💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》《MySQL数据库》
《个人在线OJ平台》《Linux网络编程》《CMake自动化构建工具》《Redis数据库》
🌸Yupureki🌸的简介:

目录
[1. 多表查询](#1. 多表查询)
[1.1 显示各部门内所有员工的工资](#1.1 显示各部门内所有员工的工资)
[1.2 显示部门编号为10的员工的名称和工资](#1.2 显示部门编号为10的员工的名称和工资)
[1.3 显示各员工的名称,工资和工资等级](#1.3 显示各员工的名称,工资和工资等级)
[2. 子查询](#2. 子查询)
[2.1 标量子查询:作为单一值](#2.1 标量子查询:作为单一值)
[2.2 多行子查询 + IN,ALL,ANY](#2.2 多行子查询 + IN,ALL,ANY)
[2.3 多列子查询](#2.3 多列子查询)
[2.4 在from中使用子查询](#2.4 在from中使用子查询)
[2.4.1 场景 1:预先聚合,然后关联其他表](#2.4.1 场景 1:预先聚合,然后关联其他表)
[2.4.2 场景 2:多步骤筛选------先找出数据,再过滤](#2.4.2 场景 2:多步骤筛选——先找出数据,再过滤)
[2.4.3 场景 3:用派生表代替临时表存储中间结果](#2.4.3 场景 3:用派生表代替临时表存储中间结果)
[3. 连接查询](#3. 连接查询)
[3.1 查询员工姓名、工资、部门名称和所在地](#3.1 查询员工姓名、工资、部门名称和所在地)
[3.2 查询所有员工及其领导的姓名(自连接)](#3.2 查询所有员工及其领导的姓名(自连接))
1. 多表查询
实际开发中往往数据来自不同的表,所以需要多表查询。本节我们用一个简单的公司管理系统,有三张表EMP,DEPT,SALGRADE来演示如何进行多表查询。
部门表 dept
sql
CREATE TABLE dept (
deptno INT PRIMARY KEY COMMENT '部门编号',
dname VARCHAR(20) COMMENT '部门名称',
loc VARCHAR(20) COMMENT '所在地'
);
INSERT INTO dept VALUES
(10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON');员工表 emp
sql
CREATE TABLE emp (
empno INT PRIMARY KEY COMMENT '员工编号',
ename VARCHAR(20) COMMENT '员工姓名',
job VARCHAR(20) COMMENT '岗位',
mgr INT COMMENT '上级编号',
hiredate DATE COMMENT '入职日期',
sal DECIMAL(10,2) COMMENT '工资',
comm DECIMAL(10,2) COMMENT '奖金',
