1. 聊天模型 - 定义工具
工具调用根本作用是让大语言模型(LLM)具备与外部世界交互的能力。
LLM本身是一个封闭的知识系统,其能力受限于其训练的数据(存在滞后性)和内在的文本生成逻辑。他无法进行直接的计算,查询实时的信息,操作数据库和调用外部的API。工具调用打破了这层壁垒,其作用具体体现在:
-
扩展能力边界:模型可以借助工具完成它自身无法完成的任务,如执行数学计算、搜索网络、查询数据库等。
-
保证信息实时性:通过调用搜索工具或数据库查询工具,LLM 可以获取最新的、训练数据中不存在的信息,避免回答过时或"一本正经地胡说八道"。
-
处理复杂任务:将一个复杂的用户请求(如"分析我上个月的消费趋势")分解成多个步骤,并依次调用不同的工具(如"从数据库获取数据"->"用Python 进行数据分析"->"生成图表")来协同完成。协调这件事这更体现在Agent 智能体上。
-
连接现有系统:可以将企业内部已有的系统、API 和数据库封装成工具,让LLM 成为一个用自然语言驱动的统一接口,极大地提升了自动化和集成能力。
在LangChain 中,聊天模型提供了额外的功能:工具调用。它能使LLM 与外部服务、API 和数据库进行交互。工具调用还可用于从非结构化数据中提取结构化信息并执行各种其他任务。
例如,当我们希望获取当前天气情况时,由于LLM 无法获取实时信息,此时我们就可以借助工具,通过外部服务进行搜索完成查询。
1.1. 创建工具
1.1.1. 使用 @tool 装饰器创建工具
在LangChain 中,实现了一个@tool 装饰器来创建工具,@tool 装饰器是自定义工具的最简单方法。如下所示:
python
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int)->int:
"""Multiply two integers.
Args:
a: First integer
b: Second integer
"""
return a * b
print(multiply.invoke({"a": 2, "b": 3}))
print(multiply.name)
print(multiply.description)
print(multiply.args)运行结果:
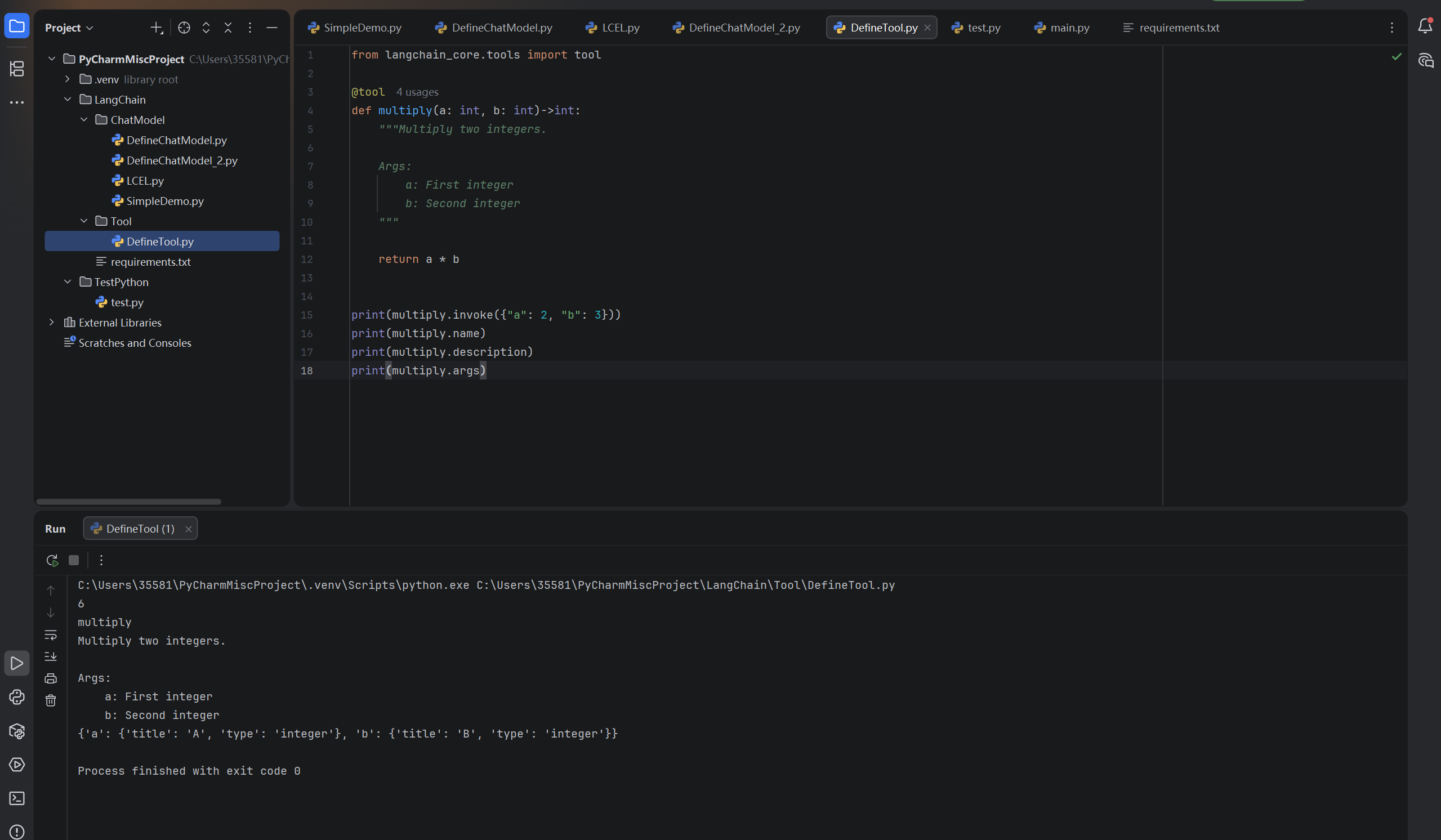
可以看出,工具通过@tool加上Python函数来实现的,其中:
- 该装饰器默认使用文档字符串当作工具的描述
- 该装饰器默认使用函数名充当工具名
因此,函数名、类型提示和文档字符串都是传递给工具Schema的一部分,不可缺失。定义好的描述是使模型良好运行的重要部分。
Schema是什么?
