前言
很高兴看到你对CTF密码学(Crypto)感兴趣!这就像网络世界的"谍战"游戏,烧脑又有成就感。
针对你的需求,我为你整理了一份**"密码学入门实战指南"**。与其盲目报班,不如先看清这个领域的知识地图,掌握核心工具,再决定如何进阶。
🗺️ 第一步:搞懂密码学在CTF里考什么?
CTF中的密码学题目通常遵循**"先识别,后破解"**的逻辑。根据主流的培训体系,知识体系主要分为以下三个层级:
| 难度阶段 | 核心内容 | 常见考点与特征 |
|---|---|---|
| 入门级 | 古典密码 & 编码 | 凯撒密码 (字母移位)、栅栏密码(分组重组)、Base64/Hex编码。特征是密文看起来像乱码但有规律。 |
| 进阶级 | 对称加密 & 流密码 | AES/DES (分组模式)、RC4(流密码)。常涉及密钥重用、ECB模式块重排等漏洞。 |
| 高阶级 | 非对称加密 (RSA) | RSA算法是绝对核心。涉及大数分解、共模攻击、低加密指数攻击等数学原理。 |
🛠️ 第二步:打造你的"军火库"(必备工具)
工欲善其事,必先利其器。在CTF密码学中,你不需要手写所有算法,但必须知道用什么工具去"跑"出Flag。
- 神器级工具:CyberChef
- 用途: 这是一个在线的"瑞士军刀",支持编码转换(Base64, Hex)、哈希计算、简单的加密解密。
- 场景: 遇到一串乱码,先扔进去试试各种解码,很多时候Flag就出来了。
- 在线官网: CyberChef
- 离线github下载: https://github.com/gchq/CyberChef/releases
- 自动化识别:Ciphey
- 用途: 自动检测加密类型并尝试破解。
- 场景: 你完全看不出这是什么加密方式时,用它"一键"尝试。
- 编程与脚本:Python + PyCryptodome
- 用途: Python是CTF选手的母语。
pycryptodome库提供了几乎所有现代密码算法的实现。 - 场景: 编写脚本进行暴力破解(如遍历凯撒密码的26种偏移)或处理复杂的RSA攻击。
- 用途: Python是CTF选手的母语。
- 数学辅助:YAFU / Factordb
- 用途: 专门用于大整数分解。
- 场景: RSA题目中,如果模数
n比较小,直接用这些工具分解出p和q。
本文章内容
crypto1
签到题,提示倒序,直接}wohs.ftc{galf,反过来就行
crypto2
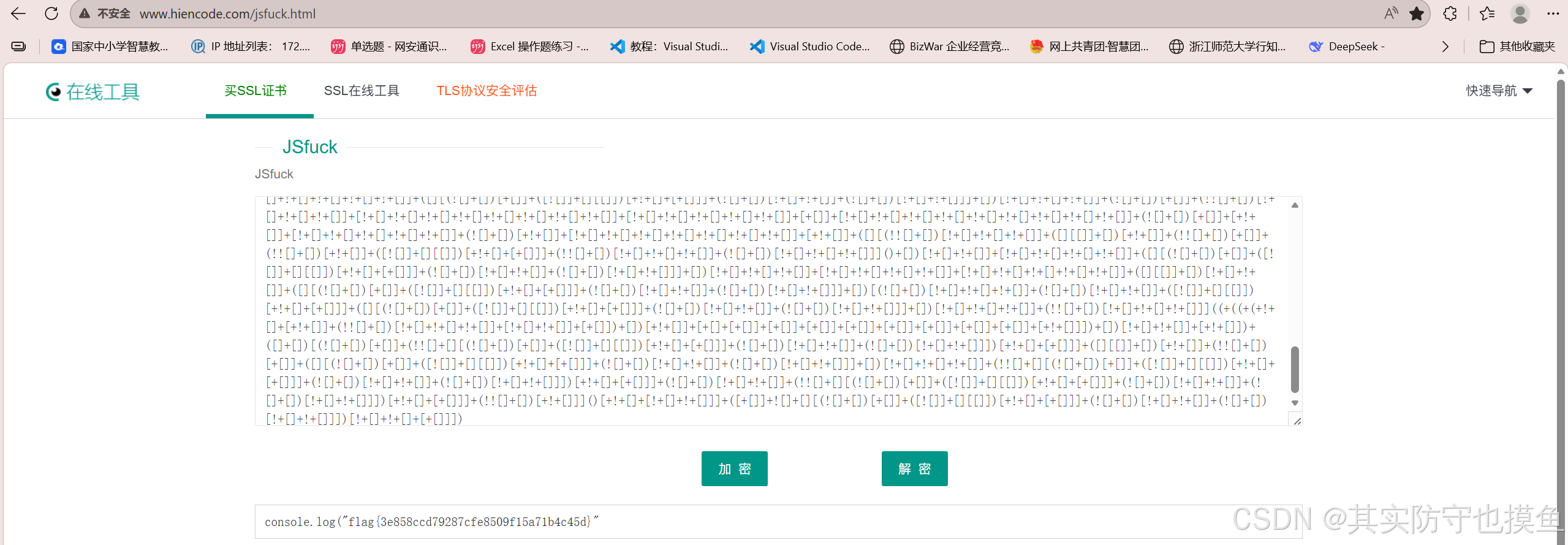
打开链接看见一串编码直接copy
CTF在线工具-在线JSfuck加密|在线JSfuck解密|JSfuck|JSfuck原理|JSfuck算法
crypto3
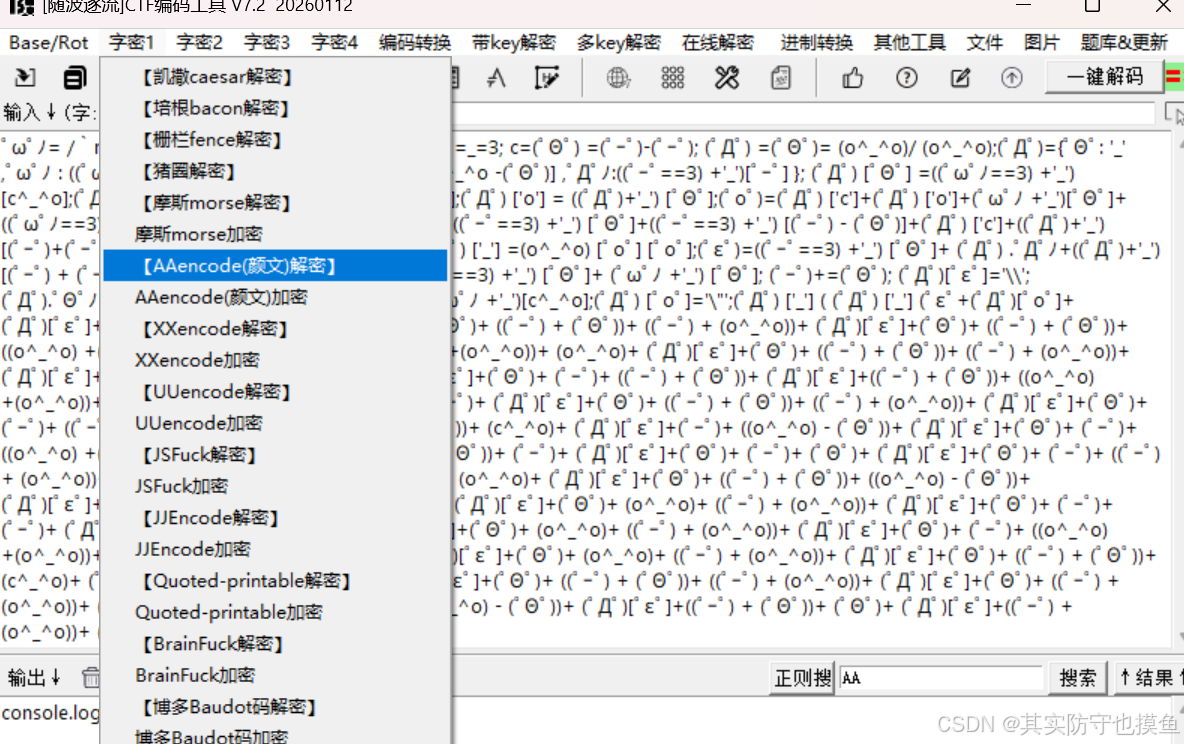
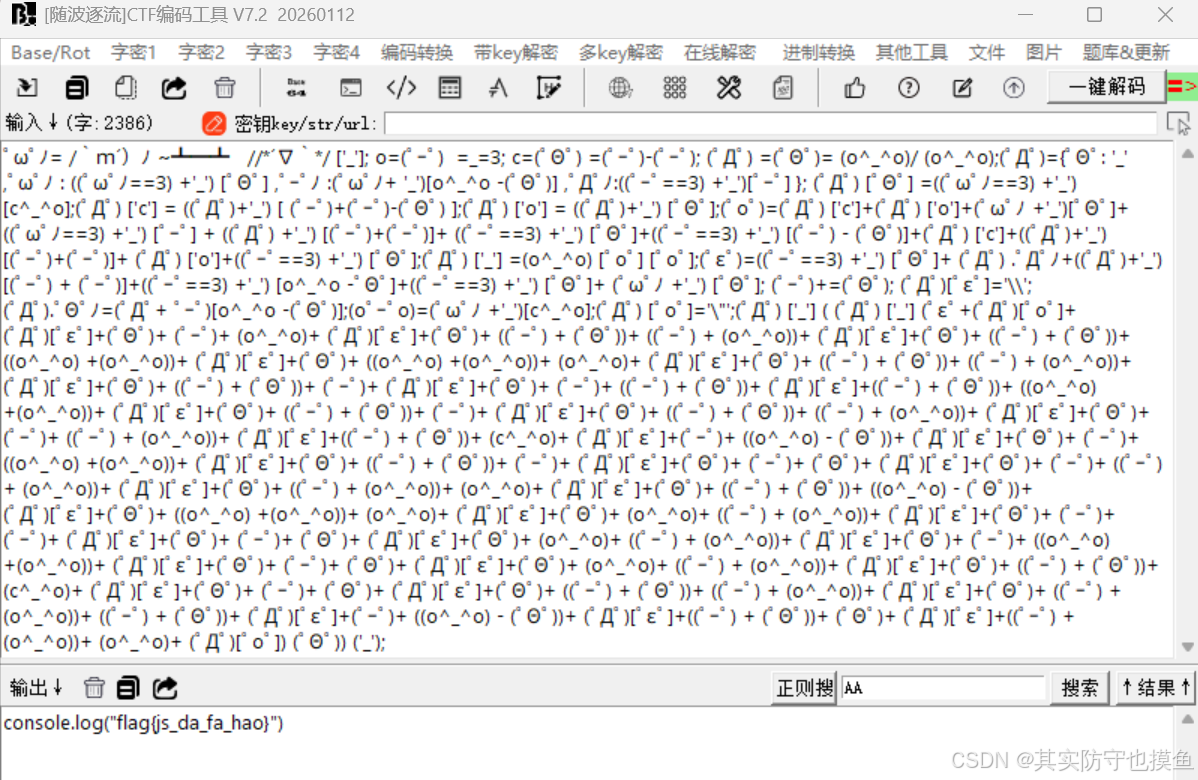
aaencode颜文字加密,在线网站解密即可
或者直接丢到随波逐流里
crypto4
方法一:最笨最耗时最基础
RSA手算:(想省时省力就看后面的方法,步步深入)
- p=447685307
- q=2037
根据RSA算法- r=(p-1)(q-1)=911487283016
e=17,d是e关于r的模逆元
暴力算法
d=(nr+1)/e,其中n为正整数,不断尝试n的值直到得出的d为整数
解得n=1时d=53616899001
方法二:使用在线网站(可现搜,可积累)
在线工具:RSA 加密/解密 - 锤子在线工具
离线:RSA-Tool2bytE资源文件下载介绍:基于 RSA 加密算法的工具资源项目 - AtomGit | GitCode
方法三:自己做一个网页用于解码(进阶玩法)
之后会更新相关内容,教你怎么自己编python脚本解题,在编辑内容了!超详细!讲的透透的
VS code,用AI编码功能自己编一个:
之后相关代码我也会整理一下发出来,关注我了解最新情况!
