
目录
[1. 聊一聊硬件](#1. 聊一聊硬件)
[2. 文件系统](#2. 文件系统)
[2.1 结构](#2.1 结构)
[2.2 路径解析](#2.2 路径解析)
[2.3 挂载分区](#2.3 挂载分区)
[2.4 总结](#2.4 总结)
1. 聊一聊硬件
想知道文件是如何管理的和硬件是分不开的,这里看一下硬件磁盘的组成和原理
磁盘存储的基本单位是扇区 ,一个扇区通常能存储512字节,除了扇区一个磁盘还有磁道,柱面,传动臂等结构
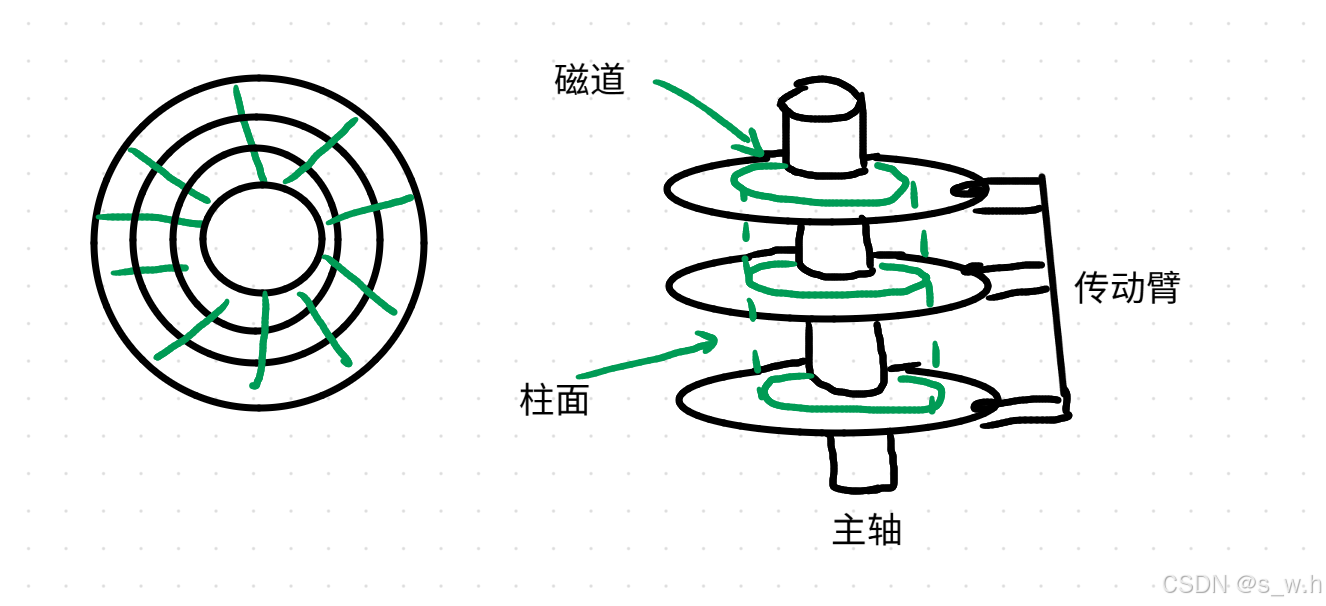
柱面,磁头,扇区三者组成了CHS定址
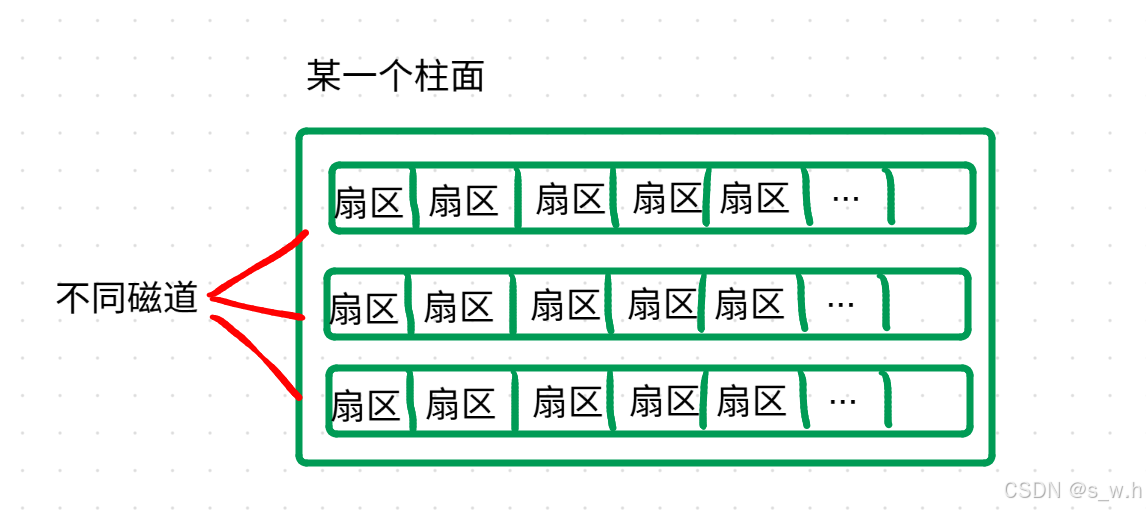
OS文件系统访问磁盘,不以扇区为单位,而是以"块 "为单位,一般是4KB,连续8个扇区,"块"是文件存取的最小单位

为了便于管理,OS对磁盘进行了分区分组。这样对一组的管理就是对磁盘的管理
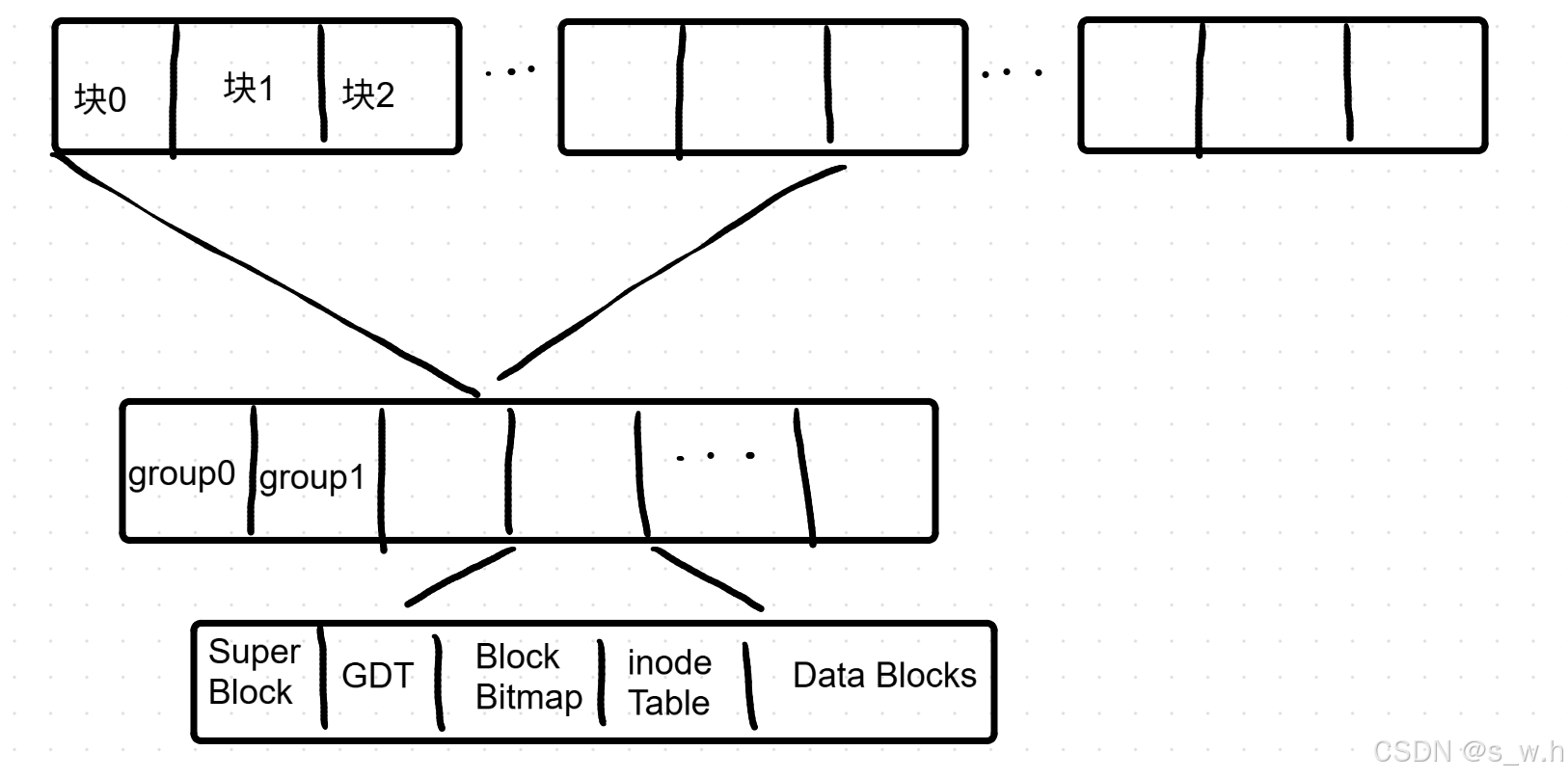
文件=内容+属性,linux下,内容和属性是分开存储的,内容存储在Data Blocks区,属性存储在inode区,一个文件,一个inode
一个文件的属性inode长这样
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
union...文件名属性并未纳入inode数据结构中,任何文件的内容大小可以不同,但是属性大小是相同的
认识了硬盘这种"块"设备,块是分区下的结构,如何找到块,又如何管理这些inode就是文件系统的工作
2. 文件系统
2.1 结构
