
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》 《MySQL数据库学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在 Linux 系统学习中,进程 是一个绕不开的核心概念.无论是我们在终端中执行一条简单的
ls命令,还是运行一个复杂的服务器程序,系统背后都在不断地进行进程创建、调度、终止与资源回收.理解进程控制,不仅能够帮助我们看懂 Linux 系统的运行机制,也能为后续学习系统编程、网络编程以及 Shell 实现打下坚实基础.本文将围绕 Linux 下的进程控制展开,重点讲解进程的创建、终止与等待机制,分析fork、exit、wait/waitpid等关键接口的使用方式与底层逻辑.同时,我们还会进一步学习进程程序替换的相关内容,理解exec系列函数如何让一个进程"换壳不换身",从而执行新的程序.在此基础上,本文还会结合前面所学知识,逐步实现一个简单的自主 Shell 命令行解释器。通过模拟命令读取、进程创建、程序替换以及父进程等待子进程退出等流程,我们可以更加直观地理解 Linux 终端命令背后的执行原理.希望通过本文的学习,你不仅能掌握进程控制相关接口的基本用法,更能从整体上建立起对Linux 进程运行机制的清晰认识.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!

目录
1.进程创建
1.1fork函数初识
在linux中fork函数是⾮常重要的函数,它从已存在进程中创建⼀个新进程.新进程为⼦进程,⽽原进程为⽗进程.
cpp
#include <unistd.h>
pid_t fork(void);
返回值:⼦进程中返回0,⽗进程返回⼦进程id,出错返回-1fork() 的作用是:从当前进程复制出一个新的子进程.调用之后,原来的进程叫父进程,新复制出来的叫子进程.
1.为什么子进程返回 0,父进程返回子进程 pid?
因为父进程和子进程需要通过返回值判断自己是谁.
调用 fork() 之后,父子进程会从同一行代码继续往下执行.为了让它们走不同逻辑,系统设计了不同返回值:
c
pid_t pid = fork();
if (pid == 0) {
// 子进程执行这里
} else if (pid > 0) {
// 父进程执行这里
} else {
// fork 失败
}为什么子进程返回 0?
因为子进程可以通过:
c
getpid()知道自己的 pid,所以不需要 fork() 再返回自己的 pid.
为什么父进程返回子进程 pid?
因为父进程通常需要管理子进程,比如等待子进程结束:
c
waitpid(pid, NULL, 0);所以父进程必须知道刚刚创建的子进程 pid.
2.为什么一个函数fork()会有两个返回值?
严格说,fork() 不是"一个进程里返回两次"而是:
调用 fork() 后,进程变成了两个.
原来只有一个进程:
text
父进程执行 fork() 后变成:
text
父进程
子进程两个进程都会从 fork() 调用结束的位置继续执行.
所以你看到的是:
text
父进程中:fork() 返回子进程 pid
子进程中:fork() 返回 0看起来像一个函数返回了两次,其实是因为有两个进程分别得到了一次返回值.
3.为什么一个 id 即等于 0,又大于 0?
这里容易误解.
不是同一个变量在同一个进程里既等于 0 又大于 0.
而是:
c
pid_t pid = fork();这行代码执行后,父进程和子进程各自都有一份自己的 pid 变量副本 .
例如:
text
父进程中的 pid = 12345
子进程中的 pid = 0它们的变量名都叫 pid,代码位置也一样,但它们属于不同进程,内存空间是独立的.
所以不是:
text
同一个 pid 既等于 0 又大于 0而是:
text
父进程里的 pid > 0
子进程里的 pid == 0可以把它理解成:fork() 像是把当前程序"克隆"了一份.克隆完成后,父进程拿到子进程的编号,子进程拿到 0,这样双方就知道自己是谁.
进程调⽤ fork ,当控制转移到内核中的 fork 代码后,内核做:
• 分配新的内存块和内核数据结构给⼦进程.
• 将⽗进程部分数据结构内容拷⻉⾄⼦进程.
• 添加⼦进程到系统进程列表当中.
• fork 返回,开始调度器调度.
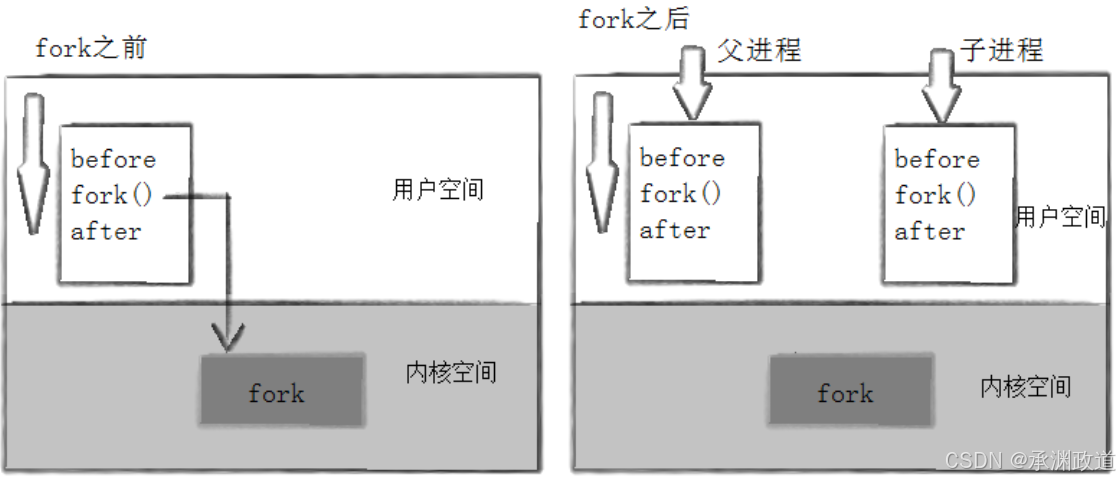
当⼀个进程调⽤fork之后,就有两个⼆进制代码相同的进程.⽽且它们都运⾏到相同的地⽅.但每个进程都将可以开始它们⾃⼰的旅程,看如下程序.
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ((pid = fork()) == -1) {
perror("fork()");
exit(1);
}
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}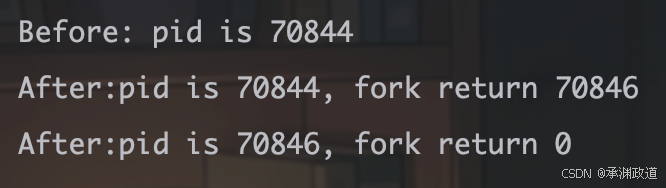
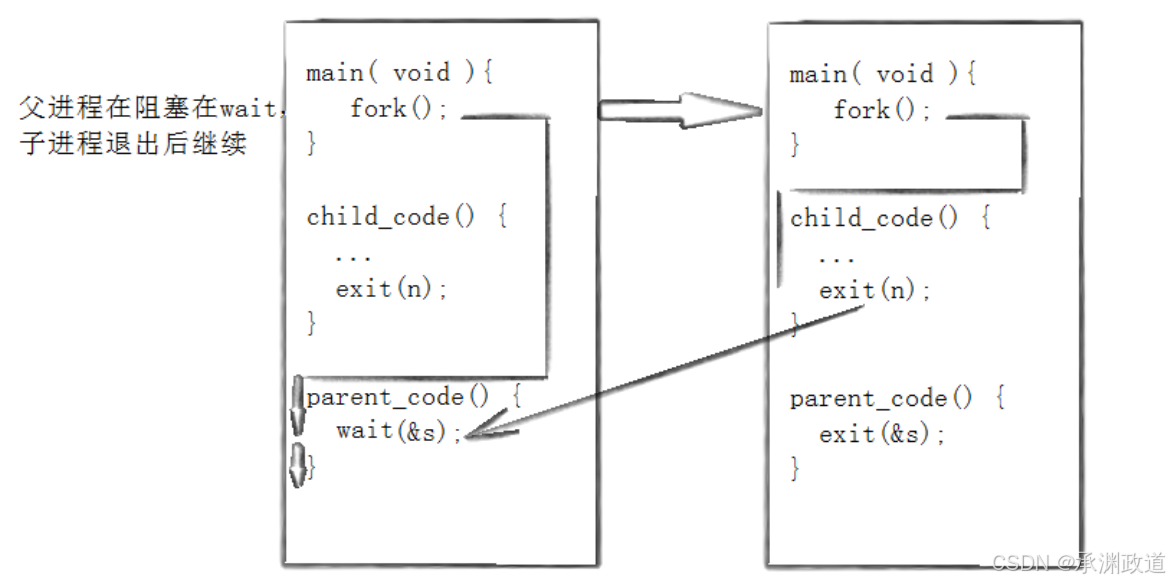
这⾥看到了三⾏输出,⼀⾏before,两⾏after.进程70844先打印before消息,然后它有打印after.
另⼀个after消息有70846打印的.注意到进程70846没有打印before,为什么呢?如下图所示:
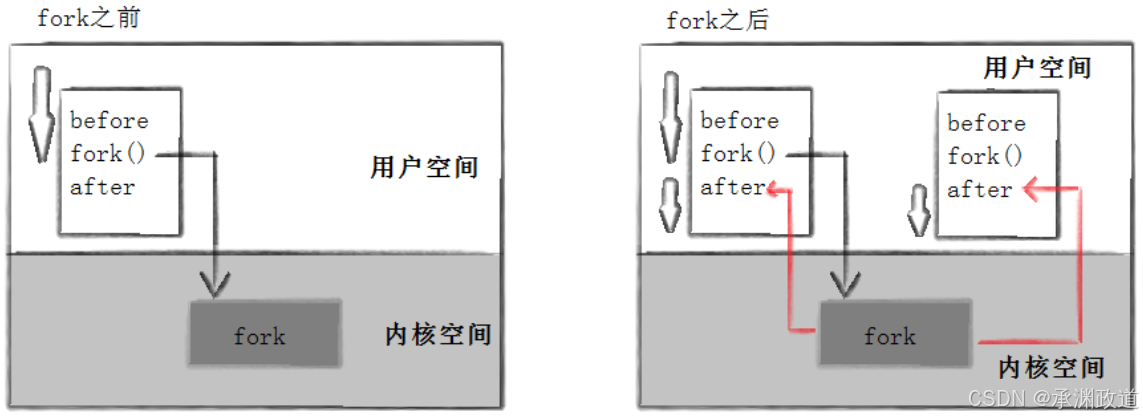
所以,fork之前⽗进程独⽴执⾏,fork之后,⽗⼦两个执⾏流分别执⾏.注意,fork之后,谁先执⾏完
全由调度器决定.
1.2fork函数返回值
fork() 的返回值有 三种情况:
c
pid_t pid = fork();| 返回值 | 出现在哪个进程 | 含义 |
|---|---|---|
pid > 0 |
父进程 | 返回的是子进程的 PID |
pid == 0 |
子进程 | 表示当前正在运行的是子进程 |
pid == -1 |
父进程 | 创建子进程失败 |
典型写法:
c
#include <unistd.h>
#include <stdio.h>
int main() {
pid_t pid = fork();
if (pid > 0) {
printf("父进程:子进程 pid = %d\n", pid);
} else if (pid == 0) {
printf("子进程:fork 返回值 = %d\n", pid);
} else {
printf("fork 失败\n");
}
return 0;
}重点是:fork() 调用一次,但成功后会产生两个进程,所以会有两个返回值:
text
父进程中 fork() 返回 子进程 pid
子进程中 fork() 返回 0不是同一个 pid 同时等于 0 又大于 0,而是父进程和子进程各自有一份自己的 pid 变量.
1.3写时拷⻉
写时拷贝 ,英文叫 Copy-On-Write,COW .
它是 fork() 能高效创建子进程的关键机制.
1.普通理解
fork() 创建子进程时,理论上子进程要复制父进程的内存.
比如父进程有:
text
代码区
数据区
堆
栈如果每次 fork() 都完整复制一份内存,会很慢,也很浪费.
所以操作系统不会马上复制全部内存,而是让父进程和子进程暂时共享同一份物理内存.
只有当父进程或子进程要修改某块内存时,系统才真正复制那一块.
这就叫:
text
写时拷贝:读的时候共享,写的时候复制2.fork 后内存是什么样?
执行:
c
pid_t pid = fork();刚 fork 成功后:
text
父进程虚拟地址空间 ──┐
├── 指向同一份物理内存
子进程虚拟地址空间 ──┘也就是说,父子进程看到的变量地址可能一样,但底层暂时共用物理页.
3.什么时候会复制?
比如:
c
int a = 10;
pid_t pid = fork();
if (pid == 0) {
a = 20;
}刚 fork() 后:
text
父进程 a = 10
子进程 a = 10子进程执行:
c
a = 20;这时子进程要修改内存,操作系统发现这块内存是共享的,就复制一份新的物理页给子进程.
之后变成:
text
父进程 a = 10
子进程 a = 20父子进程互不影响.
4.为什么需要写时拷贝?
主要是为了提高效率.
很多时候,fork() 后子进程马上会调用:
c
exec()比如 shell 执行命令:
bash
ls大致流程是:
text
shell 进程 fork 出子进程
子进程 exec 加载 ls 程序如果 fork() 时把 shell 的全部内存复制一遍,马上又被 exec() 替换掉,就很浪费.
所以用写时拷贝:
text
fork 时不复制内存
真正写入时才复制5.总结
写时拷贝就是:父子进程 fork 后先共享内存;谁要修改,才给谁复制一份.
它保证了两个目标:
text
1. fork 创建子进程更快
2. 父子进程修改变量时互不影响通常,⽗⼦代码共享,⽗⼦再不写⼊时,数据也是共享的,当任意⼀⽅试图写⼊,便以写时拷⻉的⽅
式各⾃⼀份副本.具体⻅下图:
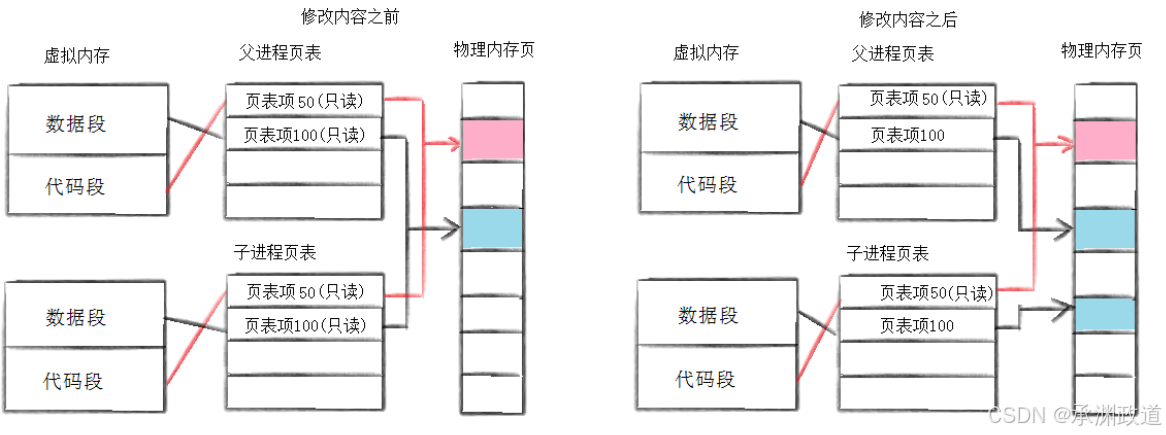
因为有写时拷⻉技术的存在,所以⽗⼦进程得以彻底分离离!完成了进程独⽴性的技术保证!写时拷⻉,是⼀种延时申请技术,可以提⾼整机内存的使⽤率.
