一、快速开始
1. 新建工程
打开SEGGER Embbed Studio。进行软件启动界面。
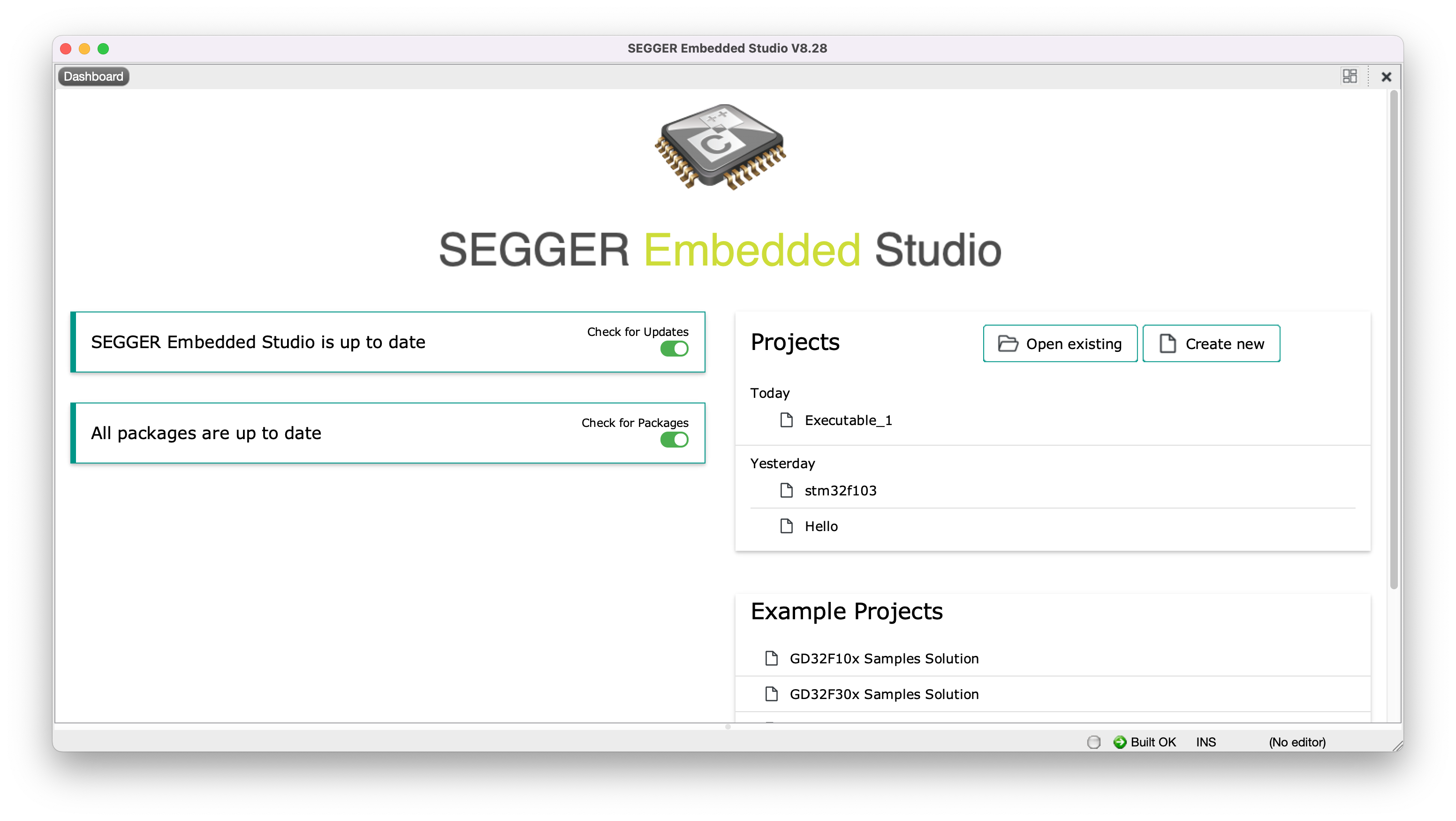
选择"Create New"创建一个新的项目。我们选择Cortex- M3处理器。
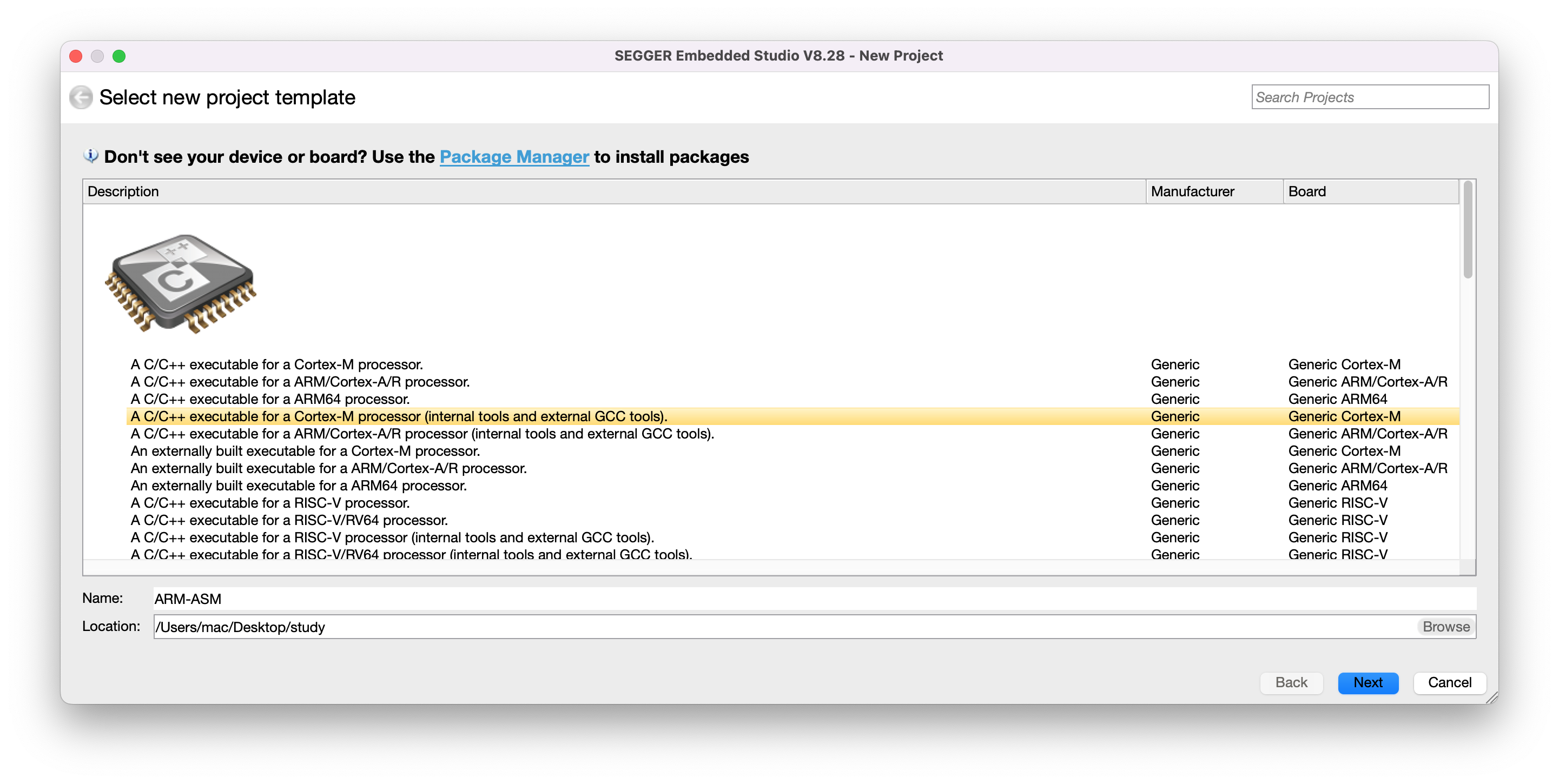
设置项目通用选项,包括目标处理器架构,存储位置,编译器,下载器等。如果不需要下载到开发板上运行,默认项即可。
2. 创建代码
然后进入主界面,左侧为项目导航区。在Source目录(如果没有就手动创建)上右键菜单,选择Add New File。
新添加一个汇编语言文件main.s。
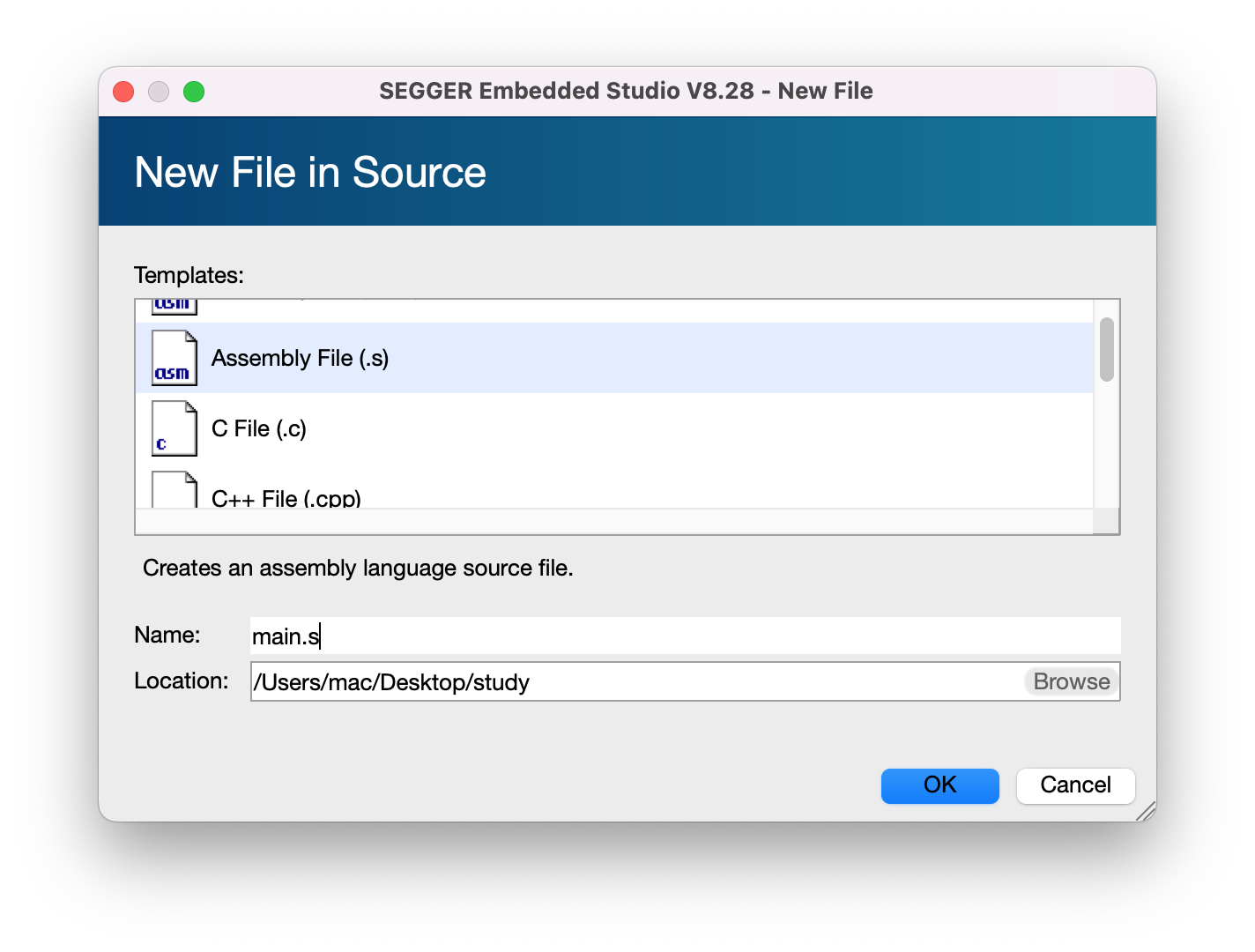
写一段简单的代码,测试是否能够正常编译
.text
.align 2
.global main
.thumb_func
main:
movs r0,#0
bx lr
.data
arrary: .byte 5,2,8,1,9,3
array_end:3. 编译构建
在项目名称上右键菜单,选择build编译代码,Output Files目录下将生成可烧录文件。
4. 模拟调试
在main.s中movs r0,#0处设置断点。

窗口菜单选择Debug->Go(F5)启动调试,如果没有使用连接器(如J-Link)连接开发板,就不能进行在系统调试,但可以使用模拟器。这时软件会提示,选择Yes,进入调试界面。
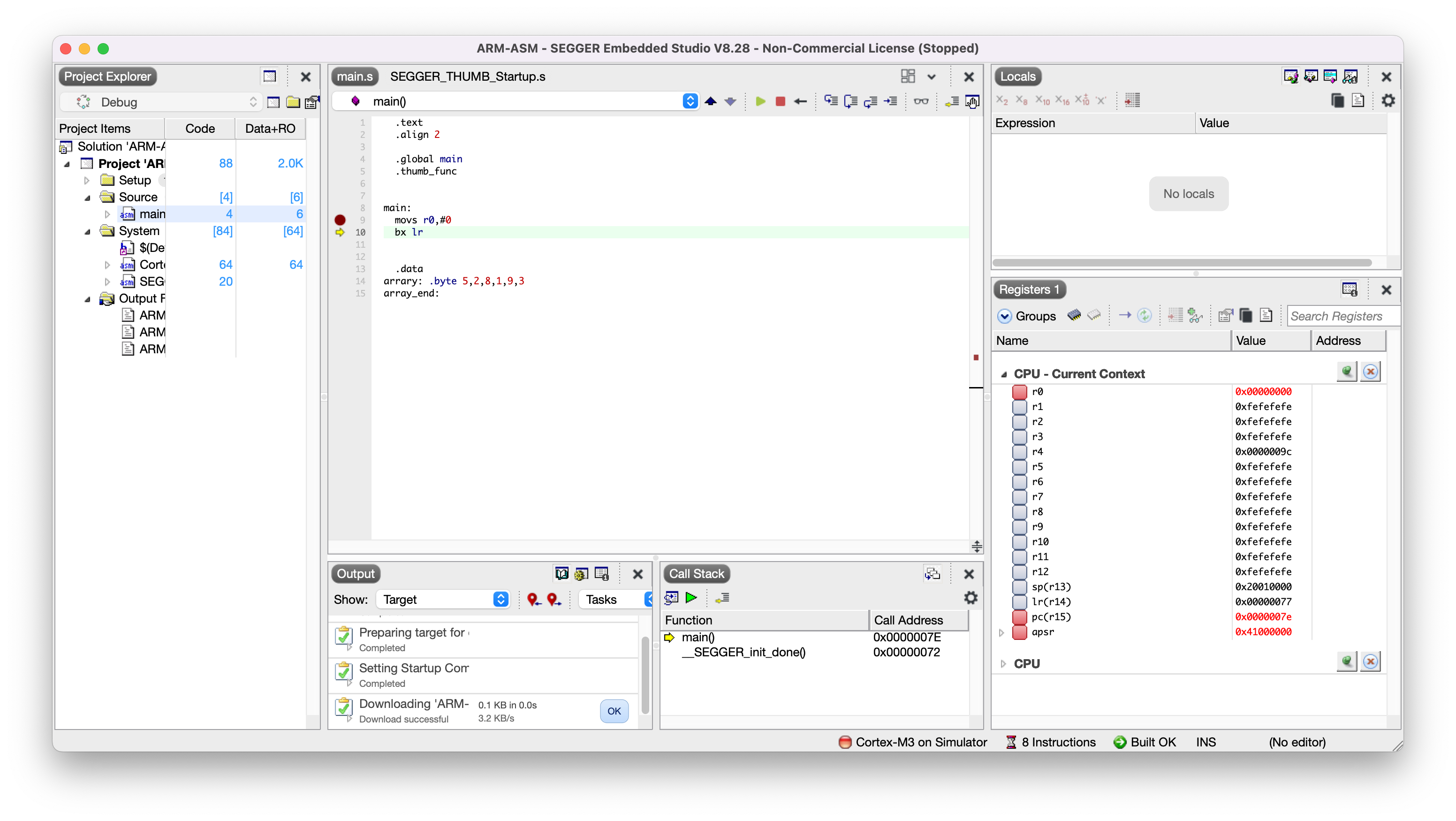
选择代码区右上角的调试按纽,可以启动单步调试等通用功能。
调试界面与其它IDE基本相似,你这么厉害,一定能望图生义,自不必多言。
二、ARMv7-A编程模型
编程模型定义了程序员可见的处理器资源:运行模式、寄存器组、指令集、异常处理机制和内存管理方式。ARMv7-A是ARMv7架构的应用处理器变体,主要面向需要运行复杂操作系统(如Linux、Android)的高性能场景。
ARMv7架构的三个系列对比:
| 系列 | 应用场景 | 代表处理器 | 核心特性 |
|---|---|---|---|
| Cortex-A | 应用处理器 | Cortex-A7/A8/A9/A15 | MMU、多核、高级OS支持 |
| Cortex-R | 实时处理器 | Cortex-R4/R5/R7 | 快速响应、容错性 |
| Cortex-M | 微控制器 | Cortex-M0/M3/M4/M7 | 极简设计、低延迟中断 |
ARMv7-A编程模型的核心由以下组件构成:
- 7种处理器模式:用户、系统、快中断、中断、管理、中止、未定义
- 31个通用寄存器:各模式间部分物理独立
- 两类状态寄存器:CPSR(当前状态)和SPSR(保存状态)
- 异常处理机制:8种异常类型,向量表驱动
- MMU与Cache:虚拟内存管理,多级页表
- CP15协处理器:系统配置中枢
1. 工作模式
ARMv7-A处理器共支持7种操作模式,每种模式对应不同的功能角色和寄存器组。理解这些模式是掌握异常处理和OS工作的前提。
| 模式 | 缩写 | 模式号 | 触发条件 | 主要用途 |
|---|---|---|---|---|
| 用户模式 | USR | 0x10 | 正常程序执行 | 用户应用程序运行,非特权模式 |
| 系统模式 | SYS | 0x1F | 通过MSR指令主动切换 | OS特权任务,共用USR寄存器 |
| 管理模式 | SVC | 0x13 | 复位、SWI/SVC指令 | OS内核、系统调用处理 |
| 中断模式 | IRQ | 0x12 | 外部IRQ信号 | 普通外设中断处理 |
