从零开始理解 CNN(下):拆开卷积层、池化层、通道数和训练流程

🔥 星恒随风: 个人主页 ❄️ 个人专栏: 《指针合集》 | 《C语言基础》 | 《数据结构》 | 《机器学习导论》 | 《前端基础》 ✨ 数据即知识,压缩即智能
写在前面:
上篇我们讲了 CNN 为什么适合处理图像。简单来说,CNN 通过 局部连接、参数共享和层次化特征提取 更自然地利用了图像的空间结构。
这一篇我们继续深入,把一个基础 CNN 拆开来看。
目录
- [从零开始理解 CNN(下):拆开卷积层、池化层、通道数和训练流程](#从零开始理解 CNN(下):拆开卷积层、池化层、通道数和训练流程)
-
- [一、基础 CNN 通常由模块组成](#一、基础 CNN 通常由模块组成)
- 二、卷积层:负责"找特征"
- 三、卷积层中的输入通道和输出通道
- 四、ReLU:负责"筛选有效响应"
- [五、如何生动理解 ReLU](#五、如何生动理解 ReLU)
- 六、池化层:负责"抓重点"
- 七、池化层有什么作用?
- 八、池化是不是必须的?
- [九、CNN 中几个重要参数](#九、CNN 中几个重要参数)
- 十、kernel_size:决定视野范围
- 十一、stride:每次走几步
- 十二、padding:给图片加边框
- 十三、channels:一张图不只有一个平面
- 十四、中间特征图的通道数是什么意思?
- 十五、特征图尺寸怎么算?
- [十六、一个基础 CNN 的结构长什么样?](#十六、一个基础 CNN 的结构长什么样?)
- [十七、基础 CNN 的数据形状怎么变化?](#十七、基础 CNN 的数据形状怎么变化?)
- [十八、CNN 的训练过程和 MLP 有什么区别?](#十八、CNN 的训练过程和 MLP 有什么区别?)
- 十九、一个极简训练流程
- [二十、CNN 最容易误解的几个点](#二十、CNN 最容易误解的几个点)
-
- 误解一:卷积核是人工设计好的
- 误解二:池化越多越好
- 误解三:通道数就是颜色数
- [误解四:CNN 只是在识别边缘](#误解四:CNN 只是在识别边缘)
- [二十一、CNN 在后续学习中的位置](#二十一、CNN 在后续学习中的位置)
- 二十二、下篇总结
一、基础 CNN 通常由模块组成
一个基础 CNN 一般包含以下模块:
输入图片
↓
卷积层提取局部特征
↓
ReLU 进行非线性筛选
↓
池化层压缩信息、保留重点
↓
多次重复
↓
全连接层整合特征