1.4fork常规⽤法
fork() 的常规用法就是:父进程创建子进程,然后根据返回值让父子进程执行不同代码.
最典型结构:
c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
pid_t pid = fork();
if (pid < 0) {
// fork 失败
perror("fork");
exit(1);
} else if (pid == 0) {
// 子进程执行的代码
printf("我是子进程,我的 pid = %d\n", getpid());
} else {
// 父进程执行的代码
printf("我是父进程,我创建的子进程 pid = %d\n", pid);
}
return 0;
}1.根据返回值区分父子进程
c
pid_t pid = fork();
if (pid == 0) {
// 子进程
} else if (pid > 0) {
// 父进程
} else {
// 出错
}含义是:
text
pid < 0:fork 失败
pid == 0:当前是子进程
pid > 0:当前是父进程,pid 是子进程的进程号2.常规用法一:父子进程执行不同任务
c
#include <unistd.h>
#include <stdio.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
printf("子进程:执行子任务\n");
} else if (pid > 0) {
printf("父进程:执行父任务\n");
} else {
perror("fork");
}
return 0;
}运行后可能输出:
text
父进程:执行父任务
子进程:执行子任务也可能先输出子进程那一句,因为父子进程谁先执行由操作系统调度决定.
3.常规用法二:父进程等待子进程结束
如果父进程不等待子进程,子进程结束后可能短暂变成僵尸进程 .
所以常配合 wait() 或 waitpid() 使用:
c
#include <unistd.h>
#include <stdio.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
printf("子进程开始执行\n");
sleep(2);
printf("子进程结束\n");
} else if (pid > 0) {
printf("父进程等待子进程结束\n");
wait(NULL);
printf("父进程回收子进程资源\n");
} else {
perror("fork");
}
return 0;
}执行流程大致是:
text
父进程 fork 子进程
子进程执行任务
父进程 wait 等待
子进程结束
父进程回收子进程资源4.常规用法三:fork + exec 执行新程序
这是 shell 最常见的用法.
比如你在终端输入:
bash
lsshell 大致会这样做:
text
shell fork 出一个子进程
子进程 exec 执行 ls
父进程 wait 等待 ls 执行结束示例代码:
c
#include <unistd.h>
#include <stdio.h>
#include <sys/wait.h>
#include <stdlib.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
execlp("ls", "ls", "-l", NULL);
// 如果 execlp 成功,下面这行不会执行
perror("execlp");
exit(1);
} else if (pid > 0) {
wait(NULL);
printf("子进程执行完毕\n");
} else {
perror("fork");
}
return 0;
}注意:
c
execlp("ls", "ls", "-l", NULL);如果执行成功,子进程原来的代码会被 ls 程序替换,所以后面的代码不会再执行.
5.最常见模板
实际写代码时,可以记这个模板:
c
pid_t pid = fork();
if (pid < 0) {
perror("fork");
exit(1);
}
if (pid == 0) {
// 子进程代码
exit(0);
}
// 父进程代码
wait(NULL);更完整一点:
c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid < 0) {
perror("fork failed");
exit(1);
}
if (pid == 0) {
printf("child process\n");
exit(0);
}
printf("parent process, child pid = %d\n", pid);
wait(NULL);
return 0;
}一句话总结:
fork() 常规用法就是:先 fork 创建子进程,再用返回值判断父子进程,子进程执行任务,父进程通常用 wait() 回收子进程.
1.5fork调⽤失败的原因
fork() 调用失败时,返回值是 -1,不会创建子进程.
典型写法:
c
pid_t pid = fork();
if (pid < 0) {
perror("fork");
exit(1);
}常见失败原因主要有这些:
1.进程数量达到上限
系统对进程数量有限制.
可能是:
text
当前用户能创建的进程数达到上限
系统总进程数达到上限常见错误码:
text
EAGAIN可以用这些命令查看限制:
bash
ulimit -u或者:
bash
cat /proc/sys/kernel/pid_max
cat /proc/sys/kernel/threads-max2.内存资源不足
虽然 fork() 使用写时拷贝,不会立刻复制所有内存,但它仍然需要创建:
text
进程控制块
页表
内核栈
文件描述符表等结构如果系统内存不足,也可能失败.
常见错误码:
text
ENOMEM3.用户资源限制
Linux 会限制每个用户最多能创建多少进程.
比如某个用户已经创建了太多进程,再调用 fork() 就可能失败.
可以查看:
bash
ulimit -a重点看:
text
max user processes4.进程表或内核资源耗尽
操作系统需要维护进程相关的数据结构.
如果内核资源耗尽,例如进程表、线程数、PID 资源不足,也可能导致 fork() 失败.
5.系统策略限制
某些环境会主动限制创建进程,比如:
text
容器环境
沙箱环境
服务器安全策略
cgroup 限制例如 Docker、Kubernetes 中可能限制了最大进程数.
示例:打印失败原因
c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
int main() {
pid_t pid = fork();
if (pid < 0) {
printf("fork failed: %s\n", strerror(errno));
exit(1);
}
if (pid == 0) {
printf("child process\n");
} else {
printf("parent process, child pid = %d\n", pid);
}
return 0;
}也可以直接用:
c
perror("fork");它会根据 errno 输出失败原因.
一句话总结:
fork() 失败通常是因为系统资源不够,最常见的是进程数量达到限制或内存不足.
2.进程终⽌
进程终⽌的本质是释放系统资源,就是释放进程申请的相关内核数据结构和对应的数据和代码.
2.1进程退出场景
进程终止,一共有几种情况?
1.代码运行完毕,结果正确
这是最理想的情况.
程序从 main() 开始执行,所有语句正常执行完,最后正常退出.
例如:
c
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
printf("%d\n", a + b);
return 0;
}输出:
text
30程序正常结束,结果也是正确的.
这种情况叫:
text
正常终止,结果正确2.代码运行完毕,结果不正确
这种情况是:程序没有崩溃,也正常结束了,但是结果是错的.
例如:
c
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
printf("%d\n", a - b);
return 0;
}程序可以正常运行结束,但是如果本来想算加法,结果却输出:
text
-10这就属于:
text
程序正常结束,但逻辑错误也就是说,进程正常终止了,但程序结果不对 .
常见原因有:
text
算法写错
条件判断写错
循环次数写错
变量使用错误
计算公式错误3.代码异常终止
这种情况是程序还没正常运行完,就因为错误被系统强制结束了.
例如:
c
#include <stdio.h>
int main() {
int *p = NULL;
*p = 100;
return 0;
}这里访问了空指针,程序可能直接崩溃:
text
Segmentation fault这就是异常终止.
常见原因有:
text
空指针访问
数组越界
除以 0
非法内存访问
栈溢出
收到 kill 信号
断言失败和进程退出状态的关系
在 Linux/C 语言里,程序结束时通常会返回一个退出码.
c
return 0;一般表示:
text
程序正常结束而:
c
return 1;或者其他非 0 值,通常表示:
text
程序出错或结果异常比如:
c
int main() {
return 0; // 正常退出
}
c
int main() {
return 1; // 表示程序执行过程中出现问题
}2.2进程常⻅退出⽅法
进程常见退出方法主要有5种:return、exit()、_exit()、异常终止、被信号杀死.
2.2.1退出码
退出码(退出状态)可以告诉我们最后⼀次执⾏的命令的状态.在命令结束以后,我们可以知道命令是成功完成的还是以错误结束的.其基本思想是,程序返回退出代码0时表⽰执⾏成功,没有问题.代码 1 或 0 以外的任何代码都被视为不成功.我们可以通过echo $?查看进程退出码.

Linux Shell 中的主要退出码:

2.2.2main函数中return
最常见、最正常的退出方式.
c
int main() {
return 0;
}含义:
text
return 0; 表示程序正常结束
return 非0; 表示程序异常或结果不正确在 main() 里:
c
return 0;基本等价于:
c
exit(0);2.2.3调用exit()
exit() 用来主动终止当前进程.
需要头文件:
c
#include <stdlib.h>示例:
c
#include <stdlib.h>
int main() {
exit(0);
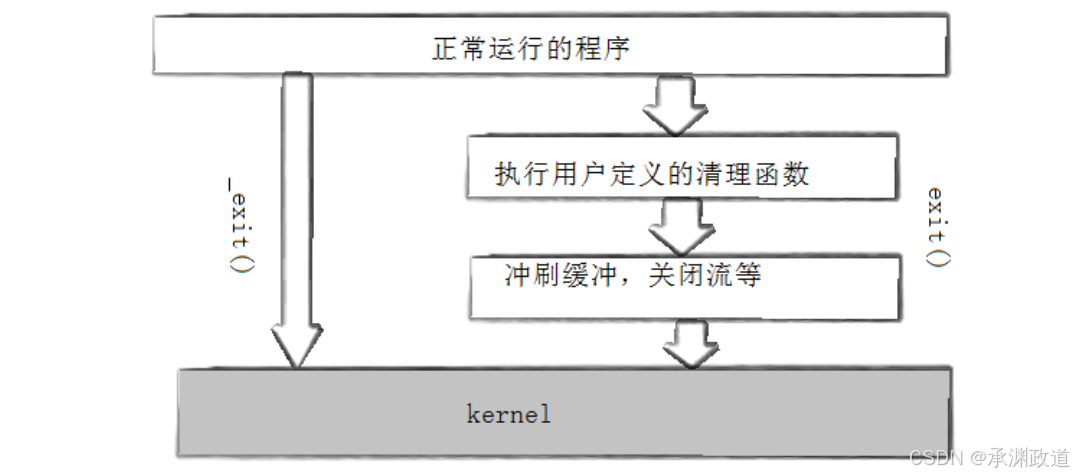
}exit() 会做一些清理工作,比如:
text
刷新缓冲区
关闭打开的文件
执行通过 atexit() 注册的函数所以它属于比较"正常"的退出方式.
2.2.4调用_exit()
_exit() 也会直接终止进程.
需要头文件:
c
#include <unistd.h>示例:
c
#include <unistd.h>
int main() {
_exit(0);
}它和 exit() 的区别是:
text
exit() 会做清理工作
_exit() 不做用户态清理,直接进入内核结束进程比如:
c
printf("hello");
_exit(0);因为没有换行,也没有刷新缓冲区,hello 可能不会输出.
而:
c
printf("hello");
exit(0);exit() 会刷新缓冲区,hello 通常可以输出.
2.2.5异常终止
程序运行过程中出现严重错误,被系统终止.
常见情况:
text
访问空指针
数组越界
除以 0
非法内存访问
栈溢出
断言失败例如:
c
int main() {
int *p = NULL;
*p = 10;
return 0;
}可能结果:
text
Segmentation fault这就是异常终止.
2.2.6被信号终止
进程也可以被其他进程或操作系统发送信号杀死.
例如命令行中:
bash
kill -9 进程PID常见信号:
text
SIGKILL 强制杀死进程
SIGTERM 请求进程终止
SIGSEGV 段错误
SIGINT Ctrl + C 产生的中断信号比如你在终端运行一个程序,然后按:
text
Ctrl + C程序一般会收到 SIGINT 信号并终止.
3.进程等待
3.1进程等待必要性
进程等待的必要性主要体现在:让进程之间有序协作,避免资源浪费和结果错误.
1.保证执行顺序
有些任务必须等另一个进程完成后才能继续.例如父进程要等子进程计算完成,再读取结果.
2.避免忙等浪费 CPU
如果没有等待机制,进程可能会一直循环检查条件:
c
while (!ready) {
// 一直检查
}这会浪费 CPU.进入等待状态后,CPU 可以去执行其他进程.
3.实现进程同步
多个进程共享资源时,需要等待锁、信号量等同步机制,否则可能出现数据竞争.
4.处理 I/O 操作
文件读取、网络通信、键盘输入等都可能很慢.进程等待 I/O 完成,可以避免无意义地占用 CPU.
5.回收子进程资源
父进程通过 wait() 等待子进程结束,可以获取子进程退出状态,并回收其进程表项,避免产生僵尸进程.
总结一句话:
进程等待是操作系统实现同步、资源管理和高效调度的重要机制.
3.2进程等待的⽅法
3.2.1wait⽅法
作用:
等待子进程结束
回收子进程资源
获取子进程退出状态
避免僵尸进程
c
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int* status);
返回值:
成功返回被等待进程pid,失败返回-1。
参数:
输出型参数,获取⼦进程退出状态,不关⼼则可以设置成为NULL如果父进程wait子进程,但是子进程就是没有退出,则父进程会阻塞在wait函数中.
3.2.2waitpid⽅法
bash
pid_ t waitpid(pid_t pid, int *status, int options);
返回值:
当正常返回的时候waitpid返回收集到的⼦进程的进程ID;
如果设置了选项WNOHANG,⽽调⽤中waitpid发现没有已退出的⼦进程可收集,则返回0;
如果调⽤中出错,则返回-1,这时errno会被设置成相应的值以指⽰错误所在;
参数:
pid:
Pid=-1,等待任⼀个⼦进程。与wait等效。
Pid>0.等待其进程ID与pid相等的⼦进程。
status: 输出型参数
WIFEXITED(status): 若为正常终⽌⼦进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED⾮零,提取⼦进程退出码。(查看进程的退出码)
options:默认为0,表示阻塞等待
WNOHANG: 若pid指定的⼦进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该⼦进程的ID。• 如果⼦进程已经退出,调⽤wait/waitpid时,wait/waitpid会⽴即返回,并且释放资源,获得⼦进程退出信息.
• 如果在任意时刻调⽤wait/waitpid,⼦进程存在且正常运⾏,则进程可能阻塞.
