多线程程序中频繁
malloc/free的锁竞争可能吞噬大量性能。本文拆解一个仿 Google TCMalloc 的高并发内存池,看如何用"每线程缓存 + 三级架构"解决这个问题。
核心文件清单
| 文件 | 作用 |
|---|---|
Common.h |
公共头文件:SizeClass、FreeList、Span、SpanList、系统内存接口 |
ObjectPool.h |
定长内存池(Span 对象的专用内存池) |
ThreadCache.h/cpp |
线程局部缓存 |
CentralCache.h/cpp |
中心缓存 |
PageMap.h |
基数树,页号到 Span 的 O(1) 映射 |
PageCache.h/cpp |
页缓存 |
conCurrentAlloc.h |
对外统一分配/释放接口 |
代码详见gitee
一、概述
为什么需要内存池?
| 问题 | 说明 |
|---|---|
malloc 慢 |
库函数,多线程下需加锁,竞争激烈时性能急剧下降 |
| 系统调用慢 | mmap/brk 每次陷入内核 |
| 内存碎片 | 频繁申请释放小对象会导致大量碎片,降低缓存命中率 |
性能表现
| 指标 | malloc | 本内存池 |
|---|---|---|
| 多线程吞吐 | 慢(全局锁竞争) | 快(TLS 无锁分配) |
| 小对象分配 | 慢 | 极快(TLS 中直接 Pop) |
| 大对象分配 | 一般 | 直接 PageCache 或系统申请 |
二、整体架构
整个内存池分三层,每一层解决特定粒度的问题:
┌──────────────────────────────────────────────────────┐
│ ThreadCache (TLS) │
