前言:哈希表(散列表)是数据结构与算法的核心模块,更是字节、腾讯、阿里等大厂面试的"必考题",无论是基础概念辨析,还是结合缓存、数据去重、频次统计等实际场景的代码实现,都是面试官重点考查的方向。很多学习者在入门时容易陷入"只懂概念、不会编码""熟记API、不懂底层"的误区,面试时频繁踩坑。本文按「基础概念&用途→C语言代码示例→细节注意事项(细化常见误区)→面试高频题&避坑指南(精细总结)」的逻辑,从入门到实战、从理论到代码,完整梳理哈希表核心知识点,兼顾新手学习、考前复习和面试突击,助力大家吃透哈希表,轻松应对面试考查。
目录
-
一、哈希表基础概念
-
二、哈希函数(核心)
-
三、哈希冲突(必考)
-
四、哈希表查找操作(核心操作)
-
五、哈希表删除操作(易踩坑)
-
六、负载因子(关键指标)
-
七、哈希表扩容(底层逻辑)
-
八、完整可运行C语言Demo
-
九、面试高频考点&避坑指南
一、哈希表基础概念
1、是什么&有什么用
是什么 :哈希表(Hash Table)又称散列表,是一种通过「哈希函数」将关键字(key)映射到数组下标,从而实现快速存储、查找、删除的数据结构,核心是"键值对"映射。
核心原理 :存储位置 = f(key),其中f为哈希函数,本质是"空间换时间",用额外的存储空间降低查找的时间复杂度。
实际应用场景:
-
日常开发:字典(如C语言中的哈希字典)、数据去重(如统计数组中不重复元素)、频次统计(如统计字符串中字符出现次数);
-
工业级应用:缓存(Redis底层核心结构)、数据库索引(MySQL的哈希索引)、分布式系统中的负载均衡;
-
算法场景:哈希表常用于优化暴力查找,将O(n)复杂度降至O(1),如两数之和、无重复字符的最长子串等经典算法题。
2、结构体设计
cpp
//链地址法:有效节点结构体设计
typedef struct LANode
{
int data; //数据域
struct LANode* next; //指针域
}LANode;
#define M 13 //桶个数
//链地址法:辅助节点结构体设计
typedef struct LinkAddress
{
LANode* arr[M];
};3、需要注意什么(细化误区)
核心误区:很多初学者认为哈希表只有"数组",忽略了哈希函数和冲突解决,三者缺一不可,缺少任何一个都不是完整的哈希表。
-
结构组成: 哈希表本质是「数组+哈希函数+冲突解决策略」的结合体,数组是存储载体,哈希函数是定位核心,冲突解决是保障正常运行的关键;
-
容量设置: 初始容量不能太小(如小于5),否则会导致冲突急剧增加,哈希表性能退化;也不能太大,否则会造成大量空间浪费,建议初始容量设为质数(后续会讲解原因);
-
内存管理: C语言中没有自动垃圾回收,哈希表的节点(Node)都是动态分配(malloc)的,必须手动管理内存,避免内存泄漏(如删除节点后未free、程序结束前未释放所有节点);
-
**关键字唯一性:**哈希表的key必须唯一,插入时若遇到相同key,需做覆盖处理(否则会出现查找混乱),初学者常忽略这一点,导致数据冗余;
-
性能认知:哈希表的O(1)是「平均时间复杂度」,不是绝对的,极端情况下(所有key哈希后映射到同一个下标)会退化为O(n),这是初学者最易误解的点。
4、面试问题及坑点
面试高频:哈希表的核心优势、时间复杂度相关问题,几乎是所有大厂一面必问,重点避开"绝对O(1)"的坑。
面试题1:哈希表的核心优势是什么?为什么能实现O(1)的查找、插入、删除?
✅ 正确回答:核心优势是"快速定位",通过哈希函数将key直接映射到数组下标,无需遍历整个容器,因此平均时间复杂度为O(1);插入和删除同理,先定位下标,再操作链表(拉链法),效率极高。
❌ 坑点/误区:直接说"哈希表所有操作都是O(1)",忽略极端情况(全部冲突时退化为O(n));或只说"快",说不出底层原理(哈希函数映射)。
面试题2:哈希表和数组、链表的区别是什么?适用场景有哪些?
✅ 正确回答:数组查找慢(O(n))、插入删除慢(O(n)),但随机访问快;链表插入删除快(O(1))、查找慢(O(n));哈希表兼顾两者优势,查找、插入、删除平均O(1),适合需要频繁增删查的场景(如缓存、字典)。
❌ 坑点/误区:混淆三者的时间复杂度;或认为哈希表"万能",忽略其空间开销(比数组、链表消耗更多内存)。
面试题3:哈希表的核心组成部分有哪些?