↓
输出类别
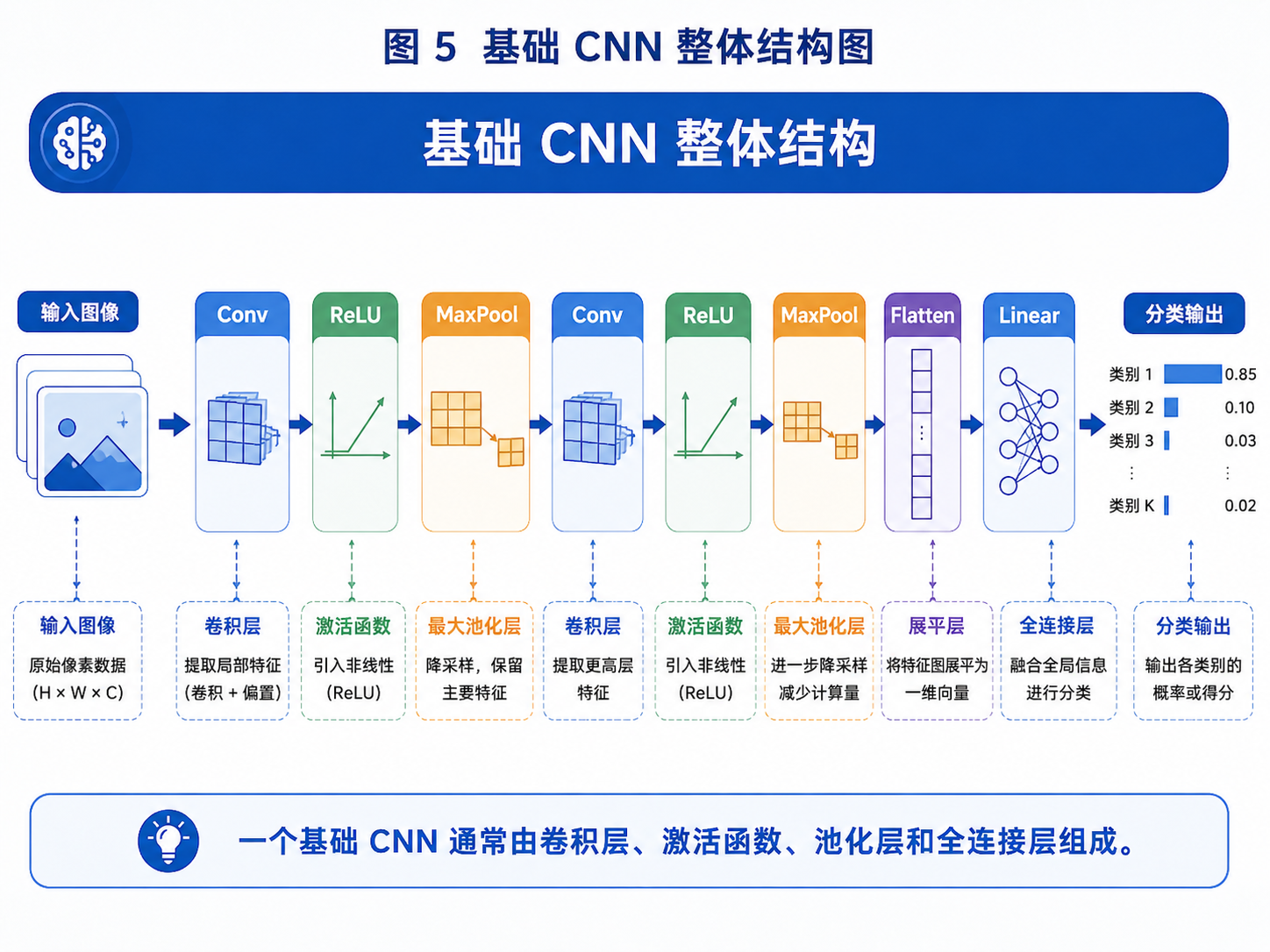
图 5:一个基础 CNN 通常由卷积层、激活函数、池化层和全连接层组成。
二、卷积层:负责"找特征"
卷积层是 CNN 的核心。
它的作用是:
从图像中提取局部特征。
输入可以是原始图片,也可以是上一层输出的特征图。
输出则是新的特征图。
例如输入是一张 RGB 图片:
text
3 × 224 × 224如果这一层有 32 个卷积核,输出可能是:
text
32 × 224 × 224这里的 32 表示什么?
它表示模型提取出了 32 种不同的特征响应图。
每一个输出通道,都可以理解为一种特征的检测结果。
三、卷积层中的输入通道和输出通道
很多初学者第一次看到下面这行代码会有点懵:
python
nn.Conv2d(3, 32, kernel_size=3, padding=1)它到底表示什么?
| 参数 | 含义 |
|---|---|
| 3 | 输入通道数。RGB 图片有 3 个通道 |
| 32 | 输出通道数,也就是卷积核个数 |
| kernel_size=3 | 卷积核大小是 3×3 |
| padding=1 | 在图像边缘补一圈 0 |
如果输入是 RGB 图片,那么输入通道数就是 3。
如果输出通道数是 32,就说明这一层会产生 32 张特征图。
四、ReLU:负责"筛选有效响应"
卷积层本身是一种线性操作。
如果只有卷积,没有激活函数,模型的表达能力会受到限制。
这里我们前文就已经介绍过了,不过多解释原因
所以卷积后通常会接一个激活函数。
最常见的是 ReLU。
ReLU 的形式非常简单:
ReLU(x) = max(0, x)
也就是说:
text
小于 0 的值变成 0;
大于 0 的值保留。五、如何生动理解 ReLU
可以把 ReLU 理解成一个筛选开关。
如果某个特征响应很明显,就让它通过。
如果某个特征响应很弱,甚至是负的,就把它压掉。
比如一个卷积核在寻找"边缘"。
在某些位置,它确实发现了边缘,响应值很高。
在另一些位置,它没有发现边缘,响应值很低。
ReLU 就会保留那些更有意义的正响应,把没用的负响应过滤掉。
六、池化层:负责"抓重点"
池化层最常见的是最大池化 Max Pooling。
例如一个 2×2 区域:
text
1 3
2 4经过最大池化后,只保留:
text
4它的思想非常直观:
在一个小区域里,只保留最强的特征响应。
七、池化层有什么作用?