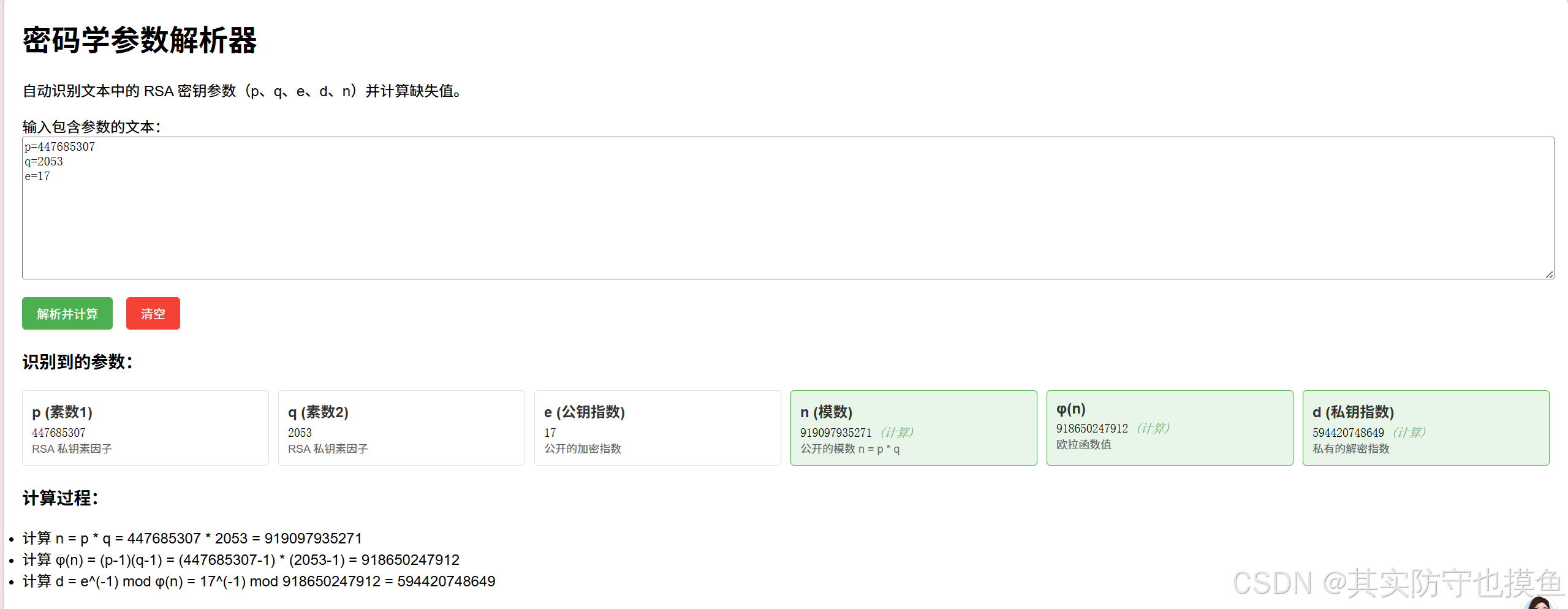
解出d=594420748649
crypto5
方法一:脚本
安装运行库:pip install libnum
执行解码文件:python rsa.py
其中rsa.py代码段为:
import libnum from Crypto.Util.number import long_to_bytesq = 2037 p = 447685307
e = 17
c = 704796792
n = q*p
d = libnum.invmod(e, (p - 1) * (q - 1))
m = pow(c, d, n)

解出m=904332399012
方法二:直接使用在线工具

crypto6
题目提示:密钥为 加密方式 名称,区分大小写
下载文件:
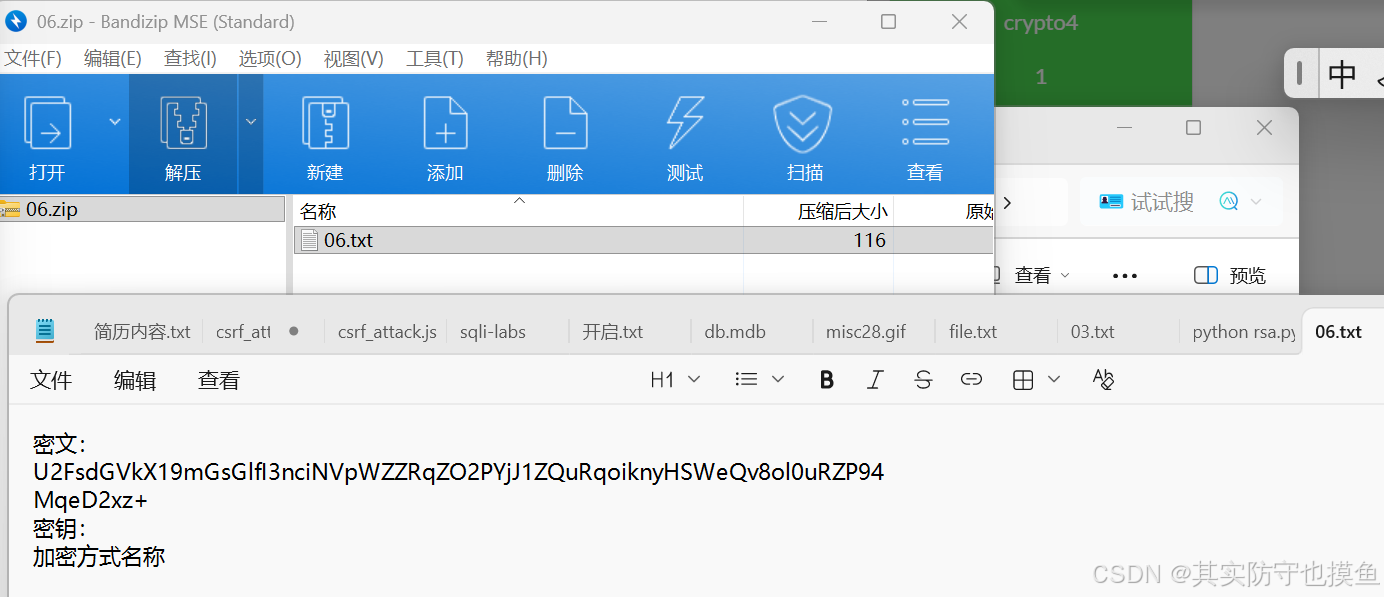
1、U2FsdGVkX1开头的可能是rabbit,AES,DES,此题为Rabbit加密
2、在线Rabbit加密,Rabbit解密工具-我爱工具网 (acy.moe)解码:https://tool.acy.moe/rabbitencrypt/
3、密码是Rabbit
