关联博客:
1.关于全局锁的设计问题,为什么没有优化全局锁:全局锁的性能优势,以及链路优化为何常常低于预期------基于 `MatPoolsTest` 中小图池与大图池的实战复盘-CSDN博客
摘要
在基于 `OpenCvSharp` 的视觉系统中,`Mat` 的创建与销毁往往是性能波动、内存抖动和稳定性问题的核心来源之一。很多文章在讨论池化时,容易简单归因于"减少 GC",但对于 `Mat` 这类以非托管像素缓冲为主的数据结构,这种结论并不充分。本文结合我编写的开源Demo项目中的池化实现并结合我现有维护的大型视觉软件,从 .NET Framework 4.8 的运行特征出发,系统说明池化的工程意义、大图池与小图池的分治理由、与 `.NET 8 MemoryPool<T>` 的异同、完整调用链以及 GC 与堆碎片化的真实关系,并分析为什么合理的池化架构通常能够显著优于直接向系统随机申请内存。
引言,实际项目池化与非池化效果差异
github地址:https://github.com/2825077535/MatPoolsTest.git
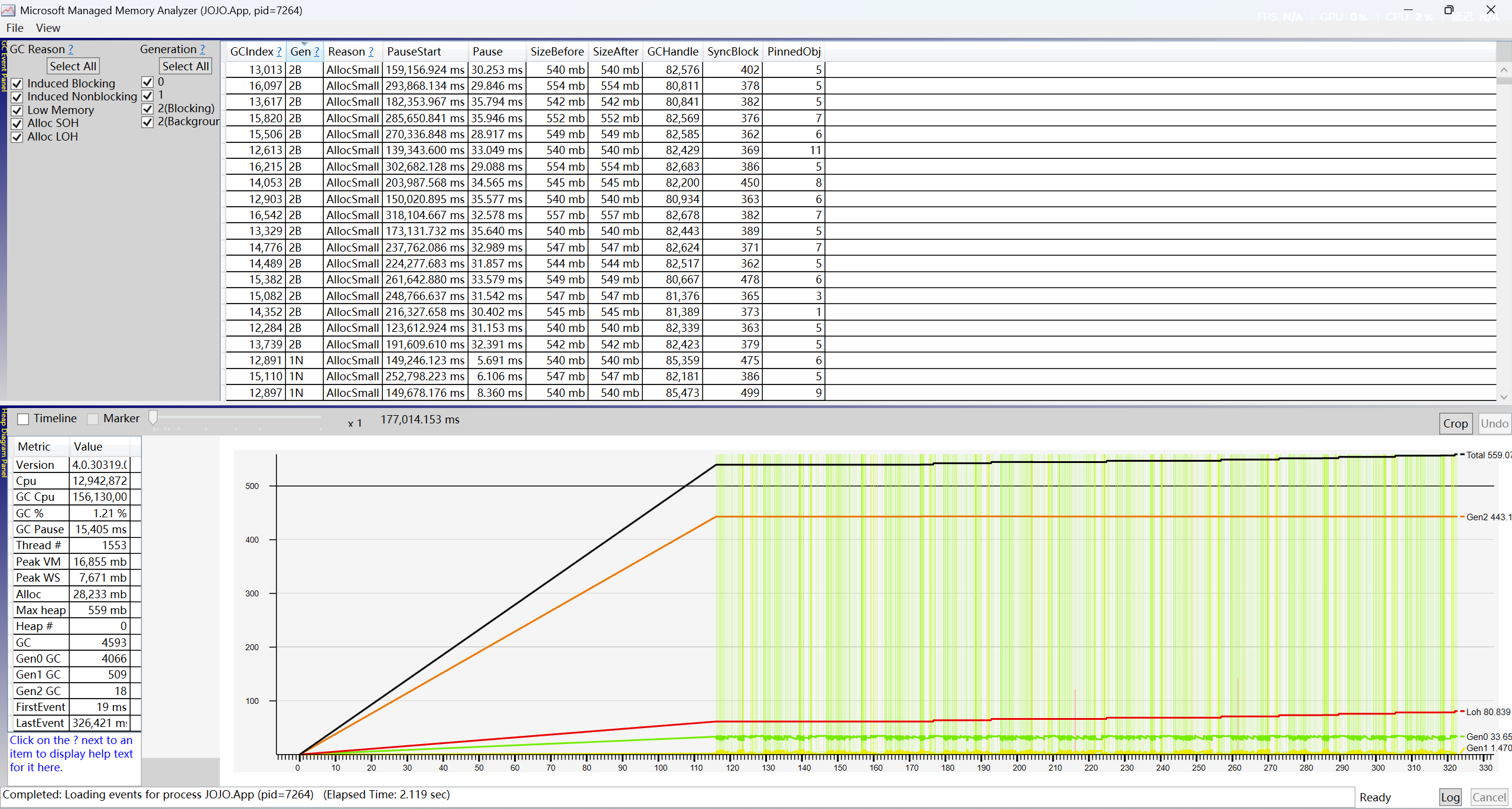
在项目上的池化前后GC和内存的对比:
池化后:
池化前:
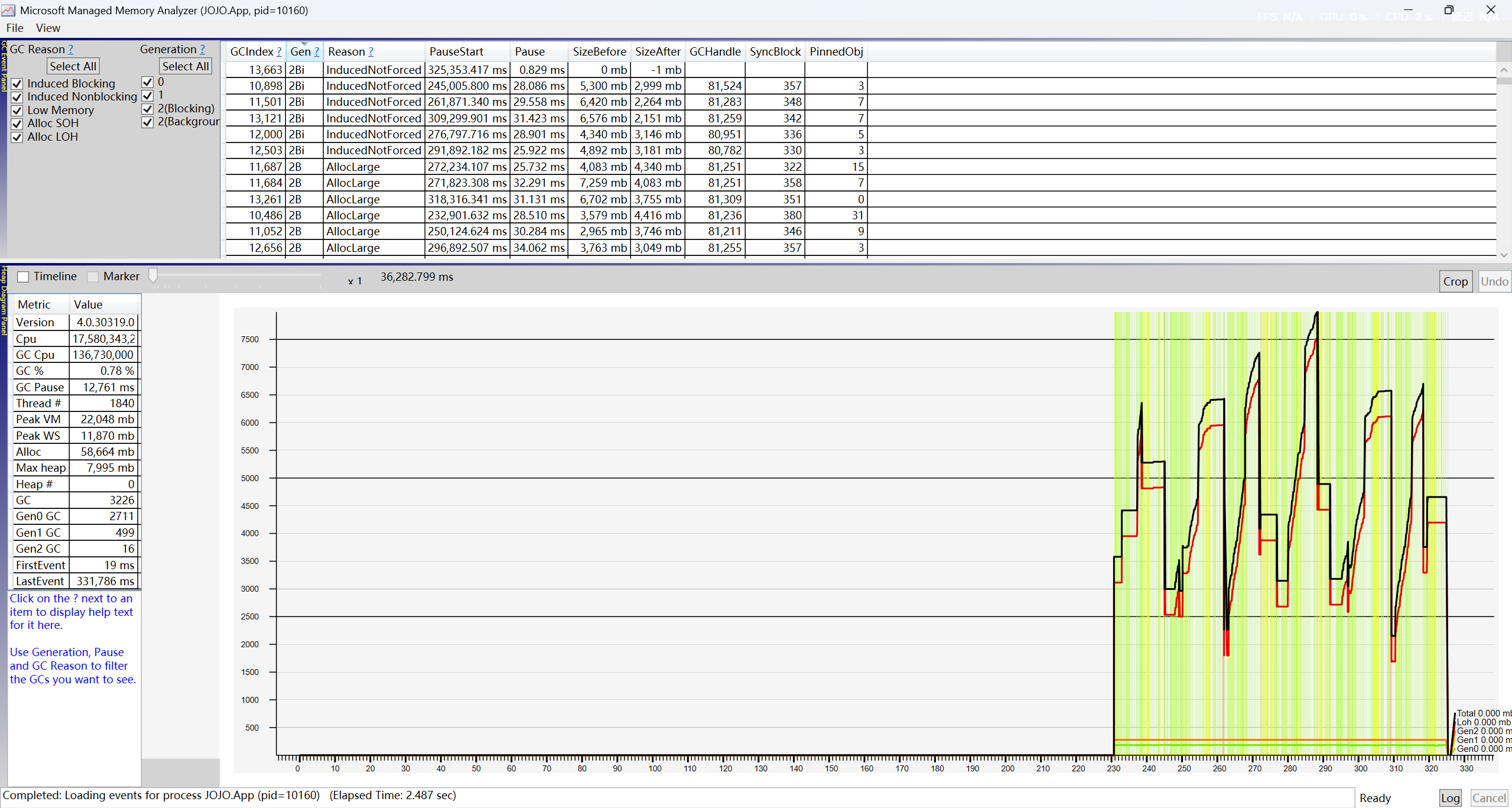
从池化前和池化后的GC对比就可以很明显的发现池化的优势了。
1.稳定的LOH和Gen2;在池化中,大图预热与小图的高比例命中几乎不会产出LOH和Gen2的碎片化开销。
2.更少的GC次数;在同样325秒的采样中,池化GC命中:GC总次数7108次,其中GC1命中783次,GC2命中27次,GC暂停时间16,023。非池化GC命中:GC总次数11,129次,其中GC1命中1,721次,GC2命中55次,GC暂停时间44,025MS。GC性能上池化几乎是非池化的1倍。(图中计算方式:池化图为例子。总采样时间325s,实际有效时间215s,那么采样比例为215/325=1.54 所以GC总次数=4593*1.54=7108次。因为采样时都是等待软件运行一段时间后采样的,所以可以假定软件运行是稳定的。采样软件会采样达到一定大小后自动复写之前的采样数据,所以缺失数据是正常的)
围绕问题点
当前工程目标框架为 `net8.0`,但本文分析的问题本质上并不依赖 `net8.0` 的语言特性,而是围绕以下共性展开:
1.`Mat` 的像素数据主要位于非托管内存;
2.托管堆中主要承载的是 `Mat` 头对象与管理对象;
3.高频图像处理中的核心瓶颈,往往来自非托管内存分配、释放、扩容和地址连续性,而不是单纯的对象实例化语法本身;
- `.NET Framework 4.8` 下托管堆碎片化、对象生命周期长度不均和频繁小对象分配,仍会明显影响系统稳定性。
一、池化的意义:不是"把对象放回去"这么简单
从工程角度看,池化的本质不是缓存对象,而是重构内存分配模型。
在没有池化时,系统的典型行为是:来一个图像需求,就申请一次新的内存;处理结束,就释放;下一次再重新向系统申请;高峰期遇到请求抖动时,内存行为完全依赖操作系统分配器和当前地址空间状态。
这种模式的问题在于,它把最不可控、最容易失败的操作放在了业务热点路径上。
而池化做的事情正好相反:把大部分内存申请前置到初始化、预热或扩容阶段;把运行期"申请内存"的动作改造成"在既有内存组织中租一个槽位";把离散、随机、不可观测的行为,改造成连续、规则、可观测的内部调度行为。
这也是为什么池化的最大价值并不只是"复用对象",而是:
-
减少随机的大块非托管内存申请与释放。
-
降低高峰期地址空间不连续带来的申请失败概率。
-
让内存开销具备容量规划基础,而不再完全依赖运行时碰运气。
-
把耗时从业务热路径迁移到可接受的预热或扩容阶段。
-
让系统具备统计能力、回收能力和退化能力。
这套工程中,大图和小图的池化都体现了这一点。
例如:
-
