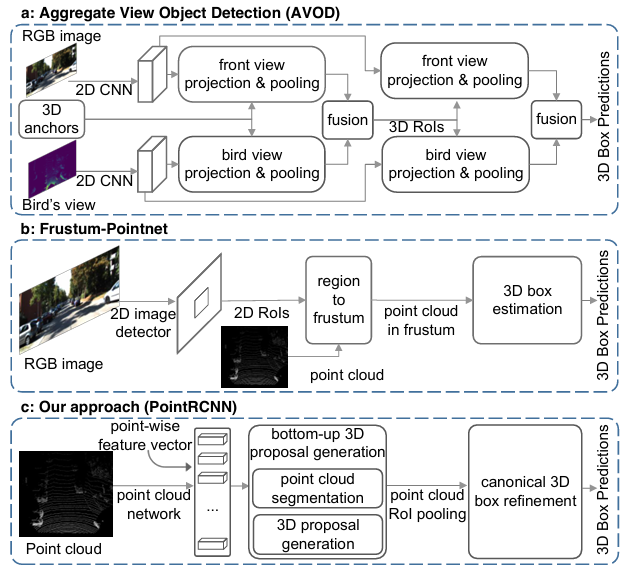
如果说 PointPillars 是工程导向的极致简化,那么 PointRCNN 就是另一个方向的探索:在不做任何体素化、鸟瞰图投影或 2D 图像辅助的前提下,能不能直接从原始点云做出高质量的 3D 目标检测?
PointRCNN 发表于 CVPR 2019,作者来自香港中文大学。它是第一个纯点云输入的两阶段 3D 检测器,在 KITTI benchmark 上以仅使用激光雷达点云的配置,打败了所有使用 LiDAR + RGB 图像融合的方法,这在当时是一个极具冲击力的结果。
第一部分:问题背景与设计动机
1.1 既有方法的局限
在 PointRCNN 之前,基于点云的 3D 目标检测方法大致分为三类,每类都有各自的代价:
第一类:鸟瞰图(BEV)投影(PIXOR、PointPillars、SECOND 等):把点云投影到 x-y 平面的俯视图,形成伪图像,然后用 2D CNN 检测。代价是高度信息被压缩,z 轴方向的精细结构丢失。
第二类:体素化(VoxelNet、3D Sparse CNN 等):把点云划分成 3D 体素格,用 3D 卷积提取特征。代价是量化误差,且 3D 卷积计算量巨大,分辨率受限。
第三类:图像先验引导(Frustum-PointNet、AVOD 等):先用 2D RGB 检测器生成候选框,再把对应视锥(frustum)内的点云送给 PointNet 估计 3D 框。代价是对 2D 检测质量有强依赖,一旦 2D 检测失败就无法恢复。
这三类方法都存在一个共同问题:没有充分利用点云数据的 3D 空间信息,或者在某个中间步骤引入了不可逆的信息损失。
1.2 3D 框天然提供语义分割标签
PointRCNN 的出发点来自一个简单但关键的观察:
在 3D 目标检测的训练数据里,每个 GT 3D 框的内部点,天然就是该物体的前景点(foreground),其余点是背景点(background)。
在 2D 检测里,这个逻辑不成立------一个 2D 矩形框里可能同时包含目标和背景,框内的语义分割需要额外标注,监督信号很弱。但在 3D 空间里,激光雷达点云和 3D 标注框的空间对应关系非常精确:一个车辆的 3D 框几乎只包含车辆本身的反射点,不会有太多背景干扰。
这就意味着:可以直接用 3D 框的标注生成逐点的语义分割伪标签,而不需要任何额外的分割标注工作。这个免费的监督信号是 PointRCNN Stage-1 能够工作的根本原因。
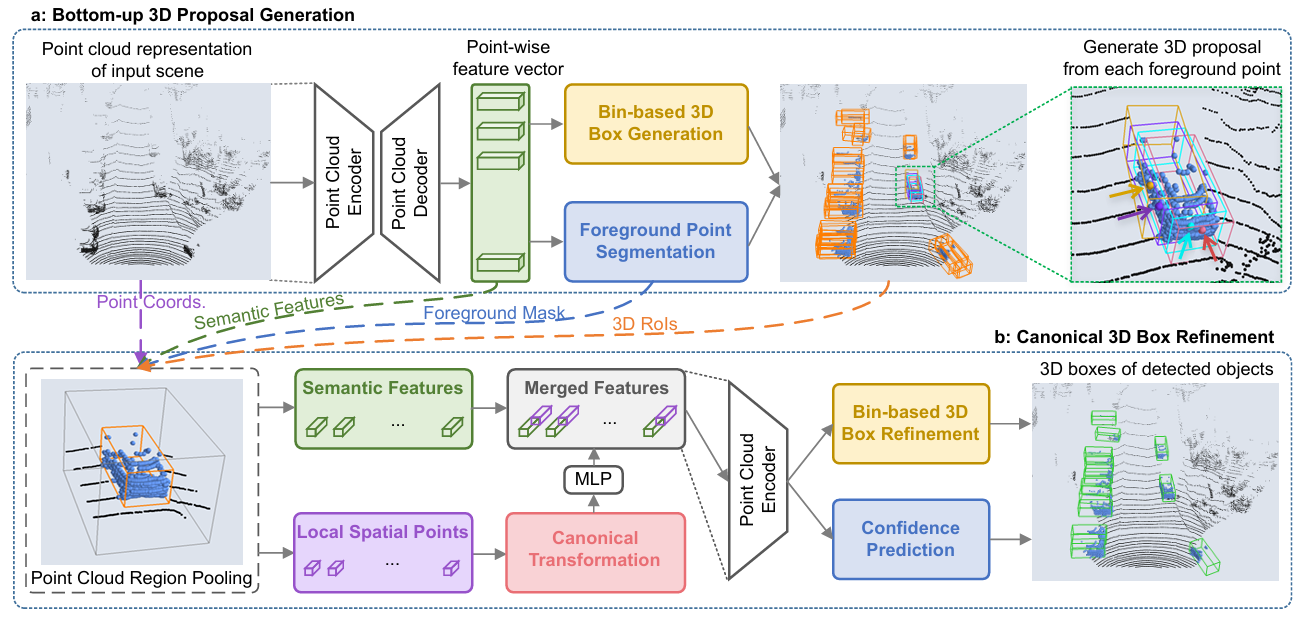
第二部分:整体架构概览
PointRCNN 是一个两阶段框架:
Stage-1(Bottom-up 3D Proposal Generation):用 PointNet++ 处理整个场景的点云,同时完成两个任务:
- 前景/背景二分类分割(Foreground Point Segmentation)
- 从每个前景点出发生成一个 3D 候选框(Bottom-up 3D Box Proposal)
Stage-2(Canonical 3D Box Refinement):
- 对 Stage-1 生成的每个候选框,通过 Point Cloud Region Pooling 汇集框内的点及其特征
- 将这些点转换到正则坐标系(Canonical Coordinate System)
- 结合局部空间特征和全局语义特征,精化候选框并预测置信度
第三部分:Stage-1------自底向上的三维候选框生成
3.1 骨干网络:PointNet++ 的 MSG 变体
Stage-1 的骨干网络使用 PointNet++(Multi-Scale Grouping 版本),这是目前最强的逐点特征提取器之一。
