一、引言
在 Flink 1.13 版本之前,StateBackend 接口是一个"大杂烩",它同时负责两件事:
- 状态的本地访问与存储(Task 运行时状态存在哪?内存还是 RocksDB?)
- Checkpoint 数据的持久化(做快照时,状态备份到哪?JobManager 还是 HDFS?)
这种设计导致了概念上的混淆(例如 FsStateBackend 运行时其实使用的是 TaskManager 的堆内存,但名字却带有 Fs)。为了让职责更清晰,Flink 1.13+ 正式将这两者解耦。
| 概念 | 职责 | 类比 |
|---|---|---|
| State Backend | 管理运行时状态的存储与访问方式 | 相当于"内存/磁盘"------决定你在工作时把数据放在哪里 |
| Checkpoint Storage | 管理检查点快照的持久化存储位置 | 相当于"备份仓库"------决定你把备份数据存到哪里 |
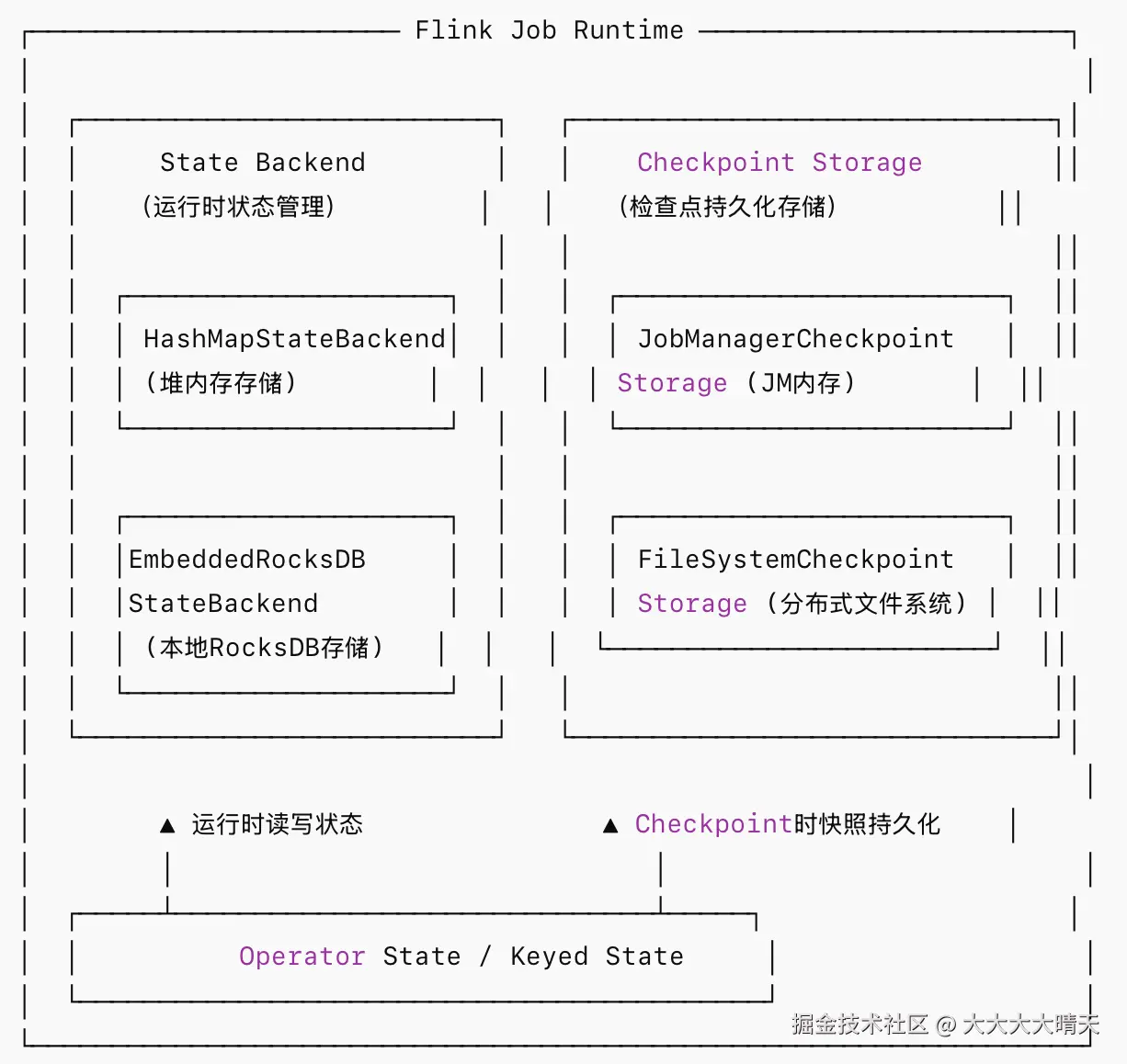
二、State Backend
State Backend 决定了运行时状态数据的存储介质和访问方式,目前主推两种 State Backend。
1.HashMapStateBackend
- 状态以 Java 对象形式直接存储在 TaskManager 的 JVM 堆内存中
- 读写速度最快(直接内存访问,无序列化/反序列化开销)
- 状态大小受限于 JVM 堆内存容量
- 不支持增量 Checkpoint(每次 Checkpoint 需要全量序列化整个状态)
2.EmbeddedRocksDBStateBackend
- 状态存储在 TaskManager 本地磁盘上的嵌入式 RocksDB 实例中
- 读写涉及序列化/反序列化(Java 对象 ↔ byte\[\]),有一定性能开销
- 状态大小仅受限于本地磁盘容量,可以管理超大规模状态(TB 级别)
- 支持增量 Checkpoint(基于 RocksDB SST 文件的增量上传)
- RocksDB 的 Block Cache 和 Write Buffer 会占用 堆外内存(Off-Heap)
