AI Agent正在把企业技术管理的对象,从确定性的代码、接口和流程,推向具备感知、推理、记忆与行动能力的"数字劳动力"。这意味着管理者不能再只关注模型能力或提示词技巧,而要把上下文、权限、工具、审计、成本、组织角色与业务结果放入同一套工程体系中。本文围绕Agent架构、生产化难点、驾驭工程、安全治理、AgentOps与组织变革,整理一套面向企业落地的技术管理框架。
导语
过去几年,AI系统的主流形态仍然是"助手":人提出问题,模型给出回答,结果是否进入业务流程,通常由人来判断。Agent时代的变化在于,模型不再停留在回答层,而是可以拆解任务、调用工具、读取上下文、访问系统、执行动作,并根据反馈继续调整路径。它开始进入研发、运维、客服、数据分析、内容生产和管理决策等场景,成为一种可以被调度、被约束、被审计的数字劳动力。
这场变化对技术管理提出了更高要求。传统软件工程主要管理确定性代码:需求、设计、开发、测试、上线、监控,每个环节都能围绕明确逻辑和可复现行为展开。Agent系统则不同,它的推理是概率性的,输入上下文会改变结果,工具调用会影响现实系统,多Agent协作还可能产生不可预期的涌现行为。因此,技术管理的核心问题不再只是"怎样把模型接进系统",而是"怎样让具备自主性的系统在可控边界内稳定创造价值"。
从"能用"到"可管",是Agent时代真正的分水岭。

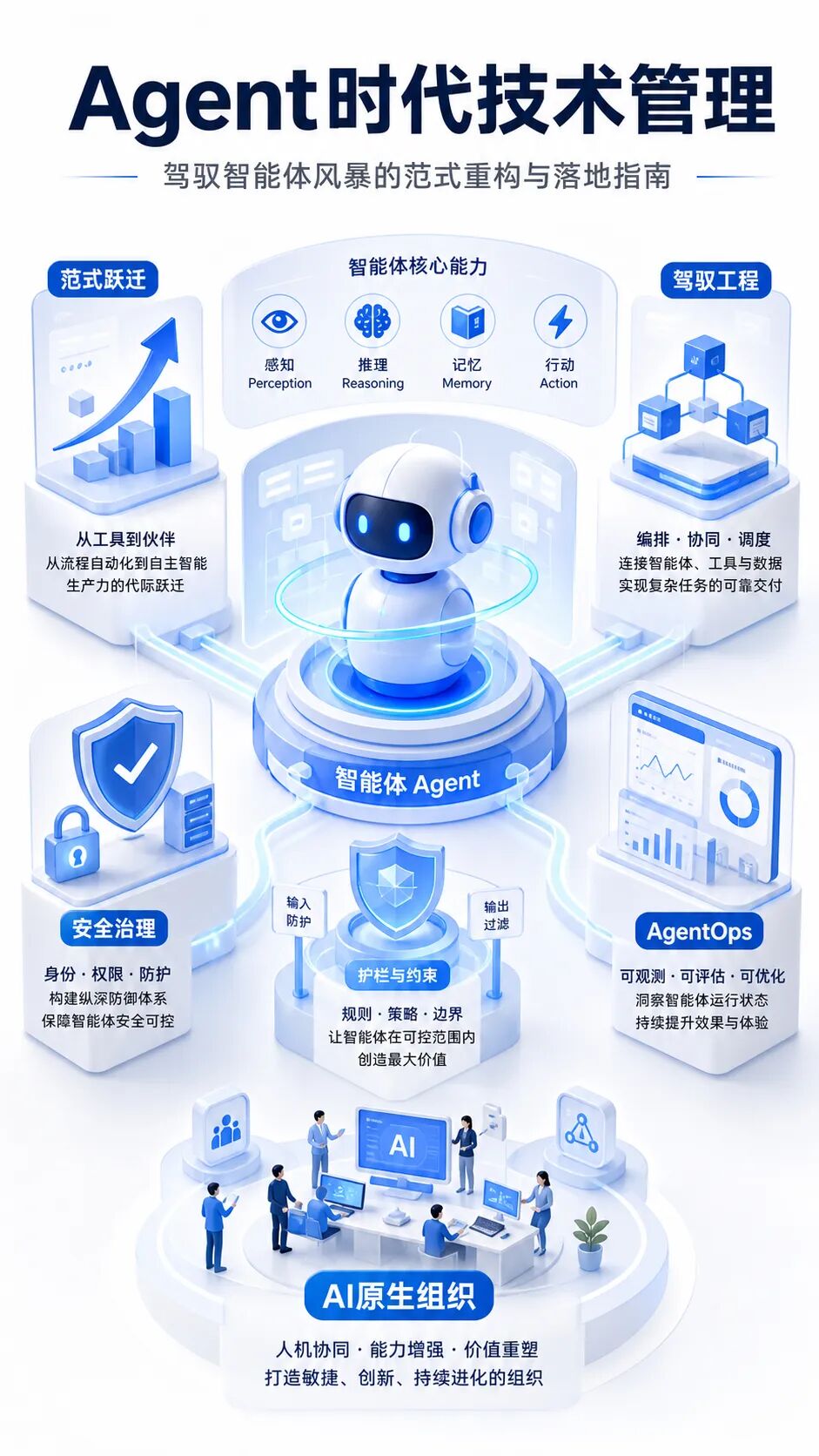
一、范式跃迁:技术管理对象从软件系统变为数字劳动力
从"辅助工具"到"行动主体"
Agent并不是一个更会聊天的机器人,而是一个具备闭环能力的智能实体。它能够感知外部信息,基于目标进行推理和规划,选择合适工具执行操作,再根据结果反馈修正下一步行动。这个闭环使Agent具备了"行动主体"的特征:它不只是生成建议,还会推动流程发生真实变化。对企业而言,这意味着AI系统从知识问答层进入了业务执行层。