4、解得:flag{a8db1d82db78ed452ba0882fb9554fc9}
ctrpto7
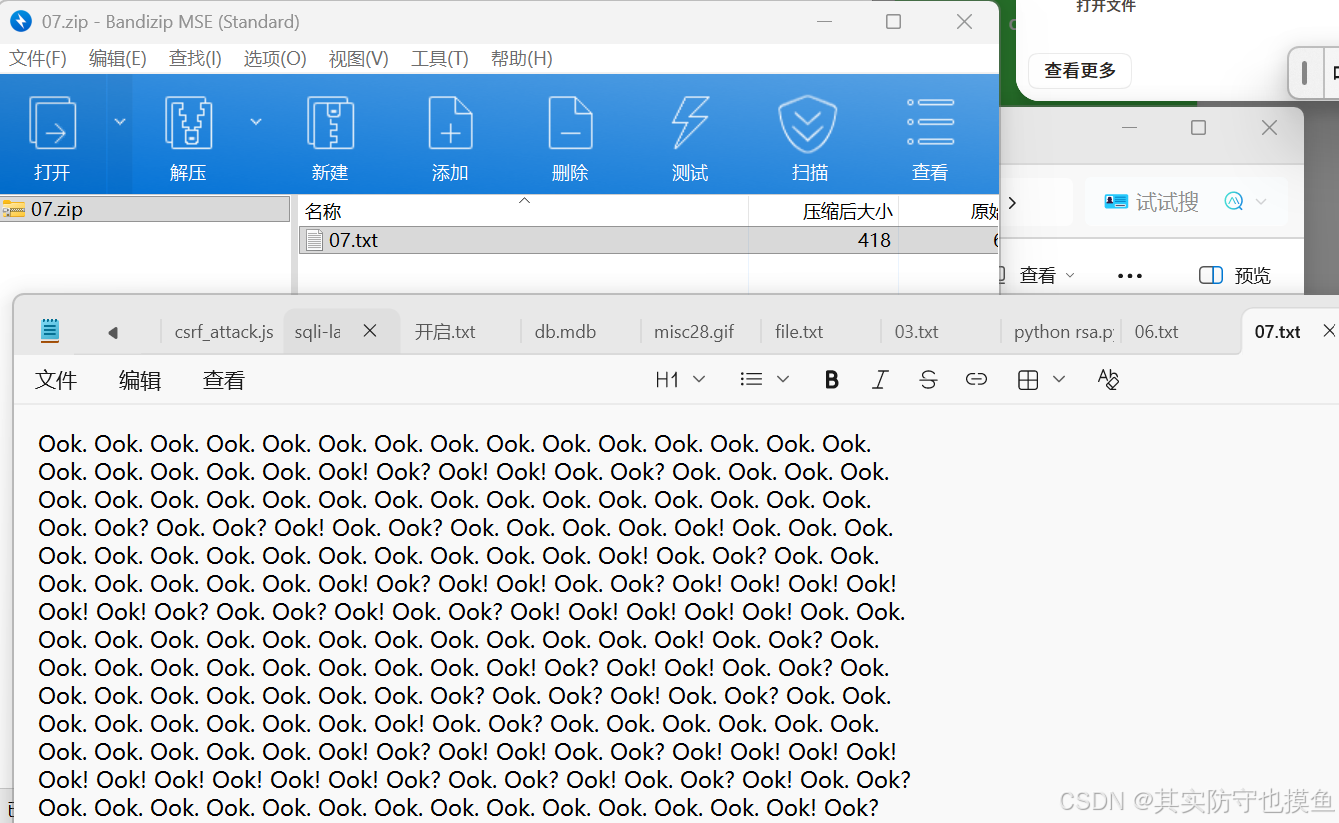
ook编码即是BrainFuck编码。 打开网站https://www.splitbrain.org/services/ook 即可解码。
注:CTF常见编码及加解密(超全),编解码网站在此都可找到。 https://www.cnblogs.com/ruoli-s/p/14206145.html#brainfuck编码
crypto8
题目提示:口出F伸中指
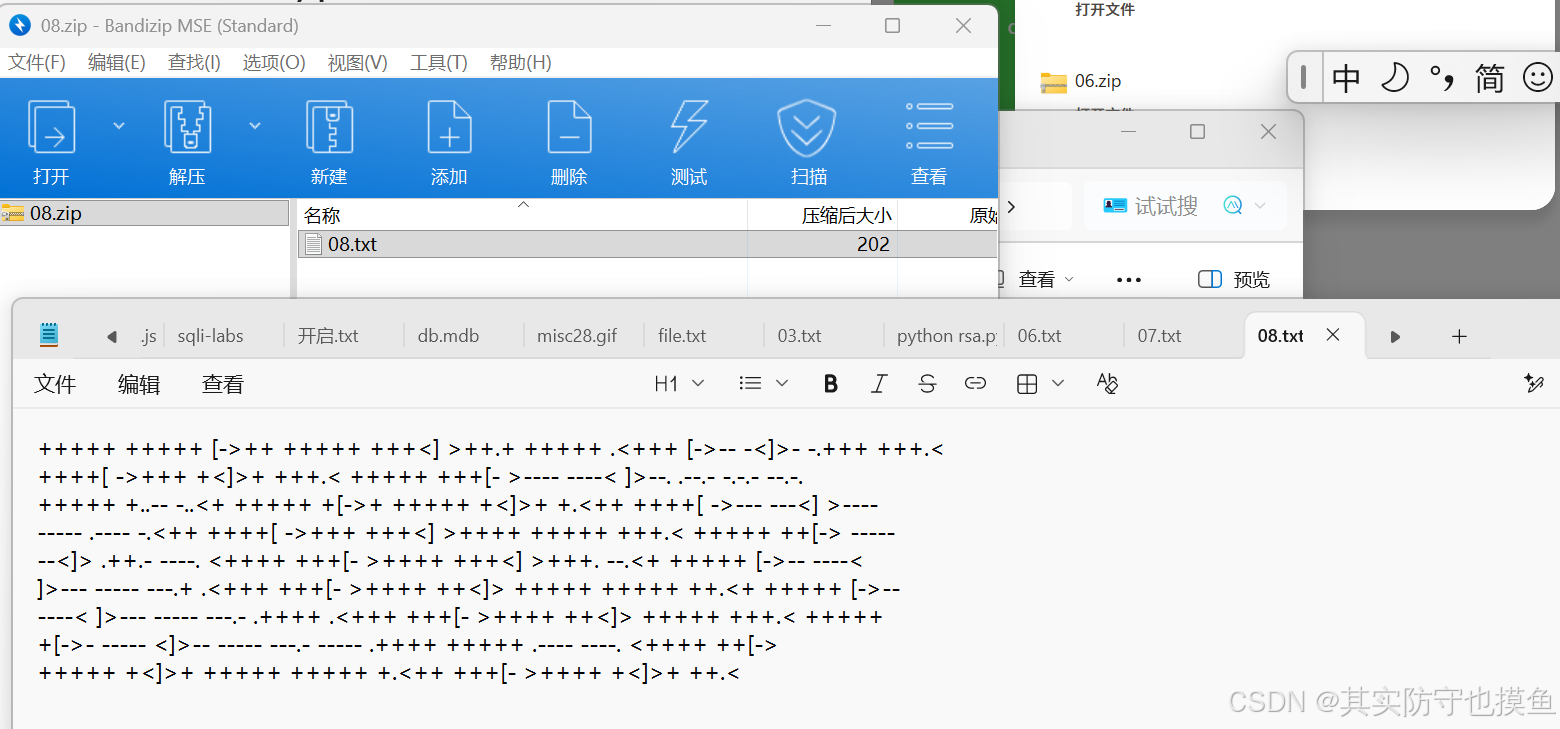

ctrpto9
想要解压文件发现要密码
下载密码破解软件压缩包密码解压工具(ARCHPR)下载_压缩包密码解压工具(ARCHPR)2026官方最新正版_压缩包密码解压工具(ARCHPR)v4.54免费下载_华军软件园
ARCHPR 支持暴力破解、字典攻击和掩码攻击,界面直观,适合不知道密码任何线索的情况。
首先默认是试所有大写字母,发现没有
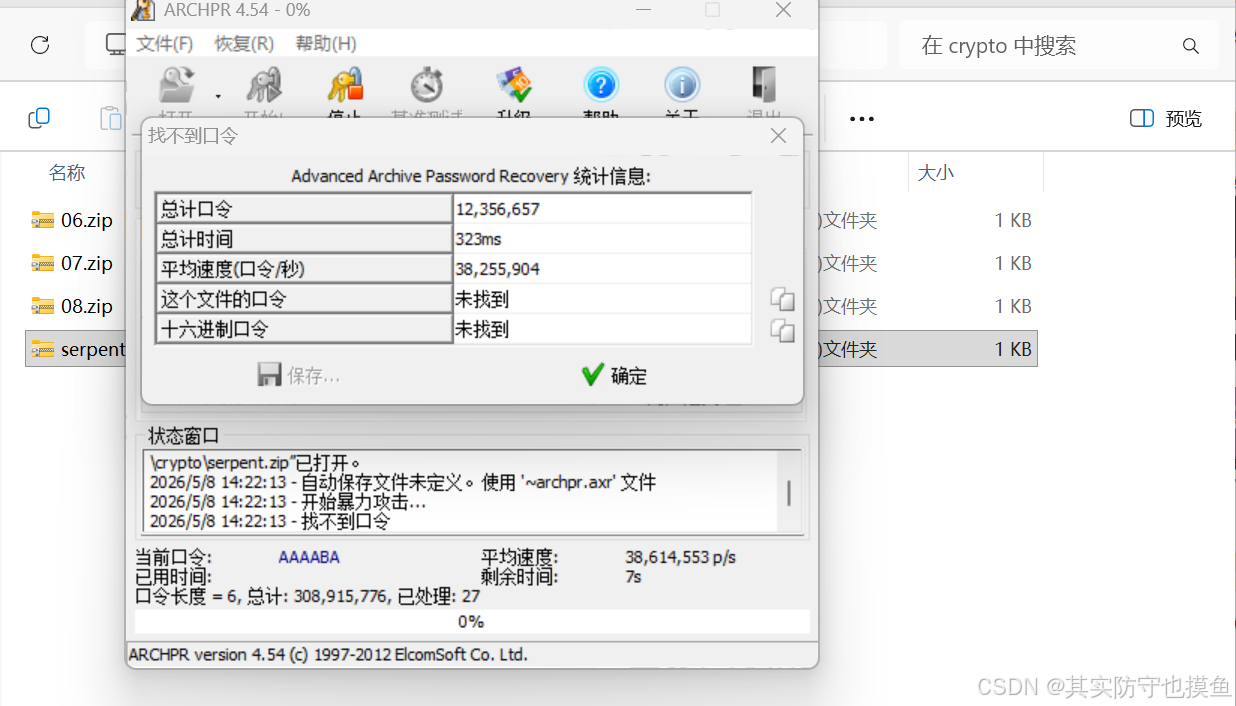
后面换到,暴力范围选项换到所有数字就破出来
密码是4132,也要记住34 31 33 32(这是ASCLL码值)