想象以不同的方式,在JSON中表示一个人的相关信息:
示例1:
cpp{ "name" : "小明", "birthday" : "2005年1月1日", "address" : "湖南省长沙市芙蓉区" }示例2:
cpp{ "surname" : "李" "given name" : "四" "birthday" : "2006-09-01" "address":{ "district": "萧山区", "city": "杭州市", "province": "浙江省" "country": "中国" } }这两种表述同样有效,尽管示例2显然比示例1更正式。记录的设计在很大程度上取决于其在应用程序中的预期用途,因此这里没有正确或错误的答案。
但是,当应用程序说"给我一个人的JSON 记录"时,重要的是要确切地知道该如何组织记录。例如,我们需要知道需要哪些字段,以及如何表示这些值。这就是JSON Schema 的用武之地
转化成编码格式,则为以下内容(此JSON Schema 片段描述了上述第二个示例的结构):
cpp{ "type": "object", "properties":{ "surname": { "type": "string" }, "given_name": { "type": "string" }, "birthday": { "type": "string", "format": "date" }, "address":{ "type": "object", "properties":{ "district": { "type": "string" } "city": { "type": "string" }, "province": { "type": "string" }, "country": { "type" : "string" } } } } }若用此JSON Schema"验证"示例1,那么示例1是不符合当前JSON Schema 的,但是示例2可以"验证"通过。
注意,JSON Schema 是数据本身,而不是计算机程序,它只是一种"描述其他数据结构"的声明格式。简明扼要地描述数据的表面结构,并根据数据自动验证数据很容易。但是,由于JSON Schema能包含任意代码,因此无法表达数据元素之间的关系存在某些约束。
因此,对于足够复杂的数据格式,任何"验证工具"都可能有两个验证阶段:一个在schema(或结构)级别,一个在语义级别。后一种检查可能需要使用更通用的编程语言来实现。
最后回答一下问题,Schema 就是描述其他数据结构的声明格式,用于自动验证数据而存在。
总而言之:JSON Schema是判断JSON数据是否符合预先设计要求的数据格式"答案"
有了以上概念铺垫,对于工具schema,它将从函数名、类型提示和文档字符串中获取相关属性,以此来声明一个工具,包括其名称、描述、输入参数、输出类型等等。这里需要说明的是,若是简单定义工具,如上述示例,工具schema 需要解析Google 风格的文档字符串去获取【参数描述】.
什么是Google 风格的文档字符串?Google 风格是Python 文档字符串的一种写作规范。它并非 Python 语言官方强制要求,而是由Google 为其内部Python 项目制定的规范,后来因为其极高的可读性和简洁性而在整个Python 社区中变得非常流行。它使用Args :,Returns :等关键字,参数描述简洁明了,如下所示:
python
def fetch_data(url , retries=3):
"""从给定的URL获取数据。
Args :
url (str):要从中获取数据的URL。
retries (int , optional):失败时重试的次数。默认为3。
Returns :
dict :从URL解析的JSON响应。
"""
# 函数实现 除了这种方式,还有其他方式可以让工具schema,获取相关工具声明需要的内容。下面再展示其他常用的工具定义模式:
1.1.1.1. 模式1:依赖Pydantic类
若使用@tool 定义工具时,没有提供文档字符串,则会报错:
python
@tool
def add(a: int, b: int)->int:
return a + b
@tool
def sub(a: int, b: int) -> int:
return a - b运行结果:
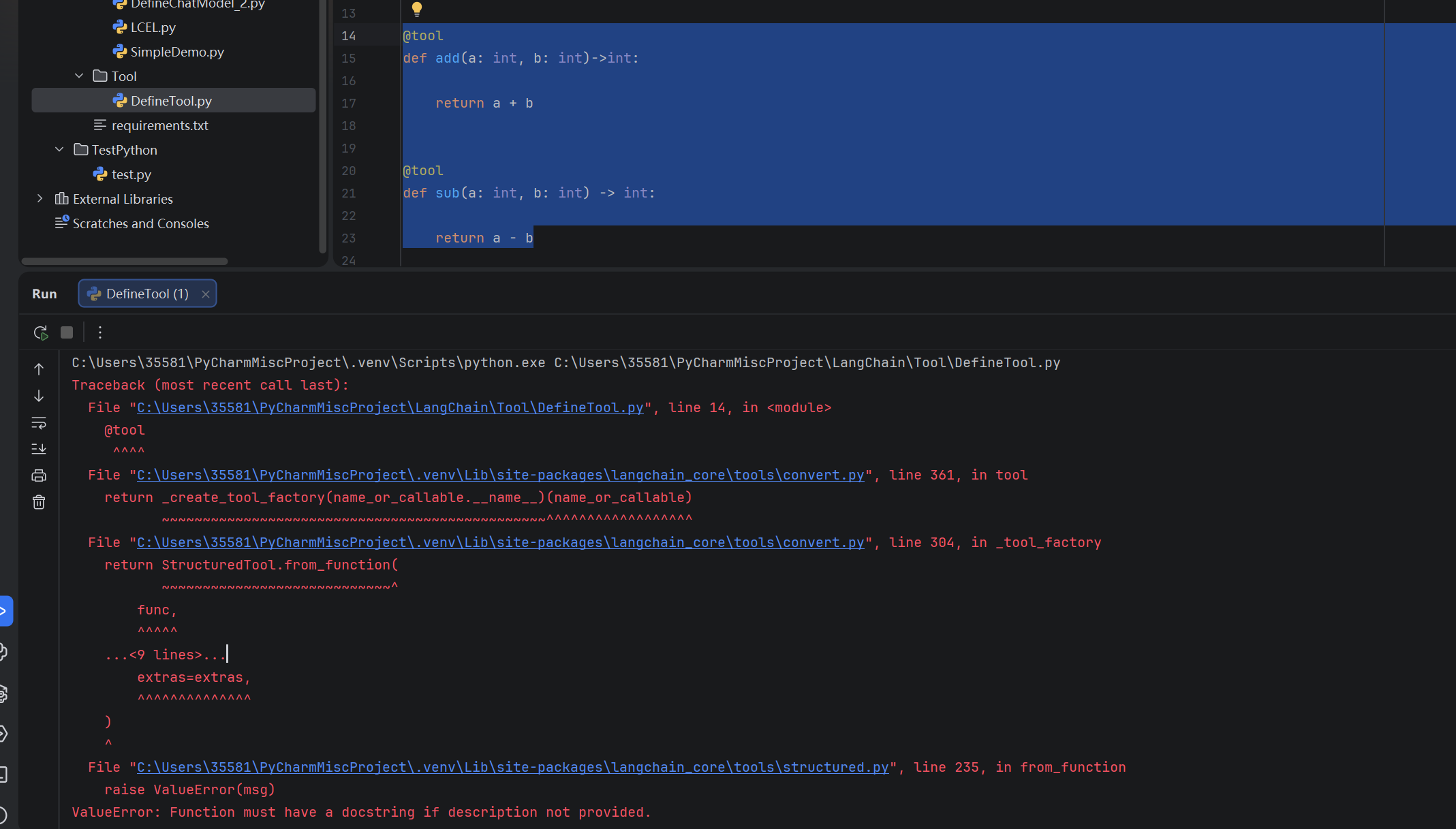
此时,在LangChain 中,可以使用Pydantic 类,提供运行时数据验证和类型检查。通过Field (description ="...") 添加字段描述,LangChain 会自动提取。
python
from pydantic import BaseModel, Filed
class AddInput(BaseModel):
"""Add two integers"""
a: int = Filed(..., description="First integer")
b: int = Filed(..., description="Second integer")
class Multiply(BaseModel):
"""Multiply two integers"""
a: int = Filed(..., description = "First integer")
b: int = Filed(..., description = "Second integer")完整的代码如下:
python
from pydantic import BaseModel, Field
from langchain_core.tools import tool
class AddInput(BaseModel):
"""Add two integers"""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
class Multiply(BaseModel):
"""Multiply two integers"""
a: int = Field(..., description = "First integer")
b: int = Field(..., description = "Second integer")
@tool(args_schema=AddInput)
def add(a: int, b: int) -> int:
# 未提供工具描述
return a + b
@tool(args_schema=Multiply)
def multiply(a: int, b: int) -> int:
# 未提供工具描述
return a * b
print(add.invoke({"a": 2, "b": 3}))
print(add.name)
print(add.description)
print(add.args)
print(multiply.invoke({"a": 2, "b": 3}))
print(multiply.name)
print(multiply.description)
print(multiply.args)运行结果:
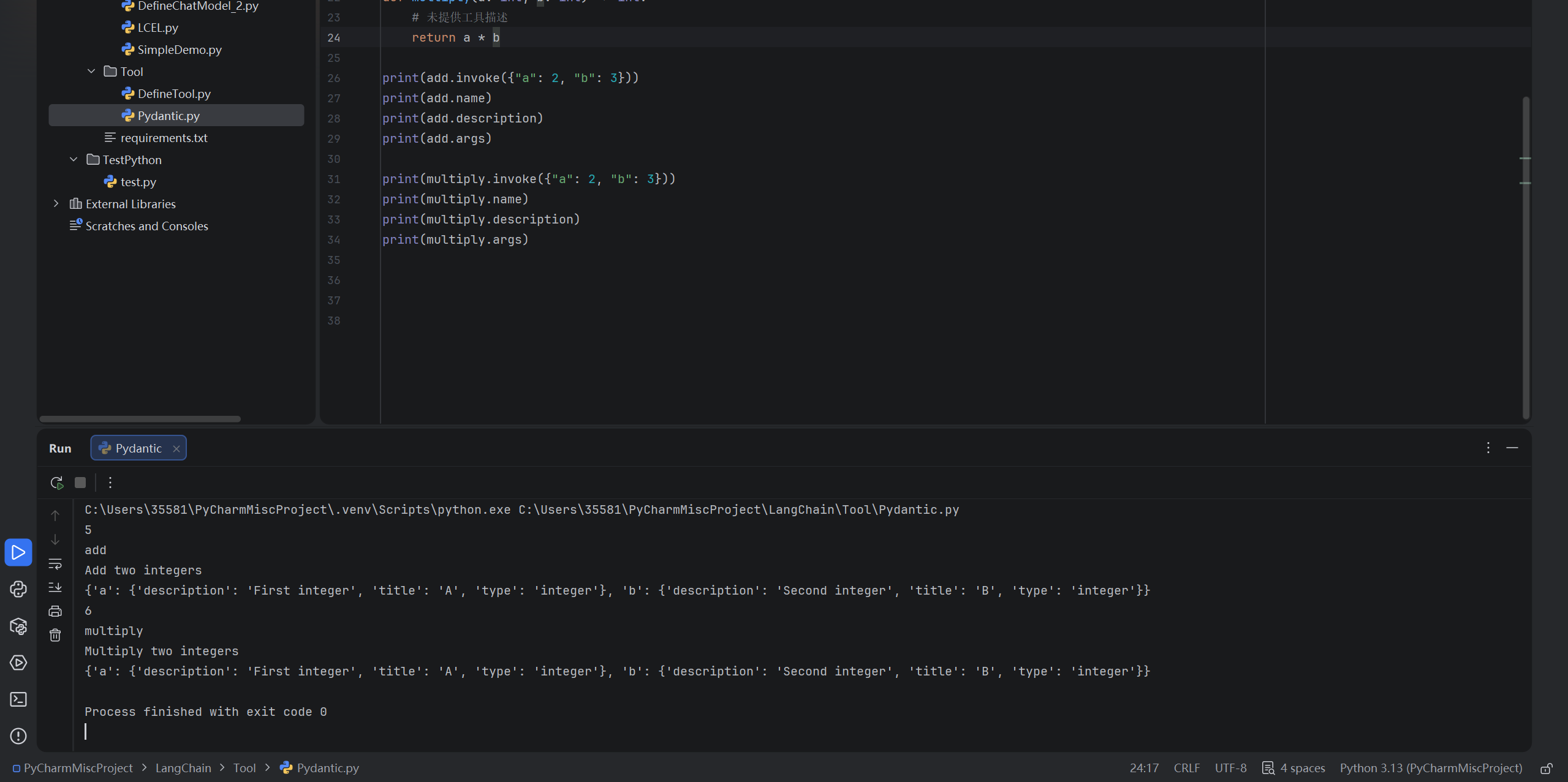
在AI应用开发领域我们最好是不直接使用@tool来进行工具的定义。
1.1.1.2. 模式2:依赖Annotated
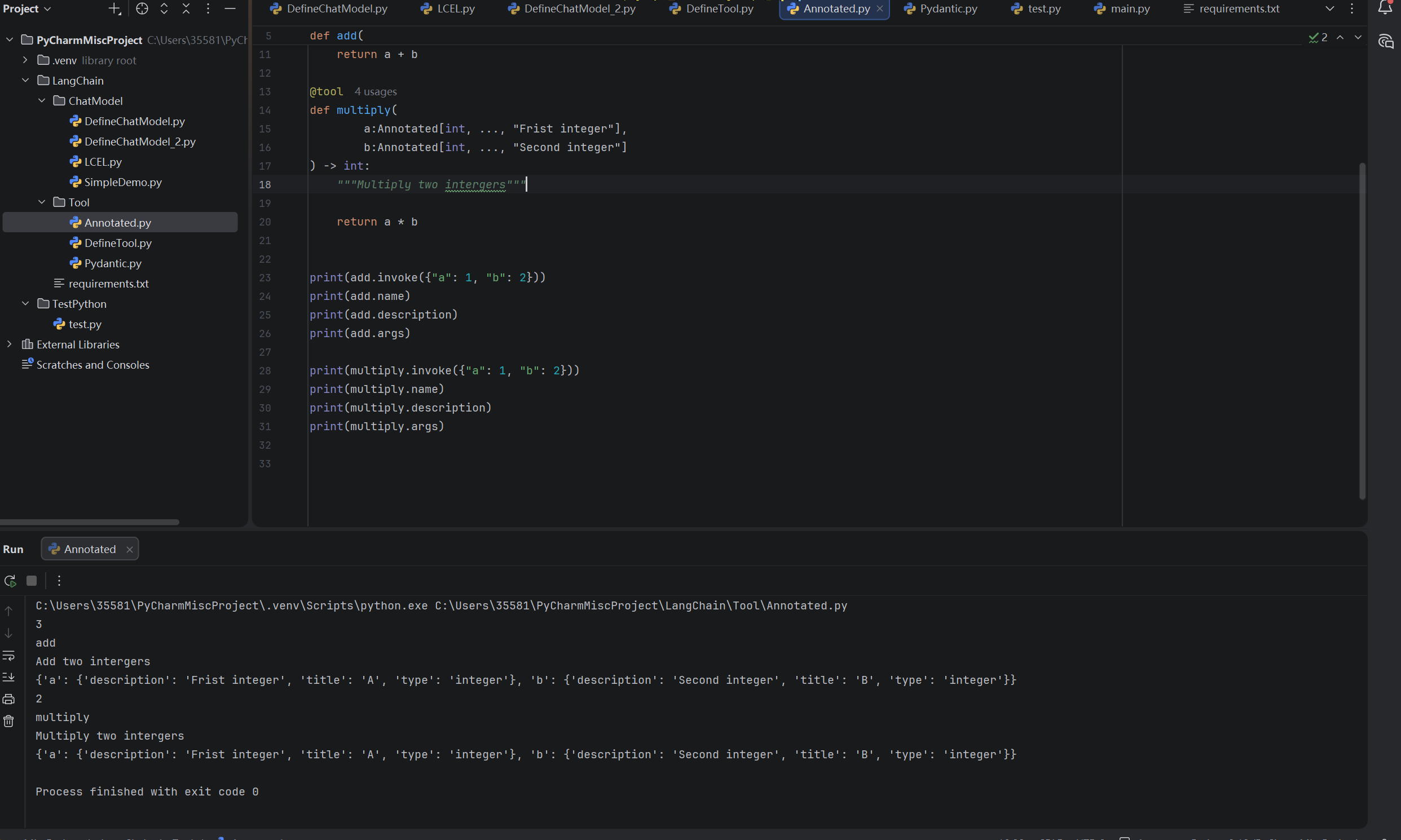
在LangChain 中,可以依赖Annotated 和文档字符串传递给工具Schema 。如下所示:
python
from langchain_core.tools import tool
from typing_extensions import Annotated
@tool
def add(
a:Annotated[int, ..., "Frist integer"],
b:Annotated[int, ..., "Second integer"]
) -> int:
"""Add two intergers"""
return a + b