✅ 正确回答:三个核心部分------数组(存储载体)、哈希函数(定位下标)、冲突解决策略(拉链法/开放寻址法),三者缺一不可。
❌ 坑点/误区:只回答"数组",遗漏哈希函数和冲突解决;或把"负载因子""扩容"当作核心组成(两者是优化手段,不是核心组成)。
二、哈希函数
1、是什么&有什么用
是什么: 哈希函数(Hash Function)是将任意长度、任意类型的关键字(key),转换为固定范围(哈希表数组下标范围)整数的函数,记为f(key)。
核心作用:决定key的存储位置(桶下标),直接影响哈希冲突的概率------哈希函数设计越好,key的分布越均匀,冲突概率越低,哈希表性能越好。
常用哈希函数(工业级常用3种):
-
除留余数法 :最简单、最常用,公式为f(key) = key % 哈希表长度(本文所有示例均采用这种方法)
-
直接定址法:f(key) = a*key + b(a、b为常数) ,适合key范围固定、连续的场景(如学生学号、员工工号)
-
平方取中法:将key平方后,取中间几位作为哈希值 ,适合key范围不固定、位数多变的场景(如字符串key)。假设关键字是1234,那么它的平方就是1522756,再抽取中间的3位就是227,用作散列地址
2、C语言最小可运行示例
cpp
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10 // 哈希表长度(推荐设为质数)
// 哈希函数:除留余数法(最常用,重点掌握)
// 传入key,返回对应的哈希表下标(0~MAX_SIZE-1)
int hash(int key) {
// 注意:若key为负数,需先转换为正数,避免下标为负(初学者易忽略)
return (key < 0 ? -key : key) % MAX_SIZE;
}
// 测试哈希函数(可直接运行)
int main() {
printf("key=1 → 下标:%d\n", hash(1)); // 1%10=1
printf("key=11 → 下标:%d\n", hash(11)); // 11%10=1(模拟冲突)
printf("key=-5 → 下标:%d\n", hash(-5)); // 转换为5,5%10=5
return 0;
}注意:key为负数时,必须先转换为正数,否则会得到负下标,导致数组越界报错
3、需要注意什么(细化误区)
核心误区:认为"哈希函数越复杂越好",实则不然,哈希函数的核心是"高效+均匀",复杂的哈希函数会增加计算耗时,反而降低哈希表性能。
-
计算效率:哈希函数的计算必须简单、快速,避免复杂的运算(如大量乘法、除法),否则会抵消哈希表O(1)的优势;
-
分布均匀性: 这是哈希函数的核心要求,必须保证不同的key尽可能映射到不同的下标,避免大量key集中在同一个下标(导致冲突激增);
-
哈希表长度选择: 哈希表长度最好取「质数」,且该质数应尽可能接近分配的桶个数,这是减少冲突的关键------若长度为合数,容易与key产生公因子,导致哈希值分布不均(如长度为4,key为2、6、10,都会映射到下标0);
-
负数key处理:若key可能为负数,必须先转换为正数(如取绝对值),否则会得到负下标,导致数组越界(C语言中数组下标不能为负);
-
字符串key处理: 若key是字符串(如"abc"),不能直接用除留余数法,需先将字符串转换为整数(如ASCII码求和、多项式哈希),再进行哈希计算,初学者常直接用字符串地址哈希,导致结果混乱。
4、面试问题及坑点
面试题1:为什么哈希表长度推荐用质数?
✅ 正确回答:核心是"减少冲突,让key分布更均匀"。若长度为合数,key与长度容易产生公因子(如长度4,key=2、6、10),会导致这些key映射到同一个下标;而质数的约数只有1和自身,能大幅降低这种情况,让哈希值分布更均匀,减少冲突。
❌ 坑点/误区:说"质数更高效"、"质数更容易计算哈希值",本质原因是"减少公因子,降低冲突",而非效率问题。
面试题2:常用的哈希函数有哪些?除留余数法的注意事项是什么?
✅ 正确回答:常用的有除留余数法、直接定址法、平方取中法,还有数字分析法、折叠法、随机数法;除留余数法的注意事项有两点:① 哈希表长度最好为质数;② 处理负数key,避免负下标;③ 确保哈希值在数组下标范围内。
❌ 坑点/误区:遗漏负数key的处理;或不知道除留余数法的长度要求。
面试题3:哈希函数设计的核心原则是什么?
✅ 正确回答:两个核心原则------① 高效性 (计算速度快,不消耗过多资源);② 均匀性(哈希值分布均匀,减少冲突)。
❌ 坑点/误区:只说"均匀性",忽略"高效性";或说"唯一性"(哈希函数不要求唯一,冲突是不可避免的)。
面试题4:字符串key如何设计哈希函数?(进阶题)
✅ 正确回答:先将字符串转换为整数(①每个字符的 ASCII 码加权求和 或 ②多项式哈希:f(s) = s0*p^(n-1) + s1*p^(n-2) + ... + sn-1,其中p为质数,如31),再对哈希表长度取余,得到下标。
❌ 坑点 / 误区 :直接使用字符串的地址(指针值)作为哈希值,而不是根据字符串内容 计算哈希。这会导致:内容完全相同的字符串,因为存储地址不同,被哈希到不同桶中,哈希表无法正确识别 "相同字符串",查找、插入逻辑全部失效。
三、哈希冲突
1、是什么&有什么用
是什么:两个或多个不同的关键字(key1 ≠ key2),通过哈希函数计算后得到「相同的下标」(f(key1) = f(key2)),这种现象称为哈希冲突(也叫哈希碰撞)。
核心认知: 哈希冲突「无法完全避免」------无论哈希函数设计得多好,只要key的数量超过哈希表容量,就一定会出现冲突(鸽巢原理),因此必须有对应的冲突解决策略。
两大核心解决方法:
-
链地址法(拉链法):哈希表数组的每个下标,挂一条单链表,发生冲突时,将新节点插入到对应下标的链表中(本文重点实现,工业界最常用);
-
开放寻址法: 发生冲突时,不使用链表,而是继续在数组中寻找下一个空位置(常用方法:线性探测、二次探测、双重哈希),适合数据量小、内存紧张的场景。
-
线性探测:冲突后逐个往后找空位 ,实现简单,但容易出现元素扎堆聚集,性能退化快。

-

- 二次探测:冲突后按平方步长跳跃查找,缓解聚集问题,但仍存在二次聚集,且可能找不到空位。

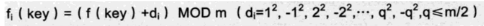
-
双重哈希:使用两个独立哈希函数 ,一个定起点、一个定步长,探测序列分布最均匀,聚集最少、开放寻址法最优。
2、C语言最小可运行示例(链地址法解决冲突)
cpp
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//结构体用前面设计的
//1.初始化
void Init_LA(LinkAddress* pla)
{
assert(pla != NULL);
for (int i = 0; i < M; i++)
{
pla->arr[i] = NULL;
}
}
//2.插入
bool Insert_LA(LinkAddress* pla, int val)
{
//0. assert
assert(pla != NULL);
//1. 求出val对应的桶下标
int index = Hash(val);
//2. 购买一个新节点
LANode* pnewNode = (LANode*)malloc(sizeof(LANode));
if (NULL == pnewNode)
exit(EXIT_FAILURE);
pnewNode->data = val;
pnewNode->next = NULL;
//3. 头插
if (pla->arr[index] == NULL || pla->arr[index]->data > val)
{
pnewNode->next = pla->arr[index];
pla->arr[index] = pnewNode;
return true;
}
//4. 判断第一个节点是不是重复
if (pla->arr[index]->data == val)
{
free(pnewNode); // 释放重复的节点
return false;
}
//5. 找插入位置
LANode* p = pla->arr[index];
while (p->next != NULL)
{
if (p->next->data < val)
p = p->next;
else if (p->next->data == val)
{
free(pnewNode); // 释放重复的节点
return false;
}
else
break;
}
//6. 插入
pnewNode->next = p->next;
p->next = pnewNode;
return true;
}
int main()
{
LinkAddress head;
Init_LA(&head);
Insert_LA(&head, 19);
Insert_LA(&head, 14);
Insert_LA(&head, 23);
Insert_LA(&head, 1);
Insert_LA(&head, 68);
Insert_LA(&head, 20);
Insert_LA(&head, 84);
Insert_LA(&head, 27);
Insert_LA(&head, 55);
Insert_LA(&head, 11);
Insert_LA(&head, 10);
Insert_LA(&head, 79);
Show_LA(head);
return 0;
}注意:1. 插入时必须判断内存分配是否成功(malloc可能返回NULL),否则会出现野指针;2. 拉链法常用头插法(效率高),尾插法需遍历链表到末尾,效率低;3. 冲突节点会挂在同一链表,查找时需遍历链表匹配key。
3、需要注意什么(细化误区)
核心误区:认为"冲突越少越好",实则无需追求"零冲突",过度优化哈希函数反而会增加计算成本,合理控制冲突率(通过负载因子)即可。
-
方法选择:链地址法是「工业界最常用」的冲突解决方法 (Redis、Java HashMap、C++ unordered_map均采用),原因是内存灵活、冲突处理简单,且适合数据量大的场景 ;开放寻址法不适合数据量大的场景 (容易出现"聚集"现象,冲突越来越多),仅适合内存紧张、数据量小的场景;
-
链表长度控制:拉链法中,单个链表的长度不宜过长(建议不超过8),否则查找效率会退化为O(n),此时需通过扩容降低负载因子,减少链表长度;
-
**开放寻址法注意事项:**① 不能直接删除元素(会导致查找路径中断),只能标记为"已删除"(逻辑删除);② 容易出现"聚集"现象(多个冲突节点连续排列),导致后续插入、查找效率下降;
-
内存管理:链地址法中,每个冲突节点都是动态分配的,删除时必须逐个free,否则会导致内存泄漏;开放寻址法无需动态分配节点,内存开销更小,但空间利用率低;
-
冲突率认知:冲突率 = 冲突次数 / 插入次数,合理的冲突率应控制在10%~20%,超过则需优化哈希函数或扩容,初学者常忽略冲突率,导致哈希表性能退化。
4、面试问题及坑点
面试题1:哈希冲突的解决方法有哪些?各自的优缺点是什么?(重要)
✅ 正确回答:主要有两种------① 链地址法: 优点是内存灵活、冲突处理简单、适合大数据量,缺点是需要额外存储链表指针,空间开销略大;② **开放寻址法:**优点是无需额外空间、内存利用率高,缺点是容易出现聚集现象、不适合大数据量、删除需标记(不能直接删)。
❌ 坑点/误区:只说方法名称,说不出优缺点;或混淆两种方法的适用场景(如说开放寻址法适合大数据量);或遗漏"标记删除"的细节。
面试题2:链地址法中,头插法和尾插法的区别是什么?为什么用头插法?
✅ 正确回答:头插法 是将新节点插入到链表头部(无需遍历链表),时间复杂度O(1);尾插法是插入到链表尾部(需遍历链表到末尾),时间复杂度O(n);用头插法的核心原因是"高效",插入时无需遍历链表,能保证O(1)的插入效率。当然,如果要求必须在插入时保证链表按照升序/降序,则需要遍历链表。
❌ 坑点/误区:说"尾插法更高效";或不知道头插法的优势;或混淆头插法和尾插法的实现逻辑。
面试题3:开放寻址法为什么不能直接删除元素?(高频坑点)
✅ 正确回答:因为开放寻址法的查找逻辑是"根据哈希值找下标,若该位置有元素且key不匹配,继续找下一个位置 ",若直接删除元素,会导致后续元素的查找路径中断(找不到目标元素);因此只能标记为"已删除",后续插入时可覆盖该位置,查找时跳过"已删除"位置。
❌ 坑点/误区:说"删除后会导致数组空位置过多";或不知道"标记删除"的解决方案;或混淆开放寻址法和链地址法的删除逻辑。
四、哈希表查找操作(核心操作)
1、是什么&有什么用
**是什么:**根据给定的关键字(key),通过哈希函数计算出对应下标,再遍历该下标对应的链表(拉链法),找到与key匹配的节点,返回对应的值(value);若未找到,返回指定标识(如-1)。
**核心作用:**哈希表最核心的功能,也是"空间换时间"的核心体现,实现平均O(1)的查找效率,是字典、缓存等场景的核心操作。
**查找流程:**计算哈希下标,找到对应桶 → 遍历对应链表 → 匹配key → 返回value/未找到。
2、代码示例
cpp
LANode* Search_LA(LinkAddress la, int val)
{
int index = Hash(val);
LANode* p = la.arr[index];
while (p != NULL)
{
if (p->data == val)
return p;
p = p->next;
}
return NULL;
}注意:1. 查找的核心是"先定位下标,再遍历链表匹配key",不能直接根据下标取值(因为下标可能有多个冲突节点);2. 返回-1时,需注意:若value本身可能为-1,需用其他标识(如INT_MIN)区分"未找到"和"value为-1",避免混淆。
3、需要注意什么(细化误区)
核心误区:认为"哈希查找是直接根据下标取值,无需遍历",忽略了冲突 的存在------下标对应的是链表,必须遍历链表匹配key,否则会返回错误的value。
-
查找流程不能省略:必须严格遵循"计算下标→遍历链表→匹配key"的流程,初学者常省略"遍历链表",直接取下标对应的第一个节点的value,导致取错数据(当有冲突时);
-
key匹配的重要性:哈希值相同≠key相同(冲突场景),必须通过"p->key == key"判断,不能只判断哈希值,否则会返回错误的value;
-
未找到的标识设计:返回-1时,需考虑value的取值范围------若value可能为-1(如统计负数次数),需用其他标识(如INT_MIN,需包含<limits.h>头文件),避免混淆"未找到"和"value为-1";
-
链表长度影响:单个链表越长,查找效率越低(退化为O(n)),因此需控制负载因子,避免链表过长;
-
空指针判断:遍历链表时,必须判断p != NULL,否则会出现空指针解引用(程序崩溃),初学者常忽略这一点。
4、面试问题及坑点
面试题1:哈希表查找的完整流程是什么?(重要)
✅ 正确回答:共三步------① 根据key通过哈希函数计算出对应的哈希下标;② 找到该下标对应的链表,遍历链表;③ 逐个对比链表节点的key,若匹配则返回对应value,若遍历完链表仍未匹配,则返回"未找到"标识。
❌ 坑点/误区:省略"遍历链表"步骤,说"直接根据下标取值";或遗漏"key匹配"的细节,说"哈希值相同就返回value"。
面试题2:哈希表查找的时间复杂度为什么是O(1)?最坏情况是什么?
✅ 正确回答:平均时间复杂度O(1)的原因是:哈希函数能直接定位到下标,遍历链表的平均长度是常数(通过控制负载因子和冲突率);最坏情况是所有key都冲突,链表长度等于元素个数,此时时间复杂度退化为O(n)(如所有key都映射到同一个下标)。
❌ 坑点/误区:说"查找时间复杂度永远是O(1)";或不知道最坏情况的时间复杂度;或说不出平均O(1)的底层原因。
面试题3:查找时,为什么不能直接根据哈希下标取值,还要遍历链表?
✅ 正确回答:因为存在哈希冲突------多个不同的key可能映射到同一个下标,下标对应的是一条链表(拉链法),每个节点的key不同,因此必须遍历链表,匹配目标key,才能找到正确的value,否则会取到冲突节点的错误value。
❌ 坑点/误区:说"哈希函数不会产生冲突";或不知道冲突导致下标对应多个节点。
面试题4:如何优化哈希表的查找效率?(进阶题)
✅ 正确回答:有三种方式------① 优化哈希函数,让key分布更均匀,减少冲突;② 控制负载因子(不超过0.75),及时扩容,缩短链表长度;③ 当链表长度超过阈值(如8),将链表转为红黑树,将查找复杂度从O(n)优化为O(logn)。
❌ 坑点/误区:只说"扩容",忽略哈希函数优化和链表转红黑树的细节;或不知道负载因子与查找效率的关系。
五、哈希表删除操作
1、是什么&有什么用
**是什么:**根据给定的key,找到对应的节点,将其从哈希表中移除,并释放其占用的内存(C语言),同时保证哈希表的查找、插入功能正常。
**核心作用:**动态维护哈希表中的数据,删除无用元素,释放内存,避免内存泄漏,同时保证哈希表的性能稳定。
**核心难点:**拉链法中,需处理"头节点、中间节点、尾节点"三种删除场景;开放寻址法中,不能直接删除,只能标记删除。
2、代码示例
cpp
//删除:删除指定val,成功返回true,失败(不存在)返回false
bool Delete_LA(LinkAddress* pla, int val)
{
assert(pla != NULL);
//1. 计算桶下标
int index = Hash(val);
LANode* p = pla->arr[index];
LANode* prev = NULL;
//2. 遍历对应桶的升序链表,找val
while (p != NULL)
{
if (p->data == val)
{
//情况1:删除的是头节点
if (prev == NULL)
{
pla->arr[index] = p->next;
}
//情况2:删除中间/尾节点
else
{
prev->next = p->next;
}
free(p);
return true;
}
//升序链表,当前节点已大于val,直接退出
else if (p->data > val)
{
break;
}
prev = p;
p = p->next;
}
//遍历完未找到
return false;
}注意:1. 删除的核心是"找到节点→调整链表指针→释放内存 ",三者缺一不可;2. 必须处理三种场景(头、中、尾节点 ),否则会导致链表断裂;3. free后必须将指针置为NULL,避免野指针;4. 开放寻址法删除需标记"已删除",不能直接free(本文暂不实现开放寻址法删除)。
3、需要注意什么(细化误区)
核心误区:删除节点后忘记free,或只free节点但不调整链表指针,导致内存泄漏或链表断裂(查找时出现空指针)。
-
内存释放:删除节点后,必须用free释放节点内存,否则会导致内存泄漏(长期运行会耗尽内存);free后必须将指针置为NULL,避免野指针(后续操作该指针会导致程序崩溃);
-
链表指针调整:删除节点时,必须调整前驱节点和后继节点的指针(prev->next = p->next),否则会导致链表断裂,后续节点无法被查找;尤其注意头节点的删除(需将链表头更新为p->next);
-
三种删除场景:必须覆盖"头节点、中间节点、尾节点"三种情况,初学者常忽略头节点(prev为NULL)的场景,导致删除头节点后,链表头仍指向已删除节点(野指针);
-
开放寻址法删除:不能直接删除节点,只能标记为"已删除"(如用一个flag标识),否则会中断查找路径;标记后,后续插入时可覆盖该位置,查找时跳过"已删除"位置;
-
删除后验证:删除后建议通过查找函数验证,确认节点已被删除,避免因指针调整错误导致删除失败;
-