| 快中断模式 | FIQ | 0x11 | 外部FIQ信号 | 高速/高优先级中断 |
| 中止模式 | ABT | 0x17 | 数据/指令预取中止 | 内存访问异常处理 |
| 未定义模式 | UND | 0x1B | 未定义指令 | 指令模拟/调试 |
关键概念 :只有用户模式是非特权模式,其他都是特权模式。操作系统通常在SVC模式下运行内核,用户程序在USR模式下,需要特权操作时通过SVC指令进行系统调用。
💡 技巧提示:FIQ模式有独立的R8~R12寄存器,这意味着在FIQ中断服务程序中,不需要保存这些寄存器,响应速度更快。因此FIQ适合需要极低延迟的紧急处理。
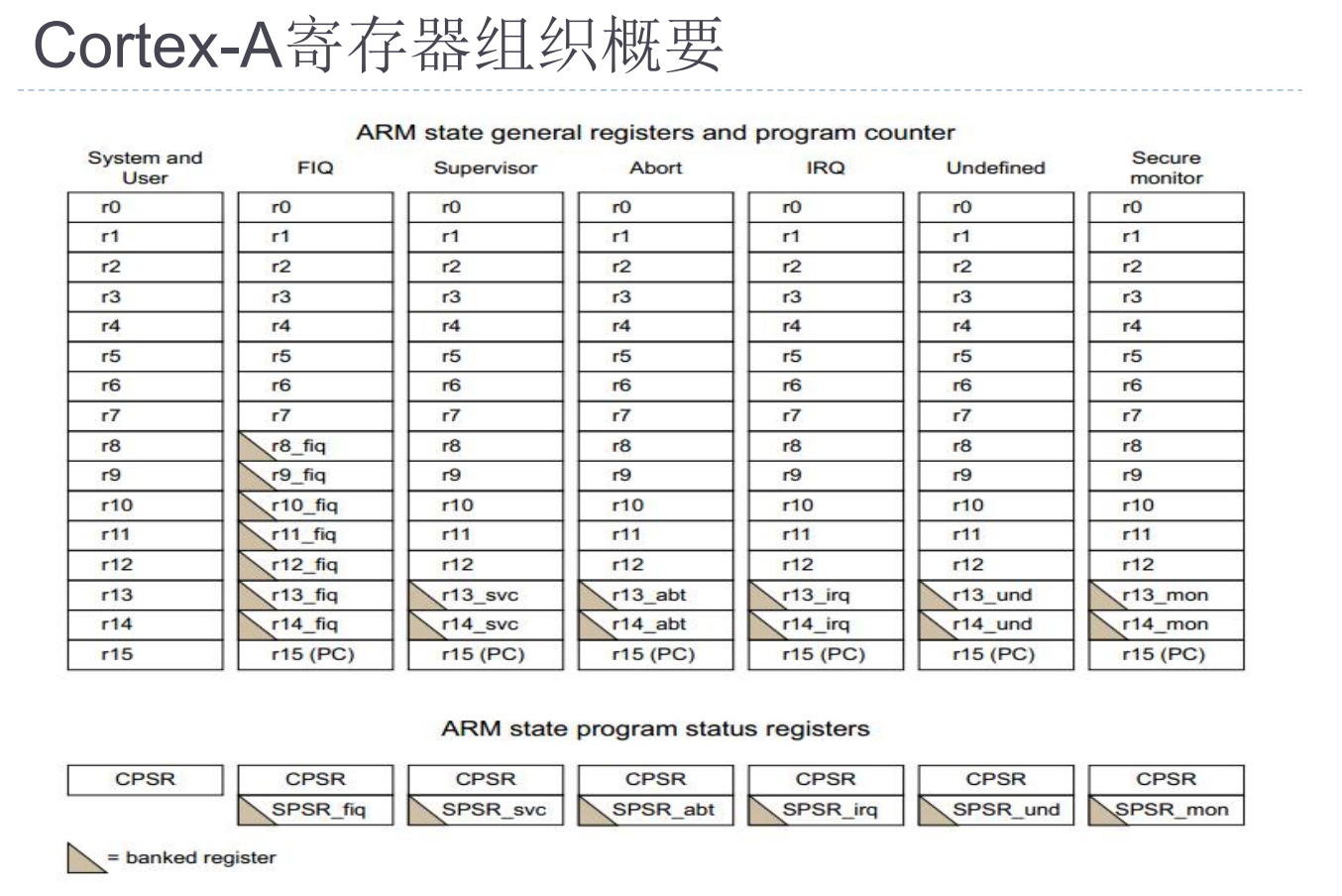
2. 寄存器
ARMv7-A架构最多拥有31个通用32位寄存器和6个状态寄存器。但由于寄存器的部分物理复制,不同模式看到的寄存器集合是不同的。
(1)寄存器概要
(2)通用寄存器
i. R0-R7:所有模式共享
这些是真正的通用寄存器,没有备份。任何模式下修改都会被其他模式看到。
ii.R8-R12:FIQ模式下有独立备份
- 用户/系统/IRQ/SVC/ABT/UND模式:共用R8-R12
- FIQ模式:使用独立的R8_fiq ~ R12_fiq,无需保存现场
iii.R13 (Stack Pointer, SP):各模式独立
每个模式都有自己的堆栈指针,这是设计精巧之处------进入异常处理时自动切换堆栈,避免污染用户栈。
| 模式 | SP寄存器 | 典型初始化值 |
|---|---|---|
| 用户/系统 | R13 | 用户栈顶 |
| SVC | R13_svc | 内核栈顶 |
| IRQ | R13_irq | 中断栈顶 |
| FIQ | R13_fiq | FIQ栈顶 |
| ABT | R13_abt | 中止处理栈 |
| UND | R13_und | 未定义指令栈 |
iv.R14 (Link Register, LR):保存返回地址
- 执行
BL分支跳转时:自动保存返回地址 - 发生异常时:保存异常返回地址
- 各特权模式有独立备份:R14_svc、R14_irq、R14_fiq、R14_abt、R14_und
v.R15 (Program Counter, PC)
- 当前执行的指令地址
- 读取PC的值:当前指令地址 + 8(由于流水线)
- 写入PC:实现程序跳转
(3) 程序状态寄存器(CPSR)
CPSR是控制处理器行为的核心寄存器,包含条件标志 、控制位 和状态位。
i.CPSR位域结构
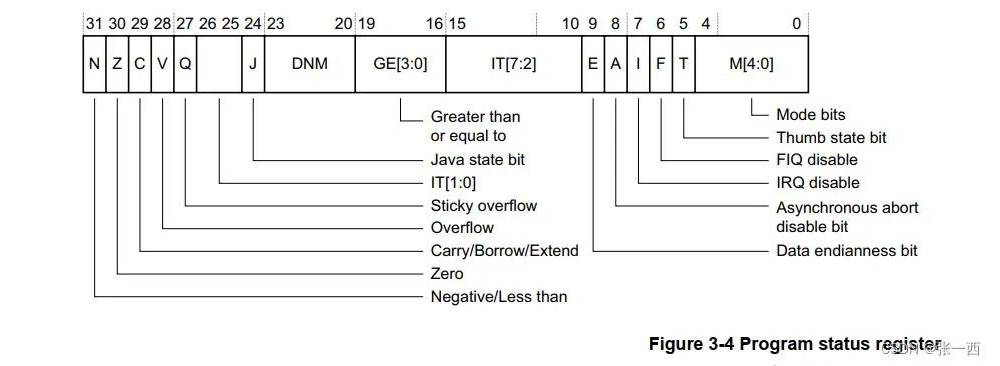
ii.关键标志位解析
| 位域 | 名称 | 含义 | 使用场景 |
|---|---|---|---|
| N(31) | 负数标志 | 运算结果最高位为1时设为1 | 有符号数比较 |
| Z(30) | 零标志 | 运算结果为0时设为1 | 相等性判断 |
| C(29) | 进位/借位标志 | 加法进位/减法无借位时设为1 | 无符号整数比较 |
| V(28) | 溢出标志 | 有符号运算结果超出范围时设为1 | 有符号整数溢出检测 |
| Q(27) | 饱和标志 | DSP指令发生饱和时设为1 | DSP算法 |
| J(24) | Jazelle标志 | 处理器是否处于Jazelle状态 | Java加速 |
| T(5) | Thumb标志 | 1=Thumb状态,0=ARM状态 | 指令集切换 |
| M4:0 | 模式位 | 见下表 | 模式切换 |
iii.处理器模式编码
| M4:0 | 模式 | 可访问寄存器 |
|---|---|---|
