论文信息
- 标题:DACS: DOMAIN ADAPTATION VIA CROSS-DOMAIN MIXED SAMPLING
- 会议:arXiv 2020
- 单位:Volvo Cars & Chalmers University of Technology
- 代码:github.com/vikolss/DACS
- 论文:https://arxiv.org/pdf/2007.08702v1
引言:自动驾驶里的"水土不服"难题
想象一下,你是一名自动驾驶算法工程师,花了三个月训练了一个语义分割模型,用的是GTA5游戏里的2.5万张合成图像------标注免费又精准,连每根电线杆的像素都标得清清楚楚。结果你把模型装到真实测试车上,一开出去就傻眼了:模型把所有人行道都当成了马路,把骑自行车的骑手全归成了行人,连路边的围栏都识别成了植被。
这就是深度学习里臭名昭著的域偏移(Domain Shift)问题:模型在训练数据(源域)上学得好好的,一到测试数据(目标域)就彻底翻车。更头疼的是,真实世界的标注成本高得吓人------标注一张Cityscapes级别的语义分割图要花3个小时,一个熟练标注师一个月也标不完1000张。
这时候就轮到无监督域适应(UDA)大显身手了:不用给目标域数据打任何标签,让模型把从有标签源域学到的知识,自动迁移到无标签的目标域。过去几年,基于伪标签(模型自己给自己打标签)的方法取得了不错的效果,但一直有个致命缺陷:容易出现类别混淆------模型会偏向那些容易迁移的类别,把难识别的类别直接"遗忘"掉。
今天我们要聊的DACS算法,用一个极其简单却异常有效的思路解决了这个问题:把源域有真实标签的图像和目标域无标签的图像混在一起训练。就这么一个小小的改动,直接在两个最权威的合成到真实语义分割基准上刷新了SOTA(当前最优)。
问题根源:为什么半监督的ClassMix在UDA里翻车了?
在讲DACS之前,我们得先了解它的"前身"------ClassMix,这是2020年提出的一个半监督语义分割数据增强方法,当时在半监督任务上取得了碾压性的效果。
ClassMix:半监督领域的"混合大师"
ClassMix的核心思想很简单:既然半监督学习里大部分数据没有标签,那我们就把两张无标签图像按类别混合起来,生成新的训练样本。具体流程如图1所示:
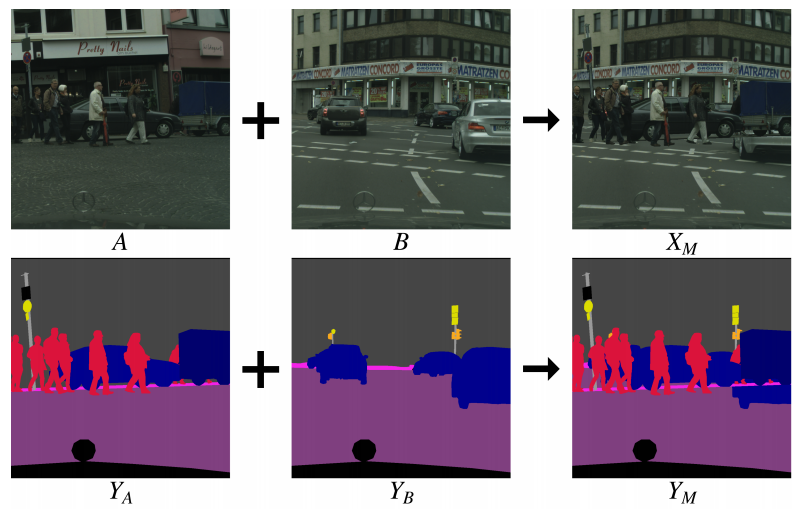
图1 ClassMix数据增强示意图(来源:论文Figure 1)
- 用当前模型对两张无标签图像A和B做预测,生成伪标签YAY_AYA和YBY_BYB
- 随机选择YAY_AYA中一半的类别,生成一个二进制掩码MMM(选中类别对应的像素为1,其余为0)
- 用掩码混合图像和标签:
XM=M⊙A+(1−M)⊙BX_M = M \odot A + (1-M) \odot BXM=M⊙A+(1−M)⊙B
YM=M⊙YA+(1−M)⊙YBY_M = M \odot Y_A + (1-M) \odot Y_BYM=M⊙YA+(1−M)⊙YB
其中:- XMX_MXM:混合后的图像