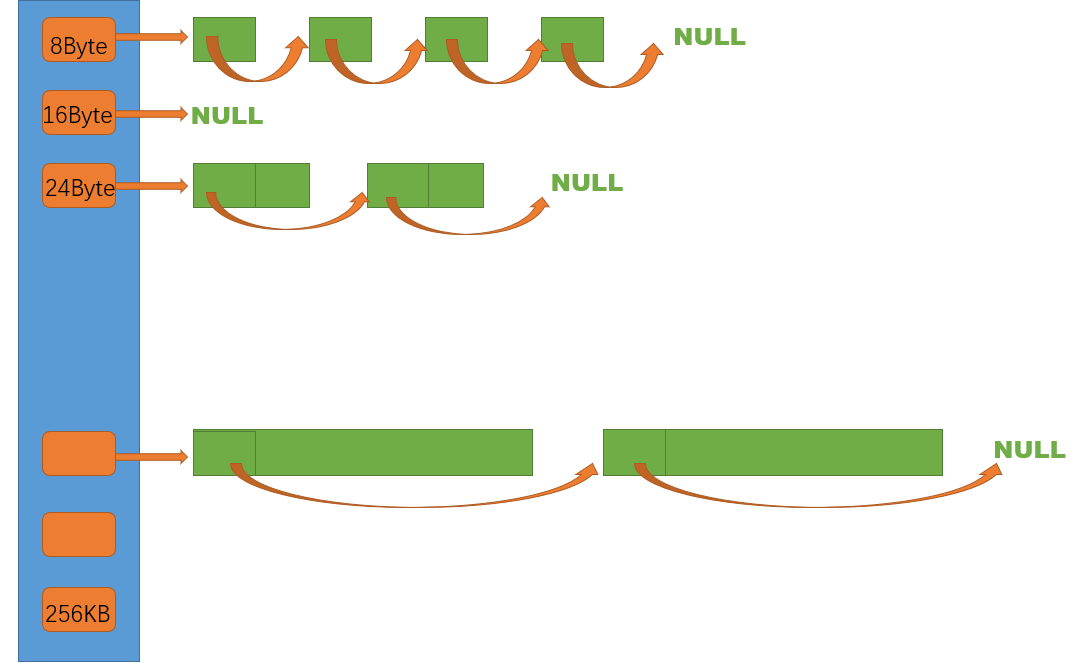
│ 每个线程独立,无锁访问,管理 208 个自由链表桶 │
└──────────────────┬───────────────────────────────────┘
│ 批量取 / 批量还
▼
┌──────────────────────────────────────────────────────┐
│ CentralCache (单例) │
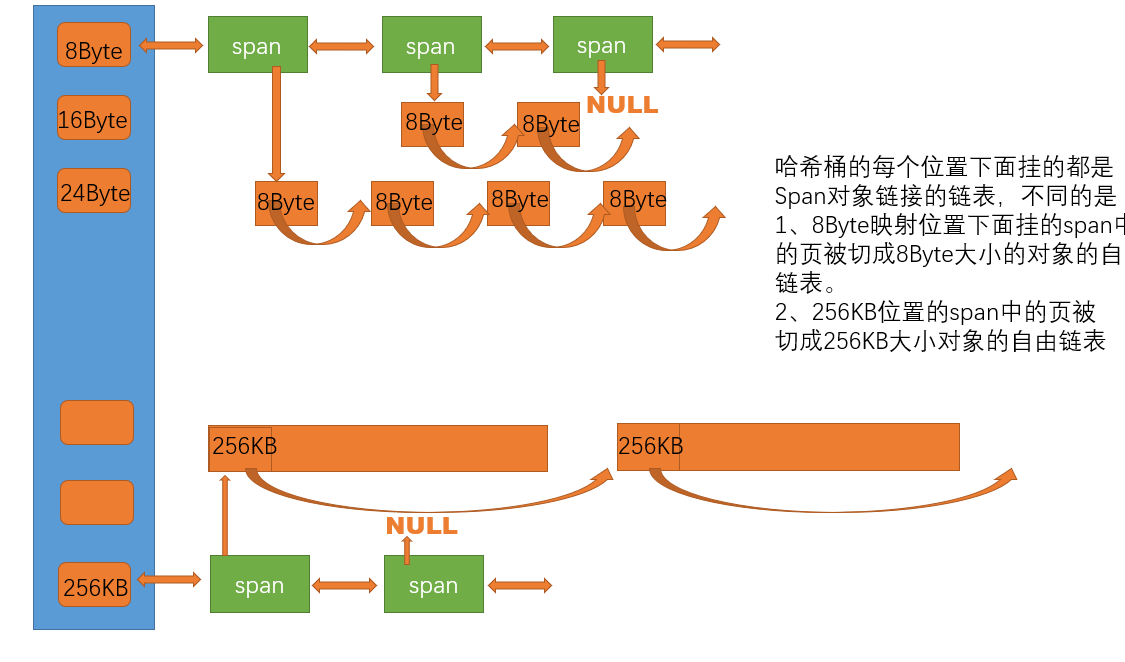
│ 所有线程共享,桶锁粒度,管理 208 个 Span 双向链表 │
└──────────────────┬───────────────────────────────────┘
│ 申请 Span / 回收 Span
▼
┌──────────────────────────────────────────────────────┐
│ PageCache (单例) │
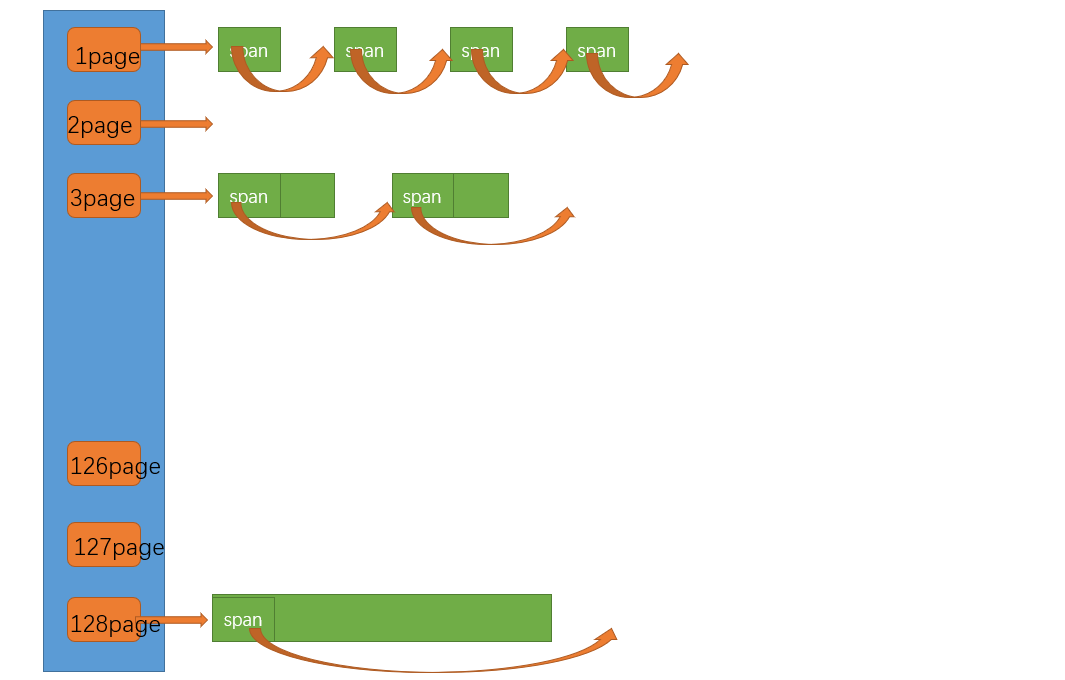
│ 管理 129 个页链表,负责 Span 的切分与前后向合并 │
│ 直接与操作系统(mmap/posix_memalign)交互 │
└──────────────────┬───────────────────────────────────┘
│ 系统申请 / 释放
▼
┌──────────────────────────────────────────────────────┐
│ System (mmap) │
└──────────────────────────────────────────────────────┘ThreadCache:
Central Cache:
Page Cache:
分配流程速览
ConCurrentAlloc(16)
│
├── size > 256KB? ──→ PageCache::NewSpan() ──→ 系统申请 → 直接返回
│
└── size <= 256KB?
│
├── ThreadCache 对应桶不为空? ──→ 直接 Pop 返回 ✅(最快)
│
└── 桶为空?
│
└── FetchFromCentralCache()
│
├── 慢启动计算 batchNum
├── CentralCache::FetchRangeObj()
│ ├── 对应 SpanList 无空闲 Span?
│ │ └── GetOneSpan()
│ │ ├── 当前桶有 Span? → 取出来切分
│ │ └── 没有? → PageCache::NewSpan()
│ │ ├── 对应页桶有? → 取出
│ │ ├── 后面大桶有? → 切分大 Span
│ │ └── 都没有? → 系统申请 128 页
│ └── 从 Span 的 freeList 取 batchNum 个对象
│
└── 1 个直接返回,其余 PushRange 到 ThreadCache释放流程速览
ConCurrentFree(ptr)
│
├── 查页表找 ptr 所属 Span → 获取 _objSize
│
├── size > 256KB? ──→ PageCache::ReleaseSpanToPageCache()
│ │ ├── 前后页合并(非使用中且不超 128 页)
│ │ └── 合并后挂回对应页链表
│
└── size <= 256KB?