输入点云首先被均匀采样到 16,384 个点(不足的随机重复填充)。然后经过四个 Set Abstraction(SA)层逐步下采样,再通过四个 Feature Propagation(FP)层把特征传播回所有 16,384 个点:
输入点云: (B, 16384, 3) ← B=batch size, 每点 (x,y,z)
== Set Abstraction 阶段(下采样 + 局部特征提取)==
SA1(MSG): (B, 4096, C₁) ← 16384 → 4096 个点
SA2(MSG): (B, 1024, C₂) ← 4096 → 1024 个点
SA3(MSG): (B, 256, C₃) ← 1024 → 256 个点
SA4(MSG): (B, 64, C₄) ← 256 → 64 个点
== Feature Propagation 阶段(上采样 + 特征传播)==
FP4: 64 → 256 个点: (B, 256, C₅)
FP3: 256 → 1024 个点: (B, 1024, C₆)
FP2: 1024→ 4096 个点: (B, 4096, C₇)
FP1: 4096→16384 个点: (B, 16384, 128) ← 最终逐点特征,128 维FP 层通过距离加权插值 + skip link + 1×1 卷积把高层语义特征传播回原始点数,最终每个点都有一个 128 维的特征向量。这个特征既包含了局部几何信息(来自底层 SA 层),又包含了全局语义信息(来自高层 SA 层经 FP 传播下来的信息)。
基于这个 128 维的逐点特征,Stage-1 分出两个头(Head):
3.2 分割头(Segmentation Head)
分割头是一个简单的 MLP,对每个点的 128 维特征做二分类(前景/背景):
逐点特征: (B, 16384, 128)
↓ MLP
分割 logit: (B, 16384, 1) ← sigmoid 之后得到前景概率为什么需要分割? 传统的 Anchor-based 方法需要在整个 3D 空间放置大量 Anchor 候选框(AVOD 使用 80,000 到 100,000 个 3D Anchor),然后对每个 Anchor 做分类和回归。这不仅计算量巨大,而且大量 Anchor 都在背景里,严重的正负样本不均衡使训练很困难。
通过前景分割,PointRCNN 把候选框生成问题约束到"只从前景点出发预测框"的子问题上,大大减少了搜索空间,也规避了繁重的 Anchor 设计工作。
类别不均衡与 Focal Loss:室外自动驾驶场景里,前景点(车辆、行人内部的点)远少于背景点(地面、道路、建筑物)。这种极度不均衡的二分类问题,直接用交叉熵损失效果很差,因为背景点的损失会淹没前景点的梯度信号。
论文使用 Focal Loss 解决这个问题:
Lfocal(pt)=−αt(1−pt)γlog(pt)L_{focal}(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t)Lfocal(pt)=−αt(1−pt)γlog(pt)
其中:
pt={p若该点是前景点1−p若该点是背景点p_t = \begin{cases} p & \text{若该点是前景点} \\ 1 - p & \text{若该点是背景点} \end{cases}pt={p1−p若该点是前景点若该点是背景点
训练时使用和 Focal Loss 原论文相同的默认参数:αt=0.25\alpha_t = 0.25αt=0.25,γ=2\gamma = 2γ=2。
GT 标签的生成:把 GT 3D 框内的所有点标记为前景(label=1),框外的点标记为背景(label=0)。为了处理标注误差(GT 框可能有轻微偏移),训练时把 GT 框在每个方向各扩大 0.2m,这个扩大区域内的点在训练时被忽略(不参与损失计算),避免边界模糊的点对分割训练产生干扰。
3.3 候选框回归头(Box Regression Head)
这是 Stage-1 最核心、也是论文贡献最大的部分。