- YMY_MYM:混合后的伪标签
- ⊙\odot⊙:逐元素乘法(就是对应位置的像素相乘,相当于用掩码"抠图")
- AAA、BBB:两张待混合的原始图像
这个方法在半监督任务上效果拔群,于是大家很自然地想:能不能直接把它用到UDA里?毕竟UDA里目标域也是无标签数据啊。
Naive ClassMix:理想很丰满,现实很骨感
研究者们做了一个最直观的尝试:把ClassMix直接用在目标域内部,混合两张目标域图像,然后和源域有标签数据一起训练。这个方法被称为"Naive ClassMix",流程如图2所示:
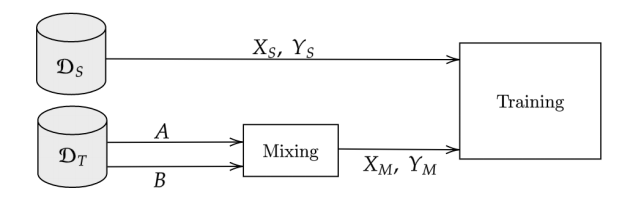
图2 Naive ClassMix在UDA中的应用流程(来源:论文Figure 2)
结果却大跌眼镜:模型性能不仅没提升,反而出现了严重的类别混淆。比如在GTA5→Cityscapes任务上,Naive ClassMix把人行道(Sidewalk)的IoU直接干到了0%,骑手(Rider)也变成了0%,全被模型当成了马路和行人。
为什么会这样?论文作者给出了一针见血的分析:
- UDA的域偏移比半监督学习大得多,目标域的伪标签质量本来就很差
- 当所有混合样本的标签都来自低质量伪标签时,模型会陷入"错误自增强"的恶性循环:越训练,对容易类别的预测越自信,对难类别的预测越差,最后直接把难类别"遗忘"了
- 更糟糕的是,模型还会偷偷学会区分源域和目标域图像,然后给两个域套用完全不同的分类规则
DACS核心思路:跨域混合,注入真实标签
既然目标域内部混合会因为伪标签质量差而翻车,那如果我们把源域有真实标签的部分混进去呢?这就是DACS的核心创新:跨域混合采样。
一个简单却天才的改动
DACS没有在目标域内部混合,而是把一张源域图像(有真实标签)和一张目标域图像(无标签)混合在一起,流程如图3所示:
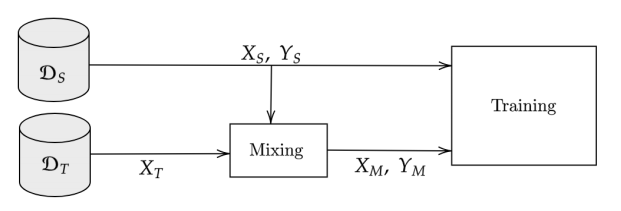
图3 DACS跨域混合采样流程(来源:论文Figure 3)
具体来说:
- 从源域采样一张图像XSX_SXS和对应的真实标签YSY_SYS
- 从目标域采样一张图像XTX_TXT,用当前模型预测得到伪标签Y^T\hat{Y}_TY^T
- 从源域真实标签YSY_SYS中随机选择一半的类别,生成二进制掩码MMM
- 用掩码混合图像和标签:
XM=M⊙XS+(1−M)⊙XTX_M = M \odot X_S + (1-M) \odot X_TXM=M⊙XS+(1−M)⊙XT
YM=M⊙YS+(1−M)⊙Y^TY_M = M \odot Y_S + (1-M) \odot \hat{Y}_TYM=M⊙YS+(1−M)⊙Y^T
图4展示了一个实际的混合例子:左边是GTA5的合成图像,中间是Cityscapes的真实图像,右边是混合后的结果。可以看到,混合图像里既有合成的汽车和建筑,也有真实的马路和天空,看起来有点奇怪,但这完全不影响训练效果。

图4 DACS混合示例:GTA5合成图像与Cityscapes真实图像混合(来源:论文Figure 4)
为什么跨域混合能解决类别混淆?
