
🌈 个人主页:Zfox_
🔥 系列专栏:LangChain-AI 应用开发框架

目录
- [一:🔥 什么是持久化能⼒?](#一:🔥 什么是持久化能⼒?)
- [二:🔥 线程级持久化](#二:🔥 线程级持久化)
-
- [🦋 线程级持久化是怎么⼯作的?](#🦋 线程级持久化是怎么⼯作的?)
- [🦋 核⼼概念](#🦋 核⼼概念)
-
- [🎀 Threads(线程)](#🎀 Threads(线程))
- [🎀 Checkpoints(检查点)](#🎀 Checkpoints(检查点))
- [🦋 线程级持久化使⽤姿势](#🦋 线程级持久化使⽤姿势)
- [三:🔥 跨会话持久化](#三:🔥 跨会话持久化)
-
- [🦋 Checkpoint 的局限性](#🦋 Checkpoint 的局限性)
-
- [🎀 问题场景:跨会话信息丢失](#🎀 问题场景:跨会话信息丢失)
- [🎀 现实世界的需求:从"单次对话"到"终⾝服务"](#🎀 现实世界的需求:从"单次对话"到"终⾝服务")
- [🦋 解决⽅案:引⼊Store](#🦋 解决⽅案:引⼊Store)
-
- [🎀 存储vs检查点](#🎀 存储vs检查点)
- [🎀 引⼊Store后,AI应⽤架构的范式转变](#🎀 引⼊Store后,AI应⽤架构的范式转变)
- [🦋 跨会话持久化使⽤姿势](#🦋 跨会话持久化使⽤姿势)
-
- [🎀 ⽅式1:内存存储](#🎀 ⽅式1:内存存储)
- [🎀 ⽅式2:Postgres存储库](#🎀 ⽅式2:Postgres存储库)
- [四:🔥 持久化实现的三⼤应⽤能⼒](#四:🔥 持久化实现的三⼤应⽤能⼒)
-
- [🦋 记忆(Memory)](#🦋 记忆(Memory))
- [🦋 ⼈机交互(Human-in-the-loop)](#🦋 ⼈机交互(Human-in-the-loop))
-
- [🎀 核⼼概念:中断(Interrupts)](#🎀 核⼼概念:中断(Interrupts))
- [🎀 中断如何实现?](#🎀 中断如何实现?)
- [🎀 中断的⻩⾦法则(规则和限制)](#🎀 中断的⻩⾦法则(规则和限制))
-
- 只传能序列化的简单数据
- [不应该将 interrupt() 调⽤包裹在 try/except 代码块中](#不应该将 interrupt() 调⽤包裹在 try/except 代码块中)
- 中断前的动作要"幂等"
- 中断顺序固定
- [🎀 ⼈机交互的应⽤场景](#🎀 ⼈机交互的应⽤场景)
- [🦋 时间旅⾏(TimeTravel)](#🦋 时间旅⾏(TimeTravel))
-
- [🎀 时间旅⾏是什么?](#🎀 时间旅⾏是什么?)
- [🎀 时间旅⾏四步法](#🎀 时间旅⾏四步法)
- [🎀 【完整示例】AI笑话⽣成器](#🎀 【完整示例】AI笑话⽣成器)
- [五:🔥 持久化⼩结](#五:🔥 持久化⼩结)
- [六:🔥 共勉](#六:🔥 共勉)
一:🔥 什么是持久化能⼒?
简单来说,在LangGraph中持久化能⼒指的是将AI应⽤的状态(如对话历史、中间结果、⽤户信息 等)保存下来,即使程序重启或系统宕机,也能恢复之前的状态,让AI"记住"之前发⽣的⼀切。
想象⼀下这个场景:你今天在和智能助⼿聊天,说了很多重要信息。然后你关闭了应⽤,明天重新打 开并重新与它对话时,希望它还记得你说过的话吗?当然希望!这就是AI应⽤需要持久化的第⼀个原因。
再看第⼆个场景:假设有⼀个助⼿,它可以搜索⽹络。流程如下所示【快速上⼿-案例⼆】。
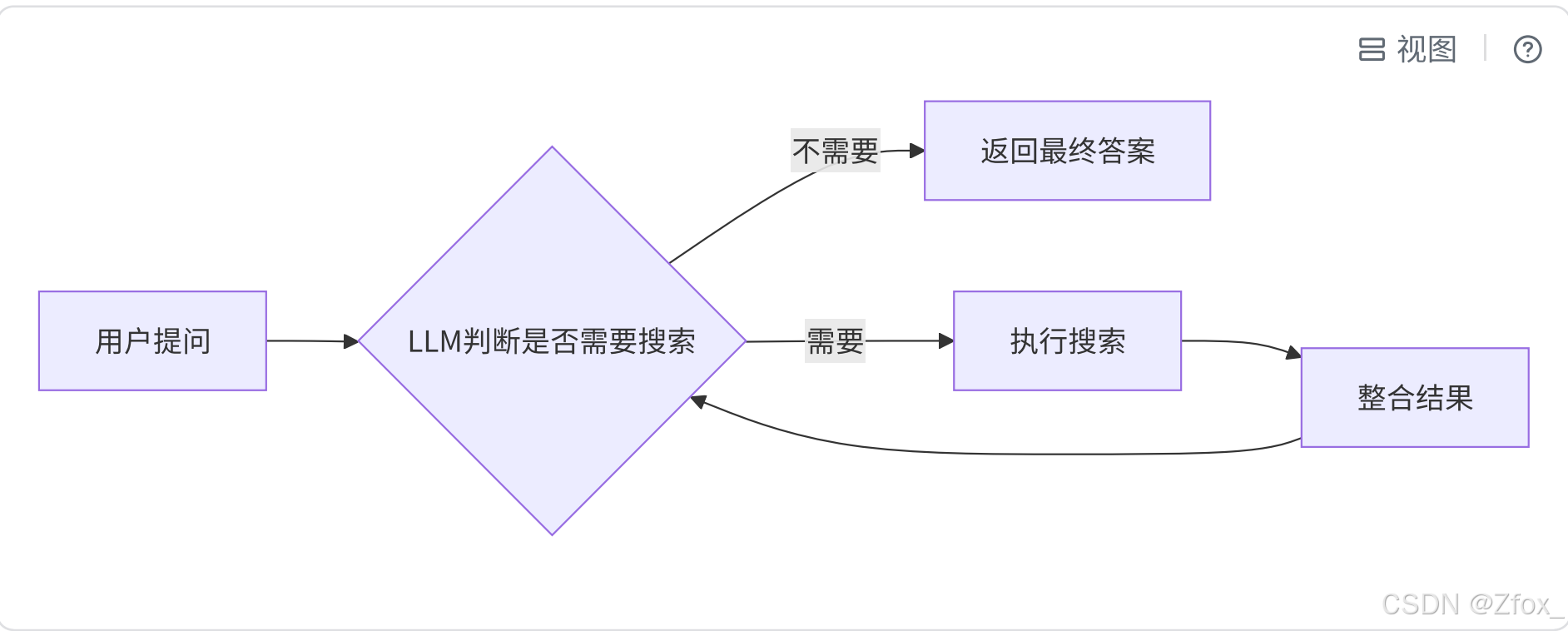
没有持久化:
- ⽤户问:"今天的天⽓怎么样?"
- 助⼿调⽤搜索⼯具,得到答案:"今天晴天,25度。"
- 程序崩溃重启。
- ⽤户再问:"那我需要带伞吗?"
- 助⼿没有之前的上下⽂,它可能⼜会去调⽤搜索⼯具,⽽不是基于"今天晴天"这个上下⽂来回答"不需要"。
有持久化:
- ⽤户问:"今天的天⽓怎么样?"
- 助⼿调⽤搜索⼯具,得到答案:"今天晴天,25度。"(这个状态,包括对话历史和⼯具调⽤结果,被⾃动保存)
- 程序崩溃重启。
- ⽤户再问:"那我需要带伞吗?"(与之前在同⼀会话下)
- LangGraph加载之前保存的状态,状态⾥记录了"今天晴天"。
- 助⼿看到上下⽂是晴天,于是直接回答:"今天是晴天,您不需要带伞。"(⽆需再次调⽤搜索⼯具)
实际上在LangGraph中,持久化能⼒具体包含两部分能⼒:
- 【线程级】持久化:能够【⾃动保存】⼯作流执⾏过程中的【状态快照】,维持单次会话的完整上 下⽂。
对应上述场景⼆;
解释1:这⾥的【线程持久化】和【操作系统线程】概念完全独⽴区分。操作系统线程是进程内 的执⾏单元,是操作系统能够进⾏调度的最⼩单位。⽽线程级持久化表示聊天过程中的单次会话的持久化信息,⽤来隔离不同的聊天会话。
解释2:这⾥的【状态快照】并⾮是之前学习过的State的快照。这个状态包含了所有必要的上下 ⽂信息,⽐如:已经调⽤过哪些⼯具、⽤户的输⼊、聊天历史、下⼀步要执⾏的节点等等。
- 【跨会话】持久化:通过存储(Store)保存⽤户信息、偏好设置等⻓期数据,实现不同对话间信 息的持久化共享。
对应上述场景⼀;
例如,可以将⽤户基本情况(有⾼⾎压病史)存储,后续⽆论在何时何地,或⽆论新开⼏个会话 窗⼝,都可以基于⽤户基本信息(有⾼⾎压病史)⽣成结果。
二:🔥 线程级持久化
🦋 线程级持久化是怎么⼯作的?
当我们开始执⾏⼯作流,过程中可能会发⽣ 崩溃或重启导致的中断 等异常情况。
根据LangGraph的持久化机制,线程级持久化表示能够【⾃动保存】⼯作流执⾏过程中的【状态快 照】,维持单次会话的完整上下⽂。当⼯作流执⾏到某⼀步时,它会⾃动保存当前步骤的状态快照。 这个状态包含了所有必要的上下⽂信息,⽐如:已经调⽤过哪些⼯具、⽤户的输⼊、聊天历史、下⼀ 步要执⾏的节点等等。
因此,⼯作流在执⾏过程中会发⽣如下图所示的流程:
- 正常执⾏:紫⾊/蓝⾊节点和实线箭头
- 异常恢复:红⾊/绿⾊节点和虚线箭头
- 检查点回滚:橙⾊节点和虚线箭头
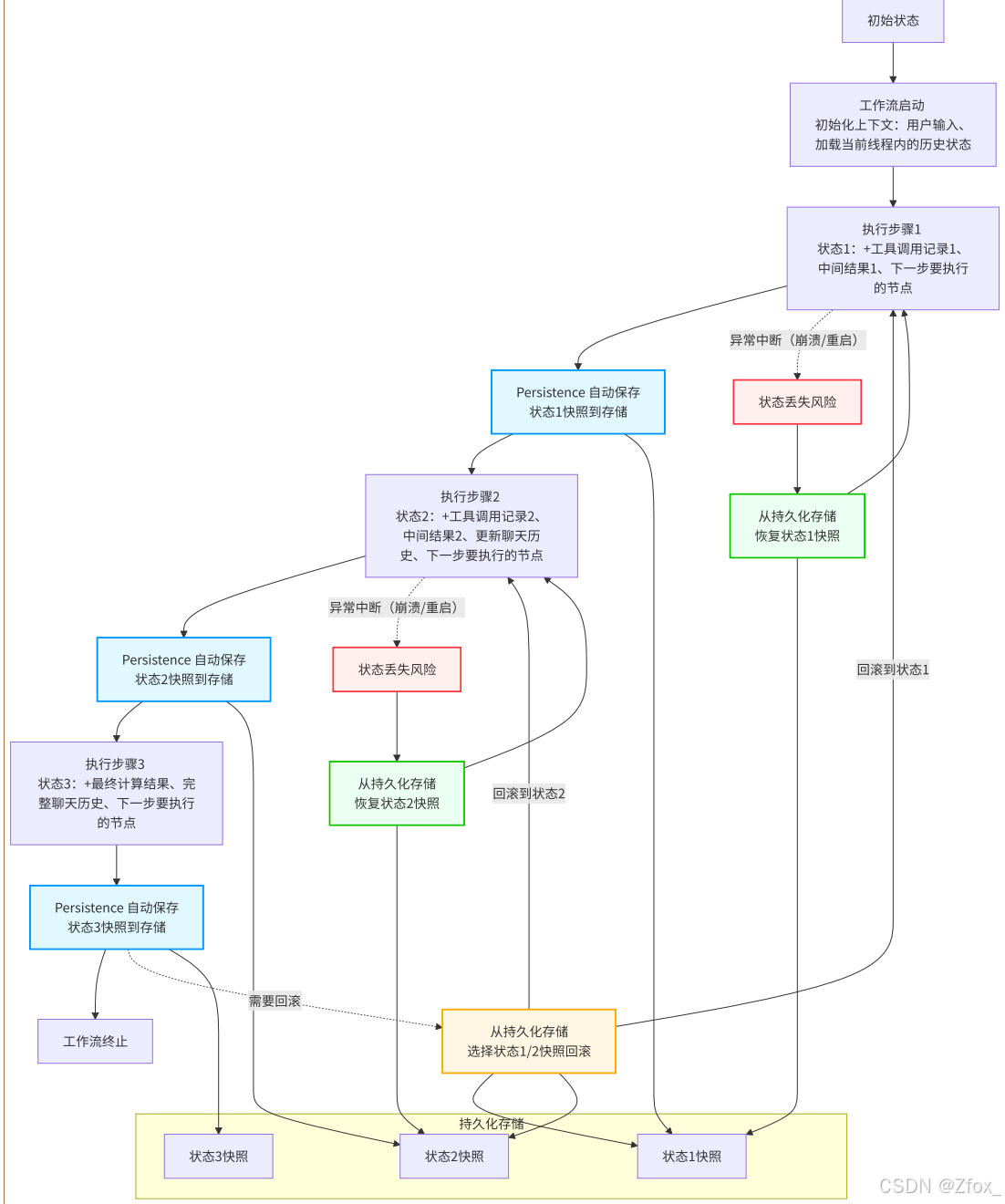
线程级持久化机制确保了:
- 状态不丢失:即使应⽤程序崩溃、重启,或者⼀个⻓时间的流程被中断,当它恢复时,可以从上次 停⽌的地⽅继续执⾏,⽽不是从头开始。
- ⽀持⻓时间运⾏的任务:对于需要与⽤户进⾏多轮交互(如多步对话助⼿)或处理耗时极⻓的流程 (如等待外部API回调),持久化是必不可少的。
- 检查点和回滚:我们可以将状态保存到某个时间点(检查点),并在需要时回滚到该状态。
🦋 核⼼概念
LangGraph的持久化机制⸺ 线程级持久化 是其核⼼功能,它通过**【线程】和【检查点】**这两个核⼼ 部分来实现。具体如下:
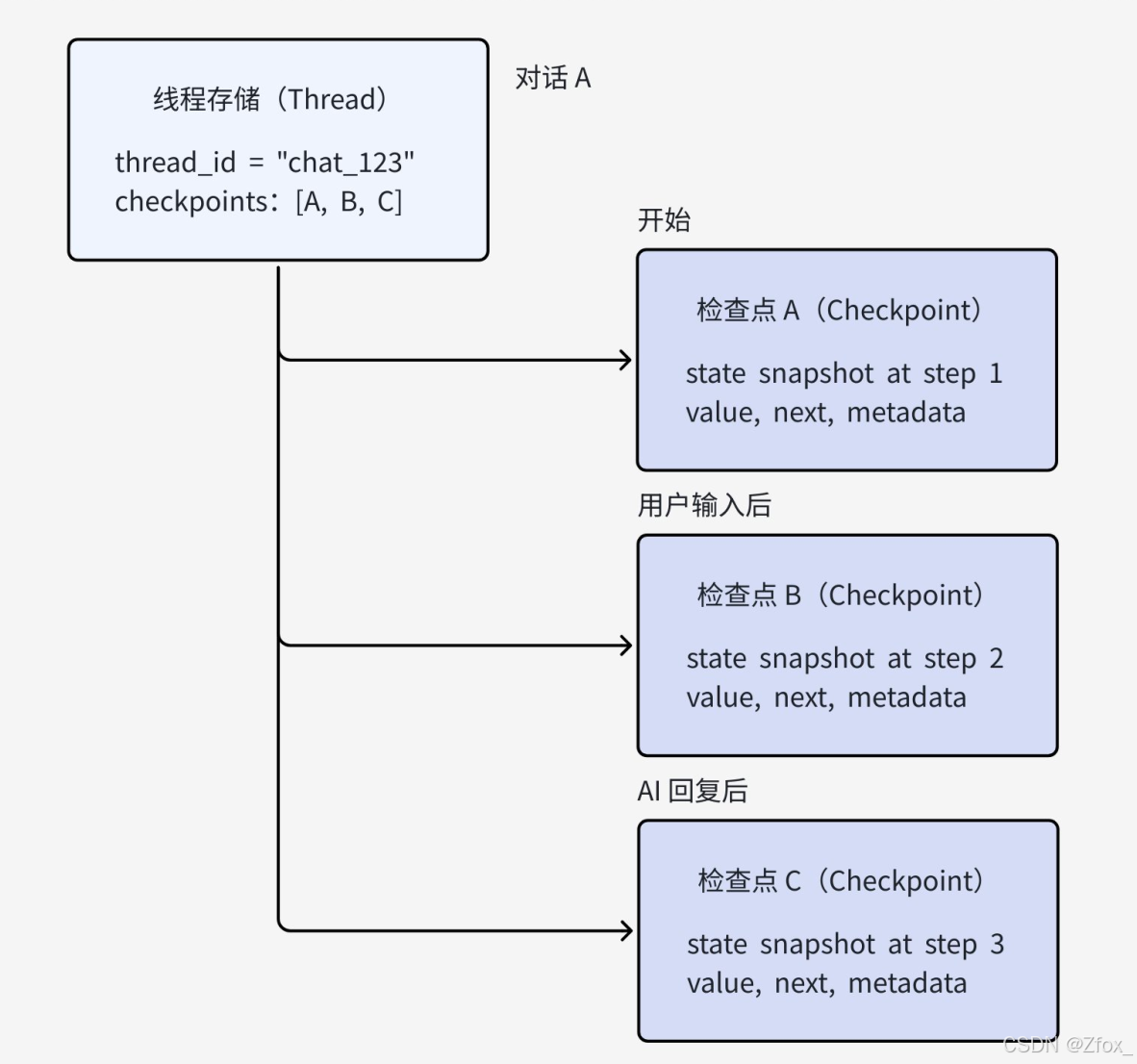
🎀 Threads(线程)
在LangGraph中,Thread代表⼀个独⽴的⼯作流执⾏会话。可以把它想象成【与某个⽤户的⼀次完 整对话历史】或【处理某个特定任务的⼀次完整执⾏过程】。例如在DS中的⼀次完整对话
Thread的关键特性如下:
- 隔离性:每个Thread都是完全独⽴的,它们的状态互不⼲扰
- 持久化单元:Thread是状态持久化的基本单位
- 标识符:通过唯⼀的 thread_id 来识别
🎀 Checkpoints(检查点)
Checkpoint是Thread在特定时刻的【状态快照】。它记录了⼯作流执⾏到某个节点时的完整状态。 例如在刚才的会话中,每⼀次⽤户输⼊和对话结束后,都可以保存⼀个最新的【状态快照】:

Checkpoint的关键特性:
- 状态快照(StateSnapshot):保存了⼯作流在某个时间点的完整状态。包含【状态值】、【下⼀步要执⾏的节点】、【与此检查点关联的配置】和【与此检查点关联的元数据】等信息。
StateSnapshot结构如下:
python
StateSnapshot(
# 当前状态值(如:对话消息列表)
values={'messages': [⽤⼾消息, AI回复, ⽤⼾消息...]},
# 接下来要执⾏的节点
next=('generate_response',),
# 配置信息
config={'configurable': {'thread_id': '123', 'checkpoint_id': 'abc'}},
# 元数据(步骤号、来源、写⼊信息等)
metadata={'step': 2, 'source': 'loop', 'writes': {...}},
# ⽗检查点(形成链表)
parent_config={'configurable': {'thread_id': '123', 'checkpoint_id': 'def...'}},
# 创建时间
created_at=''
)具体示例:
python
[
StateSnapshot(values={'messages': [HumanMessage(content='你好',
additional_kwargs={}, response_metadata={}), AIMessage(content='你好!有什么我
可以帮助你的吗?', additional_kwargs={'refusal': None}, response_metadata=
{'token_usage': {'completion_tokens': 11, 'prompt_tokens': 130,
'total_tokens': 141, 'completion_tokens_details':
{'accepted_prediction_tokens': None, 'audio_tokens': None,
'reasoning_tokens': None, 'rejected_prediction_tokens': None},
'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}},
'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_efad92c60b', 'id': 'chatcmplCiGUUZCWPLKOuRv6sdzolSVAzwtMW', 'finish_reason': 'stop', 'logprobs': None},
id='lc_run--7d1e5db6-e8b2-42c1-9fd8-ba21c42705ac-0', usage_metadata=
{'input_tokens': 130, 'output_tokens': 11, 'total_tokens': 141,
'input_token_details': {'cache_read': 0}, 'output_token_details': {}})],
'llm_calls': 1}, next=(), config={'configurable': {'thread_id': '1',
'checkpoint_ns': '', 'checkpoint_id': '1f0cf5cf-48e3-6bbb-8001-
c351576393a6'}}, metadata={'source': 'loop', 'step': 1, 'parents': {}},
created_at='2025-12-02T08:57:39.538826+00:00', parent_config=
{'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id':
'1f0cf5cf-38d7-61a8-8000-2dacafb54f11'}}, tasks=(), interrupts=()),
StateSnapshot(values={'messages': [HumanMessage(content='你好',
additional_kwargs={}, response_metadata={})]}, next=('llm_call',), config=
{'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id':
'1f0cf5cf-38d7-61a8-8000-2dacafb54f11'}}, metadata={'source': 'loop',
'step': 0, 'parents': {}}, created_at='2025-12-02T08:57:37.855930+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '',
'checkpoint_id': '1f0cf5cf-38d4-6e0c-bfff-6ce6b2a2dd01'}}, tasks=
(PregelTask(id='44c184e5-8661-3f3c-eeee-7a2f569f7e88', name='llm_call', path=
('__pregel_pull', 'llm_call'), error=None, interrupts=(), state=None, result=
{'messages': [AIMessage(content='你好!有什么我可以帮助你的吗?',
additional_kwargs={'refusal': None}, response_metadata={'token_usage':
{'completion_tokens': 11, 'prompt_tokens': 130, 'total_tokens': 141,
'completion_tokens_details': {'accepted_prediction_tokens': None,
'audio_tokens': None, 'reasoning_tokens': None,
'rejected_prediction_tokens': None}, 'prompt_tokens_details':
{'audio_tokens': None, 'cached_tokens': 0}}, 'model_provider': 'openai',
'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint':
'fp_efad92c60b', 'id': 'chatcmpl-CiGUUZCWPLKOuRv6sdzolSVAzwtMW',
'finish_reason': 'stop', 'logprobs': None}, id='lc_run--7d1e5db6-e8b2-42c1-
9fd8-ba21c42705ac-0', usage_metadata={'input_tokens': 130, 'output_tokens':
11, 'total_tokens': 141, 'input_token_details': {'cache_read': 0},
'output_token_details': {}})], 'llm_calls': 1}),), interrupts=()),
StateSnapshot(values={'messages': []}, next=('__start__',), config=
{'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id':
'1f0cf5cf-38d4-6e0c-bfff-6ce6b2a2dd01'}}, metadata={'source': 'input',
'step': -1, 'parents': {}}, created_at='2025-12-02T08:57:37.855022+00:00',
parent_config=None, tasks=(PregelTask(id='56c07f44-a6a6-a8b8-899ad5c24b2ff671', name='__start__', path=('__pregel_pull', '__start__'),
error=None, interrupts=(), state=None, result={'messages':
[HumanMessage(content='你好', additional_kwargs={}, response_metadata=
{})]}),), interrupts=())
]- 版本历史与可恢复点:⼀个Thread可以有多个Checkpoints,形成执⾏历史,使得同⼀个会话的历史状态可以从任意Checkpoint追溯和访问。
Threads与Checkpoints关系如下:
🦋 线程级持久化使⽤姿势
🎀 步骤⼀:配置 checkpointer 持久化存储
在定义图时,我们需要指定 checkpointer 。LangGraph⽀持多种 checkpointer 的定义⽅式:
⽅式1:内存存储
最简单的⽅式,状态保存在程序内存中。适⽤于开发和测试,程序重启后状态会丢失。⽤法如下所 示:
这⾥使⽤快速上⼿⸺案例2的代码,在编译图时,直接添加编译参数 checkpointer
python
from langgraph.checkpoint.memory import InMemorySaver
# 定义存储⽅式
checkpointer = InMemorySaver()
# ⽤ checkpointer 编译图
agent = agent_builder.compile(checkpointer=checkpointer)⽅式2:使⽤Postgres存储库
LangGraph提供了⼏个检查点存储实现,所有这些都通过独⽴的、可安装的库实现。适⽤于⽣产环境 或需要状态持久化的场景。
- SQLite存储( langgraph-checkpoint-sqlite ):使⽤SQLite数据库( SqliteSaver / AsyncSqliteSaver )的LangGraph检查点的实现。⾮常适合实验和本地⼯作流程。需要单 独安装。
- Postgres存储( langgraph-checkpoint-postgres ):使⽤Postgres数据库
( PostgresSaver / AsyncPostgresSaver )的LangGraph检查点的实现。⾮常适合在⽣ 产中使⽤。需要单独安装。
为什么选择PostgreSQL作为存储库?
在众多持久化存储⽅案中,PostgreSQL作为关系型数据库的佼佼者(PostgreSQL和MySQL⼀ 样,都是最流⾏的开源关系型数据库),具备以下显著优势,使其成为持久化的理想选择:
- LangGraph原⽣⽀持:LangGraph提供了 PostgresSaver ,简化了与PostgreSQL的集成过程。
- 数据结构化与⼀致性:关系型数据库天⽣适合存储结构化数据。Graph的状态,尤其是消息历史、⽤户档案、⼯具使⽤记录等,都可以很好地映射到表格结构中,确保数据的⼀致性和完整性。
- 可靠性与持久性:PostgreSQL提供了事务⽀持、ACID特性、数据备份与恢复机制,确保数据的持久性和⾼可⽤性,即使系统崩溃也能保证数据不丢失。
- 强⼤的查询能⼒:SQL语⾔提供了灵活且强⼤的数据查询能⼒,⽅便我们对历史⾏为、⽤户数据进⾏分析、统计和审计。结合 pgvector 等扩展,甚⾄可以直接在数据库中进⾏向量相似度搜 索,实现更⾼级的知识管理。
- 可扩展性:通过读写分离、分区、集群等技术,PostgreSQL可以⽀持⼤规模的并发访问和数据存储,满⾜Agent在⽣产环境中的性能需求。
- 成熟的⽣态系统:拥有庞⼤的社区⽀持、丰富的⼯具和成熟的运维经验,降低了开发和维护成本。
使⽤Docker快速安装并启动postgres:
python
# 1. 拉取 PostgreSQL 镜像
docker pull postgres:latest
# 2. 运⾏ PostgreSQL 容器
# -p 5432:5432: 将容器的5432端⼝映射到宿主机的5432端⼝
# -e POSTGRES_PASSWORD=bit: 设置PostgreSQL的postgres⽤⼾密码
# --name postgres-sql: 给容器命名
# -d: 后台运⾏
docker run --name postgres-sql -e POSTGRES_PASSWORD=bit -p 5432:5432 -d
postgres可以使⽤Navicat测试链接:注意默认连接postgres初始数据库,如果有其他数据库可以配置连 接。
- 安装 langgraph-checkpoint-postgres 包
python
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres- 设置PostgreSQL连接字符串(URI)
PostgreSQLURI通常遵循以下格式: postgresql://:@: /<database_name>
- 使⽤Postgre存储库作为检查点
使⽤ PostgresSaver.from_conn_string() ⽅法从连接字符串创建⼀个新的PostgresSaver实 例。
注意:第⼀次使⽤Postgres检查点时需要调⽤ checkpointer.setup()
python
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第⼀次使⽤ Postgres 检查点时需要调⽤ checkpointer.setup()
checkpointer.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
# ...后续调⽤...🎀 步骤⼆:使⽤Thread进⾏执⾏
当我们编译好图并准备运⾏时,我们需要通过⼀个ThreadID来标识这次执⾏。
- 如果ThreadID不存在:LangGraph会创建⼀个新的Thread,并从初始状态开始执⾏。
- 如果ThreadID已存在:LangGraph会从Checkpointer中加载该Thread的最后⼀次保存的状态,并从这个状态继续执⾏。
这⾥依旧使⽤postgres存储,进⾏第⼀次执⾏:创建⼀个新的Thread(thread_id="1")
python
from langchain.messages import HumanMessage
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第⼀次使⽤ Postgres 检查点时需要调⽤ checkpointer.setup()
checkpointer.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
# 第⼀次执⾏,创建⼀个新的 Thread (thread_id="1")
config = {"configurable": {"thread_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天西安的天⽓如何?")]},
config
)
print(f"调⽤ LLM 总次数:{result1["llm_calls"]}次")
for m in result1["messages"]:
m.pretty_print()运⾏后,可以看到postgres库中,已经存储了检查点信息:

⼀段时间后,再次使⽤相同的thread_id调⽤:
python
from langchain.messages import HumanMessage
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第⼀次使⽤ Postgres 检查点时需要调⽤ checkpointer.setup()
# checkpointer.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
# ............... ⼀段时间后,程序可能重启了(使⽤postgres存储)...............
# 再次使⽤相同的 thread_id 调⽤
# LangGraph 会从上次的状态继续,⽽不是重新开始
# 此时,result2 的上下⽂会包含之前的对话历史
config = {"configurable": {"thread_id": "1"}}
result2 = agent.invoke(
{"messages": [HumanMessage(content="我们刚才聊到哪了?")]},
config
)
print(f"调⽤ LLM 总次数:{result2["llm_calls"]}次")
for m in result2["messages"]:
m.pretty_print()第⼆次调⽤结果如下:
python
调⽤ LLM 总次数:3次
================================ Human Message =================================
今天西安的天⽓如何?
================================== Ai Message ==================================
Tool Calls:
tavily_search (call_8ALCCwF3xudzjavTFNI6rA0m)
Call ID: call_8ALCCwF3xudzjavTFNI6rA0m
Args:
query: 西安天⽓
================================= Tool Message =================================
(省略...)
================================== Ai Message
==================================
今天西安的天⽓情况如下:
- **⽓温**:最⾼温度约为18°C,最低温度约为7°C。
- **天⽓状况**:多云,空⽓质量较好。
如果你想查看更详细的天⽓预报,可以访问以下链接:
- [中国⽓象局 - 西安天⽓预报](https://weather.cma.cn/web/weather/V8870.html)
- [天⽓⽹ - 西安天⽓](https://www.weather.com.cn/weather40d/101110101.shtml)
请根据天⽓情况合理安排你的出⾏!
================================ Human Message =================================
我们刚才聊到哪了?
================================== Ai Message ==================================
我们刚才聊到西安的天⽓情况,包括今天的⽓温和天⽓状况。如果你有其他问题或者想讨论的内容,请告诉我!从结果看来,result2的上下⽂会包含之前的对话历史。LangGraph会从上次的状态继续,⽽不是重新 开始
🎀 其他基本⽤法
获取状态快照
当使⽤ checkpointer 编译图时,执⾏时就会在每个步骤处保存状态快照。在 LangGraph中状态快 照就是 StateSnapshot 对象,其具有以下关键属性:
python
StateSnapshot(
# 当前状态值(如:对话消息列表)
values={'messages': [⽤⼾消息, AI回复, ⽤⼾消息...]},
# 接下来要执⾏的节点
next=('generate_response',),
# 配置信息
config={'configurable': {'thread_id': '123', 'checkpoint_id': 'abc'}},
# 元数据(步骤号、来源、写⼊信息等)
metadata={'step': 2, 'source': 'loop', 'writes': {...}},
# ⽗检查点(形成链表)
parent_config={'configurable': {'thread_id': '123', 'checkpoint_id':
'def...'}},
# 创建时间
created_at=''
)我们可以使⽤ get_state(config) ⽅法,获取编译后的图的最新状态快照。让我们分别获取⼀下 执⾏前与执⾏后的最新状态快照:
python
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
# 调⽤前的状态快照
snapshot = agent.get_state(config)
print(snapshot)
result1 = agent.invoke(
{"messages": [HumanMessage(content="你好")]},
config
)
# 调⽤后的状态快照
snapshot = agent.get_state(config)
print(snapshot)打印结果:
python
StateSnapshot(
values={},
next=(),
config={'configurable': {'thread_id': '1'}},
metadata=None,
created_at=None,
parent_config=None,
tasks=(),
interrupts=()
)
StateSnapshot(
values={'messages': [HumanMessage(content='你好', additional_kwargs={},
response_metadata={}), AIMessage(content='你好!有什么我可以帮助你的吗?',
additional_kwargs={'refusal': None}, response_metadata={'token_usage':
{'completion_tokens': 11, 'prompt_tokens': 130, 'total_tokens': 141,
'completion_tokens_details': {'accepted_prediction_tokens': None,
'audio_tokens': None, 'reasoning_tokens': None, 'rejected_prediction_tokens':
None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}},
'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_efad92c60b', 'id': 'chatcmplCiGBdkNSGgkZ3ccpa6NEAyUHrzqls', 'finish_reason': 'stop', 'logprobs': None},
id='lc_run--f76d30e4-0e06-4f18-ab44-0e43e8ff70b8-0', usage_metadata=
{'input_tokens': 130, 'output_tokens': 11, 'total_tokens': 141,
'input_token_details': {'cache_read': 0}, 'output_token_details': {}})],
'llm_calls': 1},
next=(),
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '',
'checkpoint_id': '1f0cf5a3-b6ff-6b2e-8001-dc5cd083ad82'}},
metadata={'source': 'loop', 'step': 1, 'parents': {}},
created_at='2025-12-02T08:38:09.968610+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '',
'checkpoint_id': '1f0cf5a3-a7a5-6cf8-8000-ec666fd226fe'}},
tasks=(),
interrupts=()
)获取状态历史记录
我们可以通过调⽤ get_state_history(config) 来获取给定线程的图执⾏的完整历史记录。这 将返回与配置中提供的线程ID关联的 StateSnapshot 对象列表。
python
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="你好")]},
config
)
# 查看状态历史记录
history = list(agent.get_state_history(config))
print(history)返回结果将按时间顺序排序,列表中的第⼀个检查点( StateSnapshot )是最新的。结果如下:
python
[
StateSnapshot(values={'messages': [HumanMessage(content='你好',
additional_kwargs={}, response_metadata={}), AIMessage(content='你好!有什么我可
以帮助你的吗?', additional_kwargs={'refusal': None}, response_metadata=
{'token_usage': {'completion_tokens': 11, 'prompt_tokens': 130,
'total_tokens': 141, 'completion_tokens_details':
{'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens':
None, 'rejected_prediction_tokens': None}, 'prompt_tokens_details':
{'audio_tokens': None, 'cached_tokens': 0}}, 'model_provider': 'openai',
'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_efad92c60b',
'id': 'chatcmpl-CiGUUZCWPLKOuRv6sdzolSVAzwtMW', 'finish_reason': 'stop',
'logprobs': None}, id='lc_run--7d1e5db6-e8b2-42c1-9fd8-ba21c42705ac-0',
usage_metadata={'input_tokens': 130, 'output_tokens': 11, 'total_tokens': 141,
'input_token_details': {'cache_read': 0}, 'output_token_details': {}})],
'llm_calls': 1}, next=(), config={'configurable': {'thread_id': '1',
'checkpoint_ns': '', 'checkpoint_id': '1f0cf5cf-48e3-6bbb-8001-
c351576393a6'}}, metadata={'source': 'loop', 'step': 1, 'parents': {}},
created_at='2025-12-02T08:57:39.538826+00:00', parent_config={'configurable':
{'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f0cf5cf-38d7-61a8-
8000-2dacafb54f11'}}, tasks=(), interrupts=()),
StateSnapshot(values={'messages': [HumanMessage(content='你好',
additional_kwargs={}, response_metadata={})]}, next=('llm_call',), config=
{'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id':
'1f0cf5cf-38d7-61a8-8000-2dacafb54f11'}}, metadata={'source': 'loop', 'step':
0, 'parents': {}}, created_at='2025-12-02T08:57:37.855930+00:00',
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '',
'checkpoint_id': '1f0cf5cf-38d4-6e0c-bfff-6ce6b2a2dd01'}}, tasks=
(PregelTask(id='44c184e5-8661-3f3c-eeee-7a2f569f7e88', name='llm_call', path=
('__pregel_pull', 'llm_call'), error=None, interrupts=(), state=None, result=
{'messages': [AIMessage(content='你好!有什么我可以帮助你的吗?',
additional_kwargs={'refusal': None}, response_metadata={'token_usage':
{'completion_tokens': 11, 'prompt_tokens': 130, 'total_tokens': 141,
'completion_tokens_details': {'accepted_prediction_tokens': None,
'audio_tokens': None, 'reasoning_tokens': None, 'rejected_prediction_tokens':
None}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}},
'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_efad92c60b', 'id': 'chatcmplCiGUUZCWPLKOuRv6sdzolSVAzwtMW', 'finish_reason': 'stop', 'logprobs': None},
id='lc_run--7d1e5db6-e8b2-42c1-9fd8-ba21c42705ac-0', usage_metadata=
{'input_tokens': 130, 'output_tokens': 11, 'total_tokens': 141,
'input_token_details': {'cache_read': 0}, 'output_token_details': {}})],
'llm_calls': 1}),), interrupts=()),
StateSnapshot(values={'messages': []}, next=('__start__',), config=
{'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id':
'1f0cf5cf-38d4-6e0c-bfff-6ce6b2a2dd01'}}, metadata={'source': 'input', 'step':
-1, 'parents': {}}, created_at='2025-12-02T08:57:37.855022+00:00',
parent_config=None, tasks=(PregelTask(id='56c07f44-a6a6-a8b8-899ad5c24b2ff671', name='__start__', path=('__pregel_pull', '__start__'),
error=None, interrupts=(), state=None, result={'messages':
[HumanMessage(content='你好', additional_kwargs={}, response_metadata={})]}),),
interrupts=())
]重放
如果我们⽤⼀个 thread_id 和⼀个 checkpoint_id (表示检查点标识符,⽤于指代线程内的特定检查点)来调⽤⼀个图,那么我们将重新执⾏对应于 checkpoint_id 之后的步骤。如下所示:
- 先执⾏⼀次完整的流程,获取⼀次完整历史记录;
- 保存中间过程某⼀次快照,并重新执⾏快照后的步骤;
- 获取第⼆次调⽤后的完整历史记录,验证是否重放成功;
python
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
# 第⼀次执⾏
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天西安的天⽓如何?")]},
config
)
# 保存调⽤⼯具前的状态
print("-" * 80)
print(f"第⼀次执⾏历史:")
to_replay = None
for state in agent.get_state_history(config):
print("checkpoint_id: ", state.config["configurable"]["checkpoint_id"],
"消息数: ", len(state.values["messages"]),
"下⼀节点: ", state.next)
if len(state.values["messages"]) == 2: # 保存调⽤⼯具前的状态
to_replay = state
print("-" * 80)
print(f"从{to_replay.next}节点开始重新执⾏, 重放配置:{to_replay.config}")
# 第⼆次执⾏:重放
result2 = agent.invoke(None, config=to_replay.config)
print("-" * 80)
print(f"第⼆次执⾏历史:重放后")
# 查看新的历史记录
for state in agent.get_state_history(config):
print("checkpoint_id: ", state.config["configurable"]["checkpoint_id"], "消息数: ", len(state.values["messages"]), "下⼀节点: ", state.next)
result2['messages'][-1].pretty_print()执⾏结果如下所示。可以看到历史记录中帮我们记录所有的执⾏过程,包括重放前和重放后的步骤! 这同时也证明了重放成功。
python
-------------------------------------------------------------------------------
- 第⼀次执⾏历史:
checkpoint_id: 1f0cf6bc-cb09-61e3-8003-1a74660e9324 消息数: 4 下⼀节点: ()
checkpoint_id: 1f0cf6bc-b148-624e-8002-f696045e95a8 消息数: 3 下⼀节点:
('llm_call',)
checkpoint_id: 1f0cf6bc-8a86-62a5-8001-38aa0c3d8d80 消息数: 2 下⼀节点:
('tool_node',)
checkpoint_id: 1f0cf6bc-7abe-6d9a-8000-ef816c492e36 消息数: 1 下⼀节点:
('llm_call',)
checkpoint_id: 1f0cf6bc-7abc-6ce5-bfff-5241076b5574 消息数: 0 下⼀节点:
('__start__',)
-------------------------------------------------------------------------------
- 从
('tool_node',)节点开始重新执⾏, 重放配置:{'configurable': {'thread_id': '1',
'checkpoint_ns': '', 'checkpoint_id': '1f0cf6bc-8a86-62a5-8001-38aa0c3d8d80'}}
-------------------------------------------------------------------------------
- 第⼆次执⾏历史:重放后
checkpoint_id: 1f0cf6bd-0e30-6cf9-8003-f22545cde7b2 消息数: 4 下⼀节点: ()
checkpoint_id: 1f0cf6bc-e376-6e52-8002-9c66bdb5577a 消息数: 3 下⼀节点:
('llm_call',)
checkpoint_id: 1f0cf6bc-cb09-61e3-8003-1a74660e9324 消息数: 4 下⼀节点: ()
checkpoint_id: 1f0cf6bc-b148-624e-8002-f696045e95a8 消息数: 3 下⼀节点:
('llm_call',)
checkpoint_id: 1f0cf6bc-8a86-62a5-8001-38aa0c3d8d80 消息数: 2 下⼀节点:
('tool_node',)
checkpoint_id: 1f0cf6bc-7abe-6d9a-8000-ef816c492e36 消息数: 1 下⼀节点:
('llm_call',)
checkpoint_id: 1f0cf6bc-7abc-6ce5-bfff-5241076b5574 消息数: 0 下⼀节点:
('__start__',)
================================== Ai Message
==================================
今天西安的天⽓情况如下:
- **天⽓**:晴
- **⽓温**:最⾼温度约为 13°C,最低温度约为 2°C
- **⻛速**:东北⻛,约 6 英⾥/⼩时
- **空⽓质量**:不健康重放功能实际应⽤为时间旅⾏,详⻅下⽂【时间旅⾏(TimeTravel)】篇章。
更新状态
我们还可以编辑图状态。我们使⽤ update_state() ⽅法来做到这⼀点。
让我们更新⽤户的输⼊,换成其他搜索内容:
-
先执⾏⼀次完整的流程,获取⼀次完整历史记录;
-
保存第⼀次调⽤LLM前的步骤快照,修改⽤户输⼊来更新快照,并重新执⾏更新后快照步骤;
代码如下:
python
from langchain.messages import HumanMessage
from langgraph.types import Overwrite
config = {"configurable": {"thread_id": "1"}}
# 第⼀次执⾏
result1 = agent.invoke(
{"messages": [HumanMessage(content="今天西安的天⽓如何?")]},
config
)
# 找到调⽤LLM前的步骤
print("-" * 80)
print(f"第⼀次执⾏历史:")
selected_state = None
for state in agent.get_state_history(config):
print("checkpoint_id: ", state.config["configurable"]["checkpoint_id"], "消息数: ", len(state.values["messages"]),
"下⼀节点: ", state.next)
if len(state.values["messages"]) == 1: # 此时消息数为1;下⼀节点是'llm_call'
selected_state = state
print("-" * 80)
print(f"更新前配置:{selected_state.config}")
# 根据指定的config,更新对于步骤的值
# 更新⽤⼾输⼊
new_config = agent.update_state(
selected_state.config,
{"messages": Overwrite([HumanMessage(content="今天北京的天⽓如何?")])} # 清
空消息,重新写⼊
)
print("-" * 80)
print(f"更新后配置:{new_config}")
# 第⼆次执⾏:重放更新后的配置
result2 = agent.invoke(None, config=new_config)
for message in result2['messages']:
message.pretty_print()执⾏结果如下:
python
-------------------------------------------------------------------------------
- 第⼀次执⾏历史:
checkpoint_id: 1f0cf6c8-743c-6b8d-8003-d8a1130c15e0 消息数: 4 下⼀节点: ()
checkpoint_id: 1f0cf6c8-4244-682c-8002-bdc8b86d460d 消息数: 3 下⼀节点:
('llm_call',)
checkpoint_id: 1f0cf6c8-3304-6782-8001-7ebc967b7bb1 消息数: 2 下⼀节点:
('tool_node',)
checkpoint_id: 1f0cf6c8-1b1c-62a0-8000-42b9d34bb01d 消息数: 1 下⼀节点:
('llm_call',)
checkpoint_id: 1f0cf6c8-1b19-6adb-bfff-915f44142490 消息数: 0 下⼀节点:
('__start__',)
-------------------------------------------------------------------------------
- 更新前配置:{'configurable': {'thread_id': '1', 'checkpoint_ns': '',
'checkpoint_id': '1f0cf6c8-1b1c-62a0-8000-42b9d34bb01d'}}
-------------------------------------------------------------------------------
- 更新后配置:{'configurable': {'thread_id': '1', 'checkpoint_ns': '',
'checkpoint_id': '1f0cf6c8-7444-61e3-8001-d9eb91c95052'}}
================================ Human Message
=================================
今天北京的天⽓如何?
================================== Ai Message
==================================
Tool Calls:
tavily_search (call_FfUFDwThpNTBHoijgvNmwtMr)
Call ID: call_FfUFDwThpNTBHoijgvNmwtMr
Args:
query: 北京天⽓
================================= Tool Message
=================================
(省略...)
================================== Ai Message
==================================
今天北京的天⽓情况如下:
- 当前⽓温:-4°C
- 湿度:23%
- ⻛速:25.2 km/h
- 天⽓状况:晴朗
- 最⾼⽓温:预计为16°C三:🔥 跨会话持久化
🦋 Checkpoint 的局限性
🎀 问题场景:跨会话信息丢失
LangGraph的Checkpoint机制提供了强⼤的短期记忆能⼒,它能够:
- ⾃动保存⼯作流每个步骤的状态快照
- 维持单次对话的完整上下⽂
- 隔离不同线程(Thread)的执⾏状态
简单示例(仅调⽤了下LLM):
python
import operator
from typing import TypedDict, Annotated
from langchain.chat_models import init_chat_model
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
# 定义状态
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
# 定义模型节点
model = init_chat_model("gpt-4o-mini", temperature=0)
def llm_call(state: dict):
"""LLM调⽤"""
return {
"messages": [
model.invoke([SystemMessage(content="你是⼀个乐于助⼈的助⼿。")]
+ state["messages"])
]
}
# 构件图
builder = StateGraph(MessagesState)
builder.add_node("llm_call", llm_call)
builder.add_edge(START, "llm_call")
builder.add_edge("llm_call", END)
graph = builder.compile(checkpointer=InMemorySaver())检查点可以完美处理会话内记忆,如下所示:
python
config1 = {"configurable": {"thread_id": "1"}}
# 第⼀次对话
result1 = graph.invoke({"messages": [HumanMessage(content="我爱吃汉堡,推荐⼀家餐厅")]}, config1)# AI记得:你爱吃汉堡
result2 = graph.invoke({"messages": [HumanMessage(content="我爱吃什么?")]},config1)
result2["messages"][-1].pretty_print()
# 输出:你提到你爱吃汉堡,所以可以推测你喜欢美味的快餐和丰富的⼝味组合。如果你有其他喜欢的⻝物或菜系,也可以告诉我,我可以为你推荐更多相关的美⻝或餐厅!想象⼀个多会话的AI助⼿场景:
-
星期⼀,⽤户⾸次对话
-
星期⼆,⽤户开启⼀个新对话
如下所示:
python
# 星期⼀,⽤⼾⾸次对话
config1 = {"configurable": {"thread_id": "day_1"}}
result1 = graph.invoke({"messages": [HumanMessage(content="我爱吃汉堡,推荐⼀家餐厅")]}, config1)
# 星期⼆,⽤⼾开启⼀个新对话
config2 = {"configurable": {"thread_id": "day_2"}}
result2 = graph.invoke({"messages": [HumanMessage(content="我爱吃什么?")]},config2)
result2["messages"][-1].pretty_print()
# 输出:我不知道你具体喜欢吃什么,但可以根据⼀些常⻅的⻝物类型来猜测。⽐如,有些⼈喜欢甜⻝,如蛋糕和冰淇淋;有些⼈喜欢咸⻝,如薯条和披萨;还有些⼈喜欢健康的⻝物,如沙拉和⽔果。你可以告诉我你喜欢的⻝物类型,我可以给你⼀些推荐!问题出现:AI不记得⽤户喜欢汉堡!每次对话都要"重新认识"。
🎀 现实世界的需求:从"单次对话"到"终⾝服务"
例如⼀个智能客服系统,具有以下实际业务需求:
- 识别VIP客户,优先服务
- 避免重复询问相同问题
- 基于历史投诉优化服务
仅是检查点⽆法满⾜这些需求:
go
graph = builder.compile(checkpointer=InMemorySaver())
config1 = {"configurable": {"thread_id": "query_1"}}
result1 = graph.invoke({"messages": [HumanMessage(content="我的账⼾被冻结了")]},config1)
# ⽤⼾第⼀次投诉账⼾问题,已解决。智能客服了如下过程:
# - 搜集⽤⼾信息
# - 了解⽤⼾问题与需求
# - 处理问题
config2 = {"configurable": {"thread_id": "query_2"}}
result2 = graph.invoke({"messages": [HumanMessage(content="我的账⼾⼜被冻结了")]}, config2)
# 10天后,⽤⼾第⼆次投诉账⼾问题。
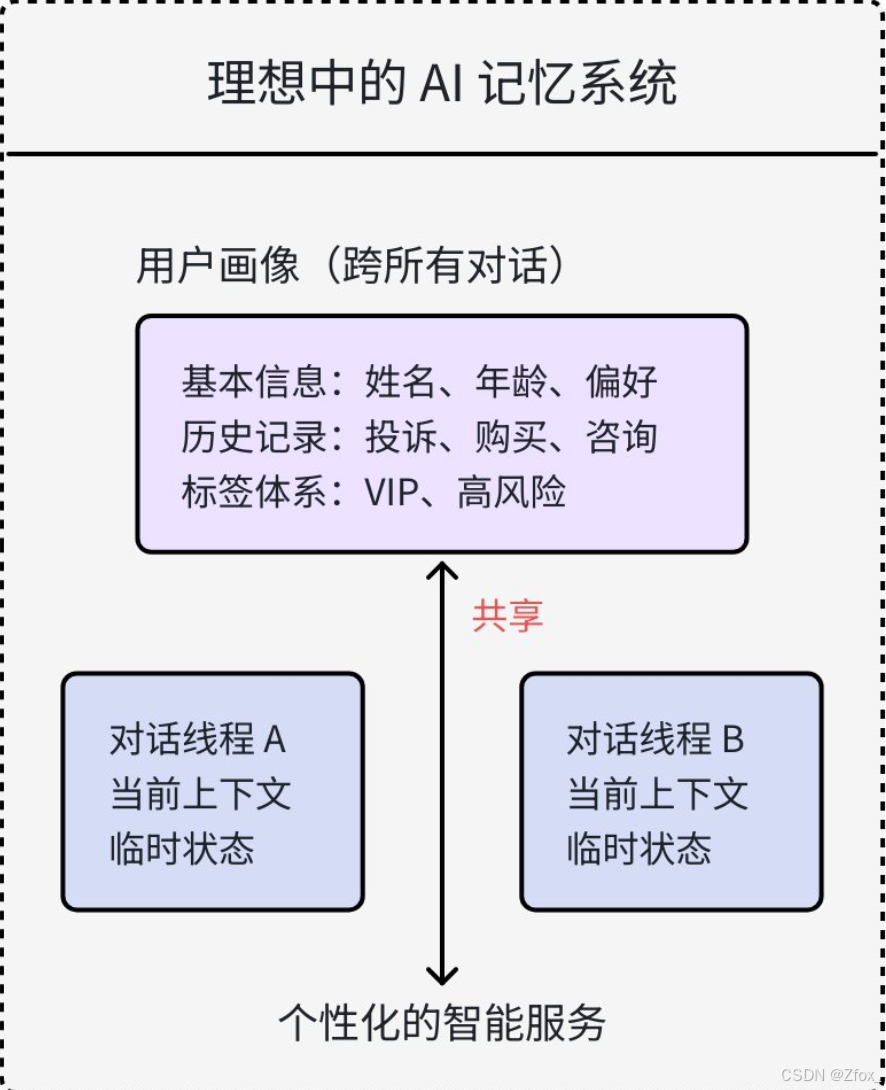
# 由于智能客服不知道⽤⼾历史,⽆法准确解决问题。还需再次了解前因后果如何做到【共享状态】的需求模型,如精准识别客户、保留VIP客户关键历史记录,是智能客服系统的 关键。如下图所示:
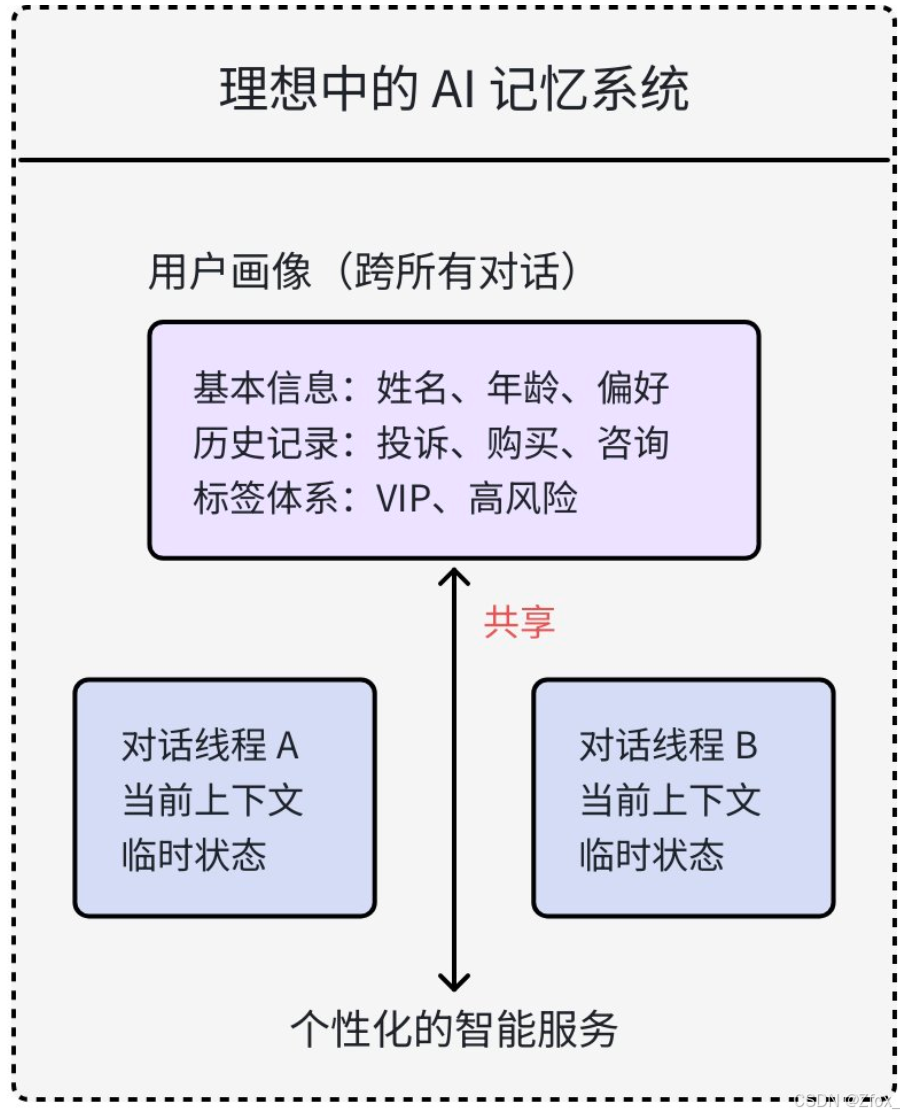
🦋 解决⽅案:引⼊Store
Store像是⼀个⻓期记忆仓库,⽀持在我们在执⾏过程中保存⽤户信息、偏好设置等⻓期数据,以实现不同对话间信息的持久化共享。
🎀 存储vs检查点
- 检查点:保存状态变化历史(时间线)
- 存储:保存结构化知识(数据库)
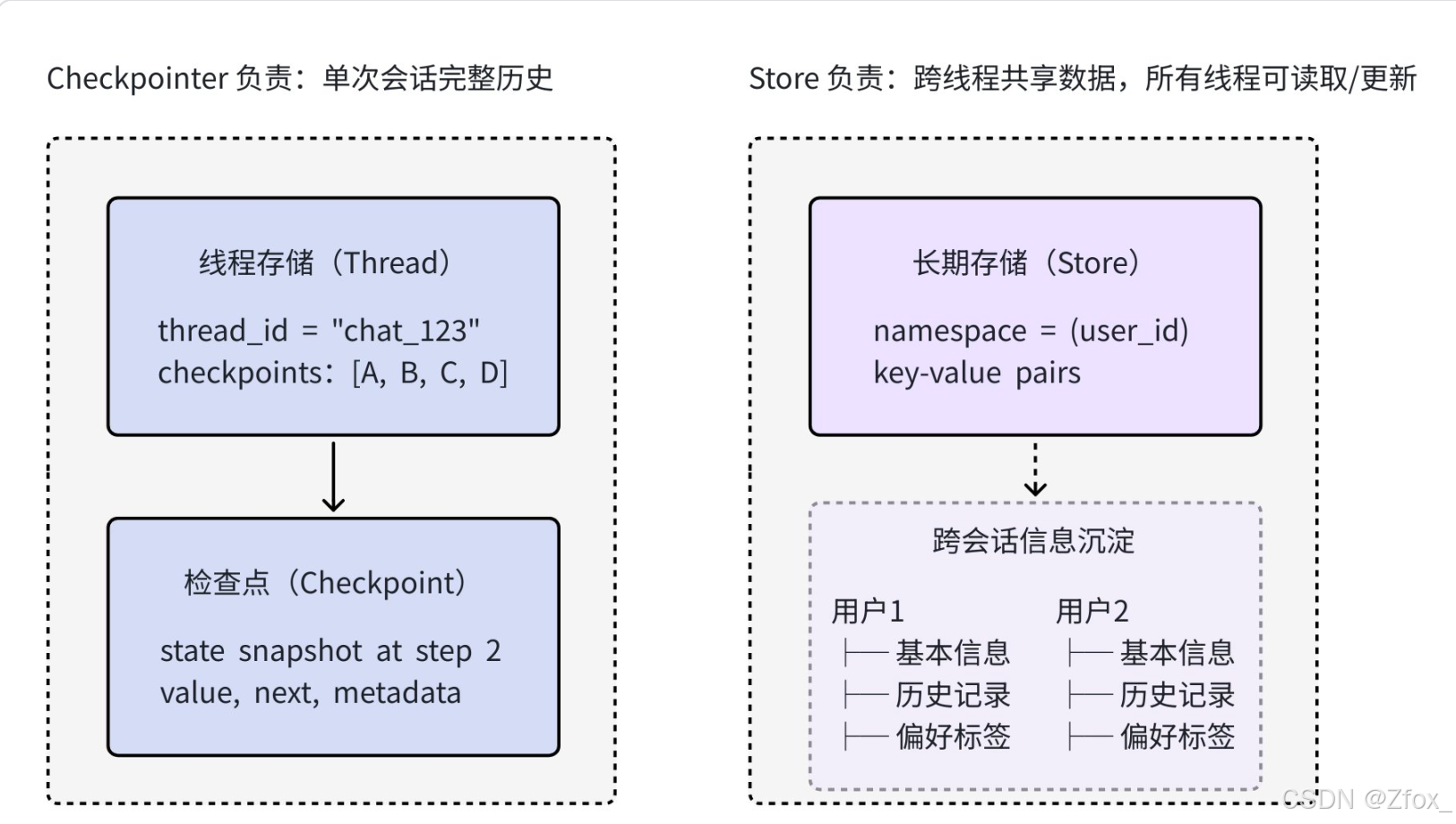
实际上,使⽤ Checkpoint + Store 模式才能够真正实现:
🎀 引⼊Store后,AI应⽤架构的范式转变
Store的引⼊,不是简单的功能增加,⽽是AI应⽤架构的范式转变:

Store的引⼊,真正能做到:
- 从关注单次交互→到关注⽤户⽣命周期
- 从处理当前请求→到利⽤历史数据
- 从通⽤回复→到深度个性化
这种转变让AI从"⼯具"进化为"伙伴",真正实现智能服务的核⼼理念:在正确的时间,以正确的⽅式,为正确的⼈提供正确的价值。
题外话:使⽤AI不要随意泄露⾃⼰的隐私信息,很容易被保存下来!
🦋 跨会话持久化使⽤姿势
要想使⽤store,我们需要创建⼀个存储实例,其也有【内存级存储】与相关【存储库存储】两种⽅ 式。例如内存级存储:
go
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()接着只需像以前⼀样使⽤Checkpoints和Store变量编译图表即可。如下所示:
go
graph = builder.compile(checkpointer=checkpointer, store=store)🎀 ⽅式1:内存存储
Store基本⽤法
Store 本⾝是通过Namespace区分不同数据,如下所示:
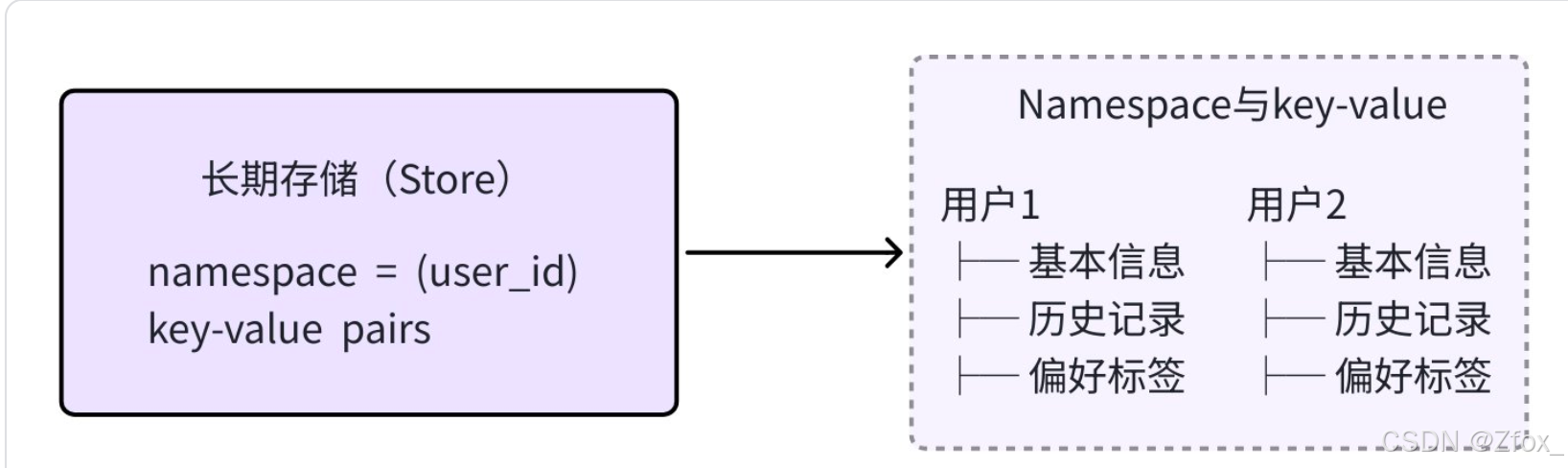
在LangGraph中,其提供了⼀个简单的内存实现 InMemoryStore 。想要进⾏存储,需要:
- 先定义命名空间:为了区分不同⽤户的记忆,需要⼀个"命名空间"。这就像在数据库⾥为每个⽤户创建⼀个独⽴的⽂件夹。命名空间⽤于组织记忆,通常按业务逻辑划分。⼀般⽤元组来定义命名 空间。如:
go
# 使⽤元组 - 层次清晰,易于扩展
namespace1 = ("user_123", "preferences", "food") # ⽤⼾⻝物偏好
namespace2 = ("user_123", "preferences", "music") # ⽤⼾⾳乐偏好
namespace3 = ("user_123", "conversations", "2025-05") # ⽤⼾某天的对话历史
# 使⽤字符串 - 扁平且易混淆
namespace4 = "user_123_preferences_food" # 需要解析,容易出错
namespace5 = "user_123_preferences_music"
namespace6 = "user_123_conversations_2024"- 当在对话中获取到⽤户的重要信息时,使⽤ store.put() ⽅法将内存保存到存储中的命名空间。该⽅法参数包含:
- namespace :决定这个记忆属于谁以及是什么类型。
- memory_id :是这个记忆条⽬的唯⼀键。
- memory_content :是记忆的具体内容,⼀个字典。
go
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
store.put(namespace, memory_id, memory_content)完整代码如下:
go
# 1. 导⼊并创建存储
from langgraph.store.memory import InMemoryStore
import uuid # ⽤于⽣成唯⼀ID
store = InMemoryStore()
# 2. 定义命名空间 (Namespace)
# 命名空间⽤于组织记忆,通常按业务逻辑划分,例如按⽤⼾。
# 这⾥我们⽤⼀个元组 (⽤⼾ID, 记忆类型)
user_id = "user_123"
namespace = (user_id, "preferences") # ⽤⼾ user_123 的偏好记忆
# 3. 存⼊⼀条记忆 (Memory)
# 每条记忆需要⼀个唯⼀的 memory_id 和 ⼀个 value (通常是字典)
memory_id = str(uuid.uuid4()) # ⽣成唯⼀ID,如 "abc-123-def-456"
memory_value = {"favorite_food": "汉堡", "allergy": "花粉"}
store.put(namespace, memory_id, memory_value)
print("记忆已存⼊!")
# 4. 读取记忆
# 可以搜索某个命名空间下的所有记忆
all_memories = store.search(namespace)
for mem in all_memories:
print(mem.dict()) # 记忆对象转成字典查看运⾏结果:
go
记忆已存⼊!
{
'namespace': [
'user_123', 'preferences'
],
'key': 'db826e33-c68c-4669-a79a-3579bff02ff1',
'value': {
'favorite_food': '汉堡',
'allergy': '花粉'
},
'created_at': '2025-12-03T08:16:14.134568+00:00',
'updated_at': '2025-12-03T08:16:14.134576+00:00',
'score': None
}因使⽤元组作为命名空间,故同样⽀持下⾯的搜索⽅式:
go
all_memories = store.search((user_id, ))在LangGraph中使⽤Store
内存存储适⽤于开发和测试,程序重启后存储的数据会丢失。这⾥依旧使⽤ 快速上⼿------案例2 的代码 进⾏演示。
由于要加⼊Store,需要在合适的地⽅加⼊与存储关键信息相关的代码。如我们可以在每次调⽤LLM 前先进⾏信息收集,然后带着收集到的共享信息进⾏LLM调⽤。因此,流程变成了:
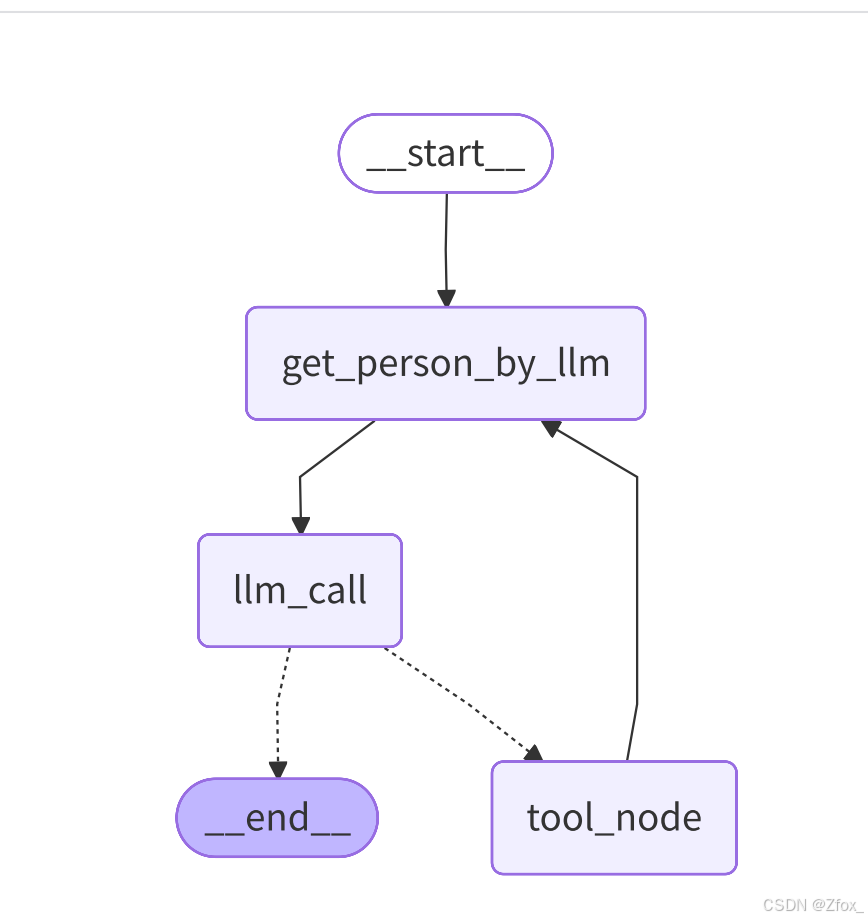
这样,两部分信息将会被收集:⼀是⽤户发的消息;⼆是通过⼯具调⽤返回的结果信息也会被采集。 代码如下:
- 在编译图时,直接添加编译参数 store ,如下所示:
go
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
# ⽤ checkpointer + store 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)现在,在任何⼀个节点的函数中,都可以通过注⼊ store 参数来访问这个全局存储。
- 新增提取⽤户信息节点
在这个节点中,我们需要根据【⽤户发的消息】和【⼯具调⽤返回的结果】来采集需要收集的信息。 收集的信息需要使⽤Store进⾏存储。关键设计如下:
- 任何节点函数,如果需要访问Store,可以通过在参数中声明 store: BaseStore 和 config: RunnableConfig 来获取。
- 在这⾥可以通过LLM提取⽤户信息,因此定义结构化返回是很有必要的。
python
# 定义结构化输出
class Person(BaseModel):
"""⼀个⼈的信息。"""
# 注意:
# 1. 每个字段都是 Optional "可选的" ------ 允许 LLM 在不知道答案时输出 None。
# 2. 每个字段都有⼀个 description "描述" ------ LLM使⽤这个描述。
name: Optional[str] = Field(default=None, description="这个⼈的名字")
height_in_meters: Optional[str] = Field(default=None, description="以⽶为单位的⾼度")
favourite_food: Optional[list[str]] = Field(default=None, description="最喜欢的⻝物列表")
model_with_structured = model.with_structured_output(Person)
# 提取⽤⼾信息节点
def get_person_by_llm(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
"""通过 LLM 提取⽤⼾信息"""
# 1. 先提取
people_info = model_with_structured.invoke(
[
SystemMessage(
content="你是⼀个提取信息的专家,只从⽂本中提取我的相关信息,不能提取别
⼈的信息。如果你不知道要提取的属性的值,属性值返回null。"
)
] +
state["messages"][-3:] # 只查看最近3条消息
)
# 2. 再保存
user_id = config["configurable"]["user_id"]
# 保存⽤⼾基本信息
namespace1 = (user_id, "info")
# 每次put前应判断是否存在,再更新。否则会有多条记录被记录。这⾥简写
store.put(
namespace1,
str(uuid.uuid4()),
{
"name": people_info.name,
"height": people_info.height_in_meters
}
)
# 保存⽤⼾偏好
namespace2 = (user_id, "preferences")
store.put(
namespace2,
str(uuid.uuid4()),
{"favourite_food": people_info.favourite_food} # 省略追加逻辑:先搜再更新
)
return {
"llm_calls": state.get('llm_calls', 0) + 1
}- 更新模型调⽤节点:添加共享信息到提示词
调⽤LLM之前,我们便可以通过查询Store获取共享信息,然后将其加⼊到提示词中,完成调⽤。
python
def llm_call(state: MessagesState, config: RunnableConfig, *, store:
BaseStore):
"""LLM决定是否调⽤⼯具"""
# 搜索⽤⼾信息
user_id = config["configurable"]["user_id"]
namespace1 = (user_id, "info")
namespace2 = (user_id, "preferences")
info_result = store.search(namespace1)
pref_result = store.search(namespace2)
return {
"messages": [
model_with_tools.invoke(
[
SystemMessage(
content=f"你是⼀个乐于助⼈的助⼿,⽀持调⽤⼯具进⾏搜索。"
f"查询 LLM 前可参考以下信息:"
f"1. ⽤⼾基本情况:{info_result[0].value} "
f"2. ⽤⼾偏好情况:{pref_result[0].value}"
)
] +
state["messages"]
)
],
"llm_calls": state.get('llm_calls', 0) + 1
}- 构件图时,加⼊新节点与调整边
根据下图完成调整:
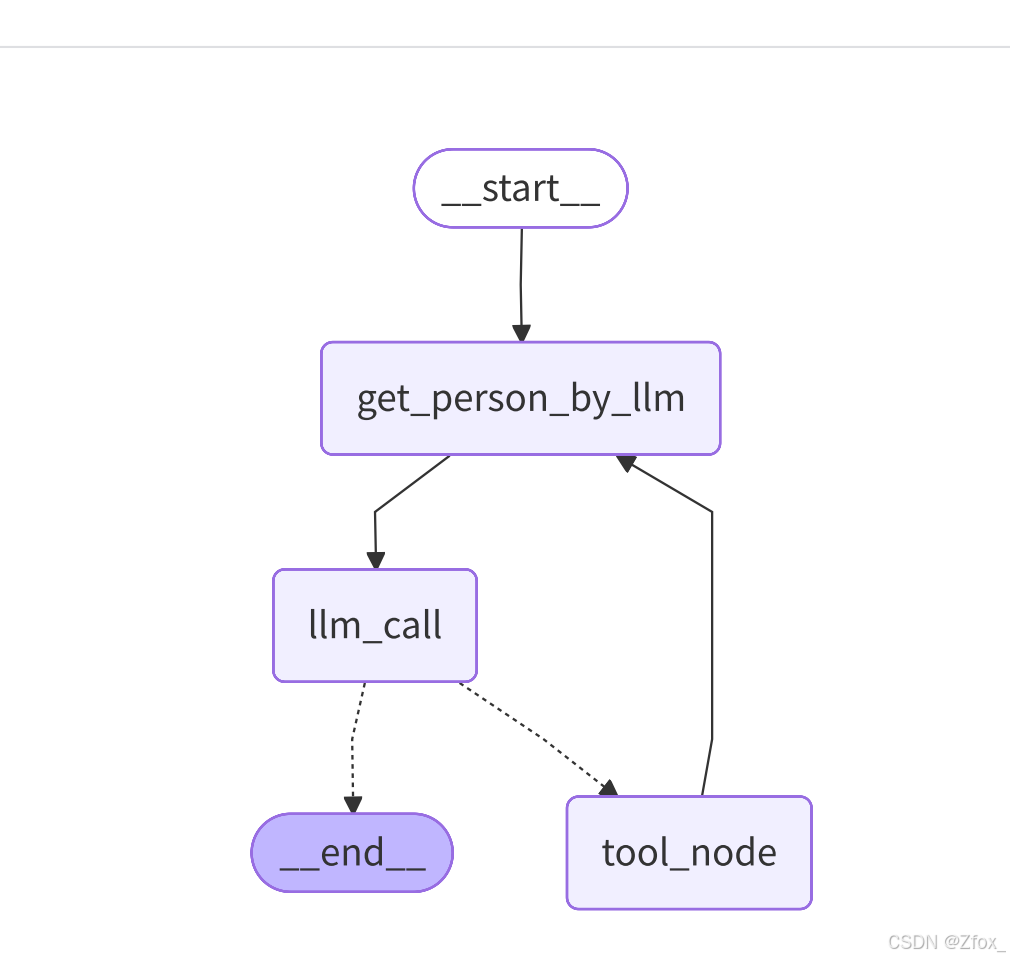
python
agent_builder = StateGraph(MessagesState)
agent_builder.add_node(llm_call)
agent_builder.add_node(tool_node)
# 新增节点
agent_builder.add_node(get_person_by_llm)
# 调整边
agent_builder.add_edge(START, "get_person_by_llm")
agent_builder.add_edge("get_person_by_llm", "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "get_person_by_llm")到此,代码已经改造完成,完整代码如下:
python
import uuid
from typing import Optional
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableConfig
from langchain_tavily import TavilySearch
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.base import BaseStore
from langgraph.store.memory import InMemoryStore
from pydantic import BaseModel, Field
# 步骤 1: 定义⼯具和模型
search = TavilySearch(max_results=4)
tools = [search]
# 绑定⼯具
model = init_chat_model("gpt-4o-mini", temperature=0)
model_with_tools = model.bind_tools(tools)
# 步骤 2: 定义状态
from langchain.messages import AnyMessage
from typing_extensions import TypedDict, Annotated
import operator
class MessagesState(TypedDict):
# 类型: list[AnyMessage] - 任意消息对象的列表
# 合并策略: operator.add - 使⽤加法操作符进⾏状态合并
# 效果: 当状态更新时,新的消息会追加到现有列表中,⽽不是替换
messages: Annotated[list[AnyMessage], operator.add]
# 类型: int - 整数值
# ⽤途: 跟踪LLM(⼤语⾔模型)的调⽤次数
llm_calls: int
# 步骤 3:新增提取信息节点
# 定义结构化输出
class Person(BaseModel):
"""⼀个⼈的信息。"""
# 注意:
# 1. 每个字段都是 Optional "可选的" ------ 允许 LLM 在不知道答案时输出 None。
# 2. 每个字段都有⼀个 description "描述" ------ LLM使⽤这个描述。
name: Optional[str] = Field(default=None, description="这个⼈的名字")
height_in_meters: Optional[str] = Field(default=None, description="以⽶为单
位的⾼度")
favourite_food: Optional[list[str]] = Field(default=None, description="最喜
欢的⻝物列表")
model_with_structured = model.with_structured_output(Person)
def get_person_by_llm(state: MessagesState, config: RunnableConfig, *, store:
BaseStore):
"""通过 LLM 提取⽤⼾信息"""
# 1. 先提取
people_info = model_with_structured.invoke(
[
SystemMessage(
content="你是⼀个提取信息的专家,只从⽂本中提取我的相关信息,不能提取别
⼈的信息。如果你不知道要提取的属性的值,属性值返回null。"
)
] +
state["messages"][-3:] # 只查看最近3条消息
) #
2. 再保存
user_id = config["configurable"]["user_id"]
# 保存⽤⼾基本信息
namespace1 = (user_id, "info")
# 每次put前应判断是否存在,再更新。否则会有多条记录被记录。这⾥简写
store.put(
namespace1,
str(uuid.uuid4()),
{
"name": people_info.name,
"height": people_info.height_in_meters
}
) #
保存⽤⼾偏好
namespace2 = (user_id, "preferences")
store.put(
namespace2,
str(uuid.uuid4()),
{"favourite_food": people_info.favourite_food} # 省略追加逻辑:先搜再更新
) r
eturn {
"llm_calls": state.get('llm_calls', 0) + 1
}
# 步骤 4: 更新模型调⽤节点:添加共享⽤⼾信息到提⽰词
from langchain.messages import SystemMessage
def llm_call(state: MessagesState, config: RunnableConfig, *, store:
BaseStore):
"""LLM决定是否调⽤⼯具"""
# 搜索⽤⼾信息
user_id = config["configurable"]["user_id"]
namespace1 = (user_id, "info")
namespace2 = (user_id, "preferences")
info_result = store.search(namespace1)
pref_result = store.search(namespace2)
return {
"messages": [
model_with_tools.invoke(
[
SystemMessage(
content=f"你是⼀个乐于助⼈的助⼿,⽀持调⽤⼯具进⾏搜索。"
f"查询 LLM 前可参考以下信息:"
f"1. ⽤⼾基本情况:{info_result[0].value} "
f"2. ⽤⼾偏好情况:{pref_result[0].value}"
)
] +
state["messages"]
)
],
"llm_calls": state.get('llm_calls', 0) + 1
}
# 步骤 5: 定义⼯具节点
from langchain.messages import ToolMessage
tools_by_name = {tool.name: tool for tool in tools}
def tool_node(state: dict):
"""执⾏⼯具调⽤"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation,
tool_call_id=tool_call["id"]))
return {"messages": result}
# 步骤 6: 构件图
from langgraph.graph import StateGraph, START, END
# 定义结束逻辑
def should_continue(state: MessagesState):
"""根据LLM是否调⽤⼯具来决定是应该继续循环(路由到⼯具节点)还是停⽌循环(END)"""
messages = state["messages"]
last_message = messages[-1]
# 如果LLM调⽤⼯具,则执⾏操作
if last_message.tool_calls:
return "tool_node"
return END
# 加⼊新节点并修改边
agent_builder = StateGraph(MessagesState)
agent_builder.add_node(llm_call)
agent_builder.add_node(tool_node)
agent_builder.add_node(get_person_by_llm)
agent_builder.add_edge(START, "get_person_by_llm")
agent_builder.add_edge("get_person_by_llm", "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
) a
gent_builder.add_edge("tool_node", "get_person_by_llm")
checkpointer = InMemorySaver()
store = InMemoryStore()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)- 运⾏与验证:同⼀⽤户但不同会话的请求
python
# 第⼀次聊天
config1 = {"configurable": {"thread_id": "1", "user_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="我叫李华,我最爱吃汉堡。我的朋友叫⼩明,他爱吃披萨")]},config1
)
print(f"\n调⽤ LLM 总次数:{result1["llm_calls"]}次")
for m in result1["messages"]:
m.pretty_print()
# ---------- 过了⼏天 ---------------
# 同⼀个⼈,再次进⾏对话
config2 = {"configurable": {"thread_id": "2", "user_id": "1"}}
result2 = agent.invoke(
{"messages": [HumanMessage(content="给我推荐下餐厅")]},
config2
)
print(f"\n调⽤ LLM 总次数:{result2["llm_calls"]}次")
for m in result2["messages"]:
m.pretty_print()执⾏结果如下:
python
调⽤ LLM 总次数:2次
================================ Human Message =================================
我叫李华,我最爱吃汉堡。我的朋友叫⼩明,他爱吃披萨
================================== Ai Message ==================================
你好,李华!很⾼兴认识你。汉堡和披萨都是很受欢迎的美⻝。你和⼩明有没有⼀起去过什么好吃的地
⽅呢?或者你们有没有想尝试的新餐厅?
调⽤ LLM 总次数:4次
================================ Human Message
=================================
给我推荐下餐厅
================================== Ai Message
==================================
Tool Calls:
tavily_search (call_btsV05aeqldqjaZNvgdlYRe9)
Call ID: call_btsV05aeqldqjaZNvgdlYRe9
Args:
query: 推荐汉堡餐厅
================================= Tool Message
=================================
{省略.....}
================================== Ai Message
==================================
以下是⼀些推荐的汉堡餐厅:
1. **[Burger She Wrote](https://www.novacircle.com/zh-CN/spots/northamerica/united-states/california/los-angeles-county/los-angeles/burger-shewrote-9ea267)** - 位于洛杉矶,这是⼀家⼩⽽温馨的餐厅,以其美味的和⽜汉堡⽽闻名。
2. **[Tripadvisor 上洛杉矶的最佳汉堡](https://cn.tripadvisor.com/Restaurantsg32655-zfd10907-zfn7231034-Los_Angeles_California-Hamburger.html)** - 包含多家受
欢迎的汉堡餐厅,如Bottega Louie和Eggslut,后者以其鸡蛋汉堡⽽著称。
希望这些推荐能帮助你找到美味的汉堡!扩展:尝试修改上⾯的例⼦,让你的AI助⼿能记住⽤户的更多信息(⽐如不喜欢的东西、上次聊到 的话题记录等),并在新的对话中聪明地利⽤这些信息。
语义搜索
Store的强⼤之处在于它⽀持语义搜索,⽽不仅仅是精确匹配。这意味着我们可以⽤⾃然语⾔问题来查 找相关记忆。
⾸先,我们需要配置带嵌⼊模型的Store,如下所示:
python
store = InMemoryStore(
index={
"embed": init_embeddings("openai:text-embedding-3-small"), # 使⽤OpenAI嵌⼊模型
"dims": 1536, # 嵌⼊向量的维度
"fields": ["$"] # 对value中的所有字段进⾏嵌⼊
}
)在节点中,可以这样搜索:
python
user_id = config["configurable"]["user_id"]
namespace = (user_id, )
# 在Store中进⾏语义搜索,找出最相关的2个记忆
# 这⾥直接在user_id维度下通过语义去找
info_result = store.search(namespace, query="⽤⼾基本信息", limit=2)
pref_result = store.search(namespace, query="⽤⼾偏好信息", limit=2)扩展:如果我们让AI助⼿能记住⽤户的更多信息(⽐如不喜欢的东西、上次聊到的话题记录等)。 在新的对话,语义搜索可以把历史记录中的相关记忆找出来,帮助AI助⼿进⾏更加准确的回复。
🎀 ⽅式2:Postgres存储库
Postgres存储库适⽤于⽣产环境或需要状态持久化的场景。由于之前已经启动过PostgresSQL,这⾥ 可以直接连接到数据库,作为 PostgresStore 使⽤。只需在编译时设置 store 即可。
修改【内存存储】部分的代码:将内存存储⽅式修改为Postgres存储库。
注意:第⼀次使⽤Postgresstore时需要调⽤ store.setup()
python
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
PostgresStore.from_conn_string(DB_URI) as store,
):
# 第⼀次使⽤ Postgres 检查点时需要调⽤ checkpointer.setup()
checkpointer.setup()
# 第⼀次使⽤ Postgres store 时需要调⽤ store.setup()
store.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)
# ...后续调⽤...模拟第⼀次聊天:
python
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
PostgresStore.from_conn_string(DB_URI) as store,
):
# 第⼀次使⽤ Postgres 检查点时需要调⽤ checkpointer.setup()
checkpointer.setup()
# 第⼀次使⽤ Postgres store 时需要调⽤ store.setup()
store.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)
# 第⼀次聊天
config1 = {"configurable": {"thread_id": "1", "user_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="我叫李华,我最爱吃汉堡。我的朋友叫⼩明,他爱吃披萨")]}, config1
)
print(f"\n调⽤ LLM 总次数:{result1["llm_calls"]}次")
for m in result1["messages"]:
m.pretty_print()运⾏系统后可以看到,postgres中新增store相关表,其中存放了⽤户基本的信息:

再次验证:同⼀⽤户但不同会话的请求
python
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
PostgresStore.from_conn_string(DB_URI) as store,
):
# 第⼀次使⽤ Postgres 检查点时需要调⽤ checkpointer.setup()
# checkpointer.setup()
# 第⼀次使⽤ Postgres store 时需要调⽤ store.setup()
# store.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)
# ---------- 过了⼏天 ---------------
# 同⼀个⼈,再次进⾏对话
config2 = {"configurable": {"thread_id": "2", "user_id": "1"}}
result2 = agent.invoke(
{"messages": [HumanMessage(content="给我推荐下餐厅")]},
config2
)
print(f"\n调⽤ LLM 总次数:{result2["llm_calls"]}次")
for m in result2["messages"]:
m.pretty_print()注意执⾏前,将以下代码注掉,因为:在存⼊store前,并没有编写 不存在存⼊,存在更新 的代码逻 辑(只是演示),因此会将空的⽤户信息误存,导致LLM调⽤前查出来空的。
python
def get_person_by_llm(state: MessagesState, config: RunnableConfig, *, store:BaseStore):
...
# 每次put前应判断是否存在,再更新。否则会有多条记录被记录。这⾥简写
# store.put(
# namespace1,
# str(uuid.uuid4()),
# {
# "name": people_info.name,
# "height": people_info.height_in_meters
# }
# )
# 保存⽤⼾偏好
# store.put(
# namespace2,
# str(uuid.uuid4()),
# {"favourite_food": people_info.favourite_food} # 省略追加逻辑:先搜再更
新
# )
...最终执⾏结果如下:
python
调⽤ LLM 总次数:3次
================================ Human Message
=================================
给我推荐下餐厅
================================== Ai Message
==================================
Tool Calls:
tavily_search (call_PkIzsQRuCS6KZM15g3noHgBU)
Call ID: call_PkIzsQRuCS6KZM15g3noHgBU
Args:
query: 推荐汉堡餐厅
================================= Tool Message
=================================
{'query': '推荐汉堡餐厅', 'follow_up_questions': None, 'answer': None, 'images':
[], 'results': [{'url':
'https://www.reddit.com/r/AskNYC/comments/1470o9z/best_burger_spot_in_nyc/?
tl=zh-hans', 'title': '纽约最好吃的汉堡店是哪家? : r/AskNYC', 'content': 'The
Thompson 的Burger Joint 和Minetta Tavern 等被推荐。汉堡餐厅推荐 ,来⾃1 个⽉前。
Smashed 和Korzo 等被推荐。纽约/布鲁克林最好的汉堡? 以及 ...Read more', 'score':
0.7336813, 'raw_content': None}, {'url':
'https://www.cosmopolitan.com/tw/lifestyle/food-and-drink/g44382807/hamburger-
20230629/', 'title': '美國旅遊必吃7⼤⼈氣漢堡店!IN-N-OUT最強勁敵', 'content':
'1.The Habit Burger Grill · 2.Cheeseburger in Paradise · 3.Five Guys · 4.IN-NOUT · 5.Shake Shack · 6.SmashburgerRead more', 'score': 0.61972505,
'raw_content': None}, {'url': 'https://cn.tripadvisor.com/Restaurants-g60763-
zfd10907-zfn7102345-New_York_City_New_York-Hamburger.html', 'title': '纽约市最佳
汉堡', 'content': "Ellen's Stardust Diner · (23,569 条点评). 美式烹饪, 晚餐 ;
Virgil's Real BBQ - NYC · (4,968 条点评). 美式烹饪, 烧烤 ; 1. S'MAC · (488 条点
评). 快餐⼩吃, 美式烹饪 ; 2.Read more", 'score': 0.56719416, 'raw_content':
None}, {'url':'https://mliesl.edu/contents/ch/%E7%BE%8E%E5%9B%BD%E6%9C%80%E4%BD%B3%E6%B1%89%E
5%A0%A1%E8%BF%9E%E9%94%81%E6%8E%92%E5%90%8D/', 'title': '美国最佳汉堡连锁排名',
'content': '最受好评的汉堡连锁店之⼀-- Five Guys -- 被康涅狄格州、乔治亚州、蒙⼤拿州、内
布拉斯加州、俄勒冈州、南卡罗来纳州、佛蒙特州和西弗吉尼亚州评为第⼀名。 那是8 个州同意,
...Read more', 'score': 0.56690645, 'raw_content': None}], 'response_time':
0.92, 'request_id': '0ee8ee23-bbd3-48e2-b4c2-ca6d1c1dfe7a'}
================================== Ai Message ==================================
以下是⼀些推荐的汉堡餐厅:
1. **[纽约最好吃的汉堡店]
(https://www.reddit.com/r/AskNYC/comments/1470o9z/best_burger_spot_in_nyc/?tl=zh-hans)** - 推荐的汉堡店包括 The Thompson 的 Burger Joint 和 Minetta Tavern等。
2. **[美国旅游必吃7⼤⼈氣漢堡店](https://www.cosmopolitan.com/tw/lifestyle/foodand-drink/g44382807/hamburger-20230629/)** - 包括 The Habit Burger Grill、
Cheeseburger in Paradise、Five Guys、IN-N-OUT、Shake Shack 和 Smashburger。
3. **[纽约市最佳汉堡](https://cn.tripadvisor.com/Restaurants-g60763-zfd10907-
zfn7102345-New_York_City_New_York-Hamburger.html)** - 推荐的餐厅有 Ellen's
Stardust Diner 和 Virgil's Real BBQ - NYC。
4. **[美国最佳汉堡连锁排名]
(https://mliesl.edu/contents/ch/%E7%BE%8E%E5%9B%BD%E6%9C%80%E4%BD%B3%E6%B1%89%E5%A0%A1%E8%BF%9E%E9%94%81%E6%8E%92%E5%90%8D/)** - Five Guys 是最受好评的汉堡连锁店之⼀。
希望这些推荐能帮助到您!如果您有特定的城市或地区需求,请告诉我四:🔥 持久化实现的三⼤应⽤能⼒
🦋 记忆(Memory)
🎀 记忆概念
记忆,是⼀种能够记住之前互动信息的系统。对于⼈⼯智能代理来说,记忆⾄关重要,因为它使他们 能够记住之前的互动,从反馈中学习,并根据⽤户偏好进⾏调整。随着代理处理涉及⼤量⽤户交互的 更复杂任务,这⼀能⼒对效率和⽤户满意度都变得⾄关重要。
注意要区分记忆和持久化的概念:
- 持久化为LangGraph底层能⼒,包含【线程级】持久化和【跨会话】持久化
- 记忆为LangGraph能实现的应⽤层能⼒,包含【短期记忆】和【⻓期记忆】
在应⽤层,短期记忆就由线程级持久化实现,⻓期记忆由跨会话持久化实现。
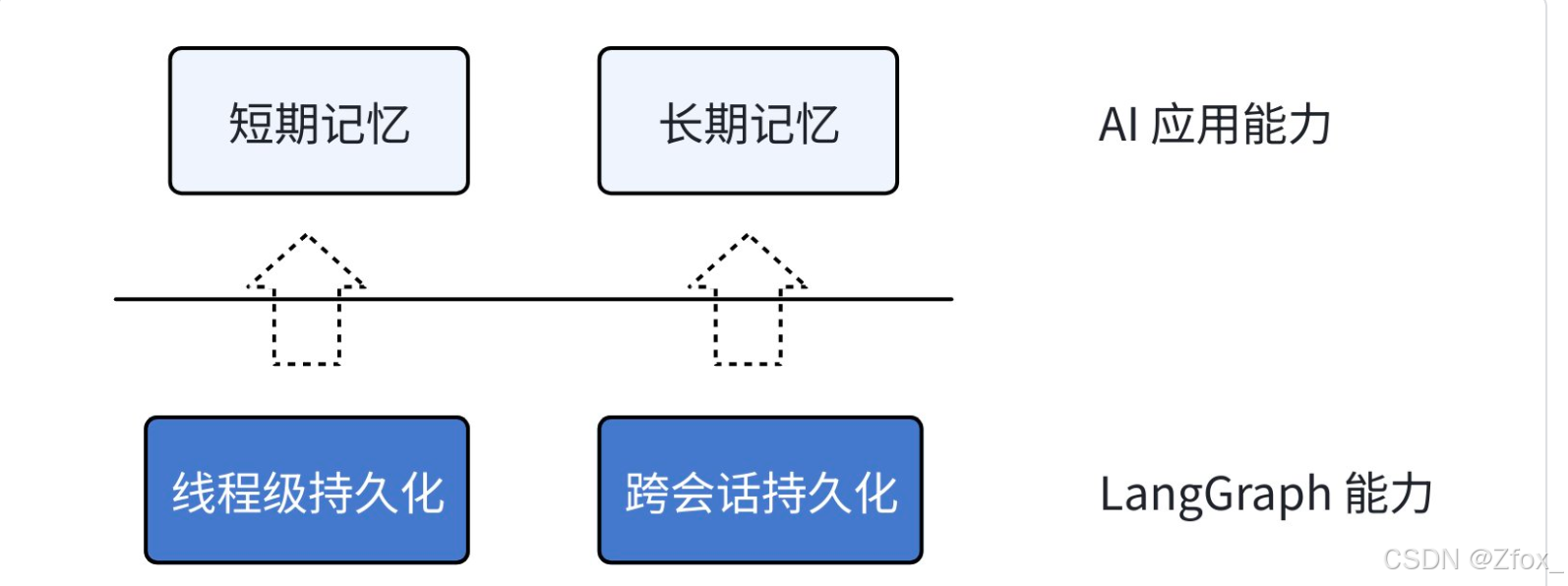
- 短期记忆:单次会话中保持的上下⽂信息
- ⻓期记忆:跨会话保存的⽤户或应⽤数据
🎀 管理短期记忆
对应短期记忆和⻓期记忆是如何添加的就不过多演示了(就是持久化部分的内容)。但在应⽤层,我们还需要掌握在应⽤系统中,出现⼀些具体场景时,如何对记忆进⾏管理。例如当消息记录过多,我 们需要进⾏消息裁剪、总结消息、消息删除等操作。
要再说明⼀点,既然是应⽤层能⼒,我们应该对记忆的存储⽅式有所选择。如下所示:
python
# 开发阶段:内存存储
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
# ⽣产阶段:数据库
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore修剪消息
⼤多数LLM都有⼀个最⼤⽀持的上下⽂窗⼝。决定何时截断消息的⼀种⽅法是对消息历史记录中的令牌进⾏计数,并在接近该限制时截断。
消息裁剪⽅法可以参考LangChain篇章部分的内容。
python
from langchain_core.messages.utils import trim_messages
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, START, MessagesState
model = init_chat_model("gpt-4o-mini", temperature=0)
def call_model(state: MessagesState):
# 只保留最近的128个token的消息
messages = trim_messages(
state["messages"],
strategy="last", # 策略:保留最后的部分
token_counter=model, # 计算token数量
max_tokens=128, # 最⼤token数
start_on="human", # 从⽤⼾消息开始
end_on=("human", "tool"), # 结束于⽤⼾或⼯具消息
)
response = model.invoke(messages)
return {"messages": [response]}
checkpointer = InMemorySaver()
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "hi, my name is bob"}, config)
graph.invoke({"messages": "write a short poem about cats"}, config)
graph.invoke({"messages": "now do the same but for dogs"}, config)
final_response = graph.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()删除消息
可以从图状态中删除消息以管理消息历史记录。当想要删除特定消息或清除整个消息历史记录时,这 ⾮常有⽤。
python
def call_model(state: MessagesState):
messages = state["messages"]
if len(messages) > 6:
# 删除最早的6条消息
return {
"messages": [RemoveMessage(id=m.id) for m in messages[:6]]
}
response = model.invoke(messages)
return {"messages": [response]}
# ....
# 测试:可以发现只剩最后⼀条消息了
for message in final_response["messages"]:
message.pretty_print()删除所有消息:
python
from langgraph.graph.message import REMOVE_ALL_MESSAGES
def call_model(state: MessagesState):
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}注意:删除后消息⽆法恢复,要确保删除后的对话仍然是有效的。
总结消息
实际上,修剪或删除消息也会存在问题:可能会因剔除消息⽽丢失信息。因此,某些应⽤更希望将消 息历史记录进⾏总结,把旧的对话内容总结成简短摘要,保留关键信息,以代替冗⻓的历史记录。
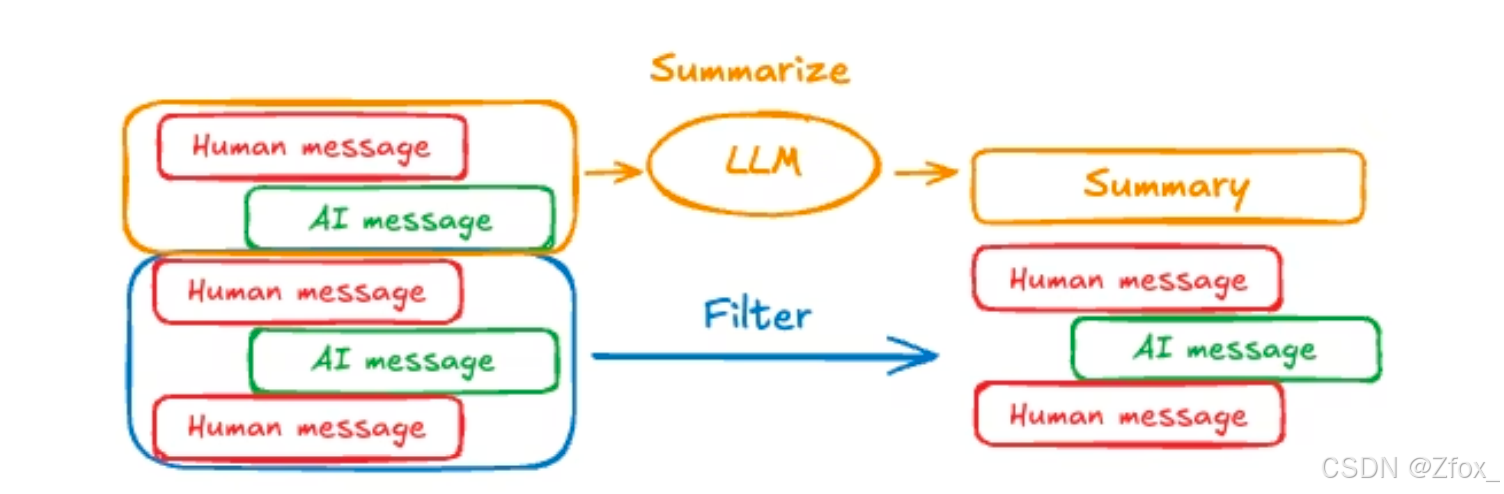
我们可以先将State进⾏扩展,除了对话记录,还包含⼀个总结摘要字段:
python
from langgraph.graph import MessagesState
class State(MessagesState):
summary: str现在要求:
- 对话记录:记录新的对话与结果
- 摘要:每次对话完成,需要进⾏总结。
- 完成总结摘要后,可以删除历史对话。
那么,在每次调⽤LLM时,便可以根据【新的请求】与【总结摘要信息】共同构建提示词来完成请求。
完整代码如下所示:
python
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, RemoveMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, START, MessagesState
model = init_chat_model("gpt-4o-mini", temperature=0)
class State(MessagesState):
summary: str
def call_model(state: State):
# 使⽤历史总结+最新消息发起调⽤
summary = state.get("summary", "")
messages = model.invoke([HumanMessage(content=summary)] +
state["messages"])
return {"messages": messages}
def summarize_conversation(state: State):
""" ⽣成历史总结 """
# 1. 创建总结提⽰词
summary = state.get("summary", "")
if summary: # 有摘要,扩展
summary_message = (
f"这是到⽬前为⽌的对话摘要:{summary}\n\n"
"基于上⾯的新消息扩展摘要:"
)
else: # ⽆摘要,新增
summary_message = "创建上⾯对话的摘要:"
# 2. ⽣成新总结:【消息列表】+【历史总结】调⽤模型
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# 3. 删除历史对话:除了最新的AI消息,都可以删除
return {
"summary": response.content, # 历史总结
"messages": [RemoveMessage(id=m.id) for m in state["messages"][:-1]] #
保留最后的消息是为了打印结果
}
checkpointer = InMemorySaver()
builder = StateGraph(State)
builder.add_node(call_model)
builder.add_node("summarize", summarize_conversation)
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "summarize") # 每次对话完,进⾏总结
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "hi, my name is bob"}, config)
graph.invoke({"messages": "write a short poem about cats"}, config)
graph.invoke({"messages": "now do the same but for dogs"}, config)
final_response = graph.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
print("\nSummary:", final_response["summary"])
# 打印结果如下:
# ================================== Ai Message
==================================
# Your name is Bob.
# Summary: 对话摘要:⽤⼾⾃我介绍为Bob,并询问如何获得帮助。随后,⽤⼾请求写⼀⾸关于猫的
短诗。接着,⽤⼾⼜请求写⼀⾸关于狗的短诗。⽤⼾对动物的诗歌表现出兴趣,可能希望进⼀步探讨与宠物相关的主题或创作。实际上,⽆需每次调⽤后都进⾏总结,可设置阈值进⾏总结。只需判断 消息数量 > 阈值 ,再进⾏总 结与删除即可。
扩展:LangMem是⼀个由LangChain维护的库。它提供了可与任何存储系统⼀起使⽤的功能原 语,也提供了与LangGraph存储层的本机集成。例如上述我们⼿动完成的汇总消息功能,在
LangMem中专⻔提供了记忆管理库(如:SummarizationNode),简化了总结消息的过程。有兴 趣的同学可以⾃⾏了解。
🦋 ⼈机交互(Human-in-the-loop)
什么是⼈机交互?想象有以下场景:
- AI⾃动发送邮件前,你想亲⾃最后确认⼀遍内容
- AI⽣成⽂章后,你想亲⾃⼿动修改⼏个段落
- ...
在AI系统中,我们希望可以在AI⾃动流程中插⼊⼀个"暂停键",等待⼈类输⼊后再继续,这就是⼈机交互功能。
🎀 核⼼概念:中断(Interrupts)
想要完成 ⼈机交互 能⼒,需要⽤到LangGraph基于持久化实现的【中断】能⼒!中断就像打游戏⼀ 样,当玩家⽆法通关某关卡时,希望暂停游戏(中断),攻略⼀下后再继续游戏:
- ⽤户可以在游戏过程中主动按下"存档键";
- 此时会将游戏当前状态等信息进⾏存档,保存下来;(实现游戏过程的中断)
- 当我们攻略后想继续游戏时,就可以读取存档继续玩。(恢复游戏继续)
在LangGraph中,中断允许⼯作流执⾏时在特定点暂停,等待外部输⼊后再继续执⾏。
🎀 中断如何实现?
在⼯作流中,想要实现暂停与恢复很简单,只需要:
- 通过调⽤ interrupt() ⽅法中断执⾏流程,依靠持久化能⼒,保存当前状态。
- 外部⽤户通过发送 Command 对象,使得⼯作流恢复执⾏流程。
交互流程如下图所示:
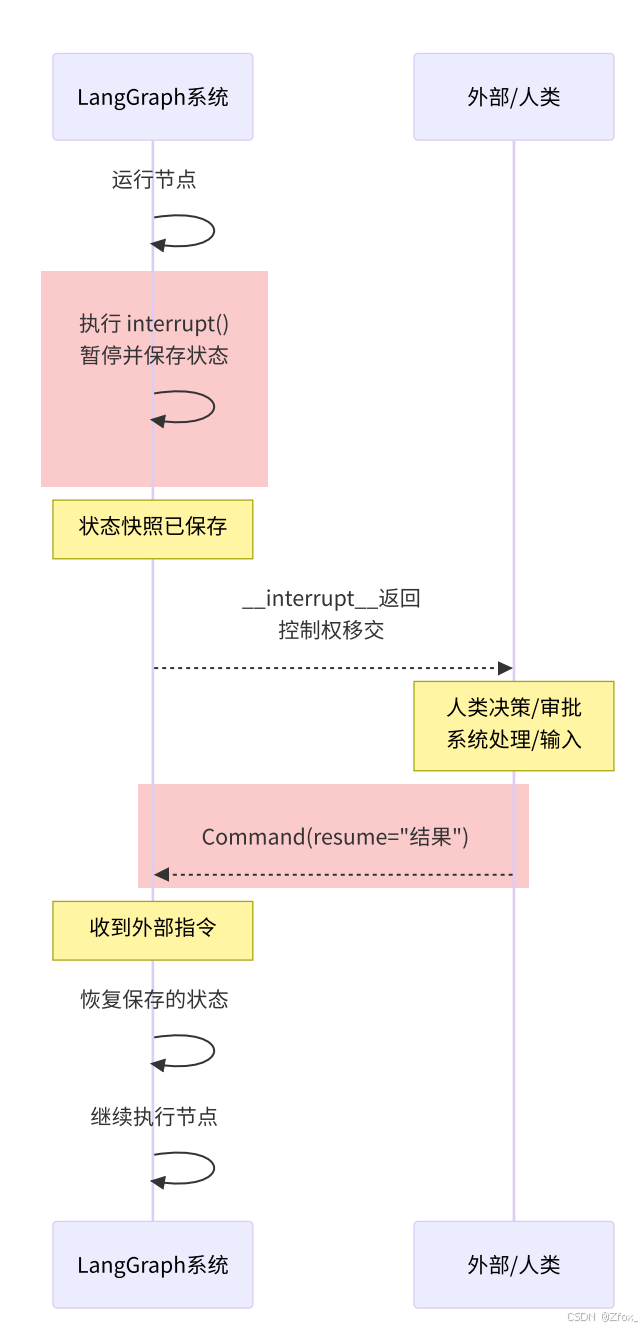
直接看代码:
python
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START
from langgraph.graph import StateGraph
from langgraph.types import interrupt, Command
class State(TypedDict):
input: str
output: str
def hello_node(state: State):
# 主动喊"停!",并传递提⽰信息
human = interrupt("暂停,是否继续?") # 第⼀次运⾏会停在这⾥
if human == "yes":
return {"output": "你好,我是你的贴⼼助⼿!"}
else:
return {"output": "拜拜"}
builder = StateGraph(State)
builder.add_node(hello_node)
builder.add_edge(START, "hello_node")
# 必须指定checkpointer,以在每个步骤后保存图状态。
graph = builder.compile(checkpointer=InMemorySaver())
# 必须使⽤thread_id运⾏ Graph,相当于告诉系统读哪个存档。
config = {"configurable": {"thread_id": "human_1"}}
# 步骤1:启动,触发暂停
first = graph.invoke({"input": "hi"}, config=config)
print(first) # 看到提问:__interrupt__
# 步骤2:恢复,把答案交回去
second = graph.invoke(Command(resume="no"), config=config)
print(second["output"])代码关键点:
- 编译图时:必须指定 checkpointer ,以在每个步骤后保存图状态。
- 调⽤ interrupt() 时:表示主动喊"停!",并传递提示信息。
- 使⽤ invoke/stream 恢复执⾏,需使⽤ Command(resume=...) 语法。
- resume 表示传回AI的响应值
- 必须使⽤ thread_id 运⾏Graph,相当于告诉系统读哪个存档。
因此实现了中断,便是实现了⼈机交互模式。
🎀 中断的⻩⾦法则(规则和限制)
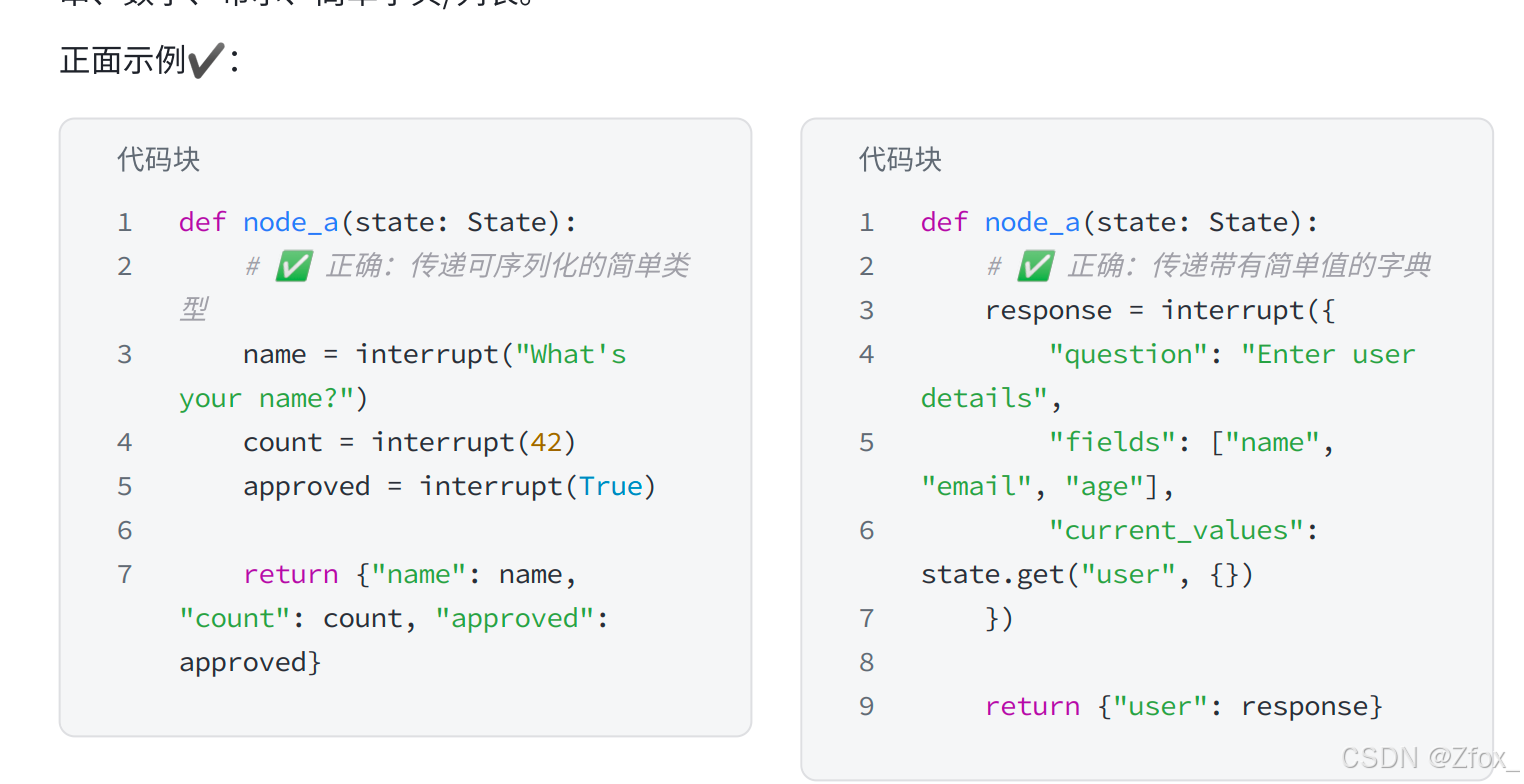
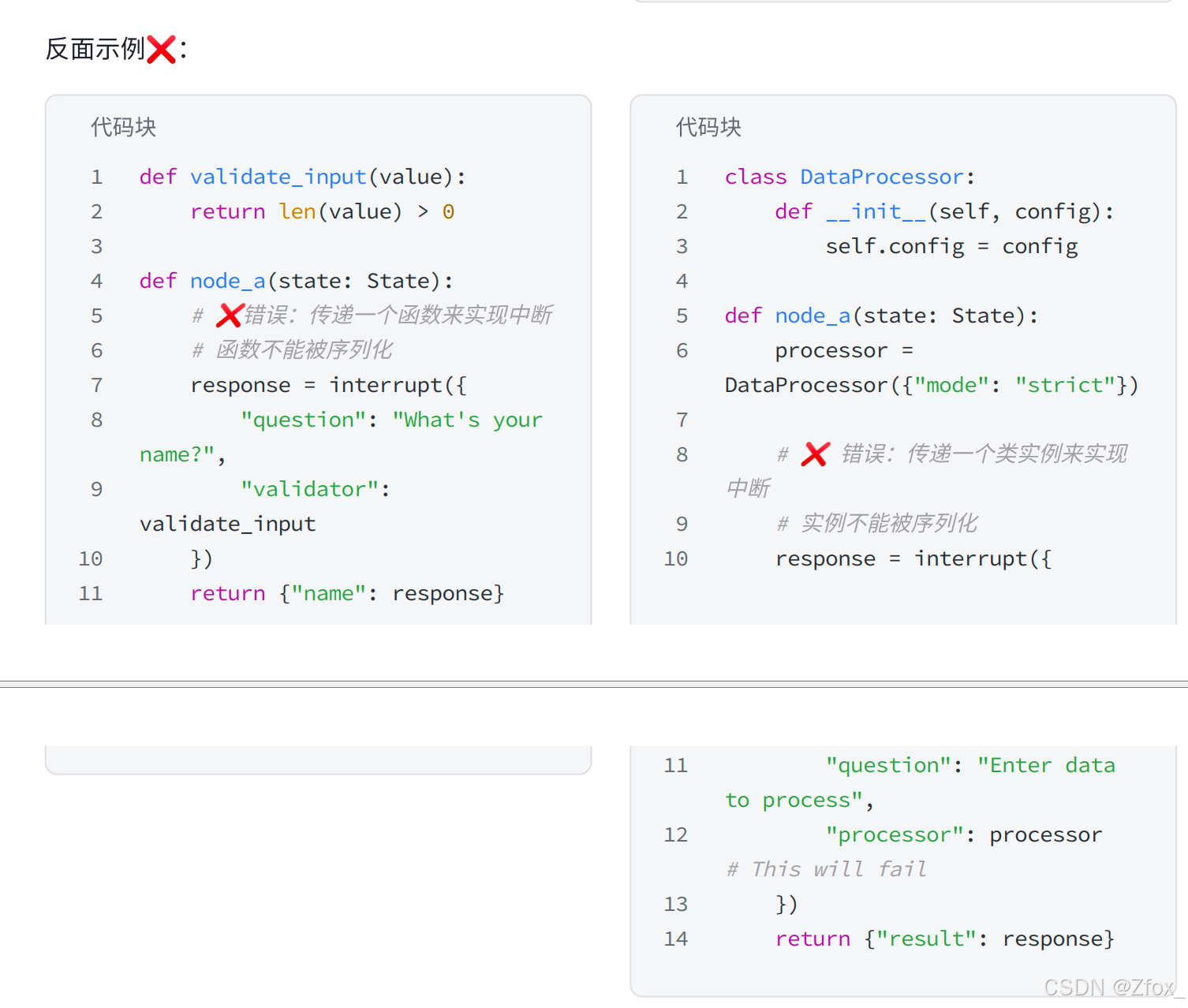
只传能序列化的简单数据
复杂值⽆法进⾏传递,例如不要传函数、类实例、数据库连接等。只传能序列化的简单数据,如字符 串、数字、布尔、简单字典/列表。
不应该将 interrupt() 调⽤包裹在 try/except 代码块中
错误做法是:如果将 interrupt() 调⽤包裹在通⽤的 try/except Exception 或 try/except (空)代码块中,你编写的代码会提前捕获这个特殊异常。这会导致运⾏时系统⽆法 感知到中断,从⽽使 interrupt() 功能失效。
反⾯示例❌:
python
def node_a(state: State):
# ❌ 错误:在try/except中包装中断
try:
interrupt("What's your name?")
except Exception as e:
print(e)
return state根本原因是 interrupt() 函数内部通过抛出⼀个特殊的异常来实现暂停执⾏。这个异常需要被 LangGraph的运⾏时系统捕获,以触发状态的保存和等待。
正确做法:
- 分离逻辑:将 interrupt() 调⽤与可能引发其他异常的代码分开。先调⽤ interrupt() ,然后再处理可能出错的操作。
- 精确捕获:在 try/except 块中只捕获你预期会发⽣的、⾮常具体的异常类型(例如 NetworkException )。这样, interrupt() 抛出的特殊异常就不会被你的代码捕获,⽽ 能顺利传递给运⾏时系统。

这部分是⼀个重要的警告,旨在避免开发者因使⽤常规的错误处理模式⽽导致 interrupt() 机制 失效。其核⼼是必须让 interrupt() 抛出的特殊异常能够"逃逸"出你编写的节点函数,以便被 LangGraph运⾏时正确处理。
中断前的动作要"幂等"
⾮常重要的是:当节点恢复执⾏时,发起中断的节点会从头再跑⼀遍。因此,对于中断前的代码,会多重复执⾏!
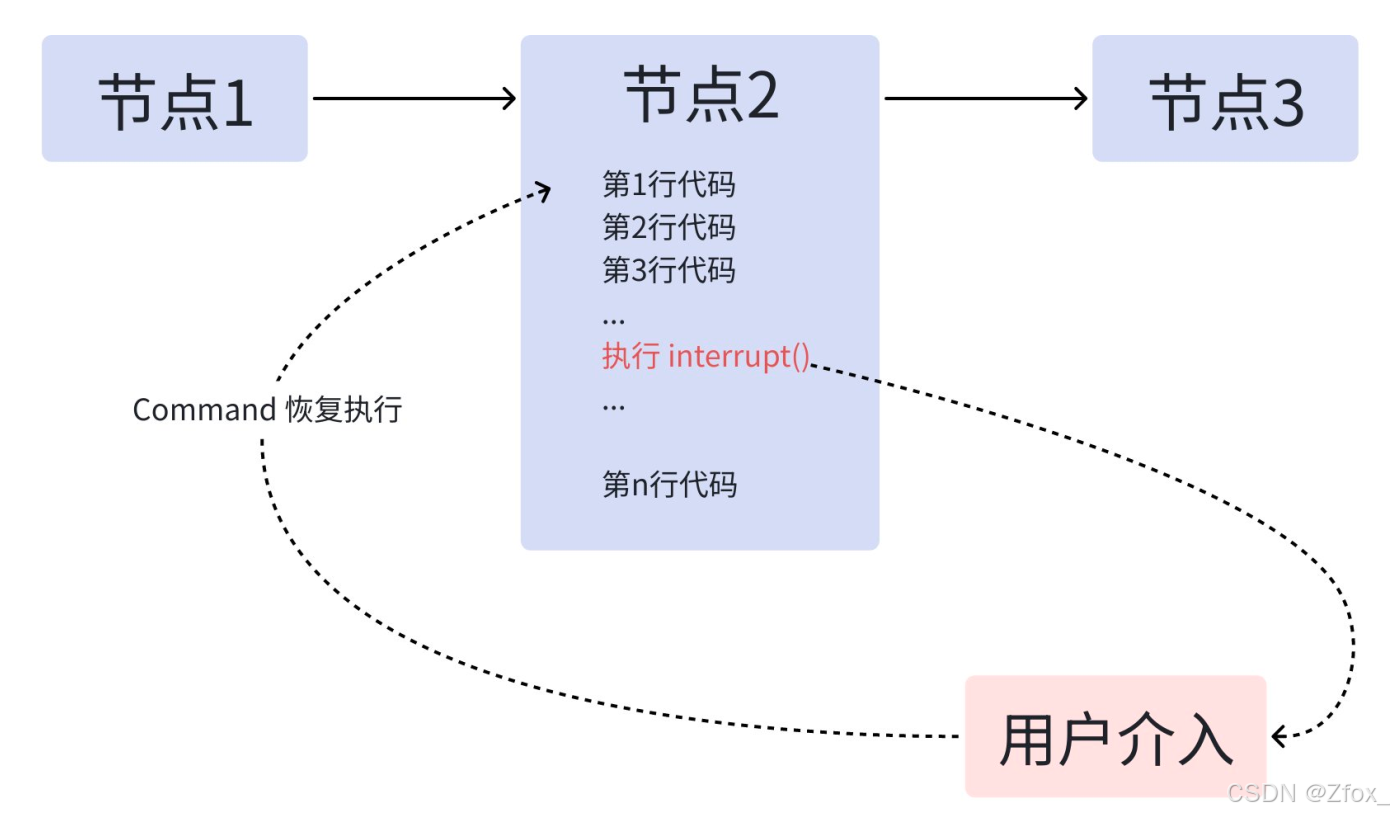
如果这些代码包含⾮幂等的副作⽤操作(如创建记录、发送消息、扣款等),每次恢复都会重复这些 操作。这可能导致数据重复、不⼀致或意外⾏为。
幂等性:⼀个操作⽆论执⾏⼀次还是多次,产⽣的效果都相同。
维护一个状态
正⾯示例✔:

将副作⽤分离到独⽴节点,中断节点单独处理中断
python
# 将副作⽤分离到独⽴节点
def approval_node(state: State):
# 只处理中断
approved = interrupt("Approve this change?")
return {"approved": approved}
def notification_node(state: State):
# ✅ 正确:副作⽤在独⽴节点中,仅在获得批准后执⾏⼀次
if state["approved"]:
send_notification(user_id=state["user_id"], status="approved")
return state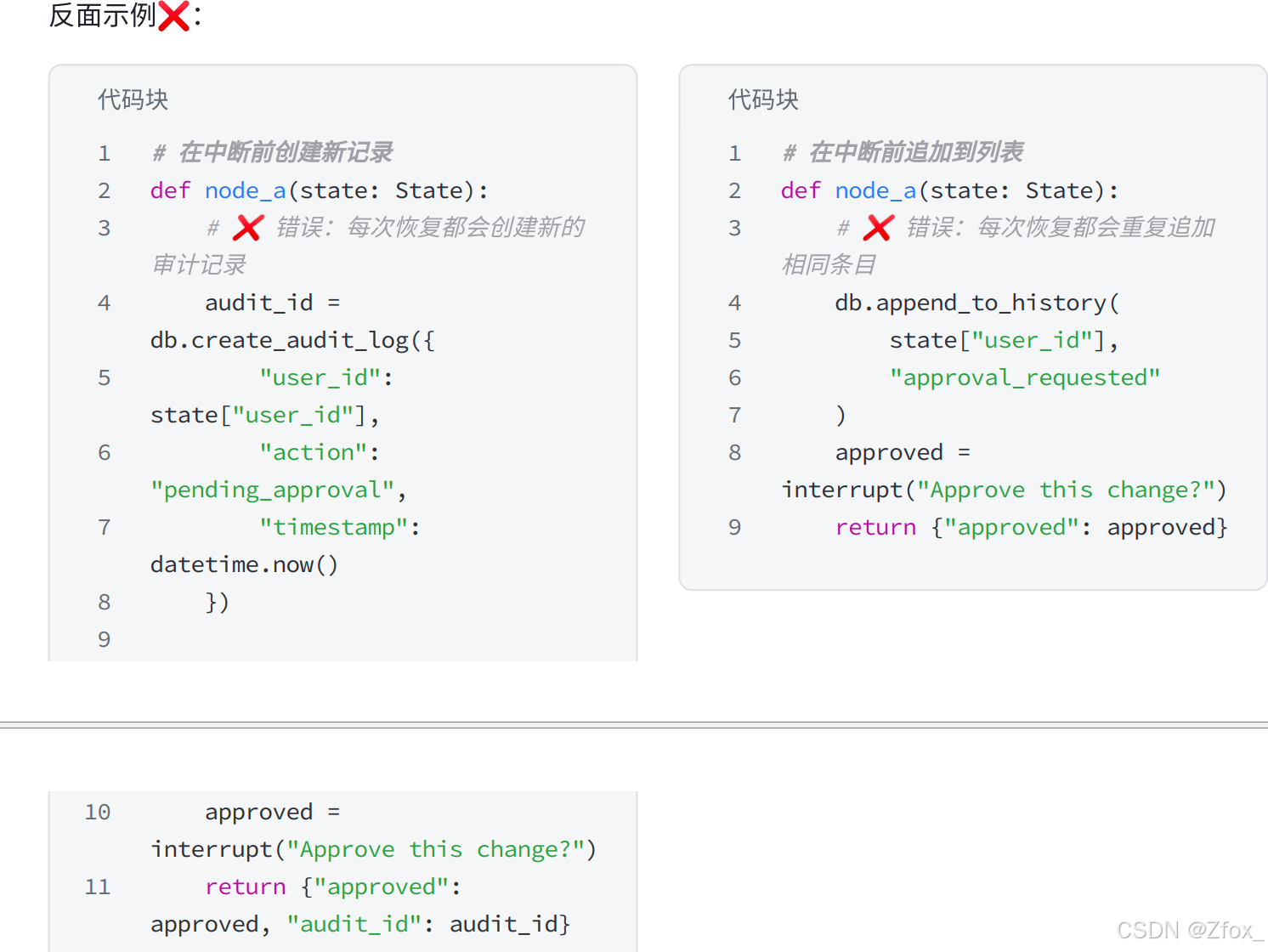
这⼀规则的核⼼是:确保在 interrupt() 调⽤之前执⾏的所有操作都是幂等的,或者将⾮幂等操 作移到 interrupt() 调⽤之后。这是为了避免因节点重新执⾏⽽导致的重复副作⽤,确保系统的 数据⼀致性和预期⾏为。
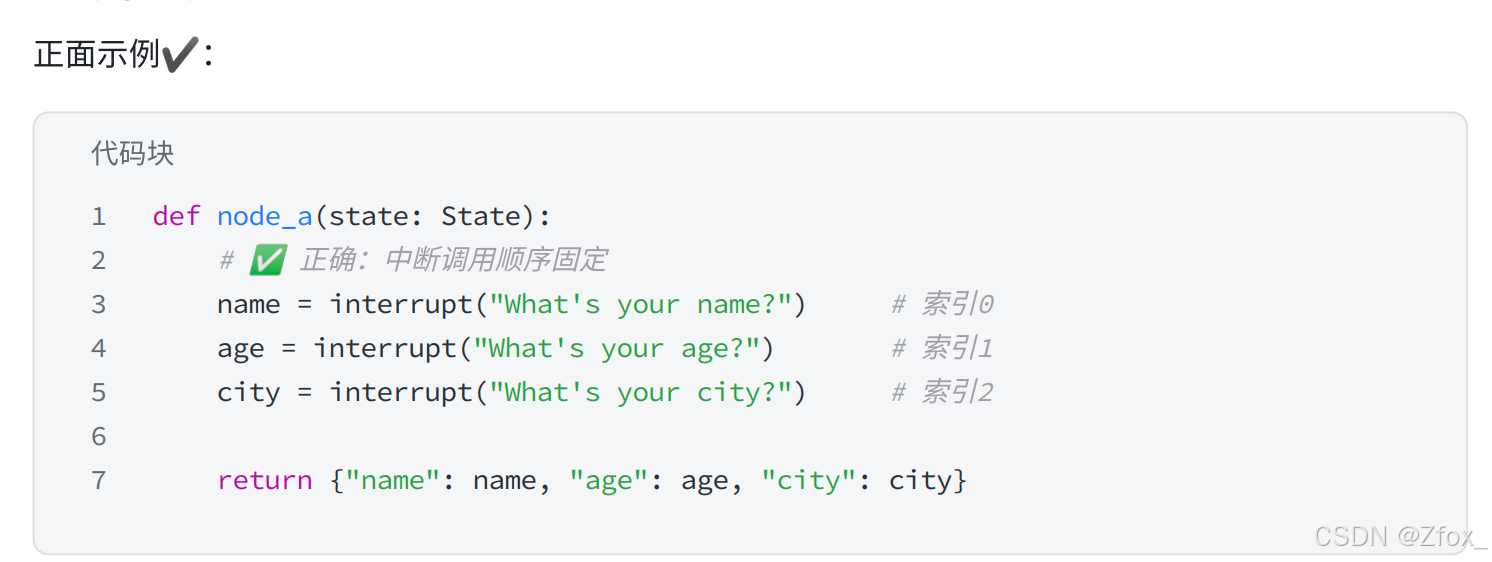
中断顺序固定
在同⼀个节点中使⽤多个 interrupt() 调⽤时需要注意的顺序和索引匹配规则。LangGraph使⽤严格的索引顺序来匹配恢复值:
- 恢复执⾏从头开始:节点恢复时会从开头重新运⾏,⽽不是从中断的精确⾏继续。
- 索引匹配:LangGraph为每个执⾏任务维护⼀个恢复值列表。遇到 interrupt() 时,按顺序从这个列表中取对应的值。
- 顺序必须⼀致:中断调⽤的顺序在每次执⾏中必须完全相同。
- 中断点数量和顺序必须是确定性的,不能依赖运行时状态动态改变。
如果没执行完也会失败

🎀 ⼈机交互的应⽤场景
使⽤中断来实现需要⼈⼯介⼊的交互式⼯作流有四种常⻅模式:
-
审批或拒绝:在执⾏关键操作(如API调⽤、数据库更改)之前暂停流程,等待⼈⼯批准或拒 绝。根据返回的指令,流程图会路由到不同的分⽀。
-
审查和编辑状态:暂停流程,让⼈⼯可以审查并修改流程图当前的状态(例如,LLM⽣成的⽂本 内容),然后将编辑后的内容传回,更新状态并继续执⾏。
-
在⼯具中中断:将中断直接置于⼯具函数内部。当LLM调⽤该⼯具时,流程会⾃动暂停,允许⼈⼯在⼯具实际执⾏前审查、编辑其调⽤参数或直接取消调⽤。
-
验证⼈⼯输⼊:通过循环使⽤中断,反复要求⼈⼯输⼊,直到输⼊内容通过验证(例如,确保输⼊⼀个有效的正数年龄)。这适⽤于需要收集和验证数据的场景。
这部分的核⼼思想是:中断功能解锁了"暂停执⾏并等待外部输⼊"的能⼒,从⽽使得构建⼈机交互 (human-in-the-loop)的应⽤成为可能。每个模式都附带了简明的代码示例,展示了如何在中途暂 停、如何将信息传递给外部系统,以及如何在获得响应后恢复执⾏。
批准或拒绝(Approveorreject)
这是中断功能最常⻅的⼀种⽤途。在执⾏关键性操作(例如调⽤API、修改数据库、进⾏⾦融交易等) 之前,暂停图(graph)的执⾏,等待⼈⼯(如管理员、⽤户)的批准或拒绝。
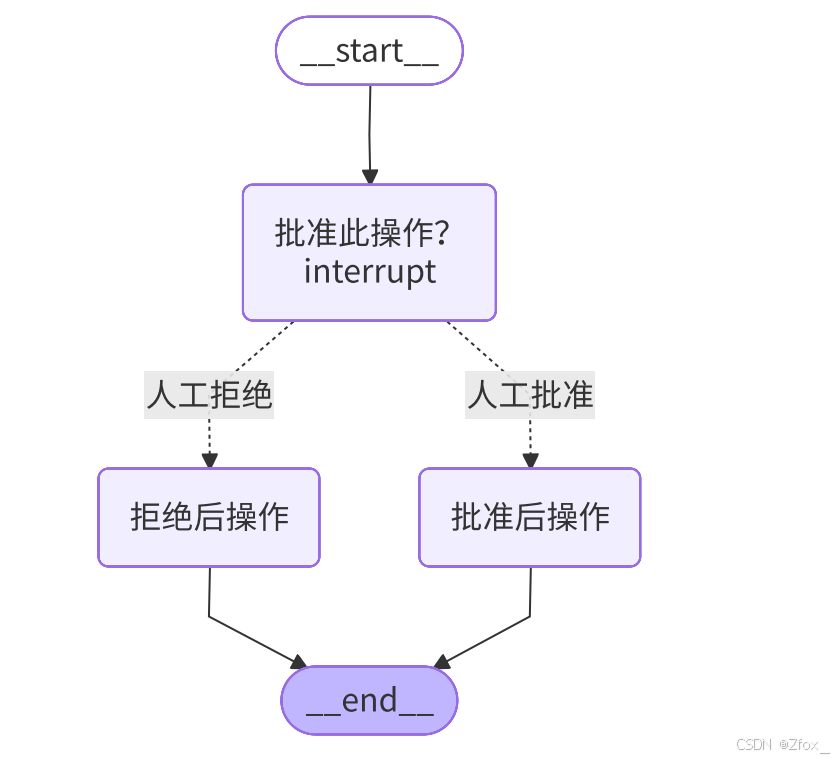
实现⽅式:
- 在节点中使⽤ interrupt() 函数暂停执⾏。传⼊⼀个包含审批问题、操作详情等信息的 JSON 可序列化对象,该对象会显示在调⽤结果 result"interrupt" 中。
- 当图被暂停后,外部系统(如UI界⾯)可以根据 interrupt 中的信息向⽤户展示审批请求。
- ⼈⼯做出决定(批准或拒绝)后,通过再次调⽤图并传⼊ Command(resume=...) 来恢复执⾏。
- 恢复时,传⼊ Command(resume=True) 表示批准,传⼊ Command(resume=False) 表示拒绝。
- 节点代码会接收这个 resume 值作为 interrupt() 函数的返回值,然后根据该值,使⽤ Command(goto=...) 将流程路由到不同的后续节点(例如"proceed"节点或"cancel"节点)。
- Command(goto=...) 表示要导航到的下⼀个节点的名称
【练习】AI转账前进⾏⼈⼯审批
python
# 中断案例
from typing import TypedDict, Optional, Literal
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import interrupt, Command
class ApprovalState(TypedDict):
action_details: str # 操作详情(如"转账30000元")
status: Optional[Literal["等待", "批准", "拒绝"]] # 审批状态
# 1. 保存审批状态,由条件边决定后续流程
# def approval_node(state:ApprovalState):
# decision = interrupt({
# "question": "是否批准此操作?",
# "details": state["action_details"],
# "ops": "请输入【批准】或【拒绝】"
# })
#
# return {
# "status": decision
# }
# 2. 节点中,直接判断后续执行流程
def approval_node(state: ApprovalState):
decision = interrupt({
"question": "是否批准此操作?",
"details": state["action_details"],
"ops": "请输入【批准】或【拒绝】"
})
if decision == "批准":
next_node = "proceed_node"
else:
next_node = "cancel_node"
return Command(goto=next_node)
def proceed_node(state:ApprovalState):
print("批准")
return {"status": "批准"}
def cancel_node(state:ApprovalState):
print("取消")
return {"status": "取消"}
builder = StateGraph(ApprovalState)
builder.add_node(approval_node)
builder.add_node(proceed_node)
builder.add_node(cancel_node)
builder.add_edge(START, "approval_node")
# def approval(state:ApprovalState):
# if state["status"] == "批准":
# return "proceed_node"
# else:
# return "cancel_node"
#
# # 条件边:根据人工审核结果决定后续流程
# builder.add_conditional_edges(
# "approval_node",
# approval,
# ["proceed_node", "cancel_node"]
# )
builder.add_edge("proceed_node", END)
builder.add_edge("cancel_node", END)
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "1"}}
print(graph.invoke({"action_details": "转账30000元", "status": "等待"}, config=config))
print(graph.invoke(Command(resume="批准"), config=config))查看和编辑状态(Reviewandeditstate)
该场景表示在流程执⾏过程,使⽤中断功能让⼈进⾏审查和编辑状态内容。
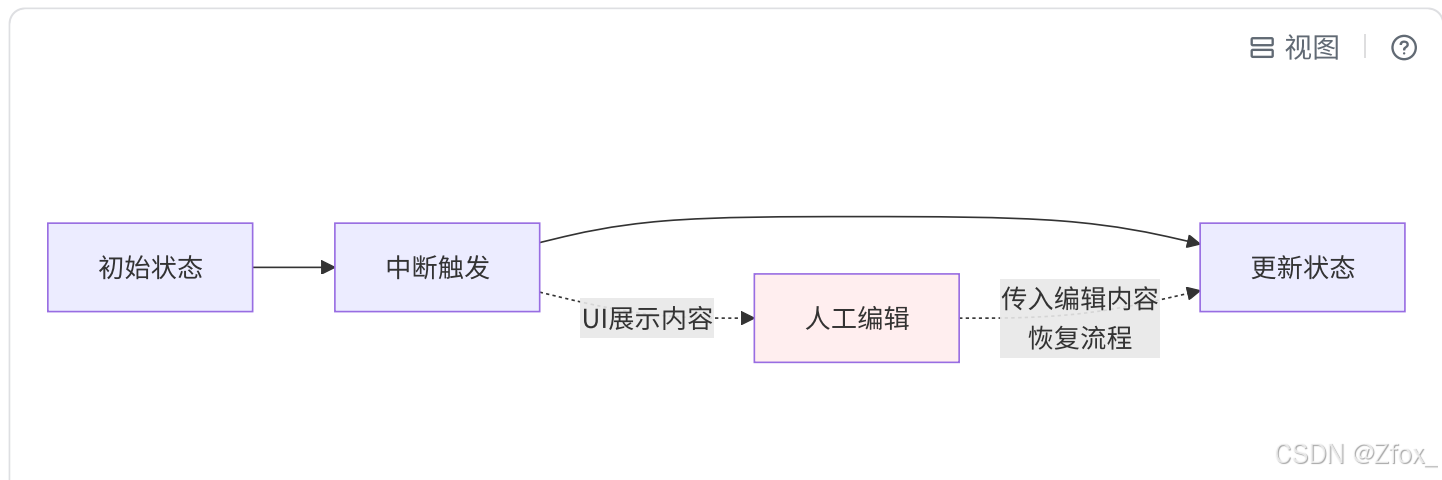
【练习】⼈⼯审核AI⽂档内容,并进⾏编辑
示例如下:
python
# 查看和编辑状态
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import interrupt, Command
class State(TypedDict):
text: str
def review_node(state: State):
"""通过中断,让审查者编辑生成的内容"""
updated = interrupt({
"instruction": "查看并编辑内容",
"content": state["text"]
})
if updated["success"] == "true":
return {}
else:
return {
"text": updated["content"]
}
builder = StateGraph(State)
builder.add_node(review_node)
builder.add_edge(START, "review_node")
builder.add_edge("review_node", END)
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "1"}}
result1 = graph.invoke({"text": "初始文章...."}, config=config)
print(result1["__interrupt__"])
# .... 审核中 ....
print(graph.invoke(Command(resume={"success": "false", "content": "编辑后的文章..."}), config=config))除此之外,还允许:
-
⼈⼯审查和修改LLM⽣成的内容(如⽂本、数据)
-
在继续执⾏前纠正错误、添加信息或进⾏微调
-
适⽤于需要质量控制或专业审核的⾃动化流程
注意恢复时传⼊的内容会完全替换原始内容。如果需要部分编辑,可以在中断载荷中标记可编辑部 分。
在⼯具中中断(Interruptsintools)
还⽀持将中断功能直接嵌⼊到⼯具(tool)函数内部,从⽽实现在⼯具调⽤前进⾏⼈⼯审查和⼲预的能 ⼒。
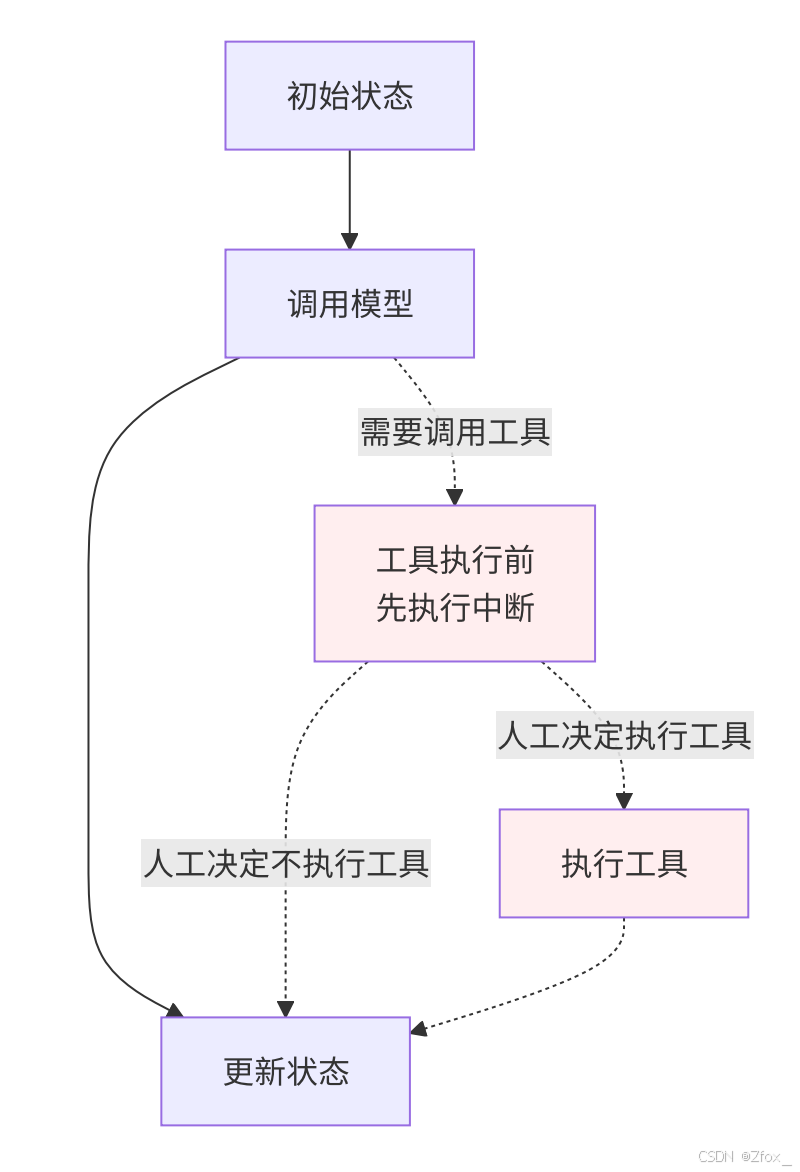
关键特点如下:
- 中断逻辑内置于⼯具,⽽⾮图的节点中。
- ⼯具变得"智能",知道何时需要⼈⼯批准。
- ⼯具可以在任何图中使⽤,⾃动具备中断能⼒
【练习】AI发送邮件前,⼈⼯审查邮件内容
代码如下:
python
import operator
from typing import TypedDict, Annotated
from langchain.chat_models import init_chat_model
from langchain.tools import tool
from langchain_core.messages import AnyMessage, SystemMessage, ToolMessage,
HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import interrupt, Command
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
@tool
def send_email(to: str, subject: str, body: str):
"""发送电⼦邮件给收件⼈"""
# 在发送前暂停
response = interrupt({
"action": "发送邮件",
"to": to,
"subject": subject,
"body": body,
"message": "同意发送这封邮件吗?",
})
if response.get("action") == "同意":
final_to = response.get("to", to)
final_subject = response.get("subject", subject)
final_body = response.get("body", body)
# 实际发送邮件(此处为⽰例,仅打印)
email_info = f"收件⼈:{final_to} 主题:{final_subject} 正⽂:
{final_body}"
print(f"[发送邮件] {email_info}")
return email_info
return "⽤⼾取消邮件"
# 使⽤绑定⼯具的模型
model_with_tools = init_chat_model("gpt-4o-mini",
temperature=0).bind_tools([send_email])
def llm_call(state: dict):
"""LLM决定是否调⽤⼯具"""
messages = model_with_tools.invoke(
[SystemMessage(content="你⽀持调⽤⼯具进⾏邮件发送。")]
+ state["messages"]
) #
直接调⽤⼯具(为了演⽰效果)
if messages.tool_calls:
tool_call = messages.tool_calls[0]
tool_result = send_email.invoke(tool_call["args"])
return {"messages": [ToolMessage(content=tool_result,
tool_call_id=tool_call["id"])]}
return {"messages": [messages]}
builder = StateGraph(MessagesState)
builder.add_node("llm_call", llm_call)
builder.add_edge(START, "llm_call")
builder.add_edge("llm_call", END)
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "email-workflow"}}
initial = graph.invoke(
{"messages": [HumanMessage(content="发送电⼦邮件⾄alice@example.com,主题是:
请假,内容是:理由如下...")]},
config=config
) p
rint(initial["__interrupt__"]) # -> [Interrupt(value={'action': '...', ...})]
# ⽤批准和可选编辑的参数恢复
resumed = graph.invoke(
# Command(resume={"action": "同意", "subject": "病假"}),
Command(resume={"action": "不同意"}),
config=config,
) p
rint(resumed["messages"][-1]) # -> ⼯具调⽤结果验证⼈⼯输⼊(Validatinghumaninput)
该场景使⽤中断功能在循环中验证⼈类输⼊,直到输⼊有效为⽌。
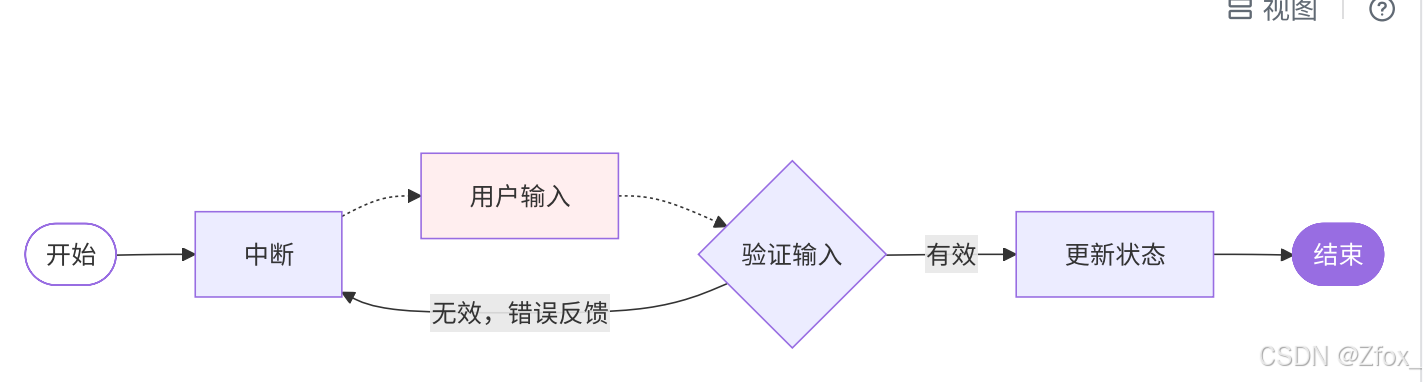
【练习】⽤户注册流程中的年龄验证
python
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command, interrupt
class FormState(TypedDict):
age: int | None
def get_age_node(state: FormState):
prompt = "你多⼤了?"
while True:
answer = interrupt(prompt) # 有效载荷出现在 result["__interrupt__"] 中
if isinstance(answer, int) and answer > 0:
return {"age": answer}
# 每次验证失败后,提⽰信息会更新
prompt = f"'{answer}' 不是⼀个有效的年龄。请输⼊正数。"
# 构建图
builder = StateGraph(FormState)
builder.add_node(get_age_node)
builder.add_edge(START, "get_age_node")
builder.add_edge("get_age_node", END)
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "form-1"}}
# ⾸次调⽤:显⽰初始提⽰
first = graph.invoke({"age": None}, config=config)
print(first["__interrupt__"]) # -> [Interrupt(value='你多⼤了?', ...)]
# 提供⽆效数据:节点重新提⽰
retry = graph.invoke(Command(resume="三⼗"), config=config)
print(retry["__interrupt__"]) # -> [Interrupt(value="'三⼗' 不是⼀个有效的年龄...", ...)]
# 提供有效数据:循环退出,状态更新
final = graph.invoke(Command(resume=30), config=config)
print(final["age"]) # -> 30🦋 时间旅⾏(TimeTravel)
🎀 时间旅⾏是什么?
AI⼯作流具有⾮确定性:⼤语⾔模型每次运⾏可能产⽣不同结果。且复杂任务需要多个AI调⽤协同完 成时,错误可能出现在任何步骤,难以定位。
LangGraph的⼯作⽅式:每个节点执⾏后都会⾃动"存档"。时间旅⾏允许⽤户重放先前的执⾏以查 看或调试特定的步骤。
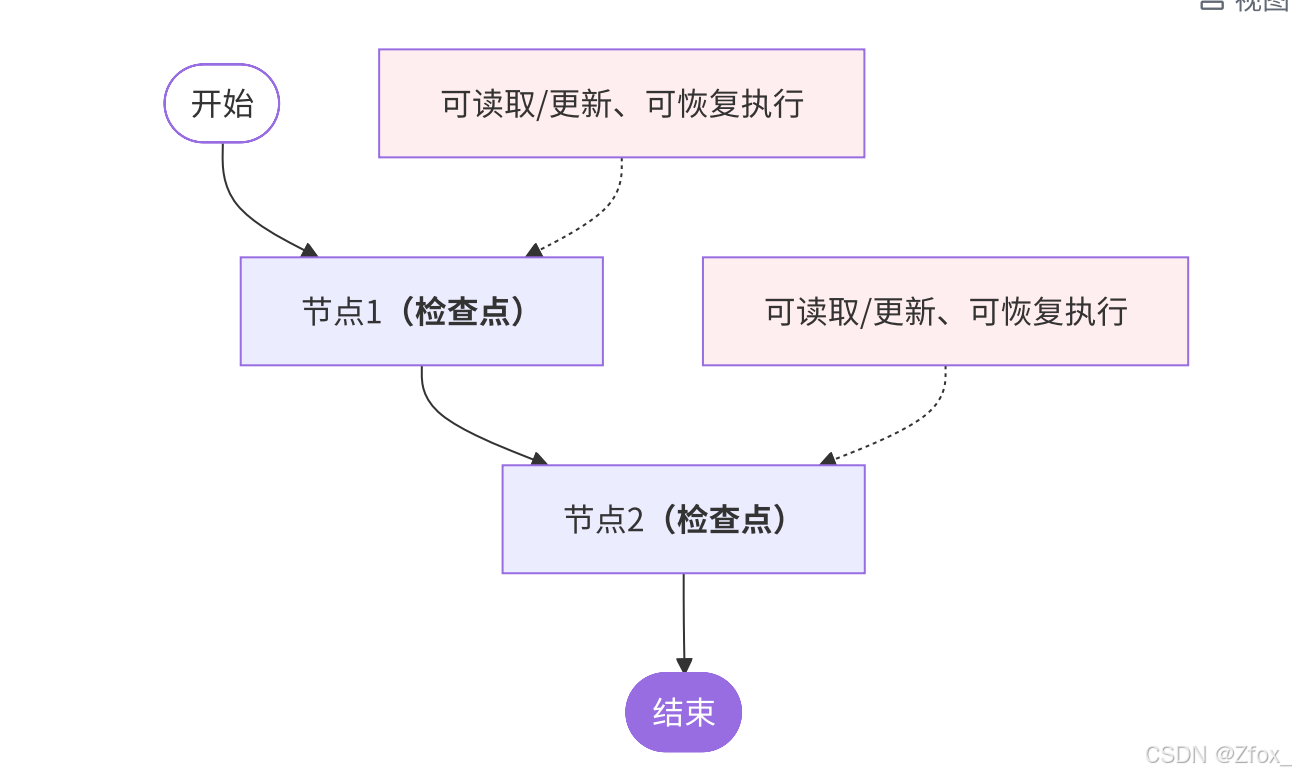
这个能⼒会很有⽤:
- 分析推理过程:理解AI如何得出最终结果,学习成功的决策路径。(看看AI是怎么"想"出好答案 的)
- 定位和修复错误:精确找到错误发⽣的节点,测试修复⽅案⽽不影响原始流程。(找出AI在哪⼀ 步"想歪了")
- 探索替代⽅案:尝试不同的输⼊或中间状态,⽐较不同路径的效果。(试试不同的选择会不会更 好)
🎀 时间旅⾏四步法
第⼀步:初始执⾏⼯作流
伪代码:
python
# 编译需要checkpointer
graph = workflow.compile(checkpointer=InMemorySaver())
# 创建执⾏线程
import uuid
config = {
"configurable": {
"thread_id": uuid.uuid4(), # 唯⼀线程标识
}
}
# 执⾏⼯作流
state = graph.invoke({}, config)第⼆步:查看历史检查点
伪代码:
python
# 获取所有历史状态(按时间倒序)
states = list(graph.get_state_history(config))
for state in states:
print(f"检查点ID: {state.config['configurable']['checkpoint_id']}")
print(f"下⼀步节点: {state.next}")
print(f"当前状态: {state.values}")
print("-" * 50)
# 输出⽰例:
# 检查点ID: 1f0d4d2b-bdc2-6f06-8002-9b67bb1d3867
# 下⼀步节点: ()
# 当前状态: {'...': '...'}
# 检查点ID: 1f0d4d2b-9506-6bf8-8001-6af0cdc2fea0
# 下⼀步节点: ('write_joke',)
# 当前状态: {'...': '...'}
# 检查点ID: 1f0d4d2b-7a6e-6dd7-8000-5cc1931477df
# 下⼀步节点: ('generate_topic',)
# 当前状态: {}
# 检查点ID: 1f0d4d2b-7a6c-643e-bfff-77054fa568c8
# 下⼀步节点: ('__start__',)
# 当前状态: {}第三步:修改状态(可选)
- update_state 更新状态(会创建新的检查点分⽀)
- 原始检查点保持不变
- 新分⽀可以独⽴发展
伪代码:
python
# 选择特定检查点
selected_state = states[1] # 写笑话之前的检查点
# 修改状态数据
new_config = graph.update_state(
selected_state.config, # 原始配置
values={"topic": "程序员"} # 修改主题
)第四步:从检查点恢复执⾏
- 输⼊为 None ,因为状态已在检查点中
- 配置必须包含有效的 checkpoint_id :通过指定 thread_id 和 checkpoint_id 来调⽤图,可以从历史某个检查点开始重放执⾏,⽤于调试或探索不同路径。
- 执⾏从指定检查点继续,⽣成新的历史分⽀
python
# 从修改后的检查点继续执⾏
result = graph.invoke(None, new_config) # 输⼊为None,因为状态已存在
print(result["joke"]) # 输出关于程序员的新笑话🎀 【完整示例】AI笑话⽣成器
我们要创建⼀个⽣成笑话的系统:
- 第⼀步:想⼀个主题
- 第⼆步:根据主题写笑话
python
from typing import TypedDict
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START
from langgraph.graph import StateGraph
class State(TypedDict):
topic: str
joke: str
model = init_chat_model("gpt-4o-mini")
def generate_topic(state: State):
"""生成笑话主题"""
return {
"topic": model.invoke("生成一个搞笑的笑话主题,仅生成5个字以内的主题").content
}
def generate_joke(state: State):
"""根据主题生成笑话"""
return {
"joke": model.invoke(f"写一个关于{state['topic']}的笑话").content
}
builder = StateGraph(State)
builder.add_sequence([generate_topic, generate_joke])
builder.add_edge(START, "generate_topic")
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "1"}}
# 1. 执行一次工作流,产生历史记录
print(graph.invoke({}, config=config))
# 2. 获取历史记录,找到要修改的状态快照
states = list(graph.get_state_history(config))
print(states[0])
print(states[1])
print(states[2])
# states list 顺序:按照时间排序
update = states[1]
# update.values 是当前的state
print(update.values["topic"])
print(update.config)
# 3. 更新状态
# update.config 中包含:线程id、状态快照id
new_config = graph.update_state(update.config, values={"topic": "程序员有趣的事"}, as_node="generate_topic")
# 4. 使用新的状态重放
print(graph.invoke(None, config=new_config))五:🔥 持久化⼩结
在LangGraph中,持久化能⼒提供了:
- ⾃动化:在使⽤LangGraph时,持久化基础设施(检查点和存储)是⾃动处理的,⽆需⼿动配置。
- 多种存储后端:提供了多种检查点存储后端,包括内存( InMemorySaver ⽤于开发测试)、Postgres( PostgresSaver ⽤于⽣产)。
基于上述技术,LangGraph⽀持以下强⼤功能:

掌握了这些能⼒,我们就能构建出复杂、可靠、且包含记忆能⼒的AI系统。
六:🔥 共勉
😋 以上就是我对 【LangGraph】持久化(Persistence) 的理解, 觉得这篇博客对你有帮助的,可以点赞收藏关注支持一波~ 😉