| 10000 | 用户模式(USR) | PC, R0~R14, CPSR |
| 10001 | FIQ模式 | PC, R0~R7, R8_fiq~R12_fiq, SP_fiq, LR_fiq, CPSR, SPSR_fiq |
| 10010 | IRQ模式 | PC, R0~R12, SP_irq, LR_irq, CPSR, SPSR_irq |
| 10011 | 管理模式(SVC) | PC, R0~R12, SP_svc, LR_svc, CPSR, SPSR_svc |
| 10111 | 中止模式(ABT) | PC, R0~R12, SP_abt, LR_abt, CPSR, SPSR_abt |
| 11011 | 未定义模式(UND) | PC, R0~R12, SP_und, LR_und, CPSR, SPSR_und |
| 11111 | 系统模式(SYS) | PC, R0~R14, CPSR (无SPSR) |
iv.条件执行
CPSR的标志位支持指令的条件执行,这是ARM架构的精妙之处。几乎所有指令都可以带条件码:
| 条件码 | 后缀 | 含义 | 标志位条件 |
|---|---|---|---|
| 0000 | EQ | 等于 | Z=1 |
| 0001 | NE | 不等于 | Z=0 |
| 0010 | CS/HS | 进位/无符号≥ | C=1 |
| 0011 | CC/LO | 无进位/无符号< | C=0 |
| 0100 | MI | 负数 | N=1 |
| 0101 | PL | 非负数 | N=0 |
| 0110 | VS | 溢出 | V=1 |
| 0111 | VC | 无溢出 | V=0 |
| 1000 | HI | 无符号> | C=1且Z=0 |
| 1001 | LS | 无符号≤ | C=0或Z=1 |
| 1010 | GE | 有符号≥ | N=V |
| 1011 | LT | 有符号< | N≠V |
| 1100 | GT | 有符号> | Z=0且N=V |
| 1101 | LE | 有符号≤ | Z=1或N≠V |
| 1110 | AL | 无条件执行 | 恒执行 |
| 1111 | NV | 永不执行 | 保留 |
3. 异常与中断处理
异常是ARM架构的核心机制之一,操作系统正是通过这些机制接管系统控制权。
(1) 异常向量表
ARMv7-A支持8种异常,每个异常都有固定的入口地址:
| 异常类型 | 向量地址 | 优先级 | 模式切换 | 描述 |
|---|---|---|---|---|
| 复位(Reset) | 0x00000000 | 1(最高) | SVC模式 | 系统上电或复位 |
| 未定义指令(Undef) | 0x00000004 | 6 | UND模式 | 执行未定义指令 |
| 软件中断(SVC) | 0x00000008 | 6 | SVC模式 | 执行SVC指令 |
| 预取中止(Prefetch Abort) | 0x0000000C | 5 | ABT模式 | 指令预取失败 |
| 数据中止(Data Abort) | 0x00000010 | 2 | ABT模式 | 数据访问失败 |
| 保留(Reserved) | 0x00000014 | - | - | 不使用 |
| 外部中断(IRQ) | 0x00000018 | 4 | IRQ模式 | 普通外设中断 |
| 快速中断(FIQ) | 0x0000001C | 3(最高实际中断) | FIQ模式 | 高优先级中断 |
_start:
b reset /* 0x00: 复位入口 */
ldr pc, _undefined /* 0x04: 未定义指令 */