│
└── ThreadCache::Deallocate()
├── Push 回对应桶
└── 桶太长了? → ListTooLong() → 还一批给 CentralCache
└── CentralCache::ReleaseListToSpans()
├── 根据页表找到所属 Span
├── 头插回 Span 的 freeList
└── _userCount == 0? → 整个 Span 还给 PageCache 合并三、核心组件详解
1. SizeClass --- 大小映射与对齐
将用户请求的任意字节对齐到固定粒度,映射到 208 个桶之一。将对齐后相同大小的对象放在同一个桶中,减少桶的数量,控制内碎片在 10% 以内。
对齐规则:
| 区间 | 对齐粒度 | 桶范围 |
|---|---|---|
| 1, 128 | 8 字节 | [0, 16) |
| 129, 1024 | 16 字节 | [16, 72) |
| 1025, 8K | 128 字节 | [72, 128) |
| 8K+1, 64K | 1024 字节 | [128, 184) |
| 64K+1, 256K | 8K 字节 | [184, 208) |
核心函数:
cpp
// 向上对齐到 alignNum 的整数倍,纯位运算
static inline size_t _RoundUp(size_t bytes, size_t alignNum) {
return (bytes + alignNum - 1) & ~(alignNum - 1);
}
// 桶索引:计算 size 映射到 freelist[208] 的哪个下标
static inline size_t _Index(size_t bytes, size_t alignShift) {
return ((bytes + (1 << alignShift) - 1) >> alignShift) - 1;
}_RoundUp 位运算拆解(以 8 字节对齐为例):
bytes = 5, alignNum = 8
(5 + 7) & ~7 = 12 & 0xF8 = 8 // 5 → 8
(8 + 7) & ~7 = 15 & 0xF8 = 8 // 8 → 8
(9 + 7) & ~7 = 16 & 0xF8 = 16 // 9 → 16批量大小计算:
cpp
// 一次从 CentralCache 批量取多少个对象
// 小对象批量多(最多 512),大对象批量少(最少 2)
static size_t NumMoveSize(size_t size) {
int num = MAX_BYTES / size; // 256K / size
if (num < 2) num = 2;
if (num > 512) num = 512;
return num;
}
// 这批对象需要占用多少页
static size_t NumMovePage(size_t size) {
size_t num = NumMoveSize(size);
size_t npage = num * size;
npage >>= PAGE_SHIFT; // 转为页数
if (npage == 0) npage = 1;
return npage;
}NumMoveSize 的大小依赖:小对象(如 16 字节)批量上限 512,大对象(如 128KB)批量上限 2。这保证了一次批量操作的总字节数不会超过 256KB。
2. FreeList --- 自由链表
管理切分好的同大小小块内存,本质是一个单向链表。
关键设计 :内存块的前 sizeof(void*) 字节被复用为 next 指针,不额外分配节点内存。
cpp
static void*& NextObj(void* obj) {
return *(void**)obj;
}核心接口:
| 操作 | 说明 |
|---|---|
Push(obj) |
头插一个对象 |
PushRange(start, end, n) |
头插一段范围(批量归还) |
Pop() |
头删一个对象 |
PopRange(start, end, n) |
头删一段范围(批量取出) |
MaxSize() |
慢启动上限 |
Size() |
当前节点数 |
为什么用 LIFO? 刚刚释放的内存块大概率还在 CPU 缓存中,优先使用能提高缓存命中率。
3. Span --- 内存跨度管理
Span 是内存管理的核心元数据,描述一段连续的内存页。
cpp
struct Span {
PAGE_ID _pageId = 0; // 起始页号
size_t _n = 0; // 页数
Span* _next = nullptr; // 双向链表指针
Span* _prev = nullptr;
size_t _userCount = 0; // 已分配给 ThreadCache 的小对象计数
void* _freeList = nullptr; // 切好的小块内存链表
bool _isUse = false; // 是否在使用中
size_t _objSize = 0; // 该 Span 中每个对象的大小
};关键字段:
_userCount:记录从该 Span 切出了多少个小对象。释放回来一个就减 1,归零时说明所有小块都回来了,整个 Span 可以回收_freeList:Span 从 PageCache 获得时是一整块连续内存,切分成小对象后通过这个指针组织成链表_objSize:记录 Span 里切的是多大的对象,释放时用于判断归还层级
4. SpanList --- Span 双向链表
管理 Span 的双向循环链表,带桶锁。
cpp
class SpanList {
Span* _head; // 哨兵头节点
std::mutex _mtx; // 桶锁
};每桶一把锁,线程操作不同桶时互不干扰,大幅降低锁冲突概率。
5. ObjectPool --- 定长内存池
