本文的认知流:
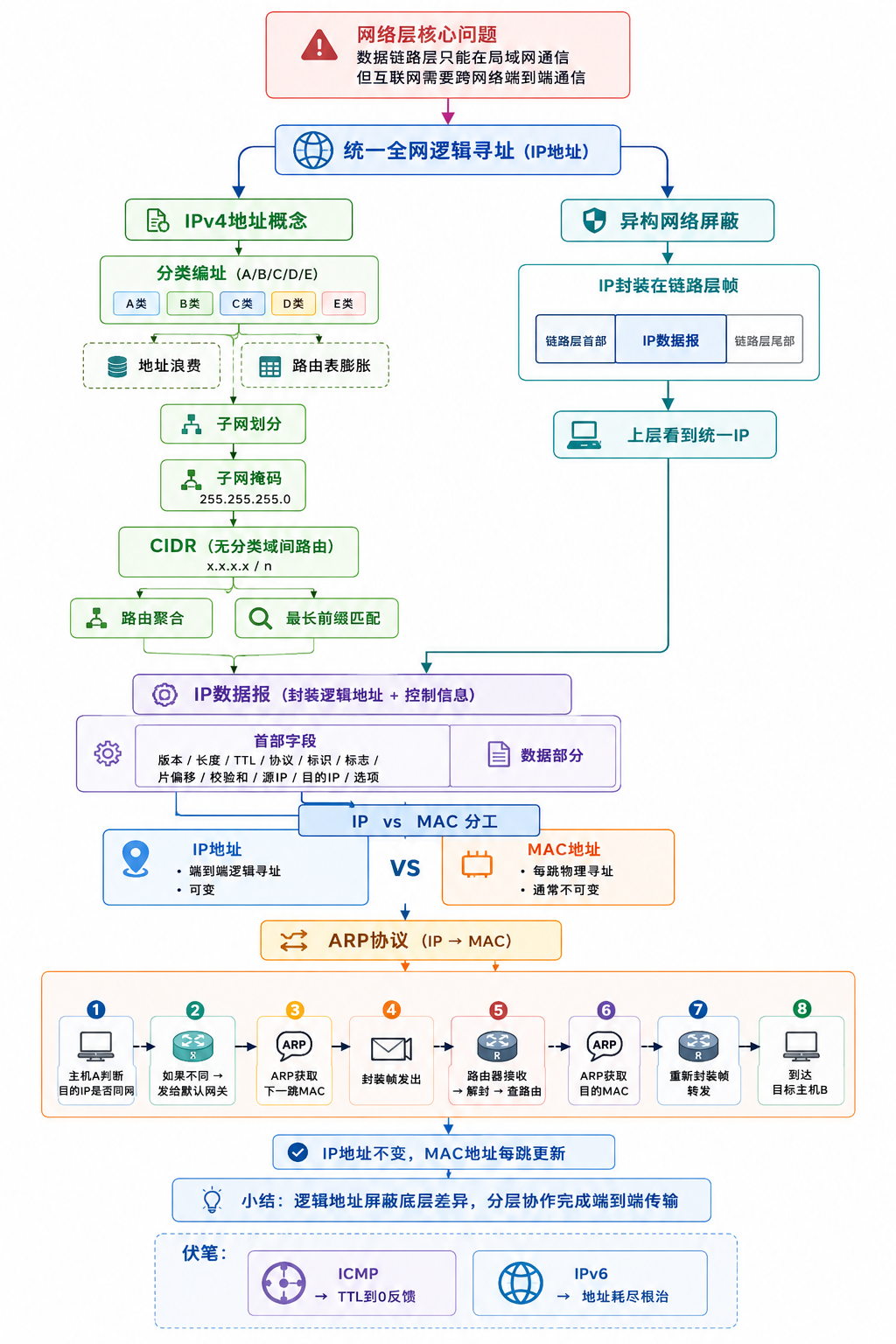
网络层要解决的核心矛盾:
数据链路层只能在局域网内通信 VS 互联网需要跨网络、端到端的通信。
同一个以太网里的设备,用MAC地址就能找到对方。但当你访问一个地球另一端的服务器时,中间要跨越无数个网络。MAC地址是平面地址,不包含位置信息,无法做大规模路由。
于是,网络层的第一个核心任务就浮现了:给全球每台设备一个统一的、可路由的逻辑地址。 这就是IP地址的使命。