ldr pc, _swi /* 0x08: 软件中断(SVC) */
ldr pc, _prefetch /* 0x0C: 预取中止 */
ldr pc, _data /* 0x10: 数据中止 */
ldr pc, _not_used /* 0x14: 保留 */
ldr pc, _irq /* 0x18: IRQ中断 */
ldr pc, _fiq /* 0x1C: FIQ中断 */
_undefined: .word do_undefined
_swi: .word do_swi
_prefetch: .word do_prefetch
_data: .word do_data
_not_used: .word 0
_irq: .word do_irq
_fiq: .word do_fiq(2) 向量表重定位(VBAR)
现代ARMv7-A处理器支持异常向量表重定位。通过CP15协处理器的VBAR寄存器,可以将向量表重定向到任意地址:
/* 将向量表重定位到0x80200000 */
ldr r0, =0x80200000
mcr p15, 0, r0, c12, c0, 0 /* 写入VBAR */(3) 异常响应流程
详细步骤:
-
保存CPSR:当前CPSR被复制到异常模式的SPSR中
-
切换模式:CPSR的模式位被设置为对应的异常模式
-
屏蔽中断:CPSR中的I位和F位自动设置(禁止同级中断)
-
保存返回地址:返回地址存入异常模式的LR寄存器
-
跳转:PC指向对应的向量表地址
(4) 异常返回机制
从异常返回的关键是用正确的地址恢复PC和CPSR:
/* 不同类型异常的返回地址修正 */
/* 复位、未定义指令、SWI */ SUBS PC, LR, #0
/* 预取中止 */ SUBS PC, LR, #4
/* 数据中止 */ SUBS PC, LR, #8
/* IRQ/FIQ */ SUBS PC, LR, #4(5) 通用异常处理框架:
IRQ_Handler:
/* 1. 保存现场 */
push {lr} /* 保存LR_irq */
push {r0-r3, r12} /* 保存通用寄存器 */
/* 2. 读取SPSR并保存 */
mrs r0, spsr
push {r0}
/* 3. 处理中断 */
bl system_irq_handler
/* 4. 恢复现场 */
pop {r0}
msr spsr_cxsf, r0 /* 恢复SPSR */
pop {r0-r3, r12} /* 恢复通用寄存器 */
pop {lr} /* 恢复LR_irq */
/* 5. 返回 */
subs pc, lr, #4(6) SVC异常详解
SVC(Supervisor Call,在旧ARM版本中称为SWI)是用户模式调用OS服务的关键指令。当用户程序需要访问特权资源时,执行SVC指令触发此异常,处理器进入SVC模式。
/* 用户程序:调用OS服务 */
svc #0x123456 /* 触发SVC异常,参数0x123456 */
/* SVC处理函数:解析服务号 */
do_swi:
/* 读取SVC指令本身获取参数 */
ldr r0, [lr, #-4] /* 读取SVC指令 */
bic r0, r0, #0xff000000 /* 提取低24位参数 */
/* 根据参数分发到对应的系统调用 */
...
movs pc, lr /* 返回 */这解释了Linux系统调用的底层实现机制------open()、read()、write()最终都会触发SVC指令进入内核。
4. 内存模型
ARM架构定义的内存模型 定义了在多核、多 master 系统(如DMA控制器)和现代外设共存时,CPU访问内存的行为规范 和硬性约束。
