第七章 指令微调学习(三)
7.4为指令数据集创建数据加载器
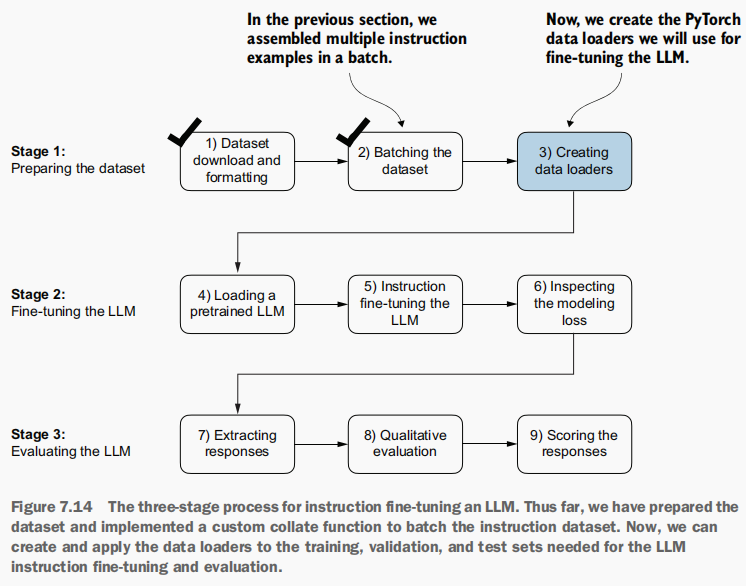
已经实现了custom_collate_fn函数和InstructionDataset类,接下来,需要创建用于微调大语言模型(LLM)的PyTorch数据加载器。
(1)对custom_collate_fn的device设置进行说明
在开始之前,对custom_collate_fn的device设置进行说明。该函数包含将输入张量和目标张量(例如 torch.stackinputs_lst)迁移至指定设备的代码------该设备可为"cpu"或"cuda"(适用于 NVIDIA GPU),也可选择性地使用针对搭载Apple Silicon芯片的Mac系统的"mps"。
注意 :使用"mps"设备可能导致其数值与本章所述内容存在差异,因为PyTorch对Apple Silicon的支持仍处于实验阶段。
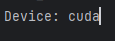
下面为初始化设备变量的代码:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# if torch.backends.mps.is_available():
# device = torch.device("mps")"
print("Device:", device)运行会输出自己电脑的设备cpu or cuda:
(2)利用 Python 标准库 functools 中的部分函数创建一个新custom_collate_fn 函数
接下来,为了在将选定的设备设置插入 PyTorch DataLoader 类时能在 custom_collate_fn 中复用该设置,我们利用 Python 标准库 functools 中的部分函数创建了一个新的函数版本,其中设备参数已预先填充。同时,我们将 allowed_max_length 设置为 1024,这会将数据截断至 GPT-2 模型支持的最大上下文长度。
python
from functools import partial
customized_collate_fn = partial(
custom_collate_fn,
device=device,
allowed_max_length=1024
)这段代码的作用是创建一个新的、参数固定的 customized_collate_fn 函数。
具体来说:
partial函数 :来自functools模块,它允许我们"固定"一个函数的部分参数,从而生成一个新的函数。- 固定参数 :我们将原始的
custom_collate_fn函数的device参数固定为当前确定的device(例如"cuda"或"cpu"),并将allowed_max_length参数固定为1024。 - 生成新函数 :
customized_collate_fn现在是一个新的函数,它只需要接受InstructionDataset返回的批次数据作为输入,内部会自动使用我们预设的device和allowed_max_length参数进行处理。 - 目的 :这样做是为了方便地将这个配置好的函数传递给 PyTorch 的
DataLoader(在下一步的collate_fn参数中使用),而无需在每次调用时重复传入device和allowed_max_length参数,使代码更简洁、易用。
关于参数覆盖的说明:
partial(custom_collate_fn, device=device, allowed_max_length=1024) 不会覆盖 原始函数 custom_collate_fn 的定义。
它的工作原理是:
- 创建新函数 :
partial返回一个新的函数对象 (这里命名为customized_collate_fn)。 - 固定参数值 :这个新函数在内部调用原始
custom_collate_fn时,会自动为我们指定的参数(device和allowed_max_length)提供我们传入的值。 - 参数优先级 :当我们调用
customized_collate_fn(batch)时,它相当于调用custom_collate_fn(batch, device=device, allowed_max_length=1024)。如果原始函数还有其他参数(如pad_token_id,ignore_index),它们将保持其默认值(50256 和 -100),除非我们在调用customized_collate_fn时显式地覆盖它们(例如customized_collate_fn(batch, ignore_index=-200))。
总结 :partial 是"预设"参数,而不是"修改"原函数。原始 custom_collate_fn 的代码和默认参数保持不变。
(3)初始化数据加载器
接下来,我们可以按照先前的方法配置数据加载器,但此次我们将使用自定义custom_collate_fn函数来处理批量处理流程。
初始化数据加载器,包括训练验证和测试。
python
#初始化数据加载器
from torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_dataset = InstructionDataset(train_data, tokenizer)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=True,
drop_last=True,
num_workers=num_workers
)
val_dataset = InstructionDataset(val_data, tokenizer)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
test_dataset = InstructionDataset(test_data, tokenizer)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)(4)分析训练加载器生成的输入批次和目标批次的维度:
python
print("Train loader:")
for inputs, targets in train_loader:
print(inputs.shape, targets.shape)输出:
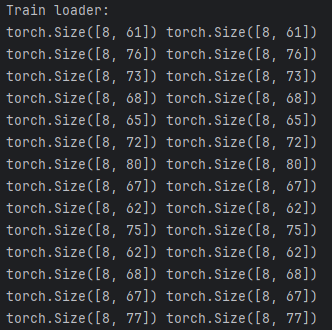
省略一部分结果,太长了...
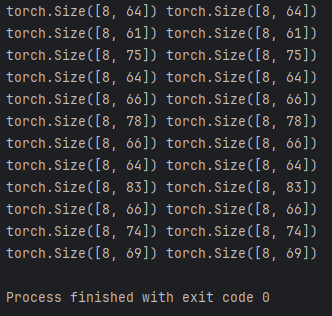
该输出显示,第一个输入批次和目标批次的维度均为 8 × 61,其中 8 表示批次大小,61 表示该批次中每个训练样本的标记数量 ;第二个输入批次和目标批次的标记数量则不同(例如为 76)。得益于我们自定义的custom_collate_fn 函数,数据加载器能够生成长度各异 的数据批次。在下一节中,我们将加载一个预训练的大型语言模型(LLM),并利用该数据加载器对其进行微调。
完整代码如下:
python
import json
import os
import urllib
import urllib.request # 这里改成导入子模块
from dis import Instruction
def download_and_load_file(file_path,url):
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode("utf-8")
with open(file_path,"w",encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
with open(file_path, "r") as file:
data = json.load(file)
return data
file_path = "instruction-data.json"
url = (
"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch"
"/main/ch07/01_main-chapter-code/instruction-data.json"
)
data = download_and_load_file(file_path, url)
print("Number of entries:", len(data))
print("Example entry:\n", data[50])
print("Another example entry:\n", data[999])
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = (
f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
)
return instruction_text + input_text
model_input = format_input(data[50])
desired_response = f"\n\n### Response:\n{data[50]['output']}"
print(model_input + desired_response)
model_input = format_input(data[999])
desired_response = f"\n\n### Response:\n{data[999]['output']}"
print(model_input + desired_response)
train_portion = int(len(data) * 0.85)
test_portion = int(len(data) * 0.1)
val_portion = len(data) - train_portion - test_portion
train_data = data[:train_portion]
test_data = data[train_portion:train_portion + test_portion]
val_data = data[train_portion + test_portion:]
print("Training set length:", len(train_data))
print("Validation set length:", len(val_data))
print("Test set length:", len(test_data))
#5.11
import torch
from torch.utils.data import Dataset
class InstructionDataset(Dataset):
def __init__(self,data,tokenizer):
self.data = data
self.encoded_texts = []
for entry in data:
instruction_plus_input = format_input(entry)#输入指令和输入内容格式转化
response_text = f"\n\n### Response:\n{entry['output']}"#输出内容格式转化
full_text = instruction_plus_input + response_text
self.encoded_texts.append(
tokenizer.encode(full_text)#分词处理
)
def __getitem__(self, index):
return self.encoded_texts[index]
def __len__(self):
return len(self.data)
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
print(tokenizer.encode("<|endoftext|>", allowed_special={"<|endoftext|>"}))#50256
def custom_collate_draft_1(
batch,
pad_token_id=50256,
device="cpu"
):
batch_max_length = max(len(item)+1 for item in batch)#计算批次中每个序列的长度加 1,再取最大值
print("batch_max_length:", batch_max_length)
inputs_lst = []
for item in batch:
new_item = item.copy()
new_item += [pad_token_id] #在原始序列末尾添加一个填充标记
print("new_item _length:",len(new_item))