大图池在命中时,不会重新向系统申请像素缓冲,而是从 `ExpandableBucketedMatPool` 的既有 block/slot 中直接取出一个可用槽位,参见 `Pools/ExpandableBucketedMatPool.cs:204-237`。
-
小图池在命中时,也不会为每一张小图单独申请内存,而是从固定页面中切分 slot,参见 `Pools/SlabSmallMatPool.cs:845-893`。
所以,池化真正提升的,是"整体效率"和"整体稳定性",而不是单次 `new Mat(...)` 的表面耗时。
二、池化最大的优势:可预测的成本使用
专业系统最怕的不是平均性能不高,而是高峰期不稳定。尤其在高性能的视觉设备中,瞬发的高峰期高达几十GB的内存消耗,每秒需要处理几十张图像的数据,大量的数据和内存使用,是的系统的内存碎片化和抖动极其严重。
很多图像处理程序在低负载时看起来一切正常,一旦进入持续处理、高并发 FOV 或多工位并行场景,性能曲线就会突然恶化。其根本原因通常不是算法变慢,而是内存分配行为失去控制。
池化的最大优势就在于:
它把系统最昂贵的内存行为,从"按次触发",变成"按计划触发"。
以大图池为例:
-
`MatPoolManager.EnsureLargeFormats(...)` 会先把本轮需要的规格注册为 `MatAllocationGroup`,再交给底层池准备容量,参见 `Pools/MatPoolManager.cs:155-169`。
-
`ExpandableBucketedMatPool.EnsureAvailable(...)` 则进一步保证指定规格至少有若干 free slot,不足时扩容,参见 `Pools/ExpandableBucketedMatPool.cs:178-199`。
这意味着在业务真正开始跑算法前,系统已经把高概率需要的内存准备好了。后续真正进入计算阶段时,命中路径更接近"取资源",而不再是"造资源"。
从工程收益看,这种设计至少带来四个直接优势:
- 延迟更稳定
热路径减少系统级内存申请后,单次耗时抖动会明显下降。
- 峰值更可控
池化把内存高峰变成"预热峰值 + 有界扩容峰值",而不是完全随机增长。
- 错误更可定位
如果容量不够,会表现为命中率下降、扩容次数增加、fallback 次数增加,而不是"系统偶发性变慢但无法解释"。
- 更适合工业长期运行
对于长时间连续运行的视觉设备,稳定性往往比单点基准测试更重要。池化本质上是在为长期运行优化。
三、为什么大图和小图必须分治,而不能用一套统一管理模型
这是我在适配业务架构着重根据实际业务需求深度优化的结果,就是明确把大图和小图拆成了两种不同的池化体系。
- 大图与小图的访问模式完全不同
大图通常具有以下特征: 单张占用大,设备采用的是高像素相机,单张图像2500万像素;规格相对固定,只存在8uc1,8uc3,32fc1 等格式,并且每张图大小一样;数量相对可控,单个工作点位拍照的数量固定;预热价值高; 失败成本高。
小图通常具有以下特征: 数量大、频次高; 尺寸分布离散;生命周期短; 使用后快速归还; 单张成本小,但总量惊人。小图全部均来自于算法计算的中间缓存图,结果图,大图的裁剪图。
如果强行用同一种算法管理:
-
对大图来说,可能显得碎片太多、管理层次太复杂;
-
对小图来说,则可能导致规格过细、桶太多、复用率太低。
因此,当前项目采用了两条完全不同的链路:
-
大图:`MatPoolManager` -> `ExpandableBucketedMatPool` -> `MatPhysicalBlock` -> `ManagedPooledMatSlot`
-
小图:`SlabSmallMatManager` -> `SlabSmallMatPool` -> `SlabBlock` -> `SlabPage` -> `slotIndex`
这种分治不是"实现风格不同",而是内存行为模型不同。
- 大图为什么适合"规格分桶 + 物理块 + 槽位"
大图池的组织方式非常明确:
-
先按 `width + height + MatType` 形成格式规格;
-
每个规格对应一个 `FormatBucket`;