程序员视角下的ARMv7-A内存模型结构概要:
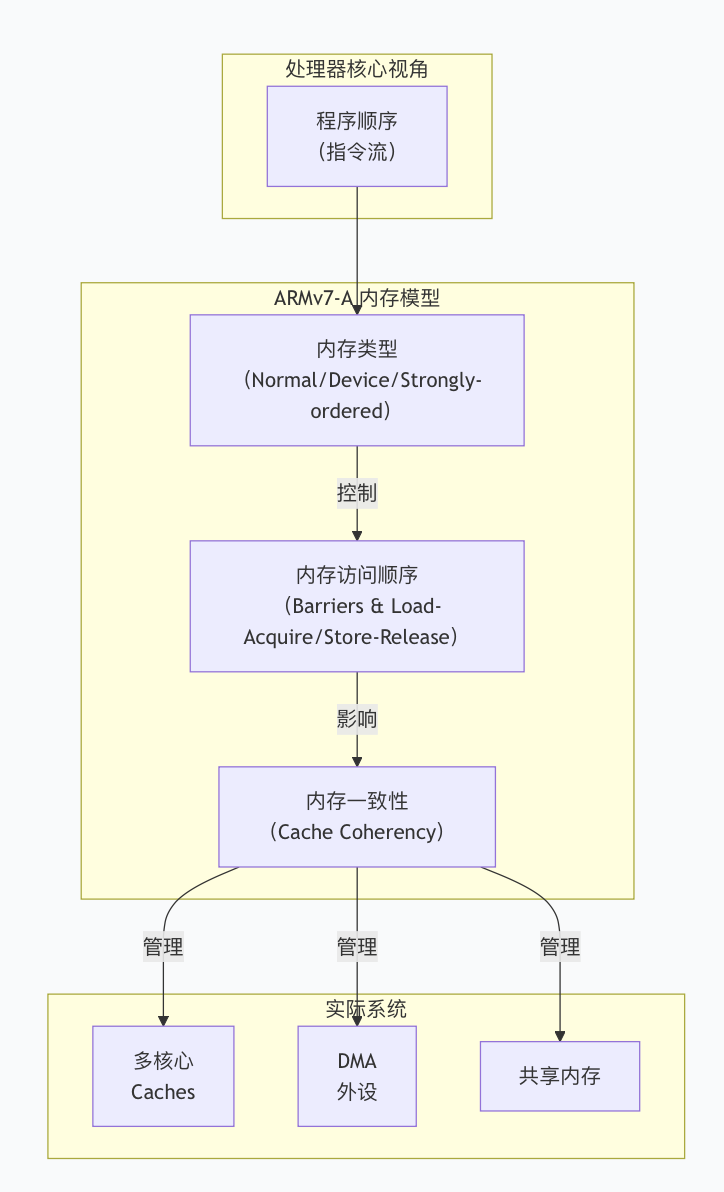
(1) 内存类型:模型的基础
ARMv7-A将内存映射区域划分为三种互斥的类型。这决定了处理器如何看待和访问该地址范围。
| 内存类型 | 典型用途 | 核心行为 |
|---|---|---|
| Normal | 普通RAM,代码段、数据堆栈 | 最强优化:允许合并访问、推测执行、乱序执行和硬件预取。为实现高性能,CPU会尽可能灵活并高效地处理它们。 |
| Device | 外设寄存器,如UART、GPIO | 副作用敏感:访问数量、顺序与程序严格一致。不能合并重复访问,不能改变访问大小(必须如代码所写)。Device内部分为nGRE等多种子类型。 |
| Strongly-ordered | 特殊外设,如中断控制器 | 最严格:访问完全按照程序顺序执行,并在访问完成前不会执行任何后续内存操作。陷入任何 CPU 的"重排序"优化。 |
内存属性 :除了类型,页表项和MPU区域还控制着 Shareable(可共享) 、Cacheable(可缓存) 和 Execute Never(不可执行) 等属性。
-
Shareable:表示该内存区域可能被多个总线 master(如另一个CPU核心或DMA)访问。CPU需使用维护一致的逻辑来保证数据同步。
-
Cacheable:允许数据缓存在L1/L2 Cache中。若为Non-cacheable,每次访问都会直接打到主存接口。
(2) 内存访问顺序:从乱序到确定性
为了性能,ARMv7-A处理器普遍采用流水线、分支预测和硬件乱序执行 。这意味着,你C代码中写出的"a=1; b=2;"在硬件层面,对内存系统来说,b=2的赋值可能发生在a=1生效之前。多核或与外设通信时此行为会出现问题。
ARMv7-A使用屏障指令 和原子操作来强制保证特定顺序。
屏障指令
| 指令 | 全称 | 作用 |
|---|---|---|
DMB |
Data Memory Barrier | 数据内存屏障 。保证DMB之前的所有内存访问,都在DMB之后的任何内存访问前对系统中所有观察者可见。 |
DSB |
Data Synchronization Barrier | 数据同步屏障 。比DMB更强。它会停顿流水线,直到所有DMB之前的访问都完成。后续指令无法执行直到屏障"同步"。 |
ISB |
Instruction Synchronization Barrier | 指令同步屏障。冲刷流水线和指令预取缓冲区,强制重新从Cache或内存中读取后续指令。用于上下文切换或修改代码后。 |
典型用法:
// 场景1:Driver写外设寄存器后,立即等待其状态位变化
REG_DATA = 0x1234; // 向FIFO写数据
DMB; // 保证写入操作在后续轮询前完成(可选DSB强制完成)
while (REG_STATUS == 0); // 等待外设状态变化
// 场景2:上下文切换后,更新页表或向量表
TTBR0 = new_page_table; // 修改页表基址
DSB; // 确保写入完成
ISB; // 冲刷流水线,重新加载指令Load-Acquire 和 Store-Release (ARMv8 引入的概念,但在ARMv7的扩展或实现中已有体现)
它们是更精细化的半屏障:
- Load-Acquire (LDAR):后续的内存读写操作必须在这次加载之后执行(不能前移)。
- Store-Release (STLR):之前的内存读写操作必须在这次存储之前完成(不能后移)。
这比完整的DMB更轻量,常用于实现互斥锁。
// 获取锁(自旋锁)
while (lock == 1) { // 条件判断
...