每个被分类为前景的点,都要预测一个 3D 候选框,框由 7 个量描述:(x,y,z,h,w,l,θ)(x, y, z, h, w, l, \theta)(x,y,z,h,w,l,θ)------中心坐标、尺寸、朝向角。
朴素想法的问题 :直接用 Smooth L1 Loss 回归这 7 个量。但有两个问题:第一,从一个点预测出物体中心的位置,这个偏移量没有先验约束,回归空间很大,收敛慢;第二,朝向角 θ\thetaθ 是周期性的,直接回归效果不好。
PointRCNN 提出了 Bin-based 损失函数,把位置和朝向的回归问题转化为"分类 + 小范围残差回归"的联合问题。
3.4 Bin-based 损失函数详解
X 和 Z 轴的 Bin-based 定位
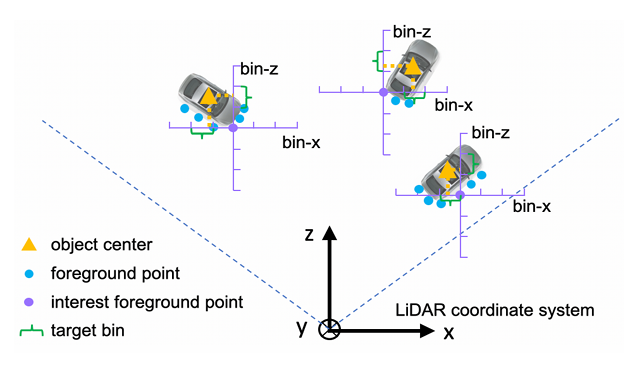
以 X 轴为例(Z 轴完全对称,处理方式相同):
设当前前景点的坐标为 (x(p),y(p),z(p))(x^{(p)}, y^{(p)}, z^{(p)})(x(p),y(p),z(p)),其对应 GT 物体中心为 (xp,yp,zp)(x^p, y^p, z^p)(xp,yp,zp)。
在这个前景点的 X 轴方向上设置一个搜索范围 SSS(超参数,S=3mS = 3mS=3m),即只在 x(p)−S,x(p)+Sx\^{(p)} - S, x\^{(p)} + Sx(p)−S,x(p)+S 这个范围内寻找物体中心。把这个 2S2S2S 宽的范围等分成若干个 bin,每个 bin 的宽度为 δ\deltaδ(超参数,δ=0.5m\delta = 0.5mδ=0.5m),总 bin 数为 ⌊2S/δ⌋=⌊6/0.5⌋=12\lfloor 2S / \delta \rfloor = \lfloor 6 / 0.5 \rfloor = 12⌊2S/δ⌋=⌊6/0.5⌋=12 个。
这样,物体中心落在哪个 bin 里,是一个 12 类的分类问题;中心在该 bin 内的精确偏移,是一个残差回归问题。
GT 目标的计算公式(论文 Eq.2):
binx(p)=⌊xp−x(p)+Sδ⌋\text{bin}^{(p)}_x = \left\lfloor \frac{x^p - x^{(p)} + S}{\delta} \right\rfloorbinx(p)=⌊δxp−x(p)+S⌋
resx(p)=1C(xp−x(p)+S−(binx(p)⋅δ+δ2))\text{res}^{(p)}_x = \frac{1}{C} \left( x^p - x^{(p)} + S - \left( \text{bin}^{(p)}_x \cdot \delta + \frac{\delta}{2} \right) \right)resx(p)=C1(xp−x(p)+S−(binx(p)⋅δ+2δ))
其中 CCC 是 bin 长度 δ\deltaδ 用于归一化,resx(p)\text{res}^{(p)}_xresx(p) 的范围是 −0.5,0.5-0.5, 0.5−0.5,0.5。
解析这个公式:
- xp−x(p)+Sx^p - x^{(p)} + Sxp−x(p)+S:GT 中心相对于前景点的偏移加上 SSS,把范围从 −S,S-S, S−S,S 平移到 0,2S0, 2S0,2S(全正数,便于取整)
- 整除 δ\deltaδ:得到该偏移落在第几个 bin 里
- 括号内的 binx(p)⋅δ+δ2\text{bin}^{(p)}_x \cdot \delta + \frac{\delta}{2}binx(p)⋅δ+2δ:该 bin 的中心位置(相对于 0,2S0, 2S0,2S 的起点)
- 整个 resx(p)\text{res}^{(p)}_xresx(p):GT 中心相对于其所在 bin 中心的残差,除以 CCC 归一化
为什么用分类而不是直接回归 X 和 Z?
