文章目录
- [1. 堆的概念及结构](#1. 堆的概念及结构)
- [2. 堆的实现及应用](#2. 堆的实现及应用)
-
- [2.1 堆的插入](#2.1 堆的插入)
- [2.2 堆的删除](#2.2 堆的删除)
- [2.3 堆排序](#2.3 堆排序)
- [2.4 堆的创建](#2.4 堆的创建)
- [2.5 建堆的时间复杂度](#2.5 建堆的时间复杂度)
- [2.6 TOP-K问题](#2.6 TOP-K问题)

1. 堆的概念及结构
堆,本质上是一棵用数组存储的完全二叉树,并且满足特定的顺序规则。你可以把它理解成一个有"等级制度"的组织结构:最大的(或最小的)总是在最顶层。
根据规则不同,堆分为两种:
- 大堆:任何一个父结点的值,都大于或等于它左右孩子的值。所以,根结点是整个堆中的最大值。
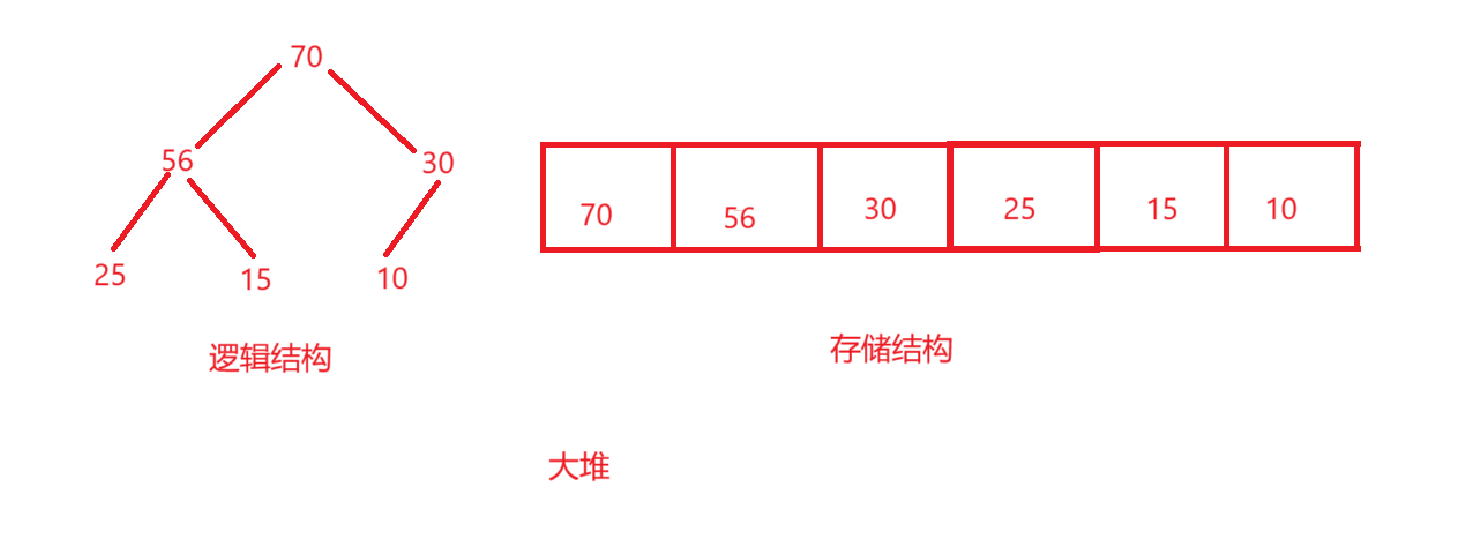
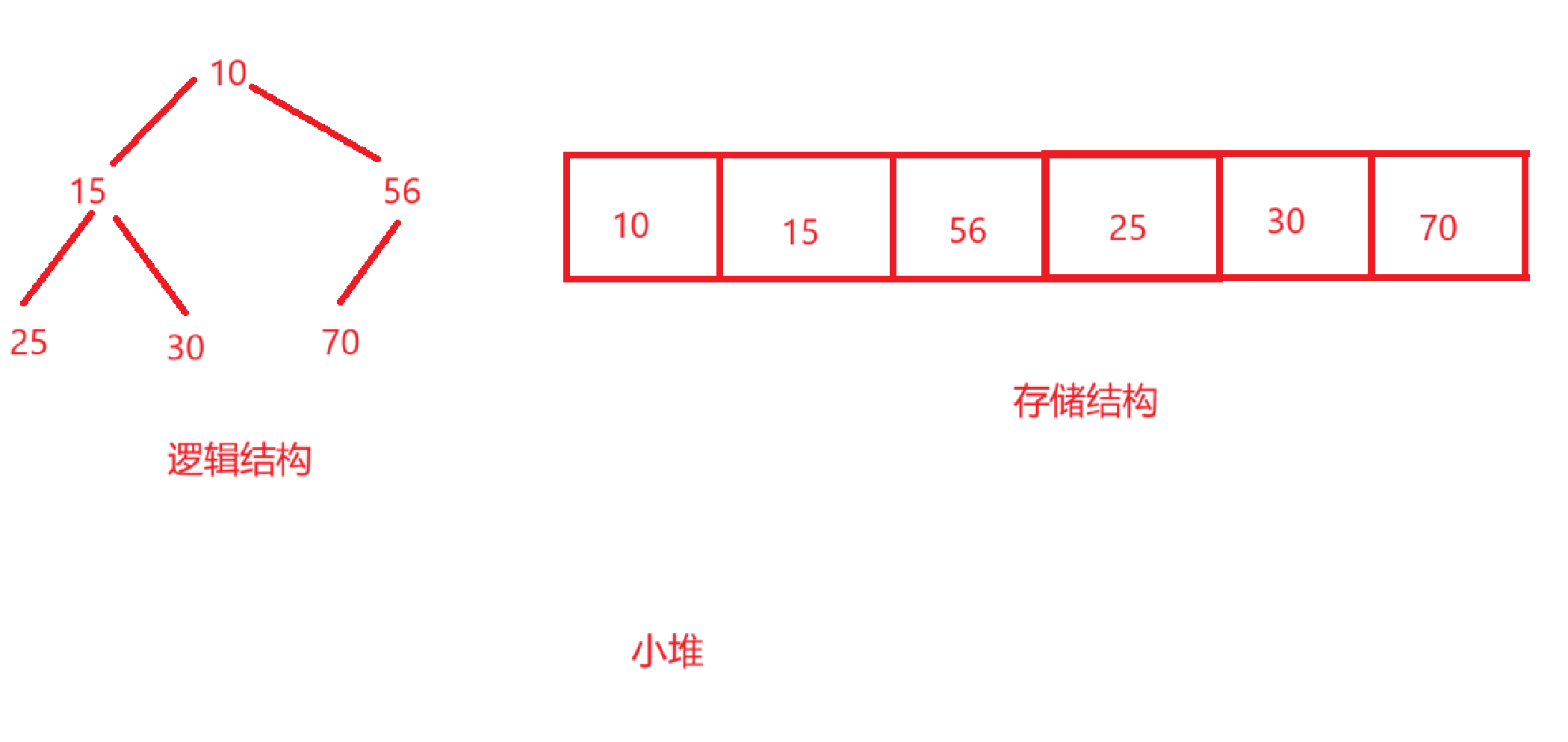
- 小堆:任何一个父结点的值,都小于或等于它左右孩子的值。所以,根结点是整个堆中的最小值
堆的核心价值:极速获取最值
有了这种结构,获取最大值(大堆)或最小值(小堆)的操作是 O(1) 的,也就是直接取数组第0个元素,非常快。这恰好解决了优先级队列的核心需求:总能快速取出优先级最高的元素。
2. 堆的实现及应用
堆的结构以及需要实现的功能:
c
//堆的实现
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size; //当前堆中有效元素的个数
int capacity; //数组的最大容量
}HP;
// 堆的构建
void HPInit(HP* php);
// 堆的销毁
void HPDestory(HP* php);
// 堆的插入
void HPPush(HP* php, HPDataType x);