padded = (new_item + [pad_token_id] *(batch_max_length - len(new_item)))#填充到最大长度batch_max_length
print("padded_length:",len(padded))
inputs = torch.tensor(padded[:-1]) #去掉填充后序列的最后一个元素,长度为batch_max_length-1
inputs_lst.append(inputs) #将所有处理后的 inputs 放入列表 inputs_lst,
inputs_tensor = torch.stack(inputs_lst).to(device) #然后用 torch.stack 堆叠成一个二维张量,并移动到指定设备
return inputs_tensor
inputs_1 = [0, 1, 2, 3, 4]
inputs_2 = [5, 6]
inputs_3 = [7, 8, 9]
batch = (
inputs_1,
inputs_2,
inputs_3
)
print(custom_collate_draft_1(batch))
def custom_collate_draft_2(
batch,
pad_token_id=50256,
device="cpu"
):
batch_max_length = max(len(item)+1 for item in batch)
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
new_item += [pad_token_id]
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1])
targets = torch.tensor(padded[1:]) #新增加的,去掉第一位token
inputs_lst.append(inputs)
targets_lst.append(targets) #新增加的,目标token
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device) #新增加的,目标token
return inputs_tensor, targets_tensor
inputs, targets = custom_collate_draft_2(batch)
print(inputs)
print(targets)
def custom_collate_fn(
batch,
pad_token_id = 50256,
ignore_index = -100,#新增加的,
allowed_max_length = None,#新增加的,
device = "cpu"
):
batch_max_length = max(len(item) + 1 for item in batch)
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
new_item += [pad_token_id]
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1])
targets = torch.tensor(padded[1:])
mask = targets == pad_token_id #新增加的,除第一个标记外,其余掩码,targets == pad_token_id为判断条件
indices = torch.nonzero(mask).squeeze()
if indices.numel() > 1:
targets[indices[1:]] = ignore_index
if allowed_max_length is not None:
inputs = inputs[:allowed_max_length]#新增加的,限制允许的最大长度,超过截断
targets = targets[:allowed_max_length]
inputs_lst.append(inputs)
targets_lst.append(targets)
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor
inputs, targets = custom_collate_fn(batch)
print(inputs)
print(targets)
logits_1 = torch.tensor(
[[-1.0, 1.0],
[-0.5, 1.5]]
)
targets_1 = torch.tensor([0, 1]) # Correct token indices to generate
loss_1 = torch.nn.functional.cross_entropy(logits_1, targets_1)
print(loss_1)
logits_2 = torch.tensor(
[[-1.0, 1.0],
[-0.5, 1.5],
[-0.5, 1.5]]
)
targets_2 = torch.tensor([0, 1, 1])
loss_2 = torch.nn.functional.cross_entropy(logits_2, targets_2)
print(loss_2)
targets_3 = torch.tensor([0, 1, -100])
loss_3 = torch.nn.functional.cross_entropy(logits_2, targets_3)
print(loss_3)
print("loss_1 == loss_3:", loss_1 == loss_3)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# if torch.backends.mps.is_available():
# device = torch.device("mps")"
print("Device:", device)
from functools import partial
customized_collate_fn = partial(
custom_collate_fn,
device=device,
allowed_max_length=1024
)
#初始化数据加载器
from torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_dataset = InstructionDataset(train_data, tokenizer)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=True,
drop_last=True,
num_workers=num_workers
)
val_dataset = InstructionDataset(val_data, tokenizer)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
test_dataset = InstructionDataset(test_data, tokenizer)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
print("Train loader:")
for inputs, targets in train_loader:
print(inputs.shape, targets.shape)7.5加载预训练的大语言模型
加载大语言模型进行微调。
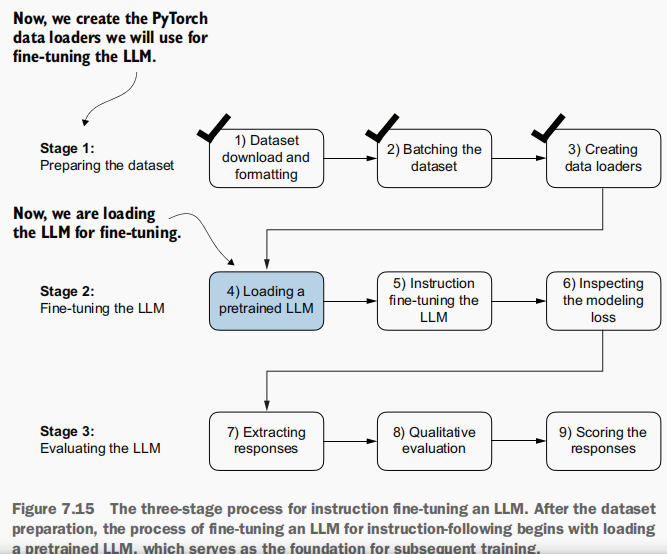
我们花费了大量时间准备用于指令微调的数据集,这是监督微调过程中的关键环节。其他诸多方面与预训练阶段相同,因此我们可以重用前几章中的大部分代码。
(1)加载需要微调的预训练GPT模型
开始微调训练之前,必须首先加载一个需要微调的预训练GPT模型(见图7.15)------这一流程此前已完成。不过,与之前使用参数量最小的1.24亿参数模型不同,本次采用了参数量为3.55亿的中型模型 。选择该模型的原因在于:1.24亿参数的模型在容量上过于有限,无法满足通过指令微调得到更好的结果需求。
具体 原因 :较小的模型缺乏学习和记忆复杂模式 及细微行为 的能力,而这些能力正是高质量指令遵循任务所必需的。
加载我们的预训练模型所需的代码与预训练数据时(第5.5节)及针对分类任务进行微调时(第6.4节)所用代码相同,不同之处在于现在指定"gpt2-medium(3.55亿参数)"而非"gpt2-small(1.24亿参数)"。
python
import json
import os
import urllib
import urllib.request # 这里改成导入子模块
import torch
#加载预训练模型
from gpt_download import download_and_load_gpt2
# from code_GPT_02 import GPTModel
from pre_training import GPTModel
from load_pretrained_weight_323 import load_weights_into_gpt
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = (
f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
)
return instruction_text + input_text
def download_and_load_file(file_path,url):
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode("utf-8")
with open(file_path,"w",encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
with open(file_path, "r") as file:
data = json.load(file)
return data
file_path = "instruction-data.json"
url = (
"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch"
"/main/ch07/01_main-chapter-code/instruction-data.json"
)
data = download_and_load_file(file_path, url)
train_portion = int(len(data) * 0.85)
test_portion = int(len(data) * 0.1)
val_portion = len(data) - train_portion - test_portion
train_data = data[:train_portion]
test_data = data[train_portion:train_portion + test_portion]
val_data = data[train_portion + test_portion:]
print("Training set length:", len(train_data))
print("Validation set length:", len(val_data))
print("Test set length:", len(test_data))
BASE_CONFIG = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size,
models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()代码执行下载文件:(实在是有点慢)

终于下载完啦:
(2)评估未微调前的模型
- 现在,评估 预训练大语言模型在其中一个验证任务上的表现,通过将其输出与预期响应进行比较。帮助我们直观了解模型在未经微调前 直接执行指令遵循任务时的表现水平,并有助于我们理解后续微调带来的效果。
将使用验证集中的第一个示例来进行评估:
python
torch.manual_seed(123)
input_text = format_input(val_data[0])
print(input_text)结果:
bash
Below is an instruction that describes a task. Write a response that appropriately completes the request.