池化层主要有三个作用:
| 作用 | 解释 |
|---|---|
| 减少特征图尺寸 | 让后续计算更轻量 |
| 降低计算量 | 减少需要处理的数据规模 |
| 保留局部最显著特征 | 保留最强响应,突出重点 |
可以把池化理解成"抓重点"。
人看一张图片时,也不会记住每个像素,而是会保留重要结构,比如说我们辨认一条狗不会去看它每一根毛发,而是看它的大致形状。
池化层也类似:它会压缩信息,同时保留强响应。
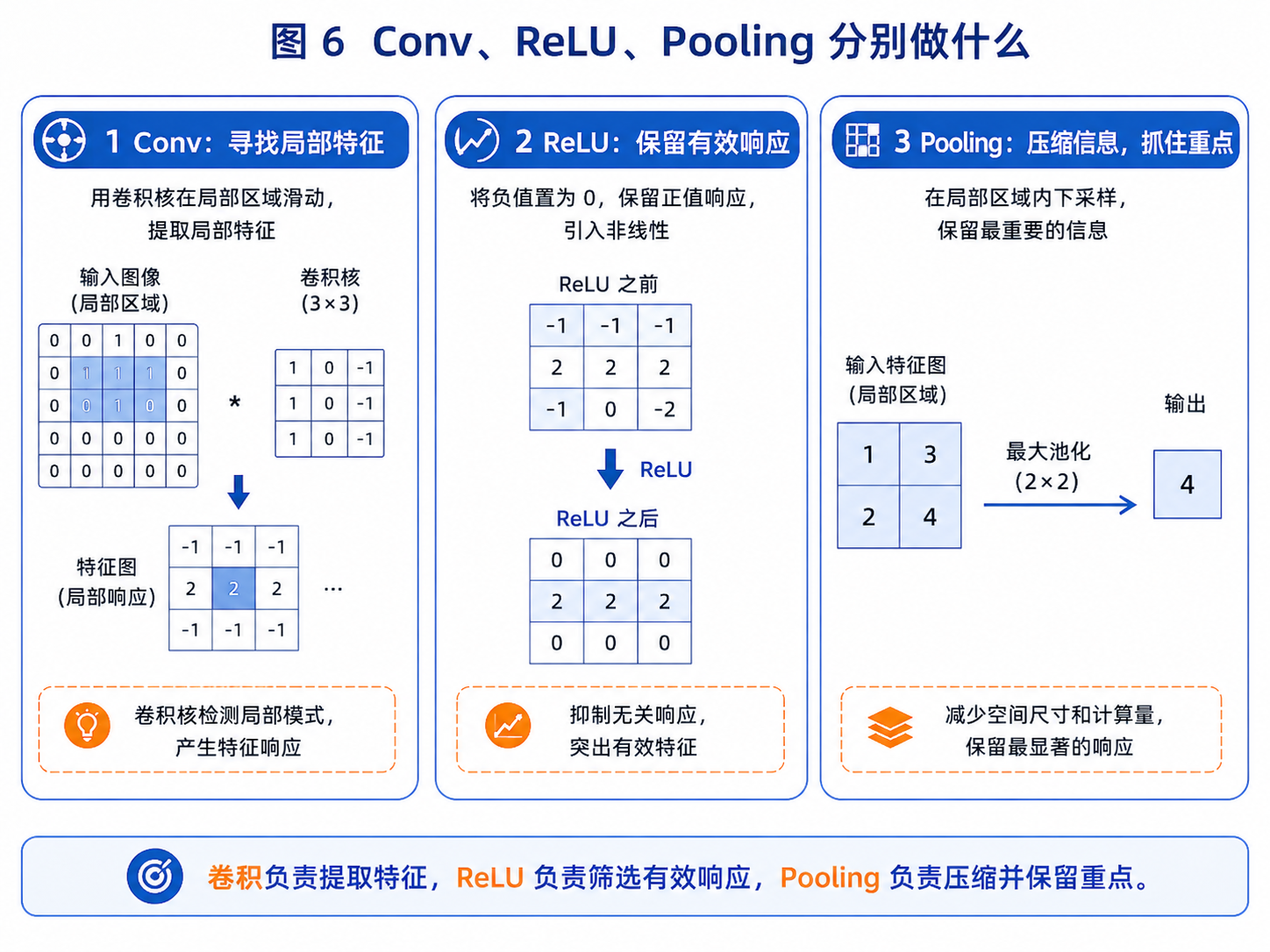
图 6:卷积负责提取特征,ReLU 负责筛选有效响应,Pooling 负责压缩并保留重点。
八、池化是不是必须的?
不是。
传统基础 CNN 中常用池化层,比如 LeNet、AlexNet 中都能看到卷积与池化的组合。
但现代 CNN 中,有时会用步幅卷积替代池化,也有一些任务会减少池化操作。
原因是:
池化虽然能减少计算量,但也会丢失空间细节。
比如目标检测和语义分割任务中,空间位置信息非常重要,过度池化可能影响定位效果。
所以对初学者来说,可以先理解:
池化是基础 CNN 中常见的降采样方式,但不是唯一方式。
九、CNN 中几个重要参数
学习 CNN,必须理解下面几个参数:
text