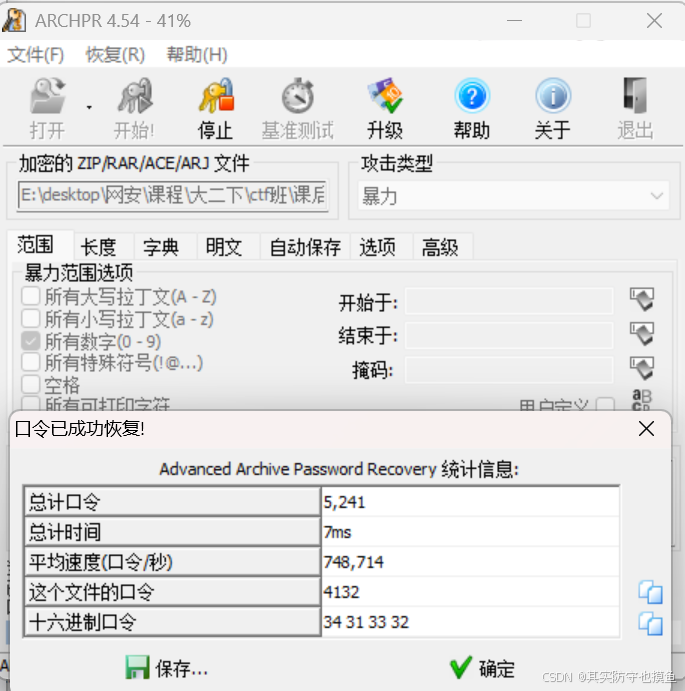
输入密码解压:

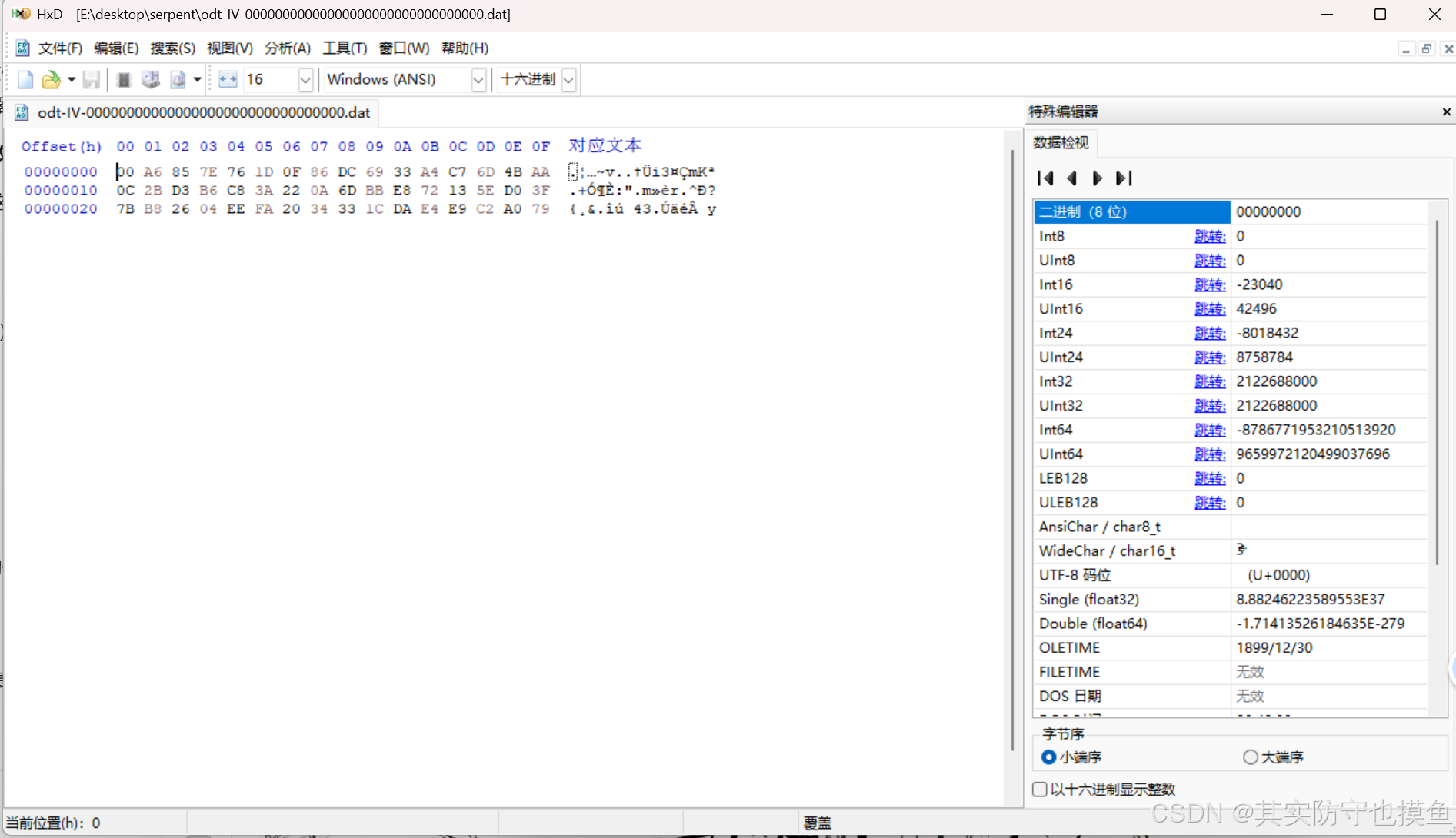
用记事本直接打开了那个 .dat 文件,看到的是一堆乱码。这很正常,因为这是一个二进制文件,用文本编辑器看就是乱码。
关键在于,你看到的这些乱码,其实就是加密后的数据(密文)。
要解密它,你不能直接复制这些乱码,而是需要把这些"乱码"对应的十六进制(Hex)代码 提取出来,填入解密工具。 HxD (免费小巧)或者 WinHex
用这个可以:https://www.codertools.net/tools/serpent.php?lang=zh 加密方式改为ECB-电子密码本模式
多试一下,我一开始一直用的CBC模式,但是实际上是ECB
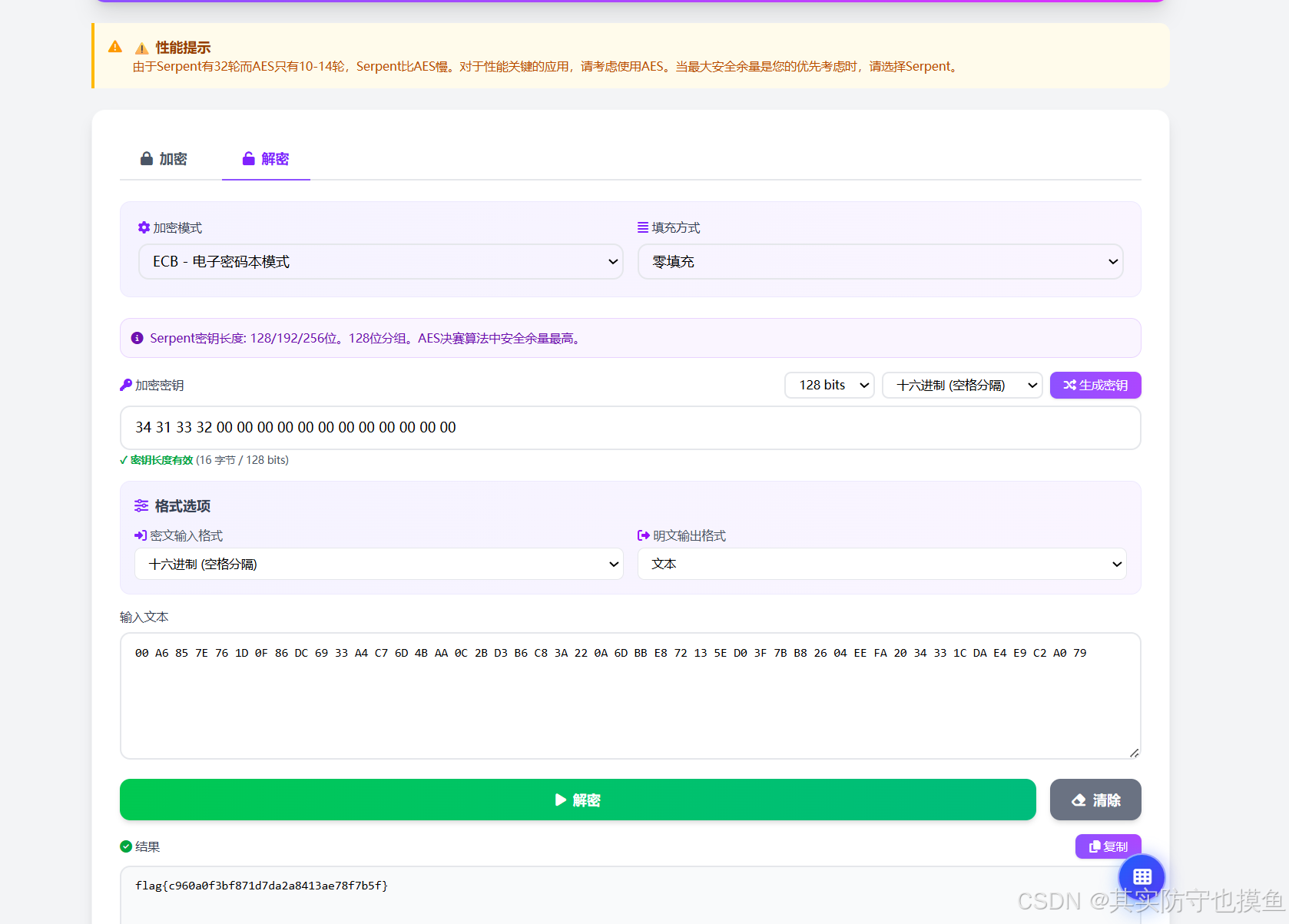
错误示例:
在结果里看到了
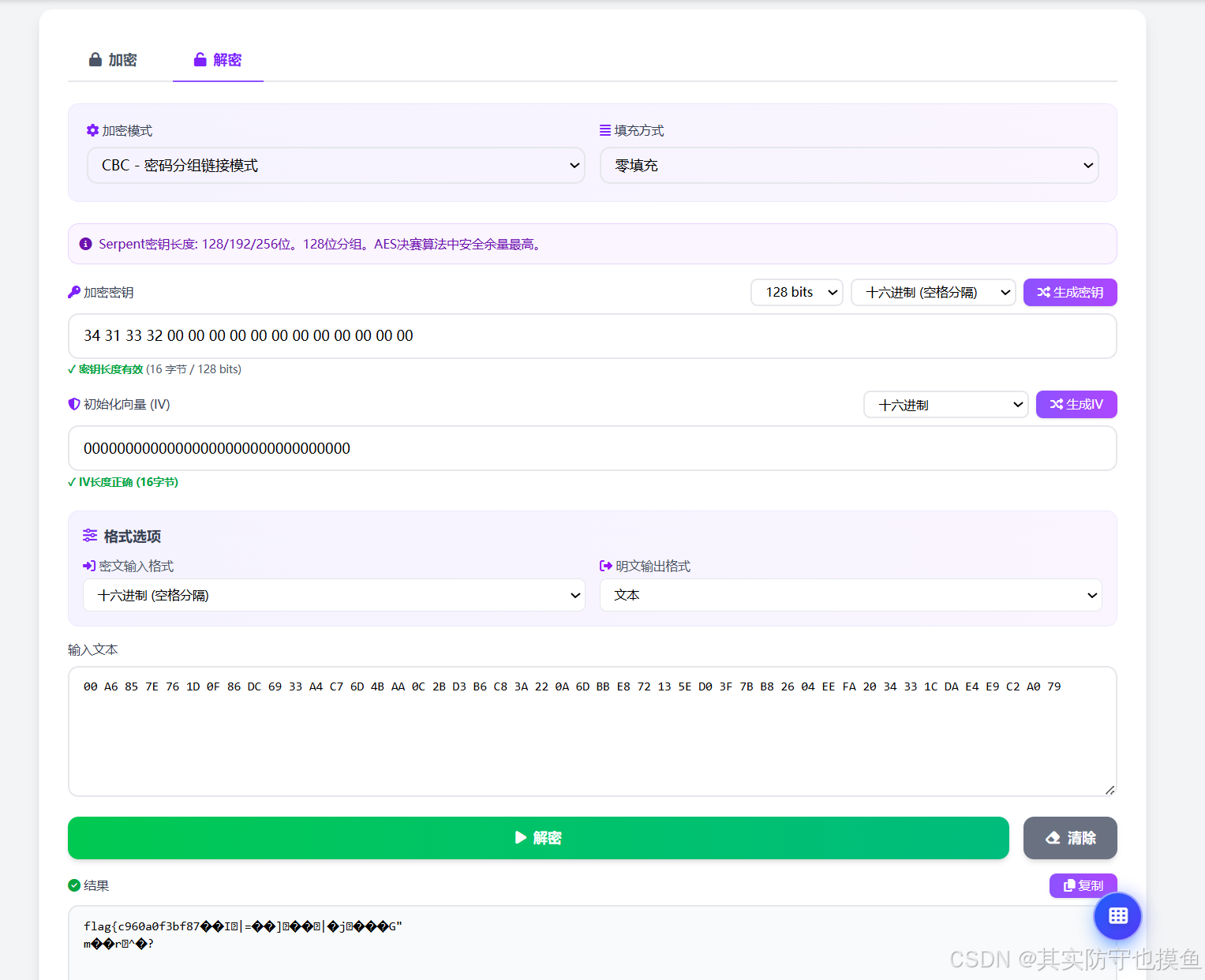
flag{开头的内容!这意味着你的密钥(34 31 33 32...)和 IV 都是正确的。之所以选"零填充"会显示乱码,选"PKCS7"会报错,是因为文件末尾的数据校验问题。
为什么会出现这种情况?