一旦AI进入执行层,管理对象就发生了变化。过去管理的是应用、服务、数据库、接口和人员权限;现在还要管理智能体的目标、记忆、工具、身份、授权范围和行为轨迹。一个客服Agent如果只负责总结工单,风险相对有限;如果它能够直接退款、改订单、查询用户隐私或改写知识库,就必须被纳入完整的技术治理体系。
确定性工程遇到非确定性系统
传统软件的可靠性建立在可复现逻辑之上。相同输入、相同代码、相同环境,理论上应当得到相同输出。Agent系统则把大模型推理、外部工具调用、动态上下文和长期记忆组合在一起,结果更接近"受约束的概率性行为"。这并不意味着Agent不可管理,而是要求管理方法从代码中心转向运行环境中心。
这种转向会改变技术管理者的工作重点。过去,管理者可以把主要精力放在架构评审、研发效能、发布稳定性和运维指标上;Agent时代还需要关注上下文质量、提示词资产、工具权限、模型漂移、意图偏移、成本发散、审计证据和人机分工。换言之,技术管理从"保证代码正确运行",扩展为"保证智能体在正确边界内行动"。
价值释放依赖管理体系,而非单点模型能力
企业引入Agent通常会从一个看得见的能力开始:自动写代码、自动查数、自动总结会议、自动处理工单。但规模化价值并不来自单个Demo,而来自可复制的工程体系。没有标准化上下文、权限治理、质量评估和上线流程,Agent很容易停留在局部提效,甚至制造新的风险。
因此,技术管理者需要把Agent视为一种新的生产力单元,并为它设计"岗位说明书":能做什么,不能做什么,在哪些系统中行动,遇到什么情况必须交给人,如何记录过程,怎样衡量质量,出现异常如何回滚。只有完成这些基础设施建设,数字劳动力才能从试验场走向生产线。
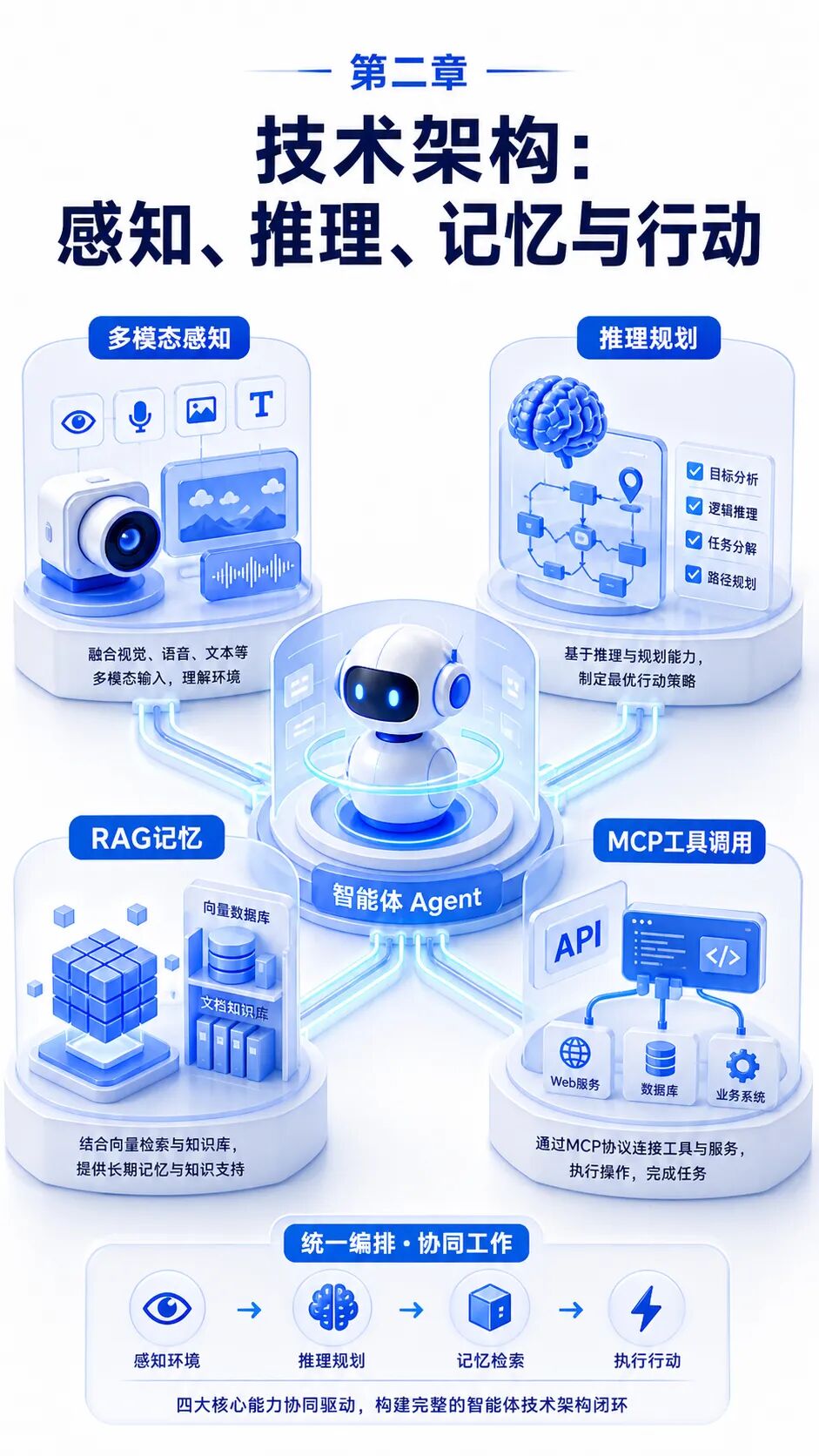
二、技术底座:Agent系统的能力闭环与架构分层
