大模型分布式训练:把"大象"装进冰箱的终极指南
随着大模型(如 GPT 系列)参数量的爆炸性增长,其训练所需的显存也呈指数级飙升 。面对动辄千亿、万亿参数的"巨兽",最现实的物理阻碍就是:单块显卡根本装不下整个模型 。
为了把这头"大象"装进冰箱,工程师们发明了分布式训练技术。整体的演进路线就像是一场不断打破物理极限的闯关游戏:
-
数据并行 (Data Parallelism, DP): 显卡勉强装得下模型,所以我们多买几台机器,每台机器复制一份完整的模型,大家分摊不同的数据,齐头并进加速训练 。
-
管线并行 (Pipeline Parallelism, PP): 模型太大,单卡彻底装不下了。但好在一台设备还能勉强装下模型的"某几层"。于是我们把模型像工厂流水线一样"按层斩断",分别放到不同的机器上接力计算 。
-
张量并行 (Tensor Parallelism, TP): 模型膨胀到连"单独一层"都塞不进一张显卡了。我们只能拿起手术刀,深入神经网络的内部,把庞大的矩阵运算拆碎到多张卡上协同计算 。
除此之外,还有针对长文本的序列并行 和针对 MoE 架构的专家并行。下面,我们将逐一揭开它们的神秘面纱。
7.1 Data Parallelism:数据并行
数据并行是最直观、最古老的并行方式。它的核心分为传统的 Parameter Server 架构和目前主流的 DDP(分布式数据并行)。
