人工智能三大概念:
知道AI,ML,DL是什么
AI:用计算机模拟人脑,让计算机能够像人类一样理性的思考和行动
ML:基于经验找规律;先训练(根据训练集找规律,找公式),再预测,最后评估
DL:基于自己构建出来的知识库
AI:给出一张图片,判断是否为西瓜
ML:结合大量有关西瓜的资料(图片,音频,文本等等),总结出规律,如何挑选一个好西瓜
DL:基于西瓜的各种资料(价格,产地,口感),搭建自己的知识库
了解AI,ML,DL之间关系
AI包含ML,ML包含DL(先辨别是不是西瓜,再判断是不是一个好西瓜,最后判断西瓜的品种)
算法的学习方式:
基于规则的学习,基于模型的学习
机器学习常用术语
知道样本是什么,知道特征是什么
样本:一行数据就是一个样本,多个样本组成数据集,有时一条样本被叫成一条记录
特征:一列数据一个特征,有时也被称为属性
知道标签/目标值是什么
标签/目标:要求和预测的结果那一列数据
理解数据集划分方法
数据集划为两部分:训练集和测试集,通常为8:2或者7:3
x_train y_train 训练集特征,训练集标签
x_test y_test 测试集特征,测试集标签
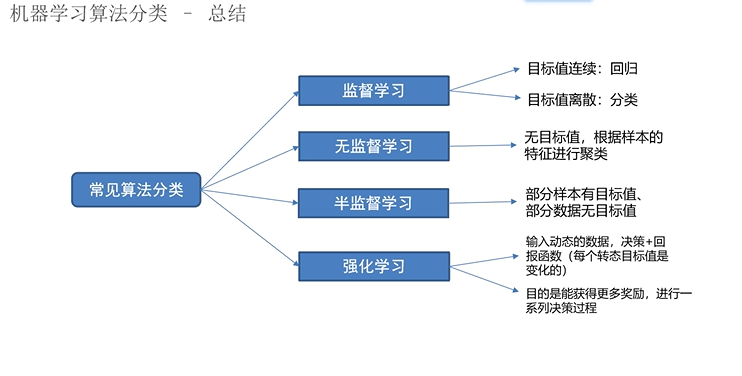
机器学习算法分类
知道有监督学习是什么
有特征有标签
有监督分类问题&回归问题
标签连续就是回归,标签不连续就是分类
分类种类:二分类,多分类
知道无监督学习是什么
有特征无标签,根据样本之间相似性对样本进行聚类,发现事务结构及相互关系(聚类)
知道半监督学习是什么
部分有标签部分无标签
1,让专家标注少量数据,利用已经标记的数据训练一个模型
2,利用该模型套用未标记的数据
3,询问领域专家分类结果和模型分类结果做对比,从而对模型进一步改善和提高
半监督学习可以大幅减低标记成本
了解强化学习是什么
强化学习=寻找最短路径(最优解),以便获取最多的奖励
就好比在OJ上(Environment)做题(Action),做对了给予AC(Reward),做错了给予WA(State)
机器学习建模流程
获取数据:搜集和完成机器学习任务相关的数据集
数据基本处理:数据集中异常值,异常值的处理等
特征工程:对数据集特征进行提取,转为向量,让模型达到最好的结果
机器学习(模型训练):选择合适的算法对模型进行训练,根据不同的任务来选中不同的算法
模型评估:评估效果好上线服务,评估效果不好则重复上述步骤
特征工程
知道特征工程是什么
理解特征提取的作用
理解特征预处理的作用
了解特征降维,特征选择,特征组合
利用专业背景知识和技巧处理数据,让机器学习算法效果最好
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
特征提取,从原始数据中提取与任务相关的特征,会改变原数据
特征预处理------>归一化,标准化
防止量纲导致某些特征对模型影响大,有些影响小
量纲:即单位(米,千克等)
打个比方:
|----------|----------|----------|
| 特征1(单位A) | 特征2(单位B) | 特征3(单位C) |
| 90 | 2 | 12 |
| 100 | 4 | 20 |
| 120 | 3 | 15 |
归一化过程:x' =(当前值 - 最小值)/(最大值 - 最小值)
|----------|----------|----------|
| 特征1(单位A) | 特征2(单位B) | 特征3(单位C) |
| 0 | 0 | 0 |
| 0.333 | 1 | 1 |
| 1 | 0.5 | 0.375 |
如果为最小值,那么归一化得到的为0,如果为最大值,那么归一化得到的为1
特征降维:将原始数据维度降低,叫做特征降维,一般对原始数据产生影响,保证数据的主要信息保留下来
特征选择:选择一个与任务相关的特征子集,不会改变原数据
(就好比体检不需要你的学历,薪资这种特征)
特征组合:多个特征合成一个特征,利用乘法或者加法完成(BMI)