一、异构网络互连:用逻辑地址屏蔽底层差异
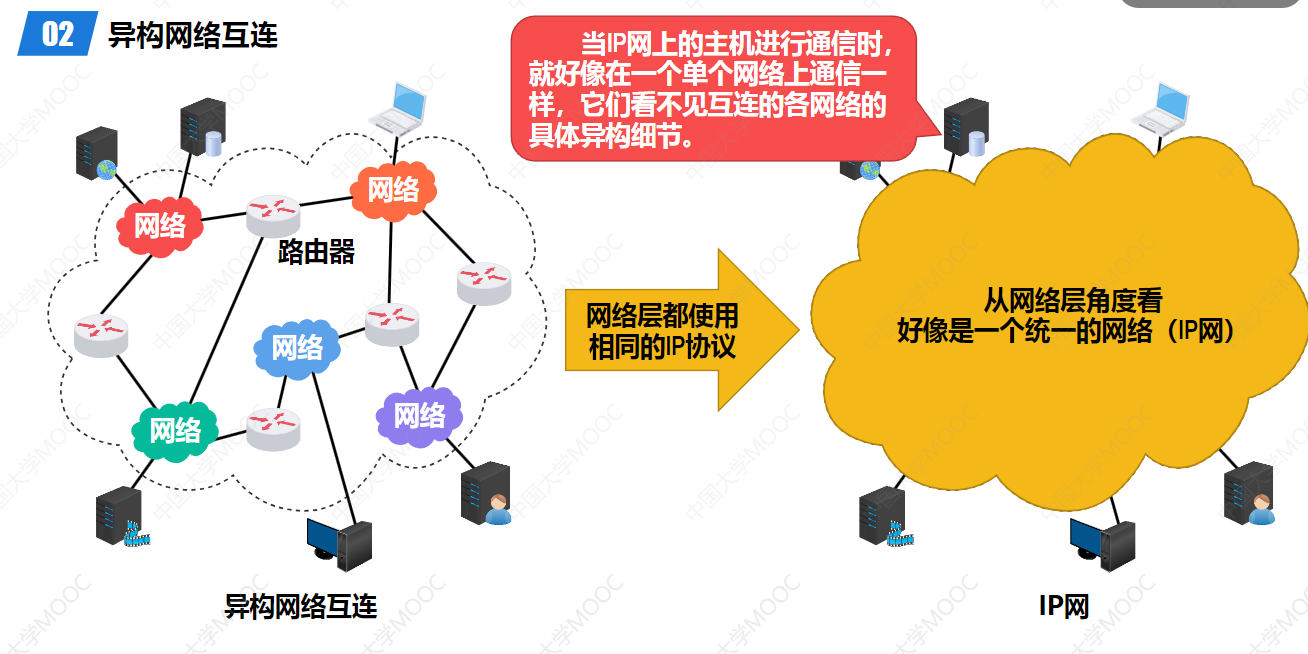
互联网不是一种单一的网络。
- 底层可能是以太网、Wi-Fi、光纤。
- 每种网络的物理地址格式不同、帧格式不同、传输方式不同。
子矛盾:底层网络类型多and不兼容 vs 需要让全球任意两台设备跨越这些异构网络通信。
how to solve?