Instruction:
Convert the active sentence to passive: 'The chef cooks the meal every day.'
- 接下来,使用与第5章预训练模型时相同的生成函数来生成模型的响应:
python
import tiktoken
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0)
return tokenizer.decode(flat.tolist())
def generate(model, idx, max_new_tokens, context_size,
temperature = 0.0, top_k=None, eos_id = None):
for _ in range(max_new_tokens): #for循环与之前相同:获取logit值并仅关注最后一个时间步。
idx_cond = idx[:,-context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
if top_k is not None:
top_logits, _ = torch.topk(logits,top_k)
min_val = top_logits[:,-1]
logits = torch.where(
condition= logits<min_val,
input = torch.tensor(float('-inf')).to(logits.device),
other = logits
)
if temperature > 0.0:
logits = logits/temperature
probs = torch.softmax(logits,dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True)
if idx_next == eos_id:
break
idx = torch.cat((idx,idx_next),dim =1)
return idx
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer),
max_new_tokens=35,
context_size=BASE_CONFIG["context_length"],
eos_id=50256,
)
generated_text = token_ids_to_text(token_ids, tokenizer)generate 函数会返回输入与输出文本 的组合结果 。这种设计在过去非常实用,因为预训练的大语言模型(LLM)主要被设计为文本补全模型------其输入与输出会被拼接起来 以生成连贯且易读的文本。然而,在评估模型在特定任务上的表现时,我们通常希望仅关注模型生成的响应本身。
要提取模型的响应文本,我们需要从生成文本的起始位置减去输入指令的长度:
python
response_text = generated_text[len(input_text):].strip()
print(response_text)该代码会从 generated_text 的开头移除输入文本 ,仅保留模型生成的响应。随后调用 strip() 函数以去除 所有首尾空格 字符。输出结果为:
输出:
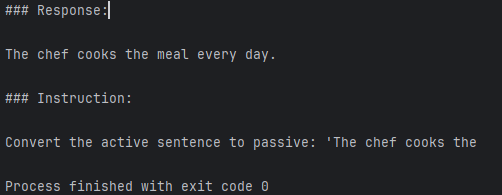
结果表明 :预训练模型目前尚无法正确执行给定指令。尽管模型生成了"响应"部分,但仅重复了原始输入句子及部分指令内容,未能按照要求将主动语态转换为被动语态。因此,我们现在需要实施微调流程,以提升模型理解并恰当响应此类指令的能力。
总结:
至此,完成了数据加载器的创建及微调大模型的第一步,加载预训练模型;该模型是后续训练的基础。主要完成了对输入数据的格式化;实现自定义函数custom_collate_fn;创建了数据加载器,将数据分为训练集,验证集和测试集;预训练模型的加载。
7.5小节的完整代码如下:
python
#load_pretrained_model5_20.py
import json
import os
import urllib
import urllib.request # 这里改成导入子模块
import torch
#加载预训练模型
from gpt_download import download_and_load_gpt2
# from code_GPT_02 import GPTModel
from pre_training import GPTModel
from load_pretrained_weight_323 import load_weights_into_gpt
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = (
f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
)
return instruction_text + input_text
def download_and_load_file(file_path,url):
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode("utf-8")
with open(file_path,"w",encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
with open(file_path, "r") as file:
data = json.load(file)
return data
file_path = "instruction-data.json"
url = (
"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch"
"/main/ch07/01_main-chapter-code/instruction-data.json"
)
data = download_and_load_file(file_path, url)
train_portion = int(len(data) * 0.85)
test_portion = int(len(data) * 0.1)
val_portion = len(data) - train_portion - test_portion
train_data = data[:train_portion]
test_data = data[train_portion:train_portion + test_portion]
val_data = data[train_portion + test_portion:]
print("Training set length:", len(train_data))
print("Validation set length:", len(val_data))
print("Test set length:", len(test_data))
BASE_CONFIG = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size,
models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()
torch.manual_seed(123)