@tool
def multiply(
a:Annotated[int, ..., "Frist integer"],
b:Annotated[int, ..., "Second integer"]
) -> int:
"""Multiply two intergers"""
return a * b
print(add.invoke({"a": 1, "b": 2}))
print(add.name)
print(add.description)
print(add.args)
print(multiply.invoke({"a": 1, "b": 2}))
print(multiply.name)
print(multiply.description)
print(multiply.args)运行结果:
1.1.2. 使用StructuredTool类提供的函数创建工具
class langchain_core.tools.structured类用来初始化工具,其中from_function类方法通过给定的函数来创建并返回一个工具。from_function 类方法定义如下:
python
classmethod from_function(
func : Callable | None = None ,
coroutine : Callable[[...],Awaitable[Any]] | None = None ,
name : str | None = None ,
description : str | None = None ,
return_direct : bool = False ,
args_schema : type[BaseModel] | dict[str ,Any] | None = None ,
infer_schema : bool =True ,
*,
response_format : Literal['content ', 'content_and_artifact '] = 'content ',
parse_docstring : bool = False ,
error_on_invalid_docstring : bool = False ,
**kwargs :Any ,
) → StructuredTool关键参数说明:
-
func:要设置的工具函数
-
coroutine:协程函数,要设置的异步工具函数 (后续的文章会有涉及)
-
name:工具名称。默认为函数名称。
-
description:工具描述。默认为函数文档字符串。
-
args_schema:工具输入参数的schema。默认为None
-
response_format:工具响应格式。默认为"content" 。如果配置为"content",则工具的输出为ToolMessage 的content 属性。
-
该类方法参数的全部含义见这里
1.1.2.1. 示例1:常规用法
对于用该类方法创建的工具,同样函数名、类型提示和文档字符串也都是传递给工具Schema的一部分,不可缺失。
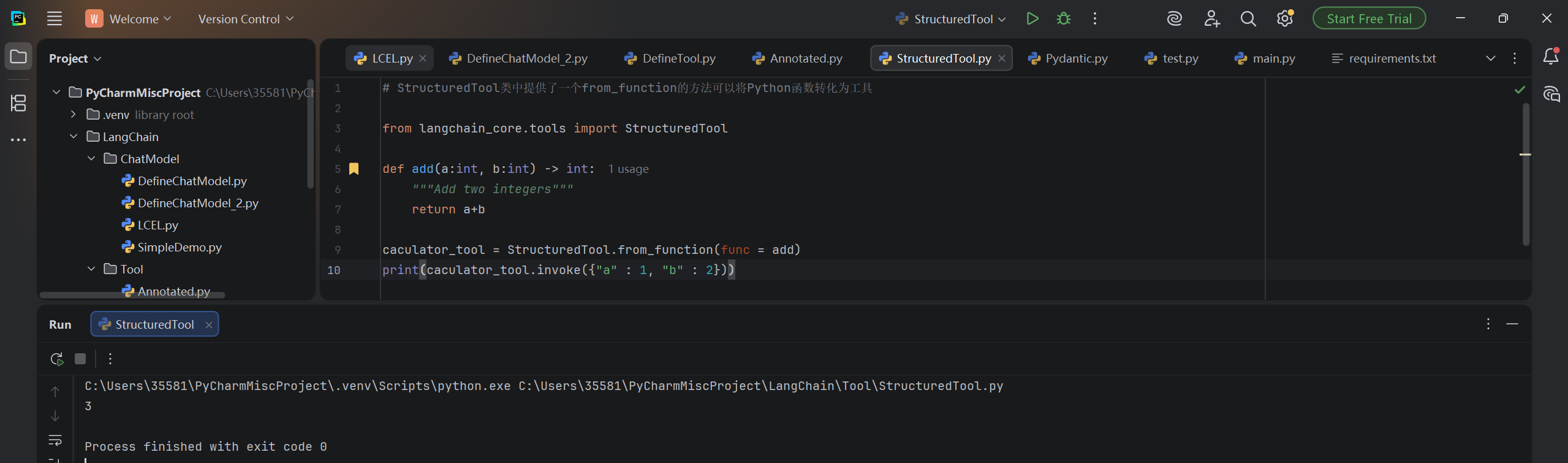
python
from langchain_core.tools import StructuredTool
def add(a:int, b:int) -> int:
"""Add two integers"""
return a+b
caculator_tool = StructuredTool.from_function(func = add)
print(caculator_tool.invoke({"a" : 1, "b" : 2}))运行结果:
1.1.2.2. 示例2:加入配置,依赖Pydantic类
同样的,让工具函数不提供描述、文档字符串等需要传递给工具Schema 的内容。
使用args_schema 参数,依赖Pydantic 类定义并提供工具输入参数的schema 属性。
使用description 参数,替代文档字符串中对于工具描述的schema 属性。
