AI 算力爆发后,瓶颈已经不只是 GPU 本身
过去几年,AI 行业一个非常明显的变化是:GPU 性能提升的速度,已经开始超过传统服务器架构的承载能力。
很多企业在部署大模型、建设智算中心时,最初关注的往往还是 GPU 型号,比如 NVIDIA H100、H200、B200、RTX PRO 6000,以及国产 AI GPU 等,但真正进入部署阶段后,问题很快就会暴露出来:GPU 在这里插入图片描述
数量越来越多,模型越来越大,但多卡训练效率并没有线性增长;NVMe SSD 性能已经很强,但数据吞吐仍然跟不上;单机 8 卡、16 卡之后,GPU 之间的数据搬运、PCIe 通道分配、交换芯片拓扑结构,开始成为新的性能瓶颈。
这也是为什么,PCI-SIG 正在持续推进 PCIe 8.0 标准,并且最近关于"1TB/s 带宽、新一代连接器、0.5V 供电里程碑、预计 2028 年完成最终认证"等消息,会在 AI 算力与服务器行业引发大量关注。
因为对于 AI 基础设施而言,PCIe 8.0 已经不仅仅是一次"总线升级",而是在重新定义未来 AI 算力服务器的数据流架构。
从 PCIe 3.0 到 PCIe 8.0:AI 算力正在推动总线迭代
如果回头看 PCIe 历代迭代,其实能够很明显地看到 AI 算力需求推动总线技术演进的轨迹。
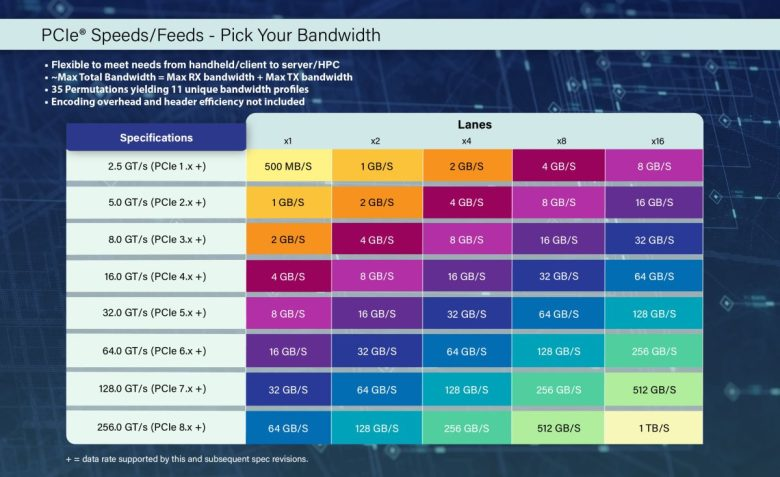
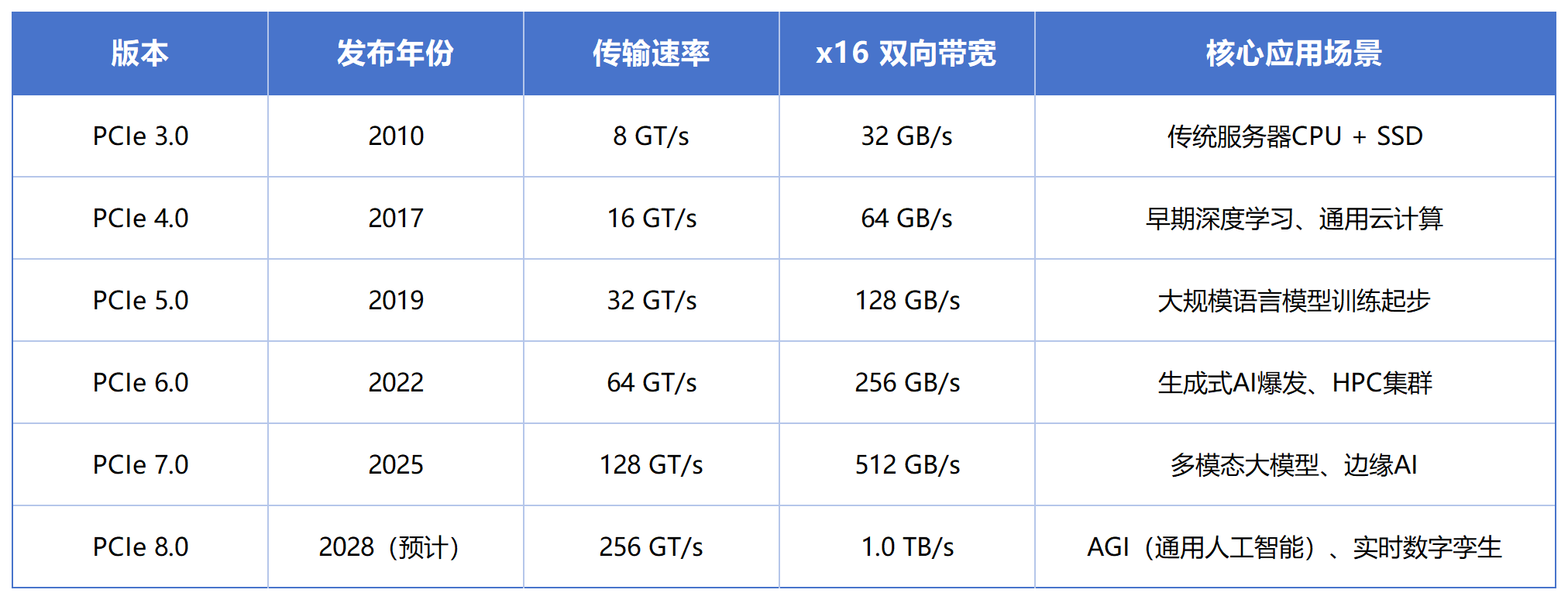
从 PCIe 3.0 开始,当时主要还是传统服务器时代,CPU + SSD 是核心应用场景,AI 训练还远没有今天这样庞大的数据吞吐需求。PCIe 3.0 的 x16 双向带宽大约在 32GB/s 左右,已经足够支撑当年的 GPU 与高速 SSD。
到了 PCIe 4.0,AI 开始进入加速阶段,深度学习训练、大规模 GPU 计算逐渐普及,带宽翻倍来到 64GB/s,AMD EPYC、NVIDIA A100 等产品开始推动 PCIe 4.0 大规模落地,企业级 AI 算力服务器正式进入高速 IO 时代。
随后 PCIe 5.0 到来,x16 双向带宽达到 128GB/s,行业开始真正进入"大模型时代"。这一阶段最大的变化并不是 GPU 更快,而是 AI 数据流规模突然暴增。无论是 DeepSeek、Qwen、Llama,还是多模态模型、RAG、AI Agent,本质上都在疯狂消耗数据吞吐能力。GPU 与 GPU 之间、GPU 与存储之间、GPU 与网络之间,开始持续产生超高频数据交换。这也是为什么现在越来越多 AI 服务器开始强调 PCIe 5.0 全闪存架构、高速 NVMe、GPU Direct Storage、多卡互联优化。
再往后,PCIe 6.0 与 PCIe 7.0,其实已经不仅是简单的"翻倍逻辑"了,而是整个高速互联体系开始进入高频信号时代。PCIe 6.0 开始引入 PAM4 信号编码,PCIe 7.0 则继续把双向带宽推进至 512GB/s。而 PCIe 8.0,则直接将 x16 双向带宽推至 1TB/s。
这个数字本身已经足够惊人。因为这意味着未来 GPU 与 GPU、GPU 与高速存储之间的数据交换能力,会进入一个全新的量级。
为什么大模型时代越来越"吃"PCIe 带宽?