• 如果不存在该⼦进程,则⽴即出错返回.
waitpid() 可以等待指定的子进程,比 wait() 更灵活。
c
#include <sys/wait.h>
#include <unistd.h>
int status;
waitpid(pid, &status, 0);参数说明:
c
waitpid(pid, &status, 0);• pid > 0:等待指定 PID 的子进程
• pid = -1:等待任意子进程,类似wait()
• status:保存子进程退出状态
• 0:阻塞等待
例如:
c
pid_t pid = fork();
if (pid == 0) {
// 子进程
return 0;
} else {
// 父进程等待指定子进程结束
waitpid(pid, NULL, 0);
}3.2.3获取⼦进程status
• wait和waitpid,都有⼀个status参数,该参数是⼀个输出型参数,由操作系统填充.
• 如果传递NULL,表示不关⼼⼦进程的退出状态信息.
• 否则,操作系统会根据该参数,将⼦进程的退出信息反馈给⽗进程.
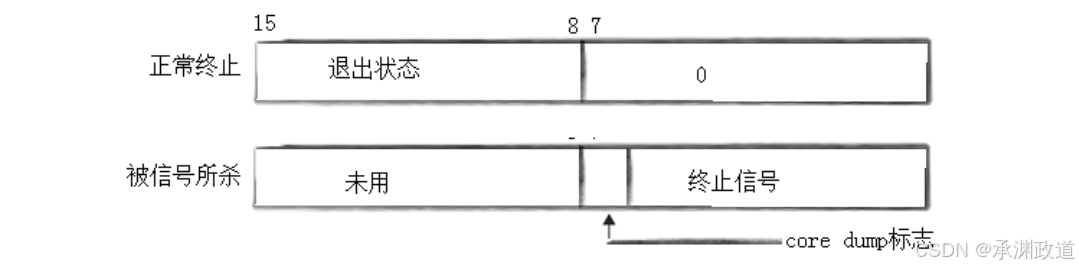
• status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只研究status低16⽐特位)
c
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h> // 定义 pid_t 类型
#include <sys/wait.h> // wait() 函数
#include <unistd.h> // fork()、sleep() 函数声明
#include <string.h>
#include <errno.h>
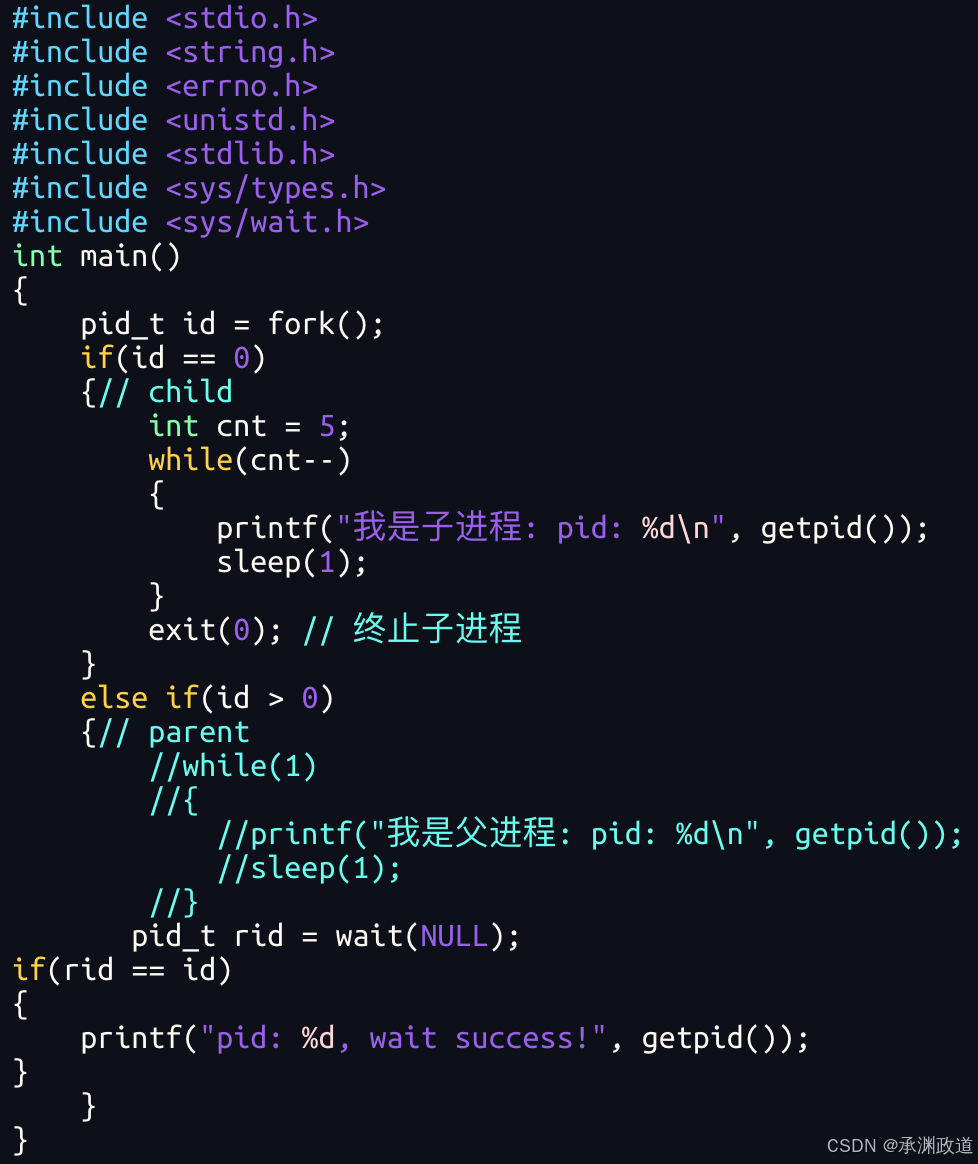
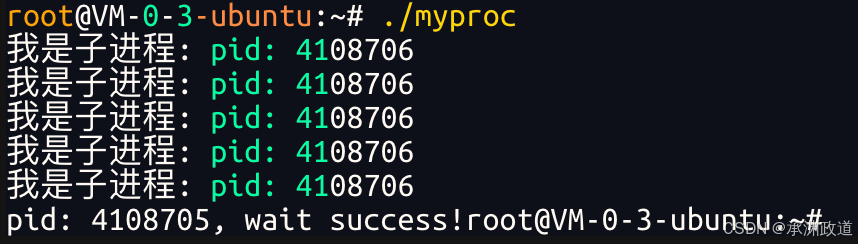
int main(void)
{
pid_t pid;
// 创建子进程
if ((pid = fork()) == -1)
{
perror("fork failed");
exit(1);
}
// 子进程逻辑
if (pid == 0)
{
printf("子进程运行,PID: %d,20秒后退出\n", getpid());
sleep(20); // 休眠20秒
exit(10); // 子进程退出码:10
}
// 父进程逻辑
else
{
int status;
printf("父进程等待子进程退出,PID: %d\n", getpid());
// 等待子进程结束,获取退出状态
pid_t ret = wait(&status);
if (ret > 0)
{
// 判断子进程是否正常退出(无信号终止)
if ((status & 0x7F) == 0)
{
// 右移8位获取退出码
printf("子进程正常退出,退出码: %d\n", (status >> 8) & 0xFF);
}
// 子进程被信号杀死(异常退出)
else
{
// 低7位是终止信号
printf("子进程异常退出,终止信号: %d\n", status & 0x7F);
}
}
}
return 0;
}
3.2.4阻塞与⾮阻塞等待
阻塞等待 是指父进程调用等待函数后,如果子进程还没有结束,父进程会暂停执行,直到子进程结束.
常用写法:
c
waitpid(pid, &status, 0);其中第三个参数是 0,表示阻塞等待.
示例:
c
pid_t pid = fork();
if (pid == 0) {
sleep(3);
return 0;
} else {
waitpid(pid, NULL, 0);
printf("子进程结束,父进程继续执行\n");
}执行过程:
text
子进程运行
父进程等待
子进程结束
父进程继续执行特点:
| 特点 | 说明 |
|---|---|
| 是否占用 CPU | 等待期间不占用 CPU |
| 父进程是否继续执行 | 不继续,直到子进程结束 |
| 适用场景 | 父进程必须等子进程结果 |
进程的阻塞等待⽅式:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
pid_t pid;
pid = fork();
if (pid < 0) {
printf("%s fork error\n", __FUNCTION__);
return 1;
}
else if (pid == 0) { // child
printf("child is run, pid is: %d\n", getpid());
sleep(5);
exit(257);
}
else { // father
int status = 0;
// 阻塞式等待,等待任意子进程退出
pid_t ret = waitpid(-1, &status, 0);
printf("this is test for wait\n");
if (WIFEXITED(status) && ret == pid) {
printf("wait child 5s success, child return code is: %d\n",
WEXITSTATUS(status));
}
else {
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}
非阻塞等待 是指父进程调用等待函数后,如果子进程还没有结束,父进程不会停下来,而是继续执行其他任务.
常用写法:
c
waitpid(pid, &status, WNOHANG);其中 WNOHANG 表示非阻塞等待.
示例:
c
pid_t pid = fork();
if (pid == 0) {
sleep(3);
return 0;
} else {
int ret;
while (1) {
ret = waitpid(pid, NULL, WNOHANG);
if (ret == 0) {
printf("子进程还没结束,父进程继续做其他事\n");
sleep(1);
} else if (ret == pid) {
printf("子进程结束,父进程回收成功\n");
break;
}
}
}waitpid() 返回值含义:
| 返回值 | 含义 |
|---|---|
ret > 0 |
等待成功,返回结束的子进程 PID |
ret == 0 |
子进程还没有结束 |
ret == -1 |
等待失败 |
进程的⾮阻塞等待⽅式:
c
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <vector>
typedef void (*handler_t)(); // 函数指针类型
std::vector<handler_t> handlers; // 函数指针数组
void fun_one() {
printf("这是一个临时任务1\n");
}
void fun_two() {
printf("这是一个临时任务2\n");
}
void Load() {
handlers.push_back(fun_one);
handlers.push_back(fun_two);
}
void handler() {
if (handlers.empty())
Load();
for (auto iter : handlers)
iter();
}
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
printf("%s fork error\n", __FUNCTION__);
return 1;
} else if (pid == 0) { // child
printf("child is run, pid is : %d\n", getpid());
sleep(5);
exit(1);
} else {
int status = 0;
pid_t ret = 0;
do {
ret = waitpid(-1, &status, WNOHANG); // 非阻塞式等待
if (ret == 0) {
printf("child is running\n");
}
handler();
} while (ret == 0);
if (WIFEXITED(status) && ret == pid) {
printf("wait child 5s success, child return code is :%d.\n",
WEXITSTATUS(status));
} else {
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}
阻塞等待和非阻塞等待区别
| 比较项 | 阻塞等待 | 非阻塞等待 |
|---|---|---|
| 第三个参数 | 0 |
WNOHANG |
| 子进程未结束时 | 父进程暂停 | 父进程继续执行 |
| CPU 利用率 | 高,不忙等 | 高,可处理其他任务 |
| 代码复杂度 | 简单 | 稍复杂 |
| 适用场景 | 必须等子进程结束 | 父进程还有其他任务 |
总结一句话:
阻塞等待是"等到子进程结束再走",非阻塞等待是"看一眼子进程有没有结束,没结束就先干别的".
3.3创建多进程
c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <stdlib.h>
typedef void (*callback_t)();
enum
{
OK,
USAGE_ERR,
FORK_ERR
};
void Task()
{
int cnt = 5;
while (cnt--)
{
printf("我是一个子进程, 我在完成Task任务, pid:%d, ppid:%d, cnt:%d\n",
getpid(), getppid(), cnt);
sleep(1);
}
}
void Hello()
{
int cnt = 5;
while (cnt--)
{
printf("我是一个子进程, 我在完成Hello任务, pid:%d, ppid:%d, cnt:%d\n",
getpid(), getppid(), cnt);
sleep(1);
}
}
void CreateChildProcess(int num, pid_t subs[], callback_t cb)
{
int i = 0;
for (i = 0; i < num; i++)
{
pid_t id = fork();
if (id < 0)
{
perror("fork");
exit(FORK_ERR);
}
else if (id == 0)
{
// child
cb();
exit(0);
}
else
{
// father
subs[i] = id;
}
}
}
void WaitAllChild(pid_t subs[], int num)
{
int i = 0;
for (i = 0; i < num; i++)
{
int status = 0;
pid_t rid = waitpid(subs[i], &status, 0);
if (rid > 0)
{
if (WIFEXITED(status))
{
printf("子进程:%d Exit, exit code:%d\n",
rid, WEXITSTATUS(status));
}
else
{
printf("子进程:%d 退出异常\n", rid);
}
}
}
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
printf("Usage: %s process_num\n", argv[0]);
exit(USAGE_ERR);
}
int num = atoi(argv[1]);
if (num <= 0)
{
printf("process_num 必须大于0\n");
exit(USAGE_ERR);
}
pid_t *subs = (pid_t *)malloc(sizeof(pid_t) * num);
if (subs == NULL)
{
perror("malloc");
exit(1);
}
// 创建多个子进程
CreateChildProcess(num, subs, Hello);
// 父进程等待所有子进程
WaitAllChild(subs, num);
free(subs);
return OK;
}
4.进程程序替换
fork() 之后,⽗⼦各⾃执⾏⽗进程代码的⼀部分如果⼦进程就想执⾏⼀个全新的程序呢?进程的程序替换来完成这个功能!程序替换是通过特定的接⼝,加载磁盘上的⼀个全新的程序(代码和数据),加载到调⽤进程的地址空间中!
进程程序替换,也叫进程替换,在Linux 中通常指的是 exec 系列函数.
它的作用是:让当前进程不再执行原来的代码,而是去执行一个新的程序.
注意:进程程序替换不会创建新进程,它只是把当前进程的代码、数据等替换成另一个程序.
4.1替换原理
⽤fork创建⼦进程后执⾏的是和⽗进程相同的程序(但有可能执⾏不同的代码分⽀),⼦进程往往要调⽤⼀种 exec 函数以执⾏另⼀个程序.当进程调⽤⼀种 exec 函数时,该进程的⽤⼾空间代码和数据完全被新程序替换,从新程序的启动例程开始执⾏.调⽤ exec 并不创建新进程,所以调⽤ exec 前后该进程的id并未改变.