kernel_size
stride
padding
channels它们决定了卷积如何滑动、看多大范围、输出多大特征图。
十、kernel_size:决定视野范围
kernel_size 表示卷积核大小。
常见有:
text
3×3
5×5
7×7如果 kernel_size = 3,就表示每次看一个 3×3 的局部区域。
卷积核越大,一次看到的范围越大,但计算量也会增加。
现代 CNN 中,3×3 卷积非常常见。
因为它足够小、计算高效,而且可以通过多层堆叠扩大感受野。
十一、stride:每次走几步
stride 表示卷积核滑动的步长。
text
stride = 1:每次移动 1 格;
stride = 2:每次移动 2 格。stride 越大,输出特征图尺寸越小。
可以类比成扫描图片:
text
步子小,看得细;
步子大,看得快,但信息更粗。十二、padding:给图片加边框
如果不加 padding,卷积核在图像边缘不好滑动,输出特征图会变小。
padding 就是在图片周围补一圈像素,通常补 0。
它的作用包括:
text
保留边缘信息;
控制输出尺寸;
让卷积操作更稳定。常见设置是:
python
kernel_size = 3
stride = 1
padding = 1这样可以让输入和输出的高宽保持不变。
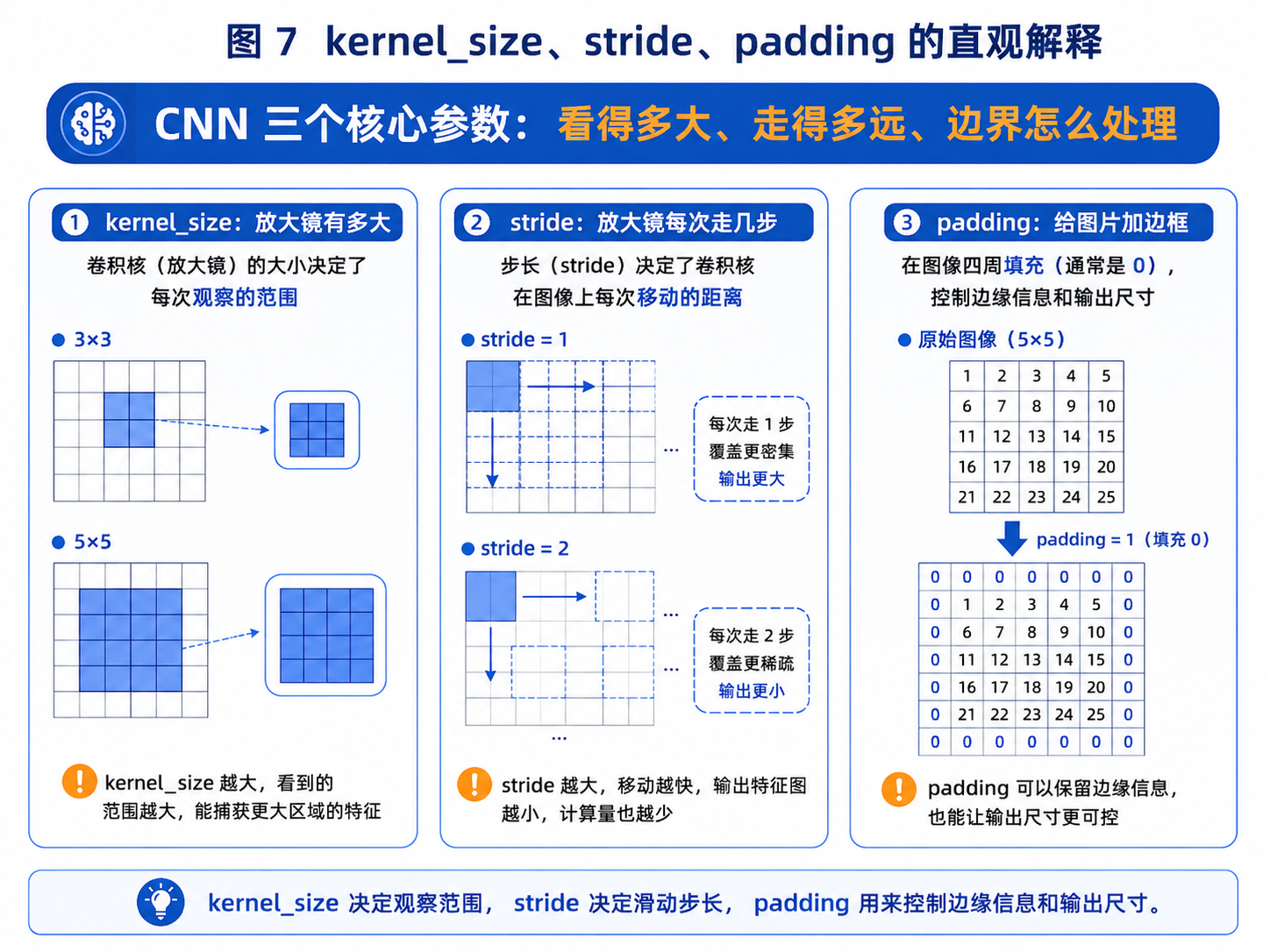
图 7:kernel_size 决定观察范围,stride 决定滑动步长,padding 用来控制边缘信息和输出尺寸。
十三、channels:一张图不只有一个平面
灰度图有 1 个通道。
RGB 彩色图有 3 个通道:
text
R
G
B所以一张 224×224 的 RGB 图片,在 PyTorch 中通常表示为:
text
3 × 224 × 224如果加上 batch 维度,则是:
text
N × C × H × W例如:
text
32 × 3 × 224 × 224表示:
text
32 张图片;
每张图片 3 个通道;
高和宽都是 224。十四、中间特征图的通道数是什么意思?
输入图片的 3 个通道是 RGB。
但是中间层的 32、64、128 个通道,已经不是颜色通道了。
它们是特征通道。
例如:
某个通道可能关注边缘;
某个通道可能关注纹理;
某个通道可能关注局部形状;
某个通道可能关注病斑区域。
所以 CNN 越往后,通道数通常会增加。
这可以理解为:
空间尺寸逐渐变小,但语义特征越来越丰富。
十五、特征图尺寸怎么算?
卷积输出尺寸的常见公式是:
H_out = floor((H_in + 2P - K) / S) + 1
其中:
| 符号 | 含义 |
|---|---|
| H_in | 输入高度 |
| P | padding |
| K | kernel size |
| S | stride |
| H_out | 输出高度 |
宽度同理。
举个例子。
输入尺寸是 224。
text
kernel_size = 3
padding = 1
stride = 1那么:
text
H_out = floor((224 + 2×1 - 3) / 1) + 1
H_out = 224所以输出尺寸不变。
如果 stride = 2:
text
H_out = floor((224 + 2×1 - 3) / 2) + 1
H_out = 112所以 stride = 2 会让特征图大约缩小一半。
十六、一个基础 CNN 的结构长什么样?
一个基础 CNN 可以写成这样的结构:
如果用 PyTorch 简单表示,核心结构大概是:
python
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)这里只是展示结构
更重要的是理解:
text
Conv 负责找特征;
ReLU 负责筛选有效响应;
Pool 负责压缩和抓重点。十七、基础 CNN 的数据形状怎么变化?
假设输入是:
text
3 × 224 × 224第一层卷积:
python
Conv2d(3, 32, kernel_size=3, padding=1)输出:
text
32 × 224 × 224经过 2×2 最大池化:
text
32 × 112 × 112第二层卷积:
python
Conv2d(32, 64, kernel_size=3, padding=1)输出:
text
64 × 112 × 112再经过 2×2 最大池化:
text
64 × 56 × 56最后 Flatten:
text
64 × 56 × 56变成一个长向量,再送入全连接层分类。
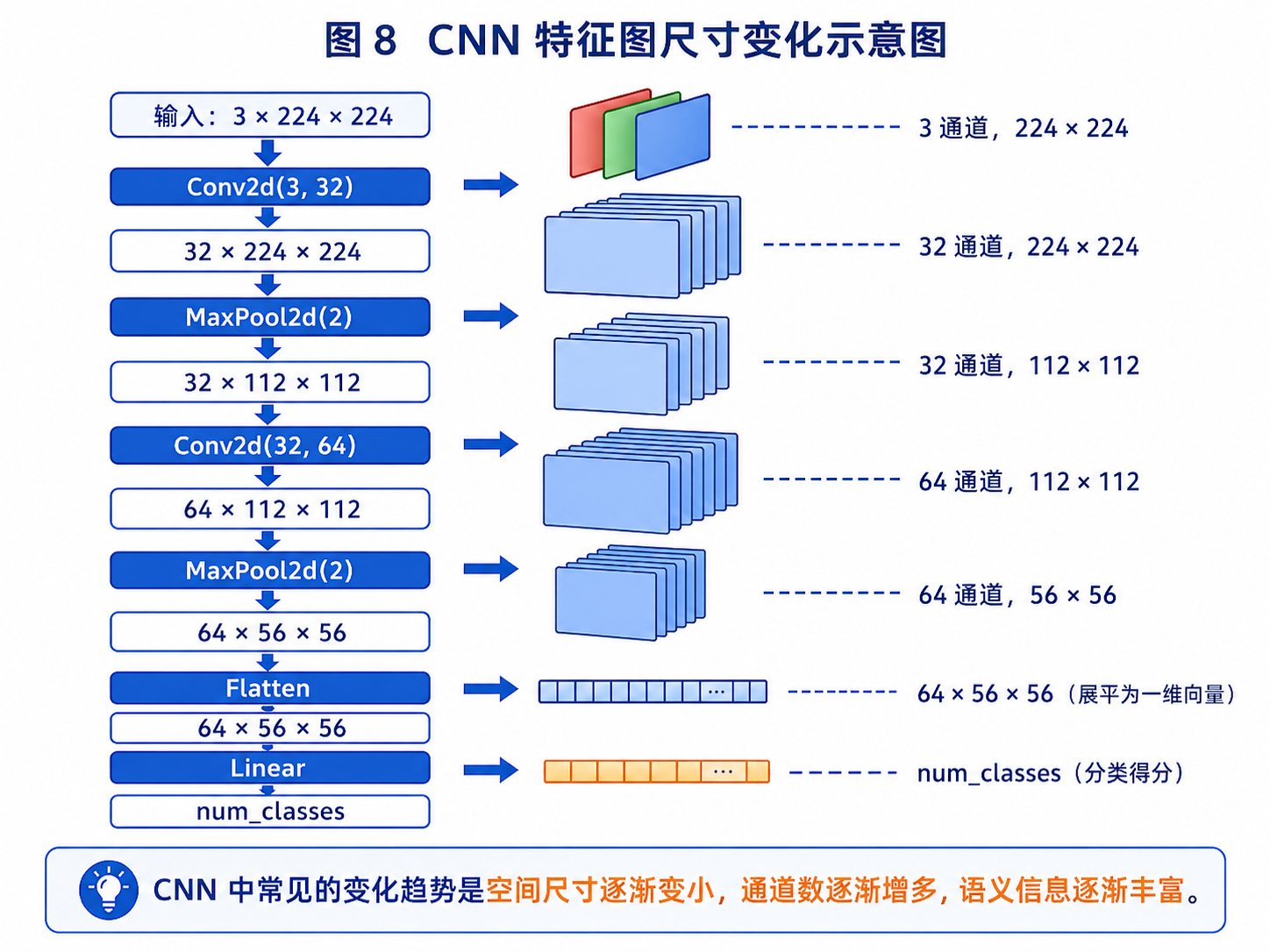
图 8:CNN 中常见的变化趋势是空间尺寸逐渐变小,通道数逐渐增多,语义信息逐渐丰富。
十八、CNN 的训练过程和 MLP 有什么区别?
训练流程几乎一样。
无论是 MLP 还是 CNN,都遵循:
text
前向传播;
计算损失;
反向传播;
参数更新。区别主要在于:
| 模型 | 主要特征提取方式 |
|---|---|
