内容参考于:图灵AI大模型全栈
向量数据库使用chromadb,它可以使用内存和持久化(就是把向量保存到硬盘上,这样重启也不会丢失)
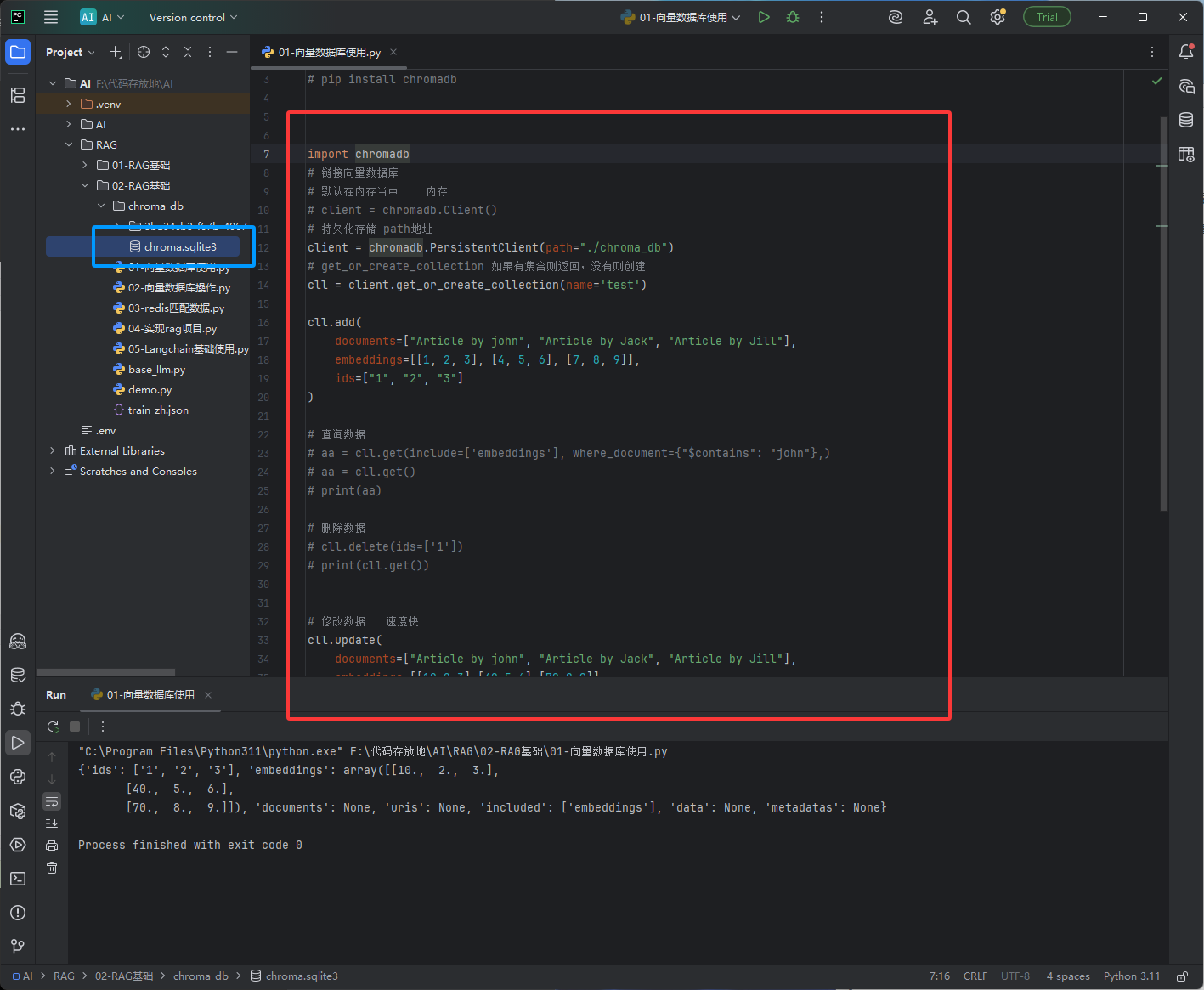
下图红框的代码运行一次后会出现下图蓝框的文件,这个文件就是把向量数据保存到本地,直接双击下图蓝框文件
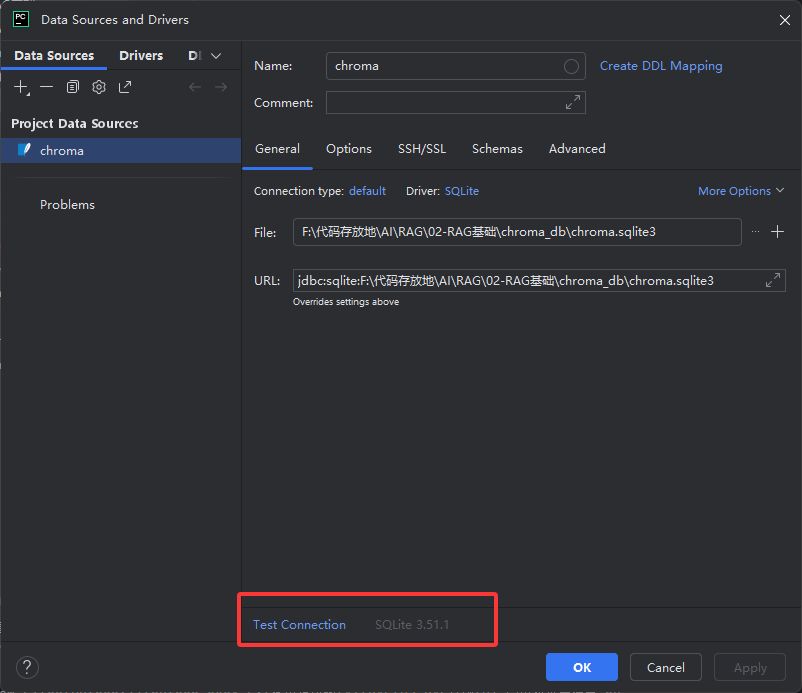
python#!/usr/bin/env python # 指定Python解释器的路径(Linux/Mac用,Windows自动忽略,不用管) # -*- coding: UTF-8 -*- # 指定文件编码为UTF-8,支持中文,防止乱码 # 安装命令:如果电脑报错找不到chromadb,在终端输入这行安装 # pip install chromadb # ===================== 1. 导入向量数据库库 ===================== # 导入chromadb:专门用来存储、管理、查询【文本向量】的轻量级数据库 # 特点:免费、本地运行、操作简单,是AI知识库/RAG最常用的向量库 import chromadb # ===================== 2. 连接/创建向量数据库 ===================== # 两种连接方式(二选一): # 方式1:纯内存模式 → 重启程序数据就消失(测试用) # client = chromadb.Client() # 方式2:持久化模式 → 数据存在电脑硬盘里,重启程序也不会丢(正式用) # path="./chroma_db":数据库文件保存在当前文件夹的 chroma_db 文件夹里 client = chromadb.PersistentClient(path="./chroma_db") # ===================== 3. 创建/获取数据集合 ===================== # 集合 = 数据库里的「一张表」,专门存一组相关的向量数据 # get_or_create_collection: # 如果名字叫 test 的表存在 → 直接用它 # 如果不存在 → 自动创建一张叫 test 的新表 cll = client.get_or_create_collection(name='test') # ===================== 4. 向集合中添加数据 ===================== # add():往表里【新增】数据,必须传3个核心参数 cll.add( documents=["Article by john", "Article by Jack", "Article by Jill"], # 原始文本(我们要存的文字) embeddings=[[1, 2, 3], [4, 5, 6], [7, 8, 9]], # 文本对应的向量(数字数组) ids=["1", "2", "3"] # 唯一ID(每个数据的身份证号,不能重复) ) # ===================== 5. 注释:查询数据(测试用) ===================== # 按条件查询:查找文本包含john的数据,只返回向量 # aa = cll.get(include=['embeddings'], where_document={"$contains": "john"},) # 查询表里所有数据 # aa = cll.get() # print(aa) # ===================== 6. 