Parameter Server 架构 (传统 DP)
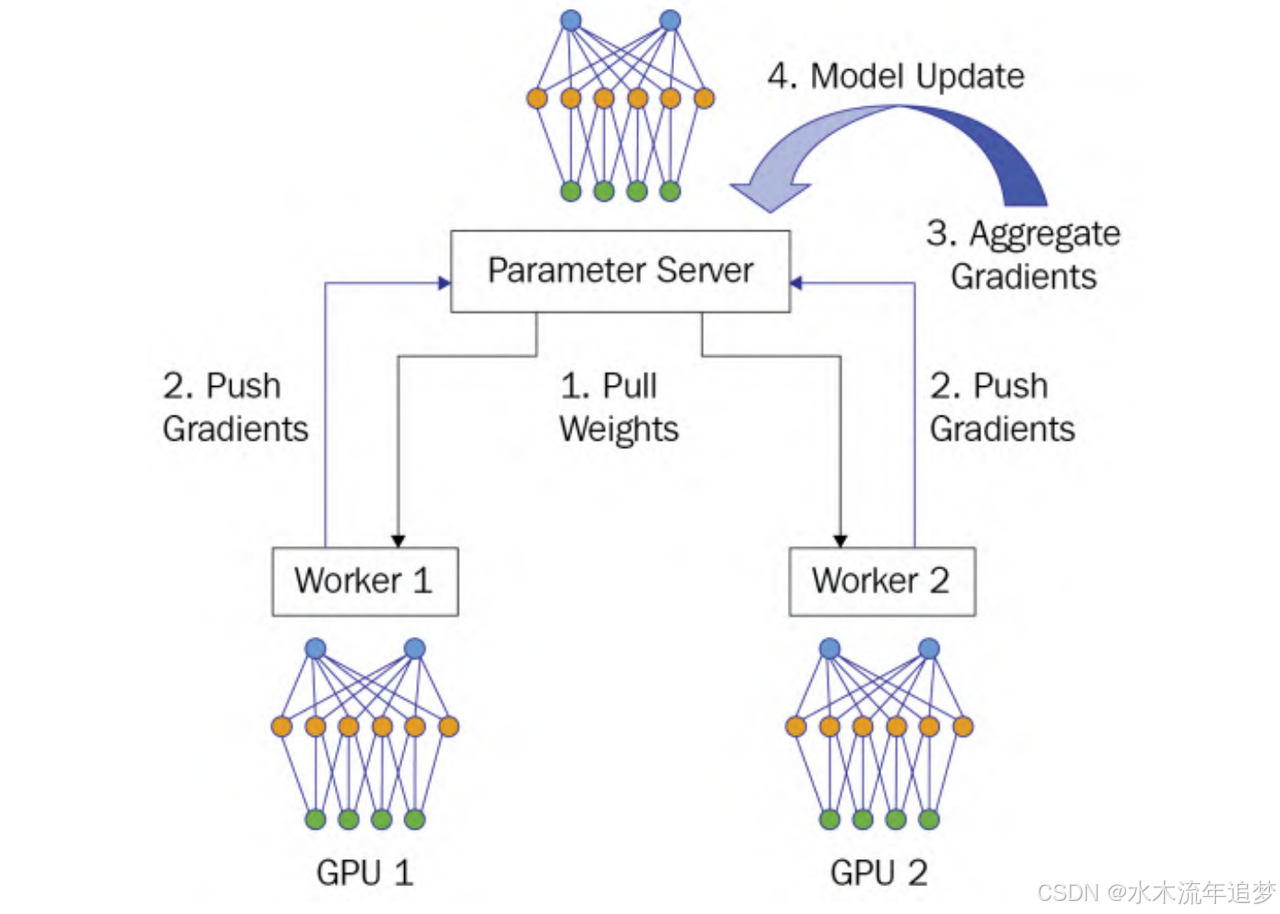
这是最早的数据并行模式,通常用于单机多卡的场景 。它引入了两种角色:"老板"(Parameter Server,参数服务器)和"打工人"(Worker 计算节点)。老板手里拿着最新的模型参数,打工人只负责埋头干活。
整个工作流程分为 4 步:
-
Pull Weights(拉取权重): 所有打工人向老板要最新版本的模型参数 。
-
Push Gradients(推送梯度): 打工人用自己分到的数据努力训练,算出误差(梯度)后,上报给老板 。
-
Aggregate Gradients(汇总梯度): 老板收齐所有打工人的汇报后,把大家的梯度加在一起汇总 。
-
Model Update(更新模型): 老板用汇总后的总梯度,更新自己手里的模型参数 。
致命痛点:老板太累了(通信瓶颈)
在分发任务时,老板要一对多发送(Fan-out);在汇报工作时,所有打工人同时向老板发数据(Fan-in)。无论网络多快,参数服务器那一端的带宽总是会被瞬间挤爆,成为整个系统的绝对瓶颈 。
Ring-AllReduce 架构 (DDP 分布式数据并行)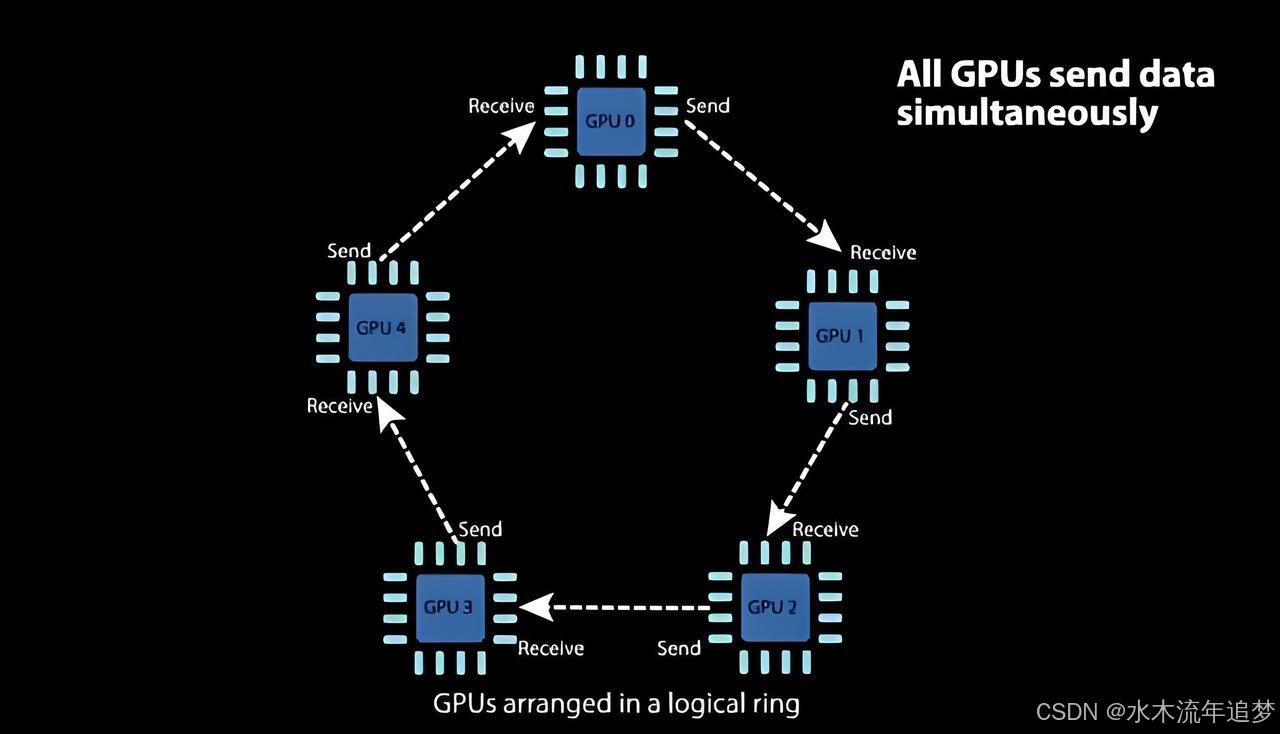
