文章目录
- [1. 堆排序](#1. 堆排序)
-
- [1.1 基本思想](#1.1 基本思想)
- [1.2 堆的前置必备知识(必看懂,不然学不会堆排序)](#1.2 堆的前置必备知识(必看懂,不然学不会堆排序))
-
- [1.2.1 完全二叉树](#1.2.1 完全二叉树)
- [1.2.2 父子节点下标公式(死记常用)](#1.2.2 父子节点下标公式(死记常用))
- [1.2.3 大顶堆 & 小顶堆](#1.2.3 大顶堆 & 小顶堆)
- [2. 堆排序整体流程](#2. 堆排序整体流程)
- [3. 堆排序代码实现](#3. 堆排序代码实现)
-
- [3.1 完整可运行代码](#3.1 完整可运行代码)
- [4. 代码逐模块精细精讲(难点全拆透)](#4. 代码逐模块精细精讲(难点全拆透))
-
- [4.1 AdjustHeap 向下堆化函数(最难核心)](#4.1 AdjustHeap 向下堆化函数(最难核心))
- [4.2 初始建堆代码逐行精讲](#4.2 初始建堆代码逐行精讲)
- [4.3 排序交换循环 for (int i = n - 1; i > 0; i--)](#4.3 排序交换循环 for (int i = n - 1; i > 0; i--))
- [5. 复杂度与稳定性详细分析](#5. 复杂度与稳定性详细分析)
-
- [5.1 时间复杂度](#5.1 时间复杂度)
- [5.2 空间复杂度](#5.2 空间复杂度)
- [6. 堆排序核心特点总结](#6. 堆排序核心特点总结)
1. 堆排序
1.1 基本思想
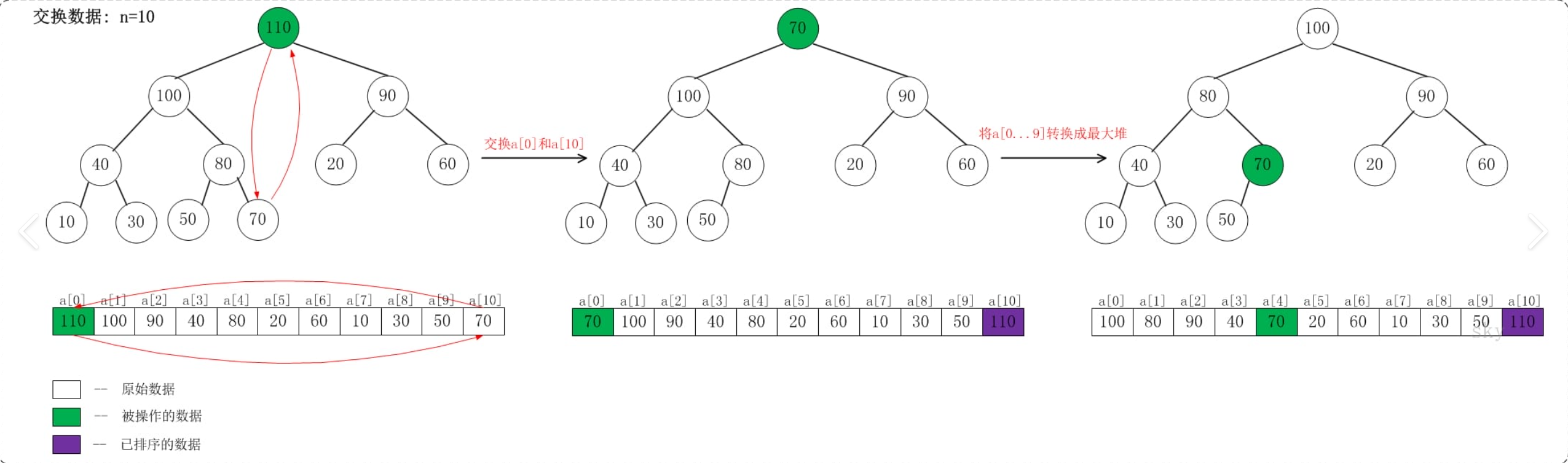
堆排序属于选择排序的优化版本。
简单选择排序每一轮都要遍历整个无序区间找最大值,效率低;堆排序利用完全二叉树 + 堆的特性,不用逐个遍历,就能快速锁定最值,把时间复杂度从 O(n2) 优化到 O(nlogn)。
核心逻辑就两句话:
- 把普通数组构建成大顶堆,堆顶天然就是当前最大值;
- 堆顶和数组末尾交换,把最大值固定到有序区间,剩余部分重新调堆,循环往复完成排序。
1.2 堆的前置必备知识(必看懂,不然学不会堆排序)
1.2.1 完全二叉树
数组逻辑上映射为完全二叉树,节点按层从左到右依次存放,没有空缺位置。
堆排序所有下标计算,都建立在完全二叉树规则上。
1.2.2 父子节点下标公式(死记常用)
设当前节点下标为 i:
- 左孩子下标:2i+1
- 右孩子下标:2i+2
- 父节点下标:(i−1)/2
1.2.3 大顶堆 & 小顶堆
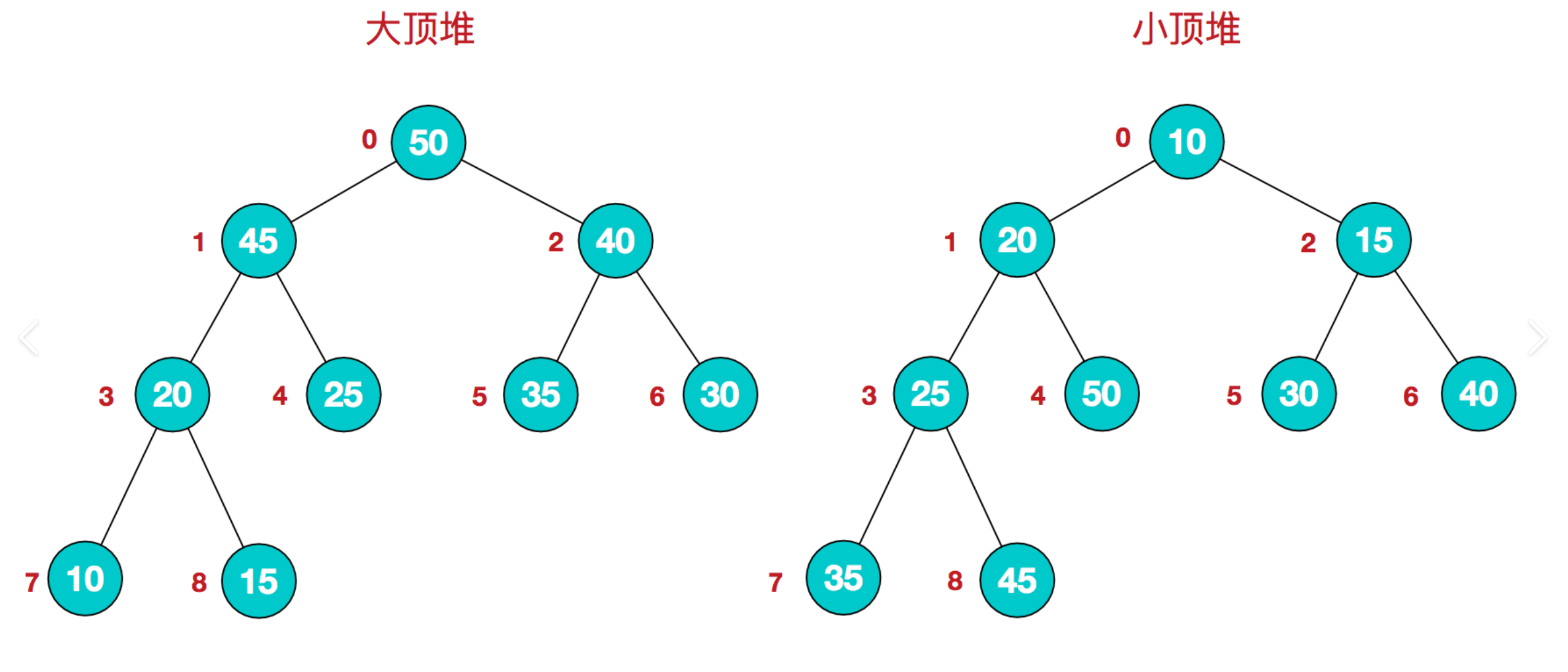
大顶堆 :每一个父节点 ≥ 左右孩子,堆顶是整棵树最大值 堆排序升序必须用大顶堆
小顶堆:每一个父节点 ≤ 左右孩子,堆顶是整棵树最小值一般用于降序、TopK 问题
2. 堆排序整体流程
- 初始建堆 :把无序数组整体调整为大顶堆;
- 交换固定最值:堆顶最大值 和 无序区间最后一个元素交换,末尾变成有序区间;
- 重新堆化:排除已经排好序的末尾元素,只对前面无序区间从根节点重新向下调整为大顶堆;
- 重复交换 + 堆化,直到所有元素全部有序。
3. 堆排序代码实现
3.1 完整可运行代码
c
#include <stdio.h>
// 向下堆化:将以parent为根的子树调整为大顶堆
void AdjustHeap(int arr[], int parent, int n)
{
int temp = arr[parent]; // 保存当前父节点值
