自然语言处理(NLP)与循环神经网络
自然语言处理(Natural Language Processing, NLP)是人工智能领域中最具挑战性也最迷人的分支之一。它不仅是实现机器智能的象征,更是人类通往真正人工智能的必经之路。
一.欢迎来到NLP的世界!
1.是智能的象征,也是通往智能之路
语言是人类文明的载体,也是思维的工具。能够理解和生成自然语言,被认为是衡量机器是否具有"智能"的核心标准。从早期的规则匹配到如今的深度学习,NLP的发展史就是人工智能寻求理解人类逻辑的过程。
2.大模型引发行业剧变
随着Transformer架构和大规模预训练模型(如GPT系列)的出现,NLP领域经历了翻天覆地的变化。"大模型"通过海量数据学习到了通用的语言表征,使得曾经需要针对特定任务精调的小模型逐渐被多才多艺的通用智能体所取代。
3.NLP领域的危险与机遇
- 危险:传统基于小规模数据集的调优技术、分词器优化等底层技术岗位的需求正在缩减,模型黑盒化带来的伦理与安全风险也日益增加。
- 机遇:对大模型底层架构(如算子优化、推理加速)的研究,以及如何将大模型应用于垂直领域(RAG、智能Agent),成为了当前最前沿的研发方向。
二.自然语言领域中的数据
1.深度学习中的时间序列数据
自然语言领域的核心数据是序列数据,这是一种在样本与样本之间存在特定顺序、且这种特定顺序不能被轻易修改的数据。
- 非序列数据:如图像数据,虽然像素之间有空间关联,但通常被视为独立的张量处理。
- 序列数据:如股价、气温、音频。在这种数据中,当前状态往往深受历史状态的影响。
时间序列数据是指在不同时间点上收集到的序列,其样本之间存在显著的前后依赖关系。
序列数据的概念很容易理解,但奇妙的是,现实中的序列数据可以是二、三、四、五任意维度,只要给原始的数据加上"时间顺序"或"位置顺序",任意数据都可以化身为序列数据。在这里,我们展现几种常见的序列数据:
单变量时间序列数据
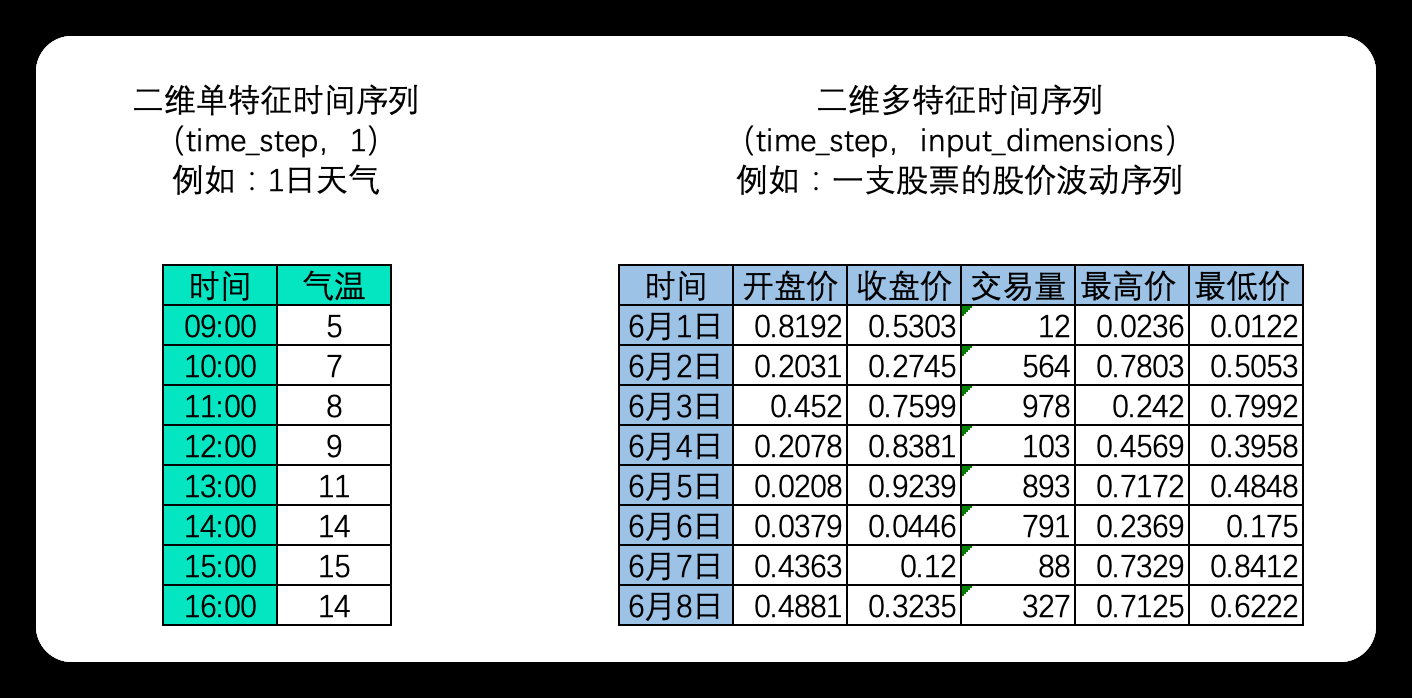
时间序列中,样本与样本之间的顺序是时间顺序,因此每个样本是一个时间点,时间顺序也就是time_step这一维度上的顺序。这种顺序在自然语言处理领域叫做时间步(time_step),它代表了当前时间序列的长度,因此也被称为序列长度(sequence_length)。对时间序列而言,时间步的顺序这正是我们要求算法必须去学习的顺序。在时序数据中,时间点可以是任意时间单位(分钟、小时、天),但时间点与时间点之间的间隔必须是一致的。
在NLP领域中,我们常常一次性处理多个时间序列,如下图所示,我们可以一次性处理多支股票的股价波动序列
三维时间序列
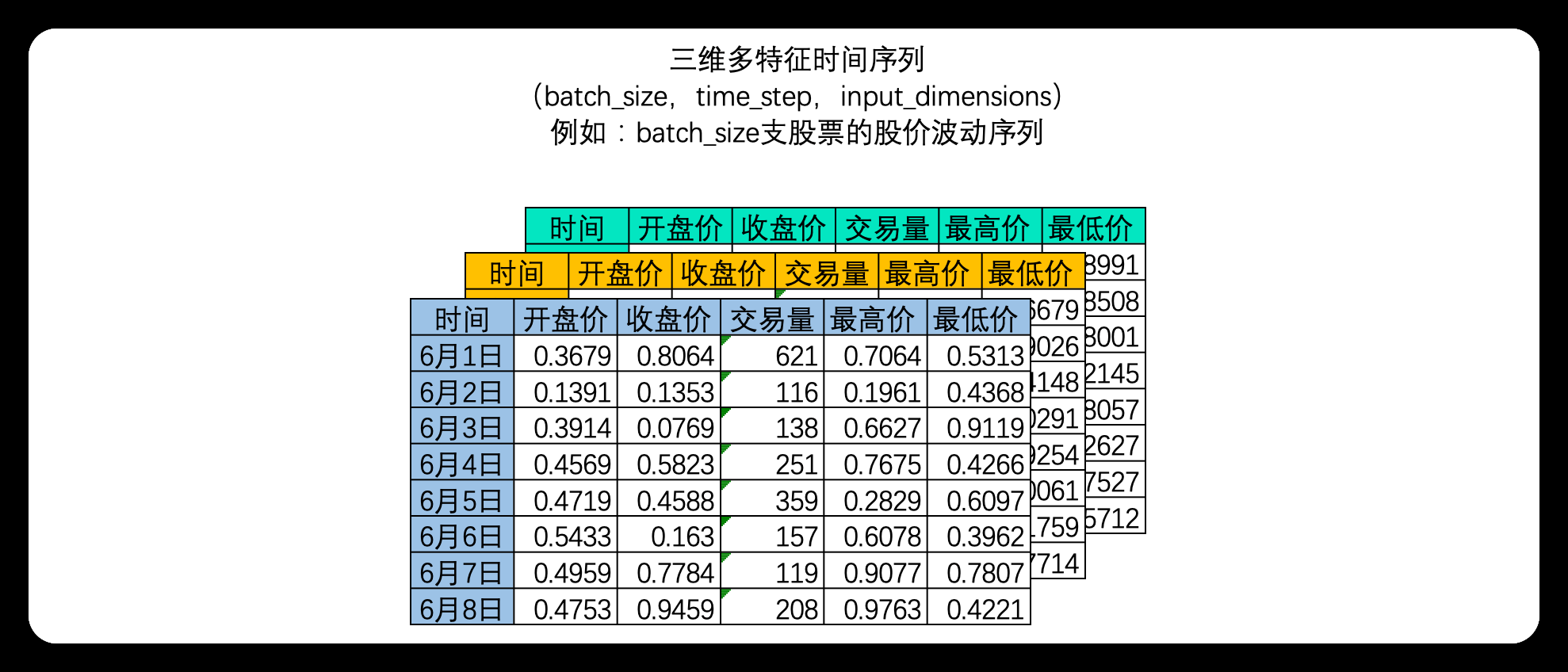
此时我们拥有的是一个三维矩阵,其中batch_size是样本量,也就是一共有多少个二维时间序列表单。其实三维时间序列数据就是机器学习中定义的"多变量时间序列数据"。在多变量时间序列数据当中,时间和另一个因素共同决定唯一的特征值。 在上面的例子中,每张时序二维表代表一支股票,因此在这个多变量时间序列数据中"时间"和"股票编号"共同决定了一个时间点上的值,如果在机器学习中,我们会看到这样的数据结构:
| 股票ID | 时间 | 开盘价 | 收盘价 | 交易量 | 最高价 | 最低价 |
|---|---|---|---|---|---|---|
| 00K621 | 6月1日 | xxx | xxx | xxx | xxx | xxx |
| 00K621 | 6月2日 | xxx | xxx | xxx | xxx | xxx |
| 00K621 | 6月3日 | xxx | xxx | xxx | xxx | xxx |
| ...... | ||||||
| 00E504 | 6月1日 | xxx | xxx | xxx | xxx | xxx |
| 00E504 | 6月2日 | xxx | xxx | xxx | xxx | xxx |
| 00E504 | 6月3日 | xxx | xxx | xxx | xxx | xxx |
| ...... | ||||||
| 00H829 | 6月1日 | xxx | xxx | xxx | xxx | xxx |
| 00H829 | 6月2日 | xxx | xxx | xxx | xxx | xxx |
| 00H829 | 6月3日 | xxx | xxx | xxx | xxx | xxx |
| ...... |
当把这张表单拆成独立的三张表单,每张表单上只显示一支股票时,就是深度学习中常见的三维时间序列数据。相似的例子还可能是------不同用户在不同时间点上的行为,不同植物在不同季节时分泌的激素值、不同商家在不同时间点上的销售额等等。
需要注意的是,虽然上述两种形式的时序数据是深度学习中最常见的时序数据,但时序数据被用于不同的算法时可能有不同的形态,有时候我们甚至不会拘泥于"时序"和"连续性"这些时间序列的常规属性,而是从时间数据的局部性和全局性来考虑,将时序数据变形为特定网络所需要的输入数据形态(例如,时间序列数据用于CNN,或时间序列数据用于GAN时,它的形态会不同于上述我们描述的形态)。
2.深度学习中的文字序列数据
(1).二维文字序列
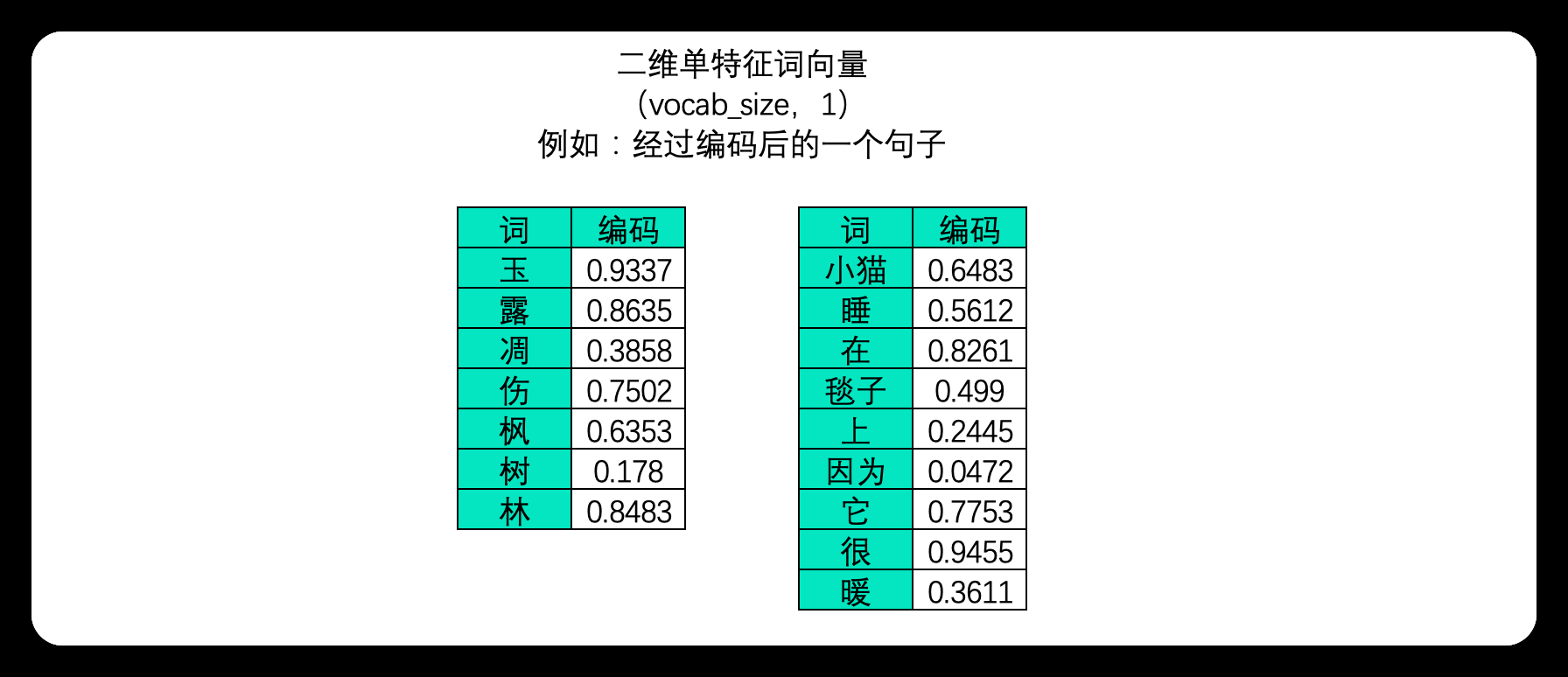
在文字数据中,样本与样本之间的联系是语义的联系,语义的联系即是词与词之间、字与字之间的联系,因此在文字序列中每个样本是一个单词或一个字(对英文来说大部分时候是一个单词,偶尔也可以是更小的语言单位,如字母或半词),故而在中文文字数据中,一张二维表往往是一个句子或一段话,而单个样本则表示单词或字。
此时,不能够打乱顺序的维度是vocab_size,它代表了一个句子/一段话中的字词总数量。一个句子或一段话越长,vocab_size也就会越大,因此这一维度的作用与时间序列中的time_step一致,vocab_size在许多时候也被称之为是序列长度(sequence_length)。同样,vocab_size这一维度上的顺序就是算法需要学习的语义顺序。
算法是不能认知文字数据的,因此我们必须将文字数据转化为"数字"来进行表示,这个过程叫做"编码"。编码是一个复杂的过程,但是现在我们不必对其进行深究,我们只需要知道,我们可以像上面的图像中一样将一个单词编码成一个数字,也可以将单词编码成一个序列。大部分时候,我们需要学习的肯定不止一个句子,当每个句子被编码成矩阵后,就会构成高维的多特征词向量。由于在实际训练时,所有句子或段落长度都一致的可能性太小(即所有句子的vocab_size都一致的可能性太小),因此我们往往为短句子进行填充、或将长句子进行裁剪,让所有的特征词向量保持在同样的维度。
(2).三维文字序列
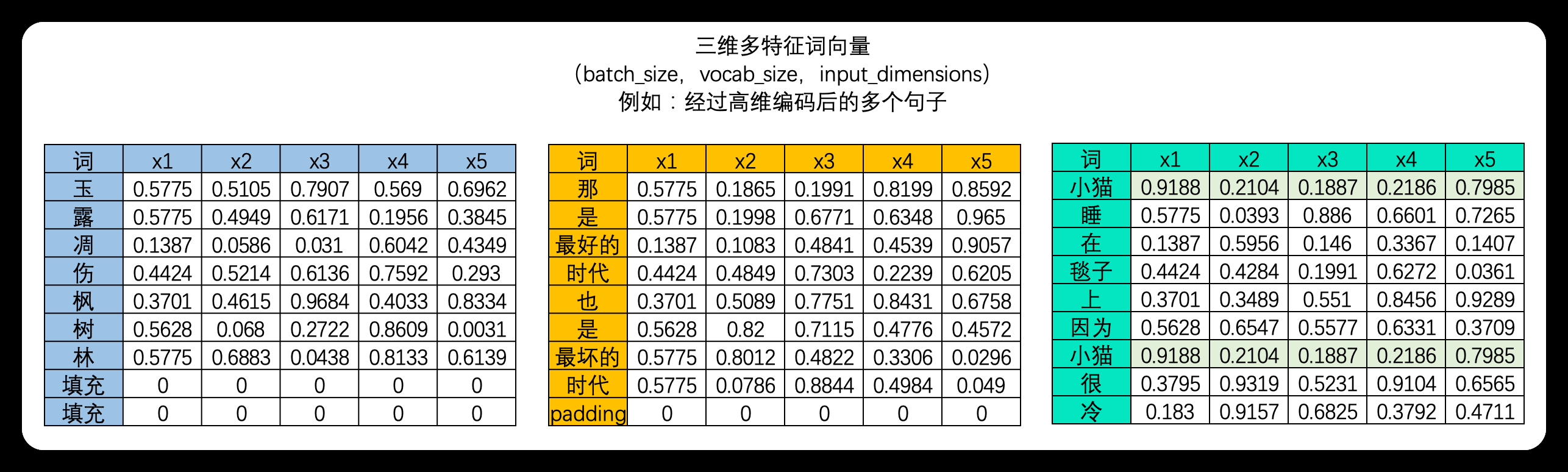
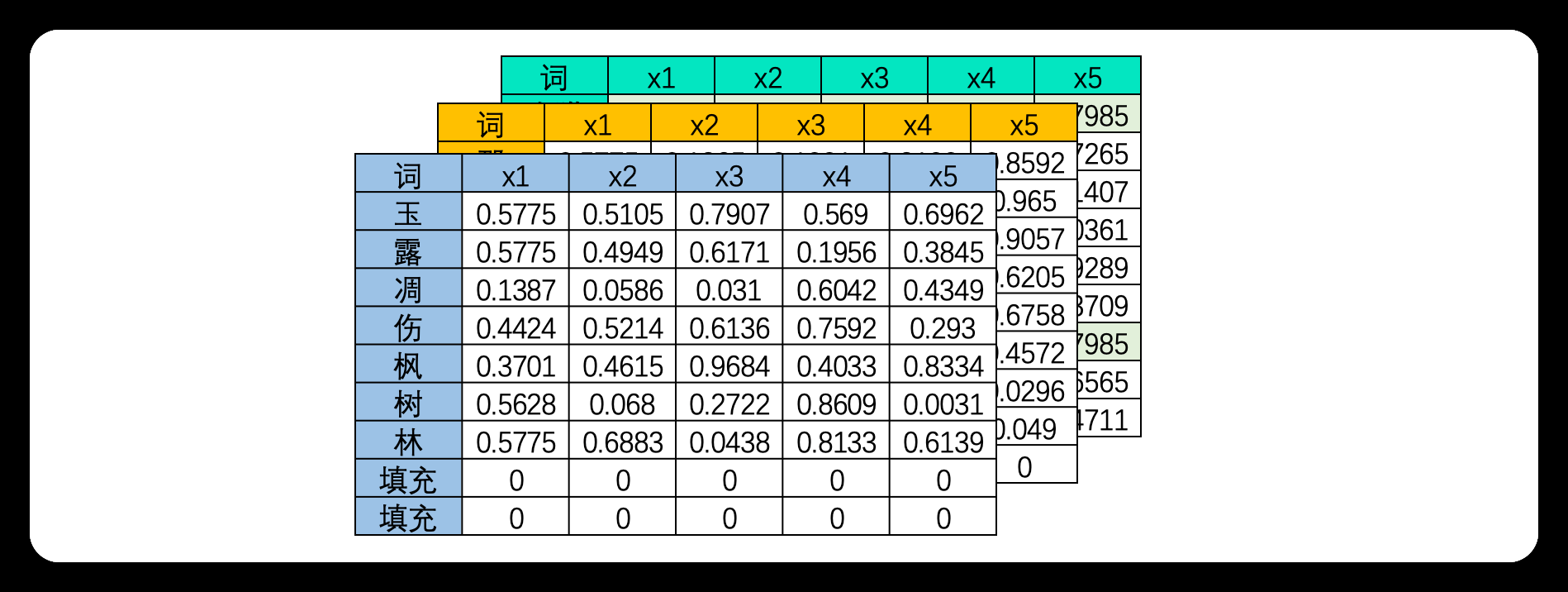
文字是典型的离散序列数据。理解一段话的意思,不仅取决于单个词的含义,更取决于词语排列的先后顺序。
(3).分词操作
原始文本数据大多是段落,但是输入到深度学习中的文字数据的样本却是词或字,因此文字数据大部分时候需要进行"分词"。分词是将连续的文本切分成一个个具有独立意义的词或词组的过程,良好的分词可以降低算法理解文本的难度,可以很好地提升模型的性能。例如,将诗句"玉露凋伤枫树林"分为"玉露","调伤","枫树林"三个词,可能会比将其分为"玉","露","凋","伤","枫","树","林"7个字更容易理解,要求每个字都自带完整的语义其实会有些困难。
由于不同的语言有不同的特色,因此每种语言所使用的分词方式也大不相同。例如,英文等拉丁语系的语言天然就有空格来分割不同的单词,只要按照空格进行分词就能够自然得到很好的结果,而中文日文韩文等语言却没有空格来进行辅助,有时分词的结果可能会造成巨大的误解。例如,经典的"吃烧烤不给你带"这一句子,分割成"吃","烧烤","不给","你","带"和"吃","烧烤","不","给你","带"就会令语义有所不同,因此中文还面临着"断句"的挑战。
现在对于不同语言的分词,我们都有丰富的手段可以操作:
中文分词:
基于词典的方法:最经典的方法,例如最大匹配法、最小匹配法等,它们基于预先定义的字典来执行分词。在使用何种方法之前需要先构造词典。
基于统计的方法:例如HMM(隐马尔科夫模型)和CRF(条件随机场)。
深度学习方法:例如基于Bi-LSTM的分词模型。
经典工具:
- jieba:是一个Python的第三方库。支持三种分词模式:精确模式、全模式和搜索引擎模式。速度相对较快,使用简单。可以自定义添加词典。
- HanLP:不仅仅是分词工具,还包括词性标注、命名实体识别等多种NLP任务。支持多种分词算法,如CRF、感知机等。同时支持繁体中文和简体中文。提供了丰富的预处理和后处理功能。
- THULAC(清华大学THU词法分析工具包):不仅支持分词,还提供词性标注功能。使用条件随机场(CRF)模型。
- FudanNLP(复旦大学NLP工具集):提供了分词、词性标注、命名实体识别等功能。使用结构化感知机模型。
- LTP(语言技术平台):由哈工大社会计算与信息检索研究中心开发。提供全套中文NLP处理工具,包括分词、词性标注、句法分析等。使用感知机模型。
- SNLP (Stanford NLP for Chinese) :斯坦福大学开发的NLP工具,支持多种语言,其中包括中文。提供分词、词性标注、命名实体识别等功能,基于都使用基于深度学习的方法。
- 选择哪种工具主要取决于特定任务的需求和使用场景。对于大部分应用,例如简单的文本预处理,jieba可能就足够了。但如果需要更深入的语言学特性或高准确性的处理,可能需要考虑如HanLP或LTP这样的更全面的工具。在NLP部分后续的代码实战环节,我们将展示使用各式分词工具的代码与结果。
英文分词:
空白字符分词 :由于英文单词之间通常由空格分隔,所以简单的空格分词在很多情况下都很有效。
基于规则的方法 :如NLTK、spaCy等工具提供的分词方法。
子词分词:如BPE或SentencePiece,它们可以将英文单词进一步切分成常见的子词或字符级别的片段。
- 按字分词:将文本拆为单个字符。优点是词表小,不会有未登录词(OOV)问题;缺点是单个字符承载信息量太小。