专门为 Span 对象本身提供的内存池,避免用 new 反复申请元数据造成开销。
cpp
template<class T>
class ObjectPool {
char* _memory = nullptr; // 大块内存指针
size_t _remainBytes = 0; // 剩余可用字节
void* _freeList = nullptr; // 回收的对象复用链表
};分配策略:
- 先看
_freeList有没有回收的对象,有则复用 - 没有则从
_memory大块上切,不够就malloc(128KB)新大块
释放策略:
- 调用
obj->~T()析构函数 - 头插到
_freeList等待复用
cpp
T* New() {
// 路径一:有回收对象 → 复用
if (_freeList) {
void* next = *(void**)_freeList;
obj = (T*)_freeList;
_freeList = next;
}
// 路径二:从大块上切
else {
if (_remainBytes < sizeof(T)) {
_memory = (char*)malloc(128 * 1024);
_remainBytes = 128 * 1024;
}
obj = (T*)_memory;
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_memory += objSize;
_remainBytes -= objSize;
}
new(obj) T; // placement new 调构造函数
return obj;
}
void Delete(T* obj) {
obj->~T(); // 先析构
*(void**)obj = _freeList; // 头插复用链表
_freeList = obj;
}6. ThreadCache --- 线程缓存
每个线程独立拥有的缓存,无锁分配,是性能关键。
cpp
static thread_local ThreadCache* pTLSThreadCache = nullptr;每个线程首次访问时,系统在 TLS 区域为该线程单独分配一个 ThreadCache*。名字相同,但物理内存完全隔离,操作自己的 ThreadCache 完全不需要加锁。
分配流程:
cpp
void* ThreadCache::Allocate(size_t size) {
size_t alignSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(size);
if (!_freeLists[index].Empty())
return _freeLists[index].Pop(); // 快路径:无锁
return FetchFromCentralCache(index, alignSize);
}释放流程:
cpp
void ThreadCache::Deallocate(void* ptr, size_t size) {
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
// 桶里攒太多了,释放一批回 CentralCache
if (_freeLists[index].Size() >= _freeLists[index].MaxSize())
ListTooLong(_freeLists[index], size);
}何时触发归还? 空闲对象数量 >= MaxSize() 时,归还 MaxSize() 个,防止某线程囤积过多空闲内存。
7. 慢启动批量获取算法
初始时不要一次拿太多,用多少拿多少,按需增长。
cpp
size_t batchNum = std::min(_freeLists[index].MaxSize(),
SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
_freeLists[index].MaxSize() += 1; // 慢增长流程:
_maxSize初始为 1,每次从 CentralCache 取 1 个- 再次用完时
_maxSize += 1,逐渐增大批量 - 上限不超过
NumMoveSize(size)
为什么? 用量少时取太多浪费;取太多可能把 CentralCache 的 Span 搬空。自适应:用得多就多取,用得少就少取。
8. CentralCache --- 中心缓存
全局共享的中心缓存,线程们在这里批量取/还内存,用桶锁保护并发。
单例模式:
cpp
class CentralCache {
static CentralCache _sInst;
static CentralCache* GetInstance() { return &_sInst; }
SpanList _spanLists[NFREELIST]; // 208 个桶
};FetchRangeObj --- 从 CentralCache 取一批对象:
cpp
size_t CentralCache::FetchRangeObj(void*& start, void*& end,
size_t batchNum, size_t size) {
Span* span = GetOneSpan(_spanLists[index], size);
start = span->_freeList;
end = start;
size_t actualNum = 1;
while (actualNum < batchNum - 1 && NextObj(end) != nullptr) {
end = NextObj(end);
++actualNum;
}
span->_freeList = NextObj(end);
NextObj(end) = nullptr;
span->_userCount += actualNum;
return actualNum;