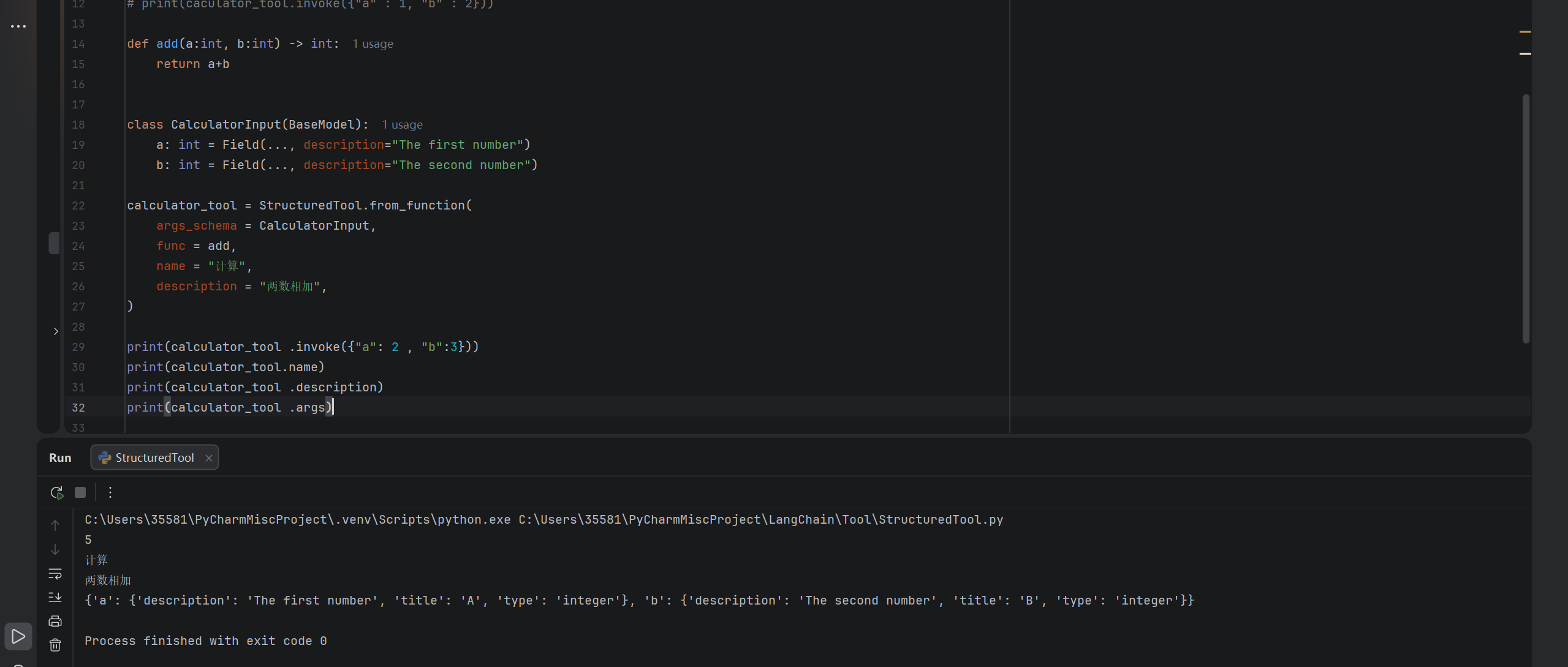
python
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
def add(a:int, b:int) -> int:
return a+b
class CalculatorInput(BaseModel):
a: int = Field(..., description="The first number")
b: int = Field(..., description="The second number")
calculator_tool = StructuredTool.from_function(
args_schema = CalculatorInput,
func = add,
name = "计算",
description = "两数相加",
)
print(calculator_tool .invoke({"a": 2 , "b":3}))
print(calculator_tool.name)
print(calculator_tool .description)
print(calculator_tool .args)运行结果:
1.1.2.3. 示例3:加入response_format配置
如果希望我们的工具区分消息内容(content)和其他工件(artifact),让大模型读取content ,而一些用来构造content 的原始数据保存下来,若后续有一些记录、分析的步骤,就可以派上用场了,这就是artifact 。artifact 通常需要使用字典Dict 或列表List 保存。
接下来举个例子再来理解下。例如我们定义了一个搜索天气的tool ,若使用搜索引擎工具询问"今天天气怎么样"时:
content 可能是:++++"根据最新搜索结果,今天北京晴,气温在25 °C++++++++到++++++++32 °C++++++++之间。建议穿短袖衣++++物。
" artifact 可能是某搜索引擎API返回的完整JSON 响应,其中包含多个搜索结果条目、每个条目的标题、链接、摘要、排名等元数据。如下所示:
cpp
#Artifact 的示例结构
{
'results': [
{
'title':'北京天气预报- 中国天气网',
'link':'https://weather.com.cn/...',
'snippet':'北京今天白天晴,最高气温32 °C,夜间晴,最低气温25 °C ...'
},
{
'title':'北京实时天气-Weather.com',
'link':'https://www.weather.com/...',
'snippet':'Bejing , China Weather . Mostly sunny . High 32C ...'
}
#...更多结果
],
'search_parameters': { ... },
'search_information': { ... }
}则对于以上原生数据,无论我们今后做日志记录、分析,或自定义后续的处理都很方便。例如存在以下场景:
-
我们不仅仅想要一个总结性的答案,还想要具体的链接、来源或多个备选答。
-
工具的content 输出不符合你的预期,我们想查看原始数据来理解问题出在哪里(是工具解析的问题,还是API本身返回的问题)。
-
需要记录每次工具调用的完整原始响应,以满足数据分析的要求。
-
.......
从这里就可以对比出只返回content 无法做到这些事情。那我们要怎么样做到使 content 和 artifact分离呢?
我们需要在定义工具时指定response_format ="content_and_artifact " 参数,并确保我们返回一个元组(content,artifact),代码如下:
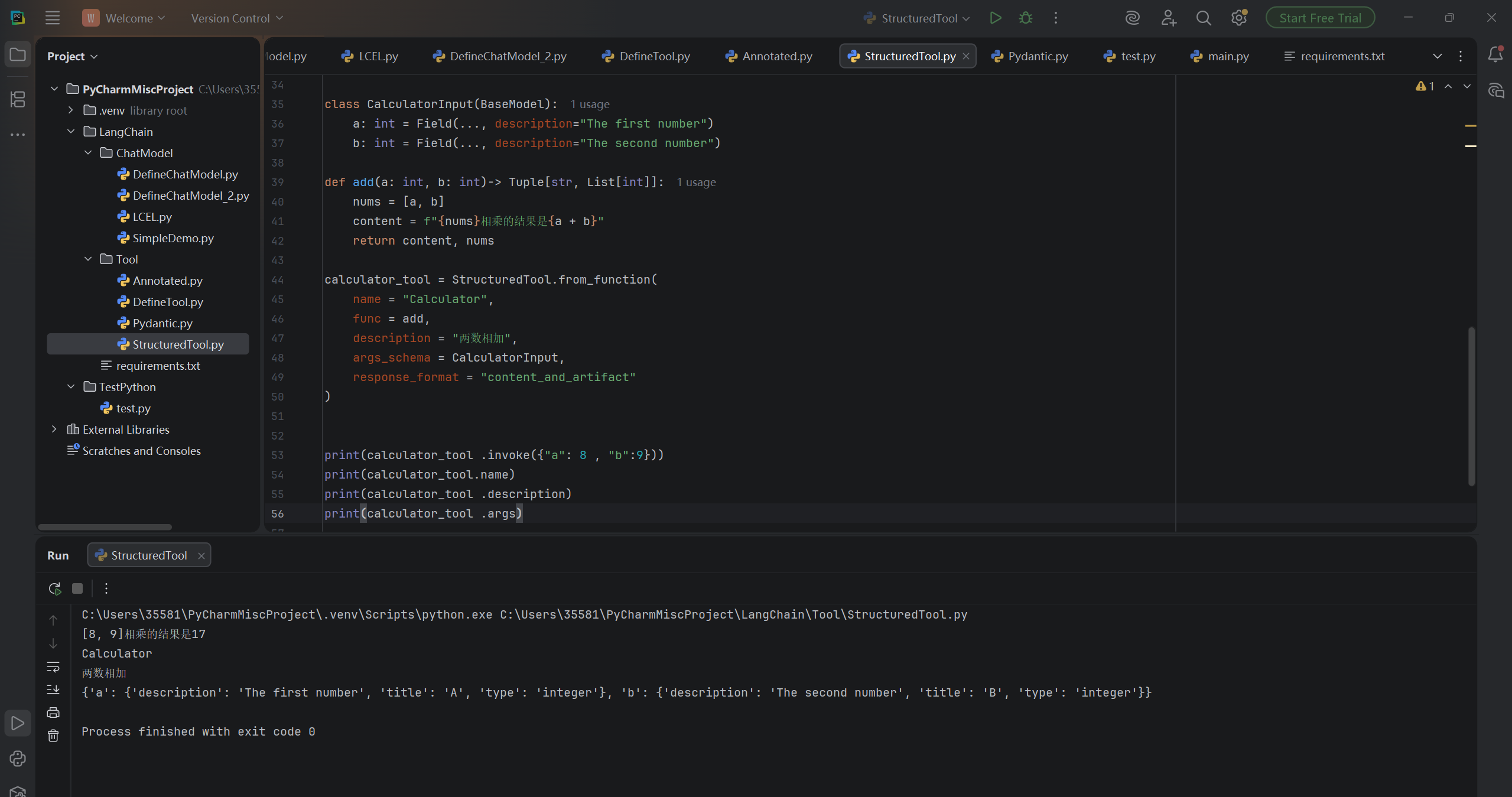
python