这个小小的改动之所以能产生奇效,主要有两个原因:
- 注入可靠的监督信号 :混合标签YMY_MYM里有一部分来自源域的真实标签,这部分是绝对正确的。无论模型的伪标签有多差,真实标签部分都会"拉着"模型,不让它把难类别彻底遗忘
- 打破域区分能力:现在源域和目标域的像素可能出现在同一张图像里,甚至是相邻的位置。模型再也不能简单地通过"这是合成图还是真实图"来套用不同的分类规则,只能真正学习到类别本身的语义特征
DACS算法详解
完整算法流程
DACS的完整算法非常简洁,伪代码如下:
算法1 DACS算法
输入:源域数据集DSD_SDS,目标域数据集DTD_TDT,分割网络fθf_\thetafθ
输出:训练好的分割网络fθf_\thetafθ
1: 随机初始化网络参数θ\thetaθ
2: for 迭代次数 i = 1 to N do
3: 从DSD_SDS采样一批源域图像和标签:XS,YS∼DSX_S, Y_S \sim D_SXS,YS∼DS
4: 从DTD_TDT采样一批目标域图像:XT∼DTX_T \sim D_TXT∼DT
5: 用当前模型预测目标域伪标签:Y^T←fθ(XT)\hat{Y}T \leftarrow f\theta(X_T)Y^T←fθ(XT)
6: 执行跨域混合,生成混合图像和标签:XM,YM←Mix(XS,YS,XT,Y^T)X_M, Y_M \leftarrow \text{Mix}(X_S, Y_S, X_T, \hat{Y}_T)XM,YM←Mix(XS,YS,XT,Y^T)
7: 前向传播得到预测结果:Y^S←fθ(XS),Y^M←fθ(XM)\hat{Y}S \leftarrow f\theta(X_S), \hat{Y}M \leftarrow f\theta(X_M)Y^S←fθ(XS),Y^M←fθ(XM)
8: 计算总损失:
L=1B∑i=1BH(Y\^Si,YSi)+λH(Y\^Mi,YMi)\mathcal{L} = \frac{1}{B} \sum_{i=1}^B \left H(\\hat{Y}_S\^i, Y_S\^i) + \\lambda H(\\hat{Y}_M\^i, Y_M\^i) \\rightL=B1i=1∑BH(Y\^Si,YSi)+λH(Y\^Mi,YMi)9: 反向传播更新参数θ\thetaθ
10: end for
11: return fθf_\thetafθ
损失函数详解
DACS的损失函数由两部分组成:源域监督损失和混合样本无监督损失:
L(θ)=EH(fθ(xS),yS)+λH(fθ(xM),yM)\mathcal{L}(\theta) = \mathbb{E}\left H(f_\\theta(x_S), y_S) + \\lambda H(f_\\theta(x_M), y_M) \\rightL(θ)=EH(fθ(xS),yS)+λH(fθ(xM),yM)
其中每个符号的含义:
- L(θ)\mathcal{L}(\theta)L(θ):模型参数θ\thetaθ对应的总损失
- E\mathbb{E}E:数学期望(对所有训练样本求平均)
- HHH:交叉熵损失(衡量预测结果和标签之间的差距,差距越大损失越高)
- fθf_\thetafθ:我们训练的语义分割网络,参数为θ\thetaθ
- xSx_SxS:源域图像(有真实标签)
- ySy_SyS:源域图像的真实标签
- λ\lambdaλ:超参数,控制无监督损失的权重(论文中使用自适应λ\lambdaλ,等于混合图像中置信度高于阈值的像素比例)
- xMx_MxM:跨域混合后的图像
- yMy_MyM:混合图像对应的标签(部分来自源域真实标签,部分来自目标域伪标签)
核心代码实现
下面是DACS跨域混合函数的PyTorch实现,完全对应论文中的算法:
python
import torch
import torch.nn.functional as F
def dacs_cross_domain_mix(
source_images: torch.Tensor,
source_labels: torch.Tensor,
target_images: torch.Tensor,
target_pseudos: torch.Tensor,
num_classes: int = 19,
ignore_label: int = 255
) -> tuple[torch.Tensor, torch.Tensor]:
"""
DACS跨域混合采样核心实现
Args:
source_images: 源域图像张量,形状为[B, 3, H, W]
source_labels: 源域真实标签张量,形状为[B, H, W]
target_images: 目标域图像张量,形状为[B, 3, H, W]
target_pseudos: 目标域伪标签张量,形状为[B, H, W]
num_classes: 语义分割类别总数
ignore_label: 忽略标签的值(通常为255)
Returns:
mixed_images: 混合后的图像张量,形状为[B, 3, H, W]
mixed_labels: 混合后的标签张量,形状为[B, H, W]
"""
batch_size, _, height, width = source_images.shape
mixed_images = torch.zeros_like(source_images)
mixed_labels = torch.zeros_like(source_labels)
for batch_idx in range(batch_size):
# 1. 从源域标签中提取所有有效类别(排除忽略标签)
unique_classes = torch.unique(source_labels[batch_idx])
valid_classes = unique_classes[unique_classes != ignore_label]
# 2. 随机选择一半的类别用于混合
num_selected = max(1, len(valid_classes) // 2) # 至少选1个类别
selected_classes = valid_classes[torch.randperm(len(valid_classes))[:num_selected]]
# 3. 生成二进制掩码:选中类别对应的像素为True,其余为False
mask = torch.zeros((height, width), dtype=torch.bool, device=source_images.device)
for cls in selected_classes:
mask = mask | (source_labels[batch_idx] == cls)
# 4. 扩展掩码到图像通道维度(3通道)
mask_3ch = mask.unsqueeze(0).expand(3, height, width)
# 5. 混合图像:掩码为True取源域像素,否则取目标域像素
mixed_images[batch_idx] = torch.where(mask_3ch, source_images[batch_idx], target_images[batch_idx])
# 6. 混合标签:掩码为True取源域真实标签,否则取目标域伪标签
mixed_labels[batch_idx] = torch.where(mask, source_labels[batch_idx], target_pseudos[batch_idx])
return mixed_images, mixed_labels实验结果与分析
为了验证DACS的有效性,作者在两个最权威的合成到真实语义分割基准上进行了测试:GTA5→Cityscapes和SYNTHIA→Cityscapes。所有实验都使用DeepLab-v2+ResNet101作为骨干网络,和之前的SOTA方法保持一致。
数据集介绍
三个数据集的示例图像和语义标签如图5所示:
- Cityscapes:目标域,包含2975张真实城市场景图像,标注19个类别
- GTA5:源域1,包含24966张GTA5游戏合成图像,标注19个和Cityscapes完全一致的类别
- SYNTHIA :源域2,包含9400张合成城市场景图像,标注16个类别

图5 三个数据集的示例图像与语义标签(来源:论文Figure 5)
GTA5→Cityscapes:碾压性的SOTA
表1展示了GTA5→Cityscapes任务的定量结果,DACS以52.14%的mIoU大幅超越了之前的所有方法,比第二名R-MRNet高出2.3个百分点。
表1 GTA5→Cityscapes任务结果对比(mIoU,%)
| 方法 | 道路 | 人行道 | 建筑 | 墙 | 围栏 | 杆 | 交通灯 | 交通标志 | 植被 | 地形 | 天空 | 行人 | 骑手 | 汽车 | 卡车 | 公交车 | 火车 | 摩托车 | 自行车 | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | 63.3 | 15.7 | 59.4 | 8.6 | 15.2 | 18.3 | 26.9 | 15.0 | 80.5 | 15.3 | 73.0 | 51.0 | 17.7 | 59.7 | 28.2 | 33.1 | 3.5 | 23.2 | 16.7 | 32.9 |
| Naive ClassMix | 84.8 | 0.0 | 82.8 | 0.3 | 0.1 | 10.6 | 48.0 | 58.9 | 86.9 | 8.1 | 91.0 | 56.1 | 0.0 | 86.9 | 40.5 | 11.4 | 0.0 | 0.5 | 0.0 | 35.1 |
| DACS | 89.9 | 39.7 | 87.9 | 30.7 | 39.5 | 38.5 | 46.4 | 52.8 | 88.0 | 44.0 | 88.8 | 67.2 | 35.8 | 84.5 | 45.7 | 50.2 | 0.0 | 27.3 | 34.0 | 52.1 |