关于"零填充"显示乱码 :
解密出来的原文后面可能带有几个不可见的填充字符(值为0),记事本或网页显示不出来,就变成了"乱码"方块。但其实前面的
flag{...}已经是正确的数据了。关于"PKCS7"报错 :
这个错误
Invalid PKCS7 padding往往是因为加密者在生成文件时,手动添加了一些非标准的数据,或者文件末尾有多余的字节,导致解密工具无法按照标准的 PKCS7 规则去"修剪"末尾。如何获取完整的 Flag?
既然你已经用"零填充"解出了开头,但后面是乱码,我们可以尝试手动去除末尾的干扰,或者尝试另一种解码方式。
方案一:直接提取可见字符(最快)
既然你已经看到了
flag{...},仔细看看乱码中间是否夹杂着可读的字符。通常 CTF 题目的 flag 格式是flag{xxxx-xxxx-xxxx}或者类似的。方案二:尝试修改"明文输出格式"
在网页中间的"格式选项"里:
- 保持解密设置为 "零填充"(因为它能跑出数据)。
- 将 "明文输出格式" 从
文本改为Hex或者Base64试试看。
- 如果改为
Hex,你会看到一串完整的十六进制。你需要找到7B(即{的Hex)和7D(即}的Hex)之间的内容。- 如果改为
Base64,可能会直接弹出一串字符,其中包含 flag。方案三:检查密文是否有多余的头部
看你的密文开头是
00 A6 85...。有时候加密文件会在最前面加一个
00或者文件头。
尝试操作 :把输入文本框里的第一个00删掉,只保留A6 85 7E...后面的内容,再次点击"解密"(保持零填充)。有时候那个开头的00会导致后面的对齐错位,产生乱码。总结:你的密钥是对的!Flag 就在结果框里,只是被末尾的乱码遮挡了,或者你需要把输出格式改成 Hex 去找那个
}结尾。
crypto10
题目提示:解密后 提交 flag{明文}
这题特好笑
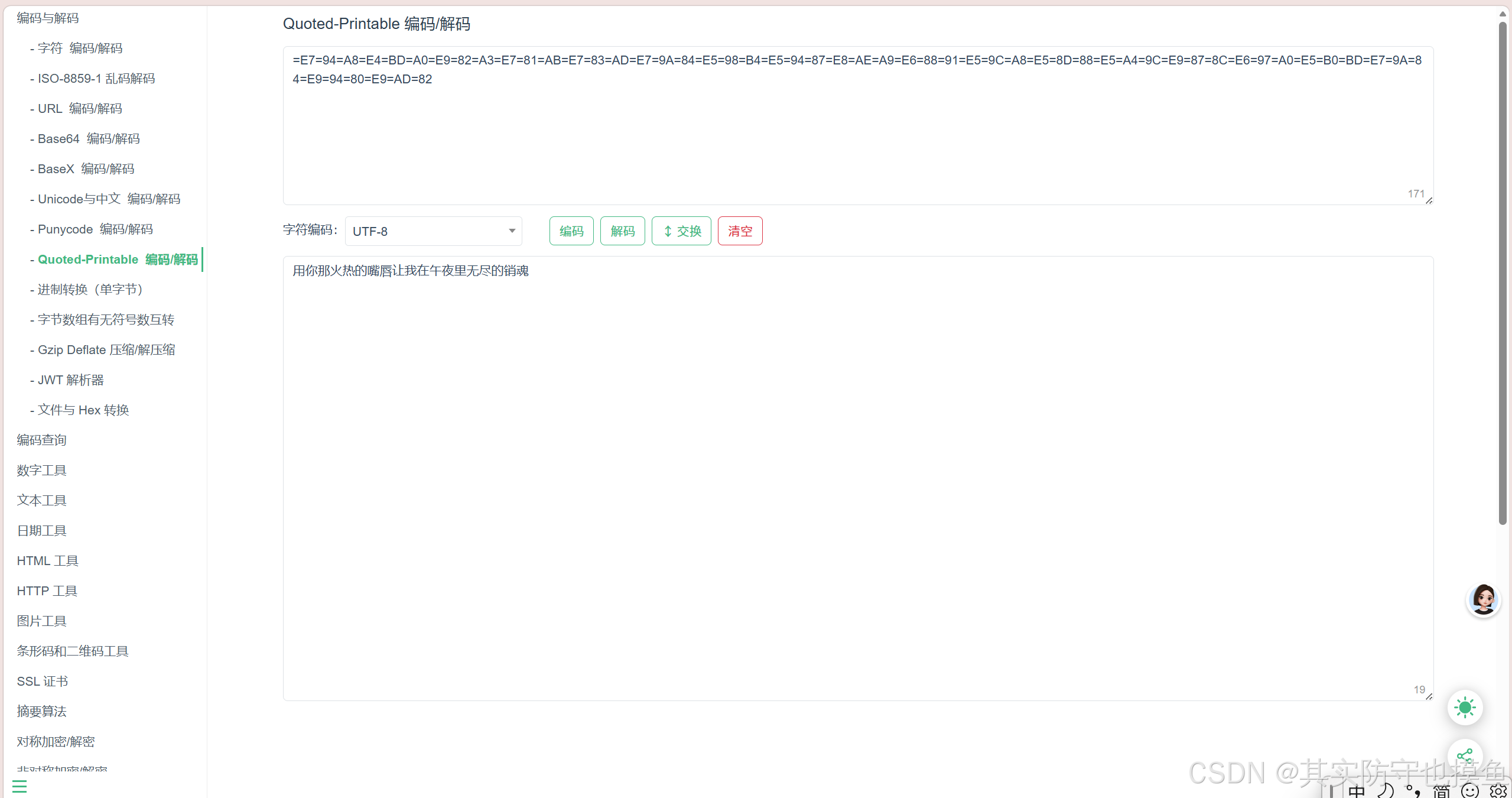
打开txt文件:=E7=94=A8=E4=BD=A0=E9=82=A3=E7=81=AB=E7=83=AD=E7=9A=84=E5=98=B4=E5=94=87=E8=AE=A9=E6=88=91=E5=9C=A8=E5=8D=88=E5=A4=9C=E9=87=8C=E6=97=A0=E5=B0=BD=E7=9A=84=E9=94=80=E9=AD=82
这一串看起来像乱码的字符 =E7=94=A8...,其实是一种非常经典的编码格式,叫做 Quoted-Printable 编码。
分析思路
-
特征识别:
- 你会看到很多等号
=后面跟着两个十六进制数字(比如=E7、=94=A8)。 - 这是电子邮件传输中常用的编码方式,用来把 8 位的非 ASCII 字符(比如中文)转换成 7 位的 ASCII 字符,以便在旧系统中传输。
- 你会看到很多等号
-
解码过程:
- 我们需要把这些
=XX的形式还原成原始的字节,然后按照 UTF-8 编码读取。
- 我们需要把这些
其实问一下AI它就给我们解密出来了:"用你那火热的嘴唇让我在午夜里无尽的销魂"
但是我们自己怎么解呢
它的原理很简单
- 每个汉字(UTF-8 编码下通常是 3 个字节)会被拆成 3 个部分。
- 每个部分前面加一个等号
=。 - 比如"用"字的 UTF-8 编码是
E7 94 A8,编码后就变成了=E7=94=A8。
怎么解码
你有三种简单的方法可以解开它:
使用在线工具(最推荐)
去搜索"Quoted-Printable 解码"或者"QP 解码",有很多在线网站可以一键转换。
Quoted-Printable 编码/解码 - 锤子在线工具
- 把那一长串粘进去,点击解码,就能看到中文了。
使用 Python 代码
如果你会一点点编程,用 Python 只需要两行代码:
import quopri
text = "=E7=94=A8=E4=BD=A0..." # 把你的字符串放这里
decoded_bytes = quopri.decodestring(text)
print(decoded_bytes.decode('utf-8'))使用浏览器控制台(黑客范儿)
如果你在电脑前,可以直接按 F12 打开浏览器的开发者工具,在 Console(控制台)里输入:
// 先把 = 替换成 %,因为 % 是 URL 编码的格式,浏览器自带解码函数
var str = "=E7=94=A8=E4=BD=A0...".replace(/=/g, '%');
console.log(decodeURIComponent(str));(注:虽然这是 URL 编码的格式,但在处理这种 Hex 转换时,把 = 换成 % 往往能直接通过浏览器的 decodeURIComponent 函数解出来,非常方便)
crypto11
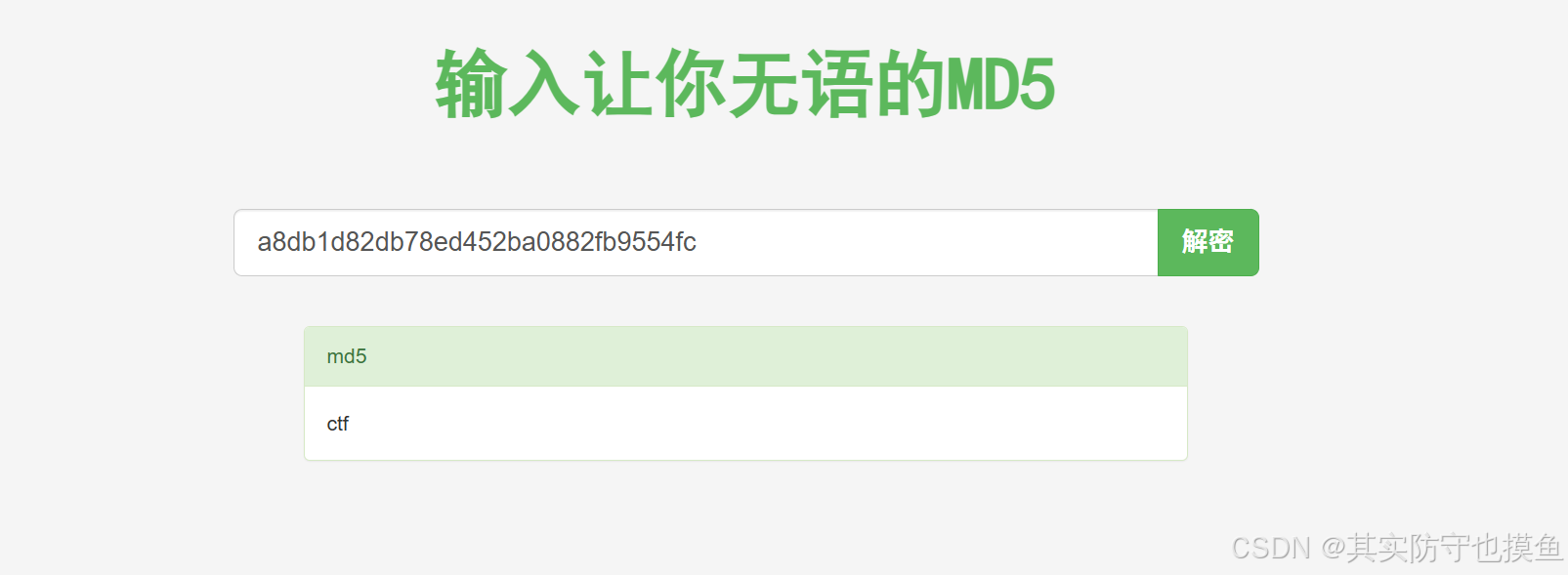
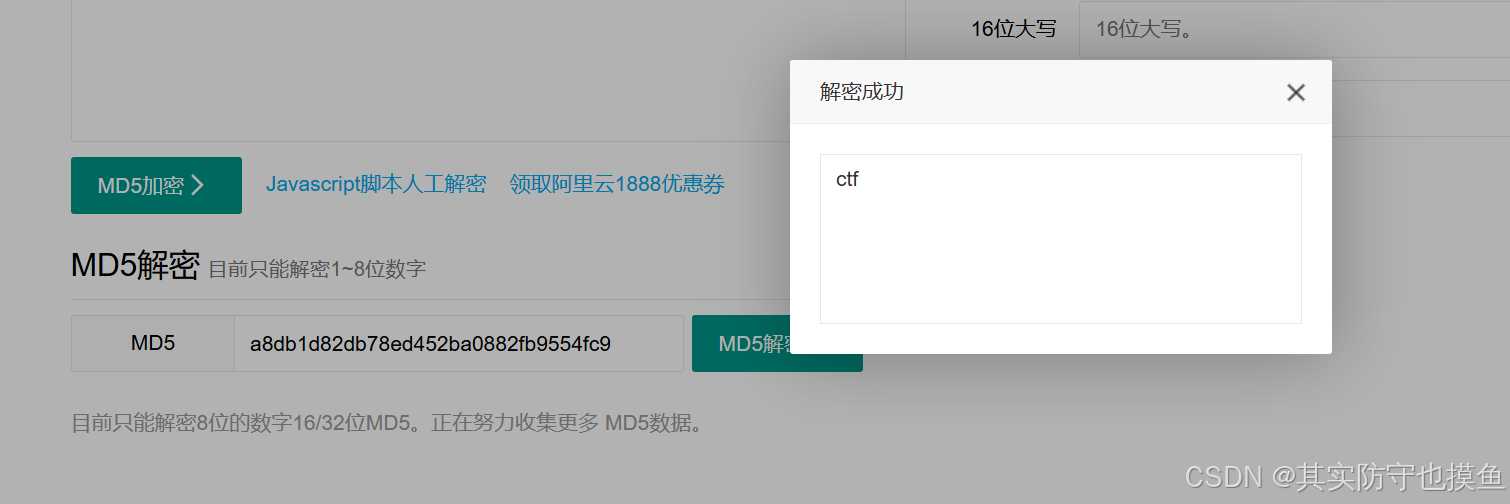
题目提示:密文:a8db1d82db78ed452ba0882fb9554fc
那我们猜测他是什么类型就好了
长度: 31 位
分析思路
-
观察特征
- 全是
0-9和a-f,这显然是十六进制。 - 长度是 31。这在加密算法里非常奇怪,因为 AES、DES 等现代算法的块大小通常是 16 的倍数(32、48、64位等)。31 是奇数,说明它不是标准的分组加密。
- 全是
-
尝试方向
由于没有密钥,这通常意味着解密过程不需要密钥,或者密钥是隐含的。
方向一:键盘密码(最可能)
观察字符在电脑键盘上的位置。
a,s,d,f是左手基准键。8,2,5是小键盘或者上面的数字。- 这种混合了字母和数字的,有时是QWERTY 键盘坐标 或者路径连线。
- 尝试:在键盘上画出这些字符的连线,看看是否构成形状或字母。
方向二:栅栏密码
把 31 个字符分成几栏。
- 比如分 2 栏:
- 奇数位:
adb1d2b8d52b08f54 - 偶数位:
8d187ed4a829b5c
- 奇数位:
- 或者分 3 栏、4 栏... 看看重组后是否有意义。
方向三:Hex 转 ASCII
因为它是奇数位,直接转 ASCII 会报错(少半个字节)。
- 尝试补全 :在前面或后面补一个
0,变成 32 位,然后尝试 Hex -> ASCII 转换。 - 如果转出来是乱码,说明不是直接的字符串。
方向四:MD5 碰撞/查询
32 位 Hex 通常是 MD5 值。虽然这个是 31 位(可能缺了一位),但你可以尝试去 MD5 解密网站(如 cmd5)查询。
- 有可能这是一段已经被 MD5 加密的文字,你需要找回原文。
- 你可以试着补全最后一位(比如补 0 到 f),看看能不能查出常见的单词。
方向五:特殊编码(Brainfuck/ Ook! 等)
有些编码看起来像乱码,但其实是 Brainfuck 的变体。不过这个看起来不太像。
建议操作
请检查题目是否还有遗漏的信息?
比如:
- 题目有没有给一张图?(可能是键盘图)
- 题目有没有给一个文件名?(比如
flag.mp3,那可能需要把这段 Hex 转成文件头) - 题目有没有提示"这是某种动物的叫声"或者"这是某种乐器"?