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
from langchain_core.tools import tool
from typing import List, Tuple
def add(a: int, b: int)-> Tuple[str, List[int]]:
nums = [a, b]
content = f"{nums}相乘的结果是{a + b}"
return content, nums
calculator_tool = StructuredTool.from_function(
name = "Calculator",
func = add,
description = "两数相加",
args_schema = CalculatorInput,
response_format = "content_and_artifact"
)
print(calculator_tool .invoke({"a": 8 , "b":9}))
print(calculator_tool.name)
print(calculator_tool .description)
print(calculator_tool .args)运行结果:
上面的代码中,我们将需要相加的数据当作原始数据,作为样例。(说明:@tool也支持response_format)
如果我们直接使用工具参数调用工具,将只会返回输出的content部分:
python
print(calculator_tool .invoke({"a": 2 , "b":3})) # 输出:[2, 3]相加的结果是5若想要看到工具返回的元组,我们需要模拟大模型调用工具的姿势,如下所示。这将返回一个 ToolMessage,代码如下:
python
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
from langchain_core.tools import tool
from typing import List, Tuple
class CalculatorInput(BaseModel):
a: int = Field(..., description="The first number")
b: int = Field(..., description="The second number")
def add(a: int, b: int)-> Tuple[str, List[int]]:
nums = [a, b]
content = f"{nums}相乘的结果是{a + b}"
return content, nums
calculator_tool = StructuredTool.from_function(
name = "Calculator",
func = add,
description = "两数相加",
args_schema = CalculatorInput,
response_format = "content_and_artifact"
)
print(calculator_tool.invoke(
{
"name" : "Calculator",
"args" : {"a" : 1, "b" : 2},
"id" : "123", # 必须,与工具调用关联的标识符,将工具调用请求与工具调用结果相关联。
"type" : "tool_call" # 必须
}
))运行结果:
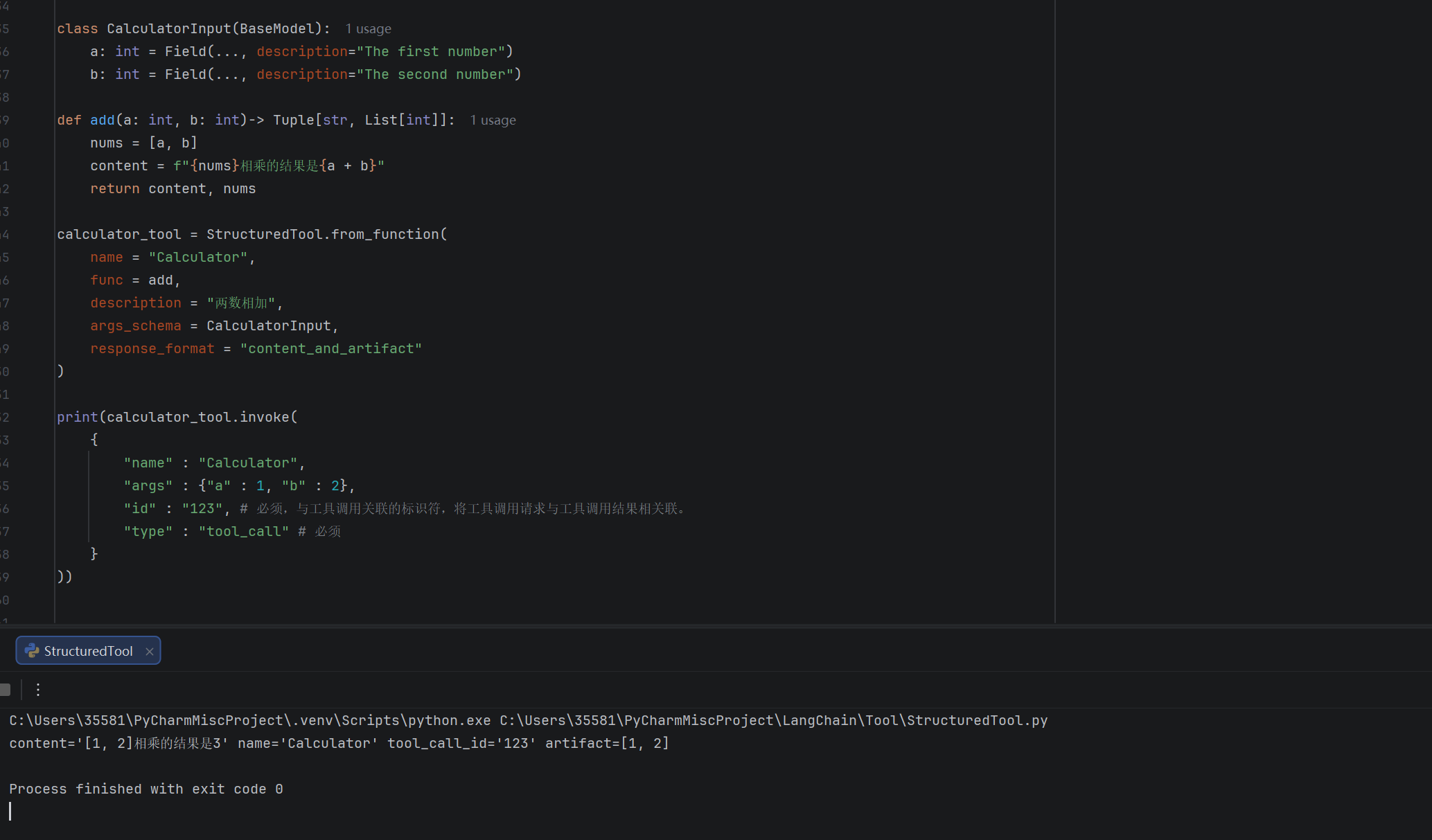
小结一下,由于LLM 大多理解文本,所以工具的主要输出content 必须是结构良好、简洁的文本,以便模型能够轻松理解和基于它进行推理、生成下一步的指令。
在链(Chain)中,工具调用之后的其他组件或函数,可能需要工具的原始且结构化数据(即 artifact)来执行特定操作。这些数据可能是庞大的、且非文本的。这些数据不适合直接塞给模型。因此,artifact 其实是为了给链中后续的组件或函数使用的,不被大模型所直接使用!!