空指针判断:遍历链表时,必须判断p != NULL,否则会出现空指针解引用(程序崩溃);未找到节点时,需给出提示,避免误判删除成功。
4、面试问题及坑点
面试题1:拉链法删除节点的完整流程是什么?需要注意什么?(重要)
✅ 正确回答:流程共五步------① 计算key对应的哈希下标;② 遍历链表,找到要删除的节点(记录当前节点p和前驱节点prev);③ 若未找到节点,返回删除失败;④ 调整链表指针(头节点直接更新链表头,中间/尾节点通过prev连接后继节点);⑤ free节点内存,置为NULL。注意事项:必须释放内存、调整指针、处理三种删除场景、避免野指针。
❌ 坑点/误区:遗漏"释放内存"或"调整指针";或不处理头节点场景;或free后不置为NULL,导致野指针。
面试题2:开放寻址法为什么不能直接删除元素?如何解决?(高频坑点)
✅ 正确回答:原因是开放寻址法的查找逻辑是"连续查找空位置 ",直接删除元素会导致后续元素的查找路径中断(找不到目标元素);解决方案是"标记删除"------给每个位置增加一个flag标识,删除时将flag设为"已删除",查找时跳过该位置,插入时可覆盖该位置。
❌ 坑点/误区:说"删除后会导致内存泄漏";或不知道"标记删除"的解决方案;或混淆拉链法和开放寻址法的删除逻辑。
面试题3:删除哈希表节点时,为什么要记录前驱节点?
✅ 正确回答:因为链表是单链表(只有next指针,没有prev指针),要删除中间节点或尾节点,必须通过前驱节点的next指针,连接当前节点的后继节点,否则会导致链表断裂,后续节点无法被访问;若不记录前驱节点,无法调整指针,删除后链表会出现断层。
❌ 坑点/误区:说"记录前驱节点是为了释放内存";或不知道单链表删除需要前驱节点;或混淆单链表和双链表的删除逻辑。
面试题4:C语言实现哈希表删除时,容易出现哪些问题?如何避免?(实战题)
✅ 正确回答:容易出现三个问题------① 内存泄漏(忘记free节点);② 链表断裂(未调整指针);③ 野指针(free后未置为NULL)。避免方法:① 删除节点后立即free;② 严格调整前驱和后继节点的指针;③ free后将指针置为NULL;④ 覆盖三种删除场景。
❌ 坑点/误区:只说"内存泄漏",遗漏链表断裂和野指针;或不知道如何避免这些问题。
六、负载因子(关键指标)
1、是什么&有什么用
是什么: 负载因子(Load Factor)是衡量哈希表拥挤程度 的核心指标,公式为:a = 已存储元素个数(n) / 哈希表长度(m)。
核心作用: 决定哈希表的冲突率和性能,负载因子越大,哈希表越拥挤,冲突概率越高,性能越差;负载因子越小,空间浪费越多,性能越好,因此需要找到时间和空间的平衡。
工业界默认阈值:0.75(Java HashMap、Redis、C++ unordered_map均采用),当负载因子超过0.75时,哈希表会自动扩容,降低负载因子,减少冲突。
2、C语言最小可运行示例
cpp
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10 // 哈希表长度
typedef struct Node {
int key;
int value;
struct Node* next;
} Node;
typedef struct HashTable {
Node* table[MAX_SIZE];
} HashTable;
void initHashTable(HashTable* ht) {
for (int i = 0; i < MAX_SIZE; i++) {
ht->table[i] = NULL;
}
}
int hash(int key) {
return (key < 0 ? -key : key) % MAX_SIZE;
}
void insert(HashTable* ht, int key, int value) {
int index = hash(key);
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
printf("内存分配失败\n");
return;
}
newNode->key = key;
newNode->value = value;
newNode->next = ht->table[index];
ht->table[index] = newNode;
}
// 计算负载因子:传入哈希表和哈希表长度
float getLoadFactor(HashTable* ht, int tableSize) {
int count = 0; // 已存储元素个数
// 遍历哈希表,统计所有节点个数
for (int i = 0; i < tableSize; i++) {
Node* p = ht->table[i];
while (p != NULL) {
count++;
p = p->next;
}
}
// 计算负载因子(强制转换为float,避免整数除法)
return (float)count / tableSize;
}
// 测试负载因子(可直接运行)
int main() {
HashTable ht;
initHashTable(&ht);
// 插入8个元素(MAX_SIZE=10,负载因子=0.8,超过0.75)
insert(&ht, 1, 100);
insert(&ht, 2, 200);
insert(&ht, 3, 300);
insert(&ht, 4, 400);
insert(&ht, 5, 500);
insert(&ht, 6, 600);
insert(&ht, 7, 700);
insert(&ht, 8, 800);
float loadFactor = getLoadFactor(&ht, MAX_SIZE);
printf("当前负载因子:%.2f\n", loadFactor); // 0.80
if (loadFactor >= 0.75) {
printf("负载因子超过阈值0.75,建议扩容\n");
}
return 0;
}注意:1. 计算负载因子时,必须统计所有节点个数(包括冲突节点),不能只统计非空下标个数;2. 注意整数除法问题,需将count或tableSize强制转换为float,否则会得到整数结果(如8/10=0);3. 负载因子超过0.75时,必须扩容,否则冲突会急剧增加。
3、需要注意什么(细化误区)
核心误区:认为"负载因子阈值0.75是固定不变的",实则0.75是工业界的"经验值",可根据实际场景调整(如内存紧张时可提高到0.8,追求极致性能时可降低到0.6)。
-
负载因子与冲突率的关系:负载因子和冲突率呈正相关------负载因子从0.1增加到0.75,冲突率缓慢上升;超过0.75后,冲突率会急剧上升,哈希表性能大幅退化;超过1.0后,哈希表会严重拥挤,链表长度过长,查找效率退化为O(n);
-
阈值选择:0.75是"时间和空间的平衡值"------低于0.75,空间浪费过多;高于0.75,冲突率激增,时间成本增加;实际开发中可根据场景调整,如缓存场景(追求快)可设为0.6,内存紧张场景可设为0.8;
-
元素个数统计:计算负载因子时,必须统计哈希表中所有节点的个数(包括冲突节点),初学者常错误统计"非空下标个数",导致负载因子计算错误;
-
整数除法问题:C语言中,整数除以整数会得到整数(如8/10=0),因此必须将其中一个 operand 强制转换为float或double,才能得到正确的小数结果;
-
扩容触发时机:负载因子达到阈值时,必须触发扩容,否则冲突会越来越多,哈希表性能会持续下降;扩容后,负载因子会降低到0.375左右(0.75/2),保证性能稳定。
4、面试问题及坑点
面试题1:什么是负载因子?公式是什么?(重要)
✅ 正确回答:负载因子是衡量哈希表拥挤程度的指标,公式为alpha = 已存储元素个数(n) / 哈希表长度(m),其中n是哈希表中所有节点的个数(包括冲突节点),m是哈希表的数组长度。
❌ 坑点/误区:公式记错(如把分子分母颠倒);或统计n时只算非空下标个数,忽略冲突节点。
面试题2:负载因子超过1.0会有什么问题?如何解决?
✅ 正确回答:负载因子超过1.0,意味着哈希表中已存储的元素个数超过了哈希表长度,此时哈希表会严重拥挤,所有下标对应的链表都会很长,查找、插入、删除的时间复杂度会退化为O(n),性能大幅退化。解决方案:① 及时扩容,将哈希表长度扩大为原来的2倍(且保证是质数),重新计算所有节点的哈希下标并迁移;② 优化哈希函数,减少冲突,缓解链表过长的问题。
❌ 坑点/误区:说"负载因子不能超过1.0"(实际可以超过,但性能极差);或不知道扩容是核心解决方案;或扩容后不重新计算哈希下标。
面试题3:负载因子越低,哈希表性能越好吗?为什么?
✅ 正确回答:不是。负载因子过低(如小于0.3),虽然冲突率极低,查找效率接近O(1),但会造成大量的空间浪费(哈希表大部分下标为空),违背了哈希表"空间换时间"的核心思想,属于"过度浪费空间换性能",不符合实际开发的资源利用原则。因此负载因子需控制在合理范围(0.6~0.8),平衡时间和空间。
❌ 坑点/误区:认为"负载因子越低越好",忽略空间浪费的问题;或不知道负载因子的合理范围。
七、哈希表扩容(底层逻辑)
1、是什么&有什么用
**是什么:**哈希表扩容是当负载因子超过阈值(默认0.75)时,将哈希表数组长度扩大为原来的2倍(且保证新长度为质数),并将原哈希表中的所有节点重新计算哈希下标,迁移到新的哈希表中的操作,本质是"扩大存储空间,降低负载因子,减少冲突"。
**核心作用:**解决负载因子过高、冲突过多、链表过长的问题,保证哈希表的性能稳定,维持查找、插入、删除的平均时间复杂度为O(1)。
扩容核心流程:判断负载因子→创建新哈希表(新长度为原长度2倍,且为质数)→迁移原节点(重新计算哈希下标)→释放原哈希表内存→更新哈希表指针。
2、C语言最小可运行示例
cpp
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10 // 初始哈希表长度(质数)
#define NEW_SIZE 23 // 扩容后长度(原长度2倍左右,且为质数)
typedef struct Node {
int key;
int value;
struct Node* next;
} Node;
typedef struct HashTable {
Node* table[MAX_SIZE];
} HashTable;
// 新哈希表结构(扩容后使用)
typedef struct NewHashTable {
Node* table[NEW_SIZE];
} NewHashTable;
void initHashTable(HashTable* ht) {
for (int i = 0; i < MAX_SIZE; i++) {
ht->table[i] = NULL;
}
}
void initNewHashTable(NewHashTable* newHt) {
for (int i = 0; i < NEW_SIZE; i++) {
newHt->table[i] = NULL;
}
}
// 原哈希函数(对应初始长度)
int hash(int key) {
return (key < 0 ? -key : key) % MAX_SIZE;
}
// 新哈希函数(对应扩容后长度)
int newHash(int key) {
return (key < 0 ? -key : key) % NEW_SIZE;
}
void insert(HashTable* ht, int key, int value) {
int index = hash(key);
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
printf("内存分配失败\n");
return;
}
newNode->key = key;
newNode->value = value;
newNode->next = ht->table[index];
ht->table[index] = newNode;
}
// 计算负载因子
float getLoadFactor(HashTable* ht, int tableSize) {
int count = 0;
for (int i = 0; i < tableSize; i++) {
Node* p = ht->table[i];
while (p != NULL) {
count++;
p = p->next;
}
}
return (float)count / tableSize;
}
// 扩容函数:将原哈希表节点迁移到新哈希表
void expandHashTable(HashTable* ht, NewHashTable* newHt) {
// 1. 遍历原哈希表的每个下标
for (int i = 0; i < MAX_SIZE; i++) {
Node* p = ht->table[i];
// 2. 遍历当前下标对应的链表,迁移每个节点
while (p != NULL) {
Node* temp = p->next; // 保存下一个节点(避免迁移后丢失)
int newIndex = newHash(p->key); // 重新计算新下标
// 头插法插入新哈希表
p->next = newHt->table[newIndex];
newHt->table[newIndex] = p;
p = temp; // 迁移下一个节点
}
ht->table[i] = NULL; // 清空原哈希表当前下标
}
printf("哈希表扩容成功,原长度:%d,新长度:%d\n", MAX_SIZE, NEW_SIZE);
}
// 测试扩容(可直接运行)
int main() {
HashTable ht;
initHashTable(&ht);
// 插入8个元素,负载因子=0.8,超过0.75,触发扩容
insert(&ht, 1, 100);
insert(&ht, 2, 200);
insert(&ht, 3, 300);
insert(&ht, 4, 400);
insert(&ht, 5, 500);
insert(&ht, 6, 600);
insert(&ht, 7, 700);
insert(&ht, 8, 800);
float loadFactor = getLoadFactor(&ht, MAX_SIZE);
printf("当前负载因子:%.2f\n", loadFactor);
if (loadFactor >= 0.75) {
NewHashTable newHt;
initNewHashTable(&newHt);
expandHashTable(&ht, &newHt); // 执行扩容
}
return 0;
}注意:1. 扩容后新长度必须是质数,且建议为原长度的2倍左右,既保证空间利用率,又减少冲突;2. 迁移节点时必须重新计算哈希下标(因为哈希函数依赖哈希表长度),不能直接复制;3. 迁移时用temp保存下一个节点,避免链表断裂;4. 扩容后需释放原哈希表节点内存(示例中未体现,实际开发需补充)。
3、需要注意什么(细化误区)
核心误区:认为"扩容只是简单扩大数组长度",忽略了"节点重新哈希迁移"和"内存释放",导致扩容后哈希表查找混乱或内存泄漏。
-
新长度选择:扩容后新长度必须是「质数」,且建议为原长度的2倍左右(如原长度10→新长度23,原长度23→新长度47),避免与key产生公因子,减少冲突;禁止选择合数或过小的长度;
-
节点迁移关键:迁移时必须重新计算每个节点的哈希下标(因为哈希函数是f(key) = key % 哈希表长度,长度变化后,哈希下标也会变化),若直接复制节点,会导致查找失败;
-
内存管理:扩容后,原哈希表的节点已迁移到新哈希表,必须释放原哈希表的节点内存(逐个free),避免内存泄漏;同时,原哈希表数组可根据需求释放(若不再使用);
-
扩容时机:必须在负载因子达到阈值(0.75)时触发扩容,过早扩容浪费空间,过晚扩容导致性能退化;实际开发中可结合冲突率,灵活调整扩容时机;
-
扩容开销:扩容是"耗时操作"(需遍历所有节点、重新哈希、迁移节点),因此哈希表设计时,初始容量不宜过小,避免频繁扩容;
4、面试问题及坑点
面试题1:哈希表扩容的完整流程是什么?(重要)
✅ 正确回答:共五步------① 计算当前负载因子,判断是否超过阈值(0.75);② 确定新哈希表长度(原长度2倍左右,且为质数);③ 创建新哈希表并初始化;④ 遍历原哈希表所有节点,重新计算哈希下标,迁移到新哈希表;⑤ 释放原哈希表节点内存,更新哈希表指针(指向新哈希表)。
❌ 坑点/误区:遗漏"重新计算哈希下标"或"释放原内存";或新长度不设为质数;或不知道扩容的触发条件。
面试题2:扩容时,为什么要重新计算所有节点的哈希下标?
✅ 正确回答:因为哈希函数的核心公式是f(key) = key % 哈希表长度,扩容后哈希表长度发生变化,若不重新计算,原哈希下标会失效(无法对应新哈希表的下标),导致查找、插入功能异常;重新计算后,节点才能正确映射到新哈希表的对应位置,保证哈希表正常工作。
❌ 坑点/误区:说"不需要重新计算";或不知道哈希下标与哈希表长度的关联;或认为"直接复制节点即可"。
面试题3:哈希表扩容的开销是什么?如何优化?(进阶题)
✅ 正确回答:扩容的核心开销是"节点遍历+重新哈希+节点迁移",属于O(n)时间复杂度操作,频繁扩容会降低哈希表性能。优化方法:① 合理设置初始容量(根据预期数据量,设为质数),减少扩容次数;② 采用"渐进式扩容"(如Java HashMap),将扩容操作拆分到多次插入、查找操作中,避免单次扩容耗时过长;③ 灵活调整负载因子阈值(如内存充足时降低阈值,减少扩容频率)。
❌ 坑点/误区:不知道扩容是O(n)开销;或不知道"渐进式扩容";或无法给出具体的优化方案。
八、完整可运行C语言Demo
说明:整合前文所有核心操作(初始化、插入、查找、删除、负载因子计算、扩容),实现一个完整的哈希表(拉链法),可直接复制运行,包含详细注释,适合实战练习和面试突击。
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
// 哈希表桶数量
#define M 11
// 链表节点结构(只有 data,没有 value)
typedef struct LANode
{
int data;
struct LANode* next;
} LANode;
// 哈希表结构(只有数组,没有 size)
typedef struct LinkAddress
{
LANode* arr[M];
} LinkAddress;
// 初始化
void Init_LA(LinkAddress* pla)
{
assert(pla != NULL);
for (int i = 0; i < M; i++)
{
pla->arr[i] = NULL;
}
}
// 哈希函数
int Hash(int tmp)
{
return (tmp < 0 ? -tmp : tmp) % M;
}
// 插入(升序 + 去重)
int Insert_LA(LinkAddress* pla, int val)
{
assert(pla != NULL);
int index = Hash(val);
LANode* pnewNode = (LANode*)malloc(sizeof(LANode));
if (pnewNode == NULL)
exit(EXIT_FAILURE);
pnewNode->data = val;
pnewNode->next = NULL;
// 头插
if (pla->arr[index] == NULL || pla->arr[index]->data > val)
{
pnewNode->next = pla->arr[index];
pla->arr[index] = pnewNode;
return 1;
}
// 第一个节点重复
if (pla->arr[index]->data == val)
{
free(pnewNode);
return 0;
}
LANode* p = pla->arr[index];
while (p->next != NULL)
{
if (p->next->data < val)
p = p->next;
else if (p->next->data == val)
{
free(pnewNode);
return 0;
}
else
break;
}
pnewNode->next = p->next;
p->next = pnewNode;
return 1;
}
// 查找
LANode* Search_LA(LinkAddress la, int val)
{
int index = Hash(val);
LANode* p = la.arr[index];
while (p != NULL)
{
if (p->data == val)
return p;
p = p->next;
}
return NULL;
}
// 删除(按你风格写的)
int Delete_LA(LinkAddress* pla, int val)
{
assert(pla != NULL);
int index = Hash(val);
LANode* p = pla->arr[index];
LANode* prev = NULL;
while (p != NULL)
{
if (p->data == val)
{
if (prev == NULL)
{
pla->arr[index] = p->next;
}
else
{
prev->next = p->next;
}
free(p);
return 1;
}
else if (p->data > val)
{
break;
}
prev = p;
p = p->next;
}
return 0;
}
// 打印
void Show_LA(LinkAddress la)
{
for (int i = 0; i < M; i++)
{
printf("%d:", i);
LANode* p = la.arr[i];
while (p != NULL)
{
printf("%d->", p->data);
p = p->next;
}
printf("NULL\n");
}
}
// ==================== 测试主函数 ====================
int main()
{
LinkAddress head;
Init_LA(&head);
Insert_LA(&head, 19);
Insert_LA(&head, 14);
Insert_LA(&head, 23);
Insert_LA(&head, 1);
Insert_LA(&head, 68);
Insert_LA(&head, 20);
Insert_LA(&head, 84);
Insert_LA(&head, 27);
Insert_LA(&head, 55);
Insert_LA(&head, 11);
Insert_LA(&head, 10);
Insert_LA(&head, 79);
printf("删除前:\n");
Show_LA(head);
Delete_LA(&head, 19);
Delete_LA(&head, 1);
Delete_LA(&head, 79);
printf("\n删除后:\n");
Show_LA(head);
return 0;
}九、面试高频考点&避坑指南
核心说明:整合前文所有面试题和误区,提炼高频考点、避坑重点,适合面试突击记忆,覆盖字节、腾讯、阿里等大厂高频提问方向,重点标注易踩坑点。
1、核心高频考点
-
哈希表核心组成:数组+哈希函数+冲突解决策略,三者缺一不可(面试必考,避免只说"数组");
-
哈希函数核心原则:高效性+均匀性,常用方法(除留余数法、直接定址法、平方取中法),重点掌握除留余数法的注意事项;
-
冲突解决方法(必考):链地址法(工业界常用,Redis/HashMap)和开放寻址法,各自的优缺点、适用场景,以及Java HashMap的优化(链表转红黑树);
-
负载因子:公式、默认阈值(0.75)、与冲突率的关系,为什么选择0.75;
-
扩容核心流程:触发条件(负载因子≥0.75)、新长度选择(原长度2倍左右,质数)、节点迁移(重新哈希);
-
核心操作流程:插入、查找、删除的完整步骤(重点是删除的三种场景和内存管理);
-
时间复杂度:平均O(1),最坏O(n)(所有key冲突),避免说"绝对O(1)"。
2、高频面试题精华
Q:哈希表和数组、链表的区别?适用场景?
A:数组:随机访问快,增删慢(O(n));链表:增删快(O(1)),查找慢(O(n));哈希表:兼顾两者,增删查平均O(1),适合频繁增删查场景(缓存、字典),缺点是空间开销大。
Q:为什么哈希表长度推荐用质数?
A:减少key与长度的公因子,让哈希值分布更均匀,降低冲突概率(核心原因),而非"更高效"。
Q:开放寻址法为什么不能直接删除元素?
A:会中断查找路径,导致后续元素无法找到;解决方案是"标记删除"。
Q:C语言实现哈希表,容易出现哪些问题?如何避免?
A:① 内存泄漏(忘记free节点);② 野指针(free后未置为NULL);③ 链表断裂(删除时未调整指针);④ 数组越界(负数key未处理);⑤ 整数除法(负载因子计算错误)。避免方法:严格做好内存管理、处理负数key、覆盖删除三种场景、强制转换float计算负载因子。
3、避坑指南(重点标注)
高频坑点汇总(面试最易踩错,务必避开):
-
❌ 误区1:哈希表只有数组,遗漏哈希函数和冲突解决;
-
❌ 误区2:哈希表所有操作都是O(1),忽略最坏情况(O(n));
-
❌ 误区3:哈希函数越复杂越好,忽略"高效性"原则;
-
❌ 误区4:删除节点后不free,或free后不置为NULL,导致内存泄漏或野指针;
-
❌ 误区5:扩容只是扩大数组长度,不重新计算哈希下标;
-
❌ 误区6:负载因子0.75是固定值,不能调整;
-
❌ 误区7:查找时直接根据下标取值,不遍历链表匹配key;
-
❌ 误区8:开放寻址法可以直接删除元素,无需标记。
4、实战总结
哈希表的核心是"空间换时间",通过哈希函数实现快速定位,通过冲突解决策略和扩容机制保证性能稳定。学习时,重点掌握C语言的内存管理(malloc/free)、三大核心组成、四大核心操作,以及面试高频问题的正确回答的逻辑,避开上述误区,即可应对大部分大厂面试的哈希表考点。实际开发中,优先使用成熟的哈希表库(如C++ unordered_map、Java HashMap),但底层实现逻辑必须掌握(面试重点考查)。