}GetOneSpan --- 要么取现有 Span,要么创建新 Span:
cpp
Span* CentralCache::GetOneSpan(SpanList& list, size_t size) {
// 1. 遍历当前桶,找有空闲对象的 Span
Span* it = list.Begin();
while (it != list.End()) {
if (it->_freeList != nullptr) return it;
it = it->_next;
}
// 2. 没有 → 去 PageCache 申请新 Span
Span* span = PageCache::GetInstance()->NewSpan(NumMovePage(size));
span->_objSize = size;
// 3. 把 Span 的大块内存切分成小对象,串成链表
char* start = (char*)(span->_pageId << PAGE_SHIFT);
char* end = start + (span->_n << PAGE_SHIFT);
span->_freeList = start;
start += size;
void* tail = span->_freeList;
while (start < end) {
NextObj(tail) = start;
tail = NextObj(tail);
start += size;
}
NextObj(tail) = nullptr;
list.PushFront(span);
return span;
}ReleaseListToSpans --- 归还一批对象:
cpp
void CentralCache::ReleaseListToSpans(void* start, size_t size) {
while (start) {
void* next = NextObj(start);
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
NextObj(start) = span->_freeList;
span->_freeList = start;
span->_userCount--;
if (span->_userCount == 0) {
// Span 完全空闲,还给 PageCache 合并
_spanLists[index].Erase(span);
span->_freeList = nullptr;
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
}
start = next;
}
}9. PageCache --- 页缓存
管理物理页,负责 Span 的切分 和合并。同样使用单例模式,管理 129 个桶,第 k 个桶管理大小为 k 页的 Span。
cpp
class PageCache {
SpanList _pageLists[NPAGES]; // 129 个桶
ObjectPool<Span> _spanPool; // Span 对象的定长内存池
PageMap _idSpanMap; // 页号 → Span 映射
std::mutex _mtx; // 全局锁
};为什么用全局锁而不是桶锁? 合并操作需要跨桶操作(前后相邻页面可能在不同桶中),桶锁无法保证。但 PageCache 访问频率远低于 CentralCache,锁竞争不激烈。
NewSpan --- 获取 k 页的 Span:
cpp
Span* PageCache::NewSpan(size_t k) {
// 1. >128 页 → 直接向系统申请
if (k > NPAGES - 1) { /* SystemAlloc + 建映射 */ }
// 2. 当前桶有 → 直接取
if (!_pageLists[k].Empty()) return _pageLists[k].PopFront();
// 3. 找后面大桶,切分
for (int i = k + 1; i < NPAGES; i++) {
if (!_pageLists[i].Empty()) {
Span* nspan = _pageLists[i].PopFront(); // 取大 Span
Span* kspan = _spanPool.New(); // 新建小 Span
kspan->_pageId = nspan->_pageId; // 头部切出 k 页
kspan->_n = k;
nspan->_pageId += k; // 剩余部分
nspan->_n -= k;
_pageLists[nspan->_n].PushFront(nspan);
// 建立映射(剩余部分首尾两页 + kspan 所有页)
_idSpanMap.set(nspan->_pageId, nspan);
_idSpanMap.set(nspan->_pageId + nspan->_n - 1, nspan);
for (PAGE_ID i = 0; i < kspan->_n; i++)
_idSpanMap.set(kspan->_pageId + i, kspan);
return kspan;
}
}
// 4. 都没有 → 系统申请 128 页大 Span,递归调用自己
Span* bigSpan = _spanPool.New();
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_pageLists[bigSpan->_n].PushFront(bigSpan);
return NewSpan(k); // 递归,第二次就能找到对应桶
}ReleaseSpanToPageCache --- 回收 Span 并尝试合并:
cpp
void PageCache::ReleaseSpanToPageCache(Span* span) {
// >128 页不合并,直接还给系统
