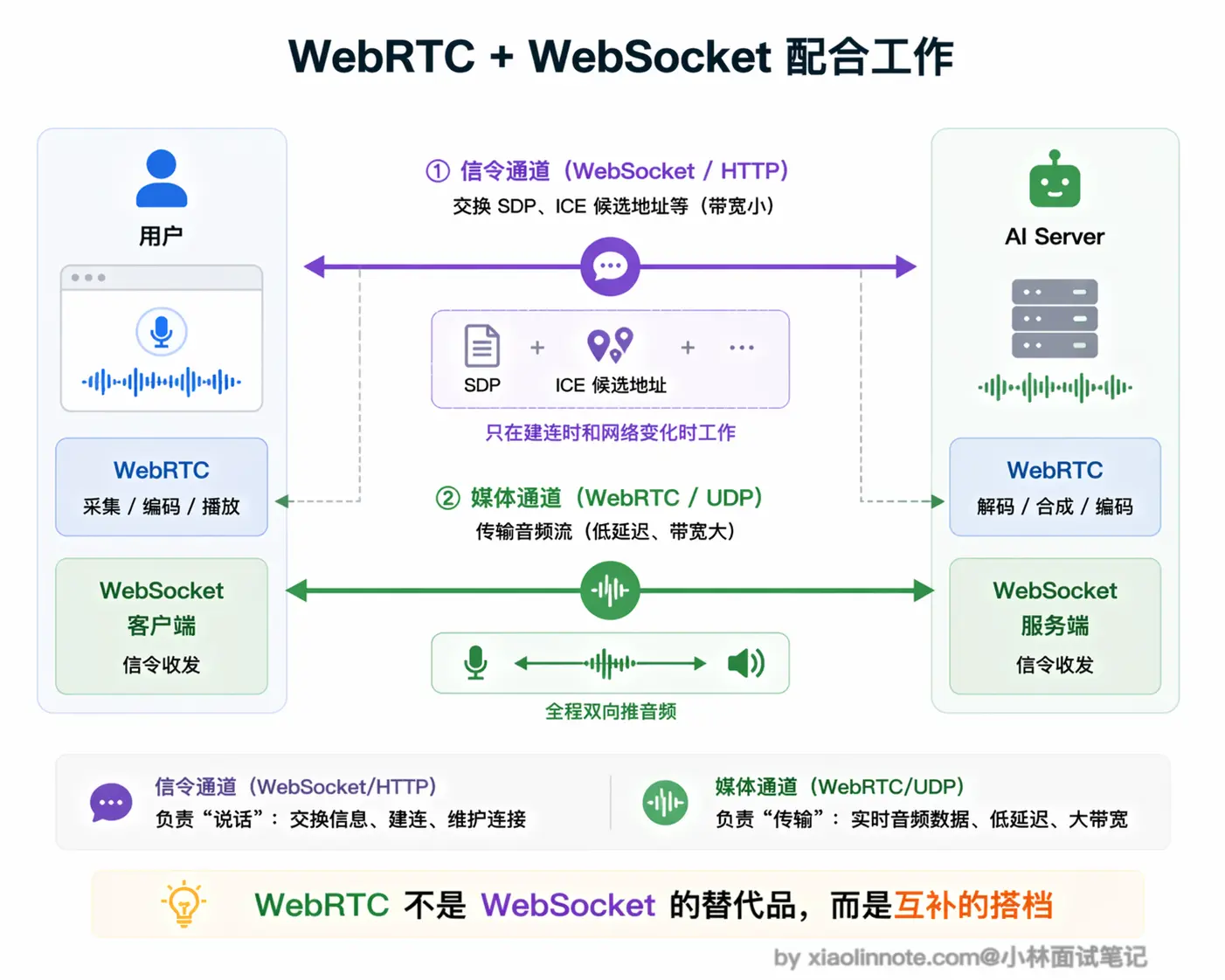
NAT 穿透:ICE/STUN/TURN 解决的问题
现实中大多数用户都在路由器后面,没有公网 IP,直接用内网地址互相连接是行不通的。WebRTC 用 ICE 框架来解决这个问题,ICE 会按优先级依次尝试三种连接方式: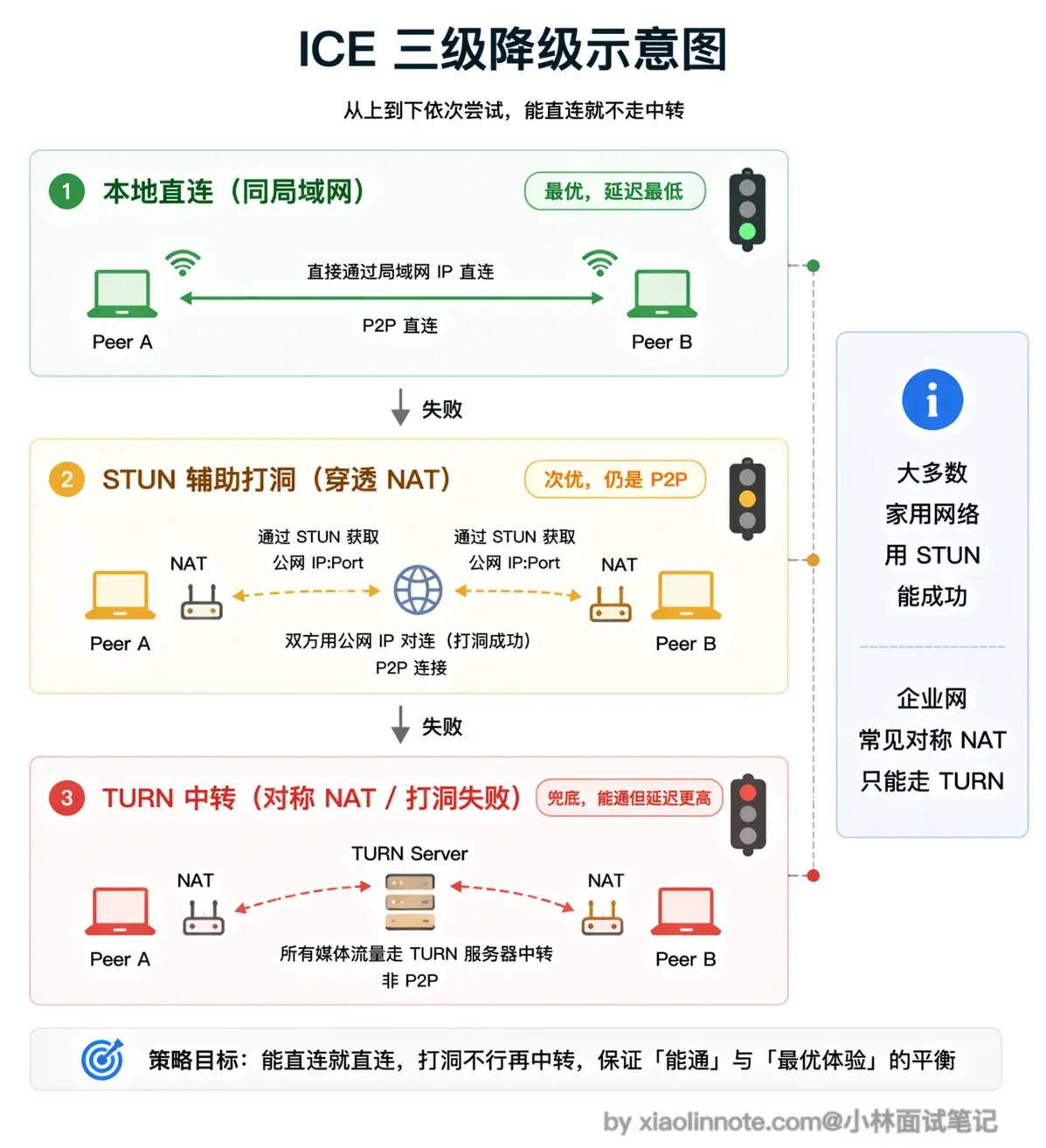
第一优先级是本地直连,如果两个用户在同一个局域网里,直接用内网地址连,延迟最低。第二优先级是 STUN 辅助的 NAT 穿透,STUN 服务器帮助客户端发现自己的公网 IP 和端口,然后双方尝试「打洞」建立 P2P 连接,大多数家用路由器环境下这个方式能成功,延迟仍然很低。第三优先级是 TURN 中转,当 NAT 打洞失败时,流量通过 TURN 服务器中转,失去了 P2P 直连的延迟优势,但至少能通。
你可能会问,为什么有些情况下打洞会失败、非得走 TURN?