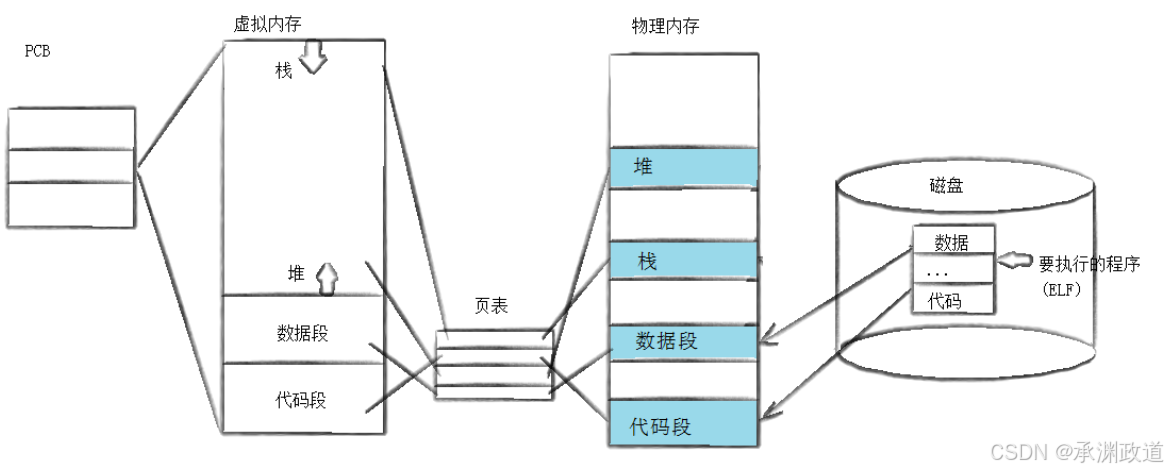
进程程序替换的原理,核心就是一句话:
用磁盘上的新程序,替换当前进程的代码和数据,让当前进程从新程序的入口开始执行.
注意:不是创建新进程,PID 不变.
1.替换前:进程正在运行原程序
比如你运行:
bash
./myproc操作系统会创建一个进程,这个进程有:
text
PCB
虚拟地址空间
页表
代码段
数据段
堆
栈可以简单理解为:
text
进程 = PCB + 地址空间 + 页表 + 程序代码和数据其中:
text
PCB:保存进程 pid、状态、优先级、上下文等信息
虚拟地址空间:代码段、数据段、堆、栈
页表:负责虚拟地址到物理地址的转换2.调用exec后:开始程序替换
比如代码中写:
c
execlp("ls", "ls", "-l", NULL);当前进程会请求操作系统:
text
我要把自己替换成 ls 程序此时操作系统会做几件事.
3.第一步:找到新程序
execlp 会根据环境变量 PATH 查找 ls 程序.
比如最终找到:
text
/usr/bin/ls如果找不到,就替换失败,execlp 返回 -1.
所以一般要写:
c
execlp("ls", "ls", "-l", NULL);
perror("execlp");
exit(1);如果 execlp 成功,后面的代码不会执行.
4.第二步:读取 ELF 文件
Linux 下可执行程序通常是 ELF 格式.
比如:
text
/usr/bin/ls它在磁盘上大概包含:
text
ELF 头
程序入口地址
代码段
数据段
动态链接信息
符号信息操作系统会解析这个 ELF 文件,知道:
text
哪些内容是代码
哪些内容是数据
程序入口在哪里
需要加载哪些动态库5.第三步:释放原来的地址空间
原来 myproc 的地址空间中有:
text
myproc 的代码段
myproc 的数据段
myproc 的堆
myproc 的栈执行 exec 后,这些内容基本都会被替换掉.
也就是说,当前进程不再执行原来程序的代码.
所以:
c
printf("before exec\n");
execlp("ls", "ls", "-l", NULL);
printf("after exec\n");如果 execlp 成功,只会看到:
text
before exec
ls -l 的输出不会看到:
text
after exec因为原来的代码已经被替换了.
6.第四步:建立新的虚拟地址空间
操作系统会为新程序建立新的地址空间布局:
text
代码段
数据段
BSS 段
堆
栈
共享库映射区也就是把原来的 myproc 地址空间换成 ls 的地址空间.
可以理解为:
text
替换前:
虚拟地址空间中放的是 myproc 的代码和数据
替换后:
虚拟地址空间中放的是 ls 的代码和数据7.第五步:建立页表映射
程序运行时,CPU 使用的是虚拟地址.
真正访问物理内存时,需要通过页表转换:
text
虚拟地址 -> 页表 -> 物理地址exec 时,操作系统会重新建立页表映射,让新程序的代码段、数据段、栈等映射到合适的物理内存.
所以你图里中间的页表就是关键.
它负责把:
text
虚拟内存中的代码段
虚拟内存中的数据段
虚拟内存中的堆
虚拟内存中的栈映射到真实物理内存中.
8.第六步:设置 CPU 执行入口
ELF 文件中有一个入口地址.
操作系统加载好新程序后,会把 CPU 的执行位置设置到新程序入口.
也就是说,原来进程可能正在执行:
c
execlp("ls", "ls", "-l", NULL);替换成功后,这个进程下一步不再返回原代码,而是从 ls 程序的入口开始执行.
9.什么没有变?
程序替换后,很多内容变了,但也有一些东西不变.
不变的有:
text
PID 不变
父进程不变
进程关系不变
部分进程属性不变
打开的文件描述符默认不关闭比如:
c
printf("pid before exec: %d\n", getpid());
execlp("ls", "ls", "-l", NULL);执行 exec 前后,还是同一个进程 PID.
10.什么变了?
改变的有:
text
代码段变了
数据段变了
堆变了
栈被重新建立
页表映射变了
CPU 执行入口变了所以它叫"程序替换".
不是把进程换掉,而是把进程里运行的程序换掉.
11.fork + exec 的完整理解
通常不会直接在父进程中 exec,因为一旦父进程 exec,父进程自己的代码就没了.
所以一般是:
c
pid_t pid = fork();
if (pid == 0)
{
execlp("ls", "ls", "-l", NULL);
perror("execlp");
exit(1);
}
else
{
waitpid(pid, NULL, 0);
}流程是:
text
父进程 fork 创建子进程
子进程调用 exec 替换成 ls
父进程继续执行原来的代码,并等待子进程退出也就是:
text
fork:创建一个新进程
exec:让这个新进程执行另一个程序
waitpid:父进程回收子进程12.用图来理解
可以这样看:
text
执行 exec 前:
进程 PID = 1234
PCB
|
|-- 虚拟地址空间
|-- myproc 代码段
|-- myproc 数据段
|-- myproc 堆
|-- myproc 栈
|
|-- 页表
|-- 映射 myproc 对应的物理内存执行:
c
execlp("ls", "ls", "-l", NULL);之后:
text
进程 PID = 1234
PCB
|
|-- 虚拟地址空间
|-- ls 代码段
|-- ls 数据段
|-- ls 堆
|-- ls 栈
|
|-- 页表
|-- 映射 ls 对应的物理内存你会发现:
text
PID 还是 1234
PCB 还是那个进程
但里面执行的程序变成了 ls4.2替换函数
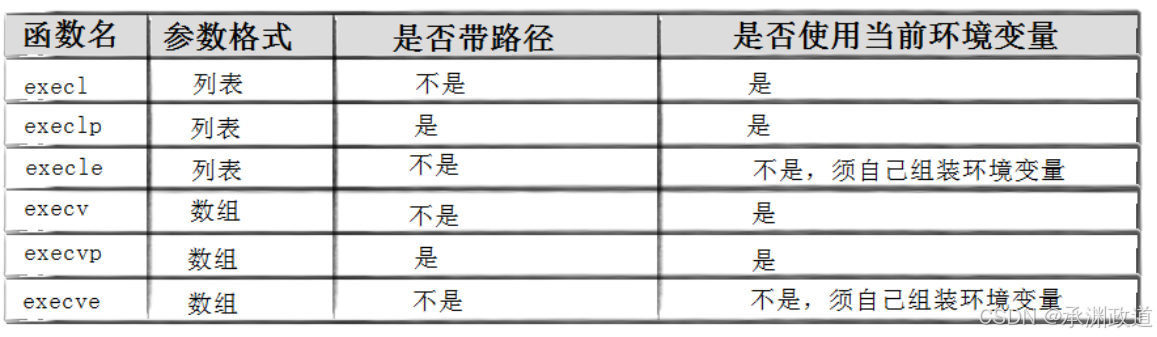
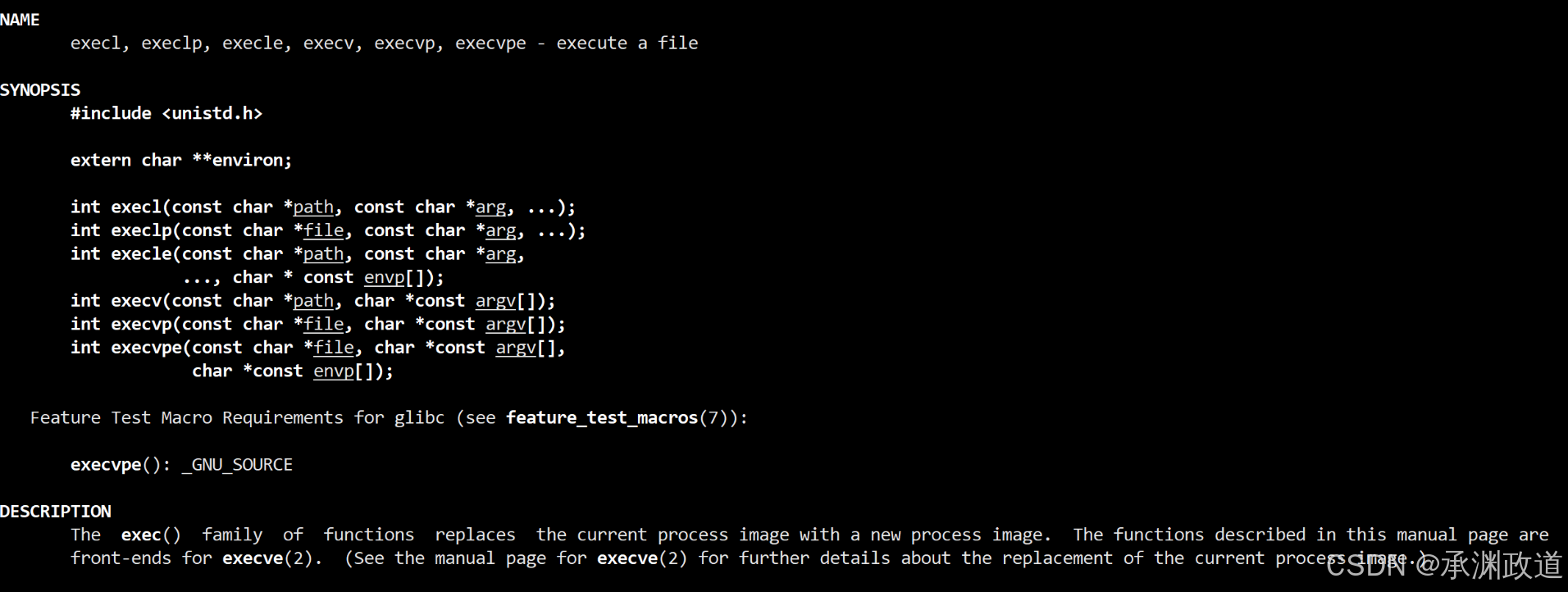
Linux 中的程序替换函数 主要是 exec 系列函数.
它们的共同作用是:
text
用一个新的程序替换当前进程正在执行的程序常见函数有 6 个:
c
execl
execlp
execle
execv
execvp
execve1.exec 系列函数总览
c
#include <unistd.h>
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);这些函数如果替换成功,不会返回 .
只有失败时才会返回 -1,所以一般后面要加:
c
perror("exec");
exit(1);2.execl
execl 使用完整路径,参数一个一个列出来.
c
execl("/usr/bin/ls", "ls", "-l", "-a", NULL);等价于在命令行执行:
bash
ls -l -a完整示例:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("before exec, pid: %d\n", getpid());
execl("/usr/bin/ls", "ls", "-l", "-a", NULL);
perror("execl");
exit(1);
}注意最后必须写 NULL,表示参数结束.
3.execlp
execlp 会自动从环境变量 PATH 中找程序,所以不需要写完整路径.
c
execlp("ls", "ls", "-l", "-a", NULL);等价于:
bash
ls -l -a这是最常用的之一.
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("before exec, pid: %d\n", getpid());
execlp("ls", "ls", "-l", NULL);
perror("execlp");
exit(1);
}4.execv
execv 使用参数数组传参.
c
char *const argv[] = {
"ls",
"-l",
"-a",
NULL
};
execv("/usr/bin/ls", argv);完整示例:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
char *const argv[] = {
"ls",
"-l",
"-a",
NULL
};
execv("/usr/bin/ls", argv);
perror("execv");
exit(1);
}5.execvp
execvp 和 execv 类似,也是数组传参,但是它会自动从 PATH 中找程序.
c
char *const argv[] = {
"ls",
"-l",
"-a",
NULL
};
execvp("ls", argv);完整示例:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
char *const argv[] = {
"ls",
"-l",
"-a",
NULL
};
execvp("ls", argv);
perror("execvp");
exit(1);
}6.execle
execle 可以自己传环境变量.
c
char *const envp[] = {
"MYENV=hello_linux",
NULL
};
execle("/usr/bin/env", "env", NULL, envp);完整示例:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
char *const envp[] = {
"MYENV=hello_linux",
NULL
};
execle("/usr/bin/env", "env", NULL, envp);
perror("execle");
exit(1);
}运行后会执行 env,打印环境变量,你能看到:
text
MYENV=hello_linux7.execve
execve 是最底层的系统调用,其他 exec 函数最终通常都会封装到它.
c
int execve(const char *path, char *const argv[], char *const envp[]);示例:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
char *const argv[] = {
"ls",
"-l",
NULL
};
char *const envp[] = {
"PATH=/usr/bin:/bin",
NULL
};
execve("/usr/bin/ls", argv, envp);
perror("execve");
exit(1);
}8.fork + exec 示例
实际中一般这样用:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fork");
exit(1);
}
else if (id == 0)
{
printf("child process, pid: %d\n", getpid());
execlp("ls", "ls", "-l", NULL);
perror("execlp");
exit(1);
}
else
{
int status = 0;
waitpid(id, &status, 0);
printf("father wait success, child exit code: %d\n",
WEXITSTATUS(status));
}
return 0;
}编译运行:
bash
gcc test.c -o test
./test子进程会被替换成 ls -l 程序,父进程等待子进程退出.
一句话总结:
text
execl / execv:需要完整路径
execlp / execvp:可以自动从 PATH 找程序
execle / execve:可以自定义环境变量初学时重点掌握:
c
execlp("ls", "ls", "-l", NULL);和:
c
char *argv[] = {"ls", "-l", NULL};
execvp("ls", argv);4.2.1函数解释
• 这些函数如果调⽤成功则加载新的程序从启动代码开始执⾏,不再返回.
• 如果调⽤出错则返回 -1.