deptno INT COMMENT '部门编号',
FOREIGN KEY (deptno) REFERENCES dept(deptno)
);
INSERT INTO emp VALUES
(7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, NULL, 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30),
(7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, NULL, 20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30),
(7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, NULL, 30),
(7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, NULL, 10),
(7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, NULL, 20),
(7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000, NULL, 10),
(7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500, 0, 30),
(7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, NULL, 20),
(7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, NULL, 30),
(7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, NULL, 20),
(7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, NULL, 10);工资等级表 salgrade
sql
CREATE TABLE salgrade (
grade INT PRIMARY KEY COMMENT '等级',
losal DECIMAL(10,2) COMMENT '最低工资',
hisal DECIMAL(10,2) COMMENT '最高工资'
);
INSERT INTO salgrade VALUES
(1, 700, 1200),
(2, 1201, 1400),
(3, 1401, 2000),
(4, 2001, 3000),
(5, 3001, 9999);1.1 显示各部门内所有员工的工资
由于员工表何部门表是独立的,中间由部门编号串联起来,因此要联合查询
sql
select emp.ename,emp.sal,dept.dname from emp,dept where emp.deptno=dept.deptno;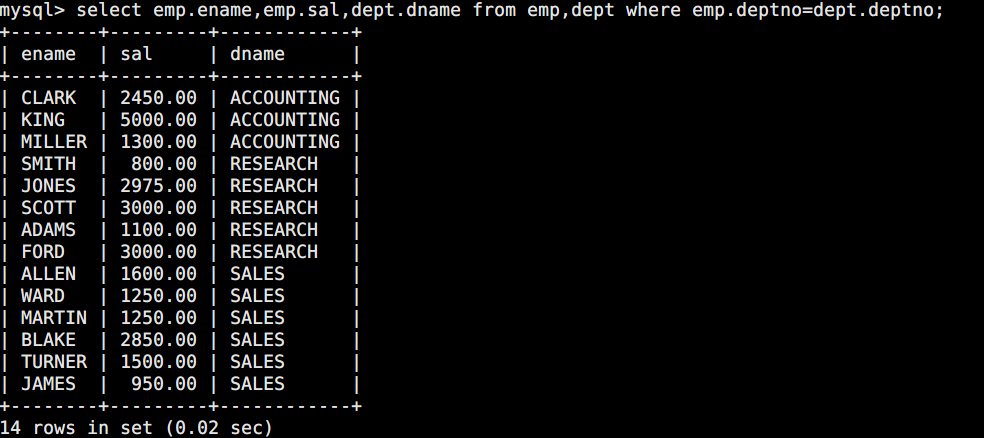
1.2 显示部门编号为10的员工的名称和工资
sql
select emp.ename,emp.sal from emp where emp.deptno=10;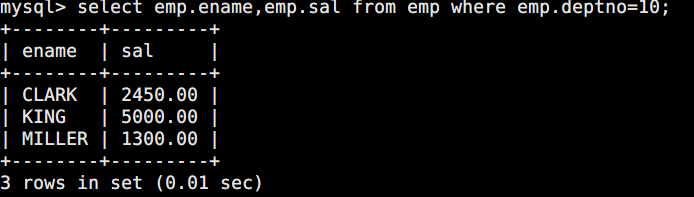
1.3 显示各员工的名称,工资和工资等级
sql
select ename,sal,grade from emp,salgrade where emp.sal between losal and hisal;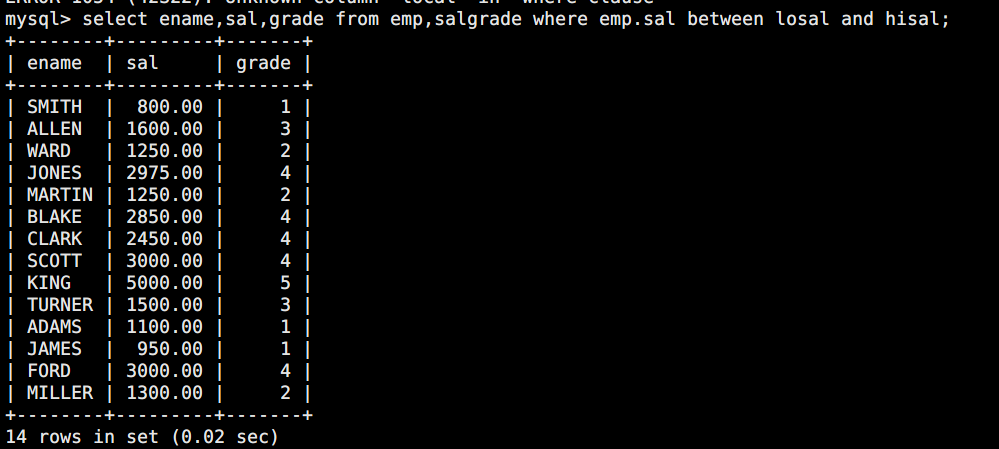
2. 子查询
子查询的核心原理可以概括为:将一个查询的结果,作为另一个查询的输入,从而实现分步、分层的数据筛选与计算。在 MySQL 内部,它的执行方式主要取决于子查询是否引用了外层查询的列
2.1 标量子查询:作为单一值
问题:查询工资比 ALLEN 高的员工
sql
SELECT ename, sal FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename = 'ALLEN');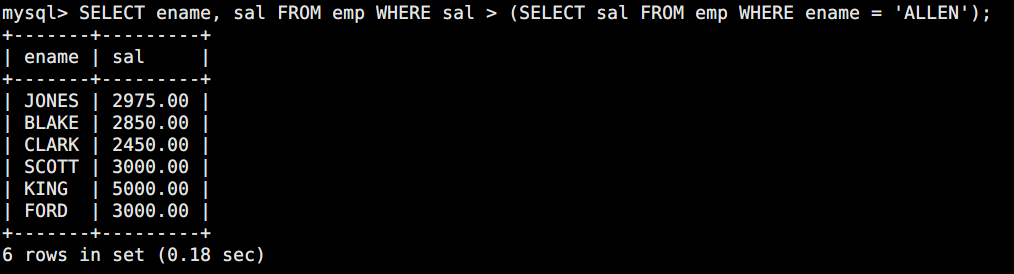
这里内层的 SELECT sal FROM emp WHERE ename = 'ALLEN' 就是一个子查询。MySQL 处理这个语句的逻辑是:
-
先独立执行内层子查询,得到ALLEN的薪资;
-
再将这个值代入外层查询 ,变成
WHERE sal > 1600.00; -
执行外层查询,返回最终结果。
这就是"非相关子查询"的基本流程:子查询可以脱离外层独立运行,只执行一次,结果被外层当作常量使用。
2.2 多行子查询 + IN,ALL,ANY
问题:查询与 SALESMAN 岗位相同部门的员工
sql
select ename from emp where deptno in (select deptno from emp where job = 'SALESMAN');-
先独立执行内层子查询,得到 job 为 SALESMAN的所有部门号;
-
再将这个值代入外层查询 ,变成
WHERE depton in (30); -
执行外层查询,返回最终结果。
**问题:**查询工资比任意一个 SALESMAN 高的员工(即只要超过最少的那个 SALESMAN 工资就行)
sql
SELECT ename, sal
FROM emp
WHERE sal > ANY (
SELECT sal FROM emp WHERE job = 'SALESMAN'
);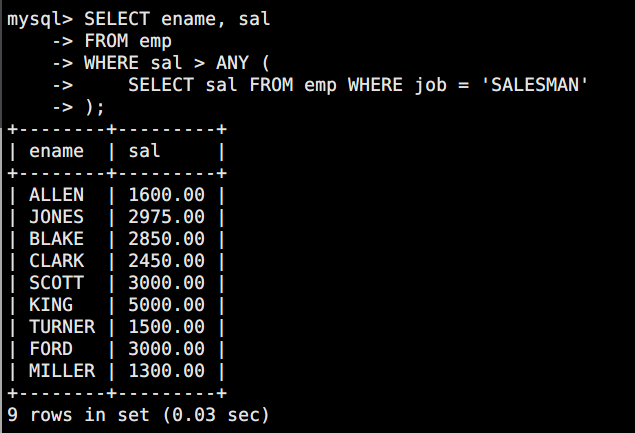
SALESMAN 的工资有:1600, 1250, 1250, 1500。
