LangGraph 是 LangChain 生态中专为构建复杂、有状态、支持循环迭代的 AI 工作流而设计的图编排框架,其核心突破在于通过有向循环图(DCG)结构替代传统线性链式流程,解决了多步骤推理、多智能体协作等场景中的动态流程控制问题。与 LangChain 的线性链式调用不同,LangGraph 原生支持条件分支、循环迭代和状态持久化,尤其适用于需要动态调整执行路径的复杂 AI 系统(如多智能体协作、需人工干预的高风险任务)
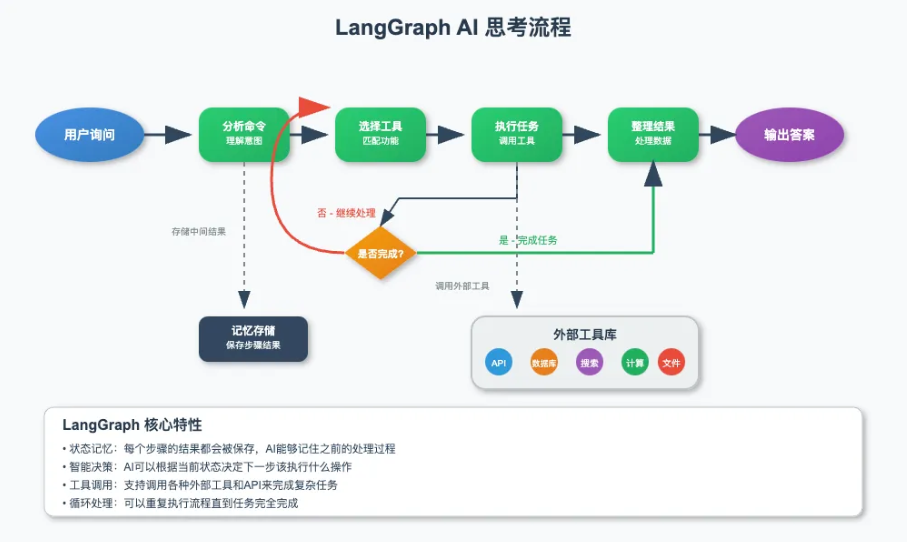
一 框架概述与设计哲学
1.1 核心定位
LangGraph 不是 RAG 框架,也不是 LLM 封装层,而是专注于Agent 编排与生命周期管理的底层框架。它不隐藏执行细节,让开发者完全掌控节点、边和状态的每一个环节。
1.2 五大设计原则
| 设计原则 | 说明 |
|---|---|
| 低级可控 | 不做黑盒抽象,开发者完全掌控执行流程 |
| 图即状态机 | 每个 super-step 都是一次状态快照,支持时间旅行 |
| 持久性优先 | Checkpointing 是一等公民,而非事后添加的功能 |
| 框架无关 | 不强依赖 LangChain,可独立使用任何 LLM SDK |
| 可组合性 | 图可以嵌套为子图,Graph API 与 Functional API 可混用 |
1.3 适用场景
- 多步骤 Agent 工作流(如 ReAct、Plan-and-Execute)
- 多智能体系统(Multi-Agent)
- 需要人工审核 / 干预的工作流
- 长运行、可恢复的任务
- 复杂的对话系统
二、核心概念与组件
2.1 State(状态)
State 是 LangGraph 的核心,它是一个共享数据结构,代表应用的当前快照。所有节点都从 State 读取输入,并将更新写入 State。
2.1.1 状态定义方式
LangGraph 支持三种状态定义方式:
python
# 方式1:TypedDict(推荐,性能最好)
from typing_extensions import TypedDict
from typing import Annotated, List
from operator import add
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[List, add_messages] # 使用内置消息reducer
count: int
results: Annotated[List[str], add] # 使用加法reducer
# 方式2:Pydantic BaseModel(支持运行时验证)
from pydantic import BaseModel
class State(BaseModel):
user_input: str
temperature: float = 0.7 # 支持默认值
# 方式3:dataclass(支持默认值)
from dataclasses import dataclass
@dataclass
class State:
user_input: str
temperature: float = 0.72.1.2 Reducers(归约器)
Reducers 控制如何将节点返回的更新应用到 State。每个状态键可以有独立的 reducer:
- 默认 reducer:覆盖原有值
- 加法 reducer :
operator.add,适用于列表追加 - 消息 reducer :
add_messages,专门处理消息列表,支持消息更新和序列化 - Overwrite:强制覆盖,绕过 reducer
python
from langgraph.types import Overwrite
def reset_node(state: State):
# 强制覆盖messages列表,绕过add_messages reducer
return {"messages": Overwrite([])}2.1.3 MessagesState(预构建状态)
由于消息列表在 LLM 应用中非常常见,LangGraph 提供了预构建的 MessagesState:
python
from langgraph.graph import MessagesState
class State(MessagesState):
# 继承了messages字段和add_messages reducer
extra_field: str2.2 Nodes(节点)
节点是执行实际工作的Python 函数(同步或异步)。它们接收当前 State 作为输入,返回 State 的更新。
2.2.1 节点函数签名
python
from langchain_core.runnables import RunnableConfig
from langgraph.runtime import Runtime
# 基础节点:只接收state
def basic_node(state: State) -> dict:
return {"count": state["count"] + 1}
# 带config的节点:访问thread_id等配置
def node_with_config(state: State, config: RunnableConfig) -> dict:
thread_id = config["configurable"]["thread_id"]
return {"results": [f"Processed in thread {thread_id}"]}
# 带runtime的节点:访问运行时上下文
def node_with_runtime(state: State, runtime: Runtime) -> dict:
# 可以访问store、stream_writer等
return {"results": ["Done"]}2.2.2 特殊节点
- START:图的入口点
- END:图的终止点
2.3 Edges(边)
边定义了节点之间的执行顺序。LangGraph 支持三种类型的边:
2.3.1 普通边(Normal Edges)
固定的执行顺序:
python
from langgraph.graph import START, END
graph.add_edge(START, "node1")
graph.add_edge("node1", "node2")
graph.add_edge("node2", END)2.3.2 条件边(Conditional Edges)
根据当前 State 动态决定下一个节点:
python
def should_continue(state: State) -> str:
if state["count"] < 5:
return "continue"
else:
return "end"
graph.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"end": END
}
)2.3.3 Send API(动态并行边)
用于实现 Map-Reduce 模式,动态生成多个并行任务:
python
from langgraph.types import Send
def map_node(state: State) -> list[Send]:
# 动态生成3个并行任务
return [
Send("worker", {"task": task})
for task in state["tasks"]
]
graph.add_conditional_edges("splitter", map_node)2.4 StateGraph(状态图)
StateGraph 是 LangGraph 的主类,用于构建和编译图:
python
from langgraph.graph import StateGraph
# 初始化图
builder = StateGraph(State)
# 添加节点
builder.add_node("node1", node1)
builder.add_node("node2", node2)
# 添加边
builder.add_edge(START, "node1")
builder.add_edge("node1", "node2")
builder.add_edge("node2", END)
# 编译图
graph = builder.compile()三、基础使用流程
3.1 安装
python
pip install -U langgraph
# 可选:安装检查点后端
pip install langgraph-checkpoint-sqlite # SQLite
pip install langgraph-checkpoint-redis # Redis
pip install langgraph-checkpoint-postgres # PostgreSQL3.2 完整示例:ReAct Agent
python
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from langchain_openai import ChatOpenAI
from langchain_community.tools.tavily_search import TavilySearchResults
# 1. 定义状态
class State(TypedDict):
messages: Annotated[list, add_messages]
# 2. 初始化工具和模型
tools = [TavilySearchResults(max_results=2)]
tool_node = ToolNode(tools)
model = ChatOpenAI(model="gpt-4o").bind_tools(tools)
# 3. 定义节点
def agent(state: State):
return {"messages": [model.invoke(state["messages"])]}
def should_continue(state: State):
last_message = state["messages"][-1]
if last_message.tool_calls:
return "tools"
return END
# 4. 构建图
builder = StateGraph(State)
builder.add_node("agent", agent)
builder.add_node("tools", tool_node)
builder.add_edge(START, "agent")
builder.add_conditional_edges("agent", should_continue)
builder.add_edge("tools", "agent")
# 5. 编译并运行
graph = builder.compile()
# 运行图
result = graph.invoke({
"messages": [{"role": "user", "content": "今天杭州的天气怎么样?"}]
})
# 打印结果
for message in result["messages"]:
message.pretty_print()3.3 图可视化
LangGraph 支持生成 Mermaid 图和 PNG 图:
python
from IPython.display import Image, display
# 生成Mermaid图
mermaid_graph = graph.get_graph().draw_mermaid()
# 生成并显示PNG图
display(Image(graph.get_graph().draw_mermaid_png()))四、高级功能详解
4.1 Send API 与 Map-Reduce 模式
Send API 允许在运行时动态生成多个并行任务,非常适合处理批量数据:
python
from typing import TypedDict, Annotated, List
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
import operator
# 状态定义
class State(TypedDict):
documents: List[str]
summaries: Annotated[List[str], operator.add]
final_summary: str
# Map阶段:为每个文档生成摘要
def map_summarize(state: State) -> List[Send]:
return [
Send("summarize_doc", {"document": doc})
for doc in state["documents"]
]
# Worker节点:处理单个文档
def summarize_doc(state: dict) -> dict:
# 这里调用LLM生成摘要
summary = f"Summary of: {state['document'][:20]}..."
return {"summaries": [summary]}
# Reduce阶段:合并所有摘要
def reduce_summarize(state: State) -> dict:
final_summary = "\n\n".join(state["summaries"])
return {"final_summary": final_summary}
# 构建图
builder = StateGraph(State)
builder.add_node("map_summarize", map_summarize)
builder.add_node("summarize_doc", summarize_doc)
builder.add_node("reduce_summarize", reduce_summarize)
builder.add_edge(START, "map_summarize")
builder.add_conditional_edges("map_summarize", lambda _: ["summarize_doc"])
builder.add_edge("summarize_doc", "reduce_summarize")
builder.add_edge("reduce_summarize", END)
graph = builder.compile()
# 运行
result = graph.invoke({
"documents": [
"Document 1 content...",
"Document 2 content...",
"Document 3 content..."
]
})
print(result["final_summary"])4.2 Command API
Command API 允许节点同时返回状态更新 和控制流指令,比条件边更灵活:
python
from langgraph.types import Command
from typing import Literal
def human_approval(state: State) -> Command[Literal["approved", "rejected"]]:
# 中断执行,等待人类输入
decision = interrupt({
"question": "Do you approve this action?",
"action": state["proposed_action"]
})
if decision == "approve":
return Command(
goto="approved",
update={"status": "approved"}
)
else:
return Command(
goto="rejected",
update={"status": "rejected"}
)4.3 Human-in-the-loop(人机协同)
LangGraph 提供了原生的人机协同支持,通过 interrupt() 函数暂停执行,等待人类输入后恢复:
4.3.1 基本使用
python
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import interrupt, Command
# 定义状态
class State(TypedDict):
input: str
output: str
approved: bool
# 定义节点
def generate_output(state: State) -> dict:
return {"output": f"Generated output for: {state['input']}"}
def human_review(state: State) -> Command:
# 中断执行,返回需要人类审核的内容
user_input = interrupt({
"output_to_review": state["output"],
"message": "Please review and approve or edit the output"
})
# 根据人类输入更新状态并决定下一步
if user_input.get("approved", False):
return Command(
goto="finalize",
update={"output": user_input.get("edited_output", state["output"])}
)
else:
return Command(goto="generate_output")
def finalize(state: State) -> dict:
return {"approved": True}
# 构建图
builder = StateGraph(State)
builder.add_node("generate_output", generate_output)
builder.add_node("human_review", human_review)
builder.add_node("finalize", finalize)
builder.add_edge(START, "generate_output")
builder.add_edge("generate_output", "human_review")
builder.add_edge("finalize", END)
# 编译时必须提供checkpointer
checkpointer = MemorySaver()
graph = builder.compile(checkpointer=checkpointer)
# 第一次运行:会在human_review节点中断
config = {"configurable": {"thread_id": "1"}}
result = graph.invoke({"input": "Hello World"}, config=config)
# 此时result会包含interrupts信息
print("Interrupts:", result.get("interrupts"))
# 恢复执行:提供人类输入
resume_result = graph.invoke(
Command(resume={"approved": True, "edited_output": "Edited output"}),
config=config
)
print("Final result:", resume_result)4.3.2 强制中断点
除了在节点内部调用 interrupt(),还可以在编译时指定强制中断点:
python
# 在执行"tools"节点前中断
graph = builder.compile(
checkpointer=checkpointer,
interrupt_before=["tools"]
)
# 在执行"agent"节点后中断
graph = builder.compile(
checkpointer=checkpointer,
interrupt_after=["agent"]
)4.4 Checkpointing 与持久化
Checkpointing 是 LangGraph 的核心功能之一,它允许:
- 保存和恢复图的状态
- 实现多轮对话记忆
- 支持错误恢复
- 实现时间旅行(Time Travel)
4.4.1 检查点后端
LangGraph 支持多种检查点后端:
python
# 内存后端(开发测试用)
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
# SQLite后端(本地部署用)
from langgraph.checkpoint.sqlite import SqliteSaver
checkpointer = SqliteSaver.from_conn_string("checkpoints.db")
# Redis后端(生产部署用)
from langgraph.checkpoint.redis import RedisSaver
checkpointer = RedisSaver.from_conn_string("redis://localhost:6379/0")
# PostgreSQL后端(生产部署用)
from langgraph.checkpoint.postgres import PostgresSaver
checkpointer = PostgresSaver.from_conn_string("postgresql://user:pass@localhost/db")4.4.2 状态管理
python
# 获取当前状态
snapshot = graph.get_state(config)
print("Current state:", snapshot.values)
print("Next nodes:", snapshot.next)
# 获取历史检查点
history = list(graph.get_state_history(config))
for checkpoint in history:
print(f"Step {checkpoint.metadata['step']}: {checkpoint.values}")
# 回滚到之前的检查点
graph.update_state(
config,
values={}, # 可以更新状态
as_of=history[1].config # 指定要回滚到的检查点
)4.5 流式输出
LangGraph 支持多种流式输出模式,提供实时反馈:
| 流模式 | 描述 |
|---|---|
values |
每个步骤后流式传输完整状态 |
updates |
每个步骤后只流式传输状态更新 |
messages |
流式传输 LLM 令牌和工具调用 |
custom |
从节点内部流式传输自定义数据 |
debug |
流式传输所有调试信息 |
python
# 流式输出完整状态
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "Hello"}]},
config=config,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
# 流式输出状态更新
for node_name, update in graph.stream(
{"messages": [{"role": "user", "content": "Hello"}]},
config=config,
stream_mode="updates"
):
print(f"Node {node_name} updated: {update}")
# 流式输出LLM令牌
for token, metadata in graph.stream(
{"messages": [{"role": "user", "content": "Hello"}]},
config=config,
stream_mode="messages"
):
print(token.content, end="", flush=True)4.6 子图与可组合性
LangGraph 支持将图嵌套为子图,实现模块化设计:
python
# 定义子图
sub_builder = StateGraph(SubState)
sub_builder.add_node("sub_node1", sub_node1)
sub_builder.add_node("sub_node2", sub_node2)
sub_builder.add_edge(START, "sub_node1")
sub_builder.add_edge("sub_node1", "sub_node2")
sub_builder.add_edge("sub_node2", END)
subgraph = sub_builder.compile()
# 在主图中使用子图
main_builder = StateGraph(MainState)
main_builder.add_node("subgraph", subgraph)
main_builder.add_node("main_node", main_node)
main_builder.add_edge(START, "subgraph")
main_builder.add_edge("subgraph", "main_node")
main_builder.add_edge("main_node", END)
main_graph = main_builder.compile()五、常见 Agent 模式
5.1 ReAct 模式
最基础的 Agent 模式,"思考 - 行动 - 观察" 循环:
python
START → Agent → [工具调用? → Tools → Agent] → END5.2 Plan-and-Execute 模式
先制定计划,再逐步执行:
python
START → Planner → Executor → [还有步骤? → Executor] → Finalizer → END5.3 Supervisor 模式
一个 Supervisor Agent 管理多个 Worker Agent:
python
START → Supervisor → [分配任务给Worker] → Worker1/Worker2/Worker3 → Supervisor → [完成? → END]5.4 多轮对话模式
结合 Checkpointing 实现多轮对话:
python
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.checkpoint.memory import MemorySaver
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
def chatbot(state: MessagesState):
return {"messages": [model.invoke(state["messages"])]}
builder = StateGraph(MessagesState)
builder.add_node("chatbot", chatbot)
builder.add_edge(START, "chatbot")
builder.add_edge("chatbot", END)
checkpointer = MemorySaver()
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
# 第一轮对话
graph.invoke({"messages": [{"role": "user", "content": "我叫张三"}]}, config=config)
# 第二轮对话(自动记住上下文)
result = graph.invoke({"messages": [{"role": "user", "content": "我叫什么名字?"}]}, config=config)
result["messages"][-1].pretty_print() # 会回答"你叫张三"六、生产部署与最佳实践
6.1 性能优化
- 使用
TypedDict而非 Pydantic 作为状态(性能更好) - 合理设置递归限制(默认 25):
graph.compile(recursion_limit=100) - 使用 Redis 作为检查点后端(高并发场景)
- 启用节点缓存:
graph.compile(cache=True)
6.2 错误处理
- 在节点内部添加 try-except 块
- 使用重试策略:
python
from langgraph.retry import RetryPolicy
retry_policy = RetryPolicy(max_attempts=3)
builder.add_node("flaky_node", flaky_node, retry=retry_policy)6.3 可观测性
- 集成 LangSmith 进行追踪和调试
- 使用
stream_mode="debug"获取详细执行信息 - 记录检查点历史用于事后分析
6.4 部署选项
- LangGraph Platform:官方托管平台,提供自动扩展和监控
- FastAPI + Uvicorn:自定义 API 服务
- Docker + Kubernetes:容器化部署
七、v1.1.10 最新特性
- 改进的 Redis 检查点:v0.1.0 版本重构,性能提升 10 倍以上
- 增强的 Command API:支持更复杂的控制流指令
- 更好的类型安全:改进了类型提示和运行时验证
- 优化的流式输出:支持同时使用多种流模式
- 改进的子图支持:更好的状态传递和错误处理
八、总结
LangGraph 是目前构建生产级 AI Agent 的最佳框架之一。它的核心优势在于:
- 完全可控:开发者可以精确控制 Agent 的每一步执行
- 生产就绪:提供持久化、容错、人工干预等企业级功能
- 灵活可扩展:支持多种 Agent 模式和复杂工作流
- 活跃社区:持续更新,生态系统丰富
对于需要构建复杂、可靠、可扩展的 AI Agent 系统的开发者来说,LangGraph 是一个不可或缺的工具
九 生产级多 Agent 系统
这是一个基于Supervisor-Worker 架构的生产级多 Agent 系统,完全符合 LangGraph 1.1.10 最新规范。包含工具调用、人工审核、Redis 持久化、错误重试、日志记录、任务跟踪等企业级功能
用户输入 → 主管Agent → 任务分解 → 研究Agent/写作Agent/代码Agent → 人工审核 → 结果汇总 → 输出
9.1 代码
python
import os
import logging
from typing import TypedDict, Annotated, List, Literal
from enum import Enum
from dotenv import load_dotenv
from operator import add
# LangGraph核心导入
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command, interrupt
from langgraph.checkpoint.redis import RedisSaver
from langgraph.retry import RetryPolicy
from langgraph.prebuilt import ToolNode
# LangChain导入
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.tools import PythonREPLTool
# ======================
# 配置与日志
# ======================
load_dotenv()
# 日志配置
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger("multi-agent-system")
# 环境变量检查
REQUIRED_ENV_VARS = ["OPENAI_API_KEY", "TAVILY_API_KEY", "REDIS_URL"]
for var in REQUIRED_ENV_VARS:
if not os.getenv(var):
raise ValueError(f"环境变量 {var} 未设置")
# ======================
# 状态定义
# ======================
class TaskStatus(str, Enum):
PENDING = "pending"
IN_PROGRESS = "in_progress"
COMPLETED = "completed"
FAILED = "failed"
APPROVED = "approved"
REJECTED = "rejected"
class Task(TypedDict):
task_id: str
task_type: Literal["research", "writing", "coding"]
description: str
status: TaskStatus
result: str
assigned_to: str
class State(TypedDict):
# 用户输入
user_query: str
# 任务管理
tasks: Annotated[List[Task], add]
current_task_index: int
# 消息历史
messages: Annotated[List[BaseMessage], add]
# 最终结果
final_output: str
# 系统状态
error: str
progress: float
# ======================
# 工具初始化
# ======================
# 网络搜索工具
search_tool = TavilySearchResults(max_results=3)
# Python代码执行工具(沙箱环境)
python_repl = PythonREPLTool()
# 工具节点
tools = [search_tool, python_repl]
tool_node = ToolNode(tools)
# LLM模型初始化
supervisor_llm = ChatOpenAI(model="gpt-4o", temperature=0.2)
research_llm = ChatOpenAI(model="gpt-4o", temperature=0.1)
writing_llm = ChatOpenAI(model="gpt-4o", temperature=0.7)
coding_llm = ChatOpenAI(model="gpt-4o", temperature=0.0)
# 绑定工具
research_llm_with_tools = research_llm.bind_tools([search_tool])
coding_llm_with_tools = coding_llm.bind_tools([python_repl])
# ======================
# 重试策略
# ======================
default_retry_policy = RetryPolicy(
max_attempts=3,
backoff_factor=2,
retry_exceptions=[Exception]
)
# ======================
# 节点定义
# ======================
def supervisor_node(state: State, config: RunnableConfig) -> Command:
"""主管Agent:负责任务分解、分配和进度跟踪"""
logger.info(f"主管Agent开始处理查询: {state['user_query']}")
# 如果是第一次运行,分解任务
if not state.get("tasks"):
prompt = f"""
请将用户的查询分解为最多3个具体任务,任务类型只能是:research(研究)、writing(写作)、coding(编码)。
用户查询:{state['user_query']}
请以JSON格式返回,格式如下:
{{
"tasks": [
{{
"task_id": "task_1",
"task_type": "research",
"description": "详细描述任务内容"
}}
]
}}
"""
response = supervisor_llm.invoke(prompt)
import json
try:
task_data = json.loads(response.content)
tasks = task_data["tasks"]
for task in tasks:
task["status"] = TaskStatus.PENDING
task["result"] = ""
task["assigned_to"] = ""
except Exception as e:
logger.error(f"任务分解失败: {e}")
return Command(
goto=END,
update={"error": f"任务分解失败: {str(e)}"}
)
return Command(
update={
"tasks": tasks,
"current_task_index": 0,
"messages": [AIMessage(content="我已将您的查询分解为以下任务:\n" +
"\n".join([f"- {t['task_type']}: {t['description']}" for t in tasks]))]
},
goto="assign_task"
)
# 检查所有任务是否完成
all_completed = all(task["status"] == TaskStatus.APPROVED for task in state["tasks"])
if all_completed:
return Command(goto="finalize")
# 检查是否有任务失败
failed_tasks = [task for task in state["tasks"] if task["status"] == TaskStatus.FAILED]
if failed_tasks:
return Command(
goto=END,
update={"error": f"以下任务执行失败:{', '.join([t['task_id'] for t in failed_tasks])}"}
)
# 继续下一个任务
current_index = state["current_task_index"]
if current_index < len(state["tasks"]):
return Command(goto="assign_task")
return Command(goto="finalize")
def assign_task_node(state: State) -> Command:
"""任务分配节点"""
current_index = state["current_task_index"]
current_task = state["tasks"][current_index]
logger.info(f"分配任务: {current_task['task_id']} - {current_task['task_type']}")
# 更新任务状态
current_task["status"] = TaskStatus.IN_PROGRESS
# 根据任务类型分配给对应的Agent
if current_task["task_type"] == "research":
return Command(
update={"tasks": state["tasks"]},
goto="research_agent"
)
elif current_task["task_type"] == "writing":
return Command(
update={"tasks": state["tasks"]},
goto="writing_agent"
)
elif current_task["task_type"] == "coding":
return Command(
update={"tasks": state["tasks"]},
goto="coding_agent"
)
else:
current_task["status"] = TaskStatus.FAILED
current_task["result"] = f"不支持的任务类型: {current_task['task_type']}"
return Command(
update={"tasks": state["tasks"]},
goto="supervisor"
)
def research_agent_node(state: State) -> Command:
"""研究Agent:负责网络搜索和信息收集"""
current_index = state["current_task_index"]
current_task = state["tasks"][current_index]
logger.info(f"研究Agent执行任务: {current_task['task_id']}")
messages = [
HumanMessage(content=f"请完成以下研究任务:{current_task['description']}\n"
f"使用搜索工具获取最新、最准确的信息。")
]
response = research_llm_with_tools.invoke(messages)
if response.tool_calls:
# 需要调用工具
return Command(
update={
"messages": [response],
"current_task_index": current_index
},
goto="tools"
)
else:
# 直接返回结果
current_task["status"] = TaskStatus.COMPLETED
current_task["result"] = response.content
return Command(
update={
"tasks": state["tasks"],
"messages": [response]
},
goto="human_review"
)
def writing_agent_node(state: State) -> Command:
"""写作Agent:负责生成内容"""
current_index = state["current_task_index"]
current_task = state["tasks"][current_index]
logger.info(f"写作Agent执行任务: {current_task['task_id']}")
# 收集之前任务的结果作为上下文
context = "\n\n".join([
f"任务 {t['task_id']} 结果:\n{t['result']}"
for t in state["tasks"][:current_index]
if t["status"] == TaskStatus.APPROVED
])
prompt = f"""
请完成以下写作任务:{current_task['description']}
上下文信息:
{context}
请生成高质量、结构清晰的内容。
"""
response = writing_llm.invoke(prompt)
current_task["status"] = TaskStatus.COMPLETED
current_task["result"] = response.content
return Command(
update={
"tasks": state["tasks"],
"messages": [response]
},
goto="human_review"
)
def coding_agent_node(state: State) -> Command:
"""代码Agent:负责编写和执行代码"""
current_index = state["current_task_index"]
current_task = state["tasks"][current_index]
logger.info(f"代码Agent执行任务: {current_task['task_id']}")
messages = [
HumanMessage(content=f"请完成以下编码任务:{current_task['description']}\n"
f"编写清晰、可运行的Python代码。如果需要执行代码验证结果,请使用PythonREPL工具。")
]
response = coding_llm_with_tools.invoke(messages)
if response.tool_calls:
# 需要调用工具执行代码
return Command(
update={
"messages": [response],
"current_task_index": current_index
},
goto="tools"
)
else:
# 直接返回代码
current_task["status"] = TaskStatus.COMPLETED
current_task["result"] = response.content
return Command(
update={
"tasks": state["tasks"],
"messages": [response]
},
goto="human_review"
)
def tool_result_handler(state: State) -> Command:
"""工具结果处理节点"""
current_index = state["current_task_index"]
current_task = state["tasks"][current_index]
last_message = state["messages"][-1]
# 根据任务类型调用对应的LLM处理工具结果
if current_task["task_type"] == "research":
response = research_llm_with_tools.invoke(state["messages"])
elif current_task["task_type"] == "coding":
response = coding_llm_with_tools.invoke(state["messages"])
else:
response = supervisor_llm.invoke(state["messages"])
if response.tool_calls:
# 还需要继续调用工具
return Command(
update={"messages": [response]},
goto="tools"
)
else:
# 工具调用完成,返回结果
current_task["status"] = TaskStatus.COMPLETED
current_task["result"] = response.content
return Command(
update={
"tasks": state["tasks"],
"messages": [response]
},
goto="human_review"
)
def human_review_node(state: State) -> Command:
"""人工审核节点:关键步骤必须经过人类确认"""
current_index = state["current_task_index"]
current_task = state["tasks"][current_index]
logger.info(f"等待人工审核任务: {current_task['task_id']}")
# 中断执行,等待人类输入
review_result = interrupt({
"task_id": current_task["task_id"],
"task_type": current_task["task_type"],
"task_description": current_task["description"],
"task_result": current_task["result"],
"message": "请审核以下任务结果,选择'approve'批准或'reject'拒绝并提供修改意见"
})
if review_result.get("decision") == "approve":
current_task["status"] = TaskStatus.APPROVED
current_task["result"] = review_result.get("edited_result", current_task["result"])
return Command(
update={
"tasks": state["tasks"],
"current_task_index": current_index + 1,
"progress": (current_index + 1) / len(state["tasks"]) * 100
},
goto="supervisor"
)
else:
current_task["status"] = TaskStatus.PENDING
current_task["result"] = ""
feedback = review_result.get("feedback", "请重新执行任务")
return Command(
update={
"tasks": state["tasks"],
"messages": [HumanMessage(content=f"人工审核不通过,反馈意见:{feedback}")]
},
goto="assign_task"
)
def finalize_node(state: State) -> Command:
"""结果汇总节点"""
logger.info("开始汇总最终结果")
# 收集所有已批准的任务结果
task_results = "\n\n".join([
f"## 任务 {t['task_id']}:{t['description']}\n{t['result']}"
for t in state["tasks"]
if t["status"] == TaskStatus.APPROVED
])
# 生成最终输出
prompt = f"""
请根据以下所有任务的结果,生成一个完整、连贯的最终回答:
用户原始查询:{state['user_query']}
任务结果:
{task_results}
请确保最终回答结构清晰、逻辑严谨、内容全面。
"""
final_response = supervisor_llm.invoke(prompt)
return Command(
update={
"final_output": final_response.content,
"messages": [final_response],
"progress": 100.0
},
goto=END
)
# ======================
# 图构建与编译
# ======================
def build_multi_agent_graph():
"""构建多Agent系统图"""
builder = StateGraph(State)
# 添加节点
builder.add_node("supervisor", supervisor_node, retry=default_retry_policy)
builder.add_node("assign_task", assign_task_node, retry=default_retry_policy)
builder.add_node("research_agent", research_agent_node, retry=default_retry_policy)
builder.add_node("writing_agent", writing_agent_node, retry=default_retry_policy)
builder.add_node("coding_agent", coding_agent_node, retry=default_retry_policy)
builder.add_node("tools", tool_node, retry=default_retry_policy)
builder.add_node("tool_result_handler", tool_result_handler, retry=default_retry_policy)
builder.add_node("human_review", human_review_node)
builder.add_node("finalize", finalize_node, retry=default_retry_policy)
# 添加边
builder.add_edge(START, "supervisor")
builder.add_edge("assign_task", "supervisor")
builder.add_edge("research_agent", "supervisor")
builder.add_edge("writing_agent", "supervisor")
builder.add_edge("coding_agent", "supervisor")
builder.add_edge("tools", "tool_result_handler")
builder.add_edge("tool_result_handler", "supervisor")
builder.add_edge("human_review", "supervisor")
builder.add_edge("finalize", END)
# Redis持久化
redis_checkpointer = RedisSaver.from_conn_string(os.getenv("REDIS_URL"))
# 编译图
graph = builder.compile(
checkpointer=redis_checkpointer,
recursion_limit=100,
interrupt_before=["human_review"] # 也可以在这里强制设置中断点
)
return graph
# ======================
# 使用示例
# ======================
if __name__ == "__main__":
# 构建图
graph = build_multi_agent_graph()
# 生成唯一的线程ID(每个用户会话一个)
import uuid
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
print(f"会话ID: {thread_id}")
print("="*50)
# 用户查询
user_query = "帮我研究一下LangGraph的最新特性,然后写一篇500字左右的介绍文章,最后写一个简单的Hello World示例代码"
# 第一次运行
print("系统正在处理您的查询...")
result = graph.invoke(
{"user_query": user_query},
config=config,
stream_mode="values"
)
# 检查是否需要人工审核
while True:
snapshot = graph.get_state(config)
if "interrupts" in snapshot.metadata:
# 有中断,需要人工输入
interrupt_data = snapshot.metadata["interrupts"][0]["value"]
print("\n" + "="*50)
print("需要人工审核")
print(f"任务ID: {interrupt_data['task_id']}")
print(f"任务类型: {interrupt_data['task_type']}")
print(f"任务描述: {interrupt_data['task_description']}")
print("\n任务结果:")
print(interrupt_data['task_result'])
print("\n" + "="*50)
# 模拟人工输入
decision = input("请输入审核结果 (approve/reject): ").strip().lower()
if decision == "approve":
resume_data = {"decision": "approve"}
else:
feedback = input("请输入修改意见: ").strip()
resume_data = {"decision": "reject", "feedback": feedback}
# 恢复执行
print("\n继续执行...")
result = graph.invoke(
Command(resume=resume_data),
config=config,
stream_mode="values"
)
else:
# 执行完成
break
# 输出最终结果
print("\n" + "="*50)
print("最终结果:")
print(result["final_output"])
print("="*50)
# 查看会话历史
print("\n会话历史:")
history = list(graph.get_state_history(config))
for i, checkpoint in enumerate(reversed(history)):
print(f"\n步骤 {i}:")
print(f"进度: {checkpoint.values.get('progress', 0)}%")
if checkpoint.values.get('messages'):
last_message = checkpoint.values['messages'][-1]
print(f"最后消息: {last_message.content[:100]}...")9.2 特性详解
9.2.1 Redis 持久化
- 使用
RedisSaver作为检查点后端,支持高并发和分布式部署 - 每个会话通过唯一的
thread_id隔离 - 自动保存所有状态快照,支持随时恢复和回滚
- 支持查看完整的会话历史和执行轨迹
9.2.2 人工审核机制
- 在
human_review节点自动中断执行 - 向人类展示任务详情和结果
- 支持批准、拒绝并提供修改意见
- 支持编辑结果后再批准
- 审核不通过时自动重新执行任务
9.2.3 工具调用
- 集成 Tavily 网络搜索工具,获取最新信息
- 集成 PythonREPL 工具,安全执行代码
- 支持多轮工具调用
- 自动处理工具结果并生成最终回答
9.2.4 错误处理与重试
- 为所有节点配置了默认重试策略
- 最多重试 3 次,指数退避
- 自动记录错误信息
- 任务失败时优雅终止并提示用户
9.2.5 任务管理
- 自动将复杂查询分解为多个子任务
- 跟踪每个任务的状态和进度
- 支持任务依赖和上下文传递
- 动态分配任务给最合适的 Agent
9.3 部署与扩展
9.3.1 创建.env文件:
python
OPENAI_API_KEY=your_openai_api_key
TAVILY_API_KEY=your_tavily_api_key
REDIS_URL=redis://localhost:6379/09.3.2扩展新的 Agent 类型
- 定义新的任务类型
- 创建对应的 Agent 节点函数
- 在
assign_task_node中添加任务分配逻辑 - 如有需要,添加新的工具
9.3.3 部署为 API 服务
python
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
app = FastAPI()
graph = build_multi_agent_graph()
class QueryRequest(BaseModel):
user_query: str
thread_id: str = None
class ResumeRequest(BaseModel):
thread_id: str
decision: str
feedback: str = None
edited_result: str = None
@app.post("/query")
async def create_query(request: QueryRequest):
thread_id = request.thread_id or str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
try:
result = graph.invoke(
{"user_query": request.user_query},
config=config
)
snapshot = graph.get_state(config)
if "interrupts" in snapshot.metadata:
return {
"thread_id": thread_id,
"status": "interrupted",
"interrupt_data": snapshot.metadata["interrupts"][0]["value"]
}
else:
return {
"thread_id": thread_id,
"status": "completed",
"final_output": result["final_output"]
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/resume")
async def resume_query(request: ResumeRequest):
config = {"configurable": {"thread_id": request.thread_id}}
try:
resume_data = {
"decision": request.decision,
"feedback": request.feedback,
"edited_result": request.edited_result
}
result = graph.invoke(
Command(resume=resume_data),
config=config
)
snapshot = graph.get_state(config)
if "interrupts" in snapshot.metadata:
return {
"status": "interrupted",
"interrupt_data": snapshot.metadata["interrupts"][0]["value"]
}
else:
return {
"status": "completed",
"final_output": result["final_output"]
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))