为了解决"老板过劳死"的问题,DDP 采用了一种极其聪明的无中心架构------Ring-AllReduce(逻辑环)。这里没有老板,所有的 GPU 首尾相连围成一个圆圈 。
假设有 4 块 GPU,我们将数据切成 4 块。它主要分两大招式:
-
Scatter-Reduce(分散-规约): 每个 GPU 只和它右手边的兄弟偷偷传纸条 。每次传递对应位置的数据并进行梯度累加。经过 3 轮击鼓传花后,每块 GPU 上都有一块数据完美融合了所有人的梯度 。
-
All-Gather(全收集): 现在大家手里都有 1/4 的"最终真理"。接下来再来 3 轮击鼓传花,把这 1/4 的真理原封不动地抄送给其他人 。
总结: 虽然 DP 和 DDP 搬运的数据总量一模一样,但 DDP 巧妙地把通信压力完美均摊到了圆环上的每一个节点上,彻底消除了瓶颈,使得跨机器的扩展变得极其高效 。
7.2 Pipeline Parallelism:管线并行 (流水线并行)
当单卡装不下模型时,我们把网络层像切蛋糕一样切开,放进多张卡。但简单的串行接力会导致严重的"消极怠工"问题。
痛点:可怕的 Bubble (气泡)
如果 GPU 0 在算第一层,算完后传给 GPU 1 算第二层。那么在 GPU 1 苦苦等待数据传过来的时间里,它是完全闲置的。这种机器空闲的时间,我们称之为 Bubble(气泡) 。模型越大,GPU 数量越多,气泡占用的时间就越恐怖,算力全被浪费在等待上了 。
GPipe:把任务切得更碎