3.两种StateBackend对比
| 维度 | HashMapStateBackend | EmbeddedRocksDBStateBackend |
|---|---|---|
| 存储介质 | JVM 堆内存 | 本地磁盘(RocksDB) |
| 访问速度 | ⚡ 极快(直接内存访问) | 🐢 较慢(涉及序列化 + 磁盘I/O) |
| 状态规模上限 | 受限于堆内存(通常 GB 级) | 受限于磁盘(可达 TB 级) |
| 增量 Checkpoint | ❌ 不支持 | ✅ 支持 |
| 内存管理 | JVM GC 管理 | Flink Managed Memory 管理 |
| 典型吞吐量影响 | 对吞吐量影响小 | 约降低 30%~50%(取决于状态访问频率) |
| 适用场景 | 小状态、高吞吐 | 大状态、超大 Key 数量 |
三、Checkpoint Storage
Checkpoint Storage 决定了Checkpoint 快照数据的持久化位置,目前主推两种 Checkpoint Storage。
1.JobManagerCheckpointStorage
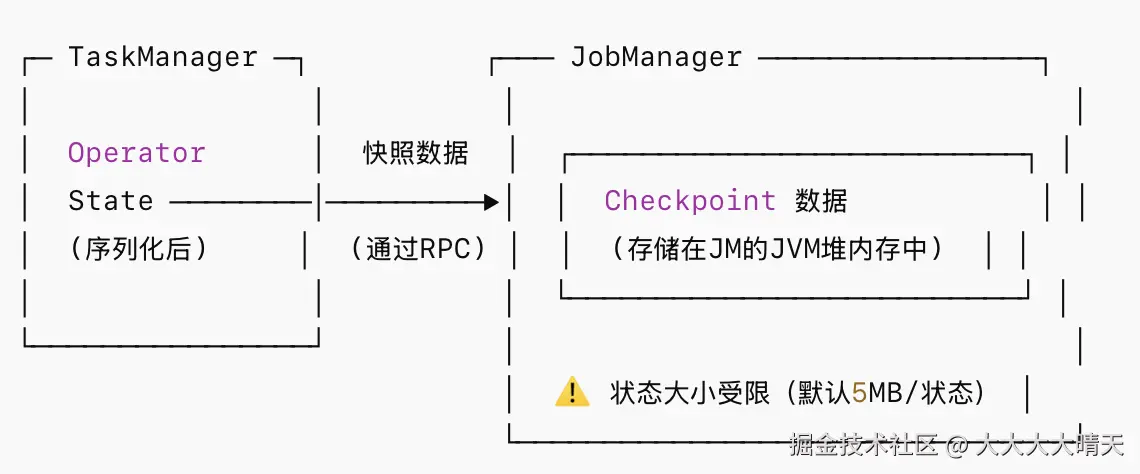
- Checkpoint 数据通过 RPC 发送至 JobManager,存储在其堆内存中
- 每个独立状态的大小上限默认为 5 MB(可配置
MAX_STATE_SIZE) - 仅适用于本地开发/测试,生产环境绝不应使用
- 作业失败时如果 JobManager 也崩溃,Checkpoint 数据丢失
2.FileSystemCheckpointStorage
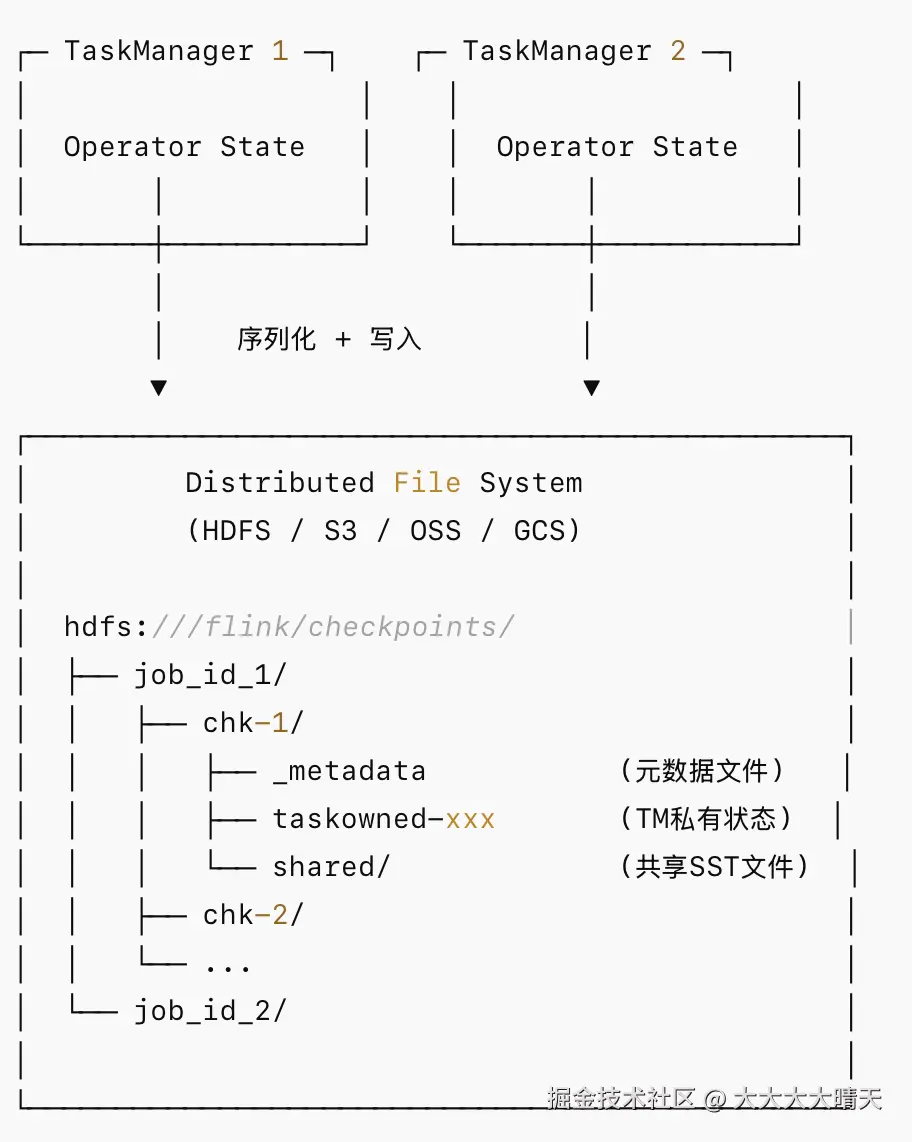
- Checkpoint 数据写入分布式文件系统,具备高可用性和持久性
- 小状态(默认阈值 20KB)仍会内联存储在
_metadata文件中,避免创建过多小文件 - 生产环境唯一推荐的 Checkpoint Storage
- 支持与 EmbeddedRocksDBStateBackend 配合实现增量 Checkpoint
3.Checkpoint完整流程
