【LLM】第三章:项目实操案例:智能输入法项目
说明:本篇是根据 https://www.bilibili.com/video/BV1k44LzPEhU?spm_id_from=333.788.player.switch&vd_source=b6780e06031ac609460f6fbf017bbb39&p=38 视频中的案例重构整理而成的,很多细节地方加入了自己的想法和操作。anyway,感谢并致敬原作者!
一、项目需求和项目思路
1、本项目的任务是:模型需要根据用户已经输入的文本,预测用户下一个可能要输入的词语。
2、数据来源是一些真实场景的对话语料,有助于模型学习用户的输入习惯和上下文关系。具体获取途径详见大标题二。
3、数据处理 :为了构造适用于下一词预测任务的训练样本,首先需要对原始语料进行分词-->采用滑动窗口的方式,从分词后的序列中提取连续的上下文词片段-->暂且规定以6个分词单位为一个窗口,把这些窗口片段作为训练集。以每个窗口的前5个词为特征、以最后1个词为标签,构建训练集。
4、使用什么模型?
全连接神经网络搭建模型也是可以的。比如像word2vec算法的思想,用滑窗的前五个词当作输入,最后一个词当作标签,来训练模型。当然我们和word2vec算法的输入构造是不同的、目的也是不同的。所以,虽然都是全连接架构,但是输入输出是不一样的。此外word2vec是训练词向量的,所以它训练完毕后,是只取模型参数,当作词向量即可。而我们这里却是要用训练完毕的模型进行预测的。就是训练模型的目的是不同的。所以这个任务是不能直接用word2vec算法来实现的,就是我们得自己搭建网络,自己训练模型,不能使用已有得成熟算法,或者说就是没有现成的轮子供我们直接调用,得自己造轮子。
考虑到文本预测中的输入输出一般都是序列数据 ,所以使用序列模型 应该效果会更好一些,所以考虑使用rnn/lstm 等传统序列模型。但是为了技术更加前沿,本篇再搭建一个transformer架构中的编码器作为备选模型架构。也就是说要训练两个模型。
5、项目架构
这个案例不再像从前那样,我都是写成单文件的形式,本项目采取多文件架构 。所以这次我用Visual Studio Code作为IDE,项目架构和功能实现的设计如下左图 ,具体项目架构搭建如下右图 :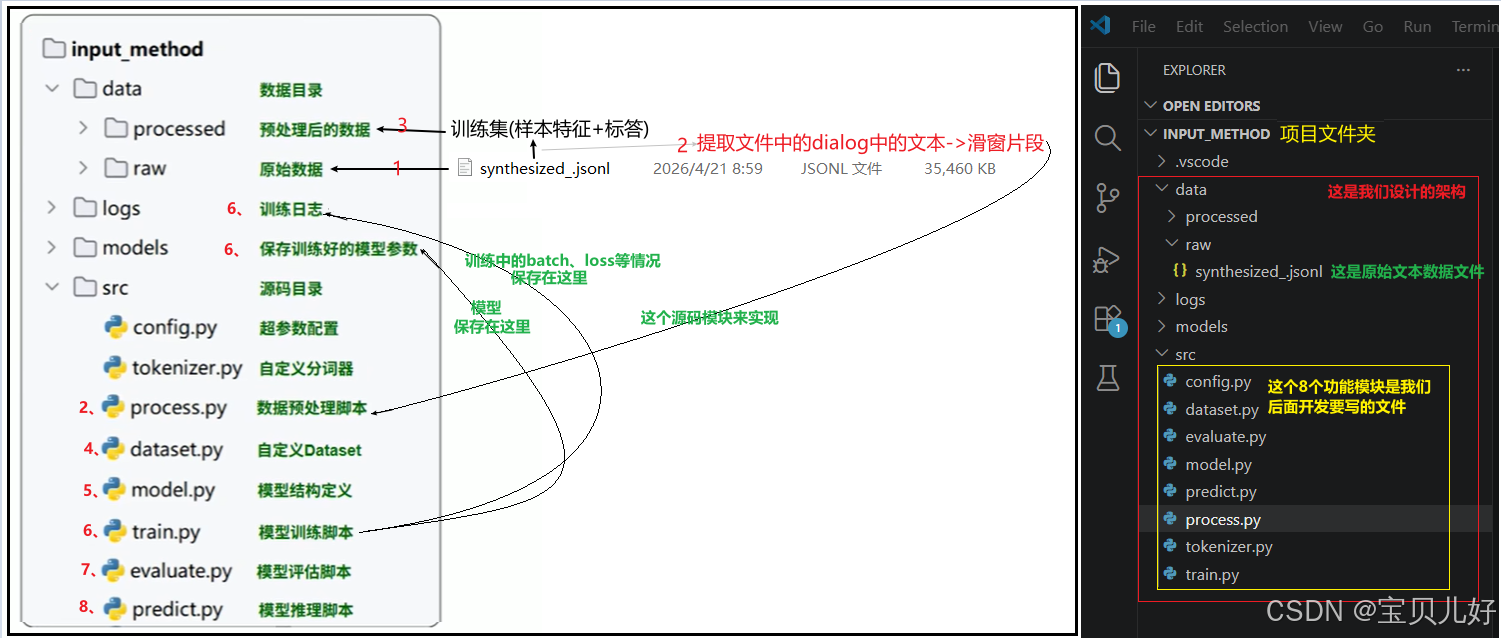 所以,本项目的开发工作就是上右图中的8个.py文件,也就是8个模块。具体开发过程详见大标题三。
所以,本项目的开发工作就是上右图中的8个.py文件,也就是8个模块。具体开发过程详见大标题三。
二、训练数据集
1、训练数据集来源:https://huggingface.co/datasets/Jax-dan/HundredCV-Chat
huggingface是预训练模型的平台、预训练模型的权重、使用模型的工具、数据集等。
如果huggingface打不开,就用hf-mirror.com代替:https://hf-mirror.com/datasets/Jax-dan/HundredCV-Chathttps://hf-mirror.com/datasets/Jax-dan/HundredCV-Chat 具体操作见下图:
2、查看训练数据集
synthesized_.jsonl文件下载完毕后,就放到项目架构中的data-raw文件夹中,以后我们读取原始数据就从这里读取。
(1)json主要是用于前后端交互 的字符串格式 。一个{}字典就是一个json对象 。
(2)从文件名上看,这个文件叫.jsonl,l表示是Line的意思,就是说这个这个文件中的每一行就是一个json字符串 ,不是 整个文件是一个json对象。
(3)对本项目来说,文件中的topic\user1\user2的数据都没用,本项目只用dialog中的文本。
三、项目开发
(一)编写config.py文件
config.py文件的作用 有:
(1)让src文件夹中的其他模块都可以简单快捷的找到保存在其他文件夹中的文件 。所以其他文件夹的路径要写到config.py中。
(2)数据处理过程中、搭建模型过程中、训练模型过程中的参数、超参数 ,也都写到config.py文件中,这样我们方便调参。
所以,config.py文件是边开发别的模块,边添加的。下面是config.py文件的全部代码:
python
# 这是项目文件中其他文件夹的路径
from pathlib import Path
PROJECT_ROOT_DIR = Path(__file__).parent.parent #项目目录, 动态获取项目的根目录
RAW_DATA_DIR = PROJECT_ROOT_DIR/"data"/"raw" #原始语料目录, 语料文件所在的文件夹
PROCESSED_DATA_DIR = PROJECT_ROOT_DIR/"data"/"processed" #经处理的语料,可以直接喂入模型的样本和标签
LOGS_DIR = PROJECT_ROOT_DIR/"logs" #日志文件的保存目录
MODELS_DIR = PROJECT_ROOT_DIR/"models" #词表、模型等保存的目录
#这是数据处理过程中的超参数
SLID_WINDOW_SIZE = 6 #滑窗的大小
#定义喂入模型的小批次
BATCH_SIZE = 64
#待补充。。。。下面讲解一下这些代码中细节和重点注意点: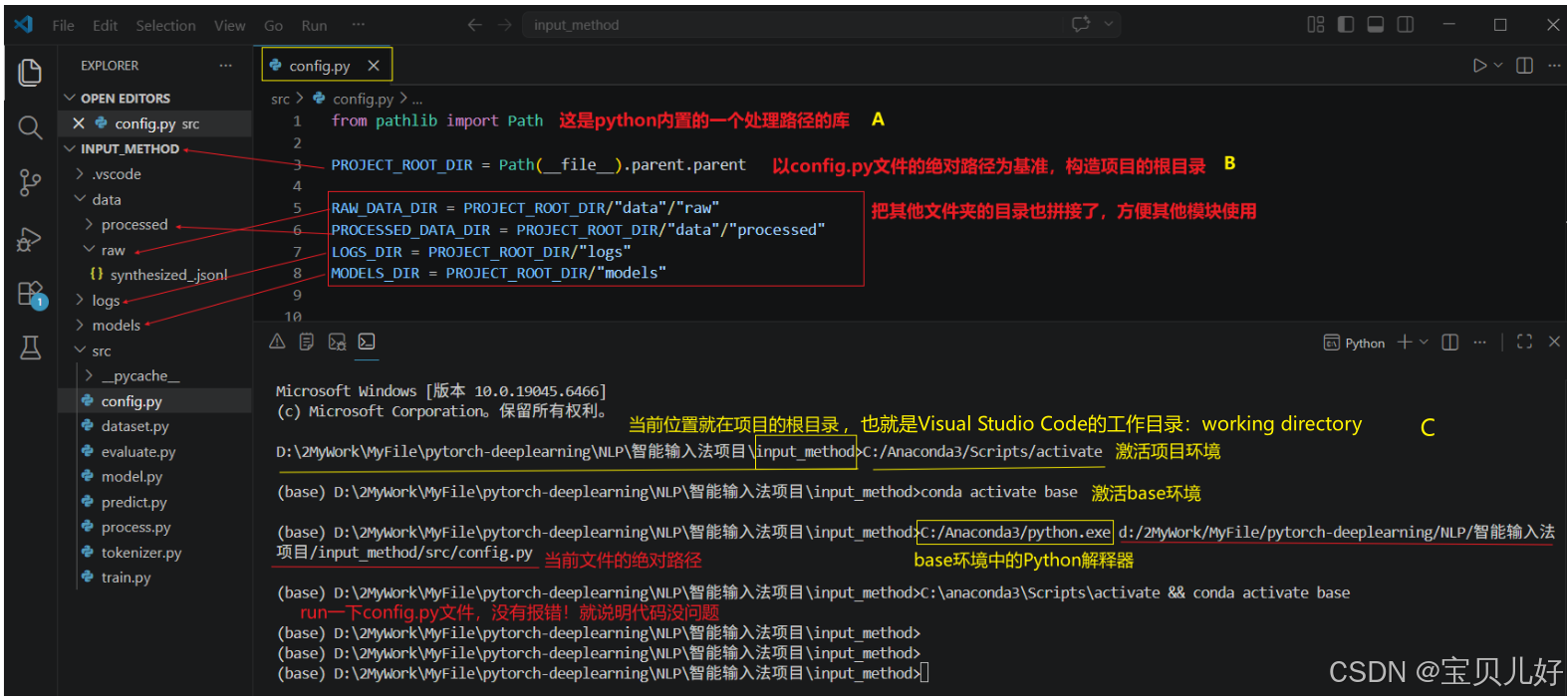 A:我们尽量用python自带的pathlib库,这样你的项目开发完毕后->打包->部署到其他平台上,就不会因为路径问题,比如斜杠还是反斜杠、相对路径还是绝对路径等问题而跑不通了。
A:我们尽量用python自带的pathlib库,这样你的项目开发完毕后->打包->部署到其他平台上,就不会因为路径问题,比如斜杠还是反斜杠、相对路径还是绝对路径等问题而跑不通了。
B:Path(file )返回的是config.py文件的绝对路径 。.parent表示config.py文件的上一级目录(也就是src文件夹的目录)。所以两个.parent就是input_method的目录,也就是我们项目的根目录 。此后不管找项目中的任何文件都从这个根目录开始寻找。这种操作就是我们软编码了项目的根目录,或者说我们动态生成了项目的根目录。项目中的其他文件都以此目录为起始点,拼接需要的相对路径即可。这样,以后不管项目部署在什么平台,还是部署在云端,只要pathlib库找到config.py文件在那个平台上的绝对路径,就可以生成这个项目的根目录,这样所有的相对路径就可以顺利拼接正确了,项目才可以正常跑通。否则,你会被斜杠、反斜杠、转义符等弄得晕头转向。
C:这个目录是IDE的工作目录 ,也就是我们是在这个目录下打开项目的。此时我们会配置 项目的虚拟环境,所以在这个目录下我们可以调用虚拟环境中的python解释器。下面我项目的实际存储地址: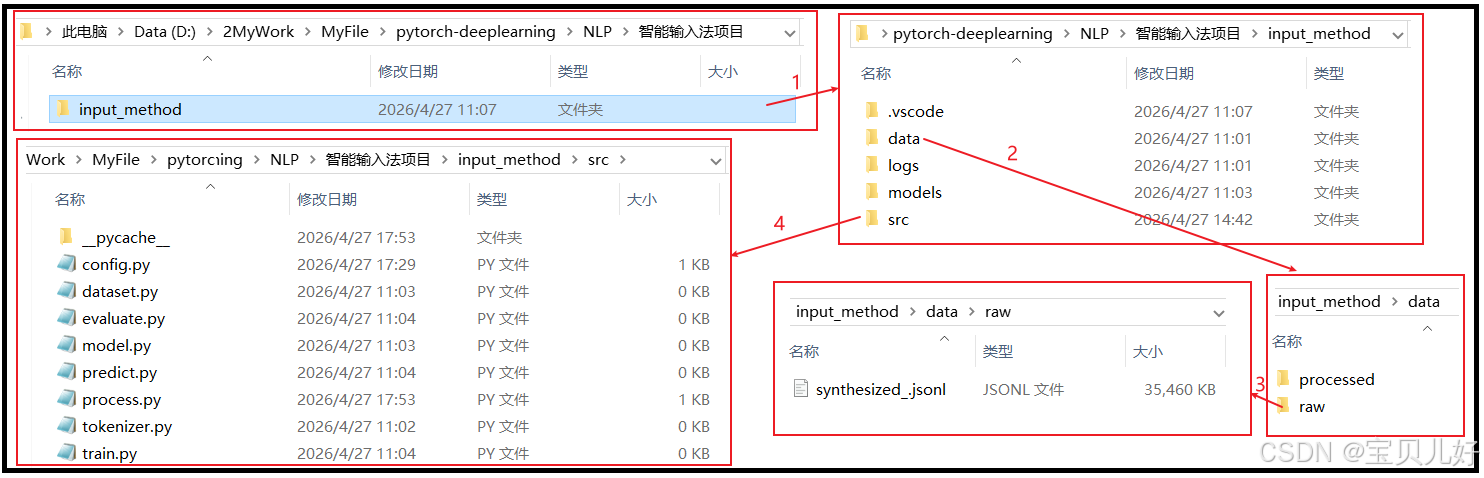
(二)编写:原始文本数据的预处理文件 process.py
process.py模块的作用是进行数据预处理的,主要步骤有:读synthesized_.jsonl文件-->提取文件中的对话句子-->将所有句子划分训练句子和测试句子-->用训练集的句子构建词表、保存词表到model文件夹-->用滑窗构建训练集和测试集并保存。下面用图示说明一下这些步骤: 细节考虑:
细节考虑:
一是,为什么要划分训练句子和测试句子?因为模型训练完毕进入使用阶段,肯定会遇到没有被训练过的句子,如果这里我们划出少量的句子作为测试句子,就可以适当的评估模型了。尽管我们是希望模型能见到更多的句子是最好的,但终有模型没见过的句子,所以还是得留测试集。
二是,词表是为了生成词和id之间的映射,构建词表是必须的,因为我们在测试阶段,根据用户的输入,分词后,需要用词表将用户的输入转化为数字编码。
三是,词表是根据训练句子构建?还是根据全部句子构建?根据训练句子构建词表!因为如果把测试句子的词也放入词表,但是在模型训练过程中,测试句子的一些词,只要它不在训练集中,那它也是无法被模型训练的,所以词表根据训练句子构建即可,其他所有模型没见过的词都用<unk>标识代替。这也是我们此后处理所有未登录词的处理方法。
python
# process.py模块的具体代码如下:
import pandas as pd
import config
from sklearn.model_selection import train_test_split
import jieba
from tqdm import tqdm
from pathlib import Path
# 这是单独提出来的、下面的process函数中的一段可以复用的逻辑:用滑窗 从前往后 切训练集的样本和标签
def window_build_dataset(indexed_sentence, desc, window_size):
dataset = []
for s in tqdm(indexed_sentence, desc=desc):
if len(s) <= window_size:
slid_window = [0] * (window_size-len(s)) + s
input_sample = slid_window[:-1]
target_sample = slid_window[-1]
dataset.append({'input':input_sample, 'target':target_sample})
else:
for i in range(len(s)-window_size+1):
slid_window = s[i:i+window_size]
input_sample = slid_window[:-1]
target_sample = slid_window[-1]
dataset.append({'input':input_sample, 'target':target_sample})
return dataset
# 这个函数才是本文件的主函数
def process():
df = pd.read_json(path_or_buf=config.RAW_DATA_DIR/"synthesized_.jsonl", lines=True, orient='records') #1、读jsonl文件
sentence = [sentence.split(':')[1] for dialog in df['dialog'] for sentence in dialog] #2、提取文件中的所有对话句子
train_sentences, test_sentences = train_test_split(sentence, test_size=0.2, random_state=0) #3、将句子划分为训练句子和测试句子,固定随机性,方便复现
#4、对训练句子切词-去重-加<unk>标识,构造词表,保存词表
vocab_s = [jieba.lcut(sentence) for sentence in tqdm(train_sentences,desc='训练句子分词中...')] #结巴切词
vocab_v = [v for s in vocab_s for v in s] #二维拉成一维
#vocab_list = ['<unk>'] + list(set(vocab_v)) #去重、加<unk>标识 ,生成词表,set去重会打乱顺序
vocab_list = ['<unk>'] + list(dict.fromkeys(vocab_v)) #去重也可以用字典去,字典可以保留词的顺序
with open(config.MODELS_DIR/'vocab.txt', 'w', encoding='utf-8') as f: #保存词表到model文件夹
save = f.write('\n'.join(vocab_list))
print('词表保存成功。。。。。' if save!=0 else '词表保存失败.......')
#5、用滑窗构建训练集和测试集并保存
word2index = {word:key for key, word in enumerate(vocab_list)} #5.1 构建word到index之间的映射
#5.2.1 将训练句子转化为数字 ---- 下面代码中的0是未登录词,就是<unk>标识符
indexed_train_sentence = [[word2index[w] if w in word2index.keys() else 0 for w in s] for s in vocab_s]
#5.2.2 用滑窗 从前往后 切训练集的样本和标签
train_dataset = window_build_dataset(indexed_sentence=indexed_train_sentence, desc='生成训练集中...', window_size=config.SLID_WINDOW_SIZE)
#5.2.3 保存训练集
pd.DataFrame(train_dataset).to_json(config.PROCESSED_DATA_DIR/'train.jsonl', orient='records', lines=True)
train_file = config.PROCESSED_DATA_DIR/'train.jsonl'
print('训练集保存成功!' if (Path(train_file).exists() and Path(train_file).stat().st_size != 0) else '训练集保存失败!')
#5.3 相同方式处理测试集句子
vocab_test = [jieba.lcut(sentence) for sentence in tqdm(test_sentences,desc='测试句子分词中...')] #切词
indexed_test_sentence = [[word2index[w] if w in word2index.keys() else 0 for w in s] for s in vocab_test] #转数字
test_dataset = window_build_dataset(indexed_sentence=indexed_test_sentence, desc='生成测试集中...', window_size=config.SLID_WINDOW_SIZE) #滑窗切分
pd.DataFrame(test_dataset).to_json(config.PROCESSED_DATA_DIR/'test.jsonl', orient='records', lines=True) #保存测试集
test_file = config.PROCESSED_DATA_DIR/'test.jsonl'
print('测试集保存成功!' if (Path(test_file).exists() and Path(test_file).stat().st_size != 0) else '测试集保存失败!')下面分步解读上面代码的各个细节:
1、读取synthesized_.jsonl文件
json文件是一种非常灵活的标准化数据,当我们用pd.read_json()函数去读取json文件时,我们得先知道 这个json文件是如何生成的,也就是知道这个json文件是如何编码 自己的数据格式的,然后我们才能知道如何读取这个json文件,也就是知道如何解码 这个json文件: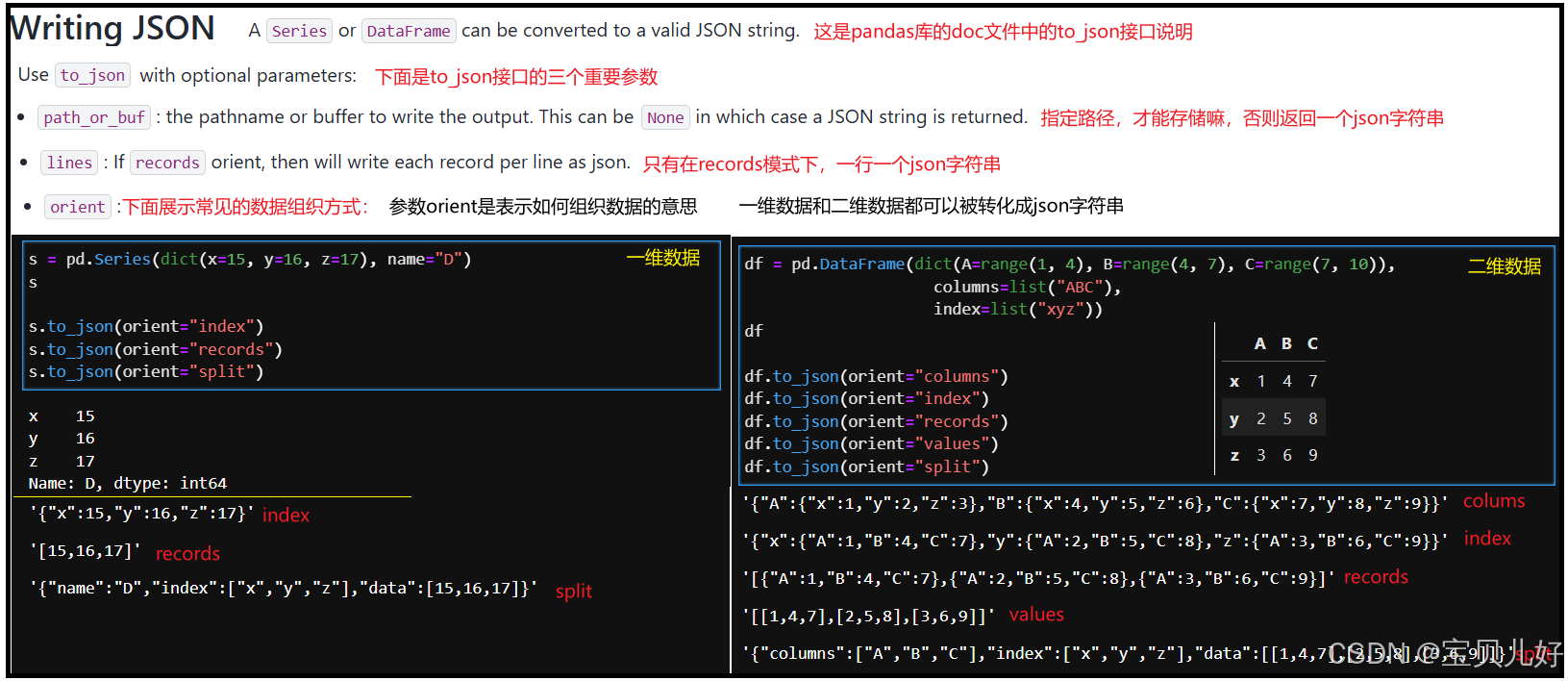
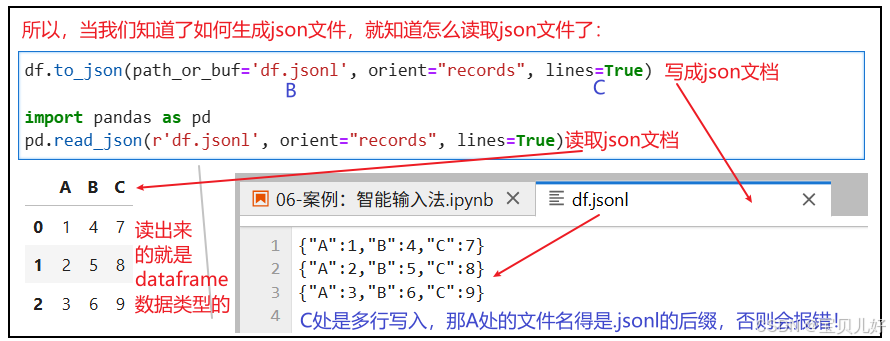
所以,synthesized_.jsonl文件其实就是从二维dataframe数据结构编码而来的,只要照着上面的解码方式就可以顺利解码了: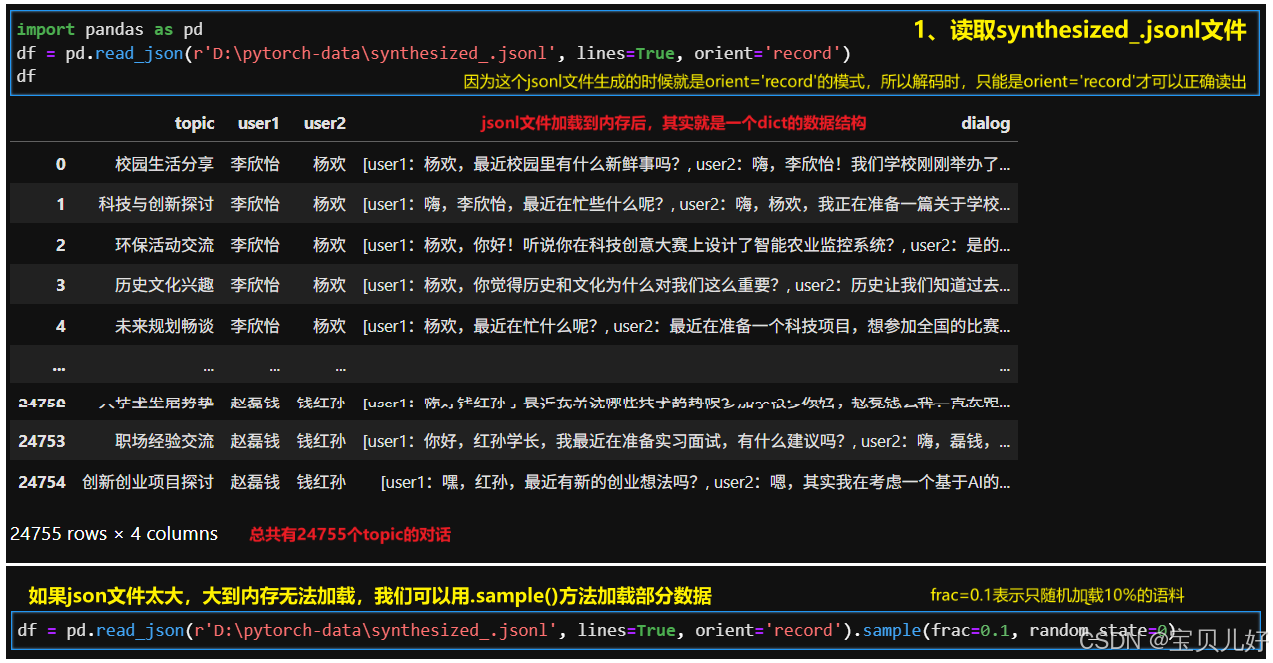
2、提取文件中的所有对话句子
读出的synthesized_.jsonl文件,其实就是dataframe对象,我们只要'dialog'就可以切到我们想要的对话文本了,然后用split,根据冒号,切割成一个个句子: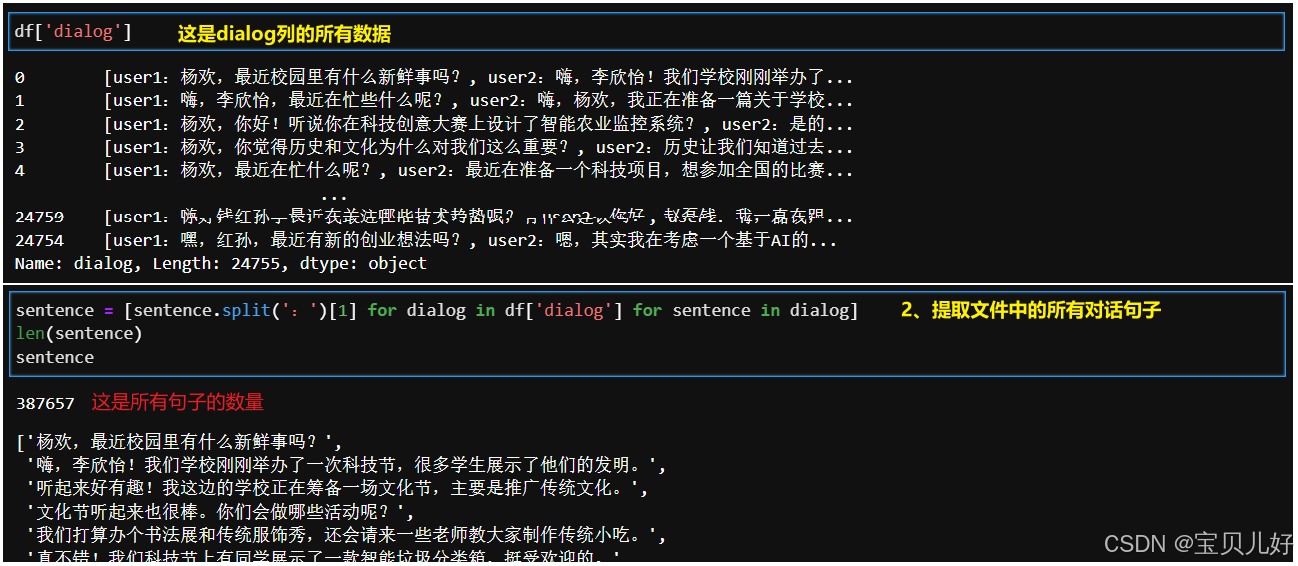
3、将所有句子打乱,划分为训练句子和测试句子 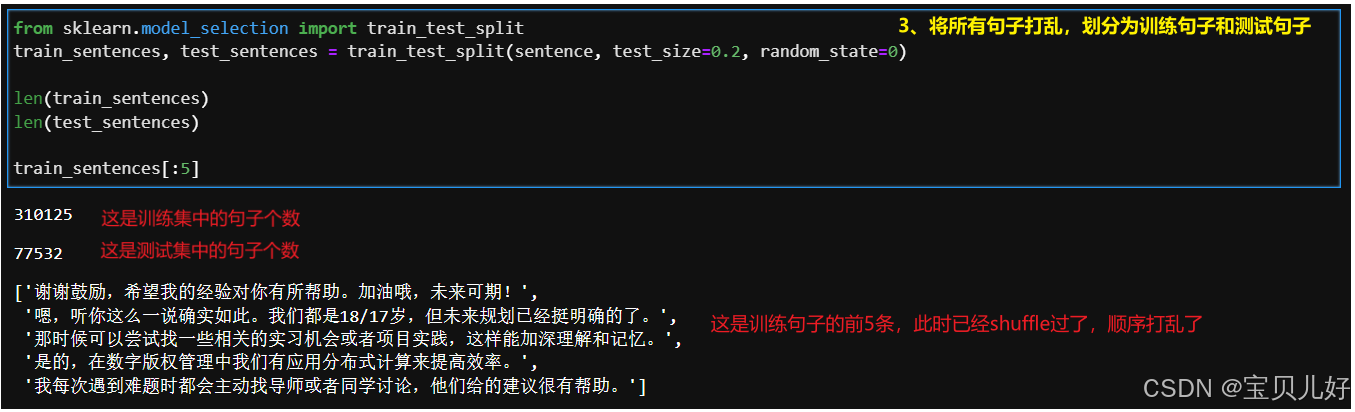
4、用训练句子构建词表,并保存词表 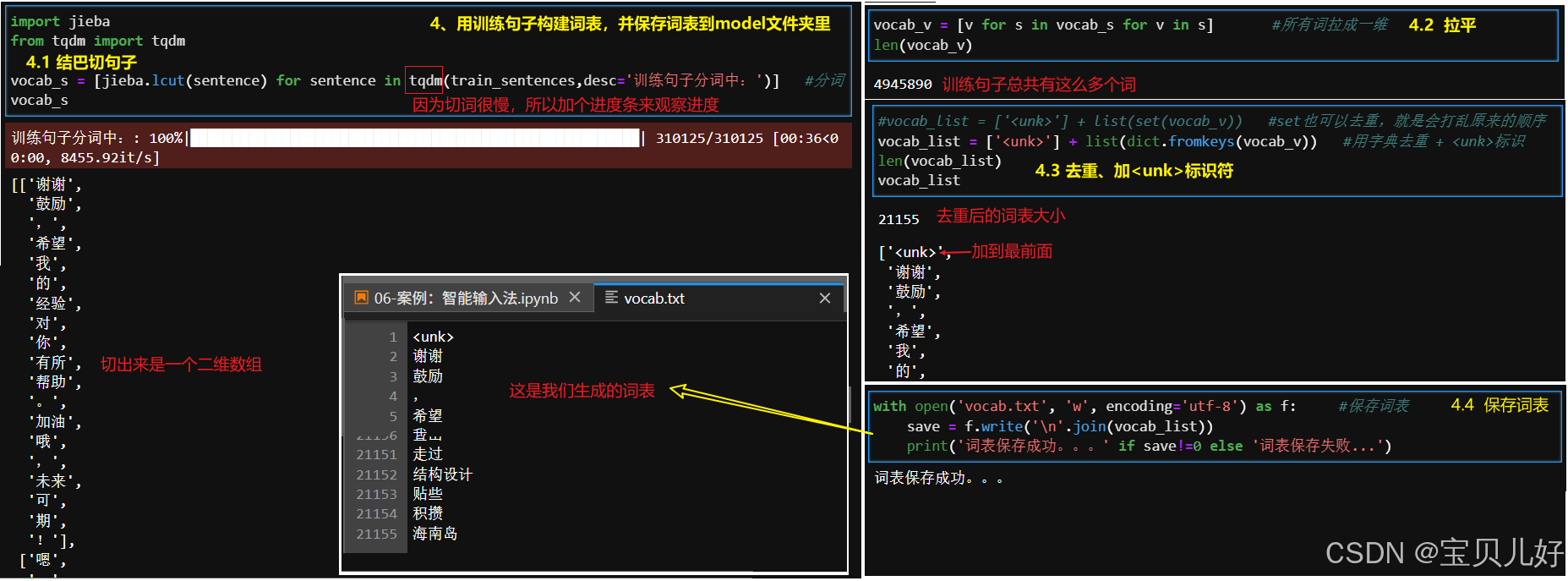 这里仅仅示例如何保存,至于要保存到model文件夹中,见最前面的代码。
这里仅仅示例如何保存,至于要保存到model文件夹中,见最前面的代码。
5、用滑窗构建训练集和测试集并保存
下面只展示这个过程中的重点环节: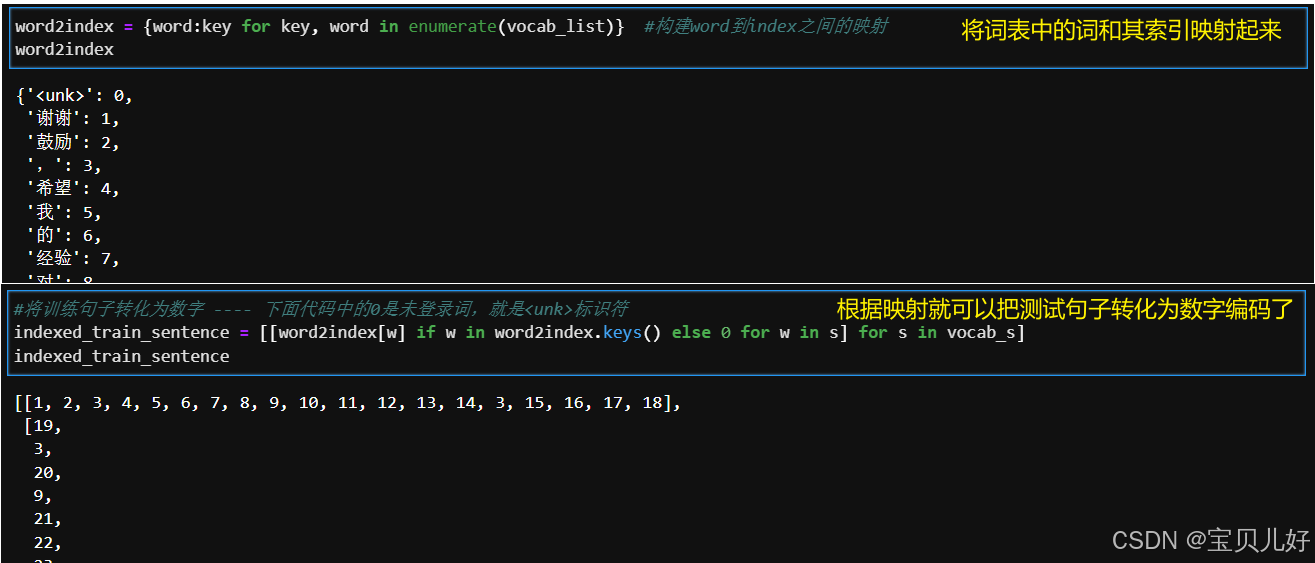
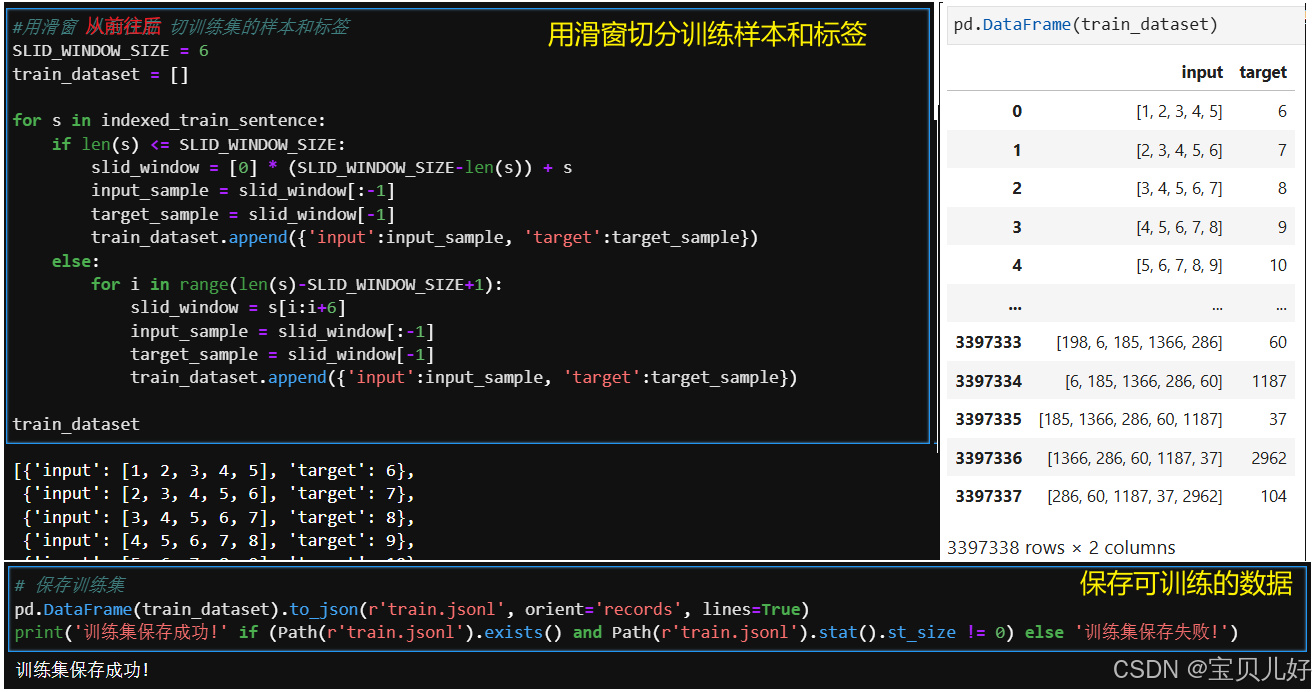 上面展示的代码,仅仅是对训练句子的处理过程。测试句子的处理同理。
上面展示的代码,仅仅是对训练句子的处理过程。测试句子的处理同理。
(三)编写dataset.py文件
dataset.py模块的功能是:封装数据+分小批次 = 可以直接训练模型的数据。
我们后面要搭建模型架构、训练模型,这些操作都在pytorch框架下,所以喂入模型的数据,除了必须是tensor类型外,还得把数据的特征和标签打包到一起 ,然后再分小批次batch,才能一个一个batch地喂入模型,进行模型训练。
为什么如此繁琐?因为深度学习中的数据一般都是海量的,就是样本量非常多,比如10万以上的样本量。训练过程也不像机器学习中的算法模型一样,先把数据全部加载到内存,然后学习出一个模型。深度学习都是分批次batch加载数据的,分批次batch学习和迭代的,也正是这种机制才使得深度学习可以处理海量数据而避免内存不足的限制。
所以pytorch给我们提供了Dataset类 来封装数据,也提供了DataLoader函数来对训练集和测试集进行分小批次。我们直接拿来用即可。
python
# dataset.py模块的具体代码如下:
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import pandas as pd
import config
#封装数据
class ReadData(Dataset):
def __init__(self, path):
super(ReadData, self).__init__()
self.data = pd.read_json(path, lines=True, orient='records')
def __getitem__(self, index):
input_tensor = torch.tensor(self.data.iloc[index]['input'], dtype=torch.long)
target_tensor = torch.tensor(self.data.iloc[index]['target'], dtype=torch.long)
return input_tensor, target_tensor
def __len__(self):
return len(self.data)
#分小批次batch
def get_batchdata(train=True):
path = config.PROCESSED_DATA_DIR / ('train.jsonl' if train else 'test.jsonl')
dataset = ReadData(path)
batchdata = DataLoader(dataset, batch_size=config.BATCH_SIZE, shuffle=True, drop_last=True)
return batchdata说明:pytorch在对数据进行生成、打包、shuffle、切分、分小批次,以及数据预处理(比如转化数据类型、数据归一化)等操作,pytorch都是仅仅存储着数据转化的逻辑关系,不是真正的去新生成一些数据转化结果数据,而是生成一些映射式或者迭代式的对象,在使用的时候也是迭代查询或者递归查询这些对象,这种底层的巧妙设计机制主要就是为了适应海量数据而设计的。这些操作中的细节非常非常多,这里不可能一一说明,想了解更多的细节可参考我以前的博文:
https://blog.csdn.net/friday1203/article/details/135208594
https://blog.csdn.net/friday1203/article/details/135469813
https://blog.csdn.net/friday1203/article/details/136943295
https://blog.csdn.net/friday1203/article/details/137709966
上面后两篇博文中都有案例,通过案例,你可以对pytorch的使用流程了然于胸。下图是这部分代码的效果: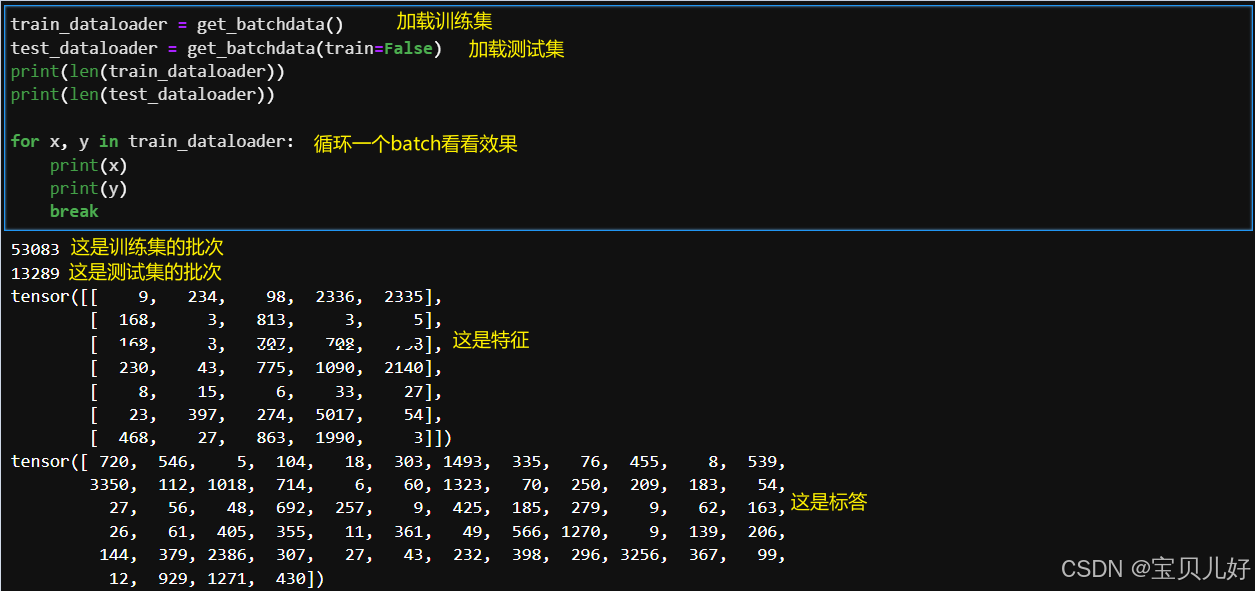
(四)编写model.py文件 ¶
待续。。。。