解法是抽象出一层独立于物理网络的逻辑地址 。
无论底层是什么,上层看到的都是统一的IP地址。IP数据报被封装在链路层帧中传输。到达一个路由器后,帧被解封,取出IP数据报,根据目的IP决定下一跳,然后重新封装进新的链路层帧继续传输。
比喻 :IP地址是快递上的"收件人地址"(北京市海淀区XX路XX号),MAC地址是每一段运输中的"卡车车牌号"。
从北京到上海,包裹可能换了三辆卡车,车牌号每段不同,但包裹上的收件人地址始终不变。IP地址就是这个始终不变的逻辑地址,它屏蔽了每段运输工具的变化。
二、IPv4地址:32位的全球唯一逻辑地址
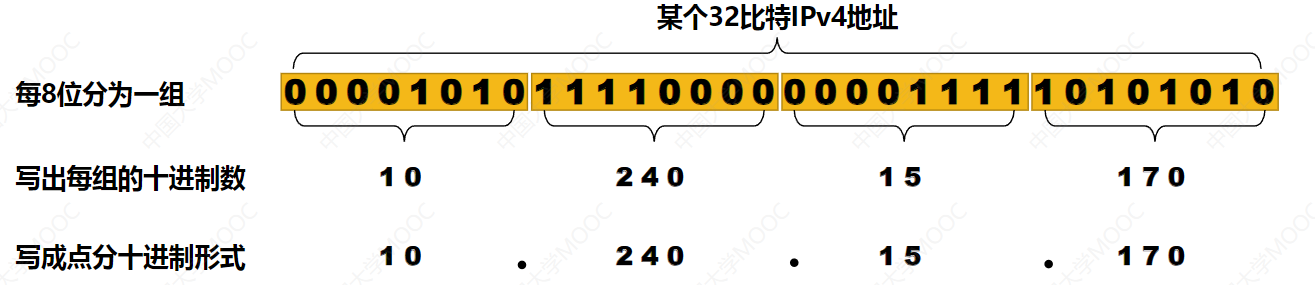
IPv4地址由32位二进制组成,通常写成四个十进制数,用点分隔,例如192.168.1.1。32位意味着约43亿个地址。在互联网早期,这看起来足够,但是后来就不够了。
关键问题不是地址有多少,而是怎么分配和路由。这就引出了IPv4编址方式的演进史。
三、分类编址 → 子网划分 → CIDR:地址不够用的进化史
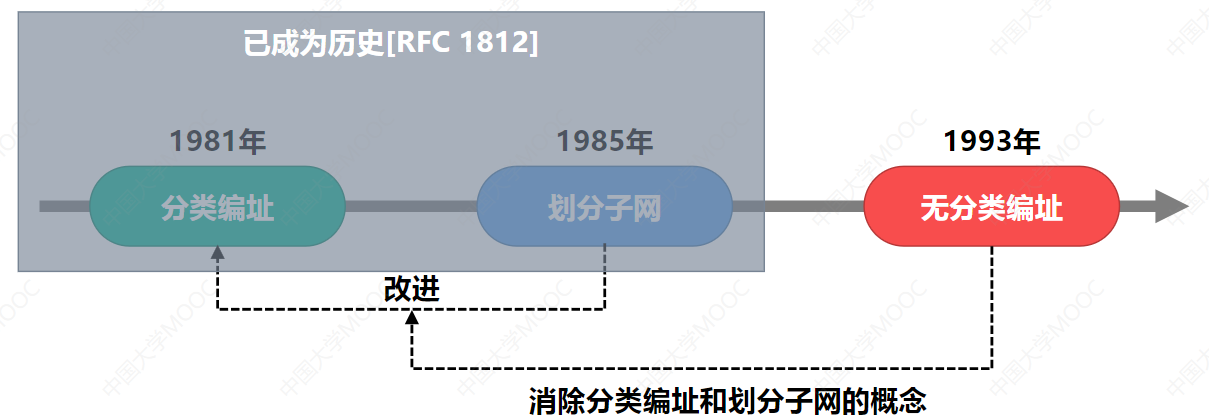
第一阶段:分类编址

早期互联网采用分类编址。IP地址按高位特征分为A、B、C、D、E五类,每类有固定的网络号和主机号长度。
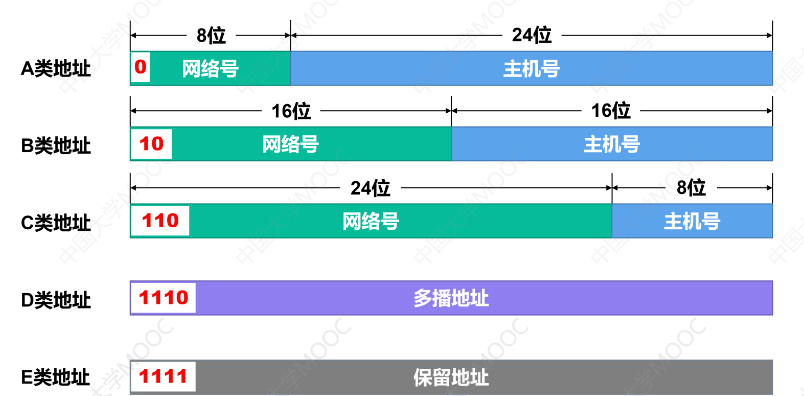
| 类别 | 最高位 | 网络号位数 | 适用规模 |
|---|---|---|---|
| A类 | 0 | 8位 | 大型网络(1600万台主机) |
| B类 | 10 | 16位 | 中型网络(6.5万台主机) |
