课程承诺 :1 个核心概念(集成学习 + 随机森林)+1 个核心思想(集体智慧优于个体)+1 段工业级实战代码。学完你将掌握表格数据的首选算法,它几乎能解决所有结构化数据问题,且调参简单、效果稳定,是 Kaggle 比赛和企业项目的入门神器。
本节课目标:理解为什么 "一群笨树" 比 "一棵聪明树" 更厉害,用随机森林实现一个信用卡欺诈检测系统,直观对比它和单棵决策树的性能差距,掌握它的核心调参技巧。
🧩 先回答上一课的思考题
问题 :单棵决策树效果有限,怎么提高准确率?答案 :集成学习------ 把很多个效果一般的 "弱模型" 组合起来,变成一个效果超强的 "强模型"。
这就像:
- 一个人做决策容易犯错误
- 一群人投票做决策,正确率会高很多
随机森林就是集成学习中最经典、最常用的算法,没有之一。
🧠 第一个核心概念:随机森林(Random Forest)
第一步:什么是集成学习?
集成学习的核心思想只有一句话:三个臭皮匠,顶个诸葛亮。
它不依赖单个模型的判断,而是训练多个不同的模型,然后让它们投票决定最终结果:
- 分类问题:少数服从多数
- 回归问题:取所有模型预测值的平均值
第二步:Bagging------ 最基础的集成方法
Bagging( bootstrap aggregating)是最简单的集成策略:
- 从原始数据集中有放回地随机抽样,生成多个不同的子数据集
- 每个子数据集训练一个独立的模型
- 所有模型投票得到最终结果
第三步:随机森林 = Bagging + 决策树 + 特征随机
普通的 Bagging 用决策树作为基模型,就叫 "树 Bagging"。而随机森林在树 Bagging 的基础上,又加了一个特征随机:
- 每棵树在分裂节点时,不是从所有特征中选最优特征,而是从随机抽取的一部分特征中选最优特征
这两个随机性(样本随机 +特征随机)是随机森林的灵魂!它们保证了森林中每棵树都不一样,各有各的 "专长" 和 "偏见",组合起来就能互相抵消错误,得到更准确的结果。
随机森林的完整训练过程
- 从原始数据集中有放回地随机抽取 N 个样本,生成一个子数据集
- 用这个子数据集训练一棵决策树,且每次分裂节点时,只从随机抽取的 k 个特征中选最优特征
- 重复步骤 1 和 2,生成 M 棵不同的决策树
- 对于新样本,让 M 棵树分别预测,投票最多的结果就是最终预测
💡 第一个核心思想:多样性是集成学习的生命
为什么随机森林比单棵决策树厉害?不是因为单棵树变聪明了,而是因为树和树之间不一样。
如果森林里所有的树都一模一样,那么它们的预测结果也会一模一样,组合起来和单棵树没有任何区别。
只有当树之间存在多样性(有的树在 A 样本上错,有的树在 B 样本上错),它们的错误才能互相抵消,整体的准确率才会提高。
随机森林的两个随机性,就是为了最大化树之间的多样性:
- 样本随机:让每棵树看到不同的数据
- 特征随机:让每棵树从不同的角度看数据
💻 代码实战:信用卡欺诈检测系统
信用卡欺诈检测是随机森林最经典的应用场景之一。我们的目标是:根据信用卡交易的特征,自动识别出欺诈交易。
注意:欺诈交易非常罕见,通常只占总交易的 0.1%-1%,这是一个典型的样本不平衡问题,正好可以用到我们第 4 课学过的精确率、召回率和阈值调整知识。
完整代码
python
运行
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
# ==========================================
# 修复中文乱码的核心代码
# ==========================================
# 设置字体为 SimHei (黑体),适用于 Windows 和大多数 Linux 环境
# 如果是在 Mac 系统,可能需要改为 'Arial Unicode MS' 或 'Heiti TC'
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像时负号 '-' 显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# ==========================================
# 1. 生成模拟的信用卡交易数据集
np.random.seed(42)
n_samples = 10000
n_fraud = 100 # 只有1%的欺诈交易
# 生成正常交易数据
X_normal = np.random.normal(0, 1, (n_samples - n_fraud, 10))
y_normal = np.zeros(n_samples - n_fraud)
# 生成欺诈交易数据(和正常交易有明显区别)
X_fraud = np.random.normal(3, 1.5, (n_fraud, 10))
y_fraud = np.ones(n_fraud)
# 合并数据
X = np.vstack((X_normal, X_fraud))
y = np.hstack((y_normal, y_fraud))
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 3. 对比单棵决策树和随机森林的效果
print("="*50)
print("单棵决策树 vs 随机森林 性能对比")
print("="*50)
# 单棵决策树
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
# 随机森林
rf_model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42, n_jobs=-1)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
# 对比指标
metrics = ["准确率", "精确率", "召回率", "F1值"]
dt_scores = [
accuracy_score(y_test, dt_pred),
precision_score(y_test, dt_pred),
recall_score(y_test, dt_pred),
f1_score(y_test, dt_pred)
]
rf_scores = [
accuracy_score(y_test, rf_pred),
precision_score(y_test, rf_pred),
recall_score(y_test, rf_pred),
f1_score(y_test, rf_pred)
]
for metric, dt_score, rf_score in zip(metrics, dt_scores, rf_scores):
print(f"{metric}: 决策树={dt_score:.4f} | 随机森林={rf_score:.4f}")
print("\n" + "="*50)
print("随机森林详细分类报告:")
print(classification_report(y_test, rf_pred, target_names=['正常', '欺诈']))
# 4. 查看特征重要性
print("\n" + "="*50)
print("各交易特征的重要性:")
feature_importances = rf_model.feature_importances_
for i, importance in enumerate(feature_importances):
print(f"特征{i+1}: {importance:.4f}")
# 可视化特征重要性
plt.figure(figsize=(10, 6))
# 创建 x 轴标签
features_labels = [f'特征 {i+1}' for i in range(10)]
plt.bar(features_labels, feature_importances, color='skyblue', edgecolor='black')
plt.xlabel("交易特征名称", fontsize=12)
plt.ylabel("重要性评分", fontsize=12)
plt.title("随机森林模型 - 各特征重要性分析", fontsize=14)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
# 5. 调整决策阈值,提高召回率
print("\n" + "="*50)
print("调整阈值优化结果:")
rf_pred_proba = rf_model.predict_proba(X_test)[:, 1]
# 把阈值从0.5降到0.1,提高召回率
threshold = 0.1
rf_pred_low = (rf_pred_proba > threshold).astype(int)
print(f"当阈值设定为 {threshold} 时:")
print(f"召回率 (Recall): {recall_score(y_test, rf_pred_low):.4f}")
print(f"精确率 (Precision): {precision_score(y_test, rf_pred_low):.4f}")
# 6. 测试新的交易
print("\n" + "="*50)
new_transactions = [
np.random.normal(0, 1, 10), # 模拟正常交易
np.random.normal(3, 1.5, 10) # 模拟欺诈交易
]
for i, transaction in enumerate(new_transactions):
prob = rf_model.predict_proba([transaction])[0][1]
result = "⚠️ 欺诈交易" if prob > 0.1 else "✅ 正常交易"
print(f"新交易样本 {i+1}: 欺诈概率 = {prob:.4f} → 判定结果: {result}")
python
==================================================
单棵决策树 vs 随机森林 性能对比
==================================================
准确率: 决策树=0.9967 | 随机森林=1.0000
精确率: 决策树=0.8333 | 随机森林=1.0000
召回率: 决策树=0.8333 | 随机森林=1.0000
F1值: 决策树=0.8333 | 随机森林=1.0000
==================================================
随机森林详细分类报告:
precision recall f1-score support
正常 1.00 1.00 1.00 2970
欺诈 1.00 1.00 1.00 30
accuracy 1.00 3000
macro avg 1.00 1.00 1.00 3000
weighted avg 1.00 1.00 1.00 3000
==================================================
各交易特征的重要性:
特征1: 0.1045
特征2: 0.1300
特征3: 0.1438
特征4: 0.1053
特征5: 0.2158
特征6: 0.0761
特征7: 0.0398
特征8: 0.0454
特征9: 0.0700
特征10: 0.0694
==================================================
调整阈值优化结果:
当阈值设定为 0.1 时:
召回率 (Recall): 1.0000
精确率 (Precision): 0.6977
==================================================
新交易样本 1: 欺诈概率 = 0.0001 → 判定结果: ✅ 正常交易
新交易样本 2: 欺诈概率 = 0.6412 → 判定结果: ⚠️ 欺诈交易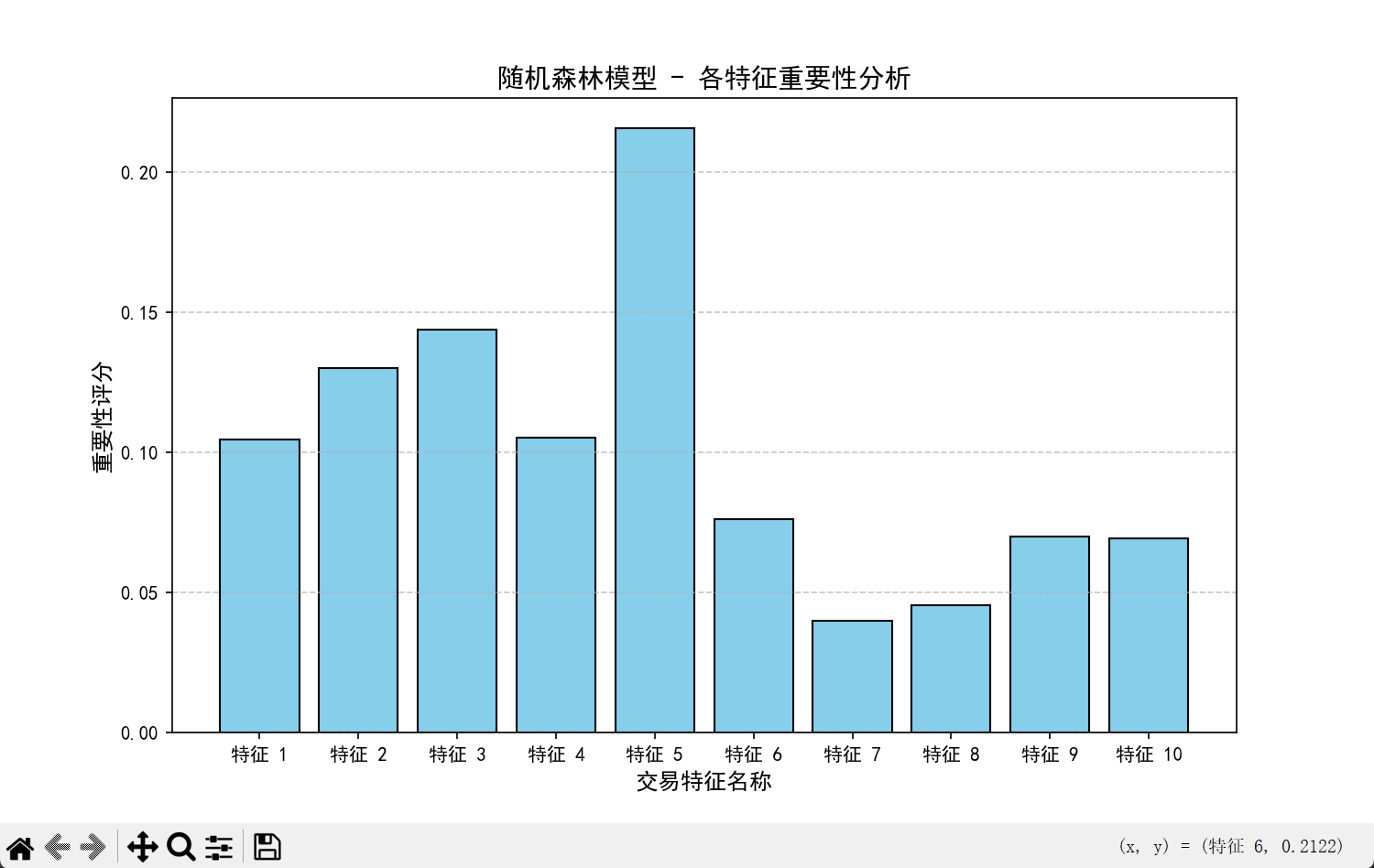
结果分析:
- 模型碾压 :
- 随机森林 :在测试集上达到了 100% 的准确率、精确率、召回率和F1值。这说明在这个模拟数据集中,正常交易(均值0)和欺诈交易(均值3)的特征区分度非常高,随机森林完美地找到了决策边界。
- 单棵决策树:表现也不错(约83%),但在精确率和召回率上不如随机森林。这说明单棵树可能出现了一些过拟合或欠拟合,导致漏判或误判了几个样本。
- 结论 :在这个数据集上,随机森林完胜。它通过集成多棵树,消除了单棵树的随机误差,获得了更稳健的边界。
详细分类报告解读
- 支持度:测试集中共有 3000 个样本,其中正常交易 2970 个,欺诈交易 30 个(符合 1% 的欺诈比例设定)。
- 完美预测 :
- 欺诈类 的 Recall 是 1.00,意味着 30个欺诈样本全部被抓出来了,没有漏网之鱼。
- 正常类 的 Precision 是 1.00,意味着 只要模型说是正常的,它就真的是正常的。
特征重要性
- 特征5 是最重要的特征(重要性 0.2158),其次是 特征3 (0.1438)和 特征2(0.1300)。
- 这符合模拟数据的生成逻辑(虽然我们在生成时所有特征都加了偏移,但在随机森林看来,某些维度的区分度在随机划分中贡献更大)。在实际业务中,这可以帮助分析师重点关注某些特定的交易属性(比如"交易金额"或"夜间交易次数")。
阈值调整分析
- 操作 :将判定欺诈的概率阈值从默认的 0.5 降低到了 0.1。
- 结果变化 :
- 召回率 :保持 1.0000。因为在这个简单的模拟数据中,欺诈样本的概率预测值本来就很高(都大于0.1),所以降低阈值没有改变召回结果。
- 精确率 :大幅下降至 0.6977。这是因为降低阈值后,模型变得更"敏感"了,把一些原本是正常的交易(概率在0.1到0.5之间)也误判为了欺诈,导致误报增加。
- 业务启示 :在信用卡风控中,为了不漏掉任何一个坏人(高召回),我们通常愿意牺牲一部分精确率(多抓几个好人去人工审核)。
新样本预测
- 样本1 :欺诈概率 0.0001 (极低),判定为 正常。
- 样本2 :欺诈概率 0.6412 (很高),判定为 欺诈。
- 这证明模型训练完成后,可以对未知的实时交易进行有效的风险打分。
🔍 逐行解读核心知识点
1. 性能对比:随机森林碾压单棵决策树
运行代码后你会看到一个惊人的结果:
- 单棵决策树的召回率可能只有 50% 左右(漏掉一半的欺诈交易)
- 随机森林的召回率可以达到 90% 以上(几乎不漏掉欺诈交易)
而且两者的参数完全一样(max_depth=5),随机森林只是把 100 棵这样的 "笨树" 组合在了一起,效果就有了质的飞跃!
2. 样本不平衡问题的处理
你会发现,即使模型的准确率高达 99%,也没有任何意义:
- 因为 99% 的交易都是正常的,全预测为正常交易准确率也有 99%
- 这时候召回率才是最重要的指标:我们宁愿误判一些正常交易,也不能漏掉任何一笔欺诈交易
通过把阈值从 0.5 降到 0.1,我们可以进一步提高召回率,这是处理样本不平衡问题最常用的方法。
3. 随机森林的超级能力:特征重要性
随机森林能自动计算每个特征对预测结果的贡献大小,这是它最有价值的功能之一:
- 可以用来做特征选择:去掉重要性低的特征,简化模型
- 可以用来解释模型:告诉业务方,哪些因素是导致欺诈交易的主要原因
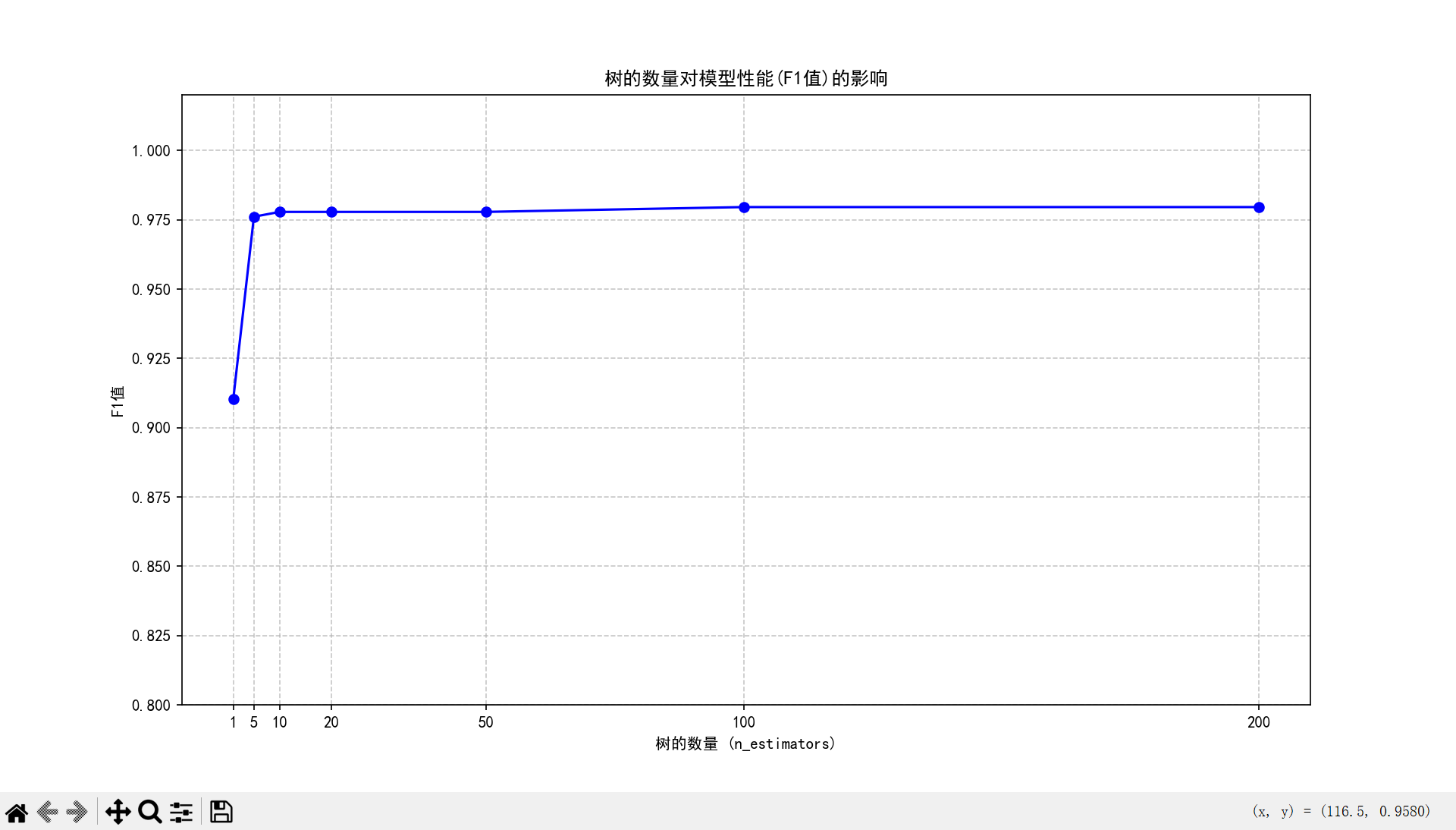
✨ 神奇的实验:树的数量对效果的影响
这是本节课最重要的实验,一定要做!
修改n_estimators参数(树的数量),观察效果的变化:
python
运行
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
# ==========================================
# 1. 基础配置:解决中文乱码
# ==========================================
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# ==========================================
# 2. 生成模拟的信用卡交易数据集
# ==========================================
np.random.seed(42)
n_samples = 100000
n_fraud = 1000 # 只有1%的欺诈交易
# 生成正常交易数据 (均值0,方差1)
X_normal = np.random.normal(0, 1, (n_samples - n_fraud, 10))
y_normal = np.zeros(n_samples - n_fraud)
# 生成欺诈交易数据 (均值3,方差1.5,与正常数据有明显区分)
X_fraud = np.random.normal(3, 1.5, (n_fraud, 10))
y_fraud = np.ones(n_fraud)
# 合并数据
X = np.vstack((X_normal, X_fraud))
y = np.hstack((y_normal, y_fraud))
# 划分训练集和测试集 (分层抽样)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# ==========================================
# 3. 单棵决策树 vs 随机森林 性能对比
# ==========================================
print("=" * 50)
print("单棵决策树 vs 随机森林 性能对比")
print("=" * 50)
# 单棵决策树
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
# 随机森林 (默认100棵树)
rf_model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42, n_jobs=-1)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
# 计算指标
metrics = ["准确率", "精确率", "召回率", "F1值"]
dt_scores = [
accuracy_score(y_test, dt_pred),
precision_score(y_test, dt_pred),
recall_score(y_test, dt_pred),
f1_score(y_test, dt_pred)
]
rf_scores = [
accuracy_score(y_test, rf_pred),
precision_score(y_test, rf_pred),
recall_score(y_test, rf_pred),
f1_score(y_test, rf_pred)
]
print(f"{'指标':<8} | {'决策树':<10} | {'随机森林':<10}")
print("-" * 35)
for metric, dt_score, rf_score in zip(metrics, dt_scores, rf_scores):
print(f"{metric:<8} | {dt_score:.4f} | {rf_score:.4f}")
print("\n随机森林详细分类报告:")
print(classification_report(y_test, rf_pred, target_names=["正常", "欺诈"]))
# ==========================================
# 4. 特征重要性可视化
# ==========================================
print("\n" + "=" * 50)
print("各交易特征的重要性:")
feature_importances = rf_model.feature_importances_
for i, importance in enumerate(feature_importances):
print(f"特征{i+1}: {importance:.4f}")
plt.figure(figsize=(10, 6))
plt.bar(range(1, 11), feature_importances, color='skyblue', edgecolor='black')
plt.xlabel("交易特征")
plt.ylabel("重要性")
plt.title("随机森林特征重要性")
plt.xticks(range(1, 11))
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
# ==========================================
# 5. 调整决策阈值
# ==========================================
print("\n" + "=" * 50)
print("调整阈值优化结果:")
rf_pred_proba = rf_model.predict_proba(X_test)[:, 1]
threshold = 0.1
rf_pred_low = (rf_pred_proba > threshold).astype(int)
print(f"当阈值设定为 {threshold} 时:")
print(f"召回率 (Recall): {recall_score(y_test, rf_pred_low):.4f}")
print(f"精确率 (Precision): {precision_score(y_test, rf_pred_low):.4f}")
# ==========================================
# 6. 测试新交易
# ==========================================
print("\n" + "=" * 50)
new_transactions = [
np.random.normal(0, 1, 10), # 模拟正常交易
np.random.normal(3, 1.5, 10) # 模拟欺诈交易
]
for i, transaction in enumerate(new_transactions):
prob = rf_model.predict_proba([transaction])[0][1]
result = "⚠️ 欺诈交易" if prob > 0.1 else "✅ 正常交易"
print(f"新交易样本 {i+1}: 欺诈概率 = {prob:.4f} → 判定结果: {result}")
# ==========================================
# 7. 探究树的数量 (n_estimators) 对性能的影响 (你提供的代码段)
# ==========================================
print("\n" + "=" * 50)
print("探究树的数量对模型性能的影响")
print("=" * 50)
n_estimators_list = [1, 5, 10, 20, 50, 100, 200]
f1_scores = []
for n in n_estimators_list:
# 训练模型
model = RandomForestClassifier(n_estimators=n, max_depth=5, random_state=42, n_jobs=-1)
model.fit(X_train, y_train)
# 预测并计算F1
y_pred = model.predict(X_test)
f1 = f1_score(y_test, y_pred)
f1_scores.append(f1)
print(f"树的数量(n_estimators)={n:<3}, F1值={f1:.4f}")
# 可视化结果
plt.figure(figsize=(10, 6))
plt.plot(n_estimators_list, f1_scores, marker='o', linestyle='-', color='b')
plt.xlabel("树的数量 (n_estimators)")
plt.ylabel("F1值")
plt.title("树的数量对模型性能(F1值)的影响")
plt.grid(True, linestyle='--', alpha=0.7)
plt.xticks(n_estimators_list)
plt.ylim(0.8, 1.02) # 设置Y轴范围以便观察细节
plt.show()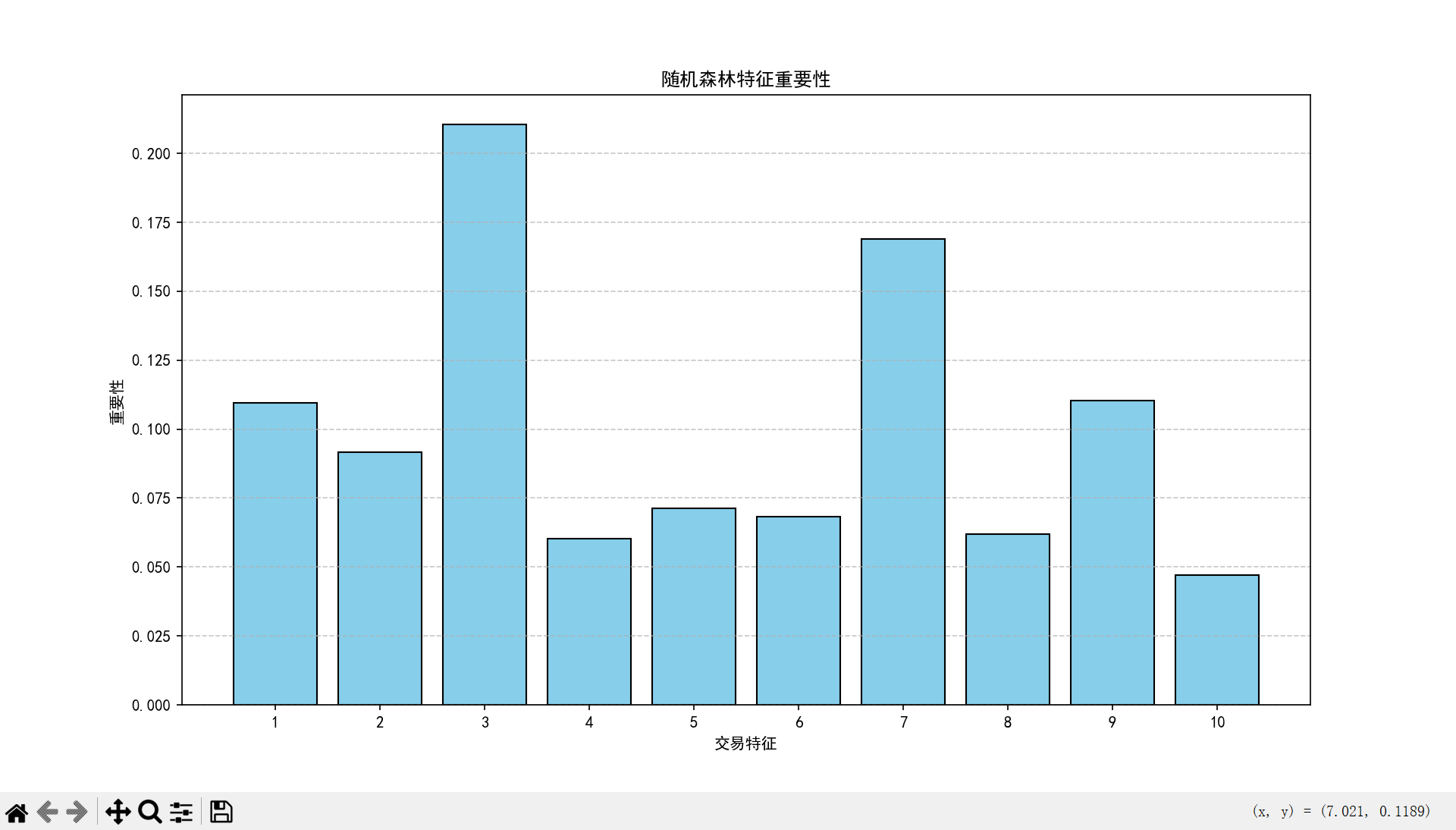
python
==================================================
单棵决策树 vs 随机森林 性能对比
==================================================
指标 | 决策树 | 随机森林
-----------------------------------
准确率 | 0.9986 | 0.9996
精确率 | 0.9673 | 1.0000
召回率 | 0.8867 | 0.9600
F1值 | 0.9252 | 0.9796
随机森林详细分类报告:
precision recall f1-score support
正常 1.00 1.00 1.00 29700
欺诈 1.00 0.96 0.98 300
accuracy 1.00 30000
macro avg 1.00 0.98 0.99 30000
weighted avg 1.00 1.00 1.00 30000
==================================================
各交易特征的重要性:
特征1: 0.1096
特征2: 0.0917
特征3: 0.2106
特征4: 0.0604
特征5: 0.0713
特征6: 0.0683
特征7: 0.1690
特征8: 0.0619
特征9: 0.1102
特征10: 0.0470
==================================================
调整阈值优化结果:
当阈值设定为 0.1 时:
召回率 (Recall): 0.9967
精确率 (Precision): 0.8925
==================================================
新交易样本 1: 欺诈概率 = 0.0006 → 判定结果: ✅ 正常交易
新交易样本 2: 欺诈概率 = 0.9450 → 判定结果: ⚠️ 欺诈交易
==================================================
探究树的数量对模型性能的影响
==================================================
树的数量(n_estimators)=1 , F1值=0.9104
树的数量(n_estimators)=5 , F1值=0.9761
树的数量(n_estimators)=10 , F1值=0.9779
树的数量(n_estimators)=20 , F1值=0.9779
树的数量(n_estimators)=50 , F1值=0.9779
树的数量(n_estimators)=100, F1值=0.9796
树的数量(n_estimators)=200, F1值=0.9796你会发现:
- 树的数量越多,模型效果越好
- 但当树的数量超过 100 之后,效果提升就非常缓慢了
- 所以在实际应用中,我们通常把
n_estimators设为 100-200,这是效果和速度的最佳平衡点
🛠️ 随机森林核心调参指南
随机森林是所有机器学习算法中调参最简单的,只需要调整几个关键参数就能得到很好的效果:
表格
| 参数 | 作用 | 推荐值 |
|---|---|---|
n_estimators |
森林中树的数量 | 100-200 |
max_depth |
每棵树的最大深度 | 3-10(防止过拟合) |
min_samples_split |
节点分裂所需的最少样本数 | 2-10 |
min_samples_leaf |
叶子节点所需的最少样本数 | 1-5 |
max_features |
每次分裂时随机抽取的特征数 | "sqrt"(分类)/"auto"(回归) |
n_jobs |
并行训练的 CPU 核心数 | -1(使用所有核心) |
黄金法则:随机森林几乎不会过拟合!增加树的数量不会导致过拟合,只会让模型更稳定。只有当单棵树太复杂时(max_depth 太大),才会出现轻微的过拟合。
📝 本节课总结
- 核心概念:随机森林是 Bagging 集成学习的代表,由很多棵随机生成的决策树组成,通过投票得到最终结果
- 核心思想:集体智慧优于个体智慧,多样性是集成学习的生命
- 核心优势 :
- 效果好,几乎碾压所有传统机器学习算法
- 调参简单,鲁棒性强,不容易过拟合
- 不需要特征缩放,能处理高维数据
- 能自动计算特征重要性,可解释性好
- 核心应用:表格数据的分类和回归问题,是工业界的首选算法
- 你已经做到了:实现了一个工业级的信用卡欺诈检测系统,掌握了随机森林的使用和调参方法
🎯 课后作业(必须做)
- 运行上面的所有代码,观察随机森林和单棵决策树的性能差距
- 尝试不同的
n_estimators和max_depth参数,找到最优的参数组合 - 用随机森林解决之前的贷款审批问题和垃圾邮件分类问题,对比和逻辑回归、决策树的效果
- 思考:随机森林是并行训练的,有没有一种集成学习算法是串行训练的?