论文做了消融对比(不同损失函数的 Recall 曲线):直接 Smooth L1 回归的方法(RB-Loss)收敛慢,且最终 Recall 较低;Bin-based 分类 + 残差回归(BB-Loss)收敛快得多,且最终 Recall 显著更高。
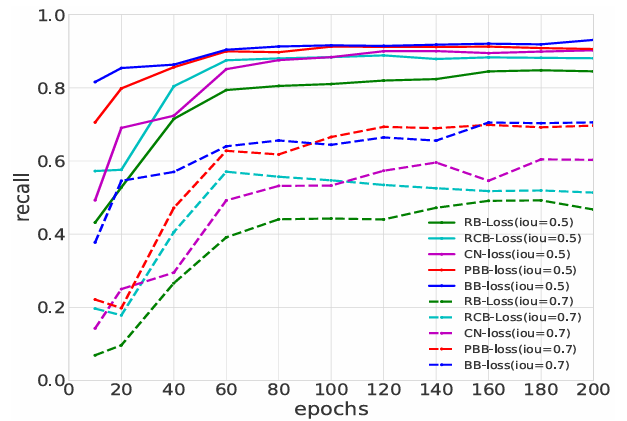
原因在于分类问题的优化比回归问题更稳定------Cross-Entropy 损失对于多类分类有清晰的梯度信号,而 L1 回归在搜索范围大时梯度信号较弱。把大范围的位置估计问题先用分类缩小范围,再在小范围内做精确残差回归,是一种"粗到精"的有效分解。
Y 轴的直接回归
Y 轴(垂直于地面方向)不做 bin 划分,直接用 Smooth L1 Loss 回归残差:
resy(p)=yp−y(p)\text{res}^{(p)}_y = y^p - y^{(p)}resy(p)=yp−y(p)
为什么 Y 轴不需要 bin?因为在 KITTI 自动驾驶场景里,物体(汽车、行人、骑行者)都在地面上,Y 方向的变化范围非常小,直接回归就足够精确。从训练数据来看,绝大多数车辆的 Y 坐标集中在很窄的范围内。对 Y 做 bin 划分的收益不大,还增加了复杂度。
朝向角 θ 的 Bin-based 编码
朝向角 θ∈[0,2π)\theta \in [0, 2\pi)θ∈[0,2π) 同样用 bin 分类。把整个 2π2\pi2π 均匀划分成 nnn 个 bin(超参数,n=12n = 12n=12,每个 bin 覆盖 30°):
binθ(p)=⌊θp2π/n⌋\text{bin}^{(p)}_\theta = \left\lfloor \frac{\theta^p}{2\pi / n} \right\rfloorbinθ(p)=⌊2π/nθp⌋
resθ(p)=2π/n(θp−(binθ(p)⋅2πn+πn))\text{res}^{(p)}\theta = \frac{2}{\pi / n} \left( \theta^p - \left( \text{bin}^{(p)}\theta \cdot \frac{2\pi}{n} + \frac{\pi}{n} \right) \right)resθ(p)=π/n2(θp−(binθ(p)⋅n2π+nπ))
残差范围归一化到 −1,1-1, 1−1,1。
尺寸的回归
物体尺寸 (h,w,l)(h, w, l)(h,w,l) 相对于训练集中该类别的平均尺寸来回归残差:
resh(p)=hp−hˉ,resw(p)=wp−wˉ,resl(p)=lp−lˉ\text{res}^{(p)}_h = h^p - \bar{h},\quad \text{res}^{(p)}_w = w^p - \bar{w},\quad \text{res}^{(p)}_l = l^p - \bar{l}resh(p)=hp−hˉ,resw(p)=wp−wˉ,resl(p)=lp−lˉ
其中 hˉ,wˉ,lˉ\bar{h}, \bar{w}, \bar{l}hˉ,wˉ,lˉ 是训练集中该类别所有 GT 框的平均高度、宽度、长度。不用 bin 分类的原因是同类别物体的尺寸变化范围较小(汽车都差不多大),直接回归已经足够精确。
总损失函数
Lbin(p)=∑u∈{x,z,θ}(Fcls(bin^u(p), binu(p))+Freg(res^u(p), resu(p)))L^{(p)}{\text{bin}} = \sum{u \in \{x, z, \theta\}} \left( F_{\text{cls}}(\hat{\text{bin}}^{(p)}_u,\ \text{bin}^{(p)}u) + F{\text{reg}}(\hat{\text{res}}^{(p)}_u,\ \text{res}^{(p)}_u) \right)Lbin(p)=u∈{x,z,θ}∑(Fcls(bin^u(p), binu(p))+Freg(res^u(p), resu(p)))
Lres(p)=∑v∈{y,h,w,l}Freg(res^v(p), resv(p))L^{(p)}{\text{res}} = \sum{v \in \{y, h, w, l\}} F_{\text{reg}}(\hat{\text{res}}^{(p)}_v,\ \text{res}^{(p)}_v)Lres(p)=v∈{y,h,w,l}∑Freg(res^v(p), resv(p))