-
`FormatBucket` 下有多个 `MatPhysicalBlock`;
-
每个 `MatPhysicalBlock` 中维护多个 `ManagedPooledMatSlot`;
-
每个 slot 在初始化时即绑定自己的底层地址与 `Mat` 头对象。
关键实现可参见:
-
`Pools/MatPoolManager.cs:186-191`
-
`Pools/ExpandableBucketedMatPool.cs:16-63`
-
`Pools/MatPhysicalBlock.cs:37-55`
-
`Pools/ManagedPooledMatSlot.cs:20-26`
它的优势在于:
第一,规格高度稳定。
FOV 大图通常不会出现大量离散尺寸,按规格分桶天然合理。
第二,头对象可以预建。
`ManagedPooledMatSlot` 在构造时调用 `Mat.FromPixelData(...)` 生成 `Mat` 头对象,后续只需反复租借和归还,参见 `Pools/ManagedPooledMatSlot.cs:25`。
第三,复用路径极短。
命中时无需重新构造大图 `Mat` 头,也无需重新申请底层缓冲。
第四,统计天然清晰。
大图通常更适合按规格、按 block、按 usageTag 分析命中率和容量使用情况。
- 小图为什么适合"size class + page + slab"
小图池的关键常量定义在 `Pools/SlabSmallMatPool.cs:15-20`:
-
对齐:`64B`
-
页大小:`8MB`
-
常驻块:`128MB`
-
扩容块:`80MB`
-
最大扩容块数:`8`
-
最大池化对象:`4MB`
同时,小图采用离散的 size class,定义在 `Pools/SlabSmallMatPool.cs:22-33`,范围从 `16KB` 到 `4MB`。
这意味着小图池不是按图像精确规格管理,而是按"所需字节数落入哪个尺寸等级"来管理。其优点在于:
-
复用率更高:相近大小的小图不需要拆分成太多独立桶,而是映射到同一 class。
-
页级组织更适合高频场景:一页只服务一个 size class,slot 划分简单,租借和归还都可控。
-
扩容与回收粒度更合理:不是每张小图一申请一释放,而是按 page / block 粒度管理。
-
更适合做"白页"回收:小图归还后可以回到 assigned page,也可以在条件满足时退回 white page,最终支持 expansion block 整块 shrink。
四、为什么小图不能继续采用"ROI 管理"的直观方案
从实现便利性看,ROI 方案一开始似乎更简单。在上面说明了,小图和大图走的并不是同一套系统,在原本设计的初版方案时,将大图裁剪一个ROI,然后输出ROI的小图,因为在opencv中,输出ROI小图是浅拷贝,在内存上是没有额外的底层开辟的。从逻辑上,管理上都会更简单,并且根据需要维护几个阶梯型的ROI上层图即可。
一种常见思路是:
-
维护一批阶梯格式大图 `Mat`;
-
小图需求来了,就从阶梯上一级的大图上切 ROI;
-
用 ROI 视图参与后续计算;
-
回收时只回收大图。
这套方案的问题并不在于能不能实现,而在于性能语义发生了变化。
在 `OpenCvSharp`的许多计算中,连续内存往往比非连续内存拥有更好的吞吐表现。如果小图大量依赖 ROI 视图,就会不可避免地引入非连续内存访问。在我实际的测试中发现,非连续内存的访问会使计算速度下降 1 倍以上。这不是特殊现象,在opencv的底层计算中,天然对连续的图像内存有专用加速模式。如果采用非连续内存访问,会极大的影响处理速度。
因此,小图池最终采用了"分页分级但保证 slot 连续"的方式:
-
不通过 ROI 视图复用;
-
而是通过页内切片复用;
-
每张小图都拿到一个独立连续 slot 的起始地址;
-
然后基于该地址构造 `Mat` 头对象。
对应代码是:
`Mat.FromPixelData(height, width, type, page.GetSlotAddress(slotIndex))`
参见 `Pools/SlabSmallMatPool.cs:891`。
这意味着小图复用的是"连续的像素切片",而不是"上层 ROI 视图"。
从工程上看,这是一种更适合opencv图像计算的池化设计,因为它同时兼顾了:内存复用; 访问连续性;
五、小图分页分级与 `.NET 8 MemoryPool<T>` 的关系:借鉴了思路,但不是同一类实现
- 相似点:两者都在做"租借式内存复用"
从理念层面看,当前小图池与 `.NET` 的 `MemoryPool<T>` 有明显相似性:
第一,都是租借模型。
上层不直接控制底层内存分配策略,而是通过"租借 / 归还"的方式使用资源。
第二,都是为了减少重复分配。
`MemoryPool<T>` 的文档强调其目标是避免不必要的复制和托管堆分配;小图池则是在图像场景下避免频繁申请像素缓冲。
第三,都是"至少满足请求",而不强求精确尺寸一一对应。
`MemoryPool<T>.Rent(minBufferSize)` 返回至少满足需求的块;小图池则是把请求映射到某个 size class,而不是为每个尺寸单独建池。
第四,都是将使用者与底层组织隔离。
上层只拿结果,不关心底层块来自哪一页、哪一块。
- 不同点:当前实现是"图像专用 slab allocator",不是通用 `MemoryPool<T>`
虽然思想相通,但实现层的差异非常大。
区别一:内存类型不同
-
`MemoryPool<T>.Shared` 的官方定义明确指出它是一个基于数组的共享池,本质上更偏向托管数组内存模型。
-
当前小图池底层明确是非托管内存,通过 `AlignedNativeAllocator.Allocate(...)` 申请对齐块,参见 `Pools/AlignedNativeAllocator.cs:19-33`。
区别二:返回对象不同
-
`MemoryPool<T>` 面向 `IMemoryOwner<T>` / `Memory<T>`。
-
当前小图池最终必须产出的是 `OpenCvSharp.Mat`,因为上层算法直接消费的是 `Mat`。
区别三:归还策略不同
-
`MemoryPool<T>` 的归还通常依赖 owner 的生命周期。
-
当前小图池归还时通过 `Mat.Data` 地址反查 `page + slotIndex`,再将 slot 放回相应页中,参见 `Pools/SlabSmallMatPool.cs:582-599`、`1143-1179`。
区别四:调度维度不同
-
`MemoryPool<T>` 是通用内存抽象。
-
当前小图池是图像感知的:它知道宽、高、`MatType`、字节数、size class、resident/expansion 状态以及 shrink 周期。
区别五:头对象策略不同
-
`MemoryPool<T>` 的核心是 buffer owner,而不是 `Mat` 头对象。
-
当前小图池必须在命中后动态创建可被 OpenCV 调用的 `Mat` 头对象,这是一层图像计算框架特有的适配成本。
在实际编码小图池的分页分级时,直接参考了.net原生的池化,MemoryPool本质上其实是分桶策略,但又由于是原生的池化,所以在实际项目中更多是操作托管内存的,opencv的mat是引用非托管内存的所以MemoryPool并不合适使用。并且MemoryPool只有在.net5以上版本才能使用。在分桶的情况下,增加了分页分级,也是有效对内存块进行划分。
六、整个池化调用链和架构
- 总入口:`MatPools`
`MatPools` 是整个体系的 facade,负责对外提供统一入口。参见 `Pools/MatPools.cs:123-257`。
其核心职责包括:
-
创建板级作用域:`CreateBoardScope(...)` / `GetOrCreateBoardScope(...)`
-
创建算法作用域:`CreateAlgoScope(...)`
-
创建长期保留作用域:`CreateRetainedScope(...)`
-
在一块板处理结束后通知全局池做 shrink 检查:`NotifyBoardProcessed()`
从架构意义上说,`MatPools` 隔离了调用侧与底层复杂实现之间的耦合,使业务代码不必直接接触 block、page、slot 等内部结构。
- 大图准备链路
推荐调用顺序为:
`MatPools.CreateBoardScope(...)`
-> `BoardFovMatScope.PrepareRound(...)`
-> `RoundFovMatPool.PrepareRound(...)`
-> `MatPoolManager.EnsureLargeFormats(...)`
-> `ExpandableBucketedMatPool.EnsureAvailable(...)`
关键位置:
-
`Pools/BoardFovMatScope.cs:95-102`
-
`Pools/FovMatPool.cs:291-315`
-
`Pools/MatPoolManager.cs:155-169`
-
`Pools/ExpandableBucketedMatPool.cs:178-199`
这个阶段的专业含义是:
在真正进入图像处理前,先把本轮会用到的资源需求显式化,并提前让底层池达到足够可用状态。
- 大图租借链路
运行期租借链路为:
`BoardFovMatScope.Rent(...)`
-> `RoundFovMatPool.Rent(...)`
-> `MatPoolManager.RentLarge(...)`
-> `ExpandableBucketedMatPool.TryRent(...)`
-> `MatPhysicalBlock.TryRent(...)`
-> `ManagedPooledMatSlot.TryRent()`
关键位置:
-
`Pools/BoardFovMatScope.cs:107-108`
-
`Pools/FovMatPool.cs:321-340`
-
`Pools/MatPoolManager.cs:186-191`
-
`Pools/ExpandableBucketedMatPool.cs:204-237`
-
`Pools/MatPhysicalBlock.cs:138-155`
-
`Pools/ManagedPooledMatSlot.cs:56-62`
在这个链路中,真正决定效率的不是方法层数,而是是否命中既有资源:
-
一旦命中,不申请新像素缓冲;
-
不重新构造大图 `Mat` 头对象;
-
只是在内部标记 slot 的租借状态。
- 大图归还链路
归还过程为:
`BoardFovMatScope.Return(mat)`
-> `RoundFovMatPool.Return(mat)`
-> `MatPoolManager.Return(mat)`
-> `ExpandableBucketedMatPool.TryReturn(mat, out group)`
-> `MatPhysicalBlock.Return(slot)`
-> `ManagedPooledMatSlot.TryReturn()`
关键位置:
-
`Pools/BoardFovMatScope.cs:146-147`
-
`Pools/MatPoolManager.cs:196-227`
-
`Pools/ExpandableBucketedMatPool.cs:243-287`
-
`Pools/MatPhysicalBlock.cs:160-175`
-
`Pools/ManagedPooledMatSlot.cs:67-73`
如果归还对象不属于池内管理资源,则会落入 fallback 路径:
-
`MatPoolManager` 使用 `_fallbackMats` 记录池未命中时临时创建的对象;
-
这些对象归还时直接释放,而不是重新回池。
这体现了一个很成熟的工程策略:
池化体系不能因为未命中就让业务失败,而应在性能与可用性之间提供可退化的兜底路径。
- 小图租借链路
推荐调用方式是通过 `MatScope.RentSmall(...)` 统一管理。调用链为:
`MatScope.RentSmall(...)`
-> `SlabSmallMatManager.Instance.Rent(...)`
-> `SlabSmallMatPool.Rent(...)`
-> `TryRentPooled(...)`
-> `AcquirePageUnderLock(...)`
-> `page.TryRent(out slotIndex)`
-> `Mat.FromPixelData(...)`
关键位置:
-
`Pools/MatScope.cs:125-147`
-
`Pools/SlabSmallMatPool.cs:500-547`
-
`Pools/SlabSmallMatPool.cs:845-893`
-
`Pools/SlabSmallMatPool.cs:943-975`
其中,`AcquirePageUnderLock(...)` 的优先级非常典型:
-
先在当前 size class 内,从其 available page 列表尝试租借;
-
available page 不足,再进入块结构锁路径拿 white page;
-
white page 仍不足,则只对当前块结构做 expansion block 扩容;
-
新页加入当前 size class 后,再回到页级租借路径。
这是一种典型的"尽量复用现有资源 -> 延迟扩容 -> 扩容后立即纳入统一调度"的高频资源管理策略。
- 小图归还链路
归还通常在 `MatScope.Dispose()` 时统一触发,调用链为:
`MatScope.Dispose()`
-> `SlabSmallMatManager.Instance.Return(mat)`
-> `SlabSmallMatPool.Return(mat)`
-> 根据 `mat.Data` 反查 `page + slotIndex`
-> `ReturnPooledUnderLock(...)`
关键位置:
-
`Pools/MatScope.cs:263-290`
-
`Pools/SlabSmallMatPool.cs:562-627`
-
`Pools/SlabSmallMatPool.cs:896-940`
这里最关键的不是"归还成功",而是"归还后页面状态如何迁移":
-
resident page 通常保留 assigned 状态,便于下次快速复用;
-
expansion page 如果整页空闲,则可回退为 white page;
-
若 expansion block 内所有页都回到 white,则 block 可以整体释放,参见 `Pools/SlabSmallMatPool.cs:994-1029`。
当前实现还额外做了一步关键优化:
-
小图池不再让所有借还都竞争单一全局锁;
-
普通借还优先走"size class 锁 + 页锁";
-
只有扩容、整页回白、shrink 这类结构性动作才进入块结构锁。
这意味着小图池已经从"整体串行化"演进成"分级锁 + 直接句柄归还"的混合模型,更接近高并发场景下可持续扩展的工程形态。
这种状态迁移机制是小图池能够兼顾复用率与回收能力的关键。
- `MatScope` 的作用:它解决的是资源边界问题,而不只是简化代码
在复杂图像流程中,一个阶段可能同时持有:
-
大图借用对象;
-
小图借用对象;
-
standalone 对象;
-
外部传入对象;
-
需要移交或保留的对象。
如果没有统一作用域,调用代码就必须自己记录每个对象的来源与释放方式。这不仅麻烦,而且非常容易出错。
`MatScope` 的意义就在于:
把"这个对象是谁借来的、该怎么还、什么时候还"统一纳入一个生命周期边界中。
更值得注意的是,它内部并没有采用频繁 new 管理节点的方式,而是:
-
使用 `struct ScopeItem` 承载跟踪信息,参见 `Pools/MatScope.cs:21-40`;
-
使用数组与空闲索引栈管理条目,参见 `Pools/MatScope.cs:47-55`、`321-360`。
因为池化架构如果内部自己制造大量短命管理对象,就会在托管堆上制造新的问题。所以尽可能的使用结构体可以有效避免堆的分配。
七、GC、堆碎片化与 `Mat`:需要严格区分的几个概念
- `Mat` 的大头是非托管像素缓冲,而不是托管对象本身
这是理解池化价值的前提。
在大多数 `Mat` 使用场景里,真正消耗内存的是像素缓冲,而不是 `Mat` 头对象本身。头对象只是在托管堆中持有对底层数据的引用与状态。
因此,池化最大的收益首先体现在:
-
避免频繁申请/释放非托管大块内存;
-
降低地址空间碎片化导致的失败概率;
-
稳定图像处理过程中的内存行为。
- 池化并不天然等于"减少 GC 次数"
这是一个需要明确纠正的常见误区。
GC 的触发与托管堆状态相关,而不是直接由非托管内存大小决定。由于 `Mat` 的像素缓冲大多在非托管侧,因此在托管堆中的直接体现主要是:
-
`Mat` 头对象;
-
包装对象;
-
各类池化管理对象;
-
统计和生命周期管理结构。
因此,如果某个池化方案只复用了底层像素缓冲,但每次仍然新建 `Mat` 头对象,那么:
-
非托管申请压力会下降;
-
但托管头对象分配并不会消失;
-
因此不能简单宣传为"池化减少了 GC 次数"。
这正是本文需要特别补充说明的一点:
`Mat` 的内存主要来自非托管内存,因此托管堆中表现出来的主要是 `Mat` 头对象。池化并不会天然消除头对象分配,所以不能直接等价为"减少 GC 次数"。
- 当前工程的大图池,比"只复用底层内存"的池更进一步
这一点需要结合代码客观分析。
在当前工程里:
-
大图池的 `ManagedPooledMatSlot` 在构造时就创建了 `Mat` 头对象,参见 `Pools/ManagedPooledMatSlot.cs:20-26`;
-
因此大图路径命中时,不仅复用了底层像素缓冲,也复用了 `Mat` 头对象;
-
所以大图路径相对于"小图命中但仍新建头对象"的模型,对 GC 更友好。
但这不改变总体结论:
池化的主收益依然是稳定非托管内存行为,而不是把 GC 本身作为最主要卖点。
- 池化设计不当,反而会加剧托管堆碎片化
这是一个容易被忽略、但非常重要的补充。
池化架构如果流程过长、层次过深、每次租借都伴随大量关联对象构造,就会出现一种反向效果:
-
虽然底层像素内存复用了;
-
但为了管理这套池,托管堆上频繁产生更多短命对象;
-
最终堆碎片化更严重,GC 压力反而增大。
因此,池化实现必须遵守几个原则:
-
高频路径上的管理对象尽量少;
-
频繁使用的元数据尽量常驻;
-
高频跟踪结构尽量结构体化;
-
统计信息尽量增量维护,而不是反复全表聚合。
例如在项目中
-
`MatScope.ScopeItem` 使用 `struct`;
-
大图的 `ManagedPooledMatSlot`、`MatPhysicalBlock` 都是长期存在的结构;
-
小图页中的 `_freeSlotIndexes` 与 `_rentedStates` 是按页复用,而不是按请求新建;
-
小图统计通过 `_currentFreeSlots`、`_currentAllocatedBytes` 等字段增量维护,参见 `Pools/SlabSmallMatPool.cs:468-476`。
八、OpenCvSharp 中哪些 `Mat` 创建方式会使用托管数据
为什么需要着重的强调这个问题。因为在实际使用中,我们可能会预先给Mat new一个新的对象。然后定义好宽高,然后setto 0或255 用于计算掩码。但是重点是这些Mat的创建方式,他的内存不在非托管内存中,而是在托管堆中。这样子会直接导致LOH在实际运行中内存碎片化和占用量极大提升,从而引起GC2频繁的复用。因为我在中间测试池化的优化效果时就因为这个问题思考了好一段时间。
先给出结论:
`var mask = new Mat(size, MatType.CV_8UC1, new Scalar(0));`
通常不应被归类为"数据放在托管内存中"的典型方式。
原因在于该构造函数的文档语义是:
"constructs 2D matrix and fills it with the specified Scalar value"
即"构造一个二维矩阵并用指定标量填充"。
它并没有声明"使用用户提供的外部数组作为底层数据"。因此更合理的理解是:
-
由 OpenCV / OpenCvSharp 分配矩阵数据;
-
再对其做初始化填充;
-
而不是把用户托管数组直接作为底层像素缓冲。
真正明确属于"Mat 头指向用户提供数据"的重载包括:
- `new Mat(rows, cols, type, Array data, long step = ...)`
文档说明这类构造函数是:
-
`constructor for matrix headers pointing to user-allocated data`
-
`do not allocate matrix data`
-
`they just initialize the matrix header that points to the specified data`
这意味着如果这里传入的是托管数组,那么底层数据就来自托管侧提供的内存。
- `new Mat(IEnumerable<int> sizes, MatType type, Array data, IEnumerable<long> steps)`
这是多维版本,语义相同。
- 泛型 `Mat<T>` 的数组重载
如果使用的是泛型 `Mat<T>` 并传入数组,本质上也属于"Mat 头对象指向用户提供数组"的方式。
- `new Mat(rows, cols, type, IntPtr data, long step = ...)`
这同样属于"Mat 不自己申请像素数据"的路径,但它对应的是外部指针,通常是非托管数据,不属于托管数组方式。
因此,可将常见创建方式归为三类:
第一类:OpenCV 自己申请像素内存
-
`new Mat(rows, cols, type)`
-
`new Mat(size, type)`
-
`new Mat(rows, cols, type, new Scalar(...))`
-
`new Mat(size, type, new Scalar(...))`
第二类:Mat 头对象指向外部非托管数据
-
`new Mat(rows, cols, type, IntPtr data, step)`
-
本工程中的 `Mat.FromPixelData(...)`
第三类:Mat 头对象指向外部托管数组数据
-
`new Mat(rows, cols, type, Array data, step)`
-
`new Mat(sizes, type, Array data, steps)`
-
对应 `Mat<T>` 数组重载
九、这套池化架构真正解决了什么问题
如果只从表面看,这套系统像是在"缓存 Mat"。
但从工程深度看,它实际上解决了四类更关键的问题:
- 非托管内存复用问题
大图与小图都尽量减少随机内存申请与释放。
- 生命周期边界问题
`BoardFovMatScope`、`MatScope`、`RetainedMatScope` 把板级、算法级、长期保留三类生命周期拆清楚了。
- 性能稳定性问题
通过预热、分页、扩容、shrink 与 fallback,把不确定性控制在架构层。
- 可观测性问题
通过 snapshot、统计和运行期诊断,池化系统不再是黑盒,而是可分析、可调优的对象。
十、结语与展望
对于 `OpenCvSharp.Mat` 而言,池化的核心价值从来不是一句简单的"减少 GC"。更准确地说,它是把高频图像处理里最不可控、最容易失败的那部分行为------随机的非托管内存申请与释放------重构为一套可规划、可复用、可统计、可退化的资源调度体系。