• 所以 exec 函数只有出错的返回值⽽没有成功的返回值.
4.2.2命名理解
这些函数原型看起来很容易混,但只要掌握了规律就很好记.
• l(list) : 表示参数采⽤列表
• v(vector) : 参数⽤数组
• p(path) : 有p⾃动搜索环境变量 PATH
• e(env) : 表示⾃⼰维护环境变量
exec调⽤举例如下:
c
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
char *const argv[] = {"ps", "-ef", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
// 1. execl:指定完整路径,逐个传参
execl("/bin/ps", "ps", "-ef", NULL);
// 若 execl 失败,才会执行 perror 提示
perror("execl failed");
// 2. execlp:自动从 PATH 找命令,逐个传参(带 p)
// execlp("ps", "ps", "-ef", NULL);
// perror("execlp failed");
// 3. execle:指定完整路径,传参+自定义环境变量(带 e)
// execle("/bin/ps", "ps", "-ef", NULL, envp);
// perror("execle failed");
// 4. execv:指定完整路径,传参用数组
// execv("/bin/ps", argv);
// perror("execv failed");
// 5. execvp:自动从 PATH 找命令,传参用数组(带 p)
// execvp("ps", argv);
// perror("execvp failed");
// 6. execve:指定完整路径,传参数组+自定义环境变量(系统调用)
// execve("/bin/ps", argv, envp);
// perror("execve failed");
// 只有所有 exec 都失败时,才会执行 exit
exit(EXIT_FAILURE);
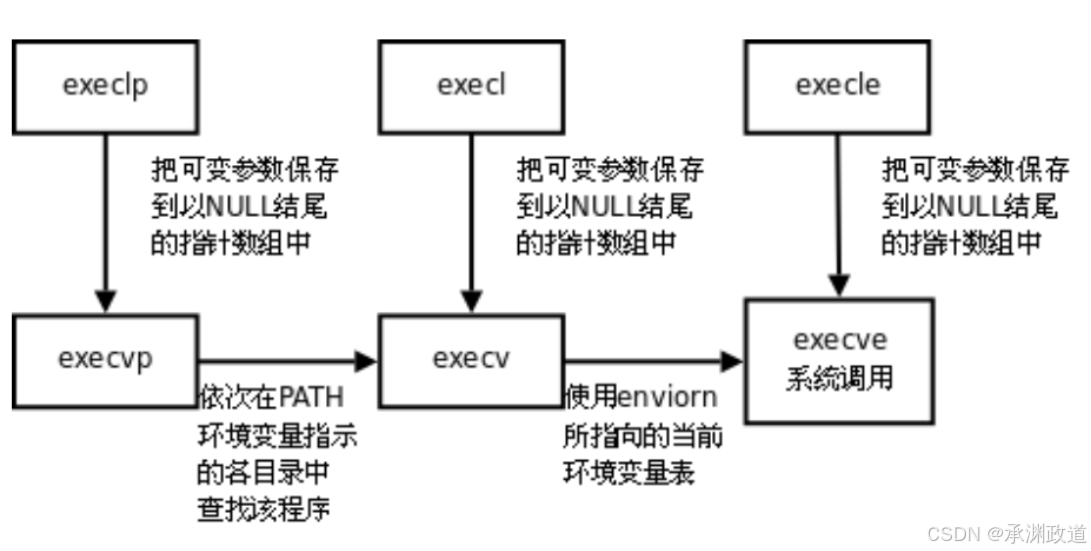
}事实上,只有 execve 是真正的系统调⽤,其它五个函数最终都调⽤execve,所以execve在man⼿册第2节,其它函数在man⼿册第3节.这些函数之间的关系如下图所示.下图exec函数簇 ⼀个完整的例⼦:
📌下面演示环境变量如何传⼊的问题
c
#define _GNU_SOURCE
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
//测试环境变量传递的主函数
int main() {
pid_t pid;
//自定义环境变量数组(必须以NULL结尾)
char *const custom_env[] = {
"MY_NAME=LCZ", //自定义变量
"PATH=/bin:/usr/bin", //必须包含命令路径
"LANG=en_US.UTF-8",
NULL //终止标记,必不可少
};
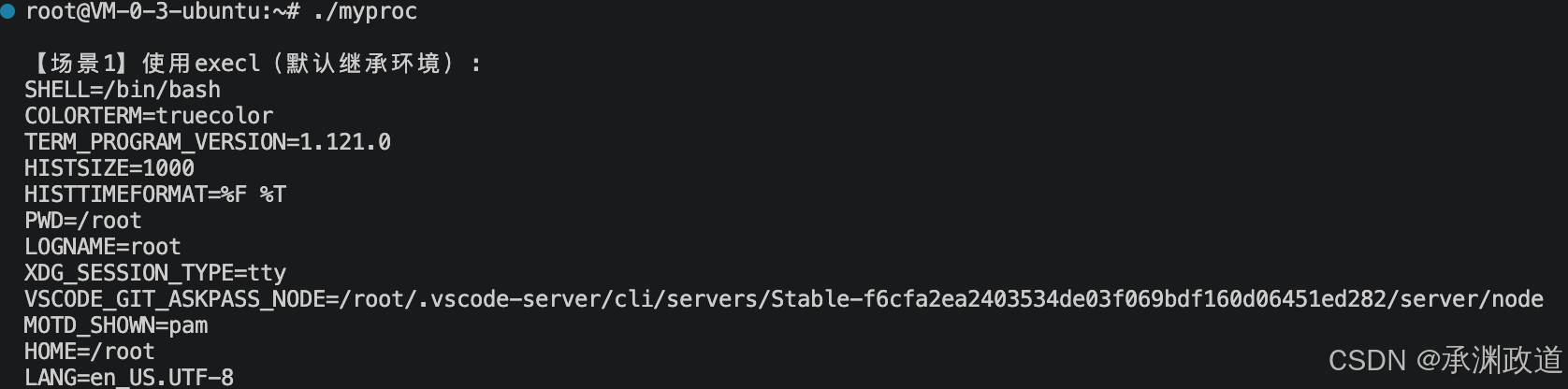
//场景1:默认继承环境变量(execl)
pid = fork();
if (pid == 0) { // 子进程
printf("\n【场景1】使用execl(默认继承环境):\n");
execl("/usr/bin/env", "env", NULL); //执行env命令查看环境变量
perror("execl failed");
exit(EXIT_FAILURE);
}
wait(NULL); //等待子进程结束
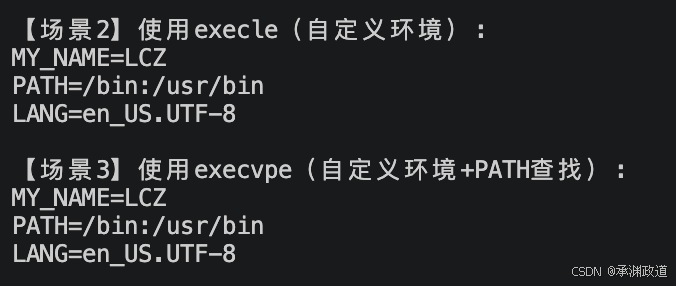
//场景2:自定义环境变量(execle)
pid = fork();
if (pid == 0) { //子进程
printf("\n【场景2】使用execle(自定义环境):\n");
//execle最后一个参数是自定义环境变量数组
execle("/usr/bin/env", "env", NULL, custom_env);
perror("execle failed");
exit(EXIT_FAILURE);
}
wait(NULL);
//场景3:自定义环境+自动路径查找(execvpe)
pid = fork();
if (pid == 0) { // 子进程
char *const argv[] = {"env", NULL}; //参数数组
printf("\n【场景3】使用execvpe(自定义环境+PATH查找):\n");
//execvpe:v=数组参数,p=PATH查找,e=自定义环境
execvpe("env", argv, custom_env);
perror("execvpe failed");
exit(EXIT_FAILURE);
}
wait(NULL);
printf("\n所有测试完成!\n");
return 0;
}
5.⾃主Shell命令⾏解释器
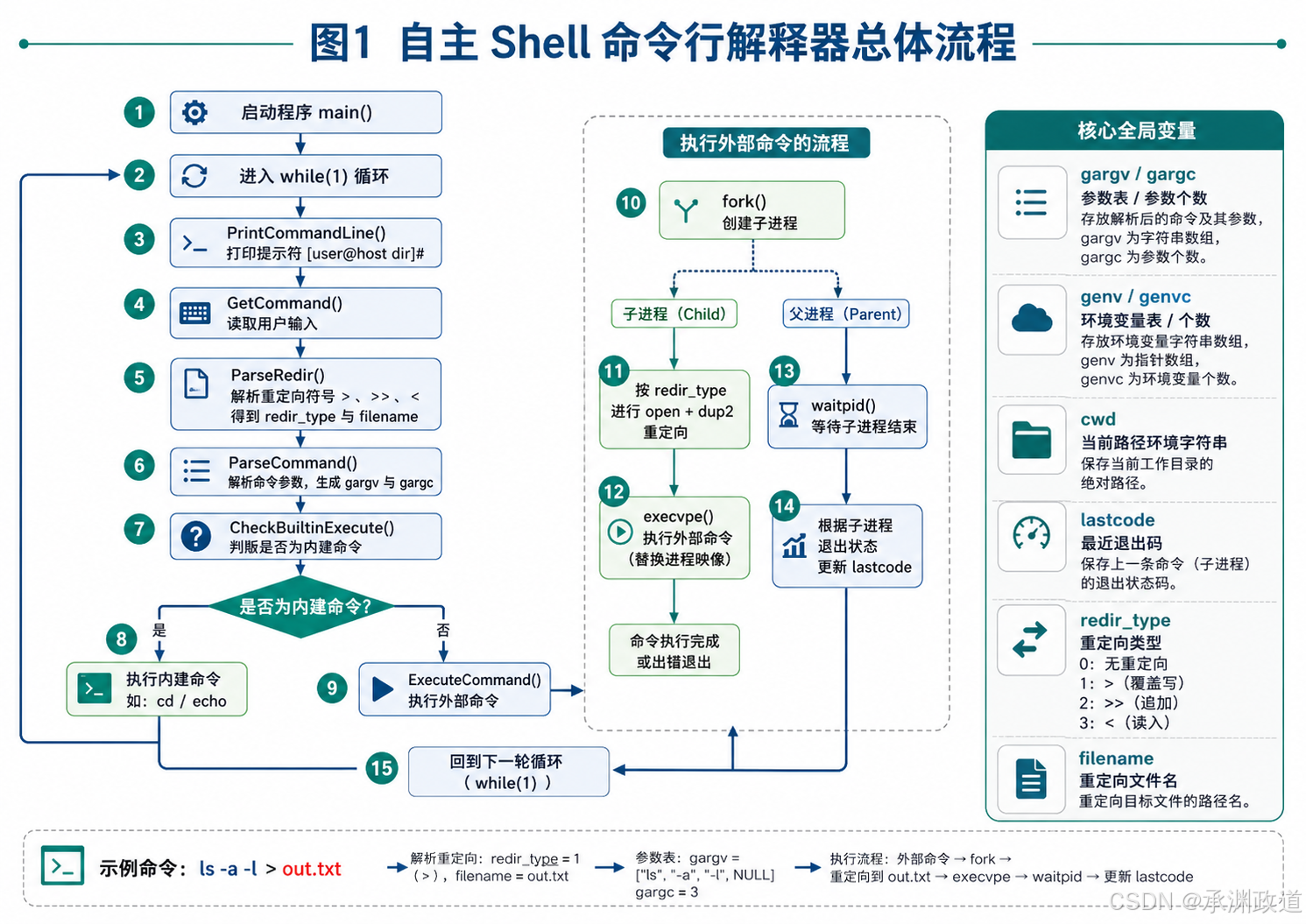
自主Shell 命令行解释器是一个模拟Linux Shell 基本功能的命令行程序.它能够接收用户输入的命令,对命令进行解析、判断和执行,并将执行结果反馈给用户.通过实现该模块,可以加深对操作系统进程管理、命令解析、程序执行以及输入输出机制的理解.
本项目中的 Shell 解释器主要实现了命令提示符显示、用户命令读取、命令解析、内置命令处理以及外部程序调用等功能.用户可以像使用普通终端一样输入命令,例如 ls、pwd、cd、exit 等,程序会根据输入内容完成相应操作.
5.1目标
本模块的主要目标是设计并实现一个简单的自主 Shell 命令行解释器,使其具备基本的命令交互能力.具体目标如下:
首先,程序需要能够循环显示命令提示符,等待用户输入命令.用户输入命令后,Shell 应能够读取完整的命令字符串,并对其进行初步处理,例如去除换行符、判断是否为空命令等.
其次,Shell 需要能够对输入的命令进行解析.对于一条命令,程序应能将其拆分为命令名和参数列表.例如用户输入:
bash
ls -l /home解释器应将 ls 识别为命令名,将 -l 和 /home 识别为参数.
再次,Shell 需要支持部分内置命令.由于某些命令必须由 Shell 自身执行,例如 cd 用于改变当前工作目录,exit 用于退出 Shell,因此这些命令不能简单地交给外部程序执行,而需要在解释器内部单独处理.
最后,Shell 需要能够执行普通外部命令.当用户输入的命令不是内置命令时,程序应创建子进程,并在子进程中调用系统函数执行对应程序,父进程则等待子进程结束后继续接收下一条命令.
通过完成该模块,可以达到以下学习目的:
- 理解 Shell 命令解释器的基本工作流程;
- 掌握字符串解析和参数拆分方法;
- 熟悉进程创建、程序替换和进程等待机制;
- 理解内置命令与外部命令的区别;
- 提高对操作系统命令执行过程的理解。
5-2 实现原理
自主 Shell 命令行解释器的核心思想可以概括为:读取命令、解析命令、判断命令类型、执行命令、返回等待下一次输入.
程序运行后首先进入一个循环.在每次循环中,Shell 会打印一个命令提示符,例如:
bash
myshell>随后程序调用输入函数读取用户输入的一整行命令.如果用户直接按下回车,说明输入为空,程序会忽略本次输入并继续显示提示符.