if (span->_n > NPAGES) { SystemFree(ptr, span->_n); return; }
// 向前合并
while (1) {
PAGE_ID prevId = span->_pageId - 1;
Span* prev = (Span*)_idSpanMap.get(prevId);
if (!prev || prev->_isUse) break;
if (prev->_n + span->_n > NPAGES - 1) break;
span->_pageId = prev->_pageId;
span->_n += prev->_n;
_pageLists[prev->_n].Erase(prev);
_spanPool.Delete(prev);
}
// 向后合并(对称逻辑)
// 重建整段映射 --- ★ 不然后续查映射读到野指针
_pageLists[span->_n].PushFront(span);
span->_isUse = false;
for (PAGE_ID i = span->_pageId; i < span->_pageId + span->_n; i++)
_idSpanMap.set(i, span);
}合并条件:
- 邻居页号映射存在
- 邻居 Span 不在使用中
- 合并后不超过 128 页
为什么释放时必须重建整段映射? 合并前旧 Span 的中间页映射仍指向已回收的对象,不重建的话后续 MapObjectToSpan 返回野指针,读 _objSize 时会段错误。
10. PageMap --- 基数树
替代 std::unordered_map 实现页号到 Span 指针的快速映射。项目使用 PageMap3<36>。
| 特性 | std::unordered_map |
基数树 |
|---|---|---|
| 时间复杂度 | O(1) 均摊,最坏 O(n) | O(1) 严格 |
| 哈希冲突 | 有 | 无 |
| 缓存友好 | 否 | 是 |
| 内存占用 | 固定较大 | 按需分配 |
三种变体:
| 变体 | 层级 | BITS=36 时的可行性 |
|---|---|---|
PageMap1 |
1 级 | 需要 512GB 连续内存,不可能 |
PageMap2 |
2 级 | 叶子 16GB,仍不现实 |
PageMap3 |
3 级 | 每节点 32KB,按需分配,可行 |
PageMap3 分层结构(BITS=36):
cpp
INTERIOR_BITS = (36 + 2) / 3 = 12 // 每层 4096 项
LEAF_BITS = 36 - 2 * 12 = 12 // 叶子 4096 项地址解码:
cpp
PAGE_ID id = addr >> PAGE_SHIFT; // 36 bit 页号
i1 = id >> (12 + 12); // 高 12 位 → 根节点索引
i2 = (id >> 12) & 0xFFF; // 中 12 位 → 内节点索引
i3 = id & 0xFFF; // 低 12 位 → 叶子节点索引节点按需分配:未访问的页号范围不消耗内存。
四、辅助组件
SystemAlloc / SystemFree
跨平台封装系统级内存申请/释放:
- Linux :
posix_memalign(&ptr, 4096, size)--- 4KB 对齐 - Windows :
VirtualAlloc(0, size, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE) - 释放:Linux 用
free(),Windows 用VirtualFree()
ConCurrentAlloc / ConCurrentFree
对外统一分配/释放接口:
cpp
static void* ConCurrentAlloc(size_t size) {
if (size > MAX_BYTES) { // 大对象 > 256KB
// 直接走 PageCache(或系统),不经过前两层缓存
Span* span = PageCache::GetInstance()->NewSpan(kpage);
return (void*)(span->_pageId << PAGE_SHIFT);
}
// 小对象:走 ThreadCache
if (pTLSThreadCache == nullptr)
pTLSThreadCache = new ThreadCache;
return pTLSThreadCache->Allocate(size);
}
static void ConCurrentFree(void* ptr) {
Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);
size_t size = span->_objSize;
if (size > MAX_BYTES) // 大对象直接还给 PageCache
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
else // 小对象还给 ThreadCache
pTLSThreadCache->Deallocate(ptr, size);
}五、数据流全景
malloc(16) ──→ ConCurrentAlloc(16)
│
├─ RoundUp(16) = 16, Index(16) = 1
│
├─ ThreadCache 桶[1] 有? → Pop() ✅
│
└─ 没有?
├─ MaxSize=1, NumMoveSize(16)=512
├─ batchNum = min(1,512) = 1
├─ MaxSize() += 1 → 2
│
└─ CentralCache::FetchRangeObj(batchNum=1)
├─ _spanLists[1] 有 Span?