| MLP | Linear 全连接层 |
| CNN | Conv 卷积层 |
| Transformer | Attention 注意力机制 |
所以 CNN 并不是完全新的训练范式。
它仍然使用之前学过的那套训练流程,只是把特征提取模块换成了更适合图像的卷积层。
十九、一个极简训练流程
下面只看训练骨架:
python
for images, labels in train_loader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()这几行背后的含义是:
text
模型看图片;
模型做预测;
损失函数告诉它错了多少;
反向传播告诉它参数该怎么改;
优化器更新参数;
下一轮继续变好。二十、CNN 最容易误解的几个点
误解一:卷积核是人工设计好的
在传统图像处理中,确实有一些人工设计的卷积核,比如边缘检测算子。
但在 CNN 中,卷积核通常是训练出来的。
也就是说,模型会自己学习哪些局部模式对任务有用。
误解二:池化越多越好
池化可以减少计算量,也能保留局部强响应。
但池化太多会丢失空间细节。
所以池化不是越多越好,而是要根据任务合理设计。
误解三:通道数就是颜色数
输入图片的 3 个通道是 RGB。
但中间层的 32、64、128 个通道是特征通道,不是颜色通道。
每个特征通道代表一种模型学到的特征响应。
误解四:CNN 只是在识别边缘
浅层卷积可能更多关注边缘和纹理。
但深层卷积会组合这些低级特征,形成更高层的语义表示。
CNN 的能力来自逐层组合,而不是某一个卷积核单独很强。
二十一、CNN 在后续学习中的位置
CNN 它是计算机视觉学习路线中的关键桥梁。
| 阶段 | 学习重点 |
|---|---|
| MLP | 理解神经网络的基础训练逻辑 |
| CNN | 理解图像任务中的特征提取 |
| VGG / ResNet | 理解更深的 CNN 结构设计 |
| YOLO | 理解 CNN 在目标检测中的应用 |
所以 CNN 是后面学习 ResNet、VGG、YOLO 的基础。
二十二、下篇总结
这一篇我们把基础 CNN 拆开看了。
可以总结为:
卷积层 负责提取局部特征;
ReLU 负责引入非线性和筛选有效响应;
池化层 负责压缩信息和保留重点;
通道数 表示模型学到的不同特征响应;
CNN 的训练流程和 MLP 本质一致,仍然是前向传播、计算损失、反向传播和参数更新。
理解了这一点,再去看 VGG、ResNet、YOLO,就不会只看到复杂结构,而能看懂它们背后的设计逻辑。