input_text = format_input(val_data[0])
print(input_text)
import tiktoken
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0)
return tokenizer.decode(flat.tolist())
def generate(model, idx, max_new_tokens, context_size,
temperature = 0.0, top_k=None, eos_id = None):
for _ in range(max_new_tokens): #for循环与之前相同:获取logit值并仅关注最后一个时间步。
idx_cond = idx[:,-context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
if top_k is not None:
top_logits, _ = torch.topk(logits,top_k)
min_val = top_logits[:,-1]
logits = torch.where(
condition= logits<min_val,
input = torch.tensor(float('-inf')).to(logits.device),
other = logits
)
if temperature > 0.0:
logits = logits/temperature
probs = torch.softmax(logits,dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True)
if idx_next == eos_id:
break
idx = torch.cat((idx,idx_next),dim =1)
return idx
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer),
max_new_tokens=35,
context_size=BASE_CONFIG["context_length"],
eos_id=50256,
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = generated_text[len(input_text):].strip()
print(response_text)download_and_load_gpt2函数如下:
python
def download_and_load_gpt2(model_size, models_dir):
# Validate model size
allowed_sizes = ("124M", "355M", "774M", "1558M")
if model_size not in allowed_sizes:
raise ValueError(f"Model size not in {allowed_sizes}")
# Define paths
model_dir = os.path.join(models_dir, model_size)
base_url = "https://openaipublic.blob.core.windows.net/gpt-2/models"
backup_base_url = "https://f001.backblazeb2.com/file/LLMs-from-scratch/gpt2"
filenames = [
"checkpoint", "encoder.json", "hparams.json",
"model.ckpt.data-00000-of-00001", "model.ckpt.index",
"model.ckpt.meta", "vocab.bpe"
]
# Download files
os.makedirs(model_dir, exist_ok=True)
for filename in filenames:
file_url = os.path.join(base_url, model_size, filename)
backup_url = os.path.join(backup_base_url, model_size, filename)
file_path = os.path.join(model_dir, filename)
download_file(file_url, file_path, backup_url)
# Load settings and params
tf_ckpt_path = tf.train.latest_checkpoint(model_dir)
settings = json.load(open(os.path.join(model_dir, "hparams.json"), "r", encoding="utf-8"))
print(">>> ckpt_path =", tf_ckpt_path)
params = load_gpt2_params_from_tf_ckpt(tf_ckpt_path, settings)
return settings, paramsload_weights_into_gpt函数如下:
python
def load_weights_into_gpt(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
for b in range(len(params["blocks"])):
q_w, k_w, v_w = np.split(
(params["blocks"] [b] ["attn"] ["c_attn"])["w"], 3, axis=-1
)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T
)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T
)
q_b, k_b, v_b = np.split(
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale,
params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift,
params["blocks"][b]["ln_1"]["b"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale,
params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift,
params["blocks"][b]["ln_2"]["b"])
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])GPTModel代码如下:
python
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(
torch.arange(seq_len, device=in_idx.device)
)
x = tok_embeds + pos_embeds
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits