🔥 本文专栏:Redis
🌸作者主页:努力努力再努力wz



💪 今日博客励志语录 :
别着急向世界解释你的潜力,先安静地把它兑现成作品、实力和选择权。
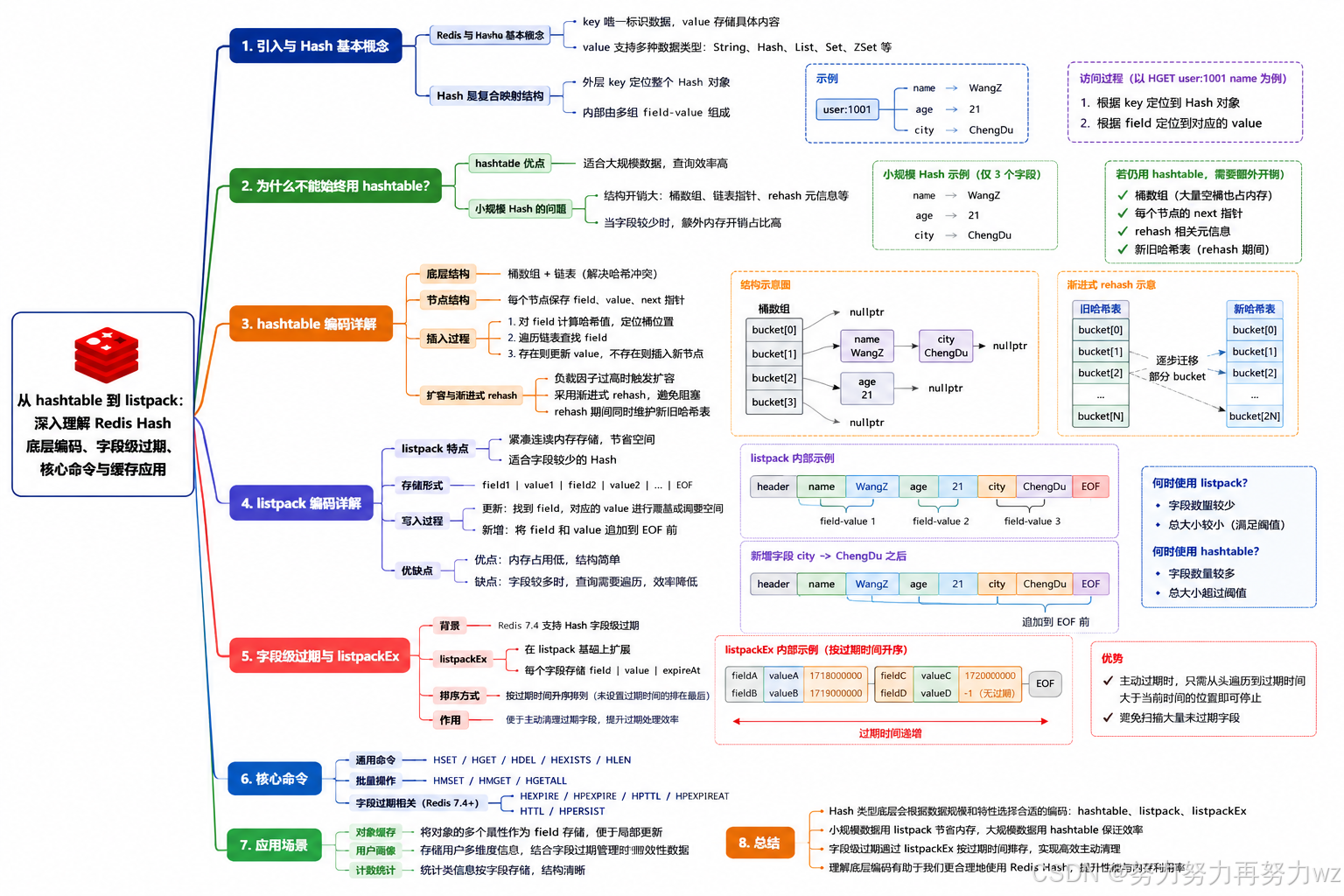
思维导图
引入
在此前的学习中,我们已经认识了 Redis 的基本存储结构、内部编码机制以及第一个核心数据类型 String。
Redis 本质上是一个采用 key-value 存储结构的客户端-服务器式内存数据库服务程序。其中,每一份数据都会以键值对的形式进行组织:key 用于唯一标识一份数据,而 value 则负责存储具体的数据内容。
需要注意的是,Redis 中的 value 并不只有一种固定的数据类型。根据不同的业务需求,Redis 提供了 String、Hash、List、Set、ZSet 等多种数据类型。与此同时,即使是同一种逻辑数据类型,其底层也不一定始终采用同一种存储方式。Redis 会根据当前对象的数据内容、数据规模等因素,选择更加合适的内部编码,从而在内存占用 与访问效率之间取得平衡。
在上一篇博客中,我们已经学习了 Redis 中最基础的数据类型------String。其中,String 会根据保存内容的不同,分别采用 int、embstr 和 raw 三种编码方式进行存储。在理解底层编码之后,我们又进一步认识了围绕 String 类型进行操作的一系列核心命令。
本文将继续沿用这种自底向上 的学习思路,认识 Redis 中另一个非常重要的数据类型:Hash。
接下来,就让我们正式进入 Redis Hash 类型的学习。
Redis Hash 底层编码详解:从 hashtable、listpack 到字段级过期实现
从 hashtable 的结构开销到 listpack:Redis Hash 多编码设计的必要性
为什么 Hash 不能始终采用 hashtable 编码?
提到哈希表,相信各位读者并不陌生。对于学习 C++ 的同学来说,在学习 STL 容器时,通常都会接触到 unordered_map。unordered_map 底层采用的就是哈希表结构,它可以根据键快速定位对应的值,因此非常适合用于保存具有映射关系的数据。
而 Redis 中的 Hash 类型,从逻辑上看同样也是一种映射结构。
我们知道,Redis 整体采用的是 key-value 形式来组织数据。对于此前学习的 String 类型来说,一个 key 对应的 value 本身就是需要保存的数据内容,例如:
text
name -> "WangZ"此时,当我们通过 key 查询数据时,定位到的就是对应的字符串内容。
但是,当一个 Redis key 对应的 value 为 Hash 类型时,情况就会有所不同。因为此时的 value 并不是一个简单值,而是一个内部又包含多组映射关系的复合结构。
例如,我们可以使用一个 Hash 对象来保存某个用户的基础信息:
text
user:1001
├── name -> WangZ
├── age -> 21
└── city -> ChengDu在这个结构中,user:1001 是 Redis 外层用于定位整个 Hash 对象的键;而 name、age、city 则是该 Hash 对象内部用于定位具体属性的键。
为了区分 Redis 外层的键和 Hash 对象内部的键,Redis 将外层用于定位整个对象的键称为 key,而将 Hash 对象内部用于定位具体字段值的键称为 field。因此,一个 Hash 对象内部保存的实际上是多组 field-value 数据。
text
Redis 外层结构:
key -> value
当 value 为 Hash 类型时:
key -> {
field1 -> value1,
field2 -> value2,
field3 -> value3
}这也意味着,对于 HGET 这类按照字段查询数据的命令来说,访问 Hash 对象中的某个具体字段值,需要经过两层定位过程:
text
第一步:根据 Redis 外层的 key,定位到对应的 Hash 对象
第二步:根据 Hash 对象内部的 field,定位到对应的 value例如,当我们需要查询 user:1001 用户的姓名时,实际访问过程可以理解为:
text
user:1001 -> Hash 对象 -> name -> WangZ既然 Hash 对象内部保存的就是多组 field-value 映射关系,那么最直观的一种底层实现方式,自然就是使用哈希表来组织这些数据。
但是,根据此前学习 String 类型的经验,我们已经知道:Redis 对外提供的一种逻辑数据类型,其底层并不一定始终只采用一种固定的编码方式。因此,对于 Hash 类型来说,其底层也并不是始终只使用哈希表进行存储。
那么这里就产生了一个问题:
既然 Hash 内部保存的就是多组映射关系,为什么 Redis 不直接让所有 Hash 对象都采用哈希表存储,而是还需要设计其他编码方式?
要回答这个问题,我们首先需要简单回顾 Redis 中 hashtable 编码所采用的哈希表结构。
Redis 中 hashtable 编码的底层结构
当一个 Hash 对象采用 hashtable 编码时,Redis 会使用哈希表来组织该对象内部的多组 field-value 数据。
Redis 中的哈希表采用的是桶数组加链表的结构。其中,桶数组本质上就是一个指针数组:数组中的每一个元素都是一个指针,用于指向当前桶所对应链表的头节点。
如果某个桶下还没有保存任何数据,那么该位置保存的就是空指针;如果某个桶下已经存在数据,那么该位置保存的就是指向链表头节点的指针。
而链表中的每一个节点,都会保存一组 field-value 数据,并且维护一个 next 指针,用于指向同一个桶下的下一个节点。当多个不同的 field 经过哈希计算后定位到了同一个桶位置时,这些节点就会通过 next 指针连接成一条链表,从而解决哈希冲突问题。
其结构可以简单理解为:
text
桶数组
├── bucket[0] -> nullptr
│
├── bucket[1] -> [field: name, value: WangZ, next]
│ ↓
│ [field: city, value: ChengDu, next]
│ ↓
│ nullptr
│
├── bucket[2] -> [field: age, value: 21, next] -> nullptr
│
└── bucket[3] -> nullptr在这个结构中,桶数组本身并不直接保存真正的 field-value 数据,而是保存指向链表头节点的指针。真正的字段与字段值,则保存在对应的链表节点中。
field-value 数据是如何插入哈希表中的?
当我们向一个 Hash 对象中插入一组新的 field-value 数据时,Redis 首先会根据 field 计算出对应的哈希值,再根据哈希值定位到桶数组中的某一个位置。
例如,假设当前需要向 user:1001 中插入以下字段:
text
name -> WangZ此时,Redis 会根据 name 计算出对应的桶位置,随后访问该桶所指向的链表。
如果该链表中已经存在 field 为 name 的节点,说明此前已经保存过该字段,此时只需要更新其对应的 value 即可。
如果该链表中不存在 field 为 name 的节点,说明这是一个新的字段,此时就需要创建一个新的链表节点,并将其插入到该桶所关联的链表中。
例如,假设 name 和 city 经过哈希计算后都被定位到了 bucket[1],那么这两个字段对应的节点就会被组织到同一条链表中:
text
bucket[1]
↓
[field: name, value: WangZ]
↓
[field: city, value: ChengDu]
↓
nullptr通过这种结构,当 Hash 对象内部保存的字段数量较多时,Redis 就可以先根据 field 的哈希结果快速定位到某一个桶,再在该桶对应的链表中查找目标字段,而不需要每次都从头到尾遍历所有 field-value 数据。
哈希表规模增大后还需要考虑扩容问题
随着 Hash 对象内部保存的字段数量不断增加,哈希表中的节点数量也会逐渐增多。如果桶数组的长度始终保持不变,那么不同 field 被映射到同一个桶位置的概率就会不断增加,对应链表的长度也可能逐渐增长。
当链表过长时,哈希表的查询与修改效率就会受到影响。因此,当哈希表满足扩容条件后,Redis 就需要为其分配一个容量更大的新桶数组,并将旧桶数组中的节点重新映射到新的桶数组中。
按照最直接的思路,扩容时可以一次性将旧桶数组中的所有节点全部迁移到新桶数组中,待迁移完成之后,再释放旧桶数组。
但是,对于 Redis 而言,这种处理方式并不合适。
在实际场景中,一个哈希表中可能已经保存了大量节点。如果 Redis 在处理某一次命令时,一口气完成所有节点的迁移,那么这个过程就可能消耗较长时间,从而导致当前命令执行时间过长,并影响其他请求的处理延迟。
因此,Redis 在进行哈希表扩容时,采用的并不是一次性迁移全部节点的方式,而是渐进式 rehash。
所谓渐进式 rehash,就是 Redis 不会在一次操作中将旧桶数组中的所有链表节点全部迁移到新桶数组中,而是将迁移过程拆分开来,在后续执行相关操作的过程中,逐步完成部分桶中节点的迁移。
这也意味着,在 rehash 进行期间,Redis 需要同时维护两张哈希表:
text
旧桶数组:保存尚未完成迁移的节点
新桶数组:保存已经迁移完成的节点,以及 rehash 期间新插入的节点由于此时一部分数据可能仍然位于旧桶数组中,而另一部分数据已经迁移到了新桶数组中,因此,在 rehash 尚未完成之前,Redis 在访问数据时就需要同时考虑这两张哈希表。
除此之外,Redis 还需要记录当前 rehash 的执行进度,知道旧桶数组中的哪些位置已经完成迁移,哪些位置仍然等待迁移。当旧桶数组中的所有节点都完成迁移之后,Redis 才能够释放旧桶数组,并结束当前的 rehash 过程。
因此,采用 hashtable 编码存储数据时,Redis 除了需要保存真正的 field-value 数据之外,还需要维护桶数组、每个节点中额外的 next 指针,以及桶数组长度、链表节点数量、是否正在进行 rehash 和当前迁移进度等元信息。而当哈希表真正触发 rehash 时,Redis 还需要同时使用新旧两个桶数组来组织数据,直到迁移完成后,旧桶数组才会被释放。
对于保存大量字段的 Hash 对象来说,这些额外结构是有意义的。因为在数据规模较大时,哈希表可以提供更加高效的字段定位能力。
但是,如果一个 Hash 对象内部只保存了少量字段,情况就不同了。
小规模 Hash 直接使用哈希表会造成额外内存开销
假设当前我们只需要保存一个非常简单的用户对象:
text
user:1001
├── name -> WangZ
├── age -> 21
└── city -> ChengDu这个 Hash 对象内部只保存了三组 field-value 数据。真正有业务意义的数据内容,本身其实并不多。
但是,如果此时仍然使用 hashtable 编码进行存储,那么 Redis 除了需要保存这三组 field-value 数据之外,还需要额外维护:
text
桶数组
每个数据节点中额外维护的 next 指针
桶数组长度、链表节点数量等基本元信息
是否正在进行 rehash 以及当前迁移进度等状态信息例如,即使当前只保存了几个字段,哈希表也仍然需要分配桶数组。而桶数组中的每一个位置本质上都是一个指针,其中可能只有少数几个桶真正挂载了数据节点,其他桶即使为空,也仍然会占据对应的内存空间。
同时,每一组 field-value 数据也不能只是紧凑地保存自身内容,而是需要被封装到链表节点中,并额外维护用于解决哈希冲突的 next 指针。
也就是说,对于一个只保存少量字段的小规模 Hash 对象而言,哈希表本身的结构开销可能会占据相当高的比例。此时,哈希表在查询效率方面的优势还没有充分体现出来,但桶数组、节点指针等额外内存开销却已经存在了。
对于单独一个小规模 Hash 对象来说,这部分额外开销或许并不明显。但是在实际业务中,Redis 往往会保存大量类似的小对象。例如,系统可能会将大量用户的基础信息分别保存为不同的 Hash 对象:
text
user:1001 -> {
name -> WangZ,
age -> 21
}
user:1002 -> {
name -> ZhangSan,
age -> 22
}
user:1003 -> {
name -> LiSi,
age -> 20
}如果每一个只包含少量字段的 Hash 对象都直接使用 hashtable 编码,那么每一个对象都会附带桶数组、链表节点以及相关结构信息带来的额外内存开销。
单个对象浪费的空间可能有限,但当 Redis 中存在大量类似的小规模 Hash 对象时,这部分额外开销就会不断累积,最终造成非常明显的内存浪费。
为什么需要额外的编码方式?
通过前面的分析,我们就可以理解:虽然 hashtable 非常适合用于组织映射关系,但它并不是所有 Hash 对象都最适合使用的底层存储结构。
对于字段数量较多的 Hash 对象来说,使用哈希表可以根据 field 较为高效地定位对应的 value,因此适合处理规模较大的字段数据。
但是,对于只保存少量 field-value 数据,并且字段与字段值本身都比较短的 Hash 对象来说,直接使用哈希表就会引入较高比例的额外结构开销。在这种场景下,相比于追求更强的查询效率,如何更加紧凑地保存数据、降低内存消耗反而更加重要。
因此,Redis 并不会让所有 Hash 对象从一开始就直接采用 hashtable 编码进行存储。对于小规模的 Hash 对象,Redis 会优先采用一种更加紧凑的内部编码方式:listpack。
listpack 是如何紧凑存储 Hash 数据的?
根据上文的分析,我们已经明白了 listpack 存在的意义:对于字段数量较少,并且 field 与 value 内容都比较短的小规模 Hash 对象来说,直接使用 hashtable 编码会引入桶数组、next 指针以及哈希表元信息等额外结构开销。因此,Redis 会优先使用更加紧凑的 listpack 编码来保存这类 Hash 对象,从而减少内存占用。
所谓紧凑存储,核心思想就是:Redis 不再为每一组数据单独维护哈希节点和指针关系,而是直接开辟一段连续的内存空间,将需要保存的数据依次编码在这段空间中。
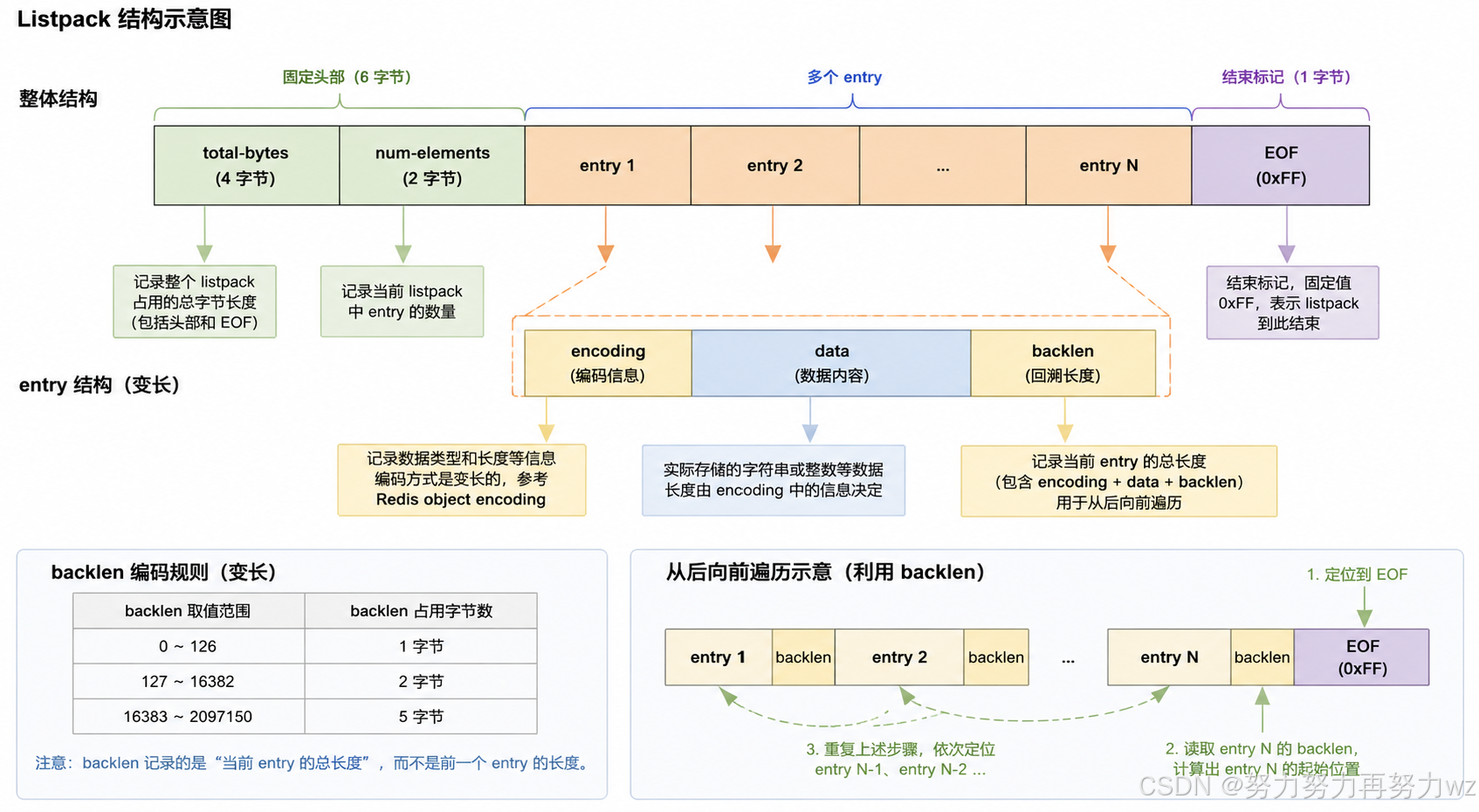
一个 listpack 整体可以分为三个部分:
text
listpack
├── 元数据头部
├── 多个连续存储的 entry
└── 结束标记对于一个采用 listpack 编码的 Hash 对象来说,其内部的 field 与 value 会作为相邻的两个 entry,依次存储在这段连续内存空间中。
例如,假设当前存在如下 Hash 对象:
text
user:1001
├── name -> WangZ
└── age -> 21那么,当其采用 listpack 编码时,内部数据的组织形式可以简单理解为:
text
header | name | WangZ | age | 21 | EOF这里需要注意,name -> WangZ 是一组 field-value 数据,但在 listpack 内部会被拆分为两个相邻的 entry;同理,age -> 21 也会占据两个相邻的 entry。
因此,上面的 Hash 对象虽然只包含两组 field-value 数据,但在 listpack 中实际保存了四个 entry:
text
field-value 数量:2
entry 数量:4listpack 的元数据头部
listpack 开头的元数据头部,用于记录当前这段连续内存空间的基本信息,其中主要包含两部分内容:
text
当前 listpack 占用的总字节长度
当前 listpack 内部保存的 entry 数量这里不能将第二项理解为 Hash 对象中保存的键值对数量。因为对于 Hash 来说,一组 field-value 数据会分别占据两个 entry:一个 entry 保存 field,另一个 entry 保存其对应的 value。
例如:
text
name -> WangZ
age -> 21在 listpack 中实际会按照如下顺序存储:
text
name | WangZ | age | 21因此,listpack 头部记录的是其中保存了四个元素,而不是两组键值对。
Hash 内部的 field 和 value 如何保存?
在此前学习 Redis 整体存储结构时,我们已经知道,Redis 外层采用的是 key-value 结构;而当外层的 value 为 Hash 类型时,Hash 对象内部又会继续保存多组 field-value 数据。
text
key -> {
field1 -> value1,
field2 -> value2
}不过,这里需要注意:Hash 对象内部的 value 不能继续保存另一个 Hash、List 或 Set 等 Redis 数据类型。对于命令层面来说,Hash 内部的 field 与 value 都表现为字符串内容。
但是,这并不意味着当 Hash 采用 listpack 编码时,其内部每一个 field 和 value 都会单独使用此前学习过的 SDS 结构进行保存。
对于一个独立的 Redis String 对象来说,其字符串内容可以通过 SDS 等结构进行组织;而对于采用 listpack 编码的 Hash 对象来说,内部的 field 与 value 不会被分别创建为一个个独立的 String 对象,而是会直接被编码为 listpack 连续内存空间中的一个个 entry。
例如:
text
header | name | WangZ | age | 21 | EOF其中,name、WangZ、age 和 21 都是 listpack 中独立保存的 entry。
这样做的好处在于,Redis 不需要为每一个字段和值分别维护一套额外的字符串对象结构,而是可以将它们直接紧凑排列在一段连续内存中,从而进一步降低小规模 Hash 对象的存储开销。
listpack 中的 entry 结构
接下来,我们进一步来看 listpack 中最核心的组成单位:entry。
需要注意的是,这里的 entry 并不是一个单独分配出来的结构体对象,而是连续内存空间中的一段变长编码数据。一个 entry 的整体组成可以简单理解为:
text
entry = 编码信息 + 数据内容 + backlen其中,各部分的作用如下:
text
编码信息:
用于说明当前 entry 保存的是字符串内容还是整数内容;
如果保存的是字符串,还会包含对应字符串长度的信息。
数据内容:
用于保存当前 entry 对应的实际内容。
如果当前内容是普通字符串,这里保存的就是对应的字符数据;
如果当前内容可以直接按照整数进行编码,这里保存的则是更加紧凑的整数数据。
backlen:
用于记录当前 entry 前面部分所占用的字节长度,
从而支持从后向前定位前一个 entry。例如,对于保存普通字符串内容的 entry,可以简单理解为:
text
编码信息 | 字符串内容 | backlen而对于可以使用整数形式保存的内容,则可以理解为:
text
整数编码信息及整数数据 | backlen为什么 entry 还要区分字符串编码和整数编码?
虽然 Hash 对象内部的 field 与 value 在命令层面都表现为字符串内容,但是这些字符串中,有一部分内容本身可能就是整数形式的数据。
例如:
text
age -> "21"
score -> "100"
count -> "8"如果 Redis 无论面对什么内容,都直接将其按照普通字符串保存,那么像 "21"、"100" 这类本身可以表示为整数的数据,也需要逐字节保存其字符内容。
而 listpack 为了进一步节省内存,会判断当前 entry 保存的内容是否能够以整数形式进行编码。如果某个 field 或 value 的内容可以被无损转换为整数,那么 Redis 就可以直接使用对应的整数编码形式保存该数据,而不是继续按照普通字符串保存。
例如:
text
age -> "21"从命令层面看,21 仍然是 Hash 中保存的字段值;但是在 listpack 内部,Redis 可以将其按照整数形式进行紧凑编码,而不是分别保存字符 '2' 与字符 '1'。
因此,listpack 中的 entry 并不是只有一种固定的编码形式,而是会根据实际保存的内容选择更加合适的表示方式:
text
普通字符串内容:
使用字符串编码,保存字符串长度以及实际字符数据
可以转为整数的内容:
使用整数编码,直接保存对应的整数数据entry 前面的编码信息如何区分字符串与整数?
对于 listpack 中的每一个 entry 来说,其开头都存在一段编码信息。需要注意的是,这里的编码信息并不只是单纯记录当前数据的长度,它首先需要解决一个更基础的问题:
当前这个 entry 保存的内容,究竟是按照字符串形式存储,还是按照整数形式存储?
因为 listpack 中的一个 entry 既可以保存普通字符串,也可以保存能够被无损转换为整数的数据。因此,Redis 会通过 entry 开头若干个二进制位的不同组合,来区分当前 entry 采用的是哪一种编码方式。
对于字符串内容来说,编码信息需要记录两类信息:
text
当前 entry 保存的是字符串
该字符串内容占用多少个字节而对于整数内容来说,编码信息则需要记录:
text
当前 entry 保存的是整数
该整数采用哪一种长度的整数编码之所以需要区分不同长度,是因为整数本身的大小不同。如果一个整数的值非常小,那么就没有必要始终使用 8 字节的 int64 来保存;Redis 可以根据整数实际所处的范围,选择更短的编码方式,以进一步减少内存占用。
字符串编码
对于字符串来说,listpack 会根据字符串长度的不同,选择三种不同的编码方式。
第一种是长度不超过 63 字节的短字符串。此时,entry 的第一个字节格式如下:
text
10xxxxxx其中:
text
10 :表示当前 entry 保存的是短字符串
xxxxxx :用于记录字符串长度,共 6 个二进制位由于 6 个二进制位最多能够表示 63,因此这种编码可以用于保存长度为 0 ~ 63 字节的字符串。
例如,字符串 "name" 的长度为 4,那么其编码信息可以简单理解为:
text
10 000100 | n a m e | backlen
长度为4第二种是长度不超过 4095 字节的字符串。此时,entry 的编码格式为:
text
1110xxxx xxxxxxxx <字符串内容>其中:
text
1110xxxx xxxxxxxx
1110 :前 4 位固定标志,表示当前 entry 采用中等长度字符串编码
xxxx xxxxxxxx :剩余 12 位共同保存字符串长度由于 12 个二进制位最多能够表示 4095,因此这种编码可以保存长度为 0 ~ 4095 字节的字符串。
第三种则用于保存更长的字符串,其编码格式为:
text
11110000 <4字节字符串长度> <字符串内容>此时,第一个字节 11110000 只负责表示当前 entry 采用的是长字符串编码,后续再使用 4 个字节专门记录字符串长度。
因此,字符串编码可以归纳为:
text
字符串长度较短:
10xxxxxx <字符串内容> | backlen
字符串长度中等:
1110xxxx xxxxxxxx <字符串内容> | backlen
字符串长度较长:
11110000 <4字节长度> <字符串内容> | backlen也就是说,对于字符串来说,entry 前面的编码信息不仅说明"这是一个字符串",还会尽可能利用有限的二进制位直接保存字符串长度,从而避免固定使用较大的长度字段。listpack 规范定义了长度为 0 至 63 字节、0 至 4095 字节以及更长字符串对应的三类字符串编码。
整数编码
除了字符串编码之外,listpack 还专门为整数内容提供了多种编码方式。
例如,假设 Hash 对象中保存了如下字段:
text
age -> "21"从我们执行 Redis 命令的角度来看,"21" 是作为字段值写入 Hash 对象中的字符串内容。但是,由于这个字符串能够被无损转换为整数 21,并且将整数再次转换为字符串后仍然能够得到完全相同的内容,因此 Redis 没有必要继续按照两个字符 '2' 和 '1' 来保存它,而是可以直接使用整数编码。
对于范围在 0 ~ 127 之间的小整数,listpack 可以直接使用一个字节完成编码:
text
0xxxxxxx其中:
text
0 :表示当前 entry 保存的是 7 位无符号整数
xxxxxxx :直接保存整数的数值例如,整数 21 的二进制表示为:
text
0010101那么该 entry 的编码部分就可以直接保存为:
text
0 0010101也就是说,对于 21 这样的小整数来说,其数值本身就已经被编码在第一个字节中,不需要再额外开辟数据区域保存字符串 "21"。
text
字符串形式保存 "21":
编码信息 | '2' | '1' | backlen
整数形式保存 21:
0xxxxxxx | backlen当整数无法使用 7 位表示时,listpack 还会继续根据数值范围选择其他整数编码形式:
text
0xxxxxxx :7 位无符号整数,数值直接包含在当前字节中
110xxxxx xxxxxxxx :13 位有符号整数,数值由当前字节与后续 1 字节共同保存
11110001 <2字节整数数据> :16 位有符号整数
11110010 <3字节整数数据> :24 位有符号整数
11110011 <4字节整数数据> :32 位有符号整数
11110100 <8字节整数数据> :64 位有符号整数这里可以发现,对于整数内容来说,entry 前面的编码信息同样承担了两层作用:
text
第一层:说明当前 entry 保存的是整数,而不是字符串
第二层:说明当前整数应当按照多少位的数据范围进行保存整数越小,Redis 使用的编码就越短;只有当整数范围不断增大时,才会逐步使用更长的整数编码形式。因此,对于 "21"、"100" 这类本身能够表示为整数的内容来说,使用整数编码通常会比按照普通字符串逐字节保存更加节省空间。listpack 规范定义了 7 位无符号整数、13 位有符号整数以及 16/24/32/64 位有符号整数等编码形式;Redis 当前源码也会先判断输入字符串能否被无损解析为 int64,再选择适合的整数编码。
字符串编码与整数编码的核心区别
因此,对于一个 entry 来说,其内部并不是简单地按照"编码信息 + 字符内容"的固定方式进行组织,而是会根据当前保存的数据内容选择不同的形式:
text
保存普通字符串时:
编码信息 | 字符串数据 | backlen
保存较小整数时:
编码信息中直接包含整数值 | backlen
保存较大整数时:
编码信息 | 整数二进制数据 | backlen例如,对于 Hash 对象:
text
user:1001
├── name -> WangZ
└── age -> 21其内部使用 listpack 保存时,可以简单理解为:
text
header
|
|-- [字符串编码 + "name" + backlen]
|
|-- [字符串编码 + "WangZ" + backlen]
|
|-- [字符串编码 + "age" + backlen]
|
|-- [整数编码 + 21 + backlen]
|
EOF其中,name、WangZ 和 age 无法按照整数表示,因此采用字符串编码;而 21 可以被无损转换为整数,因此 Redis 可以直接使用更加紧凑的整数编码进行保存。
这正是 listpack 相比于简单连续保存字符串内容更进一步的内存优化:它不仅省去了哈希表中的桶数组与 next 指针等结构开销,还会根据每一个 entry 的实际内容,选择更紧凑的字符串编码或整数编码方式。
listpack 编码下 Hash 数据的插入过程
在认识了 listpack 中每一个 field 与 value 所对应的 entry 编码结构之后,接下来我们进一步关注:当 Hash 对象采用 listpack 编码时,新的 field-value 数据是如何插入其中的。
我们知道,listpack 采用的是一种紧凑存储结构。它会申请一段连续的内存空间,并将 Hash 对象内部的多个 field 与 value 直接编码为一个个相邻的 entry,按照如下形式交替排列:
text
header | field1 | value1 | field2 | value2 | ... | EOF例如,对于如下 Hash 对象:
text
user:1001
├── name -> WangZ
└── age -> 21如果其采用 listpack 编码,那么内部存储形式可以简单理解为:
text
header | name | WangZ | age | 21 | EOF其中,field 与对应的 value 会作为相邻的两个 entry 进行保存。也就是说,Redis 在定位到某个 field 之后,其后面紧邻的下一个 entry,就是该字段对应的 value。
这里需要注意,Hash 对象内部的多组 field-value 数据之间,并不存在类似有序集合那样的顺序语义。例如,name -> WangZ 位于 age -> 21 之前还是之后,并不会影响这个 Hash 对象在逻辑上所表示的数据内容。
因此,当我们向一个采用 listpack 编码的 Hash 对象中写入数据时,需要分为两种情况。
如果当前写入的 field 已经存在,那么 Redis 会先定位到该 field 对应的 entry,随后找到其后面相邻的 value entry,并将原有的字段值替换为新的字段值。
这里需要注意,由于 listpack 中的多个 entry 是连续紧凑排列的,因此更新 value 时,需要关注新的字段值编码为 entry 后所占用的实际字节长度。如果新的 value entry 与原 entry 占用的字节数相同,那么可以直接复用原有位置完成覆盖;如果新的 value entry 占用空间更大,那么原有位置就无法容纳新的内容,此时后续 entry 与末尾的 EOF 需要相应向后移动,为新的 value entry 腾出空间;反过来,如果新的 value entry 占用空间更小,后续内容也会相应前移,以继续保持 listpack 的紧凑存储结构。
text
写入前:
header | name | WangZ | age | 21 | EOF
执行更新:
name -> ZhangSan
写入后:
header | name | ZhangSan | age | 21 | EOF而如果当前写入的 field 此前并不存在,那么 Redis 就不需要在已有数据之间寻找某个特定的插入位置,而是会将新的 field 与 value 对应的两个 entry 直接追加到当前 listpack 的尾部,也就是原有 EOF 结束标记之前。
例如,当前 listpack 中已经保存了:
text
header | name | WangZ | age | 21 | EOF此时新增一组字段数据:
text
city -> ChengDu那么插入之后,其内部结构就可以理解为:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF之所以将新的 field-value 追加到尾部,原因在于:Hash 内部的字段之间不存在顺序关系,将新数据插入到中间位置并不会带来额外意义,反而还可能导致插入位置之后的已有数据发生移动。因此,对于一个新的字段来说,直接追加到 EOF 之前就是更加自然的处理方式。
追加数据时如何处理内存空间?
由于 listpack 中的所有 entry 都保存在一段连续内存空间中,所以当新的 field-value 被追加到尾部时,Redis 还需要判断当前已经分配的内存空间是否能够容纳新增的数据。
这里需要区分两个概念:
text
listpack 当前有效内容所占用的字节长度
listpack 底层实际已经分配到的内存空间大小listpack 头部记录的总字节长度,表示的是当前真正有效的数据内容所占用的空间,也就是从 header 开始,到 EOF 结束标记为止的长度。
但是,底层实际分配到的内存空间可能会大于当前有效内容所占用的长度。也就是说,在 EOF 标记之后,可能还存在一部分已经分配、但暂时尚未被有效数据使用的内存空间。
例如,假设底层当前已经为一个 listpack 分配了 50 字节的内存空间,而真正用于保存头部、多个 entry 与 EOF 的有效内容只占用了 30 字节,那么其结构可以简单理解为:
text
| header | field1 | value1 | field2 | value2 | EOF | 尚未使用的空间 |
|<---------------- 当前有效长度:30 字节 ------------>|<-- 20 字节 -->|
|<------------------- 实际分配空间:50 字节 ----------------------->|此时,如果继续追加一组新的 field-value 数据,并且新增数据所需要的空间不超过尾部尚未使用的空间,那么 Redis 就不需要重新分配内存,而是可以直接在原有 EOF 所在的位置开始写入新的 entry,随后将 EOF 标记移动到新的有效内容末尾。
例如:
text
追加前:
| header | name | WangZ | EOF | 尚未使用的空间 |
新增:
age -> 21
追加后:
| header | name | WangZ | age | 21 | EOF | 尚未使用的空间 |而如果当前已经分配的内存空间不足以容纳新增的 field-value 数据,那么 Redis 就需要重新分配一段更大的连续内存空间,使其能够保存原有数据以及本次新增的数据。完成空间扩展之后,再将新的 field 与 value 对应的 entry 写入尾部,并更新 EOF 的位置以及头部记录的有效字节长度和元素数量。
因此,对于采用 listpack 编码的 Hash 对象来说,新增字段数据的过程可以概括为:
text
首先判断 field 是否已经存在:
如果 field 已经存在:
定位到其后相邻的 value entry,并替换原有字段值。
如果 field 不存在:
将 field 和 value 对应的 entry 追加到 EOF 之前。
如果当前已分配空间足够,则直接写入并后移 EOF;
如果当前已分配空间不足,则扩展连续内存空间后再完成追加。通过这种连续排列并在尾部追加的存储方式,listpack 不需要维护桶数组,也不需要为每一组 field-value 数据额外保存用于连接后继节点的 next 指针,因此能够以更加紧凑的方式保存小规模 Hash 对象。
listpack结构示意图
listpack 编码下 Hash 数据的查询过程
在认识了如何向采用 listpack 编码的 Hash 对象中插入数据之后,接下来我们进一步分析:Redis 是如何在 listpack 中定位某一个 field 对应的 value 的。
对于 String 类型来说,当我们根据外层的 key 定位到对应的 Redis 对象之后,就可以进一步获取其保存的字符串数据。
而对于 Hash 类型来说,查询过程会多出一层定位。原因在于,Hash 对象本身并不是一个简单值,而是由多组 field-value 数据组成的复合结构。因此,当我们执行类似下面的查询命令时:
bash
HGET user:1001 cityRedis 需要完成两层定位:
text
第一层定位:
根据外层 key:user:1001
找到对应的 Hash 类型 Redis 对象
第二层定位:
根据内部 field:city
在该 Hash 对象中找到对应的 value:ChengDu在此前学习 String 类型时,我们已经接触过 Redis 对象这一概念。Redis 中保存的值会通过 Redis 对象进行描述,其中记录了当前对象的数据类型、底层编码方式,以及指向实际底层数据结构的指针。
当一个 Hash 对象采用 listpack 编码时,可以简单理解为:
text
Redis 对象
├── type = Hash
├── encoding = listpack
└── ptr = 指向 listpack 连续内存空间的起始位置因此,Redis 首先根据外层的 key 定位到对应的 Hash 对象。随后,根据该对象的编码方式以及内部指针,进一步访问底层的 listpack 连续内存空间。
我们知道,采用 listpack 编码的 Hash 对象,其内部的 field 与 value 会以相邻 entry 的形式交替排列:
text
header | field1 | value1 | field2 | value2 | field3 | value3 | EOF例如,对于如下 Hash 对象:
text
user:1001
├── name -> WangZ
├── age -> 21
└── city -> ChengDu其底层 listpack 可以简单理解为:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF此时,如果我们执行:
bash
HGET user:1001 cityRedis 在定位到该 Hash 对象所对应的 listpack 之后,会跳过头部区域,从第一个保存 field 的 entry 开始进行匹配。
首先,Redis 读取当前 entry 前面的编码信息,根据其编码方式获取当前保存的字段内容,并将其与目标字段 city 进行比较。
如果当前 field 与目标字段不匹配,那么 Redis 就会跳过紧随其后的 value entry,继续检查下一组 field-value 数据中的 field。
整个过程可以简单理解为:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF
× 跳过 × 跳过 √ 返回具体来说:
text
第一次比较:
name 与 city 不匹配
跳过 name 对应的 value:WangZ
第二次比较:
age 与 city 不匹配
跳过 age 对应的 value:21
第三次比较:
city 与 city 匹配
读取其后相邻的 value:ChengDu因此,在 listpack 编码下,Redis 查询某一个字段值时,并不是通过哈希计算直接定位到对应位置,而是需要按照 field-value 交替排列的方式,从前向后依次扫描其中的 field。当找到目标 field 之后,其后面紧邻的下一个 entry,就是该字段对应的 value。
这里需要注意,listpack 中根据 field 定位数据的过程,本质上属于线性遍历。如果当前 Hash 对象中保存了 N 个字段,那么在最坏情况下,Redis 可能需要扫描完这 N 个字段之后,才能确定目标字段是否存在。因此,从底层编码行为来看,该查询过程的时间复杂度为 O(N)。
不过,这并不意味着 listpack 的查询性能一定很差。因为 Redis 只会让字段数量较少,并且字段与字段值内容都比较短的小规模 Hash 对象保持 listpack 编码。也就是说,虽然 listpack 内部采用的是线性扫描方式,但其实际需要遍历的数据规模会被限制在较小范围内,因此查询代价通常是可以接受的。
而当 Hash 对象中的字段数量不断增多,继续使用线性扫描的代价逐渐增大时,Redis 就会将其转换为 hashtable 编码。此时,Redis 就可以根据 field 的哈希结果定位对应的数据,从而获得更适合大规模字段查询的访问能力。
因此,listpack 与 hashtable 的区别也可以进一步理解为:
text
listpack:
通过连续内存紧凑存储数据,节省内存空间;
查询 field 时需要线性扫描,适合小规模 Hash 对象。
hashtable:
通过桶数组与链表组织数据,引入一定结构开销;
但能够根据 field 的哈希结果进行定位,更适合规模较大的 Hash 对象。这也再次体现了 Redis 针对 Hash 类型选择不同编码方式的核心思路:对于小规模数据,优先使用 listpack 降低内存占用;而当数据规模增大后,则转换为 hashtable,以获得更适合查询与修改操作的访问效率。
从 ziplist 到 listpack:如何避免连锁更新问题?
这里还需要补充一点:在较早版本的 Redis 中,对于数据规模较小的 Hash 对象,底层采用的紧凑编码方式并不是 listpack,而是 ziplist。直到 Redis 7.0,Redis 才将这类紧凑编码统一替换为 listpack。二者都会使用一段连续内存空间来紧凑保存数据,但在 entry 的组织方式上存在一个非常关键的区别。
对于 ziplist 来说,每一个 entry 的结构可以简单理解为:
text
ziplist entry:
prevlen | encoding | data其中,prevlen 用于记录前一个 entry 完整占用的字节长度 。这样,当 Redis 从后向前遍历 ziplist 时,就可以根据当前 entry 中保存的 prevlen,定位到前一个 entry 的起始位置。
text
entry1 entry2 entry3
| encoding | data | | prevlen | encoding | data | | prevlen | encoding | data |
↑ ↑
记录 entry1 长度 记录 entry2 长度但是,这种设计会带来一个问题:后一个 entry 依赖前一个 entry 的长度信息。
例如,对于采用 ziplist 编码的 Hash 对象来说,假设我们修改了某一个 field 对应的 value,并且新的 value 编码成 entry 之后,占用的字节长度比原来更大。由于 ziplist 采用连续存储方式,位于该 value 后面的内容本身就可能需要调整位置。
更关键的是,在 ziplist 中,后继 entry 还需要通过 prevlen 记录这个 value entry 的长度。而 prevlen 本身并不是始终占用固定长度的空间:
text
前一个 entry 长度小于 254 字节:
prevlen 使用 1 字节保存
前一个 entry 长度大于等于 254 字节:
prevlen 使用 5 字节保存假设某一个 value entry 原本只占用 250 字节,那么其后继 entry 只需要使用 1 字节的 prevlen 来记录它的长度:
text
[value entry:250 字节] [后继 entry:1 字节 prevlen | encoding | data]但是,如果更新之后,该 value entry 增长到了 260 字节,那么后继 entry 中原本只占用 1 字节的 prevlen 就无法继续保存这一长度信息,而需要扩展为 5 字节:
text
[value entry:260 字节] [后继 entry:5 字节 prevlen | encoding | data]此时,后继 entry 自身又因为 prevlen 的扩展而增大了。如果后继 entry 增大之后,其整体长度又影响到了再后一个 entry 的 prevlen 编码长度,那么这一变化就可能继续向后传播。
text
某个 value entry 更新后长度增大
↓
后继 entry 的 prevlen 从 1 字节扩展为 5 字节
↓
后继 entry 自身长度增大
↓
再后继 entry 的 prevlen 也可能需要扩展
↓
变化继续向后传播这种现象就是 ziplist 可能出现的连锁更新问题 。需要注意的是,并不是某个 entry 只要变长就一定会产生连锁更新。只有当前一个 entry 更新后的总长度从小于 254 字节增长到大于等于 254 字节时,后继 entry 中用于记录其长度的 prevlen 才会从 1 字节扩展为 5 字节,并可能进一步影响后面的 entry。
而 listpack 对这一部分结构进行了重新设计。对于 listpack 来说,每一个 entry 不再在开头记录前一个 entry 的长度,而是在自身末尾维护一个 backlen 字段:
text
listpack entry:
编码信息 | 数据内容 | backlen其中,backlen 记录的是当前 entry 中编码信息与数据内容所占用的字节长度 ,并不包含 backlen 自身所占用的字节数。
text
entry1 entry2
| 编码信息 | 数据内容 | backlen | 编码信息 | 数据内容 | backlen |
↑
记录 entry1 自身前面部分的长度这样一来,当 Redis 需要从后向前遍历 listpack 时,可以通过前一个 entry 末尾的 backlen,计算出该 entry 的起始位置,从而实现反向定位。
listpack 与 ziplist 的关键区别就在于:
text
ziplist:
当前 entry 的长度信息保存在后一个 entry 的开头
listpack:
当前 entry 的长度信息保存在当前 entry 自己的末尾因此,当 listpack 中某一个 value entry 更新后长度发生变化时,需要修改的是该 entry 自己的数据内容以及末尾的 backlen,而不会迫使后一个 entry 再去修改"前一个 entry 的长度信息"。
当然,由于 listpack 本身仍然采用连续内存空间紧凑存储数据,如果新的 value entry 占用空间比原 entry 更大,那么其后的其他 entry 与 EOF 仍然需要调整位置,为新的内容腾出空间;如果新的 value entry 占用空间更小,后续内容也会相应向前调整,以保持数据连续紧凑排列。
但是,listpack 避免了 ziplist 中因为后继 entry 的 prevlen 字段扩展,而进一步影响再后继 entry 的连锁更新问题。
text
ziplist:
连续存储导致数据位置可能调整,
并且 prevlen 扩展可能进一步引发连锁更新
listpack:
连续存储仍可能导致数据位置调整,
但不会因为后继 entry 保存前驱长度而产生连锁更新因此,listpack 不仅保留了紧凑存储结构节省内存的优势,也通过重新设计 entry 的长度记录方式,避免了 ziplist 在特定更新场景下可能产生的连锁更新问题。这也是 Redis 后续使用 listpack 替代 ziplist 的重要原因之一。
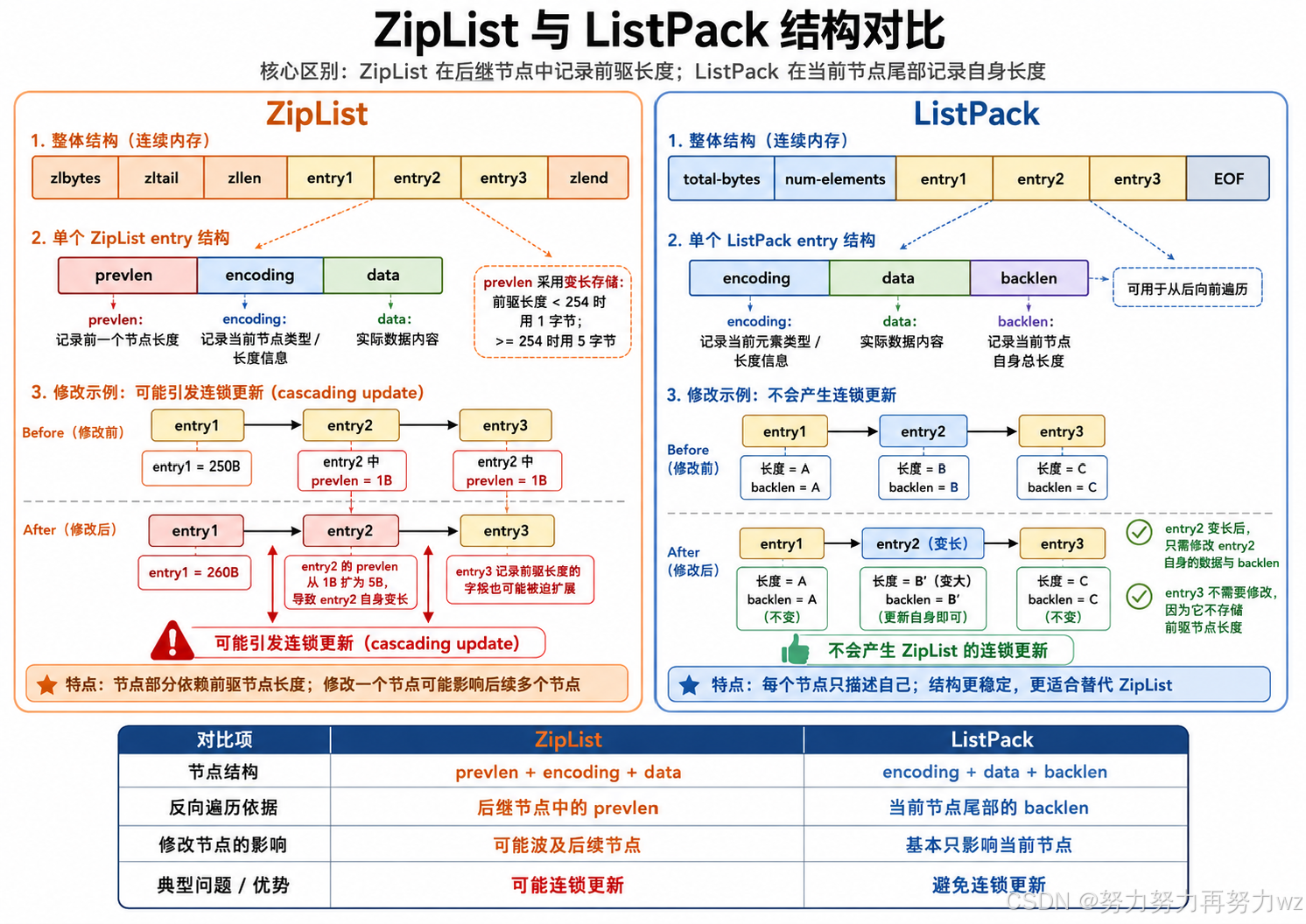
其中,对于 ziplist 来说,其整体结构与 listpack 之间也存在区别。ziplist 的整体结构如下:
zlbytes | zltail | zllen | entry1 | entry2 | ... | zlend其中,头部包含三个字段:
cpp
zlbytes:整个 ziplist 当前占用的总字节长度
zltail :最后一个 entry 相对于 ziplist 起始位置的偏移量
zllen :当前保存的 entry 数量
zlend :结束标记ziplist 由于每一个 entry 保存的是前一个 entry 的长度信息,为了能够直接从尾部开始遍历,还需要在头部额外保存最后一个 entry 的偏移量 zltail。而 listpack 将当前 entry 的长度信息保存到自身末尾的 backlen 中,最后一个 entry 的 backlen 就紧邻 EOF 标记,因此 Redis 可以直接通过 EOF 前面的 backlen 定位最后一个 entry,不再需要单独维护尾节点偏移量。
listpack 与 hashtable 编码之间的转换
至此,我们已经认识了 listpack 编码的基本实现方式。接下来还需要关注一个重要问题:对于 Redis 的 Hash 类型来说,listpack 与 hashtable 之间究竟是什么关系?
我们知道,listpack 的优势在于能够以更加紧凑的方式保存数据。对于字段数量较少,并且 field 与 value 内容都比较短的小规模 Hash 对象来说,使用 listpack 可以避免桶数组、节点中额外的 next 指针以及哈希表元信息带来的额外内存开销。
因此,在 Redis 7.0 及之后的版本中,新创建的 Hash 对象会优先尝试使用 listpack 编码进行存储。
例如,当我们首次向 Redis 中写入如下 Hash 数据时:
bash
HSET user:1001 name WangZ age 21 city ChengDu由于当前 Hash 对象中保存的字段数量较少,并且每一个 field 与 value 的内容都比较短,因此该对象通常会保持为 listpack 编码:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF不过,listpack 并不适合始终用于保存 Hash 数据。原因在于,采用 listpack 编码时,Hash 对象内部的多个 field-value 会按照相邻 entry 的形式连续排列。当 Redis 需要查询某一个字段对应的值时,必须从前向后依次扫描其中的 field,直到找到目标字段为止。
例如,查询 city 字段时:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF
× 跳过 × 跳过 √ 返回因此,在 listpack 编码下,根据 field 定位对应 value 的过程本质上属于线性遍历,其底层查询代价为 O(N),其中 N 表示当前 Hash 对象中保存的字段数量。
当 Hash 对象内部只保存少量字段时,即使采用线性遍历,实际需要扫描的数据规模也很小,因此这种查询代价通常是可以接受的。此时,相比于引入完整哈希表结构,使用 listpack 节省内存空间更加划算。
但是,如果后续不断向该 Hash 对象中写入新的 field-value 数据,导致其保存的字段数量越来越多,那么继续采用 listpack 就不再合适了。因为随着字段数量增加,线性扫描所需要访问的数据也会逐渐增多,查询与修改操作的代价也会随之增大。
在这种情况下,Redis 就会将该 Hash 对象从 listpack 编码转换为 hashtable 编码。
text
字段数量较少:
header | field1 | value1 | field2 | value2 | EOF
↓
使用 listpack 编码
字段数量不断增加:
header | field1 | value1 | field2 | value2 | ... | fieldN | valueN | EOF
↓
线性扫描代价逐渐增大
↓
转换为 hashtable 编码虽然 hashtable 编码需要维护桶数组、每个数据节点中额外的 next 指针,以及桶数组长度、链表节点数量、是否正在进行 rehash 和当前迁移进度等元信息,因此会带来额外的结构开销;但是,当 Hash 对象中保存的数据规模已经较大时,继续使用 listpack 所带来的线性扫描代价也会越来越明显。
此时,Redis 更需要关注的是字段查询与修改操作的访问效率。通过将编码转换为 hashtable,Redis 就可以根据 field 的哈希结果定位对应的数据,而不需要继续从头到尾扫描所有字段。
因此,二者之间的选择本质上是一种权衡:
text
小规模 Hash:
字段数量较少,线性扫描代价较低
使用 listpack 编码,优先降低内存开销
规模较大的 Hash:
字段数量较多,线性扫描代价逐渐增大
转换为 hashtable 编码,优先保证访问效率这里还需要注意,影响 Hash 编码转换的条件并不只有字段数量。由于 listpack 会将每一个 field 与 value 都编码为连续内存中的 entry,因此,如果某一个 field 或 value 保存的内容过长,即使当前 Hash 对象中的字段数量并不多,也不再适合继续使用 listpack 进行紧凑存储。
例如,假设当前只向 Hash 对象中写入一组数据:
bash
HSET article:1001 content "一段非常长的文章内容......"
虽然该 Hash 对象中只有一个 field,但如果 content 对应的 value 内容过长,那么 Redis 仍然可能将其转换为 hashtable 编码。

同理,如果某一个 field 本身过长,也会影响编码方式的选择。因此,判断一个 Hash 对象是否适合继续使用 listpack 编码,需要同时考虑两个方面:
text
Hash 对象内部保存的 field-value 数量
任意一个 field 或 value 所占用的字节长度在默认配置下,Redis 7.0 及之后版本通过以下两个配置项控制 Hash 对象是否能够保持 listpack 编码:
text
hash-max-listpack-entries 512
hash-max-listpack-value 64其中:
text
hash-max-listpack-entries:
表示采用 listpack 编码时,Hash 对象允许保存的最大 field-value 数量,
默认值为 512。
hash-max-listpack-value:
表示采用 listpack 编码时,任意一个 field 或 value 允许占用的最大字节长度,
默认值为 64 字节。也就是说,在默认配置下,只有当一个 Hash 对象中保存的字段数量不超过 512,并且其中任意一个 field 与 value 的长度都不超过 64 字节时,该对象才适合继续保持 listpack 编码。
一旦字段数量超过限制,或者任意一个 field、value 的长度超过限制,Redis 就会将该 Hash 对象转换为 hashtable 编码:
text
field-value 数量不超过 512,
并且每个 field/value 长度不超过 64 字节
↓
保持 listpack 编码
field-value 数量超过 512,
或者某个 field/value 长度超过 64 字节
↓
转换为 hashtable 编码因此,listpack 与 hashtable 并不是两种互不相关的存储结构,而是 Redis 针对不同规模 Hash 对象提供的两种底层编码方式:
对于字段数量较少、字段内容较短的小规模 Hash 对象,Redis 使用
listpack编码紧凑存储数据,从而降低内存开销;而当 Hash 对象中的字段数量不断增多,或者某一个field、value的内容过长时,Redis 就会将其转换为hashtable编码,以获得更适合大规模数据查询与修改的访问能力。
这也再次体现了 Redis 内部编码机制的核心思想:逻辑上相同的数据类型,在不同的数据规模下,可以采用不同的底层存储结构,从而在内存占用与访问效率之间取得平衡。
Hash 字段级过期时间是如何实现的?
在认识了 listpack 与 hashtable 这两种 Hash 底层编码方式之后,接下来还需要关注一个更加细致的问题:Redis 是否能够只为 Hash 对象中的某一个 field-value 设置过期时间?
在此前学习过期时间相关命令时,我们接触到的 EXPIRE 命令,设置的是 Redis 外层 key 的过期时间。例如:
bash
EXPIRE user:1001 60如果 user:1001 对应的是一个 Hash 对象,那么当该过期时间到达之后,被删除的是整个 Hash 对象,其中保存的所有 field-value 数据都会一并消失。
但是,在某些业务场景中,我们并不希望整个 Hash 对象同时过期,而是只希望其中某一个字段在指定时间后失效。例如,一个用户对象中可能同时保存基础信息和验证码:
text
user:1001
├── name -> WangZ
├── age -> 21
└── code -> 123456其中,name 与 age 需要长期保存,而 code 可能只允许存在较短时间。此时,如果直接给整个 user:1001 设置过期时间,就会导致用户基础信息也随验证码一起被删除,显然并不合适。
因此,从 Redis 7.4 开始,Redis 为 Hash 类型提供了字段级过期能力,可以通过 HEXPIRE 等命令,只给 Hash 对象内部的指定字段设置过期时间。这样,当过期时间到达后,被删除的只是对应的 field-value,而不是整个 Hash 对象。
例如:
bash
HEXPIRE user:1001 60 FIELDS 1 code该命令表示:为 user:1001 中的 code 字段设置 60 秒的过期时间。过期之后,code -> 123456 会被删除,而 name 与 age 仍然会继续保留。
那么,这种字段级过期信息在底层又是如何保存的呢?
普通 listpack 为什么不能直接保存字段过期时间?
根据前文的分析,我们知道,当一个小规模 Hash 对象采用普通 listpack 编码时,其内部会将多个 field 与 value 作为相邻的 entry,连续存储在同一段内存空间中:
text
header | field1 | value1 | field2 | value2 | ... | EOF例如:
text
header | name | WangZ | age | 21 | code | 123456 | EOF在这种结构中,每一组 Hash 数据都是由两个相邻的 entry组成的:
text
field | value其中,field 对应的 entry 只负责保存字段名称,value 对应的 entry 只负责保存字段值。普通 listpack 的数据布局中,并不存在用于记录某个字段过期时间的位置。
因此,如果我们希望只为 code 字段设置过期时间,就不能简单地将过期时间直接插入 code 对应的 field entry 中,也不能破坏原本 field-value 两两相邻的组织关系。
为了解决这个问题,当一个原本采用普通 listpack 编码的 Hash 对象第一次需要保存字段级过期信息时,Redis 会将其转换为一种扩展后的编码结构:listpackEx。
listpackEx:将二元组扩展为三元组
需要注意的是,listpackEx 并不是简单地在原有 listpack 中随意插入几个过期时间字段。它会在普通 listpack 的基础上,为每一组 field-value 数据额外追加一个过期时间 entry。
普通 listpack 中的数据布局为:
text
field | value而 listpackEx 中的数据布局则会扩展为:
text
field | value | expireAt也就是说,原本的二元组结构会变为三元组结构:
text
普通 listpack:
header | field1 | value1 | field2 | value2 | ... | EOF
listpackEx:
header | field1 | value1 | expireAt1 |
field2 | value2 | expireAt2 |
... |
EOF例如,原本的 Hash 对象为:
text
user:1001
├── name -> WangZ
├── age -> 21
└── code -> 123456在普通 listpack 编码下,其内部结构可以理解为:
text
header | name | WangZ | age | 21 | code | 123456 | EOF当我们为其中的 code 字段设置过期时间后,该 Hash 对象会转换为 listpackEx 编码,其内部结构可以理解为:
text
header
|
|-- name | WangZ | 0
|
|-- age | 21 | 0
|
|-- code | 123456 | expireAt
|
EOF这里的第三个 entry 保存的是该字段对应的绝对过期时间点,而不是还剩多少秒过期。
对于没有设置过期时间的字段,第三个 entry 同样存在,只不过其中保存的值为 0,表示该字段是一个不会自动过期的持久字段。
因此,在 listpackEx 中,每一组字段数据的结构都是统一的:
text
设置了过期时间的字段:
field | value | expireAt
没有设置过期时间的字段:
field | value | 0从源码实现来看,当普通 listpack 编码的 Hash 第一次执行字段过期相关操作时,Redis 会将其转换为 OBJ_ENCODING_LISTPACK_EX 编码,并为原有的每一组 field-value 追加一个过期时间 entry;没有过期时间的字段以 0 作为过期值保存。
listpackEx 并不只是增加了一个过期时间 entry
普通 listpack 编码下,Redis 对象中的指针可以直接指向保存数据的连续内存空间:
text
Redis 对象
├── type = Hash
├── encoding = listpack
└── ptr -> listpack 连续内存空间但是,当 Hash 对象转换为 listpackEx 编码之后,Redis 对象的指针不再只是简单指向一段 listpack 内存,而是指向一个额外的 listpackEx 结构:
text
Redis 对象
├── type = Hash
├── encoding = listpackEx
└── ptr
↓
listpackEx 结构
├── lp -> 保存 field-value-expireAt 三元组的连续内存空间
└── 字段过期管理所需的元信息也就是说,listpackEx 内部仍然使用紧凑连续存储的方式保存多个三元组,但是它还需要额外维护与字段过期管理相关的信息,从而使该 Hash 对象能够参与 Redis 的字段级主动过期处理。
为什么 listpackEx 需要按照过期时间排列字段?
对于普通 listpack 编码来说,Hash 内部的多个 field-value 之间不存在顺序上的语义关联。
例如:
text
name | WangZ | age | 21 | city | ChengDu与:
text
city | ChengDu | name | WangZ | age | 21在逻辑上都表示同一个 Hash 对象。因此,普通 listpack 在新增字段时,可以直接将新的 field-value 追加到 EOF 之前。
但是,当 Hash 对象需要支持字段级过期之后,情况就不同了。
因为 Redis 除了需要在访问某个字段时判断它是否已经过期,还需要主动清理那些已经过期、但长期没有被访问的字段。如果 listpackEx 中设置了过期时间的字段是无序排列的,那么 Redis 在主动清理时,就可能需要扫描其中的大量三元组,才能确定哪些字段已经到期。
因此,listpackEx 会按照字段的到期时间来组织其中的三元组:
text
到期时间越早的字段,越靠前保存
到期时间越晚的字段,越靠后保存
没有设置过期时间的字段,保存到末尾例如:
text
header
|
|-- code | 123456 | 10:00:30
|
|-- token | abc123 | 10:05:00
|
|-- name | WangZ | 0
|
|-- age | 21 | 0
|
EOF在这个结构中,code 最先到期,因此位于最前面;token 的到期时间更晚,因此排在其后;而 name 与 age 没有设置过期时间,因此它们会被放置到最后。
这样一来,当 Redis 主动清理过期字段时,就可以从 listpackEx 的前部开始检查:
text
如果当前字段已经过期:
删除当前 field-value-expireAt 三元组,
继续检查下一组三元组。
如果当前字段还没有过期:
由于后面的字段到期时间只会更晚,
本轮检查可以停止。
如果当前 expireAt 为 0:
说明已经进入没有设置过期时间的字段区域,
后续同样不需要继续检查。因此,listpackEx 与普通 listpack 的一个重要区别就在于:
text
普通 listpack:
field-value 之间没有物理排列要求,
新增字段通常可以直接追加到末尾。
listpackEx:
field-value-expireAt 三元组需要按照到期时间组织,
设置了过期时间的字段需要插入到合适的位置,
从而便于 Redis 快速清理过期字段。Redis 源码中明确说明,listpackEx 中的字段会按照过期时间排序,最早到期的字段排在最前面,而没有过期时间的字段会被放置在末尾。
字段过期同样包含惰性删除与主动删除
在此前学习普通 key 的过期机制时,我们已经认识了 Redis 的两种过期删除策略:惰性删除与主动删除。
对于 Hash 字段级过期来说,其整体思想仍然类似。
首先是惰性删除。当客户端访问某一个 Hash 字段时,Redis 会检查该字段是否已经到期。如果字段已经过期,那么 Redis 会将其从当前 Hash 对象中删除,并按照字段不存在的情况进行处理。
例如:
bash
HGET user:1001 code如果 code 字段已经到期,那么 Redis 不会继续返回原来的验证码内容,而是会将该字段删除,并向客户端反馈字段不存在。
其次是主动删除。如果某一个字段已经过期,但之后一直没有客户端继续访问它,仅依靠惰性删除就会导致这些无效数据长期占用内存空间。因此,Redis 还需要主动检查存在字段级过期信息的 Hash 对象,并删除其中已经到期的字段。
对于 listpackEx 来说,由于其中的三元组已经按照到期时间排列,因此 Redis 在主动检查时,可以从最前面的三元组开始处理,连续删除已经过期的数据;一旦遇到尚未到期或者没有设置过期时间的字段,就可以停止继续扫描。
text
listpackEx 主动过期检查:
从头部开始
↓
删除已经到期的三元组
↓
遇到第一个未到期字段或 expireAt = 0 的字段
↓
停止本轮检查hashtable 编码下如何保存字段过期信息?
对于采用 hashtable 编码的 Hash 对象来说,Redis 需要让某一个 field 能够独立携带自己的过期信息。因此,在支持字段级过期之后,Redis 不再使用普通的 SDS 来保存 Hash 节点中的 field,而是使用一种能够附加元信息的字符串结构 MSTR。
当某个字段没有设置过期时间时,MSTR 只负责保存该字段名称;而当某个字段设置了过期时间后,Redis 就会在这个 MSTR 上附加对应的过期元信息,其中包含该字段的到期时间以及参与主动过期管理所需的信息。
与此同时,字段对应的 value 仍然按照普通字符串内容进行保存。也就是说,字段过期信息附加在用于标识该字段的 field 上,而不是写入 value 的数据内容中。
用结构图表示就是:
text
未设置字段过期时间:
哈希节点
├── field -> MSTR("name")
├── value -> SDS("WangZ")
└── next
设置字段过期时间:
哈希节点
├── field -> MSTR("code") + ExpireMeta
│ └── expireAt 等过期管理信息
├── value -> SDS("123456")
└── next这里需要注意,字段的过期时间并不是简单地添加到 value 中。Redis 实际上改变了 field 的保存方式,使其能够附加字段级过期所需的元信息。
也就是说:
text
没有设置字段过期时间的 field:
field -> MSTR
value -> SDS
设置了字段过期时间的 field:
field -> MSTR + ExpireMeta
value -> SDS这样,每一个需要独立过期的字段,就都能够携带自己的到期时间信息。Redis 官方对 Hash Field Expiration 的架构说明中提到,为了将过期信息附加到 Hash 字段上,哈希表中的字段由普通 SDS 字符串调整为可以附加元数据的 MSTR;源码中也将这种字段表示为 hfield。
hashtable 如何管理大量设置了过期时间的字段?
仅仅在每一个字段上保存到期时间还不够。因为 Redis 还需要主动找到那些已经到期的字段,并及时将它们删除。
一种直观的思路是使用小根堆,根据过期时间组织所有字段。但 Redis 在实现 Hash 字段级过期时,并没有直接采用小根堆,而是设计了一种专门用于过期管理的数据结构:ebuckets。
对于每一个存在字段级过期信息的 Hash 对象来说,Redis 会维护一份属于该 Hash 自己的私有 ebuckets,用于管理当前 Hash 对象内部哪些字段设置了过期时间,以及这些字段的到期顺序。
text
单个 Hash 对象
↓
私有 ebuckets
↓
组织当前 Hash 内部设置了过期时间的 field但是,Redis 数据库中可能同时存在很多个拥有字段级过期信息的 Hash 对象。因此,Redis 还需要在全局范围内维护一份 ebuckets,用于记录哪些 Hash 对象当前包含待过期字段。
对于全局 ebuckets 来说,每一个 Hash 对象会按照其内部最早即将到期字段的时间参与管理:
text
全局 ebuckets
↓
记录存在字段级过期信息的多个 Hash 对象
↓
每个 Hash 以内部最早过期字段的时间参与调度例如:
text
user:1001:
最早过期字段 code,过期时间为 10:00:30
user:1002:
最早过期字段 token,过期时间为 10:02:00
user:1003:
最早过期字段 session,过期时间为 10:01:00那么,全局过期管理结构需要优先关注 user:1001,随后关注 user:1003 与 user:1002。当 Redis 找到某个需要执行过期处理的 Hash 对象后,再进入该 Hash 自己的字段过期管理结构中,删除其中已经到期的字段。
因此,对于采用 hashtable 编码的 Hash 对象来说,字段级过期管理可以简单理解为两层结构:
text
数据库级别:
全局 ebuckets 管理哪些 Hash 对象需要进行字段过期检查
Hash 对象级别:
私有 ebuckets 管理当前 Hash 内部哪些 field 需要过期Redis 官方架构说明中指出,ebuckets 会按照到期时间组织待过期条目;规模较小时可以使用链表结构,规模增大后则会使用基于 RAX 树的结构进行管理,而不是使用传统的小根堆。
Redis Hash 核心命令详解:字段读写、过期控制与数值运算
Hash 类型的核心操作命令:HSET、HGET 与 HMGET
根据上文,我们已经认识了 Redis 中 Hash 类型底层采用的核心编码方式,即适用于小规模数据的 listpack,以及适用于较大规模数据的 hashtable。接下来,我们就可以重新回到上层操作,认识围绕 Hash 类型进行数据写入与查询的核心命令,并结合底层编码进一步理解这些命令的执行过程。
使用 HSET 写入 field-value 数据
对于 Hash 类型来说,最核心的写入命令就是 HSET。其基本语法结构如下:
bash
HSET key field value [field value ...]这里需要再次区分两个概念:
text
key:
Redis 外层的键,用于定位整个 Hash 对象。
field:
Hash 对象内部的字段,用于定位该字段对应的 value。例如,我们可以通过下面的命令保存某个用户的基础信息:
bash
HSET user:1001 name WangZ age 21 city ChengDu执行之后,其逻辑结构可以理解为:
text
user:1001
├── name -> WangZ
├── age -> 21
└── city -> ChengDu这里,user:1001 是 Redis 外层的 key,而 name、age、city 则是该 Hash 对象内部的多个 field。
需要注意,HSET 不仅可以一次写入一组 field-value 数据,也可以在一次命令中同时写入多组字段数据:
bash
HSET user:1001 name WangZ age 21 city ChengDu相比于分别执行三次命令:
bash
HSET user:1001 name WangZ
HSET user:1001 age 21
HSET user:1001 city ChengDu当多个字段本来就属于同一个 Hash 对象时,通过一次 HSET 完成写入,可以减少客户端与 Redis 服务端之间不必要的网络往返开销。
除此之外,如果当前写入的 field 在 Hash 对象中已经存在,那么 HSET 并不会重复保存一个新的字段,而是会覆盖该字段原本对应的 value。
例如,当前已经存在:
text
user:1001
├── name -> WangZ
└── age -> 21此时执行:
bash
HSET user:1001 name ZhangSan city ChengDu其中,name 字段已经存在,因此其对应的值会由 WangZ 更新为 ZhangSan;而 city 字段此前不存在,因此会作为新的字段被插入。
执行之后:
text
user:1001
├── name -> ZhangSan
├── age -> 21
└── city -> ChengDu同时,HSET 命令的返回值表示的是本次真正新增的 field 数量 ,覆盖已有字段不会被计入返回结果。因此,上述命令中只有 city 属于新增字段,返回值为:
bash
(integer) 1从底层编码分析 HSET 的执行过程
在认识了 HSET 的基本行为之后,我们还可以结合前文学习的底层编码方式,进一步分析该命令在不同编码下的执行过程。
执行 HSET key field value 时,Redis 首先会根据外层的 key,定位到对应的 Hash 对象。随后,再根据当前 Hash 对象采用的底层编码方式,完成内部字段的写入。
listpack 编码下的写入过程
当当前 Hash 对象采用 listpack 编码时,其内部的多组 field-value 数据会以相邻 entry 的形式交替存储:
text
header | field1 | value1 | field2 | value2 | ... | EOF例如:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF此时,如果我们执行:
bash
HSET user:1001 age 22Redis 不能直接将 age -> 22 追加到 EOF 之前,因为它首先需要判断 age 字段是否已经存在。因此,Redis 会从前向后扫描 listpack 中保存的各个 field:
text
header | name | WangZ | age | 21 | city | ChengDU | EOF
× 跳过 √当定位到 age 字段之后,Redis 会找到其后面相邻的 value entry,并使用新的内容替换原来的值:
text
写入前:
header | name | WangZ | age | 21 | city | ChengDu | EOF
写入后:
header | name | WangZ | age | 22 | city | ChengDu | EOF这里还需要注意,由于 listpack 中的多个 entry 是连续紧凑排列的,因此覆盖已有字段值时,真正决定后续数据是否需要调整位置的,并不是命令层面看到的字符串内容是否发生变化,而是新的 value 编码为完整 entry 后所占用的字节长度是否发生变化。
如果新的 value entry 与原 entry 占用的字节数相同,那么 Redis 可以直接复用原有位置完成替换,后续 entry 不需要调整。
如果新的 value entry 占用空间更大,那么原有位置不足以容纳新的内容,位于其后的其他 entry 与 EOF 就需要相应调整位置,为新的 value entry 腾出空间;如果当前已经分配的内存空间不足以容纳更新后的有效内容,Redis 还需要扩展这段连续内存空间。
反过来,如果新的 value entry 占用空间更小,那么后续内容也需要相应向前调整,以继续保持 listpack 的紧凑排列。
而如果我们写入的是一个此前不存在的新字段,例如:
bash
HSET user:1001 token abc123Redis 同样需要先扫描当前 listpack,确认其中不存在 token 字段:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF
× 跳过 × 跳过 × 跳过只有在扫描结束并确认该字段不存在之后,Redis 才会将新的 field 与 value 对应的两个 entry 追加到 EOF 之前:
text
header | name | WangZ | age | 21 | city | ChengDu | token | abc123 | EOF因此,在 listpack 编码下,无论最终执行的是覆盖已有字段,还是追加新的字段,Redis 都需要先在线性结构中定位目标 field。如果当前 Hash 中保存了 N 个字段,那么从底层执行过程来看,写入单组 field-value 的查找过程具有 O(N) 的线性扫描特征。
不过,listpack 本身只适用于字段数量较少,并且 field 与 value 内容都比较短的小规模 Hash 对象。因此,虽然其底层需要线性扫描,但实际遍历的数据规模通常较小,写入代价仍然处于可接受范围内。
另外,如果本次写入导致字段数量超过限制,或者新写入的某个 field、value 内容过长,Redis 还可能将当前 Hash 对象从 listpack 编码转换为 hashtable 编码。
hashtable 编码下的写入过程
当 Hash 对象采用 hashtable 编码时,其内部会通过桶数组与链表节点组织多组 field-value 数据:
text
桶数组
├── bucket[0] -> nullptr
│
├── bucket[1] -> [field: name, value: WangZ, next]
│ ↓
│ [field: city, value: ChengDu, next]
│ ↓
│ nullptr
│
└── bucket[2] -> [field: age, value: 21, next] -> nullptr此时,执行 HSET 时,Redis 会根据目标 field 计算哈希结果,并定位到桶数组中的对应位置。随后,再在该桶所关联的链表中查找是否已经存在相同的 field:
text
field 已经存在:
更新对应节点中的 value。
field 不存在:
创建新的数据节点,并插入到该桶对应的链表中。例如,执行:
bash
HSET user:1001 age 22Redis 会根据 age 定位到对应桶,找到已经存在的 age 节点,然后将其保存的 value 由 21 更新为 22。
而如果执行:
bash
HSET user:1001 token abc123并且当前桶对应的链表中不存在 token 字段,那么 Redis 就会创建新的节点,并将其挂载到对应桶下。
在哈希分布较为均匀的情况下,每一个桶下关联的链表通常不会过长。因此,对于采用 hashtable 编码的 Hash 对象来说,写入单组 field-value 数据的平均时间复杂度可以认为是 O(1)。
当然,如果大量不同字段发生严重哈希冲突,被集中映射到同一个桶下,那么链表查找代价也会随链表长度增加。但在通常情况下,哈希表能够提供比线性扫描更加适合大规模字段操作的访问能力。
需要说明的是,Redis 官方命令文档通常将 HSET 每写入一组 field-value 的时间复杂度标记为 O(1);而这里我们是在结合对象具体编码方式,进一步分析命令在底层不同分支中的实际执行过程。因此,对于仍然采用 listpack 编码的小规模 Hash,可以理解为其内部存在对 field 的线性定位过程,只不过数据规模受到限制,因此实际开销较低。
使用 HGET 查询单个字段
与 HSET 对应,HGET 用于查询某个 Hash 对象内部指定 field 所对应的 value。其语法结构如下:
bash
HGET key field例如,查询用户的姓名:
bash
HGET user:1001 name返回结果为:
bash
"WangZ"这里同样需要经历两层定位过程:
text
第一步:
根据外层 key:user:1001
定位到对应的 Hash 对象。
第二步:
根据内部 field:name
定位到该字段对应的 value。如果当前 Hash 对象采用 listpack 编码,那么 Redis 需要按照 field-value 交替排列的方式,从前向后依次扫描其中的 field,直到找到目标字段为止:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF
√ 返回如果查询的是 city:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF
× 跳过 × 跳过 √ 返回因此,从底层编码行为来看,listpack 编码下查询某一个字段同样具有 O(N) 的线性扫描特征。
而如果当前 Hash 对象采用 hashtable 编码,那么 Redis 就可以根据 field 的哈希结果定位到对应桶,再在该桶关联的链表中查找目标字段。在哈希分布较为均匀的情况下,其平均查询代价可以认为是 O(1)。
使用 HMGET 一次查询多个字段
HGET 一次只能查询一个 field 对应的 value。如果我们希望一次获取同一个 Hash 对象中的多个字段,就可以使用 HMGET 命令。
其语法结构如下:
bash
HMGET key field [field ...]例如:
bash
HMGET user:1001 name age city返回结果为:
bash
1) "WangZ"
2) "21"
3) "ChengDu"HMGET 返回结果的顺序,与命令中传入的 field 顺序保持一致。如果某一个字段不存在,那么其对应位置会返回 nil。
例如:
bash
HMGET user:1001 name email city假设 email 字段不存在,则返回结果为:
bash
1) "WangZ"
2) (nil)
3) "ChengDu"由于 Redis 本质上是客户端与服务端之间通过网络进行交互的服务程序,当我们需要查询同一个 Hash 对象中的多个字段时,使用一次 HMGET 通常比连续发送多条 HGET 命令更加合适,因为这样可以减少多次网络请求带来的往返开销。
从底层执行角度来看,HMGET 可以理解为:在定位到外层 key 对应的 Hash 对象之后,依次查询命令中给出的多个 field。
因此,如果一次查询 M 个字段:
text
listpack 编码:
每个 field 都可能需要在线性结构中进行定位,
最坏情况下,整体扫描代价可能达到 O(M × N)。
hashtable 编码:
每个 field 平均可以通过哈希表完成 O(1) 级别定位,
因此查询 M 个字段的平均代价可以理解为 O(M)。其中,N 表示当前 Hash 对象内部保存的字段数量,M 表示本次需要查询的字段数量。
不过,对于 listpack 来说,其本身只会用于保存小规模 Hash 对象,因此即使内部查询依赖线性扫描,实际执行代价通常也不会过高。而当对象规模逐渐增大后,Redis 会将其转换为 hashtable 编码,以获得更适合大量字段查询与修改操作的访问能力。
获取 Hash 中全部字段或字段值:HKEYS、HVALS 与 HGETALL
在认识了 HSET、HGET 与 HMGET 之后,接下来我们再来看几条用于获取 Hash 对象中全部数据的命令:HKEYS、HVALS 与 HGETALL。
其中,HKEYS 用于返回当前 Hash 对象中保存的所有 field,其语法结构如下:
bash
HKEYS key例如,当前存在如下 Hash 对象:
text
user:1001
├── name -> WangZ
├── age -> 21
└── city -> ChengDu执行:
bash
HKEYS user:1001则会返回该 Hash 对象中的所有 field:
bash
1) "name"
2) "age"
3) "city"而 HVALS 命令则用于返回当前 Hash 对象中的所有 value,其语法结构如下:
bash
HVALS key例如:
bash
HVALS user:1001返回结果为:
bash
1) "WangZ"
2) "21"
3) "ChengDu"从底层编码分析全量查询过程
结合前文介绍的底层编码方式,我们可以发现:无论当前 Hash 对象采用的是 listpack 编码,还是 hashtable 编码,执行 HKEYS 或 HVALS 时,都需要遍历当前 Hash 对象中的全部 field-value 数据。
对于采用 listpack 编码的 Hash 对象来说,其内部的数据按照 field-value 相邻的形式连续排列:
text
header | field1 | value1 | field2 | value2 | ... | EOF因此,执行 HKEYS 时,Redis 需要从头到尾遍历这段连续内存空间,并依次返回每一组数据中的 field:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF
↑ ↑ ↑
返回 field 返回 field 返回 field而执行 HVALS 时,同样需要遍历整个 listpack,只不过返回的是每一个 field 后面相邻的 value:
text
header | name | WangZ | age | 21 | city | ChengDu | EOF
↑ ↑ ↑
返回 value 返回 value 返回 value对于采用 hashtable 编码的 Hash 对象来说,Redis 同样需要遍历整个哈希表:依次访问桶数组中的各个桶,并继续遍历每一个桶下所挂载的链表节点,从而获取其中保存的所有 field 或 value。
text
桶数组
├── bucket[0] -> nullptr
│
├── bucket[1] -> [name, WangZ] -> [city, ChengDu]
│
└── bucket[2] -> [age, 21]因此,HKEYS 与 HVALS 都需要访问当前 Hash 对象中保存的全部字段,其时间复杂度均为 O(N),其中 N 表示该 Hash 对象中保存的字段数量。
对于字段数量较少的小规模 Hash 对象来说,执行这类全量查询操作通常不会带来明显问题。但是,如果某一个 Hash 对象中保存了大量字段,那么一次性遍历并返回所有字段或字段值,就可能增加命令执行时间与网络返回数据量,进而影响其他请求的处理延迟。
因此,HKEYS 与 HVALS 并不是完全不能使用,而是不适合频繁用于字段数量较大的 Hash 对象进行全量查询。
不要依赖 HVALS 的返回顺序
在使用 HVALS 时,还需要注意一个容易出现的误区:不能认为其返回的多个 value 会按照此前执行 HSET 时的写入顺序排列。
Hash 本质上是一种映射结构,其核心语义是根据 field 定位对应的 value,而不是维护字段之间的插入顺序。
对于采用 listpack 编码的小规模 Hash 来说,由于新增字段通常会被追加到尾部,在某些简单实验中,查询结果可能看起来与写入顺序一致。但是,这种现象不能作为业务代码依赖的规则。
尤其当 Hash 对象转换为 hashtable 编码之后,多个 field-value 数据会根据各自的哈希结果分布到不同桶中。后续随着哈希表扩容与 rehash 的发生,底层节点的遍历顺序也可能发生变化。
例如,我们按如下顺序写入数据:
bash
HSET user:1001 name WangZ age 21 city ChengDu不能因此认为:
bash
HVALS user:1001返回的第一个值一定永远对应 name,第二个值一定永远对应 age,第三个值一定永远对应 city。
因此,如果业务中只需要获取所有字段值,可以使用 HVALS;但是,如果还需要明确知道每一个 value 对应的是哪个 field,就不能只查询字段值,而应当同时获取字段与字段值之间的对应关系。
使用 HGETALL 获取全部 field-value 数据
当我们需要同时获取一个 Hash 对象中的所有 field 及其对应的 value 时,可以使用 HGETALL 命令。
其语法结构如下:
bash
HGETALL key例如:
bash
HGETALL user:1001返回结果可以理解为:
bash
1) "name"
2) "WangZ"
3) "age"
4) "21"
5) "city"
6) "ChengDu"其中,返回结果中的每两个相邻元素组成一组 field-value 数据:
text
name -> WangZ
age -> 21
city -> ChengDu相比于单独使用 HVALS,HGETALL 能够同时返回字段名称与字段值,因此不会出现"只得到了 value,却无法确定其对应 field"的问题。
不过,需要注意的是,HGETALL 并不是对大规模 Hash 全量查询的性能优化方案。因为它同样需要遍历当前 Hash 对象中的全部字段,而且返回的数据量还包括所有 field 与 value。
因此,HGETALL 的时间复杂度同样为 O(N)。对于只保存少量字段的小规模 Hash 对象,例如用户基础信息、商品简单属性等,直接使用 HGETALL 获取完整对象通常是合适的;但是,对于字段数量可能非常多的 Hash 对象,仍然应当避免频繁使用 HGETALL 一次性读取全部内容。
Hash 字段级过期操作:HEXPIRE 与 HSETEX
根据上文,我们已经知道,Redis 不仅可以为整个 key 设置过期时间,还可以将过期控制进一步细化到 Hash 对象内部的某一个 field-value。
例如,当前存在如下用户对象:
text
user:1001
├── name -> WangZ
├── age -> 21
└── code -> 123456其中,name 与 age 属于需要长期保存的用户基础信息,而 code 可以表示一个只在短时间内有效的验证码。此时,如果我们直接为整个 user:1001 设置过期时间,那么验证码过期时,用户的基础信息也会一并被删除。
因此,更合理的需求应当是:只让 code -> 123456 这一组字段数据在指定时间后失效,而不影响同一个 Hash 对象中的其他字段。
在 Redis 7.4 之前,Redis 并不支持 Hash 内部字段的独立过期,只能为整个外层 key 设置过期时间。而从 Redis 7.4 开始,Redis 引入了字段级过期能力,可以通过 HEXPIRE 为 Hash 中已经存在的一个或多个 field 设置独立的过期时间。
例如,我们可以先通过 HSET 写入验证码字段:
bash
HSET user:1001 code 123456随后,再通过 HEXPIRE 为该字段设置 60 秒的过期时间:
bash
HEXPIRE user:1001 60 FIELDS 1 code这条命令可以拆解为:
text
HEXPIRE user:1001 60 FIELDS 1 code
│ │ │ │ │
│ │ │ │ └── 要设置过期时间的 field
│ │ │ └───── 本次操作 1 个 field
│ │ └──────────── 后面开始指定 field
│ └─────────────── 60 秒后过期
└───────────────────────── Hash 对象的外层 key执行成功后,code 字段会在 60 秒后被自动删除,而 name 与 age 字段仍然会继续保留:
text
user:1001
├── name -> WangZ
├── age -> 21
└── code -> 123456 // 60 秒后过期不过,这种"先写入字段,再单独设置过期时间"的方式存在一个问题:字段写入与过期时间设置需要通过两条命令分别完成。
bash
HSET user:1001 code 123456
HEXPIRE user:1001 60 FIELDS 1 code首先,这意味着客户端与 Redis 服务端之间需要进行两次命令交互,增加了一次网络往返开销。
更重要的是,这两个动作并不属于同一次命令执行。如果客户端成功发送了 HSET,但是在继续发送 HEXPIRE 之前发生异常,例如程序崩溃、连接中断或者请求流程提前退出,那么就可能出现如下中间状态:
text
code -> 123456 已经成功写入
但是 code 没有按照预期设置过期时间对于验证码、临时令牌、短期会话状态等本应自动失效的数据来说,这种情况显然是不合理的。
因此,从 Redis 8.0 开始,Redis 新增了 HSETEX 命令。该命令可以在写入一组或多组 field-value 数据的同时,直接为这些字段设置过期时间,从而将字段写入与字段过期控制合并到同一次命令执行中。
HSETEX 的基本语法结构如下:
bash
HSETEX key [FNX | FXX]
[EX seconds | PX milliseconds | EXAT unix-time-seconds | PXAT unix-time-milliseconds | KEEPTTL]
FIELDS numfields field value [field value ...]例如,我们可以在写入验证码字段的同时,直接将其设置为 60 秒后过期:
bash
HSETEX user:1001 EX 60 FIELDS 1 code 123456这条命令可以拆解为:
text
HSETEX user:1001 EX 60 FIELDS 1 code 123456
│ │ │ │ │ │ │
│ │ │ │ │ │ └── value
│ │ │ │ │ └─────── field
│ │ │ │ └───────── 后面有 1 组 field-value
│ │ │ └──────────────── 字段数据开始
│ │ └─────────────────── 过期时长为 60 秒
│ └────────────────────── 以秒为单位设置相对过期时间
└──────────────────────────────── Hash 对象的外层 key这里的 FIELDS 1 表示:当前命令后面需要写入 1 组 field-value 数据,即:
text
code -> 123456同时,这组字段数据会被设置为 60 秒后过期。
因此,下面两种写法表达的业务目标是一致的:
bash
# Redis 7.4 中的两步写法
HSET user:1001 code 123456
HEXPIRE user:1001 60 FIELDS 1 code
bash
# Redis 8.0 中的一步写法
HSETEX user:1001 EX 60 FIELDS 1 code 123456但是,后者能够将字段写入与过期时间设置放在同一次命令执行中完成,从而减少一次网络往返,并避免字段已经写入成功、但过期时间尚未设置的中间状态。
HSETEX 的过期时间选项
HSETEX 不仅可以指定多少秒后过期,还可以根据业务需求选择不同的过期时间设置方式:
text
EX seconds:
以秒为单位,设置字段在指定时长后过期。
PX milliseconds:
以毫秒为单位,设置字段在指定时长后过期。
EXAT unix-time-seconds:
设置字段在指定的 Unix 秒级时间戳到达时过期。
PXAT unix-time-milliseconds:
设置字段在指定的 Unix 毫秒级时间戳到达时过期。
KEEPTTL:
覆盖字段值时,保留该字段原本已有的过期时间。例如,设置验证码字段在 60 秒后过期:
bash
HSETEX user:1001 EX 60 FIELDS 1 code 123456设置某个字段在 5000 毫秒后过期:
bash
HSETEX user:1001 PX 5000 FIELDS 1 code 123456如果某个字段此前已经具有过期时间,而当前只希望更新其字段值,同时继续保留原有过期时间,就可以使用 KEEPTTL:
bash
HSETEX user:1001 KEEPTTL FIELDS 1 code 654321需要注意,EX、PX、EXAT、PXAT 与 KEEPTTL 表达的是不同的过期处理方式,因此它们之间不能同时指定。
HSETEX 的条件写入选项
除了设置过期时间之外,HSETEX 还可以控制本次字段写入的条件。
在默认情况下,如果指定的 field 不存在,HSETEX 会写入新的字段;如果指定的 field 已经存在,则会覆盖其原有字段值。
除此之外,HSETEX 还支持两个条件选项:
text
FNX:
只有当本次指定的所有 field 都不存在时,才执行写入。
FXX:
只有当本次指定的所有 field 都已经存在时,才执行写入。例如,对于验证码字段来说,我们可能不希望在验证码仍然有效时重复覆盖原有验证码。此时,就可以使用 FNX:
bash
HSETEX user:1001 FNX EX 60 FIELDS 1 code 123456其含义为:
text
只有当 user:1001 中不存在 code 字段时,
才写入 code -> 123456,
并将其设置为 60 秒后过期。如果当前 code 字段已经存在,那么本次写入就不会执行。
而 FXX 则适用于只允许更新已有字段、不允许创建新字段的场景:
bash
HSETEX user:1001 FXX EX 60 FIELDS 1 code 654321其含义为:
text
只有当 user:1001 中已经存在 code 字段时,
才更新其字段值并重新设置过期时间。需要注意,FNX 和 FXX 针对的是本次命令中指定的全部字段:FNX 要求这些字段全部不存在,FXX 要求这些字段全部已经存在。
一次写入多个带过期时间的字段
与 HSET 类似,HSETEX 同样支持在一次命令中同时写入多组 field-value 数据。
例如,假设我们需要保存一个会话对象中的访问令牌与刷新令牌,并让二者都在 1800 秒后过期:
bash
HSETEX session:1001 EX 1800 FIELDS 2 token abc123 refreshToken xyz456这里:
text
FIELDS 2表示后面存在两组 field-value 数据:
text
token -> abc123
refreshToken -> xyz456执行之后,其逻辑结构可以理解为:
text
session:1001
├── token -> abc123 // 1800 秒后过期
└── refreshToken -> xyz456 // 1800 秒后过期当多个字段属于同一个 Hash 对象,并且具有相同的过期规则时,通过一次 HSETEX 完成写入与过期时间设置,可以减少多次命令交互带来的开销。
HEXPIRE 与 HSETEX 的使用场景区别
虽然 HSETEX 能够在写入字段时直接设置过期时间,但这并不意味着 HEXPIRE 没有存在价值。二者所适合的场景并不完全相同:
text
HEXPIRE:
字段已经存在,
当前只需要新增或更新该字段的过期时间。
HSETEX:
当前需要写入或覆盖字段值,
并在写入的同时处理该字段的过期时间。例如,如果 code 字段已经存在,而我们只是希望重新延长其有效期,那么可以使用:
bash
HEXPIRE user:1001 60 FIELDS 1 code而如果我们需要生成一个新的验证码,并在写入新值的同时设置其有效期,那么使用 HSETEX 更加合适:
bash
HSETEX user:1001 EX 60 FIELDS 1 code 654321因此,可以将这两条命令理解为:
text
HEXPIRE:
只修改字段的过期规则。
HSETEX:
修改字段内容,并同时处理字段的过期规则。Hash 中的数值运算命令:HINCRBY 与 HINCRBYFLOAT
根据上文,我们已经知道,当 Hash 对象采用 listpack 编码时,其内部的 field 与 value 都会作为一个个 entry 紧凑地存储在连续内存空间中。
对于 listpack 来说,如果某一个 entry 保存的字符串内容能够被无损转换为 64 位有符号整数,那么 Redis 就不必继续按照普通字符串的形式存储该内容,而是可以直接采用更加紧凑的整数编码进行保存。
例如,当前存在如下 Hash 对象:
text
user:1001
├── name -> WangZ
├── age -> 21
└── score -> 100如果该 Hash 对象采用 listpack 编码,那么其中的 name、age、score 等字段名称会按照字符串内容保存;而 21 与 100 这种能够无损转换为整数的字段值,则可以采用整数 entry 进行紧凑存储。
text
header | name | WangZ | age | 21 | score | 100 | EOF
↑ ↑
整数编码 整数编码这里所谓的无损转换,是指字符串转换为整数之后,再重新转换回字符串,其内容仍然与原始字符串完全一致。
例如:
text
"21" -> 可以按照整数 21 存储
"-100" -> 可以按照整数 -100 存储
"001" -> 不能直接按照整数 1 存储
因为重新读取时会得到 "1",原始字符串形式已经发生改变不过,需要注意的是,这种"将数字字符串直接编码为整数"的能力,属于 listpack 中 entry 的紧凑编码优化,并不能直接推广到 hashtable 编码。
当 Hash 对象采用 hashtable 编码时,其内部的数据通过哈希节点进行组织。对于字段对应的 value 来说,即使其内容是 "21"、"100" 这类能够表示为整数的字符串,底层仍然会按照字符串内容进行保存,而不会像 listpack entry 一样自动切换为整数编码。
因此,可以将二者的区别简单理解为:
text
listpack 编码:
如果某个 field 或 value 的内容能够无损表示为 int64,
对应 entry 可以直接选择整数编码进行紧凑存储。
hashtable 编码:
value 仍然按照字符串内容保存,
不会因为内容可以表示为整数,就自动改为整数编码。使用 HINCRBY 对整数 value 进行增减操作
虽然 Hash 中保存的字段值在命令层面表现为字符串内容,但 Redis 同样提供了针对数值型字段值进行运算的命令。
其中,HINCRBY 用于对 Hash 对象中某一个 field 对应的整数 value 进行增减操作。
其语法结构如下:
bash
HINCRBY key field increment例如,当前存在如下数据:
bash
HSET user:1001 score 100此时,我们可以通过 HINCRBY 将 score 增加 20:
bash
HINCRBY user:1001 score 20执行之后:
text
user:1001
└── score -> 120这里需要注意,HINCRBY 操作的对象并不是 field 本身,而是该 field 对应的 value。
text
score -> 100
│ │
│ └── 真正参与整数运算的数据
└────────── 用于定位该数据的 field此外,Redis 并没有专门提供一个名为 HDECRBY 的整数递减命令。原因在于,HINCRBY 的增量参数本身可以为负数,因此传入一个负数,就可以完成减法操作。
例如:
bash
HSET user:1001 score 100
HINCRBY user:1001 score 20
# score -> 120
HINCRBY user:1001 score -30
# score -> 90如果当前指定的 field 不存在,那么 Redis 会将其原始值视为 0,然后再执行对应的加法操作。
例如:
bash
HINCRBY user:1001 loginCount 1如果 loginCount 此前不存在,那么执行之后就会得到:
text
loginCount -> 1需要注意,HINCRBY 只能用于能够被正确解析为 64 位有符号整数的字段值。如果目标字段保存的是普通字符串,或者执行运算后的结果超出了 64 位有符号整数范围,那么命令就会执行失败。
不同编码下 HINCRBY 的底层行为
结合此前学习的两种底层编码方式,我们还可以进一步分析 HINCRBY 在不同编码下的执行特点。
如果当前 Hash 对象采用 listpack 编码,并且目标字段对应的 value 已经使用整数 entry 进行保存,那么 Redis 可以读取该整数值,完成加法运算后,再将新的结果写回对应位置。
例如:
text
写入前:
header | score | 100 | EOF
↑
整数 entry
执行:
HINCRBY user:1001 score 20
写入后:
header | score | 120 | EOF
↑
整数 entry当然,如果运算结果编码为新的 entry 后,其占用空间与原 entry 不同,那么由于 listpack 采用连续紧凑存储,后续内容的位置也可能需要进行相应调整。
而如果当前 Hash 对象采用 hashtable 编码,那么目标字段对应的 value 本身仍然是按照字符串内容保存的。因此,在执行整数运算时,Redis 需要先将字符串内容解析为整数,完成计算之后,再将新的结果重新保存为字符串值。
text
hashtable 编码下:
value -> "100"
↓
解析为整数 100
↓
执行加法得到 120
↓
保存新的字符串值 "120"因此,虽然 HINCRBY 在上层使用方式上完全一致,但在不同底层编码下,其内部数据的保存形式并不相同。
使用 HINCRBYFLOAT 对浮点数 value 进行增减操作
除了针对整数的 HINCRBY 之外,Redis 还提供了 HINCRBYFLOAT 命令,用于对 Hash 对象中某一个 field 对应的浮点数值进行增减操作。
其语法结构如下:
bash
HINCRBYFLOAT key field increment例如,我们可以使用 Hash 保存某个商品的价格:
bash
HSET product:1001 price 10.5随后,通过 HINCRBYFLOAT 将价格增加 0.8:
bash
HINCRBYFLOAT product:1001 price 0.8执行之后:
text
product:1001
└── price -> 11.3与 HINCRBY 类似,HINCRBYFLOAT 同样可以通过传入负数完成减法操作:
bash
HINCRBYFLOAT product:1001 price -1.5执行之后:
text
product:1001
└── price -> 9.8如果当前指定的 field 不存在,那么 Redis 同样会将其原始值视为 0,再执行对应的浮点数运算。
例如:
bash
HINCRBYFLOAT product:1001 discount 0.5如果 discount 此前不存在,那么执行之后:
text
discount -> 0.5这里需要注意,Redis 并不会像 listpack 处理整数那样,专门为浮点数字符串提供一套浮点数紧凑编码。对于 HINCRBYFLOAT 来说,Redis 会先将字段原有内容解析为浮点数,完成计算之后,再将结果以字符串内容的形式写回 Hash 对象。
text
price -> "10.5"
↓
解析为浮点数
↓
执行运算得到 11.3
↓
将结果 "11.3" 写回如果当前 Hash 对象采用 listpack 编码,那么写回后的结果仍然会作为一个 entry 保存;如果采用 hashtable 编码,则会作为字段对应的字符串值保存。
获取字段值长度:HSTRLEN
最后要介绍的一条命令是 HSTRLEN。该命令用于获取 Hash 对象中某一个 field 对应的 value 的字节长度。
其语法结构如下:
bash
HSTRLEN key field例如,当前存在如下 Hash 对象:
bash
HSET user:1001 name WangZ age 21此时执行:
bash
HSTRLEN user:1001 name由于 "WangZ" 占用 6 个字节,因此返回结果为:
bash
(integer) 6这里需要注意,HSTRLEN 返回的是字段值所占用的字节数,而不是字符数量。对于英文字符来说,一个字符通常对应一个字节,因此二者看起来没有区别;但是对于中文等多字节字符来说,字节长度与字符数量并不相同。
例如,在 UTF-8 编码下:
text
"张三" 包含 2 个中文字符
但通常占用 6 个字节因此,如果执行:
bash
HSET user:1001 name 张三
HSTRLEN user:1001 name其返回结果通常为:
bash
(integer) 6如果指定的 key 不存在,或者当前 Hash 对象中不存在对应的 field,那么 HSTRLEN 会返回 0。
从底层编码分析 HSTRLEN 的执行过程
结合前文介绍的 listpack 与 hashtable 两种编码方式,我们还可以进一步分析 HSTRLEN 在底层是如何获取字段值长度的。
listpack 编码下的执行过程
当 Hash 对象采用 listpack 编码时,其内部的多个 field 与 value 会作为相邻的 entry,按照交替排列的方式紧凑存储在一段连续内存空间中:
text
header | field1 | value1 | field2 | value2 | ... | EOF例如:
text
header | name | WangZ | age | 21 | EOF当我们执行:
bash
HSTRLEN user:1001 nameRedis 首先会根据外层的 key,定位到对应的 Hash 对象。随后,再访问该对象所指向的 listpack 连续内存空间,并从前向后依次扫描其中保存的 field,直到找到目标字段 name:
text
header | name | WangZ | age | 21 | EOF
√ ↑
目标 value当 Redis 找到目标 field 之后,其后面相邻的下一个 entry,就是该字段对应的 value。
如果当前 value entry 保存的是普通字符串内容,例如 WangZ ,那么 Redis 就可以根据该 entry 中的编码信息,获取其中保存的字符串数据长度:
text
value entry:
编码信息 | "WangZ" | backlen
↑
字节长度为 6因此,返回结果为:
bash
(integer) 6不过,根据前文对 listpack entry 编码的分析,我们知道:如果某一个字段值的内容能够被无损表示为 64 位有符号整数,那么该 value entry 可能会直接采用整数编码,而不是按照普通字符串形式保存。
例如:
text
age -> 21在 listpack 内部,21 可能直接采用整数 entry 进行紧凑存储:
text
header | age | 21 | EOF
↑
整数 entry此时,如果执行:
bash
HSTRLEN user:1001 ageRedis 不能简单地读取"字符串数据区域"的长度,因为底层保存的并不是字符 '2' 和字符 '1',而是整数 21。
但是,从命令层面来看,HSTRLEN 获取的仍然是该字段值以字符串形式返回时所占用的字节长度。因此,Redis 会计算整数 21 转换为字符串 "21" 之后的长度:
text
整数编码保存的值:21
↓
字符串形式返回:"21"
↓
字节长度:2因此:
bash
HSTRLEN user:1001 age返回结果仍然为:
bash
(integer) 2所以,对于采用 listpack 编码的 Hash 对象来说,HSTRLEN 的执行过程可以概括为:
text
根据外层 key 定位 Hash 对象
↓
在线性排列的 listpack 中查找目标 field
↓
定位其后相邻的 value entry
↓
如果 value 采用字符串编码:
直接获取字符串数据长度
如果 value 采用整数编码:
计算整数转换为字符串后的字节长度需要注意,listpack 中读取某一个已经定位到的 value 长度本身并不复杂,真正需要付出查找代价的是:Redis 必须先在线性结构中定位目标 field。因此,从底层执行过程来看,listpack 编码下的字段定位仍然具有 O(N) 的线性扫描特征,其中 N 表示当前 Hash 对象中的字段数量。
不过,由于 listpack 只适用于小规模 Hash 对象,因此实际需要扫描的数据量通常较小。
hashtable 编码下的执行过程
当 Hash 对象采用 hashtable 编码时,其内部会通过桶数组与链表节点组织多组 field-value 数据。
例如:
text
桶数组
├── bucket[0] -> nullptr
│
├── bucket[1] -> [field: name, value: "WangZ", next]
│
└── bucket[2] -> [field: age, value: "21", next]此时,执行:
bash
HSTRLEN user:1001 nameRedis 会先根据 field name 计算哈希结果,定位到对应的桶,再在该桶关联的链表中找到目标字段所在的节点。
对于采用 hashtable 编码的 Hash 对象来说,节点中的 value 仍然按照字符串内容进行保存,并且其字符串结构本身已经记录了当前字符缓冲区的长度信息。因此,当 Redis 定位到目标节点之后,就可以直接读取该 value 所记录的字节长度。
text
哈希节点
├── field -> "name"
├── value -> SDS("WangZ")
│ └── 长度信息:6
└── next因此,对于 hashtable 编码来说,HSTRLEN 的执行过程可以概括为:
text
根据外层 key 定位 Hash 对象
↓
根据 field 的哈希结果定位对应桶
↓
在桶下链表中找到目标节点
↓
直接读取 value 字符串结构中保存的长度信息在哈希分布较为均匀的情况下,hashtable 编码下定位目标字段的平均代价可以认为是 O(1),而读取其 value 长度本身同样是一个非常轻量的操作。
Hash 的应用场景:缓存对象的部分属性信息
根据上文,我们已经认识了 Redis 中 Hash 类型的底层编码实现,以及围绕 Hash 类型进行操作的一系列核心命令。接下来,我们再来看 Hash 类型在实际业务中的一个典型应用场景:缓存由多个简单属性组成的对象数据。
我们知道,Redis 的一个核心用途就是作为缓存系统存在。在常见的业务架构中,MySQL 负责保存完整且可靠的业务数据,而 Redis 则用于缓存访问频率较高的热点数据,从而减少数据库的访问压力,提高数据查询效率。
例如,在一个用户系统中,MySQL 可能保存了用户完整的基础资料:
text
id name age city phone
1001 WangZ 21 ChengDu 187xxxxxx如果某个用户的信息会被频繁查询,那么我们就可以将其中常用的基础资料缓存到 Redis 中。
为什么用户基础信息适合使用 Hash 保存?
对于用户基础资料来说,一个用户对象通常包含多个属性,例如:
text
用户 1001:
name -> WangZ
age -> 21
city -> ChengDu这些属性本质上都可以表示为一组字段与字段值之间的映射关系。因此,我们可以使用一个 Redis key 表示整个用户对象,再使用 Hash 内部的多个 field-value 保存该用户的各项属性:
text
user:profile:1001
├── name -> WangZ
├── age -> 21
└── city -> ChengDu其中:
text
user:profile:1001:
表示用户 1001 的基础资料缓存
name、age、city:
表示该用户对象内部的多个属性字段这里的 Redis key 不直接只使用用户 id,而是在用户 id 前拼接业务前缀:
text
user:profile:<userId>这样设计主要有两个作用:
text
第一,能够直接表达当前 key 所保存的数据语义,
便于后续识别、管理与排查问题。
第二,能够建立业务命名空间,
避免不同类型的数据因为 id 相同而发生 key 冲突。例如:
text
user:profile:1001 -> 用户资料
product:detail:1001 -> 商品详情
order:detail:1001 -> 订单信息虽然它们的业务 id 都是 1001,但由于前缀不同,因此在 Redis 的键空间中不会发生冲突。
String + JSON 与 Hash 的选择
当然,保存用户对象并不是只能使用 Hash。我们同样可以将整个用户对象序列化为 JSON 字符串,再将其作为一个 String 类型的 value 保存:
text
user:profile:1001
->
"{\"name\":\"WangZ\",\"age\":21,\"city\":\"ChengDu\"}"这种方式在某些场景下是合理的。例如,如果业务中每次查询用户资料时,都需要完整读取整个对象,并且更新时也通常整体覆盖,那么直接使用 String + JSON 保存对象会更加自然。
但是,如果业务中经常只需要读取或修改用户对象中的某一个属性,那么使用 Hash 会更加合适。
例如,如果我们只需要查询用户年龄,使用 Hash 时可以直接执行:
bash
HGET user:profile:1001 age返回:
text
"21"如果需要修改用户所在城市,也可以直接执行:
bash
HSET user:profile:1001 city Beijing此时,Redis 只需要修改 city 这一字段对应的值,而不需要重新处理整个用户对象。
但是,如果用户信息被保存为 JSON 字符串,那么只读取其中一个字段时,Redis 返回的仍然是完整 JSON 内容,应用程序还需要对其进行反序列化,再从解析后的对象中取得目标属性。
而如果需要修改其中某一个字段,通常还需要经历如下过程:
text
从 Redis 读取完整 JSON 字符串
↓
反序列化为程序中的对象
↓
修改目标字段
↓
重新序列化为 JSON 字符串
↓
将完整字符串重新写回 Redis因此,这两种方式并不存在绝对的优劣关系,而是适用于不同的访问模式:
text
整体读取、整体更新为主:
可以使用 String + JSON。
经常按字段读取或修改:
更适合使用 Hash。对于用户基础资料这类结构较为扁平、字段数量有限,并且可能存在字段级查询与修改需求的数据,使用 Hash 进行缓存通常会更加方便。
将 MySQL 中的用户信息缓存到 Redis
需要注意的是,在当前场景中,Redis 扮演的是缓存角色,而 MySQL 才是保存真实业务数据的数据源。
也就是说,Redis 中保存的只是为了提高查询效率而缓存的一份热点数据。即使这份缓存因为过期或者内存淘汰而消失,后续仍然可以重新从 MySQL 中查询并建立缓存;但是,MySQL 中保存的真实业务数据必须保持完整与正确。
这里采用的缓存处理方式,也就是常见的旁路缓存模式(Cache Aside):应用程序需要同时负责访问缓存与数据库,并根据缓存是否命中,决定后续的数据读取与缓存更新流程。
在这种模式下,数据查询与数据修改的处理方式并不相同:
text
查询数据:
先查询 Redis 缓存;
如果缓存不存在,再查询 MySQL;
随后将查询结果重新写入 Redis。
修改数据:
先修改 MySQL 中的真实数据;
修改成功后,删除 Redis 中可能已经失效的旧缓存;
等待后续查询重新建立最新缓存。接下来,我们就分别从数据查询与数据修改两个角度,分析如何使用 Redis Hash 缓存用户基础资料。
查询流程:先查 Redis,缓存未命中再查 MySQL
假设当前需要查询用户 1001 的基础资料。首先,应用程序可以根据用户 id 构造对应的缓存 key:
text
user:profile:1001随后,先访问 Redis 查询缓存数据:
bash
HGETALL user:profile:1001如果 Redis 中已经存在该用户的缓存信息,就可以直接将查询结果返回给客户端,而不需要继续访问 MySQL。
text
请求查询用户资料
↓
构造缓存 key:user:profile:1001
↓
查询 Redis
↓
缓存命中
↓
直接返回用户资料但是,如果 Redis 中不存在该用户的缓存数据,说明当前发生了缓存未命中。此时,应用程序就需要继续访问 MySQL,查询其中保存的真实用户资料:
text
请求查询用户资料
↓
构造缓存 key:user:profile:1001
↓
查询 Redis
↓
缓存未命中
↓
查询 MySQL 获取用户资料
↓
将查询结果写入 Redis Hash 缓存
↓
返回用户资料例如,当从 MySQL 中查询到:
text
id = 1001
name = WangZ
age = 21
city = ChengDu应用程序就可以将这些热点字段写入 Redis:
bash
HSET user:profile:1001 name WangZ age 21 city ChengDu这样,后续如果再次查询该用户资料,就可以优先从 Redis 中直接获取缓存结果,减少对 MySQL 的访问压力。
这种查询缓存的处理方式可以简单概括为:
text
先查询缓存
↓
缓存存在:直接返回
缓存不存在:
查询数据库
将结果回填到缓存
返回数据修改流程:先修改 MySQL,再处理 Redis 缓存
如果业务需要修改用户信息,例如将用户 1001 的所在城市由 ChengDu 修改为 Beijing,此时就不能只修改 Redis 中的缓存数据。
因为 Redis 只是缓存,而 MySQL 才是真实数据来源。如果只修改缓存而没有同步修改 MySQL,那么一旦缓存失效或者被删除,后续重新从 MySQL 查询数据时,就会重新得到旧的城市信息。
因此,在修改数据时,首先需要保证 MySQL 中的数据修改成功:
text
修改用户资料请求
↓
先更新 MySQL 中的真实数据
↓
MySQL 更新成功
↓
再处理 Redis 中的缓存对于缓存的处理,一种常见做法是:MySQL 更新成功后,直接删除 Redis 中对应的旧缓存。
例如:
text
更新 MySQL:
user 1001 的 city 修改为 Beijing
↓
删除 Redis 缓存:
DEL user:profile:1001此时,当后续再次查询该用户资料时,由于 Redis 中已经不存在原来的旧缓存,应用程序会重新访问 MySQL,读取最新数据,并重新将其缓存到 Redis 中:
text
后续查询用户资料
↓
Redis 缓存未命中
↓
从 MySQL 读取最新资料
↓
重新写入 Redis 缓存
↓
返回最新结果整个更新流程可以理解为:
text
先更新 MySQL 中的真实数据
↓
数据库更新成功后,删除 Redis 中的旧缓存
↓
后续查询发生缓存未命中
↓
重新从 MySQL 获取最新数据并回填缓存这里之所以常见做法是删除缓存,而不是立即修改缓存,是因为删除旧缓存可以让后续查询重新从真实数据源中建立缓存,从而减少数据库与缓存之间出现数据不一致的风险。
Hash 缓存用户信息的整体流程
因此,使用 Hash 缓存用户基础资料时,可以将整体业务流程简单总结为:
text
缓存结构设计:
user:profile:<userId>
├── name -> 用户姓名
├── age -> 用户年龄
└── city -> 用户所在城市
text
查询流程:
根据 userId 构造 Redis key
↓
先查询 Redis Hash
↓
缓存命中:
直接返回数据
缓存未命中:
查询 MySQL
将热点字段写入 Redis Hash
返回数据
text
更新流程:
先修改 MySQL 中的真实数据
↓
修改成功后删除对应 Redis 缓存
↓
等待后续查询重新从 MySQL 回填最新缓存
cpp
// 查询用户基础资料:优先读取 Redis Hash 缓存,未命中时查询 MySQL 并回填缓存
UserProfile queryUserProfile(int userId)
{
// 1. 根据用户 id 构造 Redis key
std::string key = "user:profile:" + std::to_string(userId);
// 2. 先查询 Redis 缓存
// 对应 Redis 命令:HGETALL user:profile:1001
auto cacheResult = redis.hgetall(key);
if (!cacheResult.empty())
{
UserProfile user;
user.id = userId;
user.name = cacheResult["name"];
user.age = std::stoi(cacheResult["age"]);
user.city = cacheResult["city"];
return user;
}
// 3. 缓存未命中,则查询 MySQL 中保存的真实用户资料
// 对应 SQL:
// SELECT name, age, city FROM user_profile WHERE id = userId;
UserProfile user = mysql.queryUserProfile(userId);
// 4. 将查询结果写入 Redis Hash 缓存
// 对应 Redis 命令:
// HSET user:profile:1001 name WangZ age 21 city ChengDu
redis.hset(key,
{
{"name", user.name},
{"age", std::to_string(user.age)},
{"city", user.city}
});
// 5. 为整个用户资料缓存设置过期时间
// 对应 Redis 命令:EXPIRE user:profile:1001 300
redis.expire(key, 300);
// 6. 返回查询到的用户资料
return user;
}
cpp
// 修改用户城市信息
bool updateUserCity(int userId, const std::string& newCity)
{
// 1. 根据用户 id 构造 Redis 缓存 key
std::string key = "user:profile:" + std::to_string(userId);
// 2. 先修改 MySQL 中保存的真实数据
// 对应 SQL:
// UPDATE user SET city = 'Beijing' WHERE id = 1001;
bool ret = mysql.updateUserCity(userId, newCity);
// 3. 如果数据库修改失败,直接返回失败
if (!ret)
{
return false;
}
// 4. MySQL 修改成功后,删除 Redis 中原有的缓存数据
// 对应 Redis 命令:
// DEL user:profile:1001
redis.del(key);
// 5. 修改成功
return true;
}小结
Redis 的 Hash 类型非常适合用于缓存由多个简单字段组成的对象数据,例如用户基础资料、商品部分属性或者订单简要信息等。
相比于将整个对象序列化为 JSON 字符串后保存为 String,Hash 能够更加方便地支持字段级查询与字段级修改:
bash
HGET user:profile:1001 age
HSET user:profile:1001 city Beijing但是,需要始终明确的是:在缓存场景中,Redis 保存的是为了提高访问效率而存在的热点数据副本,而 MySQL 才是完整且可靠的真实数据来源。
因此:
text
查询数据时:
优先访问 Redis;
缓存未命中时查询 MySQL,并将结果回填到 Redis。
修改数据时:
优先保证 MySQL 中的真实数据修改成功;
随后删除或谨慎处理 Redis 中的旧缓存。这也说明,学习 Redis 中的 Hash 类型,不仅仅是学习几条数据操作命令,更重要的是理解它如何与数据库配合,用于解决实际业务中的热点对象缓存问题。
结语
那么这就是本篇文章的全部内容,我会持续更新,希望你能够多多关注,如果本文有帮助到你的话,还请三连加关注,你的支持就是我创作的最大动力!
