一、数据库
1.1 定义与概念
-
定义:数据库是存放数据的仓库,它的存储空间很大,可以存放百万条、千万条、上亿条数据。数据库是一个按数据结构来存储和管理数据的计算机软件系统,是电子化的文件柜,能够合理保管数据的"仓库",用户在该"仓库"中存放要管理的事务数据。
-
作用:对数据进行存储、删除等操作,是数据管理的新方法和技术,能更合适的组织数据、更方便的维护数据、更严密的控制数据和更有效的利用数据。
-
功能:组织、存储和管理数据。
1.2 发展趋势
-
多样化:数据库技术的多样化是未来发展的一个重要方向,包括实时分析型数据库、图数据库、内存数据库、时序数据库、分布式数据库等。
-
云化:云数据库因其灵活性和可扩展性,正在成为企业数据管理的首选。
-
智能化:数据库技术正朝着智能化的方向发展,如数据库自治、智能优化等。
1.3 分类数据库的2大类型
关系型数据库(RDBMS):mysql(数据存储的方式--》二维表)以 MySQL、Oracle 为代表,采用二维表结构存储数据,强调表与表之间的关联性(如通过 ID、姓名等字段关联用户表与理财表),适用于需要复杂查询和事务支持的场景。
非关系型数据库(NoSQL):以图片、视频、音频等媒体数据为代表,数据之间缺乏明确的逻辑关联(如两张图片在计算机层面仅为像素集合),适用于存储非结构化数据。
1.4 表结构与字段定义
数据库、数据表、行(记录)和列(字段)的基本概念
-
数据库:是存储数据的容器,通常包含多个数据表。
-
数据表:是数据库中存储数据的结构化形式,由行和列组成。
-
行(记录):数据表中的一行代表一个实体对象的信息。
-
列(字段):数据表中的一列代表实体对象的一个属性。
建表逻辑: 必须先定义表结构(字段属性),再插入具体的数据记录,这与 Excel 直接填写数据的方式不同。
常用数据类型表格
| 数据类型 | 描述 | 存储空间/范围 |
|---|---|---|
| int | 整型,分为无符号和有符号 | 无符号:0, 2\^32-1;有符号:-2\^31, 2\^31-1 |
| float | 单精度浮点类型 | 4字节(32位) |
| double | 双精度浮点类型 | 8字节(64位) |
| char(n) | 固定长度的字符类型,存储时用空格填充至指定长度 | 占用n字节 |
| varchar(n) | 可变长度的字符类型,仅占用实际字符长度加上额外长度标识字节 | 最大n字节,实际占用为字符长度 + 1或2字节(长度标识) |
| text | 用于存储大文本数据 | 根据实际内容长度动态分配 |
| image | 存储二进制数据(如图片),现代数据库中通常使用BLOB替代 | 根据实际内容长度动态分配 |
| decimal(p,s) | 定点数类型,精确存储小数,p为总位数,s为小数位数 | 取决于p和s,通常每4字节存储9位数字(如decimal(5,2)占用2字节) |
注意事项
- char与varchar:char适合长度固定的数据(如邮编),varchar适合长度变化的数据(如用户名)。
- decimal精度:适用于财务等需要精确计算的场景,避免浮点误差。
- 现代替代方案:BLOB/BINARY常用于存储二进制数据(如图片),而非过时的image类型。
**整型与浮点型:**整型用于存储数字,浮点型用于存储小数,并区分了单精度与双精度的差异。
Decimal 精确小数:`decimal(m, n)` 的用法,其中 `m` 代表总有效数字位数,`n` 代表小数位数。例如 `decimal(5, 2)` 表示最多 5 位有效数字,其中小数位最多 2 位。
版本差异处理:不同 MySQL 版本对超出精度的处理方式不同,低版本可能直接截断,高版本可能采用四舍五入(截取)。
定长与变长字符串: `char` 和 `varchar` 的区别。`char` 为定长,无论实际数据长度多少,均按定义长度存储;`varchar` 为变长,按实际数据长度存储。
大文本与二进制存储:介绍了 `text` 用于存储文本,`image` 用于存储图片,但强调对于大量高清图片的处理,不建议直接使用 MySQL 数据库存储。
二、MySQL 部署与初始化配置
2.1 版本选型与环境准备
版本策略:企业环境主要使用 MySQL 5.7 和 8.0 版本。旧项目通常沿用 5.7 以避免因 JDBC 驱动和 SQL 语法差异导致的大量代码修改成本;新项目或甲方强制要求时采用 8.0。
版本策略:企业环境主要使用 MySQL 5.7 和 8.0 版本。旧项目通常沿用 5.7 以避免因 JDBC 驱动和 SQL 语法差异导致的大量代码修改成本;新项目或甲方强制要求时采用 8.0。
2.2 服务启动与安全登录
数据库中的语句,我们称之为 sql 语句
alter user 'root'@'localhost' identified by 'abc123';
初始密码获取:MySQL 服务(mysqld)启动后,初始密码会生成在日志文件 `/var/log/mysqld.log` 中,需通过 `grep 'password'` 命令过滤获取。
密码安全规范:登录时若密码包含特殊字符(如 !、%),需在命令行中手动添加转义符(\)或使用交互式输入模式,严禁在命令行中明文输入密码以防止被 `history` 命令记录泄露。
以mysql 5.7数据库为例
sql
## YUM安装mysql 5.7 数据库
### 一、环境准备
# 下载依赖工具
yum install -y yum-utils
yum install -y unzip
#上传并解压mysql5.7 依赖环境的rpm包:
unzip mysql5720_rpms.zip
# 切换到存放所有 MySQL 及依赖 RPM 包的文件夹
cd mysql5720_rpms
# yum 会自动识别当前目录下所有 .rpm 文件,并处理依赖关系(若本地包已包含所有依赖,会直接安装;若缺依赖会提示)
yum localinstall -y *.rpm
### 二、启动mysql,获取初始密码 grep password /var/log/mysql.log
#### 登录mysql
PS:如果密码内容有特殊字符,需要/va转义
进入数据库、修改密码并验证:
#启动数据库
systemctl start mysqld
#修改配置文件:
vim /etc/my.cnf
[mysqld]
# 其他原有配置(如datadir、socket等)保持不变,新增以下两行
validate_password_policy=LOW # 降低强度策略(仅检查长度)
validate_password_length=6 # 最小密码长度设为6位
# 1. 开启错误日志(指定日志文件路径,路径可自定义,建议放/var/log下,默认已开启)
#log_error = /var/log/mysqld.log
# 2. (可选)设置错误日志级别(默认是 3)
# log_error_verbosity = 3 # 3=记录所有错误/警告/通知;2=记录错误/警告;1=仅记录错误
#关闭ssl访问
skip-ssl
# 重启mysqld
systemctl restart mysqld
grep password /var/log/mysqld.log
#进入数据库
mysql -uroot -pQNKYmiwpk8\;\%
#修改密码
alter user 'root'@'localhost' identified by 'abc123';
#验证:
show databases;
#验证2:
exit 退出
mysql -uroot -pabc123 
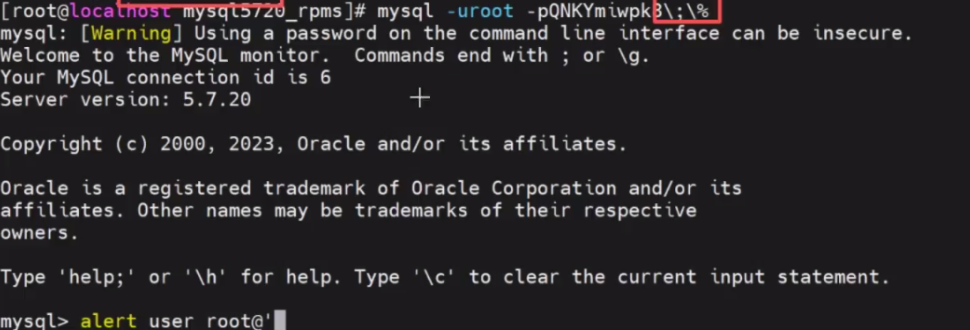
密码修改
2.3 数据库基础架构认知
2.3.1 数据库层级结构
多库并存逻辑:MySQL 服务启动后,其内部空间包含多个子数据库(Database),如 `information_schema`、`mysql`、`performance_schema` 和 `sys`。
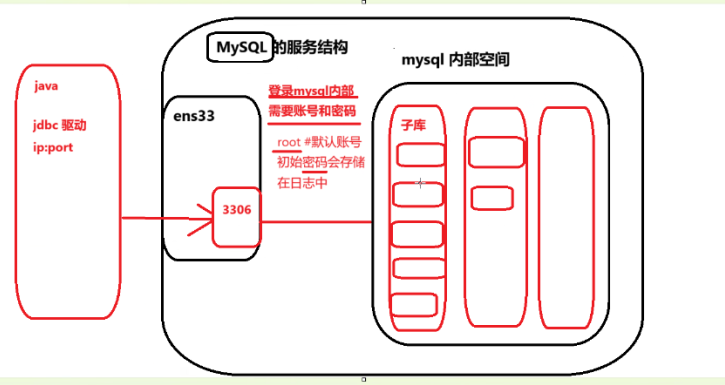
表与视图结构:每个子库内部包含多张数据表(Table),通过 `use` 命令切换数据库后,可使用 `show tables` 查看表列表。
2.3.2 数据存储形式
二维表结构:数据表以字段(Field/Column)为列,以记录(Record/Row)为行的形式存储数据,类似于 Excel 表格的结构。
数据查看方式:通过 `select * from table_name` 命令可查看表中的具体数据内容。
三、MySQL 基础操作命令与连接管理
3.1 基础操作与登录
sql
关系型数据库
mysql 内部的常用命令(SQL):
mysql -uroot -p 登录方式规范:推荐使用 `mysql -u root -p` 交互式输入密码的方式登录,避免在历史记录中明文显示密码。
3.2 远程连接工具配置Navicat
连接失败排查:演示了使用 Navicat 等工具连接时出现的 "not allowed to connect" 错误,指出原因是默认配置下 MySQL 未授权远程连接。
权限授权方案:讲解了通过 `GRANT` 命令对特定 IP 或 `%`(所有主机)进行授权,并需检查防火墙设置以确保连接成功。

3.3 SQL 语句分类与执行逻辑
3.3.1 语句类型与应用场景
SQL 分为四种类型:增、删、改、查(最重要对于运维)
增删改的sql语句:大数据、后端开发、DBA、大数据运维
角色分工协作:增删改操作主要由后端开发和大数据工程师负责(如用户注册、资料修改),而查询操作(SELECT)是使用频率最高的语句。
3.3.2 后端执行机制
变量替换逻辑:后端程序通过 JDBC 驱动连接数据库,执行 SQL 时会将用户输入(如用户名、密码)作为变量替换到 SQL 语句中,再发送至数据库执行。
3.4 DDL(数据定义语言)操作
3.4.1 数据库与表的基础操作
数据库管理: `create database` 创建数据库和 `drop database` 删除数据库的命令,并警告严禁删除系统内置数据库(如 `mysql`)。
表结构管理:`create table` 创建表结构,`drop table` 删除表,以及 `describe`(缩写 `desc`)查看表结构的命令。
跨库查询: `show tables from database_name` 的语法,用于在不切换数据库的情况下查看指定库中的表。
3.4.2 表结构修改与约束
字段增删改:使用 `alter table` 配合 `add`(添加字段)、`change`(修改字段名/类型)、`drop`(删除字段)来修改表结构。
默认值设置:在添加字段时如何设置默认值(`default`),并指出字符类型必须加引号。
主键约束(Primary Key):主键的特性(唯一且非空),并演示了通过 `alter table table_name add primary key (column_name)` 为字段添加主键约束。
3.4.3 数据插入(Insert)
单行与多行插入: `insert into ... values` 的基本语法,以及逗号分隔多组值实现批量插入。
默认值使用:在插入数据时,可通过 `default` 关键字自动填充字段的默认值。
错误处理:字符串类型必须加引号,且数据长度不得超过字段定义上限,否则会导致报错。
3.4.4 数据更新(Update)与查询(Select)
条件更新:`update ... set ... where` 的用法,强调必须使用 `where` 条件(通常基于主键)以避免全表误更新。
基础查询: `select * from` 全表查询,以及 `select column from table where condition` 的条件查询。
sql
systemctl status mysqld
mysql -uroot -p
show databases; #查看子库的信息
use database_name #进入子数据库内部
show tables; #查看当前子库中的数据表列表
select * from table_name; #查看一张表中的所有数据内容
describe table_name; #查看一张表的字段结构(字段属性、数据类型、是否允许为空、默认项是什么)
char (固定长度) : char(10) --> 123
varchar (可变长度) : varchar(10)
本质而言就是看占用存储的空间计算方式
#创建一个数据库
create database database_name;
### DDL 语句 数据定义语言
#创建库
create database database_name;
#删除库
drop database name;
#创建表
create table table_name (字段1 数据类型1 其他属性,字段2 数据类型2 其他属性...)
#删除表
drop table table_name;
#修改表结构(alter)
alter table table_name [add/change/drop] 字段名 字段属性;
#添加字段的属性(示例:给id 添加一个属性为 主键)
#主键:特性是该字段唯一且非空
alter table info01 add primary key(id);
##DML 数据操纵语言
insert into info01 values(3,'dingyi',10,default),(4,'zhaoliu',77,'hf');回顾补充
bash
一、HAProxy 核心架构与配置解析
讲师详细拆解了 HAProxy 的配置文件结构,明确了各配置区域的功能边界及核心参数定义。
1. 配置文件逻辑分层
全局配置(Global):定义了日志级别、最大连接数、PID 文件位置及守护进程模式(Daemon),确保服务在后台稳定运行。
默认配置(Default):设定了流量处理的基础规则,包括工作模式(HTTP/HTTPS)、会话保持(Keepalive)、头部跳转(IP 透传)及并发连接数等优化参数。
前端监听(Frontend):通过 `bind` 指令绑定监听端口,结合 ACL(访问控制列表)规则匹配用户请求的 URL 或路径。
后端代理(Backend):定义后端服务器池(Server Pool),支持轮询(Round Robin)等负载均衡算法,并配置健康检查(Health Check)机制。
2. 静态与动态流量分离策略
静态资源代理:通过 ACL 规则匹配图片(.png/.jpg)、样式表(.css/.js)等静态文件路径,将其转发至专门的静态资源后端(Backend Static)。
动态请求代理:默认后端(Default Backend)通常指向处理动态业务逻辑的应用服务器(如 App 后端),实现动静分离。
二、负载均衡技术选型对比
对比LVS、Nginx 与 HAProxy 三者在技术特性与适用场景上的核心差异。
1. 性能与功能特性差异
LVS(Linux Virtual Server):专注于四层(传输层)IP 和端口转发,性能极高,但不提供页面服务,通常作为底层负载均衡组件。
Nginx:主要作为七层(应用层)代理,支持正则匹配、重写等复杂逻辑,但四层代理性能弱于 LVS。
HAProxy:支持四层与七层代理,性能介于 LVS 与 Nginx 之间,其核心优势在于强大的健康检查机制。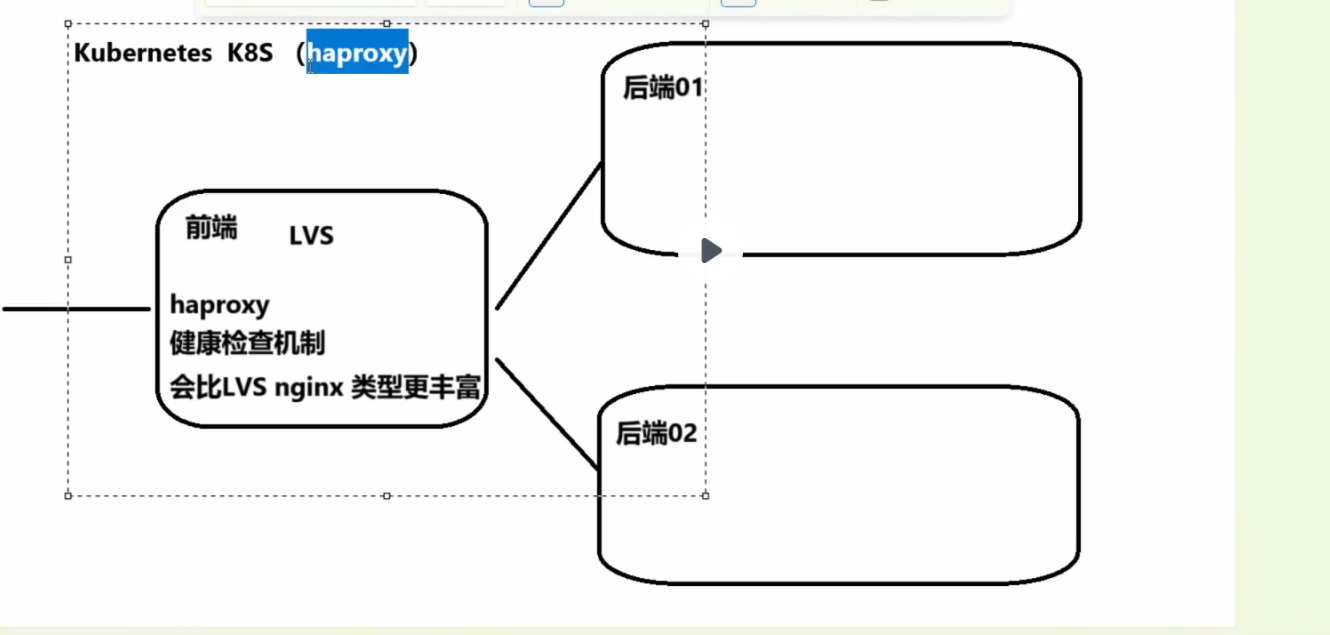
bash
2. 健康检查机制与运维复杂度
LVS 运维成本:LVS 通常需配合 iptables 防火墙规则使用,配置复杂且规则链管理繁琐,但性能优势明显。
HAProxy 健康检查:提供比 LVS 和 Nginx 更丰富、更精细的健康检查类型,能更全面地感知后端服务的健康状态,适用于 Kubernetes 等复杂集群环境。
Nginx 定位:在企业中更多用于处理静态资源和作为 Web 服务器,其负载均衡能力相对基础。
三、操作系统进程管理与学习方法论
1. 守护进程(Daemon)机制
后台运行机制:守护进程允许应用程序脱离终端在后台持续运行,不占用前台窗口资源,如 HAProxy 和 Nginx 服务。
进程管理命令:`jobs` 命令用于查看后台任务,`fg` 命令用于将后台任务拉回前台观察。
2. 技术学习路径与文档阅读
注释解读策略:强调阅读配置文件中的注释(Comments),注释不仅用于屏蔽配置,更提供了默认配置模板和功能说明。
补充:lvs L4 配置复杂 配好后代理能力很强,haproxy L4/L7 稳定性强 不支持静态资源处理 并发强 健康检查,nginx L7/L4 (都可)。