最常见的原因是「对称 NAT」:这类 NAT(常见于企业防火墙、某些运营商级 NAT)对每个目标地址都会分配一个不同的出口端口号,STUN 探测到的那个端口在对端尝试连进来时已经换了,打洞自然打不通。这时候只能退一步找一台双方都能访问到的中转服务器(TURN),把流量从一方送到服务器、再从服务器送到另一方。
这三层降级保证了 WebRTC 在各种网络环境下都能建立连接,只是在最差情况下退化成类似 WebSocket 经过服务器中转的模式。
WebRTC 内置的音频处理能力
WebRTC 不只是一个传输协议,它把多年来实时语音通信领域积累的工程经验都内置进去了,这是用 WebSocket 传语音最难补齐的部分。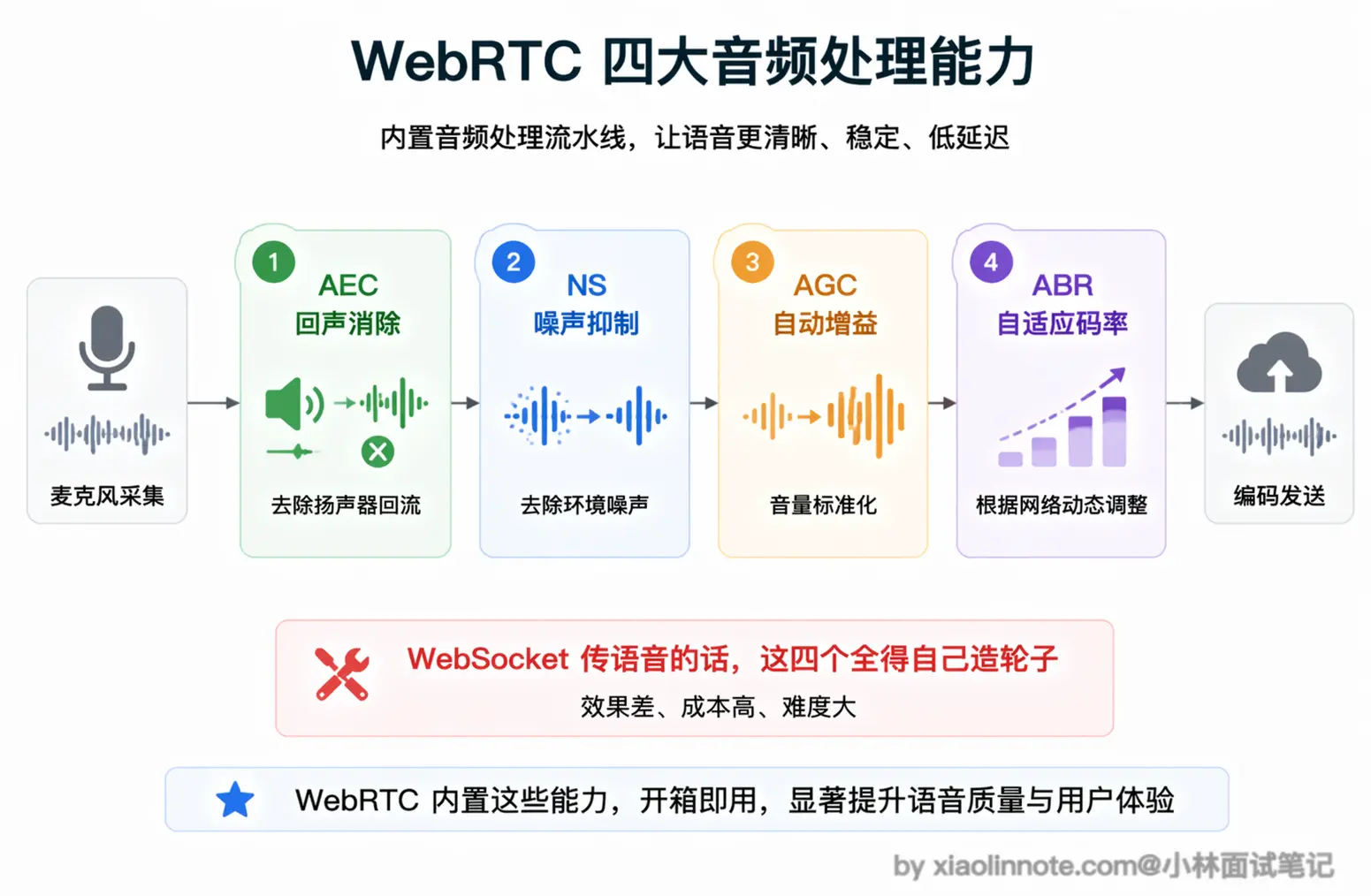
回声消除(AEC)是其中最重要的一个。当你用扬声器外放 AI 的声音时,麦克风会同时把这段声音采集进去,如果不做处理,AI 就会听到自己说话的回声,形成反馈循环。WebRTC 内置了多年优化的回声消除算法,能实时识别并消除这部分回声,让对话不产生干扰。
噪声抑制(NS)解决环境噪声问题,比如用户在嘈杂的咖啡厅说话,WebRTC 会自动把背景噪声过滤掉,只传人声。自动增益控制(AGC)解决音量不稳定的问题,说话声音太小时自动放大,太大时自动降低,保证对方听到稳定的音量。
最后是自适应码率控制(ABR):WebRTC 通过 RTCP 持续监测网络状况,动态调整音频比特率。网络好时用高码率保证音质,网络差时降低码率优先保证流畅,不会因为网络波动就直接卡死。这些能力组合在一起,才让 WebRTC 能在各种真实网络环境下维持可接受的通话质量。
OpenAI Realtime API 选择 WebRTC 的决策逻辑
OpenAI 在 2024 年发布了 Realtime API,用于实现实时语音对话:用户说话,AI 实时听,AI 说话,用户实时听,双方可以随时打断对方。
这个场景对技术方案的要求是非常苛刻的。首先,端到端延迟必须低于 300ms 才有自然的对话感,超过这个阈值用户就会明显感觉到「卡」。其次,语音必须双向同时流动,不能等一方说完再切换,这样才能实现自然的你一言我一语。再者,用户说话时必须能随时打断 AI 正在说的内容,不能让用户干等。最后还有回声消除的问题,麦克风采集的声音不能把 AI 正在播放的声音再传回去,否则会形成回声循环。