1.2. 绑定工具
为了实际将这些工具绑定到聊天模型,可以使用聊天模型的.bind_tools ()方法。如下所示:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core.tools import tool
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat", temperature=0.7, max_tokens=2048)
@tool
def multiply(a: int, b: int)->int:
"""Multiply two integers.
Args:
a (int): first integer
b (int): second integer
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Add two integers.
Args:
a (int): first integer
b (int): second integer
"""
return a + b
# 绑定工具返回一个Runnable实例
tools = [add, multiply]
model_with_tools = model.bind_tools(tools)bind_tools() 方法的定义
python
bind_tools(
tools : Sequence[dict[str ,Any] | type | Callable | BaseTool],
*,
tool_choice : dict | str | Literal ['auto ', 'none ', 'required ', 'any '] | bool
| None = None ,
strict : bool | None = None ,
parallel_tool_calls : bool | None = None ,
**kwargs :Any ,
) → Runnable[PromptValue | str | Sequence[BaseMessage | list[str] |
tuple[str , str] | str | dict[str ,Any]], BaseMessage]bind_tools()请求参数解析:
tools:绑定到此聊天模型的工具定义列表。支持的类型为:字典、pydantic.BaseModel 类、 Python 函数和BaseTool(如@tool 装饰器创建的类)。
tool_choice(默认空):要求模型调用哪个工具。可以设置为:
形式为:'<<tool_name>>'的str: 调用<tool_name>工具。 'auto':自动选择工具。'none': 不调用工具。'any'或'required'或True:强制调用至少一个工具。False或None:无效果,默认OpenAI的行为
strict(默认为空):如果为True ,则保证模型输出与工具定义中提供的JSON Schema 完全匹配。输入也将据提供的Schema 进行验证。如果为False ,则不会验证输入,也不会验证模型输出。如果为None ,则不会将strict 参数传递给模型。
parallel_tool_calls:默认为None,允许并行工具使用。设置为False 以禁用并行
工具。
kwargs(Any):任何附加参数都直接传递给bind ()。
bind_tools()返回值:返回一个Runnable实例,该实例支持多种格式的输入
1.3. 工具调用
通过.bind_tools ()方法我们可知,它返回了一个Runnable 实例,因此我们可以使用该Runnable 实例,调用.invoke ()方法,完成工具调用。示例如下:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core .messages import HumanMessage
from langchain_core.tools import tool
from typing_extensions import Annotated
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat", temperature=0.7, max_tokens=2048)
@tool
def add(
a: Annotated[int, ..., "Frist number"],
b: Annotated[int, ..., "Second number"],
) -> int:
"""Add two intergers"""
return a + b
@tool
def multiply(
a: Annotated[int, ..., "Frist number"],
b: Annotated[int, ..., "Second number"],
) -> int:
"""Multiply two integers"""
return a * b