Lreg=1Npos∑p∈pos(Lbin(p)+Lres(p))L_{\text{reg}} = \frac{1}{N_{\text{pos}}} \sum_{p \in \text{pos}} \left( L^{(p)}{\text{bin}} + L^{(p)}{\text{res}} \right)Lreg=Npos1p∈pos∑(Lbin(p)+Lres(p))
其中 FclsF_{\text{cls}}Fcls 是 Cross-Entropy 损失,FregF_{\text{reg}}Freg 是 Smooth L1 损失,NposN_{\text{pos}}Npos 是前景点数量,用于归一化。
注意:Box Regression Head 只对前景点计算损失,背景点虽然也经过了骨干网络,其特征通过感受野对前景预测有间接贡献,但不直接参与框回归的监督。
Stage-1 的总训练损失是:
Lstage1=Lfocal+LregL_{\text{stage1}} = L_{\text{focal}} + L_{\text{reg}}Lstage1=Lfocal+Lreg
3.5 推理时的候选框生成与 NMS
推理阶段,对于每个前景点(分割概率超过阈值的点),根据预测的 bin 分类和残差,还原出物体中心坐标:
- X, Z:选 bin 置信度最高的 bin,取该 bin 的中心加上预测残差
- Y:直接加残差
- θ\thetaθ:同 X、Z 的方式
然后对所有前景点生成的候选框做 Oriented NMS(基于鸟瞰图的旋转框 IoU):
- 训练时:IoU 阈值 0.85,保留 top 300 个框
- 推理时:IoU 阈值 0.8,保留 top 100 个框
只保留 100 个框已经足够------实验表明,用 50 个框就能达到 96.01% 的 Recall@IoU=0.5,300 个框达到 98.21%(Table 3)。这比 AVOD 使用 300 个框才达到 91% 好得多,且 AVOD 还同时使用了图像信息。
第四部分:Stage-2------正则坐标系中的候选框精化
4.1 Point Cloud Region Pooling
Stage-1 生成了若干个 3D 候选框 bi=(xi,yi,zi,hi,wi,li,θi)b_i = (x_i, y_i, z_i, h_i, w_i, l_i, \theta_i)bi=(xi,yi,zi,hi,wi,li,θi)。Stage-2 首先要为每个框汇集其内部的点和对应特征。
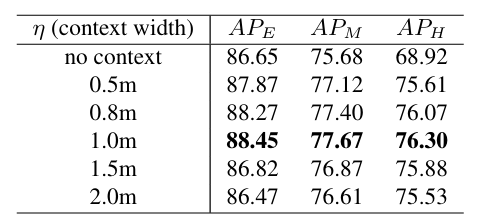
框的扩大(Context-Aware Pooling) :为了给精化阶段提供更多上下文信息,每个框在每个方向扩大 η\etaη(超参数,默认 η=1.0m\eta = 1.0mη=1.0m),形成扩大框 bie=(xi,yi,zi,hi+η,wi+η,li+η,θi)b^e_i = (x_i, y_i, z_i, h_i + \eta, w_i + \eta, l_i + \eta, \theta_i)bie=(xi,yi,zi,hi+η,wi+η,li+η,θi)。
然后对原始点云(16,384 个点)中的每个点,做一个 inside/outside 测试,判断是否在扩大框 bieb^e_ibie 内。在框内的点及其特征被保留下来。
每个框保留的特征 :对于在扩大框内的每个点 ppp,保留以下信息:
- 3D 坐标:(x(p),y(p),z(p))∈R3(x^{(p)}, y^{(p)}, z^{(p)}) \in \mathbb{R}^3(x(p),y(p),z(p))∈R3
- 激光反射强度:r(p)∈Rr^{(p)} \in \mathbb{R}r(p)∈R
- Stage-1 分割掩码:m(p)∈{0,1}m^{(p)} \in \{0, 1\}m(p)∈{0,1}(该点被 Stage-1 预测为前景还是背景)
- Stage-1 特征向量:f(p)∈R128f^{(p)} \in \mathbb{R}^{128}f(p)∈R128(PointNet++ 提取的 128 维特征)
分割掩码 m(p)m^{(p)}m(p) 的作用是帮助 Stage-2 区分扩大框内的真正前景点和上下文背景点------虽然扩大框收集了更多上下文,但 Stage-2 需要知道哪些点属于目标物体本身。
消融验证 :不收集上下文(η=0\eta = 0η=0)时,Hard 难度的 AP 显著下降,因为困难物体(遮挡、距离远)往往框内点很少,上下文信息尤为重要。η=1.0m\eta = 1.0mη=1.0m 时效果最好;η\etaη 过大时(1.5m1.5m1.5m 或 2.0m2.0m2.0m)会把周围其他物体的前景点也混入进来,引入噪声,性能反而下降。
