
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. LangChain环境搭建与核心包详解](#一. LangChain环境搭建与核心包详解)
-
- [1.1 LangChain生态包体系](#1.1 LangChain生态包体系)
- [1.2 环境安装命令](#1.2 环境安装命令)
- [二. 5分钟快速上手:LangChain接入大模型全流程](#二. 5分钟快速上手:LangChain接入大模型全流程)
-
- [2.1 核心执行链路](#2.1 核心执行链路)
- [2.2 逐行代码实战与解析](#2.2 逐行代码实战与解析)
- [三. LangChain聊天模型四大核心能力深度解析(先了解即可)](#三. LangChain聊天模型四大核心能力深度解析(先了解即可))
-
- [3.1 工具调用(Function Calling):让大模型连接真实世界](#3.1 工具调用(Function Calling):让大模型连接真实世界)
-
- [3.1.1 bind_tools方法核心API详解](#3.1.1 bind_tools方法核心API详解)
- [3.1.2 自定义工具定义与基础调用实战](#3.1.2 自定义工具定义与基础调用实战)
- [3.1.3 工具调用完整闭环实战](#3.1.3 工具调用完整闭环实战)
- [3.1.4 进阶用法:强制工具调用与搜索工具实战](#3.1.4 进阶用法:强制工具调用与搜索工具实战)
- [3.2 结构化输出:让大模型输出完全可控](#3.2 结构化输出:让大模型输出完全可控)
-
- [3.2.1 with_structured_output方法API详解](#3.2.1 with_structured_output方法API详解)
- [3.2.2 结构化输出实战场景](#3.2.2 结构化输出实战场景)
- [3.3 流式传输:打造丝滑的用户交互体验](#3.3 流式传输:打造丝滑的用户交互体验)
-
- [3.3.1 同步流式stream()方法实战](#3.3.1 同步流式stream()方法实战)
- [3.3.2 异步流式astream()方法实战](#3.3.2 异步流式astream()方法实战)
- [3.3.3 LCEL链式流式传输实战](#3.3.3 LCEL链式流式传输实战)
- [3.3.4 自定义流式输出解析器](#3.3.4 自定义流式输出解析器)
- [3.3.5 流式传输底层原理深度解析](#3.3.5 流式传输底层原理深度解析)
- [3.4 LangSmith:LLM应用的可观测性平台](#3.4 LangSmith:LLM应用的可观测性平台)
- [3.4.1 环境配置步骤](#3.4.1 环境配置步骤)
- [3.4.2 核心能力](#3.4.2 核心能力)
- [四. Runnable接口:LangChain的核心设计灵魂](#四. Runnable接口:LangChain的核心设计灵魂)
-
- [4.1 Runnable接口核心概念](#4.1 Runnable接口核心概念)
- [4.2 Runnable接口核心标准方法](#4.2 Runnable接口核心标准方法)
- [4.3 Runnable接口的最大优势:无缝切换大模型](#4.3 Runnable接口的最大优势:无缝切换大模型)
- [五. LCEL:LangChain表达式语言,链式编程的终极形态](#五. LCEL:LangChain表达式语言,链式编程的终极形态)
-
- [5.1 LCEL核心优势](#5.1 LCEL核心优势)
- [5.2 LCEL基础实战:完整的翻译链](#5.2 LCEL基础实战:完整的翻译链)
- [5.3 LCEL核心组件:RunnablePassthrough](#5.3 LCEL核心组件:RunnablePassthrough)
- [5.4 LCEL进阶:错误回退机制](#5.4 LCEL进阶:错误回退机制)
前言:
当下大模型应用开发早已不是简单调用原生API就能完成的事:切换模型需要重构大量代码、工具调用逻辑繁琐复杂、结构化输出解析极易出错、长文本生成的用户体验极差、多步骤链路调试无从下手......这些痛点几乎是每个LLM应用开发者都会遇到的问题。而LangChain作为目前全球最流行的大语言模型应用开发框架,正是为解决这些问题而生。它通过标准化的组件抽象、声明式的链式编程范式,将大模型应用开发的复杂度大幅降低,让开发者可以专注于业务逻辑,而非底层适配。本文将从环境搭建开始,一步步拆解LangChain的核心能力,从基础的模型接入,到工具调用、结构化输出、流式传输、可观测性四大核心能力,再到框架灵魂------Runnable接口与LCEL表达式语言,全程结合实战代码与底层原理解析,让你彻底掌握LangChain的开发范式,完成从入门到生产级应用的跨越。
一. LangChain环境搭建与核心包详解
很多新手刚接触LangChain会盲目安装一堆包,却不清楚每个包的作用。LangChain并非单一的安装包,而是一套完整的生态体系,不同的包负责不同的能力边界,我们先把核心包的分工讲清楚。
1.1 LangChain生态包体系
| 包名 | 核心作用 | 是否必须安装 |
|---|---|---|
langchain-core |
整个生态的核心基石,包含所有组件的基类、抽象接口、LCEL表达式语言的核心实现,其他所有包都依赖它 | 自动安装,无需手动单独安装 |
langchain |
主包,开发的主要入口,包含高阶应用组件、链的封装、Agent基础实现,是入门的核心包 | 是 |
langchain-xxx |
模型/组件集成包(如langchain-openai/langchain-deepseek),针对不同大模型服务商做了标准化封装,实现模型无缝切换 |
按需安装,本文以OpenAI为例 |
langchain-community |
社区贡献的集成包,所有未拆分为独立集成包的能力都在这里,包含海量工具、文档加载器、向量库实现 | 按需安装 |
langsmith |
LangChain官方可观测性平台SDK,用于调试、监控LLM应用全链路执行过程 | 自动安装 |
langgraph |
用于构建有状态的多智能体应用,基于状态机的编程范式,属于进阶能力 | 本文暂不涉及 |
1.2 环境安装命令
本文以OpenAI集成为例,给出最小化安装命令,使用bash代码块执行:
shell
# 安装LangChain主包
pip install langchain
# 安装OpenAI集成包
pip install langchain-openai如果需要使用社区贡献的工具/组件,额外安装:
shell
pip install langchain-community安装完成后,我们就可以开始正式的开发实战。
二. 5分钟快速上手:LangChain接入大模型全流程
LangChain的核心流程非常清晰,我们先通过一个极简的翻译案例,跑通整个链路,建立整体认知。其中关于API的创建我们在前面就讲过了,这里的话我们API可以直接配置到环境变量里面
2.1 核心执行链路
LangChain接入大模型的标准流程分为5步,也是所有LLM应用的基础范式:
- 定义大模型实例:标准化封装不同厂商的大模型,统一调用接口
- 定义对话消息:区分系统提示、用户输入等不同角色的消息,解决不同厂商格式不统一的问题
- 调用大模型 :通过标准
invoke方法发起请求,获取AI响应 - 输出解析:将模型返回的复杂消息对象,解析为业务可用的纯文本/结构化数据
- 链式编排:通过LCEL将多个组件串联为执行链,简化调用流程
2.2 逐行代码实战与解析
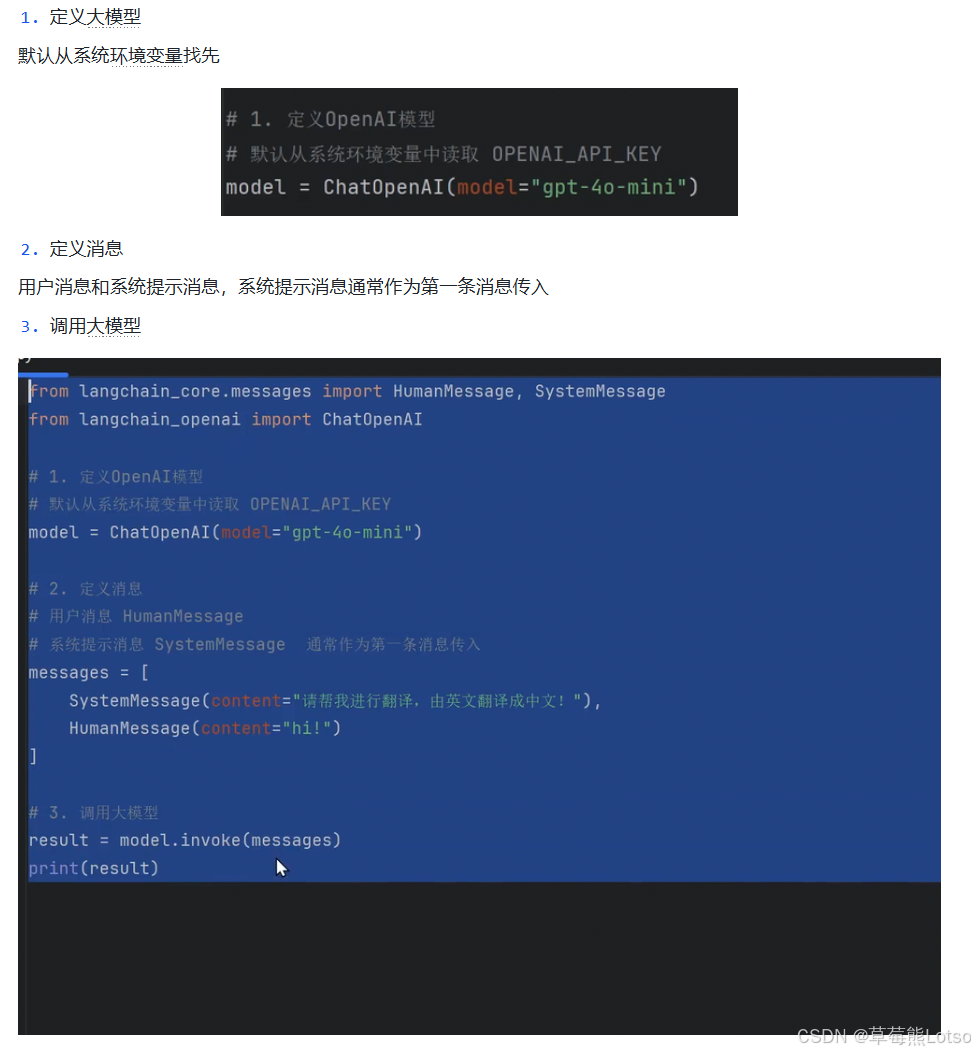
我们先实现一个基础的英文→中文翻译功能,完整代码如下:
python
# 1. 导入核心依赖
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# 2. 定义大模型实例
# 自动从系统环境变量读取OPENAI_API_KEY,也可手动传入api_key参数
model = ChatOpenAI(model="gpt-4o-mini")
# 3. 定义对话消息列表
messages = [
# SystemMessage:系统提示,给模型设定角色、行为规范,通常作为第一条消息
SystemMessage(content="你是一个专业的翻译助手,只负责将英文翻译为通顺的中文,不要添加额外内容"),
# HumanMessage:用户输入,代表用户向模型发起的请求
HumanMessage(content="my name is XiaoMing, I am a software developer")
]
# 4. 同步调用大模型
ai_response = model.invoke(messages)
print("=== 模型原始响应对象 ===")
print(ai_response)代码逐行解析:
- 模型定义 :
ChatOpenAI是LangChain对OpenAI聊天模型的标准化封装,它实现了标准的Runnable接口,这是LangChain所有组件的通用抽象,也是框架的核心设计。 - 消息类型 :LangChain定义了标准化的消息类,彻底解决了不同大模型厂商消息格式不统一的问题,核心基础类型有两个:
SystemMessage:系统角色,用于给模型设定全局行为规范、角色设定HumanMessage:用户角色,代表用户的输入内容
- invoke方法 :Runnable接口的核心同步调用方法,输入标准化的消息列表,返回
AIMessage对象,这是模型响应的标准化封装。
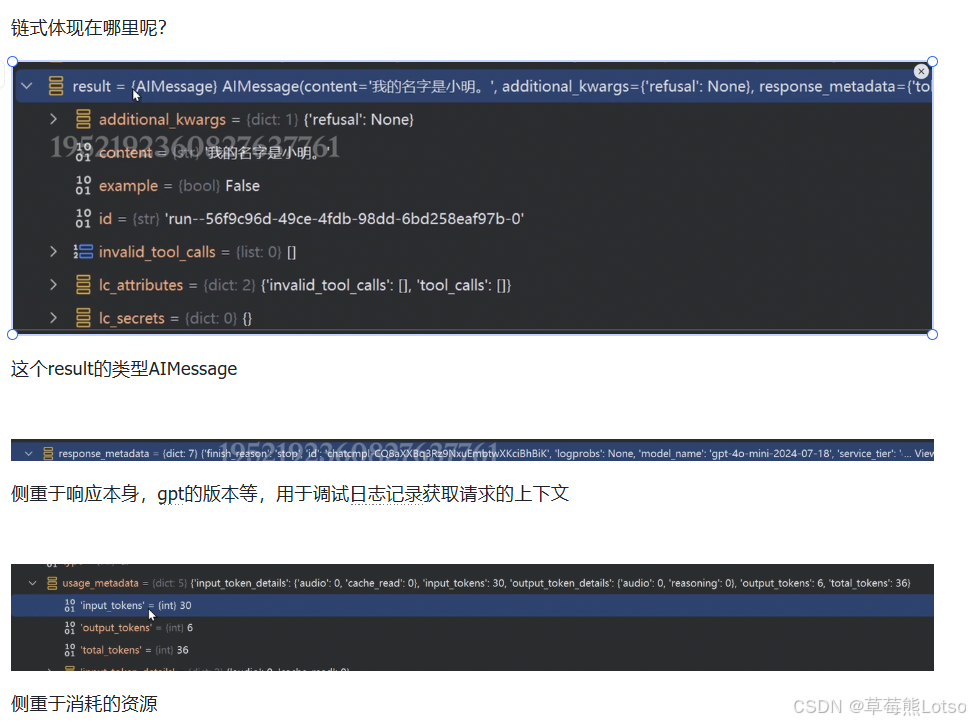
我们来看模型返回的AIMessage核心结构,这是理解LangChain模型响应的关键:
python
# AIMessage核心字段解析
AIMessage(
content='我的名字是小明,我是一名软件开发工程师', # 模型返回的纯文本内容
additional_kwargs={'refusal': None}, # 模型拒绝回答时的内容
response_metadata={ # 响应元数据,用于调试、日志、计费统计
'token_usage': { # Token消耗详情
'completion_tokens': 12,
'prompt_tokens': 38,
'total_tokens': 50
},
'model_name': 'gpt-4o-mini-2024-07-18', # 实际调用的模型版本
'finish_reason': 'stop' # 模型停止生成的原因
},
id='run--xxxx-xxxx-xxxx-xxxx', # 本次请求的唯一ID,用于链路追踪
usage_metadata={ # 跨模型统一的Token使用统计
'input_tokens': 38,
'output_tokens': 12,
'total_tokens': 50
}
)接下来,我们通过输出解析器 ,把复杂的AIMessage对象解析为纯文本,这是开发中最常用的操作:
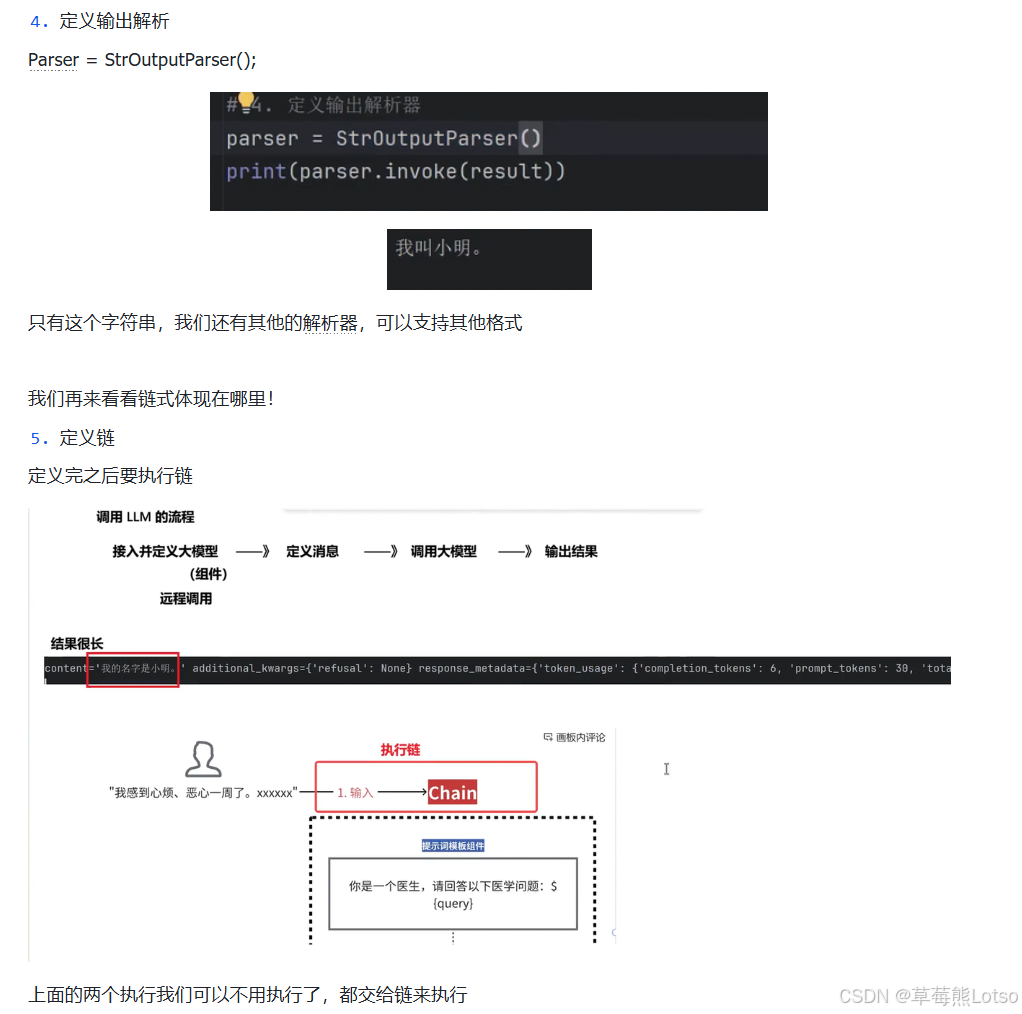
python
# 5. 定义字符串输出解析器
parser = StrOutputParser()
# 解析模型响应
text_result = parser.invoke(ai_response)
print("\n=== 解析后的纯文本结果 ===")
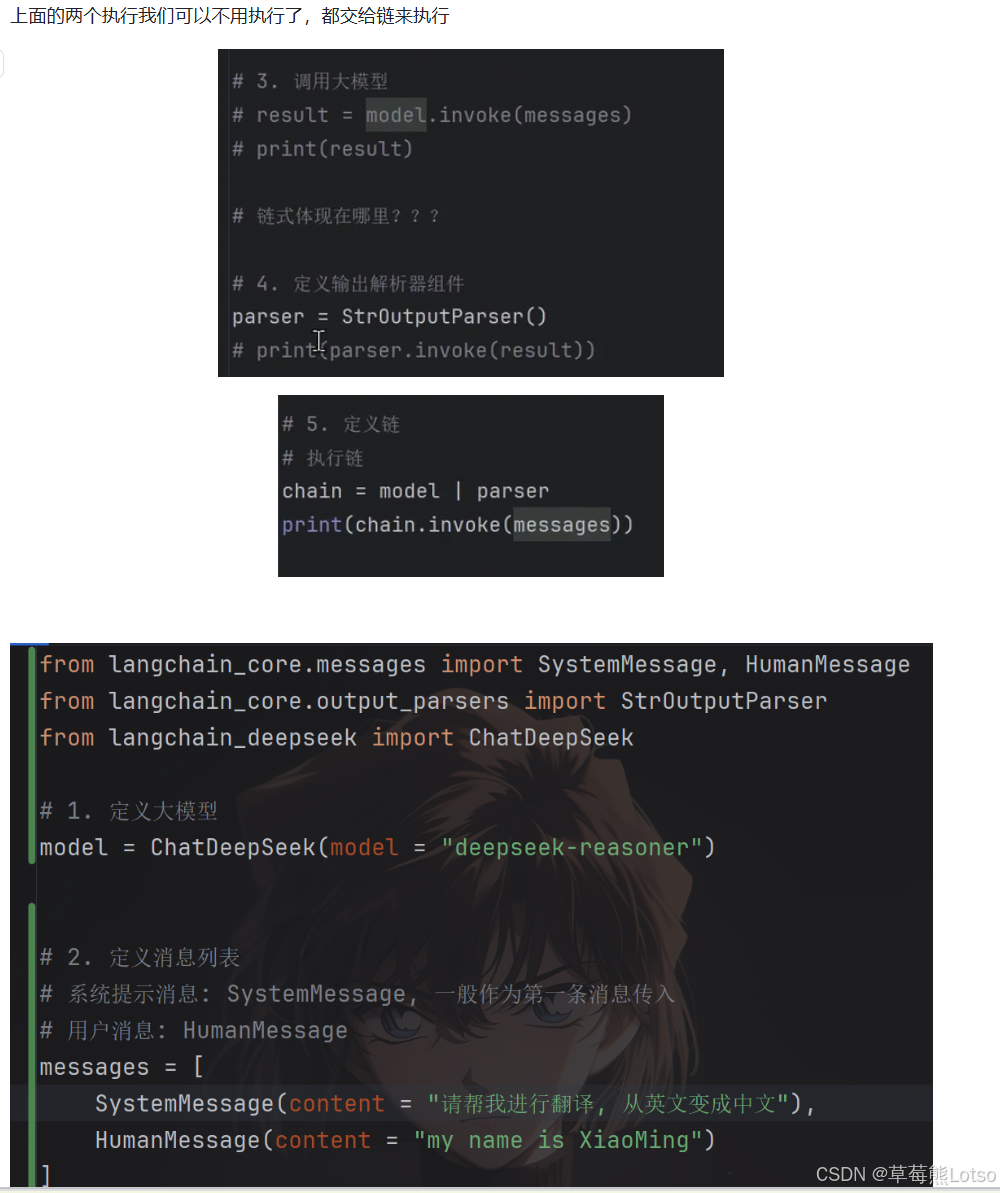
print(text_result) # 输出:我的名字是小明,我是一名软件开发工程师最后,我们通过LCEL表达式语言,把「模型调用」和「输出解析」两个组件串联成一条执行链,大幅简化代码:
python
# 6. 通过LCEL管道符|构建执行链
chain = model | parser
# 直接调用链,一步完成模型调用+结果解析
chain_result = chain.invoke(messages)
print("\n=== 链式调用结果 ===")
print(chain_result)这里的管道符|是LCEL的核心,它会把前一个组件的输出,作为后一个组件的输入,最终生成的chain也是一个Runnable实例,拥有和模型完全相同的调用方法。
到这里,我们就跑通了LangChain的完整基础流程,接下来我们深入拆解LangChain聊天模型的四大核心能力,这是开发复杂LLM应用的基础。

三. LangChain聊天模型四大核心能力深度解析(先了解即可)
LangChain对聊天模型的原生能力做了极致的封装,解决了原生API开发中的诸多痛点,其中最核心的就是工具调用、结构化输出、流式传输、可观测性四大能力,我们逐个拆解。
3.1 工具调用(Function Calling):让大模型连接真实世界
大模型本身有三个致命的局限性:知识截止日期(无法获取实时数据)、缺乏精准计算能力(复杂数学计算、代码执行易出错)、无法访问私有数据。而工具调用就是解决这些问题的核心方案,它让大模型可以自主决定何时调用外部工具,获取执行结果后再生成最终答案。
3.1.1 bind_tools方法核心API详解
LangChain通过bind_tools方法,为聊天模型绑定自定义工具,这是工具调用的核心入口,我们先拆解它的核心参数:
python
bind_tools(
# 必选:要绑定的工具列表,支持字典、Pydantic类、Python函数、BaseTool实例
tools: Sequence[dict[str, Any] | type | Callable | BaseTool],
# 可选:控制模型是否调用工具、调用哪个工具
tool_choice: str | dict | bool | None = None,
# 可选:是否严格校验工具入参与Schema完全匹配,开启后大幅降低参数解析错误
strict: bool | None = None,
# 可选:是否开启并行工具调用,默认开启
parallel_tool_calls: bool | None = None,
) -> Runnable关键参数说明:
tool_choice:控制工具调用行为,最常用的取值:auto:默认值,模型自主决定是否调用工具、调用哪个工具none:强制不调用任何工具any/required/True:强制模型至少调用一个工具- 工具名称字符串:强制模型调用指定的工具
strict=True:强烈建议开启,OpenAI官方要求开启严格模式,保证模型输出的工具入参和定义的JSON Schema完全匹配,避免解析错误。
3.1.2 自定义工具定义与基础调用实战
LangChain提供了极简的工具定义方式,通过@tool装饰器,就可以把一个普通Python函数转换为大模型可调用的工具,我们先定义两个基础的数学计算工具:
python
# 导入核心依赖
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from typing_extensions import Annotated
# 1. 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 自定义加法工具
@tool
def add(
a: Annotated[int, ..., "第一个整数"],
b: Annotated[int, ..., "第二个整数"]
) -> int:
"""两个整数相加"""
return a + b
# 3. 自定义乘法工具
@tool
def multiply(
a: Annotated[int, ..., "第一个整数"],
b: Annotated[int, ..., "第二个整数"]
) -> int:
"""两个整数相乘"""
return a * b
# 4. 绑定工具到模型
tools = [add, multiply]
model_with_tools = model.bind_tools(tools, strict=True)
# 5. 调用模型,触发工具调用
result = model_with_tools.invoke("9乘6等于多少?")
print("=== 工具调用响应 ===")
print(result.tool_calls)代码核心解析:
- @tool装饰器:会自动解析函数的参数类型、注释、返回值,生成符合OpenAI要求的工具Schema,无需手动编写JSON Schema。
- Annotated类型注解:Python的类型注解扩展,用于给参数添加描述,大模型会通过这些描述理解每个参数的含义,是工具调用准确率的关键。
- 函数文档字符串:必须写清楚工具的功能,这是大模型判断是否调用该工具的核心依据。
- tool_calls属性 :当模型决定调用工具时,返回的
AIMessage会包含tool_calls字段,这是标准化的工具调用信息,格式如下:
python
[
{
'name': 'multiply', # 要调用的工具名称
'args': {'a': 9, 'b': 6}, # 工具入参
'id': 'call_xxxxxx', # 本次工具调用的唯一ID,用于后续结果关联
'type': 'tool_call'
}
]3.1.3 工具调用完整闭环实战
上面的代码只是让模型生成了工具调用指令,并没有真正执行工具,也没有把结果返回给模型生成最终答案,完整的工具调用闭环分为4步:
- 用户提问,模型生成工具调用指令
- 根据工具调用指令,执行对应的Python函数
- 把工具执行结果封装为
ToolMessage,加入对话消息列表 - 把完整的消息列表再次传给模型,生成最终的自然语言答案
完整代码实现:
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
from langchain_core.tools import tool
from typing_extensions import Annotated
# 1. 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 定义工具
@tool
def add(
a: Annotated[int, ..., "第一个整数"],
b: Annotated[int, ..., "第二个整数"]
) -> int:
"""两个整数相加"""
return a + b
@tool
def multiply(
a: Annotated[int, ..., "第一个整数"],
b: Annotated[int, ..., "第二个整数"]
) -> int:
"""两个整数相乘"""
return a * b
# 3. 绑定工具
tools = [add, multiply]
model_with_tools = model.bind_tools(tools, strict=True)
# 4. 第一步:用户提问,模型生成工具调用
messages = [
HumanMessage(content="9乘6等于多少?5加3等于多少?")