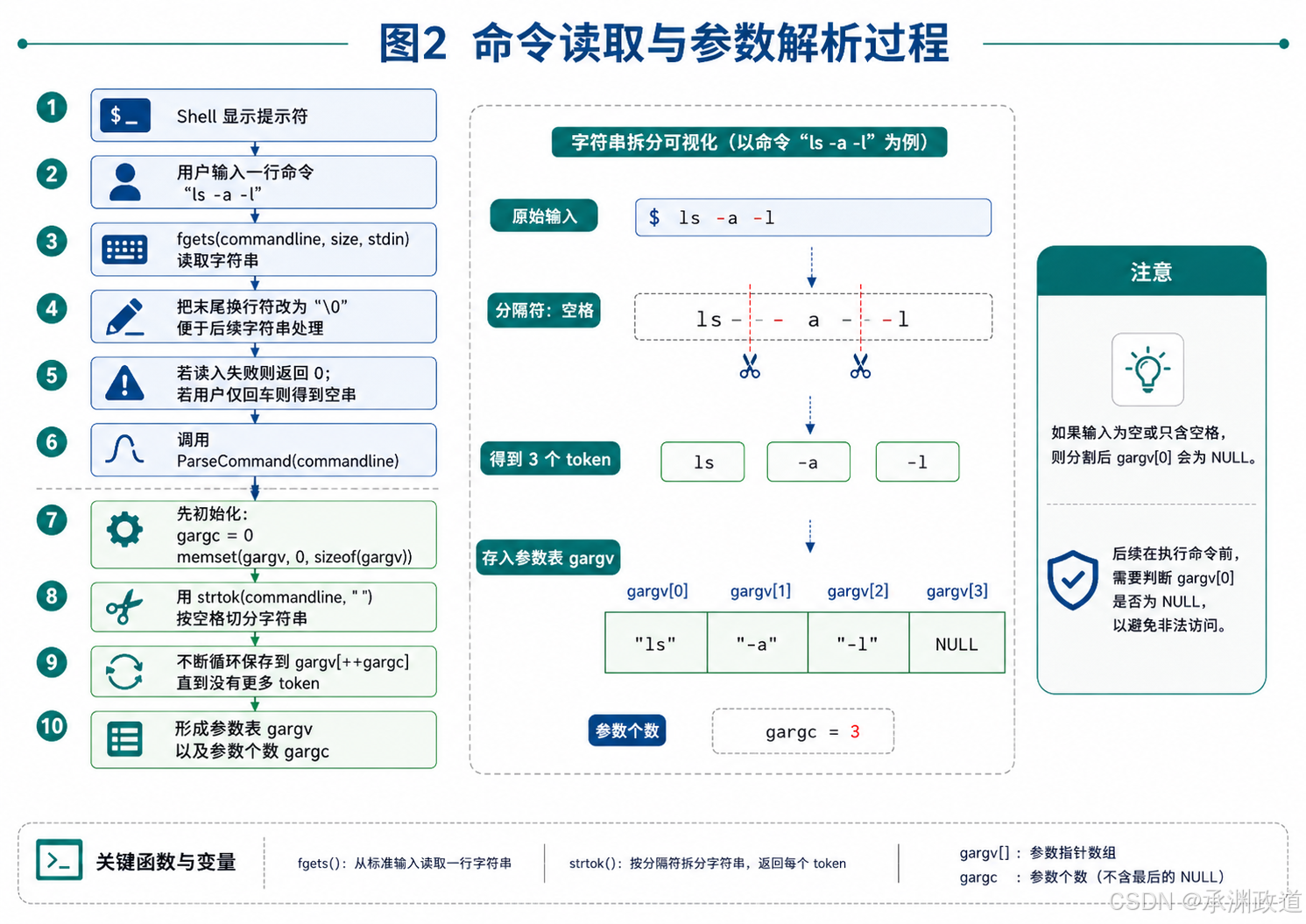
读取到命令后,程序需要对命令字符串进行解析.解析过程通常以空格作为分隔符,将输入内容拆分成多个字符串.其中第一个字符串表示命令名,后面的字符串表示命令参数.例如:
bash
echo hello world可以被解析为:
c
args[0] = "echo";
args[1] = "hello";
args[2] = "world";
args[3] = NULL;这里最后一个参数需要设置为 NULL,这是因为 execvp 等系统调用要求参数数组以空指针结尾.
解析完成后,Shell 会判断命令是否为内置命令.常见的内置命令包括:
bash
cd
exit
pwd其中,exit 用于退出当前 Shell 程序;cd 用于切换当前工作目录;pwd 用于显示当前工作目录.由于这些命令与 Shell 当前进程状态有关,因此通常需要直接在父进程中执行.
如果输入的命令不是内置命令,Shell 会将其视为外部命令.执行外部命令时,程序通常使用 fork() 创建一个子进程.子进程创建成功后,在子进程中调用 execvp() 执行用户输入的命令.execvp() 会根据环境变量 PATH 自动查找可执行程序,因此用户可以直接输入 ls、cat、gcc 等命令,而不一定需要输入完整路径.
父进程在创建子进程后,需要调用 wait() 或 waitpid() 等函数等待子进程执行完成.这样可以避免 Shell 在命令尚未执行结束时就继续接收新的输入,也可以防止产生僵尸进程.
整体流程如下:
text
启动 Shell
↓
显示命令提示符
↓
读取用户输入
↓
判断输入是否为空
↓
解析命令和参数
↓
判断是否为内置命令
↓
是:直接执行内置命令
否:创建子进程执行外部命令
↓
父进程等待子进程结束
↓
继续下一轮输入该实现方式体现了 Shell 的基本运行机制,也反映了操作系统中进程管理和程序执行之间的关系.
⽤下图的时间轴来表⽰事件的发⽣次序.其中时间从左向右.shell由标识为sh的⽅块代表,它随着时间的流逝从左向右移动.shell从⽤⼾读⼊字符串"ls".shell建⽴⼀个新的进程,然后在那个进程中运⾏ls程序并等待那个进程结束.
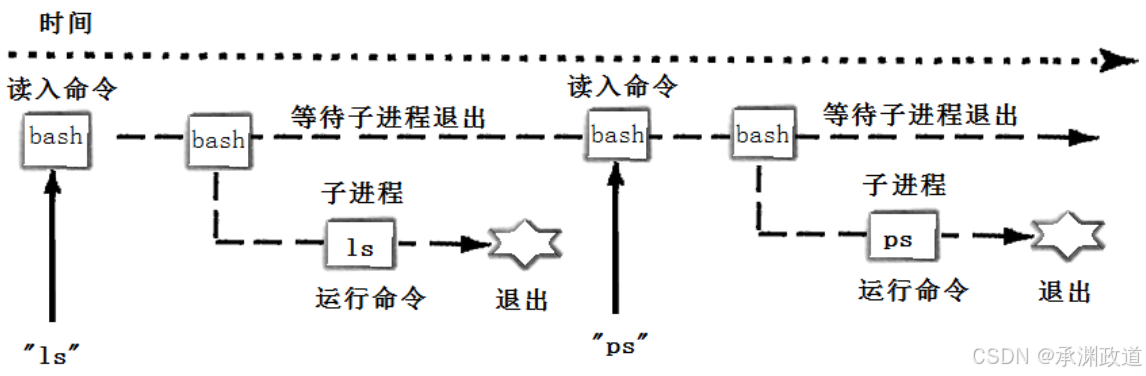
然后shell读取新的⼀⾏输⼊,建⽴⼀个新的进程,在这个进程中运⾏程序 并等待这个进程结束.
所以要写⼀个shell,需要循环以下过程:
- 获取命令⾏
- 解析命令⾏
- 建⽴⼀个⼦进程(fork)
- 替换⼦进程(execvp)
- ⽗进程等待⼦进程退出(wait)
根据这些思路,和我们前⾯的学的技术,就可以⾃⼰来实现⼀个shell了.
5.3源码
cpp
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/wait.h>
#include <iostream>
#include <string>
#define MAXSIZE 128
#define MAXARGS 32
// shell自己内部维护的第一张表: 命令行参数表
// 故意设计成为全局的
// 命令行参数表
char *gargv[MAXARGS];
int gargc = 0;
const char *gsep = " ";
// 环境变量表
char *genv[MAXARGS];
int genvc = 0;
// 我们shell自己所处的工作路径
char cwd[MAXSIZE];
// 最近一个命令执行完毕,退出码
int lastcode = 0;
// vector<std::string> cmds; // 1000
// ls -a -l > XX.txt -> "ls -a -l" && "XX.txt" && 重定向的方式
// 表明重定向的信息
#define NoneRedir 0
#define InputRedir 1
#define AppRedir 2
#define OutputRedir 3
int redir_type = NoneRedir; // 记录正在执行的执行,重定向方式
char *filename = NULL; // 保存重定向的目标文件
// 空格空格空格filename.txt
#define TrimSpace(start) do{\
while(isspace(*start)) start++;\
}while(0)
void LoadEnv()
{
// 正常情况,环境变量表内部是从配置文件来的
// 今天我们从父进程拷贝
extern char **environ;
for(; environ[genvc]; genvc++)
{
genv[genvc] = (char*)malloc(sizeof(char)*4096);
strcpy(genv[genvc], environ[genvc]);
}
genv[genvc] = NULL;
printf("Load env: \n");
for(int i = 0; genv[i]; i++)
printf("genv[%d]: %s\n", i, genv[i]);
}
static std::string rfindDir(const std::string &p)
{
if(p == "/")
return p;
const std::string psep = "/";
auto pos = p.rfind(psep);
if(pos == std::string::npos)
return std::string();
return p.substr(pos+1); // /home/whb
}
const char *GetUserName()
{
char *name = getenv("USER");
if(name == NULL)
return "None";
return name;
}
const char *GetHostName()
{
char *hostname = getenv("HOSTNAME");
if(hostname == NULL)
return "None";
return hostname;
}
const char *GetPwd()
{
char *pwd = getenv("PWD");
//char *pwd = getcwd(cwd, sizeof(cwd));
if(pwd == NULL)
return "None";
return pwd;
}
void PrintCommandLine()
{
printf("[%s@%s %s]# ", GetUserName(), GetHostName(), rfindDir(GetPwd()).c_str()); // 用户名 @ 主机名 当前路径
fflush(stdout);
}
int GetCommand(char commandline[], int size)
{
if(NULL == fgets(commandline, size, stdin))
return 0;
// 2.1 用户输入的时候,至少会摁一下回车\n abcd\n ,\n '\0'
commandline[strlen(commandline)-1] = '\0';
return strlen(commandline);
}
// ls -a -l >> filenamel.txt -> ls -a -l \0\0 filename.txt
// ls -a -l > XX.txt || ls -a -l >> XX.txt || cat < log.txt || ls -a -l
void ParseRedir(char commandline[])
{
redir_type = NoneRedir;
filename = NULL;
char *start = commandline;
char *end = commandline+strlen(commandline);
while(start < end)
{
if(*start == '>')
{
if(*(start+1) == '>')
{
// 追加重定向
*start = '\0';
start++;
*start = '\0';
start++;
TrimSpace(start); // 去掉左半部分的空格
redir_type = AppRedir;
filename = start;
break;
}
// 输出重定向
*start = '\0';
start++;
TrimSpace(start);
redir_type = OutputRedir;
filename = start;
break;
}
else if(*start == '<')
{
// 输入重定向
*start = '\0';
start++;
TrimSpace(start);
redir_type = InputRedir;
filename = start;
break;
}
else
{
// 没有重定向
start++;
}
}
}
int ParseCommand(char commandline[])
{
gargc = 0;
memset(gargv, 0, sizeof(gargv));
// ls -a -l
// 故意 commandline : ls
gargv[0] = strtok(commandline, gsep);
while((gargv[++gargc] = strtok(NULL, gsep)));
// printf("gargc: %d\n", gargc); // ?
// int i = 0;
// for(; gargv[i]; i++)
// printf("gargv[%d]: %s\n", i, gargv[i]);
return gargc;
}
// retunr val:
// 0 : 不是内建命令
// 1 : 内建命令&&执行完毕
int CheckBuiltinExecute()
{
if(strcmp(gargv[0], "cd") == 0)
{
// 内建命令
if(gargc == 2)
{
// 新的目标路径: gargv[1]
// 1. 更改进程内核中的路径
chdir(gargv[1]);
// 2. 更改环境变量
char pwd[1024];
getcwd(pwd, sizeof(pwd)); // /home/whb
snprintf(cwd, sizeof(cwd), "PWD=%s", pwd); // cwd: PWD=/home/home
putenv(cwd);
lastcode = 0;
}
return 1;
}
else if(strcmp(gargv[0], "echo") == 0) // cd , echo , env , export 内建命令
{
if(gargc == 2)
{
if(gargv[1][0] == '$')
{
// $? ? : 看做一个变量名字
if(strcmp(gargv[1]+1, "?") == 0)
{
printf("lastcode: %d\n", lastcode);
}
else if(strcmp(gargv[1]+1, "PATH") == 0)
{
// 不准你用getenv和putenv
printf("%s\n", getenv("PATH")); // putenv 和 getenv 究竟是什么, 访问环境变量表!
}
lastcode = 0;
}
return 1;
// echo helloworld
// echo $?
}
}
return 0;
}
int ExecuteCommand()
{
// 能不能让你的bash自己执行命令:ls -a -l
pid_t id = fork();
if(id < 0)
return -1;
else if(id == 0)
{
//printf("我是子进程,我是exec启动前: %dp\n", getpid());
// 子进程: 如何执行, gargv, gargc
// ls -a -l
int fd = -1;
if(redir_type == NoneRedir)
{
// Do Nothing
}
else if(redir_type == OutputRedir)
{
// 子进程要进行输出重定向
fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1);
}
else if(redir_type == AppRedir)
{
fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1);
}
else if(redir_type == InputRedir)
{
fd = open(filename, O_RDONLY);
dup2(fd, 0);
}
else{
//bug??
}
execvpe(gargv[0], gargv, genv);
exit(1);
}
else
{
// 父进程
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid > 0)
{
lastcode = WEXITSTATUS(status);
//printf("wait child process success!\n");
}
}
return 0;
}
int main()
{
// 0. 从配置文件中获取环境变量填充环境变量表的
//LoadEnv();
char command_line[MAXSIZE] = {0};
while(1)
{
// 1. 打印命令行字符串
PrintCommandLine();
// 2. 获取用户输入
if(0 == GetCommand(command_line, sizeof(command_line)))
continue;
//printf("%s\n", command_line);
// ls -a -l > XX.txt || ls -a -l >> XX.txt || cat < log.txt || ls -a -l
// ls -a -l > XX.txt -> "ls -a -l" && "XX.txt" && 重定向的方式
ParseRedir(command_line);
//printf("command: %s\n", command_line);
//printf("redir type: %d\n", redir_type);
//printf("filename: %s\n", filename);
// 4. 解析字符串 -> "ls -a -l" -> "ls" "-a" "-l" 命令行解释器,就要对用户输入的命令字符串首先进行解析!