4.2 正则坐标变换(Canonical Transformation)
这是 Stage-2 最核心的设计,也是整个 PointRCNN 里最重要的细节之一。
问题:对于不同的候选框,它们在 LiDAR 坐标系中的位置和朝向各不相同。如果直接把不同框内的点云送进同一个网络,网络需要同时处理"这些点在哪里(绝对位置)"和"这些点描述了什么形状(局部几何)"两件事,让特征学习更加困难。
解法 :把每个候选框内的点云,变换到一个以该框为中心、以该框朝向为坐标轴的局部坐标系中------这就是正则坐标系(Canonical Coordinate System,CCS)。
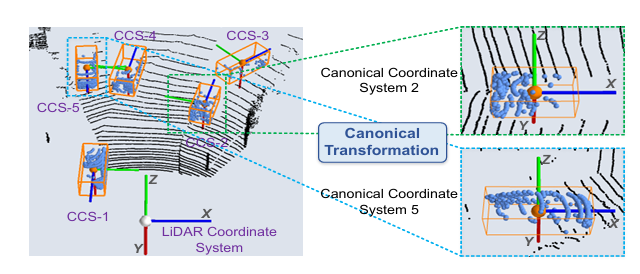
正则坐标系的定义:
- 原点 :候选框的中心 (xi,yi,zi)(x_i, y_i, z_i)(xi,yi,zi)
- X' 轴 :指向候选框的"头部方向"(heading direction),即朝向角 θi\theta_iθi 的方向,与地面平行
- Z' 轴:垂直于 X' 轴,与地面平行
- Y' 轴:与 LiDAR 坐标系的 Y 轴相同(垂直于地面向上)
变换操作是标准的旋转 + 平移:
- 平移:所有点减去框中心坐标 (xi,yi,zi)(x_i, y_i, z_i)(xi,yi,zi)
- 旋转:绕 Y 轴旋转 −θi-\theta_i−θi,把 LiDAR 坐标系的 X 轴旋转到与框的朝向 X' 对齐
变换后,框内的所有点 ppp 被转换成 p~\tilde{p}p~,变换后的候选框变为 b~i=(0,0,0,hi,wi,li,0)\tilde{b}_i = (0, 0, 0, h_i, w_i, l_i, 0)b~i=(0,0,0,hi,wi,li,0)------中心在原点,朝向为 0。
为什么这个变换很重要?
消融实验给出了量化答案:去掉正则坐标变换(CT),Stage-2 在 Moderate 难度上的 AP 从 77.67% 骤降到 13.68%,几乎完全失效。

原因很直观:正则变换把"框在哪、框朝哪"从特征学习问题里分离了出去,只剩下"框里的几何形状是什么"的问题。经过变换后,不管原来的框在场景的哪个位置、朝哪个方向,在 CCS 里的几何特征都是可以共享和复用的(就像 CNN 的平移不变性一样)。
4.3 失去的深度信息与补偿
正则变换虽然消除了位置和朝向的变异性,但也带来一个代价:深度信息丢失。
在 LiDAR 坐标系里,远处的物体点云稀疏,近处的密集------这是因为 LiDAR 以固定角分辨率扫描,物体越远,覆盖到它的激光束越少。但经过正则变换(减去框中心坐标)后,这个深度信息就消失了------变换后的局部坐标不再能反映该框距离传感器有多远。
补偿方法 :对每个点加入到 LiDAR 传感器的欧氏距离(depth)d(p)d^{(p)}d(p):
d(p)=(x(p))2+(y(p))2+(z(p))2d^{(p)} = \sqrt{(x^{(p)})^2 + (y^{(p)})^2 + (z^{(p)})^2}d(p)=(x(p))2+(y(p))2+(z(p))2
这个距离信息使用的是正则变换之前的原始坐标计算,因此保留了真实的深度信息,帮助 Stage-2 网络感知"这个框里的点来自近处的密集物体还是远处的稀疏物体"。
4.4 Stage-2 的特征融合与网络结构
每个框内随机采样 512 个点。对这 512 个点,每个点的输入特征是:
局部空间特征: 正则化坐标 [x̃, ỹ, z̃] ∈ ℝ³
额外特征: [r, m, d] ∈ ℝ³
r: 反射强度, m: 分割掩码, d: 原始深度
全局语义特征: f ∈ ℝ¹²⁸ ← Stage-1 PointNet++ 提取的特征网络处理流程:
== 局部特征编码 ==
每个点的 [x̃, ỹ, z̃, r, m, d]: (512, 6)
↓ MLP(多层全连接,升维至 128)
局部特征: (512, 128)
== 特征拼接 ==
局部特征: (512, 128)
全局语义特征(Stage-1 的 f): (512, 128)
↓ Concatenate
合并特征: (512, 256)
== Stage-2 PointNet++(SSG 版本)==
输入: (512, 256)
SA1(K=128, SSG): (128, C₁)
SA2(K=32, SSG): (32, C₂)
SA3(K=1, SSG): (1, C₃) ← 全局特征向量
== 两个输出头 ==
置信度头: FC → (1,) ← sigmoid 后是该框的前景置信度
精化框头: FC → Bin-based 回归输出注意 Stage-2 用的是 SSG(Single Scale Grouping)版本的 PointNet++,而不是 Stage-1 用的 MSG 版本。原因是:Stage-2 的输入点云已经是每个框内的 512 个局部点,范围有限,不需要多尺度策略;用 SSG 计算效率更高,且同样可以提取有效的局部特征。
4.5 Stage-2 的 Bin-based Refinement Loss
Stage-2 同样使用 Bin-based 损失,但有几处关键区别。
首先,Stage-2 工作在正则坐标系里,GT 框和候选框都需要先转换到 CCS:
b~i=(0,0,0,hi,wi,li,0)(候选框在 CCS 里,中心为原点,朝向为 0)\tilde{b}_i = (0, 0, 0, h_i, w_i, l_i, 0) \quad \text{(候选框在 CCS 里,中心为原点,朝向为 0)}b~i=(0,0,0,hi,wi,li,0)(候选框在 CCS 里,中心为原点,朝向为 0)
b~igt=(xigt−xi, yigt−yi, zigt−zi, higt, wigt, ligt, θigt−θi)\tilde{b}^{gt}_i = (x^{gt}_i - x_i,\ y^{gt}_i - y_i,\ z^{gt}_i - z_i,\ h^{gt}_i,\ w^{gt}_i,\ l^{gt}_i,\ \theta^{gt}_i - \theta_i)b~igt=(xigt−xi, yigt−yi, zigt−zi, higt, wigt, ligt, θigt−θi)
在 CCS 里,需要回归的是 GT 框相对于候选框的残差,而不是绝对坐标。这使回归问题的搜索范围比 Stage-1 小得多,精化更容易。
Stage-2 超参数(比 Stage-1 更小的搜索范围):
- 搜索范围:S=1.5mS = 1.5mS=1.5m(Stage-1 是 3m3m3m)
- bin 大小:δ=0.5m\delta = 0.5mδ=0.5m(相同)
- 方向 bin 大小:ω=10°\omega = 10°ω=10°
朝向精化的特殊设计 :在 Stage-2 里,候选框的朝向误差一般不大(因为 Stage-1 已经做了粗略估计)。论文假设角度差 θigt−θi\theta^{gt}_i - \theta_iθigt−θi 在 −π/4,π/4-\\pi/4, \\pi/4−π/4,π/4 范围内(基于 Stage-1 的候选框和 GT 框 3D IoU 至少 0.55 的约束)。因此只需要把 π/2\pi/2π/2 的范围分 bin,而不是整个 2π2\pi2π:
binΔθi=⌊θigt−θi+π/4ω⌋\text{bin}^i_{\Delta\theta} = \left\lfloor \frac{\theta^{gt}_i - \theta_i + \pi/4}{\omega} \right\rfloorbinΔθi=⌊ωθigt−θi+π/4⌋
resΔθi=2ω(θigt−θi+π4−(binΔθi⋅ω+ω2))\text{res}^i_{\Delta\theta} = \frac{2}{\omega} \left( \theta^{gt}i - \theta_i + \frac{\pi}{4} - \left( \text{bin}^i{\Delta\theta} \cdot \omega + \frac{\omega}{2} \right) \right)resΔθi=ω2(θigt−θi+4π−(binΔθi⋅ω+2ω))
Stage-2 总损失:
Lrefine=1∣B∣∑i∈BFcls(probi,labeli)+1∣Bpos∣∑i∈Bpos(L~bin(i)+L~res(i))L_{\text{refine}} = \frac{1}{|B|} \sum_{i \in B} F_{\text{cls}}(\text{prob}i, \text{label}i) + \frac{1}{|B{\text{pos}}|} \sum{i \in B_{\text{pos}}} \left( \tilde{L}^{(i)}{\text{bin}} + \tilde{L}^{(i)}{\text{res}} \right)Lrefine=∣B∣1i∈B∑Fcls(probi,labeli)+∣Bpos∣1i∈Bpos∑(L~bin(i)+L~res(i))