文件系统的目的是组织和管理硬盘中的文件,文件系统将整个分区划分成若干个大小的块组,只要能管理一个分区,就能管理所有分区,就能管理所有磁盘文件
依次介绍一下各部分的作用
1. Super Block
**存放⽂件系统本⾝的结构信息,描述整个分区的⽂件系统信息。**记录的信息主要有:bolck和inode的总量,未使⽤的block和inode的数量,⼀个block和inode的⼤⼩,最近⼀次挂载的时间,最近⼀次写⼊数据的时间,最近⼀次检验磁盘的时间等其他⽂件系统的相关信息
2. GDT
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组的描述信息,如在这个块组中从哪⾥开始是inodeTable,从哪⾥开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷⻉
3. Block Bitmap
记录着Data Blocks中哪个数据块已被占用,哪个数据块还没有被占用
4. Inode Bitmap
每个bit表示一个inode是否空闲可用
5. Inode Table
存放文件属性,当前分组所有indoe属性的集合,inode编号以分区为单位,不可跨分区
6. Data Block
数据区:存放文件内容,也就是一个个的block,根据不同的文件类型情况不同。对于普通⽂件,⽂件的数据存储在数据块中。对于⽬录,该⽬录下的所有文件名和目录名 存储在所在⽬录的数据块中,除了⽂件名外,ls-l命令 看到的其它信息保存在该⽂件的inode中,Block号按照分区划分,不可跨分区
创建一个文件的过程
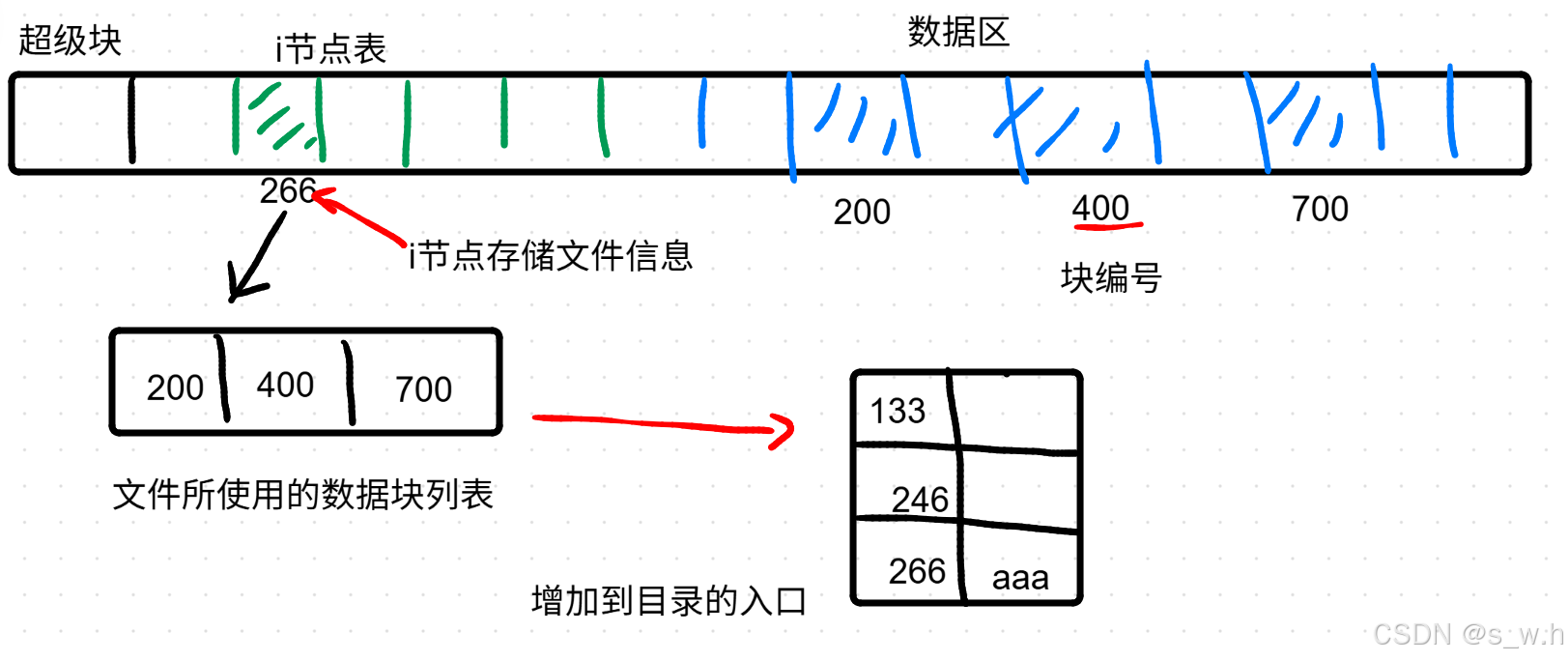