int child = 2 * parent + 1;// 先找左孩子
// 循环往下逐层调整
while (child < n)
{
// 1. 选出左右孩子中更大的那个
if (child + 1 < n && arr[child] < arr[child + 1])
{
child++;
}
// 2. 父节点已经比最大孩子还大,无需调整,直接退出
if (arr[child] <= temp)
{
break;
}
// 3. 大孩子上位,占据父节点位置
arr[parent] = arr[child];
// 往下继续遍历子树
parent = child;
child = 2 * parent + 1;
}
// 把最初的父节点值放入最终正确空位
arr[parent] = temp;
}
// 堆排序主逻辑
void HeapSort(int arr[], int n)
{
// 第一步:初始建大顶堆
for (int i = (n - 2) / 2; i >= 0; i--)
{
AdjustHeap(arr, i, n);
}
// 第二步:交换堆顶 + 反复堆化
for (int i = n - 1; i > 0; i--)
{
// 堆顶最大值 和 无序区间末尾交换
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
// 对前i个无序元素重新堆化
AdjustHeap(arr, 0, i);
}
}
// 打印数组
void PrintArr(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
// 测试用例
int main()
{
int arr[] = {49, 38, 65, 97, 76, 13, 27, 49};
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序前数组:");
PrintArr(arr, n);
HeapSort(arr, n);
printf("排序后数组:");
PrintArr(arr, n);
return 0;
}3.2 运行结果:
c
排序前数组:49 38 65 97 76 13 27 49
排序后数组:13 27 38 49 49 65 76 97 4. 代码逐模块精细精讲(难点全拆透)
这部分是堆排序的核心难点,我带你逐行、逐逻辑啃透代码,结合大顶堆规则,看懂每一行的作用。
4.1 AdjustHeap 向下堆化函数(最难核心)
作用:只把以 parent 为根的一棵子树,调整成大顶堆,不影响其他子树。
c
// 向下堆化:将以parent为根的子树调整为大顶堆
void AdjustHeap(int arr[], int parent, int n)
{
int temp = arr[parent]; // 保存当前父节点值
int child = 2 * parent + 1;// 定位左孩子节点下标
// 循环向下调整,直到越界或满足堆规则
while (child < n)
{
// 步骤1:选择左右孩子中更大的那个
if (child + 1 < n && arr[child] < arr[child + 1])
{
child++;
}
// 步骤2:父节点 ≥ 最大孩子,无需调整,直接退出
if (arr[child] <= temp)
{
break;
}
// 步骤3:大孩子上移,覆盖父节点位置
arr[parent] = arr[child];
