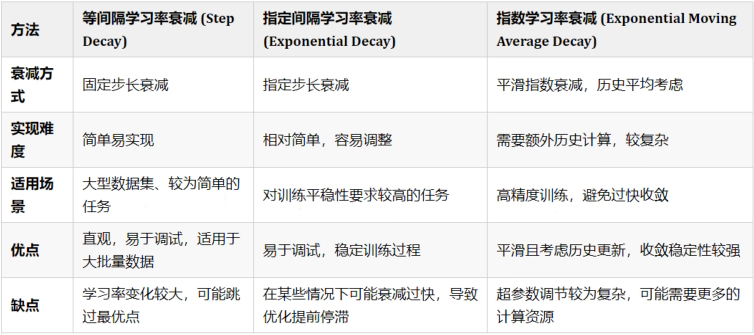
1. 学习率优化
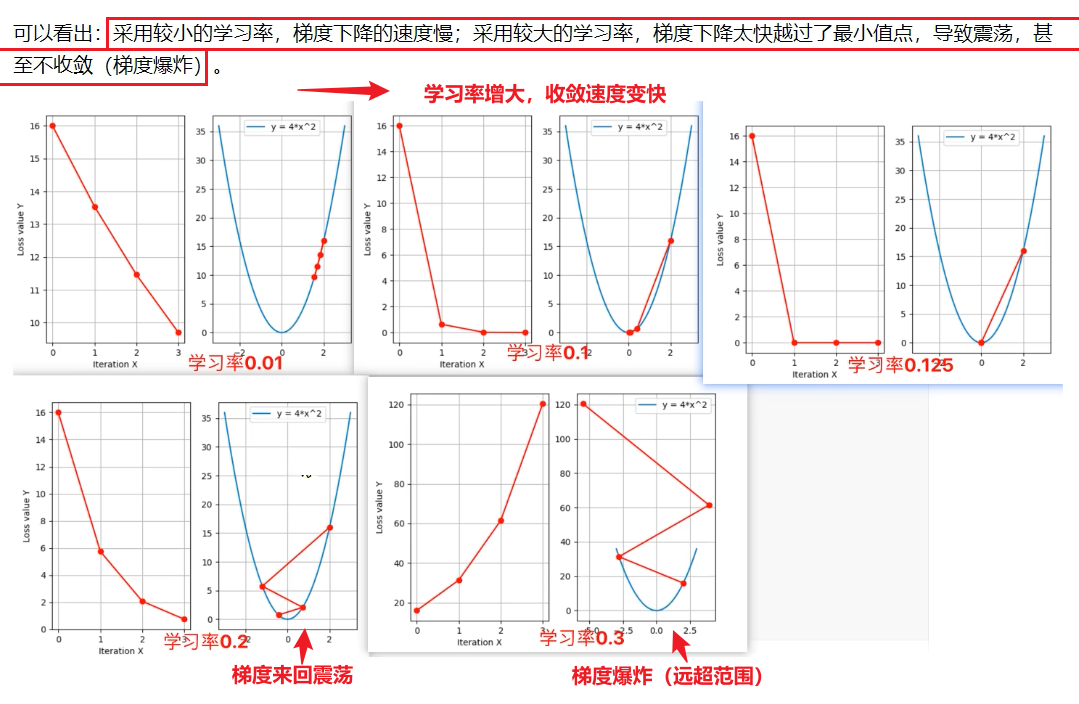
如图:学习率=0.01时收敛速度很慢,学习率=0.1时收敛速度变快,学习率越大 收敛速度越快;
学习率=0.2 即学习率较大是会 来回震荡 ,学习率=0.3 即学习率过大时会发生 梯度爆炸(即远远超出所在范围);
结论:
学习率越小,梯度下降越慢;学习率越大,梯度下降越快,可能会越过最小值,造成震荡,甚至不收敛(梯度爆炸);
2. 学习率衰减方法 (衰减策略)
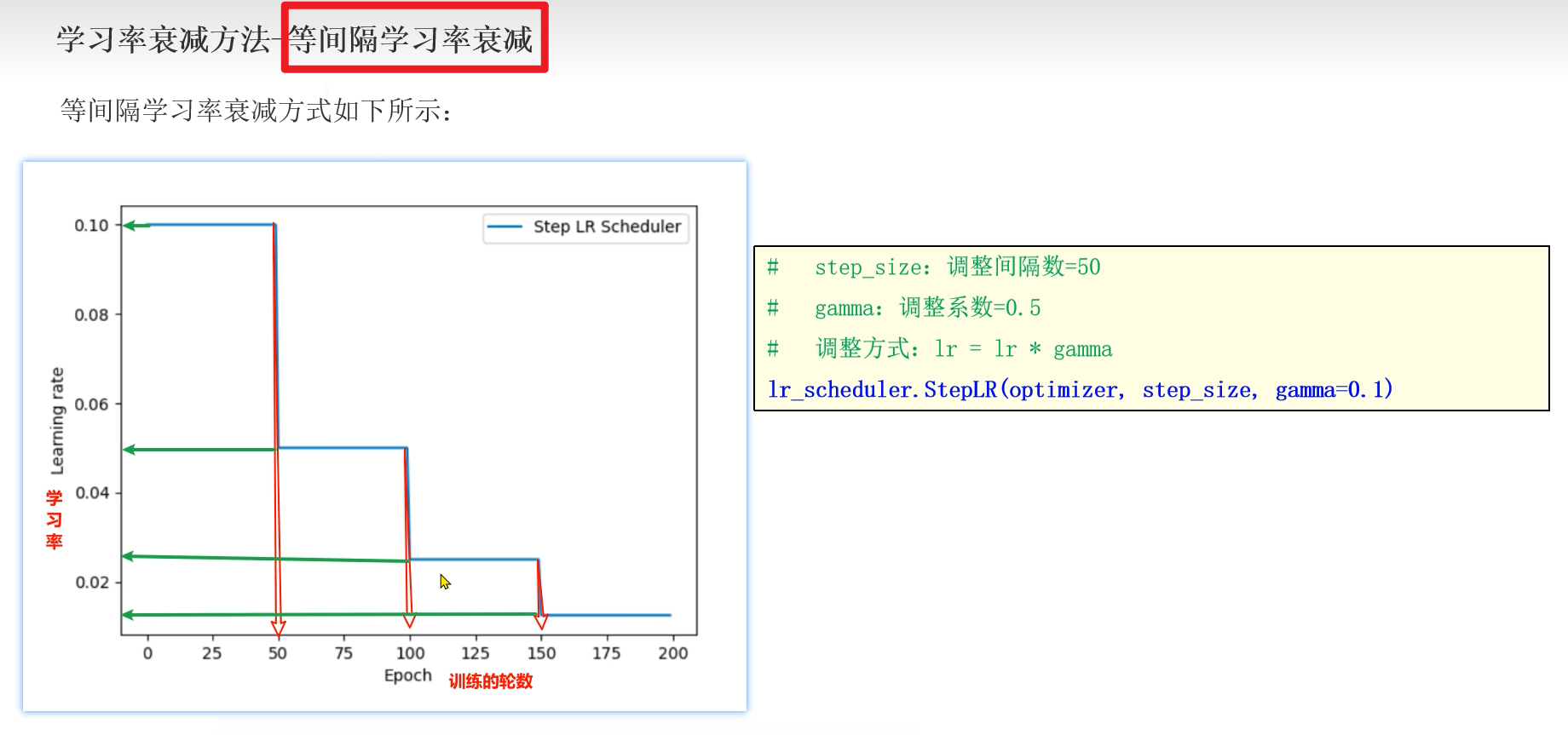
2.1 等间隔学习率衰减方法
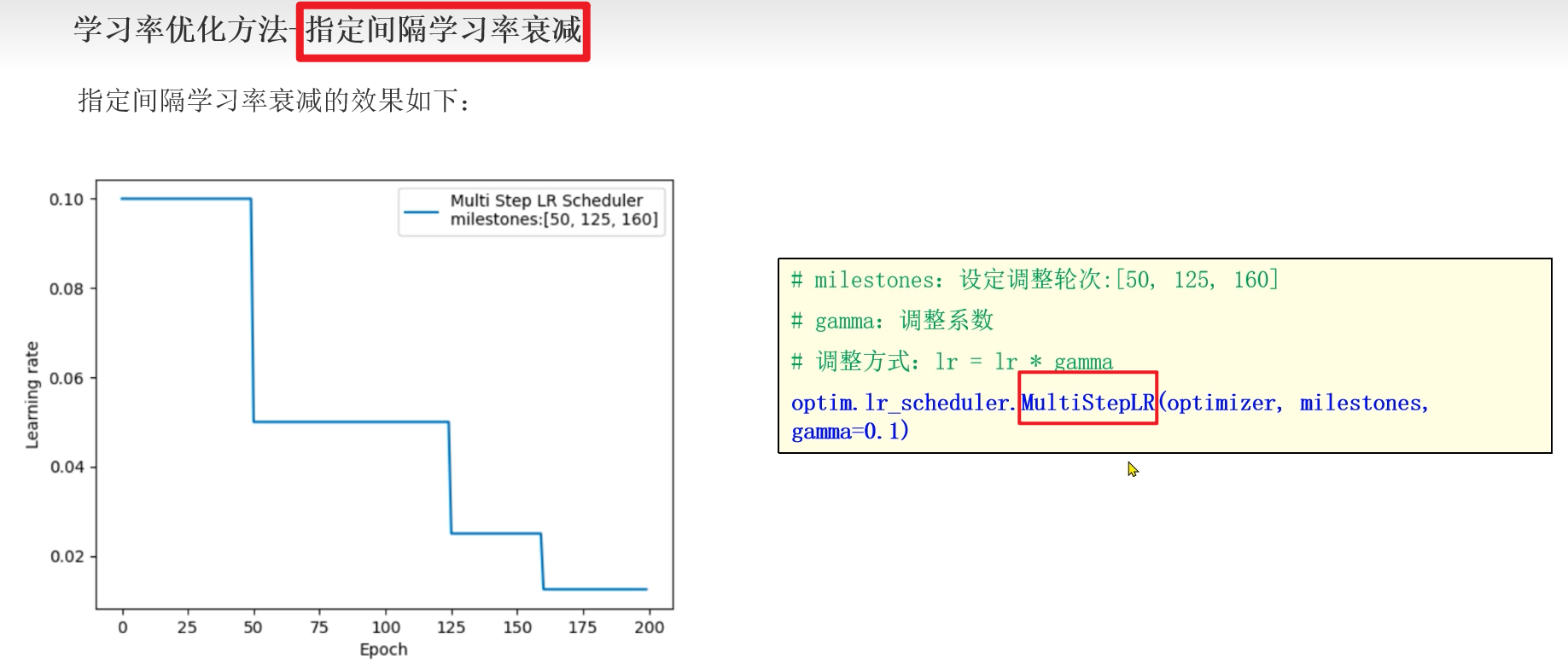
2.2 指定间隔学习率衰减方法
2.3 指数间隔学习率衰减方法

2.4 总结:
学习率衰减策略介绍:
1️⃣ 目的: 较之于AdaGrad,RMSProp,Adam方式,我们可以通过 等间隔,指定间隔,指数等方式,来手动控制学习率的调整.
2️⃣ 分类:
等间隔学习率衰减
指定间隔学习率衰减
指数学习率衰减
3️⃣ 等间隔学习率衰减:
step_size:间隔的轮数,即:多少轮调整一次学习率。
gamma:学习率衰减系数,即:Lr新=Lr旧*gamma
优点: 直观,易于调试,适用于大批量数据.
缺点: 学习率变化较大,可能跳过最优解.
应用场景: 大型数据集,较为简单的任务。
4️⃣ 指定问隔学习率衰减:
milestones = 50, 125, 160 里边定义的是要调整学习率的 轮数。
gamma: 学习率衰减系数,即: lr新 = lr旧 * gamma
优点:易于调试,稳定训练过程.
缺点: 在某些情况下可能衰减过快,导致优化提前停滞.
应用场景: 对训练平稳性要求较高的任务。
5️⃣ 指数间隔学习率衰减:
前期学习率衰减快,中期慢,后期更慢.更符合梯度下降规律
公式: Lr新 = Lr旧 * gamma ** epoch
优点: 平滑,且考虑历史更新,收敛稳定性较强.
缺点: 超参调节较为复杂,可能需要更多的资源.
应用场景: 高精度训练,避免过快收敛.