| C类 | 110 | 24位 | 小型网络(254台主机) |

分类编址的设计初衷很好------按网络规模分类。但很快就暴露了两个致命问题。
-
地址浪费:一个B类网络有6.5万个地址,很多机构用不完,剩余地址无法给别的组织使用。一个C类网络只有254个地址,稍微大一点的机构又不够用。
-
路由表膨胀:每个网络号都需要一条路由表项。如果大量分配C类地址给小型组织,骨干路由器的路由表会急剧膨胀。
矛盾:地址分配需要灵活匹配组织规模,但固定类别划分无法适应各种规模的需求。
第二阶段:子网划分
子网划分的思路是:借用主机号的高位来扩展网络号。 一个B类地址,默认网络号16位。借8位主机号作为"子网号",网络号就变成了24位,这个B类网络被划分成了256个子网。
子网划分需要一个工具:子网掩码。它是32位的数字,左边连续的1对应网络号和子网号,右边连续的0对应主机号。IP地址和子网掩码按位与,得到网络地址。
子网划分解决了内部网络的灵活管理问题,但没有彻底解决全局地址浪费和路由表膨胀。对外界来说,整个B类地址仍然是一个网络号。
第三阶段:CIDR(无分类域间路由)
真正解决问题的,是CIDR。它彻底取消了A、B、C类的固定划分。

CIDR用斜线记法 标注网络前缀长度:192.168.1.0/24表示前24位是网络前缀。网络前缀不再固定为8、16或24位,可以按需分配任意大小。
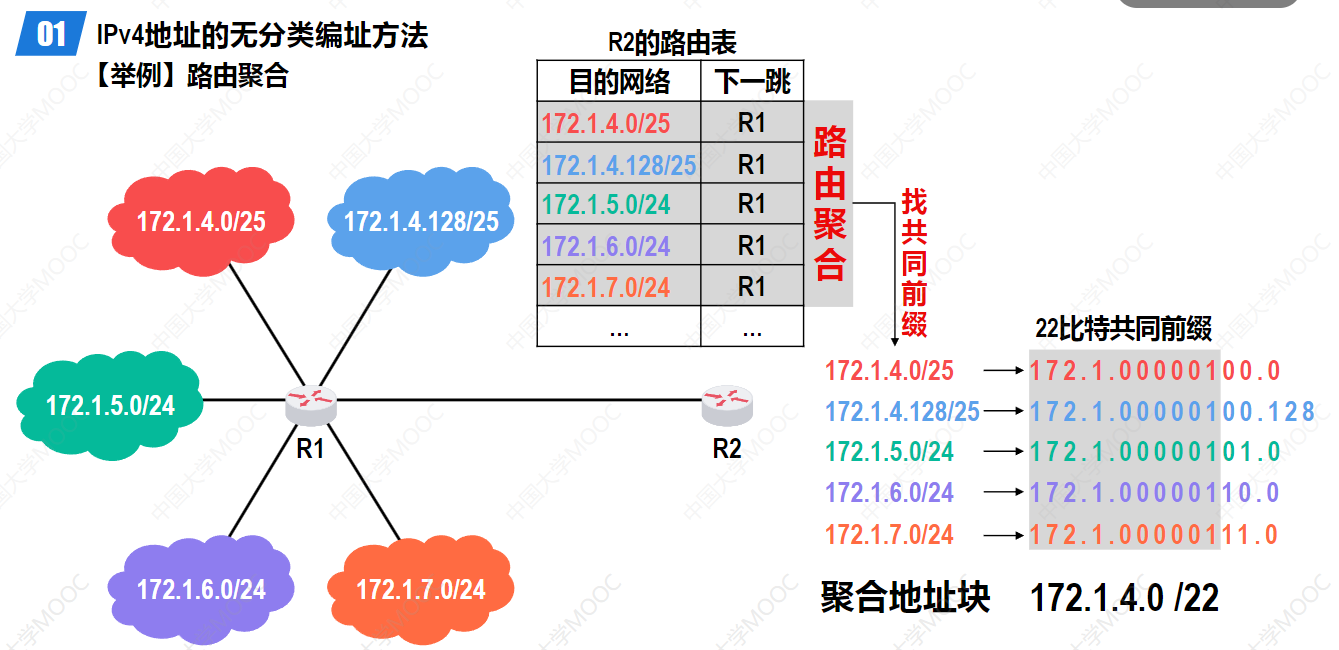
CIDR最大的创新是路由聚合 。同一个ISP下的多个网络,地址前缀可以聚合成一条。比如192.168.0.0/24到192.168.255.0/24这256个地址块,传统方式需要256条路由。CIDR把它们聚合成一条:192.168.0.0/16。路由器只需要记住这一条。