// 步骤4:继续向下遍历,处理下一层子树
parent = child;
child = 2 * parent + 1;
}
// 步骤5:将原始父节点值放入最终正确位置
arr[parent] = temp;
}逐行拆解:
- int temp = arrparent; 先保存根节点原值,防止后续孩子节点覆盖后丢失;
- **int child = 2 * parent + 1;**默认先取左孩子,完全二叉树规则;
- if (child + 1 < n && arrchild < arrchild + 1) child++;
同时存在左右孩子时,选更大的那个孩子,符合大顶堆父大子小的规则; - if (arrchild <= temp) break;
如果最大的孩子都比父节点小,说明这棵子树已经满足大顶堆,不用再往下调整; - 孩子上位、迭代往下找把大孩子赋值到父节点位置,再把指针下移到孩子节点,继续往下调整子子孙孙;
- **arrparent = temp;**循环结束后,空出来的位置放入最初保存的父节点值,调整完成。
4.2 初始建堆代码逐行精讲
作用:把无序数组,整体构建成一个完整的大顶堆。
c
// 第一步:初始建大顶堆
for (int i = (n - 2) / 2; i >= 0; i--)
{
AdjustHeap(arr, i, n);
}- i = (n - 2) / 2
这是最后一个非叶子节点的下标!
叶子节点没有子节点,天然满足大顶堆,不需要调整;
只需要调整所有非叶子节点,从最后一个开始,效率最高。 - i >= 0
从后往前,倒序遍历所有非叶子节点。 - AdjustHeap(arr, i, n)
对每一个非叶子节点,执行向下堆化,保证每一棵子树都是大顶堆;
遍历完成后,整个数组就是标准大顶堆。
4.3 排序交换循环 for (int i = n - 1; i > 0; i--)
c
// 第二步:交换堆顶 + 反复堆化
for (int i = n - 1; i > 0; i--)
{
// 堆顶最大值 和 无序区间末尾交换
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
// 对前i个无序元素重新堆化
AdjustHeap(arr, 0, i);
}- 每轮把堆顶最大值和当前末尾 i 位置交换,最大值直接落户到有序区间;
- 交换后破坏了堆结构,所以调用 AdjustHeap(arr, 0, i);
- 只调整前 i 个元素,后面已经排好序的不再参与;
- 从根节点 0 开始堆化,不用重新整棵树建堆,节省时间。
5. 复杂度与稳定性详细分析
5.1 时间复杂度
- 初始建堆:O(n)
- 每一次交换后堆化:单次 O(logn),共执行 n 次
- 整体最好 / 最坏 / 平均:稳定 O(nlogn)
重点:不管数组原本有序、逆序、乱序,堆排序效率几乎不变,碾压 O(n2) 的插入、选择排序。
5.2 空间复杂度
仅使用 temp、parent、child 临时变量,没有开辟额外数组。
空间复杂度 O(1),属于原地排序。
6. 堆排序核心特点总结
- 底层依赖完全二叉树 + 大顶堆,理解下标父子关系是关键;
- 核心三步:建大顶堆 → 堆顶末尾交换 → 从根重新堆化;
- 时间稳定 O(nlogn)、空间 O(1),原地排序;
- 代码难点集中在 AdjustHeap 向下堆化 和 初始建堆起点;
- 不适合小规模数据(常数开销大),适合大数据排序、面试手写、TopK 问题;
- 不稳定排序,不适合要求保留重复元素相对顺序的场景。