// 堆的删除
void HPPop(HP* php);
//向下调整
void AdjustDown(HPDataType* a, int n, int parent);
//向上调整
void AdjustUp(HPDataType* a, int child);
//交换逻辑
void Swap(HPDataType* p1, HPDataType* p2);
// 取堆顶的数据
HPDataType HPTop(HP* php);
// 堆的判空
bool HPEmpty(HP* php);2.1 堆的插入
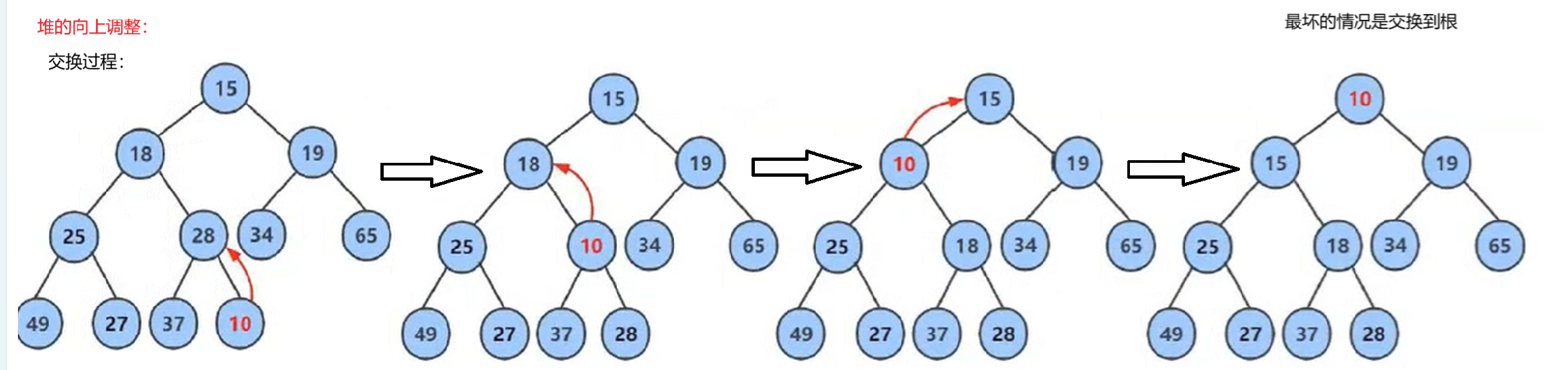
1. 先将元素插入到堆的末尾,即最后一个孩子之后,插入之后如果堆的性质遭到破坏,将新插入节点顺着其双亲往上调整到合适位置即可(向上调整算法)。
例子:
int arr = {15,18,19,25,28,34,65,49,27,37};
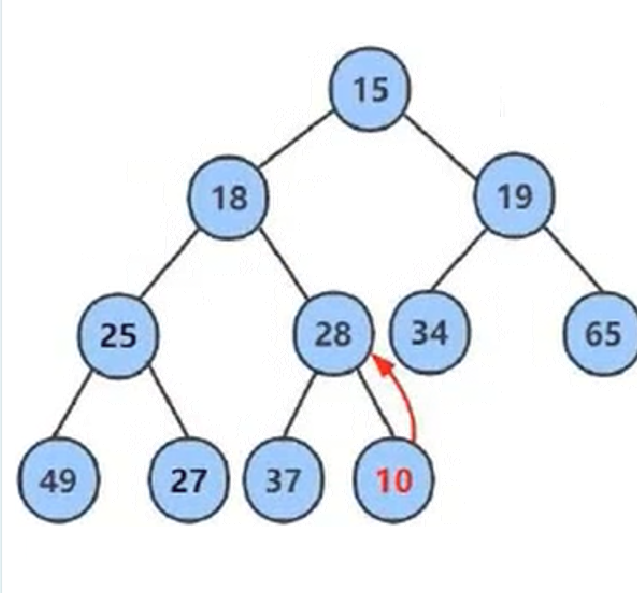
插入的数据需要和他的祖先进行比较(从当前节点到根节点都是他的祖先)不符合小堆的特性(任何一个父节点的值<=他左右孩子的值) 就向上调整 。
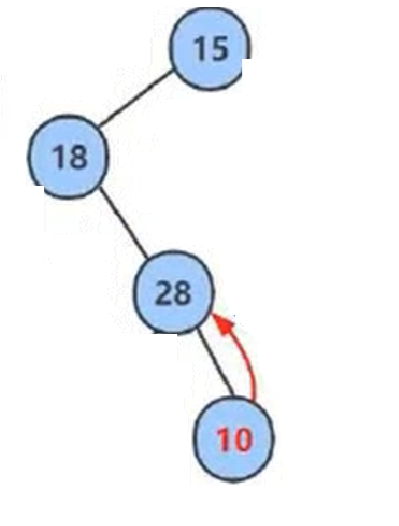
看一下代码:
c
// 堆的插入
void HPPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)//空间不够就扩容
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->a, newcapacity * sizeof(HPDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
php->a = tmp;
php->capacity = newcapacity;
}
//插入数据:插在最后一个叶子的旁边
php->a[php->size] = x;
php->size++;
AdjustUp(php->a, php->size - 1);//从新数据插入的位置开始调整(size - 1处)
}2. 向上调整算法
看一下代码:
c
//向上调整算法
void AdjustUp(HPDataType* a, int child)
{
//计算当前孩子节点的父节点下标
int parent = (child - 1) / 2;
//循环调整:child > 0 说明不是根节点,还有父节点可以调整
while (child > 0)
{
//小根堆规则:如果孩子 < 父节点 → 违反规则,需要交换
if (a[child] < a[parent])
{
//小堆向上调整:比父亲小就向上
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
//父亲小于等于孩子不做调整
break;
}
}
}
//交换逻辑
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}2.2 堆的删除
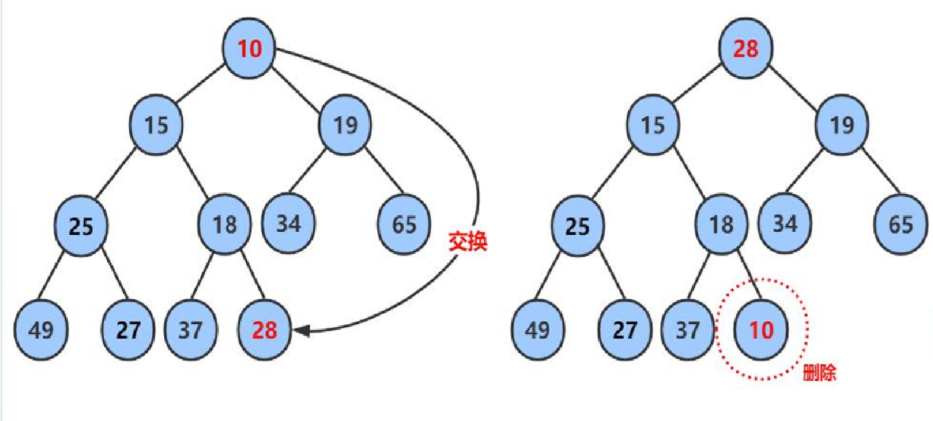
删除堆是删除堆顶的数据,将堆顶的数据和最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法,需要注意的是直接删除最后一个数据是更方便但是没有意义,根据堆的定义堆顶的数据是最大 / 最小值 ,这样操作可以方便我们去使用堆排序以及解决TOP-K问题,具体的我们下文见分晓。
1. 将堆顶元素与堆中最后一个元素进行交换然后删除堆中最后一个元素。
代码:
c
// 堆的删除:要求删除堆顶的数据(根位置)
void HPPop(HP* php)
{
assert(php);
assert(php->size > 0);
//先让堆顶数据和堆的最后一个数据交换位置
Swap(&php->a[0], &php->a[php->size - 1]);
//删除堆顶数据
php->size--;
//向下调整
AdjustDown(php->a, php->size, 0);
}2. 向下调整算法
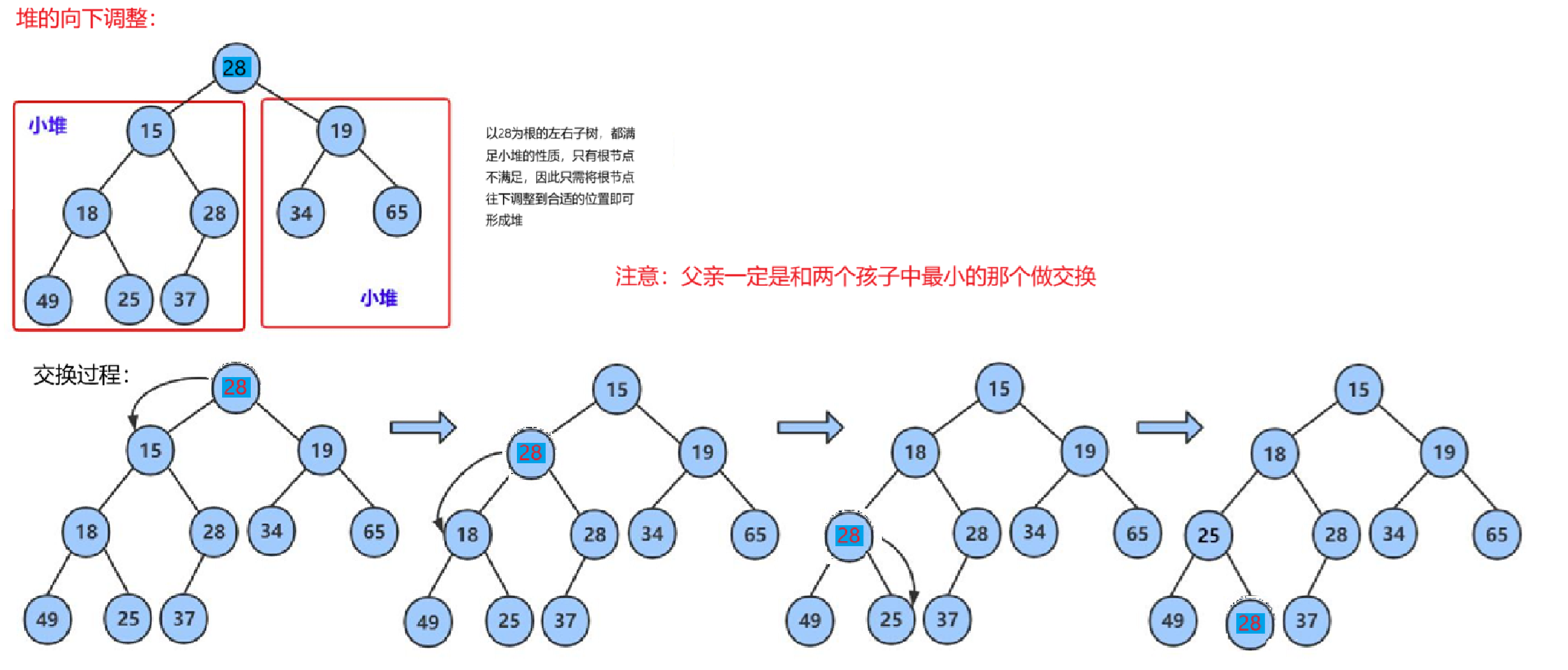
代码:
c
//向下调整
void AdjustDown(HPDataType* a, int n, int parent)
{
//利用假设法
int child = parent * 2 + 1;//假设左孩子小
while (child < n)//child >= n 说明孩子不存在,调整到叶子了调整结束
{
//选更小的孩子:
// 条件1:右孩子存在 (child+1 < n) → 防止越界访问
// 条件2:右孩子 < 左孩子 → 切换为右孩子
if (child + 1 < n && a[child + 1] < a[child])
{
++child;//最终child指向左右孩子中更小的那个
}
//如果孩子比父节点小违反小根堆规则,交换
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
//父节点已经比孩子小符合小根堆,直接结束调整
break;
}
}
}在这两种调整算法中,其实呢向下调整算法的效率更优,下文会给出详细解答。
2.3 堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
1. 建堆:
- 升序:建大堆
- 降序:建小堆
2. 利用堆删除思想来进行排序:建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
3. 常见疑问:
- 为什么升序反而要用大堆?
这是堆排序最反直觉的地方。按常理想,升序应该先找最小的,那不是用小顶堆更直接吗?
可以这样想:堆排序的本质是"原地排序,不额外开辟数组"。
如果用小顶堆,堆顶确实是最小值,把它存下来后,剩下的元素要重新建成新的小顶堆。但数组空出来的位置在末尾,这操作起来很别扭,也破坏效率。
而用大顶堆,堆顶是最大值,把它直接放到数组末尾(与最后一个元素交换),这个最大值就"退休"不动了。剩下的元素调整一下,又是个新的大顶堆,继续把最大值拿出来放在倒数第二的位置。这样一路下来,最大值从后往前依次就位,升序自然就排好了。
核心思想就是"请走最大的,留下空间给后面",空间复杂度O(1)是堆排序的精华,也是它选择大顶堆做升序的根本原因。
- 为什么降序要建小堆:
堆排序的核心是原地排序,不额外开辟数组,通过反复"交换堆顶与末尾元素+向下调整"来逐步完成排序。
如果你建的是小顶堆,那么堆顶是整个堆中的最小值。
第一步:把堆顶(最小值)和数组最后一个元素交换位置。
于是,数组的最后一个位置就变成了当前的最小值,这恰好是降序数组的最终位置(降序时最小的应该在最后)。
然后,忽略掉这个已经就位的末尾元素,对剩余部分从根开始做一次向下调整,让它重新恢复成一个小顶堆。
此时,堆顶又是剩余元素中的最小值。把它和倒数第二个位置交换...以此类推。
最终,最小值、次小值...会依次被"沉"到数组的末端,而数组的前端自然就留下了较大的值,整个数组呈现降序。
例子:int arr = {20,17,4,16,5,3}; 要求将其排为升序
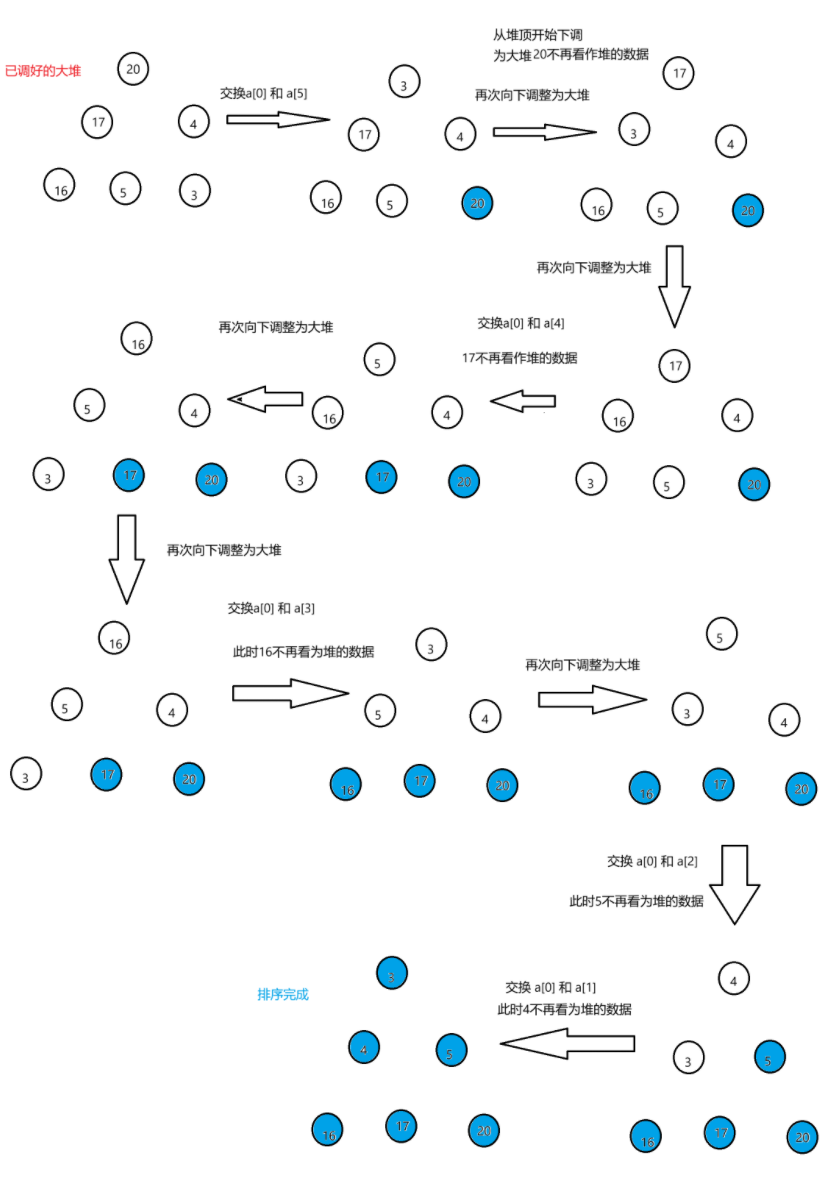
向上调整建堆算法:
c
//堆排序
void HeapSort(int* a, int n)
{
// 对数组进行建堆:
// 升序:建大堆
// 降序:建小堆
//下标1开始向上调整的方式建堆。
/*
AdjustUp 内部如果是"孩子大于父亲才上浮",建成的就是大堆;
如果是"孩子小于父亲才上浮",建成的就是小堆
*/
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}
/*
每次将堆顶元素(当前堆中的最值)与 end 位置交换,这样最值就被放到了数组的正确位置(末尾)。
然后对 [0, end-1] 范围从根开始做一次向下调整,让剩下的元素重新满足堆的性质。
end 逐步前移,最终整个数组有序。
*/
int end = n - 1;
while(end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}2.4 堆的创建
1. 向上调整建堆
在上面的代码中我们运用的建堆方法是向上调整建堆
向上调整建堆:模拟"逐个插入"的过程。一开始数组为空或只有一个元素(天然成堆),然后依次把后面的元素看作新插入的结点,对它执行向上调整,直到所有元素都进入堆中。
c
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}下标1到n-1,每次新加入一个元素a[i。AdjustUp会让它沿着父结点路径往上比较、交换。当遍
历完所有元素,整个数组就是一个合法的堆。
时间复杂度:O(NlogN)
每个结点向上调整的最坏次数,等于它到根结点的距离(深度)。约一半的结点在底层,深度接近logN总操作次数是各结点深度之和,量级为NlogN。
2. 向下调整建堆
思路:自底向上,先把较小的子树调成堆,再逐步向上合并成大堆。核心前提是:对某个结点做向下调整时,它的左右子树必须已经是堆。
c
//向下调整建堆
for (int i = (n - 2) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}(n-2)/2是最后一个非叶子结点的下标(完全二叉树中,最后一个叶子n-1的父结点)。从它开始从后往前遍历,每个结点都做一次向下调整。因为是从底部往上处理,处理某个结点时,它的孩子结点已经先被处理过,这就保证了左右子树已经成堆,满足了AdjustDown的前提。
向下调整的代价取决于结点的高度(需要下沉的距离)。底层结点数量多,但高度小(叶子高度为0,调整代价几乎为0);高层结点数量少,调整代价大。总和恰好是O(N)。精确推导:完全二叉树各结点高度之和为N-log2(N+1),所以总操作次数与N同阶。
一个例子:使用向下调整建堆为大堆
int a = {1,5,3,8,7,6};
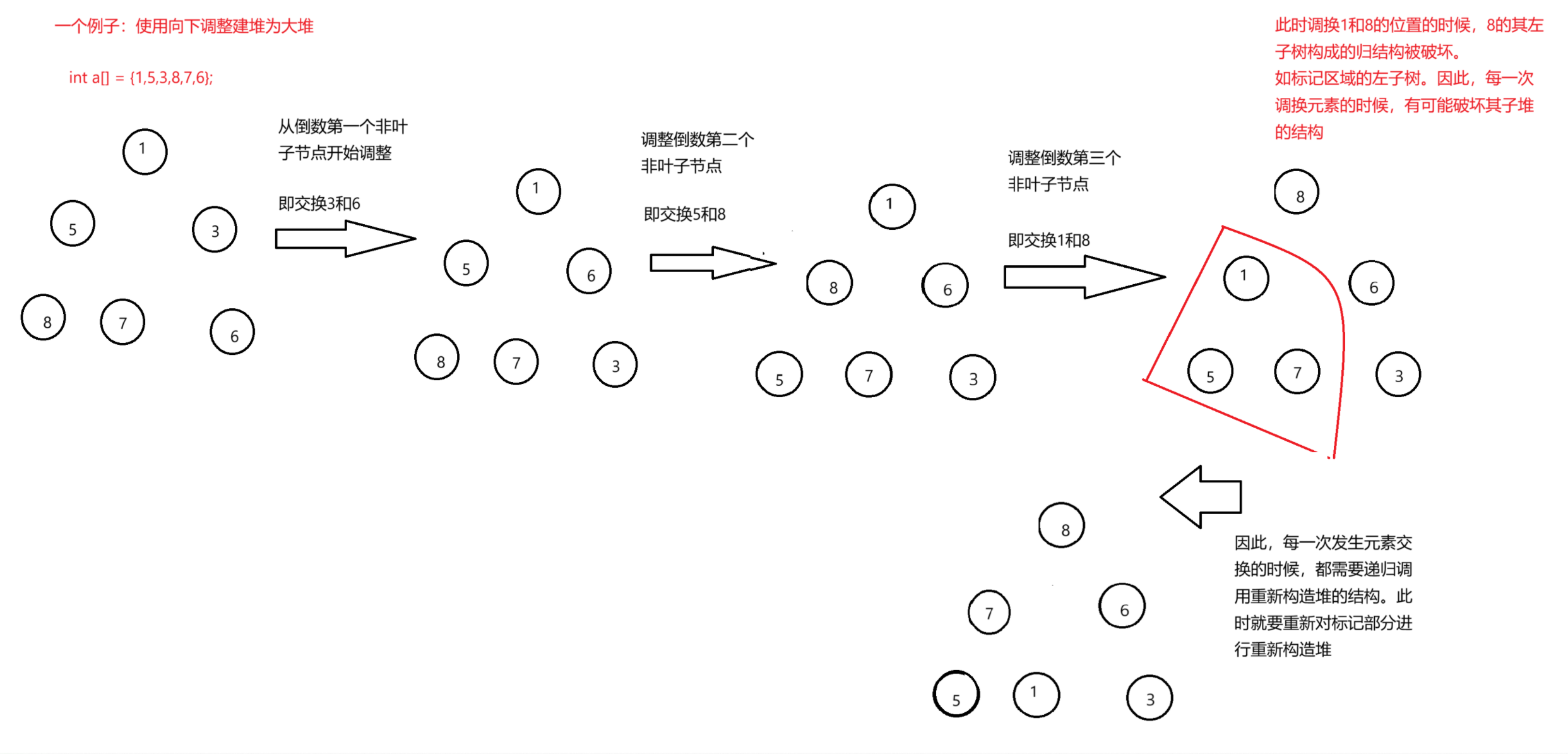
2.5 建堆的时间复杂度
向下调整建堆:
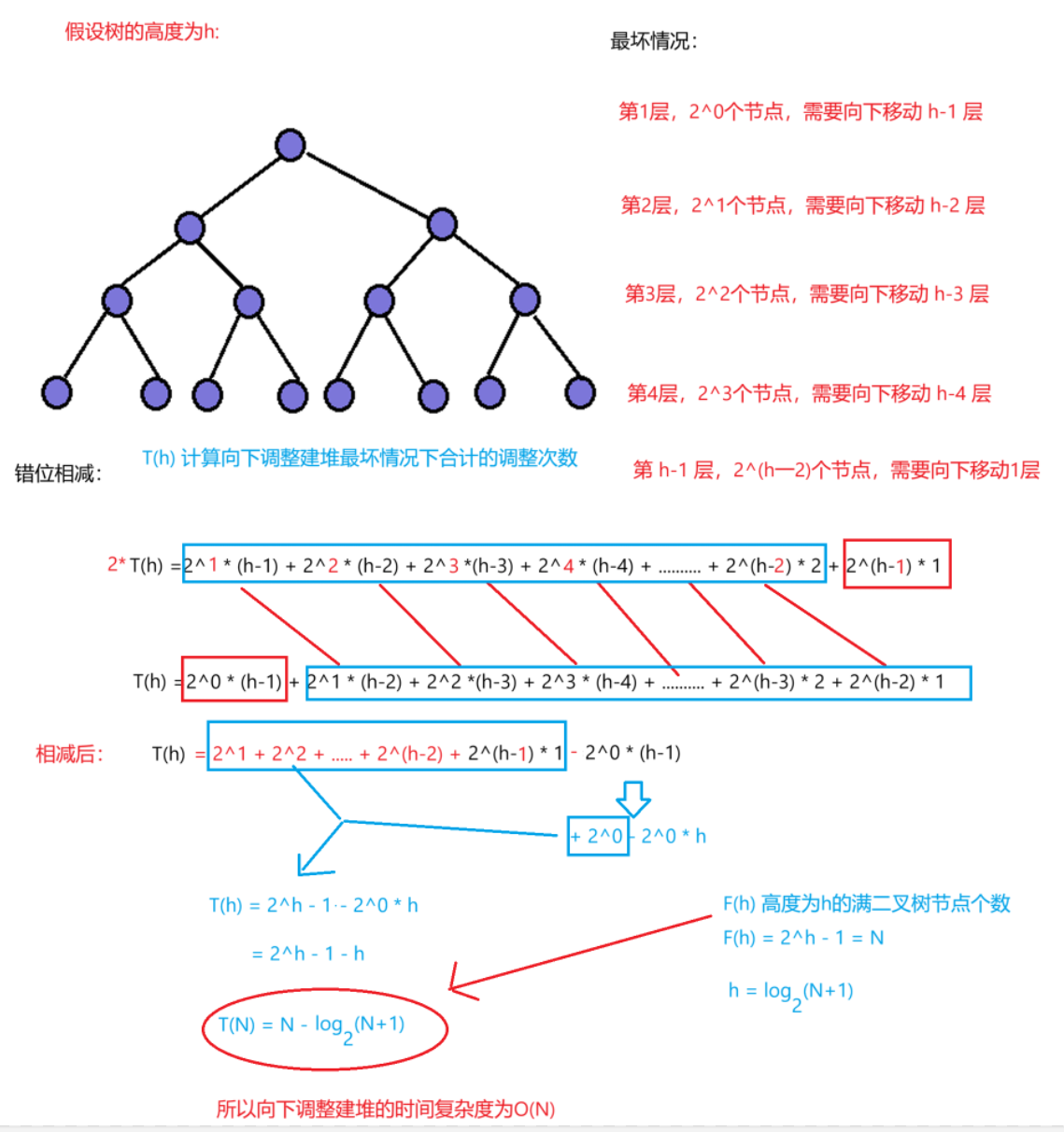
总结:因为大部分结点在底层,向下调整的代价取决于高度,叶子结点高度为0不调整,越往上结点越少,所以总代价与N同阶
比喻一下:给每个结点"记账"
假设我们要用向下调整建一个大顶堆,我们把每个结点需要"下沉"的层数,想象成它要支付的"成本"。
- 第一笔账:叶子结点
叶子结点没有孩子,它们根本不需要下沉。成本为0。而一棵完全二叉树中,超过一半的结点都是叶子。这意味着,建堆时超过一半的数据,是完全免费的。
- 第二笔账:倒数第二层
这一层的结点最多只下沉1层。成本最多为1。结点数量大概占总数的1/4。
- 第三笔账:越往上越贵,但顾客也越少
只有极少数的结点(靠近根的),才需要下沉很多层。成本虽高,但需要支付这笔昂贵成本的结点数量屈指可数。
把账本汇总:
总成本=(数量庞大的叶子×0)+(数量次多的倒数第二层×1)+...+(数量极少的根×最大高度)账本结构极其失衡------少数人付高额账单,多数人付零头或免单
这个总成本,显然会比"每个结点都交logN的钱"少得多得多。它最终是和一个常数倍的N成正比的,也就是O(N)。
而向上调整建堆和向下建堆刚好反过来,账本收支逻辑完全颠倒:
- 第一笔账:顶层根节点
第一个放入的根节点,没有父节点,不需要向上爬升。成本直接为 0,只有 1 个节点,几乎不花钱。
- 第二笔账:上层少数节点
第二层、第三层的节点,离树根很近。
就算需要调整,最多往上爬 1~2 层,单笔成本很低。这类高价层位的顾客数量很少,整体花费占比不大。
- 第三笔账:越往下,成本越贵、顾客越多
树的下半部分、底层叶子区域,聚集了绝大多数节点(占总数一半以上)。这些节点距离根节点最远,一旦不符合堆规则,最坏要一路爬到树根。单个节点最高要付出 log 2 n 的高额成本,而且花钱的节点数量极其庞大
总成本 = 少量上层节点 × 低成本 + 中层节点 × 中等成本 + 海量底层节点 × 高额爬升成本

总结:
向下调整建堆
只有身居顶层的少数 "高层节点",需要承担下沉多层的高额成本;占总数大半的底层普通节点完全无需消耗,相当于免税;中间层级也只承担少量开销。极少数个体承担高额支出,绝大多数零成本,整体总开销偏低,复杂度 O(N)。
向上调整建堆:
绝大部分都是底层节点,人群基数极其庞大;偏偏位置越靠下,向上调整付出的代价越高,相当于底层税负最重;顶层少数节点几乎没有开销。海量个体都要承担高额成本,费用叠加后总额大幅攀升,复杂度 O(NlogN)。
2.6 TOP-K问题
即求数据中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
为什么"找最大的K个"要建小堆?
这是整个算法最反直觉、也最关键的一点。
我们举例:
例子:假设要从3,7,1,9,2,5中找出最大的前3个。

解释一下我们的核心思路:
维护一个大小为K的"候选池"
想象你有一个只能容纳K个人的房间(堆)。你的目标是:从外面不断涌入的人流中,筛选出最厉害的K个人,留在房间里。
这个房间有一个规则:
房间里永远站着这K个人里最弱的那一个(堆顶)。
每来一个新的人,只需要和房间里最弱的那个人比一比:
如果新人比最弱的还弱,直接让他走人,对房间没影响。
如果新人比最弱的强,那就把最弱的踢出去,让新人进来,然后房间再重新选出新的"最弱守门员"。
结论:
-
找最大的 K 个:维护小顶堆。堆顶是候选区里最小的,也就是"淘汰线"。只有比这条线高的数,才有资格挤进来,把旧的淘汰线踢出去。
-
找最小的 K 个:维护大顶堆。堆顶是候选区里最大的,也是"淘汰线"。只有比这条线低的数,才有资格挤进来,把旧的淘汰线踢出去。
总结:Top-K用堆,是一种以空间换时间,并且能应对海量数据的经典策略。核心是:维护一个大小为K的候选池,用堆顶作为淘汰门槛。把找最大用"小顶堆守门",找最小用"大顶堆守门"
TOK-K问题的时间复杂度:
初始建堆:O(K)
遍历N-K个元素,每个元素最坏执行一次向下调整O(logK)
总时间约 O(K + (N-K) log K) ≈ O(N log K)
当K很小(如K=10,N=10亿)时,logK几乎就是常数,效率极高。
至此呢堆部分的讲解就告一段落了,下一节我们将继续学习二叉树的链式结构的实现以及二叉树的前序中序后序层序遍历方法。

保持好奇,我们下次见!!!