> ANY 等价于 大于最小值(1250)。只要工资 > 1250 就会返回。
问题:查询在 RESEARCH 部门以外的部门工作的员工
sql
SELECT ename, deptno
FROM emp
WHERE deptno <> ANY (
SELECT deptno FROM dept WHERE dname = 'RESEARCH'
);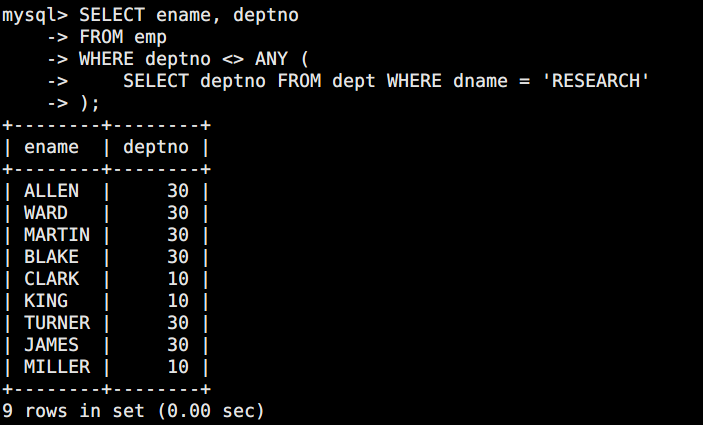
内层返回 20,<> ANY(20) 等价于 deptno <> 20,返回部门 10 和 30 的员工。
注意 :<> ANY 实际上等价于并非等于所有 ,通常不太直观,更常用 NOT IN 或 < > ALL 来描述。
2.3 多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句
问题:查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
sql
select ename from emp where (deptno,job)=(select deptno,job from emp where ename='SMITH') and ename <> 'SMITH';
2.4 在from中使用子查询
在 FROM 子句中使用子查询,其实就是把查询结果当作一张临时表 来参与后续操作。这种临时表被称为**派生表(Derived Table)**或内联视图。
基本语法(关键:必须取别名)
sql
SELECT 列名
FROM (
-- 这里是子查询,结果集就是"表"
SELECT ... FROM ... WHERE ...
) AS 别名
WHERE ...;-
子查询必须用括号括起来
-
必须跟着一个别名 ,否则 MySQL 会报错:
Every derived table must have its own alias -
你可以像使用普通表一样,对派生表进行
JOIN、GROUP BY、ORDER BY等操作
2.4.1 场景 1:预先聚合,然后关联其他表
需求:查出每个部门的名称及其平均工资,按平均工资降序显示。
如果用传统方式,需要先把 emp 按 deptno 分组计算 AVG,再和 dept 连接。用派生表就很清晰:
sql
select dept.dname,avg_sal from (select deptno,avg(sal) as avg_sal from emp group by deptno) as dept_avg join dept on dept_avg.deptno=deeptno=dept.deptno order by avg_sal desc;
派生表 dept_avg 的作用:先将聚合结果算好,再让 dept 表来"认领"部门名称。这样逻辑分层非常明确。
2.4.2 场景 2:多步骤筛选------先找出数据,再过滤
需求:查询工资高于本部门平均工资的员工,但不想用相关子查询,可以用派生表。