}
LDAR r0, [lock] // 原子操作:加载并标记为获取语义
cmp r0, #1
... // 获锁成功,临界区代码将在此之后执行
// 释放锁
STLR [lock], #0 // 原子操作:存储并标记为释放语义(3) 多核与一致性:Cache Coherency
当多个CPU核(或DMA)访问同一个共享内存地址时,会产生 Cache Coherency(缓存一致性) 问题。核心A修改了自己Cache中的数据,核心B从自己Cache中可能读到旧值。
ARMv7-A通过MESI协议变种 和SCU(Snoop Control Unit) 机制来硬件自动维护一致性:
- 硬件一致性维护 :当一个核心修改某行时,SCU会探测其他核的Cache。若其他核有此行副本,会使其无效 或更新。
- "Shareable(可共享)"属性的核心作用 :一个内存区域被标记为 Shareable ,告诉硬件这块区域是多核共享的。CPU就会对其进行一致性维护。对非Shareable的区域,CPU不会主动维护一致性 ,软件需自行冲刷Cache(通过
__clear_cache等汇编指令)来手动保证一致性。
(4) 实际编程影响与总结
| 问题场景 | 根本原因 | 解决方案 |
|---|---|---|
| Driver 控制外设失败 | 对Device内存的访问被合并或乱序执行 | 使用DMB/DSB屏障;将外设寄存器基址映射为Device内存类型。 |
| **多核数据不一致</b/ | 核心对自己Cache的修改对其他核心不可见 | 对共享内存区域设置Shareable属性;使用原子操作 (LDREX/STREX及其屏障封装)实现互斥。参考Mutex 或Spinlock。 |
| DMA 传输出错 | CPU Cache中的缓冲数据与DMA看到的物理内存不一致 | 在启动DMA前冲刷Cache(cleanCache);在DMA结束后无效化Cache(invalidate Cache);或为非一致性DMA分配Non-cacheable内存。 |
| 自修改代码运行异常 | CPU 执行了旧的、已被修改的指令缓存 | 修改代码段后:修改内存->DCache Clean->ICache Invalidate->DSB->ISB。 |
ARMv7-A架构为高性能设计的推测执行、乱序执行和写缓存 ,为开发者显式定义了控制硬件行为的规则与工具。理解和善用三种内存类型和屏障指令,是写出正确且健壮的高性能嵌入式软件(尤其是驱动和RTOS多核应用)的关键。
三、指令集
ARMv7 指令格式主要分为 ARM 指令集(32 位) 和 **Thumb/Thumb-2 指令集(16/32 位混合)**,这种设计是RISC理念的体现------用固定的指令长度换取简洁的解码逻辑和更高的流水线效率。指令由条件域、类型域和操作域三层结构组成,这种层次化编码方式在有限的32/16位空间内实现了丰富的指令表达。
1. 基本格式

**1. ARM 指令格式(32 位固定长度)**
通用格式为:
**<opcode>{<cond>}{S} <Rd>, <Rn>{, <op2>}**
- **
<opcode>** :操作码(如ADD,MOV,LDR等) - **
{<cond>}** :可选条件码(如EQ,NE,GT等),默认为AL(总是执行) - **
{S}**:可选后缀,若设置则更新 CPSR 标志位(N, Z, C, V) - **
<Rd>**:目标寄存器 - **
<Rn>**:第一个操作数寄存器 - **
{<op2>}**:第二个操作数,可以是寄存器或立即数(支持移位)
示例:
ADDEQ R1, R2, R3, LSL #2表示"若相等,则 R1 = R2 + (R3 << 2)",并更新标志位。
**2. Thumb 指令格式(16 位为主,部分 32 位扩展)**
- Thumb-1:16 位固定长度,指令集受限(仅支持基本操作)
- Thumb-2:混合 16/32 位,兼容性好,代码密度高,性能接近 ARM
通用格式类似 ARM,但更紧凑。例如:
ADD Rd, Rn, #imm3(16 位)ADD.W Rd, Rn, #imm12(32 位,.W强制为 32 位编码)
Thumb 指令中,只有部分指令支持条件执行 (如
IT块控制的条件执行)。
cond op1 操作数/功能码
31 28 27 25 24 0
┌─────────────┬───────────┬───────────────────┐
│ cond │ op1 │ operands │
│ 4 bits │ 3 bits │ 25 bits │
└─────────────┴───────────┴───────────────────┘
↑
bit 4: op三层结构解析:
- 第1层 (cond域):bits31:28------4位条件码,决定指令是否执行(16种条件)
- 第2层 (类型域):bits27:25和bit4------确定指令大类(数据处理、加载存储、分支、协处理器等)
- 第3层 (操作域):剩余bits------根据指令类型灵活定义,进一步细分具体指令
这种分层设计使ARM能在32位定长指令的限制下,通过"类型码+功能码"的组合高效编码数百条指令。
2. 条件码
ARM指令最显著的特性之一------几乎所有指令都可以条件执行。指令的bits31:28(cond域)编码了16种条件:
| cond码 | 助记符 | 含义(整数) | 条件 |
|---|---|---|---|
| 0000 | EQ | 相等 | Z == 1 |
| 0001 | NE | 不等 | Z == 0 |
| 0010 | CS/HS | 进位/无符号≥ | C == 1 |
| 0011 | CC/LO | 无进位/无符号< | C == 0 |
| 0100 | MI | 负数 | N == 1 |
| 0101 | PL | 非负数 | N == 0 |
| 0110 | VS | 溢出 | V == 1 |
| 0111 | VC | 无溢出 | V == 0 |
| 1000 | HI | 无符号大于 | C == 1 and Z == 0 |
| 1001 | LS | 无符号小于等于 | C == 0 or Z == 1 |
| 1010 | GE | 有符号≥ | N == V |
| 1011 | LT | 有符号< | N != V |
| 1100 | GT | 有符号> | Z == 0 and N == V |
| 1101 | LE | 有符号≤ | Z == 1 or N != V |
| 1110 | AL | 无条件执行 | 任何(默认) |
实用示例:
CMP R0, R1 ; 先比较
MOVEQ R0, #0 ; 如果相等,R0清零
ADDGT R1, R1, #1 ; 如果大于,R1自增这种设计能消除许多小型分支,提高代码密度和流水线效率。
3. 寻址方式
寻址方式是指令中操作数的来源和计算方法 。ARM采用Load-Store架构,只有加载(LDR/STR)和分支指令能访问内存,数据处理指令仅操作寄存器。因此寻址方式主要分为两大类:数据处理指令的立即数/寄存器寻址 和加载存储指令的内存寻址。
| 类别 | 适用指令 | 操作数来源 | 典型用途 |
|---|---|---|---|
| 立即数寻址 | 数据处理指令 | 指令中的立即数 | 常量赋值、掩码操作 |
| 寄存器寻址 | 所有指令 | 寄存器中的值 | 变量操作、运算 |
| 寄存器移位寻址 | 数据处理指令 | 移位后的寄存器值 | 乘法替代、位域提取 |
| 基址寻址 | LDR/STR | 寄存器+偏移 | 内存访问 |
| 多寄存器寻址 | LDM/STM | 多个寄存器 | 上下文切换、块拷贝 |
四、汇编指令
ARMv7 指令主要分为六类 :数据处理指令 :如 ADD, SUB, MOV, AND, ORR, EOR, CMP, TST;分支跳转指令 :如 B, BL, BX, BLX, CBZ, CBNZ;加载/存储指令 :如 LDR, STR, LDM, STM;程序状态寄存器(PSR)访问指令 :如 MRS, MSR;协处理器指令 :如 MRC, MCR;异常产生指令:如 SWI, BKPT。
根据类型域的取值,ARMv7指令分为6大类:
| cond | op1 | op | 指令类别 | 主要功能 |
|---|---|---|---|---|
| not 1111 | 00x | - | 数据处理和杂项指令 | 算术、逻辑、比较、传送、移位等 |
| not 1111 | 010 | - | 加载/存储指令 | 单数据传输(字/字节) |
| not 1111 | 011 | 0 | 加载/存储指令 | 同上 |
| not 1111 | 011 | 1 | 媒体指令 | SIMD、多媒体加速 |
| not 1111 | 10x | - | 分支指令和块数据传输 | B/BL跳转、LDM/STM批量传输 |
| not 1111 | 11x | - | 协处理器指令和SVC | CP15操作、系统调用、浮点/VFP |
注意:当cond域为0b1111时,指令无条件执行,包括Advanced SIMD等特殊指令。
| 类别 | 常用指令 |
|---|---|
| 数据处理 | MOV, MVN, ADD, ADC, SUB, SBC, RSB, MUL, AND, ORR, EOR, BIC |
| 比较 | CMP, CMN, TST, TEQ |
| 移位 | LSL, LSR, ASR, ROR, RRX |
| 加载/存储 | LDR, STR, LDRB, STRB, LDRH, STRH, LDRSB, LDRSH |
| 多寄存器 | LDMIA, STMIA, LDMDB, STMDB, PUSH, POP |
| 分支 | B, BL, BX, BLX |
| 状态寄存器 | MRS, MSR |
| 协处理器 | MCR, MRC |
| 异常 | SVC, BKPT |
ARMv7指令集的核心是32位定长编码+条件执行+Load-Store架构,加上Thumb-2的支持,在性能与代码密度之间取得平衡。掌握指令编码结构是深入理解ARM体系的基础,而数据处理、加载存储和分支这三大类指令则是日常嵌入式开发的高频操作。
1. 数据处理指令
数据处理指令是ARM指令集中数量最多的一类,执行算术、逻辑、比较和数据传送操作。
(1) 算术逻辑运算指令
| 指令 | 功能 | 示例 |
|---|---|---|
| MOV | 数据传送 | MOV R0, #0x12 --- 立即数传送 MOV R1, R2 --- 寄存器传送 |
| MVN | 按位取反传送 | MVN R0, R1 --- R0 = ~R1 |
| ADD | 加法 | ADD R0, R1, R2 --- R0 = R1 + R2 ADD R0, R1, #0x10 |
| ADC | 带进位加法 | ADC R0, R1, R2 --- R0 = R1 + R2 + C |
| SUB | 减法 | SUB R0, R1, R2 --- R0 = R1 - R2 |
| SBC | 带借位减法 | SBC R0, R1, R2 --- R0 = R1 - R2 - (1-C) |
| RSB | 反向减法 | RSB R0, R1, #0 --- R0 = 0 - R1 |
| MUL | 乘法 | MUL R0, R1, R2 --- R0 = R1 × R2 |
| AND | 按位与 | AND R0, R1, R2 --- R0 = R1 & R2 |
| ORR | 按位或 | ORR R0, R0, #0x01 --- 置最低位为1 |
| EOR | 按位异或 | EOR R0, R0, R1 --- 按位异或 |
| BIC | 位清零 | BIC R1, R1, #0x0F --- 清除最低4位 |
(2) 比较测试指令
比较指令只更新CPSR标志位,不保存结果:
| 指令 | 操作 | 影响的标志位 |
|---|---|---|
| CMP | 比较两个数 | CMP R0, R1 --- Z=1表示相等 |
| CMN | 比较负值 | CMN R0, R1 --- R0 + R1,影响进位标志 |
| TST | 位测试 | TST R0, #0x01 --- 测试最低位是否为1 |
| TEQ | 测试相等 | TEQ R0, R1 --- 按位异或测试,Z=1表示相等 |
(3) 移位指令
ARM的数据处理指令可以在ALU操作前对第二个操作数进行移位:
| 指令 | 功能 | 操作 |
|---|---|---|
| LSL | 逻辑左移 | 低位补0 |
| LSR | 逻辑右移 | 高位补0 |
| ASR | 算术右移 | 高位补符号位 |
| ROR | 循环右移 | |
| RRX | 带扩展循环右移 | 通过进位标志位循环 |
移位示例:
MOV R0, R1, LSL #2 ; R0 = R1 << 2
ADD R0, R1, R2, LSR #1 ; R0 = R1 + (R2 >> 1)(4) S后缀与标志位更新
在数据处理指令后加 S 后缀,指令结果会更新CPSR的条件标志位(N、Z、C、V):
ADDS R0, R1, R2 ; 执行加法并更新标志位
SUBS R0, R0, #1 ; 减法并更新标志位
CMP R0, R1 ; CMP指令隐含S后缀2. 加载与存储指令
ARM采用 Load-Store架构,只有LDR和STR指令能访问内存,数据处理指令只操作寄存器。
(1) 单寄存器传输
| 指令 | 功能 | 示例 |
|---|---|---|
| LDR | 加载字 | LDR R0, [R1] --- 从R1指向的地址读32位到R0 |
| STR | 存储字 | STR R0, [R1] --- 将R0存入R1指向的地址 |
| LDRB | 加载字节(零扩展) | LDRB R0, [R1] |
| STRB | 存储字节 | STRB R0, [R1] --- 只存低8位 |
| LDRH | 加载半字 | LDRH R0, [R1] --- 16位,零扩展 |
| LDRSB | 加载有符号字节 | LDRSB R0, [R1] --- 符号扩展到32位 |
| LDRSH | 加载有符号半字 | LDRSH R0, [R1] |
寻址模式示例:
LDR R0, [R1, #4] ; 基址偏移:R1+4
LDR R0, [R1], #4 ; 后变址:先加载R1指向地址,再R1+=4
STR R0, [R1, R2, LSL #2] ; 寄存器偏移:R1 + (R2<<2)(2) 多寄存器传输(LDM/STM)
批量加载/存储指令用一条指令传输多个寄存器,极大提高上下文切换效率:
| 指令 | 全称 | 操作 |
|---|---|---|
| LDMIA / LDMFD | 加载后递增 | 从地址加载多个寄存器,地址递增 |
| STMIA / STMEA | 存储后递增 | 存储多个寄存器,地址递增 |
| LDMDB / LDMFA | 加载前递减 | 转储备 |
| STMDB / STMFD | 存储前递减 | 压栈 |
栈操作对应关系(FD=满递减栈是ARM的标准):
STMFD SP!, {R0-R3, LR} ; 压栈:保存R0-R3和LR
LDMFD SP!, {R0-R3, PC} ; 出栈:恢复并从子程序返回PUSH和POP是以上指令的别名,在ARMv7中普遍支持。
3. 分支指令
| 指令 | 功能 | 跳转范围 | 示例 |
|---|---|---|---|
| B | 无条件跳转 | ±32MB | B label |
| B<cond> | 条件跳转 | ±32MB | BEQ label --- 相等时跳转 |
| BL | 带链接跳转(函数调用) | ±32MB | BL func --- LR=返回地址 |
| BX | 带状态切换的跳转 | 任意(寄存器指定) | BX R0 --- 若R00=1则切Thumb |
| BLX | 带链接和状态切换 | 寄存器指定 | BLX R0 --- 函数调用并切换状态 |