| 步骤 | 说明 | 涉及组件 |
|---|---|---|
| ① | CheckpointCoordinator 按配置的间隔周期性触发 | JobManager |
| ② | Checkpoint Barrier 作为特殊事件插入数据流 | Source → 下游 |
| ③ | 多输入算子等待所有 Channel 的 Barrier 到齐(对齐模式) | Operator |
| ④ | 同步阶段:创建状态快照的引用(非常快,通常 ms 级) | State Backend |
| ⑤ | 异步阶段:将状态数据写入持久化存储(可能耗时较长) | Checkpoint Storage |
| ⑥ | TaskManager 向 JobManager 报告该算子的 Checkpoint 完成 | TM → JM |
| ⑦ | 所有算子 Ack 后,Checkpoint 被标记为完成 | JobManager |
四、State Backend与Checkpoint Storage关系
| 旧版 (< 1.13,已废弃) | 等价的新版组合 (≥ 1.13) |
|---|---|
| MemoryStateBackend | HashMapStateBackend + JobManagerCheckpointStorage |
| FsStateBackend | HashMapStateBackend + FileSystemCheckpointStorage |
| RocksDBStateBackend | EmbeddedRocksDBStateBackend + FileSystemCheckpointStorage |
在Flink现在新版本的使用中,两者结合的组合矩阵建议如下:
| 组合 | State Backend | Checkpoint Storage | 适用性 |
|---|---|---|---|
| A | HashMapStateBackend | JobManagerCheckpointStorage | ⚠️ 仅开发/测试 |
| B | HashMapStateBackend | FileSystemCheckpointStorage | ✅ 生产推荐(中小状态) |
| C | EmbeddedRocksDBStateBackend | JobManagerCheckpointStorage | ❌ 不推荐(无实际意义) |
| D | EmbeddedRocksDBStateBackend | FileSystemCheckpointStorage | ✅ 生产推荐(大状态) |
以下是大多数生产环境下的推荐配置(适用于大状态、高可用场景):
yaml
# ===== State Backend =====
state.backend: rocksdb
state.backend.incremental: true
state.backend.rocksdb.localdir: /data1/flink/rocksdb,/data2/flink/rocksdb
state.backend.rocksdb.memory.managed: true
state.backend.rocksdb.predefined-options: FLASH_SSD_OPTIMIZED
# ===== Checkpoint Storage =====
state.checkpoint-storage: filesystem
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/savepoints
# ===== Checkpoint 行为 =====
execution.checkpointing.interval: 2min
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.timeout: 10min
execution.checkpointing.min-pause: 1min
execution.checkpointing.max-concurrent-checkpoints: 1
# ===== 保留策略 =====
state.checkpoints.num-retained: 3
# ===== 内存配置 =====
taskmanager.memory.managed.fraction: 0.4