1. 问题背景(技术痛点)
靶向结合分子开发中,传统抗体制备存在:
- 分子量大,扩散与穿透效率有限;
- 文库构建与淘选周期长,难以规模化;
- 原核表达与纯化体系不稳定,批次差异大;
- 筛选缺乏高通量手段,效率偏低。骆驼纳米抗体 (VHH)为单域小分子,适合标准化、高通量开发。
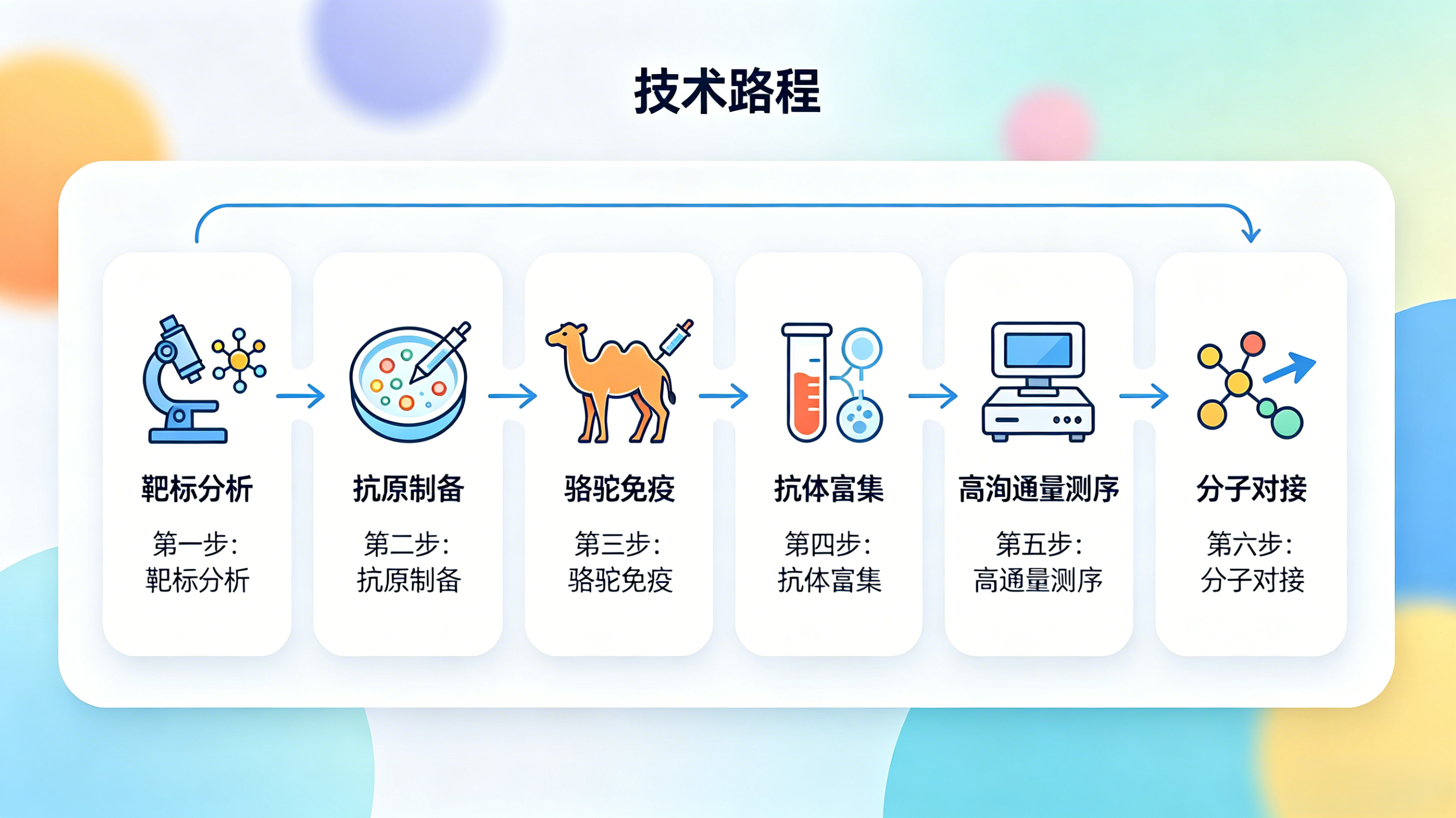
2. 问题分析
- 靶标胞外区域需经生物信息学验证,排除跨膜与信号肽干扰;
- 原核表达需优化诱导条件,提升可溶性或便于包涵体复性;
- 免疫方案直接决定骆驼纳米抗体多样性与效价;
- 高通量测序 + 质谱可替代噬菌体文库,大幅提速;
- 分子对接用于亲和力预测,减少实验验证成本。
3. 解决方案(标准化实验流程)
3.1 生物信息学分析流程
- 序列翻译→SignalP 6.0 测信号肽→TMHMM 测跨膜→ProtScale 测疏水性→PSIPRED 测二级结构→SWISS‑MODEL 建模→GMQE/QMEAN 评估质量。
3.2 基因克隆与表达(可复现)
- 引物:F1-CCGGAATTCACTGTCTGTGCCGGTGGCTG;R1-CCCAAGCTTtcaCACTCGGGCACAGGGCTT
- 体系:20 μL,cDNA 1 μL,引物各 1 μL,2×MasterMix 10 μL
- 条件:94℃ 5min;35 cycles(94℃ 30s,58℃ 30s,72℃ 90s);72℃ 10min
- 表达:BL21 (DE3),OD600=0.6,0.5% IPTG,18℃诱导 12h
3.3 纯化与免疫
- Ni‑NTA 柱:20 mM 咪唑洗杂,300 mM 咪唑洗脱
- 免疫:1 mg / 只,4 次,每 28 天一次
3.4 骆驼纳米抗体筛选
- 洗脱:0.1 M glycine‑HCl pH3.0,中和 1 M Tris‑HCl pH8.0
- 高通量测序:Illumina MiSeq,Trimmomatic 质控
3.5 分子对接
- Haddock:3 次独立运算,每次 100 构象;选取 RMSD<2Å、Haddock score 优模型
4. 实验数据(可直接引用)
- 目的条带:375 bp ;蛋白:~32 kDa;
- 效价:1:640000;
- 骆驼纳米抗体 :~15 kDa;
- VHH 独特序列:10430条;
- 高丰度分子:5 个;
- 结合能:−13.3 ~ −15.5 kcal/mol。
5. 技术结论
本流程实现骆驼纳米抗体 从抗原制备到筛选验证的全链路标准化,可直接复用于其他靶标。骆驼纳米抗体展现高特异性、高亲和力与高稳定性,为靶向蛋白工具开发提供高效方案。
参考文献:黄贞魁,李村院,李晓悦,等. HER2 特异性的驼源纳米抗体制备与筛选 J. 内蒙古农业大学学报 (自然科学版), 2025.