]
ai_msg = model_with_tools.invoke(messages)
# 把模型的工具调用响应加入消息列表
messages.append(ai_msg)
# 5. 第二步:执行工具调用,生成ToolMessage
for tool_call in ai_msg.tool_calls:
# 根据工具名称匹配对应的工具函数
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
# 执行工具,自动返回ToolMessage对象
tool_msg = selected_tool.invoke(tool_call)
# 把工具执行结果加入消息列表
messages.append(tool_msg)
# 6. 第三步:把完整消息传给模型,生成最终答案
final_result = model.invoke(messages)
print("=== 最终答案 ===")
print(final_result.content)
# 输出:9乘6等于54,5加3等于8。关键细节解析:
- 对话消息列表必须严格遵循「用户提问→AI工具调用→工具结果返回」的顺序,这是OpenAI等大模型的强制要求。
ToolMessage必须携带tool_call_id,和模型生成的工具调用ID一一对应,大模型通过这个ID关联工具调用和执行结果。- 模型支持并行工具调用,一次可以生成多个工具调用指令,我们通过循环批量执行即可。
3.1.4 进阶用法:强制工具调用与搜索工具实战
- 强制工具调用 :通过
tool_choice="any"参数,强制模型无论用户输入什么,都必须调用至少一个工具,适合必须通过工具完成的场景:
python
# 强制模型调用工具
model_with_tools = model.bind_tools(tools, tool_choice="any", strict=True)
# 即使输入和工具无关,模型也会生成工具调用
result = model_with_tools.invoke("hello world!")
print(result.tool_calls)- Tavily搜索工具实战:LangChain官方集成了专为AI设计的Tavily搜索引擎,解决大模型实时数据获取的问题,使用步骤如下:
- 安装依赖:
pip install -U langchain-tavily - 去Tavily官网申请API Key,配置到环境变量
TAVILY_API_KEY - 代码实现:
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_tavily import TavilySearch
# 定义模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义搜索工具,最多返回4条结果
search_tool = TavilySearch(max_results=4)
# 绑定工具
model_with_search = model.bind_tools([search_tool], strict=True)
# 完整工具调用闭环
messages = [HumanMessage("中国西安今天的天气怎么样?")]
ai_msg = model_with_search.invoke(messages)
messages.append(ai_msg)
for tool_call in ai_msg.tool_calls:
tool_msg = search_tool.invoke(tool_call)
messages.append(tool_msg)
final_result = model.invoke(messages)
print(final_result.content)3.2 结构化输出:让大模型输出完全可控
原生大模型的输出是自由文本,对于程序来说很难解析。比如我们想从文本中提取人物信息、把模型输出存入数据库,就需要大模型按照我们指定的格式输出,这就是结构化输出的核心价值。LangChain通过with_structured_output方法,完美解决了这个问题,保证模型输出和我们定义的Schema完全匹配。
3.2.1 with_structured_output方法API详解
python
with_structured_output(
# 必选:输出结构定义,支持Pydantic类、TypedDict、JSON Schema
schema: dict[str, Any] | type | None = None,
# 可选:结构化输出的实现方式,默认json_schema(OpenAI官方结构化输出API)
method: Literal['function_calling', 'json_mode', 'json_schema'] = 'json_schema',
# 可选:是否返回原始模型响应和解析错误
include_raw: bool = False,
# 可选:是否严格校验Schema匹配
strict: bool | None = None,
) -> Runnable关键参数说明:
schema:输出结构的核心定义,强烈推荐使用Pydantic类,它自带类型校验、字段描述、默认值,是结构化输出的最佳实践。method:json_schema:默认值,使用OpenAI官方的结构化输出API,保证输出和Schema完全匹配,准确率最高。function_calling:通过工具调用实现结构化输出,兼容旧版本模型。json_mode:通过JSON模式实现,需要在提示词中手动指定格式,兼容性最广。
3.2.2 结构化输出实战场景
我们覆盖最常用的4种输出格式,从基础到进阶逐个实战。
场景1:Pydantic对象输出(生产环境推荐) Pydantic是Python最流行的数据校验库,LangChain和它做了深度集成,支持嵌套结构、可选字段、字段描述,是生产环境的首选。
python
from langchain_openai import ChatOpenAI
from typing import Optional, List
from pydantic import BaseModel, Field
# 1. 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 定义输出结构:单个笑话
class Joke(BaseModel):
"""给用户讲一个笑话"""
setup: str = Field(description="笑话的开头铺垫")
punchline: str = Field(description="笑话的包袱/妙语")
rating: Optional[int] = Field(
default=None,
description="从1到10分给这个笑话打分,可选字段"
)
# 3. 绑定结构化输出,生成Runnable实例
structured_model = model.with_structured_output(Joke, strict=True)
# 4. 调用,直接返回Joke对象,无需手动解析
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print("=== Pydantic对象输出 ===")
print(result)
# 输出:setup='为什么歌手总是带着梯子去演出?' punchline='因为他们想要达到更高的音调!' rating=7
print(f"笑话开头:{result.setup}")
print(f"笑话包袱:{result.punchline}")进阶:嵌套Pydantic结构 支持复杂的嵌套结构,适合批量数据提取、多对象输出的场景:
python
# 嵌套结构:多个笑话的集合
class JokeList(BaseModel):
"""多个笑话的集合"""
jokes: List[Joke]
# 绑定嵌套结构
structured_model = model.with_structured_output(JokeList, strict=True)
# 调用
result = structured_model.invoke("分别讲一个关于唱歌和跳舞的笑话")