| 之前SOTA (R-MRNet) | 87.6 | 41.9 | 83.1 | 14.7 | 1.7 | 36.2 | 31.3 | 19.9 | 81.6 | 80.6 | 63.0 | 21.8 | 86.2 | 40.7 | 23.6 | 53.1 | - | - | - | 49.8 |
结果分析:
- Naive ClassMix虽然整体mIoU比Source高了2.2个百分点,但付出了惨痛的代价:人行道、骑手、摩托车、自行车这四个类别的IoU直接变成了0%,完全被模型遗忘了
- DACS不仅整体mIoU提升了17个百分点,还完美解决了类别混淆问题:人行道IoU从0%飙升到39.7%,骑手从0%到35.8%,所有类别都得到了有效学习
- DACS在8个类别上取得了最优结果,尤其是墙、围栏、杆这些难迁移的类别,提升幅度非常明显
图6展示了定性结果对比,可以直观地看到DACS的效果:
- Source模型(只在源域训练)的预测结果非常粗糙,很多细节都识别错了
- Naive ClassMix虽然整体好了一些,但完全没有识别出人行道,全当成了马路
- DACS的预测结果和真实标签非常接近,不仅准确区分了马路和人行道,还正确识别了骑手和行人

图6 定性结果对比:Source、Naive ClassMix与DACS(来源:论文Figure 6)
SYNTHIA→Cityscapes:继续刷新SOTA
表2展示了SYNTHIA→Cityscapes任务的结果,DACS同样取得了SOTA:在16类评估上达到48.34%的mIoU,在13类评估上达到54.81%的mIoU。
表2 SYNTHIA→Cityscapes任务结果对比(mIoU,%)
| 方法 | 13类mIoU | 16类mIoU |
|---|---|---|
| Source | 33.7 | 29.5 |
| AdaptSegNet | 46.7 | - |
| CLAN | 47.8 | - |
| APODA | 53.1 | - |
| CBST | 48.9 | 42.6 |
| MRKLD | 50.1 | 43.8 |
| R-MRNet | 54.9 | 47.9 |
| DACS | 54.8 | 48.3 |
结果分析:
- DACS在16类评估上超越了之前的SOTA R-MRNet(48.34% vs 47.9%)
- 在13类评估上和R-MRNet基本持平(54.81% vs 54.9%)
- 有趣的是,DACS在GTA5→Cityscapes上的提升比SYNTHIA→Cityscapes大得多。作者分析这是因为GTA5和Cityscapes的视角更相似(都是车载视角),而SYNTHIA有很多奇怪的视角(比如俯视),混合出来的图像更不真实,所以效果稍差
额外实验揭秘
早期停止的"作弊"行为
作者发现,之前很多SOTA方法都使用了基于验证集的早期停止,也就是在训练过程中不断在验证集上测试,保存效果最好的模型。但Cityscapes没有公开的测试集,大家都是用验证集来报告结果,这其实是一种"作弊"行为------模型实际上是在验证集上过拟合了。
如果DACS也使用早期停止,结果会更加惊人:
- GTA5→Cityscapes的mIoU会从52.14%提升到53.84%,比之前的SOTA高出3.5个百分点
- SYNTHIA→Cityscapes的16类mIoU会提升到49.10%,13类提升到55.98%
为什么会发生类别混淆?
为了搞清楚类别混淆的根源,作者做了一个对比实验:
- 只使用伪标签训练(不混合):结果更差,有更多类别被遗忘,mIoU只有22.97%
- 给Naive ClassMix加上分布对齐(强制伪标签的类别分布和真实分布一致):类别混淆问题解决了,mIoU达到48.04%
这说明:
- 类别混淆的根源是伪标签,而不是混合操作
- 无论是DACS的跨域混合,还是分布对齐,本质上都是在给训练过程注入"熵"------也就是让模型不要太自信,不要把难类别直接遗忘
结论与展望
DACS用一个极其简单却异常有效的思路,解决了无监督域适应语义分割中长期存在的类别混淆问题。它的核心贡献可以总结为三点:
- 首次将半监督的ClassMix方法应用到UDA中,并指出了直接应用会导致类别混淆的问题
- 提出了跨域混合采样的思路,通过注入源域真实标签,完美解决了类别混淆问题
- 在两个权威基准上刷新了SOTA,证明了方法的有效性
DACS的成功给我们一个重要启示:有时候,最复杂的问题往往有最简单的解决方案。与其花大力气去设计复杂的伪标签修正模块,不如换个思路,从数据增强的角度入手,让模型在更丰富的样本上学习。
未来,DACS还有很多可以拓展的方向:
- 如何自动选择最优的混合类别比例,而不是简单地选一半
- 如何结合不确定性估计,只混合高置信度的目标域伪标签
- 如何将跨域混合的思路应用到其他视觉任务,比如目标检测、实例分割