四项核心能力构成闭环
一个可落地的Agent系统通常由感知、推理、记忆和行动四类能力组成。感知负责接收环境输入,包括文本、表格、页面、图片、日志、数据库查询结果和业务系统状态;推理负责理解目标、拆解任务和选择路径;记忆负责保留当前任务上下文与长期知识;行动负责通过API、脚本、浏览器、命令行或外部工具改变环境。
这四项能力不是并列堆叠,而是形成循环。Agent先感知任务和环境,再推理下一步计划,调用记忆补充背景,随后执行工具动作,并把执行结果重新纳入上下文。循环次数越多,任务越复杂,对状态管理、异常处理和审计记录的要求越高。生产环境中的技术管理必须把这个循环显性化,否则很难判断Agent到底为什么做出某个动作。
自主性分级决定落地边界
Agent的风险与价值都与自主性水平相关。低等级Agent更像增强型助手,主要负责检索、总结、草拟和建议;中等级Agent可以在明确边界内调用工具、提交草案、生成代码或处理低风险事务;高等级Agent则具备跨系统协作、自我纠错、持续执行和有限自治能力。
企业落地不宜直接追求完全自主。更稳妥的路径是从"人机共管"开始:低风险动作可由Agent自动完成,中风险动作需要可追踪审批,高风险动作必须人类确认。自主性不是一个宣传口号,而是一个需要被拆解到场景、权限、数据等级和责任边界中的工程变量。
三层架构支撑规模化运行
从技术架构看,Agent平台至少需要编排层、连接层和治理层。编排层负责生命周期、任务分解、状态流转、多Agent协作与失败重试;连接层负责把智能体意图转化为API调用、数据库查询、文件操作或页面动作;治理层负责身份认证、权限控制、输入输出过滤、审计日志和合规检查。
MCP、Function Calling、A2A等协议的价值,在于降低工具接入和多Agent协作的复杂度。但协议本身不等于治理完成。真正决定系统质量的,是企业能否把工具目录、权限矩阵、上下文版本、执行审计和异常处理放入统一平台。否则,工具越多,Agent越容易从"能力增强"滑向"风险放大"。