与路由聚合配合的是最长前缀匹配:当多条路由表项都能匹配一个目的地址时,选择前缀最长的那条。这意味着精细路由优先于粗略路由,让地址分配和路由决策更加灵活。
CIDR解决了两个核心矛盾:
- 地址分配灵活性(不再有固定大小)
- 路由表膨胀(聚合大幅减少表项)
这是互联网能扩展到今天规模的关键设计。
四、IP数据报:网络层的传输单位
编址方式解决了"怎么编址",接下来要回答"数据怎么封装"。
IPv4数据报由首部 和数据部分组成。首部最少20字节,结构如下:
| 字段 | 长度 | 作用 |
|---|---|---|
| 版本 | 4位 | IPv4固定为4 |
| 首部长度 | 4位 | 以4字节为单位,最小值为5(20字节) |
| 总长度 | 16位 | 首部加数据的总字节数,最大65535 |
| 标识/标志/片偏移 | 共32位 | IP分片与重组 |
| TTL | 8位 | 每跳减1,减到0丢弃,防止无限循环 |
| 协议 | 8位 | 上层协议类型:6=TCP,17=UDP,1=ICMP |
| 首部校验和 | 16位 | 只校验首部,每跳重新计算 |
| 源IP / 目的IP | 各32位 | 核心寻址字段 |
TTL是一个很有代表性的设计。没有TTL,路由环路会导致数据报无限转发。用8位计数器,每跳减1,到0丢弃------成本极低,效果极好。
五、IP地址 vs MAC地址:逻辑地址和物理地址的分工
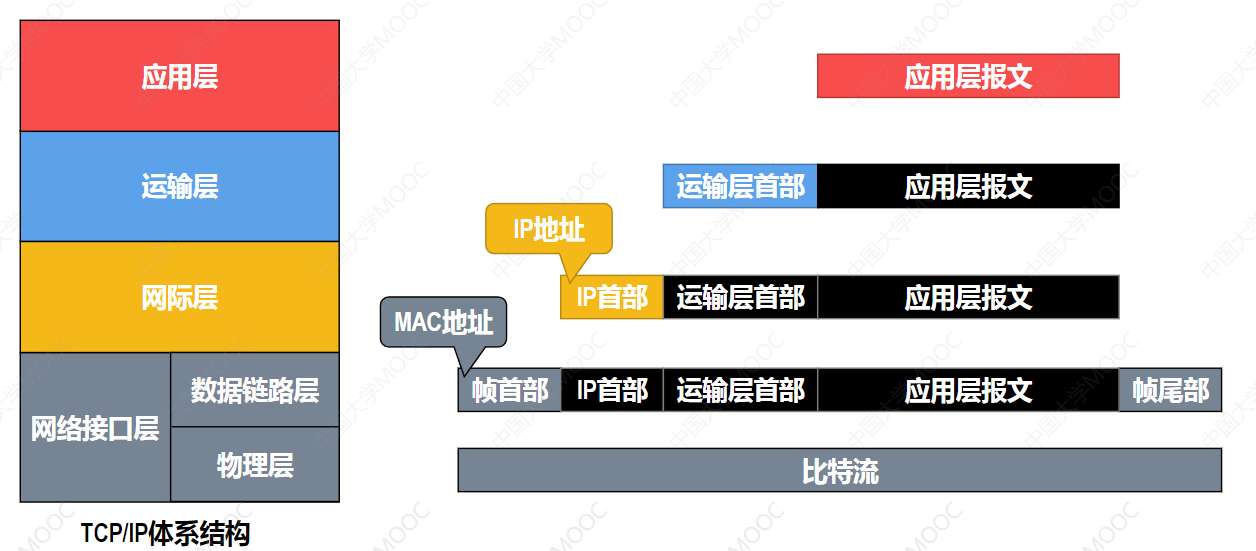
有了IP地址和MAC地址,两者如何分工?