print("=== 嵌套Pydantic输出 ===")
print(result)场景2:TypedDict字典输出 如果不想引入Pydantic,也可以使用Python原生的TypedDict定义输出结构,最终返回Python字典:
python
from langchain_openai import ChatOpenAI
from typing import Optional
from typing_extensions import Annotated, TypedDict
# 定义TypedDict结构
class Joke(TypedDict):
"""给用户讲一个笑话"""
setup: Annotated[str, "笑话的开头铺垫"]
punchline: Annotated[str, "笑话的包袱/妙语"]
rating: Annotated[Optional[int], "从1到10分给这个笑话打分"]
# 绑定结构化输出
structured_model = model.with_structured_output(Joke, strict=True)
result = structured_model.invoke("给我讲一个关于唱歌的笑话")
print("=== TypedDict字典输出 ===")
print(result)
# 输出:{'setup': 'xxx', 'punchline': 'xxx', 'rating': 7}场景3:联合类型动态输出格式 支持定义多种输出格式,让模型根据用户输入自动选择合适的格式返回,适合对话机器人、智能客服等场景:
python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Union
# 格式1:笑话
class Joke(BaseModel):
"""给用户讲一个笑话"""
setup: str = Field(description="笑话的开头铺垫")
punchline: str = Field(description="笑话的包袱/妙语")
# 格式2:日常对话回复
class ConversationalResponse(BaseModel):
"""以友好的对话方式回应用户"""
response: str = Field(description="对用户查询的会话响应")
# 联合类型:最终输出是两种格式中的一种
class FinalResponse(BaseModel):
final_output: Union[Joke, ConversationalResponse]
# 绑定结构化输出
structured_model = model.with_structured_output(FinalResponse, strict=True)
# 测试1:讲笑话,返回Joke格式
result1 = structured_model.invoke("给我讲一个关于唱歌的笑话")
print("=== 笑话格式输出 ===")
print(result1)
# 测试2:日常问候,返回对话格式
result2 = structured_model.invoke("你好")
print("=== 对话格式输出 ===")
print(result2)3.3 流式传输:打造丝滑的用户交互体验
我们直接使用invoke方法调用模型,必须等模型生成完所有内容才会返回结果,如果生成的内容很长,用户会面临长时间的白屏等待,体验极差。而流式传输可以让模型生成一个token,就实时返回一个token,实现ChatGPT官网的打字机效果,这是生产级LLM应用的必备能力。
LangChain对流式传输做了标准化封装,所有实现了Runnable接口的组件,都支持流式传输,我们从基础到原理逐个拆解。
3.3.1 同步流式stream()方法实战
stream()是同步流式传输的核心方法,它返回一个迭代器,模型每生成一个消息块,就会通过迭代器实时产出,我们可以通过for循环实时处理。
python
from langchain_openai import ChatOpenAI
# 定义模型
model = ChatOpenAI(model="gpt-4o-mini")
# 同步流式输出
print("=== 同步流式输出 ===")
chunks = []
for chunk in model.stream("讲一个50字的笑话"):
chunks.append(chunk)
# 实时打印每个块的内容,end=""不换行,flush=True强制刷新缓冲区
print(chunk.content, end="", flush=True)
# 消息块可以直接相加,还原完整的消息
print("\n\n=== 完整消息还原 ===")
full_message = sum(chunks[1:], chunks[0])
print(full_message.content)核心概念解析:
AIMessageChunk:流式传输中每个迭代器返回的对象,代表AIMessage的一个片段,它和AIMessage拥有完全相同的结构,支持直接相加合并,这是LangChain流式传输的核心设计。- 流式传输的本质:底层通过SSE(Server-Sent Events)协议实现,模型生成内容后,通过HTTP长连接实时推送给客户端,无需等待完整响应。
3.3.2 异步流式astream()方法实战
在Web服务、异步框架中,我们通常使用异步流式传输,避免阻塞事件循环。在讲解代码前,我们先搞清楚3个核心概念:
- 协程 :用
async def定义的特殊函数,可以在执行过程中暂停,让出控制权给其他协程,等待IO完成后再恢复执行,是Python异步编程的核心。 - 事件循环:异步编程的调度器,负责管理协程的执行,在协程等待IO时,切换到其他就绪的协程,最大化CPU利用率。
- await:用于暂停协程的执行,等待异步操作完成,期间让出控制权给事件循环。
异步流式传输完整代码:
python
import asyncio
from langchain_openai import ChatOpenAI
# 定义模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义异步流式处理函数
async def async_stream():
print("=== 异步流式输出 ===")
# async for 异步遍历流式迭代器
async for chunk in model.astream("讲一个50字的笑话"):
print(chunk.content, end="", flush=True)
# 运行异步函数
asyncio.run(async_stream())3.3.3 LCEL链式流式传输实战
通过LCEL构建的链,天然支持流式传输,我们结合提示词模板、模型、输出解析器,实现一个完整的翻译链流式输出:
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 1. 定义组件
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
# 定义聊天提示词模板
prompt_template = ChatPromptTemplate([
("system", "你是一个专业的翻译助手,将用户输入的文本翻译为{language}"),
("user", "{text}")
])
# 2. 构建LCEL链
chain = prompt_template | model | parser
# 3. 链式流式输出
print("=== 链式流式翻译 ===")
for chunk in chain.stream({
"language": "Chinese",
"text": "LangChain is a framework for developing applications powered by large language models."
}):
print(chunk, end="", flush=True)可以看到,整个链的流式传输和单个模型的流式调用方式完全一致,这就是LCEL的核心优势:统一的接口规范,无论链有多复杂,调用方式都完全相同。