GPipe 的解法是:化整为零。它把原先的一大包数据(mini-batch)进一步切碎成极小的 micro-batch 。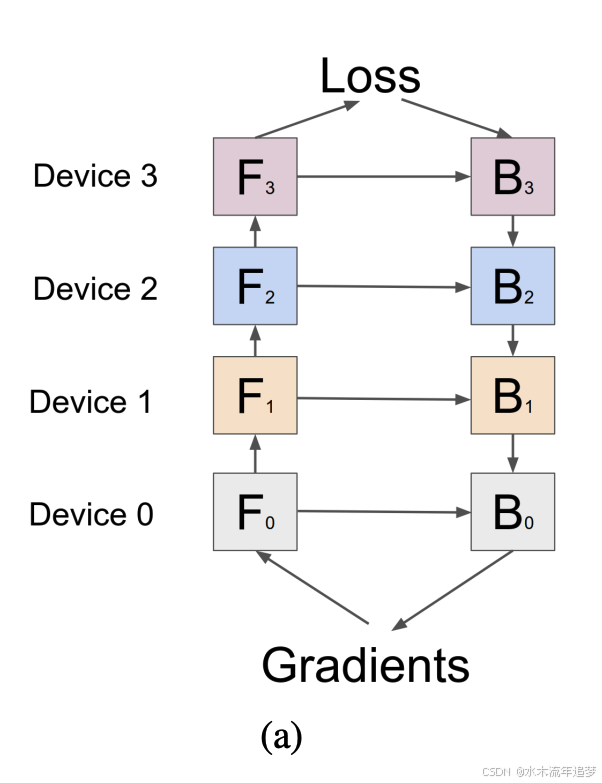
既然每次只算一点点,GPU 0 瞬间就能算完并扔给 GPU 1,然后立马接着算下一小块 。只要切分得足够细(划分的块数 M≥4KM \ge 4KM≥4K,K为机器数),大家接力运转起来后,气泡产生的影响就微乎其微了 。
- 显存危机与主动重算: 管线并行的反向传播需要保留前向的中间激活值,极其吃显存 。GPipe 采用了一种"用时间换空间"的狠招------Re-materialization (Active Checkpoint) 。每块 GPU 只记下一个极小的锚点输入 zzz,其余中间结果全丢掉。等反向传播真的需要时,再拿 zzz 临时重新算一遍 。
PipeDream:1F1B 永不停歇的机器
GPipe 必须等所有前向计算(Forward)全跑完,才肯统一进行反向计算(Backward)。
PipeDream 则提出了更激进的 1F1B(1次 Forward,1次 Backward) 调度策略 。只要前向传完一个小块,立刻回头做反向,让正反向交替执行,彻底榨干 GPU 的每一秒空闲 。
- 解决参数错乱: 一边算前向一边算后向,会导致使用的权重版本发生错乱 。PipeDream 通过 Weight Stashing(权重暂存) 解决:前向计算时用哪版权重算出来的,就用哪版权重去做对应的反向计算,绝不串台 。
