一句话介绍
所有人都在堆 CPT、SFT、RL 三段式训练,而本文选择把全部筹码押在数据合成上:只用 1.06w 条高难度轨迹和一次纯 SFT,就在四个主流 deep search 榜单上反超阿里通义 DeepResearch 等工业级模型
- 论文标题:OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
- 论文地址 :https://arxiv.org/pdf/2605.04036
- 作者背景:上海交通大学
- 代码 :github.com/PolarSeeker/OpenSeeker
- 模型 :huggingface.co/PolarSeeker/OpenSeeker-v2-30B-SFT
一、动机
deep research 已经成为大模型 agent 的核心能力,市面上大多数 Agent 产品都会实现这一功能。它要求模型像研究员一样自己规划查询、反复调用工具、跨多个来源做交叉对照,最后给出有依据的回答
但训练一个能打的搜索 agent,门槛相对较高。下面是几个代表性工作的训练 pipeline:
| 工作 | 训练范式 | 团队 |
|---|---|---|
| Tongyi DeepResearch | CPT + SFT + RL | 阿里通义 |
| RedSearcher | CPT + SFT + RL | 小红书 |
| WebSailor-V2 | SFT + RL | 阿里 |
CPT(继续预训练)这一步本身就要在数百 B token 的网页语料上从头训练,几十张 H100 跑几周;后面叠 RL,环境搭建、reward 设计、稳定性调优,每一步都是工程黑洞,学术界几乎无法构造出生产级应用
OpenSeeker-v2 想问的是一个非常朴素但少有人认真回答的问题:
这套 "重型工业流水线" 真的是必要的吗?还是我们只是没认真挖过 "数据质量" 这一侧的潜力?
二、核心赌注
工程实践里大家都默认一个 "训练范式阶梯":监督微调(SFT)门槛最低、工程量最小,是首选;只有当 SFT 搞不定时,才不得已往上爬到 CPT 或者 RL。deep search 长期被归类到 "SFT 必然搞不定" 的硬场景里------做 agent 嘛,怎么能没有 RL
OpenSeeker-v2 的核心赌注一句话:
真正稀缺的不是算力,也不是训练阶段的复杂度,而是数据本身的难度和信息密度。如果一开始喂给 SFT 的数据,就已经携带了 "长程检索 + 多工具协同" 的范式信号,那 CPT 和 RL 这两步,至少在搜索 agent 这条线上,可能并没有那么不可替代
整个工作几乎没碰训练这一侧,所有功夫都花在了数据合成 pipeline 上
三、实现过程
OpenSeeker-v2 的方法部分朴素得让人怀疑
3.1 扩大知识图谱
deep search 的训练数据通常从一个知识图谱出发,每个节点是一个事实或文档,节点之间有语义关联。原来的合成流程会在每个种子节点周围采一个小子图,然后让 LLM 基于这块子图编一个 query
子图小,意味着相关线索就那几条,模型不需要绕远路就能拼出答案。OpenSeeker-v2 大幅提高了扩展预算,使合成出来的 query 在结构上就强制要求多跳:必须跨越多个节点、做多次交叉对照才能闭环
多跳数据合成本身不是什么新鲜技术,相关工作里几乎是个标配
3.2 扩展工具集
参考 MiroThinker 的做法,把 agent 可用的工具集扩到更大、更细分。原来 agent 可能只有 search、web_browse 两三个工具,能选的策略很单一;扩展后包含学术搜索、跨域搜索、URL 抓取、代码执行等等
工具多了之后,模型在轨迹里会自然出现 "先用 A 工具拉一批结果 → B 工具精读 → C 工具验算" 这种组合式调用
3.3 更严格的过滤
第三个改动是作者最看重的:设定一个工具调用步数阈值,任何步数低于它的样本都被舍弃
这一刀为什么关键?合成 pipeline 里简单题永远占大头,因为 LLM 编 query 时倾向于走捷径,工具调用 1~2 步就能拿到答案的占比可能高达 40~60%。如果不过滤,这些水题会稀释整个训练集的难度,让 SFT 信号偏向 "快速查 → 直接答",长程检索的耐力反而练不出来
四、实验结果
4.1 训练设置
为了把 "数据质量决定一切" 这个赌注落实,训练这一侧故意做得很克制:
- 基模:Qwen3-30B-A3B-Thinking-2507(30B 总参,3B 激活的 MoE)
- 范式:标准 ReAct(Reasoning → Action → Observation 循环)
- 数据量:10.6k 条精选高难度轨迹
- 训练:单次 SFT,没有 RL,没有 CPT,连超参数 sweep 都没做
- 上下文:256k 窗口,单条轨迹最多 200 次工具调用
整个训练过程基本就是:给一个开源大模型,喂一份小而精的数据,按标准流程跑一次 SFT
4.2 四个 benchmark 全面 SOTA
在 BrowseComp、BrowseComp-ZH、Humanity's Last Exam(HLE)、xbench 这四个代表性 deep search 榜单上,OpenSeeker-v2-30B-SFT 拿到了所有 30B 量级 ReAct Agent 中最强的成绩:
| Benchmark | OpenSeeker-v2 (SFT only) | Tongyi DeepResearch (CPT+SFT+RL) | 差距 |
|---|---|---|---|
| BrowseComp | 46.0% | 43.4% | +2.6 |
| BrowseComp-ZH | 58.1% | 46.7% | +11.4 |
| HLE | 34.6% | 32.9% | +1.7 |
| xbench | 78.0% | 75.0% | +3.0 |
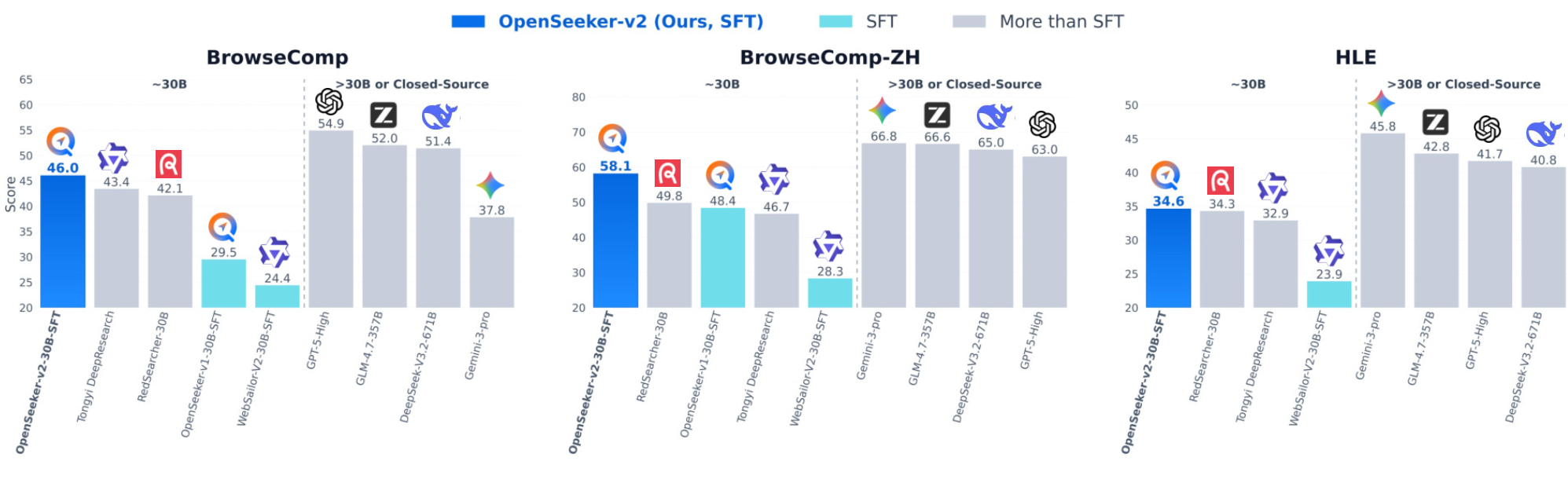
更进一步,OpenSeeker-v2 不止赢了同量级。在 BrowseComp 等多个 benchmark 上,它也压过了 Claude-4.5-Sonnet、DeepSeek-V3.1-671B、GLM-4.6-357B、Minimax-M2-230B 这些参数量大得多的开源/闭源模型 ------ 以 30B 的体量打掉一群百亿到千亿的对手
4.3 对比 OpenSeeker-v1
OpenSeeker-v2 的对照组是它自己的前身 v1,模型规模、训练范式(SFT-only)都一致,唯一变量就是数据合成 pipeline:
- BrowseComp: 29.5 → 46.0(+16.5)
- BrowseComp-ZH: 48.4 → 58.1(+9.7)
- xbench: 74.0 → 78.0(+4.0)
这是检验 "数据真的是瓶颈" 最干净的对照实验
4.4 数据难度
作者还给出了一个非常直接的指标 ------ 训练轨迹的平均工具调用步数:
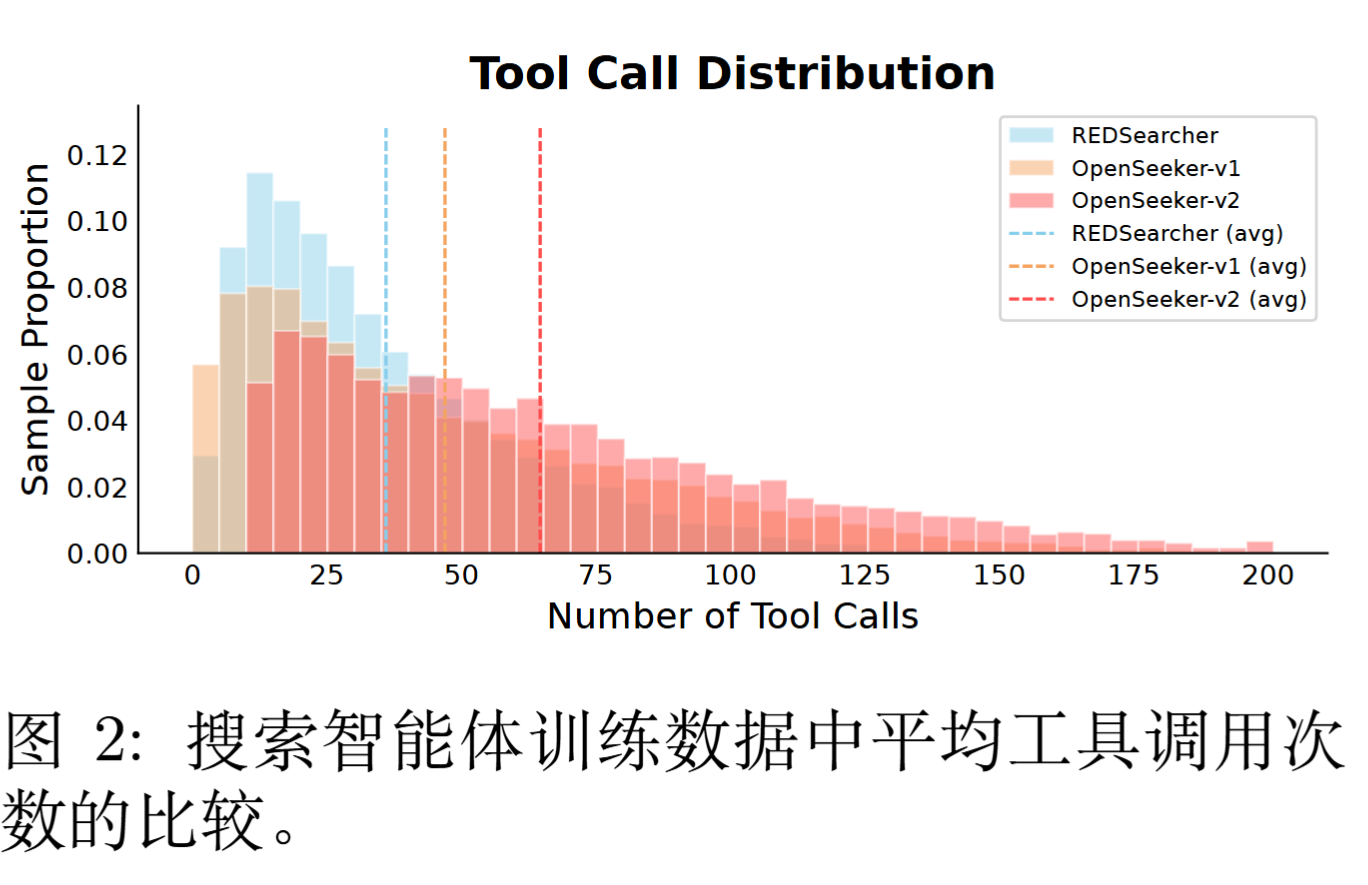
- OpenSeeker-v2:64.67 步
- OpenSeeker-v1:46.97 步
- RedSearcher:36.01 步
也就是说,OpenSeeker-v2 的训练数据每条都要执行 60 多次工具调用才能闭环。这种长度的轨迹本身就是 "必须长程推理 + 多次回滚 + 复杂工具组合" 的硬证据。模型在这种数据上学到的,不是某种 pattern matching 的快速答题套路,而是 "扛住不确定性继续搜下去" 的耐力
五、启发
OpenSeeker-v2 给社区最值得带走的,不是某个具体技术,而是一次有力的反例
过去两年,deep search agent 这条线一直在往"流程越来越长、阶段越来越多"的方向走------CPT 是必备项、RL 是新军备竞赛、reward modeling 又是另一个领域。整个行业默认了 "要做强 agent 就必须 CPT + SFT + RL"
OpenSeeker-v2 没有否定 RL 或 CPT 的价值(作者的态度其实非常克制),但它认认真真撬了一下这个共识的 "不可替代性" ------ 当训练数据本身就携带了足够强、足够多样的范式信号,SFT 这一道工序就足以把搜索 agent 推到不错的高度
往更大的图景看,这其实是延续了一个一直在 LLM 时代被反复验证的精神:
- LIMA 用 1k 高质量指令打过几十万条数据的 SFT
- Phi 系列用合成的高密度推理数据训出小模型的强推理
- DeepSeek-R1 的成功也很大程度来自 "长 CoT 数据怎么造" 这件事被想明白
OpenSeeker-v2 把 "数据胜算力" 的这个传承,延伸到了 deep search agent 这条线上。它告诉我们:真正稀缺的可能既不是算力也不是训练技巧,而是 "知道什么是好的训练样本" 这个判断力