如果只有这一行字,建议先尝试:
- 补全最后一位 (比如补
0),变成...554fc0,然后去在线 Hex 转文本工具转一下,看看是不是乱码。 - 去 MD5 解密网站,把补全后的字符串放进去查一下。
- 在键盘上画一下路径。
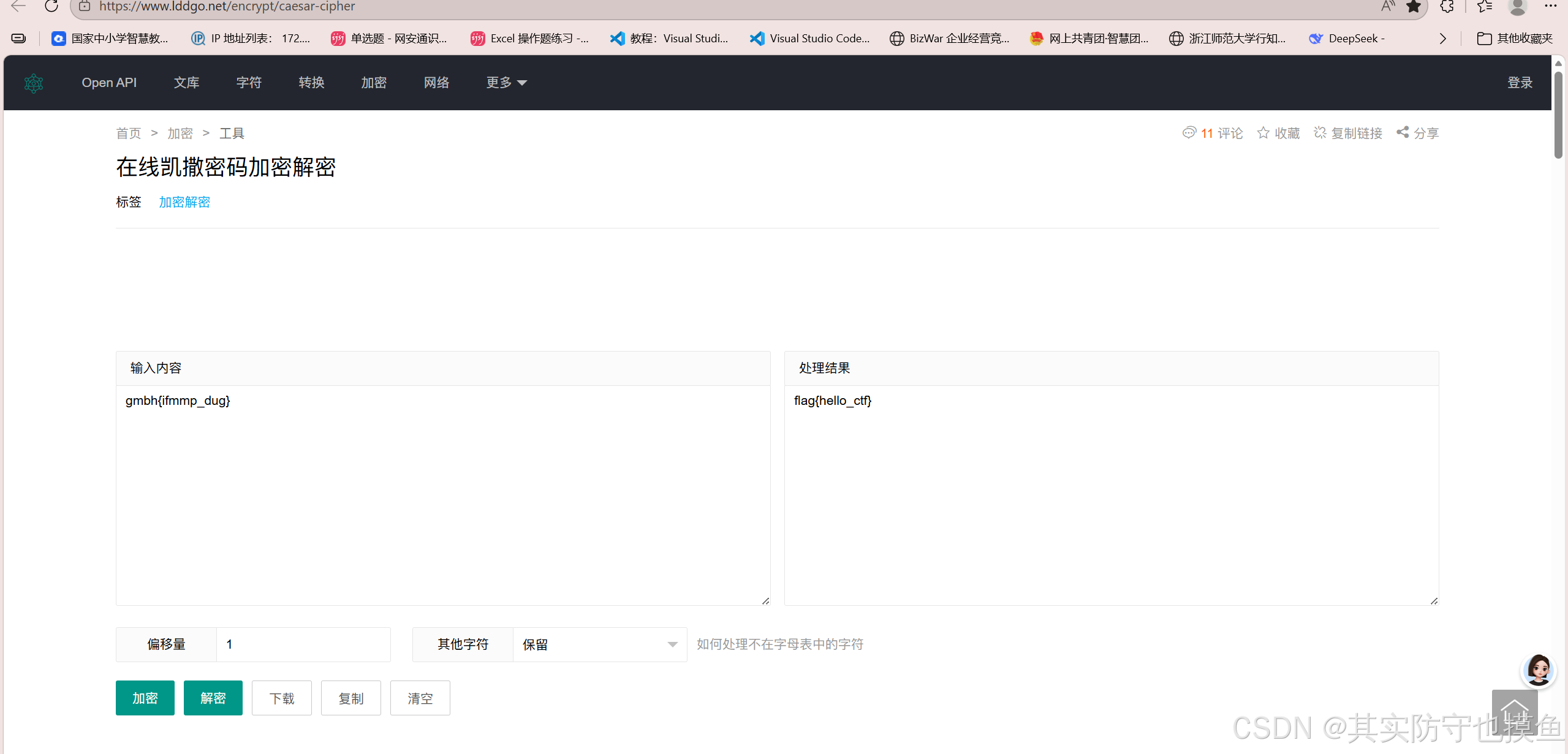
crypto0
题目提示:gmbh{ifmmp_dug}
crypto12
题目提示:uozt{Zgyzhv_xlwv_uiln_xguhsld},不用看了,没提示
解题步骤:
1. 观察特征
- 格式 :
uozt{...},这很明显是flag{...}的变体。 - 内容 :
Zgyzhv_xlwv_uiln_xguhsld。 - 字母对应 :
- 密文开头
uozt对应 明文开头flag。 u->fo->lz->at->g
- 密文开头
2. 分析规律
我们来算一下字母表中的位置关系(A=1, B=2...):
u(21) +f(6) = 27o(15) +l(12) = 27z(26) +a(1) = 27t(20) +g(7) = 27
结论 :两个字母相加等于 27,这意味着这是一种倒序替换。即:A 变成 Z,B 变成 Y,C 变成 X......
3. 确定加密方式
这种加密方式叫做 埃特巴什码。
- 原理:字母表的最后一个字母(Z)代表第一个字母(A),倒数第二个(Y)代表第二个(B),以此类推。
4. 解密结果
根据这个规则,我们可以直接解密 uozt{Zgyzhv_xlwv_uiln_xguhsld}:
uozt-> flagZgyzhv-> atbase (Z->a, g->t, y->b, z->a, h->s, v->e)xlwv-> code (x->c, l->o, w->d, v->e)uiln-> from (u->f, i->r, l->o, n->m)xguhsld-> ctfshow (x->c, g->t, u->f, h->s, s->h, l->o, d->w)
最终答案
flag{Atbase_code_from_ctfshow}
🛠️ 使用在线解密工具
这是最快的方法。你只需要:
- 在搜索引擎里搜索关键词 "Atbash Cipher online" 或 "埃特巴什码 在线解密"。
- 打开任意一个在线工具网站。
- 把密文
uozt{Zgyzhv_xlwv_uiln_xguhsld}粘贴到输入框里。 - 点击"解密"(Decrypt)按钮,结果就会立刻显示出来。
💻 使用 Python 脚本
如果你习惯用脚本,一段简单的 Python 代码就能自动完成所有替换,连复制粘贴都省了:
ciphertext = 'uozt{Zgyzhv_xlwv_uiln_xguhsld}'
plaintext = ''
for char in ciphertext:
if 'a' <= char <= 'z':
# 小写字母转换:a<->z, b<->y...
plaintext += chr(ord('z') - (ord(char) - ord('a')))
elif 'A' <= char <= 'Z':
# 大写字母转换:A<->Z, B<->Y...
plaintext += chr(ord('Z') - (ord(char) - ord('A')))
else:
# 非字母字符(如 {, }, _)保持不变
plaintext += char
print(plaintext)运行这段代码,就能直接得到最终的 flag。
🤖 使用 AI 自动化工具
还有一些更强大的工具,比如 Ciphey,它利用人工智能技术,可以自动识别加密方式(包括 Atbash 码)并直接解密。你只需要把密文喂给它,它就能在几秒钟内给出答案,完全不需要你事先知道这是什么密码。
crypto13
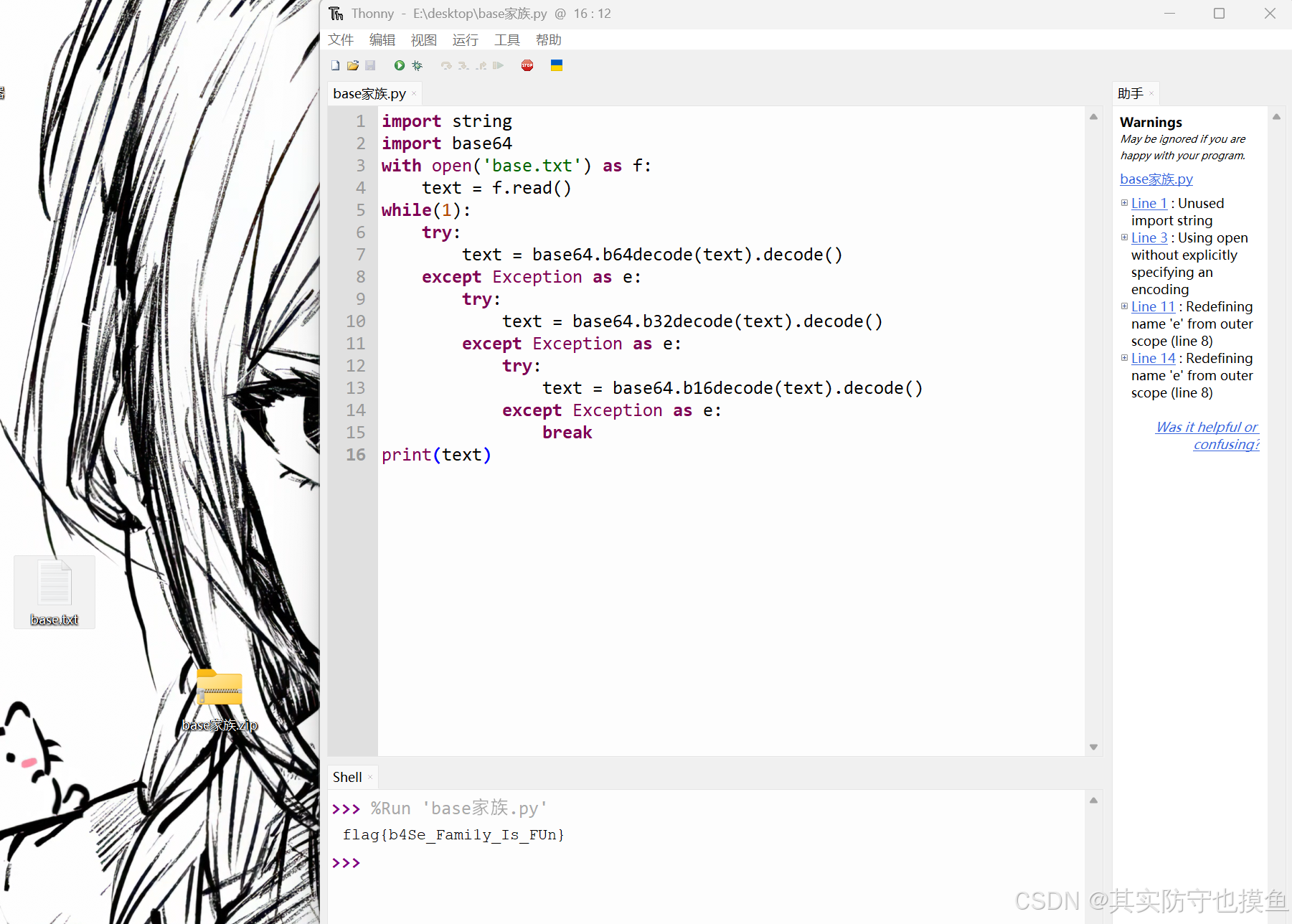
本题需要会写python代码,进行Base64解密。
根据python的base64库进行多层解码,试出来是base32解码20次,再base64解码12次就可以获得flag。
import string
import base64
with open('base.txt') as f:
text = f.read()
while(1):
try:
text = base64.b64decode(text).decode()
except Exception as e:
try:
text = base64.b32decode(text).decode()
except Exception as e:
try:
text = base64.b16decode(text).decode()
except Exception as e:
break
print(text)将代码文件和txt文件放在同一个目录下
crypto14
题目提示:00110011 00110011 00100000 00110100 00110101 00100000 00110101 00110000 00100000 00110010 01100110 00100000 00110011 00110011 00100000 00110101 00110110 00100000 00110100 01100101 00100000 00110100 00110110 00100000 00110100 00110110 00100000 00110110 01100100 00100000 00110100 01100101 00100000 00110100 00110101 00100000 00110100 00110001 00100000 00110110 01100101 00100000 00110110 01100011 00100000 00110100 00111000 00100000 00110100 00110100 00100000 00110011 00110101 00100000 00110110 00110100 00100000 00110100 00110011 00100000 00110100 01100100 00100000 00110110 01100100 00100000 00110101 00110110 00100000 00110100 00111000 00100000 00110100 00110100 00100000 00110011 00110101 00100000 00110110 00110001 00100000 00110110 00110100 00100000 00110011 00111001 00100000 00110111 00110101 00100000 00110100 00110111 00100000 00110000 01100001