7.3 Tensor Parallelism:张量并行
当模型的一层网络也塞不进单卡时,英伟达的 Megatron-LM 站了出来,它选择将 Transformer 内部庞大的矩阵运算直接撕裂 。
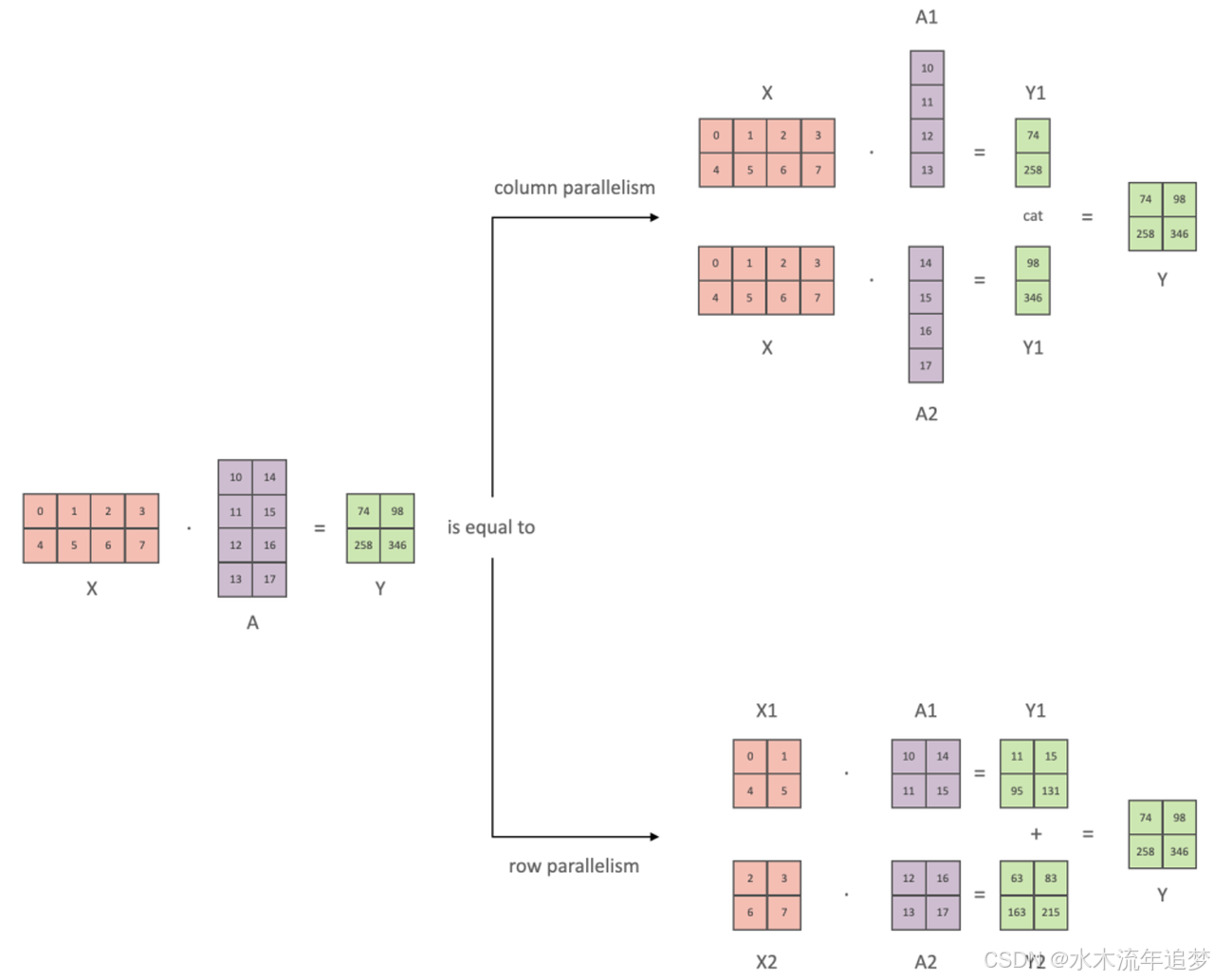
MLP 层如何劈开?
在 MLP 层有两次矩阵乘法,我们可以把大矩阵 AAA 按列切割 ,把矩阵 BBB 按行切割 。
- 为什么 AAA 必须列切?因为 AAA 算完后要过一个非线性激活函数 GeLU。如果你按行切,大家算出的结果必须经过耗时的 AllReduce 通信拼接后,才能去算 GeLU,代价太大 。按列切,大家各算各的 GeLU,互不干涉,完美独立 。
MHA (多头注意力) 层如何劈开?
思路雷同:对注意力机制的核心矩阵 Q,K,VQ, K, VQ,K,V 进行列切割 ,对输出的线性层 BBB 进行行切割 。在实际设计时,我们通常保证 Attention 的 Head(头)总数能被 GPU 的个数整除,这样每块卡正好均分几个 Head,大家各自安好,并行计算 。
在一个 Transformer 层的正反向走一圈,TP 一共只需要产生 4 次 All-Reduce 极速通信 。
bash
print('hello')