B/BL的相对跳转原理:指令编码中26位(含隐含2位)存放相对偏移,实现±32MB范围的PC相对跳转。
4. 程序状态寄存器(PSR)指令
| 指令 | 功能 | 示例 |
|---|---|---|
| MRS | PSR → 通用寄存器 | MRS R0, CPSR --- 读取当前状态 |
| MSR | 通用寄存器 → PSR | MSR CPSR_c, #0xD3 --- 只写控制域 |
PSR域选择:
-
_c:控制域(bits7:0)--- 模式位、中断使能 -
_x:扩展域(bits15:8) -
_s:状态域(bits23:16) -
_f:标志域(bits31:24)--- N、Z、C、V标志
5. 协处理器指令
主要用于系统控制(特别是 CP15)和浮点运算:
| 指令 | 功能 | 示例 |
|---|---|---|
| MCR | ARM寄存器 → 协处理器 | MCR p15, 0, R0, c1, c0, 0 --- 写SCTLR |
| MRC | 协处理器 → ARM寄存器 | MRC p15, 0, R0, c12, c0, 0 --- 读VBAR |
| LDC | 内存 → 协处理器 | 加载浮点寄存器 |
| STC | 协处理器 → 内存 | 存储浮点寄存器 |
| CDP | 协处理器内部操作 | 协处理器数据操作 |
CP15的作用:MMU配置、Cache管理、TLB控制、向量表重定位(VBAR)等系统级功能都通过MCR/MRC访问CP15实现。
6. 异常产生指令
| 指令 | 功能 | 用途 |
|---|---|---|
| SVC(旧称SWI) | 软中断 | 系统调用,触发SVC异常进入内核 |
| BKPT | 断点 | 调试支持,触发调试异常 |
SVC示例:
SVC #0x12 ; 触发SVC异常,参数0x127. 伪指令
伪指令不是ARM指令,而是给汇编器的编译指示,方便程序编写:
| 伪指令 | 功能 | 说明 |
|---|---|---|
| LDR Rd, =constant | 加载32位立即数 | 大常数自动放入文字池 |
| ADR Rd, label | 加载相对地址 | 基于PC的地址加载 |
| NOP | 空操作 | 实际编译为MOV R0, R0 |
| ALIGN | 对齐伪指令 | 确保下一条指令对齐 |
LDR伪指令的妙用:
LDR R0, =0x12345678 ; ARM MOV无法直接加载32位立即数
; 汇编器自动生成:PC相对LDR从文字池加载五、SEGGER编译选项设置
1. 进入工程选项配置
在SEGGER Embedded Studio中,所有编译选项都在工程属性中设置:
- 右键点击项目 → 选择
Options(或选中项目后按Alt+Enter) - 也可以在菜单栏选择
Project→Options...
配置窗口结构如下:
| 配置类型 | 说明 | 用途 |
|---|---|---|
| Common | 公共配置,被所有构建配置继承 | 芯片型号、包含路径等共享设置 |
| Debug | 调试版本配置 | 关闭优化、生成调试信息 |
| Release | 发布版本配置 | 开启优化、移除调试符号 |
设计理念:Common中设置共享选项,Debug和Release继承后可以按需覆盖。
2. 代码编译选项(Code Options)
(1)Build 选项卡
| 选项 | 说明 | 典型设置 |
|---|---|---|
| Output Directory | 编译输出目录 | ./Output/Debug/ |
| Memory Map File | 内存映射文件 | 通常设为None |
| Memory Settings | RAM/Flash起始地址和大小 | 根据芯片数据手册填写 |
| Project Macros | 作用于编译器的宏定义 | 如NORDIC、BOARD_CUSTOM |
(2)Preprocessor 选项卡
这是最常用的配置区域:
cpp
// Preprocessor Definitions - 代码中使用的宏
DEBUG=1
STM32F407xx
USE_HAL_DRIVER
// User Include Directories - 头文件路径
../Inc
../Drivers/CMSIS/Include
../Drivers/STM32F4xx_HAL_Driver/Inc⚠️ 优先级警告:SES默认会优先编译Package安装目录下的头文件。如果修改自己工程中的.h文件不生效,需要检查并删除Common配置中inherits继承的路径。
(3)Compiler 选项卡
| 设置项 | Debug配置 | Release配置 |
|---|---|---|
| Optimization Level | None (-O0) |
Optimize for Size (-Os) 或 Optimize for Speed (-O2) |
| Generate Debug Information | Yes (-g) |
No |
| Warning Level | All (-Wall -Wextra) |
All |
Debug优化的特殊选项 :在使用Nordic SDK时,可以在prj.conf中配置CONFIG_DEBUG=y,或在菜单Project → Configure nRF Connect SDK Project → Build and Link Features → Compiler Options中选择"Optimize for debugging experience"。
(4)Linker 选项卡
| 选项 | 说明 |
|---|---|
| Section Placement File | 链接脚本(.icf或.xml),描述代码段分布 |
| Additional Output Format | Intel HEX 或 Binary(生成.hex/.bin) |
| Entry Point | 程序入口,如Reset_Handler |
| Stack Size / Heap Size | 栈和堆大小设置 |
自定义链接器选项 :若需要传递-Wl,风格的参数给链接器,可在Linker 选项卡的Additional Flags中添加。
(5)User Build Steps 选项卡
支持在编译前后执行自定义命令:
| 选项 | 说明 |
|---|---|
| Post-Compile Command | 编译完成后执行 |
| Post-Link Command | 链接完成后执行 |
| Post-Build Command Control | 控制何时执行自定义命令 |
3. 调试选项(Debug Options)
(1)Debugger 选项卡
| 选项 | 典型设置 | 说明 |
|---|---|---|
| Target Connection | J-Link |
调试器类型 |
| Target Device | nRF52840_xxAA |
目标芯片型号 |
| Run To | main |
调试启动后运行到main函数 |
| Register Definition File | 芯片对应的.xml | 寄存器定义 |
(2)J-Link 选项卡
| 选项 | 典型设置 |
|---|---|
| Host Connection | USB |
| Target Interface Type | SWD 或 JTAG |
| Speed | 4000 kHz(SWD模式常用4MHz) |
(3)Loader 选项卡
| 选项 | 说明 |
|---|---|
| Additional Load File0 | 附加下载文件(如协议栈.hex) |
| Additional Load File Type0 | 文件类型,通常保持Detect |
(4)Target Script 选项卡
| 选项 | 典型设置 |
|---|---|
| Reset Script | TargetInterface.resetAndStop() |
| Target Script File | 复杂项目可指定自定义脚本 |