| 对比维度 | IP地址 | MAC地址 |
|---|---|---|
| 层次 | 网络层 | 数据链路层 |
| 作用范围 | 端到端,跨越多个网络 | 本地,同一个广播域内 |
| 是否可变 | 设备移动网络时可能变 | 出厂固定,通常不可变 |
| 结构 | 层级结构,可聚合 | 平面结构,无位置信息 |
| 类比 | 收件人地址 | 每一段运输的卡车车牌号 |
分工逻辑 :IP地址负责端到端逻辑寻址,MAC地址负责每一跳物理寻址。
数据报经过多个路由器时,源IP和目的IP始终不变,但每一跳的源MAC和目的MAC都会改变------因为每一段链路的两端是不同的设备。
只用MAC地址做全局寻址,路由表会大到无法工作。只用IP地址做本地通信,局域网里也要经过路由器,完全多余。两者互补。
六、ARP协议:从IP到MAC的翻译官
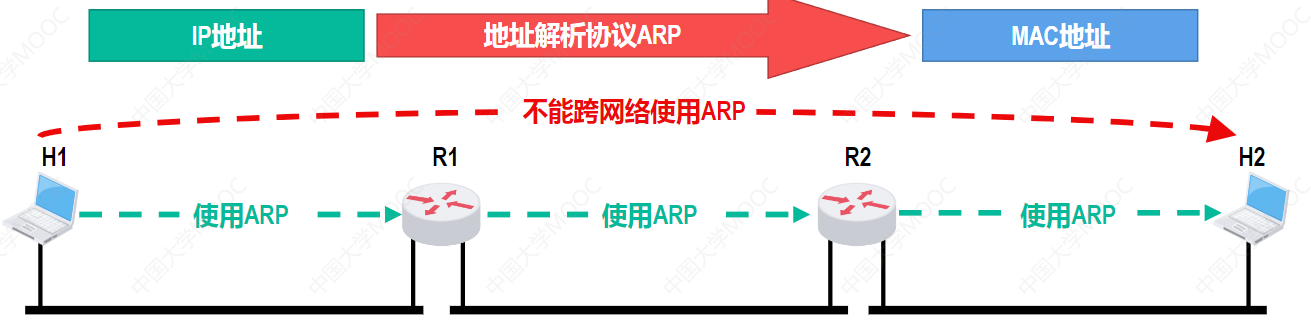
当设备知道了目标的IP,却不知道目标的MAC地址时,怎么封装帧?这就是ARP要解决的问题。
ARP的过程:主机A广播一个ARP请求:"谁的IP是192.168.1.2?告诉我你的MAC。"目标主机B单播回复自己的MAC地址。A收到后,把映射关系存入ARP缓存,下次直接用。
ARP的"广播请求+单播回复"模式,完美利用了广播域的特性。目标在另一个网络时,主机会把数据报发给默认网关,ARP解析的是网关的MAC地址。
七、完整流程:数据报的发送与转发
把IP、ARP、路由表结合起来,走一遍完整流程。
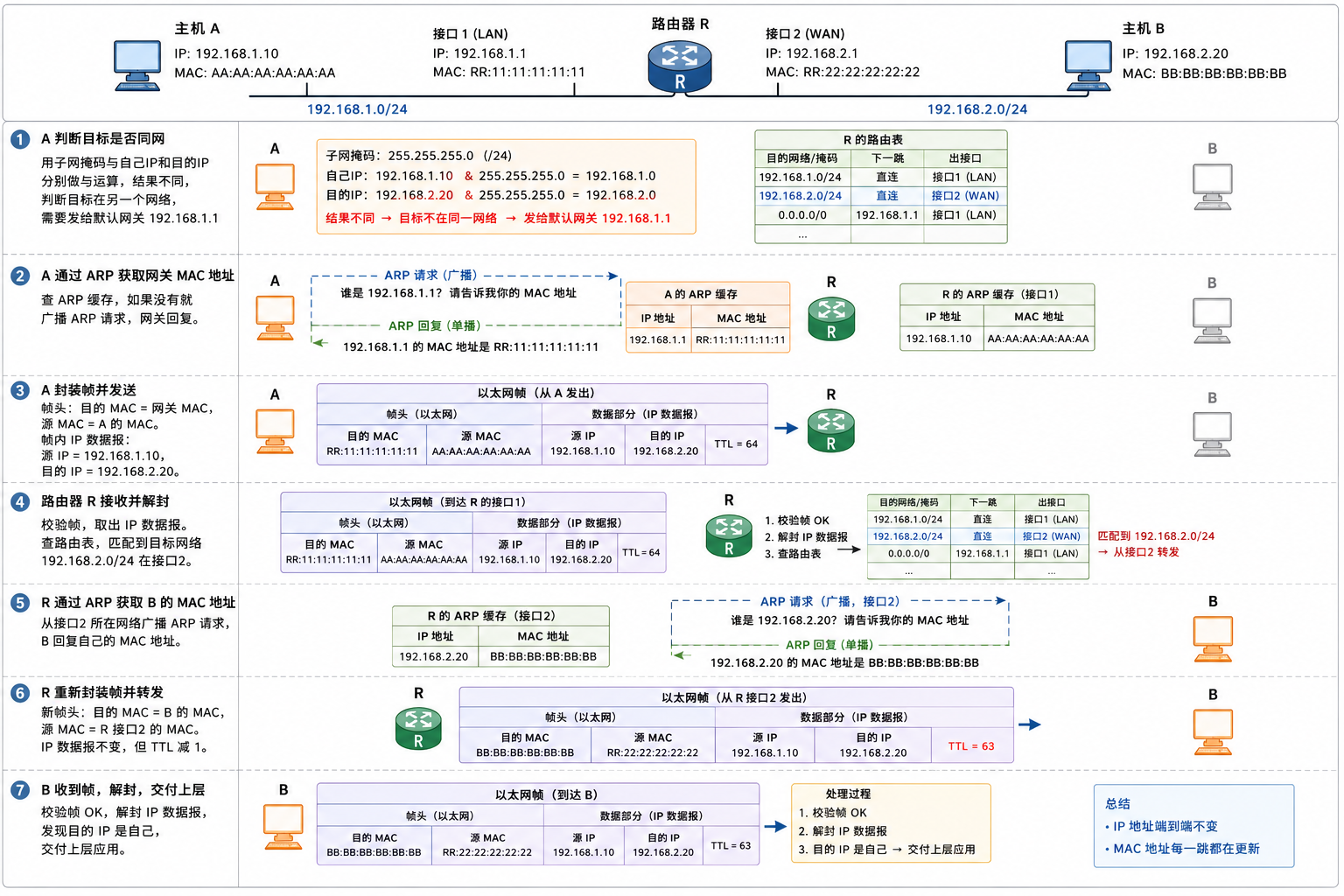