│ ├─ 有 → 从其 freeList 取 1 个
│ └─ 没有 → GetOneSpan()
│ ├─ PageCache::NewSpan(1)
│ │ ├─ _pageLists[1] 有? → 直接取
│ │ ├─ 没有 → 找 _pageLists[2..128]
│ │ │ → 找到 _pageLists[4] 有 4 页 Span
│ │ │ → 切出 1 页给新 Span
│ │ │ → 剩下 3 页挂 _pageLists[3]
│ │ └─ 后面都没? → 系统申请 128 页
│ │ → 挂 _pageLists[128]
│ │ → 递归 NewSpan(1) 重新找
│ │
│ └─ 把 Span 切成 16 字节对象链表
│
└─ 返回 1 个对象给 ThreadCache ✅
free(ptr) ──→ ConCurrentFree(ptr)
│
├─ MapObjectToSpan(ptr) → 查页表得 Span
├─ 得 _objSize = 16
│
├─ ThreadCache 桶[1] Push(ptr)
│
└─ Size() >= MaxSize()?
└─ 是 → ListTooLong()
├─ PopRange() 取一批
└─ CentralCache::ReleaseListToSpans()
├─ MapObjectToSpan 找 Span
├─ 头插回 Span 的 freeList
└─ _userCount == 0?
└─ 是 → 整个 Span 还给 PageCache
├─ 向前向后合并空闲 Span
└─ 挂回对应页桶六、常见面试问题
Q1:为什么用三层架构?两层不行吗?
如果只有 ThreadCache + 系统堆:ThreadCache 用完只能找系统,系统调用代价大,也无法线程间借调。如果只有 CentralCache + 系统堆:所有线程竞争桶锁,没有快路径。
三层架构的巧妙之处:
- ThreadCache:最频繁的操作完全无锁
- CentralCache:线程间内存调度,桶锁减小竞争
- PageCache:底层页管理,切分与合并对抗碎片
Q2:thread_local 关键字的作用?
每个线程独立拥有一个 ThreadCache* 变量,互不干扰。完全避免了锁的开销------这是速度优势的核心来源。首次使用时创建,线程结束时系统自动回收。
Q3:Span 中的 _userCount 有什么作用?
引用计数,记录从该 Span 切出了多少小对象。_userCount == 0 时意味着此 Span 的所有小块都归还了,可以还给 PageCache 尝试合并。
为什么不能只看 freeList? 当前 Span 的 freeList 可能为空,但 ThreadCache 还持有该 Span 的部分对象。必须用 _userCount 才能真正确定。
Q4:内碎片和外碎片是什么?
| 类型 | 说明 | 解决方法 |
|---|---|---|
| 内碎片 | 分配比实际需要大 | SizeClass 对齐控制在 10% 以内 |
| 外碎片 | 已分配内存之间的空洞 | PageCache 的 Span 合并机制 |
Q5:什么是慢启动算法?
控制 ThreadCache 每次从 CentralCache 批量获取的数量:初始 1,每次 Fetch 时增长,上限不超过 NumMoveSize(size)。用多少取多少,用得少不多拿。
Q6:MapObjectToSpan 如何工作?
地址右移 13 位得到页号,通过基数树找到对应的 Span 对象。不同于 unordered_map,基数树通过位运算直接算下标,O(1) 且无哈希冲突。
Q7:为什么选 PageMap3<36> 而不是 PageMap1 或 PageMap2?
BITS=36 时,PageMap1 需要 512GB 连续数组,PageMap2 叶子节点 16GB,都不现实。PageMap3 每节点仅 32KB,按需分配,总开销与使用量成正比。
Q8:大对象(>256KB)的分配释放有何不同?
不经过 ThreadCache 和 CentralCache,直接由 PageCache 分配(或系统直接分配)。大对象操作频率低,走缓存意义不大,反而影响小对象的缓存效率。
Q9:这个项目的瓶颈在哪里?如何改进?
| 瓶颈 | 说明 | 可能的改进 |
|---|---|---|
| PageCache 全局锁 | 所有 CentralCache 没 Span 时都等这把锁 | 分段锁、无锁数据结构 |
| 内存占用 | ThreadCache 可能缓存大量空闲内存 | 更激进的归还策略、自适应水位线 |
| 跨平台 | posix_memalign 部分系统性能不如 mmap |
按平台优化底层内存申请 |