# 绑定工具返回一个Runnable实例
tools = [add, multiply]
model_with_tools = model.bind_tools(tools)
print(model_with_tools.invoke("3加2等于多少"))
print(model_with_tools.invoke("2乘4等于多少"))代码运行结果:
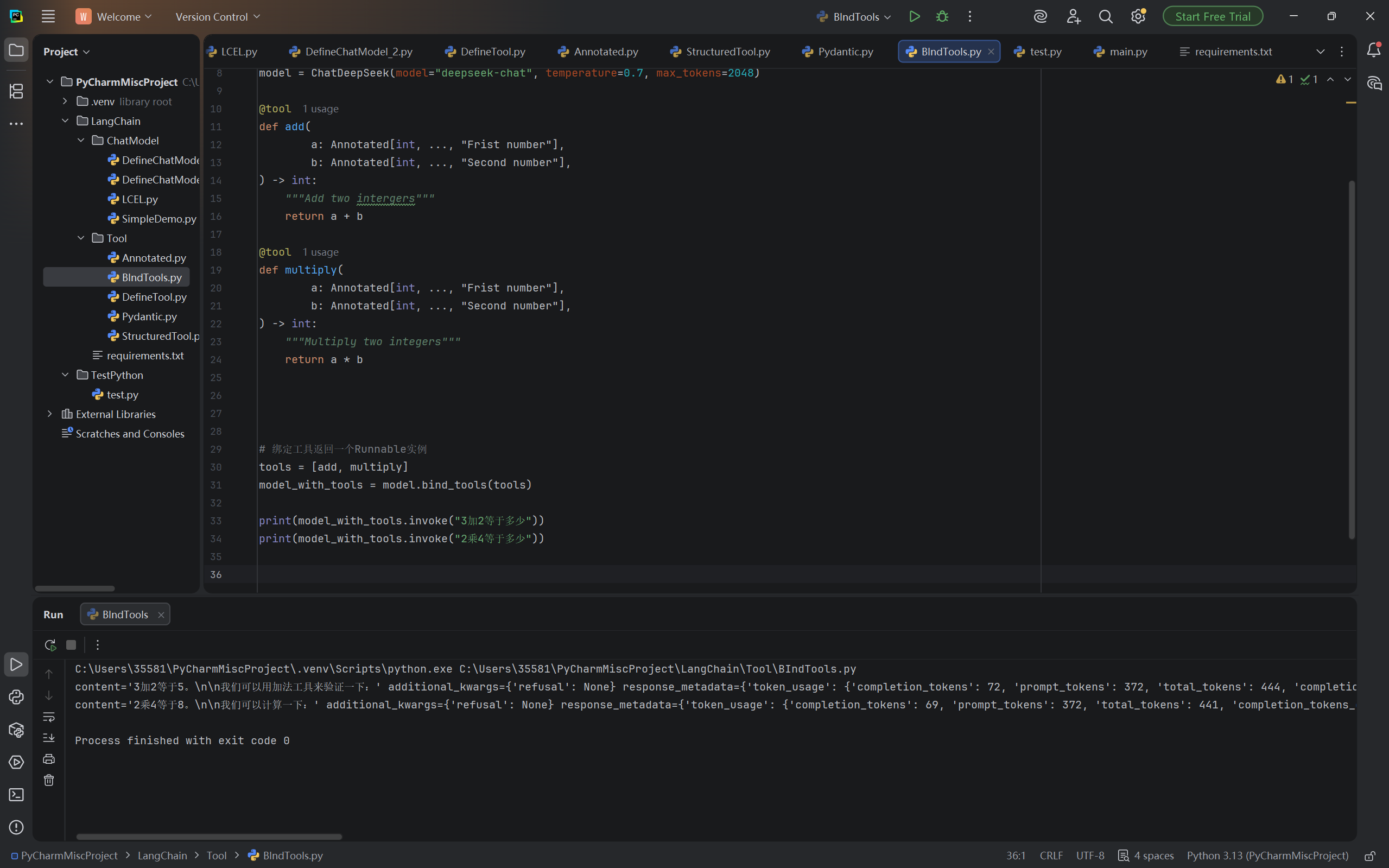
观察模型输出:
python
content='3加2等于5。'
additional_kwargs={'refusal': None}
response_metadata={'token_usage': {'completion_tokens': 70, 'prompt_tokens': 372, 'total_tokens': 442, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 256}, 'prompt_cache_hit_tokens': 256, 'prompt_cache_miss_tokens': 116}, 'model_provider': 'openai', 'model_name': 'deepseek-v4-flash', 'system_fingerprint': 'fp_058df29938_prod0820_fp8_kvcache_20260402', 'id': 'd1828603-d7a2-4380-961d-e6472fdd06cb', 'finish_reason': 'tool_calls', 'logprobs': None} id='lc_run--019df115-737b-7452-a650-9fa9a66b52eb-0'
tool_calls=[{'name': 'add', 'args': {'a': 3, 'b': 2}, 'id': 'call_00_CwNJlIoYHHWuuC8Gpjd94820', 'type': 'tool_call'}] invalid_tool_calls=[] usage_metadata={'input_tokens': 372, 'output_tokens': 70, 'total_tokens': 442, 'input_token_details': {'cache_read': 256}, 'output_token_details': {}}输出说明:
AIMessage:来自AI 的消息。从聊天模型返回,作为对提示(输入)的响应。
content:消息的内容。
additional_kwargs:与消息关联的其他有效负载数据。对于来自AI 的消息,可能包括模
型提供程序编码的工具调用。
response_metadata:响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。
工具调用的一个关键原则是,模型根据输入的相关性决定何时使用工具。模型并不总是需要调用工具。例如,给定一个不相关的输入,模型不会调用该工具。
1.4. 强制调用工具
当然我们也可以让模型强制调用工具,那就需要在绑定工具时,设置tool_choice ="any ",表示
强制调用至少一个工具。示例如下:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core .messages import HumanMessage
from langchain_core.tools import tool
from typing_extensions import Annotated
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat", temperature=0.7, max_tokens=2048)
@tool
def add(
a: Annotated[int, ..., "Frist number"],
b: Annotated[int, ..., "Second number"],
) -> int:
"""Add two intergers"""
return a + b
@tool
def multiply(
a: Annotated[int, ..., "Frist number"],
b: Annotated[int, ..., "Second number"],
) -> int:
"""Multiply two integers"""
return a * b
# 绑定工具返回一个Runnable实例
tools = [add, multiply]
model_with_tools = model.bind_tools(tools, tool_choice= 'any')
result = model_with_tools.invoke("hello world!")
print(result)运行结果:
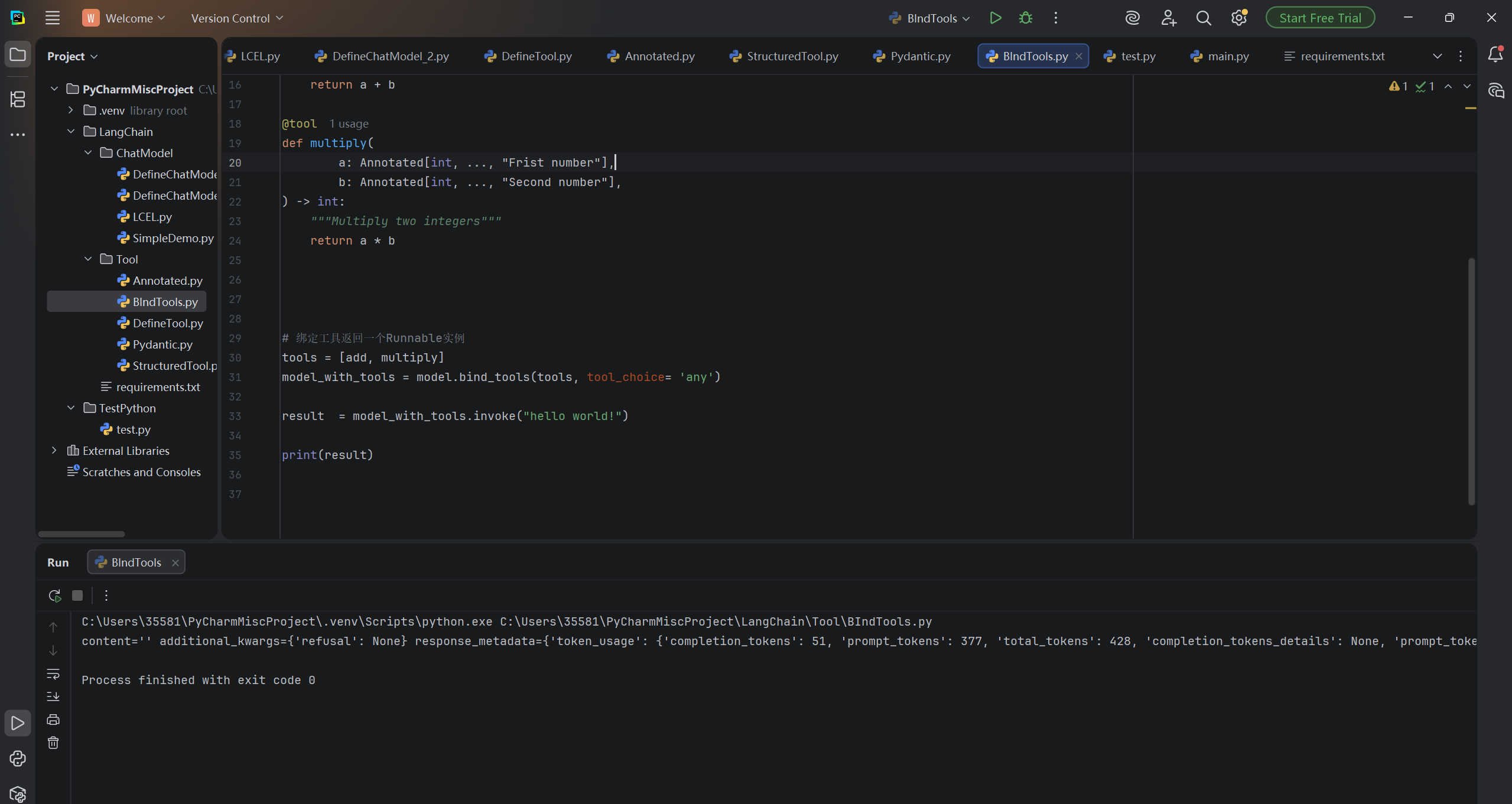
我们可以看到运行输出的结果为空。