目录也是文件,属性不用多说,内容保存的是文件名和inode的映射关系
Filename: mnt, Inode:
1048577
Filename: tmp, Inode: 1179650
Filename: sys, Inode: 917506
Filename: libx32, Inode: 17
Filename: srv, Inode: 786434
Filename: lib64, Inode: 16
Filename: sbin, Inode: 18
Filename: dev, Inode: 131073
Filename: swapfile, Inode: 12
Filename: run, Inode: 104857所以,访问文件,必须打开当前目录,获得对应的inode号,然后进行文件访问
2.2 路径解析
要想访问当前文件需要知道当前文件的目录,目录也是文件,所以也需要知道上一级目录,如此递归下去,出口就是根目录。从根目录开始依次访问每个目录下指定的目录,直到访问到文件,这个过程叫linux路径解析
如果访问任何文件,都从/目录开始进行路径解析太慢了,所以linux会缓存历史路径结构,Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry
cs
struct dentry
{
struct inode *d_inode; /* Where the name belongs to - NULL is
negative */
struct dentry *d_parent; /* parent directory */
struct list_head d_lru; /* LRU list */
struct list_head d_subdirs; /* our children */
struct super_block *d_sb; /* The root of the dentry tree */
...
}每个文件都有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构。dentry是纯内存结构,磁盘上不存在dentry,磁盘上只有目录文件的数据块,内核读取后转化成内存中的dentry
2.3 挂载分区
挂载分区是为了解决跨分区问题,
挂载 = 把分区的根目录"嫁接"到现有目录树的某个节点上
cs
挂载前: 挂载后 (mount /dev/sdb1 /mnt/data):
/ /
├── home ├── home
├── etc ├── etc
└── mnt └── mnt
└── data ← (空目录) └── data ← 现在指向 /dev/sdb1 的根目录
├── photos/
├── videos/
└── backup.tar.gz挂载的本质是在 VFS 层创建一个特殊的 dentry,其 d_flags 标记为 DCACHE_MOUNTED,并将该 dentry 的 d_inode 指向新分区的根 inode,路径解析时,内核遇到带 DCACHE_MOUNTED 标志的 dentry,会自动跳转到对应文件系统的根 dentry 继续解析
2.4 总结
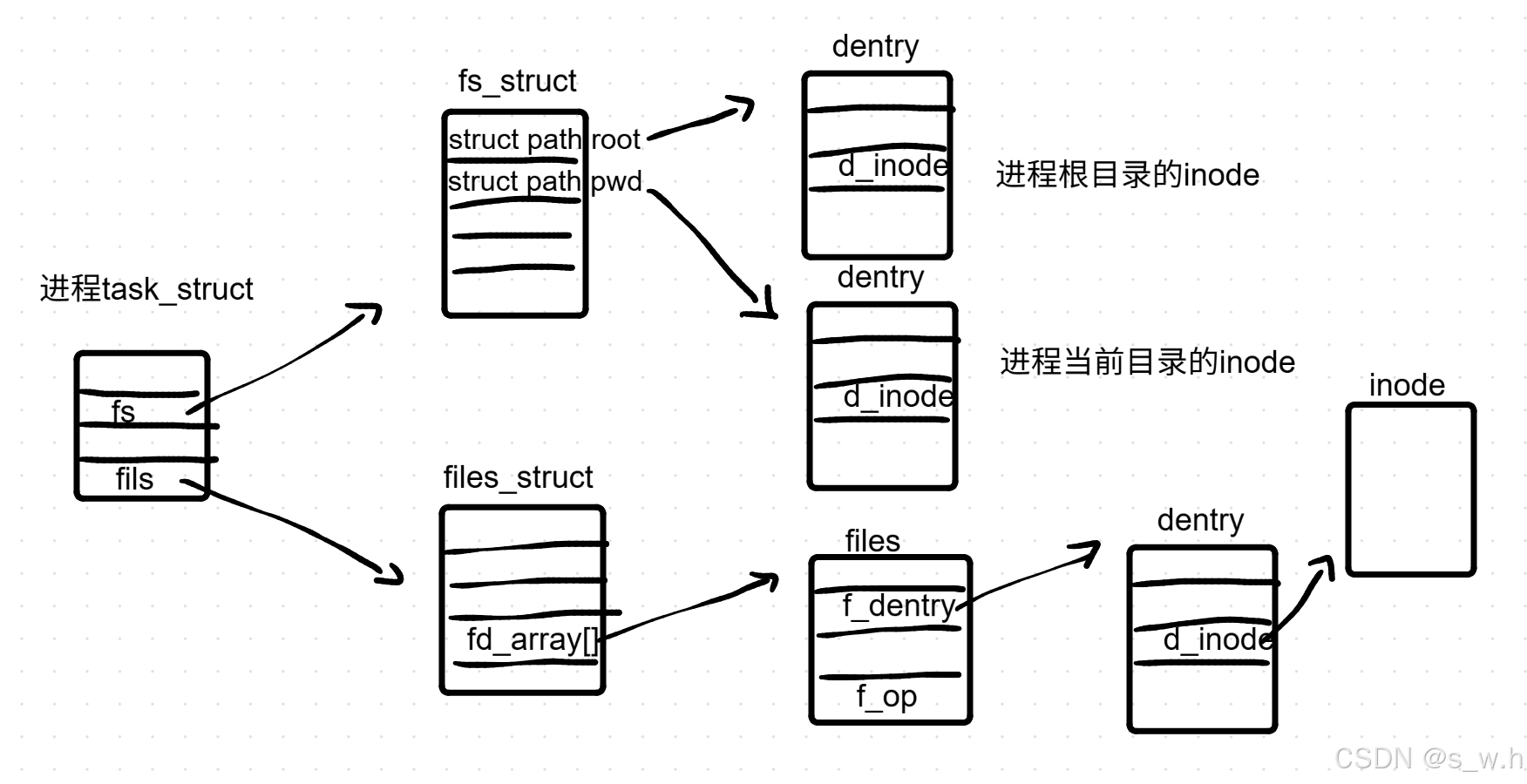
