
🔥个人主页:Cx330🌸
❄️个人专栏:《C语言》《LeetCode刷题集》《数据结构-初阶》《C++知识分享》
《优选算法指南-必刷经典100题》《Linux操作系统》:从入门到入魔
🌟心向往之行必能
🎥Cx330🌸的简介:

目录
[一、 同一个局域网内,主机是如何通信的?](#一、 同一个局域网内,主机是如何通信的?)
[1.1 局域网通信的基石:MAC 地址](#1.1 局域网通信的基石:MAC 地址)
[1.2 共享资源与"碰撞检测"机制](#1.2 共享资源与“碰撞检测”机制)
[二. 协议分层的本质:为什么会有"以太网"?](#二. 协议分层的本质:为什么会有“以太网”?)
[2.1 数据的封装与解封装](#2.1 数据的封装与解封装)
[2.2 每一个接收方,必须做的两件事](#2.2 每一个接收方,必须做的两件事)
[三. 网络层协同:为什么同时需要 IP 地址与 MAC 地址?](#三. 网络层协同:为什么同时需要 IP 地址与 MAC 地址?)
[3.1 路由与路径选择的本质](#3.1 路由与路径选择的本质)
[3.2 IP 地址的结构与网络层意义](#3.2 IP 地址的结构与网络层意义)
[3.3 Port 地址的结构与网络层意义](#3.3 Port 地址的结构与网络层意义)
[3.3.1 端口号的范围划分](#3.3.1 端口号的范围划分)
[四. 传输层核心:把数据交付给进程](#四. 传输层核心:把数据交付给进程)
[4.1 IP + Port = Socket](#4.1 IP + Port = Socket)
[4.2 PID 与 Port 的区别](#4.2 PID 与 Port 的区别)
[4.3 主机如何把报文交给进程?](#4.3 主机如何把报文交给进程?)
[五. Socket:网络通信的核心基石](#五. Socket:网络通信的核心基石)
[5.1 Socket 的核心定义](#5.1 Socket 的核心定义)
[5.2 四元组与五元组:唯一标识网络通信](#5.2 四元组与五元组:唯一标识网络通信)
[5.3 Linux 中 Socket 的本质](#5.3 Linux 中 Socket 的本质)
[六. 传输层两大核心协议:TCP 与 UDP](#六. 传输层两大核心协议:TCP 与 UDP)
[6.1 TCP 协议(传输控制协议)](#6.1 TCP 协议(传输控制协议))
[6.2 UDP 协议(用户数据报协议)](#6.2 UDP 协议(用户数据报协议))
[七. 避坑指南:网络字节序与大端、小端问题](#七. 避坑指南:网络字节序与大端、小端问题)
[7.1 什么是大小端?](#7.1 什么是大小端?)
[7.2 网络字节序的强制规定](#7.2 网络字节序的强制规定)
[7.3 常用字节序转换函数详解](#7.3 常用字节序转换函数详解)
[(1) 函数族命名规则(记忆密码)](#(1) 函数族命名规则(记忆密码))
[(2) 函数原型与声明](#(2) 函数原型与声明)
[(3) 现代 IP 地址转换函数(隐含字节序转换)](#(3) 现代 IP 地址转换函数(隐含字节序转换))
[(4) 转换示例代码](#(4) 转换示例代码)
[八. 进阶:C++ Socket 核心 API 详解](#八. 进阶:C++ Socket 核心 API 详解)
[8.1 socket() ------ 创建网卡抽象文件](#8.1 socket() —— 创建网卡抽象文件)
[8.2 bind() ------ 关联物理地址(IP + Port)](#8.2 bind() —— 关联物理地址(IP + Port))
[8.3 listen() ------ 让套接字进入监听状态](#8.3 listen() —— 让套接字进入监听状态)
[8.4 accept() ------ 阻塞获取客户端连接](#8.4 accept() —— 阻塞获取客户端连接)
[8.5 connect() ------ 客户端发起连接](#8.5 connect() —— 客户端发起连接)
[8.6 send() & recv() ------ 数据收发](#8.6 send() & recv() —— 数据收发)
前言:
在现代软件开发中,网络编程是每一位 C++ 程序员必须掌握的核心技能。然而,许多人在编写 socket代码时,往往只停留在 API 的调用层面,忽略了底层网络协议栈的流转本质。
今天,我将结合一份极具实战沉淀的网络协议底层笔记,带大家从最基础的局域网物理碰撞 出发,一层层剥离网络封装的真相 ,彻底理清 IP 与 MAC 的本质区别,再到传输层端口分发与网络字节序。
最重要的是,我们将延伸至 Linux C/C++ Socket 核心 API 的完整调用链、衔接设计、注意事项以及经典面试常见问题。读完这篇,你对网络通信的理解将更上一层楼!
一、 同一个局域网内,主机是如何通信的?
我们首先将视角拉到最底层的物理世界:局域网(LAN,以太网)。
1.1 局域网通信的基石:MAC 地址
-
问题:两台主机在同一个局域网,能直接通信吗?
-
答案 :能。
-
原理 :要实现直接通信,必须有一种方式能够对主机进行唯一性标识 。这个标识就是 MAC 地址(烧录在网卡中的物理地址)。
-
MAC 地址在出厂时就已确定,全球唯一。
-
主要应用场景就是局域网内部。
-
当我们从主机 A 向主机 E 发送数据时:
-
物理媒介通过以太网传输。
-
数据包中携带源 MAC(A)与目的 MAC(E)。
-
网卡在数据链路层决定要不要接收该数据(如果是发给自己的,就接收;否则丢弃)。
1.2 共享资源与"碰撞检测"机制
以太网在物理本质上是一个共享资源 。在任意时刻,只允许一台主机发送数据。
-
碰撞(数据碰撞) :如果多台主机同时发送信息,无线电或电信号就会相互干扰,发生数据碰撞,导致相关主机都无法识别数据。
-
碰撞检测与避免 :为了解决这一互斥与同步问题,以太网引入了碰撞检测机制。一旦检测到碰撞,主机会等待随机时间,稍后再发。
💡 黑客思维------如何黑掉一个局域网? 如果我们想要瘫痪一个局域网,原理其实非常简单:只需要写一个脚本,源源不断地向该局域网中塞入大量垃圾数据。这会导致正常的网络数据与垃圾数据不断发生碰撞,从而让整个局域网的主机都在"等待、重发"中死锁。
二. 协议分层的本质:为什么会有"以太网"?
网络通信的一般"动力"是用户。逻辑上,我们认为同层协议在直接通信(如应用层 A 与应用层 B 对话)。但实际上,数据是必须向下流转、经过包装,再向上传递的。
2.1 数据的封装与解封装
当用户 A 向用户 B 发送一句 "你好" 时,数据在各层协议中的流转过程如下:
[ 发送端 A ] [ 接收端 B ]
+---------------+ +---------------+
| 应用层 ("你好")| === 逻辑上直接通信 (等同) === | 应用层 ("你好")|
+-------+-------+ +-------+-------+
| 封装 (加头) ^ 解封装 (拆头)
v |
+-------+-------+ +-------+-------+
| 传输层 | | 传输层 |
+-------+-------+ +-------+-------+
| ^
v |
+-------+-------+ +-------+-------+
| 网络层 | | 网络层 |
+-------+-------+ +-------+-------+
| |
v |
+-------+-------+ +-------+-------+
| 数据链路层 | | 数据链路层 |
+-------+-------+ +-------+-------+
| ^
v [ 物理网卡 ] | [ 物理网卡 ]
A 的网卡 ===================================> B 的网卡数据在链路层发送出去前,最终会被打包成一个数据帧。其物理结构(有效载荷封装)如下:
{ 数据链路层报头 } + { 网络层报头 } + { 传输层报头 } + { 有效载荷 (应用层数据) }
2.2 每一个接收方,必须做的两件事
任何一个网络接收端(网卡/协议栈)在收到数据包后,必须无条件执行以下两个动作,这也是所有网络协议的共性(表征其为填表结构与变量):
-
报头与有效载荷分离:将当前层的报头剥离,提取出有效载荷。
-
分发给上层对应的协议 :每一层的协议报头中,都必须有一个特殊字段 (如 IP 报头中的协议字段,以太网帧中的类型字段),用以表明应当将解包后的有效载荷交付给上层的哪一个协议(例如:分发给 TCP 还是 UDP )。
三. 网络层协同:为什么同时需要 IP 地址与 MAC 地址?
在网络中,每层处理的数据单元名称不同:
-
应用层 : 请求与响应
-
传输层 : 数据段(Segment)
-
网络层 : 数据报(Packet)
-
数据链路层 : 数据帧(Frame)
大家常问的一个经典面试题:既然已经有了 MAC 地址,为什么还需要 IP 地址?
3.1 路由与路径选择的本质
我们可以用一个非常通俗的"旅游路线"来解释这两者的根本区别:
-
IP 地址 :解决的是"从哪里来,到哪里去"的终极目标。
-
它是永远不变的(长远目标,如:我要从北京去往拉萨)。
-
用于在全网内唯一定位一台主机。
-
-
MAC 地址 :解决的是"上一步从哪来,下一步到哪去"的路径衔接。
-
它是一直在变的(短期目标,如:先坐飞机到成都,再坐大巴到雅安)。
-
每经过一个路由器进行转发,数据帧的源 MAC 和目的 MAC 就会被重写一次。
[ 源主机 ] --------> [ 路由器 1 ] --------> [ 路由器 2 ] --------> [ 目标主机 ]
IP 始终不变 (源:源主机IP -> 目:目标主机IP)
MAC 每一跳都在变:
[源MAC->R1_MAC] [R1_MAC->R2_MAC] [R2_MAC->目标MAC]
-
3.2 IP 地址的结构与网络层意义
IP 地址(以 IPv4 为例,共 4 字节,32 位,通常用点分十进制表示,如 193.168.100.9;而 IPv6 则是 128 位,16 字节,由于 IPv4 耗尽而推行):
{IP 地址} = {网络号} + {主机号}
-
网络号:标识主机所连接的局域网网段。
-
主机号:标识在该网段内的具体主机。
3.3 Port 地址的结构与网络层意义
- 数据类型与范围 :端口号是一个2 字节 16 位的无符号整数 ,取值范围是0 ~ 65535;
- 核心作用:唯一标识主机内的一个网络进程,告诉操作系统,当前收到的网络数据,应该交给哪一个进程来处理;
- 核心结论 :IP 地址 + 端口号,能够唯一标识互联网中某一台主机上的某一个进程。
3.3.1 端口号的范围划分
操作系统对端口号的使用做了明确的范围划分,主要分为两大类:
| 划分区间 | 端口范围 | 分配原则与管理方式 | 典型协议应用举例 |
|---|---|---|---|
| 知名端口 / 系统端口 (Well-Known Ports) | 0 \ 1023 | 由 IANA (互联网地址分配机构)统一分配和管理绑定了固定的应用层标准协议在类 Unix 系统中,绑定这些端口通常需要系统管理员(root)权限 | 21: FTP22: SSH80: HTTP443: HTTPS |
| 注册端口 & 动态/私有端口 (Registered & Dynamic Ports) | 1024 \ 65535 | 注册端口 (1024 \\sim 49151): 可向 IANA 注册以避免冲突,普通用户进程常用动态/客户端临时端口 (49152 \\sim 65535): 操作系统在客户端发起连接(调用 connect)时,动态随机分配的临时端口 |
3306: MySQL6379: Redis8080: Tomcat 默认端口客户端发起请求时生成的临时大端口 |
网络层存在的意义 :它提供了一个网络虚拟层。在网络层看来,向上看到的报文格式都是高度统一的(都是 IP 报文),它屏蔽了底层物理介质和链路层协议的差异(向下看时,不同的物理链路报文格式各不相同),从而让世界上的所有网络都能连通成一个统一的"IP 网络"。
四. 传输层核心:把数据交付给进程
把数据从主机 A发送到主机 B并不是终点,这只是手段。真正的终点是把数据交付给主机 B上的某一个具体进程。
4.1 IP + Port = Socket
-
IP 地址:在全网内唯一标识一台主机。
-
端口号(Port) :在当前主机内唯一标识一个进程。
-
套接字(Socket) :将两者结合,IP + Port就能在全网内唯一标识一个进程。网络通信的本质就是两个进程(通过 Socket)跨网络进行进程间通信。
4.2 PID 与 Port 的区别
既然操作系统里已经有了进程 PID,为什么网络还要单独搞一套端口号 Port 呢?
-
解耦 :系统层面的 PID 经常会发生变化(进程重启后 PID 就会变),且不同的操作系统 PID 实现机制不同。网络协议栈属于系统底层的独立模块,使用端口号 Port 可以实现网络与系统底层进程管理机制的解耦。
-
绑定:不是所有进程都需要网络通信(它们只有 PID)。只有需要网络通信的进程,才会去申请并绑定一个端口号。
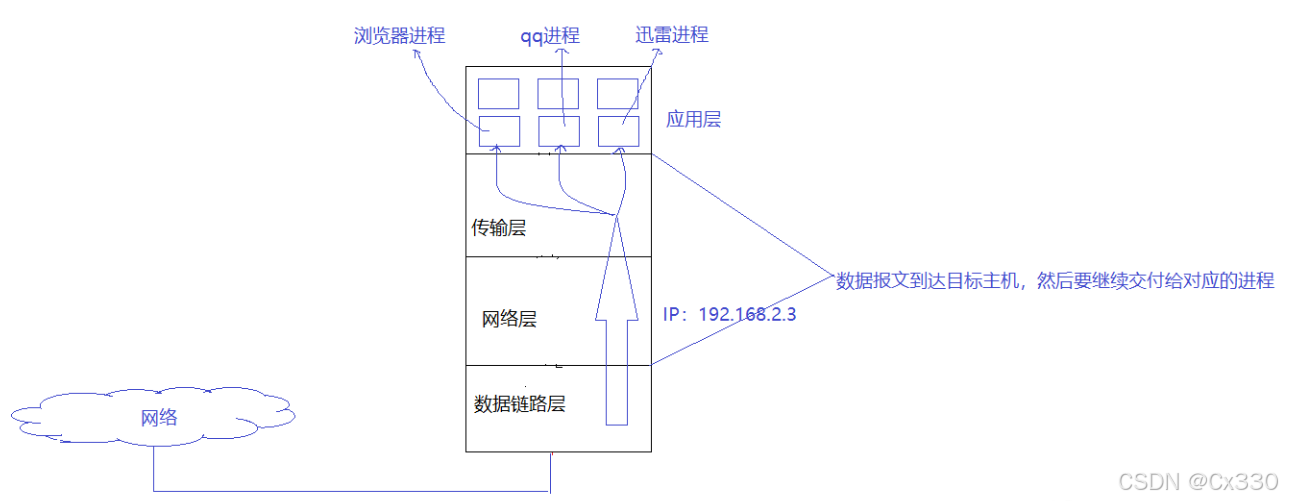
4.3 主机如何把报文交给进程?
在目标主机内部,当传输层收到数据后,会通过一个哈希表(Hash Map)进行检索。通过报文中的"目的端口号"(例如 8080),快速检索到对应的进程控制块(PCB),进而把数据推入该进程对应的接收缓冲区中。
[ 传输层收到报文 (目的端口号: 8080) ]
|
v 查哈希表 (Port -> PCB)
+-------------+
| Port | PCB |
+-------------+
| 8080 | 进程A | ======> 塞入进程 A 的缓冲区
| 8888 | 进程B |
+-------------+
inet_hashinfo内部细分了三个核心哈希表,分别应对不同的场景:
// Linux内核中inet_hashinfo核心结构(精简版)
struct inet_hashinfo {
// 1. 已建立连接哈希表:核心表,存储所有ESTABLISHED状态的socket
struct inet_ehash_bucket *ehash;
// 2. 绑定哈希表:以本地端口为索引,存储绑定到特定端口的socket,检查端口是否占用
struct inet_bind_hashbucket *bhash;
// 3. 监听哈希表:以本地IP+端口为索引,存储LISTEN状态的socket,处理新连接请求
struct inet_listen_hashbucket *lhash2;
};内核从报文到进程的完整查找流程:
- 网卡收到数据报文,经过数据链路层、网络层校验后,交付给传输层;
- 传输层提取报文的五元组(源 IP、源端口、目的 IP、目的端口、协议);
- 调用__inet_lookup函数,先在ehash已建立连接表中,通过五元组计算哈希值,快速找到对应的 Socket 结构体;
- 如果是新的连接请求(SYN 包),则在lhash2监听表中,通过目的端口查找对应的监听 Socket;
- 找到 Socket 后,内核通过它关联的文件结构体,最终找到拥有这个 Socket 的进程task_struct,完成数据交付。
五. Socket:网络通信的核心基石
理解了 IP 和端口号,我们就能彻底搞懂 Socket 的本质。
5.1 Socket 的核心定义
IP 地址标识互联网中唯一的一台主机,端口号标识该主机上唯一的一个网络进程,因此「IP 地址 + 端口号」就能唯一标识互联网中的一个进程,我们把这个组合叫做套接字(Socket)。
Socket 的英文原意是「插座」,这个命名极其形象:
- 网络通信就像电器通电,IP 地址是你家的地址,端口号是你家墙上的插座编号,电器(进程)插上插座(绑定 Socket),就能通过电网(互联网)和远端的电器通信。
5.2 四元组与五元组:唯一标识网络通信
- 四元组 :{源IP, 源端口, 目的IP, 目的端口},能够唯一标识互联网中唯二的两个通信进程,定义了通信的两个端点;
- 五元组 :在四元组的基础上,增加了传输层协议(TCP/UDP),内核通过五元组,唯一标识一个完整的网络双向连接。
5.3 Linux 中 Socket 的本质
在 Linux 系统中,有一个核心哲学:一切皆文件,Socket 也不例外。
- 从用户态视角 :Socket 本质是一个文件描述符(fd) ,我们可以通过
read/write系统调用,对这个 fd 进行读写,实现数据的收发; - 从内核态视角:Socket 是一个复杂的结构体,里面绑定了 IP、端口、协议类型、收发缓冲区、连接状态等所有网络通信相关的信息,是内核网络协议栈与用户态进程之间的桥梁。
六. 传输层两大核心协议:TCP 与 UDP
Socket 编程基于传输层协议,我们需要先对两大核心协议建立直观的认知,为后续编程打下基础。
6.1 TCP 协议(传输控制协议)
TCP(Transmission Control Protocol)是面向连接的、可靠的、面向字节流的传输层协议,核心特性:
- 有连接:通信前必须先通过「三次握手」建立连接,断开时通过「四次挥手」释放连接,就像打电话,必须先拨通电话、对方接听,才能正常对话;(三次握手,四次挥手------以后会见到)
- 可靠传输 :TCP 会通过确认应答、超时重传、序列号、校验和等机制,保证数据不丢失、不重复、按序到达,不会出现数据错乱、丢包的情况;
- 面向字节流:数据以无边界的字节流形式传输,就像自来水,发送端一次发 1000 字节,接收端可以分 10 次每次收 100 字节,收发次数没有严格的对应关系,上层需要自己处理数据边界。
6.2 UDP 协议(用户数据报协议)
UDP(User Datagram Protocol)是无连接的、不可靠的、面向数据报的传输层协议,核心特性:
- 无连接:通信前不需要建立连接,知道对方的 IP 和端口,就可以直接发送数据,就像发邮件,不需要提前和对方确认,直接投递即可;
- 不可靠传输:UDP 不提供确认应答、重传机制,只保证把数据发出去,不保证数据能到达对方,也不保证数据按序到达;
- 面向数据报:数据以报文为单位传输,收发次数严格匹配,发送端一次发一个 100 字节的报文,接收端必须一次完整接收 100 字节,不能分多次读取,天然保留了数据边界。
重要提醒:可靠和不可靠是协议的特性,不是优缺点。TCP 的可靠是有代价的,它需要额外的开销维护连接、保证可靠性,传输效率更低;UDP虽然不可靠,但它头部开销小、传输效率高、延迟低。
- 对数据完整性要求高的场景(文件传输、银行转账、HTTP 通信),用 TCP;
- 对实时性要求高、能容忍少量丢包的场景(直播、视频通话、游戏),用 UDP。
七. 避坑指南:网络字节序与大端、小端问题
在 C/C++ 进行套接字编程时,有一个新手必踩的雷区:字节序。
7.1 什么是大小端?
假设我们在内存中存储一个 32 位的整型数值 0x1234abcd:
-
大端模式(Big-endian) :低地址存高字节。
-
小端模式(Little-endian) :低地址存低字节(目前我们常用的 x86 / ARM 个人电脑大多是小端模式)。
以地址由低到高 0x0000 ~ 0x0003 存储 0x1234abcd 为例:
| 内存地址 | 大端模式 (Big-endian) | 小端模式 (Little-endian) |
|---|---|---|
0x0000 (低地址) |
0x12 (高字节) |
0xcd (低字节) |
0x0001 |
0x34 |
0xab |
0x0002 |
0xab |
0x34 |
0x0003 (高地址) |
0xcd (低字节) |
0x12 (高字节) |
- 大端序 :高位字节(0x12)存储在低地址,低位字节(0xCD)存储在高地址。
- 小端序 :低位字节(0xCD)存储在低地址,高位字节(0x12)存储在高地址。
7.2 网络字节序的强制规定
TCP/IP 协议明确规定:网络数据流必须采用大端字节序,即低地址高字节。
- 无论发送端主机是大端还是小端,发送数据前,必须将多字节数据从主机字节序转换为网络字节序(大端);
- 无论接收端主机是大端还是小端,收到数据后,必须将多字节数据从网络字节序转换为主机字节序,再进行处理。
为什么选择大端序作为网络字节序?因为网络数据的发送规则是「内存低地址的数据先发送」,大端序的存储方式,让先发送的是数据的高字节,抓包分析时更符合人类的阅读习惯,可读性更好。
7.3 常用字节序转换函数详解
在 Linux C/C++ 网络编程中,系统提供了一组专门用于在"主机字节序"与"网络字节序"之间进行转换的底层函数。
(1) 函数族命名规则(记忆密码)
这组函数非常容易记错,但只要理清其命名的字母含义,就能过目不忘:
-
h:Host(主机字节序,多为小端)
-
n:Network(网络字节序,大端)
-
to:转换到
-
s:Short(16位无符号整型,多用于端口号转换)
-
l:Long(32位无符号整型,多用于IP地址转换)
(2) 函数原型与声明
这些函数声明在 **<arpa/inet.h>**头文件中:
#include <arpa/inet.h>
// 1. 16位无符号整数:主机字节序 -> 网络字节序(主要用于 Port)
uint16_t htons(uint16_t hostshort);
// 2. 32位无符号整数:主机字节序 -> 网络字节序(主要用于 IPv4 地址)
uint32_t htonl(uint32_t hostlong);
// 3. 16位无符号整数:网络字节序 -> 主机字节序(解析收到的 Port)
uint16_t ntohs(uint16_t netshort);
// 4. 32位无符号整数:网络字节序 -> 主机字节序(解析收到的 IP)
uint32_t ntohl(uint32_t netlong);(3) 现代 IP 地址转换函数(隐含字节序转换)
在网络编程中,我们很少直接对 32 位的 IP 整型值手动调用 htonl(),而是使用更高级的 IP 字符串与网络字节序整数相互转换 的 API。这些现代接口已经把"字节序转换"的工作在底层封装好了:
#include <arpa/inet.h>
// 1. 字符串IP("127.0.0.1") -> 网络字节序的二进制IP (P: Presentation, N: Network)
int inet_pton(int af, const char *src, void *dst);
// 示例:inet_pton(AF_INET, "192.168.1.1", &server_addr.sin_addr);
// 2. 网络字节序的二进制IP -> 字符串IP
const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);
// 示例:char ip_str[INET_ADDRSTRLEN];
// inet_ntop(AF_INET, &client_addr.sin_addr, ip_str, sizeof(ip_str));(4) 转换示例代码
#include <iostream>
#include <arpa/inet.h>
int main() {
uint16_t host_port = 8888;
// 转换为网络字节序
uint16_t net_port = htons(host_port);
std::cout << "主机端口: " << host_port << " -> 网络字节序(十六进制): 0x"
<< std::hex << net_port << std::endl;
// 再转换回来
uint16_t decoded_port = ntohs(net_port);
std::cout << std::dec; // 恢复十进制打印
std::cout << "还原后主机端口: " << decoded_port << std::endl;
return 0;
}八. 进阶:C++ Socket 核心 API 详解
有了前面的理论支撑,我们接下来看看在 C++ 中,操作系统是如何用一组 API 来完成这些操作的。
8.1 socket() ------ 创建网卡抽象文件
int socket(int domain, int type, int protocol);-
作用 :向操作系统申请一个网络通信端点(底层其实是打开了一个特殊文件,返回文件描述符
fd)。 -
参数:
-
domain:地址族。常用AF_INET(IPv4) 或AF_INET6(IPv6)。 -
type:套接字类型。SOCK_STREAM(面向字节流,即 TCP);SOCK_DGRAM(面向数据报,即 UDP)。 -
protocol:协议,一般填0,系统会根据type自动匹配。
-
8.2 bind() ------ 关联物理地址(IP + Port)
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);-
作用:将创建好的套接字与当前主机的 IP 和端口进行绑定。
-
参数:
-
sockfd:socket()函数返回的文件描述符。 -
addr:指向sockaddr结构体的指针(实际使用中常用struct sockaddr_in强转,用于填充具体的 IP 和端口)。
-
8.3 listen() ------ 让套接字进入监听状态
int listen(int sockfd, int backlog);-
作用 :仅用于 TCP 服务器,告诉操作系统:"我已经准备好接收连接请求了,请帮我建立起连接队列"。
-
backlog:底层未完成连接队列(SYN_RCVD)与已完成连接队列(ESTABLISHED)的最大长度 and 上限。
8.4 accept() ------ 阻塞获取客户端连接
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);-
作用 :从已完成三次握手的连接队列中,取出一个连接。
-
返回值 :成功时会返回一个全新的文件描述符 (专门负责与该客户端进行数据收发)。而原本的
sockfd继续保留,专门用来监听新的客户端连接(分工明确!)。
8.5 connect() ------ 客户端发起连接
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);- 作用 :仅用于 客户端。向指定的服务器发起 TCP 三次握手连接。
8.6 send() & recv() ------ 数据收发
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);- 作用:在建立连接的套接字上收发数据。实质是将数据在"用户缓冲区"与"操作系统内核套接字缓冲区"之间进行拷贝。
结语
从局域网内网卡的碰撞避让,到 IP/MAC 的接力运载,再到传输层通过 Port 精准投递给应用进程,最终在内存中通过大端字节序落带------网络通信的每一层设计都充满了计算机科学家们智慧。
而掌握好 Socket 核心 API 的流转机制,并熟悉它在面对高并发、网络抖动等特殊复杂场景下的边界处理,是你从 C++ 初学者蜕变成为后端专家的必经之路。