其中 BBB 是 Stage-1 传入的所有候选框,BposB_{\text{pos}}Bpos 是正样本候选框(3D IoU 与 GT 框 ≥0.55\geq 0.55≥0.55)。分类头(置信度)用 Cross-Entropy 监督,回归头用 Bin-based 损失监督(与 Stage-1 形式相同,只是目标换成了 CCS 里的残差)。
正负样本划分:
- 正样本 :与某个 GT 框的 3D IoU ≥0.6\geq 0.6≥0.6(参与分类和回归)
- 负样本 :3D IoU <0.45< 0.45<0.45(只参与分类)
- 忽略 :0.45≤0.45 \leq0.45≤ IoU <0.6< 0.6<0.6(不参与任何损失)
4.6 推理时的最终输出
Stage-2 输出每个候选框的精化坐标和置信度,最后用 Oriented NMS(IoU 阈值 0.01,非常低的阈值,几乎只去除完全重叠的框)生成最终的 3D 检测框。
第五部分:训练细节与数据增强
6.1 GT-AUG:从其他场景借用物体
受 SECOND 启发,PointRCNN 使用 GT-AUG(Ground Truth Augmentation):预先建立所有训练帧里 GT 框内点云的数据库,训练时从数据库中随机挑选非重叠的 GT 框及其点云,插入到当前帧中。
这个操作大幅增加了每帧中目标物体的密度,让网络见到更多不同背景下的前景物体,是最重要的数据增强手段。
6.2 其他增强
- 随机水平翻转(50%)
- 全局随机缩放(比例因子从 0.95,1.050.95, 1.050.95,1.05 均匀采样)
- 全局随机旋转(绕 Y 轴,−10°,10°-10°, 10°−10°,10°)
6.3 两阶段分别训练
Stage-1 和 Stage-2 分别训练,不是端到端联合训练:
- Stage-1:训练 200 epochs,batch size 16,学习率 0.002
- Stage-2:固定 Stage-1 权重,训练 50 epochs,batch size 256,学习率 0.002
Stage-2 训练时,用 Stage-1 的固定输出作为候选框,并加入随机小扰动(对框的位置和朝向加随机噪声)来增加候选框的多样性,提升 Stage-2 对不完美候选框的鲁棒性。
第七部分:PointRCNN 与同时期方法的设计对比
理解 PointRCNN 不能只看它做了什么,还要看它和同期方法的根本区别在哪里。
vs. PointPillars(2019 CVPR):同期发表,但思路截然不同。PointPillars 是工程优先,把点云压缩成伪图像,追求实时性(62Hz);PointRCNN 是精度优先,直接在原始点云上操作,两阶段设计追求最高检测质量(当时 KITTI SOTA)。PointPillars 在工业落地上更常见,PointRCNN 的思路则推动了后续高精度点云检测的研究方向。
vs. Frustum-PointNet(2018 CVPR):同样使用 PointNet 处理点云,但 F-PointNet 依赖 2D 图像检测器生成 frustum 候选区域。PointRCNN 彻底摆脱了对图像的依赖,在 3D 空间里自主完成候选框生成,检测性能反而更好,验证了纯 3D 方法的可行性。
vs. AVOD(2018 IROS):AVOD 在鸟瞰图和前视图上都建立 3D Anchor,用多视角特征融合生成候选框,需要 80,000-100,000 个 3D Anchor。PointRCNN 的前景点直接生成候选框,只需要几百个高质量候选框就能达到更高的 Recall,计算更高效,精度更高。
结语
PointRCNN 的价值在于它展示了一条清晰的路:利用 3D 标注框的天然语义标签做前景分割,把候选框生成问题从大规模 Anchor 搜索转化成逐点的局部预测;再通过正则坐标变换和两阶段精化,把粗略候选框提炼成精确的 3D 检测结果。
Bin-based 损失函数把难以优化的大范围连续回归问题,分解成"先分类定范围、再精回归"的两步走,这个思路本身也具有普遍意义,在后续的很多 3D 检测工作中都能看到它的身影。
当然,PointRCNN 也有明显的局限性:逐点生成候选框使得推理速度较慢,达不到实时要求;对行人等小目标的检测受限于点云稀疏性;两阶段分别训练也降低了优化效率。这些问题,在后续的 Part-A2、VoteNet、CenterPoint 等工作中被逐步解决------但 PointRCNN 奠定的两阶段点云检测范式,至今仍然是追求极致精度的检测系统的首选框架。