三、核心挑战:自主性、可靠性与安全性的三难困境
生产化的最后一英里最难
许多Agent原型可以在演示中快速完成任务,但进入生产环境后会遇到完全不同的问题:上下文不干净、工具返回不稳定、系统权限复杂、业务规则存在例外、数据口径不统一、用户输入不可控。这些问题不属于模型能力本身,却决定了Agent能否稳定交付结果。
生产化的难点还在于故障形态发生变化。传统系统故障常表现为接口报错、服务不可用或响应超时;Agent故障则可能表现为"看起来正常但结果错误"。它可能生成格式正确的报告,却引用了错误口径;可能成功调用工具,却执行了不应执行的动作;可能完成任务,却偏离了业务意图。技术管理必须从错误码监控转向行为轨迹与意图一致性监控。
多Agent协作放大复杂度
当任务被拆成规划、检索、开发、测试、审查、发布等多个角色后,多Agent协作可以提升并行度,也会引入交接风险。每一次任务交接都可能丢失上下文、误解目标或放大前一环节的错误。一个规划Agent给出含糊方案,开发Agent可能据此生成大量无效代码;审查Agent如果只检查语法,不检查业务意图,错误仍会进入后续流程。
因此,多Agent系统不能只靠"角色扮演"提示词维系。它需要明确的交接协议、检查点、状态机、失败重试、质量门禁和人工兜底。对关键任务而言,每个Agent都应有输入规范、输出契约、责任边界和可审计记录。
安全风险从信息泄露扩展到行动失控
Agent具备行动能力后,安全风险不再只是回答不当或泄露信息,而是可能直接触发文件删除、权限变更、资金操作、数据外发、代码提交和系统配置修改。尤其是GUI Agent和侵入式Agent通过读屏、点击和键盘模拟接管界面,泛化能力强,但也更容易受到界面变化、误识别和提示注入影响。
供应链风险同样值得重视。Agent技能、插件和工具连接器一旦来自第三方,就可能成为特洛伊木马:窃取API Key、读取Session Token、扫描本地文件或向外部服务器发送敏感数据。企业不能把技能市场等同于可信软件仓库,而应采用白名单、签名校验、沙箱运行和最小权限原则。
成本、合规与责任归属进入同一张账
Agent系统的成本不是单一模型调用费用,而包括Token消耗、检索存储、上下文管理、推理延迟、工具调用、人工复核和安全审计。若缺少预算控制和任务级成本观测,同一类任务可能因提示词膨胀、反复重试或思维链发散导致成本不可预测。
合规问题也更复杂。Agent可能访问个人信息、商业机密和受限数据;可能把内部内容发送给外部模型;也可能在没有明确授权的情况下跨系统执行操作。当事故发生时,责任到底归属于业务提出者、Agent设计者、模型供应商、平台管理员还是审批人,需要在流程设计阶段就通过日志、审批和权限边界提前固化。
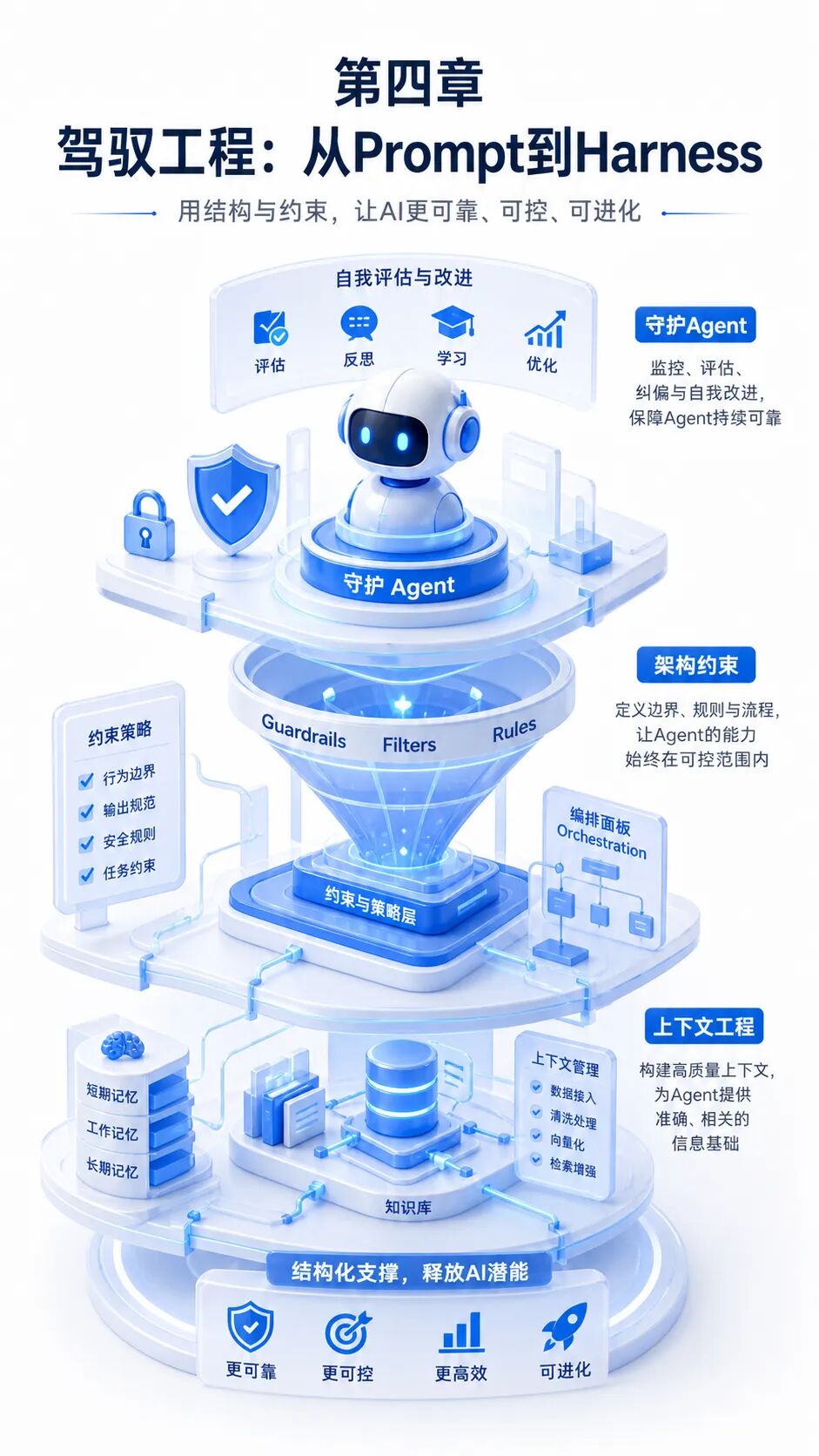
四、驾驭工程与AgentOps:把概率性模型变成可交付系统
从Prompt Engineering走向Harness Engineering
提示词工程解决的是"如何更好地让模型回答问题",驾驭工程解决的是"如何让模型在工程约束中稳定完成任务"。前者偏向语言技巧,后者偏向系统设计。Agent时代,提示词仍然重要,但它只是驾驭体系的一部分,不能替代上下文治理、工具编排、权限控制、质量评估和审计机制。
驾驭工程的关键思想是:不要试图让概率模型天然可靠,而要为它构建可控环境。这个环境包括清洁的上下文、明确的目标、受限的工具、可回滚的动作、可追踪的日志、可复核的输出和可执行的质量门禁。模型越强,越需要边界;Agent越自主,越需要驾驭。
上下文工程是第一道质量门
上下文决定Agent看到什么,也决定它忽略什么。企业知识库如果充满过期制度、重复文档、错误口径和无关内容,Agent就会把噪声带入推理。上下文工程的核心不是把所有材料塞给模型,而是建立"必要、准确、可追溯、可更新"的知识供给机制。
实践中可以采用分层知识架构:稳定规则进入基础层,频繁变化的政策进入版本层,业务案例进入场景层,个人偏好和任务记录进入工作记忆层。长期记忆要有生命周期管理,过期内容需要TTL策略和定期清理,关键知识要能追溯来源和版本。这样才能降低幻觉漂移和知识污染。
架构约束让产出符合工程标准
Agent生成代码、配置或流程文档时,容易出现"局部正确、整体不合规"的问题。例如命名风格不一致、架构分层被打破、安全策略被绕过、日志规范缺失、测试覆盖不足。靠人工事后审查无法支撑规模化。
更稳妥的做法是把企业工程规范变成机器可执行的约束:自定义Linter、架构规则文件、模板仓库、代码生成边界、自动测试和安全扫描。Agent的产出必须先经过这些门禁,再进入人类审查或发布流程。这样,Agent不是替代工程体系,而是被嵌入工程体系。
AgentOps重构运维与质量保障
AgentOps面向智能体全生命周期,覆盖开发、评测、发布、运行、监控、审计和回滚。它与DevOps的区别在于,监控对象不只是服务指标,还包括推理路径、工具调用、上下文来源、决策依据、输出质量和成本行为。传统的CPU、延迟、错误率仍然重要,但不足以解释Agent为什么做错事。
生产级Agent需要Trace级观测。每一次任务执行应记录目标、计划、检索内容、工具参数、返回结果、模型输出、审批节点和最终动作。质量保障也要升级:通过Golden Dataset、LLM Judge、红队测试、影子模式和灰度发布,持续评估Agent在真实业务场景中的稳定性。出现异常时,应能快速定位是模型问题、上下文问题、工具问题、编排问题还是权限问题。
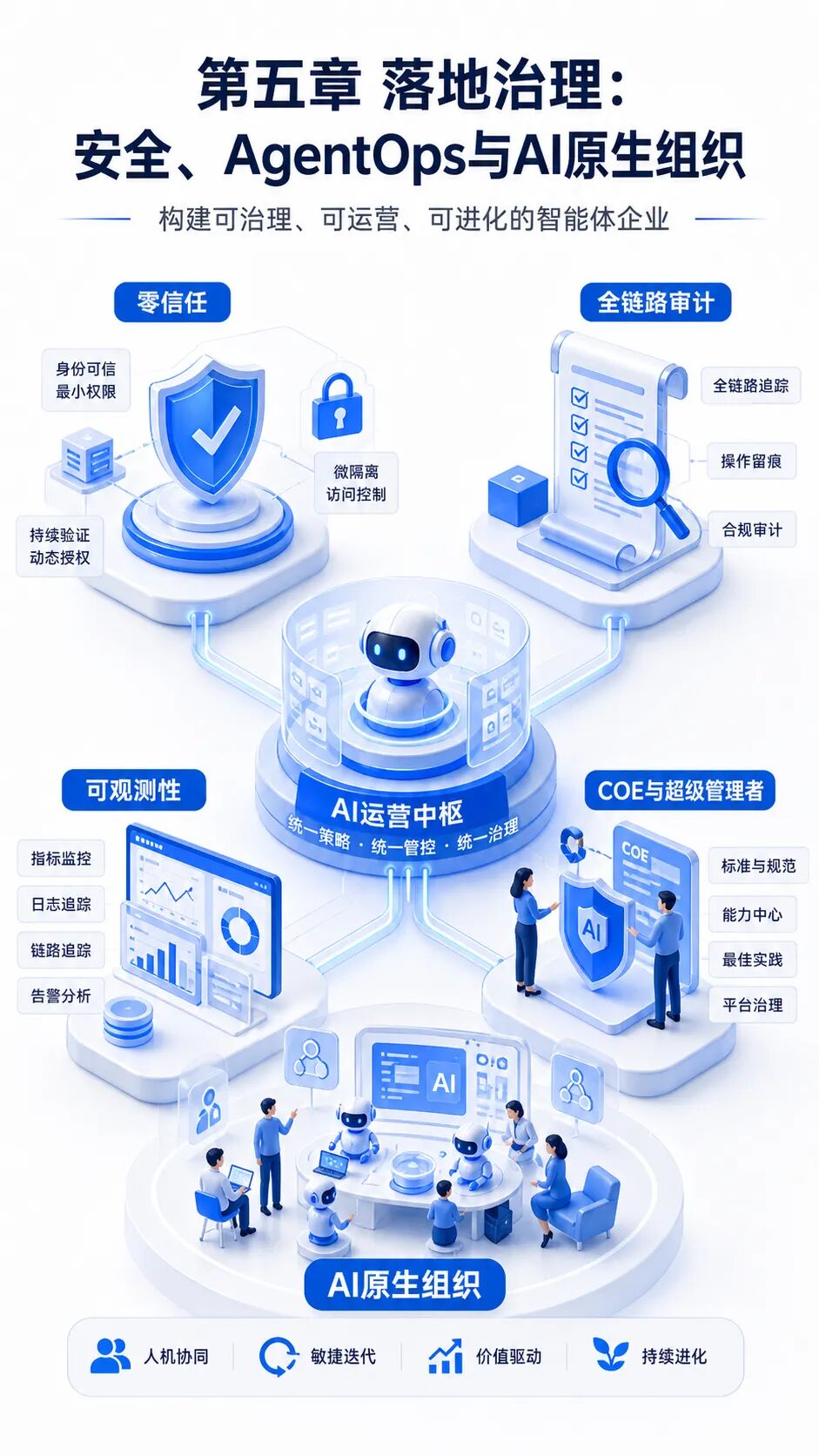
五、治理与落地:从AI工具采购走向AI原生组织建设
零信任是Agent安全的默认前提
企业应把Agent视为非人类身份,而不是复用员工账号或共享系统Token。每个Agent都应拥有独立身份、独立权限、独立日志和独立生命周期。权限授予应遵循最小权限、按需授权和时间窗口原则:只在任务需要时授予必要权限,任务结束后立即收回。
高风险动作必须设置人类确认或双重授权。例如资金支付、数据删除、权限提升、代码合并、生产配置修改和外发敏感数据,都不应由Agent单独完成。对GUI Agent还应采用沙箱隔离、屏幕区域限制、敏感信息遮罩和操作白名单,避免它在不可控界面中越界行动。
全链路审计是责任边界的基础设施
Agent治理不能只看最终结果,还要保留过程证据。全链路审计应记录输入、上下文来源、检索命中、推理摘要、工具调用、审批记录、异常处理和输出结果。审计日志既用于排障,也用于合规复核和责任追溯。
审计设计要避免两个极端:一是日志过少,事故发生后无法复盘;二是日志过度暴露,反而保存了大量敏感数据。合理做法是按数据分级、风险等级和行业要求设置留存周期、脱敏规则和访问权限。对于涉及个人信息、商业机密和核心数据的场景,应优先采用脱敏、匿名化、内网模型或物理隔离方案。
组织角色从执行者转向设计者
Agent落地不是单纯采购工具,而是重构团队能力。工程师的角色会从重复编码转向架构设计、规则制定、评审验收和异常兜底;管理者会从任务分派者转向工作流架构师;新的岗位会围绕提示词资产、上下文知识库、Agent编排、安全治理和质量评估出现。
企业可以建立跨职能AI卓越中心(COE),统一管理Agent平台、Prompt资产、工具接入、技能市场、安全策略、评测基准和复用组件。COE不应替代业务团队,而应提供标准、平台和治理能力,让各业务线在统一边界内创新。
三阶段路线图:从试点到AI原生