3.3.4 自定义流式输出解析器
默认的流式输出是逐token返回,我们可以通过生成器函数,自定义流式输出的规则,比如实现按句子返回,而不是逐字返回:
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from typing import Iterator, List
# 定义组件
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
# 自定义生成器:按句号分割,按句子返回
def split_into_sentences(input: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
# 遍历流式输入的每个token
for chunk in input:
buffer += chunk
# 只要缓冲区中有句号,就拆分出完整句子
while "。" in buffer:
# 找到第一个句号的位置
stop_index = buffer.index("。")
# 产出完整句子
yield [buffer[:stop_index].strip() + "。"]
# 更新缓冲区,保留句号之后的内容
buffer = buffer[stop_index + 1 :]
# 最后产出缓冲区中剩余的内容
yield [buffer.strip()]
# 构建带自定义解析的链
chain = model | parser | split_into_sentences
# 流式输出,按句子返回
print("=== 按句子流式输出 ===")
for chunk in chain.stream("写一段关于春天的文案,3句话,每句话用句号结尾"):
print(chunk, end="|", flush=True)3.3.5 流式传输底层原理深度解析
作为有C/C++系统编程经验的开发者,我们深入源码拆解整个流式传输的实现流程。
1. 底层协议:SSE(Server-Sent Events) HTTP协议本身是请求-响应模式,无法实现服务器主动推送,而SSE协议基于HTTP长连接,允许服务器向客户端单向推送数据流,是大模型流式传输的事实标准。
- 服务器响应头必须设置:
Content-Type: text/event-stream;charset=utf-8、Connection: keep-alive,声明这是一个事件流,保持连接不关闭。 - 数据格式:每次推送的消息以
data:开头,以\n\n结尾,客户端收到后实时解析。
2. LangChain流式传输源码流程 LangChain的流式传输核心实现,在BaseChatOpenAI类的_stream()方法中,整个流程分为5步:
- 流式配置 :强制设置
stream=True,告诉OpenAI API以SSE协议返回流式数据。 - 请求构建 :通过
_get_request_payload()方法构建请求体,包含消息、模型参数等。 - 发起调用:通过OpenAI SDK发起流式请求,获取SSE事件流响应。
- 响应处理 :遍历SSE事件流的每个块,通过
_convert_chunk_to_generation_chunk()方法,将OpenAI返回的原始数据块,转换为LangChain标准化的AIMessageChunk对象。 - 产出生成块 :通过
yield关键字,把每个转换后的消息块实时产出给调用方。
核心转换逻辑 :_convert_delta_to_message_chunk()方法,它会把OpenAI返回的delta增量数据,映射为LangChain的消息块对象,同时处理工具调用、元数据等信息,保证流式传输中,即使是工具调用、结构化输出,也能实现增量解析。
3.4 LangSmith:LLM应用的可观测性平台
当我们的LLM应用变得复杂,比如包含多轮工具调用、多层LCEL链、多智能体时,调试会变得非常困难------我们不知道链的每个步骤执行了什么、消耗了多少Token、哪里出了错。而LangSmith就是LangChain官方推出的可观测性平台,专门解决这个问题,它可以跟踪LLM应用的全链路执行过程,无需修改业务代码,只需要简单的环境配置。
3.4.1 环境配置步骤
- 去LangSmith官网注册账号,申请API Key。
- 配置系统环境变量:
LANGSMITH_TRACING="true":开启链路追踪LANGSMITH_API_KEY="你的LangSmith API Key":配置API密钥
- 配置完成后,所有LangChain的Runnable组件的调用,都会自动被LangSmith跟踪,无需修改业务代码。
3.4.2 核心能力
运行之前的工具调用代码,打开LangSmith平台,就可以看到本次调用的完整追踪链路:
- 瀑布流展示每个步骤的执行顺序、耗时、Token消耗。
- 可以查看每个步骤的输入、输出、元数据,包括模型调用的完整消息列表、工具调用的参数和执行结果。
- 可以查看错误日志、重试记录,快速定位问题。
- 支持自定义标签、项目分组,方便管理不同的应用和环境。
LangSmith是生产级LLM应用调试、监控、性能优化的必备工具,强烈建议在开发过程中开启。
四. Runnable接口:LangChain的核心设计灵魂
到这里,我们已经接触了大量的LangChain组件:模型、输出解析器、提示词模板、工具、链,它们都有相同的调用方法invoke、stream、batch,这就是因为它们都实现了Runnable接口,这是LangChain最核心的抽象设计,也是整个框架的基石。
4.1 Runnable接口核心概念
Runnable接口定义了一套标准的调用规范,所有LangChain组件(模型、解析器、检索器、工具、链等)都实现了这个接口,它带来了3个革命性的优势:
- 统一的调用方式:无论组件多么复杂,调用方式完全一致,学习成本极低。
- 无限的组合能力:任何两个Runnable组件都可以通过LCEL串联成新的Runnable链,实现复杂的业务逻辑。
- 无缝的能力继承:所有Runnable组件都天然支持同步/异步调用、批处理、流式传输、可观测性、回退机制,无需额外开发。
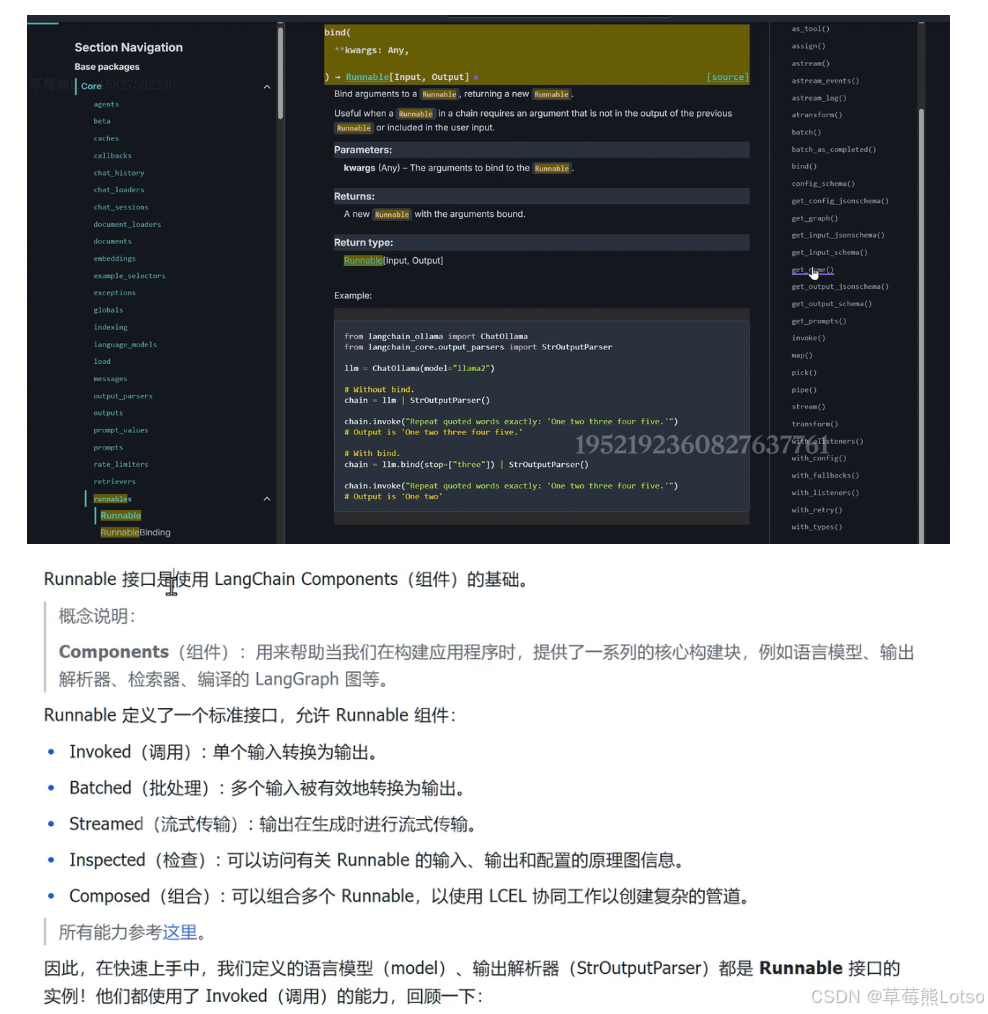
4.2 Runnable接口核心标准方法
Runnable接口定义了6个核心方法,覆盖了所有开发场景:
| 能力 | 同步方法 | 异步方法 | 核心作用 |
|---|---|---|---|
| 单次调用 | invoke() |
ainvoke() |
单个输入转换为输出,最常用的方法 |
| 批处理 | batch() |
abatch() |
多个输入批量转换为输出,提升并发效率 |
| 流式传输 | stream() |
astream() |
流式生成输出,实时返回结果 |
批处理实战示例:
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
chain = model | parser
# 批量输入
inputs = [
"讲一个关于猫的笑话",
"讲一个关于狗的笑话",
"讲一个关于程序员的笑话"
]
# 批量调用,一次性处理3个输入
results = chain.batch(inputs, max_concurrency=2)
for i, res in enumerate(results):
print(f"=== 结果{i+1} ===")
print(res)max_concurrency参数控制最大并发数,避免触发大模型API的速率限制。
4.3 Runnable接口的最大优势:无缝切换大模型
原生API开发中,切换大模型需要修改大量的业务代码,而基于Runnable接口,切换模型只需要修改一行代码,其他业务逻辑完全不变。比如我们从OpenAI切换到DeepSeek模型,只需要:
python
# 只需要修改模型定义,其他代码完全不变
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")
# 之前的链、调用代码完全不用改
chain = model | parser
result = chain.invoke("你好")