- 按词分词:按照语义拆分词语。优点是语义明确;缺点是词表规模巨大且容易产生歧义。
- 子词分词(Subword):如BPE算法,折中处理常见词与罕见词。
(2).词、字与token
Token是自然语言处理世界中的重要概念,Token是当前分词模式下的最小语义单元,根据分词方式的不同,它可能是一个单词(upstair)、一个半词(up,stair)或一个字母(u,p,s,t...),也可能是一个短语(攀登高峰)、一个词语(攀登、高峰)或一个字(攀,登,高,峰)。之前我们提到,分词是将连续的文本切分成一个个具有独立意义的词或词组的过程,其实本质上来说分词就是分割Token的过程,因此文字数据表单中的一行行样本也就是一个个token。
Token在自然语言处理世界中有什么意义呢?
首先,它是语义的最小组成部分,同时也是大部分深度学习算法输入数据时的"单一样本"。Token的数量代表了样本的数量,也就代表了当前文本的长度和当前算法需要处理的数据量,直接对当前算法运行需要多少资源(算力、时间、电力)产生影响,也就会影响模型开发、模型训练、模型调用的成本。在NLP和大语言模型的世界中,OpenAI等模型开发厂商是以Token使用程度来进行计价和使用限制的,我们也以大模型训练和微调时所必须使用的token数量来衡量大模型的性能。随着大模型的发展,Token已成为NLP世界中广受认可的数据量/模型吞吐量计量单位
- Token:是文本处理的最小单元。它可以是一个字、一个词或者一个短语。
- 词表(Vocabulary):所有唯一Token的集合,用于将Token映射为数字索引。
(3).编码
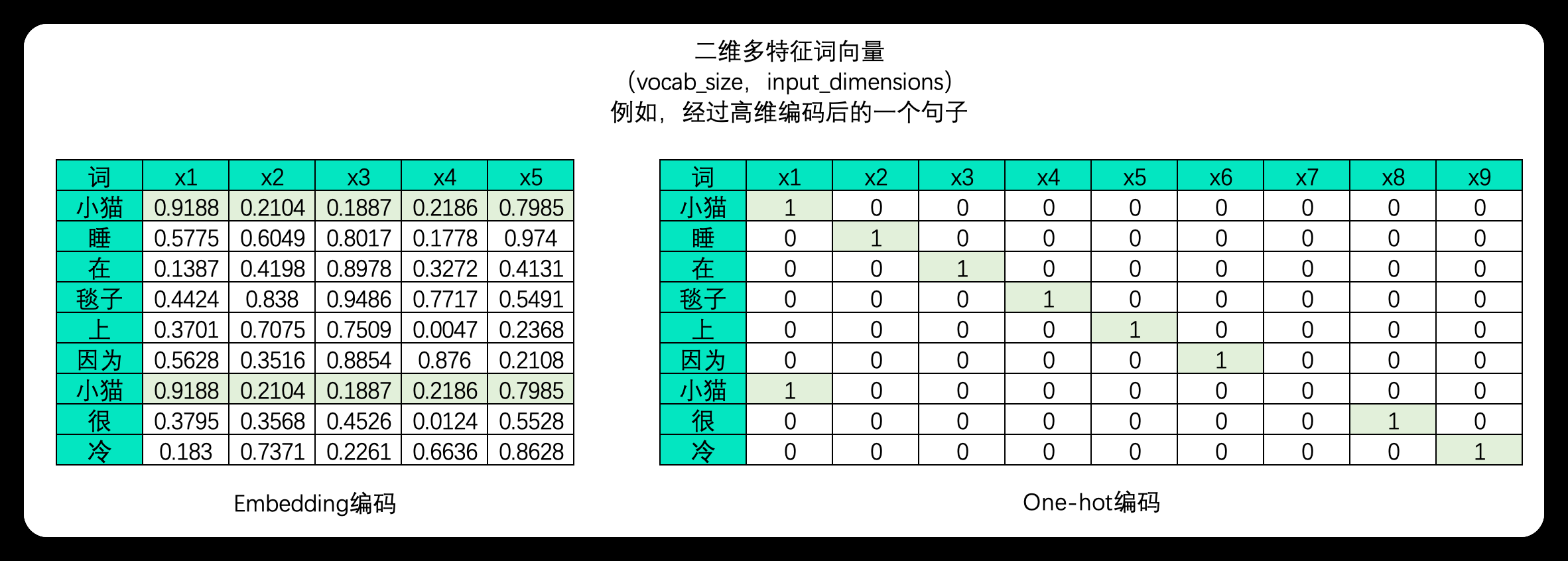
一直以来,文字序列是不能直接放入算法进行运行的,必须要要编码成数字数据才能供算法学习,因此在NLP领域中我们大概率会将文字数据进行编码。编码的方式有很多种,但无一例外的,编码的本质是用单一数字或一串数字的组合去代表某个字/词,在同一套规则下,同一个字会被编码为同样的序列或同样的数字,而使用一个数字还是一串数字则可以由算法工程师自行决定。目前深度学习中常见的编码方式有:
-
One-hot编码:将每个词表示为一个长向量,这个向量的维度等于词汇表的大小,其中只有一个维度的值为1,其余为0。这个1的位置对应于该词在词汇表中的位置。
-
词嵌入(Word Embeddings):词嵌入是一种将词或短语映射到高维空间的表示方法,使得语义上相似的词在这个高维空间中彼此接近。例如,通过训练得到的词嵌入模型,我们可能发现"king"和"queen"、"man"和"woman"在向量空间中是相似的。词嵌入通常通过大量的文本数据训练得到,目的是捕捉单词之间的语义关系。
-
对句子分别进行embedding编码和独热编码后产生的二维表单:
经典的词嵌入方法有:
Word2Vec:通过神经网络模型学习单词的向量表示,常见的有CBOW和Skip-Gram两种模型。
GloVe(Global Vectors for Word Representation):基于单词共现统计信息来学习单词的向量表示。
FastText:与Word2Vec类似,但考虑了单词内部的子词信息。
固定编码:例如使用BERT、GPT等预训练的深度学习模型来编码文本。这些模型通常使用大量数据进行预训练,并可以为新任务进行微调。
基于大语言模型进行编码:在OpenAI研发的大模型生态矩阵当中,存在专用于构建语义空间的embeddings大模型。
除了最为经典的one-hot和embedding之外,还有以下方法可以进行编码:
-
TF-IDF:基于单词在文档中的频率和在整个数据集中的反向文档频率来为单词分配权重。
-
Byte Pair Encoding (BPE) / SentencePiece:这是子词级别的编码,能够处理词汇外的单词和多种语言的文本。
-
ElMo:深度上下文化词嵌入,考虑了单词的上下文信息来生成词向量。
-
Seq2Seq等序列变化模型:如果将"编码"的概念拓展到"如何将非结构化数据(如文本)转换为结构化的数字表示",那seq2seq等序列转化模型也可以作为编码的手段之一。seq2seq,即sequence-to-sequence,是一个在多种NLP任务中广泛应用的神经网络结构,常常被用在机器翻译、文本摘要、问答系统等需要从一个序列生成另一个序列的任务中,因此seq2seq本质与encoder-decoder非常相似,是输入序列、输出序列的模型。seq2seq模型的编码器涉及到了与文本编码很类似的过程,它将输入序列(如一个句子)转换为一个固定大小的向量。但这个向量通常是为了特定的seq2seq任务(如翻译)而生成的,并不是用于一般的文本表示。因此,虽然seq2seq的编码器确实进行了"编码",但它和我们之前讨论的文本编码方法(如Word2Vec或TF-IDF)有些不同。
循环神经网络是深度学习中为数不多的、可以在网络架构不变的情况下、同时接受二、三维数据的网络。但是在pytorch中,要求输入三维张量,可以将二维张量加个size=1的维度传入。
3.nn.Embedding类 - 词嵌入层
nn.Embedding类是nn.Module类的子类
(1). nn.Embedding类类型
作用:
nn.Embedding 是 PyTorch 中处理自然语言处理(NLP)任务的"看门大爷"。它的本质是一个巨大的、可训练的"查表字典"(Lookup Table)。它负责将人类用来表示单词的、干巴巴的离散整数索引(如 5, 89, 23),瞬间映射为蕴含丰富语义的密集浮点数向量(Dense Vectors)。使用这个类,我们不需要像以前那样手动去写 for 循环提取矩阵的行,PyTorch 会在底层用极高的并行速度帮我们完成查表,并且这个字典是参与梯度下降、可以自动更新学习的!
python
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None)数学公式:
严格来说,Embedding 层的查表操作等价于:将输入的单词先转换为One-Hot独热编码向量,然后乘以一个权重矩阵 WWW。对于单词索引 iii,其计算过程等价于:
ei=OneHot(i)×We_i = \text{OneHot}(i) \times Wei=OneHot(i)×W
(注:eie_iei 是提取出的词向量,WWW 是形状为 [num_embeddings, embedding_dim] 的权重矩阵。但在底层代码实现中,PyTorch 并不做这步极其浪费显存的矩阵乘法,而是直接根据索引 iii 把矩阵的第 iii 行"抽"出来,速度极快。)
核心参数:
- 词表大小 (num_embeddings):对应你构建的字典里一共有多少个不重复的词汇 (int)。
- 词向量维度 (embedding_dim):你希望用多长的浮点数数组来代表一个单词 (int)。通常设置为
128,256,512等。 - 填充索引 (padding_idx):NLP中极其常用的参数! 如果指定了这个参数,字典中对应这个索引的向量会被强行初始化为全 0,并且在训练过程中不会计算梯度,永远保持为 0。通常用于处理长度不一的句子,补齐(Pad)用的空白符(如
<PAD>)不应该具有任何实际语义 (int, optional)。 - 最大范数 (max_norm):如果指定了该值,任何范数大于此值的词向量在反向传播后,都会被强行缩放(重归一化)回这个最大范数值,常用于防止梯度爆炸和正则化模型 (float, optional)。
核心属性 (Attributes):
Embedding 层内部非常纯粹,只维护了一个核心的参数矩阵:
.weight:形状为(num_embeddings, embedding_dim)的权重矩阵。这就是那本真正的"新华字典"。它是可学习的参数(Learnable Parameters)。
(2). call - 实例调用(执行前向传播)
作用:将装满整数索引的张量喂给 Embedding 层,让其返回对应的浮点数词向量。与所有 nn.Module 一样,严禁直接调用 .forward(),直接把实例当函数调用即可。
python
# 实例化后,传入包含单词ID索引的张量input_indices
embedded_output = embed_layer(input_indices)参数:
- 输入张量 (input_indices): 里面装的必须是代表词汇 ID 的整数。避坑注意:数据类型必须是
torch.LongTensor(即torch.int64)! 绝对不能传浮点数进去,字典的页码没有小数。其形状通常是(batch_size, seq_len)。
返回值:
- 成功: 返回查表后的浮点数特征张量。其形状是在输入形状的最后,追加一个特征维度,即
(batch_size, seq_len, embedding_dim)。
维度符号释义 (极其重要:理解维度的"无端膨胀"):
batch_size(批次大小):一次并行处理多少个句子。seq_len(序列长度):每个句子包含多少个单词索引。embedding_dim(词向量维度):每个单词被拉伸成了多长的向量。
补充:关于 Embedding 的高频踩坑点 (极其重要)
-
维度扩展 (Dimension Expansion):
nn.Embedding最神奇的地方在于它会给数据=="升维"==。如果你的输入是一个 1 维向量
[seq_len](一句话),出来就会变成 2 维矩阵[seq_len, embedding_dim]。如果你的输入是 2 维矩阵
[batch_size, seq_len](几句话构成的批次),出来就会变成 3 维张量[batch_size, seq_len, embedding_dim]。
记住规律:输出形状永远等于(输入的形状, embedding_dim)。 -
索引越界 (IndexError):
在使用nn.Embedding时最常遇到的报错:Index out of range in self。如果你的
num_embeddings=10000,意味着你的词典只有 10000 页,合法的索引范围是0到9999。如果你的输入张量中哪怕只有一个数字是10000甚至更大,PyTorch 就会因为找不到这一页而立刻崩溃。在把数据喂给 Embedding 层之前,务必确保所有的 ID 都在合法范围内!
示例:
python
import torch
import torch.nn as nn
# 1. 假设我们的词表总共有 101255 个词,每个词想用 128 维的向量表示
vocab_size = 101255
embed_dim = 128
# 2. 实例化 Embedding 层
embed_layer = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embed_dim)
# 3. 准备假数据:模拟一个Batch有3句话,每句话有50个词。
# 注意:使用 torch.randint 生成随机整数,范围限定在[0, vocab_size-1],数据类型默认为 int64
X_indices = torch.randint(low=0, high=vocab_size, size=(3, 50))
print("输入张量的形状:", X_indices.shape)
# [batch_size, seq_len]
# 返回: 输入张量的形状: torch.Size([3, 50])
print("输入张量的数据类型:", X_indices.dtype)
# 返回: 输入张量的数据类型: torch.int64
# 4. 前向传播:执行批量查表
embedded_X = embed_layer(X_indices)
print("输出张量的形状:", embedded_X.shape)
# [batch_size, seq_len, embedding_dim]
# 返回: 输出张量的形状: torch.Size([3, 50, 128])
# 解释:原本3行50列的干瘪二维整数表格,瞬间变成了3D的浮点数特征立方体,刚好可以无缝喂给 nn.RNN!三.循环神经网络
1.RNN的基本架构与数据流
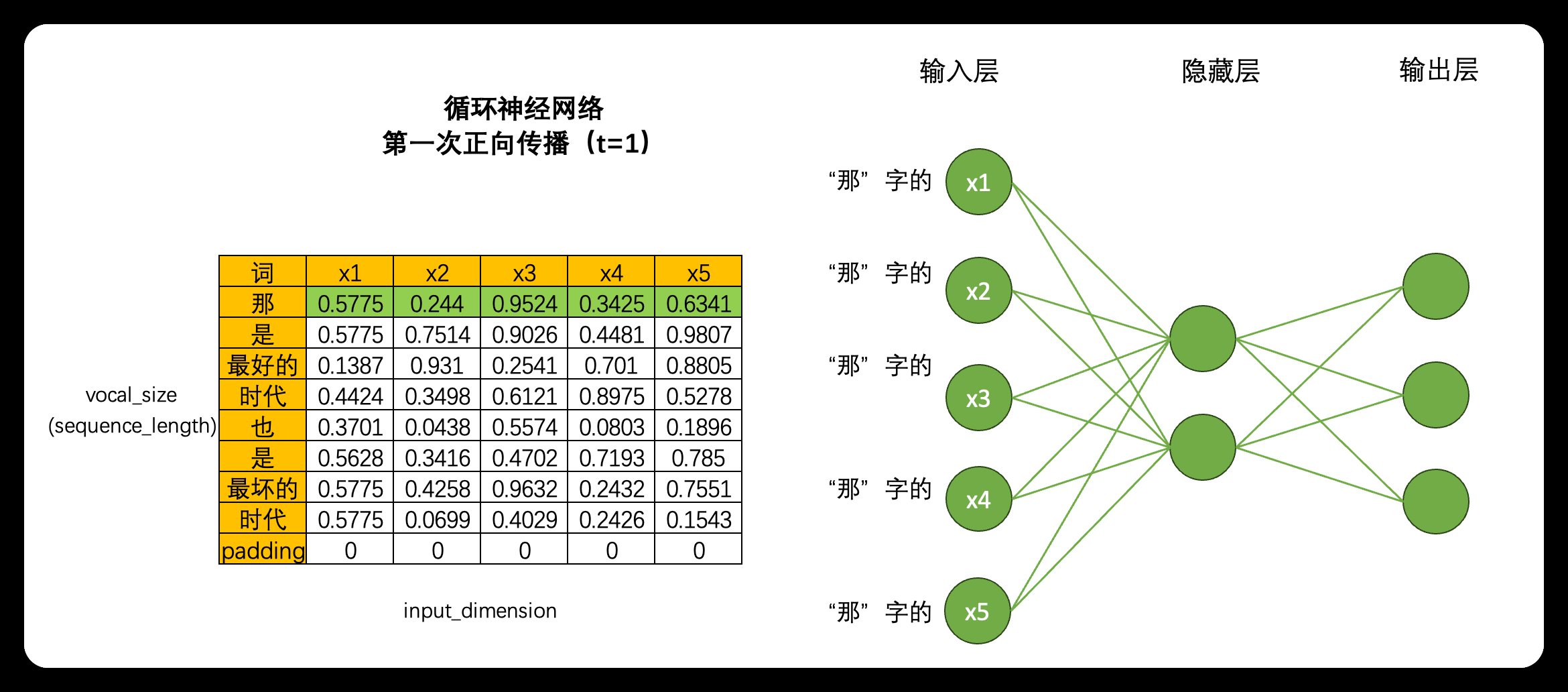
首先,循环神经网络由输入层、隐藏层和输出层构成,并且这三类层都是线性层。和深度神经网络中的线性层一样,输入层的神经元个数由输入数据的特征数量决定,隐藏层数量和隐藏层上神经元的个数都可自己设置,而输出层的神经元数量则需要根据输出的任务目标进行设置。 以下面的数据为例,现在我们将每个单词都编码成了5个特征构成的词向量,因此输入层就会需要5个神经元,我们将该文字数据输入循环神经网络执行三分类的"情感分类"任务(三分类分别是积极,消极,中性),那输出层就会需要三个神经元。假设有一个隐藏层,而隐藏层上有2个神经元,一个最为简单的循环网络的网络结构如下:
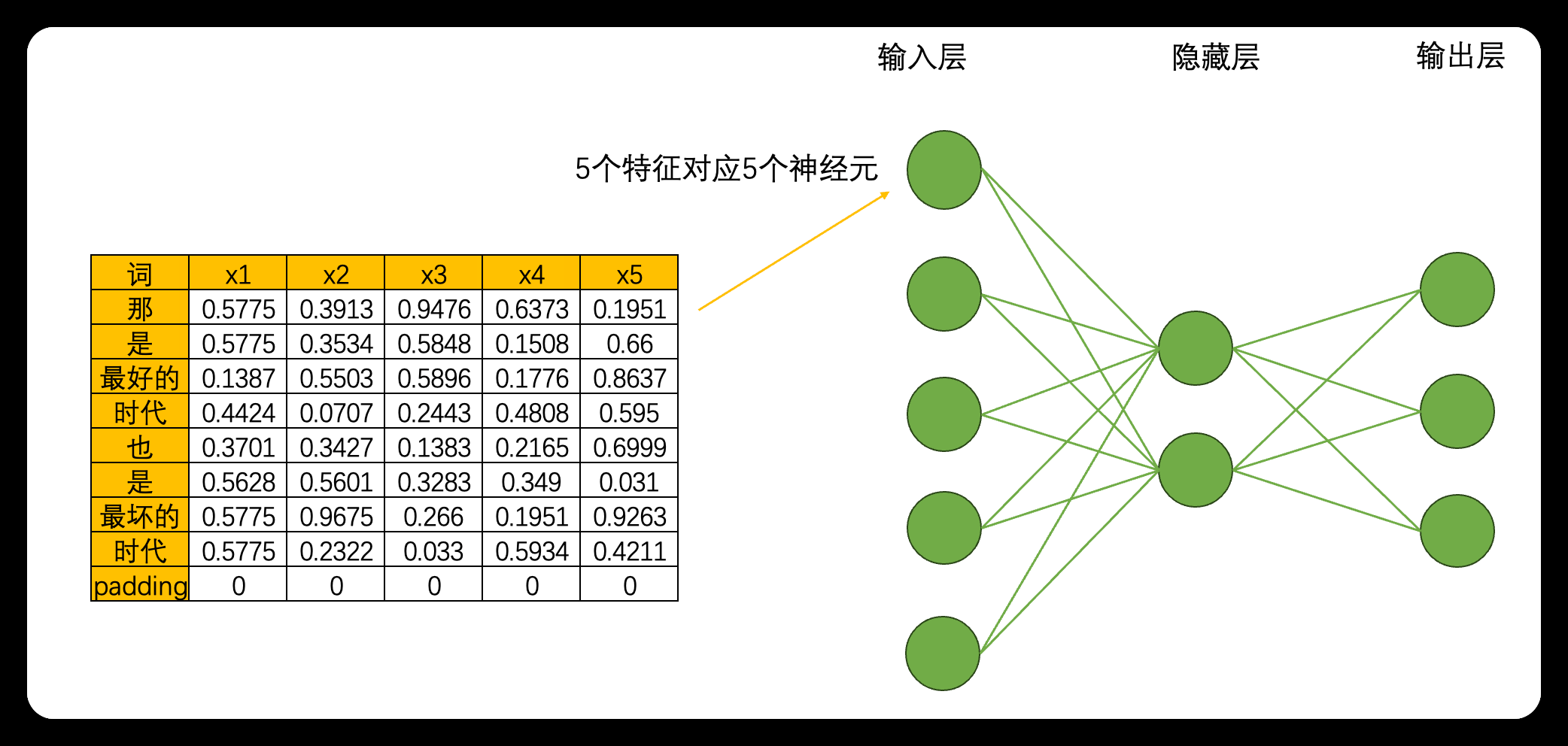
在这个结构中,激活函数的设置、神经元的连接方式等都与深度神经网络一致,因此循环神经网络在网络构建方面没有太多可以深究的内容,循环网络真正精彩的地方在于其创造了全新的数据流
当我们将数据输入深度神经网络DNN时,一个神经元会一次性处理一列数据,5个神经元会涵盖整张表的数据,在一次正向传播中深度神经网络就会接触到完整的一张数据表。这种方式计算效率很高,同时矩阵计算也很简单:输入结构为(9,5),中间层输出为(9,2),最终输出结果为(9,3),整个计算过程完全只考虑每个单词的特征之间的转换(5->2->3),而完全忽略"单词与单词之间的联系",毕竟输入9个单词,输出9个单词,并没有对单词之间的关系进行任何学习。
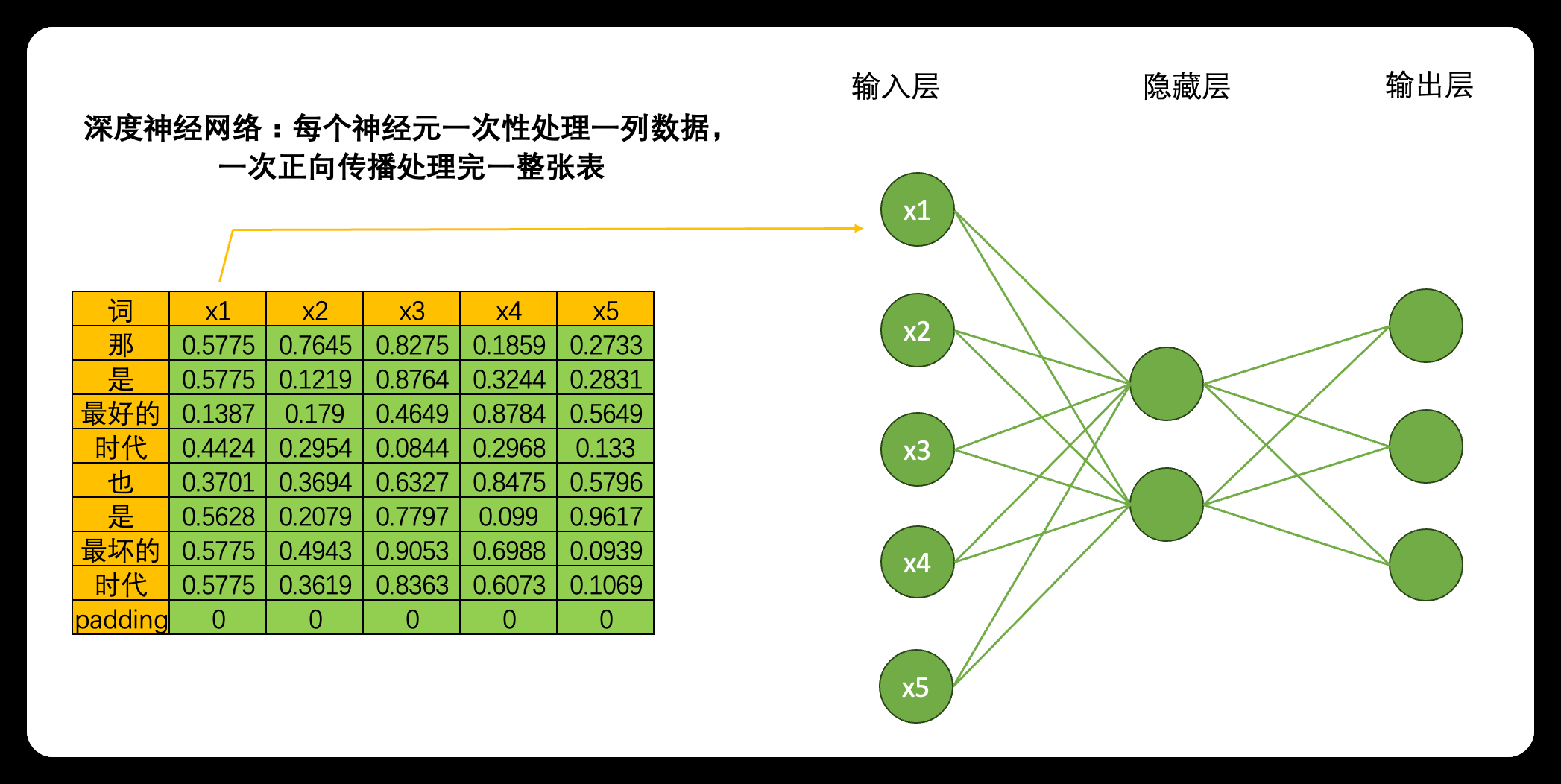
但是,在循环神经网络当中就不一样了。虽然是一模一样的网络结构,但当我们将数据输入到循环神经网络时,一个神经元一次性只会处理一行(也就是一个单词)的数据,5个神经元会覆盖当前单词的5个特征,在一次正向传播中,循环神经网络只会接触到一个单词的全部信息,而不会接触到整张表。
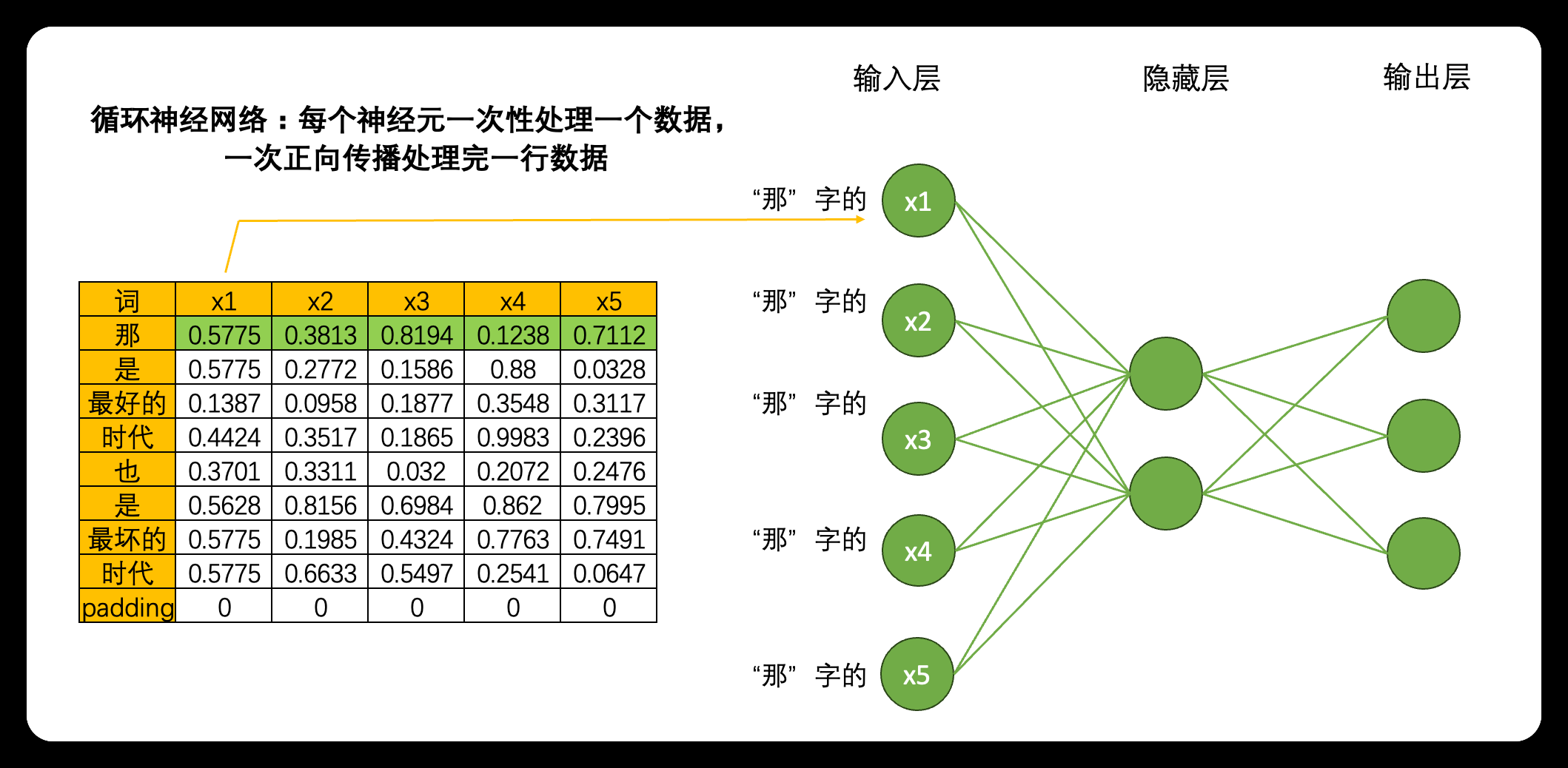
一行一行处理数据,如果一次正向传播只处理一行数据,那对于结构为(vocab_size,input_dimension)的文字数据来说,就需要在同一个网络上进行vocab_size次正向传播。同样的,对于结构为(time_step,input_dimension)的时间序列数据来说,就需要在同一个网络上进行time_step次正向传播。所以为了便利,vocab_size和time_step这个维度可以统称为时间步,对任意数据来说,循环神经网络都需要进行时间步次正向传播,而每个时间步上是一个单词或一个时间点的数据。
基于这样的数据流设置,循环神经网络构建了自己的灵魂结构:循环数据流。在多次进行正向传播的过程中,循环神经网络会将每个单词的信息向下传递给下一个单词,从而让网络在处理下一个单词时还能够"记得"上一个单词的信息。
如下图所示,在Tt−1T_{t-1}Tt−1时间步上时,循环网络处理了一个单词,此时隐藏层上输出的中间变量Ht−1H_{t-1}Ht−1会走向两条数据流,一条数据流是继续向输出层的方向正向传播,另一条则流向了下一个时间步的隐藏层。在TtT_{t}Tt时间步时,隐藏层会结合当前正向传播的输入层传入的XtX_tXt和上个时间不的隐藏层传来的中间变量Ht−1H_{t-1}Ht−1共同计算当前隐藏层的输出HtH_{t}Ht。如此,HtH_{t}Ht当中就包含了上一个单词的信息。
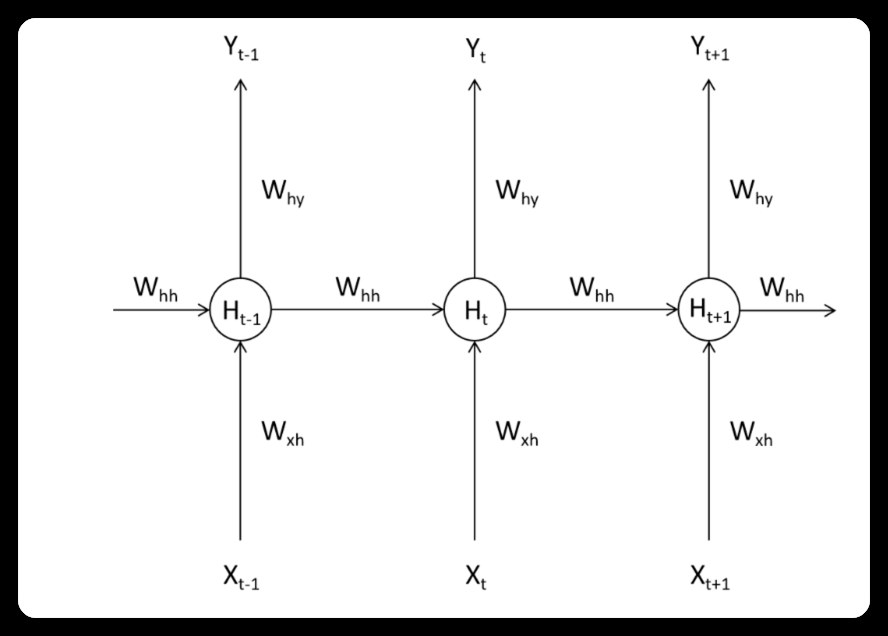
使用数学公式表示如下:
Ht=f(WhhHt−1+WxhXt)H_t = f(W_{hh}H_{t-1} + W_{xh}X_t)Ht=f(WhhHt−1+WxhXt)
=f(Whhf(WhhHt−2+WxhXt−1)+WxhXt) = f(W_{hh}f(W_{hh}H_{t-2} + W_{xh}X_{t-1}) + W_{xh}X_t)=f(Whhf(WhhHt−2+WxhXt−1)+WxhXt)
=f(Whhf(Whhf(WhhHt−3+WxhXt−2)+WxhXt−1)+WxhXt) = f(W_{hh}f(W_{hh}f(W_{hh}H_{t-3} + W_{xh}X_{t-2}) + W_{xh}X_{t-1}) + W_{xh}X_t)=f(Whhf(Whhf(WhhHt−3+WxhXt−2)+WxhXt−1)+WxhXt)
⋮ \vdots⋮
使用架构图表示,则可表示如下:
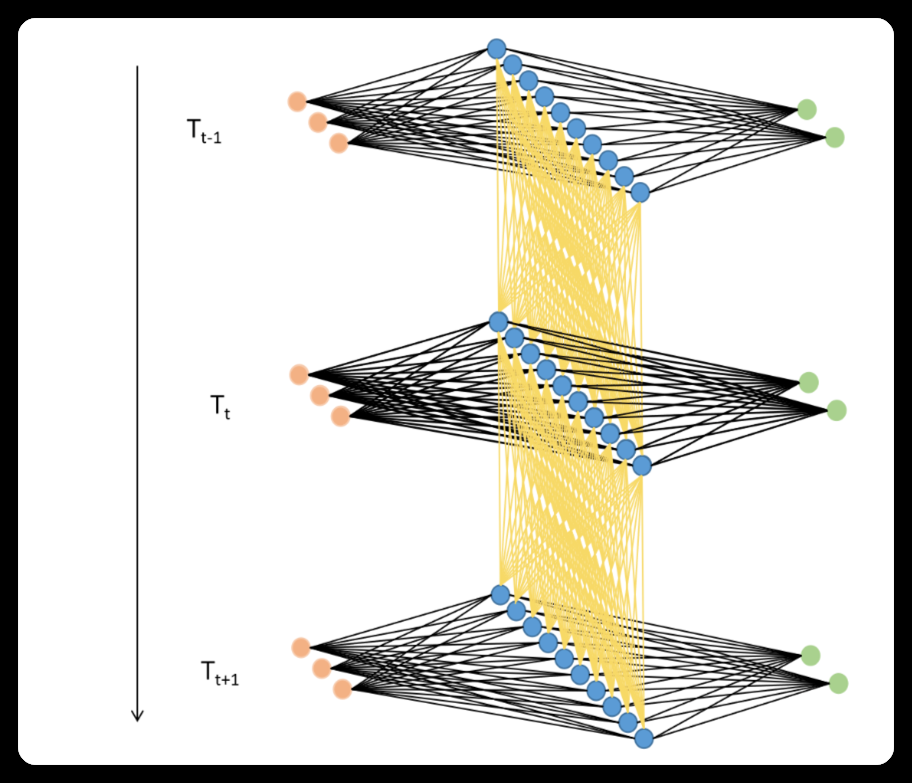
==利用这种方式,只要进行vocal_size次向前传播,并且每次都将上一个时间步中隐藏层上诞生的中间变量传递给下一个时间步的隐藏层,整个网络就能在全部的正向传播完成后获得整个句子上的全部信息。==在这个过程中,我们在同一个网络上不断运行正向传播,此过程在神经网络结构上是循环,在数学逻辑上是递归,这也是循环神经网络名称的由来。
==在这个过程中,H被称之为是"隐藏状态"(Hidden Representation 或 Hidden State),它特指在循环神经网络的隐藏层上诞生的中间变量,一般在代码中也表示为小写的字母h。==当然,在循环神经网络中我们也是可以有多个隐藏层的,虽然我们的图像上只显示了最为简单的情况(一个输入层、一个隐藏层、一个输出层)
2.RNN的效率问题与权值共享
在循环神经网络(RNN)中,所有的权重矩阵(Weights)和偏置向量(Biases)在所有时间步(Time Steps)内都是严格共用的(共享的)。
循环网络的数据流和基本结构已经明晰了,但我们还面临一个巨大的问题------效率。刚才我们以一张表为例讲解了循环神经网络的迭代过程,但循环网络在实际应用时可能面临batch_size张表单,如果每张表单都需要一行一行进行向前传播的话,那循环神经网络运行一次需要(batch_size * time_step)次向前传播,这样整个网络的运行效率必然是非常非常低的。
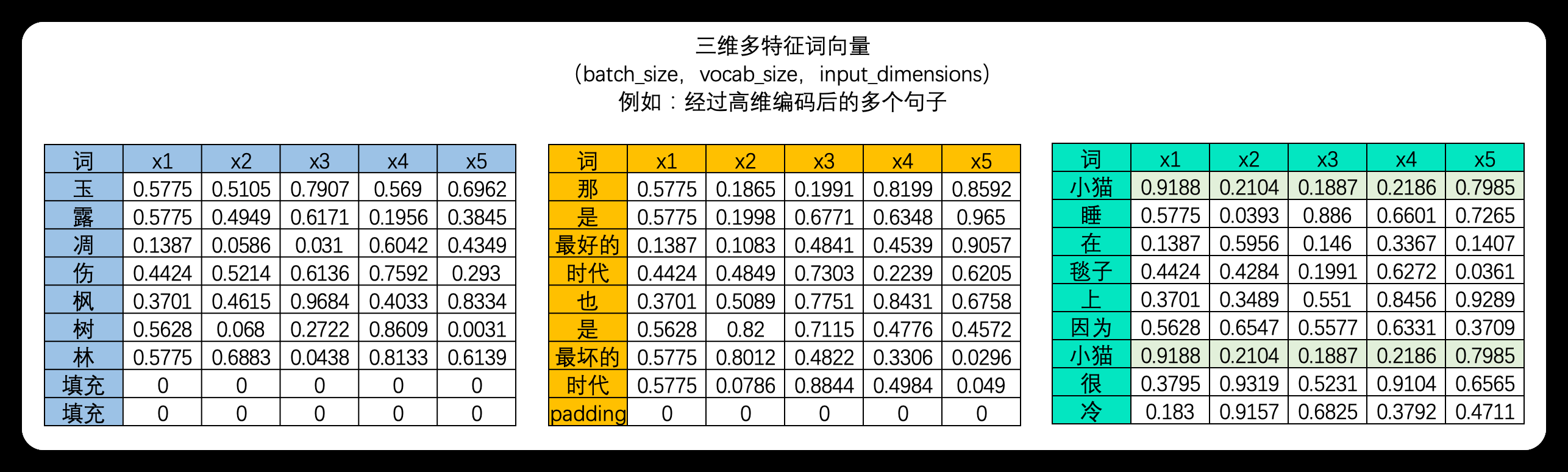
在现实中使用循环神经网络的时候,我们所使用的输入数据结构往往是三维时间或三维文字数据,也就是说数据中大概率会包括不止一张时序二维表、会包括不止一个句子或一个段落。之前我们提到过,循环神经网络要顺利运行的前提是所有的句子/时间序列被处理成同等的长度,因此编码后每张二维表需要循环的时间步数量是相等的,因此在实际训练的时候循环神经网络是会一次性将所有的batch_size张二维表的第一行数据都放入神经元进行处理,故而RNN并不需要对每张表单一一处理,而是对全部表单的每一行进行一一处理,所以最终循环神经网络只会进行time_step次向前传播,所有的batch是共享权重的。
如果将三维数据看作是一个立方体,那循环神经网络就是一次性处理位于最上层的一整个平面的数据,因此循环神经网络一次性处理的数据结构与深度神经网络一样都是二维的,只不过这个二维数据不是(vocal_size,input_dimension)结构,而是(batch_size,input_dimension)结构罢了。
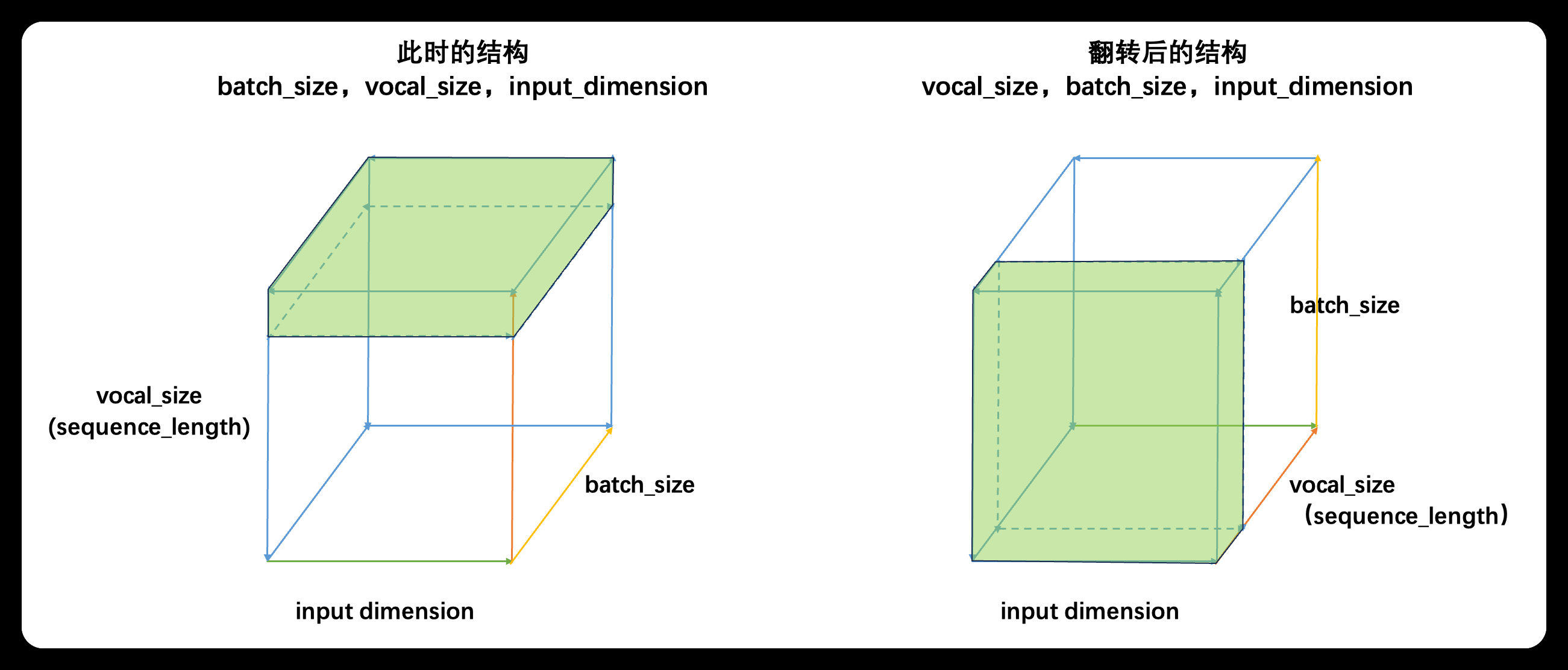
总结:
- 权值共享:在RNN的每一个时间步中,所使用的参数都是同一套。这极大减少了参数量,并允许模型处理变长序列。
- 效率瓶颈:由于RNN是串行计算的(必须先算完前一时刻的隐藏状态,才能计算当前时刻),无法像卷积神经网络那样在时间维度上进行并行加速,计算效率较低。
3.RNN的输入与输出结构
(1).输入结构
循环神经网络是为数不多的、能够在不改变网络结构情况下同时处理二维数据和三维数据的网络,但在PyTorch或tensorflow这样的深度学习框架的要求下,循环神经网络的输入结构一律为三维数据。
通常来说,最常见的结构就是上面提到过无数次的(batch_size,vocal_size,input_dimension),且循环是在vocal_size维度进行。不过,在某些材料当中,循环神经网络的输入被描述为(vocal_size,batch_size,input_dimension)结构。事实上,这两种结构是同一种结构:
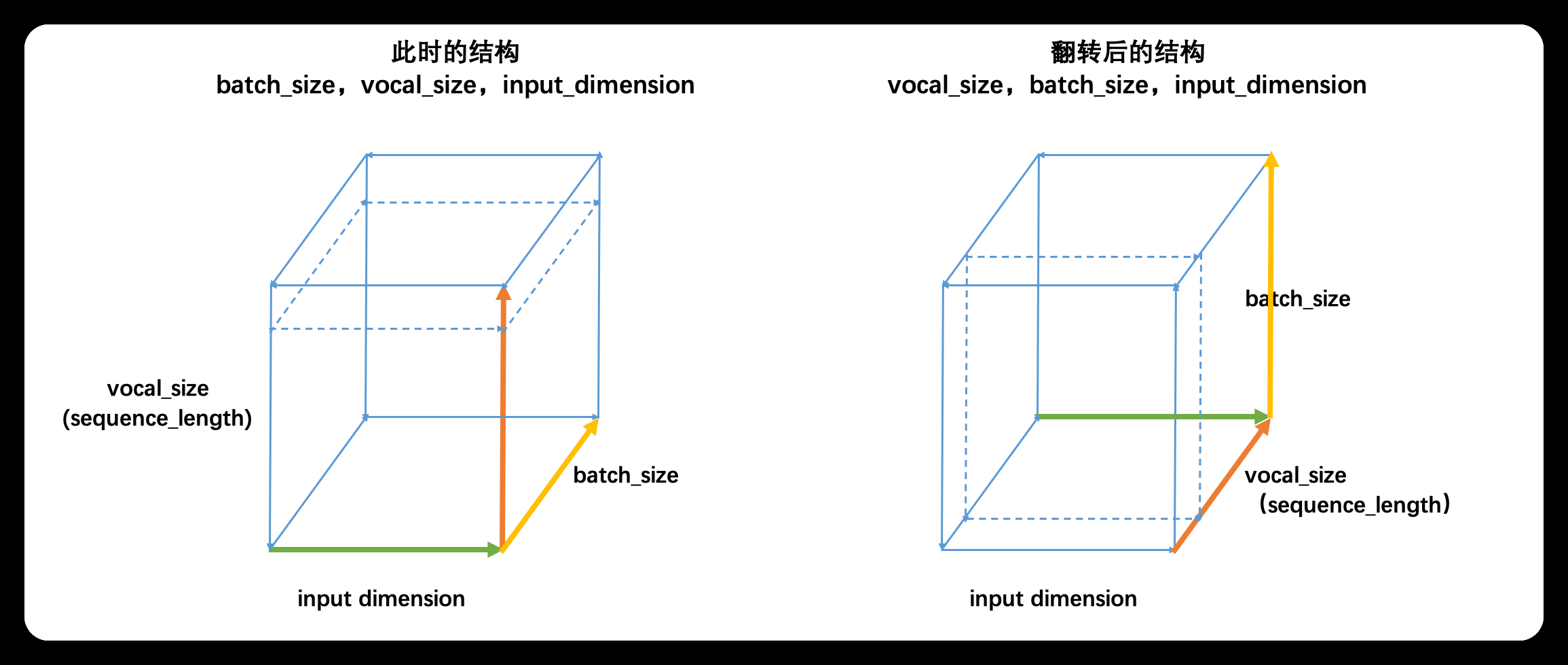
- 这两种在pytorch中都对
普通的结构(batch_size,vocal_size,input_dimension)如左图,此时循环神经网络会在vocal_size这一维度上循环,执行vocal_size个时间步的正向传播、即从上至下不断处理面向上方的二维表单(虚线标注处)。但立方体是可以被旋转的,当我们将立方体旋转一个角度,即需要处理的二维表单由正上方专向正前方时,我们就得到了(vocal_size,batch_size,input_dimension)的数据结构,此时循环神经网络依然是在vocal_size方向进行循环,只不过我们需要处理的表单方向由从上到下变成了从前往后。
因此不难发现,本质上这两种结构是一模一样的,但无论是哪种结构,循环神经网络都必须在时间步的方向进行循环。对于时序数据来说,这个方向是time_step的方向,对于文字数据来说,这个方向是vocab_size的方向。
(2).输出结构
循环神经网络的输出层结构是由具体的输出任务决定的,但丰富的NLP任务让RNN输出层也变得丰富多彩。从网络结构的角度,我们可以将NLP的任务大略分成以下三类:
-
对语义/关系/文字本身进行有标签分类/标注的任务,包括但不限于
文本分类 :如情感分析、新闻分类、垃圾邮件检测等。
命名实体识别(NER) :识别文本中的人名、地点、日期、组织等实体。
关系抽取 :从文本中抽取实体之间的关系。
词性标注 :为文本中的每个词指定其词性(名词、动词等)。
依存句法分析 :解析句子中词语之间的依存关系。
核心指代消解:确定文本中的代词或名词短语指的是什么。对这类有标签的经典任务,RNN的行为与CNN、DNN相似,会一次性判断出所有样本的标签。此时,输出层的神经元数量通常是标签的类别数量 ,例如具体有多少分类、具体有多少种关系、具体有多少种词性等等。所使用的损失也是相对常规的损失函数,例如交叉熵损失、Hinge损失(Hinge Loss)、负对数似然损失(Negative Log Likelihood Loss),特别的,如果是标注任务或NER任务,我们还可能使用Dice损失、条件随机场CRF损失(Conditional Random Fields Loss)等。
-
其他基于时序/语义的分类/回归任务,包括但不限于
文本匹配和相似度计算 :如自动问答评分、重复问题检测等。
时序任务:预测趋势变化(温度变化、股价变化)、根据历史行为预测未来行为变化(特定时间点下,用户是否购买、是否留存、是否点击)等等。**在这一类任务中,输出层神经元的情况是相当灵活的。例如,如果是对趋势进行预测的时序问题,在采用单步预测方法时,可能一次性输出未来所有时间点上的预测值,此时输出层上可能会有test_size个神经元;在采用多步预测方法时,一次只能预测一个值,则可能输出层上只有1个神经元。如果要一次性输出一个时间点下的多个行为变化(例如,输出下午4点的空气适度、温度、风向等指标),那神经元的数量可能与要输出的类别数量一致。**整体来说,这个类别的任务在输出层面时比较简单的。
-
序列到序列、或对序列进行补充或回应的生成式任务,包括但不限于
依据指令进行文本生成 :如生成诗歌、生成故事、生成一段话,对现有的内容进行续写等等。
图-文生成、语音识别 :根据输入的语音数据、图像数据生成描述、进行语音识别等等。
问答系统或对话生成 :对用户的问题给出直接的答案,或针对用户给出的关键词生成一系列自问自答的对话等等
摘要生成 :从长文本中生成简短的摘要、写总结、提取信息。
机器翻译:将一种语言翻译成另一种语言。尽管NLP世界的预测任务都有非常专业的流程,但总体来说生成式任务的流程比分类/回归任务要复杂得多。在生成式任务中,RNN需要一个字、一个字、或一个词一个词地进行生成,在多次生成中逐渐构建出一个完整的句子或段落(所以你可能会观察到,ChatGPT这样的产品在说话的时候是一个词一个词往外蹦),所以生成式RNN的输出层和分类任务中的输出层有很大的区别。
首先,NLP算法的生成并不能"无中生有",模型只能从它曾经见过的字/词/短语中挑选它认为当下最能在语义上自洽的字/词/短语来进行输出,所以生成的本质是"在模型曾见过的字/词/短语中,挑选出最有可能使句子语义自洽的那个字/词/短语"。在进行实际生成时,模型会对它所见过的每个字/词/短语 都输出一个概率,预测这个字/词/短语是当前最佳输出的可能性,再从中挑选出可能性最高或较高的词进行输出。因此本质上来说,生成模型是多分类概率模型。
在生成式任务中,输出层神经元数量原则上需要与词汇表的大小一致,但是通常输出层神经元数量比词汇表的大小小,让输出只能输出到一个较小的语义空间。比如输入可以输入可以认识十万个词,但输出只能认识五万个词,但五万个词足以表达内容了。
所以不难发现,一个生成式模型想要进行灵活、丰富的文字生成,就必须先见过巨量文字数据。同时,分词越细致,生成式模型在生成时的创造力就会越强。如果模型是基于字符级别的,那么输出层的神经元数量就是所有可能字符的数量,模型就可能基于字符构建新的词语。如果模型是基于词级别的,那么输出层的神经元数量就是词汇表中所有词的数量,模型就可能基于词语构建新的短语。但这样,模型自然对数据量、算力就会有更高的要求。
当然,在实际进行生成式任务时,我们会有很多手段来解决生成式模型中的问题------例如,每次预测下一个字时都必须对全部的数十万个字/单词生成概率,那计算效率实在是会过低;同时,如果模型只能生成"曾经见过"的词/短语的话,那远远达不到具备"认知智能"的水准,因此业内也有相当多的手段用于增强语言模型的创造力和泛化能力。在后续我们讲解Transformer的生成式案例时,我们将会详细展开来聊聊这些技术。
(3).RNN分类
核心判断法则:判断是否丢弃前 n−1n-1n−1 个输出,只需看该任务"是否需要在中途开口说话"。若只需最终总结则丢弃,若需逐词生成或打标签则全保留。
"1"代表脱离时间属性的"一次性静态特征"(如一张图),而"N"代表随时间步逐帧展开的"动态数据序列"(如一句话)。
1. N-to-1 (多对一) ------ 序列浓缩
- 输入输出:输入完整序列,仅在最后输出单一结果。
- 典型任务:文本分类(情感分析)、单步时序预测。
- 输出层设计:神经元数等于类别数或回归值数。
- 是否丢弃输出 :全部丢弃。 前 n−1n-1n−1 个时间步的输出层被完全剥离,模型只在此阶段"专心听讲"压缩信息,仅利用最后一步的隐藏状态得出最终结论。
2. 1-to-N (一对多) ------ 静态发散
- 输入输出:输入静态特征,随时间步展开输出序列。
- 典型任务:图文生成(看图说话)、指令文本生成(指令不是一句自然语言,而是一个离散的类别标签或单一的控制向量)。
- 输出层设计:本质是多分类,神经元数对应缩减后的词汇表大小。
- 是否丢弃输出 :不丢弃。 这是一个生成任务,必须在每一个时间步往外吐出字/词,所有输出共同拼成完整句子,均需保留并计算 Loss。
3. N-to-N (多对多,同步模式) ------ 逐帧映射
- 输入输出:输入与输出序列长度严格一致。
- 典型任务:命名实体识别 (NER)、词性标注。
- **输出层设计:神经元数等于标签类别数,**常配合CRF或Dice损失(交叉熵损失默认每个词的预测是完全独立的,不管前后文的死活)。
- 是否丢弃输出 :不丢弃。 每一个输入词都必须立刻对应打上一个标签,因此所有时间步的输出都必须保留并计算 Loss。
4. M-to-N (多对多,异步模式 / Seq2Seq) ------ 语义转译
- 输入输出:分为 Encoder(编码)和 Decoder(解码)两阶段,输入输出长度可不一致。
- 典型任务:机器翻译、摘要生成、复杂对话。
- 输出层设计:生成式逻辑,神经元数对应词表大小。
- 是否丢弃输出 :视阶段而定。
- Encoder 阶段全部丢弃: 类似 N-to-1,丢弃所有中间输出,只为凝聚出一个包含全文语义的终极隐藏状态。
- Decoder 阶段绝不丢弃: 类似 1-to-N,拿到终极状态后开始逐词翻译,每一刻的输出都代表生成的单词,必须全保留。
(4). 生成式任务的数据喂入机制:Teacher Forcing 与 Autoregressive
在序列到序列(Seq2Seq)或文本生成任务(1-to-N, M-to-N)中,模型在"训练阶段"和"推理/生成阶段"所使用的数据喂入方式是截然不同的。这是因为训练时我们拥有"上帝视角"(完整答案),而生成时只能靠模型自己"摸着石头过河"。
1. 训练阶段:Teacher Forcing (教师强制)
- 核心思想:在训练生成式模型(预测下一个词)时,我们不使用模型自己上一步预测出的词作为当前步的输入,而是直接将真实的正确答案(Ground Truth)强行喂给模型作为当前步的输入。
- 直观比喻:就像老师教小孩写字,小孩写错了一个字,老师马上纠正,并让小孩基于"正确的字"继续往下想,而不是让小孩顺着自己的错字一直错下去。
- 工程与效率优势 :
- 收敛极快且稳定:防止了初期模型由于胡言乱语导致的"一步错、步步错"的误差累积(Error Accumulation)。
- 极致的并行加速:在 PyTorch 底层,因为所有时间步的"正确输入数据"我们提前全都知道(就是一整句完整的语料),所以我们可以将长度为
seq_len的整个句子一次性打包喂给nn.RNN。GPU 会利用矩阵运算同时算出所有时间步的输出和 Loss,完全不需要写for循环一个字一个字地算。
2. 生成/推理阶段:Autoregressive (自回归)
- 核心思想:在实际生成文本时,由于没有真实标签,模型必须将自己上一个时间步生成的输出,作为下一个时间步的输入喂给自己。
- 直观比喻:考试时的闭卷作文。写出第一个字后,只能根据自己写的第一个字去构思第二个字,依次连击,直到写出完整的文章。
- 工程实现(必备=="记忆预热"==) :
- 由于是一步步顺序生成的,未来是不确定的,因此绝对无法像训练时那样一次性输入完整矩阵。
- 预热(Warm-up):我们必须先将已有的"前缀词(Prefix)"按顺序逐个输入模型,这一步不为了预测,只为了让 RNN 累积和更新隐藏状态,如:RNN的h_0(Hidden State,即记忆)。
- 生成:记忆"养肥"后,提取最新生成的 1 个单词和当前的隐藏状态一起喂给模型,吐出下一个词;再把新词和新状态继续喂进去,循环往复。
3. 隐患与前沿扩展:Exposure Bias (暴露偏差)
- 由于训练时一直有"老师"喂正确答案(Teacher Forcing),模型从未学过如何处理自己生成的错误;而在生成时(Autoregressive),一旦模型自己生成了一个不那么准确的词,后续的生成可能会彻底跑偏甚至崩溃。
- 这种训练与推理阶段输入分布不一致导致的现象,在 NLP 中被称为暴露偏差(Exposure Bias)。
- (注:在更高级的任务中,常采用 Scheduled Sampling(计划采样)策略,即在训练初期 100% 使用 Teacher Forcing,在训练后期逐渐掷骰子决定是喂真实标签还是喂模型自己的预测,让模型提前适应自回归的节奏。)
四.在PyTorch中实现循环神经网络
1.torch.nn中NLP常用类
在NLP入门的世界中,我们常常用到的是torch.nn下各类经典元素,下面这些都是类:
-
词嵌入层Embedding Layers:
torch.nn.Embedding: 用于将离散的词汇ID转换为连续的词向量。注意,Embedding层不能直接接收文字,只能接收经过序列化/独热编码/词嵌入后的文字;普通的Embedding层与Word2Vec,GloVe等方法有巨大的区别。 -
用于处理序列数据的各类神经网络层:
torch.nn.RNN,torch.nn.LSTM, 和torch.nn.GRU等。当然,对RNN来说,我们可以使用nn.Linear来替代nn.RNN,毕竟二者的网络结构是完全一样的,只要将数据流设置正确,torch.nn.RNN和torch.nn.Linear有时可以实现完全一致的效果。 -
服务于Transformer架构的各类神经网络层和模型:例如
nn.Transformer、nn.TransformerEncoder、nn.TransformerDecoder、nn.TransformerEncoderLayer、nn.TransformerDecoderLayer、nn.MultiheadAttention等。 -
在文本任务中常常出现的各类损失函数:例如,在各种NLP任务场景下都可以使用的交叉熵损失
torch.nn.CrossEntropyLoss、均方误差nn.MSELoss、合页损失nn.MarginRankingLoss等损失函数。
2.nn.RNN类 - 循环神经网络层
nn.RNN类是nn.Module类的子类
(1). nn.RNN类类型
作用:
nn.RNN 是 PyTorch 中处理序列数据(如文本、时间序列、语音)的基础网络层。与 nn.Linear 只能孤立地处理单个样本不同,RNN 能够在时间步(Time Step)之间传递"记忆"。使用这个类,我们不需要手动写循环来一步步更新隐藏状态,PyTorch 会在底层自动帮我们沿时间轴展开网络,并创建管理输入到隐藏层的权重 (WihW_{ih}Wih)、隐藏层到隐藏层的权重 (WhhW_{hh}Whh) 以及对应的偏置项 (bih,bhhb_{ih}, b_{hh}bih,bhh)。
python
torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True, batch_first=False, dropout=0.0, bidirectional=False)数学公式:
对于序列中时间步 ttt 的元素,RNN 底层的计算公式为:
ht=tanh(Wihxt+bih+Whhht−1+bhh)h_t = \tanh(W_{ih} x_t + b_{ih} + W_{hh} h_{t-1} + b_{hh})ht=tanh(Wihxt+bih+Whhht−1+bhh)
(注:hth_tht 是当前时间步的隐藏状态,xtx_txt 是当前时间步的输入,ht−1h_{t-1}ht−1 是上一个时间步传过来的隐藏状态。)
核心参数:
- 输入特征维度 (input_size):对应每个时间步输入的特征向量长度。如果是文本,这通常是词向量(Embedding)的维度(如 128 或 256)(int)。
- 隐藏层维度 (hidden_size):RNN 内部记忆向量 (hth_tht) 的长度,这也是 RNN 层最终输出的特征维度 (int)。
- 网络层数 (num_layers):决定了 RNN 的深度。默认为 1。如果填 2,意味着会有两层 RNN 叠加,第一层的输出会作为第二层的输入 (int)。
- 激活函数 (nonlinearity):可选择
'tanh'或'relu',默认为'tanh'(str)。 - 是否批次优先 (batch_first):极其容易踩坑的参数! 默认为
False,这意味着 PyTorch 默认要求的输入形状是(序列长度, 样本数, 特征数)。如果设为True,输入形状就变成了更符合人类直觉的(样本数, 序列长度, 特征数)(bool)。 - 随机失活概率 (dropout):用于防止模型过拟合,默认为 0.0。如果设为大于 0 的值(如 0.5),PyTorch 会在除最后一层外的每一层 RNN 输出后自动应用 Dropout。避坑注意: 此参数仅在
num_layers > 1(多层网络)时才会生效!如果你定义的是单层 RNN,无论设多大都毫无作用 (float)。 - 是否双向 (bidirectional):设为
True则变成双向 RNN (Bi-RNN),会同时从前往后和从后往前扫描序列 (bool)。
核心属性 (Attributes):
由于 RNN 包含时间和层级两个维度,其底层参数比 Linear 复杂得多。以单层单向 RNN 为例:
.weight_ih_l0:第 0 层输入到隐藏层的权重矩阵。.weight_hh_l0:第 0 层隐藏层到隐藏层的权重矩阵(也就是负责跨时间步传递记忆的权重)。.bias_ih_l0与.bias_hh_l0:对应的偏置项。- 注:多层单向 RNN 同理,只需将变量名后缀的
l0替换为对应的层数索引即可。
例如第二层的参数为.weight_ih_l1、.weight_hh_l1等。
(2). call - 实例调用(执行前向传播)
作用:将序列数据(通常还有初始隐藏状态)喂给 RNN 进行时间轴上的展开计算。与所有 nn.Module 一样,严禁直接调用 .forward(),直接把实例当函数调用即可。
python
# 实例化后,传入输入序列 x 和 可选的初始隐藏状态 h_0
output, h_n = rnn_layer(input, h_0)参数:
- 输入张量 (input): 时间序列特征。如果开启了
batch_first=True,形状必须为(batch_size, seq_len, input_size)。 - 初始隐藏状态 (h_0): 可选。形状为
(num_layers * num_directions, batch_size, hidden_size)。如果不提供,PyTorch 会自动生成一个全 0 的张量作为初始记忆。
返回值:
- 成功: 返回一个包含两个张量的元组
(output, h_n)。
维度符号释义 (极其重要:贯穿所有时序网络模型):
batch_size(批次大小):一次性喂给模型的样本总数(例如:一次并行处理32句话)seq_len(序列长度):单个样本在时间轴上的跨度,即:包含的时间步总数。(例如:一句话包含15个单词)input_size(输入特征维度):每一个具体时间步上的数据被表示成了多长的向量(例如:用256维的词向量表示一个具体的单词)hidden_size(隐藏层维度): RNN 内部记忆胶囊的容量大小,也是这一层经过计算后吐出的特征向量长度。num_layers(网络层数): 纵向堆叠了多少层 RNN(普通单层为1,深层网络可能为2或以上)。num_directions(方向数): 决定了模型看数据的方向。单向RNN为1(只从左到右读);双向RNN (bidirectional=True)为2(一个核心从左往右读,另一个核心同时从右往左读,最后拼在一起)。
补充:output 与 h_n 的区别 (极其重要)
当你将数据传入 nn.RNN 时,它会同时返回两个完全不同的张量:output 和 h_n。
-
output(全过程记录):它包含了序列中所有时间步最后一层 RNN 的输出 (即 h1,h2,...,hth_1, h_2, ..., h_th1,h2,...,ht)。
如果
batch_first=True,它的标准形状是[batch_size, seq_len, num_directions * hidden_size]。如果
batch_first=False,它的标准形状是[seq_len, batch_size, num_directions * hidden_size]。用途: 用于 Many-to-Many 任务(如机器翻译、序列标注),因为你需要每一个词对应的预测特征。
(避坑注:无论网络有多深,
output永远只返回最顶层的特征,不受num_layers影响!但如果是双向 RNN,正向和反向的特征会在最后一个维度拼接,导致特征长度翻倍。) -
h_n(终极记忆胶囊):
它包含了所有 RNN 层在最后一个时间步的隐藏状态。它相当于整段序列的"浓缩总结"。
它的形状永远是[num_layers * num_directions, batch_size, hidden_size],不受batch_first影响!
用途: 用于 Many-to-One 任务(如情感分析、文本分类),因为你只需要最后那个综合了全局信息的向量来做最终分类。
总结:
-
output:代表所有时间步上最后一个隐藏层上输出的隐藏状态的集合。 -
h_n: 最后一个时间步的、所有隐藏层上的隐藏状态。
虽然每个时间步、每个隐藏层都会输出隐藏状态,但是RNN类却只会选择性地帮助我们输出部分隐藏状态,output在深层神经网络中只会保留最后一个隐藏层的隐藏状态,而h_n则是只显示最后一个时间步的隐藏状态。通常来说当我们在实现rnn时,所有隐藏状态都是需要向下一个时间步、以及下一个隐藏层传递的,因此output和hn都不能代表nn.RNN层在循环中所传输的信息。
**在很多情况下,我们确实也只会关心最后一个时间步的隐藏状态,或者最后一个隐藏层的隐藏状态。output关注全部时间步,h_n关注全部隐藏层。**在NLP经典任务当中:
-
如果我们需要执行对每一个时间步进行预测的任务(比如,预测每一分钟的股价,预测明天是否会下雨,预测每个单词的情感倾向,预测每个单词的词性),此时我们就会关注每个时间步在最后一个隐藏层上的输出。此时我们要关注的是整个output。
-
如果我们需要执行的是对每张表单、每个句子进行预测的任务时(比如对句子进行情感分类,预测某个时间段内用户的行为),我们就只会关注最后一个时间步的输出。此时我们更可能使用h_n。
但需要注意的是,无论是output还是h_n,都只是循环层的输出,不是循环神经网络真正的输出,因为nn.RNN层缺乏关键性结构:输出层。一般来说,我们不会把循环层的输出直接当作RNN的输出,但这个操作也不是完全不符合规定,毕竟很多时候,我们可能会结合RNN和其他更高级的神经网络,此时循环层的输出需要作为其他神经网络的输入来使用,那循环层本身也可以被认为是构建了一个网络本身,但这种定义是不严谨的,通常来说我们还是需要给循环神经网络加上一个输出层。
示例:
python
import torch
import torch.nn as nn
# 1. 准备假数据:模拟3句话,每句话50个词,每个词被编码为10维的向量
# 形状: (batch_size=3, seq_len=50, input_size=10)
X = torch.randn(3, 50, 10)
# 2. 实例化 RNN 层
rnn_layer = nn.RNN(input_size=10, hidden_size=20, batch_first=True)
# 3. 前向传播:直接把X喂给实例化后的对象
# 没有传入h_0,系统默认为全0状态
output, h_n = rnn_layer(X)
print(output.shape)
# [batch_size, seq_len, num_directions * hidden_size]
# 返回: torch.Size([3, 50, 20])
# 解释: 3个样本,50个时间步,每个时间步吐出一个20维的特征向量。
print(h_n.shape)
# [num_layers * num_directions, batch_size, hidden_size]
# 返回: torch.Size([1, 3, 20])
# 解释: 1个层级(num_layers=1),3个样本,最后一个时间步浓缩出的20维特征向量。
# 最后一层RNN层在最后一个时间步的隐藏状态是output和h_n交集
tmp1 = output[:, -1, :]
tmp2 = h_n[-1, :, :]
print(torch.allclose(tmp1, tmp2))
# True3.单层循环神经网络
同上示例:
python
import torch
import torch.nn as nn
# 1. 准备假数据:模拟3句话,每句话50个词,每个词被编码为10维的向量
# 形状: (batch_size=3, seq_len=50, input_size=10)
X = torch.randn(3, 50, 10)
# 2. 实例化 RNN 层
rnn_layer = nn.RNN(input_size=10, hidden_size=20, batch_first=True)
# 3. 前向传播:直接把X喂给实例化后的对象
# 没有传入h_0,系统默认为全0状态
output, h_n = rnn_layer(X)
print(output.shape)
# [batch_size, seq_len, num_directions * hidden_size]
# 返回: torch.Size([3, 50, 20])
# 解释: 3个样本,50个时间步,每个时间步吐出一个20维的特征向量。
print(h_n.shape)
# [num_layers * num_directions, batch_size, hidden_size]
# 返回: torch.Size([1, 3, 20])
# 解释: 1个层级(num_layers=1),3个样本,最后一个时间步浓缩出的20维特征向量。
# 最后一层RNN层在最后一个时间步的隐藏状态是output和h_n交集
tmp1 = output[:, -1, :]
tmp2 = h_n[-1, :, :]
print(torch.allclose(tmp1, tmp2))
# True4.深层循环神经网络
通过堆叠多个RNN层,让上一层的输出作为下一层的输入,可以提取更高层次的特征。在代码中通过设置num_layers参数即可实现。
在PyTorch中,循环神经网络的每一层隐藏层的尺寸都是相同的,及:num_layers大于1时,每层的hidden_size都一样。
想改成不一样的话,可以自己手动堆叠nn.RNN
python
import torch
import torch.nn as nn
# 1. 准备假数据:模拟3句话,每句话50个词,每个词被编码为10维的向量
# 形状: (batch_size=3, seq_len=50, input_size=10)
X = torch.randn(3, 50, 10)
# 2. 实例化 RNN 层
rnn_layer = nn.RNN(input_size=10, hidden_size=20,num_layers=4, batch_first=True)
# 3. 前向传播:直接把X喂给实例化后的对象
# 没有传入h_0,系统默认为全0状态
output, h_n = rnn_layer(X)
print(output.shape)
# [batch_size, seq_len, num_directions * hidden_size]
# 返回: torch.Size([3, 50, 20])
# 解释: 3个样本,50个时间步,每个时间步吐出一个20维的特征向量。
print(h_n.shape)
# [num_layers * num_directions, batch_size, hidden_size]
# 返回: torch.Size([4, 3, 20])
# 解释: 1个层级(num_layers=1),3个样本,最后一个时间步浓缩出的20维特征向量。
# 最后一层RNN层在最后一个时间步的隐藏状态是output和h_n交集
tmp1 = output[:, -1, :]
tmp2 = h_n[-1, :, :]
print(torch.allclose(tmp1, tmp2))
# True使用nn.RNN来实现一个简单的深度循环神经网络,我们设置输入层为100个神经元,输出层为3个神经元(假设这是一个最为单纯的三分类任务,需要对每个句子进行情感分类),其中每个隐藏层都有256个神经元。
python
import torch
import torch.nn as nn
#我们设置输入层为100个神经元,输出层为3个神经元
#假设这是一个三分类任务,需要对每个句子进行情感分类
class MyRNN(nn.Module):
def __init__(self,input_size=100,hidden_size=[256, 256, 512, 512],num_layers=2,output_size=3):
super().__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.rnn1 = nn.RNN(
input_size=input_size,
hidden_size=hidden_size[0],
num_layers=num_layers,
batch_first=True)
self.rnn2 = nn.RNN(
input_size=hidden_size[0],
hidden_size=hidden_size[1],
num_layers=num_layers,
batch_first=True)
self.rnn3 = nn.RNN(
input_size=hidden_size[1],
hidden_size=hidden_size[2],
num_layers=num_layers,
batch_first=True)
self.rnn4 = nn.RNN(
input_size=hidden_size[2],
hidden_size=hidden_size[3],
num_layers=num_layers,
batch_first=True)
self.fc = nn.Linear(hidden_size[3],output_size)
def forward(self,x):
# x的形状: (batch_size, seq_length, input_size)
# h_0的形状:(num_layers*(1/2), batch_size, hidden_size)
# 初始化h0,需要对4个隐藏层都初始化
# 但由于此时4个隐藏层是分开的,且神经元数量不同,因此需要分开初始化
h_0 = [torch.zeros(self.num_layers, len(x), self.hidden_size[0],device=device)
,torch.zeros(self.num_layers, len(x), self.hidden_size[1],device=device)
,torch.zeros(self.num_layers, len(x), self.hidden_size[2],device=device)
,torch.zeros(self.num_layers, len(x), self.hidden_size[3],device=device)]
output1,_ = self.rnn1(x,h_0[0]) #h_n用不上,用_占位符提取一下
# output1的形状:(batch_size,seq_length,self.hidden_size[0])
output2,_ = self.rnn2(output1,h_0[1])
output3,_ = self.rnn3(output2,h_0[2])
output4,_ = self.rnn4(output3,h_0[3])
predict = self.fc(output4[:,-1,:])
return predict
torch.random.manual_seed(420)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model =MyRNN(input_size=100,hidden_size=[256, 256, 512, 512],num_layers=2,output_size=3)
# 准备假数据:模拟3句话,每句话50个词,每个词被编码为100维的向量
X = torch.rand(3,50,100)
# GPU优化
model = model.to(device)
X = X.to(device)
print(model(X))
# tensor([[0.0331, 0.0613, 0.0566],
# [0.0373, 0.0653, 0.0541],
# [0.0347, 0.0629, 0.0524]], device='cuda:0', grad_fn=<AddmmBackward0>)5.双向循环神经网络
双向RNN(Bi-RNN)同时考虑序列的过去和未来信息,分别从前向后和从后向前扫描,最后将隐藏状态拼接。常用于需要全局语义信息的任务。
BiRNN的核心思想是同时在序列的两个方向上运行两个独立的RNN。其中一个RNN按正常顺序处理输入序列,就像我们在之前的可成中讲解的那样,从第一个词语开始一个一个、从前向后将词语输入网络;而另一个RNN则从句子的最末端开始,从最后一个词语开始,一个一个、从后向前地将词语输入网络。这意味着,对于序列中的任意一个时间点,BiRNN都可以捕获其前向和后向的信息。这两个方向上的RNN输出随后通常会被联结或合并,以形成一个统一的输出表示。
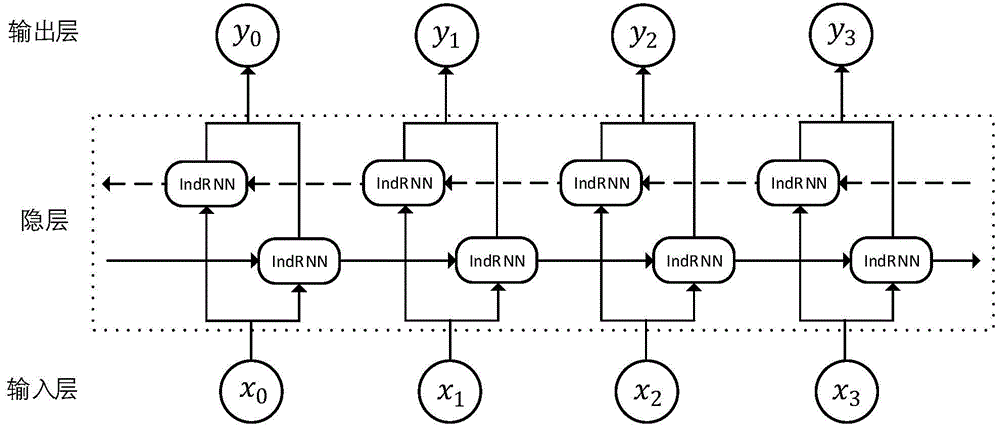
需要注意的是,虽然架构图上展示的过程似乎表示正向和反向的循环过程是同时进行的,但在实际代码实现过程中,正向和反向循环网络是按顺序进行的,没有任何并行处理。虽然从理论上说,正向和反向RNN在每个时间步都是独立的(即它们不需要相互的输出作为输入),但在大多数深度学习框架的实现中,双向RNN是按照上述顺序分步骤执行的,主要是为了代码的简洁和效率。一般来说,正向的循环结束之后,反向的循环才会开始,因此BiRNN的运行时间是更长的。
在实际应用中,双向RNN与其他深度学习结构(如LSTM或GRU)的结合已经显示出了卓越的性能,特别是在序列标注、文本分类和机器翻译等任务中。但是很明显,与传统RNN相比,双向RNN的计算需求成倍增加,所以双向RNN所带来的性能提升也不是完全无代价的。
在代码中通过设置bidirectional参数即可实现。代码同理如上
五.RNN的反向传播与缺陷
1.RNN反向传播的数学过程
首先,由于循环层的存在,RNN数据流存在两个方向 :第一个方向是与普通神经网络一致的【输入层-隐藏层-输出层】方向,第二个维度则是沿着时间步进行传播的【输入-t时刻隐藏层-t+1时刻隐藏层】方向。由于反向传播是正向传播的逆过程,因此循环神经网络在反向传播上也同样有两个方向:一个是从与普通神经网络一致的【输出层-隐藏层-输入层】方向,另一个则是循环网络独特的【输出-t时刻隐藏层-t+1时刻隐藏层】的方向。这种同时在两个方向上进行反向传播的方式被称之为"通过时间的反向传播"(Backpropagation Through Time,BPTT),是循环神经网络的特色之一。
通过时间的反向传播(BPTT)比一般的反向传播要更为复杂,不过它也是从损失函数开始不断向各级的权重WWW求导、并利用导数来迭代权重的过程。我们来仔细看一下它的具体流程:
-
明确NLP任务,明确标签输出的方式
在之前我们提到,在不同类型NLP任务会有不同的输出层结构、会有不同的标签输出方式。例如,在对词语/样本进行预测的任务中(情感分类、词性标注、时间序列等任务),RNN会在每个时间步都输出词语对应的相应预测标签 ;但是,在对句子进行预测的任务中(例如,生成式任务、seq2seq的任务、或以句子为单位进行标注、分类的任务),RNN很可能只会在最后一个时间步输出句子相对应的预测标签。输出标签的方式不同,反向传播的流程自然会有所区别。
考虑到生成式任务的多样性和复杂性,在这里我们使用词语情感分类任务(即:每个时间步都输出预测标签)作为例子来讲解RNN反向传播中的各种特点与问题。
-
正向/反向传播的数学过程
假设现在我们有一个最为简单的RNN,需要完成针对每个词语的情感分类任务。该RNN由输入层、一个隐藏层和一个输出层构成,全部层都没有截距项,总共循环ttt个时间步。该网络的输入数据为XXX,输出的预测标签为y^\hat{y}y^,真实标签为yyy,激活函数为σ\sigmaσ,输入层与隐藏层之间的权重矩阵为WxhW_{xh}Wxh,隐藏层与输出层之间的权重矩阵为WhyW_{hy}Why,隐藏层与隐藏层之间的权重为WhhW_{hh}Whh,损失函数为L(y^,y)L(\hat{y},y)L(y^,y),t时刻的损失函数我们简写为LtL_tLt。 此时,这个RNN的**正向传播过程**可以展示如下:
时间步1,初始化h0h_0h0,并且初始化需要迭代的参数WhhW_{hh}Whh、Wxh{W}{xh}Wxh、Why{W}{hy}Whyh1=σ(WxhX1+Whhh0)y^1=Whyh1L1=L(y^1,y1) \begin{align*} \mathbf{h}1 &= \sigma(\mathbf{W}{xh} \mathbf{X}1 + \mathbf{W}{hh} \mathbf{h}_0) \\ \\ \mathbf{\hat{y}}1 &= \mathbf{W}{hy} \mathbf{h}_1 \\ \\ L_1 &= L(\mathbf{\hat{y}}_1,\mathbf{y}_1) \end{align*} h1y^1L1=σ(WxhX1+Whhh0)=Whyh1=L(y^1,y1)
时间步2
h2=σ(WxhX2+Whhh1)=σ(WxhX2+Whhσ(WxhX1+Whhh0))y^2=Whyh2L2=L(y^2,y2) \begin{align*} \mathbf{h}2 &= \sigma(\mathbf{W}{xh} \mathbf{X}2 + \mathbf{W}{hh} \color{red}{\mathbf{h}1}) \\ & = \sigma(\mathbf{W}{xh} \mathbf{X}2 + \mathbf{W}{hh} \color{red}{\sigma(\mathbf{W}_{xh} \mathbf{X}1 + \mathbf{W}{hh} \mathbf{h}_0)}) \\ \\ \mathbf{\hat{y}}2 &= \mathbf{W}{hy} \mathbf{h}_2 \\ \\ L_2 &= L(\mathbf{\hat{y}}_2,\mathbf{y}_2) \end{align*} h2y^2L2=σ(WxhX2+Whhh1)=σ(WxhX2+Whhσ(WxhX1+Whhh0))=Whyh2=L(y^2,y2)
......
时间步t−1t-1t−1
ht−1=σ(WxhXt−1+Whhht−2)=σ(WxhXt−1+Whhσ(WxhXt−2+Whhht−3))y^t−1=Whyht−1Lt−1=L(y^t−1,yt−1) \begin{align*} \mathbf{h}{t-1} &= \sigma(\mathbf{W}{xh} \mathbf{X}{t-1} + \mathbf{W}{hh} \color{red}{\mathbf{h}{t-2}}) \\ & = \sigma(\mathbf{W}{xh} \mathbf{X}{t-1} + \mathbf{W}{hh} \color{red}{\sigma(\mathbf{W}{xh} \mathbf{X}{t-2} + \mathbf{W}{hh} \mathbf{h}{t-3})}) \\ \\ \mathbf{\hat{y}}{t-1} &= \mathbf{W}{hy} \mathbf{h}{t-1} \\ \\ L{t-1} &= L(\mathbf{\hat{y}}{t-1},\mathbf{y}{t-1}) \end{align*} ht−1y^t−1Lt−1=σ(WxhXt−1+Whhht−2)=σ(WxhXt−1+Whhσ(WxhXt−2+Whhht−3))=Whyht−1=L(y^t−1,yt−1)
时间步ttt
ht=σ(WxhXt+Whhht−1)=σ(WxhXt+Whhσ(WxhXt−1+Whhht−2))y^t=WhyhtLt=L(y^t,yt) \begin{align*} \mathbf{h}{t} &= \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \color{red}{\mathbf{h}{t-1}}) \\ & = \sigma(\mathbf{W}{xh} \mathbf{X}t + \mathbf{W}{hh} \color{red}{\sigma(\mathbf{W}{xh} \mathbf{X}{t-1} + \mathbf{W}{hh} \mathbf{h}{t-2})}) \\ \\ \mathbf{\hat{y}}{t} &= \mathbf{W}{hy} \mathbf{h}{t} \\ \\ L{t} &= L(\mathbf{\hat{y}}{t},\mathbf{y}{t}) \end{align*} hty^tLt=σ(WxhXt+Whhht−1)=σ(WxhXt+Whhσ(WxhXt−1+Whhht−2))=Whyht=L(y^t,yt)
不难发现,RNN中存在至少三个权重矩阵需要迭代:输入层与隐藏层之间的权重矩阵为WxhW_{xh}Wxh,隐藏层与输出层之间的权重矩阵为WhyW_{hy}Why,隐藏层与隐藏层之间的权重为WhhW_{hh}Whh。在循环神经网络中,我们首先要完成全部时间步上的正向传播,才可以开始进行反向传播和参数迭代,因此用于计算h1h_1h1的WxhW_{xh}Wxh和WhhW_{hh}Whh与用于计算hth_tht的WxhW_{xh}Wxh和WhhW_{hh}Whh是完全相同的权重矩阵。这是循环神经网络权值共享的关键,表面上看是所有表单共享一套参数,本质是所有时间步上的所有循环共享一套参数,无论走过多少时间步,我们使用的始终都是同一套WhhW_{hh}Whh、WxhW_{xh}Wxh和WhyW_{hy}Why。
当完成正向传播后,我们需要在反向传播过程中对以上三个权重求解梯度、并迭代权重。反向传播是从最后的时间步开始,因此以最后的时间步t为例子,我们的反向传播过程为:
时间步t,我们需要求解的三个梯度为:
1)∂Lt∂Why2.1)∂Lt∂Wxh3.1)∂Lt∂Whh \begin{align*} 1)\frac{\partial L_{t}}{\partial W_{hy}}\\ \\ 2.1)\frac{\partial L_{t}}{\partial W_{xh}}\\ \\ 3.1)\frac{\partial L_{t}}{\partial W_{hh}}\\ \\ \end{align*} 1)∂Why∂Lt2.1)∂Wxh∂Lt3.1)∂Whh∂Lt
其中,1、2.1是做用于传统深度神经网络的、做用于隐藏层和输入层、输出层之间的权重矩阵,3.1则是在循环神经网络的循环层上、作用于时间步方向的权重矩阵。根据之前的数学流程,LtL_{t}Lt可以展开展示为:
Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \mathbf{h}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \mathbf{h}{t-1}), \mathbf{y}_{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)可见,LtL_{t}Lt是以y^t\hat{y}{t}y^t为自变量的函数,y^t\hat{y}{t}y^t是以WhyW_{hy}Why和hth_{t}ht为自变量的函数,hth_{t}ht又是以WxhW_{xh}Wxh和WhhW_{hh}Whh为自变量的函数,因此要求解上面三个梯度,其实是需要对复合函数进行求导。 根据链式法则规则,如果y = f(u)并且u = g(x),那y直接对x求导的公式则可写成:
dydx=dydu⋅dudx \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy=dudy⋅dxdu因此根据链式法则,我们有:
- ∂Lt∂Why=∂Lt∂y^t∗∂y^t∂Why2.1) ∂Lt∂Wxh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂Wxh3.1) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂Whh \begin{align*} \ 1) \ \frac{\partial L_{t}}{\partial W_{hy}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial W_{hy}} \\ \\ 2.1) \ \frac{\partial L_{t}}{\partial W_{xh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial W_{xh}} \\ \\ 3.1) \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial W_{hh}} \end{align*} 1) ∂Why∂Lt2.1) ∂Wxh∂Lt3.1) ∂Whh∂Lt=∂y^t∂Lt∗∂Why∂y^t=∂y^t∂Lt∗∂ht∂y^t∗∂Wxh∂ht=∂y^t∂Lt∗∂ht∂y^t∗∂Whh∂ht
到这里为止循环神经网络的反向传播过程都与普通深度神经网络类似,但上面的公式2.1和3.1中存在一个关键问题,那就是hth_tht作为一个复合函数,不止能以WxhW_{xh}Wxh和WhhW_{hh}Whh为自变量,还能以上层的隐藏状态ht−1h_{t-1}ht−1作为自变量,而ht−1h_{t-1}ht−1本身又是以WxhW_{xh}Wxh和WhhW_{hh}Whh为自变量的函数:
Lt=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt+Whhht−2),yt) \begin{align*} L_{t} &=L(\mathbf{W}{hy} \mathbf{h}{t}, \mathbf{y}{t}) \\ \\ &= L(\mathbf{W}{hy} \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \color{red}{\mathbf{h}{t-1}}), \mathbf{y}{t}) \\ \\ &= L(\mathbf{W}{hy} \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \color{red}{\sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \mathbf{h}{t-2})},\mathbf{y}{t}) \end{align*} Lt=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt+Whhht−2),yt)
在之前我们提到过,由于循环神经网络有权值共享机制,因此用于计算hth_{t}ht的WxhW_{xh}Wxh和WhhW_{hh}Whh与用于计算ht−1h_{t-1}ht−1的WxhW_{xh}Wxh和WhhW_{hh}Whh是完全相同的权重矩阵。如下面的公式所示,蓝色的部分是完全相同的矩阵,红色的部分也是完全相同的矩阵:
Lt=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt+Whhht−2),yt) \begin{align*} L_{t} &=L(\mathbf{W}{hy} \mathbf{h}{t}, \mathbf{y}{t}) \\ \\ &= L(\mathbf{W}{hy} \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} {\mathbf{h}{t-1}}), \mathbf{y}{t}) \\ \\ &= L(\mathbf{W}{hy} \sigma(\color{blue}{\mathbf{W}{xh}} \mathbf{X}{t} + \color{red}{\mathbf{W}{hh}} \sigma(\color{blue}{\mathbf{W}{xh}} \mathbf{X}{t} + \color{red}{\mathbf{W}{hh}} \mathbf{h}{t-2}),\mathbf{y}{t}) \end{align*} Lt=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt+Whhht−2),yt)
所以在求解LtL_{t}Lt对WxhW_{xh}Wxh和WhhW_{hh}Whh的导数时,不止可以求解上面所写的式子2.1和3.1,还可以继续对嵌套函数求解得到下面的梯度2.2和3.2
2.1) ∂Lt∂Wxh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂Wxh2.2) ∂Lt∂Wxh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂ht−1∗∂ht−1∂Whh3.1) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂Whh3.2) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂ht−1∗∂ht−1∂Whh \begin{align*} 2.1) \ \frac{\partial L_{t}}{\partial W_{xh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial W_{xh}} \\ \\ \color{red}{2.2)} \ \frac{\partial L_{t}}{\partial W_{xh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial h_{t-1}} * \frac{\partial h_{t-1}}{\partial W_{hh}} \\ \\ 3.1) \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial W_{hh}} \\ \\ \color{red}{3.2)} \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial h_{t-1}} * \frac{\partial h_{t-1}}{\partial W_{hh}} \\ \\ \end{align*} 2.1) ∂Wxh∂Lt2.2) ∂Wxh∂Lt3.1) ∂Whh∂Lt3.2) ∂Whh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂Wxh∂ht=∂y^t∂Lt∗∂ht∂y^t∗∂ht−1∂ht∗∂Whh∂ht−1=∂y^t∂Lt∗∂ht∂y^t∗∂Whh∂ht=∂y^t∂Lt∗∂ht∂y^t∗∂ht−1∂ht∗∂Whh∂ht−1
甚至,我们还可以将ht−1h_{t-1}ht−1继续拆解为σ(WxhXt−1+Whhht−2)\sigma(\mathbf{W}{xh} \mathbf{X}{t-1} + \mathbf{W}{hh} \mathbf{h}{t-2})σ(WxhXt−1+Whhht−2),还可以将ht−2h_{t-2}ht−2继续拆解为σ(WxhXt−2+Whhht−3)\sigma(\mathbf{W}{xh} \mathbf{X}{t-2} + \mathbf{W}{hh} \mathbf{h}{t-3})σ(WxhXt−2+Whhht−3),我们可以将嵌套函数无止尽地拆解下去,直到拆到h1=σ(WxhX1+Whhh0)\mathbf{h}1 = \sigma(\mathbf{W}{xh} \mathbf{X}1 + \mathbf{W}{hh} \mathbf{h}0)h1=σ(WxhX1+Whhh0)为止。在这个过程中,只要拆解足够多,我们可以从LtL{t}Lt求解出t个针对WxhW_{xh}Wxh和WhhW_{hh}Whh的导数。因此惊人的事实是,在时间步t上,我们可以计算t个用于迭代WxhW_{xh}Wxh和WhhW_{hh}Whh的梯度!
在整个RNN的反向传播过程中,每个时间步上可以计算的用于迭代WxhW_{xh}Wxh和WhhW_{hh}Whh的梯度等于时间步的数值本身。在时间步t上,我们可以计算t个用于迭代WxhW_{xh}Wxh和WhhW_{hh}Whh的梯度,在时间步t-1上,我们可以计算t-1个用于迭代WxhW_{xh}Wxh和WhhW_{hh}Whh的梯度,因此有t个时间步时,我们可以计算的用与迭代WxhW_{xh}Wxh和WhhW_{hh}Whh的梯度的梯度总数量为:
t+(t−1)+(t−2)+⋯+1=t(t−1)2t+(t−1)+(t−2)+⋯+1=\frac{t(t-1)}{2}t+(t−1)+(t−2)+⋯+1=2t(t−1)
这是一个算数级数之和。那我们现在该如何使用这么多梯度来对WhhW_{hh}Whh进行迭代呢?通常来说,我们可以对这些梯度进行求和、求均值等聚合计算,并将聚合后的值用与迭代。以下是一个聚合的例子:
ΔWhh=∑i=1t(t−1)2∂L∂Whh(i)Whh=Whh−η⋅ΔWhh \begin{align*} \Delta W_{hh} &= \sum_{i=1}^{\frac{t(t-1)}{2}}\frac{\partial L}{\partial W_{hh}^{(i)}} \\ \\ W_{hh} &= W_{hh} - \eta \cdot \Delta W_{hh} \end{align*} ΔWhhWhh=i=1∑2t(t−1)∂Whh(i)∂L=Whh−η⋅ΔWhh
其中,η\etaη是迭代中的学习率,也可写做α\alphaα等字母。以上迭代流程在每个batch会发生一次。
2.RNN的反向传播带来的问题
作为NLP入门级经典算法,RNN处理序列数据的思路精彩非凡,但同时它也有众多不可忽视的缺陷,而这些缺陷大多与它的复杂的反向传播过程有关,让我们来一一看看这些问题:
(1).极其容易发生梯度消失和梯度爆炸
梯度消失和梯度爆炸是神经网络在训练过程中很常见的问题之一,其中梯度消失是指随着迭代进行、权重的梯度变得越来越小,从而导致迭代失效的现象;梯度爆炸是指随着迭代进行、权重的梯度变得越来越大、从而导致迭代失效的现象,这种现象一般是由反向传播中的偏导数连乘引起的。相比起一般的深度学习算法,RNN算法更容易发生梯度消失和梯度爆炸现象,因为RNN反向传播中的连乘过程会比DNN反向传播中的连乘过程更加极端。 来看RNN反向传播过程中损失函数的表达式,在时间步t上我们有:
Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt−1+Whhht−2)),yt)⋮=L(Whyσ(WxhXt+Whhσ(WxhXt−1+⋯+Whhσ(WxhX1+Whhh0))...),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \mathbf{h}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \mathbf{h}{t-1}), \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \sigma(\mathbf{W}{xh} \mathbf{X}{t-1} + \mathbf{W}{hh} \mathbf{h}{t-2})), \mathbf{y}{t}) \\ \\ & \vdots \\ \\ &=L(\mathbf{W}{hy} \sigma(\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \sigma(\mathbf{W}{xh} \mathbf{X}{t-1} + \dots + \mathbf{W}{hh} \sigma(\mathbf{W}{xh} \mathbf{X}{1} + \mathbf{W}{hh} \mathbf{h}{0}))...), \mathbf{y}{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Whyσ(WxhXt+Whhht−1),yt)=L(Whyσ(WxhXt+Whhσ(WxhXt−1+Whhht−2)),yt)⋮=L(Whyσ(WxhXt+Whhσ(WxhXt−1+⋯+Whhσ(WxhX1+Whhh0))...),yt)
这个公式嵌套了t层公式,共有hth_tht到h0h_0h0的t个自变量,且每个自变量h都与权重WhhW_{hh}Whh相乘。假设此时我们令激活函数σ\sigmaσ为恒等函数f(x)=xf(x) = xf(x)=x,则损失函数的公式可以改写为:
Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \mathbf{h}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} (\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \mathbf{h}{t-1}), \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} (\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} (\mathbf{W}{xh} \mathbf{X}{t-1} + \mathbf{W}{hh} \mathbf{h}{t-2})), \mathbf{y}{t}) \\ \\ & \vdots \\ \\ &=L(\mathbf{W}{hy} (\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} (\mathbf{W}{xh} \mathbf{X}{t-1} + \dots + \mathbf{W}{hh} (\mathbf{W}{xh} \mathbf{X}{1} + \mathbf{W}{hh} \mathbf{h}{0}))...), \mathbf{y}{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt)
在这个彻底拆解后的公式上,我们可以求解出嵌套了t层的WhhW_{hh}Whh的梯度(如公式3.t):
3.t) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂ht−1∗∂ht−1∂ht−2∗ ... ∗∂h2∂h1∗∂h1∂Whh \begin{align*} {3.t)} \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial h_{t-1}} * \frac{\partial h_{t-1}}{\partial h_{t-2}} * \ \ ... \ \ * \frac{\partial h_2}{\partial h_1} * \frac{\partial h_1}{\partial W_{hh}} \\ \\ \end{align*} 3.t) ∂Whh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂ht−1∂ht∗∂ht−2∂ht−1∗ ... ∗∂h1∂h2∗∂Whh∂h1
此时在这个公式中,许多偏导数的求解就变得非常简单,例如:
∵y^t=Whyht, ∴∂y^t∂ht=Why∵ht=WxhXt+Whhht−1, ∴∂ht∂ht−1=Whh∵ht−1=WxhXt−1+Whhht−2, ∴∂ht−1∂ht−2=Whh⋮∵h2=WxhX2+Whhh1, ∴∂h2∂h1=Whh∵h1=WxhX1+Whhh0, ∴∂h1∂Whh=h0 \begin{align*} &\because {\hat{y}}{t} = W{hy} h_{t},\ \ \therefore \frac{\partial \hat{y}{t}}{\partial h{t}} = {W}{hy} \\ \\ &\because {h}{t} = {W}{xh} {X}{t} + {W}{hh} {h}{t-1}, \ \ \therefore \frac{\partial h_{t}}{\partial h_{t-1}} = {W}{hh} \\ \\ &\because {h}{t-1} = {W}{xh} {X}{t-1} + {W}{hh} {h}{t-2}, \ \ \therefore \frac{\partial h_{t-1}}{\partial h_{t-2}} = {W}{hh} \\ \\ & \vdots \\ \\ &\because {h}2 = {W}{xh} {X}{2} + {W}{hh} {h}{1}, \ \ \therefore \frac{\partial h_2}{\partial h_1} = {W}{hh} \\ \\ &\because {h}1 = {W}{xh} {X}{1} + {W}{hh} {h}{0}, \ \ \therefore \frac{\partial h_1}{\partial {W}{hh}} = {h}{0} \end{align*} ∵y^t=Whyht, ∴∂ht∂y^t=Why∵ht=WxhXt+Whhht−1, ∴∂ht−1∂ht=Whh∵ht−1=WxhXt−1+Whhht−2, ∴∂ht−2∂ht−1=Whh⋮∵h2=WxhX2+Whhh1, ∴∂h1∂h2=Whh∵h1=WxhX1+Whhh0, ∴∂Whh∂h1=h0
所以最终的梯度表达式为:
3.t) ∂Lt∂Whh=∂Lt∂y^t∗∂y^t∂ht∗∂ht∂ht−1∗∂ht−1∂ht−2∗ ... ∗∂h2∂h1∗∂h1∂Whh=∂Lt∂y^t∗Why∗Whh∗Whh∗ ... ∗Whh∗h0=∂Lt∂y^t∗Why∗(Whh)t−1∗h0 \begin{align*} {3.t)} \ \frac{\partial L_{t}}{\partial W_{hh}} &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * \frac{\partial \hat{y}{t}}{\partial h_{t}} * \frac{\partial h_{t}}{\partial h_{t-1}} * \frac{\partial h_{t-1}}{\partial h_{t-2}} * \ \ ... \ \ * \frac{\partial h_2}{\partial h_1} * \frac{\partial h_1}{\partial W_{hh}} \\ \\ &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * W{hy} * W_{hh} * W_{hh} * \ \ ... \ \ * W_{hh} * h_0 \\ \\ &= \frac{\partial L_{t}}{\partial \hat{y}{t}} * W{hy} * (W_{hh})^{t-1}* h_0 \\ \\ \end{align*} 3.t) ∂Whh∂Lt=∂y^t∂Lt∗∂ht∂y^t∗∂ht−1∂ht∗∂ht−2∂ht−1∗ ... ∗∂h1∂h2∗∂Whh∂h1=∂y^t∂Lt∗Why∗Whh∗Whh∗ ... ∗Whh∗h0=∂y^t∂Lt∗Why∗(Whh)t−1∗h0
不难发现,在这个梯度表达式中出现了(Whh)t−1(W_{hh})^{t-1}(Whh)t−1这样的高次项,这就是循环神经网络非常容易梯度爆炸和梯度消失的根源所在------假设WhhW_{hh}Whh是一个小于1的值,那(Whh)t−1(W_{hh})^{t-1}(Whh)t−1将会非常接近于0,从而导致梯度消失;假设WhhW_{hh}Whh大于1,那(Whh)t−1(W_{hh})^{t-1}(Whh)t−1将会接近无穷大,从而引发梯度爆炸,其中梯度消失发生的可能性又远远高于梯度爆炸。
在深度神经网络中,在应用链式法则后,我们也会面临复合函数梯度连乘的问题,但由于普通神经网络中并不存在"权值共享"的现象,因此每个偏导数的表达式求解出的值大多是不一致的,在连乘的时候有的偏导数值较大、有的偏导数值较小,相比之下就不那么容易发生梯度爆炸或梯度消失问题的问题。
当然,现在的公式是建立在"激活函数是恒等函数"这个假设上的,当激活函数不是恒等函数时,而是sigmoid或tanh时,梯度消失会更容易发生(毕竟激活函数会将连乘的值不断压缩到0-1之间),此时我们将会看到不同的公式,但公式中相同的"权重不断连乘形成高次方项"的问题本质都是一致的,因此如果你在其他教材或课程中看到不同的公式也不必惊慌。
在RNN的训练过程中,梯度消失和梯度爆炸非常常见,所以为了应对这种现象,我们有如下的解决方案:
- 权重初始化:使用适当的权重初始化策略可以帮助缓解梯度消失/爆炸的问题。例如,使用Xavier初始化。当然,不恰当的初始化更可能引发梯度爆炸,因为初始化的权重矩阵一般都是小于1的值,因此在使用该手段时要特别小心。
- 梯度截断(Gradient Clipping):通过设定一个阈值,当梯度超过这个阈值时,将其缩小到该阈值,从而避免梯度爆炸。同样的,设定一个阈值,当梯度小于这个阈值时,将其放大到阈值,从而避免梯度消失。
- 在RNN中适当加入残差链接、Batch Normalization等技术,对深层循环神经网络可能有用。
- 使用更高级的、改进后的RNN结构,例如:
LSTM (Long Short-Term Memory):LSTM是RNN的一个变种,设计上加入了三个门结构(输入门、遗忘门和输出门)来控制信息的流动,从而有效地缓解了梯度消失的问题。
GRU (Gated Recurrent Unit):GRU是LSTM的简化版本,它只有两个门结构(更新门和重置门)。虽然结构更简单,但在某些任务上与LSTM有着类似的表现。
(2).容易遗忘,难以捕获长期依赖关系
尽管我们说循环网络在最后一个时间步时依然能够保留第一个时间步的信息,但在循环神经网络复杂的嵌套过程中,较早的时间步中的信息重要性会被大幅削弱,从而导致网络会"遗忘掉"最初的信息,而只记得最近的时间步的信息。 在我们了解循环网络的嵌套和连乘过程后,遗忘问题其实很好理解,回到损失函数的表达式中:
Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \mathbf{h}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} (\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} \mathbf{h}{t-1}), \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} (\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} (\mathbf{W}{xh} \mathbf{X}{t-1} + \mathbf{W}{hh} \mathbf{h}{t-2})), \mathbf{y}{t}) \\ \\ & \vdots \\ \\ &=L(\mathbf{W}{hy} (\mathbf{W}{xh} \mathbf{X}{t} + \mathbf{W}{hh} (\mathbf{W}{xh} \mathbf{X}{t-1} + \dots + \mathbf{W}{hh} (\mathbf{W}{xh} \mathbf{X}{1} + \mathbf{W}{hh} \mathbf{h}{0}))...), \mathbf{y}{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt)
同样是基于σ\sigmaσ是恒等函数的假设,我们来观察上述损失函数中的输入信息XXX。不难发现,在标签输出和损失计算过程中,每个输入信息XXX前都有权重的连乘项:
Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt) \begin{align*} L_{t} &= L(\mathbf{\hat{y}}{t}, \mathbf{y}{t}) \\ \\ &=L(\mathbf{W}{hy} \mathbf{h}{t}, \mathbf{y}{t}) \\ \\ &=L(\color{red}{\mathbf{W}{hy} (\mathbf{W}{xh}} \mathbf{X}{t} + \mathbf{W}{hh} \mathbf{h}{t-1}), \mathbf{y}{t}) \\ \\ &=L(\color{red}{\mathbf{W}{hy}} (\mathbf{W}{xh} \mathbf{X}{t} + \color{red}{\mathbf{W}{hh} (\mathbf{W}{xh}} \mathbf{X}{t-1} + \mathbf{W}{hh} \mathbf{h}{t-2})), \mathbf{y}{t}) \\ \\ & \vdots \\ \\ &=L(\color{red}{\mathbf{W}{hy}} (\mathbf{W}{xh} \mathbf{X}{t} + \color{red}{\mathbf{W}{hh}} (\mathbf{W}{xh} \mathbf{X}{t-1} + \dots + \color{red}{\mathbf{W}{hh} (\mathbf{W}{xh}} \mathbf{X}{1} + \mathbf{W}{hh} \mathbf{h}{0}))...), \mathbf{y}{t}) \end{align*} Lt=L(y^t,yt)=L(Whyht,yt)=L(Why(WxhXt+Whhht−1),yt)=L(Why(WxhXt+Whh(WxhXt−1+Whhht−2)),yt)⋮=L(Why(WxhXt+Whh(WxhXt−1+⋯+Whh(WxhX1+Whhh0))...),yt)
对于最初输入的X1X_1X1来说前面的连乘项为Why(Whh)t−2Wxh\mathbf{W}{hy}(\mathbf{W}{hh})^{t-2}\mathbf{W}{xh}Why(Whh)t−2Wxh,对于X2X_2X2来说前面的连乘项为Why(Whh)t−3Wxh\mathbf{W}{hy}(\mathbf{W}{hh})^{t-3}\mathbf{W}{xh}Why(Whh)t−3Wxh,这些高次项连乘后再乘以XXX,大部分时候会极大程度地削弱XXX本身的信息传递,即便不发生梯度消失,权重连乘后的值一般也是一个比较小的数字。因此在RNN当中,越早时间步的输入越容易被遗忘,RNN也因此不擅长处理很长的序列,而这一点其实非常难以改善。
六.项目1-情感分类任务
1.任务介绍
情感分类是自然语言处理(NLP)中的一个经典任务,旨在对文本进行情感分类,通常包括将文本分为"正面"、"负面"或"中性"等情感类别。IMDb数据集是情感分类任务中的一个著名数据集,它包含来自电影评论的文本数据,并标记为正面或负面情感,因此可以用于训练和评估情感分类模型。
IMDb数据集的主要特点:
- 数据规模:IMDb数据集通常包含数万条电影评论文本,用于训练和测试情感分类模型。
- 标签:每个电影评论都被标记为"正面"或"负面"情感。
- 文本数据:评论文本是情感分类模型的输入,模型需要学习从文本中提取有关情感的特征。
- 任务复杂性:情感分类任务结果相对简单,但在处理自然语言时,涉及了文本处理、特征提取、情感理解等NLP的关键技术。
2.数据预处理
3. 完整代码
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
import pandas as pd
import re
from pathlib import Path
from sklearn.model_selection import train_test_split
# 模块 1:数据预处理与词表构建
class IMDBProcessor:
def __init__(self, max_vocab_size=50000, max_seq_len=200):
self.max_vocab_size = max_vocab_size
self.max_seq_len = max_seq_len
# 预留两个特殊标记:<PAD> 用于补齐长度,<UNK> 用于未知词汇
self.char_to_idx = {"<PAD>": 0, "<UNK>": 1}
self.idx_to_char = ["<PAD>", "<UNK>"]
self.vocab_size = 2
def tokenizer(self, text):
"""清洗并分词"""
text = str(text)
text = re.sub(r"<br />", " ", text) #删掉文本中的"<br/>"
text = re.sub(r"[^A-Za-z0-9]", " ", text) #仅保留文本中有效内容(有点草率,标点都没了)
# 注:这里加了if tok过滤,防止连续空格切出空字符串"
return [tok.lower() for tok in text.split() if tok]
def build_vocab(self, texts):
"""构建词表 (基于词频截断)"""
from collections import Counter
all_words = [word for text in texts for word in self.tokenizer(text)]
# 把所有影评压成一个一维的超长扁平列表 (list[str])。
# all_words:['i', 'love', 'it', 'the', 'movie', 'is', 'bad', 'i', 'love', ...]
word_counts = Counter(all_words)
# 只保留出现频率最高的前max_vocab_size个词
common_words = [word for word, count in word_counts.most_common(self.max_vocab_size - 2)]
for word in common_words:
self.char_to_idx[word] = self.vocab_size
self.idx_to_char.append(word)
self.vocab_size += 1
def text_to_indices(self, text):
"""将单个句子转换为等长(max_seq_len)的整数ID列表"""
sentence = self.tokenizer(text)
# sentence:['i', 'love', 'it', 'the', 'movie']
# 查表,如果遇到没见过的词,使用 <UNK> 的 ID (1)
indices = [self.char_to_idx.get(token, 1) for token in sentence]
# 长度处理:截断或补齐
if len(indices) >= self.max_seq_len:
indices = indices[:self.max_seq_len] # 截断
else:
indices = indices + [0] * (self.max_seq_len - len(indices)) # 使用 <PAD>(0) 补齐
return indices
# 模块 2:构建 PyTorch Dataset
class IMDBDataset(Dataset):
def __init__(self, data_list, labels):
# 转换为 PyTorch 张量
self.data = torch.tensor(data_list, dtype=torch.long)
self.labels = torch.tensor(labels, dtype=torch.long)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
# 模块 3:定义现代 RNN 分类模型
class RNNClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_layers=1, output_dim=2):
super(RNNClassifier, self).__init__()
# 1. 词嵌入层:padding_idx=0 保证补齐符不参与梯度更新
self.embedding = nn.Embedding(num_embeddings=vocab_size,
embedding_dim=embed_dim,
padding_idx=0)
# 2. RNN 核心层:batch_first=True 让输入维度变为 (batch, seq_len, features)
self.rnn = nn.RNN(input_size=embed_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
dropout=0.35,
bidirectional=True)
# 3. 线性分类输出层
# 因为是双向RNN,正向和反向的特征拼在一起,所以输入维度是 hidden_dim * 2
self.fc1 = nn.Linear(hidden_dim*2, hidden_dim)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x 形状: (batch_size, seq_len)
embedded = self.embedding(x) # embedded 形状: (batch_size, seq_len, embed_dim)
output, h_n = self.rnn(embedded) # h_n 形状: (num_layers, batch_size, hidden_dim)
# 提取最后一个时间步的隐藏状态
last_hidden = torch.cat((h_n[-2,:,:],h_n[-1,:,:]),dim=1) # 形状变为 (batch_size, hidden_dim*2)
# 经过全连接层+ 激活函数 + Dropout
sigma1 = self.fc1(last_hidden)
sigma1 = self.relu(sigma1)
sigma1 = self.dropout(sigma1)
out = self.fc2(sigma1)
return out
# 模块 4:训练流程架构
def main():
# 0.定义超参
max_vocab_size = 20000 #词表大小上限
max_seq_len = 150 #每句token上限
batch_size = 125
epochs = 30
save_path = Path.cwd()/"best_lstm_model.pth"
# 1. 读取数据
path = Path.cwd() / "sentiment_analysis.csv"
df = pd.read_csv(path, encoding='utf-8', encoding_errors='ignore')
train_df,test_df = train_test_split(df,test_size=0.2,train_size=0.8,random_state=420)
train_texts = train_df['movie_review'].tolist()
train_labels = train_df['sentiment'].tolist()
test_texts = test_df['movie_review'].tolist()
test_labels = test_df['sentiment'].tolist()
# 2. 数据清洗与构建词表
processor = IMDBProcessor(max_vocab_size=max_vocab_size, max_seq_len=max_seq_len)
processor.build_vocab(train_texts)
print(f"词表大小: {processor.vocab_size}")
# 3. 文本转张量并构建 DataLoader
# 处理训练集
train_encoded = [processor.text_to_indices(text) for text in train_texts]
train_dataset = IMDBDataset(train_encoded, train_labels)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 处理测试集
test_encoded = [processor.text_to_indices(text) for text in test_texts]
test_dataset = IMDBDataset(test_encoded, test_labels)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 初始化模型、优化器与损失函数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"device: {device}")
model = RNNClassifier(vocab_size=processor.vocab_size,
embed_dim=100,
hidden_dim=128,
num_layers=3,
output_dim=2).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 尝试从硬盘加载预训练参数
if save_path.exists():
print(f"发现本地保存的模型权重:{save_path}")
model.load_state_dict(torch.load(save_path, map_location=device))
print("模型权重加载成功!将在已有基础上继续...")
else:
print("未找到本地权重文件,将从头开始训练全新模型。")
# 5. 开始训练 (Training Loop)
best_acc = 0.0
for epoch in range(epochs):
model.train() # 将模型设置为训练模式
total_loss = 0
correct = 0
for batch_texts, batch_labels in train_loader:
batch_texts, batch_labels = batch_texts.to(device), batch_labels.to(device)
# 步骤 1:清空历史梯度
optimizer.zero_grad()
# 步骤 2:前向传播 (查表 -> RNN -> 全连接预测)
predictions = model(batch_texts)
# 步骤 3:计算 Loss
loss = criterion(predictions, batch_labels)
# 步骤 4:反向传播计算梯度
loss.backward()
# 步骤 5:优化器更新权重(包括Embedding词典也会被更新!)
optimizer.step()
total_loss += loss.item()
predicted_classes = torch.argmax(predictions,1)
correct += (predicted_classes == batch_labels).sum().item()
avg_train_loss = total_loss / len(train_loader)
train_accuracy = correct / len(train_dataset) * 100
print(f"Epoch: {epoch+1:02d} | 损失(Train Loss): {avg_train_loss:.4f} | 准确率(Train Acc): {train_accuracy:.2f}%")
model.eval() # 切换为评估模式
test_loss = 0
test_correct = 0
with torch.no_grad(): # 禁止计算梯度,节省显存并加速
for batch_texts, batch_labels in test_loader:
batch_texts, batch_labels = batch_texts.to(device), batch_labels.to(device)
predictions = model(batch_texts)
loss = criterion(predictions, batch_labels)
test_loss += loss.item()
predicted_classes = torch.argmax(predictions, 1)
test_correct += (predicted_classes == batch_labels).sum().item()
avg_test_loss = test_loss / len(test_loader)
test_accuracy = test_correct / len(test_dataset) * 100
print(f"Epoch: {epoch+1:02d} | 损失(Test Loss): {avg_test_loss:.4f} | 准确率(Test Acc): {test_accuracy:.2f}%")
if test_accuracy > best_acc:
best_acc = test_accuracy
# 把当前表现最好的模型权重保存到硬盘上
torch.save(model.state_dict(), save_path)
print("发现新纪录,模型已保存!")
if __name__ == "__main__":
main()七.项目2-文本生成任务
1.任务介绍
预测周杰伦歌词是一个经典的自然语言处理(NLP)任务,旨在通过构建语言模型来生成类似周杰伦歌曲的歌词,为音乐创作提供帮助。对于学习RNN来说,预测周杰伦歌词的任务是一个非常好的实践应用,因为这个任务涉及到了RNN模型,同时还需要涉及到模型的应用、调参以及歌词生成质量的评估等方面的问题。通过更好的理解这些技术和问题,学习者可以加强对RNN的理解、掌握更加实用的技能,提高实际应用的能力。

2. 数据预处理
3. 完整代码
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
from pathlib import Path
# 1. 数据集构建 (Dataset & DataLoader)
class LyricsDataset(Dataset):
def __init__(self, corpus_chars, seq_len):
"""
初始化歌词数据集
corpus_chars: 原始文本字符串
seq_len: 序列长度 (时间步数),即:一曲歌歌词长度
"""
# 1.清洗:将换行符替换为空格
corpus_chars = corpus_chars.replace('\n', ' ')
self.seq_len = seq_len
# 2.构建词表
self.chars = sorted(list(set(corpus_chars)))
self.vocab_size = len(self.chars)
self.char_to_idx = {ch: i for i, ch in enumerate(self.chars)}
self.idx_to_char = {i: ch for i, ch in enumerate(self.chars)}
# 3.将文本转化为索引序列
self.corpus_indices = [self.char_to_idx[c] for c in corpus_chars]
# self.corpus_indices的形状:(文件总字数,)
def __len__(self):
# 减去seq_len保证能取到目标值(target)
return len(self.corpus_indices) - self.seq_len
def __getitem__(self, idx):
# 特征 X: 长为 seq_len 的序列
# 标签 Y: 错位 1 个时间步的序列
x = self.corpus_indices[idx: idx + self.seq_len]
y = self.corpus_indices[idx + 1: idx + self.seq_len + 1]
# x和y的形状:(self.seq_len,)
return torch.tensor(x, dtype=torch.long), torch.tensor(y, dtype=torch.long)
# 2. 模型定义 (Model Architecture)
class CharRNN(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_size, num_layers=2):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# Embedding层
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embed_dim)
self.rnn = nn.RNN(
input_size=embed_dim,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=0.3
)
# 线性层解码输出
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden=None):
# x形状: (batch_size, seq_len)
emb = self.embedding(x)
# emb形状:(batch_size, seq_len, embed_dim)
out, hidden = self.rnn(emb, hidden)
# out形状:(batch_size, seq_len, hidden_size)
# 调整形状以适应全连接层和交叉熵损失
out = out.reshape(-1, self.hidden_size)
# out形状: (batch_size * seq_len, hidden_size)
out = self.fc(out)
# out形状: (batch_size * seq_len, vocab_size)
return out,hidden
def init_hidden(self, batch_size, device):
# 初始化h_0
return torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)
# 3. 文本生成逻辑 (Text Generation)
def generate_text(model, dataset, prefix, num_chars, device):
"""
基于前缀字符串生成后续文本
"""
model.eval()
state = model.init_hidden(batch_size=1, device=device)
outputs = [dataset.char_to_idx[c] for c in prefix] #输出内容在输入基础上拼接
# 模型读入前缀将记忆保存在state中
with torch.no_grad():
for i in range(len(prefix) - 1):
x = torch.tensor([outputs[i]]).reshape(1,-1).to(device)
_, state = model(x, state)
# 每次只读最后一个字,每次值输出一个字,输出的字加到末尾下轮继续读。
for _ in range(num_chars):
x = torch.tensor([outputs[-1]]).reshape(1,-1).to(device)
pred, state = model(x, state)
# 获取概率最大的字符索引(也可以使用 multinomial 采样增加随机性)
next_idx = pred.argmax(dim=1).item()
outputs.append(next_idx)
return ''.join([dataset.idx_to_char[i] for i in outputs])
# 4. 训练与主程序 (Training & Main Loop)
def main():
# 超参数配置
seq_len = 10
embed_dim = 256
batch_size = 128
hidden_size = 512
num_layers = 2
epochs = 20
lr = 1e-3
save_path = Path.cwd() / "best_generate_model.pth"
file_path = Path.cwd() / 'jaychou_lyrics.txt'
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. 加载数据
with open(file_path, encoding='utf-8') as f:
corpus_chars = f.read()
dataset = LyricsDataset(corpus_chars, seq_len)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)
# 2. 实例化模型、损失函数和优化器
model = CharRNN(dataset.vocab_size, embed_dim, hidden_size, num_layers).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 尝试从硬盘加载预训练参数
if save_path.exists():
print(f"发现本地保存的模型权重:{save_path}")
model.load_state_dict(torch.load(save_path,map_location=device))
else:
print("未找到本地权重文件,将从头开始训练全新模型。")
# 3. 训练循环
print(f"开始训练,设备: {device},词表大小: {dataset.vocab_size}")
best_loss = float('inf')
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_idx, (batch_x, batch_y) in enumerate(dataloader):
# 0.参数准备
# batch_x和batch_y的形状:(batch_size,seq_len)
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
# 初始化隐藏层 (每一个batch都要重复初始化,要不计算图会太长而断掉)
hidden = model.init_hidden(batch_size, device)
# 1.梯度清零
optimizer.zero_grad()
# 2.前向传播
output,_ = model(batch_x, hidden)
# 3.计算损失:y需要展平匹配预测输出的形状
loss = criterion(output, batch_y.reshape(-1))
# 4.反向传播与梯度裁剪(防止梯度爆炸)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
# 5.梯度更新
optimizer.step()
total_loss += loss.item()
if (batch_idx + 1) % 100 == 0 or batch_idx + 1 == len(dataloader):
current_avg_loss = total_loss / (batch_idx + 1)
print(f'Epoch [{epoch + 1}/{epochs}], '
f'Batch [{batch_idx + 1}/{len(dataloader)}], '
f'Loss: {current_avg_loss}, '
f'Perplexity: {np.exp(current_avg_loss):.4f}')
avg_loss = total_loss / len(dataloader)
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(),save_path)
print(f"发现新纪录(Avg Loss: {best_loss:.4f}),模型已保存!")
if (epoch + 1) % 5 == 0 or epoch == 0:
sample = generate_text(model, dataset, prefix="想要有直升机", num_chars=10, device=device)
print(f'Sample: {sample}\n')
if __name__ == '__main__':
main()