进程pcb中有两个指针*fs和*files,*fs指向fs_struct,存储的是该进程当前的文件系统上下文信息, 它保存了进程的**根目录、当前工作目录和 umask,**本质上是该进程在 VFS 目录树中的"导航状态"
注意的是fs_struct 存储的是路径解析的起点(锚点) ,而不是 路径解析过程中产生的 dentry 链或缓存结构。只存储两个特定的 dentry 引用 (root 和 pwd)作为解析基准,是进程级别的上下文配置 ,告诉 VFS "从哪里开始解析"。解析过程中经过的所有中间 dentry,都存在于全局的 dentry cache (dcache) 中,不属于任何进程的 fs_struct
struct file 中确实包含 struct path,而 struct path 内部又包含了 dentry防止路径发生变化或者相对路径缺失。struct file中的path打开后是永不改变的
串联一下
cs
open("config.txt")
│
▼
1. VFS 从 current->fs->pwd.dentry 出发 ← fs_struct 提供起点
│
▼
2. 在全局 dcache 中逐级查找 "config.txt" ← dcache 提供缓存
│
▼
3. 找到目标 dentry + inode
│
▼
4. 分配 struct file,将结果存入 f_path + f_inode ← file 记住结果
│
▼
5. 返回 fd,存入 current->files->fd[n] ← files_struct 管理描述符
│
▼
6. 后续 read(fd) 直接使用 file->f_path/f_inode ← 不再碰 fs_struct最后一张图加深记忆
终