print(result)这就是面向接口编程的魅力,也是LangChain能成为最流行LLM开发框架的核心原因之一。
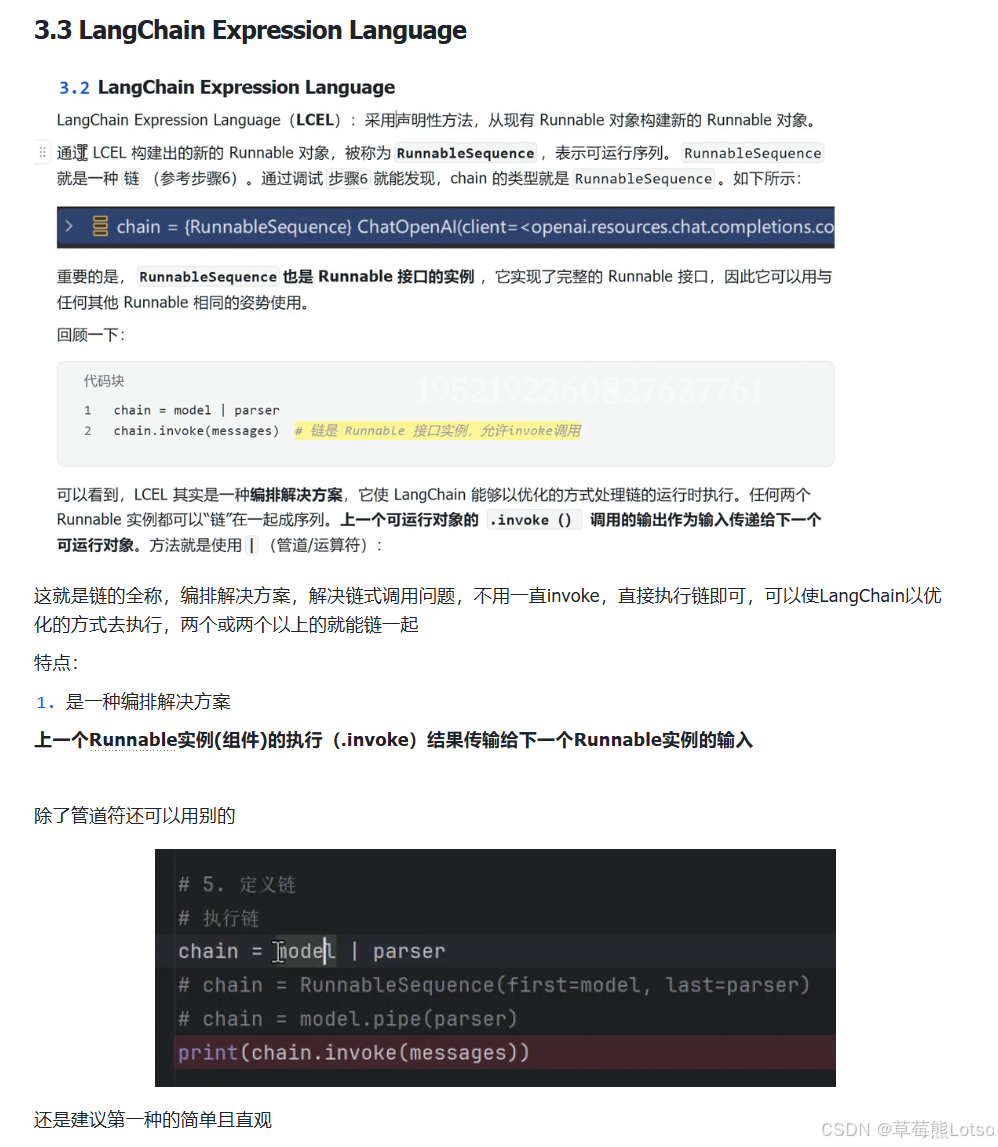
五. LCEL:LangChain表达式语言,链式编程的终极形态
LCEL(LangChain Expression Language)是LangChain推出的声明式链式编程范式,通过管道符|将多个Runnable组件串联起来,构建复杂的LLM应用链,它是LangChain开发的核心编程范式,也是我们从入门到进阶的关键。
5.1 LCEL核心优势
相比于手动一步步调用组件,LCEL有不可替代的优势:
- 统一接口:任何LCEL链都是Runnable实例,拥有完全相同的调用方法,支持同步/异步、批处理、流式传输。
- 极简的代码 :通过管道符
|,一行代码就能构建复杂的执行链,代码可读性、可维护性大幅提升。 - 内置的错误处理 :支持回退机制
with_fallbacks(),当主链执行失败时,自动切换到备用链,提升应用稳定性。 - 原生的可观测性:所有LCEL链的执行过程,都会自动被LangSmith跟踪,无需额外配置。
- 灵活的输入输出:支持多输入、多输出、分支逻辑,满足复杂的业务场景。
5.2 LCEL基础实战:完整的翻译链
我们构建一个完整的翻译链,包含「提示词模板→模型调用→输出解析」全流程,这是LCEL最常用的开发范式:
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 1. 定义组件
# 提示词模板:动态接收language和text两个输入变量
prompt = ChatPromptTemplate([
("system", "你是一个专业的翻译专家,精通{language},只输出翻译结果,不要额外内容"),
("user", "{text}")
])
# 大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 输出解析器
parser = StrOutputParser()
# 2. 通过LCEL构建链
translation_chain = prompt | model | parser
# 3. 调用链,只需要传入模板需要的变量
result = translation_chain.invoke({
"language": "日语",
"text": "我热爱编程,喜欢用LangChain开发大模型应用"
})
print("=== 翻译结果 ===")
print(result)
# 4. 流式调用,和单个组件完全一致
print("\n=== 流式翻译 ===")
for chunk in translation_chain.stream({
"language": "法语",
"text": "人工智能正在改变软件开发的方式"
}):
print(chunk, end="", flush=True)5.3 LCEL核心组件:RunnablePassthrough
RunnablePassthrough是LCEL中最常用的辅助组件,它的作用是透明地传递输入数据,不做任何修改,通常用于多输入链中,把原始输入传递给链的后续步骤。
比如我们要构建一个基础的RAG链,先对用户的问题进行检索,再把检索结果和原始问题一起传给模型,就需要用到RunnablePassthrough:
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 模拟检索器:根据问题返回相关上下文
def mock_retriever(query: str) -> str:
"""模拟检索器,实际场景中替换为向量库检索"""
return "LangChain是一个用于开发大语言模型应用的框架,核心是Runnable接口和LCEL表达式语言。"
# 提示词模板,需要question和context两个输入
prompt = ChatPromptTemplate([
("system", "你是一个AI助手,只根据提供的上下文回答用户的问题,不要编造信息。\n上下文:{context}"),
("user", "{question}")
])
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
# 构建RAG链
rag_chain = (
# 多输入:context来自检索器,question来自原始输入的透传
{
"context": lambda x: mock_retriever(x["question"]),
"question": RunnablePassthrough()
}
| prompt
| model
| parser
)
# 调用链
result = rag_chain.invoke({"question": "LangChain的核心是什么?"})
print("=== RAG链结果 ===")
print(result)这里的RunnablePassthrough()会把原始输入{"question": "xxx"}直接透传给question字段,实现多输入的传递。
5.4 LCEL进阶:错误回退机制
生产环境中,大模型API可能会出现超时、速率限制、服务不可用等问题,LCEL提供了with_fallbacks()方法,实现自动故障转移,提升应用的稳定性:
python
from langchain_openai import ChatOpenAI
from langchain_deepseek import ChatDeepSeek
from langchain_core.output_parsers import StrOutputParser
# 主模型:OpenAI
primary_model = ChatOpenAI(model="gpt-4o-mini")
# 备用模型:DeepSeek
fallback_model = ChatDeepSeek(model="deepseek-chat")
# 构建带回退的链
primary_chain = primary_model | parser
fallback_chain = fallback_model | parser
# 带故障转移的链:主链失败时,自动调用备用链
chain_with_fallback = primary_chain.with_fallbacks([fallback_chain])
# 调用,即使OpenAI API失败,也会自动切换到DeepSeek
result = chain_with_fallback.invoke("你好,介绍一下你自己")
print(result)核心知识点总结
- LangChain的核心设计思想是面向接口编程,通过Runnable接口统一了所有组件的调用规范,大幅降低了大模型应用的开发门槛,实现了大模型的无缝切换。
- 工具调用是大模型连接外部世界的核心能力,通过
@tool装饰器可以极简地定义工具,通过bind_tools方法绑定到模型,即可实现完整的工具调用闭环,解决大模型的实时数据、精准计算等痛点。 - 结构化输出通过
with_structured_output方法,让大模型的输出完全可控,推荐使用Pydantic定义输出结构,生产环境中必须开启strict=True严格校验,避免解析错误。 - 流式传输是生产级应用的必备能力,LangChain通过
stream()/astream()方法标准化了流式调用,底层基于SSE协议实现,支持自定义解析规则,打造丝滑的用户体验。 - LCEL表达式语言是LangChain的灵魂,通过管道符
|可以快速构建复杂的执行链,天然支持同步/异步、流式、批处理、错误回退、可观测性,是开发复杂LLM应用的最佳实践。
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:本文我们从LangChain的环境搭建开始,一步步拆解了从基础模型调用,到四大核心能力(工具调用、结构化输出、流式传输、可观测性),再到核心的Runnable接口和LCEL表达式语言,全程结合实战代码和底层原理解析,覆盖了LangChain开发的核心知识点。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