ParseCommand(command_line);
// 5. 这个命令,到底是让父进程bash自己执行(内建命令)?还是让子进程执行
if(CheckBuiltinExecute()) // > 0
{
continue;
}
// 6. 让子进程执行这个命令
ExecuteCommand();
}
return 0;
}这段代码实现的是一个简易版自主 Shell 命令行解释器,功能类似 Linux 终端中的 bash.它可以显示命令提示符、读取用户输入、解析命令、执行内建命令,并通过创建子进程执行普通外部命令,同时还支持简单的输入输出重定向.
1.头文件和宏定义
cpp
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/wait.h>
#include <iostream>
#include <string>这些头文件分别用于:
stdio.h 用于输入输出,例如 printf、fgets;
ctype.h 用于字符判断,例如 isspace;
string.h 用于字符串处理,例如 strlen、strcmp、strtok;
stdlib.h 用于内存申请、环境变量操作、程序退出等;
unistd.h 用于进程相关接口,例如 fork、chdir、execvpe;
fcntl.h 用于文件打开,例如 open;
sys/wait.h 用于父进程等待子进程,例如 waitpid;
iostream 和 string 用于 C++ 字符串处理.
cpp
#define MAXSIZE 128
#define MAXARGS 32MAXSIZE 表示用户输入命令的最大长度.
MAXARGS 表示一条命令最多支持的参数数量.
2.全局变量
cpp
char *gargv[MAXARGS];
int gargc = 0;
const char *gsep = " ";这几个变量用于保存解析后的命令参数.
例如用户输入:
bash
ls -a -l解析后大致为:
cpp
gargv[0] = "ls";
gargv[1] = "-a";
gargv[2] = "-l";
gargv[3] = NULL;
gargc = 3;其中 gargv 就是命令行参数表,后面会传给 execvpe 执行.
cpp
char *genv[MAXARGS];
int genvc = 0;这两个变量用于维护 Shell 自己的环境变量表.不过代码中 LoadEnv() 被注释掉了,所以目前并没有真正加载自己的环境变量表.
cpp
char cwd[MAXSIZE];用于保存当前工作路径对应的环境变量字符串,例如:
cpp
PWD=/home/user
cpp
int lastcode = 0;保存上一条命令执行结束后的退出码.
比如执行:
bash
echo $?就可以查看上一条命令的退出状态.
3.重定向相关变量
cpp
#define NoneRedir 0
#define InputRedir 1
#define AppRedir 2
#define OutputRedir 3这几个宏表示不同的重定向类型.
cpp
int redir_type = NoneRedir;
char *filename = NULL;redir_type 用来记录当前命令是否存在重定向.
filename 用来保存重定向目标文件名.
例如:
bash
ls -l > out.txt解析后:
cpp
redir_type = OutputRedir;
filename = "out.txt";再比如:
bash
cat < input.txt解析后:
cpp
redir_type = InputRedir;
filename = "input.txt";4.去除空格宏
cpp
#define TrimSpace(start) do{\
while(isspace(*start)) start++;\
}while(0)这个宏用于跳过字符串开头的空白字符.
例如:
bash
ls -l > out.txt当解析到 > 后,后面可能有很多空格,TrimSpace(start) 可以让指针直接移动到 out.txt 的位置.
5.加载环境变量:LoadEnv
cpp
void LoadEnv()
{
extern char **environ;
for(; environ[genvc]; genvc++)
{
genv[genvc] = (char*)malloc(sizeof(char)*4096);
strcpy(genv[genvc], environ[genvc]);
}
genv[genvc] = NULL;
printf("Load env: \n");
for(int i = 0; genv[i]; i++)
printf("genv[%d]: %s\n", i, genv[i]);
}这个函数的作用是从父进程中拷贝环境变量到 genv 表中.
environ 是系统提供的环境变量表,里面保存了类似下面的信息:
bash
PATH=/usr/bin:/bin
PWD=/home/user
USER=whb
HOME=/home/whb函数会遍历 environ,并把每一个环境变量复制到 genv 中.
不过在 main() 中这一行被注释了:
cpp
//LoadEnv();所以实际运行时,genv 可能没有正确初始化.如果后面调用:
cpp
execvpe(gargv[0], gargv, genv);可能会因为环境变量为空而影响命令查找.
6.获取当前目录最后一级:rfindDir
cpp
static std::string rfindDir(const std::string &p)
{
if(p == "/")
return p;
const std::string psep = "/";
auto pos = p.rfind(psep);
if(pos == std::string::npos)
return std::string();
return p.substr(pos+1);
}这个函数用于获取路径的最后一级目录名.
例如:
cpp
/home/lcz返回:
cpp
lcz如果路径是:
cpp
/则直接返回 /。
这个函数主要用于命令提示符显示.
7.获取用户名、主机名和当前路径
cpp
const char *GetUserName()
{
char *name = getenv("USER");
if(name == NULL)
return "None";
return name;
}从环境变量 USER 中获取当前用户名.
cpp
const char *GetHostName()
{
char *hostname = getenv("HOSTNAME");
if(hostname == NULL)
return "None";
return hostname;
}从环境变量 HOSTNAME 中获取主机名.
cpp
const char *GetPwd()
{
char *pwd = getenv("PWD");
if(pwd == NULL)
return "None";
return pwd;
}从环境变量 PWD 中获取当前路径.
这里没有直接调用 getcwd(),而是从环境变量中读取当前目录.因此后面执行 cd 后,需要手动更新 PWD 环境变量.
8.打印命令提示符
cpp
void PrintCommandLine()
{
printf("[%s@%s %s]# ", GetUserName(), GetHostName(), rfindDir(GetPwd()).c_str());
fflush(stdout);
}这个函数打印 Shell 的命令提示符.
例如当前用户是 lcz,主机名是 localhost,当前目录是 /home/lcz/test,那么显示效果可能是:
bash
[lcz@localhost test]#其中:
GetUserName() 获取用户名;
GetHostName() 获取主机名;
GetPwd() 获取当前路径;
rfindDir(GetPwd()) 只取路径的最后一级目录.
9.获取用户输入命令
cpp
int GetCommand(char commandline[], int size)
{
if(NULL == fgets(commandline, size, stdin))
return 0;
commandline[strlen(commandline)-1] = '\0';
return strlen(commandline);
}这个函数用于从标准输入读取用户输入的一整行命令.
例如用户输入:
bash
ls -lfgets 读到的是:
cpp
"ls -l\n"所以代码通过:
cpp
commandline[strlen(commandline)-1] = '\0';把末尾的换行符 \n 替换成字符串结束符 \0.
最后返回命令字符串长度.
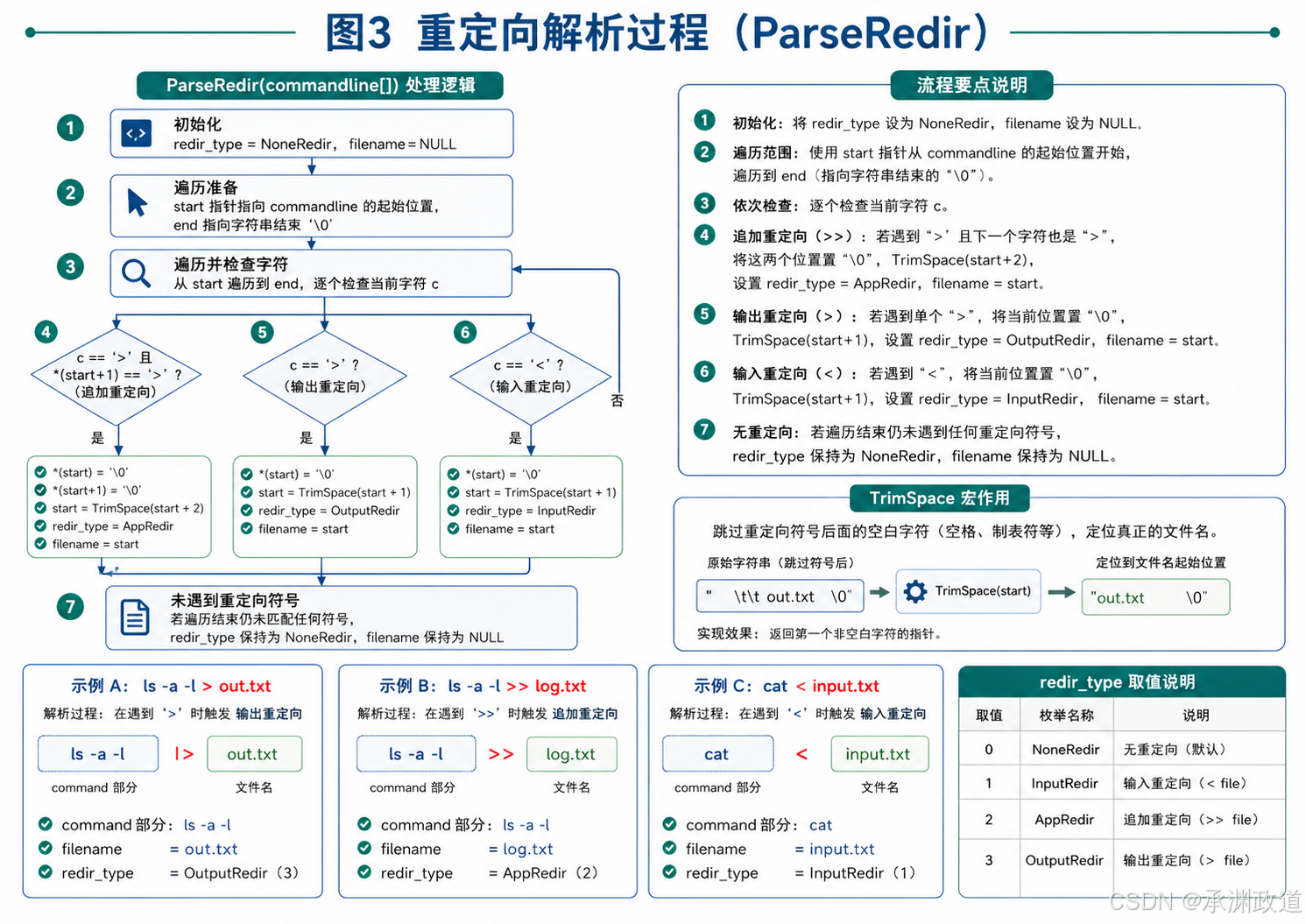
10.解析重定向:ParseRedir
cpp
void ParseRedir(char commandline[])这个函数用于判断用户输入中是否包含重定向符号.
支持三种形式:
bash
>
>>
<1)输出重定向
例如:
bash
ls -l > out.txt含义是:把 ls -l 的输出写入 out.txt,如果文件已存在就清空原内容.
代码会把原字符串拆成两部分:
cpp
"ls -l"
"out.txt"并设置:
cpp
redir_type = OutputRedir;
filename = "out.txt";2)追加重定向
例如:
bash
ls -l >> out.txt含义是:把输出追加到 out.txt 文件末尾.
代码设置:
cpp
redir_type = AppRedir;
filename = "out.txt";3)输入重定向
例如:
bash
cat < input.txt含义是:让 cat 从 input.txt 中读取内容,而不是从键盘读取.
代码设置:
cpp
redir_type = InputRedir;
filename = "input.txt";函数中的关键代码是:
cpp
*start = '\0';它会把重定向符号所在的位置改成字符串结束符.
例如原本是:
cpp
ls -l > out.txt修改后前半部分变成:
cpp
ls -l后面的 out.txt 由 filename 指针保存.
11.解析命令参数:ParseCommand
cpp
int ParseCommand(char commandline[])
{
gargc = 0;
memset(gargv, 0, sizeof(gargv));
gargv[0] = strtok(commandline, gsep);
while((gargv[++gargc] = strtok(NULL, gsep)));
return gargc;
}这个函数负责把命令字符串按空格拆分.
例如:
bash
ls -a -l会被解析成:
cpp
gargv[0] = "ls";
gargv[1] = "-a";
gargv[2] = "-l";
gargv[3] = NULL;
gargc = 3;这里使用的是 strtok,它会把分隔符位置替换成 \0,从而将一个完整字符串切割成多个小字符串.
解析后的 gargv 可以直接传给 execvpe.
12.判断并执行内建命令:CheckBuiltinExecute
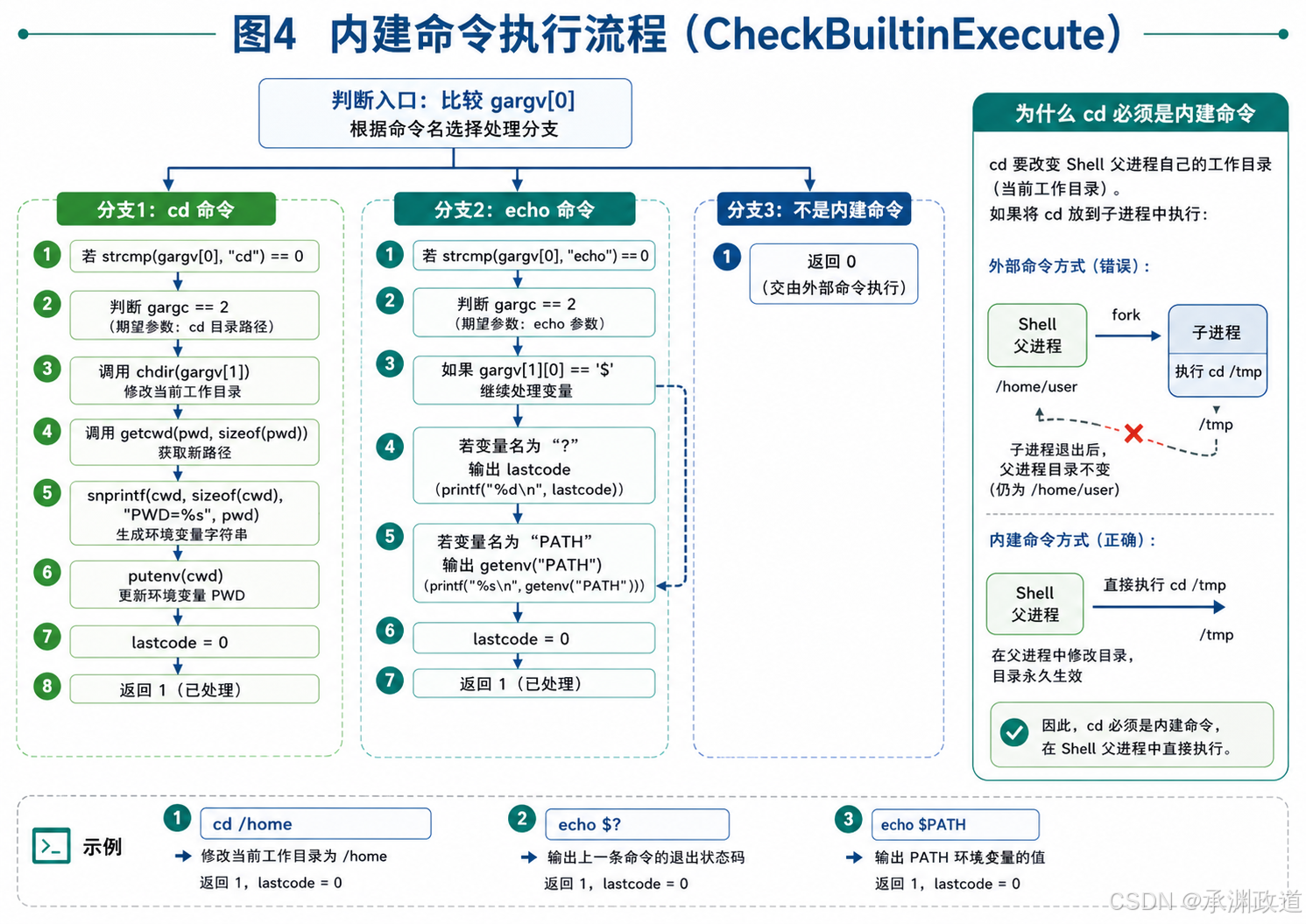
cpp
int CheckBuiltinExecute()这个函数用于判断当前命令是不是 Shell 内建命令.
内建命令不能直接交给子进程执行,因为它们会影响 Shell 自身状态.
目前代码支持两个内建命令:
bash
cd
echo1)cd 命令
cpp
if(strcmp(gargv[0], "cd") == 0)
{
if(gargc == 2)
{
chdir(gargv[1]);
char pwd[1024];
getcwd(pwd, sizeof(pwd));
snprintf(cwd, sizeof(cwd), "PWD=%s", pwd);
putenv(cwd);
lastcode = 0;
}
return 1;
}cd 用于切换当前工作目录.
例如:
bash
cd /home执行过程:
第一步:
cpp
chdir(gargv[1]);修改当前进程的工作目录.
第二步:
cpp
getcwd(pwd, sizeof(pwd));获取新的当前路径.
第三步:
cpp
snprintf(cwd, sizeof(cwd), "PWD=%s", pwd);
putenv(cwd);更新环境变量 PWD.
这里必须由父进程,也就是 Shell 自己执行 cd.
如果让子进程执行 cd,子进程退出后,父进程的当前目录不会改变,所以 Shell 看起来就像没有切换目录一样.
2)echo 命令
cpp
else if(strcmp(gargv[0], "echo") == 0)这里实现了一个简化版 echo.
支持:
bash
echo $?用于打印上一条命令退出码:
cpp
printf("lastcode: %d\n", lastcode);也支持:
bash
echo $PATH用于打印环境变量 PATH:
cpp
printf("%s\n", getenv("PATH"));不过这个 echo 功能并不完整,例如:
bash
echo hello这段代码不会真正打印 hello,因为这里只处理了 $? 和 $PATH 的情况.
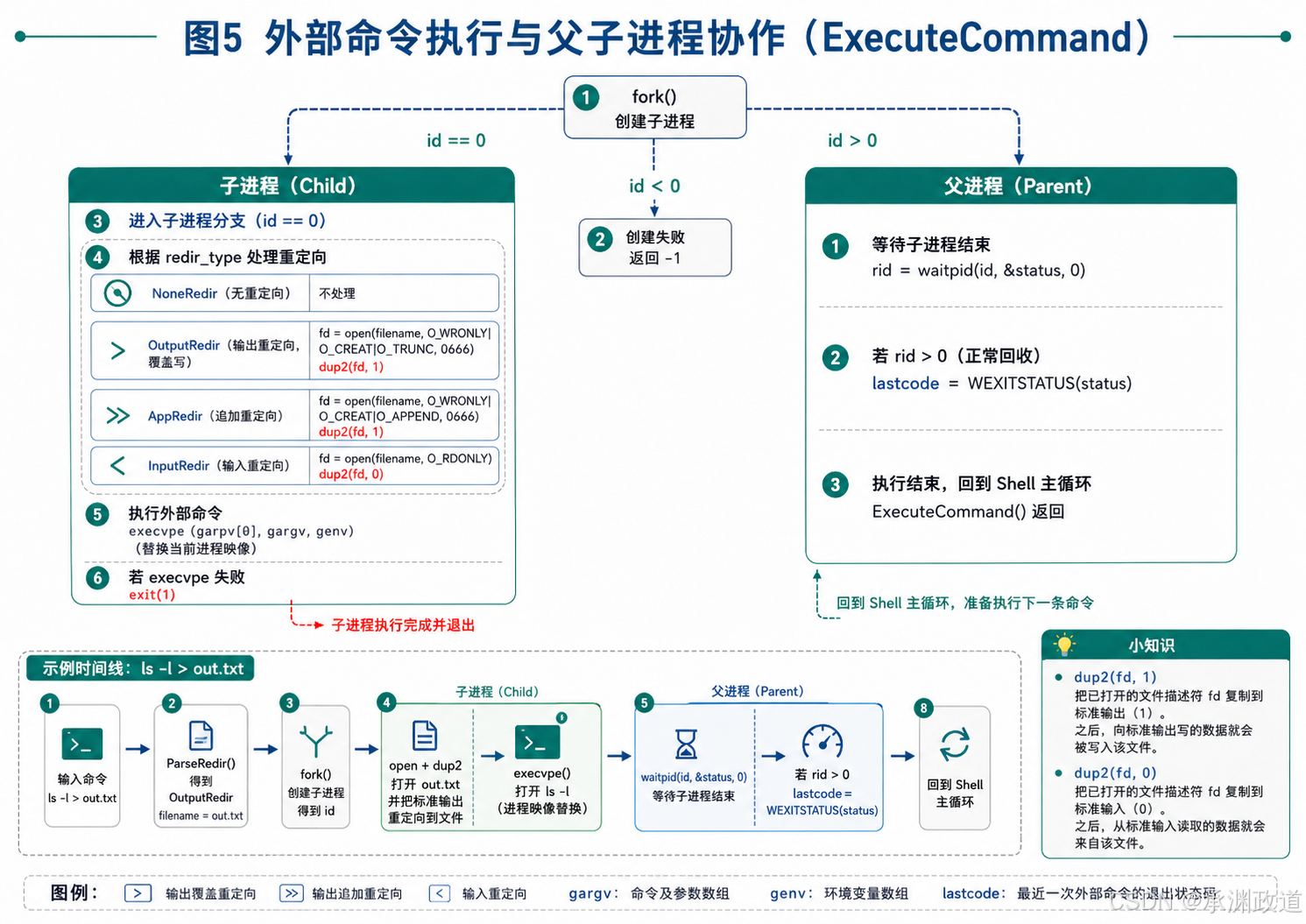
13.执行普通外部命令:ExecuteCommand
cpp
int ExecuteCommand()这个函数用于执行非内建命令.
例如:
bash
ls -l
cat file.txt
pwd
ps ajx这些命令会交给子进程执行.
1)创建子进程
cpp
pid_t id = fork();fork() 会创建一个子进程.
返回值有三种情况:
cpp
id < 0表示创建失败.
cpp
id == 0表示当前处于子进程.
cpp
id > 0表示当前处于父进程.
2)子进程处理重定向
子进程中先判断是否需要重定向.
无重定向
cpp
if(redir_type == NoneRedir)
{
// Do Nothing
}不做任何处理,正常从键盘输入,向屏幕输出.
输出重定向 >
cpp
fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1);打开目标文件,如果文件不存在就创建,如果存在就清空.
dup2(fd, 1) 的作用是把标准输出重定向到文件.
其中:
cpp
1代表标准输出 stdout.
所以后续命令原本要打印到屏幕的内容,会写入文件.
追加重定向 >>
cpp
fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1);打开文件,并把输出追加到文件末尾.
输入重定向 <
cpp
fd = open(filename, O_RDONLY);
dup2(fd, 0);打开输入文件,并把标准输入重定向到文件.
其中:
cpp
0代表标准输入 stdin.
所以命令会从文件读取数据,而不是从键盘读取.
3)子进程执行命令
cpp
execvpe(gargv[0], gargv, genv);
exit(1);execvpe 用于执行命令.
参数含义:
cpp
gargv[0]表示要执行的程序名,例如 ls。
cpp
gargv表示命令参数表.
cpp
genv表示环境变量表.
如果 execvpe 执行成功,子进程的代码会被新程序替换,后面的 exit(1) 不会执行.
如果执行失败,说明命令没有找到或执行出错,就会执行:
cpp
exit(1);表示子进程异常退出.
4)父进程等待子进程
cpp
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid > 0)
{
lastcode = WEXITSTATUS(status);
}父进程调用 waitpid 等待子进程退出.
子进程退出后,父进程通过:
cpp
WEXITSTATUS(status)获取子进程的退出码,并保存到 lastcode 中.
这样用户后面执行:
bash
echo $?就可以查看上一条命令的退出状态.
14.main 函数主流程
cpp
int main()
{
char command_line[MAXSIZE] = {0};
while(1)
{
PrintCommandLine();
if(0 == GetCommand(command_line, sizeof(command_line)))
continue;
ParseRedir(command_line);
ParseCommand(command_line);
if(CheckBuiltinExecute())
{
continue;
}
ExecuteCommand();
}
return 0;
}main 函数是整个 Shell 的核心循环.
执行流程如下:
text
1. 打印命令提示符
2. 读取用户输入
3. 解析是否存在重定向
4. 解析命令和参数
5. 判断是否为内建命令
6. 如果是内建命令,Shell 自己执行
7. 如果不是内建命令,创建子进程执行
8. 父进程等待子进程结束
9. 回到第一步继续运行整体逻辑可以理解为:
text
显示提示符 -> 读取命令 -> 解析命令 -> 判断命令类型 -> 执行命令 -> 等待下一条命令这段代码实现了一个较完整的简易 Shell.它通过循环读取用户命令,使用 strtok 解析命令参数,通过判断 cd、echo 等命令实现内建命令处理,再通过 fork 创建子进程,并使用 execvpe 执行外部程序.
同时,它还实现了基础的重定向功能,包括:
bash
>
>>
<其中重定向的核心是通过 open 打开文件,再用 dup2 修改标准输入或标准输出,使程序的输入输出方向发生改变.
从操作系统角度来看,这段代码很好地体现了 Shell 的基本原理:Shell 本身负责解释命令,而真正的外部命令由子进程执行;父进程负责等待子进程结束并维护当前 Shell 状态.
5.4总结
本节实现了一个简单的自主 Shell 命令行解释器.该解释器能够接收用户输入,对命令进行解析,并根据命令类型选择不同的执行方式.对于 cd、pwd、exit 等内置命令,程序直接在 Shell 内部完成处理;对于其他外部命令,程序通过创建子进程并调用 execvp() 执行.
通过本模块的实现,可以更加清楚地理解 Shell 的基本工作流程.Shell 并不是直接"运行命令"的神秘程序,而是通过读取输入、解析字符串、创建进程、执行程序等步骤来完成命令解释与调度.
本实验也加深了对操作系统进程机制的认识.fork() 体现了父子进程的创建关系,execvp() 展示了程序替换的过程,wait() 则保证了父进程能够正确等待子进程结束.内置命令的实现也说明,有些命令必须由 Shell 自身处理,因为它们会影响 Shell 当前进程的状态.
总体来说,该自主 Shell 命令行解释器虽然功能较为基础,但已经具备 Shell 的核心结构.后续还可以在此基础上进一步扩展,例如增加输入输出重定向、管道通信、后台运行、多命令执行、命令历史记录等功能,使其更加接近真实 Linux Shell 的使用体验.
exec/exit就像call/return
⼀个C程序有很多函数组成.⼀个函数可以调⽤另外⼀个函数,同时传递给它⼀些参数.被调⽤的函数执⾏⼀定的操作,然后返回⼀个值.每个函数都有他的局部变量,不同的函数通过call/return系统进⾏通信.这种通过参数和返回值在拥有私有数据的函数间通信的模式是结构化程序设计的基础.Linux⿎励将这种应⽤于程序之内的模式扩展到程序之间.如下图:
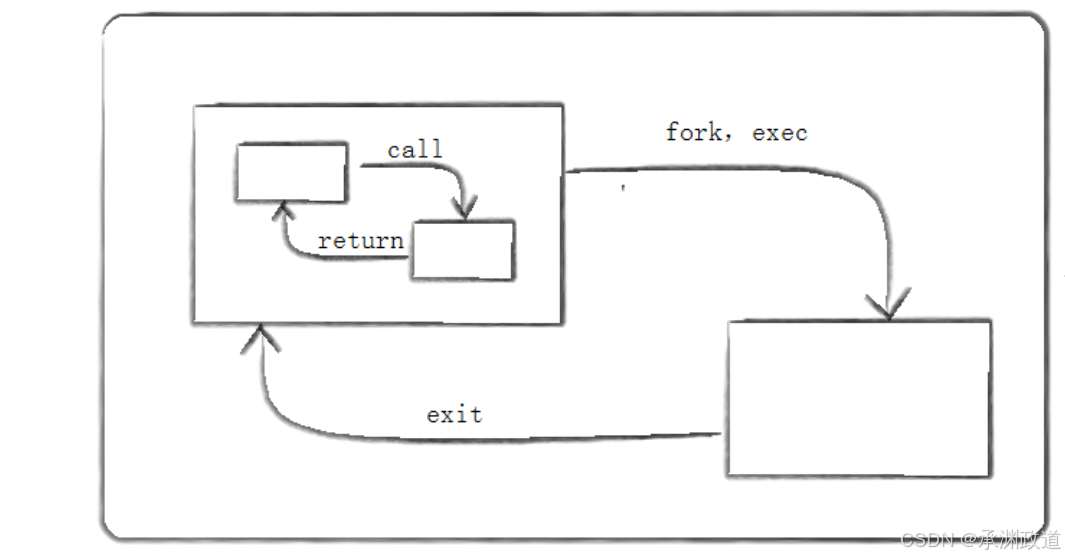
⼀个C程序可以fork/exec另⼀个程序,并传给它⼀些参数.这个被调⽤的程序执⾏⼀定的操作,然后通过exit(n)来返回值.调⽤它的进程可以通过wait(&ret)来获取exit的返回值.

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容
每日心灵鸡汤: 难走的路从来不拥挤!
难走的路,从不拥挤,但是孤独,好走的路,人山人海,但是寂寞.也许你现在做的事看不到结果,但不要害怕,你不是没有成长,而是在扎根.所以,乾坤未定,不要着急否决自己才走一半的人生.人生的每步都算数,你只需埋头播种,静等秋后丰收.待到未来回头再看,你会发现所有的成功都没有捷径,那些你暗自努力的时光,终将照亮你前行的路.