场景:主机A(IP=192.168.1.10)给主机B(IP=192.168.2.20)发送数据,两台主机不在同一网络,中间经过路由器R。
第一步:A判断目标是否同网。 用子网掩码与自己IP和目的IP分别做与运算。结果不同,判断目标在另一个网络,需要发给默认网关。
第二步:A通过ARP获取网关MAC地址。 查ARP缓存,如果没有就广播请求,网关回复。
第三步:A封装帧并发送。 帧头:目的MAC=网关MAC,源MAC=A的MAC。帧内IP数据报:源IP=192.168.1.10,目的IP=192.168.2.20。
第四步:路由器R接收并解封。 校验帧,取出IP数据报。查路由表,匹配到目标网络192.168.2.0/24在另一个接口。
第五步:R通过ARP获取B的MAC地址。 从对应接口广播ARP请求,B回复。
第六步:R重新封装帧并转发。 新帧头:目的MAC=B的MAC,源MAC=R的出口MAC。IP数据报不变,但TTL减1。
第七步:B收到帧,校验,解封,交付上层。
整个过程中,IP地址始终不变,MAC地址每跳更新。
📌 小结:这一部分构建了网络层的核心基石------统一全网寻址。IP协议通过逻辑地址屏蔽底层物理网络的差异,实现异构网络互连。IPv4编址从分类编址、子网划分到CIDR的演进,是为了解决地址浪费和路由表膨胀这两个根本矛盾。IP地址负责端到端逻辑寻址,MAC地址负责每一跳物理寻址,ARP在两者之间充当翻译官。数据报的发送和转发过程,是IP、ARP、路由表三者的协作------IP不变,MAC每跳更新。
感谢你的阅读,祝你有开心的一天