一、AutoGen是什么?
AutoGen是微软研究院于2023年9月开源的多智能体协作框架,经过两年迭代至v0.4版本,已具备企业级部署能力。
简单说,AutoGen让多个AI Agent像人一样"开会讨论"解决问题。
一个直观的例子:
用户问:"帮我分析这份销售数据并生成报告。"
AutoGen的做法是:
规划Agent拆解任务
数据Agent查询数据库
代码Agent生成分析代码
审查Agent检查结果
报告Agent输出最终文档
每个Agent各司其职,通过对话协作完成任务。
二、AutoGen的三大核心能力
2.1 对话驱动的协作机制
AutoGen的核心设计理念是"一切皆交互"。Agent之间通过自然语言消息传递实现协作,而非传统的函数调用或状态机。
核心组件:
|------------------|-----------------|
| 组件 | 职责 |
| AssistantAgent | AI代理,依赖LLM执行任务 |
| UserProxyAgent | 用户代理,可执行代码、调用工具 |
| GroupChat | 多代理群聊环境 |
| GroupChatManager | 群聊调度员,决定下一个发言人 |
代码示例(创建多Agent群聊):

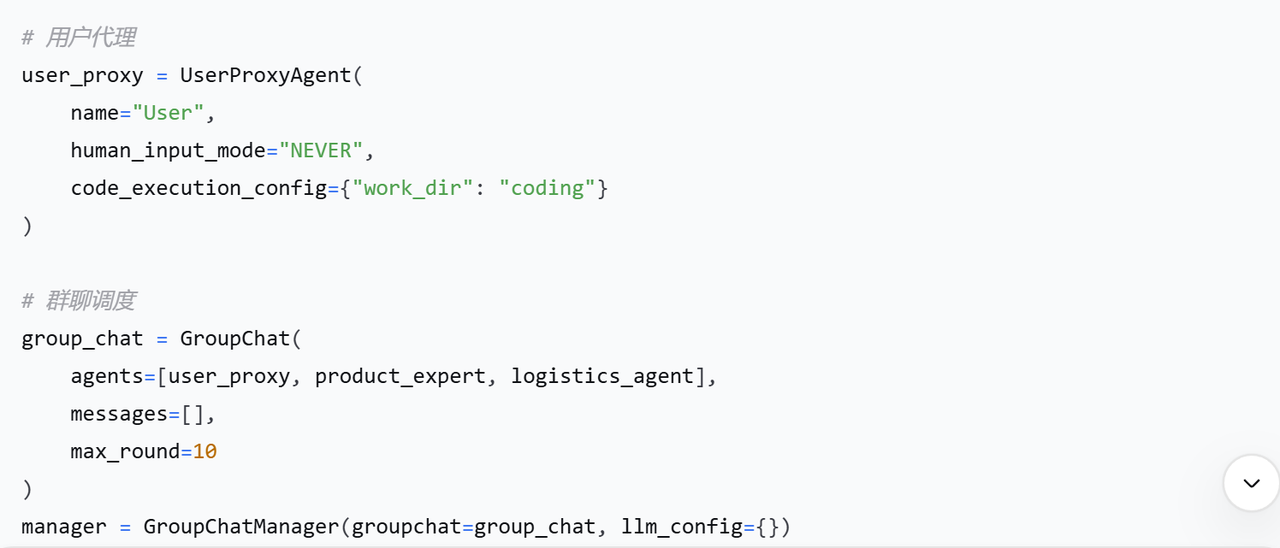
2.2 原生Human-in-the-loop支持
企业场景中,很多决策需要人工确认。AutoGen原生支持人机协作,可在关键节点暂停、等待人工输入。
适用场景:
-
医疗诊断需要医生确认
-
金融风控需要专家审核
-
代码生成需要人工审查安全漏洞
2.3 企业级生产特性
微软在生产环境方面做了充分打磨:
-
内置重试机制:LLM调用失败自动重试
-
缓存能力:相同请求可缓存结果,降低Token成本
-
错误处理:可注册自定义错误处理器
-
可观测性:支持全链路追踪和日志记录
v0.4版本的重构使"健壮性指标提升300%"。
三、AutoGen的适用场景
3.1 最佳场景:开放式协作任务
场景类型一:需求模糊的探索性任务
当业务目标尚未明确时(如"设计一个用户增长系统"),AutoGen可通过多轮对话逐步澄清需求边界。测试显示,电商团队曾用该模式在4小时内完成从需求分析到原型设计的全流程。
场景类型二:需要人类专家介入的高风险场景
医疗诊断、金融风控等场景,AutoGen内置的Human-in-the-loop机制可在关键节点请求人工确认。
场景类型三:多角色创意生成
需要产品经理、技术评审、项目经理等多角色协作的场景。AutoGen通过角色扮演系统,让不同Agent从各自视角提出意见并达成共识。
3.2 性能数据
在包含代码生成、架构设计、ETL流水线的基准测试中:
|------------|-----------|-------|---------------------|
| 测试场景 | AutoGen耗时 | 对比框架 | 核心差异 |
| 架构设计讨论 | 180秒(12轮) | 不支持 | 天然支持开放式协作 |
| 人工介入响应 | 原生支持 | 需手动集成 | 内置Human-in-the-loop |
| 单Agent代码生成 | 45秒(3轮) | 38秒 | 对话交互带来额外开销 |
Token消耗测试显示,对话驱动框架的API调用次数比角色驱动框架多约35%。这是对话模式的"灵活性税"。
四、企业场景的边界:AutoGen不擅长什么
4.1 确定性流程的执行
如果业务流程是固定的、可预测的(如ETL流水线、批量数据处理),AutoGen的"对话协商"模式反而成为负担。
问题: Agent之间需要多轮对话才能确定下一步,效率远低于预定义DAG。
对比数据: ETL流水线任务中,AutoGen耗时240秒(15轮对话),而角色驱动框架仅需95秒。
建议: 确定性流程选择LangGraph(状态机+DAG)或CrewAI(任务链)。
4.2 Token敏感的场景
问题: 多Agent多轮对话会显著增加Token消耗。
数据: 在千次任务中,对话驱动框架消耗12k Token,而角色驱动框架仅8k Token。成本高出约50%。
建议: 预算受限的团队或高频调用场景需谨慎评估成本。
4.3 需要严格状态追踪的场景
问题: AutoGen的状态管理主要依赖"对话历史",对于需要精细状态控制的场景(如复杂的多步骤审批流程),对话模式可能不够清晰。
对比: LangGraph采用显式状态传递,每一步的状态变化都可追踪和回溯,适合需要审计的场景。某医疗系统通过LangGraph的决策追踪功能,将诊断报告的可解释性评分从62%提升至89%。
4.4 大规模/高并发场景
问题: AutoGen的多Agent对话涉及多次LLM调用,端到端延迟较高。
实测数据: 在多Agent协作场景下,AutoGen延迟高达2870ms,比LlamaIndex(RAG场景)的960ms高出近2倍。
建议: 对延迟敏感的场景(如实时客服、实时交易)需谨慎评估。
4.5 企业自定义需求复杂的场景
企业级应用需要细粒度的权限管控、合规审计、系统集成,AutoGen基础版在这些方面相对薄弱:
|------|-------------|------------------|
| 需求 | AutoGen原生能力 | 企业实际要求 |
| 权限隔离 | 无 | Agent级细粒度权限 |
| 合规审计 | 仅对话日志 | 工具调用、数据访问全留痕 |
| 系统集成 | 基础HTTP/代码执行 | 需OAuth2/JWT、异步回调 |
解决方案: 可通过AutoGen自定义代理机制进行扩展,但增加了开发成本。
五、框架补位与选型决策
5.1 AutoGen的定位
AutoGen解决的是 "Agent之间如何协作" 的问题,但它不解决企业级AI平台的三个核心问题:
|--------------|-----------------|
| 企业需求 | AutoGen是否覆盖 |
| 统一的模型接入与路由 | ❌ 需要自己实现 |
| 全链路可观测性与审计 | ⚠️ 提供基础日志,企业需扩展 |
| AI资产的版本管理与复用 | ❌ 完全不涉及 |
在实际企业落地中,通常需要将AutoGen的协作能力与企业级AI底座相结合。AutoGen负责"Agent开会",底座负责"谁来开会、开会的记录、开完会怎么沉淀"。
在具体实现上,有企业采用 ZGI 作为AI底座平台,与AutoGen形成"底座+协作"的组合方案。ZGI负责统一模型接入、可观测性、资产管理,AutoGen负责多Agent对话编排,两者互补覆盖企业级需求。
5.2 一句话选型指南
|---------------|---------------|------------------|
| 场景 | 推荐方案 | 核心理由 |
| 开放式探索、创意生成 | AutoGen | 对话驱动,天然支持多角色协作 |
| 固定流程自动化 | CrewAI | 角色链+任务分解,执行效率高 |
| 复杂状态机、审计要求高 | LangGraph | DAG+显式状态管理,可解释性强 |
| 企业生产环境(需底座能力) | AutoGen + ZGI | 协作能力+企业级底座,互补覆盖 |
5.3 优化建议(如果选择AutoGen)
-
限制对话轮数:通过
max_round参数避免无限循环 -
精简Agent数量:不必要的Agent增加开销
-
使用缓存:重复请求命中缓存,降低成本
-
异步架构:高并发场景改用异步消息队列
六、写在最后
AutoGen的定位很清晰:对话驱动的多Agent协作框架。
它最强的场景是需要多角色"讨论"的开放性任务------需求探索、创意生成、人机协同。
它的边界也很清楚:确定性流程效率不如DAG框架,Token消耗高,延迟大,且不覆盖企业级底座能力。
选框架没有"最好",只有"最合适"。明确自己的场景,选对工具组合,比折腾单一框架更重要。
本文基于多Agent框架实测与企业实践整理。