第一阶段是概念验证。选择低风险、高频、规则明确的场景,例如内部知识助手、研发辅助、日志分析、会议纪要或低风险数据查询,目标是验证上下文工程、权限控制和基础编排是否可行。这个阶段不要追求全自动,而要建立最小可行Harness。
第二阶段是试点扩张。将Agent接入真实流程,但保留人类审批和灰度发布,建立AgentOps监控、质量评估、审计留痕和成本看板。这个阶段的核心指标不是"用了多少Agent",而是"是否稳定降低人工成本、缩短周期、减少错误并守住安全边界"。
第三阶段是规模化和AI原生。企业应建设统一Agent平台,标准化MCP/A2A等连接方式,形成可复用工具库、知识库、策略库和评测库。成熟状态下,Agent不再是边缘工具,而是嵌入研发、运营、管理和决策流程的生产力单元。
结语:可信的自主,才是真正的智能化
Agent时代的关键不在于让AI看起来更像人,而在于让它在企业系统中可管理、可追踪、可审计、可回滚、可问责。真正的竞争力也不只是拥有更强模型,而是拥有更稳固的驾驭工程、更清洁的知识体系、更严密的安全治理和更适配的人机协同组织。
未来的技术管理,将不再围绕"人如何使用工具"展开,而是围绕"人如何设计、监督和治理数字劳动力"展开。能率先完成这次转型的组织,会把Agent从演示中的聪明玩具,变成生产系统中的可信伙伴。
让智能体拥有自主性之前,企业必须先拥有驾驭自主性的能力。
结语:抓住大模型时代的职业机遇
AI大模型的发展不是"替代人类",而是"重塑职业价值"------它淘汰的是重复性、低附加值的工作,却催生了更多需要"技术+业务"交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为"懂技术、懂业务"的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)
