摘要
模拟退火算法是优化算法中单点搜索 算法的代表,通过模拟固体降温结晶现象,从一个解出发,以概率接受劣解来跳出局部最优。本文从物理退火结晶开始,完整推导模拟退火算法的核心原理,并手写模拟退火算法解决 Rastrigin 多峰函数求最小值问题和 TSP 旅行商问题。
引言
模拟退火算法的核心源自固体降温结晶过程,对固体加热后进行缓慢平稳的降温最后得到的是晶体,反则得到的是非晶体。
模拟退火算法模拟的就是这个降温过程,在固体的每一个温度都进行停留使得固体呈现稳态才继续降温,模拟退火的稳态过程就是寻找最优解的过程。
核心原理
模拟退火算法是单点搜索算法,不同于 PSO 和 GA 等群算法,轮次迭代中仅使用一个解(状态)来进行优化,这正是它在空间复杂度上的优势。
核心字段:
固体降温中的核心字段有 状态、能量、温度和基态 ,对应到模拟退火中就是:
- 解 x(状态):问题的一个可行解
- 适应度函数 E(能量):衡量解好坏的标准
- 可变参数 T(温度):用于控制跳出局部最优
- 全局最优解 best(基态):问题中适应度最好的解
温度系数
物理退火中,热运动动能赋予了分子在高温度下跨越势能临界点的能力。在算法映射中,高温度 T 赋予了系统跨越能量障碍(即接受劣解)的高概率窗口 。为了进一步提高后期局部开发的精细度,本文引入了与温度解耦或协同的步长衰减机制: Step∝T。
常规求最小值更新公式为:
xnew=x+step∗rand(−1,1)
变化幅度 step 的设置没有固定的形式,但是需要保持 step 与 T 呈正相关,T 越大 step 越大。
Metropolis 准则
模拟退火算法使用适应度函数 E(x) 来衡量当前解 x 的好坏,设置 ΔE=E(xnew)−E(x),求最小值问题中 ΔE≤0 说明新解 xnew 更优会直接接受 ,反则当 ΔE>0 则说明新解没有旧解好,理论上应该拒绝新解,但是为了避免全局最优会有概率接受新解。
P(Accept)={1,e−TΔE,ΔE≤0ΔE>0
按照 Metropolis 准则 接受劣解的概率为 e−TΔE (公式源于统计力学中的 Boltzmann 分布,系统处于能量 E 的状态的概率正比于 e−TE),将 TΔE 看作一个整体时图像为 e−x:
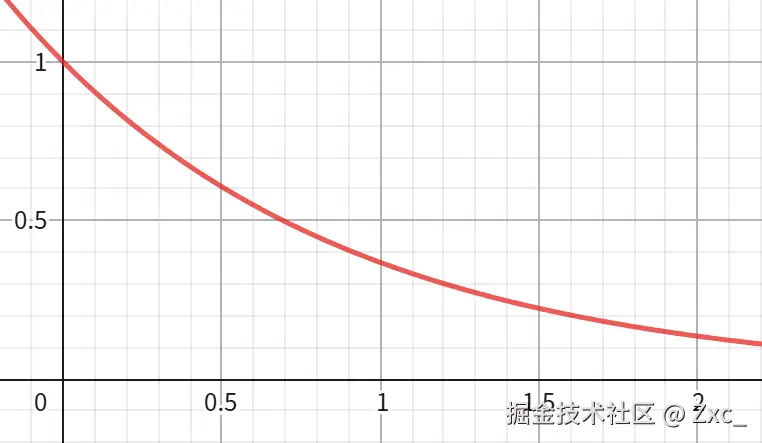
算法开始时, T 非常高, TΔE 就会很小接近于 0 , e−TΔE 接近于 1 ,算法接受劣解的概率非常高 ,随着轮次迭代 T 下降同时趋近于稳定 ΔE 也会变小, TΔE 就会很大, e−TΔE 接近于 0 ,算法接受劣解的概率非常低。
温度更新
算法逐步迭代寻找最优解,T 也会随着轮次逐步减低,常用公式为:
Tnew=αT,α∈0.85,0.99
α 类似于学习率用于控制温度下降的速度 , α 越小温度下降得越快,算法整体执行的次数也会减少,但是整体效果可能会变差。
算法执行往往会设置一个阈值 tolerance(如 1e-6) ,当 T < tolerance 时代表算法结束。
温度初始化
温度的核心作用体现在算法的迭代轮次 和接受劣解的概率 e−TΔE ,如果面对不同规模的问题设置相同的初始化 T_start 时会出现问题,若设置 T_start = 100:
- 小规模问题设
E_new = 10 , E = 8 , ΔE = 2,则 P=e−501≈0.98,过高 - 大规模问题设
E_new = 1000 , E = 800 , ΔE = 200,则 P=e−2≈0.13,过低
发现同一个 T 对不同规模的问题影响不同,理论上 T 应该与问题规模呈正相关,根据 P=e−TΔE 可以反推得到:
Tstart=−lnPstartΔE
ΔE 整体代表的是问题的规模,可以在算法开始之前取100个 Δ E = E(rand(limit)_1) - E(rand(limit)_2),最后取 ΔEavg作为问题规模代表。
Pstart 代表的就是开始时对于劣解的接受程度往往初始化为 p_start=0.85,最终公式为:
Tstart=−ln0.85ΔEavg
算法流程
按照模拟退火算法的核心原理实现算法。
参数初始化
- L :温度 T 下算法的迭代次数
- p_start :初始化劣解接受概率,常设置
p_start=0.85 - t_end :最低温度阈值,当
T < tolerance算法结束 - alpha :温度更新控制参数
- fitness_history :保存可用于查看算法流程
温度初始化
根据推导的公式 Tstart=−ln0.85ΔEavg 进行温度的初始化,其中的位置参数只有 ΔEavg ,其计算发生在模拟退火算法执行之前,可以随机取多个 ΔE 最后取均值。
如取 100 个 ΔE ,即每个轮次随机两个解 x1 和 x2,然后计算 ΔE =E(x1) - E(x2),100 轮后取均值即可得到 ΔEavg,最后代入 Tstart=−ln0.85ΔEavg 。
获取新状态
评估完当前状态的好坏后,就会获取下一个状态,其结果可能更好也可能更坏。
1.在函数求最值问题中常用的获取状态公式为:
xnew=x+step∗rand(−1,1)
同时还要进行边界处理,新状态不允许超出边界如边界为-5,5,获取x_new = 5.2时就越界了。
- 直接截断 :超出边界的状态直接设置为边界此时
x_new = 5.2-->5,但是会存在一个很大问题,如果在达到右边界x = 5后,获取新状态时如果随机到整数则还是x_new = 5,此时ΔE=0无条件接受新状态,算法会将大量的算力被浪费在边界的同一个点上。 - 镜面反弹:以边界为对称轴投影越界的状态到界内,这个做法更合理。
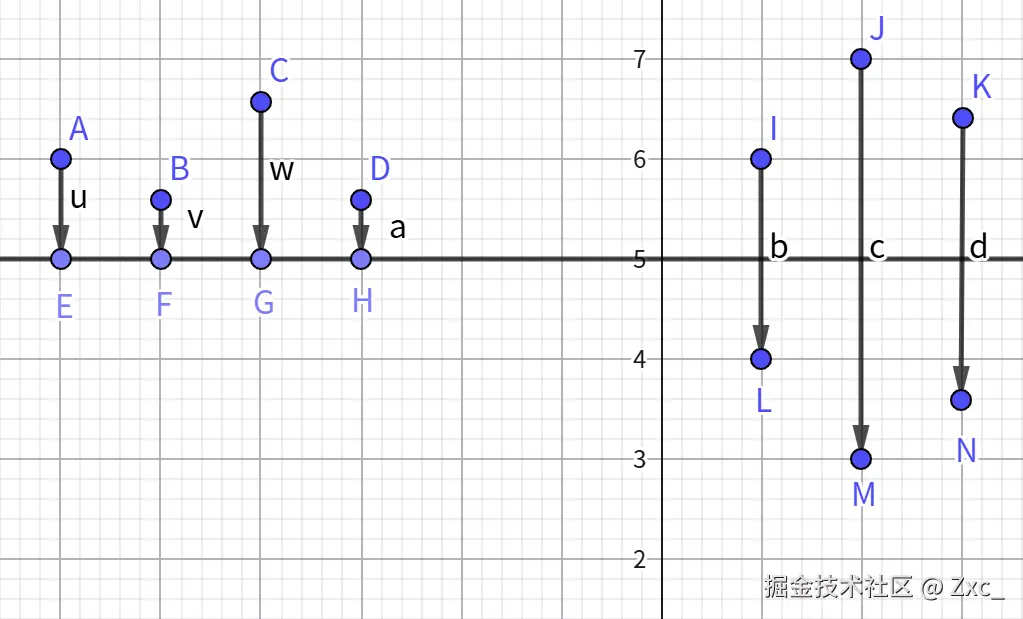
2.在TSP旅行商问题中常用的获取状态公式为:
旅行商问题中 x 是所有城市序号的组合如3,2,35,......,7,3是一个经过所有城市的回路。
- 交换算子:任取两个城市交换其位置
- 逆序算子:任取一个区间内城市逆序
- 插入算子:随机拔出一个城市插入到随机位置中
逻辑实现
算法的整体逻辑实现为:
- 在限制内随机生成初始状态 x
- 初始化起始温度值 T
- 保存历史最优数据
- 温度外循环,计算温度内移动的幅度
- 温度内循环,获取新位置并判断是否更新
手写 SA
Rastrigin
使用模拟退火算法实现二维 Rastrigin 函数求最小值问题最小值点在(0,0)值为 0 。
单点搜索
python
"""模拟退火算法 SA (Simulated Annealing)
摘要:模拟退火算法通过模拟物理现象,解决寻找最优解问题,并且实现概率更新到更差的位置以跳出局部最优。
引言:模拟退火算法源自物理中固体降温结晶原理,缓慢降温(退火)则得到晶体,快速降温得到的则是非晶体。
核心原理:
状态(解):问题的一个可行解
能量(适应度函数):衡量状态好坏的标准
温度:可变参数,用来计算跳出局部最优的概率
基态(全局最优解):问题的最优解
算法流程(最小值问题举例):
1.定义问题--适应度函数 E,解 x 的维度,解的区间
2.定义参数--迭代轮次 L,温度 T 初始值及变化函数
3.更新条件--ΔE = E(x_new) - E(x),ΔE < 0 说明新位置 x_new 更优,否则 x 更优
4.概率更新--当 ΔE > 0 时 x 更优,但是避免全局最优问题,在概率 P = e^-(ΔE/T) 更新
5.全局最优--避免最后一轮时概率 P = e^-(ΔE/T) 更新,迭代中保存历史最优 x_best
核心问题:
T 的初始化:T_Start 应该随着问题规模的变大而变大,而不是固定的,按照 P = e^-(ΔE/T) 反算 T = -ΔE/lnP,
通常设置 P_Start = 0.85,ΔE 可以在退火之前进行计算 100 轮迭代下 ΔE 的均值 ΔE_avg。
T 的变化:随着轮次 L 上升 T 应该下降,二者呈负相关。T = α * T,(α属于0-1)L 越大 α 越大,反则越小。
"""
import numpy as np
class SA:
"""模拟退火算法 SA """
def __init__(self, L=100, dim=1, p_start=0.85, t_end=1e-6, alpha=0.98):
"""初始化"""
self.L = L
self.dim = dim
self.p_start = p_start
self.t_end = t_end
self.alpha = alpha
self.fitness_history = None
self.x_history = None
def _template_init(self, fitness_function, limit):
"""
初始化温度 T_start
T_start = -ΔE_avg/lnP_start
"""
# 1.迭代 100 轮计算 ΔE
delta_E_list = []
for i in range(100):
x1 = np.random.uniform(limit[:, 0], limit[:, 1], size=self.dim)
x2 = np.random.uniform(limit[:, 0], limit[:, 1], size=self.dim)
delta_E = abs(fitness_function(x1) - fitness_function(x2))
delta_E_list.append(delta_E)
# 2.计算 ΔE_avg ,代入计算 T_start
delta_E_avg = np.mean(delta_E_list)
t_start = -delta_E_avg / np.log(self.p_start)
return t_start
def _get_next(self, x, step_size, limits):
"""
计算新解位置
x_new = x + step_size * rand(-1,1)
"""
# 1.添加随机扰动
dx = np.random.uniform(-step_size, step_size, size=self.dim)
x_new = x + dx
# 2. 反射边界处理
lb, ub = limits[:, 0], limits[:, 1]
# 处理上限越界:如果 x > ub,反弹回 ub - (x - ub) = 2*ub - x
over_ub = x_new > ub
x_new[over_ub] = 2 * ub[over_ub] - x_new[over_ub]
# 处理下限越界:如果 x < lb,反弹回 lb + (lb - x) = 2*lb - x
under_lb = x_new < lb
x_new[under_lb] = 2 * lb[under_lb] - x_new[under_lb]
return x_new
def optimize(self, fitness_function, limits):
"""算法逻辑"""
# 1,初始化参数
limits = np.atleast_2d(limits) # 确保至少是二维的
if limits.shape[0] == 1 and self.dim > 1:
limits = np.tile(limits, (self.dim, 1))
x = np.random.uniform(limits[:, 0], limits[:, 1], size=self.dim) # 利用NumPy自动广播生成单解
fitness = fitness_function(x)
template = self._template_init(fitness_function, limits) # 初始化温度
template_start = template
x_best = np.copy(x) # 保存历史最优解
fitness_best = fitness
self.fitness_history = [fitness]
self.x_history = [np.copy(x)]
# 2.迭代计算
while template > self.t_end:
# 外层循环控制 步长
cur_step_size = (limits[:, 1] - limits[:, 0]) * (template / template_start) * 0.1
for _ in range(self.L):
# 内层更新位置
x_new = self._get_next(x, cur_step_size, limits)
# 计算 ΔE
fitness_new = fitness_function(x_new)
delta_E = fitness_new - fitness
# 更新
if delta_E < 0:
# 一定更新
x = x_new
fitness = fitness_new
if fitness_new < fitness_best:
x_best = np.copy(x)
fitness_best = fitness
else:
# 概率更新 P = e^-(ΔE/T)
p = np.exp(-delta_E / template)
if np.random.rand() < p:
x = x_new
fitness = fitness_new
self.fitness_history.append(fitness)
self.x_history.append(np.copy(x))
# 更新温度
template *= self.alpha
return x_best, fitness_best主函数测试结果代码:
python
if __name__ == "__main__":
def func(x):
return 10 * len(x) + np.sum(x ** 2 - 10 * np.cos(2 * np.pi * x))
sa = SA(dim=2)
limit = [[-5.12, 5.12], [-5.12, 5.12]]
x_best, fitness_best = sa.optimize(func, limit)
print(f'最小值位置:{x_best}')
print(f'最佳适应值:{fitness_best}')
import matplotlib.pyplot as plt
# 允许 matplotlib 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 提取历史记录
fitness_history = np.array(sa.fitness_history)
x_history = np.array(sa.x_history)
total_steps = len(fitness_history)
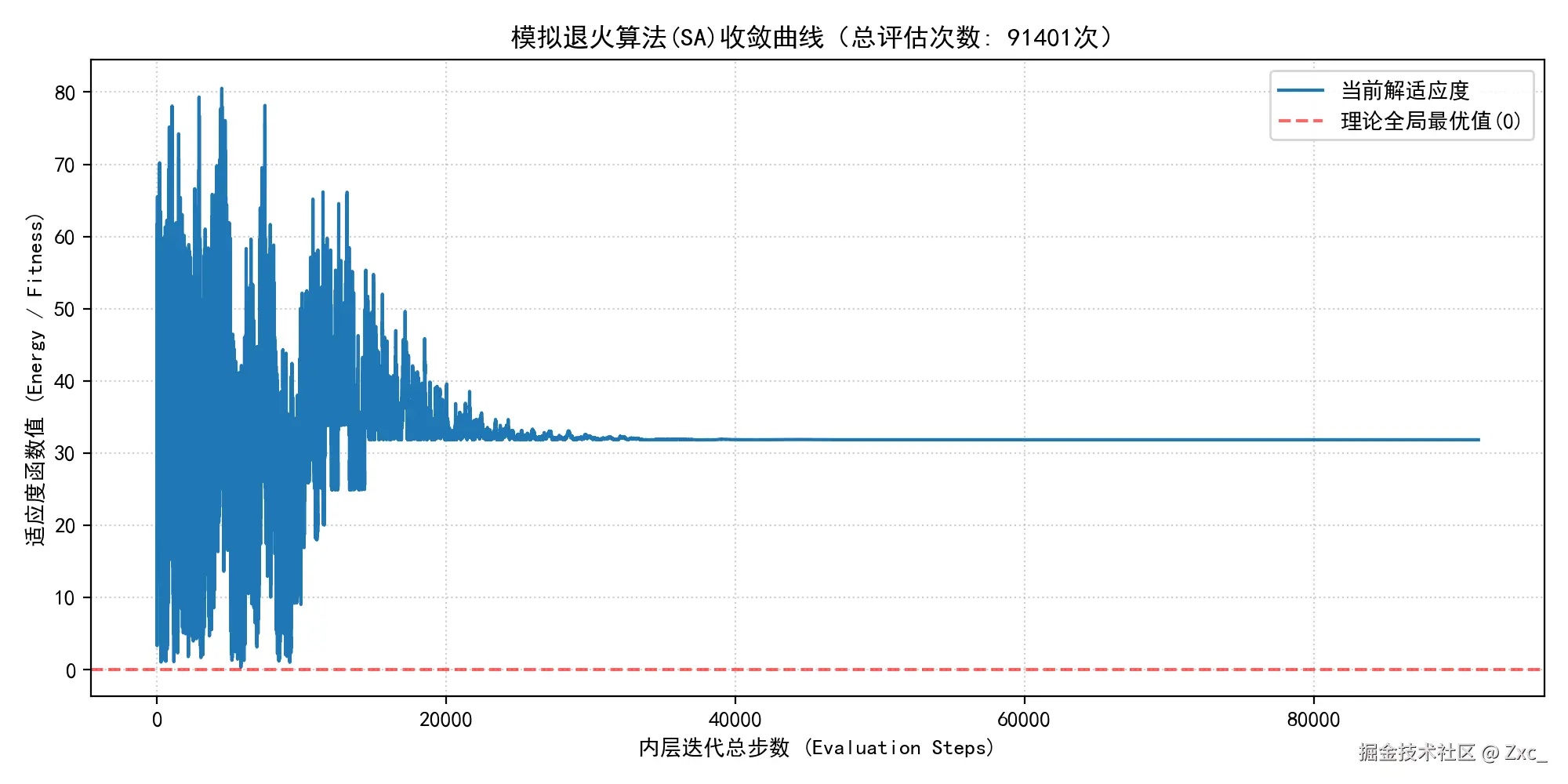
# ---------------- 图 1:收敛曲线图 ----------------
plt.figure(figsize=(10, 5), dpi=100)
plt.plot(fitness_history, color='#1f77b4', linewidth=1.5, label='当前解适应度')
plt.axhline(y=0, color='r', linestyle='--', alpha=0.6, label='理论全局最优值(0)')
plt.title(f'模拟退火算法(SA)收敛曲线(总评估次数: {total_steps}次)', fontsize=12)
plt.xlabel('内层迭代总步数 (Evaluation Steps)', fontsize=10)
plt.ylabel('适应度函数值 (Energy / Fitness)', fontsize=10)
plt.grid(True, linestyle=':', alpha=0.6)
plt.legend(loc='upper right')
# 局部放大图提示:你会看到前中期曲线上有很多"向上跳跃"的红点,那就是 Metropolis 准则在发挥作用
plt.tight_layout()
plt.show()
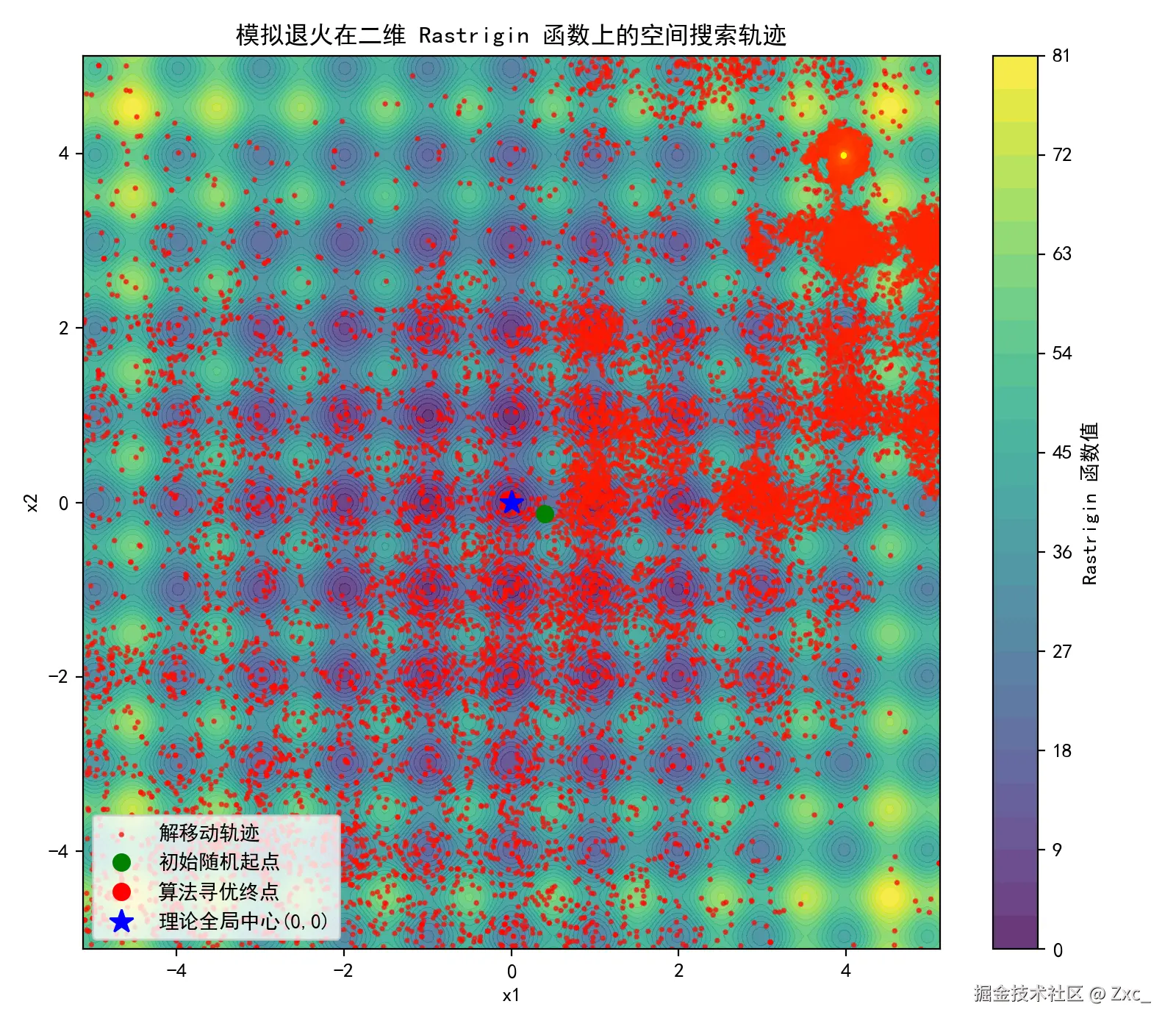
# ---------------- 图 2:2D 状态空间搜索轨迹图 ----------------
# 1. 准备 Rastrigin 函数的等高线数据
X1 = np.linspace(-5.12, 5.12, 200)
X2 = np.linspace(-5.12, 5.12, 200)
X1, X2 = np.meshgrid(X1, X2)
Z = 10 * 2 + (X1 ** 2 - 10 * np.cos(2 * np.pi * X1)) + (X2 ** 2 - 10 * np.cos(2 * np.pi * X2))
plt.figure(figsize=(8, 7), dpi=100)
# 画出绚丽的背景等高线
contour = plt.contourf(X1, X2, Z, levels=30, cmap='viridis', alpha=0.8)
plt.colorbar(contour, label='Rastrigin 函数值')
# 画出 SA 单解的移动轨迹(用渐变色代表时间先后:由浅入深)
colors = plt.cm.autumn(np.linspace(0, 1, total_steps))
plt.scatter(x_history[:, 0], x_history[:, 1], c=colors, s=3, alpha=0.6, label='解移动轨迹')
# 标出起点、终点和理论最优
plt.plot(x_history[0, 0], x_history[0, 1], 'go', markersize=8, label='初始随机起点')
plt.plot(x_best[0], x_best[1], 'ro', markersize=8, label='算法寻优终点')
plt.plot(0, 0, 'b*', markersize=12, label='理论全局中心(0,0)')
plt.title('模拟退火在二维 Rastrigin 函数上的空间搜索轨迹', fontsize=12)
plt.xlabel('x1', fontsize=10)
plt.ylabel('x2', fontsize=10)
plt.xlim(-5.12, 5.12)
plt.ylim(-5.12, 5.12)
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()结果分析
模拟退火算法是单点搜索算法,全局中更新的只有一个状态,所以结果会出现很大的随机性,非常不稳定,容易陷入局部最优问题。
观察到收敛曲线震荡是因为算法接受了劣解,所以会出现适应度跳变的情况。
多点并行
本文设计了一种多起点并行退火策略(Multi-start Parallel SA) 。该策略在搜索空间内并行部署 M 个独立的退火马尔可夫链。虽然单链仍保持单点勘探(Exploration)特征,但群体层面的多种子广度覆盖,显著降低了单一单点算法对初始状态的敏感性,起到了全局统计学保底的作用。
整体修改不大,只需要将涉及到 x 的位置由(dim,)-->(m_seeds,dim)转化为矩阵计算。
python
"""模拟退火算法(并行)"""
import numpy as np
class SA_Parallel:
"""模拟退火算法(并行)"""
def __init__(self, L=100, dim=1, p_start=0.85, t_end=1e-6, alpha=0.98, m_seeds=1):
"""初始化"""
self.L = L
self.dim = dim
self.p_start = p_start
self.t_end = t_end
self.alpha = alpha
self.fitness_history = None
self.m_seeds = m_seeds
def _template_init(self, fitness_function, limit):
"""
初始化温度 T_start
T_start = -ΔE_avg/lnP_start
"""
# 1.迭代 100 轮计算 ΔE
delta_E_list = []
for i in range(100):
x1 = np.random.uniform(limit[:, 0], limit[:, 1], size=self.dim)
x2 = np.random.uniform(limit[:, 0], limit[:, 1], size=self.dim)
delta_E = abs(fitness_function(x1) - fitness_function(x2))
delta_E_list.append(delta_E)
# 2.计算 ΔE_avg ,代入计算 T_start
delta_E_avg = np.mean(delta_E_list)
t_start = -delta_E_avg / np.log(self.p_start)
return t_start
def _get_next(self, x, step_size, limits):
"""
计算新解位置
x_new = x + step_size * rand(-1,1)
"""
# 1.添加随机扰动
dx = np.random.uniform(-step_size, step_size, size=x.shape)
x_new = x + dx
lb, ub = limits[:, 0], limits[:, 1] # 形状 (dim,)
# 1. 处理上限越界:如果 x_new > ub,则反弹回 2*ub - x_new,否则保持原样
x_new = np.where(x_new > ub, 2 * ub - x_new, x_new)
# 2. 处理下限越界:如果 x_new < lb,则反弹回 2*lb - x_new,否则保持原样
x_new = np.where(x_new < lb, 2 * lb - x_new, x_new)
return np.clip(x_new, lb, ub)
def optimize(self, fitness_function, limits):
"""算法逻辑"""
# 1,初始化参数
limits = np.atleast_2d(limits) # 确保至少是二维的
if limits.shape[0] == 1 and self.dim > 1:
limits = np.tile(limits, (self.dim, 1))
# 生成 m_seeds 个种子
x = np.random.uniform(limits[:, 0], limits[:, 1], size=(self.m_seeds,self.dim))
fitness = np.array([fitness_function(ind) for ind in x])
template = self._template_init(fitness_function, limits) # 初始化温度
template_start = template
# 全局历史最优记录 (从所有种子中挑个最好的)
best_idx = np.argmin(fitness)
x_best = np.copy(x[best_idx])
fitness_best = fitness[best_idx]
# 用于画图的收敛历史(记录每一轮里所有解之中的最好值)
self.fitness_history = [fitness_best]
# 2.迭代计算
while template > self.t_end:
# 外层循环控制 步长
cur_step_size = (limits[:, 1] - limits[:, 0]) * (template / template_start) * 0.1
for _ in range(self.L):
# 内层更新位置
x_new = self._get_next(x, cur_step_size, limits)
# 计算所有种子的 ΔE
fitness_new = np.array([fitness_function(ind) for ind in x_new])
delta_E = fitness_new - fitness
# 对每一个独立的退火进行判定
for s in range(self.m_seeds):
if delta_E[s] < 0:
x[s] = x_new[s]
fitness[s] = fitness_new[s]
# 更新全局最优
if fitness_new[s] < fitness_best:
x_best = np.copy(x_new[s])
fitness_best = fitness_new[s]
else:
p = np.exp(-delta_E[s] / template)
if np.random.rand() < p:
x[s] = x_new[s]
fitness[s] = fitness_new[s]
# 记录当前这一步的全局最优历史,平滑
# self.fitness_history.append(fitness_best)
# 记录当前这一步,整个种群里实时表现最好的个体的适应度,震荡
current_population_best = np.min(fitness)
self.fitness_history.append(current_population_best)
# 更新温度
template *= self.alpha
return x_best, fitness_best测试效果主函数:
python
if __name__ == "__main__":
def func(x):
return 10 * len(x) + np.sum(x ** 2 - 10 * np.cos(2 * np.pi * x))
sa = SA_Parallel(dim=2,m_seeds=5)
limit = [[-5.12, 5.12], [-5.12, 5.12]]
x_best, fitness_best = sa.optimize(func, limit)
print(f'最小值位置:{x_best}')
print(f'最佳适应值:{fitness_best}')
import matplotlib.pyplot as plt
# 允许 matplotlib 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 提取历史记录
fitness_history = np.array(sa.fitness_history)
total_steps = len(fitness_history)
# 收敛曲线图
plt.figure(figsize=(10, 5), dpi=100)
plt.plot(fitness_history, color='#1f77b4', linewidth=1.5, label='当前解适应度')
plt.axhline(y=0, color='r', linestyle='--', alpha=0.6, label='理论全局最优值(0)')
plt.title(f'模拟退火算法(SA)收敛曲线(总评估次数: {total_steps}次)', fontsize=12)
plt.xlabel('内层迭代总步数 (Evaluation Steps)', fontsize=10)
plt.ylabel('适应度函数值 (Energy / Fitness)', fontsize=10)
plt.grid(True, linestyle=':', alpha=0.6)
plt.legend(loc='upper right')
# 局部放大图提示:你会看到前中期曲线上有很多"向上跳跃"的红点,那就是 Metropolis 准则在发挥作用
plt.tight_layout()
plt.show()结果分析
- 记录适应度方法1:仅在全局最优的适应度更新时记录,曲线整体平滑下降
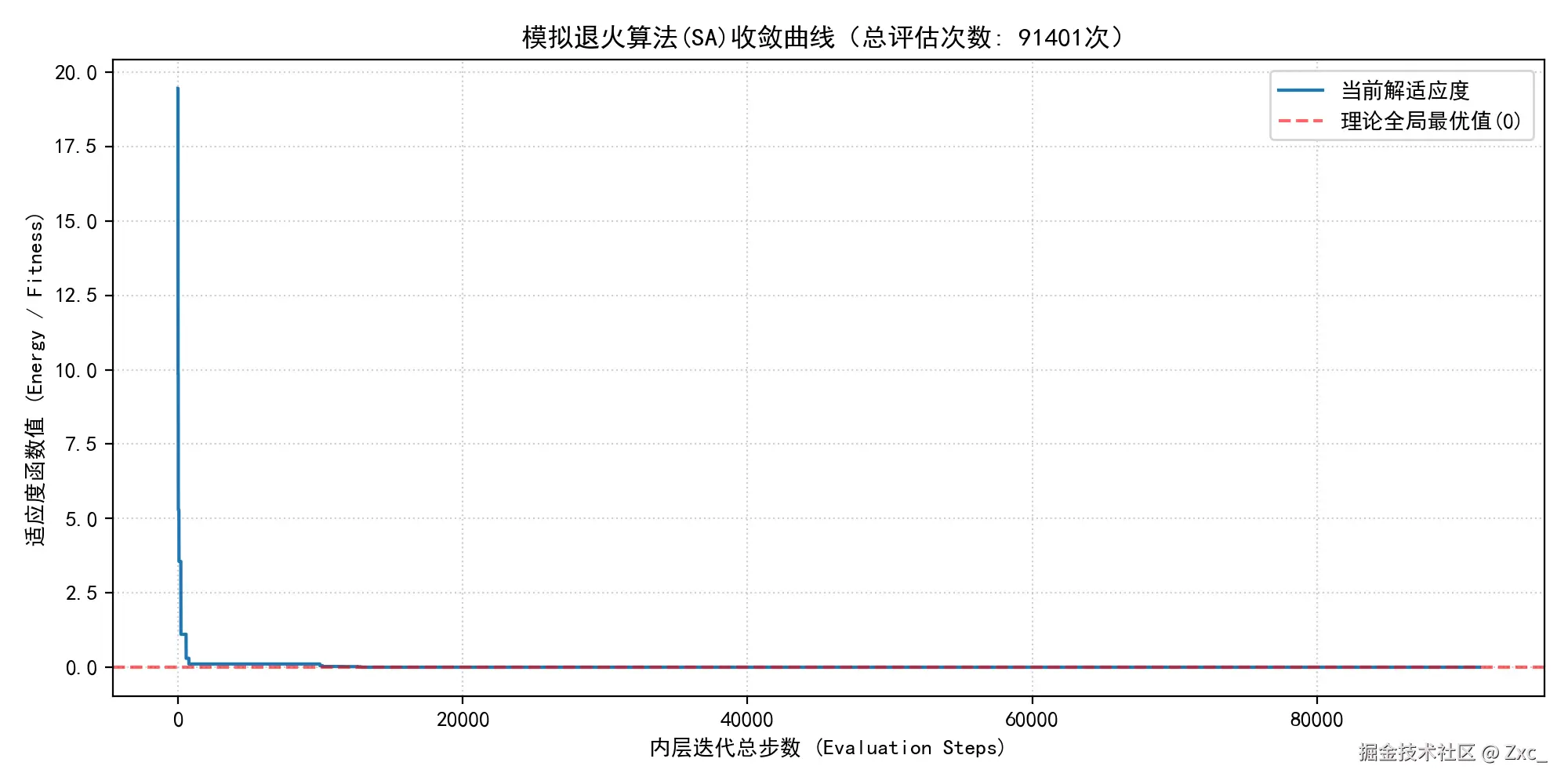
- 记录适应度方法2:记录每一次迭代中所有种子的最优适应度,会有概率 P 往上走,曲线震荡
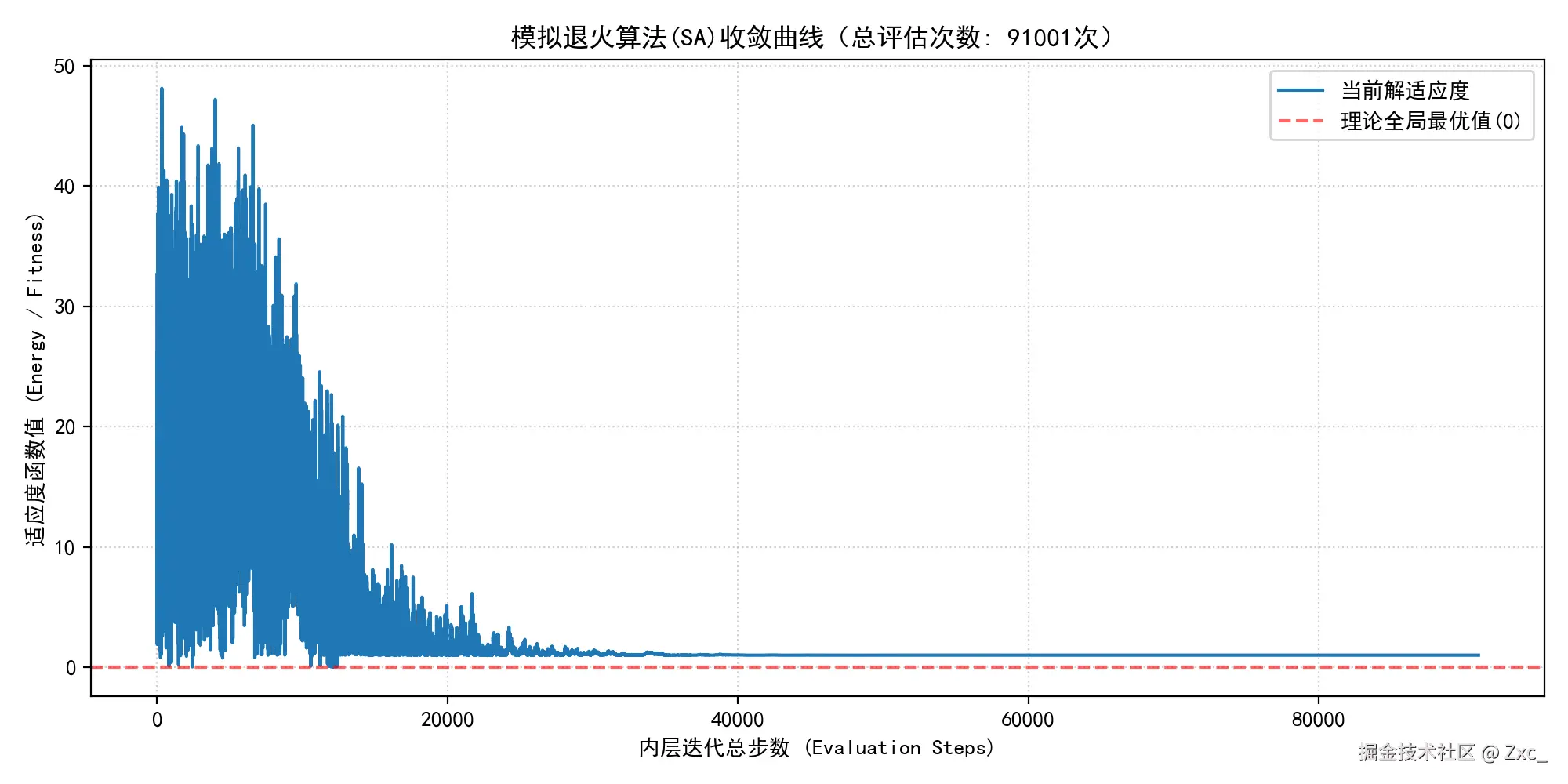
TSP 问题
旅行商问题,寻找经过所有位置的最短回路。
- 初始化状态或更新状态:由修改一个数变成修改一个序列的顺序。
- 路径长度计算:计算一个路径的长度
- 算子选择:可以选择一个,也可以多个混合
python
"""模拟退火算法(并行) TSP问题"""
import numpy as np
class SA_Parallel:
"""模拟退火算法(并行)"""
def __init__(self, L=100, p_start=0.85, t_end=1e-6, alpha=0.98, m_seeds=1):
"""初始化"""
self.L = L
self.p_start = p_start
self.num_cities = None
self.t_end = t_end
self.alpha = alpha
self.fitness_history = None
self.m_seeds = m_seeds
def _template_init(self, dist_matrix):
"""
初始化温度 T_start
T_start = -ΔE_avg/lnP_start
"""
# 1.迭代 100 轮计算 ΔE
delta_E_list = []
for i in range(100):
x1 = np.random.permutation(self.num_cities)
x2 = np.random.permutation(self.num_cities)
delta_E = abs(self.get_single_path_distance(x1, dist_matrix) -
self.get_single_path_distance(x2, dist_matrix))
delta_E_list.append(delta_E)
# 2.计算 ΔE_avg ,代入计算 T_start
delta_E_avg = np.mean(delta_E_list)
t_start = -delta_E_avg / np.log(self.p_start)
return t_start
def get_single_path_distance(self, path, dist_matrix):
""" 计算单条 TSP 路径的回路总长度 """
go_distance = np.sum(dist_matrix[path[:-1], path[1:]])
back_distance = dist_matrix[path[-1], path[0]]
return go_distance + back_distance
def _get_next(self, x, step_size):
"""
计算新解位置
策略1:交换算子,交换任意两个城市位置
策略2:逆序算子,逆序随机一个区间的城市(使用)
策略3:插入算子,随机拔出一个城市,随机插入到路径
"""
max_span = max(15, int(step_size))
x_new = np.copy(x)
# 交换算子0.2+逆序算子0.8
for s in range(self.m_seeds):
if np.random.rand() < 0.8:
# ------ 策略 1:逆序算子(保持你测试出的保底 15 跨度) ------
span = np.random.randint(2, max_span + 1)
start_idx = np.random.randint(0, self.num_cities - span + 1)
end_idx = start_idx + span
x_new[s, start_idx:end_idx] = x_new[s, start_idx:end_idx][::-1]
else:
# ------ 策略 2:基于步长约束的交换算子 ------
# 随机选第一个城市
idx1 = np.random.randint(0, self.num_cities)
# 第二个城市不能离得太远,受当前步长限制(后期退化为近邻交换,极其精准)
max_swap_dist = max(2, int(step_size * 0.5))
swap_dist = np.random.randint(1, max_swap_dist + 1)
# 环形边界处理(防止越界)
idx2 = (idx1 + swap_dist) % self.num_cities
# 执行硬交换
x_new[s, idx1], x_new[s, idx2] = x_new[s, idx2], x_new[s, idx1]
return x_new
def optimize(self, dist_matrix):
"""算法逻辑"""
# 1.初始化原始路径
self.num_cities = dist_matrix.shape[0]
x = np.array([np.random.permutation(self.num_cities) for _ in range(self.m_seeds)])
# 初始化温度
template = self._template_init(dist_matrix)
template_start = template
# 全局历史最优记录 (从所有种子中挑路径最短的)
dist = np.array([self.get_single_path_distance(path, dist_matrix) for path in x])
best_idx = np.argmin(dist)
x_best = np.copy(x[best_idx])
dist_best = dist[best_idx]
# 用于画图的收敛历史
self.fitness_history = [dist_best]
# 2.迭代计算
while template > self.t_end:
# 外层循环控制 步长
cur_step_size = (self.num_cities * 0.5) * (template / template_start)
for _ in range(self.L):
# 内层更新位置
x_new = self._get_next(x, cur_step_size)
# 计算所有种子的 ΔE
dist_new = np.array([self.get_single_path_distance(path, dist_matrix) for path in x_new])
delta_E = dist_new - dist
# 对每一个独立的退火进行判定
for s in range(self.m_seeds):
if delta_E[s] < 0:
x[s] = x_new[s]
dist[s] = dist_new[s]
# 更新全局最优
if dist_new[s] < dist_best:
x_best = np.copy(x_new[s])
dist_best = dist_new[s]
else:
p = np.exp(-delta_E[s] / template)
if np.random.rand() < p:
x[s] = x_new[s]
dist[s] = dist_new[s]
# 记录当前这一步的全局最优历史,平滑
# self.fitness_history.append(dist_best)
# 记录当前这一步,整个种群里实时表现最好的个体的适应度,震荡
current_population_best = np.min(dist)
self.fitness_history.append(current_population_best)
# 更新温度
template *= self.alpha
return x_best, dist_best使用 berlin52数据集 进行测试算法的能力:
python
if __name__ == "__main__":
# 1. berlin52数据集 52个坐标
coords = np.array([[565.0, 575.0], [25.0, 185.0], [345.0, 750.0], [945.0, 685.0], [845.0, 655.0],
[880.0, 660.0], [25.0, 230.0], [525.0, 1000.0], [580.0, 1175.0], [650.0, 1130.0],
[1605.0, 620.0], [1220.0, 580.0], [1465.0, 200.0], [1530.0, 5.0], [845.0, 680.0],
[725.0, 370.0], [145.0, 665.0], [415.0, 635.0], [510.0, 875.0], [560.0, 365.0],
[300.0, 465.0], [520.0, 585.0], [480.0, 415.0], [835.0, 625.0], [975.0, 580.0],
[1215.0, 245.0], [1320.0, 315.0], [1250.0, 400.0], [660.0, 180.0], [410.0, 250.0],
[420.0, 555.0], [575.0, 665.0], [1150.0, 1160.0], [700.0, 580.0], [685.0, 595.0],
[685.0, 610.0], [770.0, 610.0], [795.0, 645.0], [720.0, 635.0], [760.0, 650.0],
[475.0, 960.0], [95.0, 260.0], [875.0, 920.0], [700.0, 500.0], [555.0, 815.0],
[830.0, 485.0], [1170.0, 65.0], [830.0, 610.0], [605.0, 625.0], [595.0, 360.0],
[1340.0, 725.0], [1740.0, 245.0]])
# 2. 一次性预计算距离矩阵 (C语言级矩阵广播,速度极快)
num_cities = len(coords)
dist_matrix = np.sqrt(np.sum((coords[:, np.newaxis, :] - coords[np.newaxis, :, :]) ** 2, axis=-1))
# 3. 实例化算法
sa_tsp = SA_Parallel(L=300, m_seeds=12, alpha=0.98)
x_best, dist_best = sa_tsp.optimize(dist_matrix)
print(f"【优化成功】")
print(f"最优路线城市顺序:\n{x_best}")
print(f"跑出来的最短总回路长度:{dist_best:.2f} (官方理论最优值是:7542)")
import matplotlib.pyplot as plt
# 1. 允许 matplotlib 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'sans-serif']
plt.rcParams['axes.unicode_minus'] = False
# 2. 创建画布 (左图看收敛速度和震荡,右图看最终路线拓扑)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# ---- 左图:收敛历史曲线 ----
fitness_history = np.array(sa_tsp.fitness_history)
ax1.plot(fitness_history, color='#1f77b4', linewidth=1.5, label='当前种群最优')
ax1.axhline(y=7542, color='r', linestyle='--', alpha=0.7, label='官方理论最优 (7542)')
ax1.set_title("模拟退火算法 - 协同赛马收敛轨迹", fontsize=12, fontweight='bold')
ax1.set_xlabel("内层迭代总步数 (外层循环 × L)", fontsize=10)
ax1.set_ylabel("TSP 回路总长度", fontsize=10)
ax1.grid(True, linestyle=':', alpha=0.6)
ax1.legend(loc='upper right')
# ---- 右图:Berlin52 最终路线可视化 ----
# 按照求出的最优顺序重排坐标,别忘了闭环(首尾相连)
best_path_idx = list(x_best) + [x_best[0]]
ordered_coords = coords[best_path_idx]
# 画出城市节点
ax2.scatter(coords[:, 0], coords[:, 1], color='#e377c2', s=40, zorder=3, label='城市')
# 给城市标上序号
for i, (x, y) in enumerate(coords):
ax2.text(x + 10, y + 10, str(i), fontsize=8, color='#333333', zorder=4)
# 画出巡回连线
ax2.plot(ordered_coords[:, 0], ordered_coords[:, 1], color='#2ca02c', linewidth=2, alpha=0.8, label='最优航线')
ax2.set_title(f"Berlin52 最终路线轨迹 (总长: {dist_best:.2f})", fontsize=12, fontweight='bold')
ax2.set_xlabel("X 坐标", fontsize=10)
ax2.set_ylabel("Y 坐标", fontsize=10)
ax2.grid(True, linestyle=':', alpha=0.5)
ax2.legend(loc='lower left')
plt.tight_layout()
plt.show()结果分析:
最终回路总长与理论最优值7542的偏差控制在±500以内(即相对误差约±6.6%以内)。
上图为仅使用 逆序算子 策略的解法,整体趋近结果但是由于策略限制后期的细节优化上无法精准。
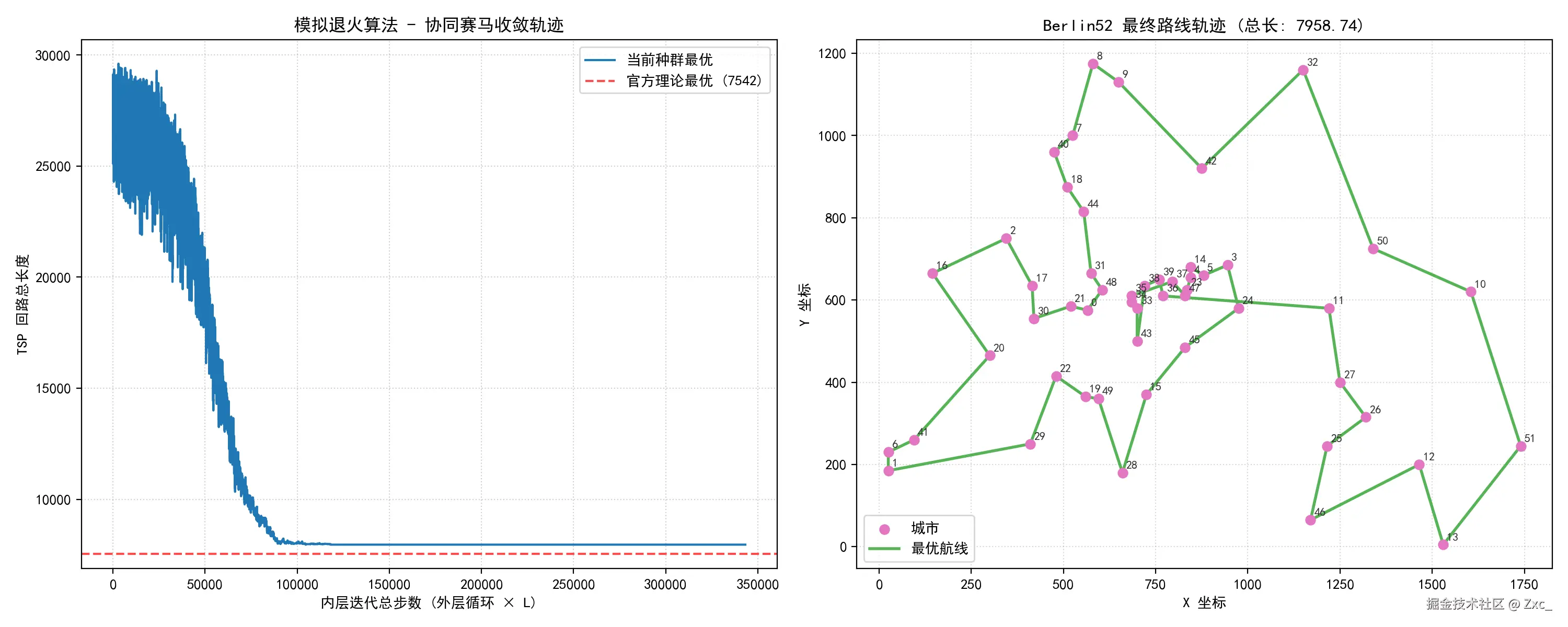
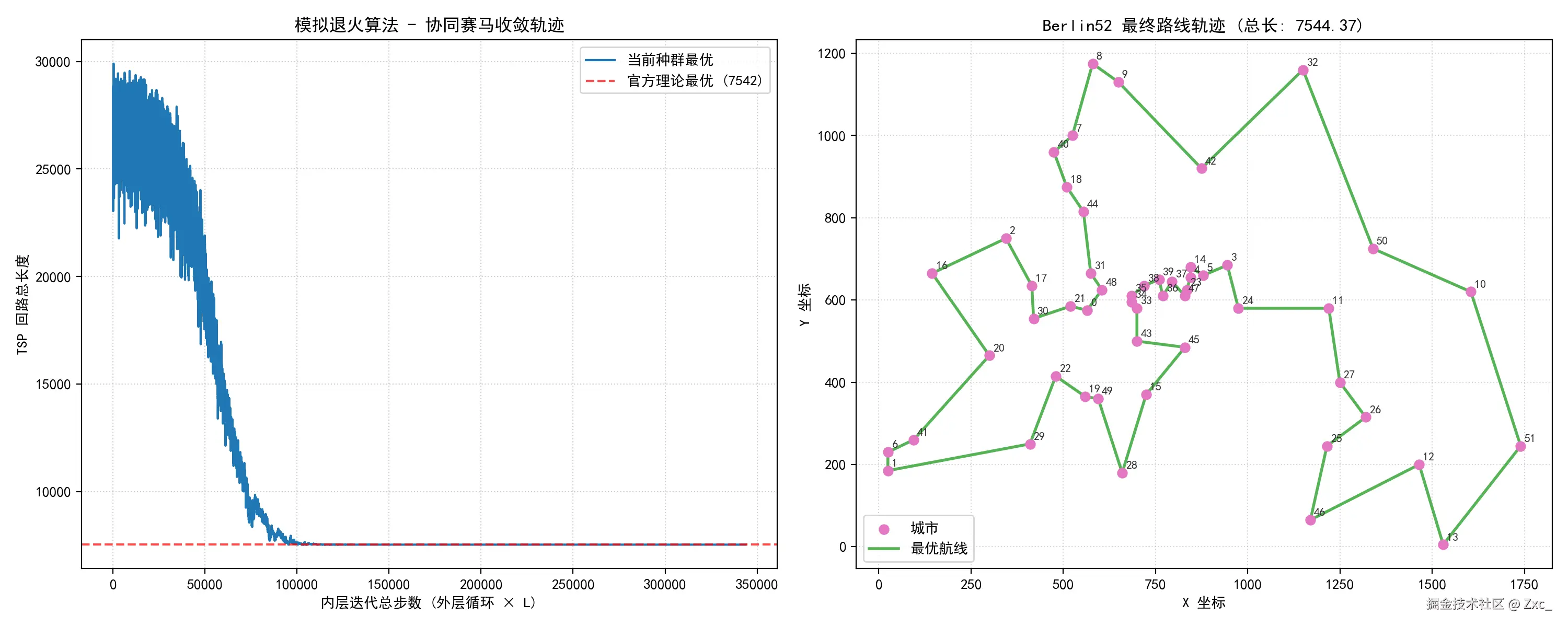
实验结果表明,单一的逆序算子Inversion Operator 容易陷入特定拓扑死结。而引入 2-Opt 交换算子(Swap Operator) 进行 20% 的邻域微调,能够有效破坏路径交叉,显著提升中后期细节微调的精度。
第三方库
SciPy 库提供的双重退火算法(Dual Annealing)展现出极佳的性能,其核心在于:一方面利用 Tsallis 广义非延伸统计力学 建立非高斯长尾访问分布(Visiting Distribution),允许解在空间中实现 Lévy 飞行式的大跨度全局跃迁;另一方面在降温各阶段无缝嵌入 L-BFGS-B 局部拟牛顿算子,实现了"全局粗勘"向"局部高精微雕"的双重耦合。
python
@_transition_to_rng("seed", position_num=10)
def dual_annealing(func, bounds, args=(), maxiter=1000,
minimizer_kwargs=None, initial_temp=5230.,
restart_temp_ratio=2.e-5, visit=2.62, accept=-5.0,
maxfun=1e7, rng=None, no_local_search=False,
callback=None, x0=None):
# 1.边界处理
if isinstance(bounds, Bounds):
bounds = new_bounds_to_old(bounds.lb, bounds.ub, len(bounds.lb))
if x0 is not None and not len(x0) == len(bounds):
raise ValueError('Bounds size does not match x0')
lu = list(zip(*bounds))
lower = np.array(lu[0]) # 下界
upper = np.array(lu[1]) # 上界
# restart_temp_ratio:重启温度比率,用于重新退火
if restart_temp_ratio <= 0. or restart_temp_ratio >= 1.:
raise ValueError('Restart temperature ratio has to be in range (0, 1)')
# 检测边界合法性
if (np.any(np.isinf(lower)) or np.any(np.isinf(upper)) or np.any(
np.isnan(lower)) or np.any(np.isnan(upper))):
raise ValueError('Some bounds values are inf values or nan values')
if not np.all(lower < upper):
raise ValueError('Bounds are not consistent min < max')
if not len(lower) == len(upper):
raise ValueError('Bounds do not have the same dimensions')
# 封装适应度函数
func_wrapper = ObjectiveFunWrapper(func, maxfun, *args)
# 局部优化器参数
minimizer_kwargs = minimizer_kwargs or {}
# 局部优化器
minimizer_wrapper = LocalSearchWrapper(
bounds, func_wrapper, *args, **minimizer_kwargs)
# 随机数生成器
rng_gen = check_random_state(rng)
# 能量管理,管理当前解、历史最优解等状态信息
energy_state = EnergyState(lower, upper, callback)
energy_state.reset(func_wrapper, rng_gen, x0)
# 重启温度阈值计算
temperature_restart = initial_temp * restart_temp_ratio
# 生成新的候选解(长尾分布)
visit_dist = VisitingDistribution(lower, upper, visit, rng_gen)
# 协调整个退火流程的核心控制器
strategy_chain = StrategyChain(accept, visit_dist, func_wrapper,
minimizer_wrapper, rng_gen, energy_state)
need_to_stop = False
iteration = 0
message = []
# 返回结果
optimize_res = OptimizeResult()
optimize_res.success = True
optimize_res.status = 0
t1 = np.exp((visit - 1) * np.log(2.0)) - 1.0
# 循环
while not need_to_stop:
for i in range(maxiter):
# 温度计算
s = float(i) + 2.0
t2 = np.exp((visit - 1) * np.log(s)) - 1.0
temperature = initial_temp * t1 / t2
# 最大迭代次数检查
if iteration >= maxiter:
message.append("Maximum number of iteration reached")
need_to_stop = True
break
# 重启检查
if temperature < temperature_restart:
energy_state.reset(func_wrapper, rng_gen)
break
# 核心退火步骤
val = strategy_chain.run(i, temperature)
if val is not None:
message.append(val)
need_to_stop = True
optimize_res.success = False
break
# 局部搜索
if not no_local_search:
val = strategy_chain.local_search()
if val is not None:
message.append(val)
need_to_stop = True
optimize_res.success = False
break
iteration += 1
# 设置返回结果
optimize_res.x = energy_state.xbest
optimize_res.fun = energy_state.ebest
optimize_res.nit = iteration
optimize_res.nfev = func_wrapper.nfev
optimize_res.njev = func_wrapper.ngev
optimize_res.nhev = func_wrapper.nhev
optimize_res.message = message
return optimize_resMain 函数实现 Rastrigin 函数求最小值:
python
""" 第三方库实现 SA"""
from scipy.optimize import dual_annealing
import numpy as np
def func(x):
return 10 * len(x) + np.sum(x ** 2 - 10 * np.cos(2 * np.pi * x))
if __name__ == "__main__":
bounds = [[-5.12,5.12],[-5.12,5.12]]
res = dual_annealing(
func,
bounds=bounds,
seed=5
)
print(f'最小值位置:{res.x}')
print(f'最佳适应值:{res.fun}')
参数实验
整个算法实现下来,有两个超参数对算法的结果有很大影响:
- 冷却速率 α :用于控制降温的速度, α 越小降温越快 ,α=0.85, 0.90, 0.95, 0.99
α 越大如 0.99 时的图像一直在震荡因为温度下降得慢 T 始终很大导致接受劣解 P 很大,但是结果是优于其他情况的,因为降得慢所以迭代的次数更多。
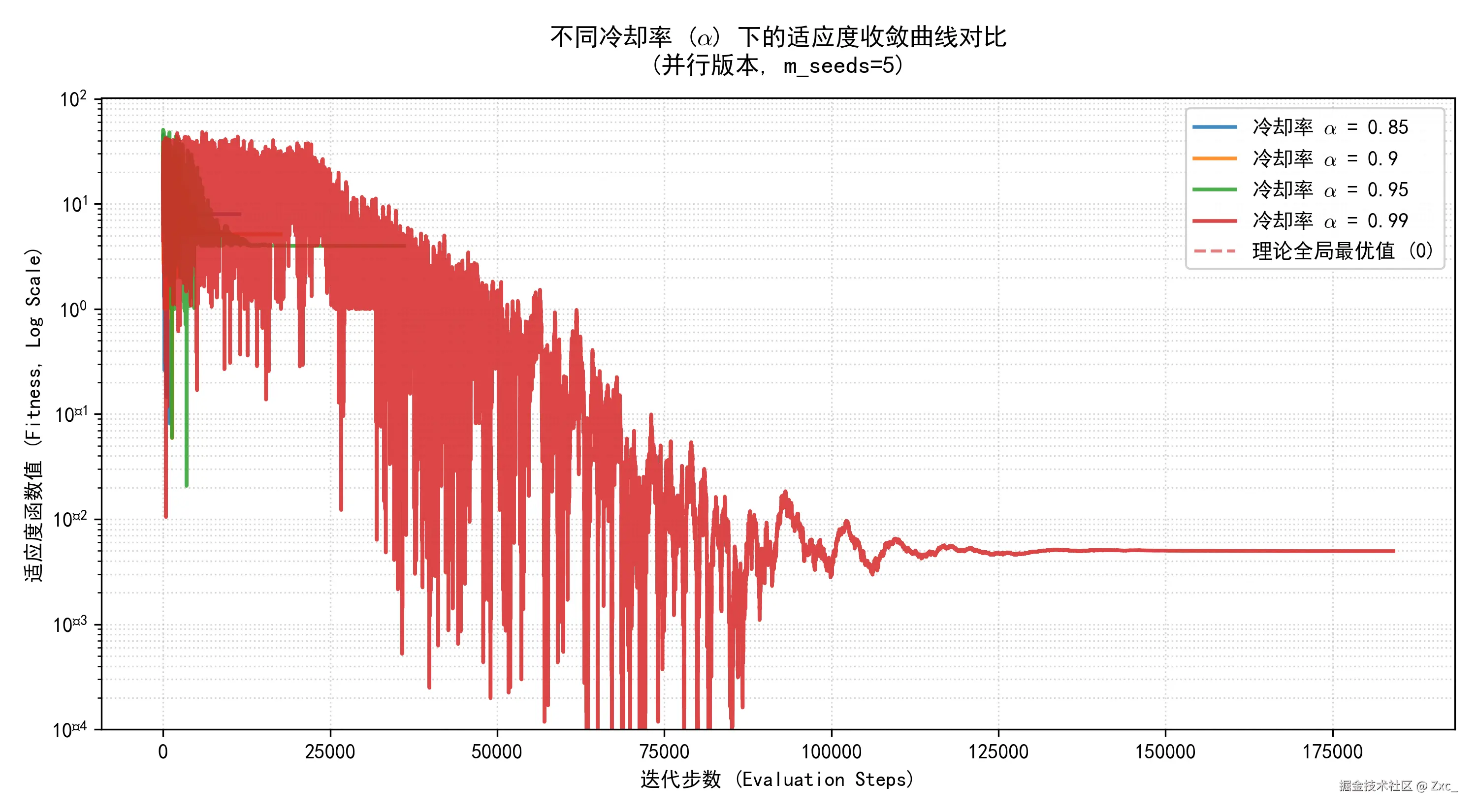
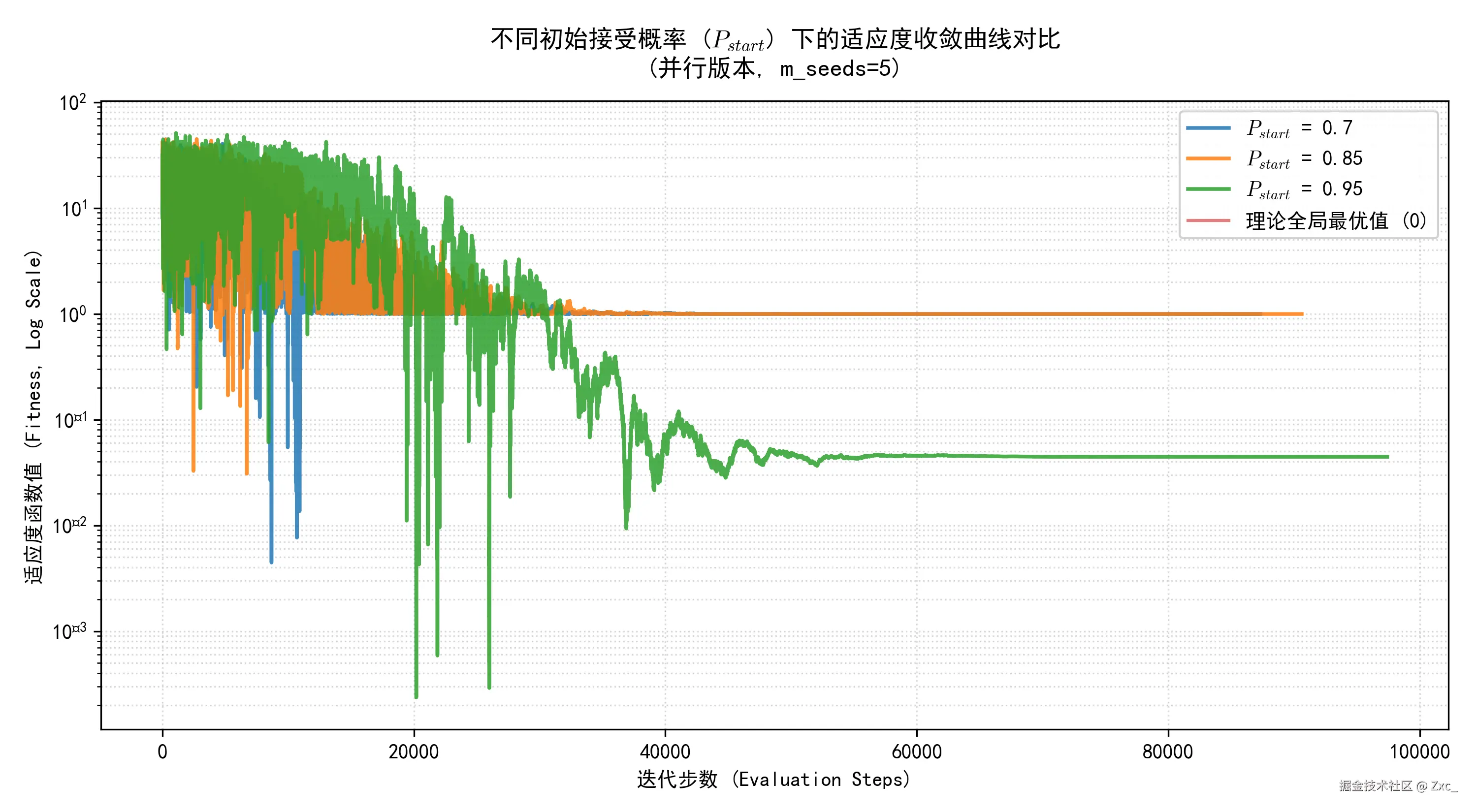
- 初始接受概率 P_start:对劣解的接受程度,P_start=0.7, 0.85, 0.95
P_start 越大代表整体对劣解的接受概率越大曲线越震荡。
前沿进展
-
量子退火与经典退火的融合:算法在后期低温时,不需要费力爬坡,而是可以直接"穿墙而过",横向击穿极高、极窄的局部阻碍势垒。这极大地加快了在高度非线性(如 Rastrigin 或超大规模 TSP)问题中的收敛速度。
-
强化学习作为内核嵌入 SA :算法能够"边跑边学"。在高温期自动加大步长去冲撞大局,在低温期敏锐地捕捉到陷入局部的信号,自动切换为高精度的近邻"微雕手术",实现了邻域搜索拓扑结构的动态自适应闭环控制。
总结
模拟退火算法是优化算法中单点搜索算法的代表,搜索空间复杂度低、Metropolis准则跳出局部最优、理论上以概率1收敛。
当前实现中目前种子之间互不相识。如果在代码的每 K 轮外层循环后,加入一个信息共享机制 ------比如表现最差的种子有概率被表现最好的种子"强行同化"或在其周围重新采样,这就是典型的并行回火(Parallel Tempering)或群体协同退火。
| 维度 | SA | PSO | GA |
|---|---|---|---|
| 搜索模式 | 单点+概率接受 | 群体+社会分享 | 群体+自然进化 |
| 核心机制 | Metropolis准则 | 速度/位置更新 | 选择/交叉/变异 |
| 空间复杂度 | O(d) | O(N·d) | O(N·d) |
| 跳出局部最优 | 温度控制下的随机跳跃 | 个体记忆+随机项 | 变异+交叉重组 |
| 适用场景 | 组合优化(TSP等) | 连续函数优化 | 组合+连续 |
参考文献:
- Kirkpatrick, S., Gelatt, C. D., & Vecchi, M. P. (1983). Optimization by simulated annealing. Science, 220(4598), 671-680.
- Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., & Teller, E. (1953). Equation of state calculations by fast computing machines. The Journal of Chemical Physics, 21(6), 1087-1092.
- Swendsen, R. H., & Wang, J. S. (1986). Replica-exchange online simulation of spin glasses. Physical Review Letters, 57(21), 2607.
- Lin, S., & Kernighan, B. W. (1973). An effective heuristic algorithm for the traveling-salesman problem. Operations Research, 21(2), 498-516.