把这些要求综合起来看,TCP 系的方案(WebSocket)在网络抖动时达不到延迟要求,而且没有内置的音频处理能力,需要大量额外工程。WebRTC 天然满足所有这些要求,所以 Realtime API 选择了 WebRTC 作为媒体传输层。 选型原则很清晰:文字对话用 SSE 或 WebSocket,实时语音用 WebRTC。WebRTC 的复杂度是真实存在的,信令服务器、STUN/TURN 服务器的部署和运维都需要成本,但这些复杂度换来的是无可替代的低延迟和音频质量,在 AI 语音助手这类产品里是值得付出的代价。
选型原则很清晰:文字对话用 SSE 或 WebSocket,实时语音用 WebRTC。WebRTC 的复杂度是真实存在的,信令服务器、STUN/TURN 服务器的部署和运维都需要成本,但这些复杂度换来的是无可替代的低延迟和音频质量,在 AI 语音助手这类产品里是值得付出的代价。
面试回答这道题,第一个必须说到的核心点是底层协议的区别:WebSocket 基于 TCP,WebRTC 基于 UDP。TCP 丢包强制重传,后续数据全部等待,延迟不可控;UDP 不重传,WebRTC 用丢包隐藏技术(插值填补)处理丢失的音频帧,用微小的音质损失换取稳定的低延迟。语音场景的铁律是「容忍丢包,绝不容忍延迟」,TCP 的设计哲学和这个需求正好相反。
第二个要点是 WebRTC 内置的音频处理能力。回声消除(AEC)、噪声抑制(NS)、自动增益控制(AGC)、自适应码率(ABR)这些都是 WebRTC 原生支持的,用 WebSocket 做语音这些全得自己造轮子,工程量巨大。这不只是传输协议的差异,而是一整套音视频工程能力的差异。
第三个加分点是 WebRTC 的连接建立机制:SDP 信令交换 + ICE/STUN/TURN NAT 穿透。特别是能说清楚「WebRTC 建连时仍然需要 WebSocket 做信令通道,两者是配合关系而不是替代关系」,会让面试官觉得你对整个架构有完整的理解。