注释:删除数据 ===================== # 根据唯一ID删除数据(删掉ID为1的数据) # cll.delete(ids=['1']) # 打印删除后的所有数据 # print(cll.get()) # ===================== 7. 核心:修改/更新数据 ===================== # update():根据【唯一ID】修改已有的数据 # 作用:替换原来的文本/向量,速度极快 # 注意:ids必须和添加时的ID一一对应,才能精准修改 cll.update( documents=["Article by john", "Article by Jack", "Article by Jill"], # 新的原始文本(这里没改文字) embeddings=[[10,2,3],[40,5,6],[70,8,9]], # 新的向量(把原来的1→10,4→40,7→70) ids=["1", "2", "3"] # 要修改的数据ID(和添加时一致) ) # ===================== 8. 打印修改后的结果 ===================== # get():查询数据 # include=["embeddings"]:只打印【向量】,不打印其他冗余信息 # 验证:向量是否被成功修改 print(cll.get(include=["embeddings"]))它使用的是sqlite3数据,如果第一次使用的话,下图红框位置会有一个下载的英文单词,需要先进行下载,下载完点击ok就可以了
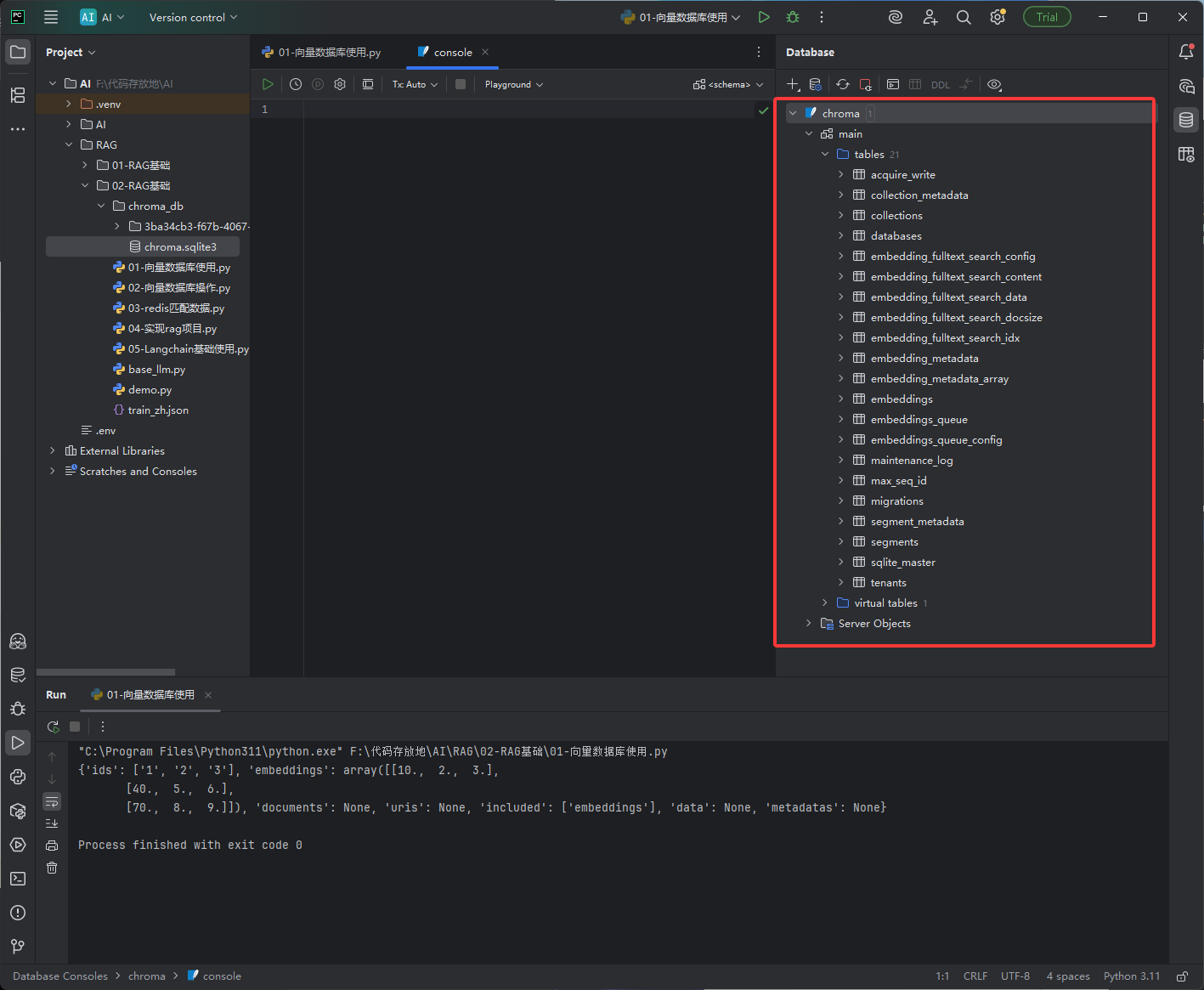
点击ok后就可以在下图红框位置看到数据库表了,如果想知道下图红框都是什么意思,去问ai大模型
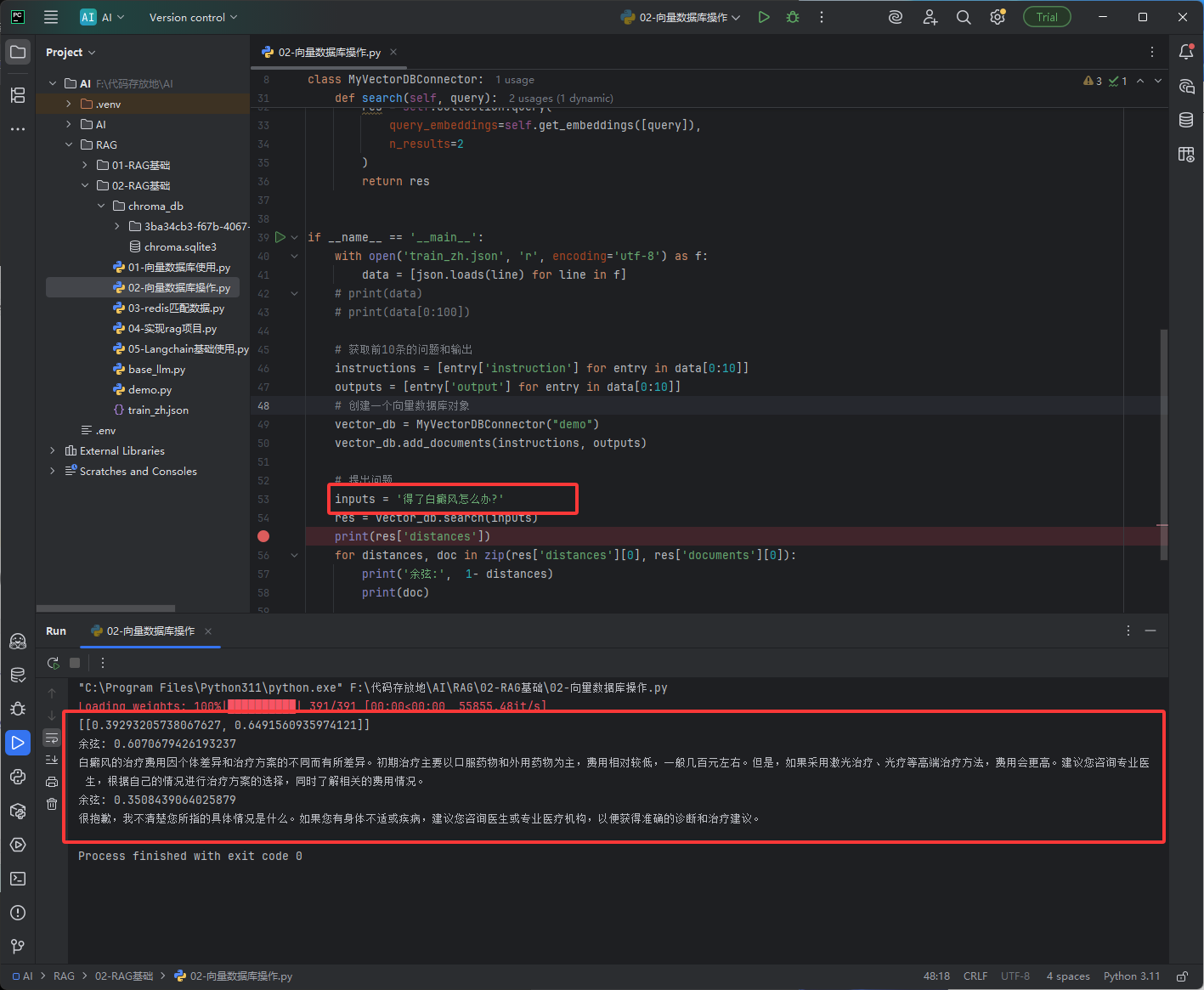
通过问题去向量数据库中查询资料
如下图
里面用到了一个资料库是一个json格式,这个内容有点多放到最后了
python#!/usr/bin/env python # Linux/Mac系统的Python解释器声明,Windows系统自动忽略,不用管 # -*- coding: UTF-8 -*- # 设置文件编码为UTF-8,支持中文,防止乱码 # 1. 导入需要的库 # json:读取本地的JSON格式问答数据文件 import json # chromadb:轻量级向量数据库,存储文本+向量,做语义检索 import chromadb # 从本地base_llm文件中导入加载好的本地嵌入模型(BGE模型) # 这个文件是你之前写的:加载SentenceTransformer模型的代码 from base_llm import model # ===================== 核心:自定义向量数据库连接器类 ===================== # 类名:MyVectorDBConnector # 作用:封装向量数据库的所有操作(连接、生成向量、存数据、查数据),复用性极强 class MyVectorDBConnector: # 初始化方法:创建类对象时自动执行 # 参数:collection_name → 向量数据库的表名(自定义) def __init__(self, collection_name): # 1. 创建ChromaDB客户端(默认:纯内存模式,程序关闭数据就消失) chroma_client = chromadb.Client() # 2. 创建/获取向量数据库的「集合」(相当于数据库的一张表) self.collection = chroma_client.get_or_create_collection( name=collection_name, # 表名 # 关键设置:指定检索用**余弦相似度** # 默认Chroma用欧式距离,这里改成cosine,更适合文本语义匹配 metadata={"hnsw:space": "cosine"} ) # 方法1:生成文本的嵌入向量 # 参数:texts → 要生成向量的文本列表 # 返回值:向量列表(给数据库使用) def get_embeddings(self, texts): # 调用本地BGE模型,生成向量 data = model.encode(texts) # 把模型输出的向量,转换成标准列表格式返回 return [x for x in data] # 方法2:向向量数据库中添加【问答对】 # 参数:questions → 问题列表 answers → 答案列表 # 逻辑:把问题转成向量 → 和答案一起存入数据库 def add_documents(self, questions, answers): # 1. 给所有问题生成向量 emb = self.get_embeddings(questions) # 2. 把【向量+答案+ID】存入数据库 self.collection.add( embeddings=emb, # 问题的向量(检索用) documents=answers, # 对应的答案(检索后返回给用户) # 自动生成唯一ID:id0,id1,id2... (每个问答对的身份证) ids=[f"id{i}" for i in range(len(answers))] ) # 方法3:语义检索(核心功能) # 参数:query → 用户的问题 # 返回值:数据库中最相似的2条答案 def search(self, query): # 1. 给用户的问题生成向量 # 2. 用向量在数据库中检索:找最相似的2条数据(n_results=2) res = self.collection.query( query_embeddings=self.get_embeddings([query]), n_results=2 ) # 返回检索结果(包含答案、相似度距离等) return res # ===================== 主程序:执行问答检索 ===================== if __name__ == '__main__': # 1. 读取本地JSON问答数据集 # train_zh.json:每行是一个JSON对象,包含instruction(问题)、output(答案) with open('train_zh.json', 'r', encoding='utf-8') as f: # 逐行读取JSON数据,存入列表 data = [json.loads(line) for line in f] # 2. 提取数据:只取前10条问答对(测试用,避免数据太多) instructions = [entry['instruction'] for entry in data[0:10]] # 前10个问题 outputs = [entry['output'] for entry in data[0:10]] # 前10个答案 # 3. 