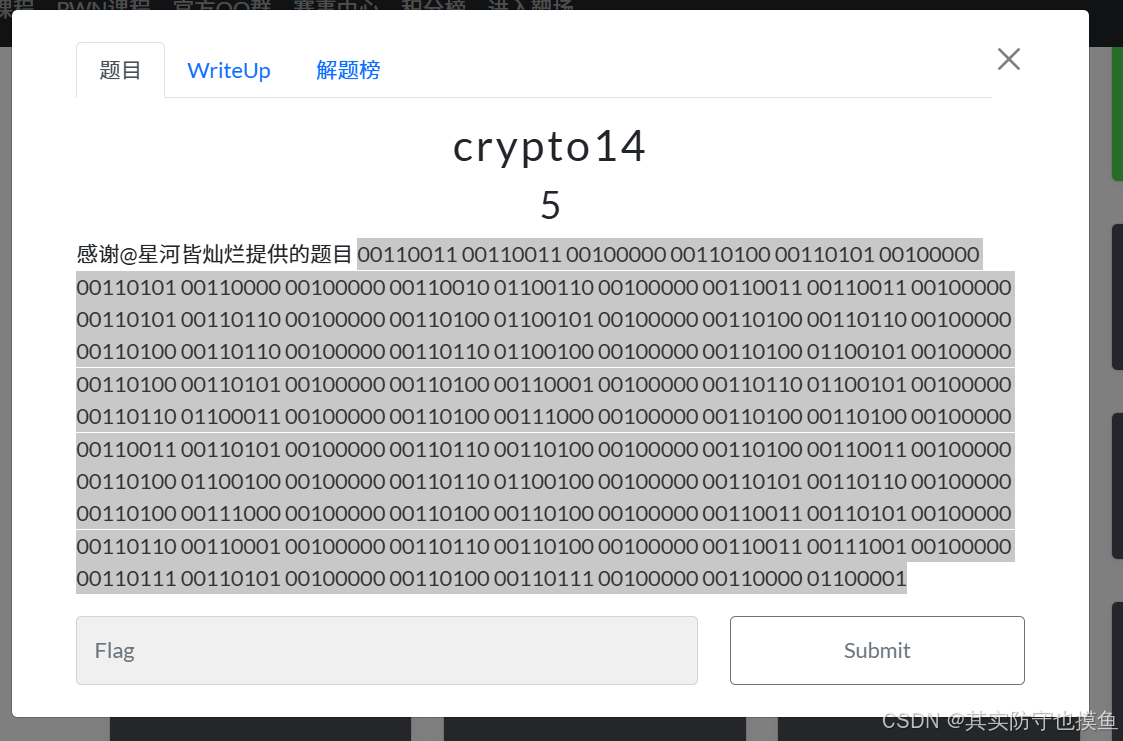
直接二进制,找个编码转换器,进行一下转换,拿到了
3EP/3VNFFmNEAnlHD5dCMmVHD5ad9uG
把这个转换成16,跟flag头的16比,发现位移30,写跟脚本-30,任何在放到base在线网站就拿到flag
这串数字看起来很长,但其实它是非常基础的二进制编码。
1. 观察特征
- 只有
0和1两种字符。 - 它们被空格分成了很多组,每组正好是 8位 (例如
00110011)。 - 8位二进制通常对应 1个字节的 ASCII 码。
2. 分析思路
我们需要把每组的二进制数转换成十进制,然后查 ASCII 表找到对应的字符。
试算前几组:
00110011(二进制) = 32+16+2+1=5132+16+2+1=51 (十进制) -> ASCII 码 51 对应字符300110011->300100000(二进制) = 3232 (十进制) -> ASCII 码 32 对应字符空格00110100-> 32+16+4=5232+16+4=52 -> ASCII 码 52 对应字符400110101-> 32+16+4+1=5332+16+4+1=53 -> ASCII 码 53 对应字符5
目前的明文: 33 45 ...
3. 快速转换方法
方法一:使用在线工具(推荐)
搜索 "二进制转文本" 或 "Binary to Text",把这一长串粘进去,选择"空格分隔",点击转换即可。
方法二:Python 脚本
binary_str = "00110011 00110011 00100000 ..." # 把那一长串放这里
bytes_list = binary_str.split()
result = ""
for byte in bytes_list:
result += chr(int(byte, 2))
print(result)4. 解密结果
转换了一下,得到的结果是:
33 45 50 2f 33 56 4e 46 46 6d 4e 45 50 41 6e 6c 48 44 35 64 6d 56 48 44 35 61 43 39 75 47 0a
5. 下一步分析
这串结果看起来像是一串 十六进制 数字。
- 里面有
0-9和a-f。 - 结尾有
0a(这是换行符的十六进制)。
把这串十六进制字符串(去掉空格)再次进行 Hex 转 ASCII 解码。
最终解码预测:
33->345->E50->P2f->/
...
这看起来像是一个 Base64 编码的字符串或者某种哈希值。请把这串十六进制转成文本,应该就是最终的 Flag 了。
或者直接写个代码
m ='00110011 00110011 00100000 00110100 00110101 00100000 00110101 00110000 00100000 00110010 01100110 00100000 00110011 00110011 00100000 00110101 00110110 00100000 00110100 01100101 00100000 00110100 00110110 00100000 00110100 00110110 00100000 00110110 01100100 00100000 00110100 01100101 00100000 00110100 00110101 00100000 00110100 00110001 00100000 00110110 01100101 00100000 00110110 01100011 00100000 00110100 00111000 00100000 00110100 00110100 00100000 00110011 00110101 00100000 00110110 00110100 00100000 00110100 00110011 00100000 00110100 01100100 00100000 00110110 01100100 00100000 00110101 00110110 00100000 00110100 00111000 00100000 00110100 00110100 00100000 00110011 00110101 00100000 00110110 00110001 00100000 00110110 00110100 00100000 00110011 00111001 00100000 00110111 00110101 00100000 00110100 00110111 00100000 00110000 01100001'
m = m.split(' ')
m1 =[]
for item in m:
m1.append(hex(int(item,2)))
m2 =''
for item in m1:
m2+=chr(int(item,16))
m2 = m2.split(" ")
m3 =''
for item in m2:
m3+=chr(int(item,16))
#s= '3EP/3VNFFmNEAnlHD5dCMmVHD5ad9uG'
print(m3)
#注意这里最后有个回车键
s = m3[:-1]
s =str(s)
t = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
l=""
for i in s:
l += t[(t.index(i)-30)%64]
##如果不是4的倍数补上等号
if len(l)%4!=0:
l=l+"="*(4-(len(l)%4))
print(l)
import base64
flag = base64.b64decode(l).decode('utf-8')
print(flag)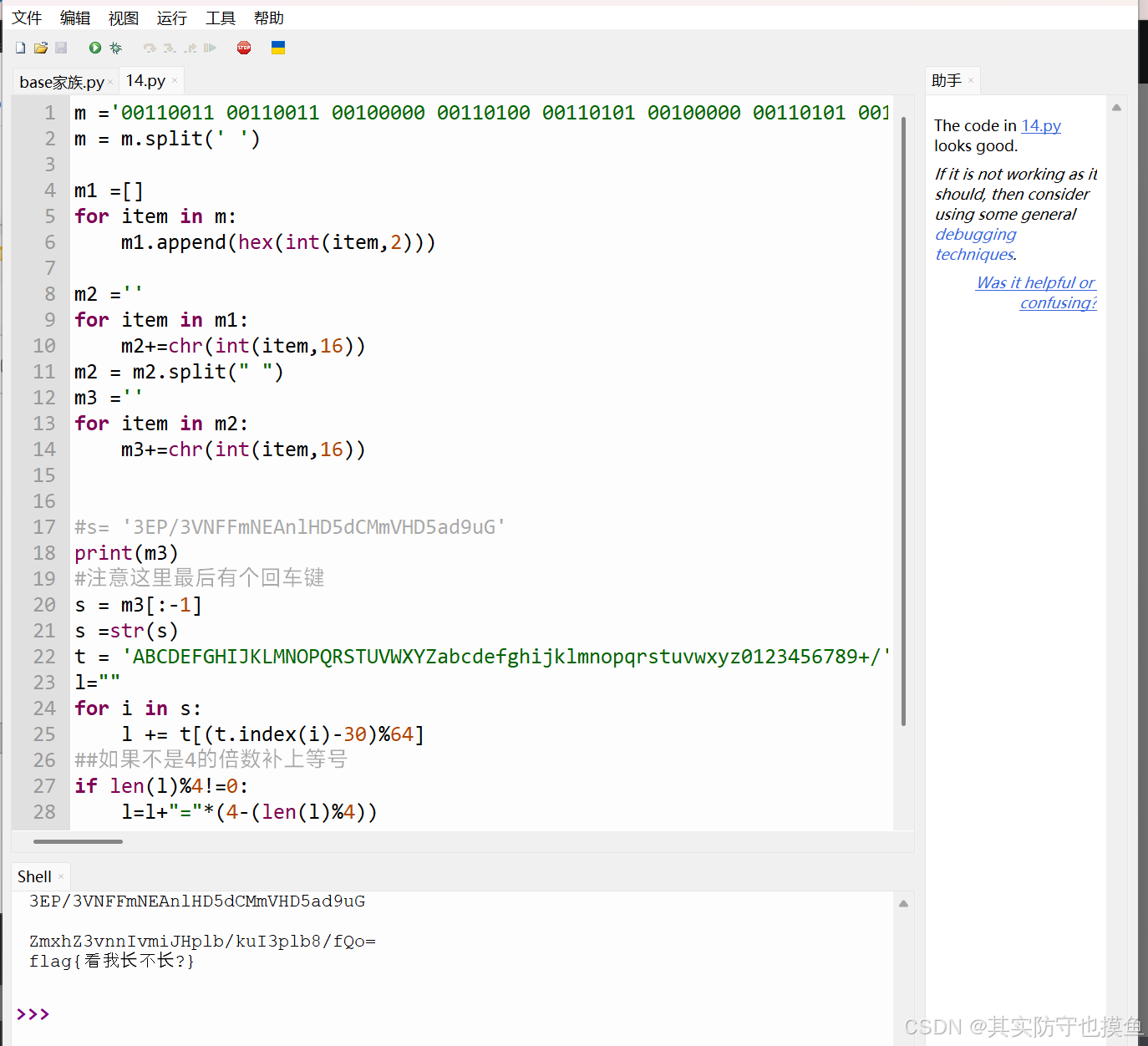
结语:
密码学相关知识专栏,带着你一步一步从头学:
CTF密码学综合教学指南_其实防守也摸鱼的博客-CSDN博客

最后整合: