博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:Python语言、Django框架、Echarts可视化、requests爬虫、HTML、MySQL数据库
功能模块:
- 药材产地占比饼图分析
- 词云图分析
- 药材价格柱状图分析
- 药材成分分析
- 历史价格分析
- 后台数据管理
- 注册登录
- 数据采集
项目介绍:本系统针对中药材领域的数据分散、行情分析困难等问题,设计了一套完整的药材数据可视化与分析方案。系统基于Python语言和Django框架构建后端,采用MySQL数据库存储药材信息,前端使用HTML结合Echarts实现多样化的图表展示。通过requests爬虫从中药材天地网采集药材产地、价格、新闻资讯等数据,经过清洗后存入数据库。系统提供产地占比饼图、价格柱状图、历史价格折线图、词云图、成分极坐标图等可视化模块,帮助用户直观了解药材市场分布与价格波动趋势。同时后台管理模块支持药方信息的搜索、新增、删除和导出,注册登录功能保障系统访问安全。
2、项目界面
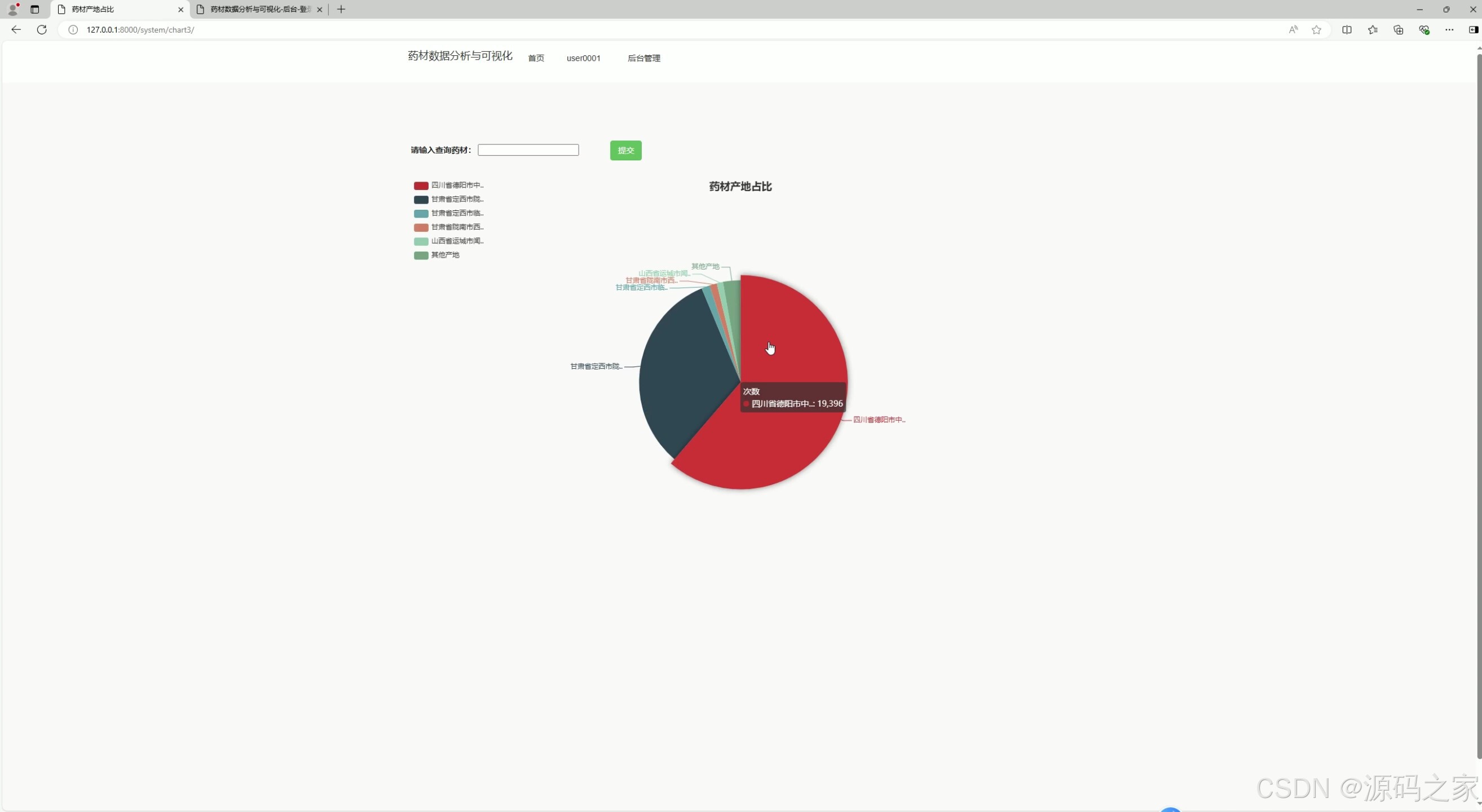
(1)药材产地占比饼图分析
该页面为药材数据分析系统的产地分布可视化模块,提供药材查询输入框与提交功能,通过饼图直观展示不同产地的药材占比情况,帮助用户了解药材的产地分布特征。
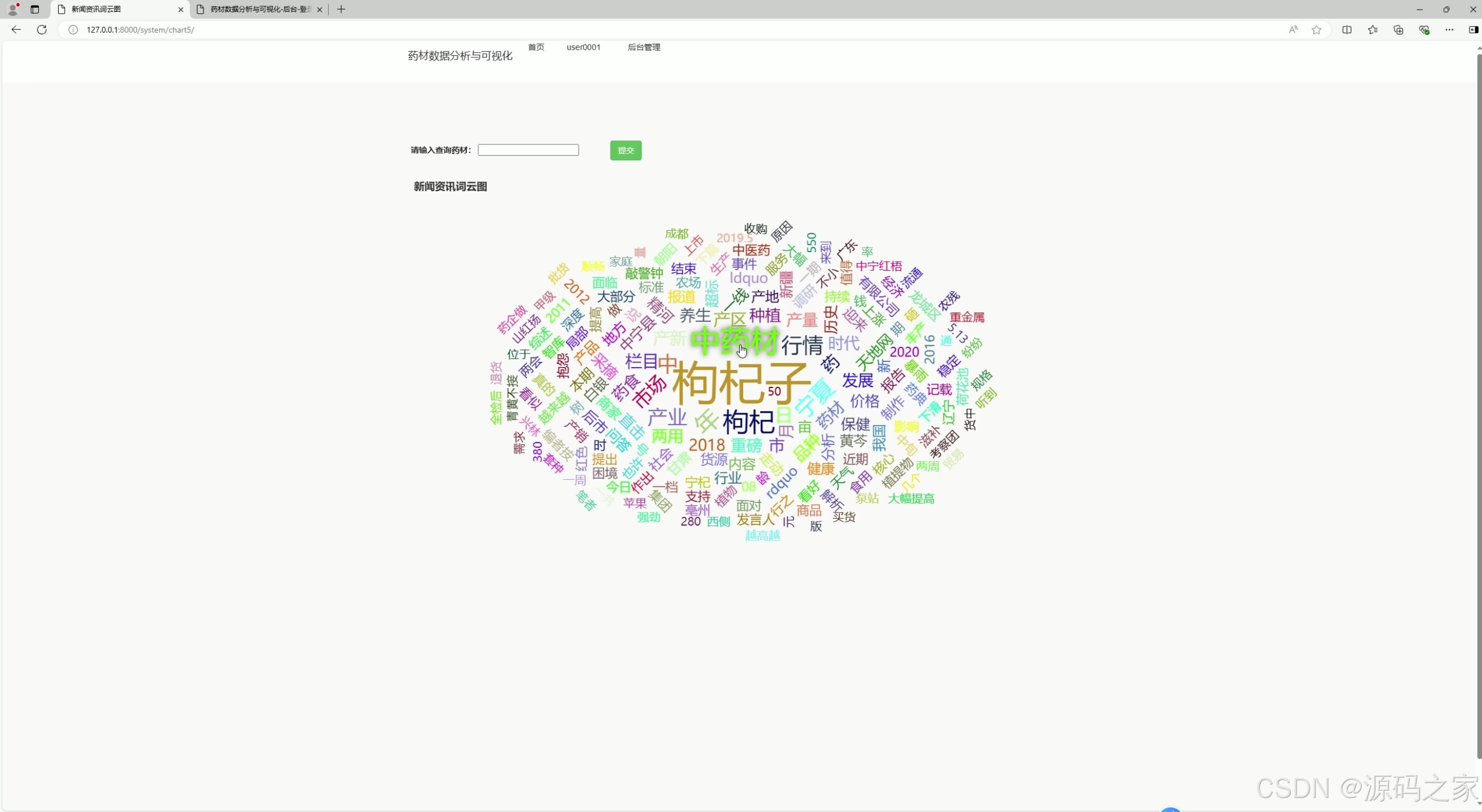
(2)词云图分析
该页面是药材数据分析系统的新闻资讯词云图模块,用户可输入药材名称查询,系统会生成词云图,直观展示相关新闻资讯中的高频关键词,帮助快速了解药材相关资讯热点与行业动态。
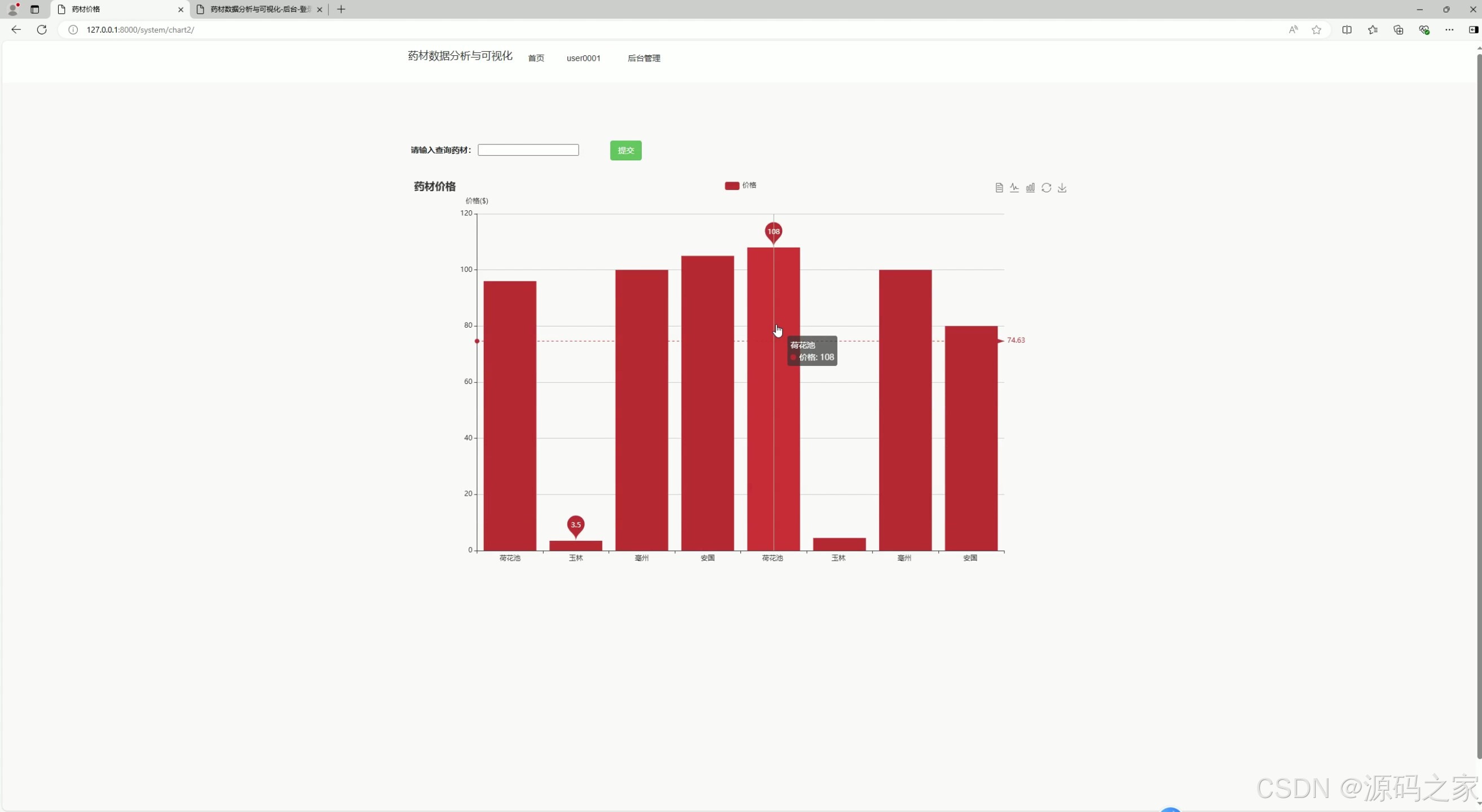
(3)药材价格柱状图分析
该页面为药材数据分析系统的价格可视化模块,用户可输入药材名称查询,系统会生成柱状图,直观展示不同市场的药材价格分布情况,帮助对比不同产地市场的价格差异。
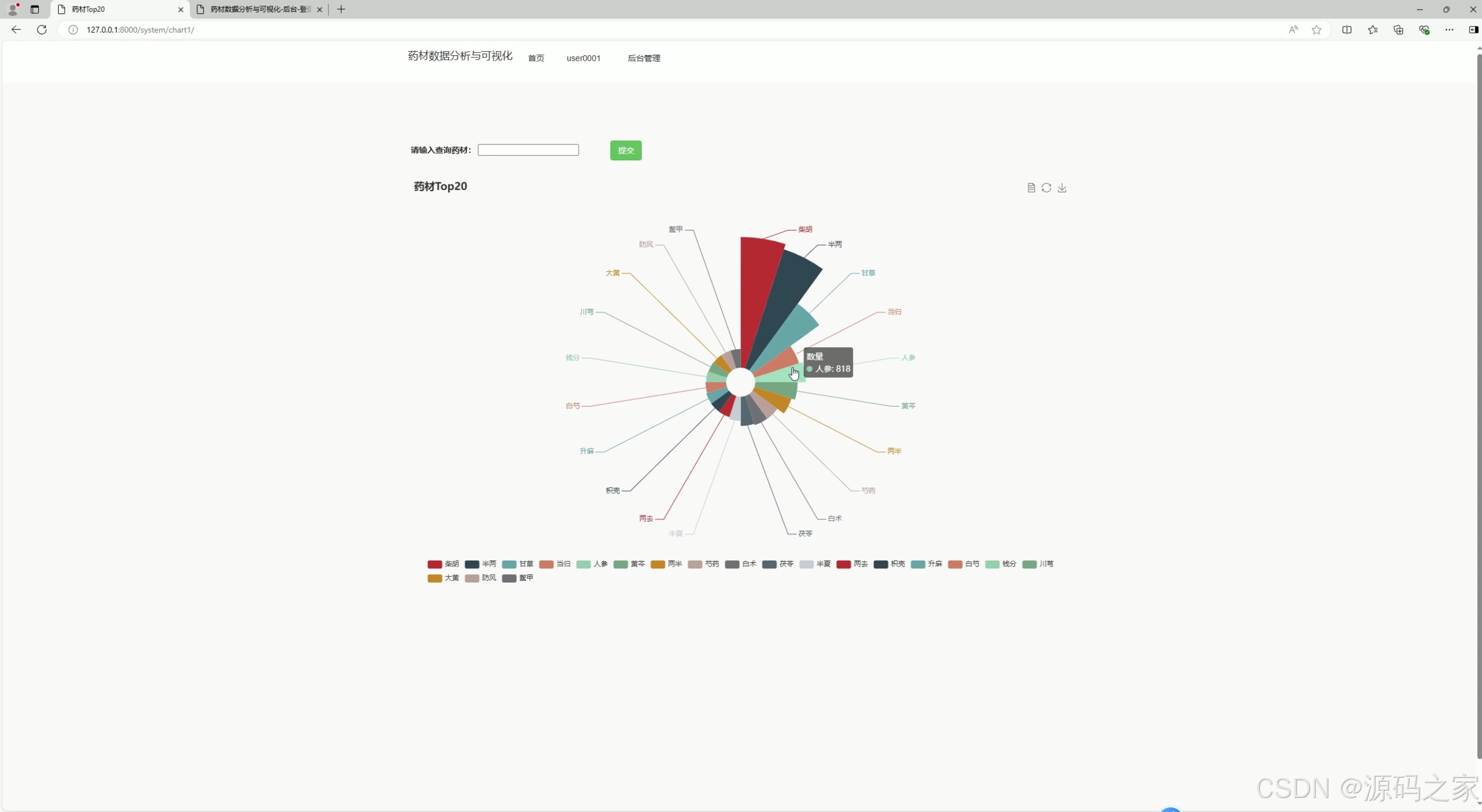
(4)药材成分分析
该页面是药材数据分析系统的热门药材分布模块,用户可输入药材名称查询,通过极坐标图直观展示不同药材的数量占比,清晰呈现热门药材的分布情况,帮助快速了解市场上主要药材的热度与占比差异。
(5)历史价格分析
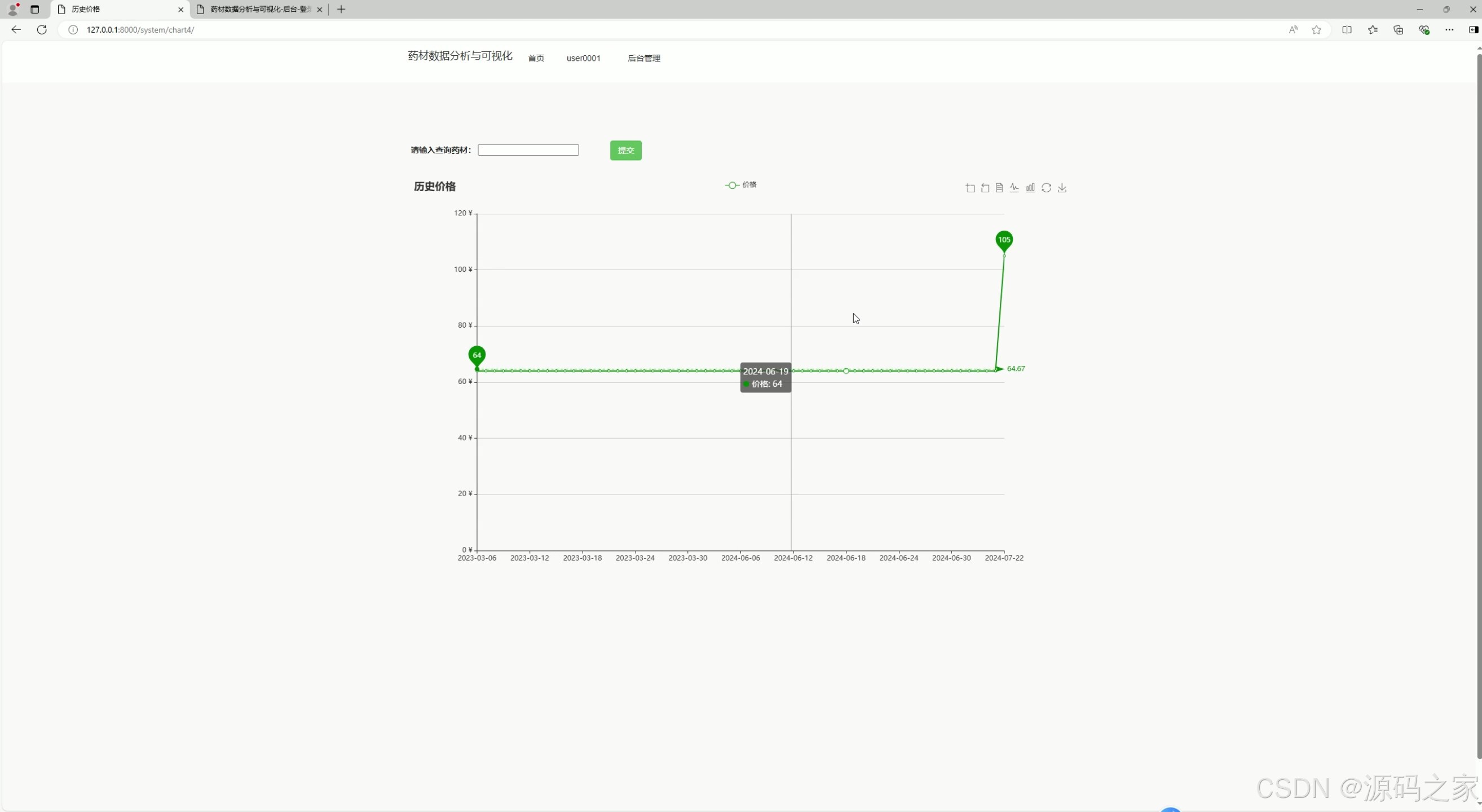
该页面是药材数据分析系统的历史价格趋势模块,用户可输入药材名称查询,通过折线图直观展示药材价格随时间的变化走势,帮助了解价格波动情况,为市场分析提供数据参考。
(6)后台数据管理
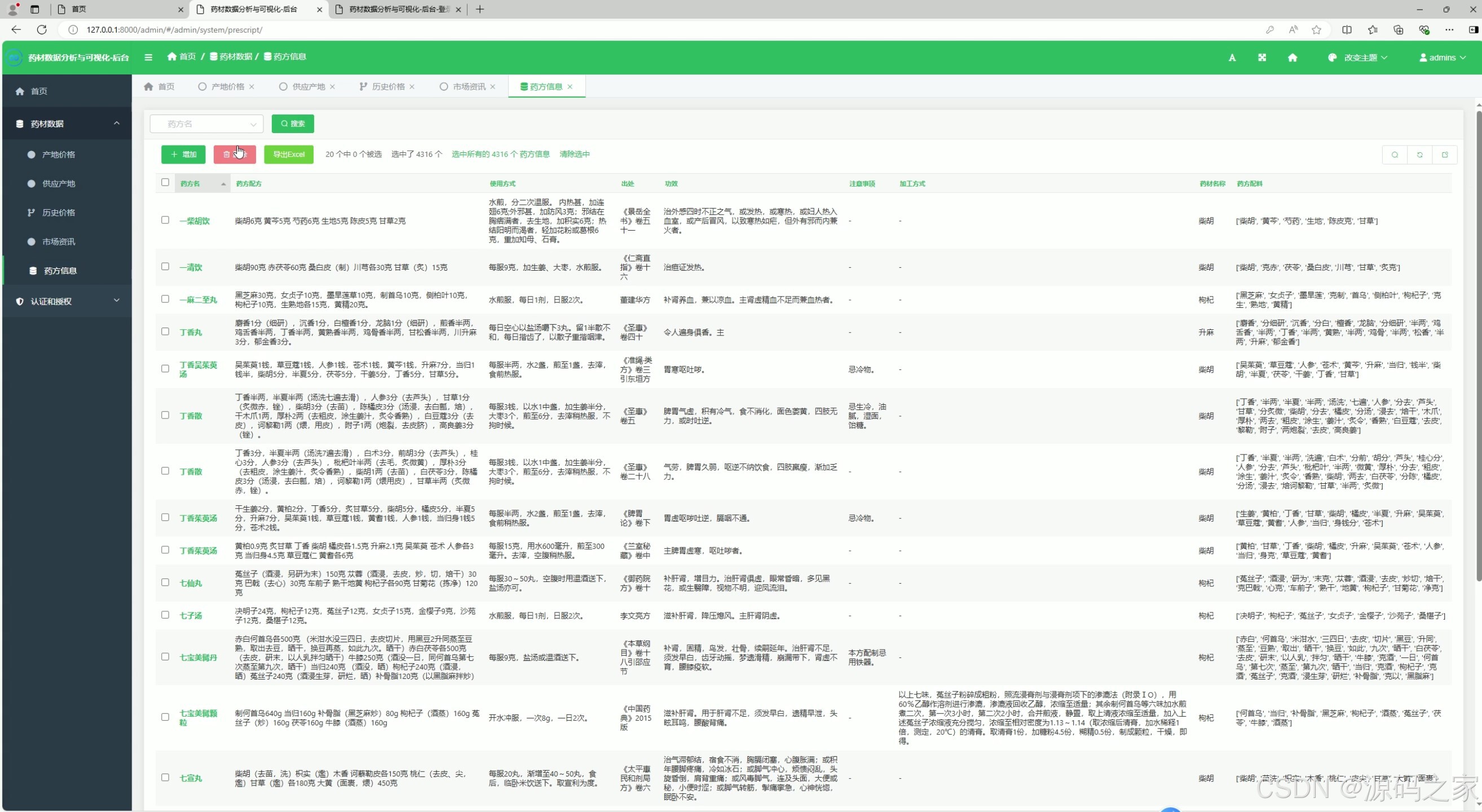
该后台管理页面是药材数据分析系统的药方信息维护模块,以表格形式集中展示药方的基本信息、使用方式、功效、药材组成等内容,支持搜索、新增、删除和导出操作,实现药方数据的统一管理。
(7)注册登录
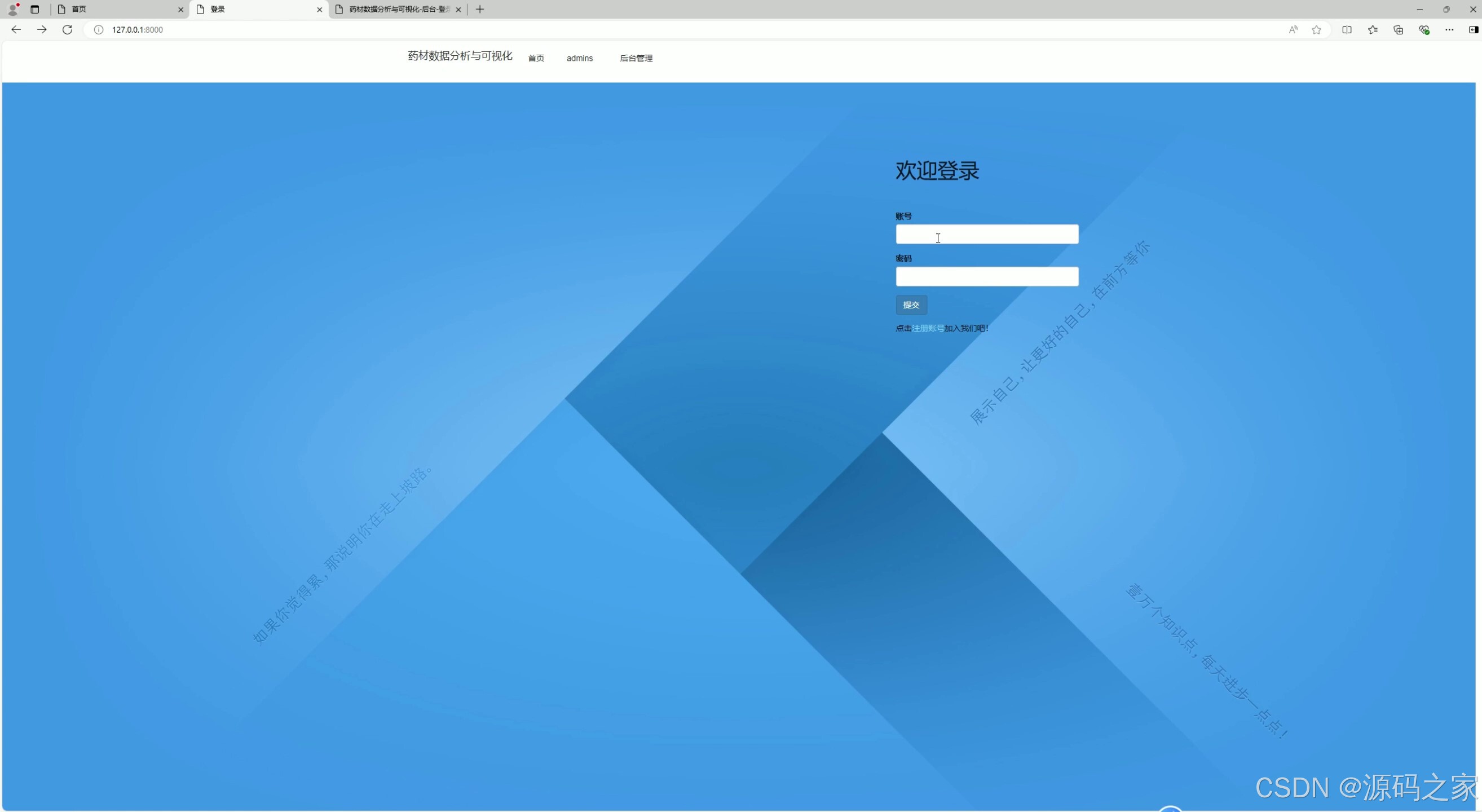
该页面是药材数据分析与可视化系统的登录界面,提供账号和密码输入框及提交按钮,支持用户输入账号密码登录系统,同时设有注册账号入口,完成身份验证以访问系统的数据分析与管理功能。
(8)数据采集
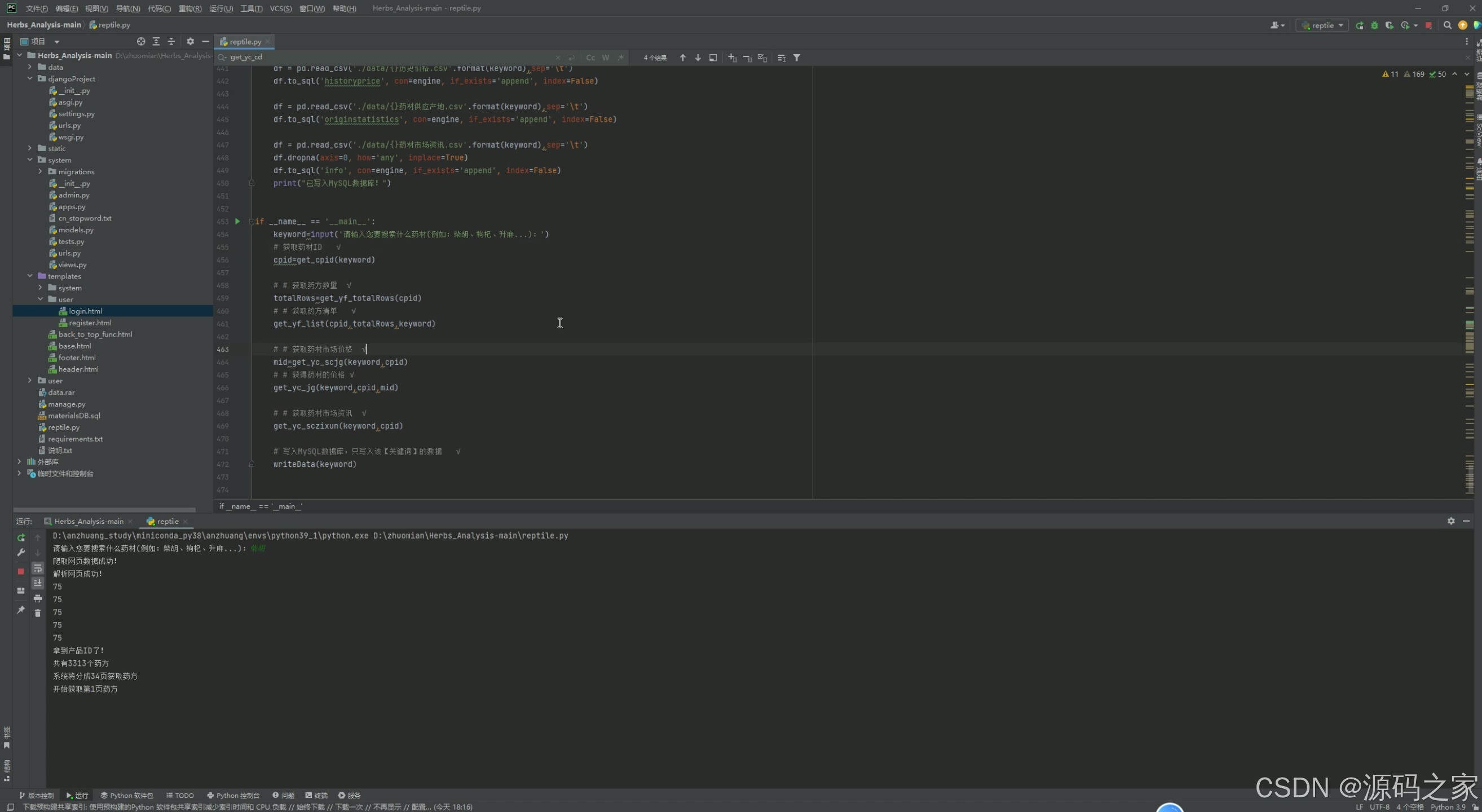
该代码编辑界面展示了药材数据分析系统的后端爬虫与数据处理模块,通过Python脚本实现药材数据的爬取、清洗与入库功能,支持药材关键词查询,可将价格、供应地、资讯等数据写入数据库,为前端可视化分析提供数据支撑。
3、项目说明
一、技术栈简要说明
本系统后端采用Python语言进行业务逻辑处理与爬虫开发,搭配Django框架构建完整的Web应用架构。数据库选用MySQL存储药材信息、药方数据及用户信息。前端使用HTML进行页面布局,结合Echarts图表库实现多样化的数据可视化展示。数据采集模块基于requests库开发爬虫程序,从第三方药材网站获取产地、价格、新闻资讯等数据。
二、功能模块详细介绍
- 药材产地占比饼图分析
该模块提供药材查询输入框与提交功能,用户输入药材名称后,系统以饼图形式展示不同产地的药材数量占比。通过直观的扇形区域对比,帮助用户快速了解特定药材的主要产地分布特征及各产地的市场贡献比例。
- 词云图分析
该模块为新闻资讯词云图展示页面,用户输入药材名称后,系统爬取相关新闻报道与行业资讯,提取高频关键词并生成词云图。关键词字体越大表示出现频率越高,帮助用户快速掌握该药材相关的资讯热点与行业动态。
- 药材价格柱状图分析
该模块用于展示药材在不同市场中的价格分布。用户输入药材名称后,系统生成柱状图,横轴为不同产地市场,纵轴为价格,通过柱体高度直观对比各市场的价格差异,为用户采购决策提供数据参考。
- 药材成分分析
该模块通过极坐标图展示热门药材的数量占比情况。用户输入药材名称后,系统分析相关数据,以极坐标图形式呈现不同药材的分布比例,帮助用户清晰了解市场上主要药材的热度差异与占比结构。
- 历史价格分析
该模块以折线图形式展示药材价格随时间的变化走势。用户输入药材名称后,系统调取该药材在不同时间点的历史价格数据,绘制价格波动曲线,帮助用户分析价格涨跌规律,为市场预测提供依据。
- 后台数据管理
该模块为药方信息维护页面,以表格形式集中展示药方的基本信息、使用方式、功效及药材组成等内容。管理员可通过搜索功能快速定位目标药方,支持新增药方、删除药方以及导出数据操作,实现对药方信息的统一管理。
- 注册登录
该模块为系统的身份验证入口,提供账号和密码输入框及提交按钮。新用户可通过注册入口创建账号,已有用户输入正确凭证后登录系统,获得访问各数据分析与管理功能的权限,保障系统使用的安全性与用户隔离。
- 数据采集
该模块通过Python爬虫脚本实现药材数据的自动采集、清洗与入库。爬虫基于requests库发送HTTP请求,从中药材天地网等来源获取药材价格、供应地、新闻资讯等原始数据,经过解析处理后写入MySQL数据库,为前端各可视化模块提供实时、准确的数据支撑。
三、项目总结
本系统针对中药材行业数据分散、行情分析效率低的问题,设计并实现了一套完整的数据可视化与分析解决方案。系统整合了爬虫采集、数据存储、可视化展示与后台管理四大环节,覆盖了从数据获取到分析呈现的全流程。通过产地占比饼图、价格柱状图、历史价格折线图、词云图、成分极坐标图等多种可视化图表,帮助用户直观了解药材产地分布、市场价格对比、价格波动趋势及行业资讯热点。后台管理模块实现了药方数据的集中维护,注册登录功能保障了系统访问安全。整体而言,系统为中药材行业的市场分析、价格监测与数据管理提供了高效的工具支持。
4、核心代码
python
import requests
from bs4 import BeautifulSoup
import re
import jieba
import pandas as pd
import time
import collections
import pymysql
from sqlalchemy import create_engine
#爬虫获取产品ID
def get_cpid (keyword):
url=f'http://www.zyctd.com/Search/Index?keyword={keyword}'
#获取网页数据
res=requests.get(url)
#编码
res.encoding = 'utf-8'
#解析网页数据
# print(res.text)
print("爬取网页数据成功!")
soup = BeautifulSoup(res.text, 'lxml')
print("解析网页成功!")
#通过正则表达式返回要的数据
# reg=re.compile('(?<=gongxiao).*?(?=.html)')
# print("正则表达式提取数据成功!")
# print(reg)
# 找到所有class为'cloud-data'的<a>标签
links = soup.find_all('a', class_='cloud-data')
for link in links:
href = link['href']
match = re.search(r'id=(\d+)', href)
if match:
cpid=match.group(1)
print(cpid) # 输出: 75
#对返回值进行数据提取。拿到产品ID
# cpid = reg.findall(str(soup.find('li','hover')))[0]
print("拿到产品ID了!")
# print(f"产品ID为:{cpid}")
return cpid
def get_yf_fun(cpid,ys=0):
# 药方: https://www.zyctd.com/data/zzjf.html?id=75
# 请求地址
url = 'https://www.zyctd.com/api/data-service/api/v1/product/getTcmPrescriptionPage'
# 设置tcmid=cpid,设置药方数量每次为100个,
j = {"init": 0, "tcmId": cpid, "nameAndIndications": '', "years": "0",
"pageRequest": {"pageNumber": ys+1, "pageSize": 100}}
# 得到链接的内容
res = requests.post(url, json=j, headers=headers)
# 编码
res.encoding = 'utf-8'
# 将返回值转化为元组,方便提取
return eval(res.text)
def get_yf_totalRows(cpid):
result=get_yf_fun(cpid,1)
if result['code']==0:
totalRows=result['data']['totalRows']
print(f"共有{totalRows}个药方")
return totalRows
else:
print('获取药方数量失败')
# 获取药方清单
def get_yf_list(cpid,totalRows,keyword):
datas = {
'uid': [],
'name': [],
'recipe': [],
'dosage': [],
'excerpt': [],
'indications': [],
'note': [],
'processing':[],
'tcmName': [],
'recipe_pz': [],
}
counts = {}
print(f"系统将分成{totalRows // 100 + 1}页获取药方")
# 去除一些语气词和没有意义的词
del_words = ['的', ' ', '克', '两', 'g', '千克', '钱', '斤','毫升','浸一宿','两钱','各克']
# 除100(每次取100个药方)向下取整然后+1,遍历所有药方清单
for row_i in range(totalRows // 100 + 1):
print(f'开始获取第{row_i+1}页药方')
result=get_yf_fun(cpid,row_i)
for res in result['data']['pageContent']:
if ('克' in res['recipe']) or ('g' in res['recipe']) or('钱' in res['recipe']) or('斤' in res['recipe'])or('两' in res['recipe']):
datas['uid'].append(res['id'])
datas['dosage'].append(res['dosage'])
datas['excerpt'].append(res['excerpt'])
datas['indications'].append(res['indications'])
datas['name'].append(res['name'])
datas['note'].append(res['note'])
datas['processing'].append(res['processing'])
datas['recipe'].append(res['recipe'])
datas['tcmName'].append(res['tcmName'])
# 对药方进行处理
# 去掉标点符号
all_quotes = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+------!,;:。?、~@#¥%......&*()]+", "", res['recipe'])
# 结巴分词自动切割,得到每个药方有什么药材
words = jieba.lcut(all_quotes)
words_final = []
# 如果词不在即将去除的内容中,就添加
for word in words:
if word not in del_words and len(word)>1:
words_final.append(word)
counts[word] = counts.get(word, 0) + 1
datas['recipe_pz'].append(words_final)
#把药方药材存到excel
pd_datas=pd.DataFrame(datas)
pd_datas.to_excel(f'./data/{keyword}药方.xlsx',index=None)
print(f"经过排除后,共获取到{len(datas['uid'])}个药方")
# # 获取药材市场价格
def get_yc_scjg(keyword,cpid):
url=f'https://www.zyctd.com/jh{cpid}.html'
# 根据要求构造请求头文件
# 得到链接的内容
res = requests.get(url, headers=headers)
# 编码
res.encoding = 'utf-8'
# 解码
soup = BeautifulSoup(res.text, 'lxml')
# print(soup)
tbody_s = soup.find('table', class_='full center price').find('tbody').find_all('tr') # 寻找 zixun-item 类型的类
# tbody_s = soup.find('table', class_='tableBase').find('tbody').find_all('tr') # 寻找 zixun-item 类型的类 #原始代码
print("已经拿到了tbody_s")
print(tbody_s)
cd_s=[] #产地
jg_s=[] #价格
for tbody in tbody_s:
td_s=tbody.find_all('td')
cd=td_s[1].text
jg=td_s[2].text.replace('¥','')
cd_s.append(cd)
jg_s.append(float(jg))
# 保存 产地价格
with open("./data/{}产地价格.csv".format(keyword),'w+',encoding='utf-8') as fp:
fp.write("keyword\torigin\tprice\n")
for idx in range(len(cd_s)):
fp.write(keyword+'\t'+cd_s[idx]+"\t"+str(jg_s[idx])+"\n")
# 获取历史价格 (取 产地价格 最后一行数据作为"历史价格")
print("获取历史价格开始--------------")
mid = jg_s[-1] # 使用-1作为索引来获取列表的最后一个元素
# print(jg_s)
# mid = jg_s
print(mid)
#原始代码: 通过正则表达式返回要的数据
# reg=re.compile('(?<=historyPriceMID = parseInt\(\").*?(?=\"\);)')
# mid = reg.findall(str(soup))[0]
#这个mid在获取历史价格的时候需要
return mid
from datetime import datetime
# 如果你只想要日期部分(格式化的字符串)
formatted_updateTime_date_only = datetime.now().strftime('%Y-%m-%d')
print(formatted_updateTime_date_only)
keyword=ycmc
updateTime=formatted_updateTime_date_only
price=mid
print(keyword,updateTime,price)
# 使用with语句打开文件,确保正确关闭,并且以追加模式打开
with open('./data/{}历史价格.csv'.format(keyword), 'a', encoding='utf-8', newline='') as fp:
# 写入一行数据,每个字段之间用制表符(\t)分隔
fp.write("{}\t{}\t{}\n".format(keyword, updateTime, price))
# with open('./data/{}历史价格.csv'.format(keyword),'w+',encoding='utf-8') as fp:
# fp.write("keyword\tupdateTime\tprice\n")
# # 写入数据行,注意每个字段之间用制表符(\t)分隔
# fp.write("{}\t{}\t{}\n".format(keyword, updateTime, price))
# for idx in range(len(x)):
# fp.write(keyword+'\t'+x[idx]+'\t'+str(y[idx])+'\n')
#
def get_yc_cd_url(cpid,ys):
url=f'https://www.zyctd.com/gqgy/{cpid}-0-p{ys}.html'
print(f'正在获取第{ys}页药材供应内容数据')
# 根据要求构造请求头文件
# 得到链接的内容
res = requests.get(url, headers=headers)
# 编码
res.encoding = 'utf-8'
return res.text
#获得药材产地
def get_yc_cd(keyword,cpid):
# url : get_yc_cd_url函数 url=f'https://www.zyctd.com/gqgy/{cpid}-0-p{ys}.html' ys是页数
sl_s=[]
kcd_s=[]
cd_s=[]
#获取前10页药材供应内容。每页10个产品
for i in range(10):
res_data=get_yc_cd_url(cpid,i+1)
# 解码
soup = BeautifulSoup(res_data, 'lxml')
div_name_list = soup.find_all('div', class_='supply_list') # 寻找 supply_list 类型的类
for div_name in div_name_list:
#数量
sl=div_name.find_all('li')[1].find('span').text
#排除供应数量少于吨的
if '吨' not in sl:
continue
sl_s.append(sl.replace('吨',''))
#库存地
kcd=div_name.find_all('li')[2].find('span').text
kcd_s.append(kcd)
#产地
cd=div_name.find_all('li')[3].find('span').text
cd_s.append(cd)
#准备数据
cd_arr=[]
cd_cd_sl_arr=[]
for cd_s_i in range(len(cd_s)):
cd_sl=0
for cd_s_j in range(cd_s_i+1,len(cd_s)):
if cd_s[cd_s_i] not in cd_arr and cd_s[cd_s_i]==cd_s[cd_s_j]:
cd_sl+=int(sl_s[cd_s_j])
if cd_s[cd_s_i] not in cd_arr:
cd_arr.append(cd_s[cd_s_i])
cd_sl+=int(sl_s[cd_s_i])
cd_cd_sl_arr.append((cd_s[cd_s_i],cd_sl))
result_sort = sorted(cd_cd_sl_arr, key=lambda x: x[1], reverse=True) # 排序
result_sort = collections.OrderedDict(result_sort)
othervalue = 0
for i in range(5, len(cd_cd_sl_arr)):
othervalue += list(result_sort.values())[i]
values = []
labels = []
for i in range(5):
values.append(list(result_sort.values())[i])
labels.append(list(result_sort.keys())[i])
values.append(othervalue)
labels.append('其他产地')
print(keyword,labels,values)
with open('./data/{}药材供应产地.csv'.format(keyword),'w+',encoding='utf-8') as fp:
fp.write("keyword\torigin\tcount\n")
for idx in range(len(values)):
fp.write(keyword+'\t'+labels[idx]+'\t'+str(values[idx])+'\n')
def get_yc_sczixun_url(cpid,ys):
url = f'https://www.zyctd.com/zixun/202/pz{cpid}-{ys}.html'
print(f'正在获取第{ys}页数据')
# 根据要求构造请求头文件
# 得到链接的内容
res = requests.get(url, headers=headers)
# 编码
res.encoding = 'utf-8'
return res.text
print(res.text)
# 市场资讯
def get_yc_sczixun(keyword,cpid):
# 爬取:get_yc_sczixun_url函数 https://www.zyctd.com/zixun/202/pz{cpid}-{ys}.html
# 例如: https://www.zyctd.com/zixun/202/pz75-1.html
zx_title=[]
zx_content=[]
#获取前3页药材市场资讯。每页10个资讯
for i in range(3):
# print("调用get_yc_sczixun_url开始")
res_data=get_yc_sczixun_url(cpid,i+1)
print("调用get_yc_sczixun_url结束")
# 解码
soup = BeautifulSoup(res_data, 'lxml')
print("解码完成")
# print(soup)
# 定位<div class="zixun-list">的内容(但这里我们通常只是用它来定位,不直接用它的内容)
# 遍历所有<div class="zixun-item-box">元素(因为它们是包含所需信息的容器)
item_boxes = soup.find_all('div', class_='zixun-item-box')
# 提取每个item-box的标题和内容
for item_box in item_boxes:
# 提取标题
title = item_box.find('div', class_='zixun-item-title').find('span').text.strip()
# 提取描述
content = item_box.find('div', class_='zixun-item-desc').find('div', class_='lay3').find('p').text.strip()
# 打印结果
print(f"标题: {title}")
print(f"描述: {content}\n")
zx_title.append(title)
zx_content.append(content)
# print(zx_title,zx_content)
print("已完成:获取前3页药材市场资讯")
print("---------------------------------------------------")
with open('./data/{}药材市场资讯.csv'.format(keyword),'w+',encoding='utf-8') as fp:
fp.write("keyword\ttitle\tcontent\n")
for i in range(len(zx_title)):
title = zx_title[i]
content = zx_content[i]
print(title,type(title))
print(content,type(content))
if not title:
continue
elif not content:
continue
elif len(content) < 50:
continue
elif "BORDER-BOTTOM" in content:
continue
elif "spanstyle" in content:
continue
else:
s = keyword+'\t'+title+'\t'+content+'\n'
if len(s) < 50:
continue
else:
fp.write(s)
print("---------------------------------------------------")
print("药材市场资讯已写入.csv文件!")
def writeData(keyword):
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/materialsDB?charset=utf8")
df = pd.read_excel('./data/{}药方.xlsx'.format(keyword))
df.to_sql('prescript', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}产地价格.csv'.format(keyword),sep='\t')
df.to_sql('originprice', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}历史价格.csv'.format(keyword),sep='\t')
df.to_sql('historyprice', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}药材供应产地.csv'.format(keyword),sep='\t')
df.to_sql('originstatistics', con=engine, if_exists='append', index=False)
df = pd.read_csv('./data/{}药材市场资讯.csv'.format(keyword),sep='\t')
df.dropna(axis=0, how='any', inplace=True)
df.to_sql('info', con=engine, if_exists='append', index=False)
print("已写入MySQL数据库!")
if __name__ == '__main__':
keyword=input('请输入您要搜索什么药材(例如:柴胡、枸杞、升麻...):')
# 获取药材ID √
cpid=get_cpid(keyword)
# # 获取药方数量 √
totalRows=get_yf_totalRows(cpid)
# # 获取药方清单 √
get_yf_list(cpid,totalRows,keyword)
# # 获取药材市场价格 √
mid=get_yc_scjg(keyword,cpid)
# # 获得药材的价格 √
get_yc_jg(keyword,cpid,mid)
# # 获取药材市场资讯 √
get_yc_sczixun(keyword,cpid)
# 写入MySQL数据库,只写入该【关键词】的数据 √
writeData(keyword)