sql
SELECT e.ename, e.sal, e.deptno, d_avg.avg_sal
FROM emp e
JOIN (
SELECT deptno, AVG(sal) AS avg_sal
FROM emp
GROUP BY deptno
) d_avg ON e.deptno = d_avg.deptno
WHERE e.sal > d_avg.avg_sal;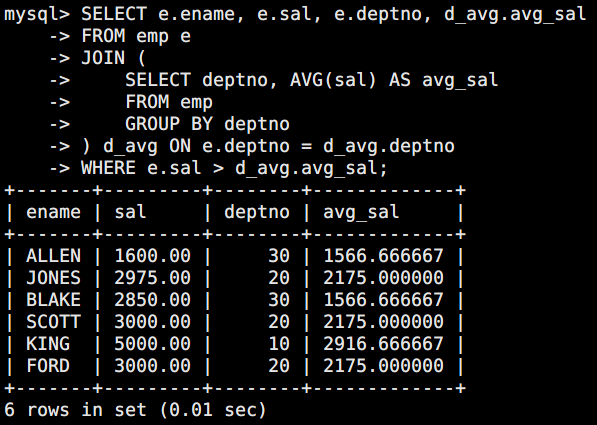
2.4.3 场景 3:用派生表代替临时表存储中间结果
需求:查出在所有员工中工资排在前 3 的员工信息,并显示他们的工资等级。
sql
SELECT top3.ename, top3.sal, s.grade
FROM (
SELECT ename, sal
FROM emp
ORDER BY sal DESC
LIMIT 3
) AS top3
JOIN salgrade s ON top3.sal BETWEEN s.losal AND s.hisal;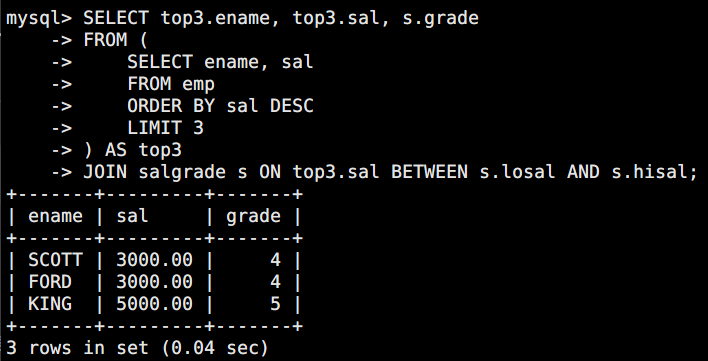
3. 连接查询
JOIN ... ON 的作用是基于关联条件,把多张表的行横向拼接成一张宽表,让不同表里的相关数据可以出现在同一行中。
SQL 的逻辑执行顺序里,JOIN ... ON 发生在 FROM 阶段:
FROM (含 JOIN ... ON) → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
-
ON 是连接条件:它决定"表 A 的这一行"和"表 B 的哪一行(或哪些行)"可以拼在一起。
-
对于
INNER JOIN,ON不满足条件的行会被直接丢弃。 -
对于
LEFT/RIGHT JOIN,保留左表/右表的所有行 ,即使右/左表没有匹配行(用NULL填充)。此时ON只控制匹配逻辑,不影响保留行。
基本语法:
sql
SELECT 列
FROM 表1
[连接类型] JOIN 表2 ON 表1.列 = 表2.列
[连接类型] JOIN 表3 ON 表2.列 = 表3.列 -- 可继续连
WHERE ... GROUP BY ... HAVING ... ORDER BY ...;3.1 查询员工姓名、工资、部门名称和所在地
sql
SELECT e.ename, e.sal, d.dname, d.loc
FROM emp e
JOIN dept d ON e.deptno = d.deptno;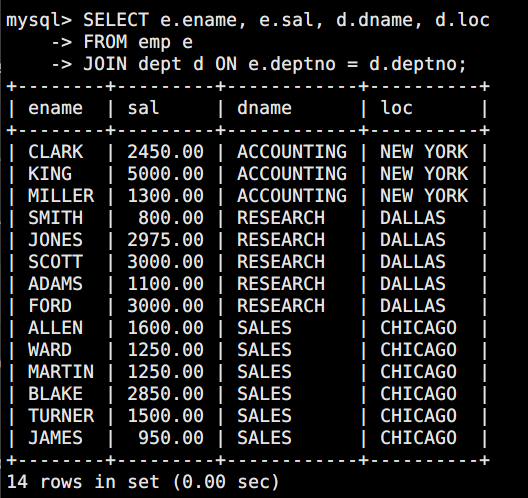
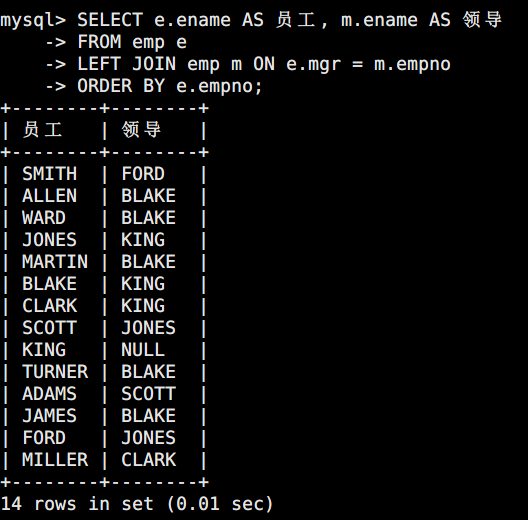
3.2 查询所有员工及其领导的姓名(自连接)
sql
SELECT e.ename AS 员工, m.ename AS 领导
FROM emp e
LEFT JOIN emp m ON e.mgr = m.empno
ORDER BY e.empno;