创建向量数据库对象,表名叫 demo vector_db = MyVectorDBConnector("demo") # 4. 把10条问答对存入向量数据库 vector_db.add_documents(instructions, outputs) # 5. 用户提问:输入要查询的问题 inputs = '得了白癜风怎么办?' # 6. 执行检索,找最相似的2条答案 res = vector_db.search(inputs) # 7. 打印结果:距离 + 余弦相似度 + 答案 print("检索的原始距离:", res['distances']) # 循环遍历2条检索结果 for distances, doc in zip(res['distances'][0], res['documents'][0]): # 关键:Chroma存储的是【余弦距离】,1 - 距离 = 【余弦相似度】 # 相似度越接近1,问题越相似 print('余弦相似度:', 1 - distances) # 打印匹配到的答案 print("匹配答案:", doc) print("-" * 50)
使用Redis实现向量数据库
这个用的少,使用chromadb的多
python# 导入json库:用于读取本地的JSON格式问答数据文件 import json # 导入redis库:用于连接和操作Redis数据库(内存型高速数据库) import redis # ===================== 1. 创建 Redis 数据库连接 ===================== # 连接本地的 Redis 服务 # host='127.0.0.1':本地地址(自己电脑上的Redis) # port=6379:Redis 默认端口号(固定不变) # decode_responses=True:核心!自动把数据转成字符串(否则返回二进制,看不懂) r = redis.Redis( host='127.0.0.1', port=6379, decode_responses=True ) # ===================== 2. 定义函数:从JSON文件读取问答数据 ===================== # 函数作用:读取本地 train_zh.json 文件,提取【问题】和【答案】 # 返回值:两个列表 → 问题列表(instructions)、答案列表(outputs) def read_data(): # 打开JSON文件,只读模式,编码utf-8防止中文乱码 with open('train_zh.json', 'r', encoding='utf-8') as f: # 逐行读取文件,每行是一个JSON对象,转换成Python列表 data = [json.loads(line) for line in f] # 只取前10条数据(测试用,避免数据过多) # 从每条数据中提取 instruction(问题),组成新列表 instructions = [entry['instruction'] for entry in data[0:10]] # 从每条数据中提取 output(答案),组成新列表 outputs = [entry['output'] for entry in data[0:10]] # 返回提取好的问题和答案 return instructions, outputs # ===================== 3. 定义函数:把问答数据存入Redis ===================== # 参数:instructions=问题列表,outputs=答案列表 # 作用:把【问题作为键(key)】,【答案作为值(value)】存入Redis def set_redis_documents(instructions, outputs): # zip():把两个列表按顺序一一配对(问题1配答案1,问题2配答案2) for instruction, output in zip(instructions, outputs): # r.set(key, value):Redis 最基础的存数据方法 # 键=问题,值=答案,后续通过问题搜索答案 r.set(instruction, output) # ===================== 4. 定义函数:Redis 关键词模糊搜索答案 ===================== # 参数:instruction_key=要搜索的关键词,top_n=最多返回几条结果(默认3条) # 作用:根据关键词,模糊匹配Redis里的问题,返回对应的答案 def search_instructions(instruction_key, top_n=3): # r.keys('*关键词*'):Redis 模糊搜索所有【包含关键词】的键(问题) # * 是通配符:代表任意字符(前面、后面有任何内容都能匹配) keys = r.keys(pattern='*' + instruction_key + '*') # 创建空列表,存放搜索到的答案 data = [] # 遍历所有匹配到的问题(键) for key in keys: # r.get(key):根据问题(键),取出对应的答案(值) data.append(r.get(key)) # 只返回前 top_n 条结果(避免太多) return data[:top_n] # ===================== 5. 主程序:执行 读取→存储→检索 流程 ===================== # 第一步:从JSON文件读取前10条 问题+答案 instructions, outputs = read_data() # 第二步:把读取到的数据,存入Redis数据库 set_redis_documents(instructions, outputs) # 第三步:在Redis中搜索【怀孕】这个关键词,返回匹配的答案 data = search_instructions('怀孕') # 打印最终检索结果 print("搜索到的答案:", data)
通过解析PTF文件生成知识库(向量数据库),然后查询,查到资料后拼接提示词去问语言模型
这里的向量模型使用的是本地的,已放到百度网盘里了,语言模型使用的是火山引擎里面的,也就是豆包
下发用到的pdf可以去网上随便找一个,然后根据里面的内容问ai进行测试就可以了
python
# 先下载解析PDF和word的模块
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx
# 操作文档 https://blog.csdn.net/PolarisRisingWar/article/details/147332412
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pdfminer.six
# 使用文档 https://www.jb51.net/python/335075me6.htm
#!/usr/bin/env python
# Linux/Mac系统的Python解释器声明,Windows自动忽略
# -*- coding: UTF-8 -*-
# 设置编码为UTF-8,保证中文不乱码
# ===================== 【模块导入】 =====================
# chromadb:轻量级向量数据库,存储文本向量,做语义检索
import chromadb
# pdfminer:专门用来提取PDF文件里的文字内容
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
# 从本地文件导入:本地嵌入模型(生成向量) + 大模型客户端(生成回答)
# base_llm.py 是你提前写好的模型加载文件
from base_llm import client_xl # 嵌入模型(BGE,生成文本向量)
from base_llm import client_yy # 大模型(DeepSeek,回答问题)
# ===================== 【函数1:滑动窗口切割长文本】 =====================
# 作用:把PDF里提取的超长文本,切成固定长度的小块(方便存入向量库)
# 参数:text=长文本,chunk_size=每块大小,stride=滑动步长
# 返回值:切割好的文本小块列表
def sliding_window_chunks(text, chunk_size, stride):
# 列表推导式:从0开始,每隔stride个字符,切chunk_size长度的文本
return [text[i:i + chunk_size] for i in range(0, len(text), stride)]
# ===================== 【函数2:从PDF中提取纯文本】 =====================
# 作用:读取PDF文件,去掉换行/空格,提取干净文字,再切割成小块
# 参数:filename=PDF文件名,page_numbers=指定要读取的页码(默认全部)
# 返回值:切割好的PDF文本小块
def extract_text_from_pdf(filename, page_numbers=None):
'''从 PDF 文件中(按指定页码)提取文字'''
# 空字符串,用来拼接所有提取的文本
full_text = ''
# 遍历PDF的每一页
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码,跳过不在范围内的页(比如只读0、1、2页)
if page_numbers is not None and i not in page_numbers:
continue
# 遍历页面里的每个元素
for element in page_layout:
# 判断:这个元素是不是【文本内容】(过滤图片、表格)
if isinstance(element, LTTextContainer):
# 提取文本,去掉换行和空格,拼接到总文本里
full_text += element.get_text().replace("\n", "").replace(" ", "")
# 调用切割函数:每块250字符,步长100(有重叠)
text_chunks = sliding_window_chunks(full_text, 250, 100)
# 返回切割好的文本小块
return text_chunks
# ===================== 【类1:向量数据库连接器】 =====================
# 作用:封装Chroma向量库的所有操作(连接、生成向量、存数据、查数据)
class MyVectorDBConnector:
# 初始化:创建向量库客户端 + 集合(相当于数据库的表)
def __init__(self, collection_name):
# 创建Chroma客户端(内存模式:关闭程序数据清空)
chroma_client = chromadb.Client()
# 创建/获取表,指定用余弦相似度(更适合语义匹配)
self.collection = chroma_client.get_or_create_collection(
name=collection_name, # 表名
metadata={"hnsw:space": "cosine"} # 余弦相似度(原代码注释掉了,建议打开)
)
# 方法:生成文本向量(调用本地BGE模型)
def get_embeddings(self, texts):
data = client_xl.encode(texts) # 模型生成向量
return [x for x in data] # 转成列表返回
# 方法:把PDF文本小块 + 向量 存入数据库
def add_documents(self, data):
emb = self.get_embeddings(data) # 给文本生成向量
self.collection.add(
embeddings=emb, # 存储向量
documents=data, # 存储原始文本
ids=[f"id{i}" for i in range(len(data))] # 自动生成唯一ID
)
# 方法:语义检索(用户提问→找最相似的文本)
# 参数:query=用户问题,n_results=返回几条结果
def search(self, query, n_results):
res = self.collection.query(
query_embeddings=self.get_embeddings([query]), # 问题转向量
n_results=n_results # 返回最相似的n条数据
)
return res
# ===================== 【类2:RAG智能问答机器人】 =====================
# RAG = 检索(Retrieval) + 生成(Generation):先找答案,再回答
class RAG_Bot:
# 初始化:绑定向量库 + 设置检索数量
def __init__(self, vector_db, n_results=2):
self.vector_db = vector_db # 向量库对象
self.n_results = n_results # 每次检索2条最相似的文本
# 方法:调用大模型,生成回答
def get_llm(self, prompt):
# 调用DeepSeek大模型
response = client_yy.responses.create(
model="deepseek-v3-2-251201",
input=[{"role": "user", "content": [{"type": "input_text", "text": prompt}]}]
)
return response.output_text # 返回模型的回答
# 核心方法:用户聊天 + 完整RAG流程
def chat(self, user_query):
# 1. 检索:根据用户问题,从向量库找相似的PDF内容
search_res = self.vector_db.search(user_query, n_results=self.n_results)
# 2. 拼接提示词:把检索到的内容 + 用户问题,填入模板
prompt = prompt_template.replace('__INFO__', '\n'.join(search_res['documents'][0])).replace('__QUERY__', user_query)
# 3. 生成:把提示词发给大模型,打印最终回答
res = self.get_llm(prompt)
print(res)
# ===================== 【主程序:启动RAG系统】 =====================
if __name__ == '__main__':
# ===================== 【提示词模板(核心规则)】 =====================
# 给大模型定规矩:只能用PDF里的信息回答,不能编造,不会就说无法回答
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
__INFO__ # 占位符:会被检索到的PDF内容替换
用户问:
__QUERY__ # 占位符:会被用户的问题替换
请用中文回答用户问题。
"""
# 1. 处理PDF:读取【财务管理文档.pdf】的前3页(0、1、2页),提取并切割文本
data = extract_text_from_pdf('财务管理文档.pdf', page_numbers=[0, 1, 2])
# 2. 创建向量库,表名test
vect = MyVectorDBConnector('test')
# 3. 把PDF文本存入向量库
vect.add_documents(data)
# 4. 用户提问:查询财务管理权限划分
user_query = "财务管理权限划分?"
# 5. 创建RAG机器人,绑定向量库
rag = RAG_Bot(vect)
# 6. 启动问答
rag.chat(user_query)json文件的内容,这个内容有点违规,是医学方面的没法全放出来,格式就是下发的格式,内容去网上找吧
json
{"instruction": "这段时间去xxxxxxxxx", "input": "", "output": "这可能是因为你的饮食习惯或者消化系统的问题导致的。建议你试着调整一下饮食,增加膳食纤维的摄入量,多喝水,避免过度依赖泻药。同时,如果问题持续存在,建议去医院检查一下,排除肠道疾病等可能性。"}
{"instruction": "医生呀!我刚被查出得了白癜风,不知道初期治疗需要多少钱?", "input": "", "output": "白癜风的治疗费用因个体差异和治疗方案的不同而有所差异。初期治疗主要以口服药物和外用药物为主,费用相对较低,一般几百元左右。但是,如果采用激光治疗、光疗等高端治疗方法,费用会更高。建议您咨询专业医生,根据自己的情况进行治疗方案的选择,同时了解相关的费用情况。"}