很多企业现在部署大模型时,会发现一个非常现实的问题:GPU 算力很强,但 GPU 经常"吃不满"。
尤其在多卡训练、分布式推理、向量数据库、长上下文推理等场景下,真正限制系统性能的,并不一定是 GPU 本身,而是:
●PCIe 通道资源不够;
●GPU 间通信效率下降;
●SSD 吞吐无法持续供给;
●数据在 CPU、GPU、存储之间搬运损耗过高;
●多节点集群组网延迟增加。
所以 PCIe 8.0 的意义,本质上是在解决:
AI 算力时代的数据流问题。
特别是在 DeepSeek、Qwen、Llama 等模型持续增大的背景下,未来 AI 基础设施会越来越依赖高速互联能力,而不仅仅是单卡算力。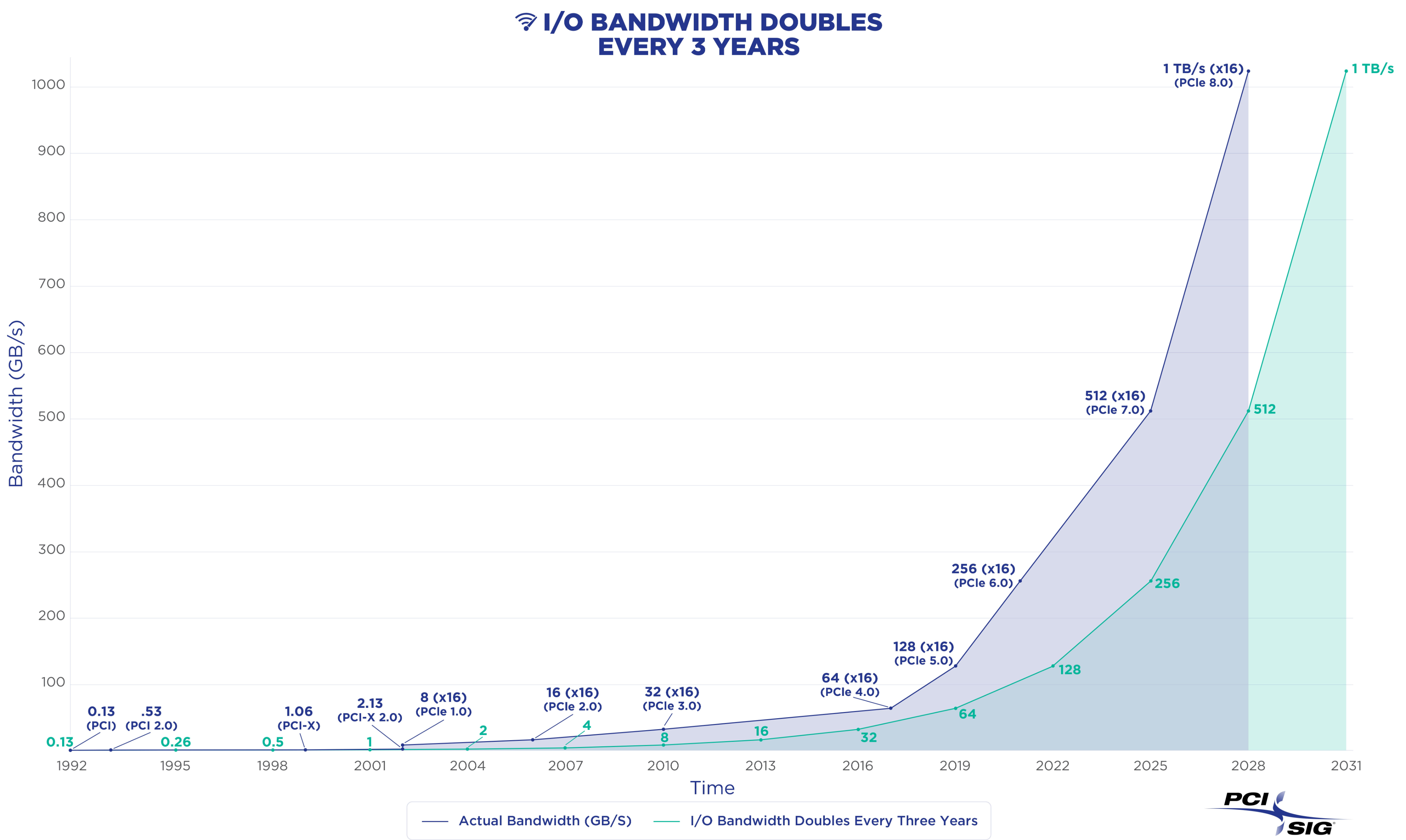
PCIe 8.0 的重点,其实不只是"更快"
尤其值得关注的是,这次 PCIe 8.0 除了带宽之外,还有两个行业内非常关键的方向:
一个是新连接器技术。
另一个是 0.5V 供电架构。
很多非硬件行业的人可能会忽略这两个点,但对于 AI 算力服务器、智算中心建设来说,这甚至比带宽本身更重要。
因为当 PCIe 速率持续提升后,传统连接器、PCB 布线、信号完整性问题会越来越严重。速率越高,损耗越大,发热越明显,对服务器主板设计、交换芯片布局、机箱散热能力的要求也会大幅提高。
而 0.5V 的低电压设计,其实意味着:
●更低功耗;
●更低发热;
●更高频率稳定性;
●更高密度部署能力;
●更适合未来超大规模 AI 集群。
这一点对于当前智算中心建设尤其重要。
因为现在很多 AI 机房真正头疼的问题,已经不是"有没有 GPU",而是:
●电力够不够;
●制冷压不压得住;
●单机柜功耗能不能承受;
●多卡服务器是否稳定;
●高速互联是否长期可靠。
尤其是在大模型训练集群场景中,一台 8 卡 GPU 服务器功耗已经非常惊人,如果未来进入更高密度 GPU 集群时代,高速互联与低功耗设计会直接影响整个机房建设成本。
所以 PCIe 8.0 的演进,实际上是在为下一代 AI 数据中心提前铺路。
NVIDIA、AMD、Intel 为什么都在强化高速互联?
现在行业里一个非常明显的趋势是,AI 基础设施正在从"堆 GPU",逐渐转向"优化数据流"。
包括 NVIDIA 最近几代产品,无论是 NVLink、NVSwitch、BlueField DPU,还是 Spectrum-X 网络,本质都在解决 GPU 数据交换问题。
AMD 也在强化 Infinity Fabric 与高速 IO。
Intel 则持续推进 CXL 与内存池化技术。
因为未来真正决定 AI 集群效率的,不一定是谁 GPU 最多,而是谁的数据流架构更合理。
这一点,在国产化 AI 服务器领域也越来越明显。
尤其在政务、科研、高校、能源、金融等行业,很多客户已经不只是关注 GPU 参数,而开始关注:
●多卡互联拓扑;
●PCIe Lane 分配;
●GPU 与 NVMe 的协同能力;
●RDMA 网络;
●存储缓存架构;
●推理集群扩展性;
●后续升级兼容性。
因为对于企业来说,AI 基础设施不是实验室项目,而是真正要长期运行的生产力平台。
PCIe 8.0 落地后,会给智算中心带来什么变化?
这也是很多企业客户最关心的问题。
未来 PCIe 8.0 真正落地后,带来的变化可能不仅是训练速度提升,还包括:
●大模型训练吞吐进一步提升;
●多卡 GPU 通信损耗下降;
●高速 NVMe 数据缓存效率提高;
●GPU 利用率更稳定;
●集群扩展成本下降;
●高密度机房部署更可行;
●AI 推理延迟进一步降低。
特别是在 AI Agent、RAG、本地知识库、多模态推理逐渐普及后,AI 工作负载已经越来越"数据密集型"。
很多企业未来会发现:
真正影响 AI 体验的,不只是 GPU FLOPS,而是整个底层数据流架构。
目前虽然 PCIe 8.0 最终认证预计在 2028 年完成,但整个行业实际上已经开始提前布局,包括:
●PCIe 6.0 Retimer;
●高速交换芯片;
●光互联方向;
●CXL 内存扩展;
●新一代 AI 背板架构;
●GPU Direct Storage;
●高密度全闪存设计。
对于企业客户来说,现在更重要的,其实不是"等 PCIe 8.0",而是提前理解:
未来 AI 算力基础设施的核心竞争力,正在从单一 GPU 参数,转向整体互联架构能力。
AI 算力服务器,正在进入"数据流架构竞争"阶段
尤其在智算中心建设、科研教育、金融推理集群、特种行业定制化 AI 算力平台等场景中,越来越多客户开始关注"整体数据流效率"而不仅是单纯 GPU 数量。对于未来 PCIe 总线持续迭代、高速互联架构升级带来的变化,提前做好服务器底层架构规划,已经成为很多企业 AI 基础设施建设中的关键一步。