作者:来自 Elastic Miguel Sánchez
本文将逐步介绍如何使用 PromQL 在 Elastic Observability 中对 Kubernetes 集群范围内的 CPU 使用情况进行调查,从集群到命名空间再到出现问题的 Pod。
Elasticsearch 现在已经原生支持 PromQL,并且你可以通过 ES|QL 中的 PROMQL source command 在 Kibana 中运行 PromQL 查询。
这意味着你可以直接使用 PromQL 查询存储在 Elasticsearch 中的 Kubernetes 指标数据,并在 Discover、Dashboards 或 alerting rules 中运行这些查询。
当集群 CPU 突然飙升 ,而你需要找出究竟是哪一个 workload 导致问题时,可以按层级逐步收敛范围:
从 fleet → namespace → pod,一步一步定位。
你需要准备的内容
-
一个 Observability Serverless project,或版本为 9.4 及以上的 self-managed / Elastic Cloud Hosted Stack(PromQL 当前作为 metrics 的预览查询语言提供)
-
Kubernetes metrics 已写入 Elasticsearch(本文示例基于 OpenTelemetry 数据)
-
至少一个正在运行 workload 的 Kubernetes 集群,以便 group by 查询可以进行对比分析
场景
你正在管理一组 Kubernetes 集群:
| 集群 | 区域 | 角色 |
|---|---|---|
| prod-us-east-1 | 美国东部 | 生产环境:服务、ML 训练 |
| prod-eu-west-1 | 欧洲西部 | 生产环境:区域 Web 层、缓存 |
| staging-us-east-1 | 美国东部 | 预发布环境:QA、集成测试 |
| dev-sandbox | 美国东部 | 开发者沙箱环境 |
美国东部的生产集群运行着多种服务以及 ML 训练任务,分布在多个 namespace 中。
此时,一个告警触发:整个集群的 CPU 使用率升高,但只有某一个团队反馈响应时间变慢。
你的排查目标是:
先定位哪个 cluster 出问题 → 再定位哪个 namespace → 最后定位具体哪个 pod。
你的目标并不是用一条查询完成完整 root-cause 证明,而是快速锁定 "嫌疑对象" 并完成交接。
你的数据
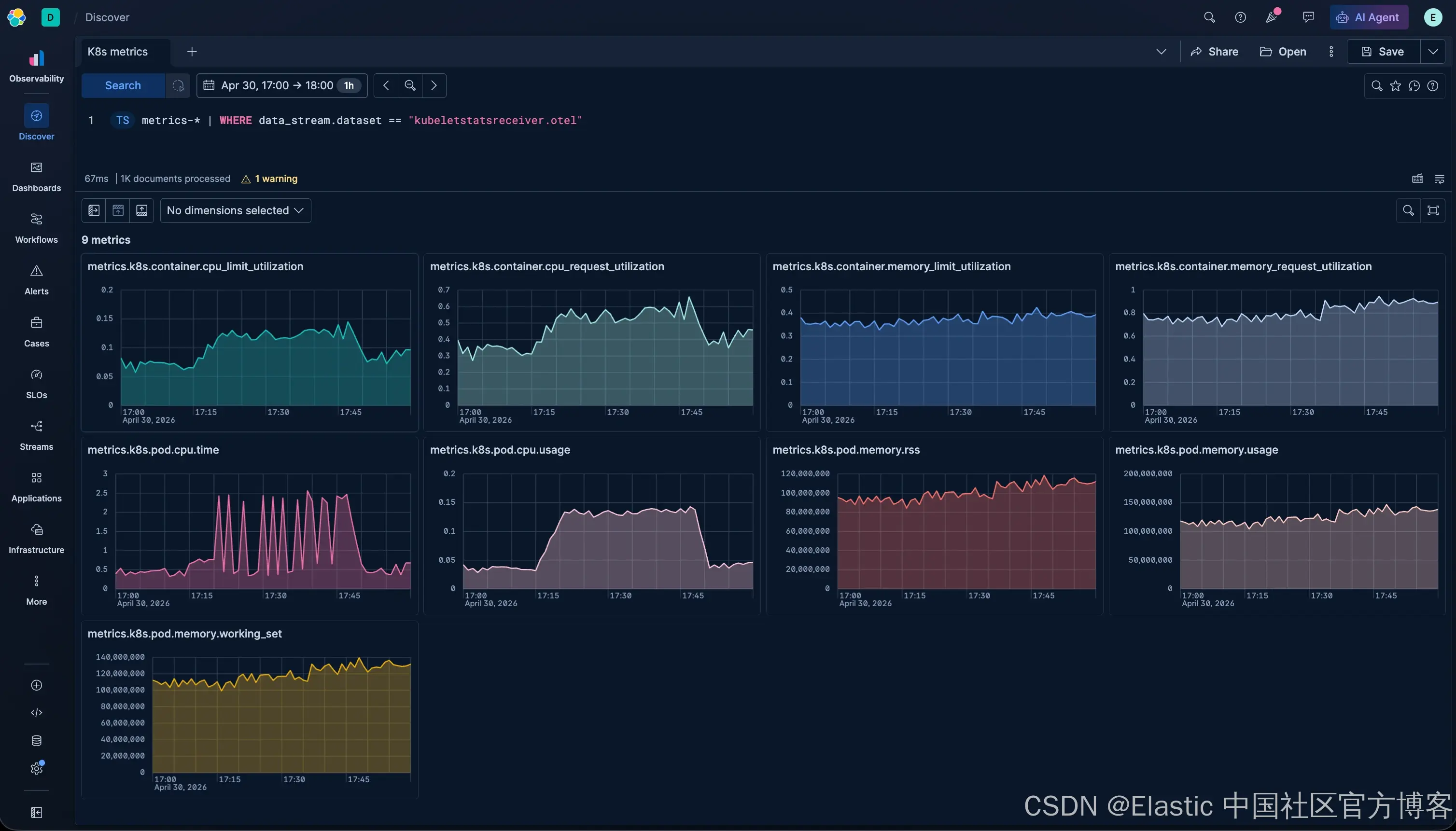
OpenTelemetry Collector 的 Kubelet Stats Receiver 会生成如下 data stream:
- metrics-kubeletstatsreceiver.otel-default
指标遵循 k8s.* 命名规范(例如 k8s.pod.cpu.usage),并通过如下标签进行切分:
这些标签允许你按 cluster、namespace 或 pod 进行分析。
为了确认数据已经存在:
打开 Discover → 切换到 ES|QL 模式 → 运行:
TS metrics-*
| WHERE data_stream.dataset == "kubeletstatsreceiver.otel"即可验证数据流是否正常写入。
调查:找出 noisy neighbor(噪声邻居)
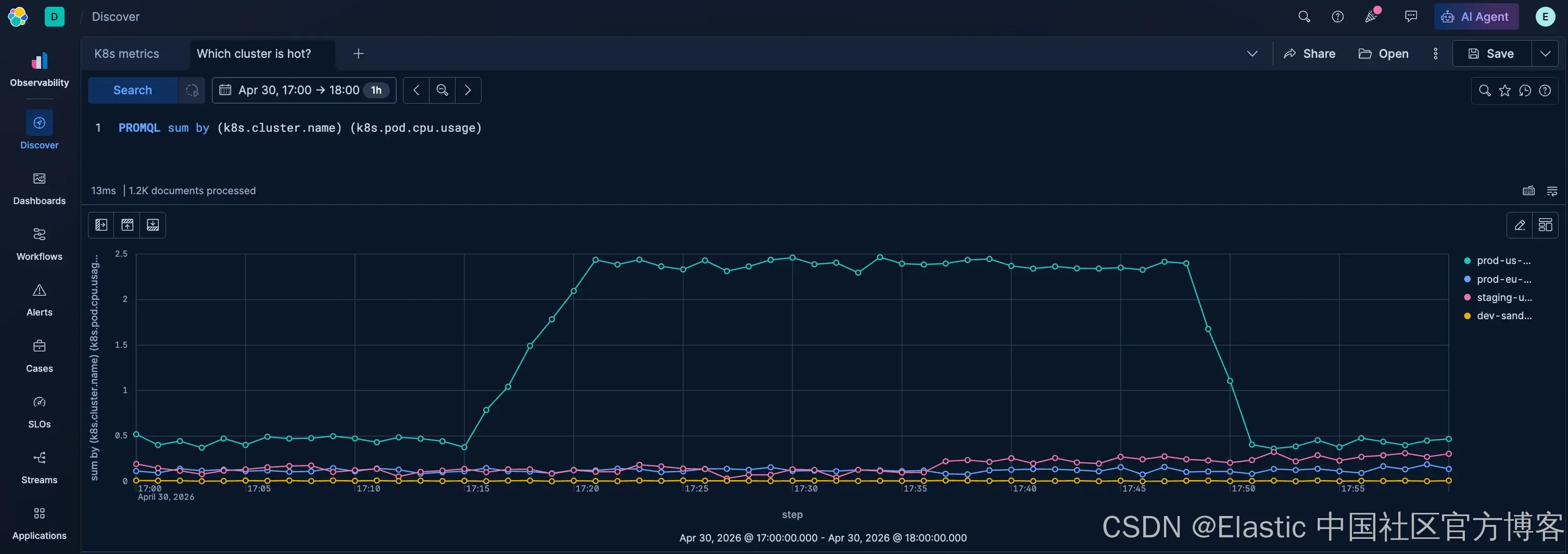
步骤 1:哪个 cluster 最"热"?
当你管理多个 Kubernetes 集群时,应先从 fleet 层级开始排查。
PROMQL sum by (k8s.cluster.name) (k8s.pod.cpu.usage)该查询会按 cluster 聚合所有 pod 的 CPU 使用量。
结果中,prod-us-east-1 立刻显现异常:其 pod 总 CPU 使用量比其他集群高出一个数量级。
而欧洲生产集群、staging,以及 dev-sandbox 都相对平稳。
现在你已经知道问题出在哪个 cluster,接下来该继续向下钻取。
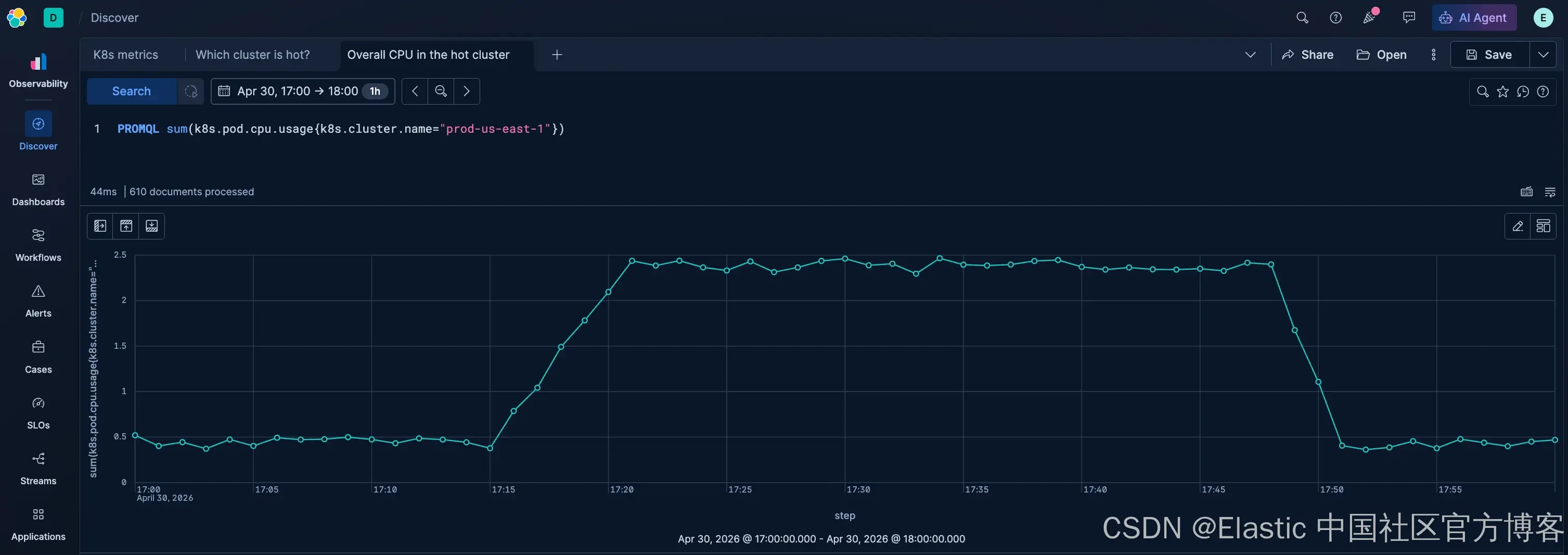
步骤 2:查看热点 cluster 的整体 CPU
先过滤到 prod-us-east-1,再观察整体 CPU 使用情况:
PROMQL sum(k8s.pod.cpu.usage{k8s.cluster.name="prod-us-east-1"})这会显示整个 cluster 中 pod CPU 使用量随时间变化的整体趋势。
如果总量持续上升或出现尖峰,说明某些 workload 发生了变化,但此时你还不知道具体是谁导致的。
步骤 3:按 namespace 拆分
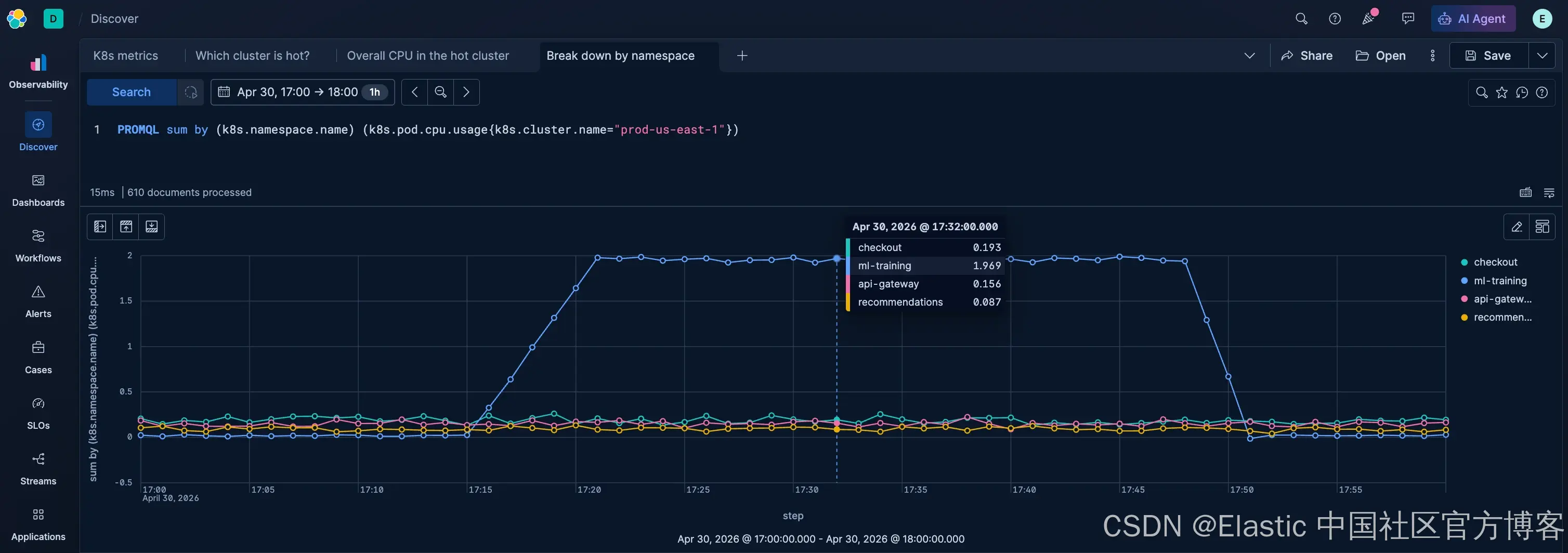
要最快定位"哪个团队在制造负载",最直接的方法就是按 namespace 进行分组分析。
PROMQL sum by (k8s.namespace.name) (k8s.pod.cpu.usage{k8s.cluster.name="prod-us-east-1"})设置 Kibana 的 time picker 覆盖你的 incident window。
ml-training 在 ~2.0 cores 时占主导,而其他每个 namespace 都远低于 0.2 cores。
步骤 4:下钻到 pod
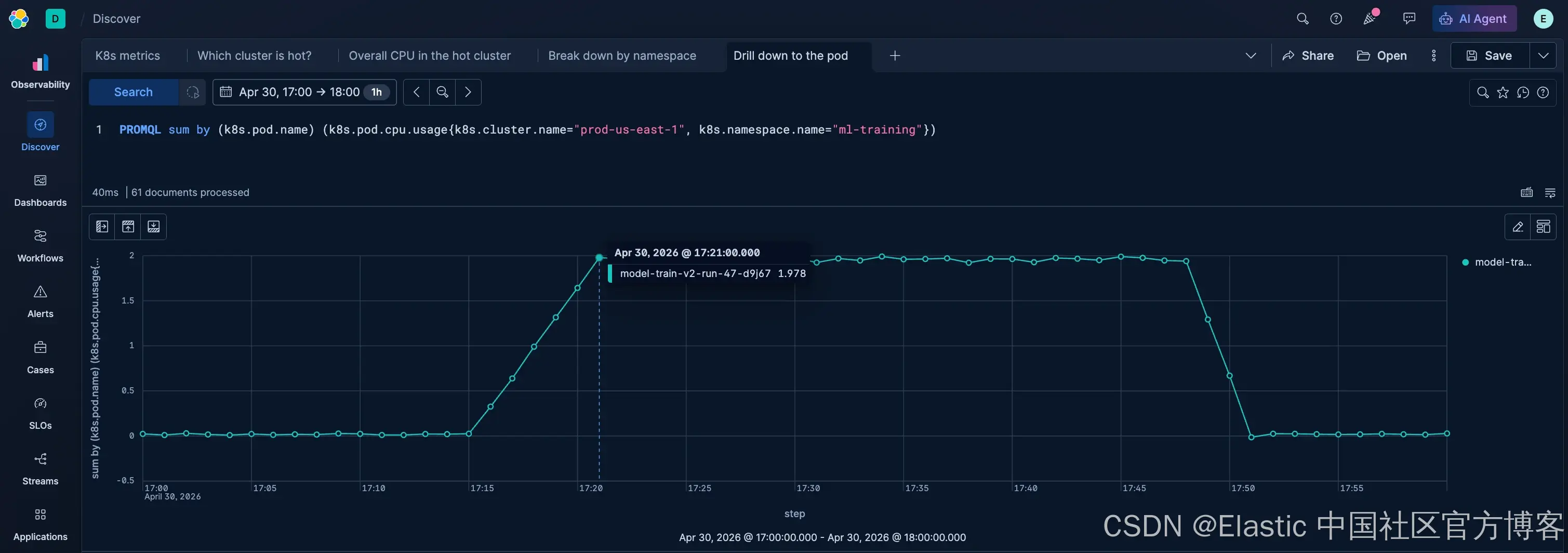
现在你已经知道 namespace,接下来定位具体的 pod:
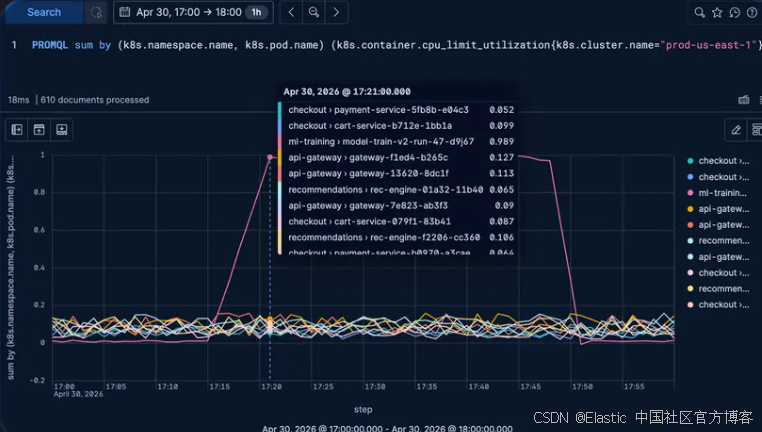
PROMQL sum by (k8s.pod.name) (k8s.pod.cpu.usage{k8s.cluster.name="prod-us-east-1", k8s.namespace.name="ml-training"})它会按该 namespace 内的 CPU 总使用量对 pod 进行排序。
这个图表应该能让异常值一目了然。
Pod model-train-v2-run-47-d9j67 正在消耗完整的 2.0 cores。它是一个训练任务,已经把分配的资源打满了。
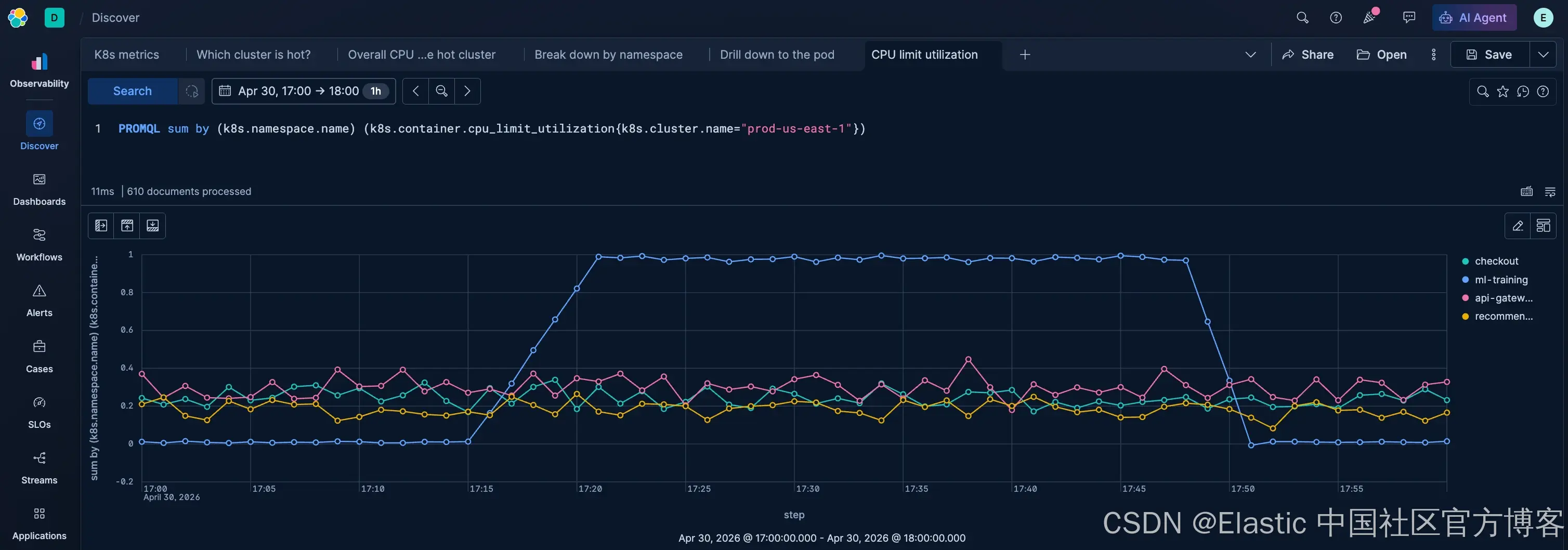
步骤 5:检查资源利用率比例
原始 CPU cores 只能告诉你用了多少,而利用率比例可以告诉你距离上限还有多近。
一个 pod 如果 CPU 利用率达到 100%,说明它正在被 throttling(限流),既是 noisy neighbor,同时也因为自身限制而受影响。
PROMQL sum by (k8s.namespace.name) (k8s.container.cpu_limit_utilization{k8s.cluster.name="prod-us-east-1"})ml-training 显示约 ~100% 的 CPU limit utilization(卡在 2-core 的上限),而其他 namespace 都低于 20%。
这进一步确认该训练任务已经耗尽其分配资源,并可能正在对共享节点造成调度压力。
接下来会发生什么
PromQL query 已经定位到嫌疑对象:训练任务 model-train-v2-run-47 在 ml-training 中。
从这里开始:
- 日志:在 Discover 中按 pod name 过滤,查看训练任务在做什么,以及是否记录了错误或警告。
- Kube events:检查同一时间窗口内是否有 OOMKilled、throttling 或 eviction 事件。
- 资源策略 :检查训练任务的 requests 和 limits 是否匹配实际使用情况。request 和 limit 之间的较大差距会让 pod 突破 scheduler 预期的资源规划。考虑在 namespace 上设置 ResourceQuota 或 LimitRange。
原文:https://www.elastic.co/observability-labs/blog/promql-investigate-kubernetes-infrastructure